
Using Machine Learning for Pharmacovigilance: A Systematic Review



Abstract
:1. Introduction
2. Background
2.1. Traditional Approaches
2.2. Improving Pharmacovigilance Using Natural Language Processing
- tokenization: the separation of text into smaller units, like words, characters, or sub-words (n-grams);
- transformation of cases, such as uniform lowercasing or uppercasing;
- stop word removal: the removal of words carrying very little meaning; and such as pronouns;
- reducing inflected words to their word stem (stemming).
3. Materials and Methods
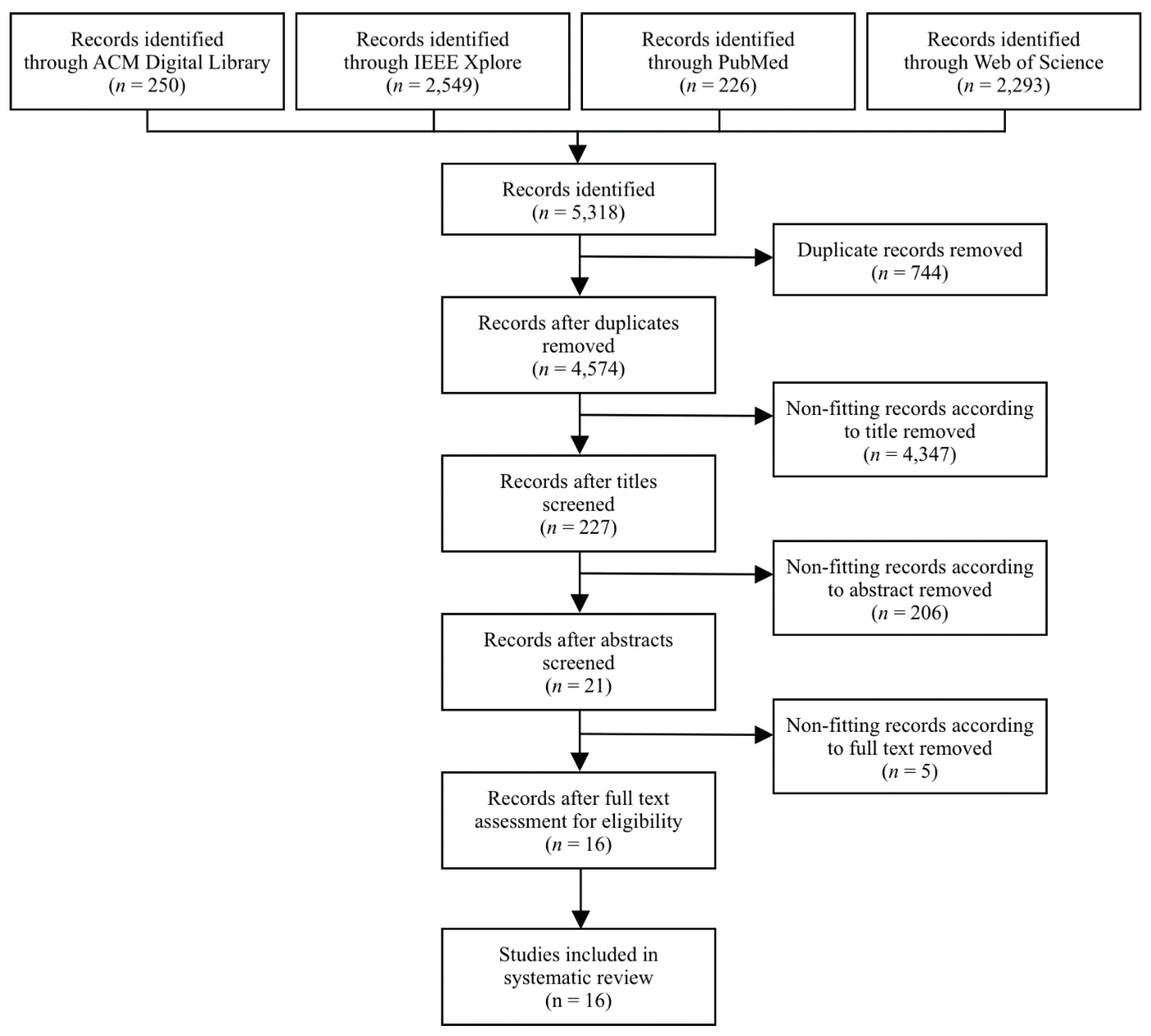
3.1. Search Strategy
3.2. Study Selection
3.3. Inclusion and Exclusion Criteria
3.4. Reliability and Validity
3.5. Data Analysis
4. Results
4.1. General Characteristics
4.2. Input Sources
4.3. Employed Methods
4.4. Study Effectiveness
5. Discussion
6. Limitations
7. Conclusions and Future Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. PRISMA 2020 Checklist

{kind=link}
| Section/Topic | # | Checklist Item | Reported on Page # |
|---|---|---|---|
| TITLE | |||
| Title | 1 | Identify the report as a systematic review, meta-analysis, or both. | 1 |
| ABSTRACT | |||
| Abstract | 2 | See the PRISMA 2020 for Abstracts checklist. | 1 |
| INTRODUCTION | |||
| Rationale | 3 | Describe the rationale for the review in the context of what is already known. | 1 |
| Objectives | 4 | Provide an explicit statement of the objective(s) or question(s) the review addresses. | 2 |
| METHOD | |||
| Eligibility criteria | 5 | Specify the inclusion and exclusion criteria for the review and how studies were grouped for the syntheses. | 5 |
| Information sources | 6 | Specify all databases, registers, websites, organisations, reference lists and other sources searched or consulted to identify studies. Specify the date when each source was last searched or consulted. | 3 |
| Search strategy | 7 | Present the full search strategies for all databases, registers and websites, including any filters and limits used. | 3, 19 |
| Selection process | 8 | Specify the methods used to decide whether a study met the inclusion criteria of the review, including how many reviewers screened each record and each report retrieved, whether they worked independently, and if applicable, details of automation tools used in the process. | 4 |
| Data collection process | 9 | Specify the methods used to collect data from reports, including how many reviewers collected data from each report, whether they worked independently, any processes for obtaining or confirming data from study investigators, and if applicable, details of automation tools used in the process. | 4 |
| Data items | 10a | List and define all outcomes for which data were sought. Specify whether all results that were compatible with each outcome domain in each study were sought (e.g. for all measures, time points, analyses), and if not, the methods used to decide which results to collect. | 4 |
| 10b | List and define all other variables for which data were sought (e.g. participant and intervention characteristics, funding sources). Describe any assumptions made about any missing or unclear information. | 4, 5 | |
| Study risk of bias assessment | 11 | Specify the methods used to assess risk of bias in the included studies, including details of the tool(s) used, how many reviewers assessed each study and whether they worked independently, and if applicable, details of automation tools used in the process. | 5 |
| Effect measures | 12 | Specify for each outcome the effect measure(s) (e.g. risk ratio, mean difference) used in the synthesis or presentation of results. | n. a. |
| Synthesis methods | 13a | Describe the processes used to decide which studies were eligible for each synthesis (e.g. tabulating the study intervention characteristics and comparing against the planned groups for each synthesis (item #5)). | 5 |
| 13b | Describe any methods required to prepare the data for presentation or synthesis, such as handling of missing summary statistics, or data conversions. | 6 | |
| 13c | Describe any methods used to tabulate or visually display results of individual studies and syntheses. | 6 | |
| 13d | Describe any methods used to synthesize results and provide a rationale for the choice(s). If meta-analysis was performed, describe the model(s), method(s) to identify the presence and extent of statistical heterogeneity, and software package(s) used. | 6 | |
| 13e | Describe any methods used to explore possible causes of heterogeneity among study results (e.g. subgroup analysis, meta-regression). | n. a. | |
| 13f | Describe any sensitivity analyses conducted to assess robustness of the synthesized results. | n. a. | |
| Reporting bias assessment | 14 | Describe any methods used to assess risk of bias due to missing results in a synthesis (arising from reporting biases). | n. a. |
| Certainty assessment | 15 | Describe any methods used to assess certainty (or confidence) in the body of evidence for an outcome. | 5 |
| RESULTS | |||
| Study selection | 16a | Describe the results of the search and selection process, from the number of records identified in the search to the number of studies included in the review, ideally using a flow diagram. | 4 |
| 16b | Cite studies that might appear to meet the inclusion criteria, but which were excluded, and explain why they were excluded. | n. a. | |
| Study characteristics | 17 | Cite each included study and present its characteristics. | 7 |
| Risk of bias within studies | 18 | Present assessments of risk of bias for each included study. | 20 |
| Results of individual studies | 19 | For all outcomes, present, for each study: (a) summary statistics for each group (where appropriate) and (b) an effect estimate and its precision (e.g. confidence/credible interval), ideally using structured tables or plots. | 9 |
| Results of syntheses | 20a | For each synthesis, briefly summarise the characteristics and risk of bias among contributing studies. | n. a. |
| 20b | Present results of all statistical syntheses conducted. If meta-analysis was done, present for each the summary estimate and its precision (e.g. confidence/credible interval) and measures of statistical heterogeneity. If comparing groups, describe the direction of the effect. | n. a. | |
| 20c | Present results of all investigations of possible causes of heterogeneity among study results. | n. a. | |
| 20d | Present results of all sensitivity analyses conducted to assess the robustness of the synthesized results. | n. a. | |
| Reporting biases | 21 | Present assessments of risk of bias due to missing results (arising from reporting biases) for each synthesis assessed. | 15 |
| Certainty of evidence | 22 | Present assessments of certainty (or confidence) in the body of evidence for each outcome assessed. | n. a. |
| DISCUSSION | |||
| Discussion | 23a | Provide a general interpretation of the results in the context of other evidence. | 14 |
| 23b | Discuss any limitations of the evidence included in the review. | 15 | |
| 23c | Discuss any limitations of the review processes used. | 15 | |
| 23d | Discuss implications of the results for practice, policy, and future research. | 16 | |
| OTHER INFORMATION | |||
| Registration and protocol | 24a | Provide registration information for the review, including register name and registration number, or state that the review was not registered. | 15 |
| 24b | Indicate where the review protocol can be accessed, or state that a protocol was not prepared. | 15 | |
| 24c | Describe and explain any amendments to information provided at registration or in the protocol. | 15 | |
| Support | 25 | Describe sources of financial or non-financial support for the review, and the role of the funders or sponsors in the review. | 16 |
| Competing interests | 26 | Declare any competing interests of review authors. | 16 |
| Availability of data, code and other materials | 27 | Report which of the following are publicly available and where they can be found: template data collection forms; data extracted from included studies; data used for all analyses; analytic code; any other materials used in the review. | n. a. |
Appendix B. Search Strategies
Appendix B.1. Search Strategy for PubMed
Appendix B.2. Search Strategy for Web of Science
Appendix B.3. Search Strategy for IEEE Xplore
Appendix B.4. Search Strategy for ACM Digital Library
Appendix C. Characteristics of Publications
| Authors | Type of Drugs | Drugs Studied | Data Source | Sample Size | Users | Unique Users | Origin of Users | Average Number of Followers | Years of Data Collection | Horizon of Data Collection | Software Used | Techniques and Classifiers Used | Outcome | Result | Description of Result | Reliability | Validity |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [31] | HIV | Atripla, Sustiva, Truvada | Social media | Twitter.com: 1642 tweets | HIV-infected persons undergoing drug treatment | 512 (male: 247; female: 83; unknown: 182) | Canada, South Africa, United Kingdom, United States (New York City, San Fransisco) | 2300 | 2010, 2011, 2012, 2013 | 3 years | Toolkit for Multivariate Analysis | Artificial Neural Networks (ANN), Boosted Decision Trees with AdaBoost (BDT), Boosted Decision Trees with Bagging (BDTG), Sentiment Analysis, Support Vector Machines (SVM) | Reported ADRs for HIV treatment | Positive | Reported adverse effects are consistent with well-recognized toxicities. | Medium | Medium |
| [32] | Depression | Citalopram, Chlorpromazine, Cyclobenzaprine, Dulexetine, Promethazine | Forums | Depression Forums.org: 7726 posts | Unknown | Unknown | Unknown | Unknown | 2004–2014 | 10 years | General Architecture for Text Engineering (GATE), NLTK Toolkit within MATLAB, RapidMiner | Hyperlink-Induced Topic Search (HITS), k-Means Clustering, Network Analysis, Term-Frequency-Inverse Document Frequency (TF-IDF) | User sentiment on depression drugs | Positive | Natural language processing is suitable to extract information on ADRs concerning depression. | Medium | Medium |
| [66] | Cancer | Avastin, Melphalan, Rupatadin, Tamoxifen, Taxotere | Social media | Twitter.com: 2,102,176,189 tweets | Unknown | Unknown | Unknown | Unknown | 2009, 2010 | 1 year | Apache Lucene | MetaMap, Support Vector Machines (SVM) | Reported ADRs for cancer | Neutral | Classification models had limited performance. Adverse events related to cancer drugs can potentially be extracted from tweets. | Medium | Medium |
| [33] | Unknown | Unknown | Social media | Twitter.com: 6528 tweets | Unknown | Unknown | Unknown | Unknown | Unknown | Unknown | GENIA tagger, Hunspell, Snowball stemmer, Stanford Topic Modelling Toolbox, Twokenizer | Backward/forward sequential feature selection (BSFS/FSFS) algorithm, k-Means Clustering, Sentiment Analysis, Support Vector Machines (SVM) | Reported ADRs | Positive | ADRs were identified reasonably well. | Medium | Medium |
| [34] | Unknown | Unknown | Social media | Twitter.com: 32,670 tweets | Unknown | Unknown | Unknown | Unknown | Unknown | Unknown | Hunspell, Twitter tokenizer | - Term Frequency-Inverse Document Frequency (TF-IDF) | Reported ADRs | Neutral | ADRs were not very well identified. | Medium | Medium |
| [67] | Unknown | 65 drugs | Social media | Twitter.com: 10,822 tweets | Unknown | Unknown | Unknown | Unknown | Unknown | Unknown | Unknown | Naive Bayes (NB), Natural Language Processing (NLP), Support Vector Machines (SVM) | Reported ADRs | Positive | ADRs were identified good. | Medium | Medium |
| [35] | Unknown | Unknown | Drug reviews | Drugs.com, Drugslib.com: 218,614 reviews | Unknown | Unknown | Unknown | Unknown | Unknown | Unknown | BeautifulSoup | Logistic Regression, Sentiment Analysis | Patient satisfaction with drugs, Reported ADRs, Reported effectiveness of drugs | Positive | Classification results were very good. | Medium | Medium |
| [36] | Unknown | 103 drugs | Social media | Twitter.com: 172,800 tweets | Unknown | 864 | Unknown | Unknown | 2014, 2015 | 1 year | Twitter4J | Decision Trees, Medical Profile Graph, Natural Language Processing (NLP) | Reported ADRs | Positive | Building a medical profile of users enables the accurate detection of adverse drug events. | Medium | Medium |
| [37] | Unknown | Unknown | Social media | Twitter.com 1245 tweets | Unknown | Unknown | Unknown | Unknown | Unknown | Unknown | CRF++ Toolkit, GENIA tagger, Hunspell, Twitter REST API, Twokenizer | Natural Language Processing (NLP) | Reported ADRs | Positive | ADRs were identified reasonably well. | Medium | Medium |
| [38] | Cancer | 146 drugs | Drug reviews | WebMD.com: Unknown | Unknown | Unknown | Unknown | Unknown | Unknown | Unknown | SentiWordNet, WordNet | Sentiment Analysis, Support Vector Machines (SVM), Term document Matrix (TDM) | User sentiment on cancer drugs | Positive | Sentiment on ADRs was identified reasonably well. | Medium | Medium |
| [39] | Unknown | 81 drugs | Drug reviews, Social media | DailyStrength.org: 6279 reviews, Twitter.com: 1784 tweets | Unknown | Unknown | Unknown | Unknown | Unknown | Unknown | Unknown | ARDMine, Lexicon-based, MetaMap, Support Vector Machines (SVM) | Reported ADRs | Positive | ADRs were identified very well. | Medium | Medium |
| [40] | Asthma, Cystic fibrosis, Rheumatoid arthritis, Type 2 diabetes | Albuterol, Azithromycin, Bromocriptine, Insulin, Ipratropium, Ivacaftor, Meloxicam, Metformin, Prednisone, Sulfasalazine | Drug reviews, Social media | PatientsLikeMe.com: 796 reviews, Twitter.com: 39,127 tweets, WebMD.com: 2567 reviews, YouTube.com: 42,544 comments | Unknown | Unknown | Unknown | Unknown | 2014 | Not applicable | Deeply Moving | Unknown | Patient-reported medication outcomes | Positive | Social media serves as a new data source to extract patient-reported medication outcomes. | Medium | Medium |
| [68] | Unknown | Medications.com: 168 drugs, SteadyHealth.com: 316 drugs | Forums | Medications.com: 8065 posts, SteadyHealth.com: 11,878 | Unknown | Unknown | Unknown | Unknown | 2012 | Not applicable | Java Hidden Markov Model library, jsoup | Hidden Markov Model (HMM), Natural Language Processing (NLP) | Reported ADRs | Positive | Reported adverse effects are consistent with well-recognized side-effects. | Medium | Medium |
| [69] | Unknown | ACE inhibitors, Bupropion, Ibuprofen, Morphine, Paroxetine, Rosiglitazone, Warfarin | Electronic Health Record (EHR) | 25,074 discharge summaries | Unknown | Unknown | Unknown | Unknown | 2004 | Not applicable | MedLEE | Unknown | Reported ADRs | Positive | Reported adverse effects are consistent with well-recognized toxicities (recall: 75%; precision: 31%). | Medium | Medium |
| [41] | Unknown | Baclofen, Duloxetine, Gabapentin, Glatiramer, Pregabalin | Social media | Twitter.com: 3251 tweets | Unknown | Unknown | Unknown | Unknown | 2015 | Not applicable | AFINN, Bing Liu sentiment words, Multi-Perspective Question Answering (MPQA), SentiWordNet, TextBlob, Tweepy, WEKA | MetaMap, Naive Bayes (NB), Natural Language Processing (NLP), Sentiment Analysis, Support Vector Machines (SVM) | Reported ADRs | Positive | Several well-known ADRs were identified. | Medium | Medium |
| [70] | Unknown | Adenosine, Biaxin, Cialis, Elidel, Lansoprazole, Lantus, Luvox, Prozac, Tacrolimus, Vyvanse | Forums | MedHelp.com: 6244 discussion threads | Unknown | Unknown | Unknown | Unknown | Unknown | Unknown | Unknown | Association Mining | Reported ADRs | Positive | ADRs were identified. | Medium | Medium |
References
- Santoro, A.; Genov, G.; Spooner, A.; Raine, J.; Arlett, P. Promoting and Protecting Public Health: How the European Union Pharmacovigilance System Works. Drug Saf. 2017, 40, 855–869. [Google Scholar] [CrossRef] [PubMed]
- Barlow, J. Managing Innovation in Healthcare; World Scientific: London, UK, 2017. [Google Scholar]
- WHO Policy Perspectives on Medicines—Pharmacovigilance: Ensuring the Safe Use of Medicines; WHO Policy Perspectives on Medicines, World Health Organization: Geneva, Switzerland, 2004.
- Strengthening Pharmacovigilance to Reduce Adverse Effects of Medicines; European Commission: Brussels, Belgium, 2008.
- Beninger, P. Pharmacovigilance: An Overview. Clin. Ther. 2018, 30, 1991–2004. [Google Scholar] [CrossRef] [Green Version]
- Pharmacovigilance; European Commission: Brussels, Belgium, 2020; Volume 2020.
- Schmider, J.; Kumar, K.; LaForest, C.; Swankoski, B.; Naim, K.; Caubel, P.M. Innovation in Pharmacovigilance: Use of Artificial Intelligence in Adverse Event Case Processing. Clin. Pharmacol. Ther. 2019, 105, 954–961. [Google Scholar] [CrossRef] [Green Version]
- Kaplan, A.M.; Haenlein, M. Users of the world, unite! The challenges and opportunities of Social Media. Bus. Horiz. 2010, 53, 59–68. [Google Scholar] [CrossRef]
- Monkman, G.F.; Kaiser, M.J.; Hyder, K. Text and data mining of social media to map wildlife recreation activity. Biol. Conserv. 2018, 228, 89–99. [Google Scholar] [CrossRef]
- Moro, S.; Rita, P.; Vala, B. Predicting social media performance metrics and evaluation of the impact on brand building: A data mining approach. J. Bus. Res. 2016, 69, 3341–3351. [Google Scholar] [CrossRef]
- Brown, R.C.; Bendig, E.; Fischer, T.; Goldwich, A.D.; Baumeister, H.; Plener, P.L. Can acute suicidality be predicted by Instagram data? Results from qualitative and quantitative language analyses. PLoS ONE 2019, 14, e0220623. [Google Scholar] [CrossRef]
- Cavazos-Rehg, P.A.; Zewdie, K.; Krauss, M.J.; Sowles, S.J. “No High Like a Brownie High”: A Content Analysis of Edible Marijuana Tweets. Am. J. Health Promot. 2018, 32, 880–886. [Google Scholar] [CrossRef]
- Cesare, N.; Dwivedi, P.; Nguyen, Q.C.; Nsoesie, E.O. Use of social media, search queries, and demographic data to assess obesity prevalence in the United States. Palgrave Commun. 2019, 5, 106. [Google Scholar] [CrossRef] [Green Version]
- Cole-Lewis, H.; Pugatch, J.; Sanders, A.; Varghese, A.; Posada, S.; Yun, C.; Schwarz, M.; Augustson, E. Social Listening: A Content Analysis of E-Cigarette Discussions on Twitter. J. Med. Internet Res. 2015, 17, e243. [Google Scholar] [CrossRef] [Green Version]
- Ji, X.; Chun, S.A.; Wei, Z.; Geller, J. Twitter sentiment classification for measuring public health concerns. Soc. Netw. Anal. Min. 2015, 5, 13. [Google Scholar] [CrossRef] [PubMed]
- Kavuluru, R.; Ramos-Morales, M.; Holaday, T.; Williams, A.G.; Haye, L.; Cerel, J.; ACM. Classification of Helpful Comments on Online Suicide Watch Forums. In Proceedings of the 7th Acm International Conference on Bioinformatics, Computational Biology, and Health Informatics, Seattle, WA, USA, 2–5 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 32–40. [Google Scholar] [CrossRef] [Green Version]
- Kent, E.E.; Prestin, A.; Gaysynsky, A.; Galica, K.; Rinker, R.; Graff, K.; Chou, W.Y.S. “Obesity is the New Major Cause of Cancer”: Connections Between Obesity and Cancer on Facebook and Twitter. J. Cancer Educ. 2016, 31, 453–459. [Google Scholar] [CrossRef] [PubMed]
- Kim, A.; Miano, T.; Chew, R.; Eggers, M.; Nonnemaker, J. Classification of Twitter Users Who Tweet About E-Cigarettes. JMIR Public Health Surveill. 2017, 3, e63. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kostygina, G.; Tran, H.; Shi, Y.; Kim, Y.; Emery, S. “Sweeter Than a Swisher”: Amount and themes of little cigar and cigarillo content on Twitter. Tob. Control 2016, 25, i75–i82. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, K.; Agrawal, A.; Choudhary, A. Mining social media streams to improve public health allergy surveillance. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Paris, France, 25–28 August 2015; pp. 815–822. [Google Scholar] [CrossRef]
- Leis, A.; Ronzano, F.; Mayer, M.A.; Furlong, L.I.; Sanz, F. Detecting Signs of Depression in Tweets in Spanish: Behavioral and Linguistic Analysis. J. Med. Internet Res. 2019, 21, 16. [Google Scholar] [CrossRef] [Green Version]
- Mowery, D.; Smith, H.; Cheney, T.; Stoddard, G.; Coppersmith, G.; Bryan, C.; Conway, M. Understanding Depressive Symptoms and Psychosocial Stressors on Twitter: A Corpus-Based Study. J. Med. Internet Res. 2017, 19, e48. [Google Scholar] [CrossRef]
- Myslin, M.; Zhu, S.H.; Chapman, W.; Conway, M. Using twitter to examine smoking behavior and perceptions of emerging tobacco products. J. Med. Internet Res. 2013, 15, e174. [Google Scholar] [CrossRef]
- Nargund, K.; Natarajan, S. Public health allergy surveillance using micro-blogs. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 1429–1433. [Google Scholar] [CrossRef]
- Phan, N.; Chun, S.A.; Bhole, M.; Geller, J. Enabling Real-Time Drug Abuse Detection in Tweets. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering, San Diego, CA, USA, 19–22 April 2017; IEEE: New York, NY, USA, 2017; pp. 1510–1514. [Google Scholar] [CrossRef]
- Rong, J.; Michalska, S.; Subramani, S.; Du, J.; Wang, H. Deep learning for pollen allergy surveillance from twitter in Australia. BMC Med. Inform. Decis. Mak. 2019, 19, 208. [Google Scholar] [CrossRef] [Green Version]
- Song, J.Y.; Song, T.M.; Seo, D.C.; Jin, J.H. Data Mining of Web-Based Documents on Social Networking Sites That Included Suicide-Related Words Among Korean Adolescents. J. Adolesc. Health 2016, 59, 668–673. [Google Scholar] [CrossRef]
- Tran, T.; Nguyen, D.; Nguyen, A.; Golen, E. Sentiment Analysis of Marijuana Content via Facebook Emoji-Based Reactions. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ward, P.J.; Rock, P.J.; Slavova, S.; Young, A.M.; Bunn, T.L.; Kavuluru, R. Enhancing timeliness of drug overdose mortality surveillance: A machine learning approach. PLoS ONE 2019, 14, e0223318. [Google Scholar] [CrossRef]
- Zucco, C.; Calabrese, B.; Cannataro, M. Sentiment analysis and affective computing for depression monitoring. In Proceedings of the 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Kansas City, MO, USA, 13–16 November 2017; pp. 1988–1995. [Google Scholar] [CrossRef]
- Adrover, C.; Bodnar, T.; Huang, Z.; Telenti, A.; Salathé, M. Identifying Adverse Effects of HIV Drug Treatment and Associated Sentiments Using Twitter. JMIR Public Health Surveill. 2015, 1, 10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akay, A.; Dragomir, A.; Erlandsson, B.E.; Akay, M. Assessing anti-depressants using intelligent data monitoring and mining of online fora. IEEE J. Biomed. Health Inform. 2016, 20, 977–986. [Google Scholar] [CrossRef] [PubMed]
- Dai, H.J.; Touray, M.; Jonnagaddala, J.; Syed-Abdul, S. Feature Engineering for Recognizing Adverse Drug Reactions from Twitter Posts. Information 2016, 7, 27. [Google Scholar] [CrossRef] [Green Version]
- Dai, H.J.; Wang, C.K. Classifying Adverse Drug Reactions from Imbalanced Twitter Data. Int. J. Med. Inform. 2019, 129, 122–132. [Google Scholar] [CrossRef] [PubMed]
- Gräßer, F.; Kallumadi, S.; Malberg, H.; Zaunseder, S. Aspect-Based Sentiment Analysis of Drug Reviews Applying Cross-Domain and Cross-Data Learning. In Proceedings of the 2018 International Conference on Digital Health, DH ’18, Lyon, France, 23–26 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 121–125. [Google Scholar] [CrossRef]
- Katragadda, S.; Karnati, H.; Pusala, M.; Raghavan, V.; Benton, R. Detecting Adverse Drug Effects Using Link Classification on Twitter Data. In Proceedings of the 2015 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Washington, DC, USA, 9–12 November 2015; pp. 675–679. [Google Scholar] [CrossRef]
- Lin, W.S.; Dai, H.J.; Jonnagaddala, J.; Chang, N.W.; Jue, T.R.; Iqbal, U.; Shao, J.Y.H.; Chiang, I.J.; Li, Y.C. Utilizing different word representation methods for twitter data in adverse drug reactions extraction. In Proceedings of the 2015 Conference on Technologies and Applications of Artificial Intelligence (TAAI), Tainan, Taiwan, 20–22 November 2015; pp. 260–265. [Google Scholar] [CrossRef]
- Mishra, A.; Malviya, A.; Aggarwal, S. Towards Automatic Pharmacovigilance: Analysing Patient Reviews and Sentiment on Oncological Drugs. In Proceedings of the 2015 IEEE 15th International Conference on Data Mining Workshops, Atlantic City, NJ, USA, 14–17 November 2015; pp. 1402–1409. [Google Scholar] [CrossRef]
- Nikfarjam, A.; Sarker, A.; O’Connor, K.; Ginn, R.; Gonzalez, G. Pharmacovigilance from social media: Mining adverse drug reaction mentions using sequence labeling with word embedding cluster features. J. Am. Med. Inform. Assoc. 2015, 22, 671–681. [Google Scholar] [CrossRef] [Green Version]
- Ru, B.; Harris, K.; Yao, L. A Content Analysis of Patient-Reported Medication Outcomes on Social Media. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop, Atlantic City, NJ, USA, 14–17 November 2015; pp. 472–479. [Google Scholar] [CrossRef]
- Wu, L.; Moh, T.S.; Khuri, N. Twitter Opinion Mining for Adverse Drug Reactions. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 1570–1574. [Google Scholar] [CrossRef]
- Mikalef, P.; Pappas, I.O.; Krogstie, J.; Pavlou, P.A. Big data and business analytics: A research agenda for realizing business value. Inf. Manag. 2020, 57, 103237. [Google Scholar] [CrossRef]
- Tekin, M.; Etlioğlu, M.; Koyuncuoğlu, Ö.; Tekin, E. Data Mining in Digital Marketing. In Proceedings of the 2018 International Symposium for Production Research, Vienna, Austria, 28–31 August 2018; Durakbasa, N.M., Gencyilmaz, M.G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 44–61. [Google Scholar]
- Wall, J.; Krummel, T. The digital surgeon: How big data, automation, and artificial intelligence will change surgical practice. J. Pediatr. Surg. 2020, 55, 47–50. [Google Scholar] [CrossRef]
- Gandomi, A.; Haider, M. Beyond the hype: Big data concepts, methods, and analytics. Int. J. Inf. Manag. 2015, 35, 137–144. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Z.; Shi, H.; Wu, Y.; Hong, Z. Survey on Natural Language Processing Techniques in Bioinformatics. Comput. Math. Methods Med. 2015, 2015, 674296. [Google Scholar] [CrossRef] [Green Version]
- Iglesias, J.A.; Tiemblo, A.; Ledezma, A.; Sanchis, A. Web news mining in an evolving framework. Inf. Fusion 2016, 28, 90–98. [Google Scholar] [CrossRef]
- Kennedy, H.; Elgesem, D.; Miguel, C. On fairness: User perspectives on social media data mining. Converg. Int. J. Res. New Media Technol. 2015, 23, 270–288. [Google Scholar] [CrossRef]
- Szpakowicz, S.; Feldman, A.; Kazantseva, A. Editorial: Computational Linguistics and Literature. Front. Digit. Humanit. 2018, 5, 1–2. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J.J. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 3rd ed.; Stanford University: Stanford, CA, USA, 2019. [Google Scholar]
- Rizk, A.; Elragal, A. Data science: Developing theoretical contributions in information systems via text analytics. J. Big Data 2020, 7, 7. [Google Scholar] [CrossRef]
- Liao, S.H.; Chu, P.H.; Hsiao, P.Y. Data mining techniques and applications—A decade review from 2000 to 2011. Expert Syst. Appl. 2012, 39, 11303–11311. [Google Scholar] [CrossRef]
- Sunikka, A.; Bragge, J. Applying text-mining to personalization and customization research literature—Who, what and where? Expert Syst. Appl. 2012, 39, 10049–10058. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Zhai, C. A Survey of Text Clustering Algorithms. In Mining Text Data; Springer: New York, NY, USA, 2012; pp. 77–128. [Google Scholar]
- Lu, Y.; Zhang, P.; Liu, J.; Li, J.; Deng, S. Health-Related Hot Topic Detection in Online Communities Using Text Clustering. PLoS ONE 2013, 8, e56221. [Google Scholar] [CrossRef] [PubMed]
- Sadiq, A.T.; Abdullah, S.M. Hybrid Intelligent Techniques for Text Categorization. Int. J. Adv. Comput. Sci. Appl. 2014, 2, 23–40. [Google Scholar]
- Tan, A. Text Mining: The State of the Art and the Challenges. In Proceedings of the PAKDD 1999 Workshop on Knowledge Discovery from Advanced Databases, Beijing, China, 26–28 April 1999; pp. 65–70. [Google Scholar]
- Nassirtoussi, A.K.; Aghabozorgi, S.; Wah, T.Y.; Ngo, D.C.L. Text mining for market prediction: A systematic review. Expert Syst. Appl. 2014, 41, 7653–7670. [Google Scholar] [CrossRef]
- Oberreuter, G.; Velsquez, J.D. Text mining applied to plagiarism detection: The use of words for detecting deviations in the writing style. Expert Syst. Appl. 2013, 40, 3756–3763. [Google Scholar] [CrossRef]
- Liberati, A.; Altman, D.G.; Tetzlaff, J.; Mulrow, C.; Gøtzsche, P.C.; Ioannidis, J.P.A.; Clarke, M.; Devereaux, P.J.; Kleijnen, J.; Moher, D. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate healthcare interventions: Explanation and elaboration. BMJ 2009, 339, b2700. [Google Scholar] [CrossRef] [Green Version]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; The, P.G. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giustini, D.; Boulos, M.N.K. Google Scholar is not enough to be used alone for systematic reviews. Online J. Public Health Inform. 2013, 5, 214. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bramer, W.M.; Giustini, D.; de Jonge, G.B.; Holland, L.; Bekhuis, T. De-duplication of database search results for systematic reviews in EndNote. J. Med. Libr. Assoc. JMLA 2016, 104, 240–243. [Google Scholar] [CrossRef] [PubMed]
- Kampmeijer, R.; Pavlova, M.; Tambor, M.; Golinowska, S.; Groot, W. The use of e-health and m-health tools in health promotion and primary prevention among older adults: A systematic literature review. BMC Health Serv. Res. 2016, 16, 290. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hsieh, H.F.; Shannon, S.E. Three Approaches to Qualitative Content Analysis. Qual. Health Res. 2005, 15, 1277–1288. [Google Scholar] [CrossRef] [PubMed]
- Bian, J.; Topaloglu, U.; Yu, F. Towards Large-Scale Twitter Mining for Drug-Related Adverse Events. In Proceedings of the 2012 International Workshop on Smart Health and Wellbeing, SHB ’12, Maui, HI, USA, 29 October 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 25–32. [Google Scholar] [CrossRef] [Green Version]
- Ginn, R.; Pimpalkhute, P.; Nikfarjam, A.; Patki, A.; O’Connor, K.; Sarker, A.; Smith, K.; Gonzalez, G. Mining Twitter for adverse drug reaction mentions: A corpus and classification benchmark. In Proceedings of the Fourth Workshop on Building and Evaluating Resources for Health and Biomedical Text Processing, Reykjavik, Iceland, 31 May 2014; pp. 1–8. [Google Scholar]
- Sampathkumar, H.; Chen, X.W.; Luo, B. Mining Adverse Drug Reactions from online healthcare forums using Hidden Markov Model. BMC Med. Inform. Decis. Mak. 2014, 14, 91. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Hripcsak, G.; Markatou, M.; Friedman, C. Active Computerized Pharmacovigilance Using Natural Language Processing, Statistics, and Electronic Health Records: A Feasibility Study. J. Am. Med. Inform. Assoc. 2009, 16, 328–337. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.C.; Yang, H.; Jiang, L.; Zhang, M. Social Media Mining for Drug Safety Signal Detection. In Proceedings of the 2012 International Workshop on Smart Health and Wellbeing, SHB ’12, Maui, HI, USA, 29 October 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 33–40. [Google Scholar] [CrossRef]
| Authors | Data Source | Sample Size | Horizon of Data Collection | Software Used | Techniques and Classifiers Used | Outcome | Result | Description of Result |
|---|---|---|---|---|---|---|---|---|
| [31] | Social media | Twitter.com: 1642 tweets | 3 years | Toolkit for Multivariate Analysis | Artificial Neural Networks (ANN), Boosted Decision Trees with AdaBoost (BDT), Boosted Decision Trees with Bagging (BDTG), Sentiment Analysis, Support Vector Machines (SVM) | Reported ADRs for HIV treatment | Positive | Reported adverse effects are consistent with well-recognized toxicities. |
| [32] | Forums | DepressionForums.org: 7726 posts | 10 years | General Architecture for Text Engineering (GATE), NLTK Toolkit within MATLAB, RapidMiner | Hyperlink-Induced Topic Search (HITS), k-Means Clustering, Network Analysis, Term-Frequency-Inverse Document Frequency (TF-IDF) | User sentiment on depression drugs | Positive | Natural language processing is suitable to extract information on ADRs concerning depression. |
| [66] | Social media | Twitter.com: 2,102,176,189 tweets | 1 year | Apache Lucene | MetaMap, Support Vector Machines (SVM) | Reported ADRs for cancer | Neutral | Classification models had limited performance. Adverse events related to cancer drugs can potentially be extracted from tweets. |
| [33] | Social media | Twitter.com: 6528 tweets | Unknown | GENIA tagger, Hunspell, Snowball stemmer, Stanford Topic Modelling Toolbox, Twokenizer | Backward/Forward Sequential Feature Selection (BSFS/FSFS) Algorithm, k-Means Clustering, Sentiment Analysis, Support Vector Machines (SVM) | Reported ADRs | Positive | ADRs were identified reasonably well. |
| [34] | Social media | Twitter.com: 32,670 tweets | Unknown | Hunspell, Twitter tokenizer | Term Frequency-Inverse Document Frequency (TF-IDF) | Reported ADRs | Neutral | ADRs were not identified very well. |
| [67] | Social media | Twitter.com: 10,822 tweets | Unknown | Unknown | Naive Bayes (NB), Natural Language Processing (NLP), Support Vector Machines (SVM) | Reported ADRs | Positive | ADRs were identified well. |
| [35] | Drug reviews | Drugs.com, Drugslib.com: 218,614 reviews | Unknown | BeautifulSoup | Logistic Regression, Sentiment Analysis | Patient satisfaction with drugs, Reported ADRs, Reported effectiveness of drugs | Positive | Classification results were very good. |
| [36] | Social media | Twitter.com: 172,800 tweets | 1 year | Twitter4J | Decision Trees, Medical Profile Graph, Natural Language Processing (NLP) | Reported ADRs | Positive | Building a medical profile of users enables the accurate detection of adverse drug events. |
| [37] | Social media | Twitter.com: 1245 tweets | Unknown | CRF++ Toolkit, GENIA tagger, Hunspell, Twitter REST API, Twokenizer | Natural Language Processing (NLP) | Reported ADRs | Positive | ADRs were identified reasonably well. |
| [38] | Drug reviews | WebMD.com: Unknown | Unknown | SentiWordNet, WordNet | Sentiment Analysis, Support Vector Machines (SVM), Term document Matrix (TDM) | User sentiment on cancer drugs | Positive | Sentiment on ADRs was identified reasonably well. |
| [39] | Drug reviews, Social media | DailyStrength.org: 6279 reviews, Twitter.com: 1784 tweets | Unknown | Unknown | ARDMine, Lexicon-based, MetaMap, Support Vector Machines (SVM) | Reported ADRs | Positive | ADRs were identified very well. |
| [40] | Drug reviews, Social media | PatientsLikeMe.com: 796 reviews, Twitter.com: 39,127 tweets, WebMD.com: 2567 reviews, YouTube.com: 42,544 comments | Not applicable | Deeply Moving | Unknown | Patient-reported medication outcomes | Positive | Social media serves as a new data source to extract patient-reported medication outcomes. |
| [68] | Forums | Medications.com: 8065 posts, SteadyHealth.com: 11,878 | Not applicable | Java Hidden Markov Model library, jsoup | Hidden Markov Model (HMM), Natural Language Processing (NLP) | Reported ADRs | Positive | Reported adverse effects are consistent with well-recognized side-effects. |
| [69] | Electronic Health Record (EHR) | 25,074 discharge summaries | Not applicable | MedLEE | Unknown | Reported ADRs | Positive | Reported adverse effects are consistent with well-recognized toxicities (recall: 75%; precision: 31%). |
| [41] | Social media | Twitter.com: 3251 tweets | Not applicable | AFINN, Bing Liu sentiment words, Multi-Perspective Question Answering (MPQA), SentiWordNet, TextBlob, Tweepy, WEKA | MetaMap, Naive Bayes (NB), Natural Language Processing (NLP), Sentiment Analysis, Support Vector Machines (SVM) | Reported ADRs | Positive | Several well-known ADRs were identified. |
| [70] | Forums | MedHelp.org: 6244 discussion threads | Unknown | Unknown | Association Mining | Reported ADRs | Positive | ADRs were identified. |
| Category | Sub-Categories | n (%) | References |
|---|---|---|---|
| Year of publication | 2009 | 1 (6) | [69] |
| 2010 | 0 (0) | - | |
| 2011 | 0 (0) | - | |
| 2012 | 2 (13) | [66,70] | |
| 2013 | 0 (0) | - | |
| 2014 | 2 (13) | [67,68] | |
| 2015 | 7 (43) | [31,36,37,38,39,40,41] | |
| 2016 | 2 (13) | [32,33] | |
| 2017 | 0 (0) | - | |
| 2018 | 1 (6) | [35] | |
| 2019 | 1 (6) | [34] | |
| Type of drugs | Asthma | 1 (5) | [40] |
| Cancer | 2 (11) | [38,66] | |
| Cystic fibrosis | 1 (5) | [40] | |
| Depression | 1 (5) | [32] | |
| HIV | 1 (5) | [31] | |
| Rheumatoid arthritis | 1 (5) | [40] | |
| Type 2 diabetes | 1 (5) | [40] | |
| Unknown | 11 (58) | [33,34,35,36,37,39,41,67,68,69,70] | |
| Data source | Drug reviews | 4 (22) | [35,38,39,40] |
| Electronic Health Records (EHR) | 1 (6) | [69] | |
| Forums | 3 (17) | [32,68,70] | |
| Social media | 10 (56) | [31,33,34,36,37,39,40,41,66,67] | |
| Sample size | Less than 5000 | 3 (19) | [31,37,41] |
| 5000 to 9999 | 4 (25) | [32,33,39,70] | |
| 10,000 to 14,999 | 1 (6) | [67] | |
| 15,000 to 19,999 | 1 (6) | [68] | |
| 20,000 or more | 6 (38) | [34,35,36,40,66,69] | |
| Unknown | 1 (6) | [38] | |
| Users | HIV-infected persons undergoing drug treatment | 1 (6) | [31] |
| Unknown | 15 (94) | [32,33,34,35,36,37,38,39,40,41,66,67,68,69,70] | |
| Unique users | Less than 5000 | 2 (13) | [31,36] |
| 5000 to 9999 | 0 (0) | - | |
| 10,000 to 14,999 | 0 (0) | - | |
| 15,000 to 19,999 | 0 (0) | - | |
| 20,000 or more | 0 (0) | - | |
| Unknown | 14 (88) | [32,33,34,35,37,38,39,40,41,66,67,68,69,70] | |
| Origin of users | Canada | 1 (5) | [31] |
| South Africa | 1 (5) | [31] | |
| United Kingdom | 1 (5) | [31] | |
| United States | 1 (5) | [31] | |
| Unknown | 15 (79) | [32,33,34,35,36,37,38,39,40,41,66,67,68,69,70] | |
| Average number of followers | Less than 5000 | 1 (6) | [31] |
| 5000 to 9999 | 0 (0) | - | |
| 10,000 to 14,999 | 0 (0) | - | |
| 15,000 to 19,999 | 0 (0) | - | |
| 20,000 or more | 0 (0) | - | |
| Unknown | 15 (94) | [32,33,34,35,36,37,38,39,40,41,66,67,68,69,70] | |
| Years of data collection | 2004 | 2 (6) | [32,69] |
| 2005 | 1 (3) | [32] | |
| 2006 | 1 (3) | [32] | |
| 2007 | 1 (3) | [32] | |
| 2008 | 1 (3) | [32] | |
| 2009 | 2 (6) | [32,66] | |
| 2010 | 3 (10) | [31,32,66] | |
| 2011 | 2 (6) | [31,32] | |
| 2012 | 3 (10) | [31,32,68] | |
| 2013 | 2 (6) | [31,32] | |
| 2014 | 3 (10) | [32,36,40] | |
| 2015 | 2 (6) | [36,41] | |
| Unknown | 8 (26) | [33,34,35,37,38,39,67,70] | |
| Horizon of data collection | 1 year | 2 (13) | [36,66] |
| 2 to 5 years | 1 (6) | [31] | |
| 6 to 10 years | 1 (6) | [32] | |
| Not applicable | 4 (25) | [40,41,68,69] | |
| Unknown | 8 (50) | [33,34,35,37,38,39,67,70] | |
| Software used | AFINN | 1 (3) | [41] |
| Apache Lucene | 1 (3) | [66] | |
| BeautifulSoup | 1 (3) | [35] | |
| Bing Liu sentiment words | 1 (3) | [41] | |
| CRF++ toolkit | 1 (3) | [37] | |
| Deeply Moving | 1 (3) | [40] | |
| General Architecture for Text Engineering (GATE) | 1 (3) | [32] | |
| GENIA tagger | 2 (6) | [33,37] | |
| Hunspell | 3 (9) | [33,34,37] | |
| Java Hidden Markov Model library | 1 (3) | [68] | |
| jsoup | 1 (3) | [68] | |
| MedLEE | 1 (3) | [69] | |
| Multi-Perspective Question Answering (MPQA) | 1 (3) | [41] | |
| NLTK toolkit within MATLAB | 1 (3) | [32] | |
| RapidMiner | 1 (3) | [32] | |
| SentiWordNet | 2 (6) | [38,41] | |
| Snowball stemmer | 1 (3) | [33] | |
| Stanford Topic Modelling Toolbox | 1 (3) | [33] | |
| TextBlob | 1 (3) | [41] | |
| Toolkit for Multivariate Analysis | 1 (3) | [31] | |
| Tweepy | 1 (3) | [41] | |
| Twitter REST API | 1 (3) | [37] | |
| Twitter tokenizer | 1 (3) | [34] | |
| Twitter4J | 1 (3) | [36] | |
| Twokenizer | 2 (6) | [33,37] | |
| Unknown | 3 (9) | [39,67,70] | |
| WEKA | 1 (3) | [41] | |
| WordNet | 1 (3) | [38] | |
| Techniques and classifiers used | ARDMine | 1 (2) | [39] |
| Artificial Neural Networks (ANN) | 1 (2) | [31] | |
| Association Mining | 1 (2) | [70] | |
| Backward/forward sequential feature selection (BSFS/FSFS) algorithm | 1 (2) | [33] | |
| Boosted Decision Trees with AdaBoost (BDT) | 1 (2) | [31] | |
| Boosted Decision Trees with Bagging (BDTG) | 1 (2) | [31] | |
| Decision Trees | 1 (2) | [36] | |
| Hidden Markov Model (HMM) | 1 (2) | [68] | |
| Hyperlink-Induced Topic Search (HITS) | 1 (2) | [32] | |
| k-Means Clustering | 2 (5) | [32,33] | |
| Lexicon-based | 1 (2) | [39] | |
| Logistic Regression | 1 (2) | [35] | |
| Medical Profile Graph | 1 (2) | [36] | |
| MetaMap | 3 (7) | [39,41,66] | |
| Naive Bayes (NB) | 2 (5) | [41,67] | |
| Natural Language Processing (NLP) | 5 (12) | [36,37,41,67,68] | |
| Network Analysis | 1 (2) | [32] | |
| Sentiment Analysis | 5 (12) | [31,33,35,38,41] | |
| Support Vector Machines (SVM) | 7 (17) | [31,33,38,39,41,66,67] | |
| Term Document Matrix (TDM) | 1 (2) | [38] | |
| Term-Frequency-Inverse Document Frequency (TF-IDF) | 2 (5) | [32,34] | |
| Unknown | 2 (5) | [40,69] | |
| Outcome | Patient satisfaction with drugs | 1 (6) | [35] |
| Patient-reported medication outcomes | 1 (6) | [40] | |
| Reported ADRs | 11 (61) | [33,34,35,36,37,39,41,67,68,69,70] | |
| Reported ADRs for cancer | 1 (6) | [66] | |
| Reported ADRs for HIV treatment | 1 (6) | [31] | |
| Reported effectiveness of drugs | 1 (6) | [35] | |
| User sentiment on depression drugs | 1 (6) | [32] | |
| User sentiment on cancer drugs | 1 (6) | [38] | |
| Drugs studied | Less than 5 | 1 (6) | [31] |
| 5 to 9 | 4 (25) | [32,41,66,69] | |
| 10 to 14 | 2 (13) | [40,70] | |
| 15 to 19 | 0 (0) | - | |
| 20 or more | 5 (31) | [36,38,39,67,68] | |
| Unknown | 4 (25) | [33,34,35,37] | |
| Result | Positive | 14 (88) | [31,32,33,35,36,37,38,39,40,41,67,68,69,70] |
| Neutral | 2 (13) | [34,66] | |
| Negative | 0 (0) | - | |
| Reliability | Low | 0 (0) | - |
| Medium | 16 (100) | [31,32,33,34,35,36,37,38,39,40,41,66,67,68,69,70] | |
| High | 0 (0) | - | |
| Validity | Low | 0 (0) | - |
| Medium | 16 (100) | [31,32,33,34,35,36,37,38,39,40,41,66,67,68,69,70] | |
| High | 0 (0) | - |
| Category | Sub-Categories | Positive (n %) | Neutral (n %) | Negative (n %) | References |
|---|---|---|---|---|---|
| Type of drugs | Asthma | 1 (5) | 0 (0) | 0 (0) | [40] |
| Cancer | 1 (5) | 1 (5) | 0 (0) | [38,66] | |
| Cystic fibrosis | 1 (5) | 0 (0) | 0 (0) | [40] | |
| Depression | 1 (5) | 0 (0) | 0 (0) | [32] | |
| HIV | 1 (5) | 0 (0) | 0 (0) | [31] | |
| Rheumatoid arthritis | 1 (5) | 0 (0) | 0 (0) | [40] | |
| Type 2 diabetes | 1 (5) | 0 (0) | 0 (0) | [40] | |
| Unknown | 10 (53) | 1 (5) | 0 (0) | [33,34,35,36,37,39,41,67,68,69,70] | |
| Data source | Drug reviews | 4 (22) | 0 (0) | 0 (0) | [35,38,39,40] |
| Electronic Health Records (EHR) | 1 (6) | 0 (0) | 0 (0) | [69] | |
| Forums | 3 (17) | 0 (0) | 0 (0) | [32,68,70] | |
| Social media | 8 (44) | 2 (11) | 0 (0) | [31,33,34,36,37,39,40,41,66,67] | |
| Origin of users | Canada | 1 (5) | 0 (0) | 0 (0) | [31] |
| South Africa | 1 (5) | 0 (0) | 0 (0) | [31] | |
| United Kingdom | 1 (5) | 0 (0) | 0 (0) | [31] | |
| United States | 1 (5) | 0 (0) | 0 (0) | [31] | |
| Unknown | 13 (68) | 2 (11) | 0 (0) | [32,33,34,35,36,37,38,39,40,41,66,67,68,69,70] | |
| Horizon of data collection | 1 year | 1 (6) | 1 (6) | 0 (0) | [36,66] |
| 2 to 5 years | 1 (6) | 0 (0) | 0 (0) | [31] | |
| 6 to 10 years | 1 (6) | 0 (0) | 0 (0) | [32] | |
| Not applicable | 4 (25) | 0 (0) | 0 (0) | [40,41,68,69] | |
| Unknown | 7 (44) | 1 (6) | 0 (0) | [33,34,35,37,38,39,67,70] | |
| Outcome | Patient satisfaction with drugs | 1 (6) | 0 (0) | 0 (0) | [35] |
| Patient-reported medication outcomes | 1 (6) | 0 (0) | 0 (0) | [40] | |
| Reported ADRs | 10 (56) | 1 (6) | 0 (0) | [33,34,35,36,37,39,41,67,68,69,70] | |
| Reported ADRs for cancer | 0 (0) | 1 (6) | 0 (0) | [66] | |
| Reported ADRs for HIV treatment | 1 (6) | 0 (0) | 0 (0) | [31] | |
| Reported effectiveness of drugs | 1 (6) | 0 (0) | 0 (0) | [35] | |
| User sentiment on depression drugs | 1 (6) | 0 (0) | 0 (0) | [32] | |
| User sentiment on cancer drugs | 1 (6) | 0 (0) | 0 (0) | [38] | |
| Drugs studied | Less than 5 | 1 (6) | 0 (0) | 0 (0) | [31] |
| 5 to 9 | 3 (19) | 1 (6) | 0 (0) | [32,41,66,69] | |
| 10 to 14 | 2 (13) | 0 (0) | 0 (0) | [40,70] | |
| 15 to 19 | 0 (0) | 0 (0) | 0 (0) | - | |
| 20 or more | 5 (31) | 0 (0) | 0 (0) | [36,38,39,67,68] | |
| Unknown | 3 (19) | 1 (6) | 0 (0) | [33,34,35,37] | |
| Reliability | Low | 0 (0) | 0 (0) | 0 (0) | - |
| Medium | 14 (88) | 2 (13) | 0 (0) | [31,32,33,34,35,36,37,38,39,40,41,66,67,68,69,70] | |
| High | 0 (0) | 0 (0) | 0 (0) | - | |
| Validity | Low | 0 (0) | 0 (0) | 0 (0) | - |
| Medium | 14 (88) | 2 (13) | 0 (0) | [31,32,33,34,35,36,37,38,39,40,41,66,67,68,69,70] | |
| High | 0 (0) | 0 (0) | 0 (0) | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pilipiec, P.; Liwicki, M.; Bota, A. Using Machine Learning for Pharmacovigilance: A Systematic Review. Pharmaceutics 2022, 14, 266. https://doi.org/10.3390/pharmaceutics14020266
Pilipiec P, Liwicki M, Bota A. Using Machine Learning for Pharmacovigilance: A Systematic Review. Pharmaceutics. 2022; 14(2):266. https://doi.org/10.3390/pharmaceutics14020266
Chicago/Turabian StylePilipiec, Patrick, Marcus Liwicki, and András Bota. 2022. "Using Machine Learning for Pharmacovigilance: A Systematic Review" Pharmaceutics 14, no. 2: 266. https://doi.org/10.3390/pharmaceutics14020266
APA StylePilipiec, P., Liwicki, M., & Bota, A. (2022). Using Machine Learning for Pharmacovigilance: A Systematic Review. Pharmaceutics, 14(2), 266. https://doi.org/10.3390/pharmaceutics14020266