Inversion Study of Nitrogen Content of Hyperspectral Apple Canopy Leaves Using Optimized Least Squares Support Vector Machine Approach



Abstract
1. Introduction
2. Materials and Methods
2.1. Overview of the Study Area
2.2. Data Acquisition
2.2.1. Apple Canopy Leaf Hyperspectral Data Acquisition
2.2.2. Determination of Nitrogen Concentration in Apple Canopy Leaves
2.2.3. Spectral Data Preprocessing
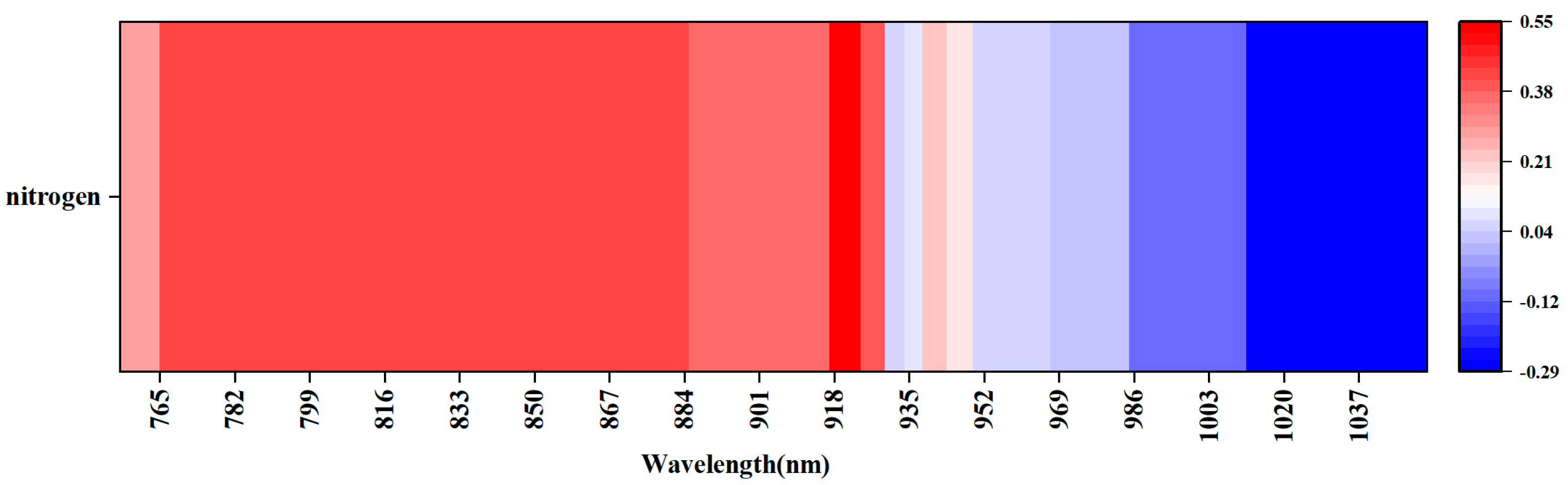
2.3. Selection of Spectral Characteristics of Apple Leaves
2.4. Algorithm Fundamentals
2.4.1. Long- and Short-Term Memory Networks
2.4.2. Support Vector Regression
2.4.3. Least Squares Support Vector Machine Algorithm
2.4.4. Frost and Ice Optimization Algorithm (RIME)
2.5. Evaluation Metrics
3. Results
3.1. Selection of Features
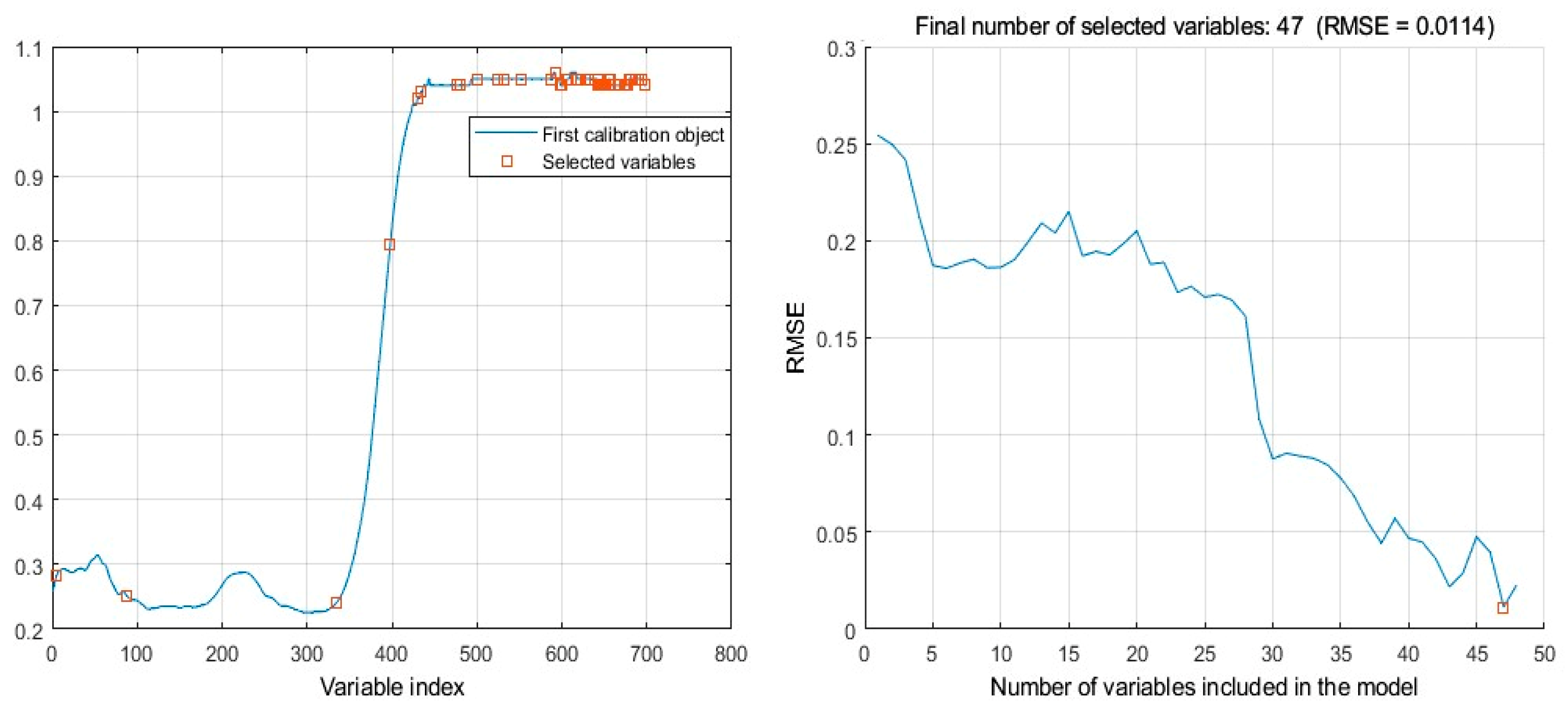
3.1.1. Selection of Features by Continuous Projection Method
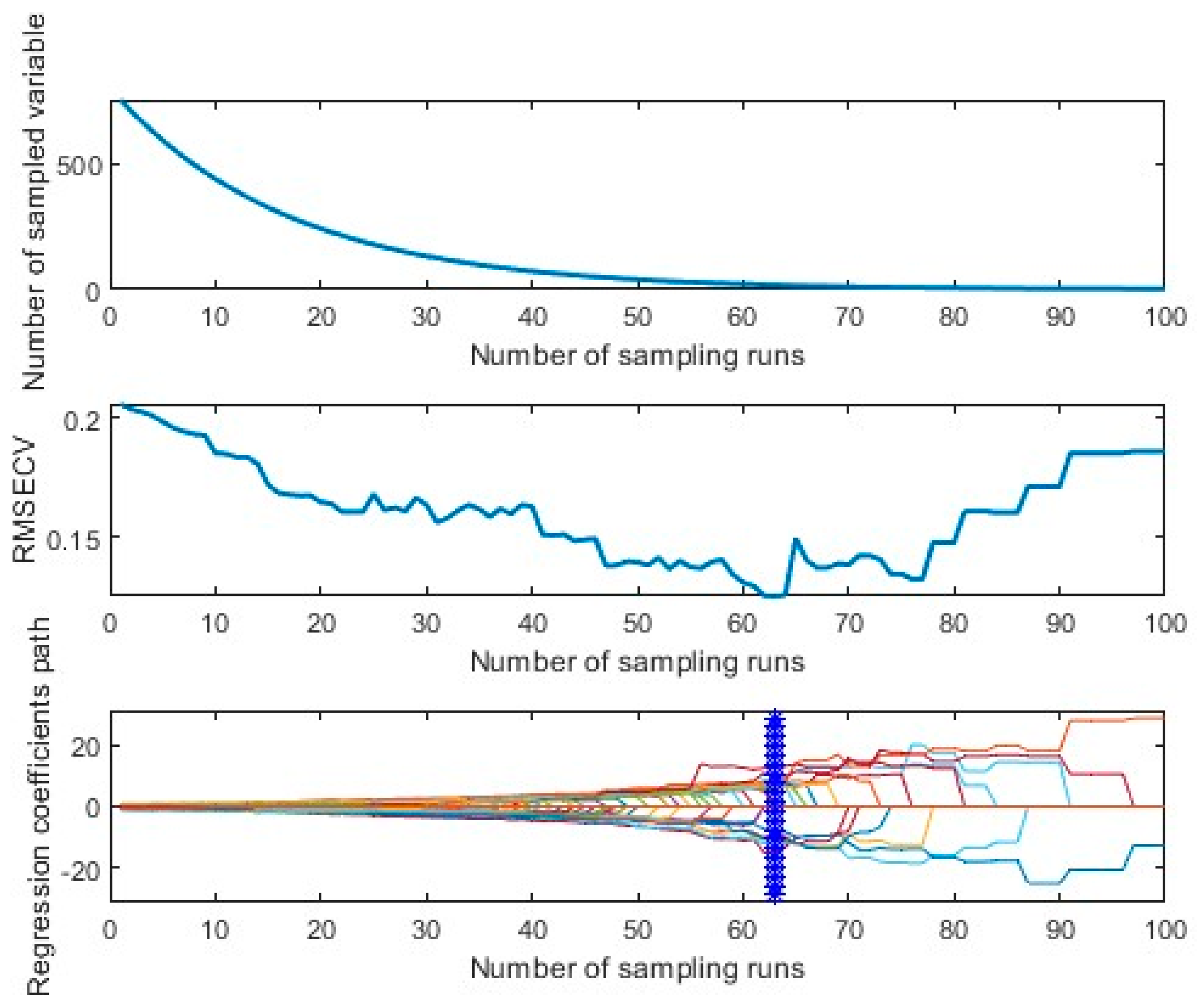
3.1.2. Competitive Adaptive Re-Weighting Method–Partial Least Squares
3.2. Inverse Modeling and Analysis of the Apple Leaf Nitrogen Content
3.2.1. Inverse Modeling Based on the Long Short-Term Memory Network, Support Vector Regression, and the RIME Optimization Algorithm Based on Least Squares Support Vector Machine Regression
3.2.2. Inverse Modeling Based on Long- and Short-Term Memory Networks
3.2.3. Inverse Modeling Based on Support Vector Regression
3.2.4. Inverse Modeling Based on the RIME Optimization Algorithm Based on Least Squares Support Vector Machine Regression
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qu, Z.; Zhou, G. Possible impact of climate change on the quality of apples from the major producing areas of China. Atmosphere 2016, 7, 113. [Google Scholar] [CrossRef]
- Cao, H.; Wang, H.; Li, Y.; Hamani, A.K.M.; Zhang, N.; Wang, X.; Gao, Y. Evapotranspiration partition and dual crop coefficients in apple orchard with dwarf stocks and dense planting in arid region, Aksu oasis, southern Xinjiang. Agriculture 2021, 11, 1167. [Google Scholar] [CrossRef]
- Colpaert, B.; Steppe, K.; Gomand, A.; Vanhoutte, B.; Remy, S.; Boeckx, P. Experimental approach to assess fertilizer nitrogen use, distribution, and loss in pear fruit trees. Plant Physiol. Biochem. 2021, 165, 207–216. [Google Scholar] [CrossRef] [PubMed]
- Poudel, D.D.; Horwath, W.R.; Mitchell, J.P.; Temple, S.R. Impacts of cropping systems on soil nitrogen storage and loss. Agric. Syst. 2001, 68, 253–268. [Google Scholar] [CrossRef]
- Wrona, D. The influence of nitrogen fertilization on growth, yield and fruit size of ‘Jonagored’apple trees. Acta Sci. Pol. Hortorum Cultus 2011, 10, 3–10. [Google Scholar]
- Anjaneyulu, T.S.R. Formaldehyde Titration Method for the Determination of Ammoniacal Nitrogen in Phosphate Fertilizers. J. Assoc. Off. Anal. Chem. 1975, 58, 1194–1196. [Google Scholar] [CrossRef]
- Sharifi, M.; Zebarth, B.J.; Burton, D.L.; Grant, C.A.; Hajabbasi, M.A.; Abbassi-Kalo, G. Sodium hydroxide direct distillation: A method for estimating total nitrogen in soil. Commun. Soil Sci. Plant Anal. 2009, 40, 2505–2520. [Google Scholar] [CrossRef]
- Ulissi, V.; Antonucci, F.; Benincasa, P.; Farneselli, M.; Tosti, G.; Guiducci, M.; Tei, F.; Costa, C.; Pallottino, F.; Pari, L. Nitrogen concentration estimation in tomato leaves by VIS-NIR non-destructive spectroscopy. Sensors 2011, 11, 6411–6424. [Google Scholar] [CrossRef]
- Wang, J.; Shen, C.; Liu, N.; Jin, X.; Fan, X.; Dong, C.; Xu, Y. Non-destructive evaluation of the leaf nitrogen concentration by in-field visible/near-infrared spectroscopy in pear orchards. Sensors 2017, 17, 538. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.; Wang, J.; Pan, R.; He, F.; Yan, L.; Xiao, J. Rapid detection of total nitrogen content in soil based on hyperspectral technology. Inf. Process. Agric. 2022, 9, 566–574. [Google Scholar] [CrossRef]
- Yuan, Z.; Ye, Y.; Wei, L.; Yang, X.; Huang, C. Study on the optimization of hyperspectral characteristic bands combined with monitoring and visualization of pepper leaf SPAD value. Sensors 2021, 22, 183. [Google Scholar] [CrossRef]
- Chen, X.; Lv, X.; Ma, L.; Chen, A.; Zhang, Q.; Zhang, Z. Optimization and Validation of Hyperspectral Estimation Capability of Cotton Leaf Nitrogen Based on SPA and RF. Remote Sens. 2022, 14, 5201. [Google Scholar] [CrossRef]
- Hu, L.; Yin, C.; Ma, S.; Liu, Z. Rapid detection of three quality parameters and classification of wine based on Vis-NIR spectroscopy with wavelength selection by ACO and CARS algorithms. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2018, 205, 574–581. [Google Scholar] [CrossRef] [PubMed]
- Heylen, R.; Parente, M.; Gader, P. A review of nonlinear hyperspectral unmixing methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1844–1868. [Google Scholar] [CrossRef]
- Miphokasap, P.; Wannasiri, W. Estimations of nitrogen concentration in sugarcane using hyperspectral imagery. Sustainability 2018, 10, 1266. [Google Scholar] [CrossRef]
- Silva, R.; Gomes, V.; Mendes-Faia, A.; Melo-Pinto, P. Using support vector regression and hyperspectral imaging for the prediction of oenological parameters on different vintages and varieties of wine grape berries. Remote Sens. 2018, 10, 312. [Google Scholar] [CrossRef]
- Khan, A.; Vibhute, A.D.; Mali, S.; Patil, C.H. A systematic review on hyperspectral imaging technology with a machine and deep learning methodology for agricultural applications. Ecol. Inform. 2022, 69, 101678. [Google Scholar] [CrossRef]
- Wang, F.; Huang, J.; Wang, Y.; Liu, Z.; Zhang, F. Estimating nitrogen concentration in rape from hyperspectral data at canopy level using support vector machines. Precis. Agric. 2013, 14, 172–183. [Google Scholar] [CrossRef]
- Bruning, B.; Liu, H.; Brien, C.; Berger, B.; Lewis, M.; Garnett, T. The development of hyperspectral distribution maps to predict the content and distribution of nitrogen and water in wheat (Triticum aestivum). Front. Plant Sci. 2019, 10, 1380. [Google Scholar] [CrossRef]
- Guo, J.; Zhang, J.; Xiong, S.; Zhang, Z.; Wei, Q.; Zhang, W.; Feng, W.; Ma, X. Hyperspectral assessment of leaf nitrogen accumulation for winter wheat using different regression modeling. Precis. Agric. 2021, 22, 1634–1658. [Google Scholar] [CrossRef]
- Yu, F.; Feng, S.; Du, W.; Wang, D.; Guo, Z.; Xing, S.; Jin, Z.; Cao, Y.; Xu, T. A study of nitrogen deficiency inversion in rice leaves based on the hyperspectral reflectance differential. Front. Plant Sci. 2020, 11, 573272. [Google Scholar] [CrossRef]
- Azadnia, R.; Rajabipour, A.; Jamshidi, B.; Omid, M. New approach for rapid estimation of leaf nitrogen, phosphorus, and potassium contents in apple-trees using Vis/NIR spectroscopy based on wavelength selection coupled with machine learning. Comput. Electron. Agric. 2023, 207, 107746. [Google Scholar] [CrossRef]
- Gómez-Casero, M.T.; López-Granados, F.; Pena-Barragán, J.M.; Jurado-Expósito, M.; García-Torres, L.; Fernández-Escobar, R. Assessing nitrogen and potassium deficiencies in olive orchards through discriminant analysis of hyperspectral data. J. Am. Soc. Hortic. Sci. 2007, 132, 611–618. [Google Scholar] [CrossRef]
- Somers, B.; Delalieux, S.; Verstraeten, W.W.; Eynde, A.V.; Barry, G.H.; Coppin, P. The contribution of the fruit component to the hyperspectral citrus canopy signal. Photogramm. Eng. Remote Sens. 2010, 76, 37–47. [Google Scholar] [CrossRef]
- Einzmann, K.; Atzberger, C.; Pinnel, N.; Glas, C.; Böck, S.; Seitz, R.; Immitzer, M. Early detection of spruce vitality loss with hyperspectral data: Results of an experimental study in Bavaria, Germany. Remote Sens. Environ. 2021, 266, 112676. [Google Scholar] [CrossRef]
- Jaroonchon, N.; Krisanapook, K.; Phavaphutanon, L. Correlation between pummelo leaf nitrogen concentrations determined by combustion method and Kjeldahl method and their relationship with SPAD values from portable chlorophyll meter. Agric. Nat. Resour. 2010, 44, 800–807. [Google Scholar]
- Kale, K.V.; Solankar, M.M.; Nalawade, D.B.; Dhumal, R.K.; Gite, H.R. A research review on hyperspectral data processing and analysis algorithms. Proc. Natl. Acad. Sci. India Sect. A Phys. Sci. 2017, 87, 541–555. [Google Scholar] [CrossRef]
- Yang, X.; Hong, H.; You, Z.; Cheng, F. Spectral and image integrated analysis of hyperspectral data for waxy corn seed variety classification. Sensors 2015, 15, 15578–15594. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Yu, H.; Guo, L.; Li, J.; Chu, Y.; Tang, Y.; Tang, S.; Wang, F. Accuracy and stability improvement in detecting Wuchang rice adulteration by piece-wise multiplicative scatter correction in the hyperspectral imaging system. Anal. Methods 2018, 10, 3224–3231. [Google Scholar] [CrossRef]
- Wei, X.; He, J.; Zheng, S.; Ye, D. Modeling for SSC and firmness detection of persimmon based on NIR hyperspectral imaging by sample partitioning and variables selection. Infrared Phys. Technol. 2020, 105, 103099. [Google Scholar] [CrossRef]
- Khan, I.H.; Liu, H.; Cheng, T.; Tian, Y.; Cao, Q.; Zhu, Y.; Cao, W.; Yao, X. Detection of wheat powdery mildew based on hyperspectral reflectance through SPA and PLS-LDA. Int. J. Precis. Agric. Aviat. 2020, 3, 13–22. [Google Scholar] [CrossRef]
- Sun, J.; Ma, B.; Dong, J.; Zhu, R.; Zhang, R.; Jiang, W. Detection of internal qualities of hami melons using hyperspectral imaging technology based on variable selection algorithms. J. Food Process Eng. 2017, 40, e12496. [Google Scholar] [CrossRef]
- Zhang, D.; Xu, Y.; Huang, W.; Tian, X.; Xia, Y.; Xu, L.; Fan, S. Nondestructive measurement of soluble solids content in apple using near infrared hyperspectral imaging coupled with wavelength selection algorithm. Infrared Phys. Technol. 2019, 98, 297–304. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Shewalkar, A.; Nyavanandi, D.; Ludwig, S.A. Performance evaluation of deep neural networks applied to speech recognition: RNN, LSTM and GRU. J. Artif. Intell. Soft Comput. Res. 2019, 9, 235–245. [Google Scholar] [CrossRef]
- Farzad, A.; Mashayekhi, H.; Hassanpour, H. A comparative performance analysis of different activation functions in LSTM networks for classification. Neural Comput. Appl. 2019, 31, 2507–2521. [Google Scholar] [CrossRef]
- Huang, S.; Cai, N.; Pacheco, P.P.; Narrandes, S.; Wang, Y.; Xu, W. Applications of support vector machine (SVM) learning in cancer genomics. Cancer Genom. Proteom. 2018, 15, 41–51. [Google Scholar]
- Awad, M.; Khanna, R.; Awad, M.; Khanna, R. Support vector regression. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Apress: New York, NY, USA, 2015; pp. 67–80. [Google Scholar]
- Suykens, J.A.; Lukas, L.; Van Dooren, P.; De Moor, B.; Vandewalle, J. Least squares support vector machine classifiers: A large scale algorithm. In Proceedings of the European Conference on Circuit Theory and Design, ECCTD, Stresa, Italy, 29 August–2 September 1999; pp. 839–842. [Google Scholar]
- Su, H.; Zhao, D.; Heidari, A.A.; Liu, L.; Zhang, X.; Mafarja, M.; Chen, H. RIME: A physics-based optimization. Neurocomputing 2023, 532, 183–214. [Google Scholar] [CrossRef]
- Alva, A.K.; Paramasivam, S.; Hostler, K.H.; Easterwood, G.W.; Southwell, J.E. Effects of nitrogen rates on dry matter and nitrogen accumulation in citrus fruits and fruit yield. J. Plant Nutr. 2001, 24, 561–572. [Google Scholar] [CrossRef]
- Hunt, E.R., Jr.; Doraiswamy, P.C.; McMurtrey, J.E.; Daughtry, C.S.; Perry, E.M.; Akhmedov, B. A visible band index for remote sensing leaf chlorophyll content at the canopy scale. Int. J. Appl. Earth Obs. Geoinf. 2013, 21, 103–112. [Google Scholar] [CrossRef]
- Jayaselan, H.A.J.; Ismail, W.I.W.; Nawi, N.M.; Shariff, A.R.M. Determination of the Optimal Pre-processing Technique for Spectral Data of Oil Palm Leaves with Respect to Nutrient. Pertanika J. Sci. Technol. 2018, 26, 1169–1182. [Google Scholar]
- Shu, M.; Shen, M.; Zuo, J.; Yin, P.; Wang, M.; Xie, Z.; Tang, J.; Wang, R.; Li, B.; Yang, X. The application of UAV-based hyperspectral imaging to estimate crop traits in maize inbred lines. Plant Phenomics 2021, 2021, 9890745. [Google Scholar] [CrossRef]
- Mishra, G.; Panda, B.K.; Ramirez, W.A.; Jung, H.; Singh, C.B.; Lee, S.H.; Lee, I. Research advancements in optical imaging and spectroscopic techniques for nondestructive detection of mold infection and mycotoxins in cereal grains and nuts. Compr. Rev. Food Sci. Food Saf. 2021, 20, 4612–4651. [Google Scholar] [CrossRef]
- Hong, G.; Abd El-Hamid, H.T. Hyperspectral imaging using multivariate analysis for simulation and prediction of agricultural crops in Ningxia, China. Comput. Electron. Agric. 2020, 172, 105355. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Extraction Method Characteristics | Inversion Model | R-Squared | RMSE | ||
|---|---|---|---|---|---|
| Training Set | Test Set | Training Set | Test Set | ||
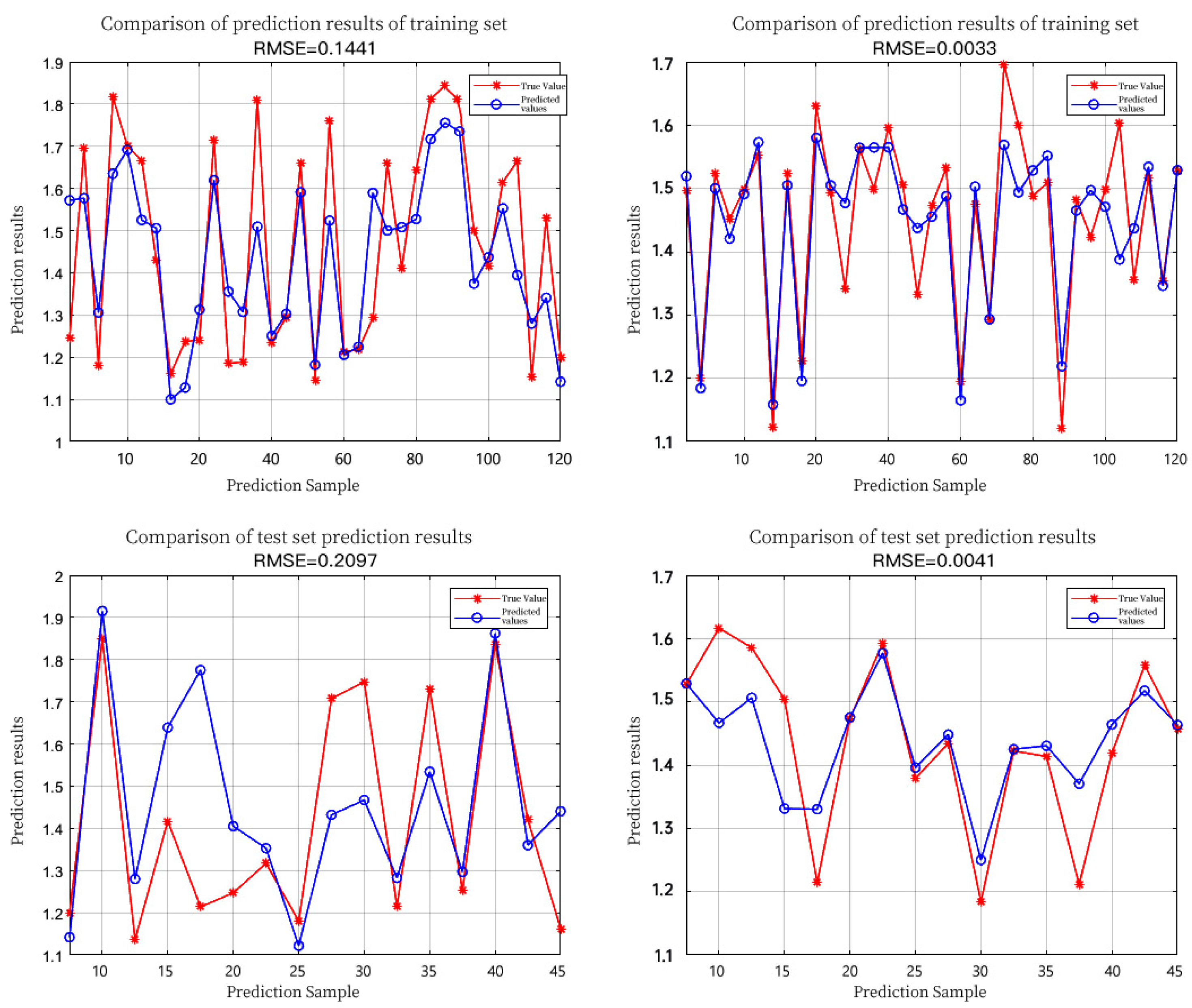
| SPA | LSTM | 0.6506 | 0.3307 | 0.1441 | 0.2097 |
| CARS-PLS | LSTM | 0.7862 | 0.6155 | 0.0033 | 0.0041 |
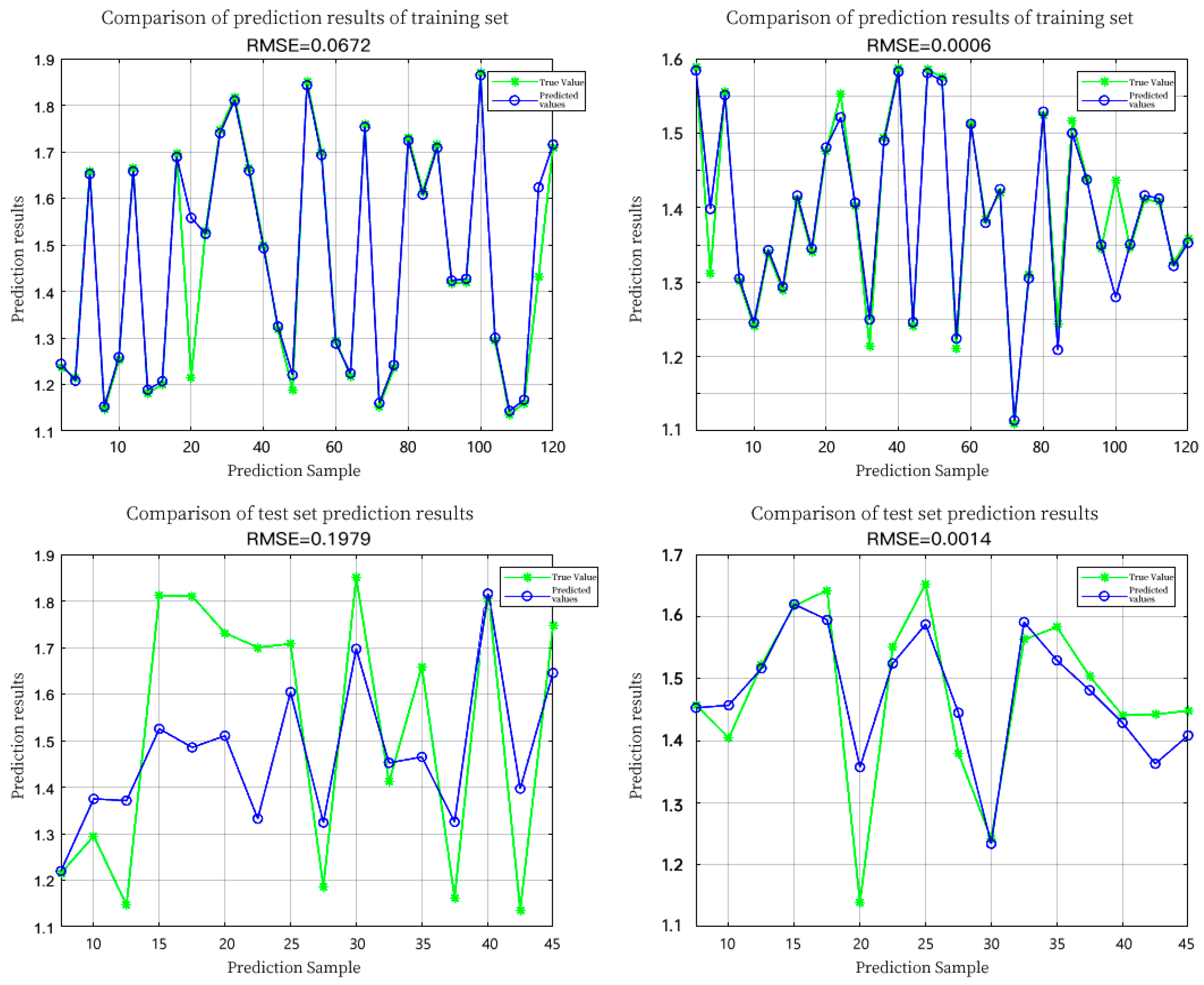
| SPA | SVR | 0.9238 | 0.4966 | 0.0672 | 0.1979 |
| CARS-PLS | SVR | 0.9306 | 0.7468 | 0.0006 | 0.0014 |
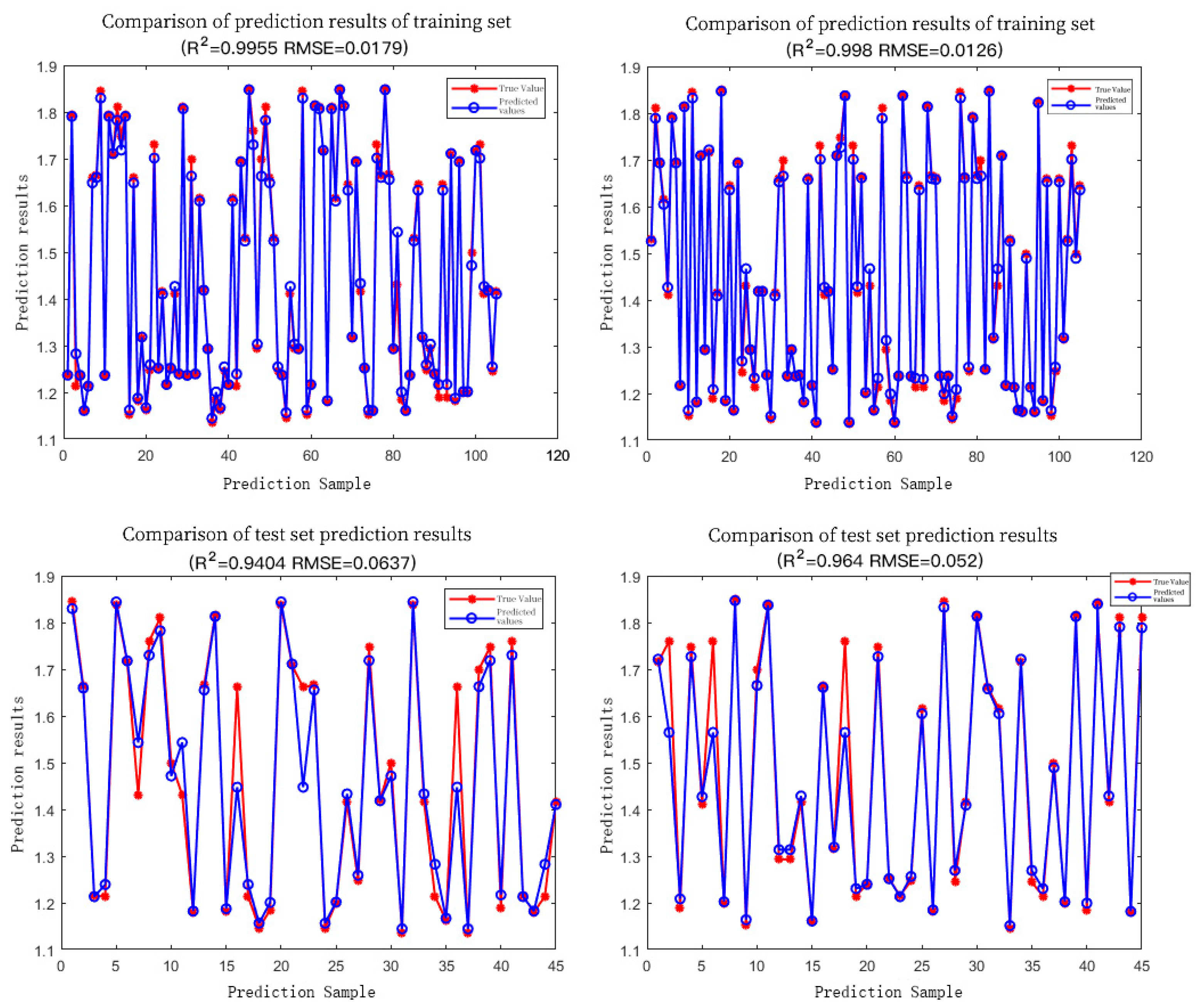
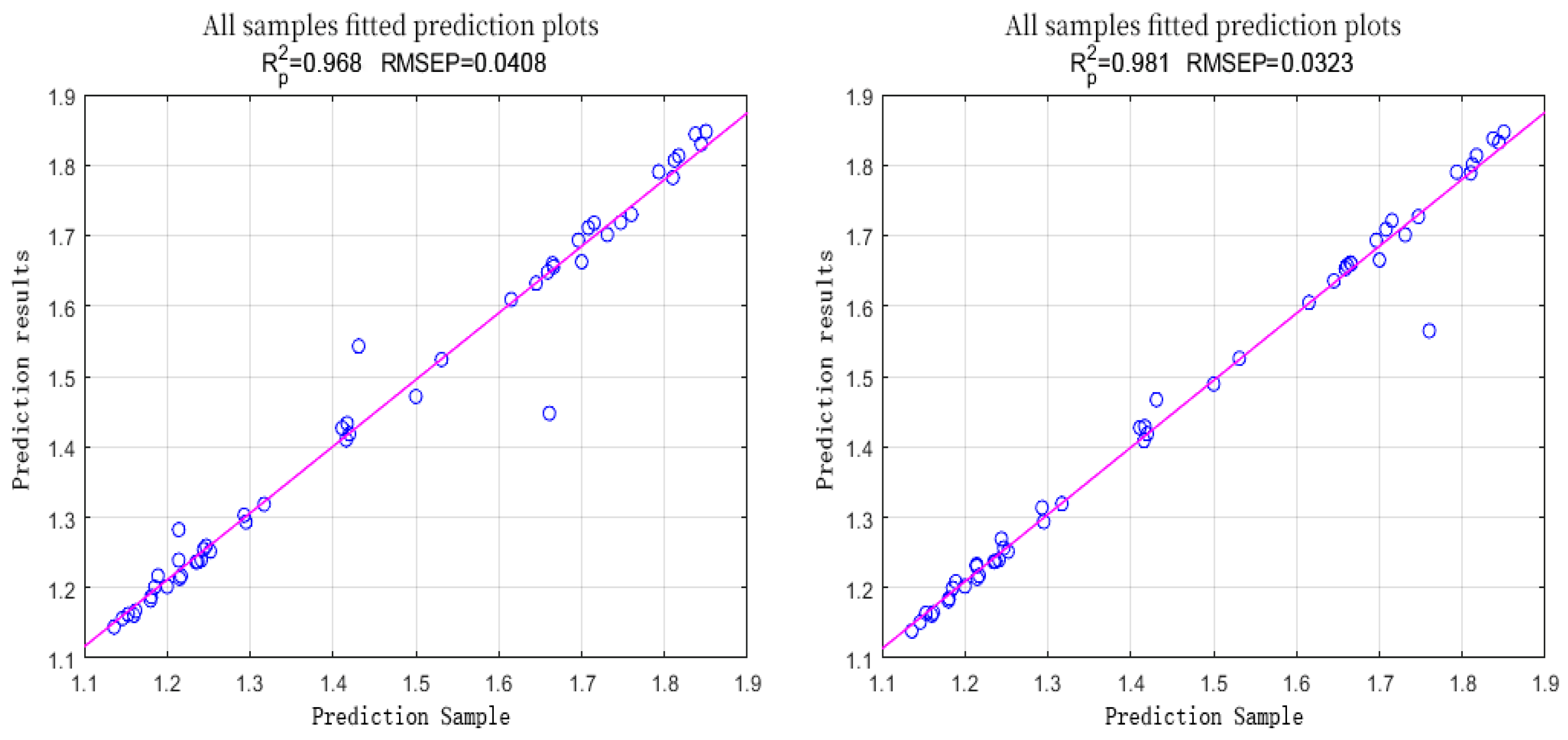
| SPA | RIME-LS-SVM | 0.9955 | 0.9404 | 0.0179 | 0.0637 |
| CARS-PLS | RIME-LS-SVM | 0.998 | 0.964 | 0.0126 | 0.052 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, K.; Bai, T.; Li, X.; Shi, Z.; Li, S. Inversion Study of Nitrogen Content of Hyperspectral Apple Canopy Leaves Using Optimized Least Squares Support Vector Machine Approach. Forests 2024, 15, 268. https://doi.org/10.3390/f15020268
Hou K, Bai T, Li X, Shi Z, Li S. Inversion Study of Nitrogen Content of Hyperspectral Apple Canopy Leaves Using Optimized Least Squares Support Vector Machine Approach. Forests. 2024; 15(2):268. https://doi.org/10.3390/f15020268
Chicago/Turabian StyleHou, Kaiyao, Tiecheng Bai, Xu Li, Ziyan Shi, and Senwei Li. 2024. "Inversion Study of Nitrogen Content of Hyperspectral Apple Canopy Leaves Using Optimized Least Squares Support Vector Machine Approach" Forests 15, no. 2: 268. https://doi.org/10.3390/f15020268
APA StyleHou, K., Bai, T., Li, X., Shi, Z., & Li, S. (2024). Inversion Study of Nitrogen Content of Hyperspectral Apple Canopy Leaves Using Optimized Least Squares Support Vector Machine Approach. Forests, 15(2), 268. https://doi.org/10.3390/f15020268