
FGYOLO: An Integrated Feature Enhancement Lightweight Unmanned Aerial Vehicle Forest Fire Detection Framework Based on YOLOv8n


Abstract
1. Introduction
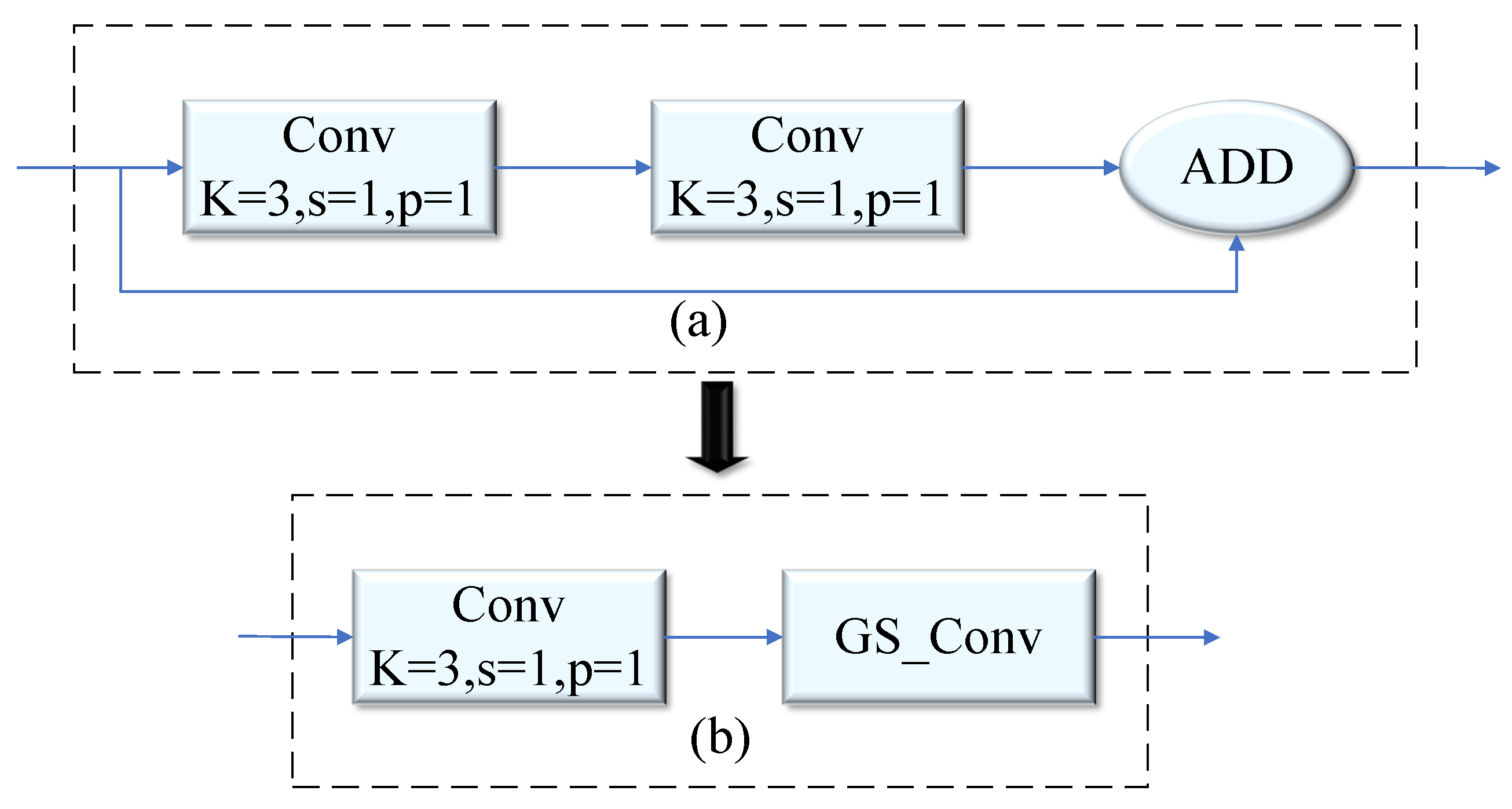
- Replacing the traditional convolution in some C2F modules with GSConv, and reconstructing its Bottleneck module to improve the residual structure. This modification significantly reduces redundant features and network parameters, accelerates model convergence, and improves detection accuracy.
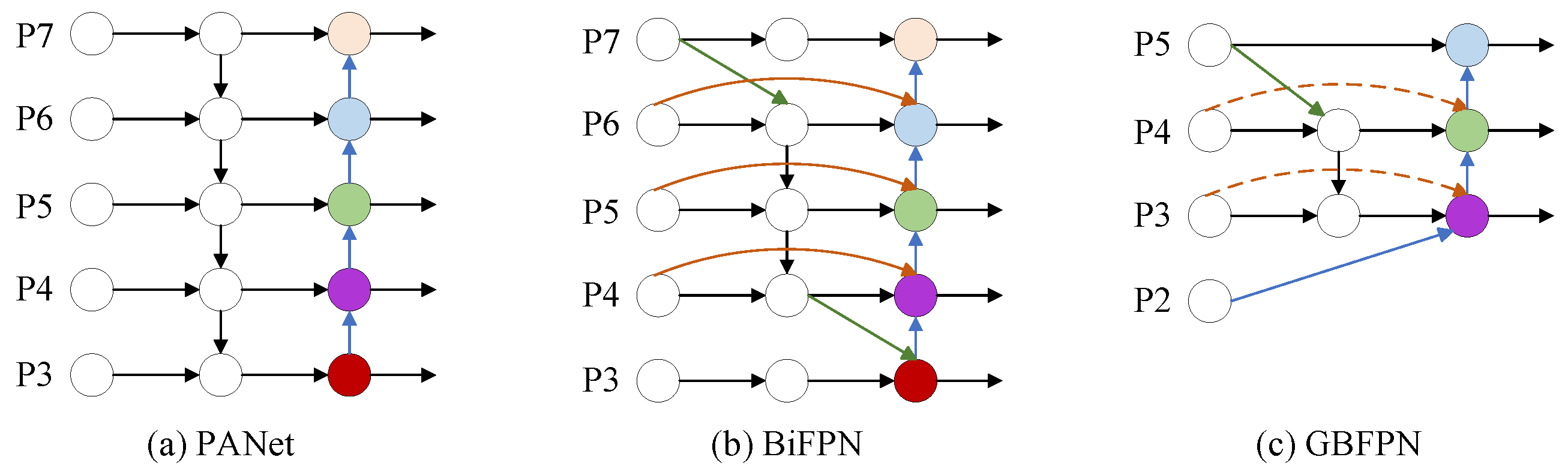
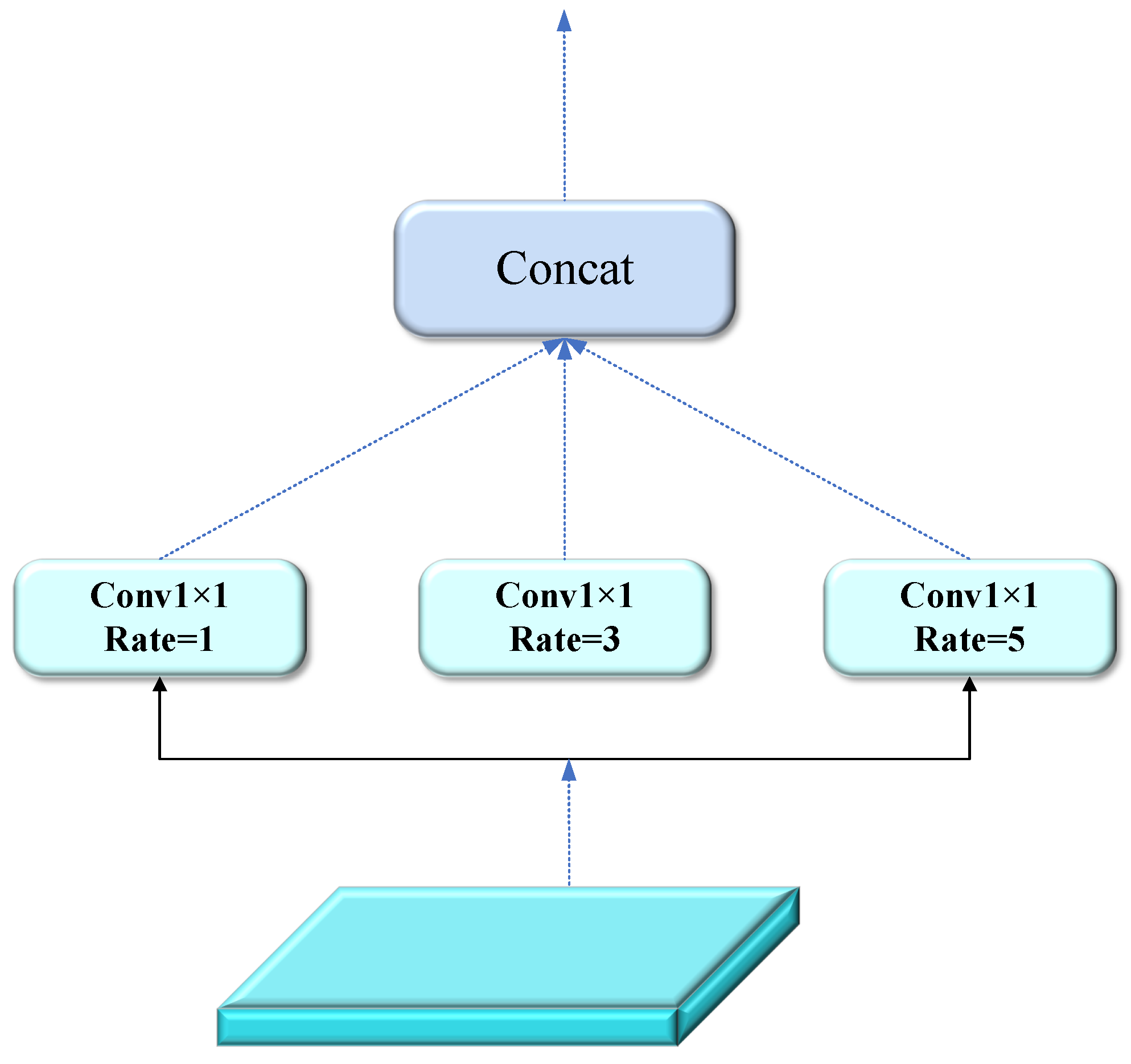
- An improved GBFPN network, based on the Bi-directional Feature Pyramid Network (BiFPN) structure, replaces the Path Aggregation Network (PANet) in the neck layer. This improvement retains bi-directional cross-scale connections, removes redundant branches, and utilizes only the P3, P4, and P5 channels for feature output. Additionally, a new fusion method based on contextual information is introduced to eliminate conflicting information between layers, further optimizing the neck layer structure to enhance computational efficiency.
- The improved neck network integrates Biformer, a dynamic sparse attention mechanism, to address the challenge of extracting salient features in complex forest environments. This mechanism helps the model focus on important features while suppressing irrelevant background information, thereby improving detection performance.
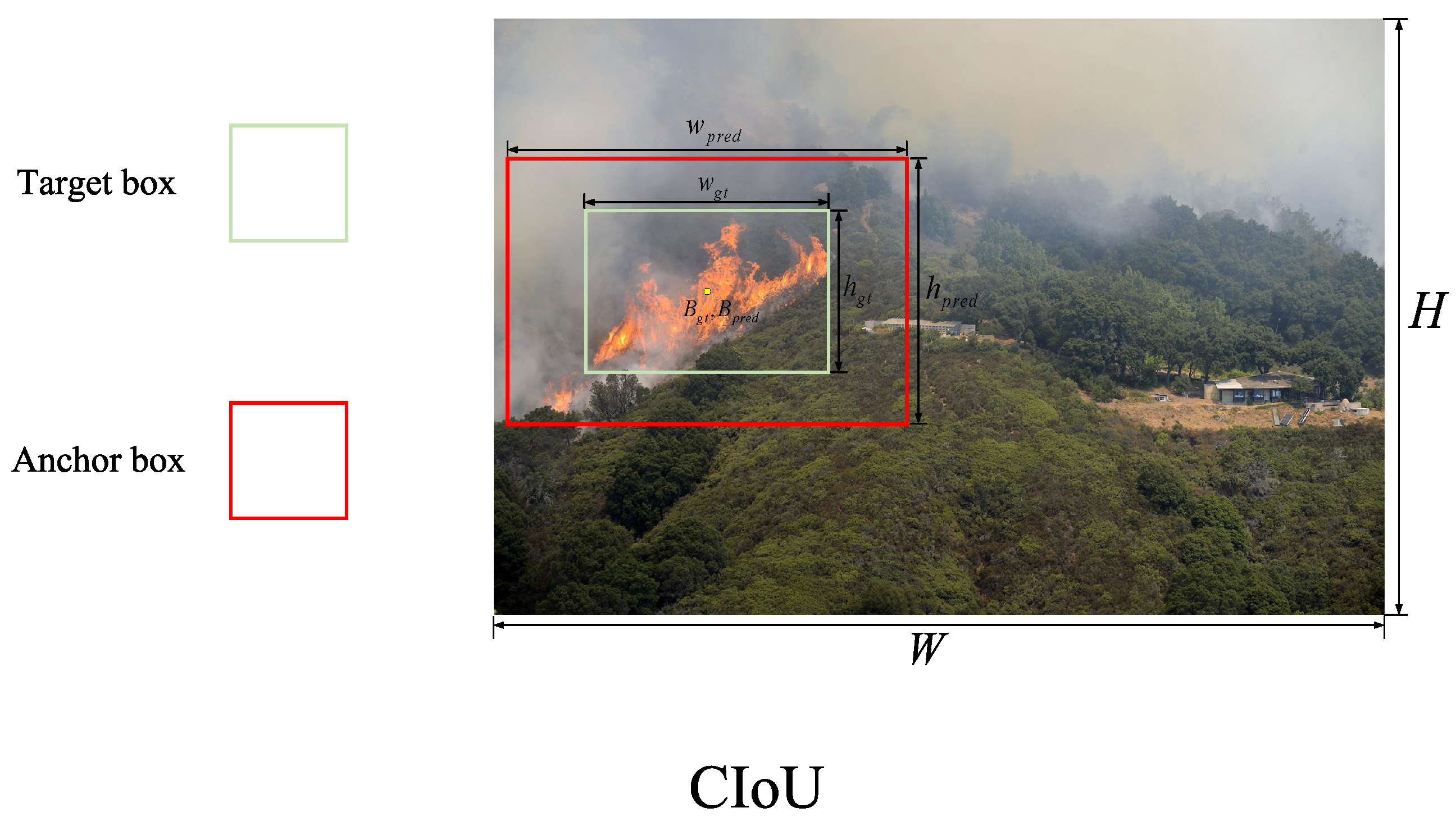
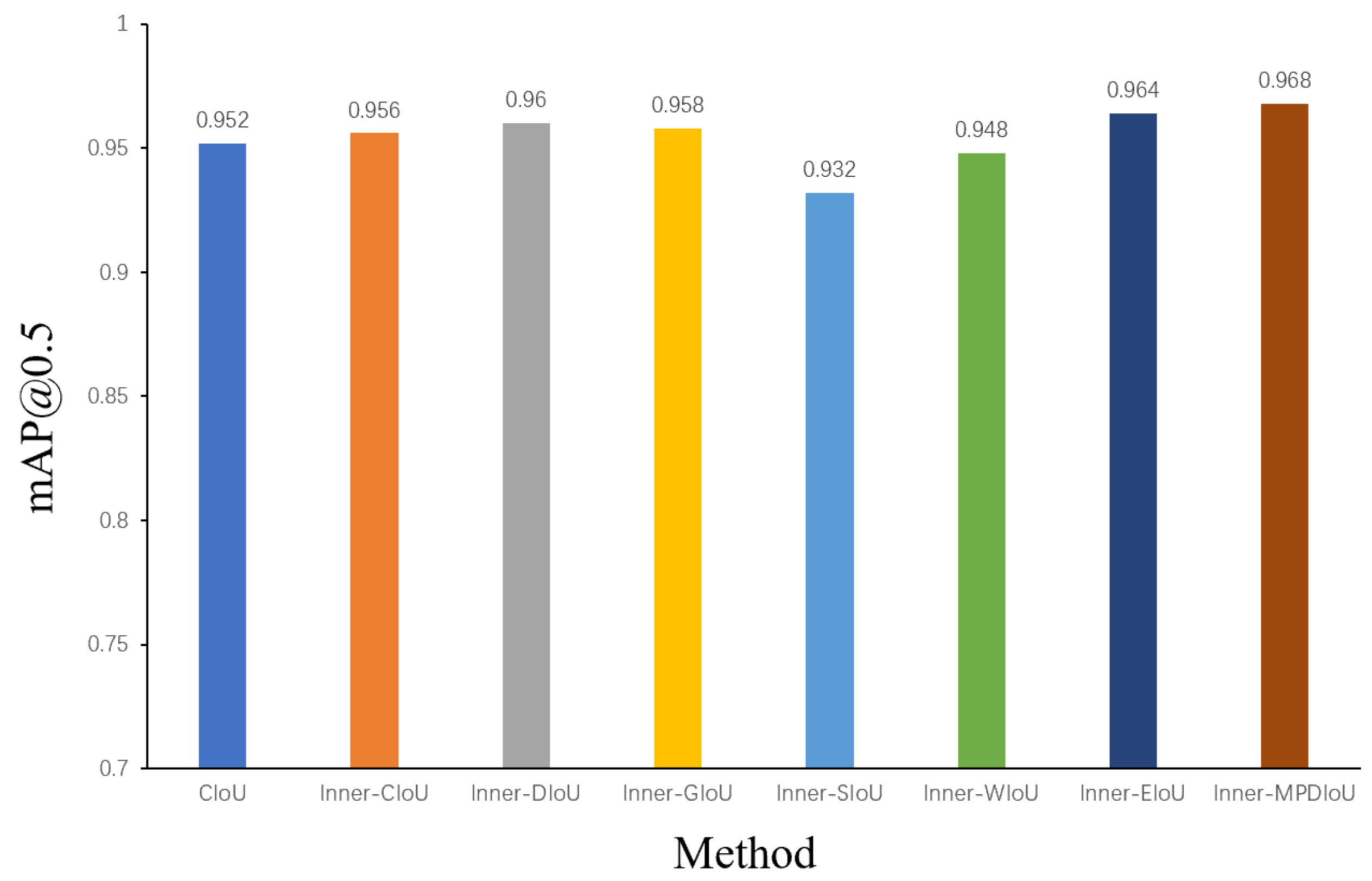
- The Inner-IoU algorithm is combined with the Maximum Possible DIoU (MPD) loss function. Inner-MPDIoU more accurately captures target position information, enhancing the model’s generalization ability and improving both regression and classification accuracy.
- A comprehensive forest fire smoke dataset, encompassing various time periods and multiple scene categories, is established. Advanced software techniques are employed for data augmentation and enhancement to prevent model overfitting. Experiments using this dataset confirm the superiority of the proposed method, achieving a 98.8% mAP, outperforming current mainstream YOLO models and other classical target detection models.
2. Related Works
3. Materials and Methods
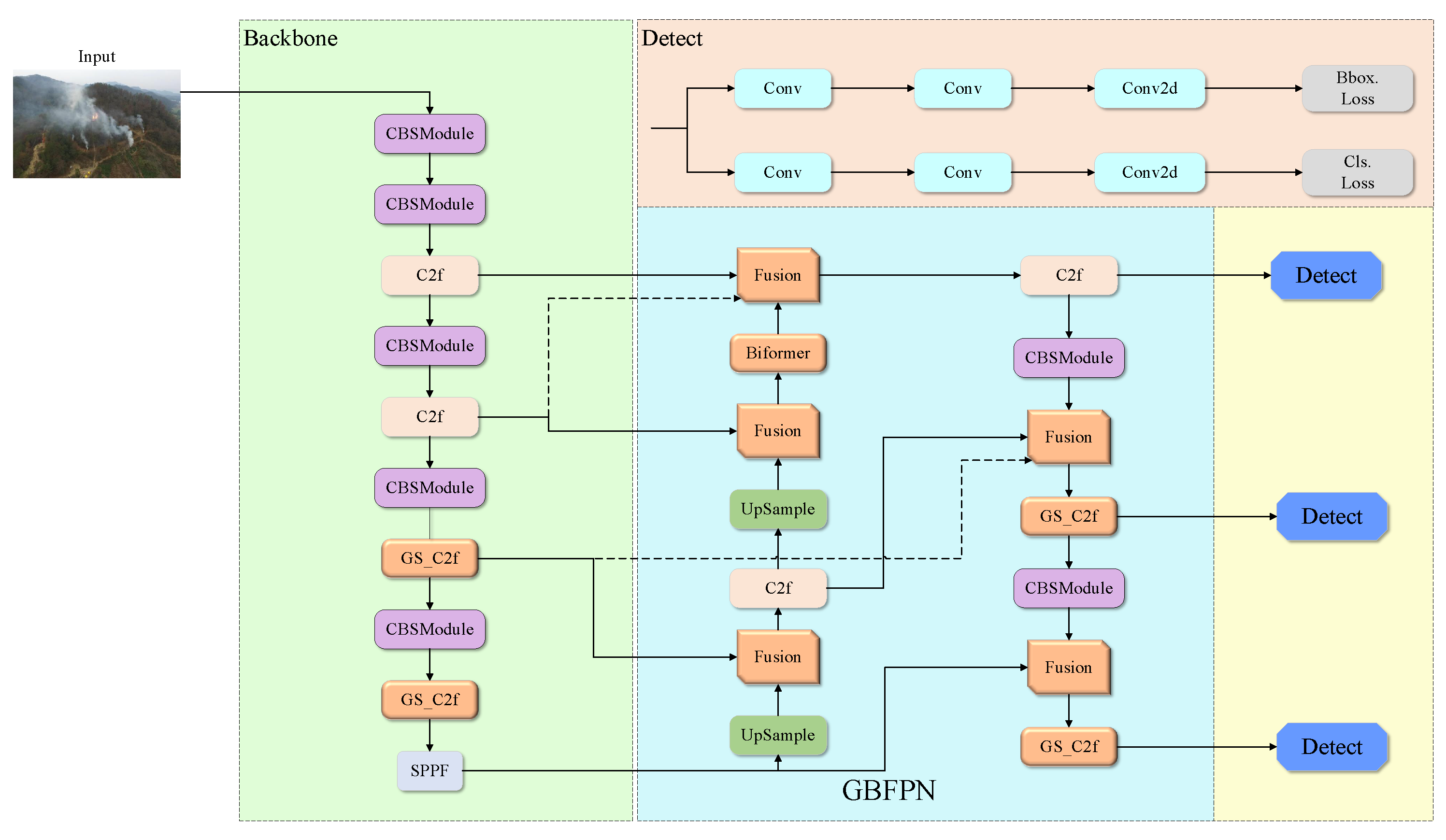
3.1. Improved Forest Fire Detection Model
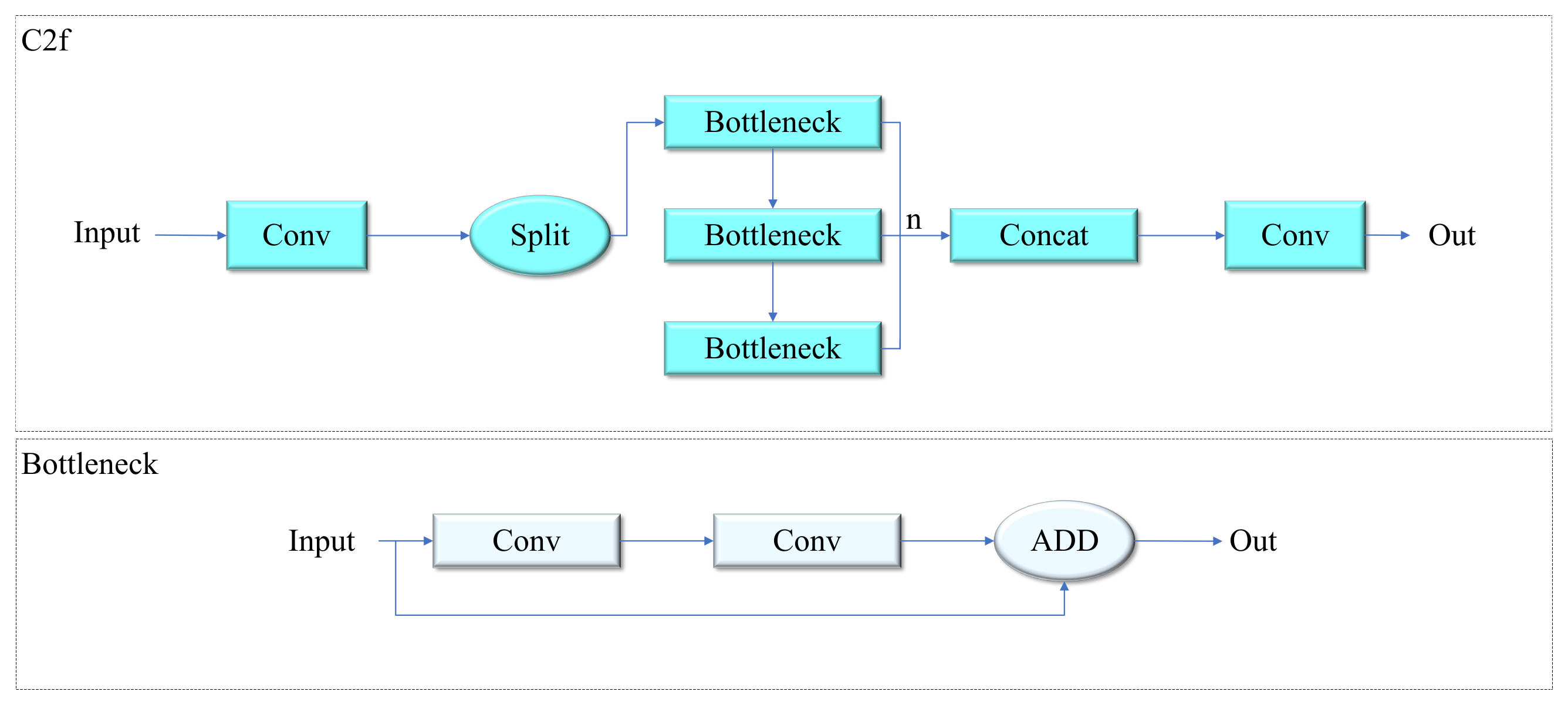
3.2. YOLOv8 Network
3.3. GS_C2f Module
3.4. GBFPN Network
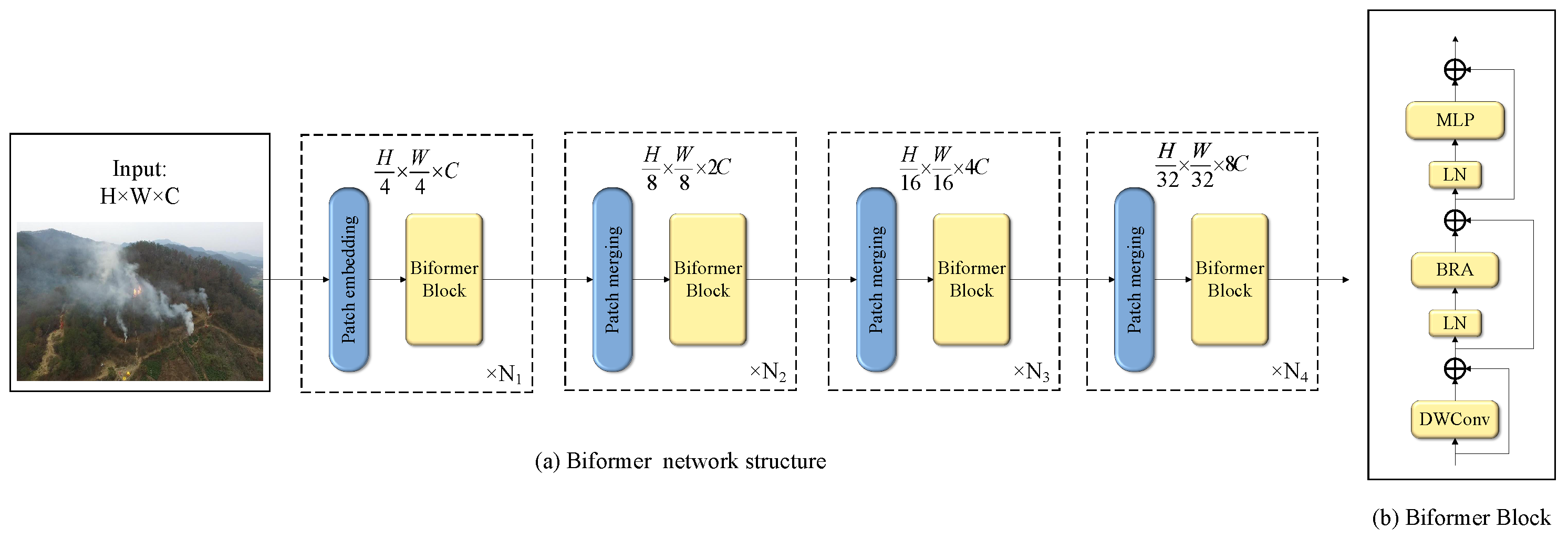
3.5. Biformer Dynamic Sparse Attention Mechanism
3.6. Inner-MPDIoU Loss Function
4. Experiment
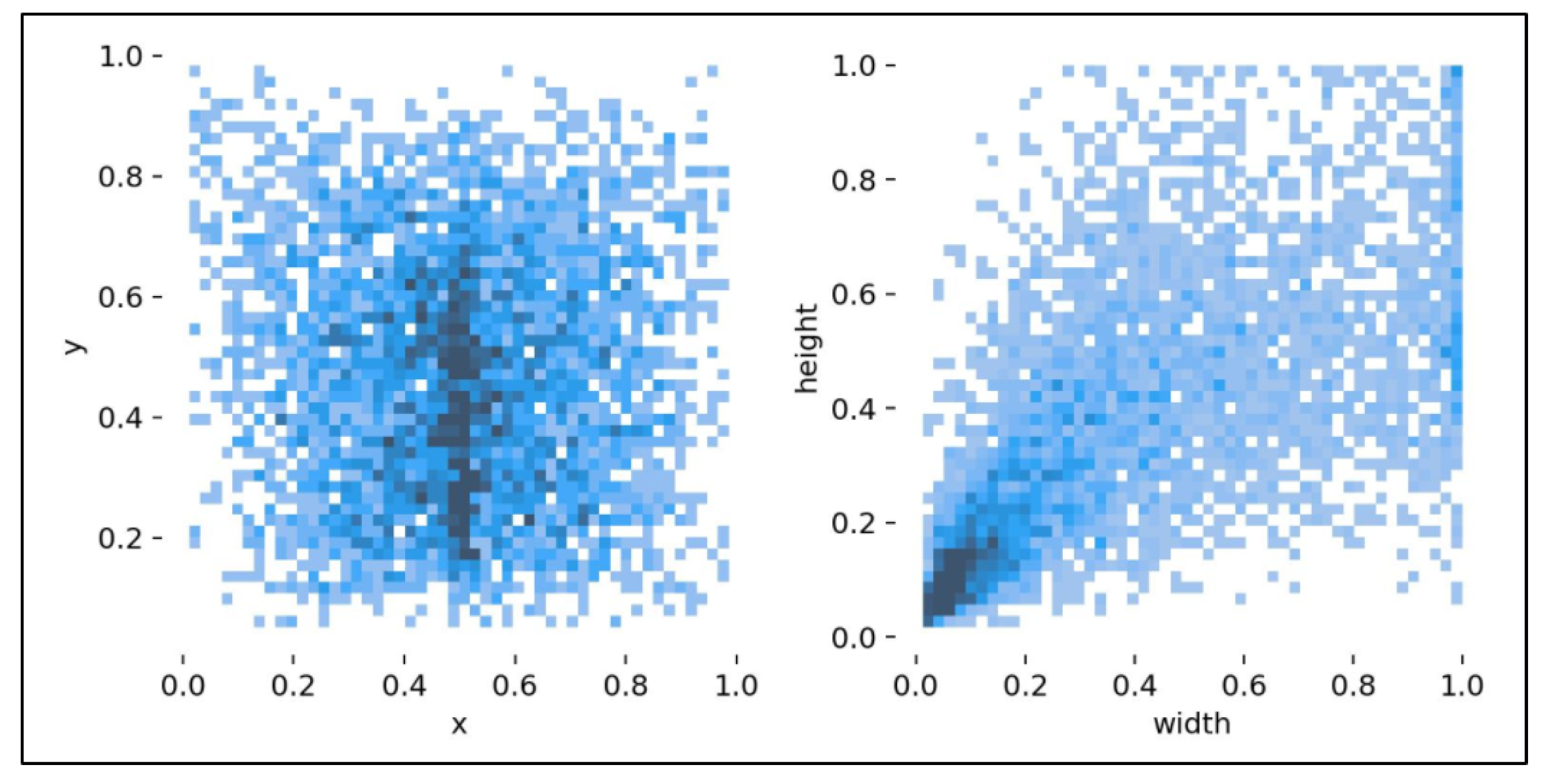
4.1. Dataset Acquisition and Processing
4.2. Experimental Environment
4.3. Model Evaluation Indexes
4.4. Analysis of Results
4.4.1. Inner-MPDIoU Validation
4.4.2. Ablation Experiments
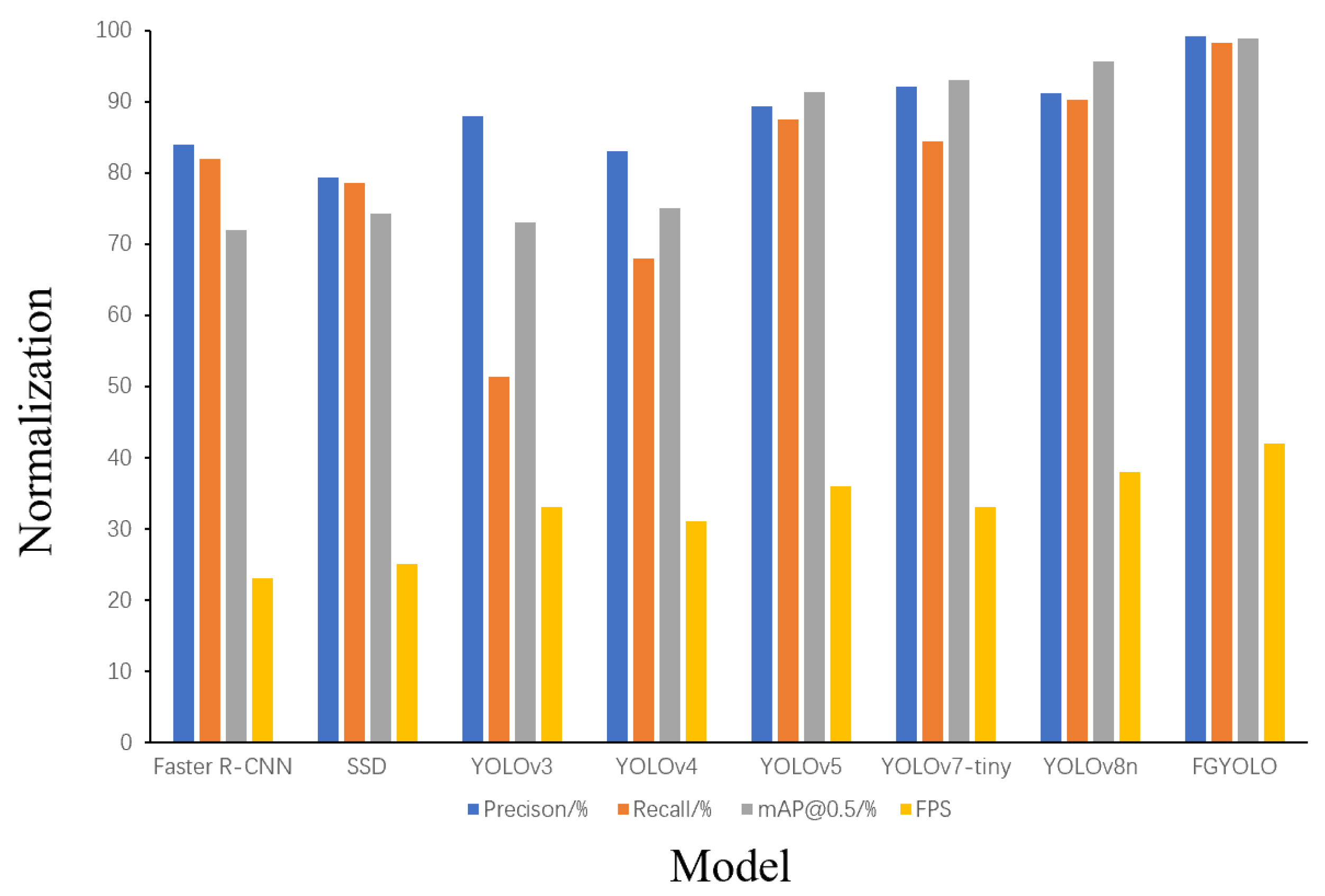
4.4.3. Comparison Analysis Experiment
4.5. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qin, X.; Li, X.; Liu, S.; Liu, Q.; Li, Z. Forest fire early warning and monitoring techniques using satellite remote sensing in China. J. Remote Sens. 2020, 24, 511–520. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Peruzzi, G.; Pozzebon, A.; Van Der Meer, M. Fight fire with fire: Detecting forest fires with embedded machine learning models dealing with audio and images on low power IoT devices. Sensors 2023, 23, 783. [Google Scholar] [CrossRef]
- Benzekri, W.; El Moussati, A.; Moussaoui, O.; Berrajaa, M. Early forest fire detection system using wireless sensor network and deep learning. Int. J. Adv. Comput. Sci. Appl. 2020, 11. [Google Scholar] [CrossRef]
- Cao, X.; Su, Y.; Geng, X.; Wang, Y. YOLO-SF: YOLO for fire segmentation detection. IEEE Access 2023, 11, 111079–111092. [Google Scholar] [CrossRef]
- Choutri, K.; Lagha, M.; Meshoul, S.; Batouche, M.; Bouzidi, F.; Charef, W. Fire detection and geo-localization using uav’s aerial images and yolo-based models. Appl. Sci. 2023, 13, 11548. [Google Scholar] [CrossRef]
- Bahhar, C.; Ksibi, A.; Ayadi, M.; Jamjoom, M.M.; Ullah, Z.; Soufiene, B.O.; Sakli, H. Wildfire and smoke detection using staged YOLO model and ensemble CNN. Electronics 2023, 12, 228. [Google Scholar] [CrossRef]
- Zhang, Q.x.; Lin, G.h.; Zhang, Y.m.; Xu, G.; Wang, J.j. Wildland forest fire smoke detection based on faster R-CNN using synthetic smoke images. Procedia Eng. 2018, 211, 441–446. [Google Scholar] [CrossRef]
- Shamta, I.; Demir, B.E. Development of a deep learning-based surveillance system for forest fire detection and monitoring using UAV. PLoS ONE 2024, 19, e0299058. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.; Duan, B.; Guan, R.; Yang, G.; Zhen, Z. LUFFD-YOLO: A Lightweight Model for UAV Remote Sensing Forest Fire Detection Based on Attention Mechanism and Multi-Level Feature Fusion. Remote. Sens. 2024, 16, 2177. [Google Scholar] [CrossRef]
- Cao, L.; Shen, Z.; Xu, S. Efficient forest fire detection based on an improved YOLO model. Vis. Intell. 2024, 2, 20. [Google Scholar] [CrossRef]
- Zhao, L.; Zhi, L.; Zhao, C.; Zheng, W. Fire-YOLO: A small target object detection method for fire inspection. Sustainability 2022, 14, 4930. [Google Scholar] [CrossRef]
- Saydirasulovich, S.N.; Mukhiddinov, M.; Djuraev, O.; Abdusalomov, A.; Cho, Y.I. An improved wildfire smoke detection based on YOLOv8 and UAV images. Sensors 2023, 23, 8374. [Google Scholar] [CrossRef] [PubMed]
- Mukhiddinov, M.; Abdusalomov, A.B.; Cho, J. A wildfire smoke detection system using unmanned aerial vehicle images based on the optimized YOLOv5. Sensors 2022, 22, 9384. [Google Scholar] [CrossRef]
- Xiao, Z.; Wan, F.; Lei, G.; Xiong, Y.; Xu, L.; Ye, Z.; Liu, W.; Zhou, W.; Xu, C. FL-YOLOv7: A lightweight small object detection algorithm in forest fire detection. Forests 2023, 14, 1812. [Google Scholar] [CrossRef]
- Yang, H.; Wang, J.; Wang, J. Efficient Detection of Forest Fire Smoke in UAV Aerial Imagery Based on an Improved Yolov5 Model and Transfer Learning. Remote. Sens. 2023, 15, 5527. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference On Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; IEEE Computer Society: Washington, DC, USA, 2021; pp. 3490–3499. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Liu, P.; Qian, W.; Wang, Y. YWnet: A convolutional block attention-based fusion deep learning method for complex underwater small target detection. Ecol. Inform. 2024, 79, 102401. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 658–666. [Google Scholar]
- Ma, S.; Xu, Y. MPDIoU: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Zhang, H.; Xu, C.; Zhang, S. Inner-IoU: More effective intersection over union loss with auxiliary bounding box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Shamsoshoara, A.; Afghah, F.; Razi, A.; Zheng, L.; Fulé, P.Z.; Blasch, E. Aerial imagery pile burn detection using deep learning: The FLAME dataset. Comput. Netw. 2021, 193, 108001. [Google Scholar] [CrossRef]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target | Quantity | Source |
|---|---|---|
| Fire only | 1400 | Public dataset |
| 1825 | Self-accessible | |
| Smoke only | 1762 | Self-accessible |
| Both fire and smoke | 2400 | Public dataset |
| 2648 | Self-accessible | |
| Empty samples | 100 | Public dataset |
| Combined datasets | 10,135 | Public dataset and Self-accessible |
| Item | Configuration |
|---|---|
| Operating System | Ubuntu 18.04.1 |
| Graphics Card | GeForce RTX 3060Ti |
| CUDA version | 11.1.1 |
| Python | 3.8.1 |
| Deep learning framework | PyTorch 1.10.0 |
| Actual Circumstances | Predicted Result | |
|---|---|---|
| Positive Example | Negative Example | |
| Positive example | ||
| negative example | ||
| P (%) | R (%) | (%) | |
|---|---|---|---|
| 0.5 | 95.3 | 95.7 | 95.5 |
| 0.65 | 95.6 | 96.1 | 95.9 |
| 0.8 | 95.4 | 95.9 | 95.7 |
| 0.9 | 95.8 | 96.1 | 96.1 |
| 1.00 | 95.1 | 96.8 | 96.5 |
| 1.15 | 95.9 | 97.1 | 96.9 |
| 1.20 | 94.5 | 96.8 | 96.7 |
| Network | P (%) | R (%) | (%) | (%) | Parameters () | GFlops |
|---|---|---|---|---|---|---|
| YOLOv8n without data enhancement | 92.8 | 89.6 | 90.4 | 92.5 | 3.01 | 8.2 |
| YOLOv8n | 93.7 | 95.1 | 95.1 | 95.3 | 3.01 | 8.2 |
| YOLOv8n + DC_C2f | 93.8 | 95.4 | 94.7 | 95.9 | 2.57 | 7.2 |
| YOLOv8n + GBFPN | 94.5 | 94.8 | 94.7 | 95.8 | 2.26 | 7.1 |
| YOLOv8n + Biformer | 94.2 | 95.6 | 97.5 | 97.1 | 3.22 | 9.5 |
| YOLOv8n + Inner-MPDIoU | 94.1 | 95.8 | 96.7 | 96.9 | 3.01 | 8.2 |
| FGYOLO | 94.5 | 96.3 | 98.7 | 98.8 | 2.38 | 7.3 |
| Algorithms | P (%) | R (%) | (%) | Parameters () | GFlops |
|---|---|---|---|---|---|
| Faster R-CNN | 83.9 | 82.0 | 81.9 | 136.73 | 401.7 |
| SSD | 89.3 | 78.5 | 84.2 | 26.29 | 62.7 |
| YOLOv5 | 95.9 | 86.3 | 94.0 | 2.51 | 7.2 |
| YOLOv7-tiny | 91.4 | 87.5 | 93.4 | 5.91 | 12.5 |
| YOLOv9 | 93.1 | 88.2 | 95.4 | 7.01 | 26.2 |
| YOLOv10 | 92.1 | 89.4 | 94.1 | 2.37 | 6.7 |
| YOLOv8n | 93.2 | 90.3 | 95.6 | 3.01 | 8.2 |
| FGYOLO | 94.5 | 96.3 | 98.8 | 2.38 | 7.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Tao, F.; Gao, Z.; Li, J. FGYOLO: An Integrated Feature Enhancement Lightweight Unmanned Aerial Vehicle Forest Fire Detection Framework Based on YOLOv8n. Forests 2024, 15, 1823. https://doi.org/10.3390/f15101823
Zheng Y, Tao F, Gao Z, Li J. FGYOLO: An Integrated Feature Enhancement Lightweight Unmanned Aerial Vehicle Forest Fire Detection Framework Based on YOLOv8n. Forests. 2024; 15(10):1823. https://doi.org/10.3390/f15101823
Chicago/Turabian StyleZheng, Yangyang, Fazhan Tao, Zhengyang Gao, and Jingyan Li. 2024. "FGYOLO: An Integrated Feature Enhancement Lightweight Unmanned Aerial Vehicle Forest Fire Detection Framework Based on YOLOv8n" Forests 15, no. 10: 1823. https://doi.org/10.3390/f15101823
APA StyleZheng, Y., Tao, F., Gao, Z., & Li, J. (2024). FGYOLO: An Integrated Feature Enhancement Lightweight Unmanned Aerial Vehicle Forest Fire Detection Framework Based on YOLOv8n. Forests, 15(10), 1823. https://doi.org/10.3390/f15101823