
An SSD-MobileNet Acceleration Strategy for FPGAs Based on Network Compression and Subgraph Fusion


Abstract
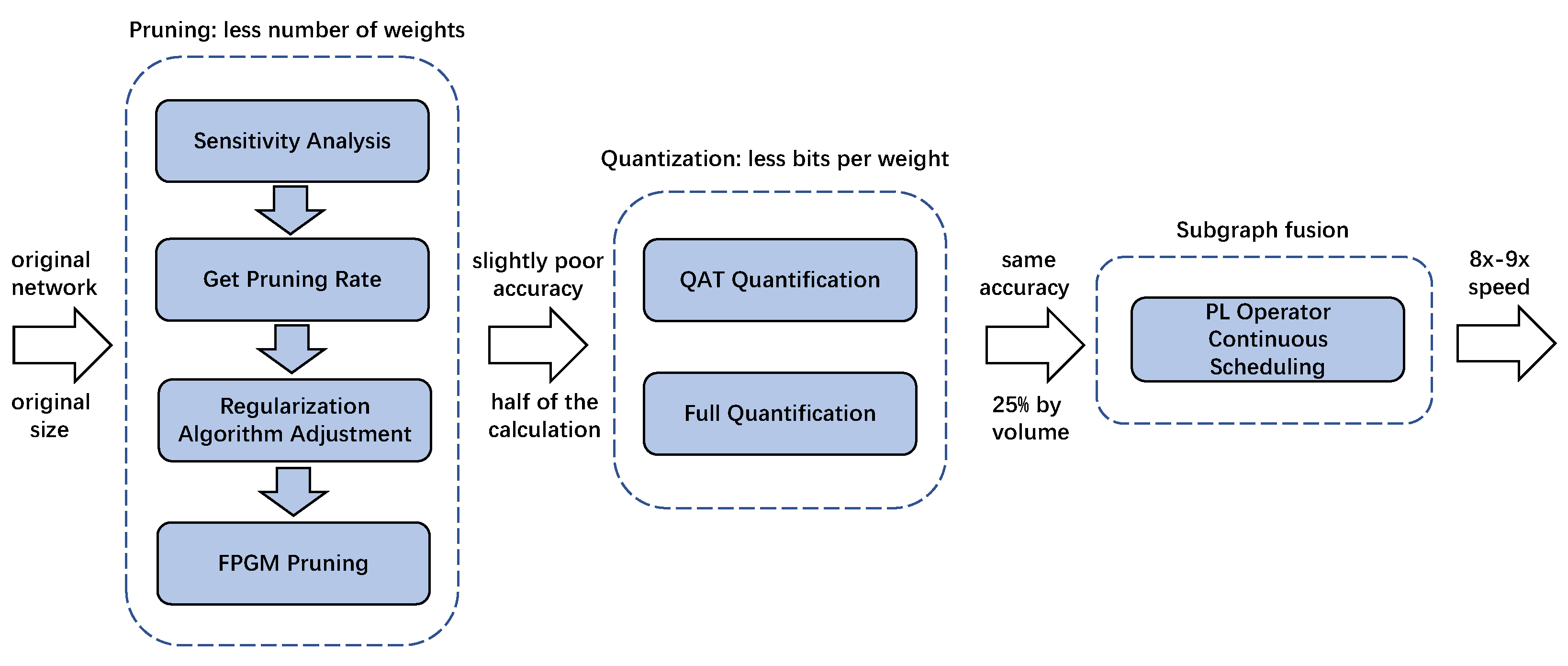
1. Introduction
2. Related Works
3. FPGM and Regular Pruning Strategy Based on Sensitivity Analysis
3.1. Sensitivity Analysis
3.2. FPGM Pruning Strategy
3.3. Regularize Pruning Strategy
4. Quantization and Computation Subgraph Fusion
4.1. Network Full Quantization Based on QAT Quantitative Training
4.2. Subgraph Optimization
5. Experiments
5.1. Dataset
5.2. Experimental Setup
5.3. Experimental and Analysis
5.3.1. Pruning Aspects
5.3.2. Quantization Aspects
5.4. Hardware Platform Verification
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, R.; Fu, Y.; Bergeron, Y.; Valeria, O.; Chavardès, R.D.; Hu, J.; Wang, Y.; Duan, J.; Li, D.; Cheng, Y. Assessing forest fire properties in Northeastern Asia and Southern China with satellite microwave Emissivity Difference Vegetation Index (EDVI). ISPRS J. Photogramm. Remote Sens. 2022, 183, 54–65. [Google Scholar] [CrossRef]
- Stakem, P. Migration of an Image Classification Algorithm to an Onboard Computer for Downlink Data Reduction. J. Aerosp. Comput. Inf. Commun. 2004, 1, 108–111. [Google Scholar] [CrossRef]
- Honda, H. On a model of target detection in molecular communication networks. Netw. Heterog. Media 2019, 14, 633. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zheng, J.; Fu, H.; Li, W.; Wu, W.; Yu, L.; Yuan, S.; Tao, W.Y.W.; Pang, T.K.; Kanniah, K.D. Growing status observation for oil palm trees using Unmanned Aerial Vehicle (UAV) images. ISPRS J. Photogramm. Remote Sens. 2021, 173, 95–121. [Google Scholar] [CrossRef]
- Arnaoudova, V.; Haiduc, S.; Marcus, A.; Antoniol, G. The use of text retrieval and natural language processing in software engineering. In Proceedings of the 2015 IEEE/ACM 37th IEEE International Conference on Software Engineering (ICSE), Florence, Italy, 16–24 May 2015; pp. 949–950. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, W.; He, C.; Fu, H.; Zheng, J.; Dong, R.; Xia, M.; Yu, L.; Luk, W. A real-time tree crown detection approach for large-scale remote sensing images on FPGAs. Remote Sens. 2019, 11, 1025. [Google Scholar] [CrossRef]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up convolutional neural networks with low rank expansions. arXiv 2014, arXiv:1405.3866. [Google Scholar]
- Chen, J.; Xu, Y.; Sun, W.; Huang, L. Joint sparse neural network compression via multi-application multi-objective optimization. Appl. Intell. 2021, 51, 7837–7854. [Google Scholar] [CrossRef]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. Adv. Neural Inf. Process. Syst. 2015, 28, 43–66. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J. BinaryConnect: Training deep neural networks with binary weights during propagations. arXiv 2015, arXiv:1511.00363. [Google Scholar]
- Pitonak, R.; Mucha, J.; Dobis, L.; Javorka, M.; Marusin, M. CloudSatNet-1: FPGA-Based Hardware-Accelerated Quantized CNN for Satellite On-Board Cloud Coverage Classification. Remote Sens. 2022, 14, 3180. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Greco, A.; Saggese, A.; Vento, M.; Vigilante, V. Effective training of convolutional neural networks for age estimation based on knowledge distillation. Neural Comput. Appl. 2021, 34, 21449–21464. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Zhou, Y.; Liu, Y.; Han, G.; Fu, Y. Face recognition based on the improved MobileNet. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 2776–2781. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Luo, J.H.; Wu, J.; Lin, W. Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5058–5066. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1389–1397. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- He, Y.; Liu, P.; Wang, Z.; Hu, Z.; Yang, Y. Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4340–4349. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 525–542. [Google Scholar]
- Li, F.; Zhang, B.; Liu, B. Ternary weight networks. arXiv 2016, arXiv:1605.04711. [Google Scholar]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental network quantization: Towards lossless cnns with low-precision weights. arXiv 2017, arXiv:1702.03044. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Wang, P.; Hu, Q.; Zhang, Y.; Zhang, C.; Liu, Y.; Cheng, J. Two-step quantization for low-bit neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4376–4384. [Google Scholar]
- Vanhoucke, V.; Senior, A.; Mao, M.Z. Improving the speed of neural networks on CPUs. In Proceedings of the Deep Learning and Unsupervised Feature Learning Workshop, NIPS 2011, Granada, Spain, 12–17 December 2011. [Google Scholar]
- Krishnamoorthi, R. Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv 2018, arXiv:1806.08342. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Layer Number | Size/MB | Flops | Parameters/M | ImageNet Top 5 Error Rates/% |
|---|---|---|---|---|---|
| AlexNet | 8 | >200 | 1.5 | 60 | 16.4 |
| VGG | 19 | >500 | 19.6 | 138 | 7.32 |
| GoogleNet | 22 | 50 | 1.556 | 6.8 | 6.67 |
| ResNet | 152 | 230 | 11.3 | 19.4 | 3.57 |
| Network Layer | Number of Original Channels | Channels before Adjustment | Channels after Adjustment |
|---|---|---|---|
| conv2d_0 | 32 | 16 | 16 |
| conv2d_2 | 64 | 39 | 48 |
| conv2d_4 | 128 | 68 | 64 |
| conv2d_6 | 128 | 77 | 64 |
| conv2d_8 | 256 | 162 | 160 |
| conv2d_10 | 256 | 163 | 160 |
| conv2d_12 | 512 | 371 | 368 |
| conv2d_14 | 512 | 411 | 400 |
| conv2d_16 | 512 | 364 | 352 |
| conv2d_18 | 512 | 408 | 400 |
| conv2d_20 | 512 | 408 | 400 |
| conv2d_22 | 1024 | 102 | 96 |
| Network | Capacity/GFLOPs | Pruned Ratio | mAP (0.5, 11 Point) |
|---|---|---|---|
| Original Network | 5.09 | / | 67.86% |
| Before Adjustment | 2.33 | 0.5416 | 61.43% |
| After Adjustment | 2.26 | 0.5564 | 61.73% |
| Network | Model Size/MB | Compression Ratio | mAP (0.5, 11 Point) | mAP Loss |
|---|---|---|---|---|
| Original Network | 22.2 | / | 67.86% | / |
| Pruning | 6.81 | 30.68% | 61.73% | 6.13% |
| Final Network | 2.26 | 10.18% | 62.17% | 5.69% |
| Network | Model Size/MB | mAP (0.5, 11 Point) | mAP Loss | Average Inference Speed/ms |
|---|---|---|---|---|
| Original Network | 22.2 | 67.86% | / | 1314 |
| Quantization | 6.25 | 67.91% | −0.05% | 841 |
| Pruning | 6.81 | 61.73% | 6.13% | 695 |
| Final Network | 2.26 | 62.17% | 5.69% | 143 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, S.; Fang, Z.; Liu, Y.; Wu, Z.; Du, H.; Xu, R.; Liu, Y. An SSD-MobileNet Acceleration Strategy for FPGAs Based on Network Compression and Subgraph Fusion. Forests 2023, 14, 53. https://doi.org/10.3390/f14010053
Tan S, Fang Z, Liu Y, Wu Z, Du H, Xu R, Liu Y. An SSD-MobileNet Acceleration Strategy for FPGAs Based on Network Compression and Subgraph Fusion. Forests. 2023; 14(1):53. https://doi.org/10.3390/f14010053
Chicago/Turabian StyleTan, Shoutao, Zhanfeng Fang, Yanyi Liu, Zhe Wu, Hang Du, Renjie Xu, and Yunfei Liu. 2023. "An SSD-MobileNet Acceleration Strategy for FPGAs Based on Network Compression and Subgraph Fusion" Forests 14, no. 1: 53. https://doi.org/10.3390/f14010053
APA StyleTan, S., Fang, Z., Liu, Y., Wu, Z., Du, H., Xu, R., & Liu, Y. (2023). An SSD-MobileNet Acceleration Strategy for FPGAs Based on Network Compression and Subgraph Fusion. Forests, 14(1), 53. https://doi.org/10.3390/f14010053