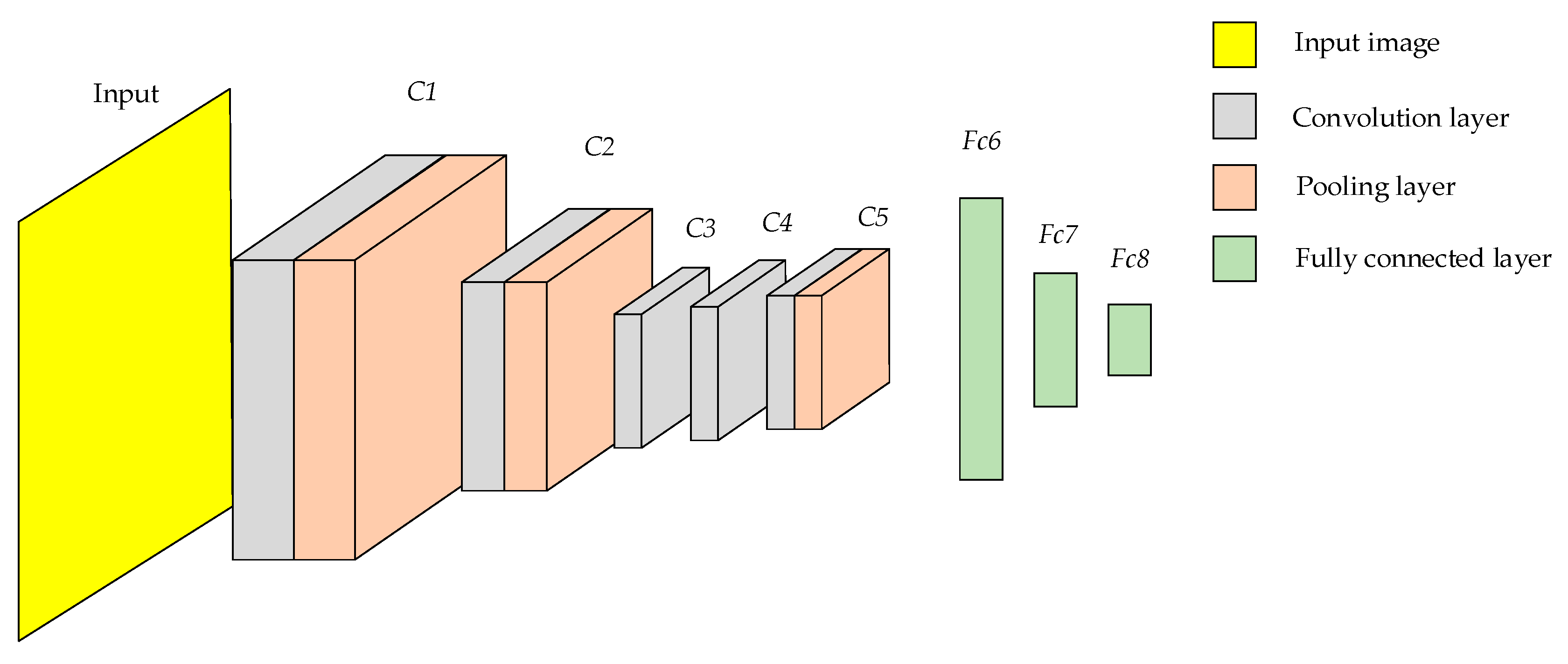
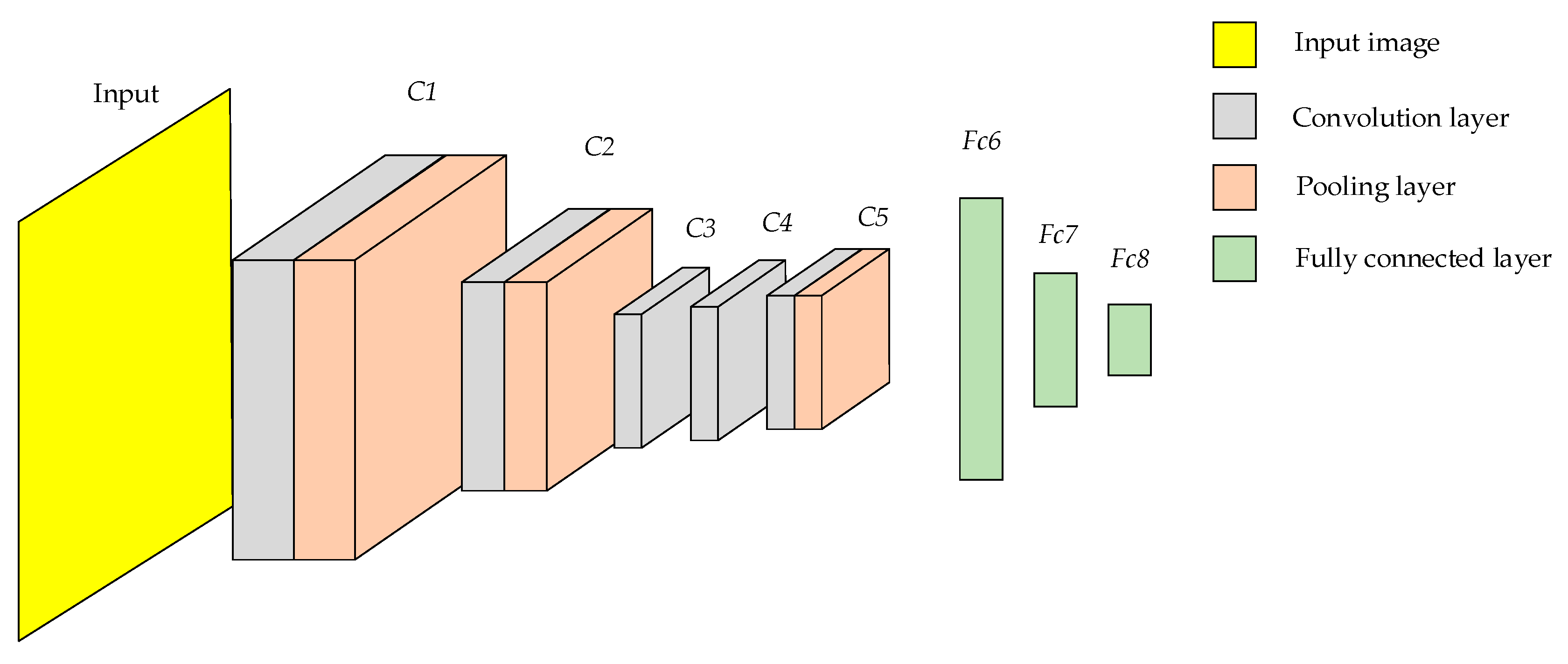
3.1. Modeling of the Alexnet Network
Deep features of fires need to be extracted by CNN. To identify wildfire, Alexnet [
19] was used as a CNN architecture in this paper. Alexnet consists of five convolution layers, three pooling layers and three fully connected layers
Fc6–
Fc8. The convolution and pooling layers form
C1–
C5. The structure of Alexnet is shown in
Figure 6.
Partial features of the image are learned through the convolution kernel of the convolution layer to generate the feature map. The convolution operation is used to extract the different features of the input. The formula for extracting image features from the convolution layer is shown in Equation (6).
where
represents the
jth feature map extracted from the
lth convolution layer,
represents the activation function,
Mj represents the feature map,
represents the convolution kernel, and
represents the offset.
Once the image features have been extracted by the convolution kernel, activation functions need to be introduced to allow the model to address non-linear issues. The ReLU activation function can address not only the non-linearity problem of the model, but also the gradient disappearance problem when the network layers are deep, and its expression is shown in Equation (7). Since Leaky ReLU does not always work better than ReLU [
20], ReLU is chosen as the activation function in this paper, and the convolution layer is calculated as shown in Equation (8).
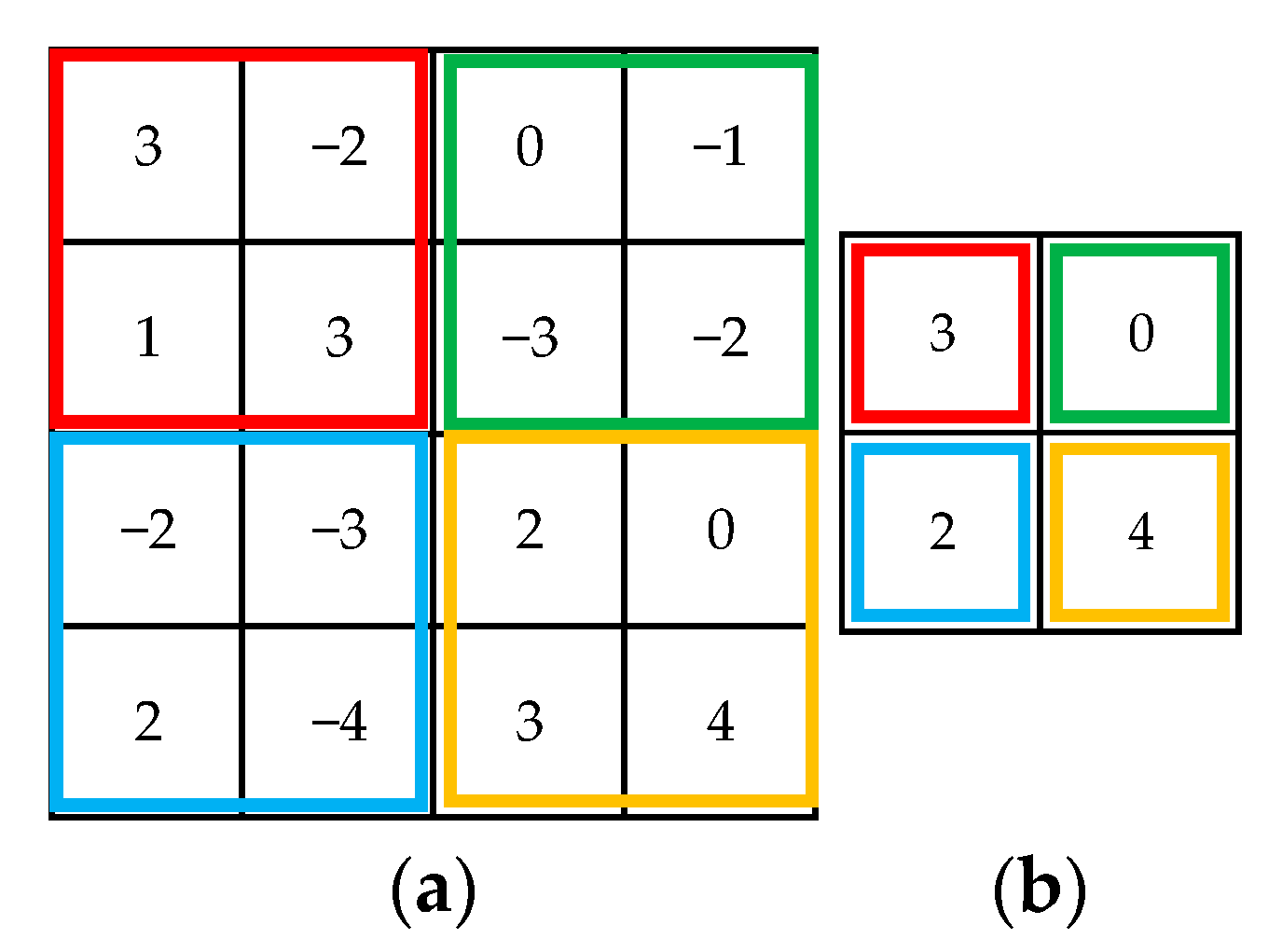
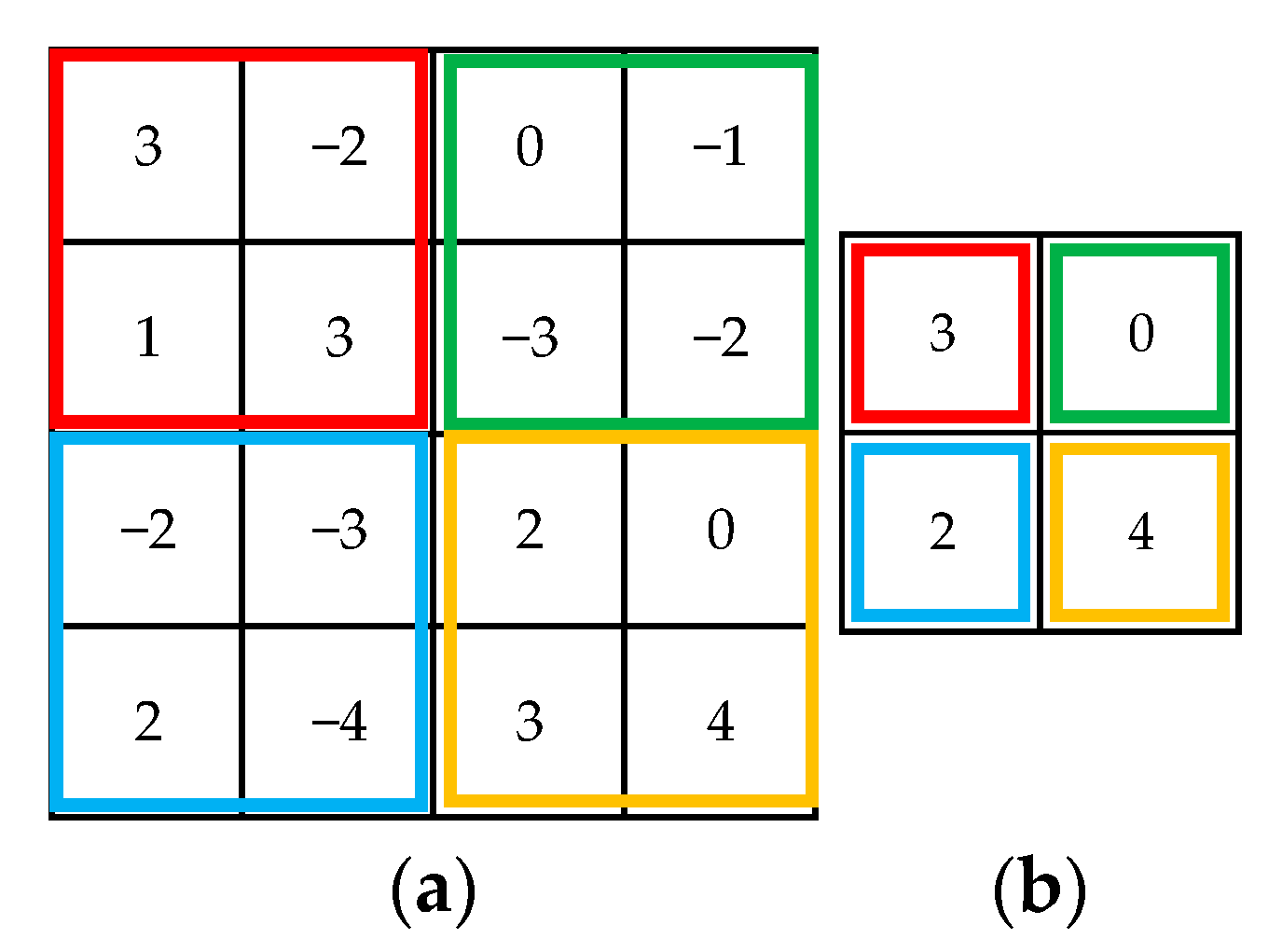
The feature maps obtained from the convolution operation are relatively large, and if they are fed directly into the fully connected layers, the performance of the network will be reduced, while the pooling layer can compress the features extracted from the convolution layer. In this paper, the maximum pooling layer is used to extract features from the convolution layer. Only the largest feature value within the region is retained by the maximum pooling layer, and all other features are ignored by the maximum pooling layer. This not only allows the features to be compressed, but also alleviates the sensitivity of the convolution layer to position, and the effect of noise is reduced. The effect of the maximum pooling layer is shown in
Figure 7.
After convolution pooling layers C1–C5, the deep features of wildfire were extracted by CNN. In order to identify fires, deep features are fed into the fully connected layers. The fully connected layers are neural networks with multiple hidden layers that identify wildfire by updating the parameters with a back propagation algorithm.
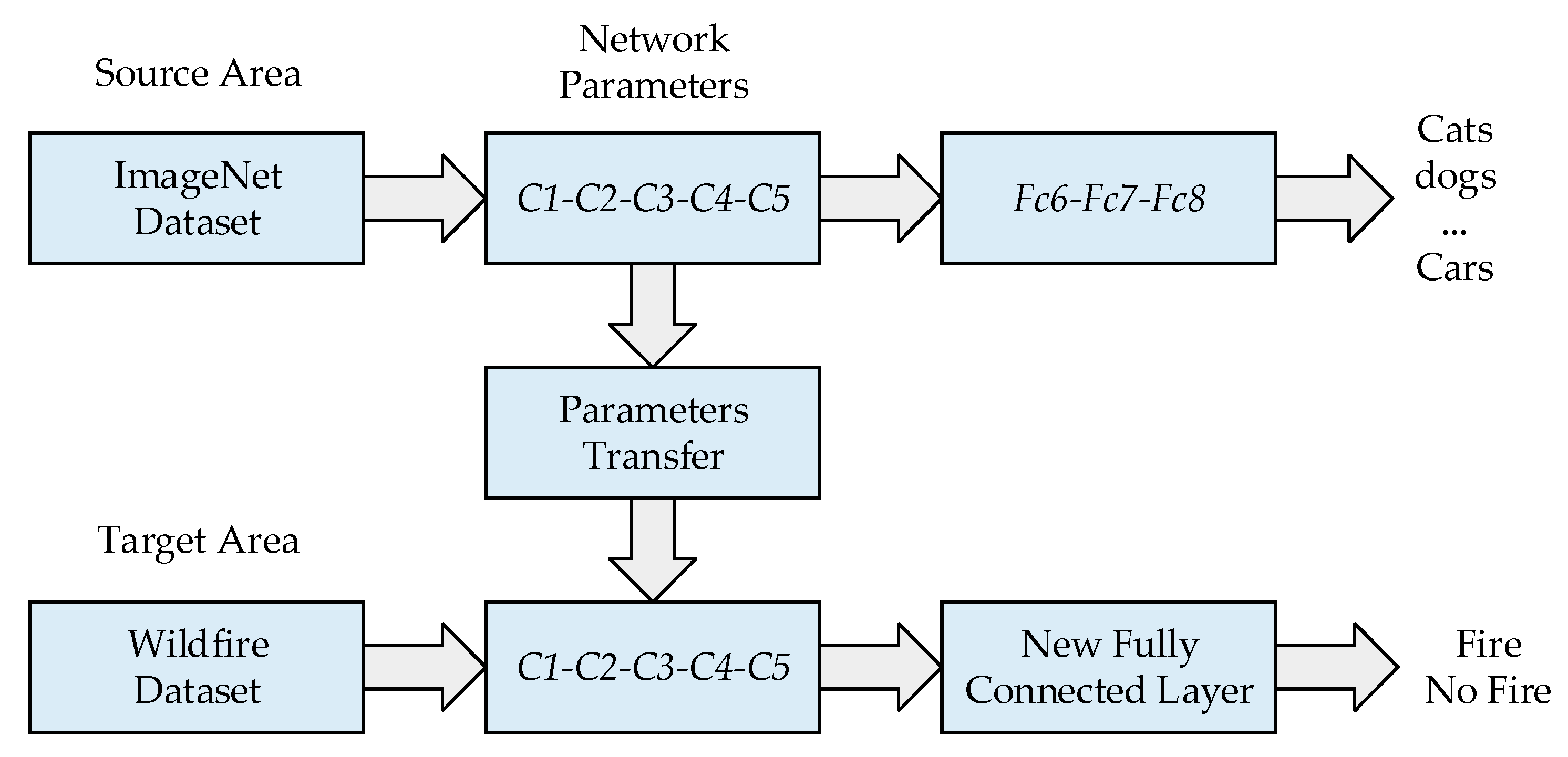
Due to the long training time of Alexnet and the tendency of the model to overfit, transfer learning is used in this paper to train the model. Transfer learning is a machine learning method that reduces the training time and overfitting of a model by transferring parameters from the source domain to the target domain. With transfer learning, the model no longer needs to be trained from a blank CNN. In this paper, the network parameters
C1–
C5 trained on the large dataset ImageNet are transferred to the target model, the model parameters are initialised, the fully connected layers
Fc6_new–
Fc8_new for the new task are designed to replace the fully connected layers
Fc6–
Fc8 in the original model, and finally the network parameters are fine-tuned using the wildfire image dataset. The transfer process in this paper is shown in
Figure 8.
In this paper, the number of input neurons of the new fully connected layers is designed to be the number of dimensions of the wildfire features extracted by the convolution pooling layers
C1–
C5. Since the output of the fully connected layers has two states, fire and no fire, the number of output neurons of the new fully connected layers is designed to be two. The features extracted from the convolution pooling layers
C1–
C5 are used as inputs to the new fully connected layers. The features extracted by
C1–
C5 are first fed to the Dropout layer, which can randomly ignore some neurons in the model, and overfitting of the model can be well avoided. Next, the features are dimensionally reduced through
Fc6_new. The features are then reduced to two dimensions through the ReLU activation function, Dropout layer,
Fc7_new, ReLU activation function and
Fc8_new, thus giving the model the ability to identify wildfire. Finally, the features are fed to the softmax layer to output the classification result, which is calculated as shown in Equation (9). The diagram of the new fully connected layers is shown in
Figure 9.
where
q denotes the
qth component in the output vector,
Sq denotes the classification probability of the
qth component, and
w denotes the sequence number of the component.
The network settings for the new model are shown in
Table 2.
The Adam optimiser is employed in this paper so as to update the model parameters of the CNN. Adam is an adaptive learning rate method with the following equations.
where
mt and
vt are the vectors initialized to zero in the first and second moment estimates of the gradient, respectively,
is the learnable parameter,
is the smoothing term,
is the adaptive learning rate, and
is the gradient distribution.
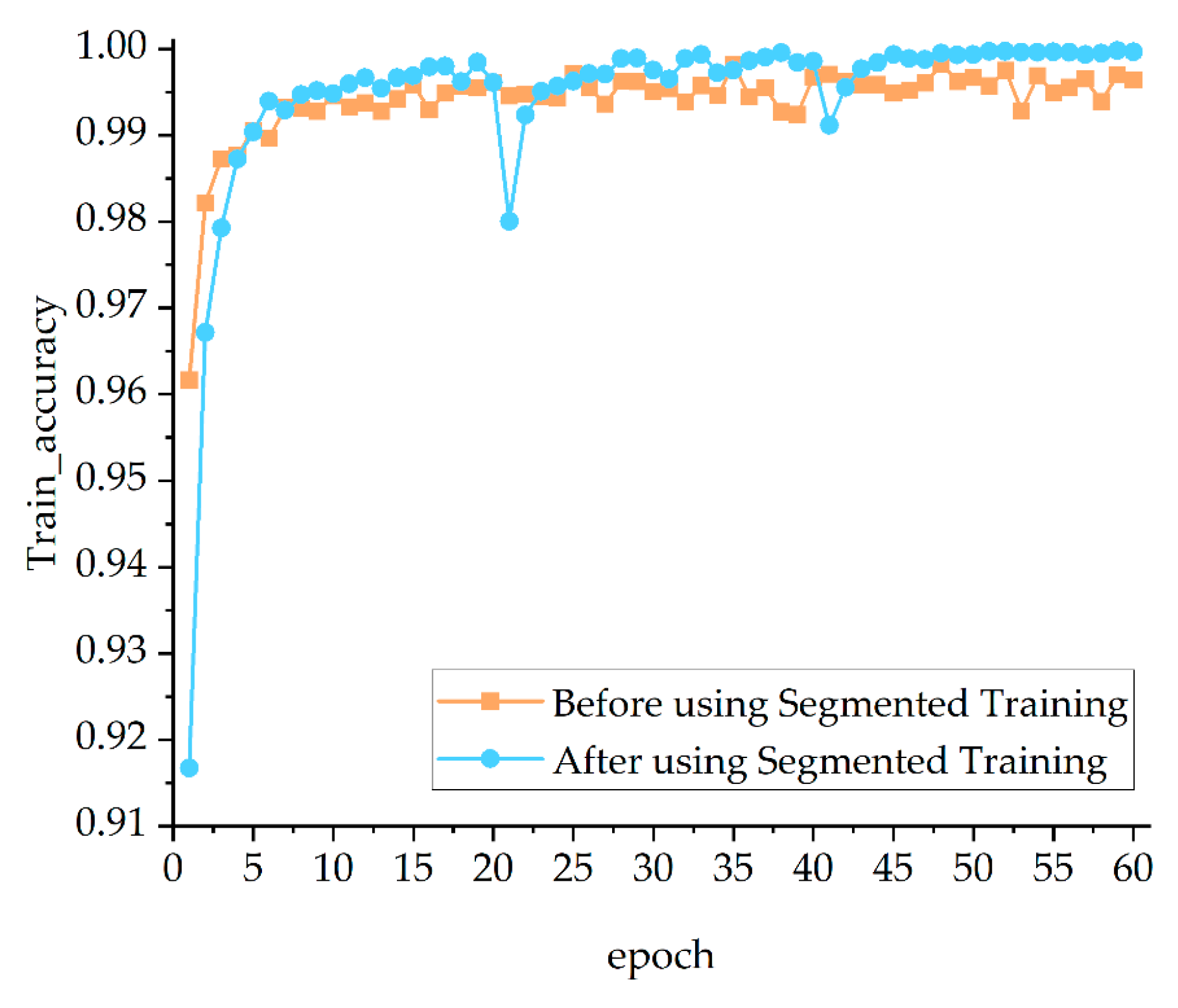
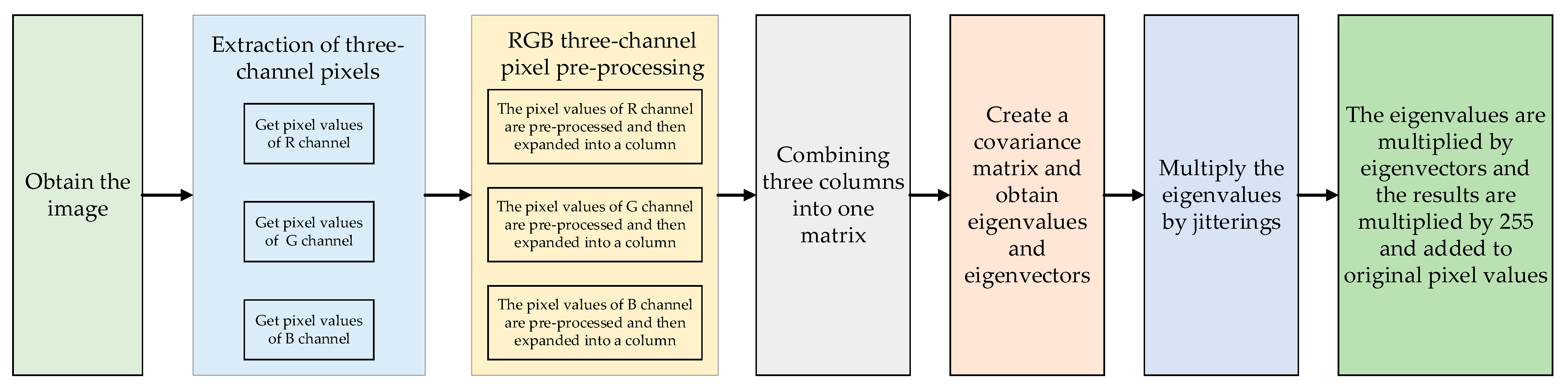
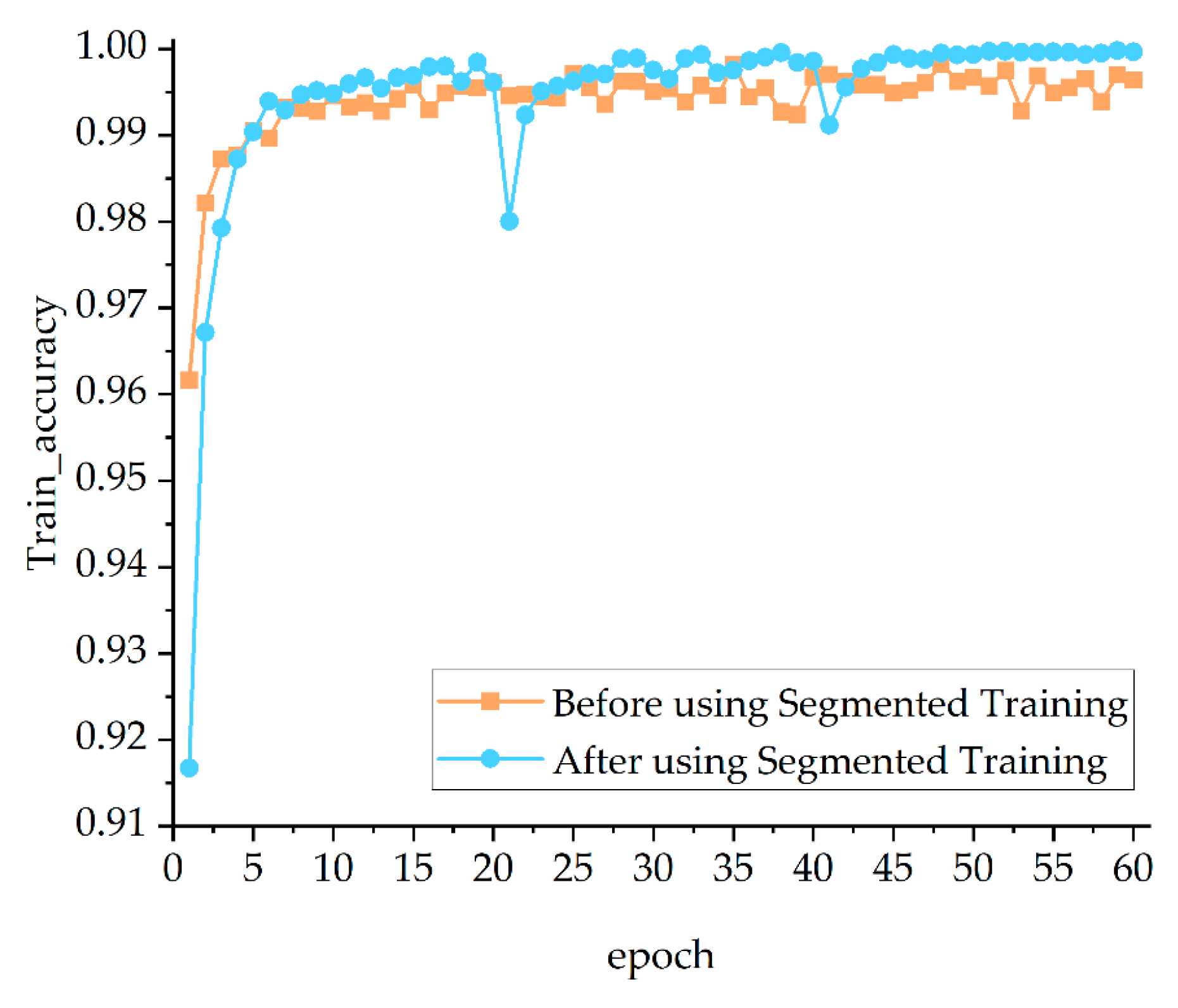
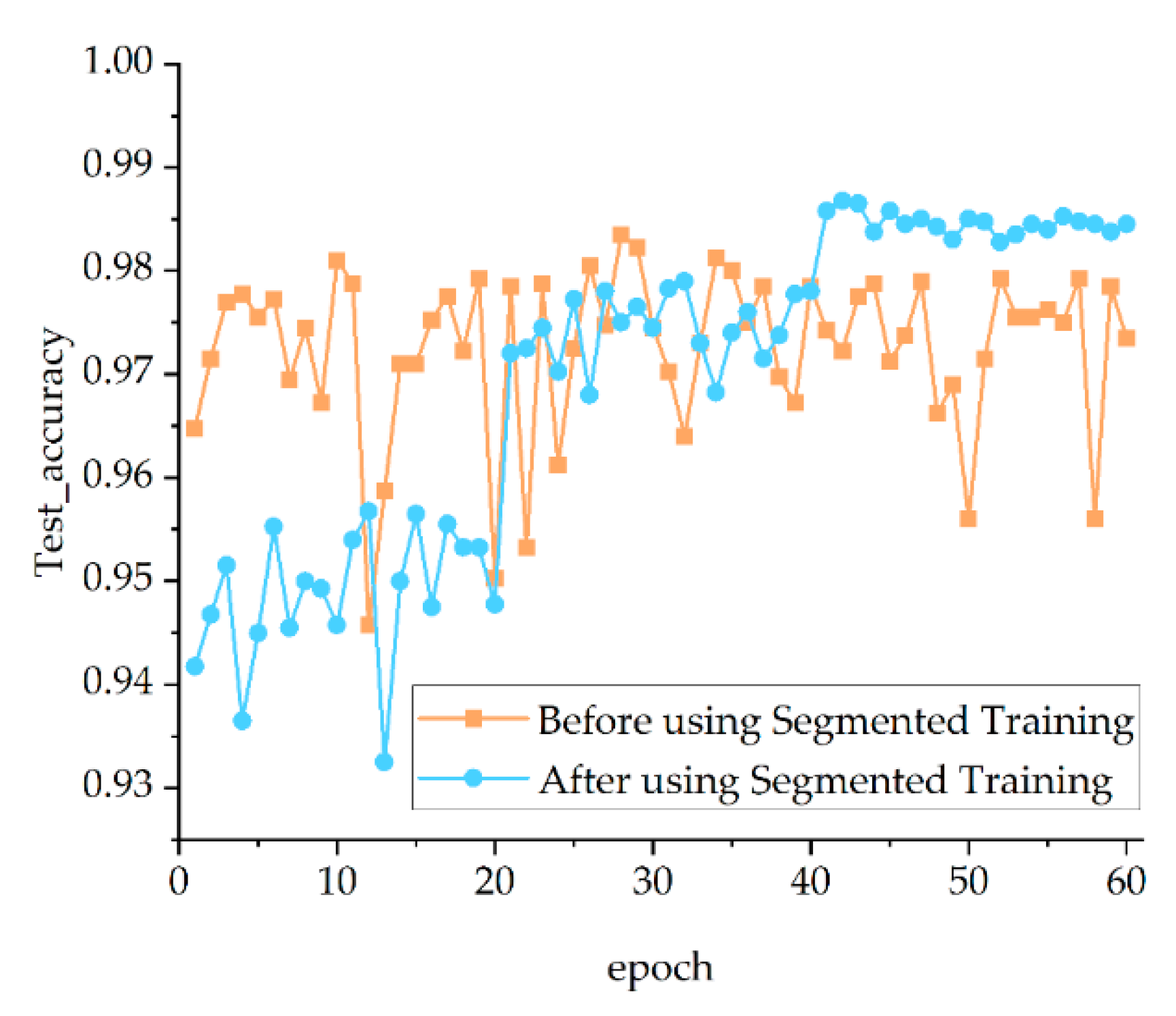
Based on transfer learning, segmented training is used in this paper to further reduce the overfitting of the model. Segmented training means that the image dataset is first set to a low resolution by the model and the model starts training using low resolution images. As the training progresses, the resolution of the dataset is gradually increased and the model parameters from the low resolution are transferred to the new model for training until the resolution reaches the specified size. When training with low resolution images, the overall structure of images is learned by the model, and this information can be refined as the resolution of images is extended.
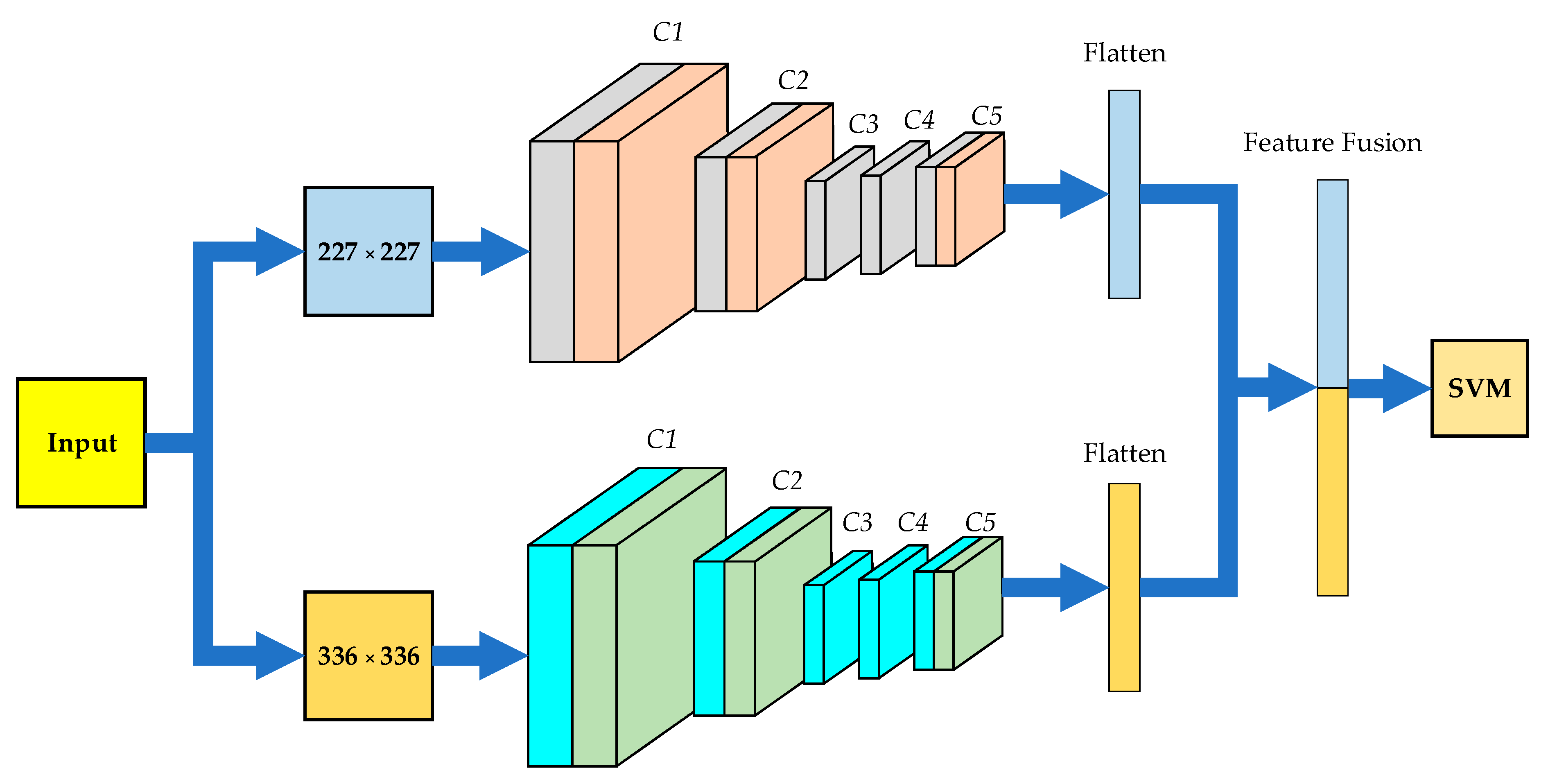
3.2. Development of a Two-Channel CNN
In order to achieve effective coverage of the model for fire scenes of different sizes and thus improve the accuracy of the model, a two-channel CNN based on different resolutions is proposed in this paper. The two-channel CNN has two convolution pooling layer channels, and the inputs of the two channels are wildfire datasets with different resolutions. The resolution of the dataset for the first channel is 227 × 227 and the resolution of the dataset for the second channel is 336 × 336. The convolution pooling layers
C1–
C5 of both channels are trained simultaneously and wildfire features are extracted independently, and the features are flattened after extraction and fused in a 1:1 ratio. Considering the unique advantages of SVM in small samples and non-linear classification problems, the fully connected layers in the original model are replaced using SVM. The structure of the two-channel CNN is shown in
Figure 10.
SVM [
21] is a machine learning algorithm that requires less training data and has high model accuracy. The features extracted and fused by the two-channel CNN are trained by SVM to find the optimal segmentation hyperplane of the model and to achieve fire classification. When given an image (
xi,
yi),
of wildfire, SVM is optimised in the form shown in Equation (13).
where
w is the normal vector perpendicular to the resulting hyperplane,
is the non-linear mapping,
is the relaxation variable, and
C is the penalty factor.
After introducing the Lagrange function
L = (
w,
b,
a) and implementing the dualisation, the decision function becomes:
where
t is the sample to be classified,
n is the number of support vectors,
xi is the fused feature vector,
yi is the corresponding category,
is the symbolic function,
is the Lagrangian factor,
is the kernel function, and
b is the classification threshold determined from the training set.
The SVM kernel function used in this paper is a Gaussian radial basis function. The advantages of few parameters and fast convergence are possessed by the Gaussian radial basis function, whose formula is shown in Equation (15).
where
is the argument to the kernel function.
3.3. Construction of an Improved Two-Channel CNN
Due to the large number of features extracted by the two-channel CNN, feeding them directly to the SVM will result in a large delay time. To address this problem, an improved two-channel CNN is proposed in this paper, which compresses the flattened features from the two channels separately. After feature compression, the improved two-channel CNN performs feature fusion and finally classifies the dataset by SVM.
In this paper, since the features after flattening are high-dimensional sparse data, and linear models have better performance in dealing with these data while being widely used in classification problems [
22], Lasso is chosen to compress the features in this paper.
Lasso is a compressed estimate in which some of the eigencoefficients in the model are made to be exactly zero by adding the
L1 parametrization to the model, that is, certain features are completely ignored by the model, thus presenting the most important features of the model and achieving the effect of subset shrinkage [
23]. Calculation time can be reduced by reducing the number of dimensions of the original data [
24].
Taking one of the two channels in the improved two-channel CNN as an example, the features extracted by the convolution pooling layers
C1–
C5 are flattened and used as inputs to Lasso, and the output is predicted using Equation (16).
where
xi denotes the features after flattening,
wi denotes the parameters of the features in the model,
b is the offset, and
is the predicted output.
Lasso calculates the loss function
from the squared error of the true value
y and the predicted value
, and adds a regular term to the loss function. Lasso’s loss function is shown in Equation (17).
where
m is the number of wildfire dataset,
n is the number of features after flattening,
is the regularisation parameter, and
is the
L1 parametrization.
The objective of Lasso is to achieve variables selection and model parameter estimation, and Lasso’s solution formula is shown in Equation (18).




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}