
Application of Unsupervised Anomaly Detection Techniques to Moisture Content Data from Wood Constructions



Abstract
1. Introduction
2. Related Work
3. Methodology
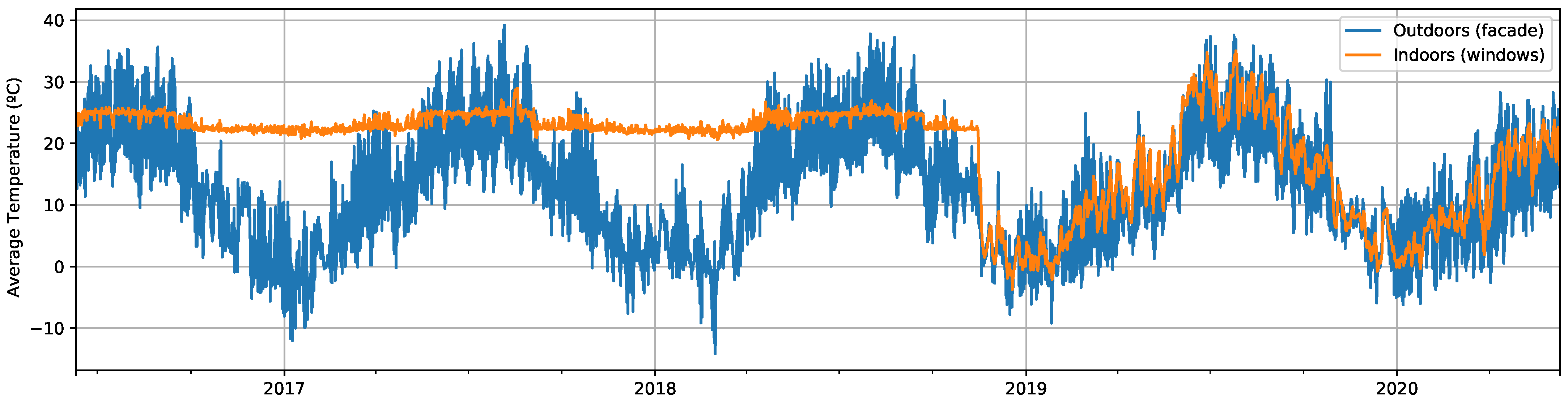
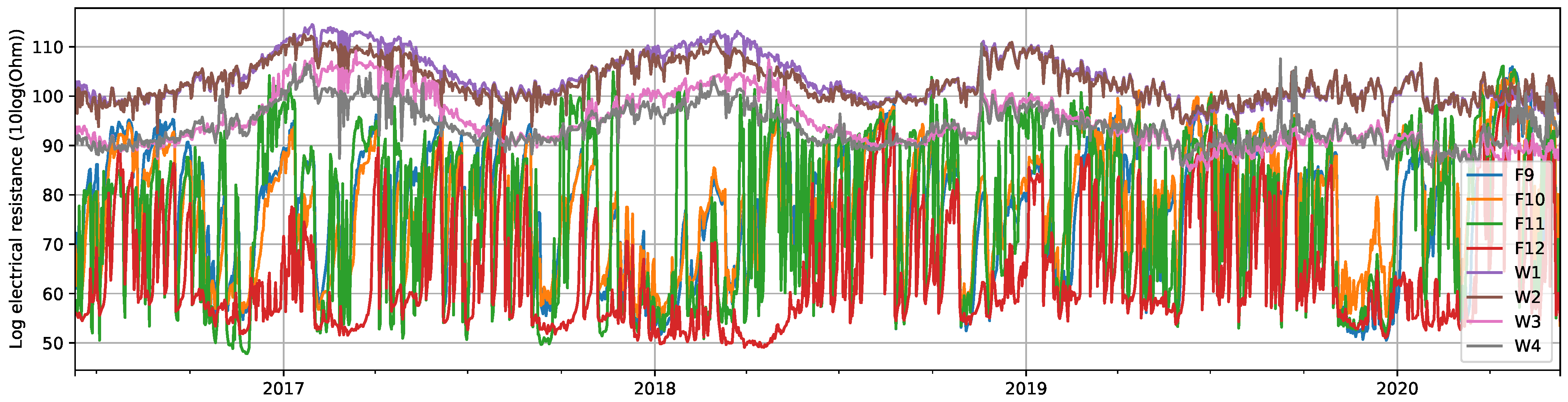
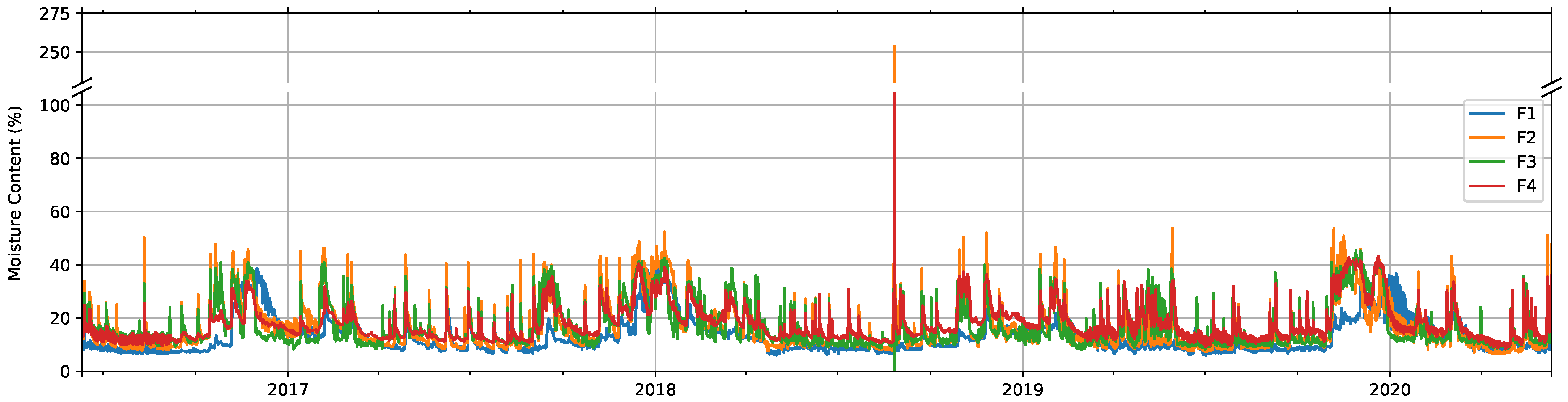
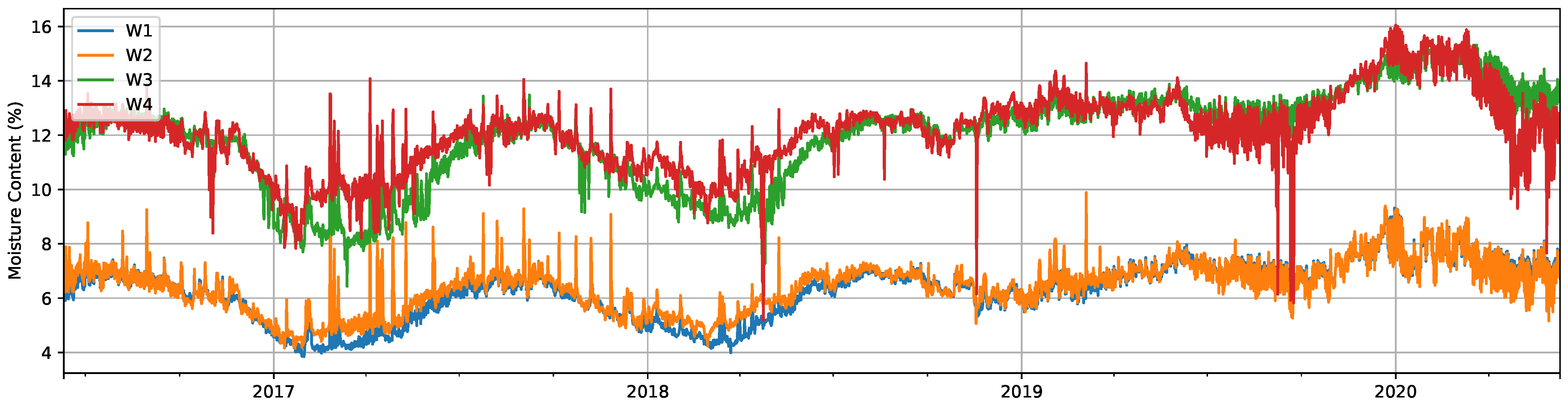
3.1. Data Description
3.2. Data Preprocessing
3.2.1. Moisture Content
3.2.2. Daily Average
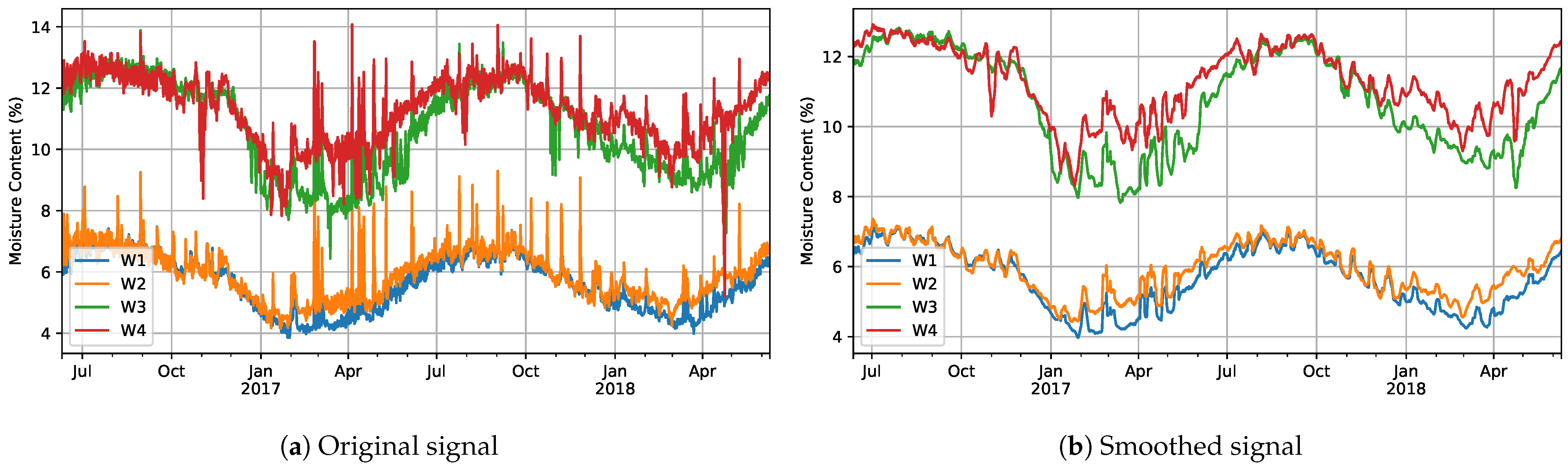
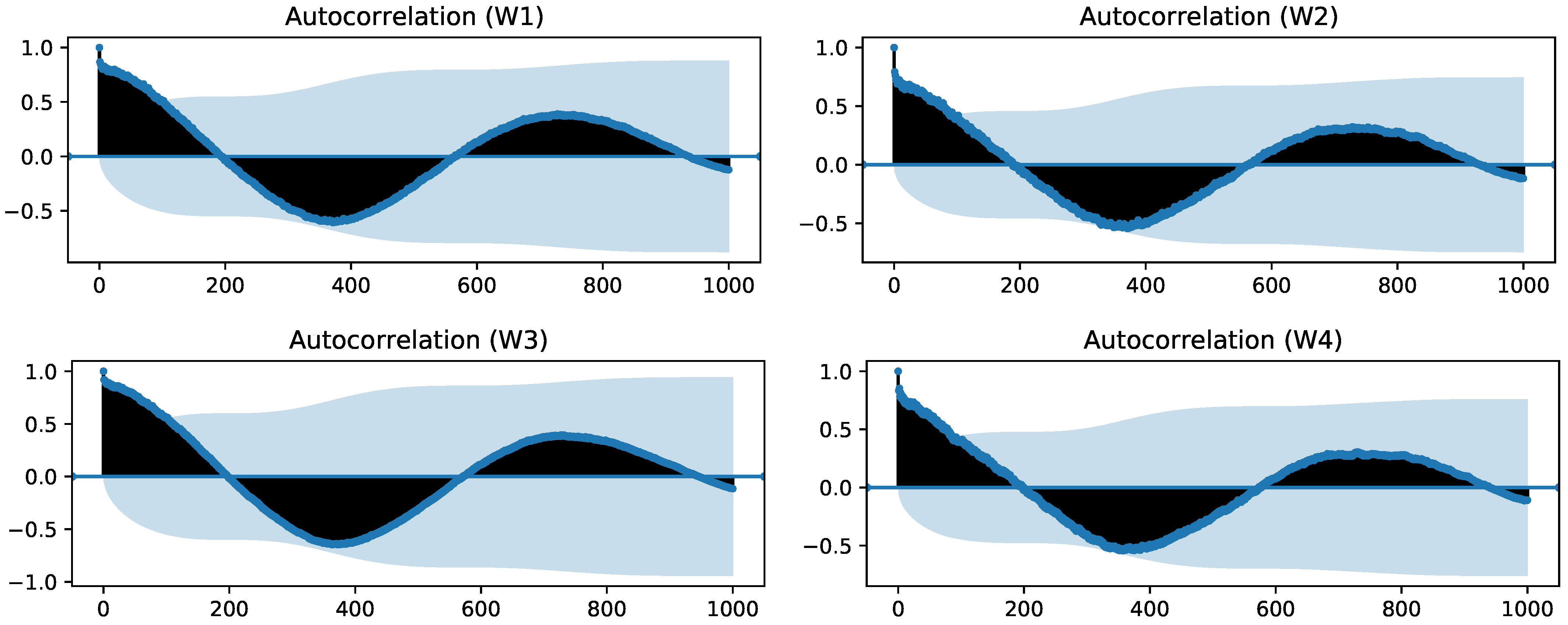
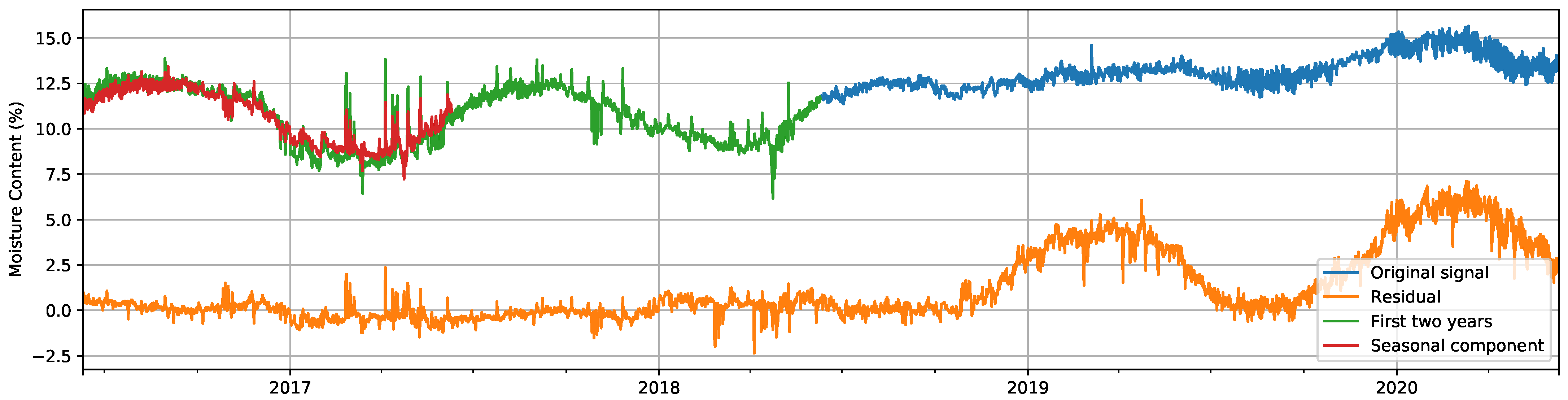
3.2.3. Seasonal Decomposition
3.3. Unsupervised Anomaly Detection Methods
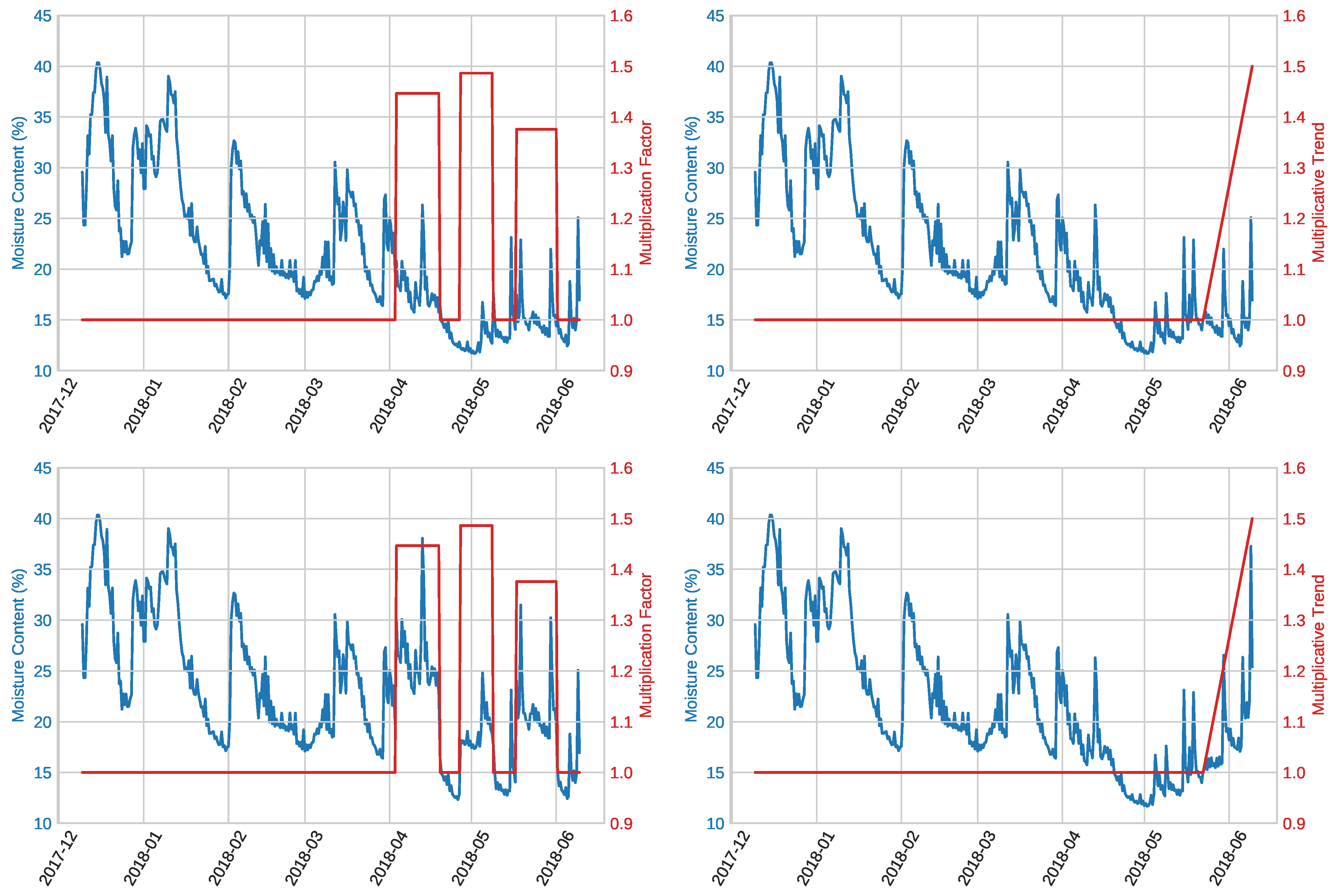
3.4. Artificial Anomaly Generation
3.4.1. Mask Product
3.4.2. Trend Component
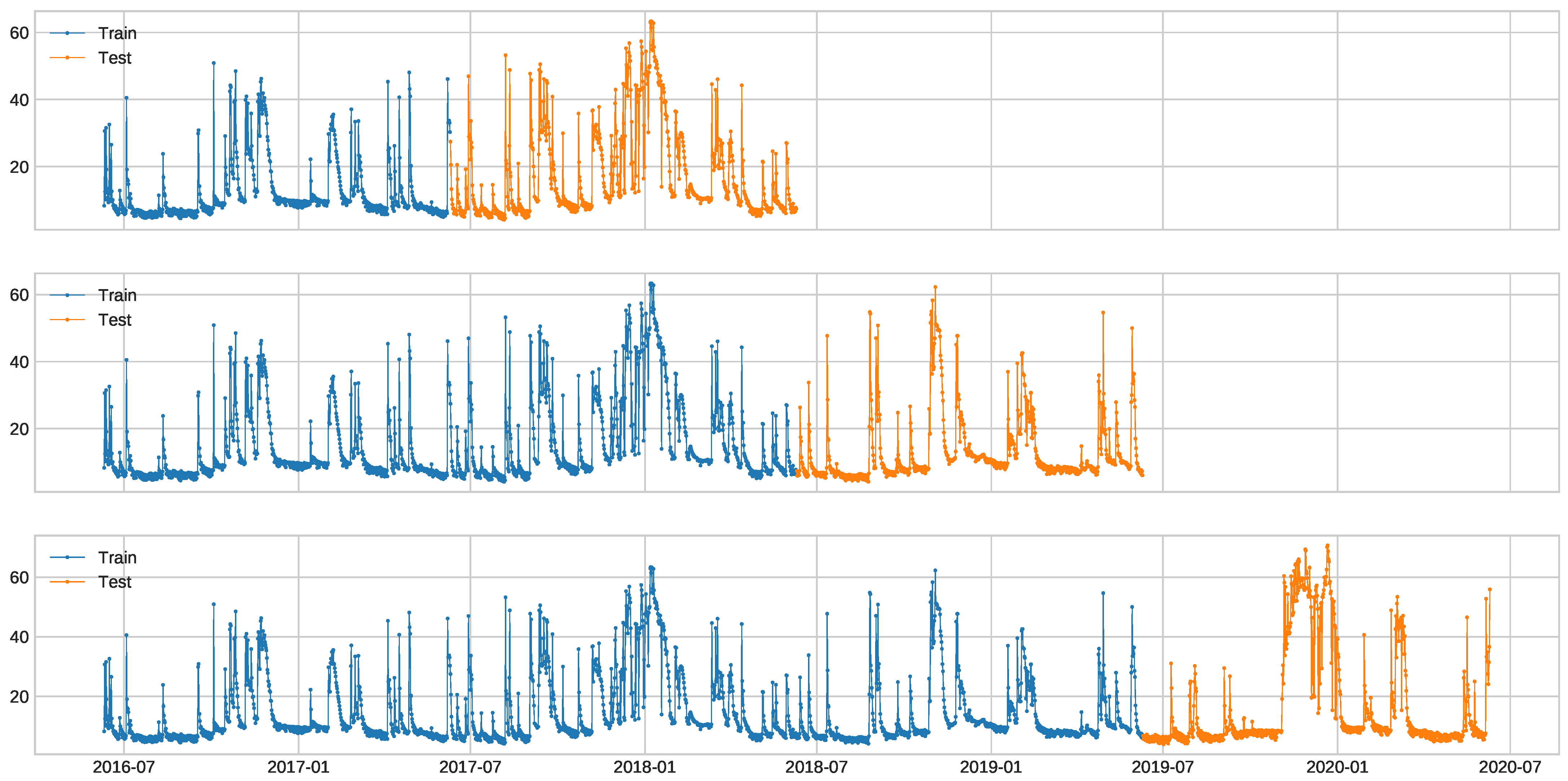
3.5. Experimental Setup
3.5.1. Facade Dataset
- EF1
- Random mask product with variable multiplication factor: We ran several experiments in which we increased the multiplication factor of the mask product, but with fixed anomalous segments. With these experiments, we wanted to explore how the magnitude of the factor by which the signal was multiplied affects the detection results.
- EF2
- Random mask product with variable anomalous sequence length: We ran several experiments in which we increased the length of the artificial anomalies for the mask product, but with a fixed multiplication factor. With these experiments, we aimed to determine how the length of the modification applied to the signal affects the detection results.
- EF3
- Linear trend at the end: We generated a linear trend at the end of the test signal with different contamination values (i.e., always until the end of the test signal, but starting at different points). The trend was applied by multiplying it with the original signal. This would emulate, to some extent, the real anomaly found in the windows dataset caused by the A/C failure.
- EF4
- Random mask product and fixed linear trend at the end: In this last set of experiments, we randomized both the multiplication factor and length for the multiplicative mask and also included a linear trend at the end of the signal, similar to experiment EF3, but with a fixed length. With these experiments, we intended to evaluate the detection methods in a less controlled environment, in which the two types of anomalies can even be overlapped.
3.5.2. Windows Dataset
4. Results and Discussion
4.1. Data Preprocessing
4.1.1. Moisture Content
4.1.2. Seasonal Decomposition
4.2. Unsupervised Anomaly Detection
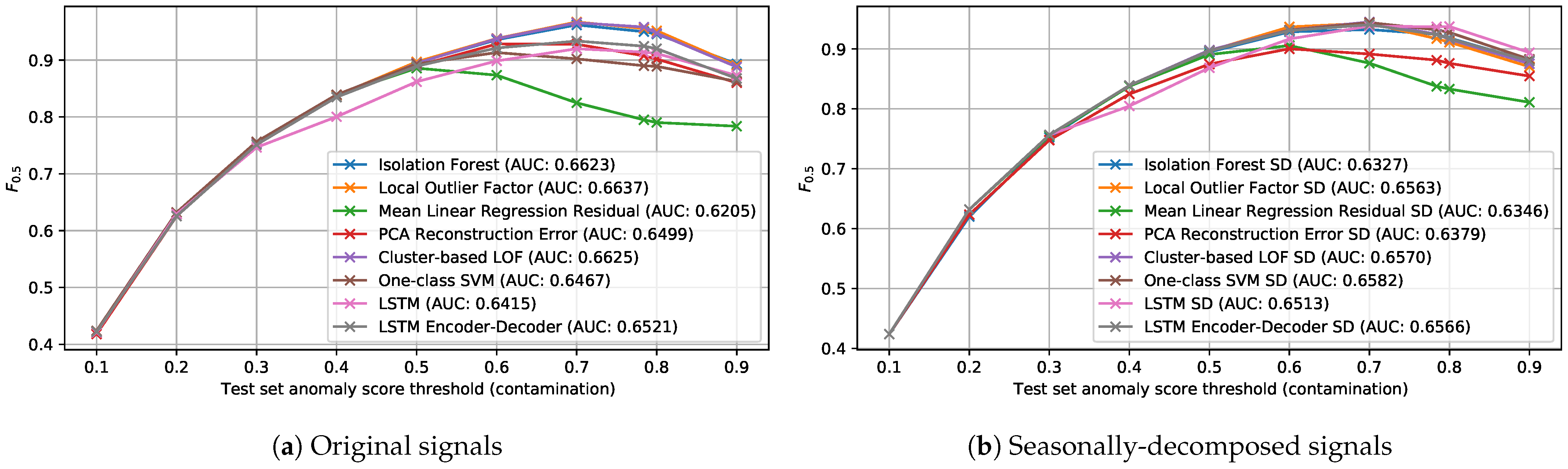
4.2.1. Facade Dataset
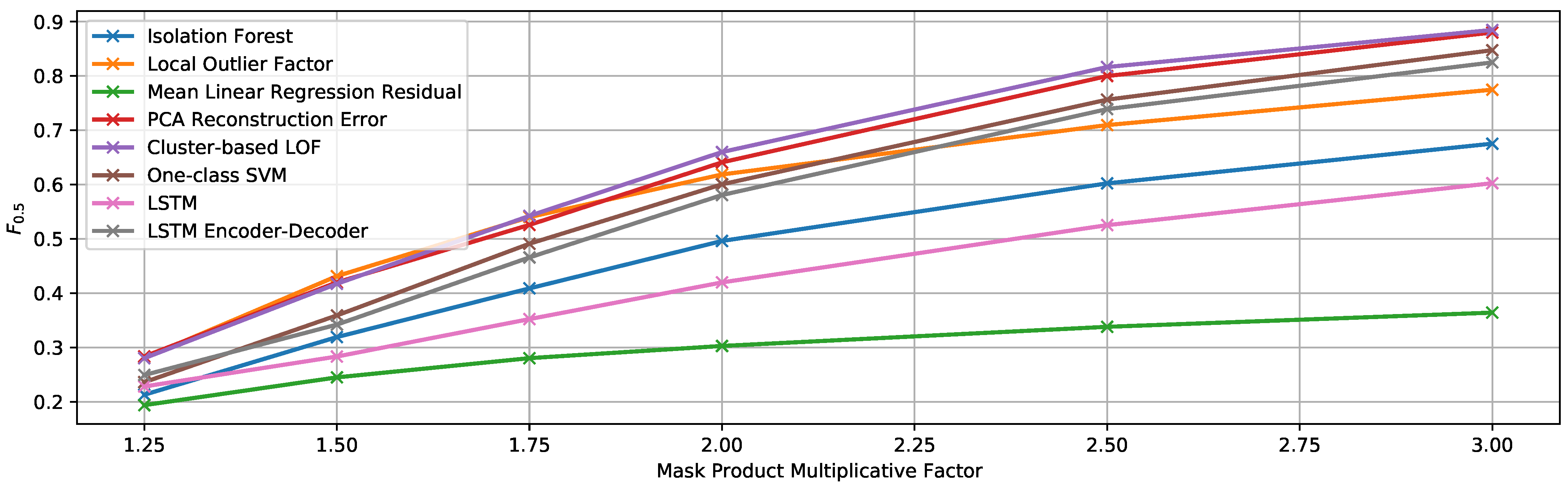
EF1. Random Mask Product with Variable Multiplication Factor
- Mask multiplication factor: variable between 1.25 and 3
- Minimum anomalous sequence length: 14 samples (equivalent to one week)
- Maximum anomalous sequence length: 28 samples (equivalent to two weeks)
- Number of anomalous sequences: 5
- Minimum separation between anomalous sequences: 14 samples
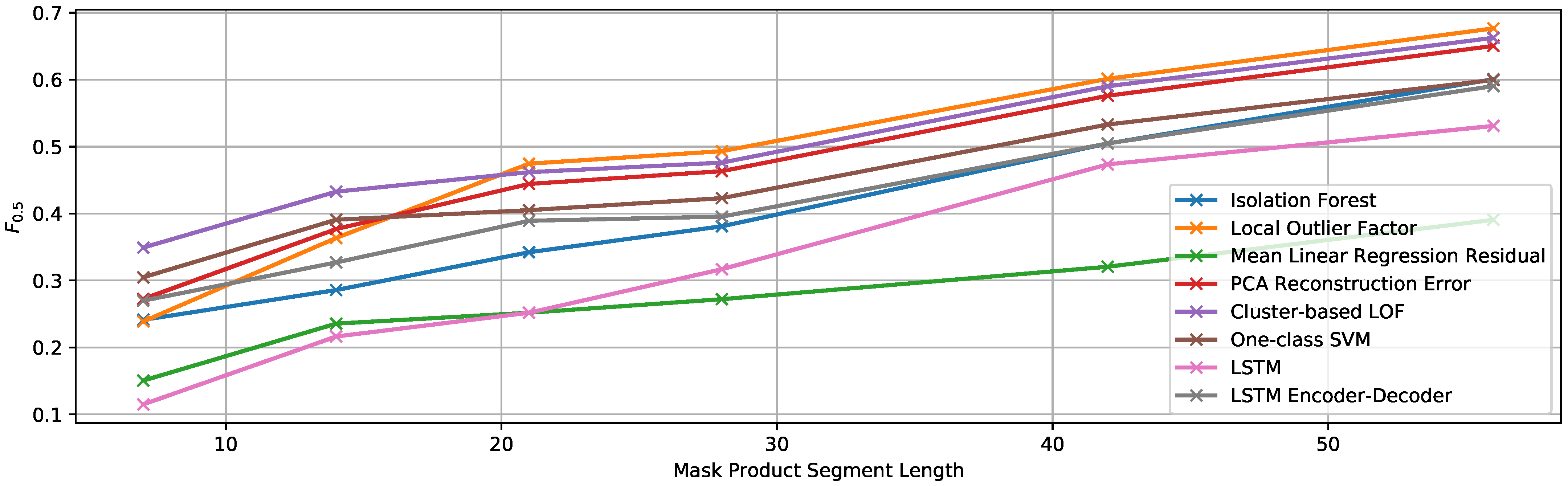
EF2. Random Mask Product with Variable Anomalous Sequence Length
- Mask multiplication factor: 1.5
- Anomalous sequence length: variable between 7 and 56 samples
- Number of anomalous sequences: 5
- Minimum separation between anomalous sequences: 14 samples
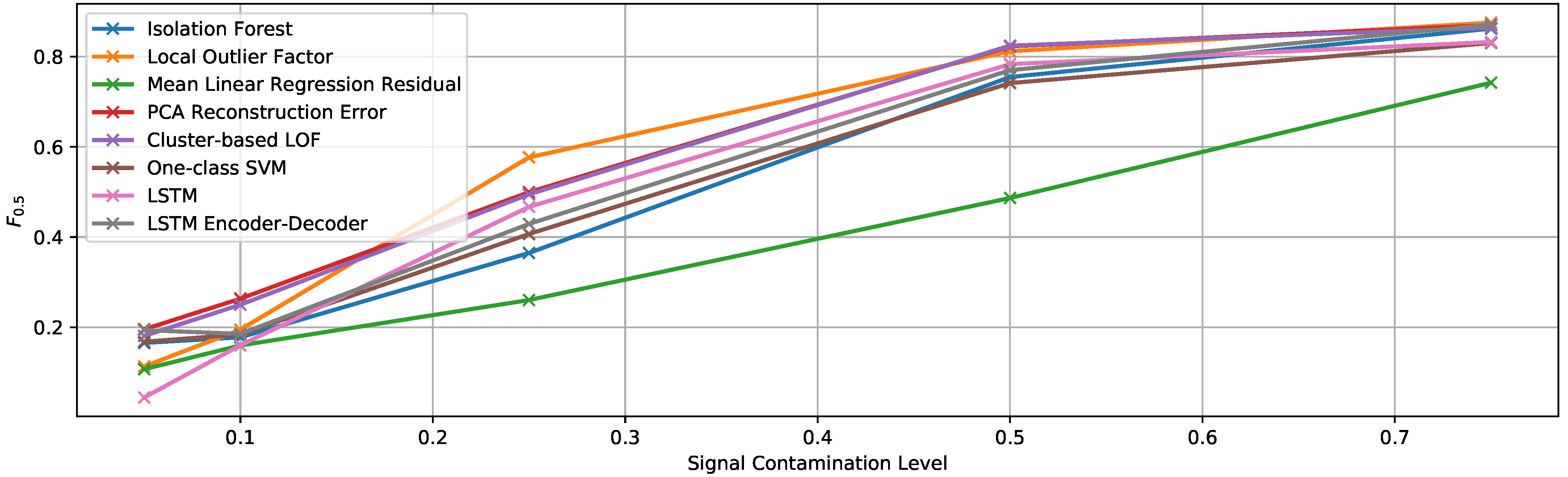
EF3. Linear Trend at the End
- Contamination level: variable between 0.05 and 0.75
- Function type: linear
- Maximum multiplicative factor (that of the final sample): 2
EF4. Random Mask Product and Fixed Linear Trend at the End
- Mask multiplication factor: random between 1 and 1.5
- Minimum anomalous sequence length: 14 samples (equivalent to 1 week)
- Maximum anomalous sequence length: 56 samples (equivalent to 4 weeks)
- Number of anomalous sequences in the mask: 3
- Minimum separation between anomalous sequences in the mask: 14 samples
- Linear trend contamination level: 0.1
- Linear trend function type: linear
- Maximum multiplicative factor (that of the final sample): 1.5
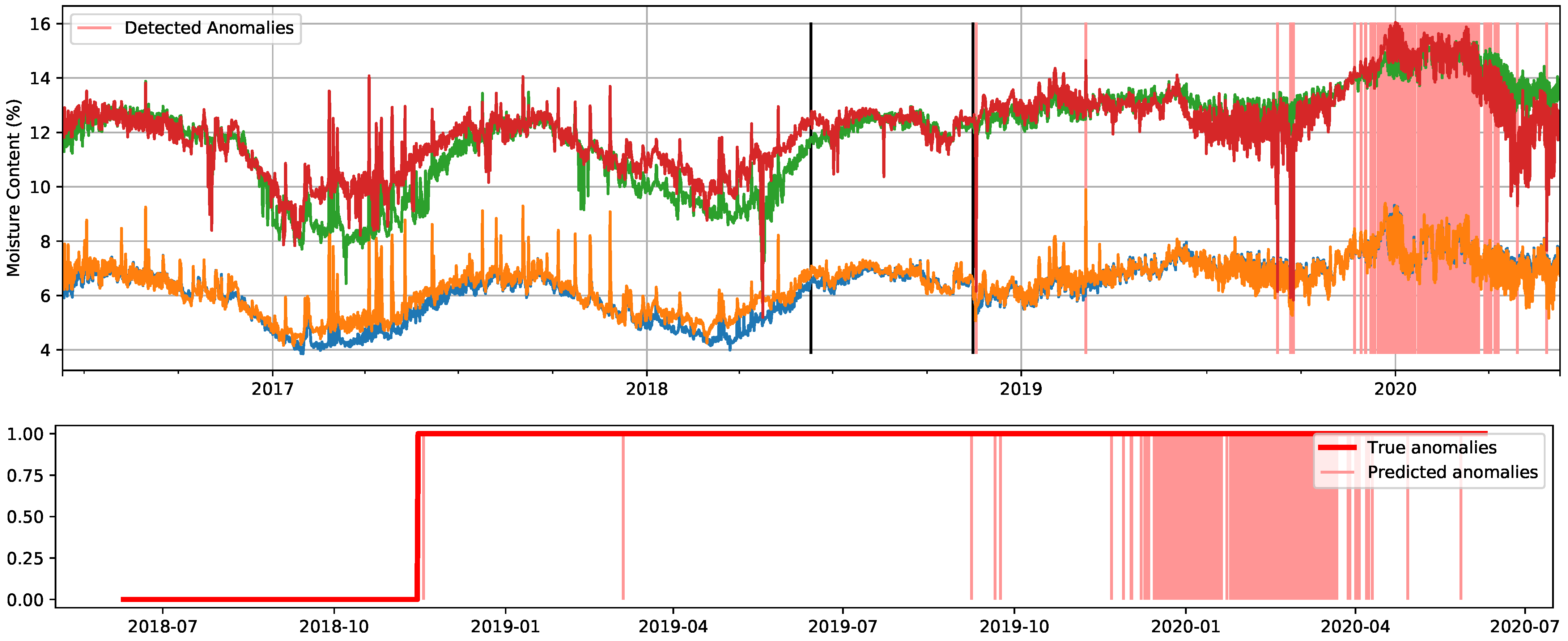
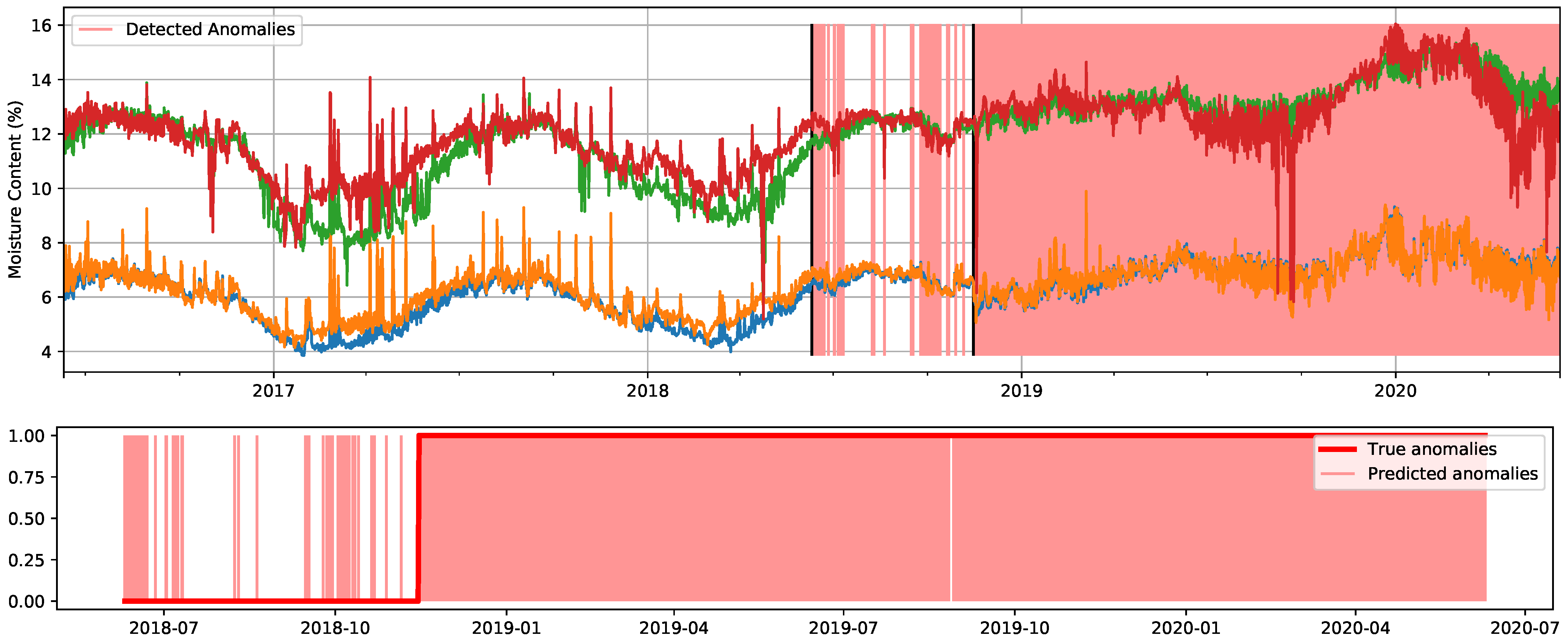
4.2.2. Windows Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zabel, R.A.; Morrell, J.J. Wood Microbiology: Decay and Its Prevention; Academic Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Reinprecht, L. Wood Deterioration, Protection and Maintenance; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Ribera, J.; Schubert, M.; Fink, S.; Cartabia, M.; Schwarze, F.W. Premature failure of utility poles in Switzerland and Germany related to wood decay basidiomycetes. Holzforschung 2017, 71, 241–247. [Google Scholar] [CrossRef][Green Version]
- Kutnik, M.; Suttie, E.; Brischke, C. European standards on durability and performance of wood and wood-based products—Trends and challenges. Wood Mater. Sci. Eng. 2014, 9, 122–133. [Google Scholar] [CrossRef]
- Schmidt, O. Wood and Tree Fungi; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Carll, C.G.; Highley, T.L. Decay of wood and wood-based products above ground in buildings. J. Test. Eval. 1999, 27, 150–158. [Google Scholar]
- Meyer, L.; Brischke, C. Fungal decay at different moisture levels of selected European-grown wood species. Int. Biodeterior. Biodegrad. 2015, 103, 23–29. [Google Scholar] [CrossRef]
- Zelinka, S.L.; Kirker, G.T.; Bishell, A.B.; Glass, S.V. Effects of wood moisture content and the level of acetylation on brown rot decay. Forests 2020, 11, 299. [Google Scholar] [CrossRef]
- Shigo, A.L. Detection of Discoloration and Decay in Living Trees and Utility Poles; Forest Service, US Department of Agriculture, Northeastern Forest Experiment Station: Morgantown, VA, USA, 1974; Volume 294. [Google Scholar]
- Goasduff, L. Internet of Things Market. Available online: https://www.gartner.com/en/newsroom/press-releases/2019-08-29-gartner-says-5-8-billion-enterprise-and-automotive-io (accessed on 28 July 2020).
- Jin, Z.; Zhang, Z.; Gu, G.X. Automated real-time detection and prediction of interlayer imperfections in additive manufacturing processes using artificial intelligence. Adv. Intell. Syst. 2020, 2, 1900130. [Google Scholar] [CrossRef]
- Farrar, C.R.; Worden, K. Structural Health Monitoring: A Machine Learning Perspective; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Seyedzadeh, S.; Rahimian, F.P.; Glesk, I.; Roper, M. Machine learning for estimation of building energy consumption and performance: A review. Vis. Eng. 2018, 6, 1–20. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Outlier analysis. In Data Mining; Springer: Berlin/Heidelberg, Germany, 2015; pp. 237–263. [Google Scholar]
- Lin, J.; Yu, W.; Zhang, N.; Yang, X.; Zhang, H.; Zhao, W. A survey on internet of things: Architecture, enabling technologies, security and privacy, and applications. IEEE Internet Things J. 2017, 4, 1125–1142. [Google Scholar] [CrossRef]
- Lu, Y. Industry 4.0: A survey on technologies, applications and open research issues. J. Ind. Inf. Integr. 2017, 6, 1–10. [Google Scholar] [CrossRef]
- Cook, A.; Mısırlı, G.; Fan, Z. Anomaly detection for IoT time series data: A survey. IEEE Internet Things J. 2019, 7, 6481–6494. [Google Scholar] [CrossRef]
- Gonzaga, J.; Meleiro, L.A.C.; Kiang, C.; Maciel Filho, R. ANN-based soft-sensor for real-time process monitoring and control of an industrial polymerization process. Comput. Chem. Eng. 2009, 33, 43–49. [Google Scholar] [CrossRef]
- Cho, S.; Asfour, S.; Onar, A.; Kaundinya, N. Tool breakage detection using support vector machine learning in a milling process. Int. J. Mach. Tools Manuf. 2005, 45, 241–249. [Google Scholar] [CrossRef]
- Chen, P.Y.; Yang, S.; McCann, J.A. Distributed real-time anomaly detection in networked industrial sensing systems. IEEE Trans. Ind. Electron. 2014, 62, 3832–3842. [Google Scholar] [CrossRef]
- Feng, C.; Li, T.; Chana, D. Multi-level anomaly detection in industrial control systems via package signatures and LSTM networks. In Proceedings of the 2017 47th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Denver, CO, USA, 26–29 June 2017; pp. 261–272. [Google Scholar]
- Akouemo, H.N.; Povinelli, R.J. Probabilistic anomaly detection in natural gas time series data. Int. J. Forecast. 2016, 32, 948–956. [Google Scholar] [CrossRef]
- Araya, D.B.; Grolinger, K.; ElYamany, H.F.; Capretz, M.A.; Bitsuamlak, G. An ensemble learning framework for anomaly detection in building energy consumption. Energy Build. 2017, 144, 191–206. [Google Scholar] [CrossRef]
- Inoue, J.; Yamagata, Y.; Chen, Y.; Poskitt, C.M.; Sun, J. Anomaly detection for a water treatment system using unsupervised machine learning. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 1058–1065. [Google Scholar]
- Laptev, N.; Amizadeh, S.; Flint, I. Generic and scalable framework for automated time series anomaly detection. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1939–1947. [Google Scholar]
- Buda, T.S.; Caglayan, B.; Assem, H. Deepad: A generic framework based on deep learning for time series anomaly detection. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2018; pp. 577–588. [Google Scholar]
- Bao, Y.; Tang, Z.; Li, H.; Zhang, Y. Computer vision and deep learning–based data anomaly detection method for structural health monitoring. Struct. Health Monit. 2019, 18, 401–421. [Google Scholar] [CrossRef]
- Rotilio, M.; Pantoli, L.; Muttillo, M.; Annibaldi, V. Performance Monitoring of Wood Construction Materials by Means of Integrated Sensors. In Key Engineering Materials; Trans. Tech. Publ.: Zurich, Switzerland, 2018; Volume 792, pp. 195–199. [Google Scholar]
- Kržišnik, D.; Brischke, C.; Lesar, B.; Thaler, N.; Humar, M. Performance of wood in the Franja partisan hospital. Wood Mater. Sci. Eng. 2019, 14, 24–32. [Google Scholar] [CrossRef]
- Humar, M.; Kržišnik, D.; Lesar, B.; Brischke, C. The performance of wood decking after five years of exposure: Verification of the combined effect of wetting ability and durability. Forests 2019, 10, 903. [Google Scholar] [CrossRef]
- Humar, M.; Lesar, B.; Kržišnik, D. Moisture Performance of Façade Elements Made of Thermally Modified Norway Spruce Wood. Forests 2020, 11, 348. [Google Scholar] [CrossRef]
- Zupanc, M.Ž.; Pogorelčnik, A.; Kržišnik, D.; Lesar, B.; Thaler, N.; Humar, M. Model za določanje življenjske dobe lesa listavcev. Les/Wood 2017, 66, 53–59. [Google Scholar] [CrossRef][Green Version]
- Otten, K.A.; Brischke, C.; Meyer, C. Material moisture content of wood and cement mortars–electrical resistance-based measurements in the high ohmic range. Constr. Build. Mater. 2017, 153, 640–646. [Google Scholar] [CrossRef]
- Brischke, C.; Lampen, S.C. Resistance based moisture content measurements on native, modified and preservative treated wood. Eur. J. Wood Wood Prod. 2014, 72, 289–292. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data (TKDD) 2012, 6, 1–39. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 93–104. [Google Scholar]
- He, Z.; Xu, X.; Deng, S. Discovering cluster-based local outliers. Pattern Recognit. Lett. 2003, 24, 1641–1650. [Google Scholar] [CrossRef]
- Schölkopf, B.; Williamson, R.C.; Smola, A.J.; Shawe-Taylor, J.; Platt, J.C. Support vector method for novelty detection. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2000; pp. 582–588. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long short term memory networks for anomaly detection in time series. In Proceedings; Presses Universitaires de Louvain: Ottignies-Louvain-la-Neuve, Belgium, 2015; Volume 89, pp. 89–94. [Google Scholar]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based encoder-decoder for multi-sensor anomaly detection. arXiv 2016, arXiv:1607.00148. [Google Scholar]
- Cleveland, R.B.; Cleveland, W.S.; McRae, J.E.; Terpenning, I. STL: A seasonal-trend decomposition. J. Off. Stat. 1990, 6, 3–73. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Signal | Position | Number of Signals |
|---|---|---|
| Logarithmic electrical resistance | 16 | |
| Spruce (TMT facade) | facade | 3 |
| Spruce (TMT window) | facade | 1 |
| Larch | facade | 2 |
| Larch (TMT) | facade | 1 |
| Beech | facade | 2 |
| Beech (TMT) | facade | 2 |
| Poplar (TMT) | facade | 1 |
| Spruce (TMT window, coating above) | windows | 1 |
| Spruce (TMT window, coating below) | windows | 1 |
| Spruce (coating above) | windows | 1 |
| Spruce (coating below) | windows | 1 |
| Wood temperature | 6 | |
| Outdoor | facade | 4 |
| Indoor | windows | 2 |
| Contaminated Signals | All | All but Two | Only Two | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Contamination | 0.05 | True | 0.5 | 0.05 | True | 0.5 | 0.05 | True | 0.5 | |
| Mean Linear Regr.Res. | 0.1663 | 0.2120 | 0.2153 | 0.0596 | 0.0936 | 0.1289 | 0.3615 | 0.4104 | 0.3481 | 0.2217 |
| Isolation Forest | 0.2854 | 0.2999 | 0.2975 | 0.2761 | 0.3099 | 0.3039 | 0.1360 | 0.2291 | 0.2528 | 0.2656 |
| One-class SVM | 0.3294 | 0.2963 | 0.2537 | 0.3002 | 0.2770 | 0.2546 | 0.2015 | 0.2653 | 0.2419 | 0.2689 |
| LSTM | 0.2797 | 0.2913 | 0.2915 | 0.3095 | 0.3119 | 0.3089 | 0.2336 | 0.2540 | 0.2645 | 0.2828 |
| LSTM Encoder-Decoder | 0.3596 | 0.2982 | 0.2991 | 0.3769 | 0.3077 | 0.2960 | 0.1433 | 0.2393 | 0.2669 | 0.2875 |
| Cluster-based LOF | 0.3466 | 0.3662 | 0.3213 | 0.3235 | 0.3434 | 0.3149 | 0.2014 | 0.3313 | 0.2794 | 0.3142 |
| PCA Reconstruct.Error | 0.3034 | 0.3702 | 0.3129 | 0.3205 | 0.3562 | 0.3243 | 0.2270 | 0.3445 | 0.2930 | 0.3169 |
| Local Outlier Factor | 0.2582 | 0.3842 | 0.3505 | 0.2416 | 0.4182 | 0.3752 | 0.2267 | 0.3003 | 0.3151 | 0.3189 |
| Contamination | 0.100 | 0.784 | 0.900 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | ||||
| Mean Linear Regression Residual | 1.0000 | 0.1283 | 0.4239 | 0.7949 | 0.7949 | 0.7949 | 0.7635 | 0.8761 | 0.7836 |
| Mean Linear Regression Residual SD | 1.0000 | 0.1283 | 0.4239 | 0.8377 | 0.8377 | 0.8377 | 0.7901 | 0.9066 | 0.8110 |
| PCA Reconstruction Error SD | 1.0000 | 0.1283 | 0.4239 | 0.8813 | 0.8813 | 0.8813 | 0.8327 | 0.9555 | 0.8547 |
| One-class SVM | 1.0000 | 0.1283 | 0.4239 | 0.8901 | 0.8901 | 0.8901 | 0.8403 | 0.9642 | 0.8625 |
| PCA Reconstruction Error | 0.9864 | 0.1265 | 0.4181 | 0.9075 | 0.9075 | 0.9075 | 0.8380 | 0.9616 | 0.8601 |
| LSTM | 0.9932 | 0.1274 | 0.4210 | 0.9140 | 0.9140 | 0.9140 | 0.8503 | 0.9764 | 0.8729 |
| Local Outlier Factor SD | 1.0000 | 0.1283 | 0.4239 | 0.9171 | 0.9171 | 0.9171 | 0.8479 | 0.9729 | 0.8703 |
| LSTM Encoder-Decoder SD | 1.0000 | 0.1283 | 0.4239 | 0.9239 | 0.9239 | 0.9239 | 0.8573 | 0.9845 | 0.8800 |
| Isolation Forest SD | 1.0000 | 0.1283 | 0.4239 | 0.9244 | 0.9244 | 0.9244 | 0.8572 | 0.9836 | 0.8798 |
| LSTM Encoder-Decoder | 0.9959 | 0.1277 | 0.4221 | 0.9244 | 0.9244 | 0.9244 | 0.8451 | 0.9705 | 0.8676 |
| Cluster-based LOF SD | 1.0000 | 0.1283 | 0.4239 | 0.9246 | 0.9246 | 0.9246 | 0.8527 | 0.9792 | 0.8754 |
| One-class SVM SD | 1.0000 | 0.1283 | 0.4239 | 0.9319 | 0.9319 | 0.9319 | 0.8601 | 0.9869 | 0.8828 |
| LSTM SD | 1.0000 | 0.1283 | 0.4239 | 0.9370 | 0.9370 | 0.9370 | 0.8708 | 1.0000 | 0.8939 |
| Isolation Forest | 1.0000 | 0.1276 | 0.4223 | 0.9499 | 0.9499 | 0.9499 | 0.8701 | 0.9984 | 0.8931 |
| Local Outlier Factor | 1.0000 | 0.1283 | 0.4239 | 0.9555 | 0.9555 | 0.9555 | 0.8677 | 0.9956 | 0.8906 |
| Cluster-based LOF | 1.0000 | 0.1283 | 0.4239 | 0.9581 | 0.9581 | 0.9581 | 0.8649 | 0.9932 | 0.8878 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
García Faura, Á.; Štepec, D.; Cankar, M.; Humar, M. Application of Unsupervised Anomaly Detection Techniques to Moisture Content Data from Wood Constructions. Forests 2021, 12, 194. https://doi.org/10.3390/f12020194
García Faura Á, Štepec D, Cankar M, Humar M. Application of Unsupervised Anomaly Detection Techniques to Moisture Content Data from Wood Constructions. Forests. 2021; 12(2):194. https://doi.org/10.3390/f12020194
Chicago/Turabian StyleGarcía Faura, Álvaro, Dejan Štepec, Matija Cankar, and Miha Humar. 2021. "Application of Unsupervised Anomaly Detection Techniques to Moisture Content Data from Wood Constructions" Forests 12, no. 2: 194. https://doi.org/10.3390/f12020194
APA StyleGarcía Faura, Á., Štepec, D., Cankar, M., & Humar, M. (2021). Application of Unsupervised Anomaly Detection Techniques to Moisture Content Data from Wood Constructions. Forests, 12(2), 194. https://doi.org/10.3390/f12020194