1. Introduction
Epicurus’ measure of eudaimonia (serenity), as a dominant characteristic in his philosophy of hedonism, influenced mathematical thinking two millennia later. Focusing on the attainment of pleasure that provides tranquillity for each individual should minimize the desires and banish the fear of gods and death. Epicurus agrees with Aristotle that happiness is the highest good, disagreeing to identify happiness with pleasure because (i) pleasure is the only thing that people seek; thus, Epicurean ethical hedonism is based on psychological hedonism. (ii) This fits Epicurus’ empiricism, the introspective experience: pleasure is good, and pain is bad. Epicurus claims that all our actions maximize the gain of pleasure for ourselves. Epicurus’ freedom was much later re-formalized in economics as the diminishing marginal utility and the marginal propensity to consume.
The quadratic investor preferences and the return distributions of normal probability are given by the von Neumann–Morgenstern axioms of choice as the main approach in many portfolio selection models that follow Markowitz’s mean variance criterion. Empirical practice and academic research have clarified that neither of the two conditions holds, as non-quadratic distributions are more efficient for describing investment patterns, and the returns are non-normally independently and identically distributed (non n.i.i.d.) (
Merton 2009). The power utility function demonstrated a slightly superior performance toward the quadratic function (
Loukeris and Eleftheriadis 2013;
Loukeris et al. 2014). Further extending the use of higher-order moments than the fourth establishes new qualities in the utility function behavior. Investors usually select positive skewness derived from high profits from extreme positive events, as described by
Boyle and Ding (
2005). They also prefer a low kurtosis of low risk caused by extreme losses or profits on both sides of the distribution (
Athayde and Flores 2003;
Ranaldo and Favre 2003;
Lai et al. 2006;
Loukeris and Eleftheriadis 2013,
2021;
Loukeris et al. 2014;
Loukeris 2021).
Loukeris and Eleftheriadis (
2021) remarked that advanced modeling is necessary to provide upgraded reliability to investors’ preferences under advanced higher-order moments. The m
10 hyperultrakurtosis, in the expected utility, reflects more detailed forms of risk, eliminating hoax, noise, or manipulation effects. The risk is not fully expressed in the m
2 (σ), while the m
4 (Kurt) includes valuable information on fat tails and leptokurtosis; thus, even higher-order moments add information. The hypothesis we make at this point is that the noise of systemic risk is provided by biased expectations or manipulation. We have seen many cases that support this phenomenon: the Madoff pyramid scheme (
Markopolos 2010), the Toxic Bonds initiative (
Antonakakis and Vergos 2013), the Greek crisis (
Fasianos and Tsoukalis 2023), and many other cases of varying magnitude that produce bubbles and instabilities.
Subrahmanyam (
2007) rejects the theories of rational utility maximizers as an optimal behavioral tool as they are non-realistic and far from the markets. Thus, we provide a more analytical tool that incorporates critical and hidden information to optimize portfolios and to conclude with the best selection, avoiding imperfect evaluations of the data and assets. The PYR model is an integrated solution in this complicated fractal domain of advanced entropy that requires robust classifiers to support it. It specializes in the following:
Incorporating advanced moments, up to the ninth of hyperskewness and the tenth of hyperultrakurtosis, as the tools to extract behavioral patterns of investors and offer them a customized solution for optimal portfolios;
Extracting hidden accounting and sentiment data through the fusion of fundamentals and price data;
Concluding on the best classifier among SVM (support vector machine), RBF (radial basis function), GFF (generalized feed-forward network), and, as a benchmark, MLP (multilayer perceptron) networks to support the complex solution process with computational intelligence;
Demonstrating the novel portfolio yield reactive model—PYR;
Removing inferior assets from the solution space (less efficient).
Based on
Markowitz’s (
1952) portfolio theory, we propose a more analytical system of integrated portfolio optimization. After calculating the investor profile in detail, we process the desired assets through the PYR model, create the solution space, and select the best portfolio. The PYR model requires robust classifiers that are determined out of the three families of AI models that are examined here in neural and hybrid neuro-genetic form. In this PYR version, the portfolio optimization problem is widened in the core philosophical questions of free will and logic that are reflected in an investor’s behavior. The PYR model is applicable in the financial industry and has made multiple advancements. High-level portfolio optimization methods are used to select the perfect companies that are best for a particular investor’s portfolio.
The rest of this paper is organized as follows.
Section 2 describes the behavioral theoretical part.
Section 3 analyzes the higher-order moments in our model of portfolio selection with the isoelastic utility and the innovative limits of fundamentals in intelligent computing.
Section 4 demonstrates the methodology.
Section 5 presents the data.
Section 6 supports the discussion of the results, and
Section 7 provides the conclusions.
1.1. Behavioral Parameters
In actual markets, a high level of bias is endogenous to a portfolio with limited diversification (
Fidora et al. 2006;
Coeurdacier and Rey 2012). The risk differentials of stocks cause a partial effect on the cross-section of expected returns (
Ang et al. 2006), while data mining is a significant aspect of empirical work. The risk effect on returns is non-linear and needs more analytical tools, such as those we develop in this study. This loss avoidance agrees with Epicurus’ (306 BC) philosophy of Hδονισμός (hedonism—the pursuit of pleasure), where the main goal of individuals is Hδονή—pleasure—through Aπονία—the avoidance of unnecessary pain (risk). The loss-averse investors with lesser emphasis on risk averseness are the core of our model because the emphasis is given on the preservation of current profits and wealth, rejecting extra risk that exposes investors to losses. The non-rational patterns of a firm’s proximity to an investor, time, period of the year, gender, etc., also have an impact on uncertainty and thus complexity.
1.2. The Free Will Problem under Higher-Order Moments
The returns are non-n.i.i.d., as the Efficient Market Hypothesis is insufficient to describe the complex real market phenomena.
Subrahmanyam (
2007) underlined that investors are mainly interested in their potential losses. The analytical matching of behavioral hedonism to detailed forms of higher-order moment returns and pain to detailed forms of loss is significant for a balanced model that optimizes the portfolio for the investors. The investors optimize their utilitarian preferences by balancing fears and expectations with their earnings.
Loukeris et al. (
2014,
2016),
Loukeris and Eleftheriadis (
2021), and
Loukeris (
2021) introduced the 5th moment of hyperskewness, the 6th moment of hyperkurtosis, the 7th moment of ultraskewness, and 8th moment of ultrakurtosis as detailed measures of gain and pain.
The principal problem in philosophy and medicine of free will has been a tantalizing science since the beginning of civilization. Ordinal perception supposes that we have full responsibility for our choices, but the limits of freedom and will are complex. On the one hand, it is believed that the freedom to select and act is produced by the freedom of will. On the other hand, it is believed that our will cannot be managed by us. The Incompatibilists support that determinism is irreconcilable with freedom, although the Incompatibilist freedom puts emphasis on randomness replacing determinism. Compatibilists support that determinism and freedom are consistent. Whilst the Libertarians declare the existence of freedom, on the contrary, Sceptics believe that freedom is impossible (
Pink 2004). Libertarian free will does not exist (
Johnson 2015). The free will concept concludes with the impossibility of our free will judgments—on the freedom of our actions—to be systematically false (
Latham 2019). Although (
Colasante and Riccetti 2021) noted that the research stops ordinarily at the fourth moment because behaviors at higher orders are often the same as making random choices, they neglect that the patterns of the subconscious that are reflected in ego and alter logical thinking should be taken into consideration. Also, the unconscious, which produces random forms of thinking, is reflected hierarchically to the previous levels, so nature follows a random pattern in its essence. Thus, higher-order moments reflect these detailed forms of behavior in gain and loss that have a non-linear form to the limits of randomness.
In this paper, we introduce the 9th moment of hyperultraskewness and the 10th moment of the hyperultrakurtosis into the isoelastic utility function. The HARA—Hyperbolic Absolute Risk Aversion family incorporates the isoelastic as well as the group of utility functions of Constant Relative Risk Aversion, the CRRA. Thus, our approach can be written as
where
where Ut(R
t+1) is the overall utility the investor receives, a proportion of the mean return in the overall happiness of the investor, E
t(R
t+1) is the expected return,
a is the proportion of the return,
b is the proportion of risk to the utility measure, Var
t(R
t+1) is the variance,
c is the proportion of skewness in the investor’s happiness, Skew
t(R
t+1) is the skewness,
d is the proportion of kurtosis, Kurt
t(R
t+1) is the kurtosis of the investment,
e is the proportion of hyperskewness, HypSkew
t(R
t+1) is the hyperskewness,
f is the proportion of hyperkurtosis, HypKurt
t(R
t+1) is the hyperkurtosis of the investment, etc. (2, 3, 4) as a series of higher-order moments can be extended to the desired level of analysis. The general form (
Loukeris et al. (
2016)) of the utility function is
where
λν is the accuracy of the investors’ utility preferences for risk, depending on the behavior;
aλν is a constant on the investors’ profile:
aλν = 1 for rational risk-averse individuals,
aλν ≠ 1 for non-rational individuals;
ri is the value of the return
i in time t;
μ is the expected return;
n is the number of assets in the portfolio; and
ω is the number of observations on the accuracy of investors’ utility preferences, according to the examined set. The isoelastic utility of Constant Relative Risk Aversion is the following for risk-averse investors:
where
λ is a measure of risk aversion, and
W is wealth.
2. Methodology
2.1. Past Models
The convex problem of quadratic utility maximization,
Markowitz (
1952), is a vague approach to the markets.
Maringer and Parpas (
2009) reformed it to
where
rp is portfolio’s
p return,
Var(
r) is the variance risk,
E(
r) is the expected return, and
λ is their proportion.
2.2. Problem Definition
Loukeris et al. (
2014,
2016), noticed the necessity of advanced higher preferences to
where
rp is portfolio’s
p return,
Var(
r) is the variance,
Kurt(
r) is the kurtosis,
HypKyrt(
r) is the hyperkurtosis,
HypUltraKurt(
r) is the hyperultrakurtosis, and
λ is their proportion.
where
ri* stock’s i return is on the efficient frontier, υ
γ is the company’s financial health (binary: 0 to bankruptcy, 1 healthy), ε
τ is the heuristic model output that is the evaluation result (binary: 0 healthy, 1 distressed), and
xi is their weights.
The superiority of the selected stocks in the portfolio is
i*
sup j if and only if R
t(
i*)
> R
t(
j), in
Although higher-order moments may not be estimated reliably, the use of historical big data create the behavioural profile of investors. Higher-order moments in terms of risk, e.g., hyperkurtosis, ultrakurtosis, and hyperultrakurtosis indicate the detailed relative importance of tails as compared to shoulders in contribution to kurtosis, hyperkurtosis, and ultrakurtosis, respectively. Thus, the propensity of higher degrees of freedom on risk can be calculated and multidimensionally depict the risk preferences to the investor. Put simply, this is the sensitivity of risk on the selected portfolio. Similar is the effect of the return and its higher-order moments.
The hoax exposure would have been filtered earlier in the fundamentals and returns’ fused new utility function.
This non-convex problem requires robust heuristics. Our novel contribution is that we extract hidden accounting and financial prototypes to a more detailed stock evaluation. The undetected trends in the asset can provide valuable information to investors. Hoax and manipulation is an important risk to investors. Hidden patterns include cooked accounting, corporate fraud, stock manipulation, hoaxes, and undetected critical accounting/financial data. (9) and (22) filter the distressed companies with no significant potential from portfolios. The evaluation
υγ in (9) is more important than the investor’s risk behavior, as they have a reverse influence on υ
γ/λ. The
minx f(
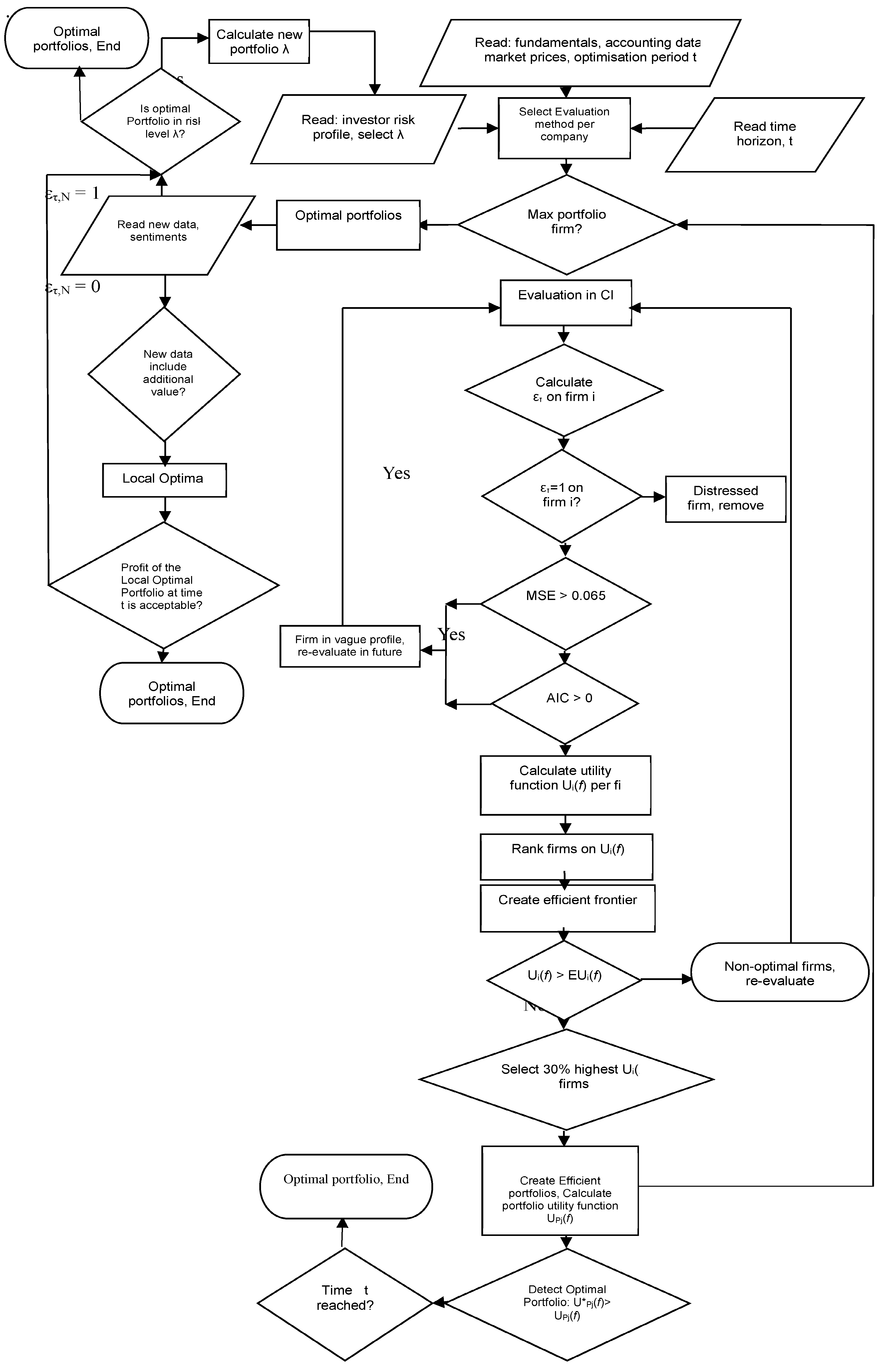
x) in (8) and (23) indicates a categorical, objective influence of a stock rather than subjective investors’ behavior. It provides measurable pricing rather than non-rational expectations and biases. The performance of portfolios is based on their detailed risk and return performance, but this will be analyzed in future papers. The flow chart of processes is in
Figure 1.
3. The Portfolio Yield Reactive (PYR)
The Portfolio Yield Reactive model (PYR) is an advanced form of the integrated PI—Portfolio Intelligence model developed by
Loukeris et al. (
2016).
In the first step, it reads the fundamentals, the accounting data, the market prices, and the preferred optimization period t.
Then, it proceeds by selecting the initial method to evaluate the companies whose stocks are candidates in the portfolio. In this step, the individual investor’s risk profile is given, and λ is selected for the isoelastic utility, or it is re-calculated depending on the new market data.
If the optimal portfolio is in risk level λ, then withhold and end.
Else, calculate new λ, and read new λ.
If the new data on the selected stocks or the rest of the market stocks and assets are different and include additional value,
Then, there is the Local Optimal Portfolio.
If the profit of the Local Optimal Portfolio on the current investment time horizon is acceptable,
Then, withhold and end.
Else, recalculate the portfolio.
In the next step, the system examines if this is the last firm to be examined and if the condition for the optimal portfolio as an efficient portfolio is satisfied.
Else, we proceed to the next of the initial evaluation, which uses a computational intelligence model to create two subsets: Subset A of the healthy companies and Subset B of the distressed firms.
In this specific model, we select the best network among the RBFs, the SVMs, and the MLP, which is the only hybrid GFF with 1 layer with GA optimization in the inputs and outputs. The ετ value is calculated (0 for the healthy and 1 for the distressed firms).
If ετ = 1, then the firm is distressed, and it is removed; else, if ετ = 0, the firm is healthy and is a candidate for the optimal efficient portfolio.
In the next step, the Ut(Rt(i)), the utility function of (14) is calculated per firm.
Next, firms are ranked according to their utility score.
Then, the efficient frontier is calculated.
Next, the firms with a higher utility score are selected for the efficient portfolio.
The sub-optimal firms, as well as the non-optimal firms, are revaluated with potential new data on step 4 of Neural Net evaluation, following all the steps.
Next, after the efficient portfolio is created, its utility function is calculated UPj(f).
Then, the optimal overall portfolio U*Pj(f), whose utility is the maximum available, is detected, if possible, by all the available efficient portfolio utilities UPj(f) recorded in U*Pj(f) > UPj(f).
The process stops when the time limit is reached and the PYR has the optimal portfolio.
The key idea is to filter fraud and speculative noise that interfere with the price and disorient investors. Thus, examining recent accounting entries and financial indexes, we conclude regarding the realistic financial health of the firm. Then, the actual healthy firms are selected, proceeding to the detection of the efficient frontier and the creation of the optimal portfolio.
The Portfolio Yield Reactive (PYR) model seeks to build a robust icon on the investor behavior based on big data; thus, it can reflect the wealth preferences more analytically. Additionally, the introduction of fundamentals as another process can support the filtration of bias in the form of manipulation, hoaxes, or other non-ethical actions. Thus, the PYR is a novel tool for portfolio optimization with cutting-edge AI classifiers. Historical data from prices, accounting statements, and investors’ sentiments are fused to determine the company’s financial health. There is a wide variety of professional data resources, e.g., Bloomberg, DataStream, CRSP, etc., used to support the system. The training is performed with a significant sample of firm data from markets. After the testing process verifies it, the network elaborates the optimization of the portfolio, concluding with an excellent combination of assets with the highest Sharpe ratio.
4. The Processing Phase
In the current research, a heuristic algorithm (SVM), a feed-forward with signal overrides (GFF), and a universal approximator (RBF) were selected to examine different philosophies of processing, performing one more test in the optimal processing of logic—if free will is an option.
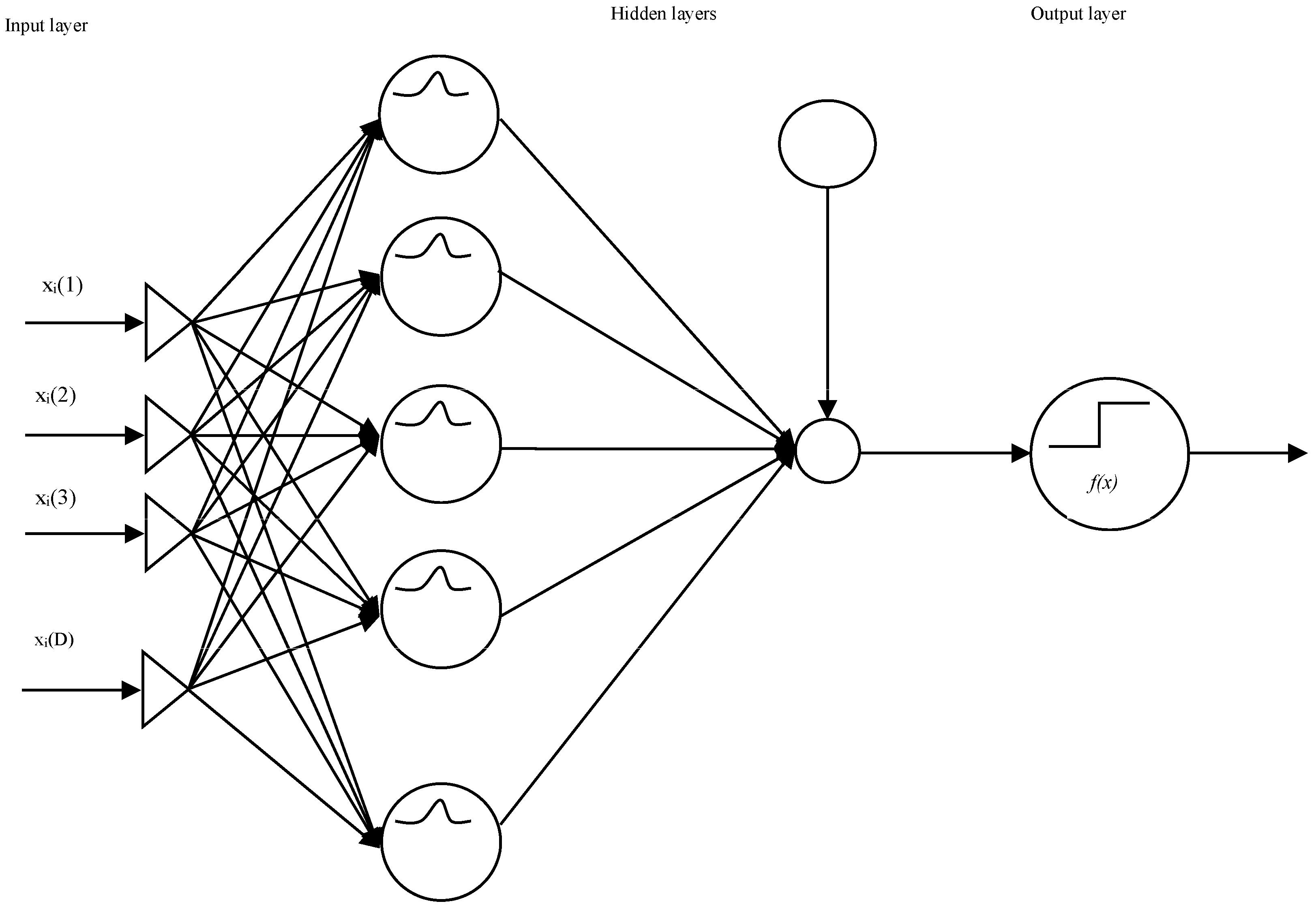
4.1. Support Vector Machines
Support Vector Machines—SVMs (
Figure 2)—produce general regression and classification functions from a set of labeled training data (
Cortes and Vapnik (
1995)), on a binary output, as input is categorical.
Courtis (
1978) noted that for instances
xi,
i = 1, …
l in labels
yi {1, −1}, the SVM is trained by optimizing:
where e is the vector of all 1, and Q is an x symmetric matrix of
K(
xi,
xj) is the kernel function, and C is the upper bound of all variables. Unstable patterns are rejected by the SVM as overfitted, receiving a statistically acceptable solution. These SVMs use the Adatron kernel algorithm (
Friess et al. (
1998)), mapping inputs to a high-dimensionality feature space, separating data into their respective classes, and isolating the inputs that fall close to the data boundaries. The converging system produces a few α
i ≠ 0, the support vectors, interacting with the closest boundary samples among classes. The Adatron kernel adjusts the RBFN in an optimal margin and prunes the RBF net so that its output for testing is as follows for
i support vectors:
where G(x, σ
2) is a Gaussian function,
gi and
αi are a set of multipliers each for a sample, and the input space is augmented by one dimension with a constant value of 1 to provide the bias
β. 4.2. The Hybrid Support Vector Machines
All the classifiers, including the SVMs, were evaluated in hybrid neural–genetic modes (
Figure 3). The inputs were 16 financial indices and the desired evaluation by executives. None of the 16 inputs has a predefined significance to the hybrid genetic SVMs. The GAs (Genetic Algorithms) select important inputs, demanding a multiple training of the network to define the minimum error. In accordance with
Min et al. (
2006), where there was optimisation emphasises on the feature subset and the SVM parameters, we move forth in examining multiple hybrid SVM models. Specifically, the GAs were elaborated in different hybrids: (i) the SVM inputs only, (ii) the SVM outputs only, and (iii) both the inputs and outputs. Batch learning was preferred for the weights after the presentation of the whole training set. All models were tested on 500 and 1000 epochs, respectively, to optimize the iterations number upon convergence.
Min et al. (
2006) performed the feature selection either using the filter or the wrapper approach. The filter approach is computationally more efficient, but the wrapper approach, although slower, selects the features more optimally. In the bankruptcy-prediction problem, feature subset selection plays an important role in the performance of prediction. Furthermore, its importance increases when the number of features is large.
This study uses the wrapper approach to select the optimal SVM training. The increase function is selected to terminate training under the cross-validation set when its MSE increases, avoiding overtraining, whilst the best training weights are loaded on the test set. The GA solved the optimal values problem in (a) the number of neurons, (b) the step size, and (c) the momentum rate, requiring multiple trainings of the network to conclude the lowest error mode. In the case of the models with GA on the output layer, they optimized the value of the step size and the momentum. The higher number of epochs allowed iterations to provide a thorough analysis of the network; the overall classification of these SVM models was excellent, taking as a benchmark the bank experts’ initial opinion. It achieved a fine performance in almost all the model parameters but failed to reduce the overtraining hazard in almost all different SVM hybrid or SVM models, questioning the model’s independence and impartiality.
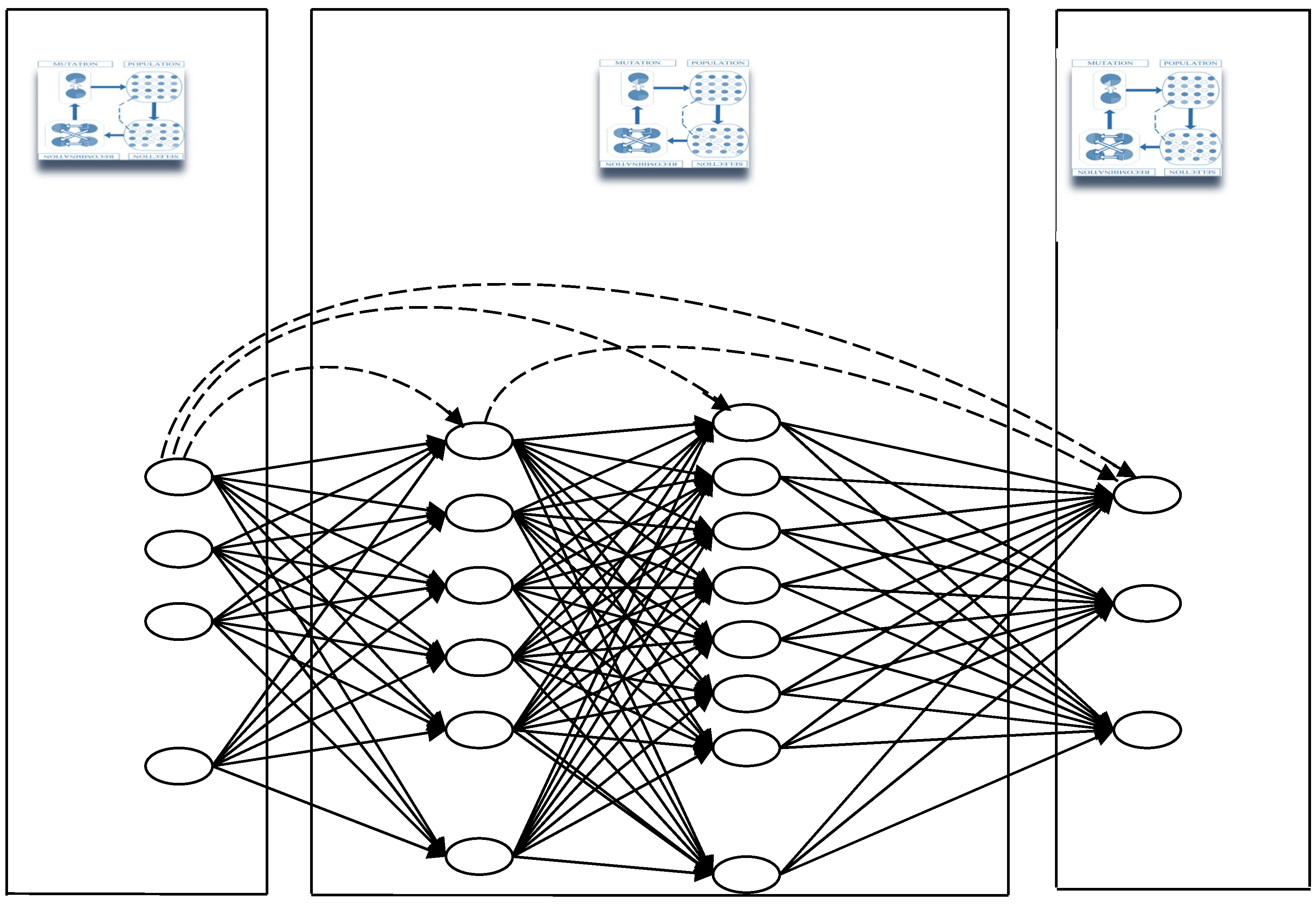
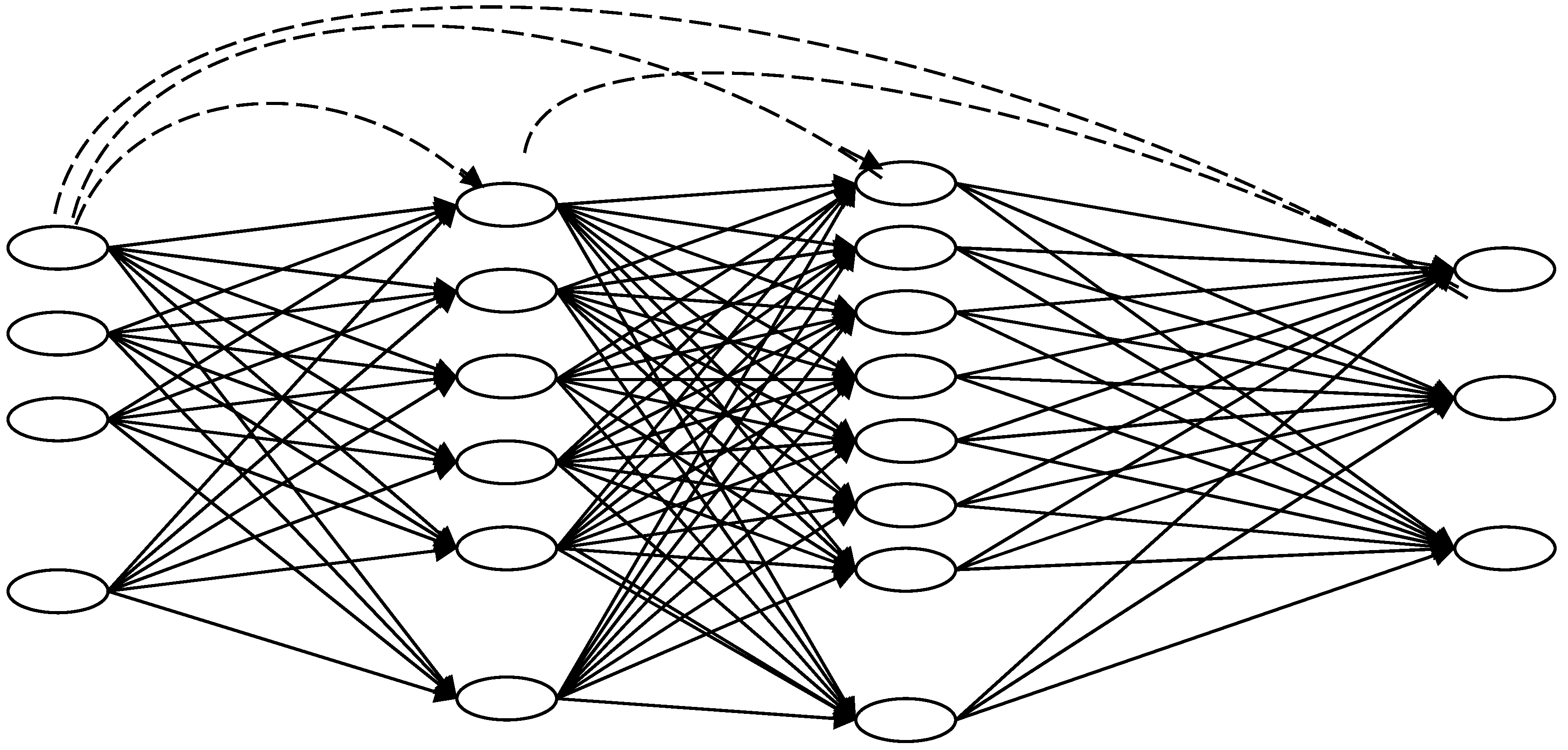
4.3. The Generalized Feedforward Neural Networks
The generalized feedforward networks (GFF) (
Figure 4) extended the Shunting Inhibitory Artificial Neural Network (SIANNs)
Bouzerdoum (
1999,
2000), consisting of a generalization of the MLP such that connections can jump over one or more layers. Although an MLP can solve any problem undergone by the GFFs theoretically, the GFFs often solve the problem much more efficiently. A typical MLP requires hundreds more training epochs than the generalized feedforward network containing the same number of neurons.
4.4. The Generalized Feedforward Hybrid Networks
The hybrid form of the GFFs (
Figure 5) can have Genetic Algorithms (
Holland (
1992)), an optimization in various layers that advances the processing of certain parameters on the core of the neural GFF. On the GFFs, the GA optimization took place in different hybrids:
- (a)
The GFF with GAs as inputs only;
- (b)
The GFF with GAs as inputs and outputs only;
- (c)
The GFFs with GAs as both inputs and outputs.
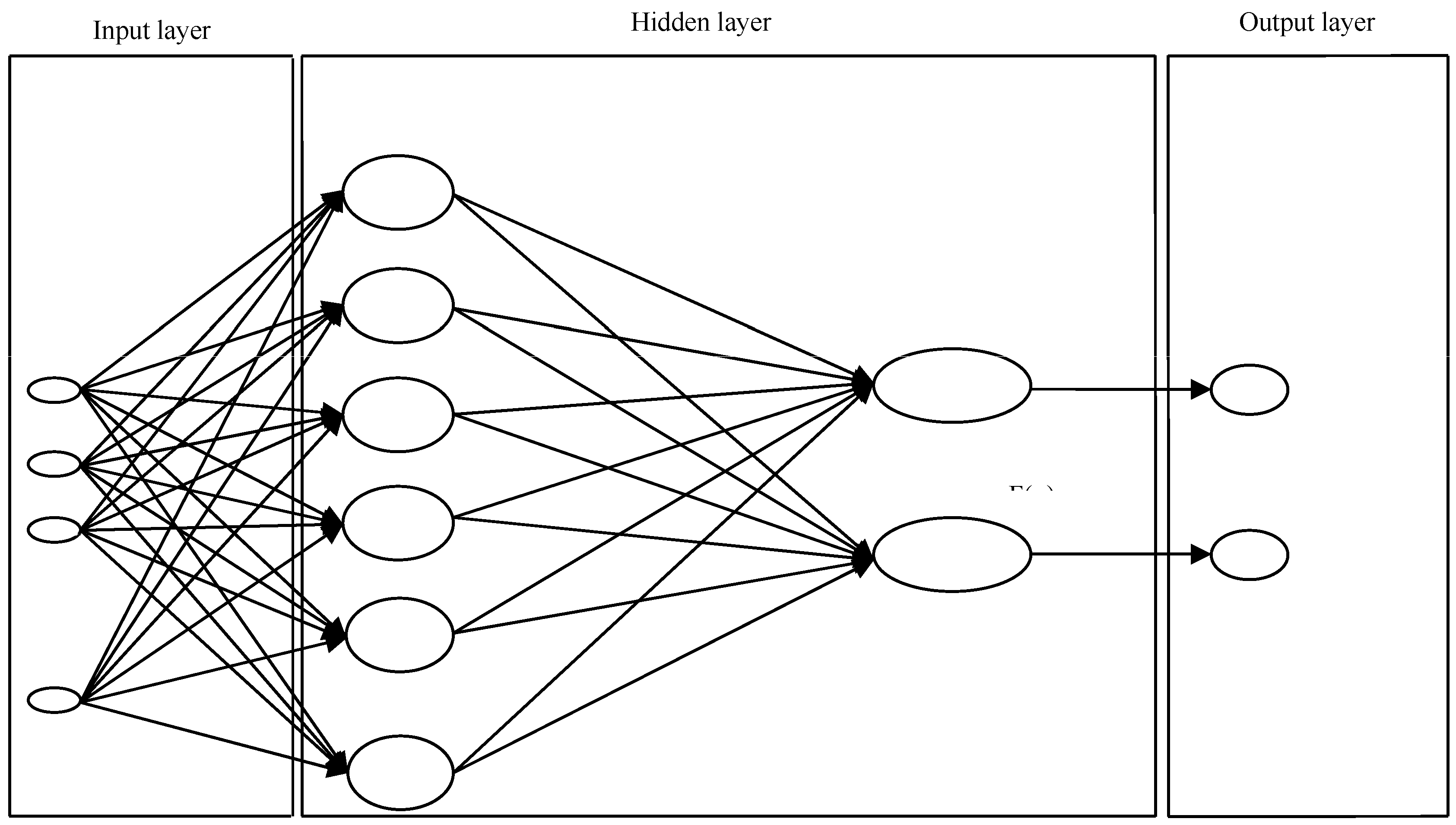
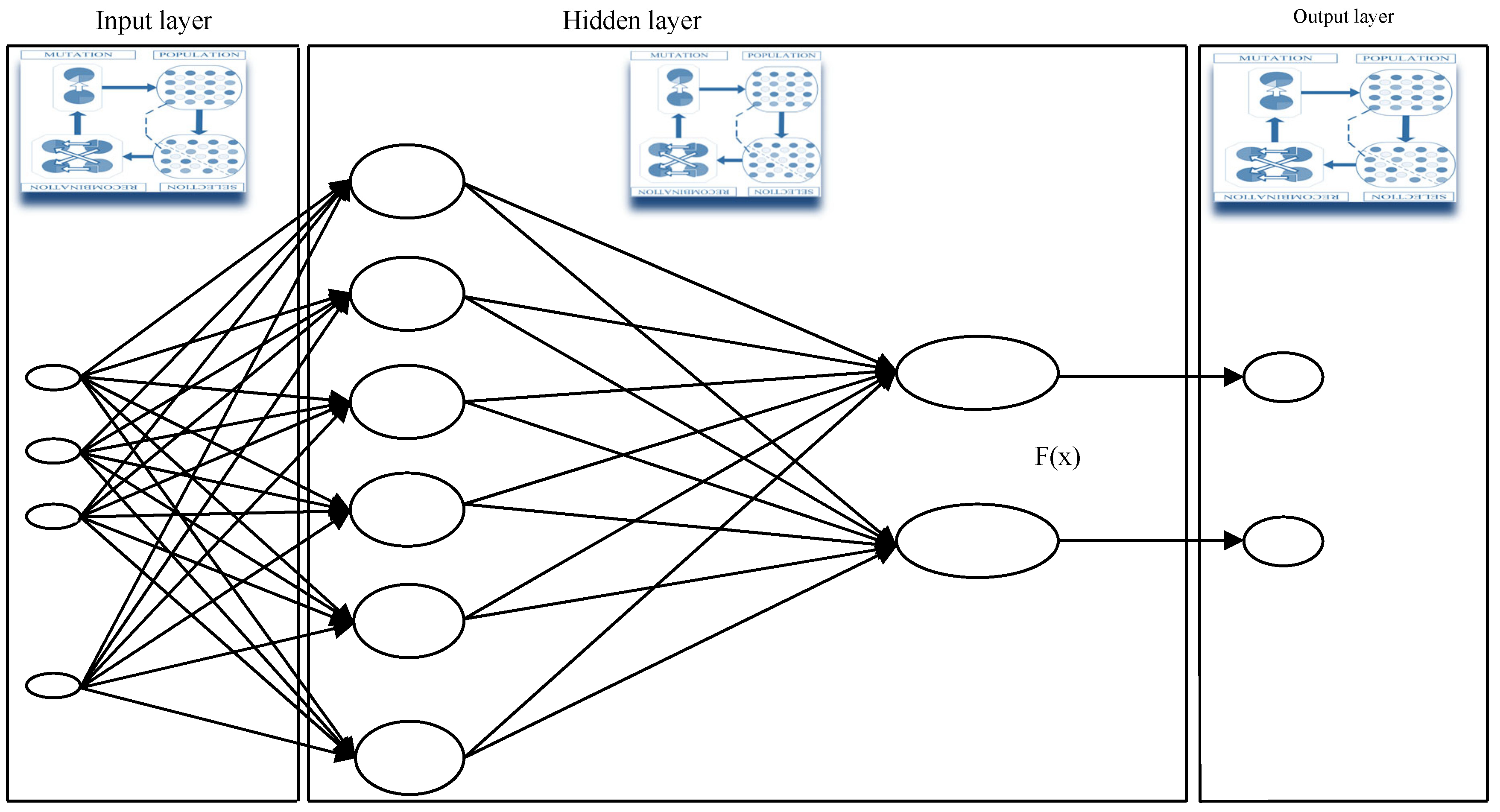
4.5. The Radial Basis Functions Neural Networks
The Radial Basis Function Neural Networks—RBFs—(
Figure 6) are linear models of regressions, classifications, and time series predictions in supervised learning, consisting of a universal approximator (
Broomhead and Lowe (
1988)), as its interpolation, and generalization properties are thoroughly investigated. The set of examples contains the independent variable, sensitive to noise, and the dependent one.
4.6. The Radial Basis Function Hybrids
The importance of each financial index out of the 16 inputs in the RBF hybrid nets (
Figure 7) is unknown to the model, and Genetic Algorithms investigate them. Each model is trained multiple times to define the input combination of the lowest error. Genetic Algorithms were implemented in different RBF hybrid models:
Figure 5.
The Hybrid GFF Net of GA optimization and cross-validation in all the layers.
Figure 5.
The Hybrid GFF Net of GA optimization and cross-validation in all the layers.
Figure 6.
The Radial Basis Function Networks.
Figure 6.
The Radial Basis Function Networks.
- (a)
On the input layers only;
- (b)
On the input and output layers only;
- (c)
In all the layers and cluster centers;
- (d)
In all the layers and cluster centers with cross-validation.
They were implemented in different topologies. Batch learning was also selected to update the weights of the hybrid neuro-genetic RBFs after the entire training set was presented. The competitive rule was the ConscienceFull function in the Euclidean metric, as the conscience mechanism keeps count of how often a neuron wins the competition and enforces a constant win rate.
Figure 7.
Hybrid Radial Basis Function in GA optimization on input and output layers only.
Figure 7.
Hybrid Radial Basis Function in GA optimization on input and output layers only.
Across the layers, there were four neurons per hidden layer when using the TanhAxon transfer function on the momentum learning rule. Genetic Algorithms resolved the problem of optimal values in (a) neurons, (b) step size, (c) momentum rate, and (d) cluster centers.
RBF nets require multiple trainings to obtain the lowest error. The output layer elaborated Genetic Algorithms in some hybrids, optimizing the step size and the momentum.
5. Data
Data were produced by 1411 companies from the loan department of a Greek commercial bank in the following 16 financial indices of liquidity, profitability, and activity:
- (1)
EBIT/Total Assets;
- (2)
Net Income/Net Worth;
- (3)
Sales/Total Assets;
- (4)
Gross Profit/Total Assets;
- (5)
Net Income/Working Capital;
- (6)
Net Worth/Total Liabilities;
- (7)
Total Liabilities/Total Assets;
- (8)
Long Term Liabilities/(Long Term Liabilities + Net Worth);
- (9)
Quick Assets/Current Liabilities;
- (10)
(Quick Assets-Inventories)/Current Liabilities;
- (11)
Floating Assets/Current Liabilities;
- (12)
Current Liabilities/Net Worth;
- (13)
Cash Flow/Total Assets;
- (14)
Total Liabilities/Working Capital;
- (15)
Working Capital/Total Assets;
- (16)
Inventories/Quick Assets.
This was performed with a 17th index with initial classification performed by bank executives. In this research, the bank executives decided if the companies were healthy or in distress on the 17th index based on historical accounting statements of 3 years. The insolvency of hoaxed companies cannot be determined only by using this fundamental approach. I developed an extensive model that fuses accounting and stock price information to filter the stock better. These data constitute the Semi-Strong Efficiency stage of the Efficient Markets Hypothesis, all the publicly available information that professional databases provide efficiently. The training set had 707 companies (50%), where 598 (84.58%) were healthy and 109 (15.41%) were distressed, according to the bank executives. The test set had 706 companies of similar proportions; the overall sample was 1411 companies with 16 fundamentals. The Mean Square Error was the minimization criterion on each training cycle. The test set was 50% of the overall data, and the training set was 50%. Multiple combinations were chosen to detect the performance of SVM, GFF, and RBF Networks:
- A.
SVM of 500 or 1000;
- B.
SVM of 500 epochs and GA on inputs;
- C.
SVM of 1000 epochs and GA on inputs;
- D.
SVM of 500 epochs and GA on outputs;
- E.
SVM of 1000 epochs and GA on outputs;
- F.
SVM of 500 epochs and GA in all layers;
- G.
SVM of 1000 epochs and GA in all layers;
- H.
SVM of 500 epochs and GA on inputs and cross-validation;
- I.
SVM of 1000 epochs and GA on inputs and cross-validation;
- J.
GFF neural nets;
- K.
GFF hybrids in inputs GA;
- L.
GFF hybrids in inputs and outputs GA;
- M.
GFF hybrids of GA in all layers;
- N.
GFF hybrids of GA in all layers and cross-validation;
- O.
RBF neural nets;
- P.
RBF hybrids in inputs GA;
- Q.
RBF hybrids in inputs and outputs GA;
- R.
RBF hybrids of GA in all layers;
- S.
RBF hybrids of GA in all layers and cross-validation.
This model has a wider approach to the stock market assets. Due to the limitations of the data, we examined private companies. The investor can select a variety of assets (common, preferred, private, bonds, and treasury bills).
6. Results
A comparison of all the outcomes would rank first—among all the SVM, RBF, GFF, and MLP models—the hybrid GFF in GAs over the input and output layer only of 1 layer, with 98.9% correct classifications for the healthy firms and 88.52% accuracy for the distressed firms. It had a fine fitness to the data at 0.908; the lowest Akaike at −1907.09, with the best impartiality; low errors (for MSE, 0.072; for NMSE, 0.170 and 5.77%); and fast processing of 55 min 18 s.
All the other models, despite their superior classification and performance, demonstrated very high values of partiality and thus are exposed to overfitting, being lower reliability classifiers for this numerical financial problem.
The second rank is given to the SVM of 500 epochs optimized by GAs on the inputs only and cross-validation, with 100% classification of the correctly classified assets; a fitness of the model to the data r of 0.999; the lowest error in MSE at 0.023, error of NMSE of 0.045, and overall error of 4.01%; but a significant partiality of Akaike 12,044.20; and extended training time of 26 h 56 min 14 s. Time is not an issue for the trained model, as the cross-validation reduces overfitting. The main vulnerability of partiality is the dependence of its performance on the desired classification given by human experts. However, this is of lower significance, as the CV set was quite good, with 94.29% correct classifications on the healthy companies, 77.98% on the distressed in a medium error of 0.309 in MSE, 0.591 on NMSE, and 12.72% overall error.
The third rank was taken by the SVM of 500 epochs, with excellent classification, performance, and a very fast time, but exposed to overfitting and partiality.
Fourth was the rank of the SVM of 100 epochs, in excellent outcomes of classification performance, and time but the same weaknesses of overfitting and partiality.
The RBFs underperformed in classification but had a very high fitness of 0.925, but high error and AIC as well. The other RBF models and the MLP significantly underperformed and ranked last compared to the SVMs (
Table 1,
Table 2 and
Table 3).
The feedforward with override GFFs and the universal approximators RBF are not specialized in multidimensional analyses and hence are more suitable for the simple world of the numerical data of financial markets. The market volatility and economic cycles in model performance do not require advanced resources for these typical classifiers.
The integrated PYR model thus will have robust classifiers depending on the needs of the users, the depth of accuracy, and the form of the data. As an overall portfolio-selection system, it eliminates market manipulation, incorporating the fundamentals as comparative parameters to the stock return in the markets, and also introduces more processes of re-evaluation for the optimization of the investment portfolio.
7. Conclusions
The integrated model Portfolio Yield Reactive—PYR—offers advanced analytical processing in Decentralized Finance (De.Fi.), supporting the real-time portfolio-selection problem. The main advantage of this system is that by extracting hidden patterns, it tries to avoid manipulation and speculation games. Although the hybrid SVM nets have a promising performance of high calibration, their high overfitting abilities make them inappropriate classifiers. The issue of overfitting limits the applicability of certain models to dedicated applications, e.g., the SVMs dominate the area of image processing; thus, their use in numerical applications is not optimal. Given their kernel trick to implicitly map their inputs into high-dimensional feature spaces, relevant 3D inputs are more suitable for them. Their hyperplane process at the edges of infinite dimensional space in classification, hopefully by the largest functional margin, seeks to minimize the classifier’s generalization error and thus overfitting. However, the classifier cannot support numerical data, in this case having very high partiality.
Thus, an optimal classification choice will be the GFF of 1 layer with GA optimization in the inputs and outputs only, with a fine classification, low error, and the lowest Akaike, with a computational time of 55 min, which can allow them to be a part of this model or its future upgrades (
Table 4). The hybrid SVM of 500 epochs optimized by GAs on the inputs only and cross-validation, although it provides a perfect performance and classification in a restricted processing time, demonstrates a significantly higher partiality, as the SVM of 500 epochs, despite its slight underperformance, demonstrates robust qualities that suffer from overfitting and partiality (
Table 4). Hence, the SVM models, despite their perfect classification, with the condition of financial data, the RBF had a quite lower performance with many more weaknesses and, even worse, some of the GFFs were inferior classifiers. The GFFs are an optimal classifier for the portfolio-selection problem compared to the SVM, RBF, and MLPs in any data set. The current research indicated a novel approach to the portfolio-optimization problem. The black-box effect, however, is the usual problem with neural nets and sets limits to the repetition of their superiority. The practical implications of these findings for portfolio management are wide, from asset allocation (defining if a single company is healthy) to fraud detection (evaluating the overall corporate operations) and portfolio selection (examining the best portfolio for investor requirements).
The specialized problem of portfolio optimization is a fraction of the fundamental problem of logic within human beings. This core philosophical problem, unanswered since the beginning of civilization, is the heart of our existence. In this approach, the answer is that logic is dynamic in a linear process that adjusts to overriding new challenging ideas that offer higher potentials than the usual series of events. This initially may seem non-linear, but it is consistent with the perception of the maximization of utility and thus investors’ economic welfare. Future work will examine in detail the numerical results of the utilities and wealth impact of the current models incorporating new trends that experience bubble effects.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}