1. Introduction
Investing according to how well companies do with respect to their Environmental, Social and Governance scores has become very appealing to a growing number of investors. Beyond moral criteria, such kinds of investments may increase the value of high-ESG-scoring companies, which will attract even the non-ESG-minded investor, thereby starting a virtuous circle both for the investors and for the beneficiaries of high ESG scores. It may also lead to successful impact investing whereby an investor generates positive environmental or societal impact while targeting a specific level of return (
Grim and Berkowitz 2020;
Townsend 2020).
From a quantitative point of view, ESG scores raise the question of their information content: do these scores contain some signal to estimate a company’s fundamental or market information? Restricting themselves to the study of the explanatory and predictive power of ESG scores regarding financial performance,
Friede et al. (
2015) aggregated the results of more than 2200 studies: 90% of them showed a non-negative relationship between ESG and corporate financial performance measures, a majority displaying a positive relationship. However, more recently,
Cornell and Damodaran (
2020),
Breedt et al. (
2019), and
Margot et al. (
2021) reached less clear-cut conclusions.
The confusion surrounding this question is mostly caused by the nature of ESG data: (i) they are quite sparse before 2015, as the interest in even computing such scores is quite recent; (ii) they are usually updated yearly; (iii) the way they are computed often changes as a function of time and may depend on the way companies disclose data; (iv) human subjectivity may be involved to a large extent in the computation of the scores, according to the methodology chosen by a given data provider. Findings are therefore inevitably data-vendor dependent. While data consistency and quality can only be solved at the data provider level, points (i) and (ii) require a tailored approach.
Here, we argue that settling this issue requires a globally robust and consistent methodology. We discuss how to solve each of the two remaining problems listed above and propose a methodology that combines a novel cross-validation procedure for time series with increasingly reliable data, explainable machine learning, and multiple hypotheses testing. Although we focus on explaining company price returns with ESG scores, this methodology can be easily adapted and extended to different settings (e.g., prediction).
Another crucial ingredient of our approach is to focus on the simplest possible question. Instead of performing sophisticated regressions, we aim to explain the sign of excess price returns. From an information-theoretic point of view, this means that we focus on a single bit of information (the sign) instead of many bits (full value), which yields significant and robust results that can then be interpreted as a function of market capitalization, industrial sector and country.
Our contributions are as follows:
We focus on the sign of either excess returns (main text) and returns discounted by Fama French factors (appendix) and use state-of-the-art sign prediction machine learning models;
We propose a company-wise cross-validation scheme that makes it possible to train and validate models with the most recent (and thus most reliable) data; from this validation scheme, we keep the models with the five best validation scores;
We show that the fitted models explain the signs of excess returns in test periods well but are not used to calibrate these models. We also show that models trained with ESG scores increasingly outperform models trained with fundamental data only;
Finally, we show how each individual ESG score contributes to the overall performance of our algorithm and the evolution of their explanatory power as a function of time. We propose a new way to build a so-called materiality matrix based on the interpretability of the chosen machine learning models, showing that the importance of ESG scores depends on both the industrial sectors and market capitalization.
In the remainder of this study, the terms ESG scores and ESG features are used interchangeably.
2. Literature Review and Uncertainties
2.1. Asset Selection, Investment Strategies, and Portfolios
According to
Chen and Mussalli (
2020), ESG integration into investment strategies mainly consists in integrating the investors’ values into their own strategies. The scientific literature describes three main ways to achieve it: filtering companies based on their ESG scores, directly looking for alpha in ESG data, or measuring ESG impact on other risk factors.
ESG scores can offer a systematic approach to screen out controversial industries, commonly referred to as “sin industries”, including but not limited to tobacco, alcohol, pornography, weapons, etc. For example, some studies advocate for selecting companies with ESG scores surpassing specific thresholds (
Schofield et al. 2019). While this method yields good portfolios ESG-wise,
Alessandrini and Jondeau (
2020) argue that this may lead to underperforming portfolios due to the reduction in the investment universe and the potentially higher returns generated by “sin industries” because of their very exclusion.
Chen and Mussalli (
2020) propose a Markowitz-like optimization method by defining an ESG-compatible efficient frontier. Similarly,
Hilario-Caballero et al. (
2020) add a third term to the mean-variance cost function, the portfolio exposure to carbon risk, and use a genetic algorithm to solve this three-criterion optimization problem. This method is equivalent to optimizing ESG criteria under the constraint of specific risk and returns levels (
Schofield et al. 2019), who also note that the resulting portfolio can have a good global ESG score while containing assets with bad ones.
Finally,
Alessandrini and Jondeau (
2020) elaborate on “smart beta” strategies, in which investors build portfolios whose assets are not weighted according to their market capitalization but rather to their exposure to some specific risk factors.
Bacon and Ossen (
2015) explain that integrating ESG into investment strategies can be simply achieved by tilting the asset weights according to their ESG scores while controlling the portfolio exposure to other risk factors. This procedure raises the question of whether ESG is a new risk factor or if optimizing ESG scores amounts to exposing the portfolio to well-known ones. It is indeed a crucial point to explore when attempting to improve portfolio performance with ESG scores (
Anson et al. 2020): instead of trying to obtain a premium by finding a suitable ESG factor, it is more judicious to understand the impact of ESG data on the exposure to well-known risk factors.
2.2. ESG Scores: Risk and Returns
Reaching a consensus on the nature of the links between ESG and returns is hard.
Friede et al. (
2015) aggregated more than 2000 studies on the topic: 41% did not find any ESG impact on returns, 48% found these impacts to be positive and 9% negative.
Alessandrini and Jondeau (
2020) and
Anson et al. (
2020) stress the fact that filtering a portfolio on ESG scores leads to improved durability of the investment but does not yield a positive alpha. However, they did not find any proof of negative alpha either; thus, there may be no added value in integrating ESG data into portfolio construction from an alpha point of view.
Plagge and Grim (
2020) find no statistically significant under- or over-performance of different equity funds specialized in ESG investing and argue that since the ESG scores are not of economic nature, they should not have any impact on the portfolios and that any information contained in ESG data should already be contained in other risk factors. However,
Lee et al. (
2022) find, using machine learning methods, that ESG granular data of considered equity funds provide information on the annual financial performance of these funds.
This lack of consensus on the links between ESG and returns may be due to the use of different assessment methodologies (including ESG scores from different data providers) or wrong use of the ESG scores (
Anson et al. 2020). Indeed,
Margot et al. (
2021) show that because ESG data have a very low signal-to-noise ratio, using aggregated ESG scores leads to a high loss of information. It is then necessary to use more granular scores to obtain more meaningful results. Moreover, they emphasize that the links between ESG and returns are highly dependent on the considered business industry and region.
Cappucci (
2018) finds that ESG scores lack information on asset price returns and that a better indicator of returns is the progress made by companies in the different ESG sub-fields.
Only a few papers are devoted to the relationship between ESG scores and risk.
Guo et al. (
2020) train a deep learning model to predict a company’s volatility using ESG news.
Chen and Mussalli (
2020) show that focusing on ESG investments can reduce the risk of underperformance as companies with good ESG scores can be less exposed to both systemic and idiosyncratic risks.
2.2.1. Risk Factors
Many studies, such as
Renshaw (
2018), find that ESG scores and well-known risk factors, such as size, are partially redundant.
Anson et al. (
2020) and
Konqui et al. (
2019) study the variation of portfolio exposure to well-known risk factors when one integrates ESG data in portfolio construction: the impact varies according to geographical regions, which reduces the significance of global studies. Similarly,
Alessandrini and Jondeau (
2020) explain that the discrepancies in ESG portfolio performances in different regions and industries can be attributed to different exposures to risk factors. Furthermore,
Breedt et al. (
2019) argue that most of the financial performance of a portfolio can be explained by well-known factors and that the residuals cannot be explained by any other factors. For
Breedt et al. (
2019), the environmental and social aspects of ESG are noise, and the governance part is strongly correlated to the quality factor; however, enriching ESG data with other types of information, or preprocessing it, can bring added value. In the same vein,
Bacon and Ossen (
2015) decorrelate the ESG scores from the other risk factors before integrating them into strategies and are able to obtain added value from ESG scores.
2.2.2. Materiality of ESG Data
For a better ESG integration, it is important to understand which ESG features are the most material, i.e., have the largest impact on the financial performance of a company. According to
Anson et al. (
2020) and
Margot et al. (
2021), materiality is highly dependent on the chosen asset class, region and industry.
Bacon and Ossen (
2015) build a materiality matrix using the LASSO method (
Tibshirani 1996). Their matrix is specific to an industry and shows the magnitude of the impact of a specific ESG feature on a company’s financial performance versus the probability of this feature having an impact.
2.2.3. Temporality of ESG Data
Alessandrini and Jondeau (
2020) warn that their results were obtained in a period when a large amount of money was poured into ESG funds, which could have increased their respective performance.
Margot et al. (
2021) also reinforce that their study was realized between 2009 and 2018 during a period when the market was particularly bullish, which may affect the overall strength of ESG-based funds. For
Mortier and Roncalli (
2019), the impact of ESG scores differs not only by region and by industry but also according to the strategy test time period. That is why
Renshaw (
2018) argues that any methodology that treats the historical ESG data in the same way for every period is likely not relevant. A solution is to use back-testing on several time periods, with several universes, to validate the results (
Anson et al. 2020). Finally,
Margot et al. (
2021) and
Plagge and Grim (
2020) apply the efficient markets theory in the context of ESG investing: it is possible that investor awareness rises as a function of time and the information included in ESG data is included in the asset prices, leading to a loss of predictive power of ESG features and thus of the embedded alpha.
3. Datasets
3.1. Financial Data
We use the following data sets:
Stock prices. We use daily close prices, adjusted for dividends and foreign exchange rates. BNP Paribas internal data sources.
Market capitalization. BNP Paribas internal data sources.
Fama–French market, size and value factors: these factors are taken from the online French data library (
Fama and French 2021). They are all computed according to the Fama and French methodology exposed in
Fama and French (
1993).
Risk-free rate: these data are also taken from
Fama and French (
2021) and computed according to the Fama and French method.
In addition, metadata such as the TRBC (the Refinitiv Business Classification) Sector at levels 1, 2 and 3 and the country of incorporation are used and come from Refinitiv data sources.
3.2. ESG Data
ESG data are provided by Refinitiv. Their database alleviates some of the challenges listed above:
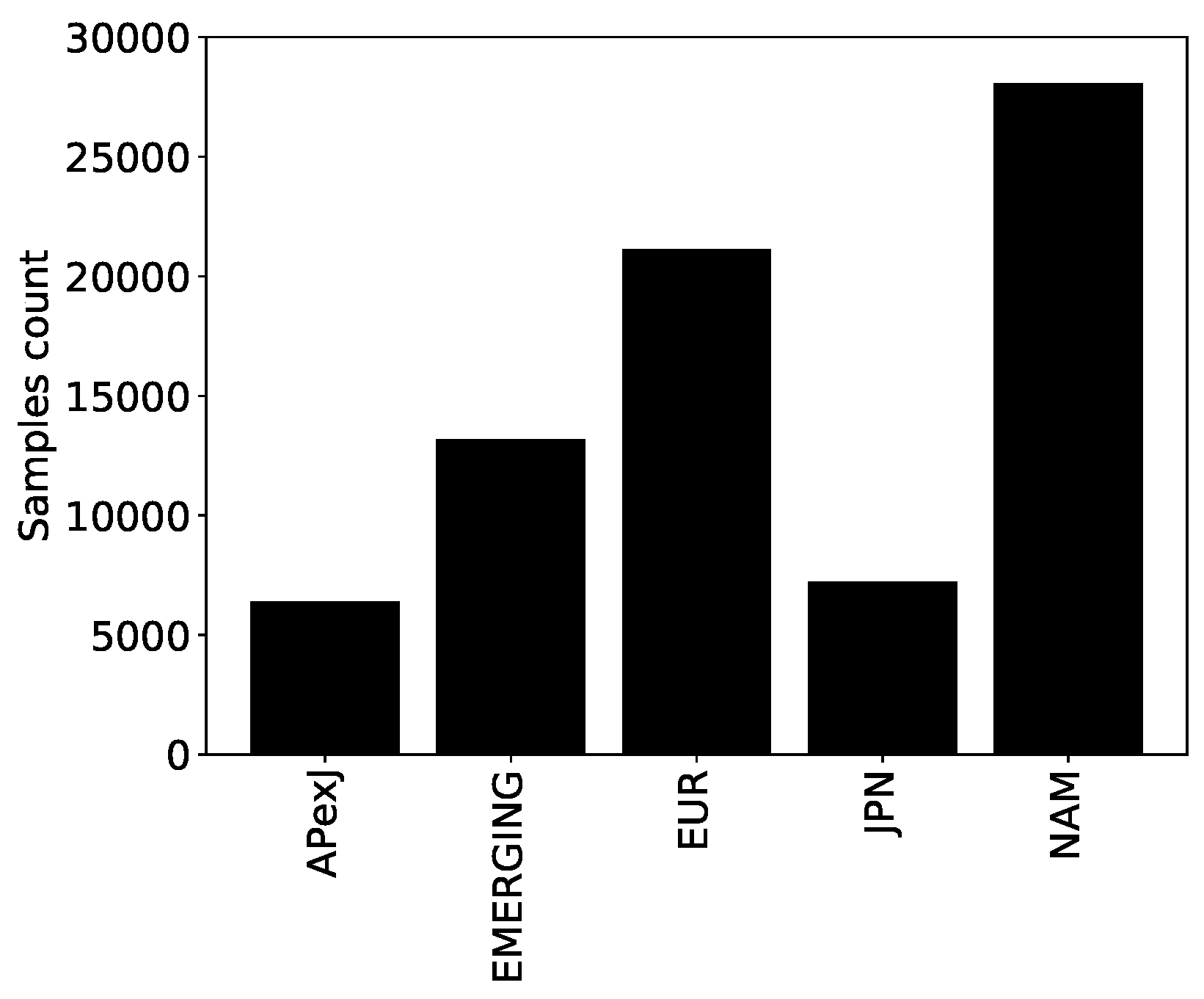
The coverage of the dataset is sufficient to extract meaningful results.
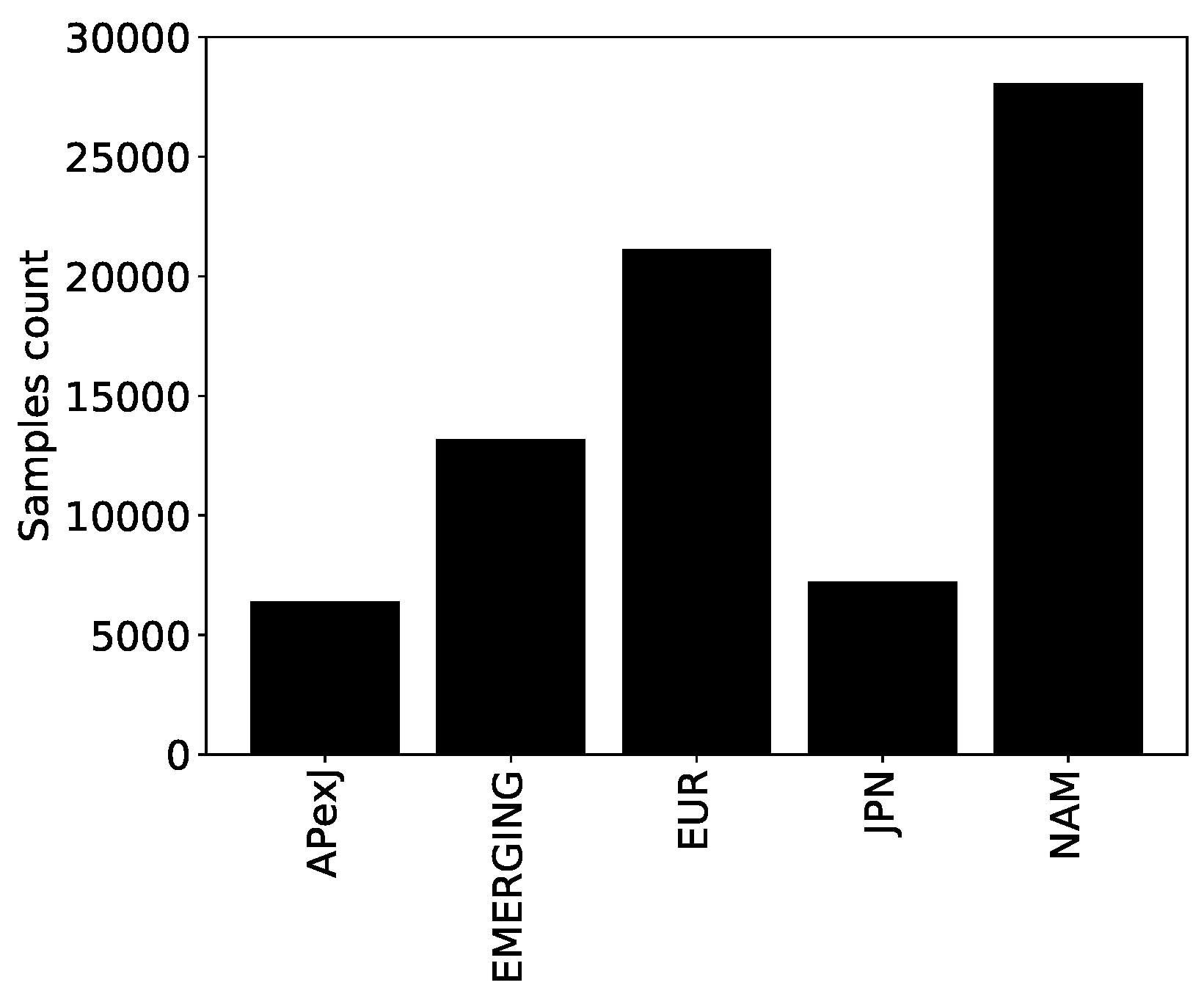
Figure 1 shows the number of samples in the geographical regions as defined by Fama and French (
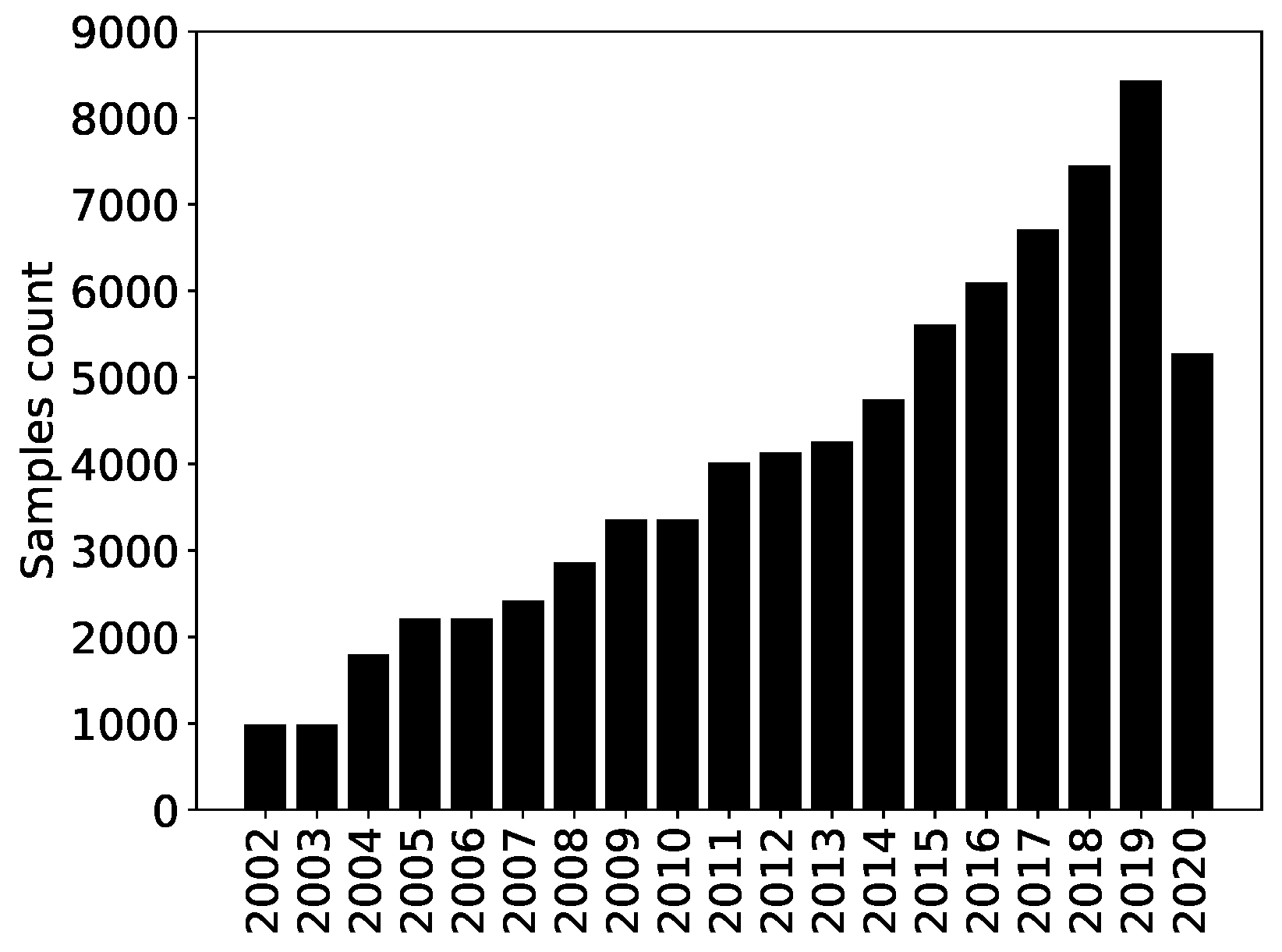
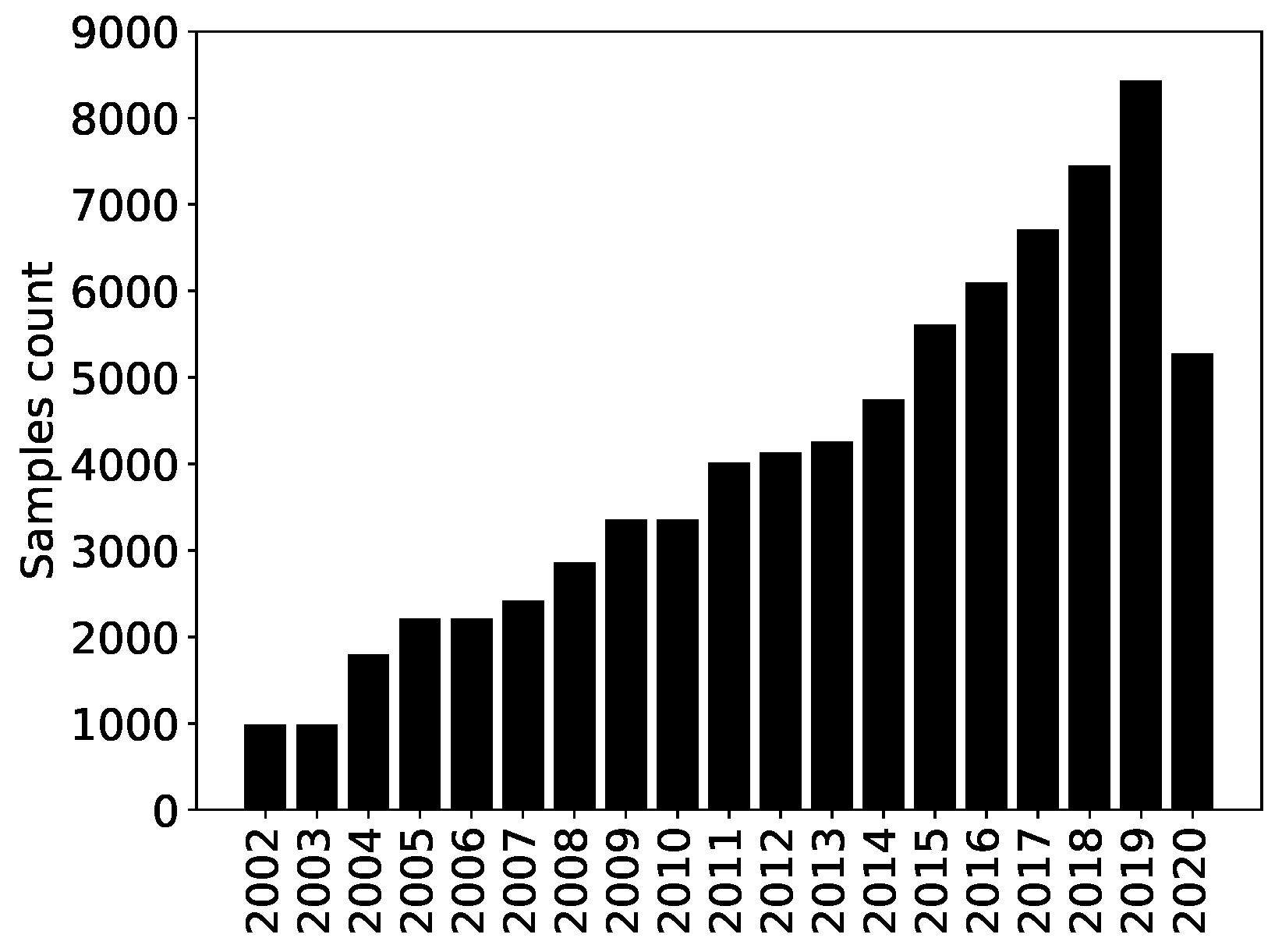
Fama and French 2021): Europe, North America, Japan, Asia-Pacific excluding Japan and emerging countries. Refinitiv ESG data started in 2002, and the number of samples per year increased severalfold until 2019, as shown in
Figure 2. The drop in 2020 is due to the fact that not all the ESG scores had been computed by Refinitv when we had access to the dataset (many companies had not yet published enough data).
Scores are built with a well-documented methodology explained in
Refinitiv (
2021). Every ESG score ranges between 0 and 1, with 1 being the best score. In addition, the same methodology is used throughout the years, yielding consistent data.
Human intervention is limited to some quality checks.
Scores can be updated up to 5 years after the first publication, which is beneficial in an explanatory setting, as the data become more accurate. In a purely predictive setting, however, this adds noise and look-ahead bias as we do not have point-in-time data, i.e., we do not know the initial and intermediate ESG estimates.
Refinitiv ESG data includes samples from different regions of the world. Each region has specific regulatory frameworks and ESG transparency rules. This is why this paper focuses on the European region and includes all the companies in the Refinitiv ESG dataset whose country of incorporation is in Europe or in a European-dependent territory.
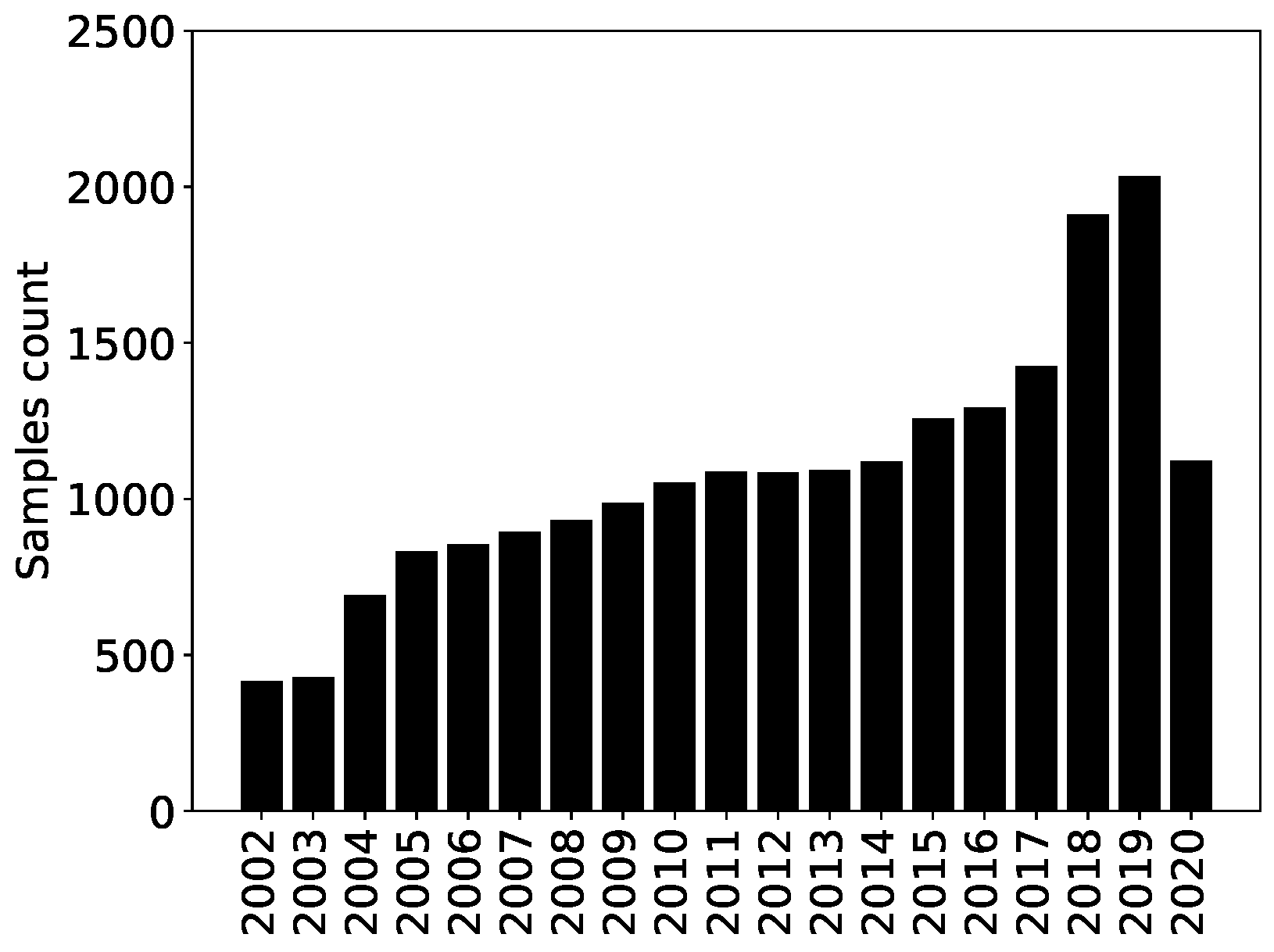
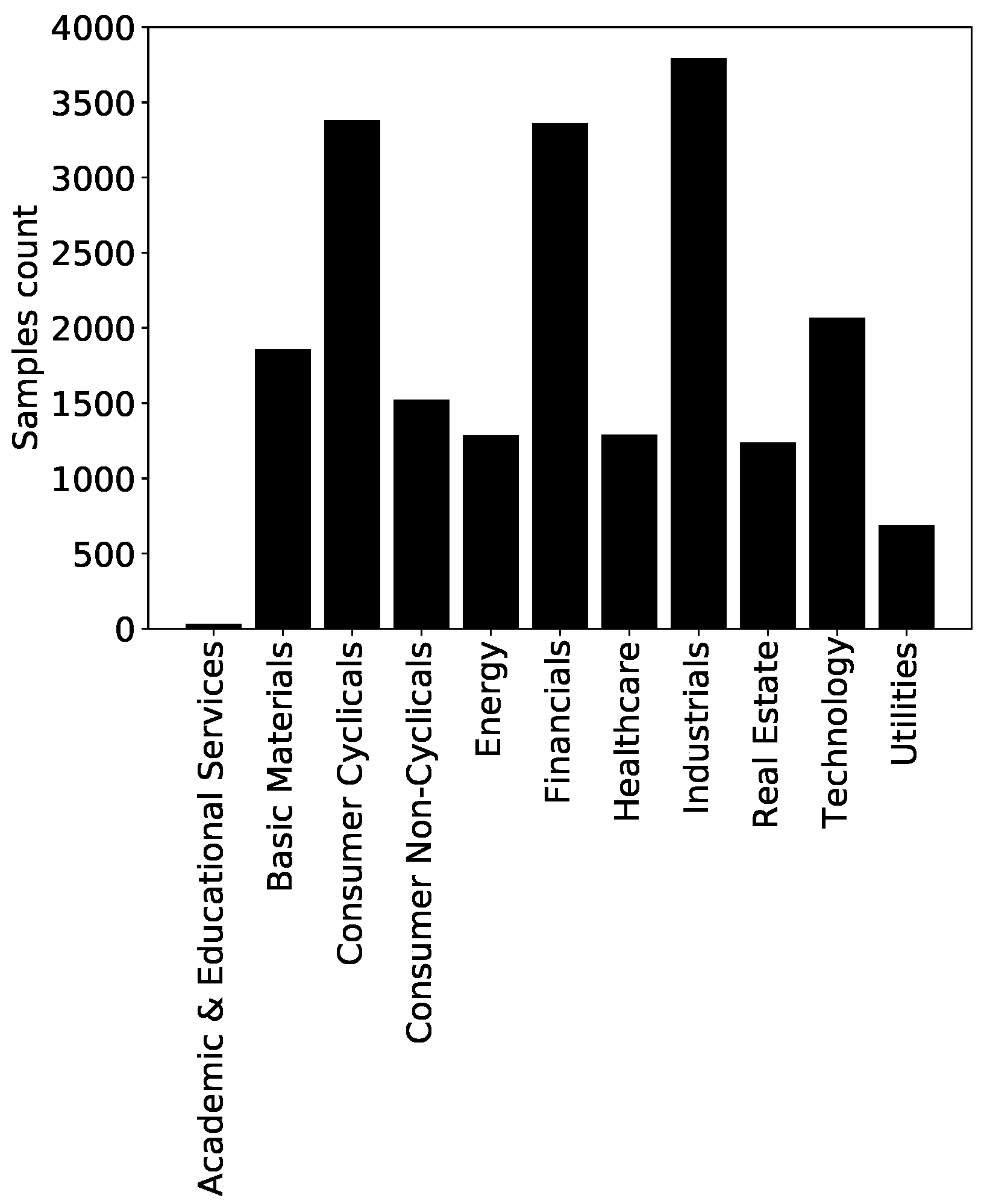
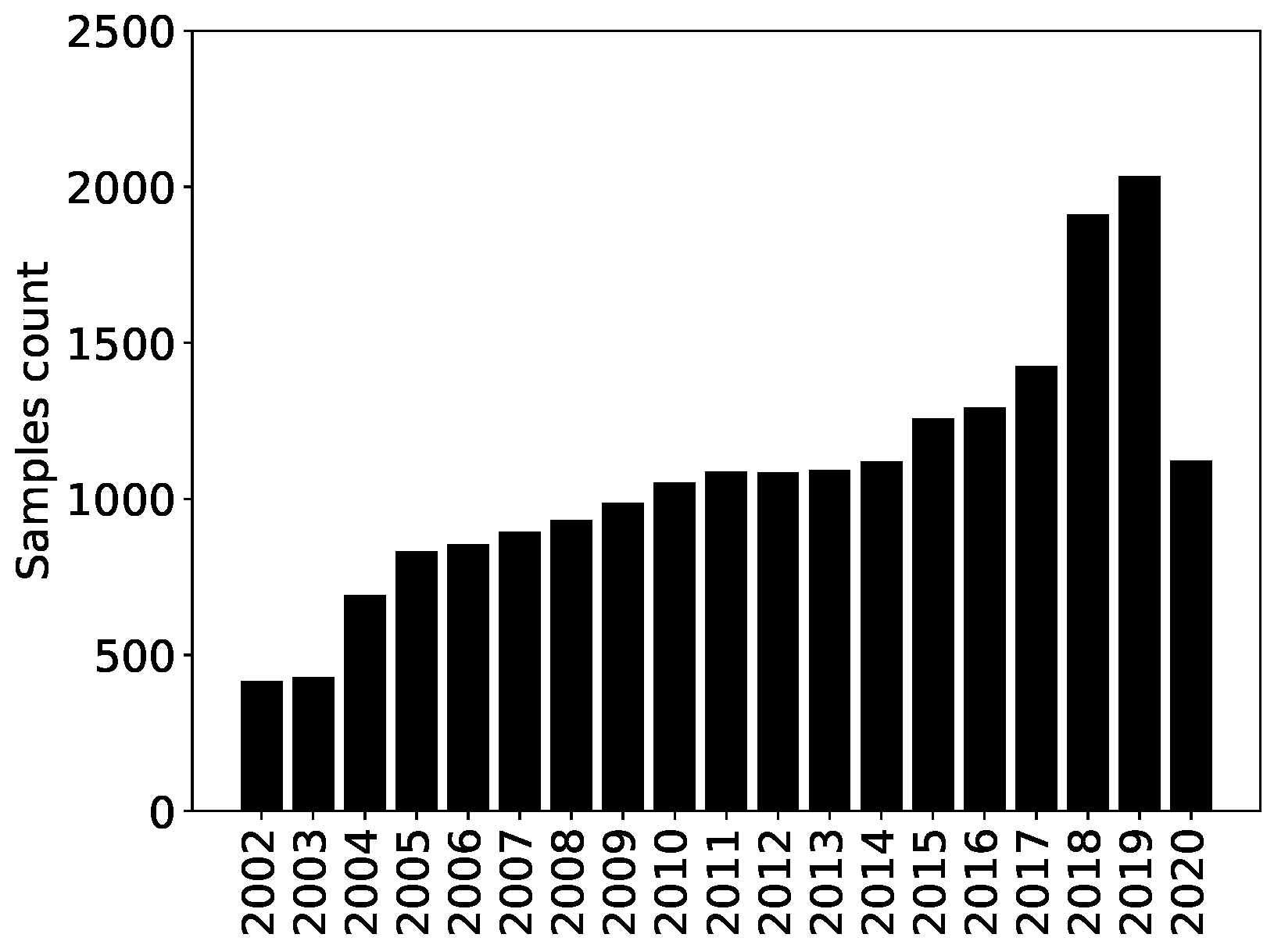
The European ESG dataset contains 20,509 samples for 2429 companies uniquely identified by their ISIN. The time evolution of the number of samples per year is reported in
Figure 3. All the sectors have enough data, with the notable exception of the Academic and Educational Services sector (see
Figure 4).
4. Methods
4.1. Problem Settings
Our goal is to understand how and what ESG features participate in the formation of price returns. Specifically, we seek to investigate whether ESG features help capture information to explain the parts of stock returns realized at the time of the publication of the ESG data that are not accounted for by well-known equity factors, especially the market, size, and value factors. In a multi-factor model, one writes at time
t
where
is the return of asset
i,
the risk-free rate,
the value of factor
k at time
t and
is the factor loading; the idiosyncratic parts are
, the unexplained average return, and the zero-average residuals
. In this work, we use the Capital Asset Pricing Model (CAPM) and its extension, the Fama–French 3-factor model that includes market (
), size Small Minus Big (SMB), and value High Minus Low (HML) factors (
Fama and French 1993).
ESG data are neither abundant nor of constantly high quality. Directly estimating the explanatory power of ESG features on price returns by estimating the idiosyncratic part of Equation (
1),
, is a challenging task. Therefore, we settle in this study for a less ambitious goal. Specifically, we investigate whether ESG features help explain the sign of the idiosyncratic part of price returns. Mathematically, one needs to explain
with the candidate features. Equation (
2) means that the chosen target is 0 if the sign of the idiosyncratic parts
+
is negative, and 1 if this sign is positive or null.
This work takes a machine learning approach to this problem and treats it as a classification problem: defines two classes as it can take two values. Thus, for each possible couple , one has a vector of P potentially explanatory factors, called features in the following. Let us relabel all the couples by the index . The classification problem consists in explaining by a vector with P components, or equivalently, explaining the vector from the lines of matrix . Y is called the target and X the feature matrix. The problem is then to train a machine learning method to learn the mapping between the lines of X and the components of vector Y. Once the training is complete, such a model takes a vector of features as the input and outputs the probability that these features correspond to one class (in a two-class problem).
The state-of-the-art for these tabular data is Gradient Boosting models (
Friedman 2001), as shown, for instance, in
Shwartz-Ziv and Armon (
2022). The spirit of gradient boosting consists in using a sequence of weak learners (wrong models) that iteratively correct the mistakes of the previous ones, which eventually yields a strong learner (good model). We use decision trees here as weak learners. Different implementations of the Gradient Boosted Decision Trees method exist, e.g., XGBoost (
Chen and Guestrin 2016), LightGBM (
Ke et al. 2017), CatBoost (
Prokhorenkova et al. 2018). We use LightGBM here. One of the primary advantages of such methods over logistic regression is their ability to learn more generic, non-linear functional forms, which in turn yields superior performance. While deep learning was not employed in this paper, a number of studies, such as
Schmitt (
2022) or
Shwartz-Ziv and Armon (
2022), have shown that gradient-boosted models are at least as effective as deep neural networks for classification purposes in the context of tabular data. Moreover, gradient-boosted models are typically much faster to train than deep neural networks. Recurrent deep learning models, such as Long Short-Term Memory (LSTM) networks, suffer from similar drawbacks and require even longer training times. Furthermore, such models are not well-suited to the dataset under consideration in this study, given that some companies have only one or two years of history, resulting in very small sequence lengths.
The models are trained to minimize the cross-entropy (cost function), also known as LogLoss, defined as
where
is the model probability that sample
i belongs in category 1 and
is the true class (which selects the suitable term of the sum for each
i). This type of loss implicitly assumes that both true classes appear with roughly the same frequency in the training set, which is the case with 51.7% of samples belonging to class 1 and 48.3% to class 0.
4.2. Training Features
The Refinitiv ESG dataset contains several levels of granularity. We choose to train our models with the 10 pillar scores described in
Appendix A (Resource Use, Emissions, Innovation, Workforce, Human Rights, Community, Product Responsibility, Management, Shareholders, CSR Strategy) and the aggregated Controversy score. This level of granularity is a good compromise.
We add five non-ESG features (market capitalization, country of incorporation and TRBC Sector at levels 1, 2 and 3). These features provide the benchmark features needed to settle the question of the additional information provided by ESG features.
4.3. Target Computation
We compute the coefficients of the regression defined in Equation (
2) with monthly factors available online at
Fama and French (
2021) and monthly price returns over periods of 5 civil years. For instance, the regression coefficients used to compute the 2017 target, possibly explained by 2017 ESG features, are computed with historical data ranging from 2013 to 2017. We then compute targets over the year corresponding to the year of the publication of the ESG features: as we are in an explanatory setting, we want to explain the return of a company for a specific year using the ESG profile of this company during the same year.
4.4. Cross-Validation and Hyperparameter Tuning in an Increasingly Good Data Universe
The usual strategy of a single data split into a causal consecutive train, validation and test data sets may not be fully appropriate for the currently available ESG features. This is because the amount of data grows from a very low baseline, both quantity- and quality-wise, which was not exploitable, to an amount that more likely is. Thus, not only are the data non-stationary but their reliability and quality keep increasing. As a consequence, the cross-validation time-splitting schemes known to work well in the context of non-stationary time series (
Bergmeir and Benítez 2012) may be improved upon.
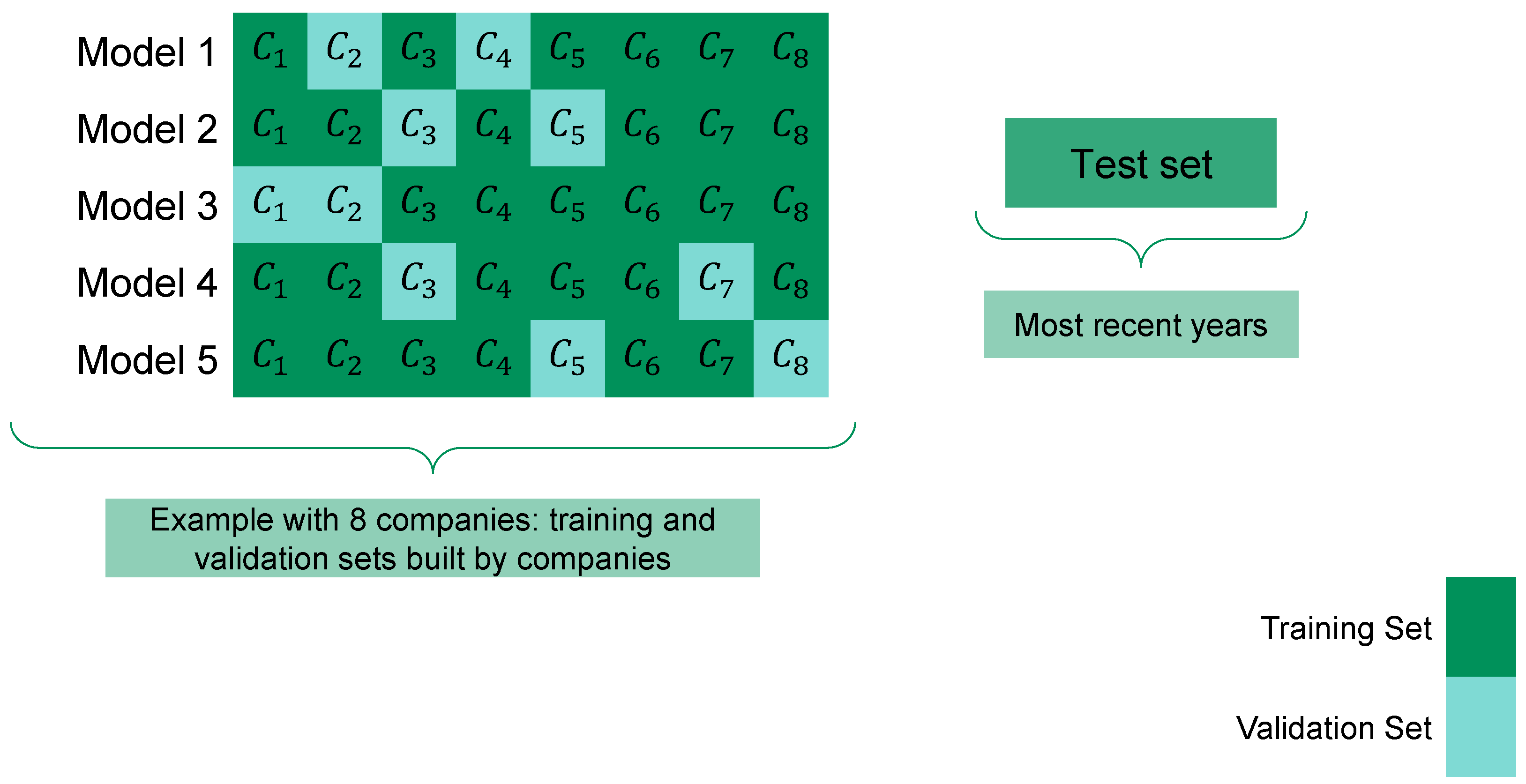
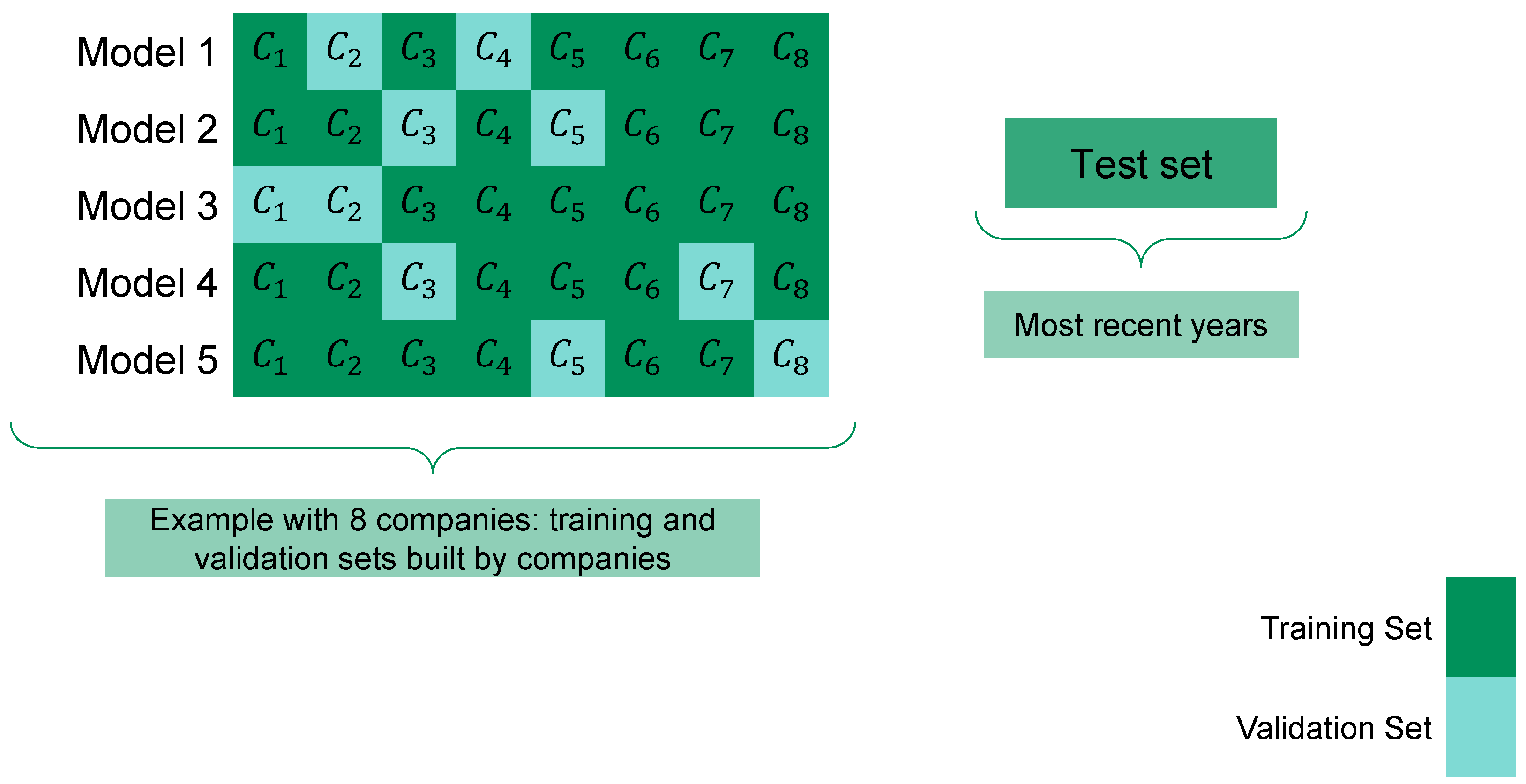
For this reason, we experiment with
K-fold company-wise cross-validation, where 75% of companies are randomly assigned to the training set and the remaining 25% to the validation set (see
Figure 5). In other words, there are
K different (train-validation) sets. For each of the
K train sets, we train 180 models, varying 12 hyperparameters of the LightGBM (maximum tree depth, learning rate, etc.) and pool the five best ones according to model performance in the respective validation sets. In this way, models are trained with most of the most recent (hence, more relevant) data while validating the model also with the most recent and best data. If the dependencies completely change every year, this validation scheme is bound to fail. As we shall see, this is not the case. We take
.
In addition, we use expanding (train+validation)-test windows, using the last year as the test window, which allows us to perform a time-wise analysis of the performance of the models. Because data are insufficient before 2015, we have five different periods: the first test year is 2016, and the last one is 2020. We thus train and validate models.
For each testing period, we will compare the performance of the company-wise 5-fold random splits with that of the standard temporal split (75% train/25% validation).
5. Results
Here we investigate the results of the standard temporal split and the 5-fold company-wise split for a target computed using the CAPM model, as described in
Section 4.1. Models trained using the Fama–French 3-factor model lead to less clear-cut performance; their results are relegated to
Appendix B.
We first assess the quality of the models according to the cross-entropy loss, using their direct probability outputs. We also assess the end result, i.e., the predicted class. As it is usual, we map the output, a probability , to classes 0 and 1 with respect to a 0.5 threshold. This allows us to compute the balanced accuracy, defined as the average of the sensitivity and the specificity. Sensitivity equals the ratio of true positives to the number of positive samples. Specificity is the ratio of the true negatives to the number of negative samples. An advantage of balanced accuracy over classical accuracy is that balanced accuracy accounts for class imbalance in the test set. By definition, it assigns a score of 0.5 if the model did not learn anything significant.
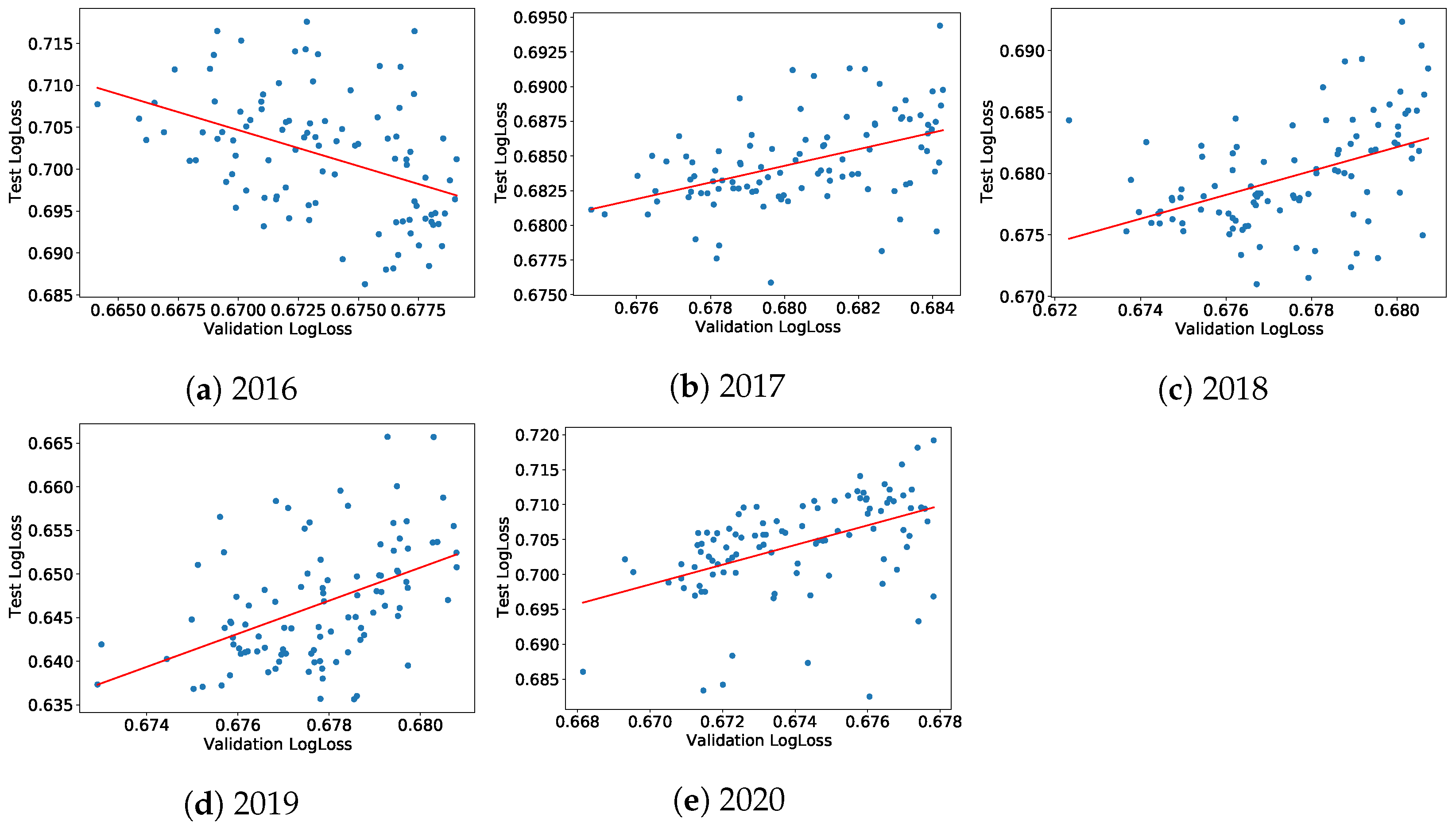
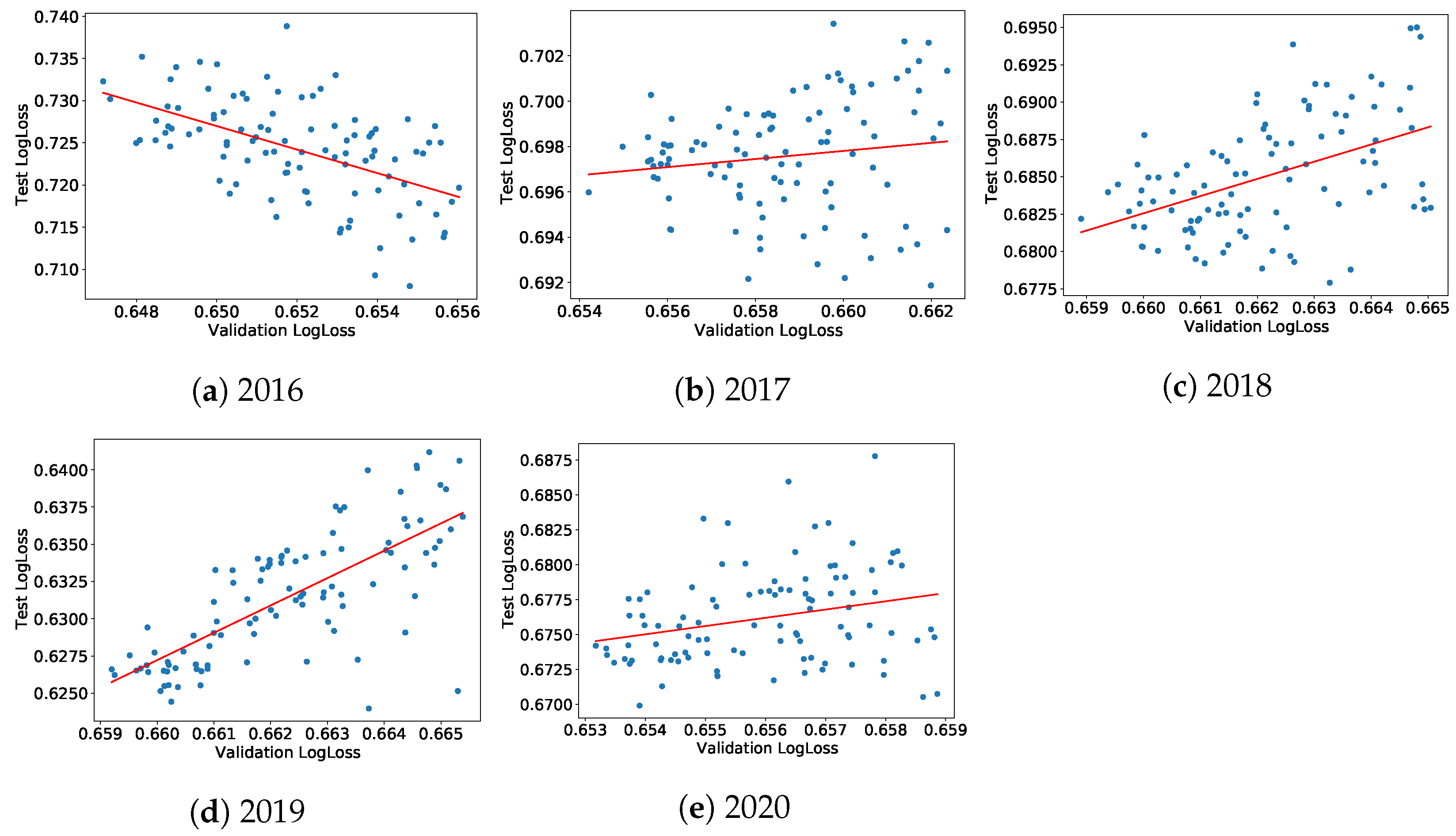
We check that the performance of the models in the test sets bears some relationships with their performance in the validation sets. More precisely, for each (train+validation)-test period, we investigate the dependence between the cross-entropy losses in the validation and test sets, respectively, noted
versus
, for the best models trained during the hyperparameters random search, which makes it possible to characterize the training quality year by year. A significantly positive relationship shows that these models did learn persistent relationships, i.e., something useful. Mathematically, we assess the relationship
versus
for each model
m, ranking for the 100 models with the best validation cross-entropy losses for each of the five sets of (train+validation)-test sets.
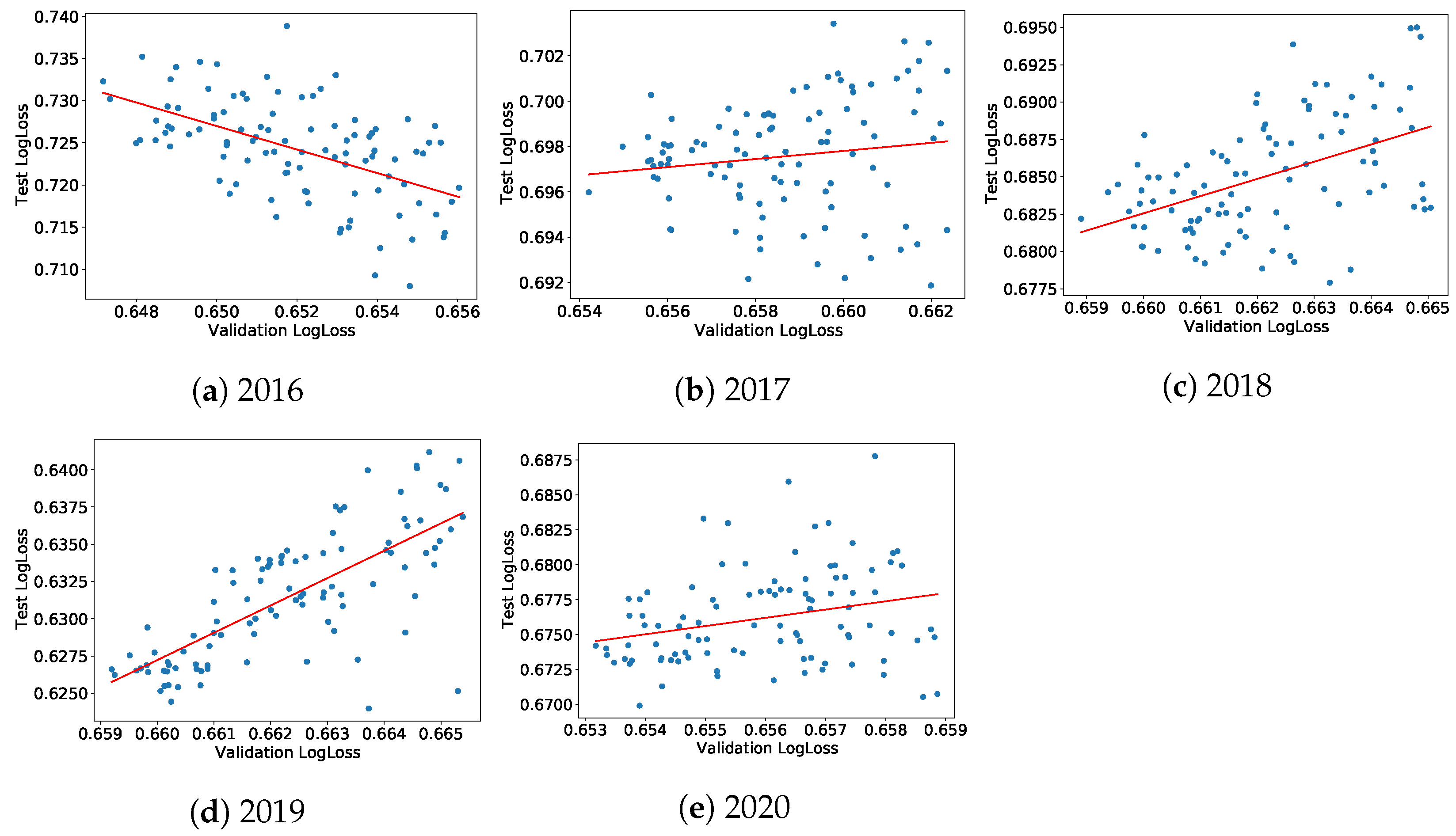
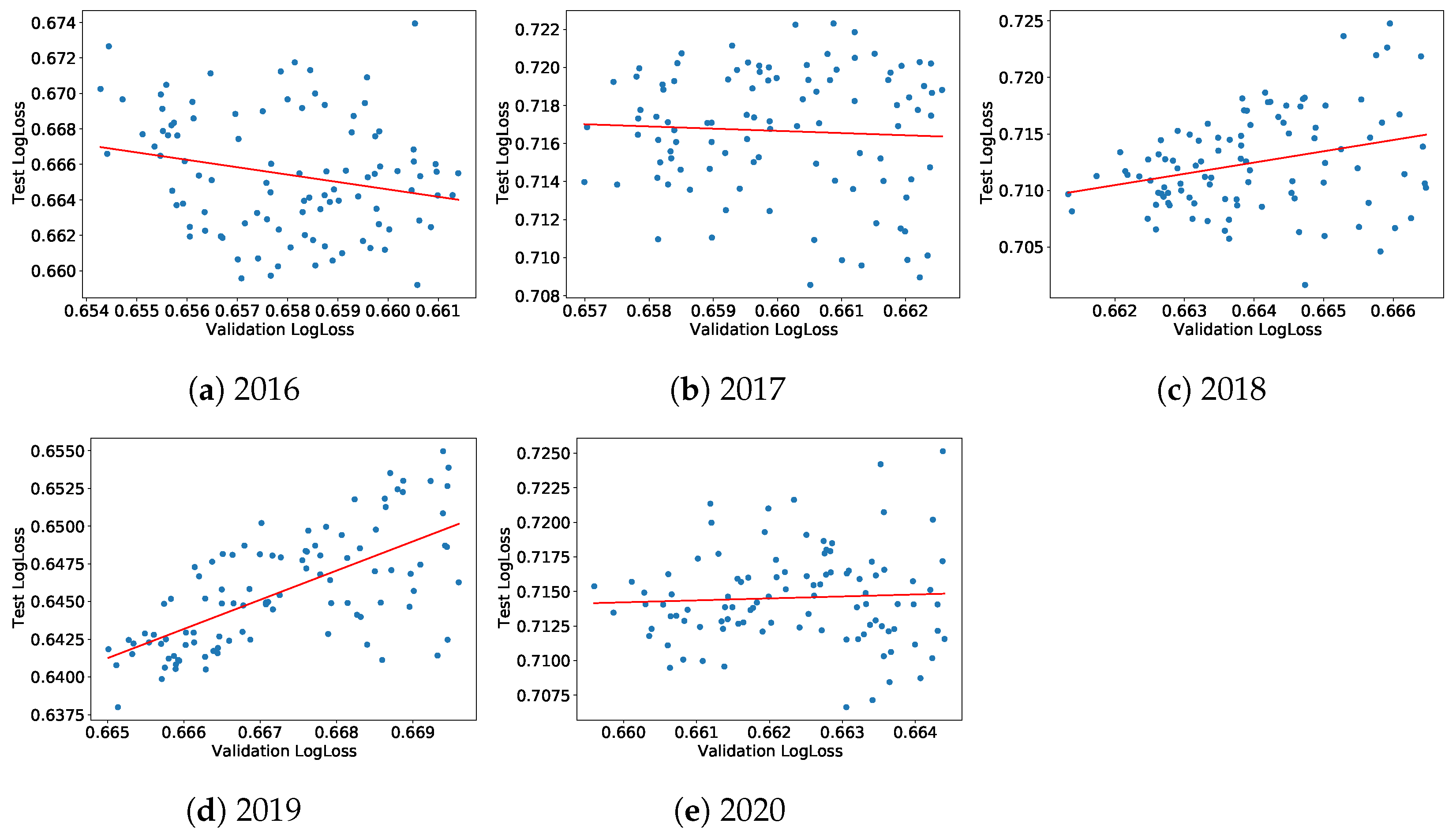
Figure 6a–e display these relationships for the company-wise cross-validation scheme and adds a linear fit. Figures of the same type for the standard time-splitting scheme can be found in
Appendix C. Generally, both test and validation cross-entropy losses are positively correlated, except for 2016. We believe that this comes from the fact that ESG data were of insufficient quality before that date. The year 2020 is also special: in addition to the coronavirus crisis, the data for 2020 were obtained at the beginning of 2021 when not all companies had ESG ratings, leading to a smaller dataset and a (mostly likely) biased test set.
We compute the Pearson correlation, the
of the linear fit, Kendall tau and its
p-value for the standard temporal split and the 5-fold company-wise split, which are reported in
Table 1. This latter allows us to compare the respective advantages and disadvantages of each validation strategy. All the dependence measures increase significantly from 2017 to 2019 for company-wise splits. The case of temporal split shows the limitations of this approach: the performance measures are roughly constant, which is consistent with the fact that adding one year of data to the train+validation dataset does not lead to much change. A display of the relationship
versus
for the standard temporal model can be found in
Appendix C, in
Figure A2.
Our second and most important aim is to establish that ESG data contain additional valuable and exploitable information on price returns in comparison to a set of benchmark features. To this end, for each training period defined above, we train a model with both ESG and benchmark features and another model with benchmark features alone. We assess both the absolute performance metrics of the models and the extent of additional information provided by ESG features by calculating the difference in performance metrics in the test sets.
The company-wise splits make it easy to compute error bars on various metrics: instead of training
models, we train 100 of them and then compute the median performance on 100 random subsets of size
among these 100 models.
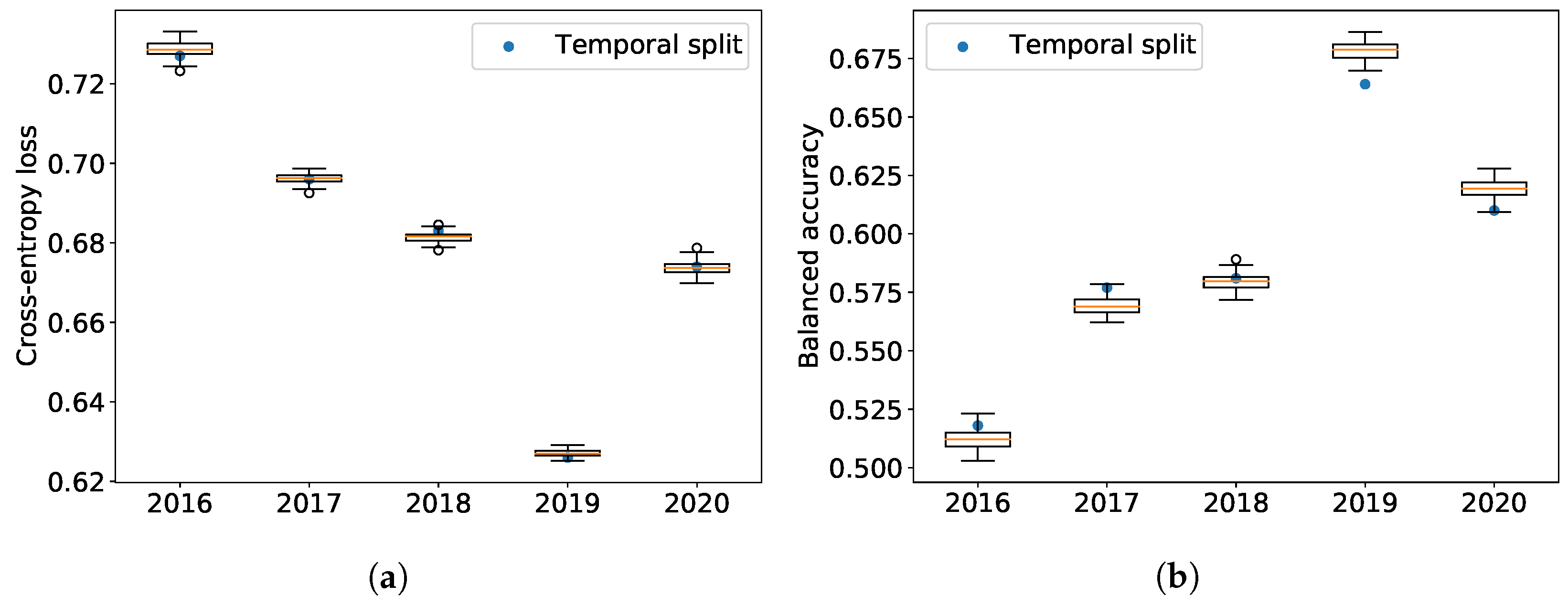
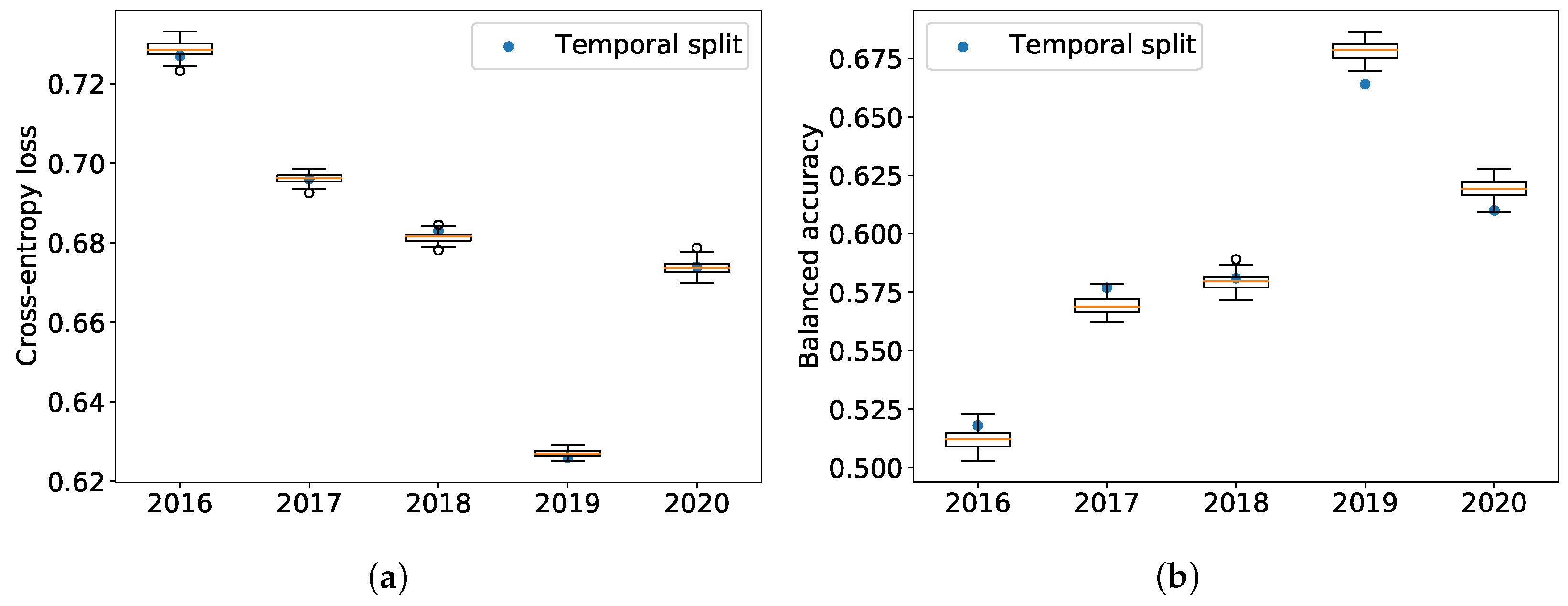
Table 2 provides results on the absolute performance of the models for each test period for both the company-wise and the standard temporal splits. Both splitting methods have a clearly decreasing cross-entropy (a proxy for prediction error) as a function of time, except for 2020, which shows once again the special nature of this year in our dataset. This shows that the relevance of ESG features in price return formation increases as a function of time. Balanced accuracy displays a similar improvement before 2020. However, this time, yields of company-wise splits are increasingly better than temporal splits, which we believe is an encouraging sign of its ability to better leverage the latest and best data.
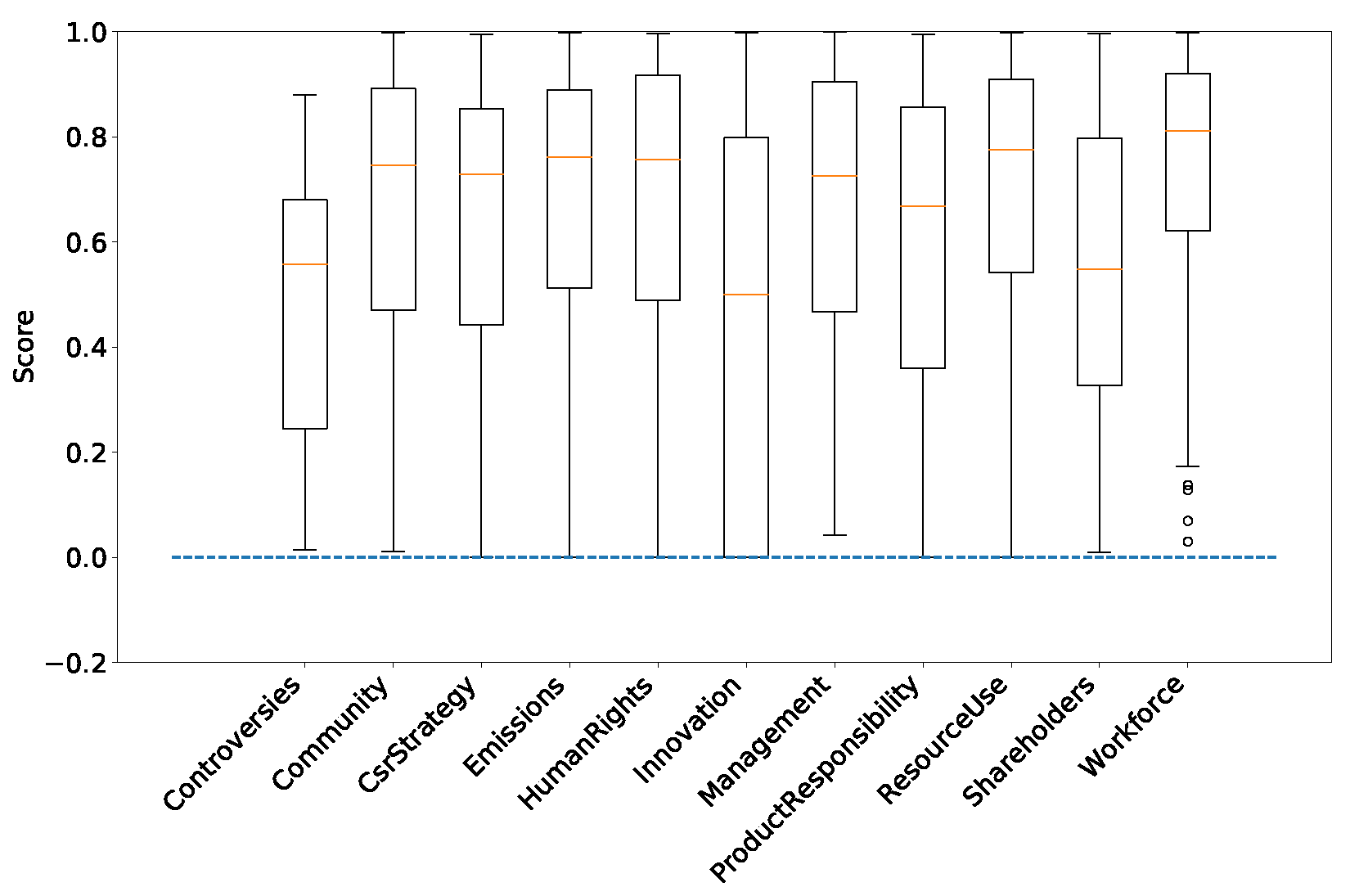
Figure 7 displays the time evolution of the cross-entropy and the balanced accuracy in the test sets. The boxplots are computed for the company-wise splits from the 100 associated predictions; the orange lines are the median of these performance measures, the rectangle delimits the first and third quartiles, and extreme limits are situated before the first quartile minus 1.5 times the interquartile range and after the third quartile plus 1.5 times the interquartile range. Any point outside of this range is considered an outlier.
Company-wise 5-fold cross-validation outperforms the standard time-splitting scheme, which supports our claim that the not fully mature nature of ESG data can be partly alleviated by a suitable validation scheme.
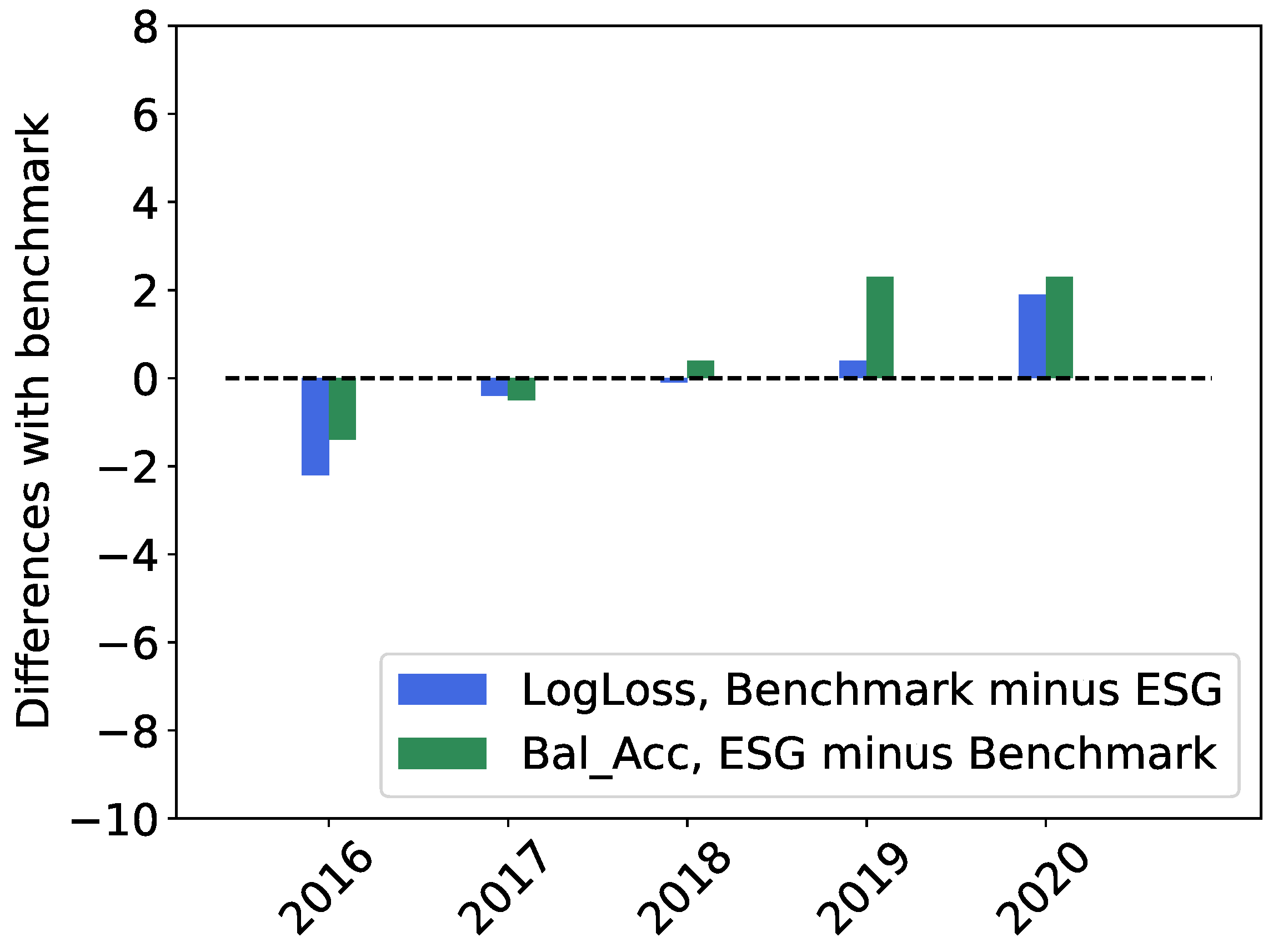
Figure 8 shows the difference in performance between the models trained on ESG and benchmark features and the models trained only on benchmark features for the company-wise 5-fold cross-validation. ESG features contain more relevant information as time goes on. Two explanations spring to mind: long positions are more and more driven by ESG-conscious investors, or the quality of data increases as a function of time, which makes the relevance of ESG scores more apparent.
6. Interpretability
We now provide a breakdown of the impact of the different ESG features on the predicted probability of having positive idiosyncratic returns in the CAPM model. Because of the superior performance of the company-wise K-fold cross-validation, we use this method in the following.
6.1. Shapley Values
Shapley values, first introduced in the context of game theory (
Shapley 1953), provide a way to characterize how each feature contributes to the formation of the final predictions. Shapley values and their uses in the context of machine learning are well described in
Molnar (
2020).
The Shapley value of a feature can be obtained by averaging the difference in prediction between all the combinations of features containing and not containing the said feature. For each sample in our dataset, each feature possesses its own Shapley value representing the contribution of this feature to the prediction for this particular sample. Shapley values have very interesting properties, one of them being the efficiency property. If we note
the Shapley value of feature
j for a sample
and
the prediction for the sample
, Shapley values must add up to the difference between the prediction for the sample
and the average of all predictions
and then follow the following formula:
The dummy property also states that the Shapley value of a feature that does not change the prediction, whatever combinations of features it is added to, should have a Shapley value of 0.
Shapley values computation is quite time-and memory-intensive.
Lundberg and Lee (
2017) and later
Lundberg et al. (
2018) proposed a fast implementation of an algorithm called TreeSHAP, which allows to approximate Shapley values for trees models such as the LightGBM, which we use in the following and refer to as SHAP values.
Let us just note that, as we are using a LightGBM model in classification, the prediction is not directly the probability of belonging to class 1, but rather the logit associated with this probability. Probability is an increasing function of the logit, and thus, SHAP values obtained for the logit can easily be transformed for the probability. Indeed, for a sample
, the predicted probability of belonging to class 1
is linked to the logit
according to:
6.1.1. Evolution of ESG Features Contribution from 2017 to 2020
In
Figure 9, we plot the distribution of SHAP values for each feature and for all test samples for models trained from 2002 to 2016 (
Figure 9a) and trained from 2002 to 2019 (
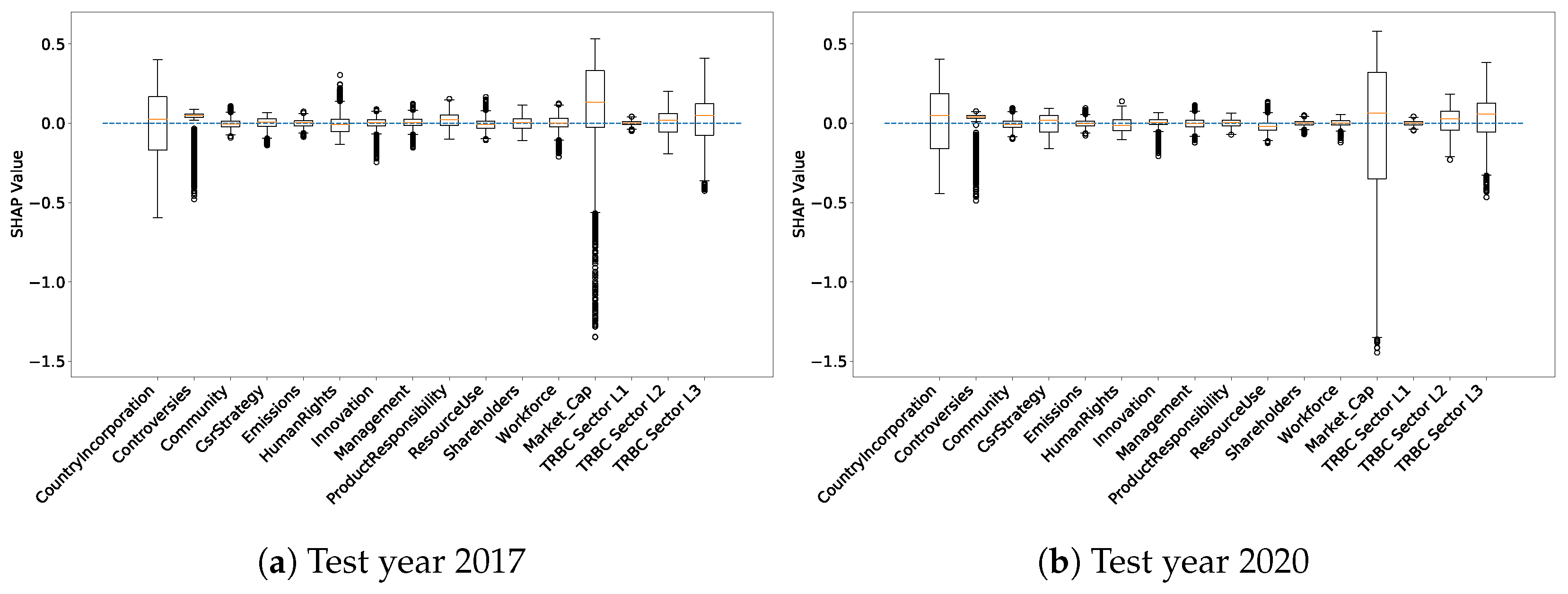
Figure 9b). The first teaching of this plot is that the contribution of ESG features to the predicted probability of having a positive return has not dramatically increased with the additional, more recent and more complete data. Benchmark features are the ones that have the biggest impact on the prediction. However, we observe an important number of outliers for some SHAP values associated with some features, demonstrating that these ESG features have more impact on the prediction for these particular samples. It would be interesting to study these outliers to understand more why ESG features are more important in explaining price returns for some samples than others.
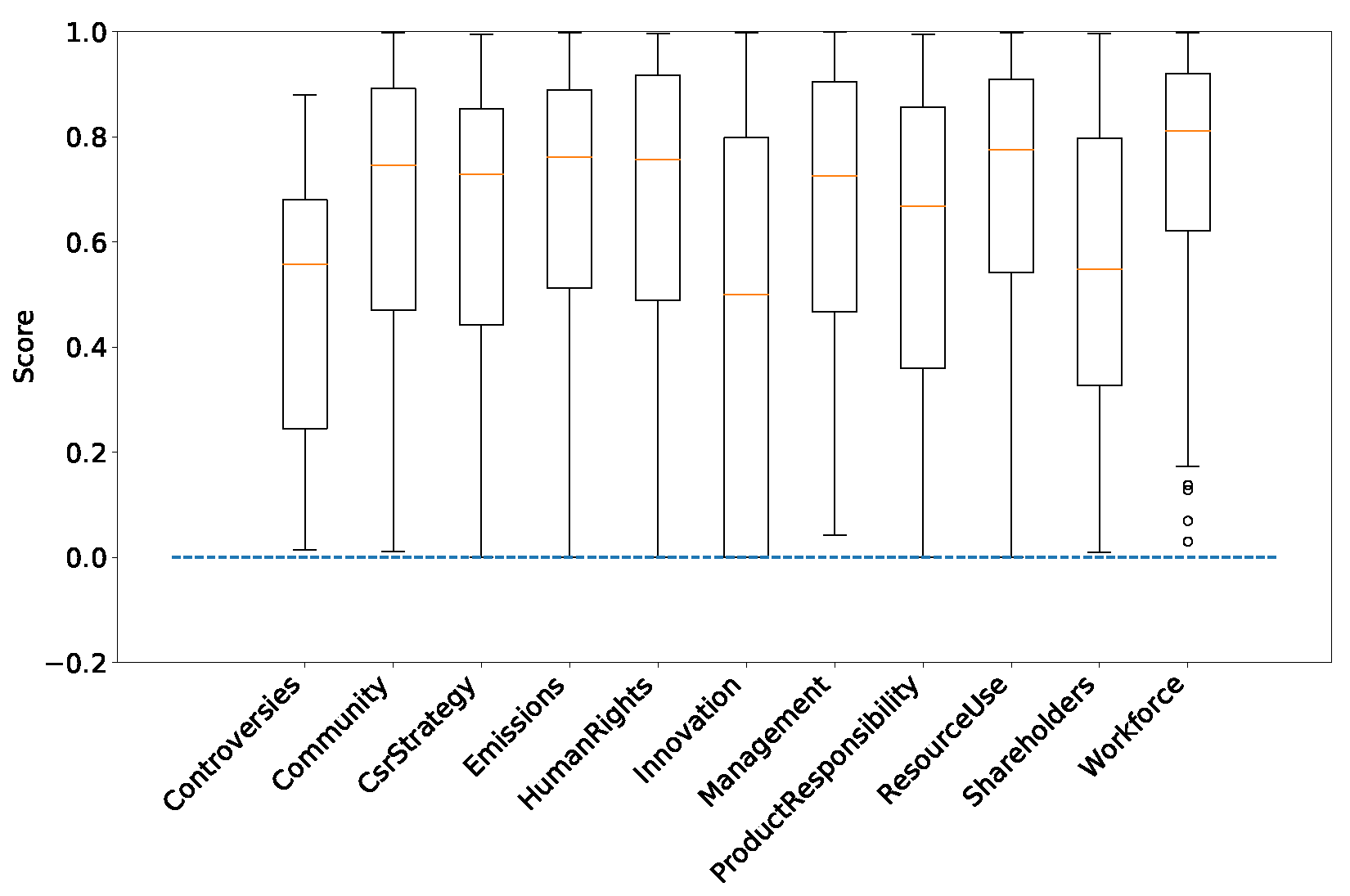
For instance, we observe in
Figure 10 the score distributions for the outliers of the Controversy SHAP values. All of these scores are below 0.9, suggesting that the Controversy score is more informative when a company has indeed suffered controversies during the year and was then not able to reach a score of 1. Observing outliers of SHAP values and their associated scores, we can make the hypothesis that ESG features are important and have a strong impact on the explanations of past returns if their score is extreme. This would mean that ESG information would lie in extreme scores, with more standard scores bringing much less information. Checking this hypothesis is beyond the scope of this work and is left for future investigations.
6.1.2. On the Choice of SHAP Values as the Interpretation Method
The use of SHAP values enables the computation of feature-specific explanations for individual samples, providing insight into the contribution of each feature to a given prediction. This approach is founded on sound theoretical principles and constitutes an exact method, as indicated by
Molnar (
2020): the cumulative sum of all SHAP values yields the predicted logit, and subsequently, the predicted probability outputted by the model can be retrieved. TreeSHAP implementation is a fast method for computing SHAP values. Although other techniques for explanatory purposes exist, they lack the beneficial properties inherent to SHAP values. We proceed to discuss two such methods, namely the feature importance derived from the LightGBM model and Local Interpretable Model-Agnostic Explanations (LIME).
As a gradient-boosted model, LightGBM allows the derivation of feature importance metrics directly from the trained model. Typically, this is computed as the number of times a particular feature is utilized in building each of the trees comprising the LightGBM model. However, such an approach to computing feature importance yields only a global measure and does not allow the derivation of per-sample feature importance. This shortcoming renders it impossible to ascertain if a given feature can yield divergent effects depending on the sample being evaluated, as shown by the SHAP values presented in
Figure 9. Consequently, the feature importance derived from LightGBM is usually deemed unsatisfactory for explaining models due to its lack of granularity.
Other machine learning interpretation methods that provide a per-sample explanation are available. One such method is LIME, developed by
Ribeiro et al. (
2016).
Molnar (
2020) discusses this methodology, highlighting its advantages and drawbacks. Although LIME provides per-sample explanations, it does not constitute an exact method and lacks robustness. Additionally, the explanations derived via LIME are unstable, as they can vary upon running the methodology on different occasions. Moreover, when the model being explained is not locally linear, the LIME methodology is not meaningful. These drawbacks are illustrated in the work of
Alvarez-Melis and Jaakkola (
2018), which discusses the limitations of LIME with respect to robustness.
6.2. Partial Dependence Plots: Marginal Effect of ESG Features
6.2.1. Definition
A partial dependence plot shows the marginal effect of features on the prediction made by the model. It is a way of understanding the links the model made from features to the target and that it had understood from the data. It also shows if this relation is linear or not, monotonic or not, etc. Partial dependence plots were first introduced by
Friedman (
2001) and are also well-described by
Molnar (
2020). Briefly, a partial dependence plot for a feature of interest is obtained by marginalizing the predicted output over the values of all other input features. This marginalization is performed by calculating averages in the training data, using a Monte-Carlo method, with a fixed value for the features of interest.
An important limitation of a partial dependence plot is that their methodology of construction assumes independence between the features, which does not seem to be the case for ESG features. This limitation is neglected here. All partial dependence plots are made with the most recent model, trained with data from 2002 to 2019, on a subsample of recent ESG data.
6.2.2. Marginal Effect of the ESG Features
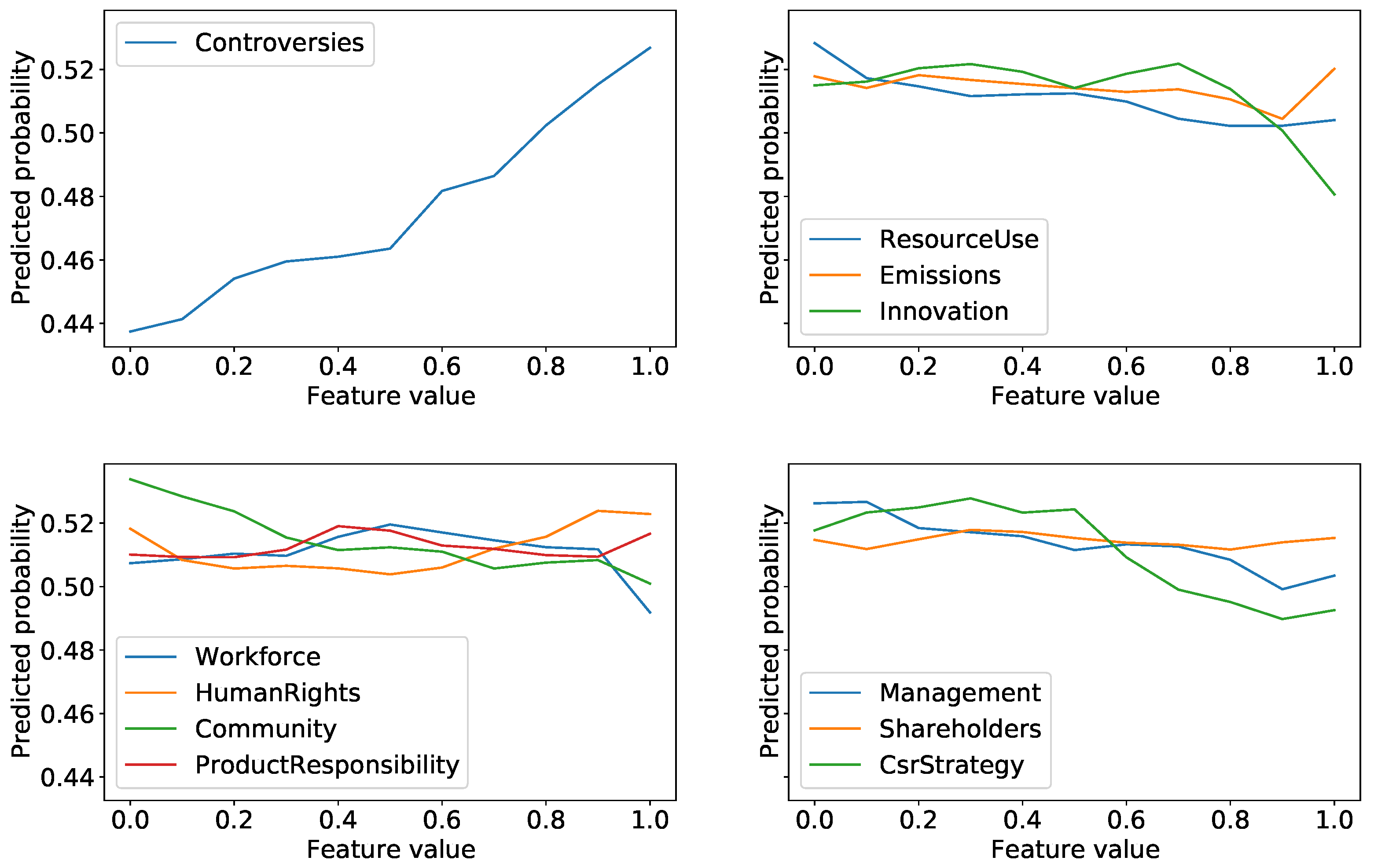
Using partial dependence plots, we first compute the marginal effect of each ESG feature on the probability of having a positive return during the year of publication of the ESG features (
Figure 11).
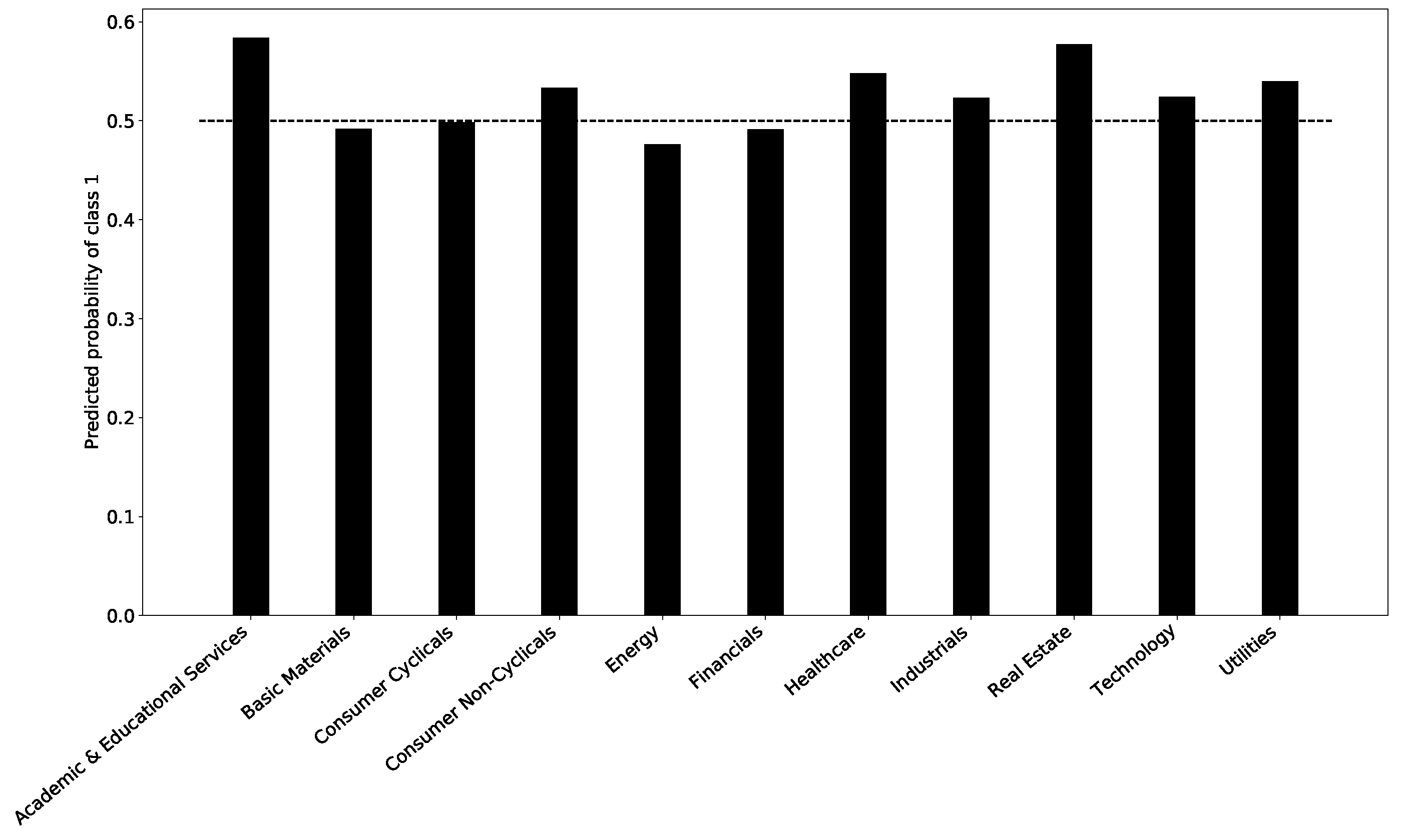
Figure 12 reports the sector by the sector probability of having a positive predicted return.
Figure 11 shows that ESG features are mostly not related in a monotonic way with the probability of having a positive return. A clear exception would be the Controversy score, on the top left, which shows a strong monotonic relation and strongly implies that being subject to controversies during a year leads to a lower probability of having a positive return. For the 10 pillar scores, one sees a much weaker dependence. For example, the probability of positive price return increases by around 1% when the Product Responsibility and Shareholders scores increase from 0 to 1. Still, a trend is present for most of these ESG features: partial dependence plots for features such as Resource Use, Innovation, Community or Management seem to be decreasing, suggesting that obtaining better ESG scores and practices comes at the price of a slightly degraded financial performance.
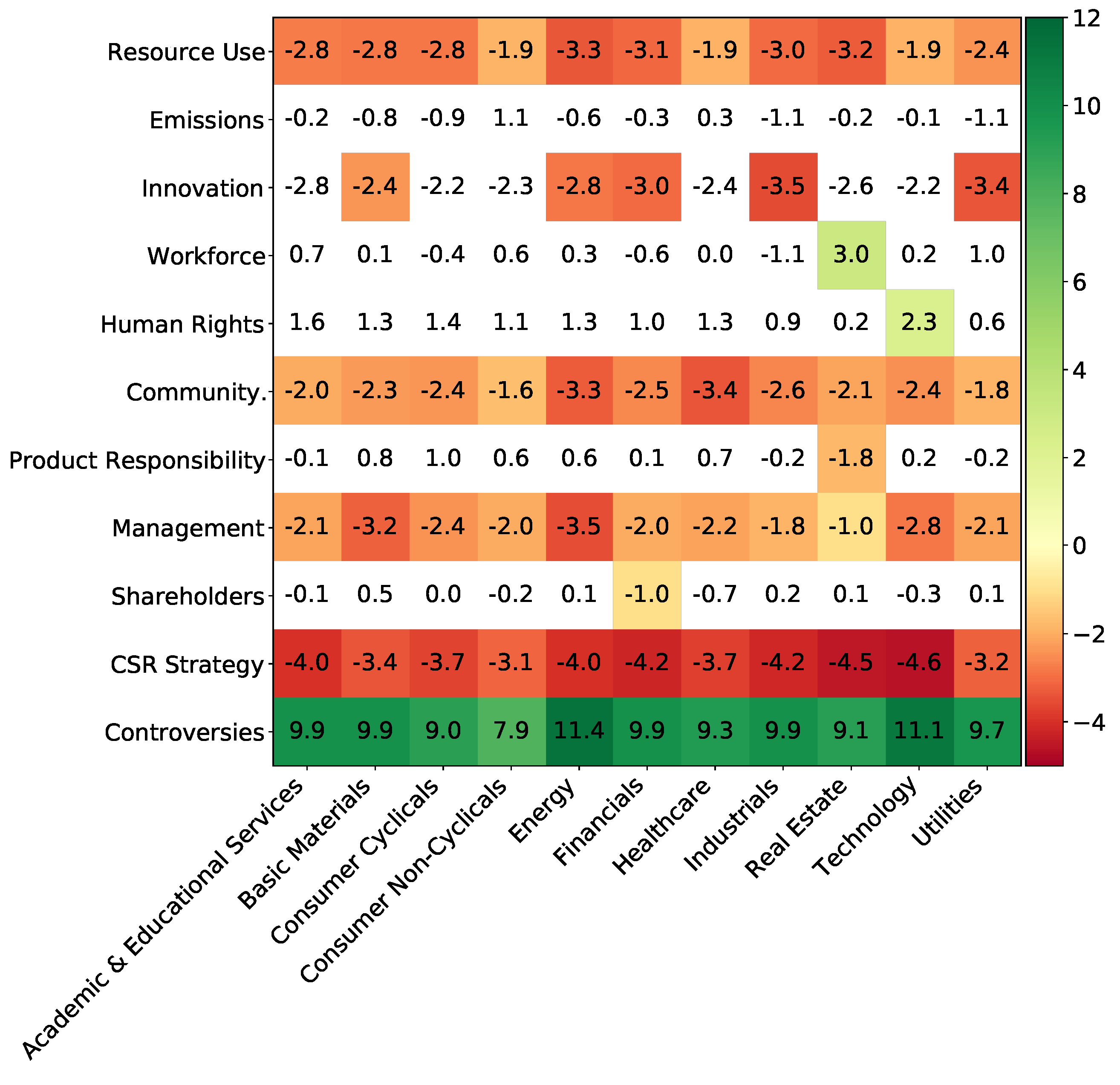
6.2.3. Marginal Effect of the ESG Features Sector by Sector: Materiality Matrices
Adding the section dimension to partial dependence plots yields so-called materiality matrices. In our setting, it is a table whose rows represent EGS features and whose columns are economic sectors. A cell of this matrix shows, in percentage, by how much the probability of having a positive return is increased by going from a low score (between 0 and 0.2) to a high one (by 0.8 to 1). This quantity is easily obtained using partial dependence plots: for a specific selected economic sector, we can plot the evolution of the predicted probability against the feature value. Making the strong hypothesis of a monotonic and close-to-linear relationship, we can compute the value in the cell as the slope of the trend line of the precedent plot.
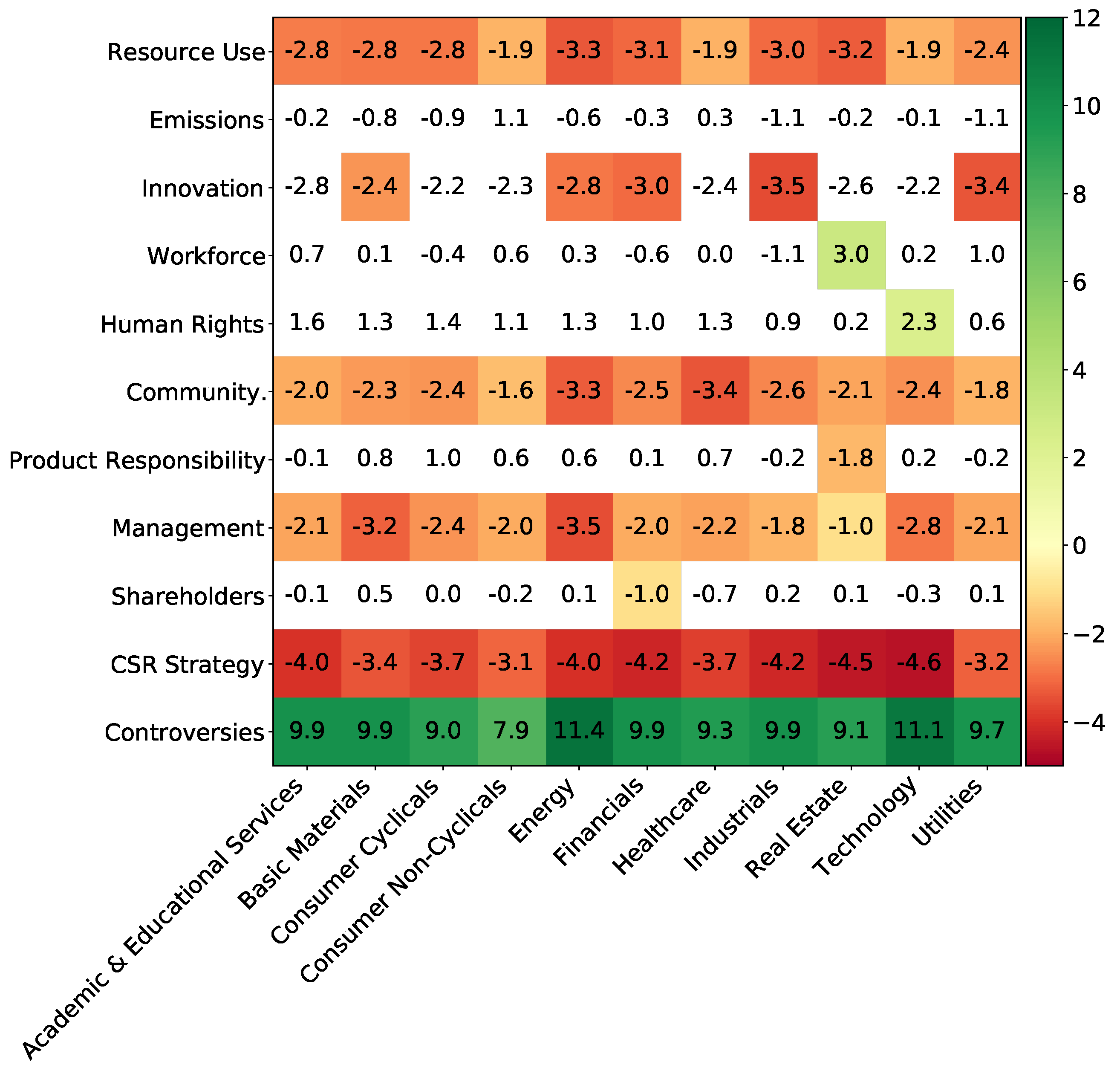
The obtained materiality matrix is presented in
Figure 13. All the TRBC Level 1 sectors are included. Results for Academic and Educational Services should be handled with care as they are not based on as many samples as the ones for other sectors, as shown in
Figure 4. Some ESG scores have a strong impact on the probability of having positive returns. The Controversy score especially has a similar impact for all sectors: not suffering controversies during the year increases the probability of having a positive return. On the contrary, the CSR Strategy row shows that working towards the integration of social and environmental dimensions into the day-to-day decision-making processes, in addition to economic and financial ones, leads to a loss of financial performance. It is also the case for Resource Use, Environmental Innovation, Community, and Management scores, each with a different magnitude.
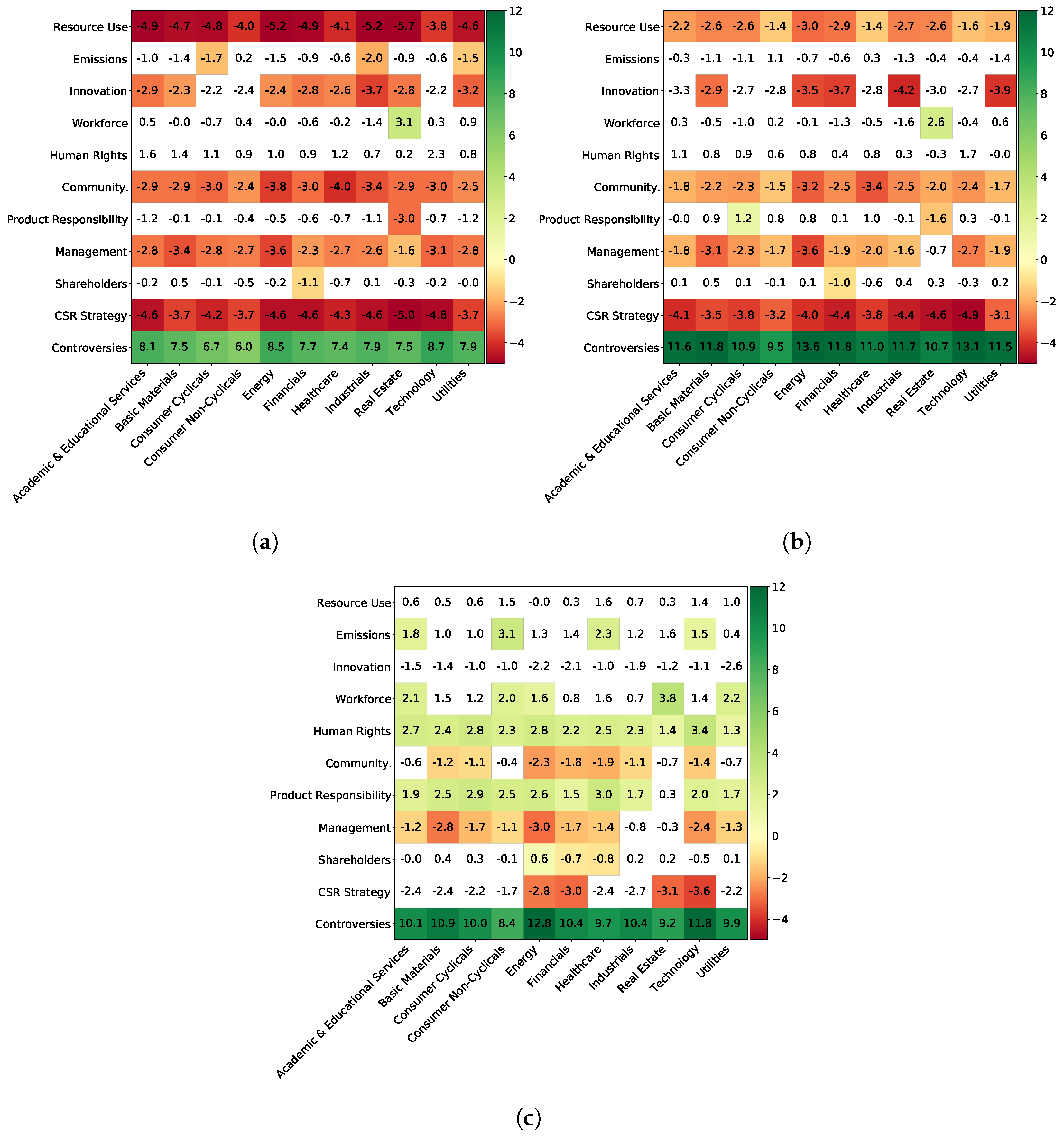
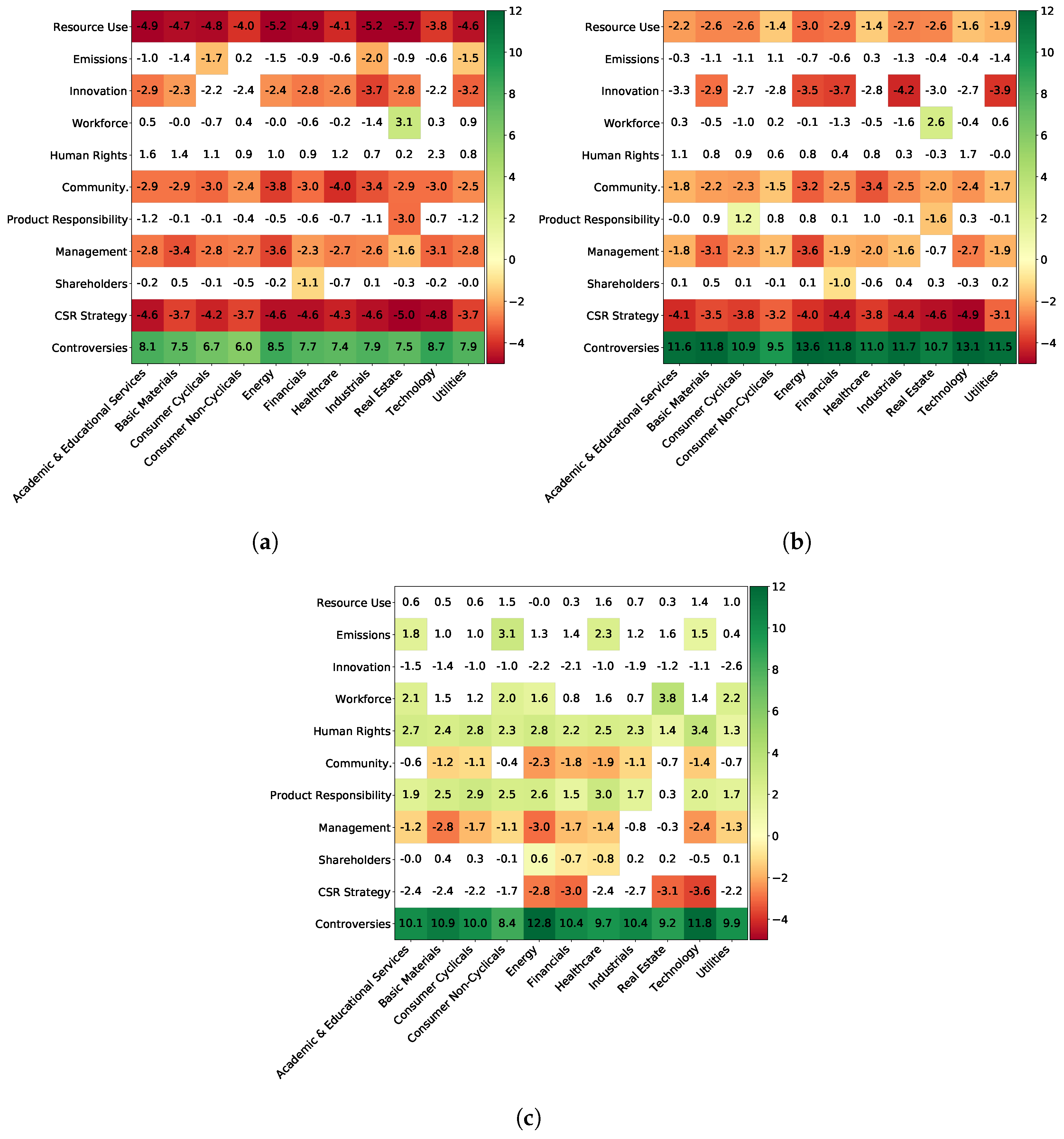
Furthermore, we bucket the companies that serve to build this materiality matrix by market capitalization. We choose three buckets, with small market capitalization being below 2 billion euros, mid ones between 2 and 10 billion euros and large ones above 10 billion euros, which correspond to the ones Refinitiv uses when calculating the Controversy score. The three obtained materiality matrices are presented in
Figure 14. The marginal effect of the Controversy score remains the same, even if it is slightly smaller for the small caps. However, companies with a large market capitalization benefit from a better impact of ESG: for some features, working toward better ESG scores can preserve or even boost financial performance, whereas it would be the opposite for small caps. For instance, large cap companies have an average materiality of 0.8 for the Resource Use score and 1.5 for the Emissions score, whereas small caps ones have, respectively, average scores of −4.6 and −1.1, denoting a clear difference.
To obtain a statistically meaningful interpretation of these results, we need to account for the fact that each cell corresponds to coefficients of a linear fit with associated
p-values, i.e., one makes one null hypothesis per cell. We thus need to use multiple hypothesis correction to check globally which cells show statistically significant results. Here, we choose to control the False Discovery Rate with the Benjamini–Hochberg procedure (
Benjamini and Hochberg 1995). We set the FDR to 5%, which means that there are only about three false discoveries in each of the reported tables.
7. Conclusions
While ESG data are not yet fully mature and lack long enough quality records to be amenable to easy conclusions, powerful machine learning and validation techniques make it already possible to show that they do influence yearly price returns, and increasingly so: ESG features successfully explain the part of annual price returns not accounted for by the market factor. By breaking down their influence sector-by-sector, subscore-wise and according to market capitalization, we have demonstrated that an average approach will fail to be informative. Our findings indicate that the relationship between controversies and price return is the most robust one. The average influence of all the other ESG scores significantly depends on the market capitalization of a company: strikingly, most of the statistically significantly influential ESG scores weigh negatively on the price returns of small or mid-size companies. Large-capitalization companies, on the other hand, have significantly advantageous ESG score types.
Our findings are specific to the Refinitiv ESG dataset for the European market, and caution should be exercised in generalizing them to other ESG datasets. This is due to the possibility of disparate ESG scores resulting from different methodological approaches to construction and from the inclusion of varying types of information. Furthermore, our study demonstrates the capacity of ESG features to provide supplementary information in explaining the fraction of annual price returns not accounted for by the market factor compared to a predetermined set of benchmark features. The benchmark features selection was tailored to the purpose of this study: alternative choices of benchmark features could have uncovered other types of additional information embodied in ESG features.
While this work focuses on explaining the sign of excess price returns derived from the CAPM model, those derived from the Fama–French 3-factor model lead to results that are less clear-cut for the time being. However, this effect seems to be weakening over time: correlations between validation and test set errors increased in both 2018 and 2019, indicating the increasing information value of ESG data in explaining price returns. Future investigations will focus on the study of the full 2020 and 2021 years to verify these initial findings. Moreover, extending this research to the study of the explanatory power of ESG data with respect to more equity factors, such as quality, would enhance its comprehensiveness.
In this work, we applied a methodology to explain the sign of price returns contemporary with ESG features. Future research could focus on using the same framework to evaluate the predictive power of ESG data by estimating the sign of future excess returns. To achieve this objective, a distinct dataset would be necessary, containing so-called “point-in-time” ESG features, wherein data are not adjusted after their publication.
Future work will also include studying outliers of the SHAP values distribution and testing the hypothesis that extreme scores in the ESG field are more informative. In addition, the link between ESG and equity returns is complete only if the systematic and idiosyncratic aspects of risks and returns are studied together (
Giese and Lee 2019): indeed, it may be that having better ESG scores not only decreases price returns but also reduces risk. Future research will concentrate on investigating the information content of ESG datasets to evaluate risk measures concerning a company’s stock, such as volatility or drawdown. This would provide a more comprehensive understanding of the interplay between ESG factors, risk, and equity returns.
Author Contributions
Conceptualization, J.A., L.C. and D.C.; methodology, J.A., L.C. and D.C.; software, J.A.; validation, J.A. and L.C.; formal analysis, J.A. and D.C.; investigation, J.A., L.C. and D.C.; resources, L.C.; data curation, J.A.; writing—original draft preparation, J.A. and D.C.; writing—review and editing: J.A., L.C. and D.C.; visualization, J.A.; supervision, L.C. and D.C.; project administration, J.A., L.C. and D.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work originates from a partnership between CentraleSupélec, Université Paris-Saclay and BNP Paribas. This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CAPM | Capital Asset Pricing Model |
| ESG | Environment Social Governance |
| HML | High Minus Low, value Fama–French factor |
| LIME | Local Interpretable Model-Agnostic Explanations |
| LSTM | Long Short-Term Memory |
| SMB | Small Minus Big, size Fama–French factor |
| TRBC | The Refinitiv Business Classification |
Appendix A. 10 Pillar Scores
Appendix A.1. Environmental Scores
Resource Use: Reduce the use of natural resources and find more eco-efficient solutions by improving supply chain management.
Emissions: Commitment and effectiveness towards reducing environmental emissions in the production and operational processes.
Innovation: Reduce the environmental costs for customers, thereby creating new market opportunities through new environmental technologies and processes or eco-designed products.
Appendix A.2. Social Scores
Workforce: Job satisfaction, healthy and safe workplace, maintaining diversity and equal opportunities, development opportunities for workforce.
Human Rights: Respecting the fundamental human rights conventions.
Community: Commitment towards being a good citizen, protecting public health and respecting business ethics.
Product Responsibility: Producing quality goods and services integrating the customer’s health and safety, integrity and data privacy.
Appendix A.3. Governance Scores
Management: Commitment and effectiveness towards following best practice corporate governance principles. Composition, remuneration, transparency of the board.
Shareholders: Equal treatment of shareholders, use of anti-takeover devices.
CSR Strategy: Integration of social and environmental dimensions into the day-to-day decision-making processes, in addition to economic and financial ones.
Appendix B. Results with the Target Derived from the Fama–French 3-Factor Model
The following results were obtained with a target derived from the Fama–French 3-factor model, as exposed in
Section 4.1. This target was not selected as the results were not as good as those obtained with the target derived from the CAPM model. How to interpret results with this target, especially in terms of materiality matrices, was also less clear. For the interested reader, we present our results, using a 5-fold company-wise splitting strategy, in
Table A1 and
Table A2. Displays of the relationship between
versus
for each model
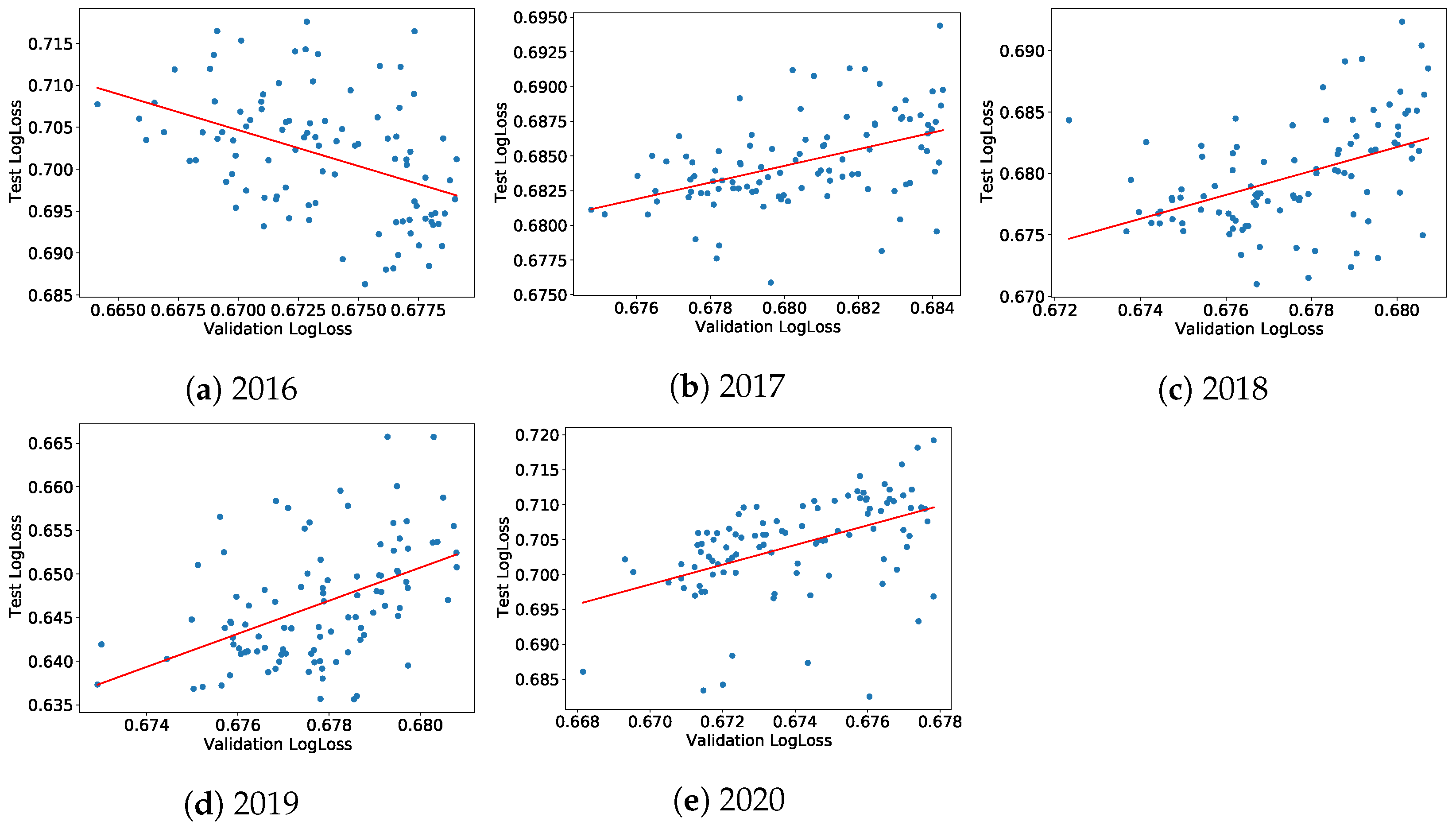
m ranking in the top 100 validation cross-entropy losses are shown in
Figure A1.
Figure A1.
Company-wise cross-validation: test set cross-entropy versus validation cross-entropy of the 100 best models of the random hyperparameters search for a target computed using the Fama–French 3-factor model.
Figure A1.
Company-wise cross-validation: test set cross-entropy versus validation cross-entropy of the 100 best models of the random hyperparameters search for a target computed using the Fama–French 3-factor model.
Table A1.
Dependence measures between the cross-entropy losses in the validation and test sets for the 100 best models of the random hyperparameters search and for a target computed using the Fama–French 3-factor model.
Table A1.
Dependence measures between the cross-entropy losses in the validation and test sets for the 100 best models of the random hyperparameters search and for a target computed using the Fama–French 3-factor model.
| | Company-Wise 5-Fold Cross-Validation |
|---|
| Year | Pearson Correlation | | Kendall Tau | p-Value of Kendall Tau |
|---|
| 2016 | −0.23 | 0.052 | −0.14 | |
| 2017 | −0.054 | 0.0030 | 0.010 | |
| 2018 | 0.29 | 0.085 | 0.19 | |
| 2019 | 0.67 | 0.44 | 0.49 | |
| 2020 | 0.053 | 0.0028 | 0.017 | |
Table A2.
Performance measures in percentage on the test set for a target computed using the Fama–French 3-factor model.
Table A2.
Performance measures in percentage on the test set for a target computed using the Fama–French 3-factor model.
| | Company-Wise 5-Fold Cross-Validation |
|---|
| | Only Benchmark Features | Benchmark and ESG Features |
|---|
| Year | Balanced Accuracy | Cross-Entropy Loss | Balanced Accuracy | Cross-Entropy Loss |
|---|
| 2016 | 57.9 | 65.8 | 56.0 | 66.7 |
| 2017 | 55.0 | 70.6 | 55.2 | 71.6 |
| 2018 | 56.0 | 70.4 | 56.0 | 71.1 |
| 2019 | 62.4 | 64.6 | 64.7 | 64.1 |
| 2020 | 56.1 | 72.2 | 55.3 | 71.3 |
Appendix C. Relationship between Validation and Test Cross-Entropy Losses for the Temporal Train/Validation Scheme
We assess the relationship
versus
for each model
m ranking for the 100 models with the best validation cross-entropy losses for each of the five sets of (train+validation)-test sets.
Figure A2a–e display these relationships for the standard time-splitting scheme.
Figure A2.
Standard temporal split: test set cross-entropy versus validation cross-entropy of the 100 best models of the random hyperparameters search.
Figure A2.
Standard temporal split: test set cross-entropy versus validation cross-entropy of the 100 best models of the random hyperparameters search.
References
- Alessandrini, Fabio, and Eric Jondeau. 2020. ESG investing: From sin stocks to smart beta. The Journal of Portfolio Management 46: 75–94. [Google Scholar] [CrossRef]
- Alvarez-Melis, David, and Tommi S. Jaakkola. 2018. On the robustness of interpretability methods. arXiv arXiv:1806.08049. [Google Scholar]
- Anson, Mark, Deborah Spalding, Kristofer Kwait, and John Delano. 2020. The sustainability conundrum. The Journal of Portfolio Management 46: 124–38. [Google Scholar] [CrossRef]
- Bacon, Steven, and Arnfried Ossen. 2015. Smart ESG Integration: Factoring in Sustainability. Zürich: RobecoSam AG. [Google Scholar]
- Benjamini, Yoav, and Yosef Hochberg. 1995. Controlling the false discovery rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society: Series B (Methodological) 57: 289–300. [Google Scholar] [CrossRef]
- Bergmeir, Christoph, and José M. Benítez. 2012. On the use of cross-validation for time series predictor evaluation. Information Sciences 191: 192–213. [Google Scholar] [CrossRef]
- Breedt, André, Stefano Ciliberti, Stanislao Gualdi, and Philip Seager. 2019. Is ESG an equity factor or just an investment guide? The Journal of Investing 28: 32–42. [Google Scholar] [CrossRef]
- Cappucci, Michael. 2018. The ESG integration paradox. Journal of Applied Corporate Finance 30: 22–28. [Google Scholar] [CrossRef]
- Chen, Mike, and George Mussalli. 2020. An integrated approach to quantitative ESG investing. The Journal of Portfolio Management 46: 65–74. [Google Scholar] [CrossRef]
- Chen, Tianqi, and Carlos Guestrin. 2016. XGBoost: A scalable tree boosting system. Paper presented at 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13–17; pp. 785–94. [Google Scholar]
- Cornell, Bradford, and Aswath Damodaran. 2020. Valuing ESG: Doing Good or Sounding Good? NYU Stern School of Business. [Google Scholar]
- Fama, Eugene F., and Kenneth R. French. 1993. Common risk factors in the returns on stocks and bonds. Journal of Financial Economics 33: 3–56. [Google Scholar] [CrossRef]
- Fama, Eugene F., and Kenneth R. French. 2021. Fama and French Portfolios and Factors Data. Available online: https://mba.tuck.dartmouth.edu/pages/faculty/ken.french/data_library.html (accessed on 22 March 2021).
- Friede, Gunnar, Timo Busch, and Alexander Bassen. 2015. ESG and financial performance: Aggregated evidence from more than 2000 empirical studies. Journal of Sustainable Finance & Investment 5: 210–33. [Google Scholar]
- Friedman, Jerome H. 2001. Greedy function approximation: A gradient boosting machine. Annals of Statistics 29: 1189–232. [Google Scholar] [CrossRef]
- Giese, Guido, and Linda-Eling Lee. 2019. Weighing the Evidence: ESG and Equity Returns. MSCI Research Insight. [Google Scholar]
- Grim, Douglas M., and Daniel B. Berkowitz. 2020. ESG, SRI, and impact investing: A primer for decision-making. The Journal of Impact and ESG Investing 1: 47–65. [Google Scholar] [CrossRef]
- Guo, Tian, Nicolas Jamet, Valentin Betrix, Louis-Alexandre Piquet, and Emmanuel Hauptmann. 2020. ESG2risk: A deep learning framework from ESG news to stock volatility prediction. arXiv arXiv:2005.02527. [Google Scholar] [CrossRef]
- Hilario-Caballero, Adolfo, Ana Garcia-Bernabeu, Jose V. Salcedo, and Marisa Vercher. 2020. Tri-criterion model for constructing low-carbon mutual fund portfolios: A preference-based multi-objective genetic algorithm approach. International Journal of Environmental Research and Public Health 17: 6324. [Google Scholar] [CrossRef] [PubMed]
- Ke, Guolin, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. 2017. LightGBM: A highly efficient gradient boosting decision tree. Advances in Neural Information Processing Systems 30: 3146–54. [Google Scholar]
- Konqui, Marlene H., François Millet, and Serge Darolles. 2019. Why using ESG helps you build better porfolios. Lyxor ETF Research Insights. [Google Scholar]
- Lee, Ook, Hanseon Joo, Hayoung Choi, and Minjong Cheon. 2022. Proposing an integrated approach to analyzing ESG data via machine learning and deep learning algorithms. Sustainability 14: 8745. [Google Scholar] [CrossRef]
- Lundberg, Scott M., Gabriel G. Erion, and Su-In Lee. 2018. Consistent individualized feature attribution for tree ensembles. arXiv arXiv:1802.03888. [Google Scholar]
- Lundberg, Scott M., and Su-In Lee. 2017. A unified approach to interpreting model predictions. Paper presented at 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, December 4–9; pp. 4768–77. [Google Scholar]
- Margot, Vincent, Christophe Geissler, Carmine de Franco, and Bruno Monnier. 2021. ESG investments: Filtering versus Machine Learning Approaches. Applied Economics and Finance 8: 1–16. [Google Scholar] [CrossRef]
- Molnar, Christoph. 2020. Interpretable Machine Learning. Available online: https://christophm.github.io/interpretable-ml-book/index.html (accessed on 4 May 2021).
- Mortier, Vincent, and Thierry Roncalli. 2019. The Alpha and Beta of ESG Investing. Paris: Amundi Asset Management. [Google Scholar]
- Plagge, Jan-Carl, and Douglas M. Grim. 2020. Have investors paid a performance price? Examining the behavior of ESG equity funds. The Journal of Portfolio Management 46: 123–40. [Google Scholar] [CrossRef]
- Prokhorenkova, Liudmila, Gleb Gusev, Aleksandr Vorobev, Anna Veronika Dorogush, and Andrey Gulin. 2018. CatBoost: Unbiased boosting with categorical features. Advances in Neural Information Processing Systems 31: 6638–48. [Google Scholar]
- Refinitiv. 2021. Environmental, Social and Governance (ESG) scores. Available online: https://www.refinitiv.com/content/dam/marketing/en_us/documents/methodology/esg-scores-methodology.pdf (accessed on 22 March 2021).
- Renshaw, Anthony A. 2018. ESG’s Evolving Performance: First, Do No Harm. Frankfurt: Axioma. [Google Scholar]
- Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. 2016. “Why should i trust you?” Explaining the predictions of any classifier. Paper presented at 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13–17; pp. 1135–44. [Google Scholar]
- Schmitt, Marc. 2022. Deep learning vs. Gradient boosting: Benchmarking state-of-the-art machine learning algorithms for credit scoring. arXiv arXiv:2205.10535. [Google Scholar]
- Schofield, David, Adam Craig, and Richard Yasenchak. 2019. What to Look for on the Road to ESG. Intech-Janus Henderson. [Google Scholar]
- Shapley, Llyod S. 1953. A value for n-person games. Contributions to the Theory of Games 2: 307–17. [Google Scholar]
- Shwartz-Ziv, Ravid, and Amitai Armon. 2022. Tabular data: Deep learning is not all you need. Information Fusion 81: 84–90. [Google Scholar] [CrossRef]
- Tibshirani, Robert. 1996. Regression shrinkage and selection via the LASSO. Journal of the Royal Statistical Society: Series B (Methodological) 58: 267–88. [Google Scholar] [CrossRef]
- Townsend, Blaine. 2020. From SRI to ESG: The origins of socially responsible and sustainable investing. The Journal of Impact and ESG Investing 1: 10–25. [Google Scholar] [CrossRef]
Figure 1.
Number of samples in each Fama–French region in the Refinitiv ESG dataset.
Figure 1.
Number of samples in each Fama–French region in the Refinitiv ESG dataset.
Figure 2.
Time evolution of the number of samples in the Refinitiv ESG dataset.
Figure 2.
Time evolution of the number of samples in the Refinitiv ESG dataset.
Figure 3.
Time evolution of the number of samples per year in the Refinitiv ESG dataset—Europe.
Figure 3.
Time evolution of the number of samples per year in the Refinitiv ESG dataset—Europe.
Figure 4.
Number of samples for TRBC L1 Sector in the Refinitiv ESG dataset—Europe.
Figure 4.
Number of samples for TRBC L1 Sector in the Refinitiv ESG dataset—Europe.
Figure 5.
Company-wise cross-validation: the validation sets consist of randomly selected companies, which allows training to account for most of the most recent data.
Figure 5.
Company-wise cross-validation: the validation sets consist of randomly selected companies, which allows training to account for most of the most recent data.
Figure 6.
Company-wise cross-validation: test set cross-entropy versus validation cross-entropy of the 100 best models of the random hyperparameters search.
Figure 6.
Company-wise cross-validation: test set cross-entropy versus validation cross-entropy of the 100 best models of the random hyperparameters search.
Figure 7.
Performance measures on the test sets of the two train and validation schemes. The boxplots show the performance of 100 random samplings of 5 models among 100 random company-wise validation splits. (a) Cross-entropy in percentage; (b) Balanced accuracy in percentage.
Figure 7.
Performance measures on the test sets of the two train and validation schemes. The boxplots show the performance of 100 random samplings of 5 models among 100 random company-wise validation splits. (a) Cross-entropy in percentage; (b) Balanced accuracy in percentage.
Figure 8.
Performance measures in comparison to the benchmark for the company-wise 5-fold cross-validation. Bal_Acc refers to the balanced accuracy metric.
Figure 8.
Performance measures in comparison to the benchmark for the company-wise 5-fold cross-validation. Bal_Acc refers to the balanced accuracy metric.
Figure 9.
SHAP values distribution.
Figure 9.
SHAP values distribution.
Figure 10.
Distribution of data for lowest outliers of SHAP values of 2020 for Controversy score.
Figure 10.
Distribution of data for lowest outliers of SHAP values of 2020 for Controversy score.
Figure 11.
Marginal effect of each ESG feature on the predicted probability of having a positive return.
Figure 11.
Marginal effect of each ESG feature on the predicted probability of having a positive return.
Figure 12.
Marginal effect of the sector (TRBC Sector L1) feature on the predicted probability of having a positive return.
Figure 12.
Marginal effect of the sector (TRBC Sector L1) feature on the predicted probability of having a positive return.
Figure 13.
Materiality matrix: marginal effects of the combination ESG feature/Sector feature on the predicted probability of having a positive return. Blank cells are those that were not found to be statistically significant by the Benjamini–Hochberg procedure.
Figure 13.
Materiality matrix: marginal effects of the combination ESG feature/Sector feature on the predicted probability of having a positive return. Blank cells are those that were not found to be statistically significant by the Benjamini–Hochberg procedure.
Figure 14.
Materiality matrices: marginal effects of the combination ESG feature/Sector feature on the predicted probability of having a positive return, bucketed by market capitalization. Blank cells are those that were not found statistically significant by the Benjamini–Hochberg procedure. (a) Small market capitalization (<2 B€); (b) Mid market capitalization (>2 B€, <10 B€); (c) Large market capitalization (>10 B€).
Figure 14.
Materiality matrices: marginal effects of the combination ESG feature/Sector feature on the predicted probability of having a positive return, bucketed by market capitalization. Blank cells are those that were not found statistically significant by the Benjamini–Hochberg procedure. (a) Small market capitalization (<2 B€); (b) Mid market capitalization (>2 B€, <10 B€); (c) Large market capitalization (>10 B€).
Table 1.
Dependence measures between the cross-entropies (prediction error) in the validation and test sets for the 100 best models of the random hyperparameters search.
Table 1.
Dependence measures between the cross-entropies (prediction error) in the validation and test sets for the 100 best models of the random hyperparameters search.
| | Company-Wise 5-Fold Cross-Validation |
| Year | Pearson Correlation | | Kendall Tau | p-Value of Kendall Tau |
| 2016 | −0.54 | 0.29 | −0.36 | |
| 2017 | 0.14 | 0.021 | 0.12 | |
| 2018 | 0.47 | 0.22 | 0.30 | |
| 2019 | 0.73 | 0.54 | 0.58 | |
| 2020 | 0.27 | 0.071 | 0.19 | |
| | Standard Temporal Split |
| Year | Pearson Correlation | | Kendall Tau | p-Value of Kendall Tau |
| 2016 | −0.43 | 0.18 | −0.29 | |
| 2017 | 0.46 | 0.21 | 0.33 | |
| 2018 | 0.46 | 0.21 | 0.34 | |
| 2019 | 0.47 | 0.22 | 0.33 | |
| 2020 | 0.47 | 0.22 | 0.39 | |
Table 2.
Performance measures in percentage on the test set for both types of validation splits. The numbers for the company-wise splits are the median values of the performance of 100 random samplings of 5 models among 100 random company-wise validation splits.
Table 2.
Performance measures in percentage on the test set for both types of validation splits. The numbers for the company-wise splits are the median values of the performance of 100 random samplings of 5 models among 100 random company-wise validation splits.
| | Company-Wise 5-Fold Cross-Validation |
| | Only Benchmark Features | Benchmark and ESG Features |
| Year | Balanced Accuracy | Cross-Entropy Loss | Balanced Accuracy | Cross-Entropy Loss |
| 2016 | 52.6 | 70.6 | 51.2 | 72.8 |
| 2017 | 57.4 | 69.2 | 56.9 | 69.6 |
| 2018 | 57.5 | 68.1 | 57.9 | 68.2 |
| 2019 | 65.6 | 63.1 | 67.9 | 62.7 |
| 2020 | 59.6 | 69.3 | 61.9 | 67.4 |
| | Standard Temporal Split |
| | Only Benchmark Features | Benchmark and ESG Features |
| Year | Balanced Accuracy | Cross-Entropy Loss | Balanced Accuracy | Cross-Entropy Loss |
| 2016 | 53.2 | 68.8 | 51.8 | 70.3 |
| 2017 | 56.1 | 68.2 | 57.7 | 68.0 |
| 2018 | 56.2 | 67.5 | 58.1 | 67.4 |
| 2019 | 64.3 | 64.5 | 66.4 | 63.8 |
| 2020 | 58.5 | 70.5 | 61.0 | 69.6 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}