
COVID-19 Mortality and Economic Losses: The Role of Policies and Structural Conditions

 , , ,
, , ,  , ,
, ,
Abstract
:1. Introduction
2. Related Literature
3. Materials and Methods
- We set up the problem in terms of the fundamental trade-off we intend to study: human versus economic losses. The construction of these two key variables is detailed in Section 3.1;
- We identify relevant variables for the study and collect them into a data set from a variety of sources (Section 3.2);
- Given the performances of countries in terms of economic and human losses built in Section 3.3, we conduct a clustering analysis that aims to partition countries into groups more or less successful along the two dimensions;
- From the six-country clusters arising from clustering, we use econometrics to estimate what are the most relevant factors that affect the probability of a country being included in each group (Section 3.4).
3.1. Economic and Human Losses
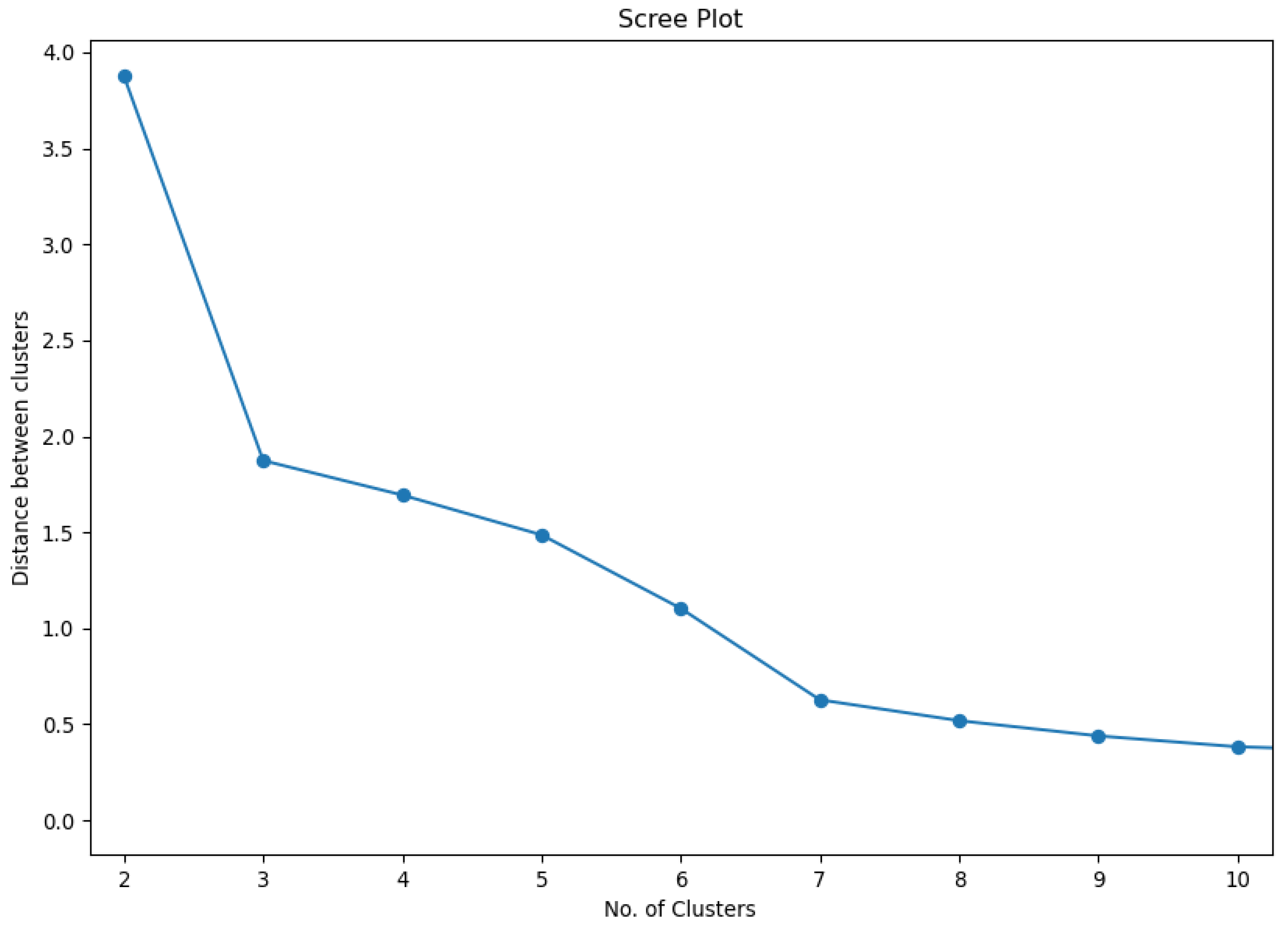
3.1.1. Economic Losses
3.1.2. COVID-19 Excess Mortality
3.2. Structural Conditions and Policy Variables
3.3. Hierarchical Clustering
3.4. Econometric Models
3.4.1. Linear Probability Model
3.4.2. LASSO
3.4.3. Logit Model
4. Results
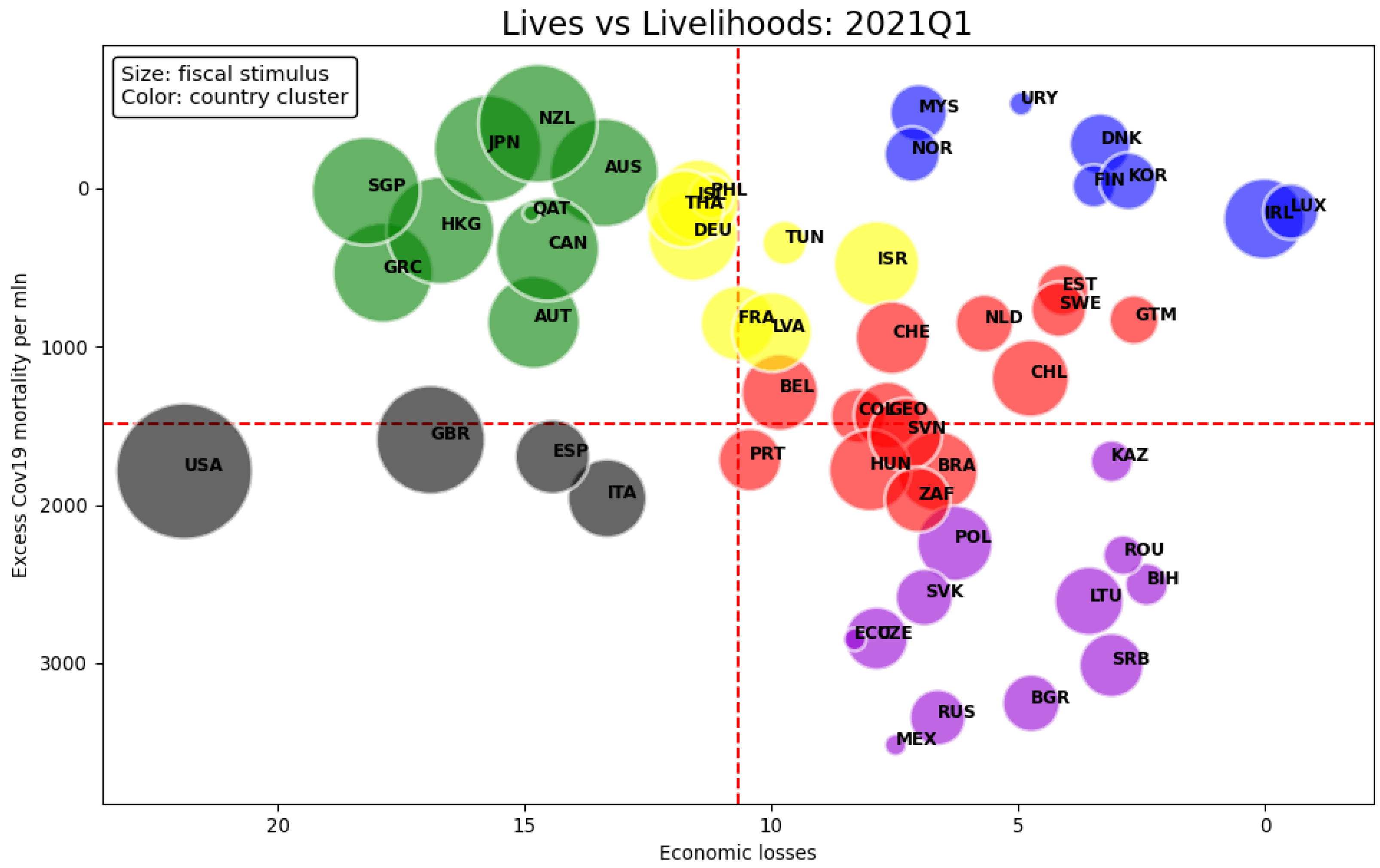
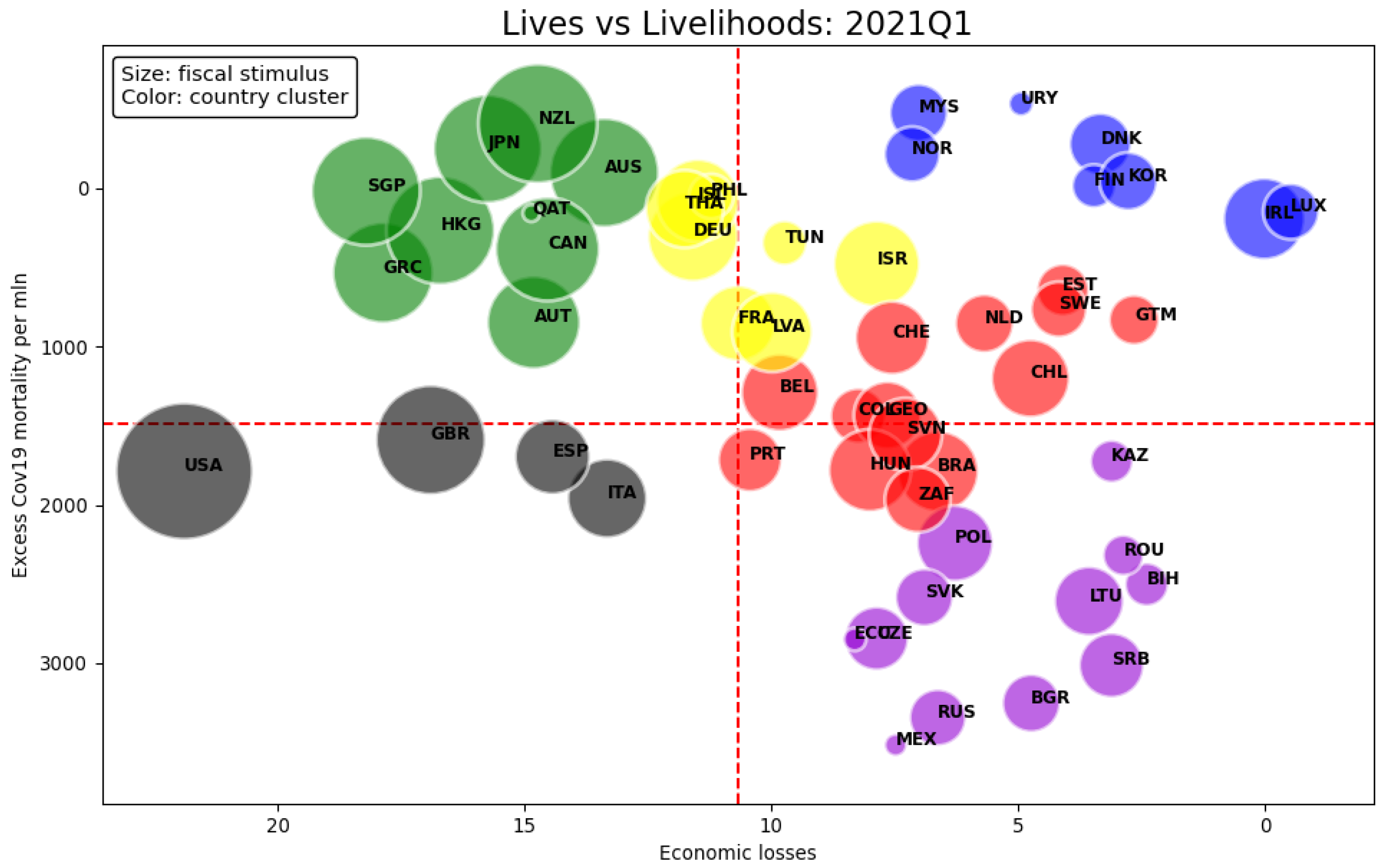
4.1. Cluster Analysis
- Countries in the blue cluster display low economic losses and excess mortality at the same time. This group represents the most successful countries since they managed to reduce human and economic losses. Remarkably, a subgroup is made of Scandinavian countries (Denmark, Finland, and Norway) except Sweden, which places itself not too far from the blue one in the red cluster. This is a first indication that some structural characteristics common to the Scandinavian region helped to mitigate the impact of the outbreak, whereas divergences in mitigation policies resulted in a detachment of Sweden from the rest of Scandinavia.14
- The green cluster is characterized by mid to high economic losses but low excess mortality. Economic losses are determined foremost by additional fiscal spending as appears by the size of bubbles. Looking at the vertical axis, one can assert that mortality was mitigated by large fiscal expenditure which could be interpreted as evidence of governments’ effort to save lives as well as to provide economic relief (e.g., financing health policies such as testing and tracing, or compensating for lockdowns). It is worth noticing that most countries in the green cluster followed an elimination strategy. 15 For them, the trade-off between saving lives and the economy is clearly visible, although the same cannot be generalized to the rest of the countries. Furthermore, many Asian countries in our sample are included in the second quadrant, despite not all being in the green cluster. This may reflect cultural or other group-specific factors, such as preparedness or previous exposure to epidemics, supporting the argument that structural conditions matter.
- The gray group only includes Western countries with mid mortality and mid to high economic losses. These are especially driven by fiscal expenditure for the US and the UK. We interpret the cluster performance as the outcome of bad policies, even if Italy’s performance might have been worsened by being the first Western country to be impacted by COVID-19. The management of the pandemic by the US and UK governments was aimed to save the economy and partly neglected the severity and reach of COVID-19. As a consequence, the public expenditure by those countries was mostly addressed to support the economy, though a substantial regional heterogeneity cannot be ignored especially for the US. As such, the gray cluster shows economic losses fairly comparable with the green group, but worse mortality: policy interventions were not as effective.16
- The least successful cluster in mitigating mortality is the purple one.17 Countries belonging to Central and Eastern Europe, in particular to the former USSR and South America, are in the group or close to it. Excess mortality is the highest across all groups, but economic losses are low with limited fiscal expenditure. The measures adopted by the purple countries to contrast contagion appear insufficient or lacked the structural conditions to be put in place.18 This gives the idea that the spreading of the virus was out of control.
- The yellow and red clusters show a moderate variability in excess mortality and economic losses. The yellow group has on average lower mortality but greater economic losses than the red one. The two clusters do not display distinctive characteristics in the context of Figure 2 but take intermediate values. Thus, some countries display features similar to those of their neighboring clusters (DEU, PHL, ISL, THA, HUN, BRA, ZAF).
4.2. LPM
4.3. LASSO and Logit Regression
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| H1N1 death | Cumulative number of H1N1 deaths |
| SARS cases | Cumulative number of SARS cases includes number of deaths |
| Share of population above 70 | Share of the population that is 70 years and older in 2015 |
| Cardiovascular death | The annual number of deaths from cardiovascular diseases per 100,000 people in 2017 |
| Diabetes prevalence | Percentage of people ages 20–79 who have type 1 or type 2 diabetes in 2017 |
| Smoking prevalence | Prevalence of current tobacco use as a percentage of adults in 2018 |
| Hospital beds | Hospital beds per thousand people, most recent year available before 2021 |
| Doctors | Physicians per 1000 people, most recent year available before 2021 |
| Neighboring countries | Number of countries bordering |
| Population density | Log number of people divided by land area measured in square kilometers, most recent year available since 2018 |
| Gini | Gini coefficient in 2019 |
| Schooling | Average number of years of total schooling across all education levels for the population aged 25 and above, most recent year available before 2020 |
| Corruption | Corruption perception index in 2019 |
| Trade reliance on services | Imports and exports of services as a percentage of GDP, most recent year available prior to 2020 |
| Trade reliance on goods | Imports and exports of goods as a percentage of GDP, most recent year available prior to 2020 |
| Digitalization | Estimated share of job that can be done at home before 2020 |
| Government debt | General Government Gross Debt as a percentage of GDP in 2019 |
| Tax Revenue | Tax revenue as a percentage of GDP in 2019 |
| Variable | Description |
|---|---|
| School closures | Daily average level from January 2020 to March 2021, normalized to 100. 0—No measures, 1—Recommend closing or all schools open, 2—Require partial closing, 3—Require closing all levels. |
| Workplace closing | Daily average level from January 2020 to March 2021, normalized to 100. 0—No measures, 1—Recommend closing, 2—Require closing for some sectors or categories of workers, 3—Require closing for all-but-essential workplaces. |
| Cancel public events | Daily average level from January 2020 to March 2021, normalized to 100. 0—No measures, 1—Recommend cancelling, 2—Require cancelling. |
| Restrictions on gatherings | Daily average level from January 2020 to March 2021, normalized to 100. 0—No restrictions, 1—Restrictions on very large gatherings above 1000 people, 2—Restrictions on gatherings between 101–1000 people, 3—Restrictions on gatherings between 11–100 people, 4—Restrictions on gatherings of 10 people or less. |
| Close public transport | Daily average level from January 2020 to March 2021, normalized to 100. 0—No measures, 1—Recommend closing, 2—Require closing. |
| Stay at home order | Daily average level from January 2020 to March 2021, normalized to 100. 1—Recommend not leaving house, 2—Require not leaving house with exceptions for daily exercise, grocery shopping, and essential trips, 3—Require not leaving house with minimal exceptions. |
| Internal movement restrictions | Daily average level from January 2020 to March 2021, normalized to 100. 0—No measures, 1—Recommend not to travel between regions or cities, 2—Internal movement restrictions in place. |
| International travel restrictions | Daily average level from January 2020 to March 2021, normalized to 100. 0—No restrictions, 1—Screening arrivals, 2—Quarantine arrivals from some or all regions, 3—Ban arrivals from some regions, 4—Ban on all regions or total border closure. |
| Public information campaigns | Daily average level from January 2020 to March 2021, normalized to 100. 0—No COVID-19 public information campaign, 1—Public officials urging caution about COVID-19, 2—Coordinate public information campaign across traditional and social media. |
| Testing policy | Daily average level from January 2020 to March 2021, normalized to 100. 0—No testing policy, 1—Only those who both have symptoms and meet specific criteria such as being key workers, 2—Testing of anyone showing COVID-19 symptoms, 3—Open public testing such as drive through testing available to asymptomatic people. |
| Manual contact tracing | Daily average level from January 2020 to March 2021, normalized to 100. 0—No contact tracing, 1—Limit contact tracing which is not done for all cases, 2—Comprehensive contact tracing done for all identified cases. |
| Facial coverings | Daily average level from January 2020 to March 2021, normalized to 100. 0—No policy, 1—Recommend, 2—Require in some specified public spaces, 3—Require in all public spaces with other people present, 4—Require in all public spaces at all time. |
| Protection of elderly people | Daily average level from January 2020 to March 2021, normalized to 100. 0—No measures, 1—Recommend isolation, hygiene, and visitor restriction measures in long term care facilities or recommend elderly people to stay at home, 2—Narrow restrictions for isolation, hygiene in long term care facilities and some limitations on external visitors, recommend restrictions protecting elderly people at home, 3—Extensive restrictions for isolation and hygiene in long term care facilities, all non-essential external visitors prohibited. All elderly people required to stay at home, not leave the home with minimal exceptions and receive no external visitors. |
| Fiscal stimulus in health | Additional fiscal spending above the lines in health as a percentage of GDP, from January 2020 to March 2021. |
| Fiscal stimulus in non-health | Additional fiscal spending above the lines in non-health sectors as a percentage of GDP, from January 2020 to March 2021. |
| Variable | Full Model | Reduced Model |
|---|---|---|
| Corruption | 35.64 | |
| School closures | 22.22 | |
| Digitalization | 16.86 | |
| Share of population above 70 | 17.56 | 8.73 |
| Facial coverings | 13.98 | 5.37 |
| Government debt (% of GDP) | 11.74 | 7.24 |
| Stay at home order | 11.65 | 9.57 |
| Cardiovascular disease | 10.59 | 4.51 |
| Schooling | 9.54 | 8.24 |
| Fiscal stimulus in non-health | 9.50 | 7.31 |
| Hospital beds | 9.43 | 4.74 |
| H1N1 death | 9.00 | 5.43 |
| Workplace closing | 8.87 | 3.41 |
| Internal movement restrictions | 8.62 | 6.51 |
| Trade reliance on goods | 7.65 | 6.23 |
| Protection of elderly people | 7.49 | 4.56 |
| Population density | 7.30 | 3.77 |
| Close public transport | 7.15 | 4.42 |
| Restrictions on gatherings | 7.09 | 6.47 |
| Gini | 6.01 | 4.77 |
| International travel restrictions | 5.81 | 5.01 |
| Testing policy | 5.62 | 4.21 |
| Doctors | 5.47 | 4.27 |
| Cancel public events | 5.35 | 4.50 |
| Public information campaigns | 4.64 | 4.43 |
| Smoking | 4.61 | 4.23 |
| Diabetes prevalence | 4.59 | 3.52 |
| Trade reliance on services | 4.54 | 2.89 |
| Neighboring countries | 4.24 | 2.32 |
| SARS cases | 4.19 | 2.87 |
| Tax Revenue (% of GDP) | 4.18 | 4.08 |
| Fiscal stimulus in health | 3.42 | 2.83 |
| Manual contact tracing | 3.40 | 3.07 |
| Mean VIF | 9.03 | 4.98 |
| 1 | As explained in Section 3.1, we construct a variable for economic losses that captures both the contraction in economic activity as well as the cost of additional fiscal stimulus. |
| 2 | See OECD: https://stats.oecd.org/ (accessed on 1 August 2022). |
| 3 | This simple approach does not account, among the rest, for country-specific fiscal multipliers or the cross-country differences in debt/GDP ratios. We defer a more detailed analysis to future research. |
| 4 | Despite the fifth quarter in should be 2020-Q1, the comparison would be wrong because COVID-19 already impacted the economy at that time. Therefore, we substitute 2020-Q1 with 2019-Q1 for consistency. |
| 5 | As for wars and natural disasters, the most significant events are the August 2020 heatwave in Europe and the Nagorno-Karabakh war. |
| 6 | Pandemic might have also increased homicide, suicide, and drug overdose in certain countries (Karlinsky and Kobak 2021). |
| 7 | For instance, the UK records deaths that occurred within 28 days of testing positive as COVID-19 deaths. Arguably, people who died 28 days after testing positive should still be treated as direct deaths caused by COVID-19. |
| 8 | We notice that the difference in COVID-19 and excess deaths correlates with the corruption perception index (): a more corrupted government might undercount COVID-19 deaths. |
| 9 | The ISO country codes of the full sample are: AUS, AUT, BEL, BIH, BRA, BGR, CAN, CHL, COL, CZE, DNK, ECU, EST, FIN, FRA, GEO, DEU, GRC, GTM, HKG, HUN, ISL, IRL, ISR, ITA, JPN, KAZ, LVA, LTU, LUX, MYS, MEX, NLD, NZL, NOR, PHL, POL, PRT, QAT, ROU, RUS, SRB, SGP, SVK, SVN, ZAF, KOR, ESP, SWE, CHE, THA, TUN, GBR, USA, URY. |
| 10 | The ISO country codes of the removed countries are: BIH, GEO, GTM, HKG, KAZ, QAT, SRB, THA, URY. |
| 11 | Distance here refers to the distance between clusters. Since we employ the Ward linkage function, distances are the sum of squared deviation from cluster averages. |
| 12 | The deviance ratio is commonly used as a prediction error measure, similarly to the R-squared in the linear models. |
| 13 | We choose six to split the high heterogeneous region made of green and red countries into two subgroups. Reducing the number to five would cause the green group to absorb some yellow countries, while the others flow into a larger central cluster with red countries. |
| 14 | In fact, until the fall of 2020, Swedish authorities had not signed any closing orders to restaurants, bars, shops, or gyms; schools for pupils aged under 16 remained open, mask-wearing was not mandated, and public gatherings of fewer than 50 people were permitted. Only in the second wave, after a significant rise in contagious and deaths, Stockholm introduced a series of new measures, including limiting public gatherings, closing gyms, libraries, and swimming pools, and recommending the use of face masks on crowded public transportation. |
| 15 | To the best of our knowledge, countries that applied an elimination or zero-COVID strategy are: Atlantic and Northern Canada, Australia, Bhutan, mainland China, Hong Kong, Iceland, Japan, Macau, New Zealand, North Korea, Scotland, Singapore, South Korea, Taiwan, Tonga, and Vietnam. |
| 16 | It is important to stress that structural characteristics related to the better preparedness of Asia and Oceania compared to the Anglo-Saxon and European Mediterranean world, as well as government-mitigation strategies, might have jointly contributed to different mortality outcomes. Whereas countries like Australia, New Zealand, and Japan adopted a “zero-COVID” strategy, the US, Great Britain, Italy, and Spain followed a mitigation strategy via closing orders and lock-downs. |
| 17 | Although Peru’s performance would be placed in the purple group, its higher excess mortality makes it an outlier. Therefore, we remove it from the clustering analysis, as the inclusion would result in the creation of a standalone cluster. |
| 18 | In particular, several countries in the purple group have as a common feature the significant size of their informal labour market, which probably hampered the effectiveness of shutdowns. |
| 19 | Trade reliance on services and digitalization are highly correlated; both variables indicate that many jobs can be conducted at home. |
| 20 | For instance, Ireland ranked second in stringency in workplace-closing policy announcements. |
| 21 | Because merely four countries are selected in the group, the group average is sometimes driven by outliers. Therefore, the interpretation will explicitly state the outliers. |
| 22 | Despite the US having a low population density as a nation, such a structural condition might not hold at the state level. For instance, the district of Columbia is an extreme outlier in terms of population density compared to other states. |
| 23 | Health spending includes spending on vaccination development and testing. Therefore, the number of excess deaths in March cannot reflect the full effect of such spending on vaccination. However, total health spending is mostly direct spending on the labor and capital supply in the health sector. Therefore, the interpretation will focus on such direct spending in health. |
| 24 | Health spending is influenced by the healthcare systems of each country in normal times. However, it is not clear whether this is still the case during the pandemic. The US has a non-universal insurance system. The UK, Spain, and Italy all have a universal government-funded health system. Despite having different healthcare systems, the UK and US both spent very heavily on health. |
| 25 | Fiscal stimulus variables are not included for the blue outcome, as they will cause MLE to not converge. |
| 26 | Compared to the literature, these two policy recommendations are based on new findings in our research. |
References
- Acemoglu, Daron, Victor Chernozhukov, Iván Werning, and Michael D. Whinston. 2021. Optimal targeted lockdowns in a multigroup sir model. American Economic Review: Insights 3: 487–502. [Google Scholar] [CrossRef]
- Alvarez, Fernando, David Argente, and Francesco Lippi. 2021. A simple planning problem for COVID-19 lock-down, testing, and tracing. American Economic Review: Insights 3: 367–82. [Google Scholar] [CrossRef]
- Alvelda, Phillip, Thomas Ferguson, and John C. Mallery. 2020. To save the economy, save people first. INET Blog, November 18. [Google Scholar]
- Arias, Jonas E., Jesús Fernández-Villaverde, Juan Rubio Ramírez, and Minchul Shin. 2021. The Causal EffEcts of Lockdown Policies on Health and Macroeconomic Outcomes; Working Paper 28617; Cambridge: National Bureau of Economic Research. [CrossRef]
- Baker, Michael G., Nick Wilson, and Tony Blakely. 2020. Elimination could be the optimal response strategy for COVID-19 and other emerging pandemic diseases. BMJ 371: m4907. [Google Scholar] [CrossRef] [PubMed]
- Barbieri Góes, Maria Cristina, and Ettore Gallo. 2021. Infection Is the Cycle: Unemployment, Output and Economic Policies in the COVID-19 Pandemic. Review of Political Economy 33: 377–93. [Google Scholar] [CrossRef]
- Basher, Syed Abul, and A. K. Enamul Haque. 2021. Public policy lessons from the COVID-19 outbreak: How to deal with it in the postpandemic world? Journal of Social and Economic Development 23: 234–47. [Google Scholar] [CrossRef]
- Blair, Alicia, Mattia de Pasquale, Valentin Gabeff, Mélanie Rufi, and Antoine Flahault. 2022. The end of the elimination strategy: Decisive factors towards sustainable management of COVID-19 in New Zealand. Epidemiologia 3: 135–47. [Google Scholar] [CrossRef]
- Boitan, Iustina A., Emilia M. Câmpeanu, and Sanja S. Mališ. 2021. Economic sentiment perceptions during COVID-19 pandemic—A european cross-country impact assessment. Amfiteatru Economic 23: 982–1002. [Google Scholar]
- Bourdin, Sébastien, John Moodie, András Igar, and Mounir Amdaoud. 2022. Territorial Impacts of COVID-19 and Policy Answers in European Regions and Cities. Report. Luxembourg: European Observation Network for Territorial Development and Cohesion. [Google Scholar]
- Bourdin, Sebastien, Slimane Ben Miled, and Jamil Salhi. 2022. The drivers of policies to limit the spread of COVID-19 in europe. Journal of Risk and Financial Management 15: 67. [Google Scholar] [CrossRef]
- Brodeur, Abel, David Gray, Anik Islam, and Suraiya Bhuiyan. 2021. A literature review of the economics of COVID-19. Journal of Economic Surveys 35: 1007–44. [Google Scholar] [CrossRef]
- Chetverikov, Denis, Zhipeng Liao, and Victor Chernozhukov. 2021. On cross-validated lasso in high dimensions. The Annals of Statistics 49: 1300–17. [Google Scholar] [CrossRef]
- Clift, Ashley K., Adam Von Ende, Pui San Tan, Hannah M. Sallis, Nicola Lindson, Carol A. C. Coupland, Marcus R. Munafò, Paul Aveyard, Julia Hippisley-Cox, and Jemma C. Hopewell. 2022. Smoking and COVID-19 outcomes: An observational and mendelian randomisation study using the uk biobank cohort. Thorax 77: 65–73. [Google Scholar] [CrossRef]
- Daumann, Frank, Florian Follert, Werner Gleißner, Endre Kamarás, and Chantal Naumann. 2021. Political decision-making in the COVID-19 pandemic: The case of germany from the perspective of risk management. International Journal of Environmental Research and Public Health 19: 397. [Google Scholar] [CrossRef] [PubMed]
- Delli Gatti, Domenico, and Severin Reissl. 2022. Agent-based covid economics (abc): Assessing non-pharmaceutical interventions and macro-stabilization policies. Industrial and Corporate Change 31: 410–47. [Google Scholar] [CrossRef]
- Dingel, Jonathan I., and Brent Neiman. 2020. How many jobs can be done at home? Journal of Public Economics 189: 104235. [Google Scholar] [CrossRef] [PubMed]
- ECDC. 2010. The 2009 a(h1n1) Pandemic in Europe. Report. Stockholm: European Centre for Disease Prevention and Control. [Google Scholar]
- Fang, Hanming, Long Wang, and Yang Yang. 2020. Human mobility restrictions and the spread of the novel coronavirus (2019-ncov) in china. Journal of Public Economics 191: 104272. [Google Scholar] [CrossRef]
- Freijeiro-González, Laura, Manuel Febrero-Bande, and Wenceslao González-Manteiga. 2022. A critical review of lasso and its derivatives for variable selection under dependence among covariates. International Statistical Review 90: 118–45. [Google Scholar] [CrossRef]
- Friedson, Andrew I., Drew McNichols, Joseph J. Sabia, and Dhaval Dave. 2020. Did California’s Shelter-in-Place Order Work? Early Coronavirus-Related Public Health Effects. Working Paper 26992. Cambridge: National Bureau of Economic Research, April. [Google Scholar] [CrossRef]
- Gan, Guojun, Chaoqun Ma, and Jianhong Wu. 2020. Data Clustering: Theory, Algorithms, and Applications. Philadelphia: Society for Industrial and Applied Mathematics. [Google Scholar]
- Geodatasource. 2022. Country Borders. Available online: https://www.geodatasource.com/addon/country-borders (accessed on 1 August 2022).
- Ghosh, Jayanta K. 2012. Statistics for high-dimensional data: Methods, theory and applications by peter bühlmann, sara van de geer. International Statistical Review 80: 486–7. [Google Scholar] [CrossRef]
- Hale, Thomas, Noam Angrist, Rafael Goldszmidt, Beatriz Kira, Anna Petherick, Toby Phillips, Samuel Webster, Emily Cameron-Blake, Laura Hallas, Saptarshi Majumdar, and et al. 2021. A global panel database of pandemic policies (oxford COVID-19 government response tracker). Nature Human Behaviour 5: 529–38. [Google Scholar] [CrossRef]
- Haug, Nils, Lukas Geyrhofer, Alessandro Londei, Elma Dervic, Amélie Desvars-Larrive, Vittorio Loreto, Beate Pinior, Stefan Thurner, and Peter Klimek. 2020. Ranking the effectiveness of worldwide COVID-19 government interventions. Nature Human Behaviour 4: 1303–12. [Google Scholar] [CrossRef]
- IMF. 2021. Fiscal Monitor Database of Country Fiscal Measures in Response to the COVID-19 Pandemic. Available online: https://www.imf.org/en/Topics/imf-and-covid19/Fiscal-Policies-Database-in-Response-to-COVID-19 (accessed on 1 August 2022).
- Islam, S. Nazrul, Hoi Wai Jackie Cheng, Kristinn Sv. Helgason, Nicole Hunt, Hiroshi Kawamura, and Marcelo LaFleur. 2020. Variations in COVID Strategies: Determinants and Lessons. Working Paper 172. New York: United Nations, Department of Economic and Social Affairs. [Google Scholar]
- Karlinsky, Ariel, and Dmitry Kobak. 2021. Tracking excess mortality across countries during the COVID-19 pandemic with the world mortality dataset. eLife 10: e69336. [Google Scholar] [CrossRef]
- Kochańczyk, Marek, and Tomasz Lipniacki. 2021. Pareto-based evaluation of national responses to COVID-19 pandemic shows that saving lives and protecting economy are non-trade-off objectives. Scientific Reports 11: 2425. [Google Scholar] [CrossRef]
- König, Michael, and Adalbert Winkler. 2021. The impact of government responses to the COVID-19 pandemic on gdp growth: Does strategy matter? PLoS ONE 16: e0259362. [Google Scholar] [CrossRef]
- Le Cessie, Saskia, and Johannes C. Van Houwelingen. 1992. Ridge estimators in logistic regression. Journal of the Royal Statistical Society: Series C (Applied Statistics) 41: 191–201. [Google Scholar] [CrossRef]
- Long, Han, Chun-Ping Chang, Sujeetha Jegajeevan, and Kai Tang. 2022. Can central bank mitigate the effects of the COVID-19 pandemic on the macroeconomy? Emerging Markets Finance and Trade 58: 2652–69. [Google Scholar] [CrossRef]
- Ludvigson, Sydney C., Sai Ma, and Serena Ng. 2020. COVID-19 and the Macroeconomic Effects of Costly Disasters. Working Paper 26987. Cambridge: National Bureau of Economic Research. [Google Scholar] [CrossRef]
- Maloney, William F., and Temel Taskin. 2020. Determinants of Social Distancing and Economic Activity during COVID-19: A Global View. Working Paper 9242. Washington: The World Bank. [Google Scholar]
- Miguel, Edward, and Ahmed Mushfiq Mobarak. 2021. The Economics of the COVID-19 Pandemic in Poor Countries. Working Paper 29339. Cambridg: National Bureau of Economic Research. [Google Scholar] [CrossRef]
- Murtagh, Fionn, and Pedro Contreras. 2017. Algorithms for hierarchical clustering: An overview, II. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 7: e1219. [Google Scholar] [CrossRef] [Green Version]
- OECD. 2022. Income Inequality. Available online: https://data.oecd.org/inequality/income-inequality.htm (accessed on 1 August 2022).
- Oliu-Barton, Miquel, Bary S. R. Pradelski, Philippe Aghion, Patrick Artus, Ilona Kickbusch, Jeffrey V. Lazarus, Devi Sridhar, and Samantha Vanderslott. 2021. Sars-cov-2 elimination, not mitigation, creates best outcomes for health, the economy, and civil liberties. The Lancet 397: 2234–6. [Google Scholar] [CrossRef]
- Our World in Data. 2022a. Death Rate from Cardiovascular Disease. 2017. Available online: https://ourworldindata.org/grapher/cardiovascular-disease-death-rates?time=2017 (accessed on 1 August 2022).
- Our World in Data. 2022b. Diabetes Prevalence, 2017. Available online: https://ourworldindata.org/grapher/diabetes-prevalence?time=2017 (accessed on 1 August 2022).
- Our World in Data. 2022c. Share of the Population that is 70 Years and Older. Available online: https://ourworldindata.org/grapher/share-of-the-population-that-is-70-years-and-older (accessed on 1 August 2022).
- Phillips, Nicky. 2021. The coronavirus is here to stay-here’s what that means. Nature 590: 382–4. [Google Scholar] [CrossRef]
- Rampini, Adriano A. 2020. Sequential Lifting of COVID-19 Interventions with Population Heterogeneity. Working Paper 27063. Cambridge: National Bureau of Economic Research. [Google Scholar] [CrossRef]
- Sanchez-Ramirez, Diana C., and Denise Mackey. 2020. Underlying respiratory diseases, specifically copd, and smoking are associated with severe COVID-19 outcomes: A systematic review and meta-analysis. Respiratory Medicine 171: 106096. [Google Scholar] [CrossRef]
- Sheridan, Adam, Asger Lau Andersen, Emil Toft Hansen, and Niels Johannesen. 2020. Social distancing laws cause only small losses of economic activity during the COVID-19 pandemic in scandinavia. Proceedings of the National Academy of Sciences 117: 20468–73. [Google Scholar] [CrossRef]
- The World Bank. 2022a. Hospital Beds (per 1000 People). Available online: https://data.worldbank.org/indicator/SH.MED.BEDS.ZS (accessed on 1 August 2022).
- The World Bank. 2022b. Physicians (per 1000 People). Available online: https://data.worldbank.org/indicator/SH.MED.PHYS.ZS (accessed on 1 August 2022).
- The World Bank. 2022c. Population Density (People per sq. km of Land Area). Available online: https://data.worldbank.org/indicator/EN.POP.DNST (accessed on 1 August 2022).
- The World Bank. 2022d. Prevalence of Current Tobacco use (Percent of Adults). Available online: https://data.worldbank.org/indicator/SH.PRV.SMOK (accessed on 1 August 2022).
- The World Bank. 2022e. Trade in Services (Percent of GDP). Available online: https://data.worldbank.org/indicator/BG.GSR.NFSV.GD.ZS (accessed on 1 August 2022).
- The World Bank. 2022f. Trade (Percent of GDP). Available online: https://data.worldbank.org/indicator/NE.TRD.GNFS.ZS (accessed on 1 August 2022).
- Tibshirani, Robert. 1996. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological) 58: 267–88. [Google Scholar] [CrossRef]
- Transparency International. 2022. Corruption Perception Index 2019. Available online: https://www.transparency.org/en/cpi/2019 (accessed on 1 August 2022).
- WHO. 2015. Summary of Probable Sars Cases with Onset of Illness from 1 November 2002 to 31 July 2003. Available online: https://www.who.int/publications/m/item/summary-of-probable-sars-cases-with-onset-of-illness-from-1-november-2002-to-31-july-2003 (accessed on 1 August 2022).
- Wildman, John. 2021. COVID-19 and income inequality in oecd countries. The European Journal of Health Economics 22: 455–62. [Google Scholar] [CrossRef]
- Zhao, Peng, and Bin Yu. 2006. On model selection consistency of lasso. The Journal of Machine Learning Research 7: 2541–63. [Google Scholar]
- Zhao, Sen, Daniela Witten, and Ali Shojaie. 2021. In Defense of the Indefensible: A Very Naïve Approach to High-Dimensional Inference. Statistical Science 36: 562–77. [Google Scholar] [CrossRef]
- Zou, Hui, and Trevor Hastie. 2005. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 67: 301–20. [Google Scholar] [CrossRef] [Green Version]
| Mean | SD | Min | Max | |
|---|---|---|---|---|
| Outcome Variables | ||||
| Excess mortality | 1120.67 | 1095.57 | −409.30 | 3441.87 |
| Economic losses | −8.92 | 4.96 | −21.90 | 0.52 |
| Structural Conditions | ||||
| H1N1 death | 269.74 | 601.30 | 2.00 | 3433.00 |
| SARS cases | 12.70 | 50.21 | 0.00 | 251.00 |
| Tax Revenue | 20.00 | 5.99 | 9.78 | 34.28 |
| Population density | 4.35 | 1.44 | 1.16 | 8.98 |
| Share of population above 70 | 10.49 | 3.84 | 2.66 | 18.49 |
| Gini | 35.27 | 7.98 | 24.20 | 65.00 |
| Smoking prevalence | 24.98 | 7.52 | 7.90 | 44.70 |
| Doctors | 3.29 | 1.17 | 0.60 | 6.35 |
| Cardiovascular death | 180.60 | 97.79 | 79.37 | 431.30 |
| Diabetes prevalence | 6.78 | 2.54 | 3.28 | 16.74 |
| Hospital beds | 4.39 | 2.66 | 1.00 | 13.05 |
| Trade reliance on services | 32.77 | 46.87 | 5.54 | 295.80 |
| Trade reliance on goods | 72.23 | 39.03 | 19.45 | 209.90 |
| Corruption | 62.70 | 17.67 | 28.00 | 87.00 |
| Neighboring countries | 3.70 | 2.99 | 0.00 | 14.00 |
| Government debt | 65.09 | 43.11 | 8.44 | 234.86 |
| Digitalization | 34.64 | 8.40 | 15.02 | 58.07 |
| Schooling | 11.56 | 1.65 | 7.20 | 14.10 |
| Policy Variables | ||||
| School closures | 54.34 | 14.18 | 17.00 | 80.25 |
| Workplace closing | 48.92 | 12.36 | 13.50 | 67.52 |
| Cancel public events | 67.43 | 12.70 | 25.22 | 87.61 |
| Restrictions on gatherings | 64.38 | 13.70 | 2.99 | 84.71 |
| Close public transport | 20.15 | 15.53 | 0.00 | 52.81 |
| Stay at home order | 30.05 | 12.67 | 0.00 | 65.81 |
| Internal movement restrictions | 37.97 | 19.54 | 0.00 | 64.29 |
| International travel restrictions | 64.23 | 12.50 | 34.93 | 90.40 |
| Public information campaigns | 88.76 | 6.80 | 54.24 | 99.78 |
| Testing policy | 61.37 | 14.97 | 26.19 | 93.01 |
| Manual contact tracing | 69.73 | 17.85 | 26.12 | 100.00 |
| Facial coverings | 44.33 | 16.58 | 5.39 | 77.40 |
| Protection of elderly people | 55.13 | 18.87 | 7.59 | 84.26 |
| Fiscal stimulus in health | 1.10 | 1.18 | 0.03 | 7.52 |
| Fiscal stimulus in non-health | 6.81 | 4.71 | 0.21 | 22.15 |
| Observations | 46 |
| Cluster | Excess Mortality | Economic Losses |
|---|---|---|
| blue | low | low |
| yellow | low | medium |
| green | low | high |
| red | medium | low |
| gray | medium | high |
| purple | high | low |
| Blue | Green | Yellow | Red | Gray | Purple | |
|---|---|---|---|---|---|---|
| Structural Conditions | ||||||
| H1N1 death | 0.000 | −0.000 ** | 0.000 | −0.000 | 0.000 | −0.000 |
| (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | |
| SARS cases | −0.000 | 0.004 *** | −0.000 | −0.003 * | −0.001 | 0.001 |
| (0.001) | (0.001) | (0.002) | (0.002) | (0.001) | (0.002) | |
| Tax Revenue | 0.013 | 0.012 | −0.007 | −0.020 | 0.003 | −0.001 |
| (0.015) | (0.014) | (0.023) | (0.015) | (0.011) | (0.015) | |
| Population density | 0.043 | −0.045 | 0.187 * | −0.208 *** | 0.088 ** | −0.065 |
| (0.066) | (0.049) | (0.105) | (0.063) | (0.040) | (0.071) | |
| Share of population above 70 | −0.010 | −0.019 | −0.032 | 0.022 | 0.070 ** | −0.032 |
| (0.028) | (0.031) | (0.069) | (0.038) | (0.028) | (0.053) | |
| Gini | 0.004 | −0.000 | −0.016 | 0.018 * | −0.002 | −0.004 |
| (0.009) | (0.008) | (0.020) | (0.010) | (0.007) | (0.014) | |
| Smoking prevalence | 0.008 | −0.007 | 0.012 | −0.002 | −0.001 | −0.010 |
| (0.010) | (0.008) | (0.022) | (0.012) | (0.009) | (0.015) | |
| Doctors | −0.010 | 0.102 | −0.049 | −0.114 | −0.053 | 0.123 |
| (0.086) | (0.062) | (0.146) | (0.116) | (0.061) | (0.138) | |
| Cardiovascular death | −0.001 | 0.000 | 0.001 | −0.002 ** | 0.000 | 0.002 |
| (0.001) | (0.001) | (0.002) | (0.001) | (0.001) | (0.001) | |
| Diabetes prevalence | 0.018 | 0.004 | −0.010 | 0.032 | −0.052 ** | 0.008 |
| (0.034) | (0.023) | (0.063) | (0.034) | (0.023) | (0.050) | |
| Hospital beds | −0.008 | 0.036 | −0.057 | 0.049 | −0.084 ** | 0.064 |
| (0.053) | (0.026) | (0.060) | (0.033) | (0.033) | (0.048) | |
| Trade reliance on services | 0.004 ** | −0.002 | −0.001 | −0.001 | 0.000 | −0.001 |
| (0.001) | (0.001) | (0.002) | (0.001) | (0.001) | (0.001) | |
| Trade reliance on goods | 0.001 | −0.001 | −0.007 | 0.007 ** | 0.000 | −0.001 |
| (0.003) | (0.002) | (0.005) | (0.003) | (0.002) | (0.005) | |
| Neighboring countries | 0.004 | −0.003 | 0.007 | 0.016 | −0.002 | −0.022 |
| (0.023) | (0.016) | (0.038) | (0.018) | (0.016) | (0.030) | |
| Government debt | 0.002 | 0.000 | −0.000 | 0.003 | −0.003 | −0.002 |
| (0.003) | (0.002) | (0.005) | (0.003) | (0.002) | (0.003) | |
| Schooling | 0.033 | 0.006 | −0.015 | −0.043 | −0.070 | 0.091 |
| (0.073) | (0.054) | (0.143) | (0.069) | (0.049) | (0.124) | |
| Workplace closing | 0.011 | −0.003 | −0.002 | −0.001 | −0.001 | −0.004 |
| (0.007) | (0.005) | (0.010) | (0.007) | (0.004) | (0.007) | |
| Cancel public events | −0.009 | 0.001 | 0.005 | −0.005 | 0.008 | 0.000 |
| (0.006) | (0.005) | (0.013) | (0.009) | (0.006) | (0.010) | |
| Restrictions on gatherings | −0.002 | −0.006 | 0.013 | 0.009 | −0.011 * | −0.002 |
| (0.008) | (0.006) | (0.015) | (0.008) | (0.006) | (0.012) | |
| Close public transport | −0.002 | −0.001 | −0.004 | 0.013 | −0.007 | 0.001 |
| (0.006) | (0.004) | (0.011) | (0.008) | (0.005) | (0.010) | |
| Stay at home order | −0.017 ** | 0.012 | −0.013 | 0.017 | −0.006 | 0.008 |
| (0.007) | (0.008) | (0.019) | (0.010) | (0.006) | (0.013) | |
| Internal movement restrictions | 0.012 * | 0.002 | −0.007 | −0.016 ** | 0.011 ** | −0.001 |
| (0.006) | (0.005) | (0.012) | (0.007) | (0.004) | (0.008) | |
| International travel restrictions | 0.004 | −0.010 * | −0.002 | 0.008 | 0.005 | −0.004 |
| (0.006) | (0.006) | (0.012) | (0.007) | (0.005) | (0.010) | |
| Public information campaigns | 0.003 | 0.014 | −0.017 | −0.004 | −0.002 | 0.005 |
| (0.011) | (0.009) | (0.020) | (0.014) | (0.008) | (0.019) | |
| Testing policy | 0.008 | 0.000 | −0.010 | −0.001 | 0.010 * | −0.008 |
| (0.005) | (0.004) | (0.011) | (0.007) | (0.005) | (0.010) | |
| Manual contact tracing | 0.003 | −0.003 | 0.004 | 0.001 | −0.000 | −0.005 |
| (0.004) | (0.003) | (0.009) | (0.005) | (0.004) | (0.008) | |
| Facial coverings | −0.013 | −0.001 | −0.009 | 0.002 | 0.004 | 0.016 |
| (0.008) | (0.005) | (0.012) | (0.008) | (0.005) | (0.010) | |
| Protection of elderly people | 0.001 | −0.004 | 0.006 | −0.003 | −0.001 | 0.002 |
| (0.005) | (0.004) | (0.009) | (0.005) | (0.005) | (0.006) | |
| Policy Variables | ||||||
| Fiscal stimulus in health | −0.040 | −0.062 | −0.075 | 0.126 ** | 0.103 ** | −0.052 |
| (0.055) | (0.036) | (0.088) | (0.047) | (0.046) | (0.073) | |
| Fiscal stimulus in non-health | −0.060 ** | 0.062 *** | 0.026 | −0.008 | 0.000 | −0.020 |
| (0.026) | (0.020) | (0.045) | (0.022) | (0.018) | (0.033) | |
| Constant | −1.099 | −0.528 | 2.768 | 0.351 | −0.028 | −0.463 |
| (1.321) | (1.468) | (3.187) | (1.782) | (1.144) | (2.619) | |
| R-squared | 0.7247 | 0.8756 | 0.4873 | 0.7988 | 0.8279 | 0.669 |
| Adjusted R-squared | 0.1741 | 0.6267 | -0.5382 | 0.3964 | 0.4836 | 0.0071 |
| F-Test (p-value) | 0.2921 | 0.0064 | 0.9596 | 0.0809 | 0.0377 | 0.5105 |
| Number of observations | 46 | 46 | 46 | 46 | 46 | 46 |
| Blue | Green | Red | Gray | Purple | |
|---|---|---|---|---|---|
| Structural Variables | |||||
| Smoking prevalence | −0.039 | ||||
| Trade reliance on services | 0.011 | ||||
| Corruption | 0.001 | −0.013 | |||
| H1N1 death | 0.00019 | ||||
| Cardiovascular disease | 0.005 | ||||
| SARS cases | 0.001 | ||||
| Schooling | −0.039 | ||||
| Policy Variables | |||||
| Testing policy | 0.008 | ||||
| Facial coverings | −0.018 | ||||
| Fiscal stimulus in health | −0.028 | 0.335 | |||
| Fiscal stimulus in non-health | −0.044 | 0.160 | |||
| Stay at home order | 0.055 | ||||
| Constant | −0.731 | −3.012 | −2.907 | −2.866 | −1.597 |
| Selected lambda | 0.058 | 0.127 | 0.086 | 0.097 | 0.115 |
| Number of coefficients selected | 7 | 2 | 2 | 2 | 2 |
| Blue | Green | Red | Gray | Purple | |
|---|---|---|---|---|---|
| Smoking prevalence | −0.127 | ||||
| (0.09) | |||||
| Trade reliance on services | 0.037 * | ||||
| (0.02) | |||||
| Corruption | −0.012 | −0.064 * | |||
| (0.04) | (0.04) | ||||
| Testing policy | 0.088 * | ||||
| (0.05) | |||||
| Facial coverings | −0.094 ** | ||||
| (0.05) | |||||
| SARS cases | 0.012 | ||||
| (0.01) | |||||
| Schooling | −0.181 | ||||
| (0.30) | |||||
| Stay at home order | 0.151 ** | ||||
| (0.08) | |||||
| H1N1 death | 0.001 | ||||
| (0.00) | |||||
| Cardiovascular disease | 0.010 * | ||||
| (0.00) | |||||
| Fiscal stimulus in health | 0.844 | ||||
| (0.54) | |||||
| Fiscal stimulus in non-health | 0.422 *** | ||||
| (0.16) | |||||
| Constant | −1.64 | −5.849 | −4.897 | −4.13 | 0.07 |
| (5.03) | (1.72) | (5.14) | (1.07) | (2.41) | |
| F-Test (p-value) | 0.003 | 0 | 0.001 | 0.007 | 0 |
| Pseudo R-squared | 0.456 | 0.543 | 0.318 | 0.366 | 0.36 |
| Number of observations | 46 | 46 | 46 | 46 | 46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Gurgone, A.; Martínez, H.; Barbieri Góes, M.C.; Gallo, E.; Kerényi, Á.; Turco, E.M.; Coburger, C.; Andrade, P.D.S. COVID-19 Mortality and Economic Losses: The Role of Policies and Structural Conditions. J. Risk Financial Manag. 2022, 15, 354. https://doi.org/10.3390/jrfm15080354
Wang W, Gurgone A, Martínez H, Barbieri Góes MC, Gallo E, Kerényi Á, Turco EM, Coburger C, Andrade PDS. COVID-19 Mortality and Economic Losses: The Role of Policies and Structural Conditions. Journal of Risk and Financial Management. 2022; 15(8):354. https://doi.org/10.3390/jrfm15080354
Chicago/Turabian StyleWang, Weichen, Andrea Gurgone, Humberto Martínez, Maria Cristina Barbieri Góes, Ettore Gallo, Ádam Kerényi, Enrico Maria Turco, Carla Coburger, and Pêdra D. S. Andrade. 2022. "COVID-19 Mortality and Economic Losses: The Role of Policies and Structural Conditions" Journal of Risk and Financial Management 15, no. 8: 354. https://doi.org/10.3390/jrfm15080354
APA StyleWang, W., Gurgone, A., Martínez, H., Barbieri Góes, M. C., Gallo, E., Kerényi, Á., Turco, E. M., Coburger, C., & Andrade, P. D. S. (2022). COVID-19 Mortality and Economic Losses: The Role of Policies and Structural Conditions. Journal of Risk and Financial Management, 15(8), 354. https://doi.org/10.3390/jrfm15080354