1. Introduction
In survival analysis, the study is based on data relating to the time until the occurrence of a particular event of interest, also known as time to failure. This data can come from the time until there is a failure in an electronic component; time until a particular disease occurs in a patient; time for a particular drug to have the desired effect, among others. The behavior of such data can be verified empirically; this approach is said to not be parametric. If the data follows a probability distribution, then this approach is called parametric; this is the most used form in this work.
The survival and hazard functions, the objects of greatest interest in survival analysis, allow the study of such behavior. The survival function is the probability of an individual or component surviving after a preset time and the hazard function is the instantaneous failure rate, which graphically can take various forms, such as constant, increasing, decreasing, unimodal or bathtub shaped. However, when the behavior of the hazard function is not monotonous, the most commonly known distributions, such as exponential and Weibull, cannot accommodate this kind of behavior.
This is because a disadvantage of these models is that they are very limited due to the small number of parameters and therefore the conclusions drawn from the models cannot be sufficiently robust to accommodate deviations from the data. There are some distributions that accommodate the non-monotonic hazard function, but they are usually very complicated and with many parameters.
We can model real survival data using almost any continuous distribution and with positive values; the simplest and most common models, such as exponential and Weibull distribution, may not be appropriate. Therefore, to find a distribution that accommodates non-monotone hazard functions is a known issue in survival analysis. Therefore, it is desirable to consider other approaches to achieve greater flexibility, and this is what has motivated studies to find distributions that accommodate these types of function.
Kumaraswamy (
1980) proposed the Kumaraswamy distribution, which was widely used in hydrology and, based on this,
Cordeiro and de Castro (
2011) proposed a new family of generalized distributions, called Kumaraswamy generalized (Kum-G). It is flexible and contains distributions with unimodal and bathtub-shaped hazard functions, as shown by
De Pascoa et al. (
2011), and has, as special cases, any distribution that is normal, exponential, Weibull, Gamma, Gumbel and inverse Gaussian. The domain of the distribution is the range in which the particular cases are set. Other examples of generalized distributions are the Generalized exponential distribution (
Gupta and Kundu 1999) and the Stoppa (or Generalized Pareto) distribution (
Stoppa 1990) and (
Calderín-Ojeda and Kwok 2016).
In a population, there may be individuals who have not experienced the event of interest until the end of the study; this is called censorship. When there are a large number of censored individuals, we have an indication that in this population there are individuals who are not subjected to the event; they are considered immune, cured or not susceptible to the event of interest.
From the traditional models of survival, it is not possible to estimate the cured fraction of the population, or the percentage of individuals who are considered cured. Thus, statistical models are needed to incorporate such fractions and these are termed long-term or cure rate models. Because of this capability, different fit methods have been proposed in several areas such as biomedical studies, financial, criminology, demography and industrial reliability, among others. For example, in biomedical data, an event of interest may be the death of the patient due to tumor recurrence, but there may be patients who are cured and do not die due to cancer. When the financial data is studied, an event of interest may be the customer’s closing of a bank account by default, but there may be customers who will never close their account. In criminology data, the event of interest may be a repeat offence and there may be people who do not repeat an offence. In industrial reliability, long duration models are used to verify the proportion of components that are not tested at zero time and are exposed to various voltage regimes or uses. In market research areas, individuals who will never buy a particular product are considered immune. See, for example, (
Anscombe 1961;
Farewell 1977;
Goldman 1984;
Broadhurst and Maller 1991;
Meeker and Escobar 1998).
Many authors have contributed to the theory of long-term models.
Boag (
1949) was the pioneer; the maximum likelihood method was used to estimate the proportion of survivors in a population of 121 women with breast cancer, in an experiment that lasted 14 years. Based on Boag’s idea,
Berkson and Gage (
1952) proposed a mixture model in order to estimate the proportion of cured patients in a population subjected to a treatment of stomach cancer. More complex long-term models, such as
Yakovlev and Tsodikov (
1996),
Chen et al. (
1999) among others, have emerged in order to better explain the biological effects involved. More recently,
Rodrigues et al. (
2009) proposed a unified theory of long duration, considering different competitive causes. In this context, most long-term models make use of this proposal, among which are (
Sy and Taylor 2000;
Castro et al. 2009;
Cancho et al. 2011;
Gu et al. 2011), besides (
Ibrahim et al. 2005;
Cooner et al. 2007;
Ortega et al. 2008,
2009;
Cancho et al. 2009).
A very important point in survival analysis is the study of covariates, because many factors can influence the survival time of an individual. Therefore, incorporate covariates enable us to have a much more complete model, full of valuable information. For example, if we are interested in studying the life time of patients with a particular disease who are receiving a certain treatment, other factors may influence the patient’s healing, so we can find new ways to treat the disease from covariates. One real situation is the study of patients that were observed for recurrence after the removal of a malignant melanoma; it is desired to know if the nodule category or the age of the patient may influence the recurrence of melanoma. We will analyze this clinical study latter.
This paper presents the unified long-term model using, as a distribution of the number of competing causes, the negative binomial distribution, as studied in
Cordeiro et al. (
2015), where the authors use the Birnbaum–Saunders distribution of times. However, our contribution is proposing the use of a different distribution of times, i.e., the family of Kum-G distributions, which were studied only in the usual models of survival analysis, as in
De Pascoa et al. (
2011),
De Santana et al. (
2012) and
Bourguignon et al. (
2013). In this new model, we propose the incorporation of covariates influencing the survival time. In addition, we performed a simulation study to see how this model would behave with different sample sizes, as well as an application to a data set to demonstrate the applicability of this model.
The paper is organized as follows: in
Section 2, we have the methodology, in which we present the family of Kumaraswamy generalized distributions, the unified cure rate model and a distribution used in this model, i.e., the negative binomial distribution; then, we propose a unified model Kumaraswamy-G cure rate as well as a regression approach, using the distribution Kumaraswamy exponential and its inferential methods.
Section 2.7 presents some simulation studies. Application to a real data set is presented in
Section 3. Finally, in
Section 4, we conclude the paper with some final remarks.
2. Methodology
2.1. Kumaraswamy Family of Distributions
The time until the occurrence of some event of interest can be generally accommodated by a probability distribution. In the literature, various distributions have been used to describe survival times but most commonly used distributions do not have the flexibility to model non-monotone hazard functions, such as unimodal and bathtub-shaped hazard functions, which are very common in biological studies. Thus, in this section, we will study the Kumaraswamy generalized distribution because it is a flexible but simple distribution.
The Kumaraswamy generalized distribution (Kum-G) presented by
Cordeiro and de Castro (
2011) has the flexibility to accommodate different shapes for the hazard function, which can be used in a variety of problems for modeling survival data. It is a generalization of the Kumaraswamy distribution with the addition of a distribution function
of a family of continuous distributions.
Definition. Let be a cumulative distribution function (cdf) of any continuous random variable. The cdf of the Kum-G distribution is given by
where
and
. Let
be the probability density function (pdf) of the distribution of
, then the pdf of Kum-G is
Thus, we obtain the survival and hazard functions, given respectively by
and
In the literature, there are different generalized distributions, one of which is the beta distribution. The pdf of beta generalizations uses the beta function, which is difficult to handle. On the other hand, the Kum-G distribution is a generalization that shows no complicated function in its pdf, and it is more advantageous than many generalizations.
As the Kum-G distribution depends on a
distribution function, for each continuous distribution, we have a case of Kum-G with the number of parameters of
over the two parameters
and
. For example, if we take the cumulative distribution function of an exponential distribution as
, then in this case we have the Kumaraswamy exponential distribution. In the literature, many cases of this distribution were studied, some of which are Kumaraswamy normal (
Correa et al. 2012), Kumaraswamy log-logistic (
De Santana et al. 2012), Kumaraswamy pareto (
Bourguignon et al. 2013), Kumaraswamy pareto generalized (
Nadarajah and Eljabri 2013), Kumaraswamy gamma generalized (
De Pascoa et al. 2011), Kumaraswamy
half-normal generalized (
Cordeiro et al. 2012), Kumaraswamy Weibull inverse (
Shahbaz et al. 2012) and Kumaraswamy Rayleigh inverse (
Hussian and A Amin 2014).
2.2. The Unified Cure Rate Model
The unified model of the cured fraction of
Rodrigues et al. (
2009) is a statistical model capable of estimating the proportion of a cured population, that is, in data sets in which many individuals do not experience the event of interest, even if observed over a long period of time, part of the population is cured or immune to the event of interest; we can estimate the cured fraction. Several authors have worked with this modeling, for example, (
Rodrigues et al. 2009,
Peng and Xu 2012;
Balakrishnan and Pal 2012,
2013a,
2013b,
2015), and others.
In general, the basic idea of the unified model of the cured fraction is based on the notion of occurrence of the event of interest in a process in two stages:
Initiation stage. Let N be a random variable representing the number of causes or competitive risks of occurrence of an event of interest. The cause of the occurrence of the event is unknown, and the variable N is not observed, with probability distribution and its tail given respectively by e with .
Maturation stage. Given that equal , , continuous random variables (non-negative), independent of a cumulative distribution function and independent of N, represent the time of occurrence of an event of interest because of the k-th cause.
In order to include individuals who are not susceptible to the event of interest, its time of occurrence is defined as
where
, admitting the possibility that a proportion
of the population lacks the occurrence of an event of interest,
T is an observable or censored random variable, and
and
N are latent variables.
Let
be a sequence of real numbers.
is defined as a function of the sequence
as follows
where
s belongs to the interval
.
The survival function of the random variable
T (population survival function) will be indicated by
where
corresponds to a genuine generating function of the sequence
. That is, in the survival function of the random variable
T, corresponding to a long-term model in two stages, the composition is a probability-generating function and survival function. The long-term survival function, in two stages
, is not a survival function.
Note that for the survival function, and . As for the improper survival function, and . Thus, is the proportion of non-event occurrences in a population of interest, that is, the cured fraction.
The population survival function has the following properties:
If , then ;
;
it is not increasing;
.
The density and hazard functions associated with long-term survival function are given respectively by
and
Any discrete distribution can be used to model N, such as Bernoulli, binomial, Poisson, negative binomial and Geometric. What follows is the negative binomial distribution, which will be used because it is a very flexible distribution with various special cases, including those resulting in the standard model mix.
2.3. Negative Binomial Distribution
Assuming the number of competitive causes
N following a negative binomial distribution,
N has the probability function defined by
where
,
e
, and then
and
.
The probability generating function is given by
Thus, the long-term survival function for the negative binomial model is given by
where
is the cumulative distribution function of the random variable
T and the cured fraction of the population is
The density function of the model (
1) is
where
. Furthermore, the corresponding hazard function is given by
We observed some particular cases in this model: from the Equation (1), when , we obtain the density function of the Poisson distribution, resulting in the promotion time model; if , we fall into the Bernoulli distribution, where we have the model of the standard mixture; if , we have the geometric distribution; when (m integer), we have a binomial distribution (m, ), where . We also observed, from expressions of expectation and the variance of the model, that the variance of the number of competing causes is very flexible. If , there is an underdispersion relative to the Poisson distribution; if , there is an overdispersion.
Table 1 presents the long-term survival function, improper density and cure rate corresponding to negative binomials and their particular cases.
2.4. Negative Binomial Kumaraswamy-G Cure Rate Model
Considering the negative binomial distribution for the number of competing causes and the time following the Kumaraswamy-G distribution, we obtain a family of long-term distributions, wherein the population survival function of the model is given by
with the cured fraction of the population given by
So, by replacing the function by the cumulative distribution function of some distribution, one obtains a negative binomial Kumaraswamy-G model of long-term survival.
The population density function is
and the population hazard function is given by
Table 2 shows the particular cases of this model. It is noteworthy that for every
, we will have different distributions.
Negative Binomial Kumaraswamy Exponential Cure Rate Model
Considering
, following an Exponential(
) distribution and substituting in (
2), we have the NegBinKumExp
, i.e., a family of cure rate models where their population survival function is given by
The population density and hazard function of this model are, respectively,
and
2.5. Negative Binomial Kumaraswamy-G Regression Cure Rate Model
The use of covariate information is essential when analyzing survival data. Here, we discuss an approach to including covariate information for the proposed models.
Suppose that is a vector of covariates from a data set and is a vector of regression coefficients. We are going to set to link the cure rate to the covariates. The only two parameters that link the cure rate to the covariates are and . Since has a positive domain, we can use it to simply model the covariates through the exponential function.
This way, the Negative Binomial Kumaraswamy-G generalized linear model is given by
for
. The cure rate
p is given by
This way, the cured fraction does not depend on the parameters of the Kumaraswamy family or the baseline distribution, but on the parameters and . They are estimated differently for each baseline distribution and then they are incorporated into the cure rate.
Other particular cure rate models can be obtained. The Bernoulli Kumaraswamy-G generalized linear model and its respective cure rate is given by
The Poisson Kumaraswamy-G generalized linear model is given by
The Geometric Kumaraswamy-G generalized linear model is given by
In
Section 2.6, we discuss the estimation procedures of the NegBinKum-G cure rate generalized linear model. An application of these models is presented in
Section 3.
2.6. Inference
Here, we present a procedure to obtain maximum likelihood estimates for the Negative Binomial Kumaraswamy Exponential generalized linear model. We consider data with right-censored information. Let
, where
are the observed failure times,
are the right-censored times and
is the covariates information. The
is equal to 1 if a failure is observed and 0 otherwise. Suppose that the sample data is independently and identically distributed and comes from a distribution with density and survival functions specified by
and
, respectively, where
denotes a vector of
parameters, with
, as described in
Section 2.5. By combining (
4) and the expression (
3), the log-likelihood function of
for the NegBinKumExp distribution is
The maximum likelihood estimates are the simultaneous solutions of
The estimates are obtained using the BFGS algorithm of maximization, which is an option for the
optim function in R (
R Core Team 2013).
If
denotes the maximum likelihood estimator of
, then it is well known that the distribution of
can be approximated by a
-variate normal distribution with zero means and a covariance matrix
, where
denotes the observed information matrix defined by
for
i and
j in
. This approximation can be used to deduce confidence intervals and tests of hypotheses. For example, an approximate
percent confidence interval for
is
, where
denotes the
ith diagonal element of the inverse of
and
denotes the
percentile of a standard normal random variable.
Asymptotic normality of the maximum likelihood estimates holds only under certain regularity conditions. These conditions are not easy to check analytically for our models.
Section 2.7 performs a simulation study to see if the usual asymptotes of the maximum likelihood estimates hold. Simulations have been used in many papers to check the asymptotic behavior of maximum likelihood estimates, especially when an analytical investigation is not trivial.
2.7. Simulation Studies
Here, we assess the performance of the maximum likelihood estimates with respect to sample size to show, among other things, that the usual asymptotes of maximum likelihood estimators still hold for defective distributions. The assessment is based on simulations. The description of data generation and details of the distributions simulated from this are described below. All computations were performed in R (
R Core Team 2013).
Suppose that the time of occurrence of an event of interest has the cumulative distribution function . We want to simulate a random sample of size n containing real times, censored times and a cured fraction of p. An algorithm for this purpose is:
Determine the desired parameter values, as well as the value of the cured fraction p;
For each , generate a random variable Bernoulli;
If set . If , take as the root of , where uniform;
Generate uniform, for , considering only the finite ;
Calculate . If set , otherwise set .
We took the sample size to vary from 100 to 1500 in steps of 200. Each sample was replicated 1000 times. The variance of the cure rate
p was estimated using the delta method with first-order Taylor’s approximation. In
Rocha et al. (
2015), we can find a simulation algorithm very similar to this one, but it was used for long duration models that use a defective distribution.
Simulation was performed for several scenarios and it was indicated that a relatively large sample size is required to produce a good interval estimation for the parameters. In some cases, even with a large sample size, standard deviations and bias are still not close to zero. The high number of parameters can explain this fact. Another reason may be the use of the optim algorithm which, in very complicated cases, cannot find the values of the global maximum of the likelihood function. One possible solution could be to use some other method of maximization.
The cure rate provides a reasonable point estimation, regardless of the sample size. Similar observations held when the simulations were repeated for a wide range of parameter values. The next section illustrates the proposed methodology in a real health risks data set.
3. Real Data Application
Here, we present an application in a health risk-related data set. The data set contains covariate information and is used to illustrate the model proposed in
Section 2.5. A similar approach for the regression was used in the Bernoulli Kumaraswamy Exponential, Poisson Kumaraswamy Exponential and Geometric Kumaraswamy Exponential distributions (BerKumExp, PoiKumExp and GeoKumExp, for short). The following measures of model selection are used to distinguish between the fitted distributions: the Akaike information criterion (AIC) and visual comparison of the fitted survival curves and the Kaplan–Meier (
Kaplan and Meier 1958) curve. All the computations were performed using the R software (
R Core Team 2013).
optim was used to maximize the log-likelihood function. The algorithm “BFGS” was chosen for maximization. For computational stability, the observed times in each data set were divided by their maximum value. As the simulations results shows large values for deviation in small sample sizes, we are going to use 1000 bootstrap estimates for the deviations of the parameters.
The data set is supposed to contain observations that are not susceptible to the event of interest. In practice, it is unknown whether the event of interest could be observed if enough time was given. Evidence of the existence of cured individuals is given in cases where the Kaplan–Meier curve reaches a plateau between zero and one. In some cases, this is clearer than others, as one can see in our examples. We can assume that some of the censored observations at the end of the study belong to the cured group. If everyone censored at the end were indeed cured, then the plateau reached by the Kaplan–Meier curve is a good estimate of the cured fraction. In general, a lower value of this plateau or a value close to it is an acceptable estimate.
This data set collected in the period 1991–1998 is related to a clinical study in which patients were observed for recurrence after the removal of a malignant melanoma. Melanoma is a type of cancer that develops in melanocytes, responsible for skin pigmentation. It is a potentially serious malignant tumor that may arise in the skin, mucous membranes, eyes and the central nervous system, with a great risk of producing metastases and high mortality rates in the latter stages. In total, 417 cases were observed, of which 232 were censored (55.63 percent). The overall survival is 3.18 years. This data set has covariate information, which is used to illustrate the generalized linear model proposed in
Section 2.5. The covariates taken represent the nodule category (
,
,
,
) and age (continuous covariate). The overall survival times for the categories are 3.60, 3.27, 3.07, 2.55 years. For more details on this data, see
Ibrahim et al. (
2001).
Table 3,
Table 4,
Table 5 and
Table 6 show the results for the Bernoulli, Poisson, Geometric and Negative Binomial Kumaraswamy Exponential models. The estimated cure rates
,
,
and
for groups 1, 2, 3 and 4, respectively, are calculated by (
5). The age covariate is taken as their average, 48, for the necessary computations.
The estimates of , and are in agreement in all models. For , the value is around −1.50, for , the value is around 0.50 and for , the value is around 0.01.
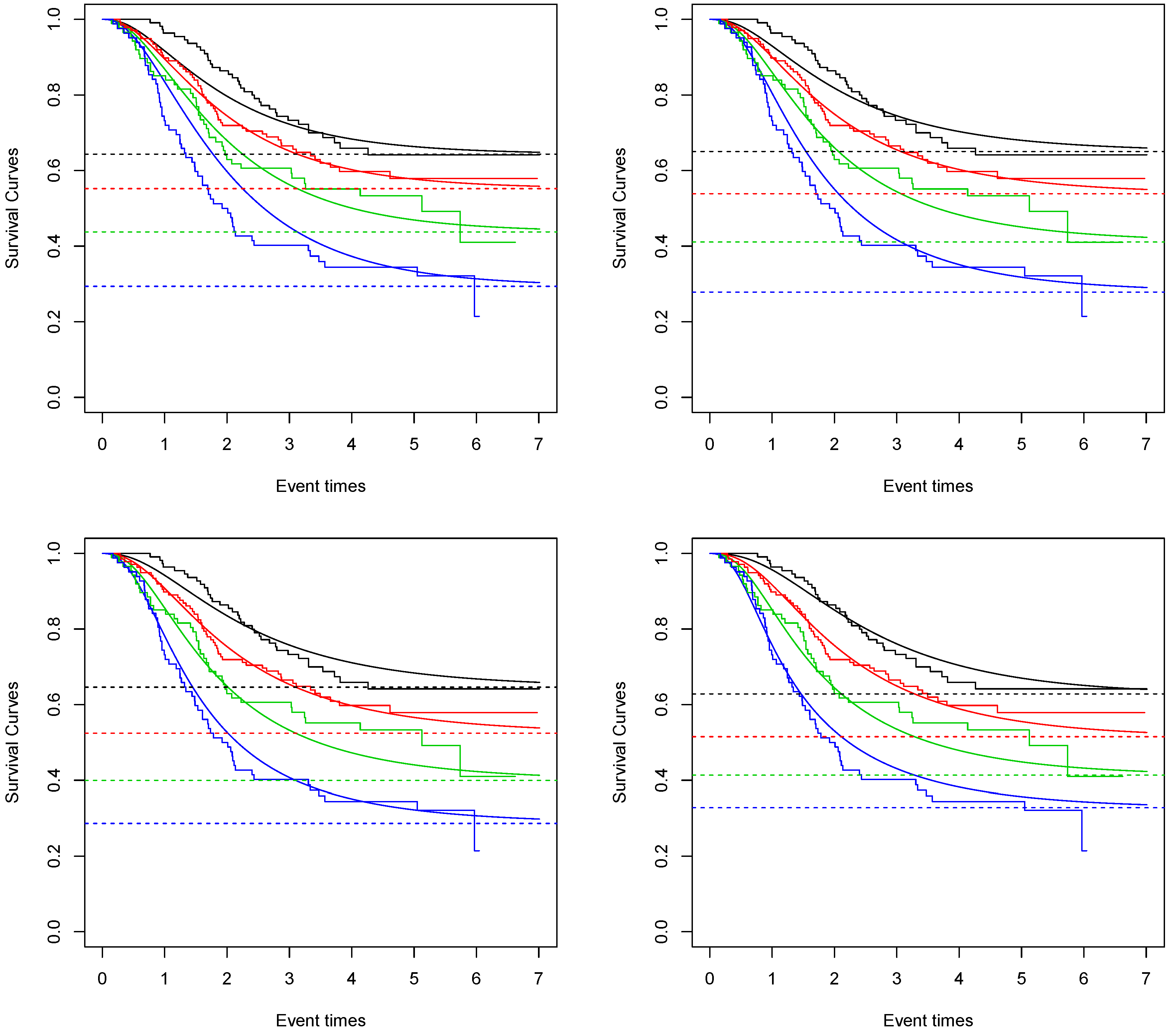
In
Figure 1, the fitted survival curves for each nodule category and each proposed model are given. We can see that the one that best captures the Kaplan–Meier curve is the Negative Binomial Kumaraswamy Exponential distribution. This result is also sustained by the AIC values. The values obtained for the Bernoulli, Poisson, Geometric and Negative Binomial Kumaraswamy Exponential models are 1029.53, 1022.77, 1017.64 and 1016.27. The Negative Binomial Kumaraswamy Exponential achieves a better AIC value even with one extra parameter than the others.
Considering the Negative Binomial Kumaraswamy Exponential model and given the average age of 48 in this study, the estimated cure rate for nodule category 1 is around 0.65. For nodule category 2, it is around 0.54. For nodule category 3, it is around 0.41. For nodule category 4, it is around 0.28.
The standard deviations of
,
,
and
are 0.0464, 0.0412, 0.0424 and 0.0525, respectively. The bootstrap 95 percent confidence intervals are (0.55, 0.73), (0.45, 0.61), (0.33, 0.49) and (0.18, 0.38), respectively. These indicate a significant difference between nodule categories 1 and 3, 1 and 4 and 2 and 4. These results agree with the results found in (
Rodrigues et al. 2009,
Balakrishnan and Pala 2013a,
2013b).



{kind=link}