1. Introduction
The Pareto (P) distribution is very versatile, and a variety of uncertainties can be usefully modelled by it. It has several applications in actuarial science, economics, finance, life testing, survival analysis and telecommunications because of its heavy tail properties. The probability density function (pdf) and cumulative distribution function (cdf) of the P distribution are given (for
) by:
where
is a scale parameter and
is a shape parameter. This distribution is a special form of the Pearson Type VI distribution. Since the P distribution has a reversed-J pdf shape and a decreasing hazard rate function (hrf), it may sometimes be insufficient to model data. Generally, practical problems require a wider range of possibilities for the medium risk, for example when the lifetime data present a bathtub-shaped hrf, such as human mortality and machine life cycles. For this reason, researchers developed various extensions and modified forms of the P distribution to obtain a more flexible model with different numbers of parameters. Some of them can be cited as follows: Exponentiated P (EP) (
Stoppa 1990;
Gupta et al. 1998), Beta P (BP) (
Akinsete et al. 2008), Kumaraswamy P (KwP) (
Bourguignon et al. 2013), Kumaraswamy generalized P (
Nadarajah and Eljabri 2013), P ArcTan (PAT) (
Gómez-Déniz and Calderín-Ojeda 2015), exponentiated Weibull P (
Afify et al. 2016) and Weibull P (WP) distributions (
Tahir et al. 2016). On the other hand,
Yousof et al. (
2016) defined the cdf of the Burr X-G(BX-G) family (for
) by:
where
is the shape parameter and
(
) is a parameter vector. The BX-G density function becomes:
This generator can supply the flexibility of pdf and hrf to any baseline distribution model (
Yousof et al. 2016).
In this paper, we introduce a new extended P distribution, called the Burr X Pareto (BXP) model, based on the BX-G family. With this idea, we construct the new BXP distribution as more flexible than the P distribution and provide a comprehensive description of some of its mathematical properties. We prove empirically that the BXP model provides better fits than some extensions and generalizations of the P, some of which have one extra model parameter, and the others have the same number of parameters, by means of two applications to real data. We hope that the new distribution will attract wider applications in reliability, engineering and other areas of research.
The rest of the paper is organized as follows. In
Section 2, we define the BXP model. In
Section 3, we provide a useful mixture representation for its pdf. In
Section 4, we derive some of its general mathematical properties. Some estimation methods of the model parameters are performed in
Section 5. In
Section 6, simulation results to assess the performance of the proposed maximum likelihood estimation procedure are discussed. In
Section 7, we provide two applications to real data to illustrate the importance and flexibility of the new family. Value-at-Risk estimation with the BXP distribution is presented in
Section 8. Finally, some concluding remarks are presented in
Section 9.
2. The New Model
In this section, we define the BXP model and provide some plots for its pdf and hrf. The BXP cdf is given by:
The pdf corresponding to (
3) is given by:
Lemma 1 provides random number generations from the BXP and some relations and of the BXP distribution with the well-known Burr X and uniform distributions.
Lemma 1. (a) If a random variable Y follows the Burr X distribution with shape parameter δ and scale parameter one, then the random variable follows the BXP distribution.
(b) If a random variable Y follows the uniform distribution on [0,1], then the random variable: follows the BXP distribution. Proof. The proofs of (a) and (b) are obtained by the transformation method. ☐
The hrf, reversed hazard rate function and cumulative hazard rate function of
are given, respectively, by:
and:
In
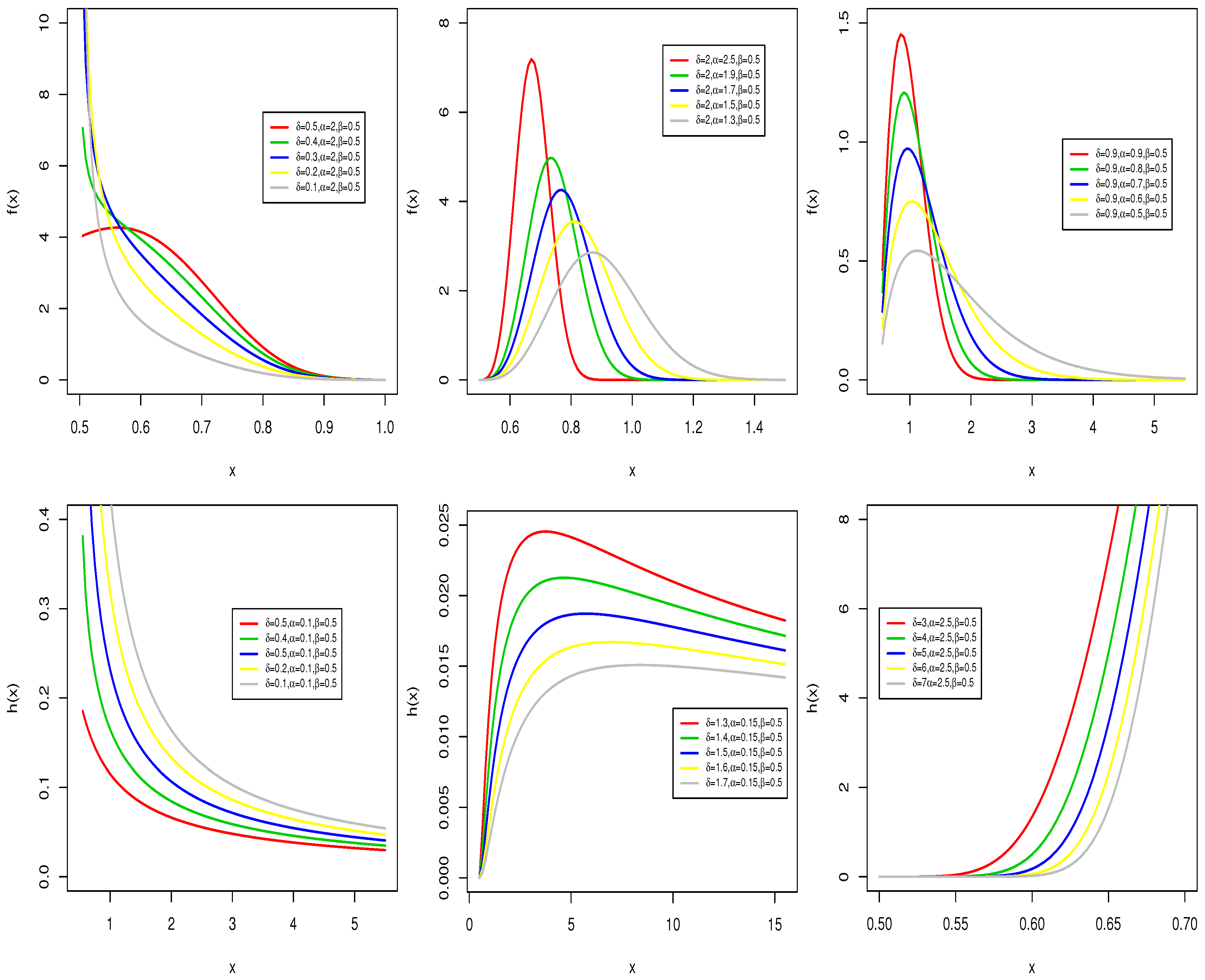
Figure 1, we sketched the possible pdf and hrf shapes of the BXP distribution for some selected parameter values.
Figure 1 shows that the BXP distribution has various pdf and hrf shapes.
3. Expansions of pdf and cdf
In this section, we provide a very useful linear representation for the BXP density function. If
and
is a real non-integer, the power series holds:
For simplicity, ignoring the dependence of
and
on
and applying (
5) to (
4), we have:
Applying the power series to the term
, Equation (6) becomes:
Consider the series expansion:
Applying the expansion in (
8) to (
7) for the term
, Equation (
7) becomes:
where:
and:
Equation (
9) reveals that the density of
X can be expressed as expansions of the EP densities. Therefore, several mathematical properties of the new family can be obtained by knowing those of the EP distribution. Similarly, the cdf of the BXP family can also be expressed as a mixture of EP cdfs given by:
where:
is the cdf of the EP family with power parameter
.
5. Estimation Methods
In this section, we consider the maximum likelihood, least square and weighted least square estimation of the parameters of the BXP distribution.
5.1. Maximum Likelihood Estimation
We consider the estimation of the unknown parameters of the BXP model from complete samples by the maximum likelihood method. The maximum likelihood estimators (MLEs) of the parameters of the BXP
model are now discussed. Let
be a random sample of this distribution with parameter vector
. The log-likelihood function for
is given by:
where
.
The last equation can be also maximized either by using the different programs such as
R (
optim function),
SAS (
PROC NLMIXED) or by solving the nonlinear likelihood equations obtained by differentiating
ℓ. We note that since
the MLE of the
parameter cannot be obtained in the usual way. Hence, the MLE of
is the first order statistic
(
Johnson et al. 1994).
The components of the score vector,
, are:
and:
where:
For fixed , the interval estimation of the model parameters requires the observed information matrix for . The multivariate normal distribution, under standard regularity conditions, can be used to provide approximate confidence intervals for the unknown parameters, where is the total observed information matrix evaluated at . Then, approximate confidence intervals for and can be determined by:
and , where is the upper -th percentile of the standard normal model.
5.2. Ordinary and Weighted Least Squares
In this section, we use the least square (LS) and weighted least square (WLS) estimators (
Swain et al. 1988) to estimate the parameters of the BXP distribution. Let
be the order statistics of a random sample of size
n from the BXP defined in (4), then the least square estimators (LSEs) of the unknown parameters
,
and
of the BXP distribution can be obtained by minimizing:
with respect to unknown parameters
,
and
.
The weighted least square estimators (WLSEs) of the unknown parameters
,
and
follow by minimizing:
with respect to unknown parameters
,
and
.
6. Simulation Study
Here, we perform the simulation study for MLEs of the BXP distribution. We generate
samples of sizes
, 100, 200 from selected BXP distributions. The random numbers generation is simulated by:
where
u is a uniform random number on [0,1]. We also calculate the empirical mean, standard deviations (sd), bias and mean square error (MSE) of the MLEs. The empirical bias and MSE are calculated by:
and:
respectively, where
. All results of MLEs were obtained using the optim-CG routine in the R programme. The empirical results of this simulation study are reported in
Table 2.
Table 2 shows that when the sample size increases, the empirical means approach the true parameter value. For the same case, the standard deviations, biases and MSEs decrease in all the cases as expected. Therefore, the MLE method works very well to estimate the model parameters of the BXP distribution.
7. Real Data Modelling
In this section, we present two applications based on the real datasets to show the flexibility of the BXP distribution. The BXP model is compared with the WP, BP, KwP, PAT and P distributions. The cdfs of the above distributions are given (for
and
) by:
and:
In order to see the best model, we obtain the Akaike Information Criteria (AIC), Corrected Akaike Information Criterion (CAIC), Bayesian Information Criterion (BIC), Hannan–Quinn Information Criterion (HQIC) and Kolmogorov–Smirnov (KS) goodness of-fit statistic to see the fitting of the models to dataset. In general, the best model can be chose as the one that has the smallest values of the AIC, CAIC, BIC, HQIC and KS statistics. All computations of the MLEs are performed by the maxLik routine in the R program.
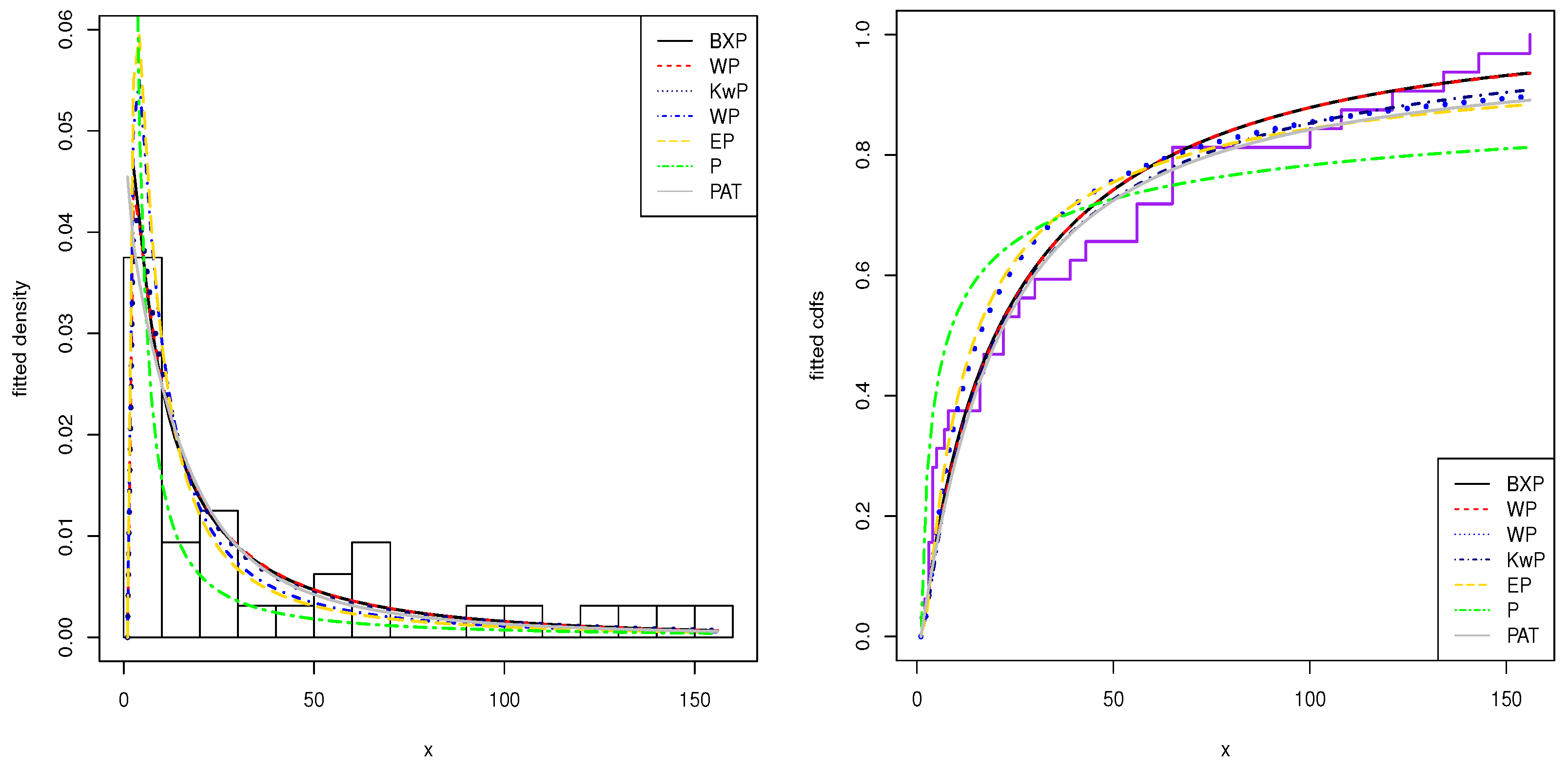
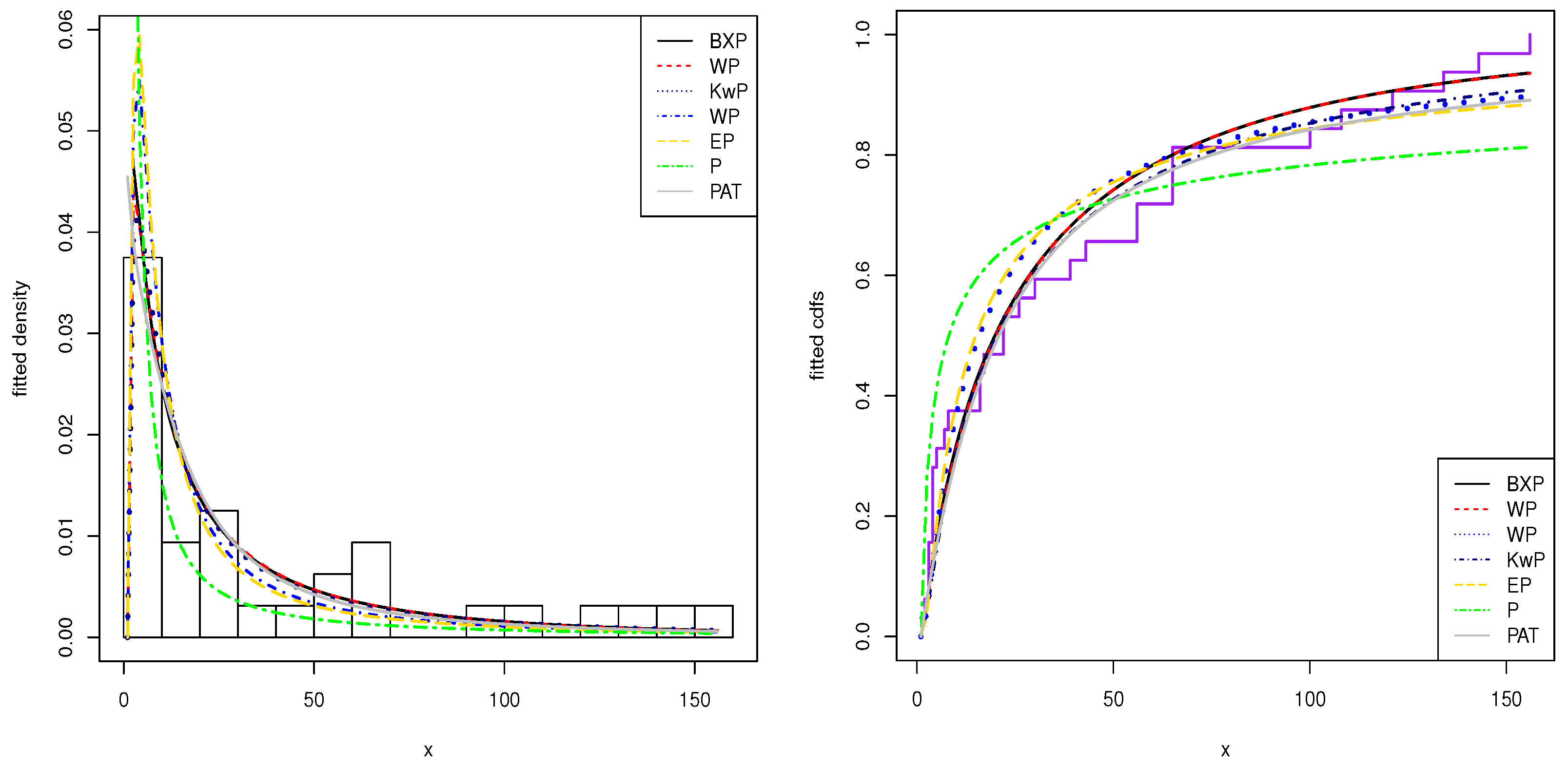
The first dataset gives the survival times, in weeks, of 33 patients suffering from acute myelogenous leukaemia. These data have been introduced by
Feigl and Zelen (
1965) and analysed by
Mead et al. (
2017). The data are: 65, 156, 100, 134, 16, 108, 121, 4, 39, 143, 56, 26, 22, 1, 1, 5, 65, 56, 65, 17, 7, 16, 22, 3, 4, 2, 3, 8, 4, 3, 30, 4, 43. This dataset is well known as being bathtub hrf-shaped.
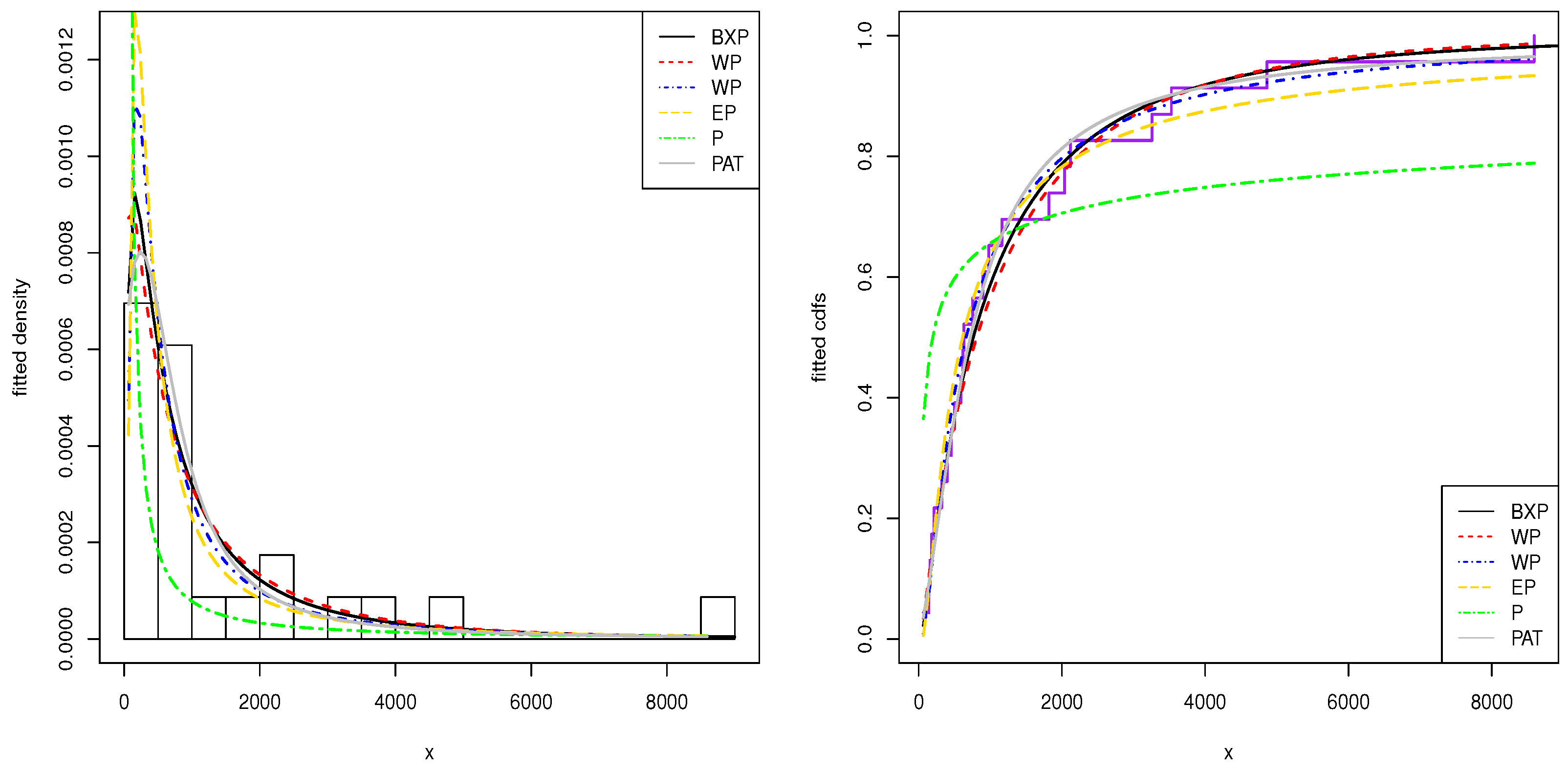
The second data-set shows the time intervals of the successive earthquakes in the last century in the North Anatolia fault zone between
to
north latitude and
to
east longitude. This dataset was introduced and analysed by
Kuş (
2007). This dataset is well known as being decreasing hrf-shaped.
For both datasets, the estimated parameters based on the MLE method are given in
Table 3, whereas the values of the information criteria and goodness-of-fit statistics are given in
Table 4. Since MLE of the
equals the minimum order statistics, we suppose it as known to be the minimum value the dataset.
Table 4 shows that the BXP distribution has the lowest values of these statistics among all the fitted models. Hence, it could be chosen as the best model under these criteria for both datasets.
The histogram of these datasets and the estimated pdfs and cdfs of the application models are displayed in
Figure 2 and
Figure 3. From the this figure, we show that the BXP model provides the best fit to these datasets as compared to other models.
8. Value-at-Risk Estimation with the BXP Distribution
In this section, the performance of BXP distribution in estimating Value-at-Risk (VaR) is discussed and compared with the Generalized P (GP) distribution. GP is a widely-used distribution in actuarial sciences, economics and statistics to model the tail of the distribution that contains extreme events. VaR is one of the most popular approaches to measure market risk. From a statistical point of view, the VaR entails the estimation of the quantile of the distribution of returns. The VaR for a long position (left tail of the distribution function) over a given time horizon tis defined as:
where
F is the distribution function of financial losses,
denotes the inverse of
F and
p is the quantile at which VaR is calculated.
The Peaks-Over-Threshold (POT) method is used to model the tail of the distribution. POT is based on the distribution of exceedances over a given threshold. The conditional excess distribution,
, can be defined as follows:
where random variable
X represents the financial losses,
u is the threshold,
are the excesses and
is the right endpoint of
F.
can be re-defined as follows:
The
Balkema and De Haan (
1974) and
Pickands (
1975) theorem shows that for a sufficiently high threshold
u, the excess distribution function
can be approximated by the GP distribution:
where
for
and
for
and
and
are shape and scale parameters of the GP distribution, respectively. Isolating
from (
14), we get:
where
is the GP distribution and
. Then, substituting (
14) in (
16), the following estimate for
is obtained:
where
and
are maximum likelihood estimates of
and
, respectively. Inverting (
17) for a given probability
p,
can be obtained as:
Threshold selection is a difficult task and an essential part for tail modelling with the GP distribution. The most used method is the Mean Excess (ME) plot for the determination of the threshold. The ME function can be defined as follows:
where
I is the indicator function. When the empirical ME function is a positively sloped straight line above a certain threshold
u, it is evidence that the used dataset follows the GP distribution with a positive
parameter.
Here, the BXP distribution is adopted in the POT method. It is assumed that BXP provides a good approximation to
for a sufficiently high threshold
u. Then, substituting the cdf of BXP in (
16), the new estimate for
can be obtained as:
The
can be obtained by inverting (
20) for a given probability
p, as follows:
where
and
are the maximum likelihood estimates of
and
, respectively.
8.1. S&P-500
To evaluate and compare the performance of the BXP with GP distribution in terms of VaR accuracy, the S&P-500 index is used. The used time series data contain 1465 daily log returns from 4 January 2012 to 27 October 2017. The descriptive statistics of S&P-500 are given in
Table 4.
Table 5 shows that the mean returns are closed to zero. The Jarque–Bera statistics in
Table 5 also show that the null hypothesis of normality is rejected at any level of significance, as evidenced by the high excess kurtosis and negative skewness. Thus, it is clear that log returns of S&P-500 indexes have non-normal characteristics, excess kurtosis and fat tails. The result of the Ljung–Box test indicates that the raw returns are free from autocorrelation. Therefore, BXP and GP distributions could be applied to the independent and identically distributed observations.
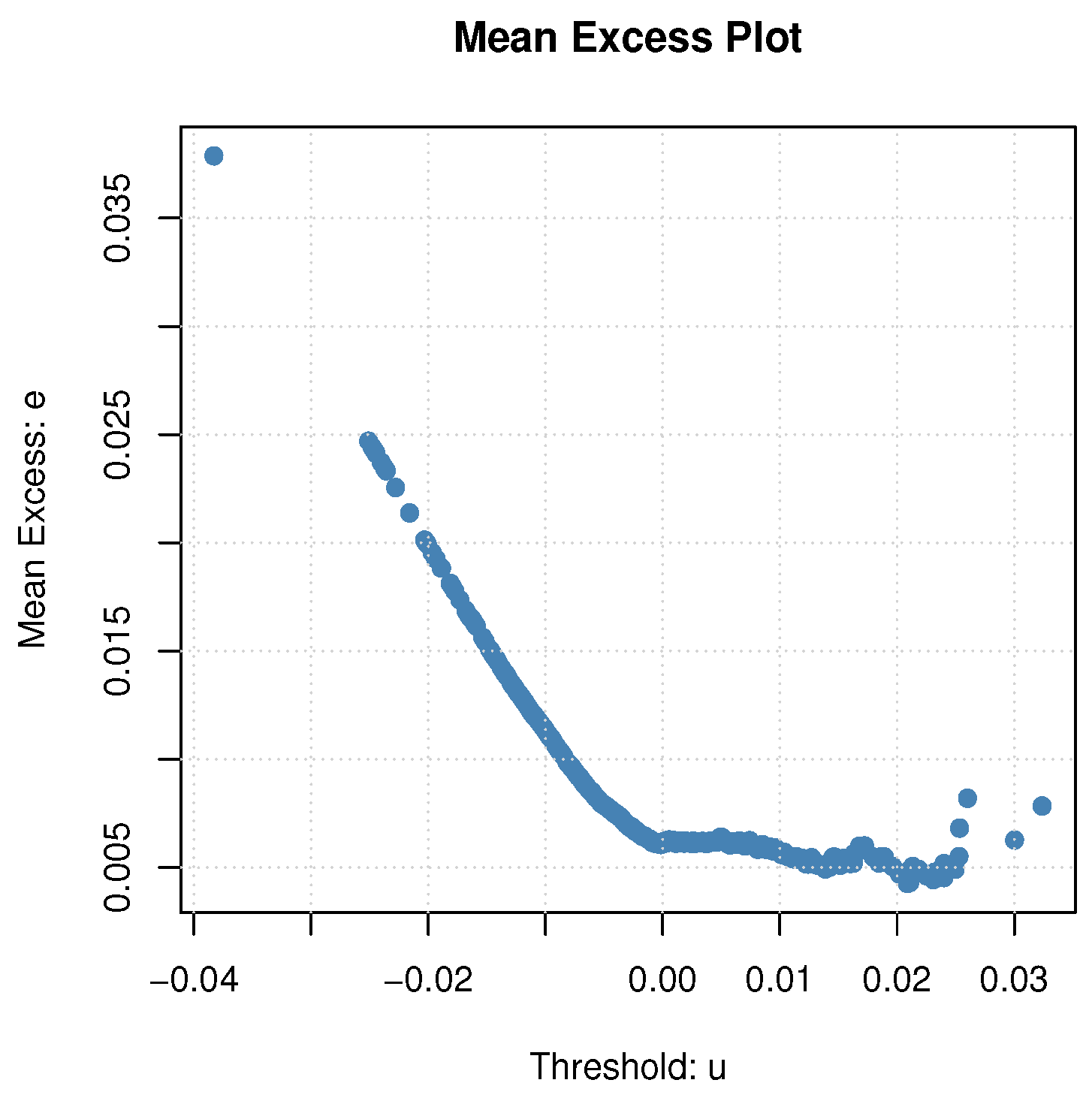
The ME plot is used to determine the optimal threshold value for the POT method.
Figure 4 displays the ME plot of the S&P-500 dataset. The optimal threshold could be chosen as 0.02 for the used dataset. It is near the 90% quantile value of the S&P-500.
Table 6 shows the estimated parameters of BXP distribution and GP distribution using the POT method for the S&P-500 dataset. Based on the figures in
Table 6, we conclude that since the BXP distribution has the lowest values of these statistics, BXP provides better fits than the GP distribution for tail modelling of S&P-500 indexes.
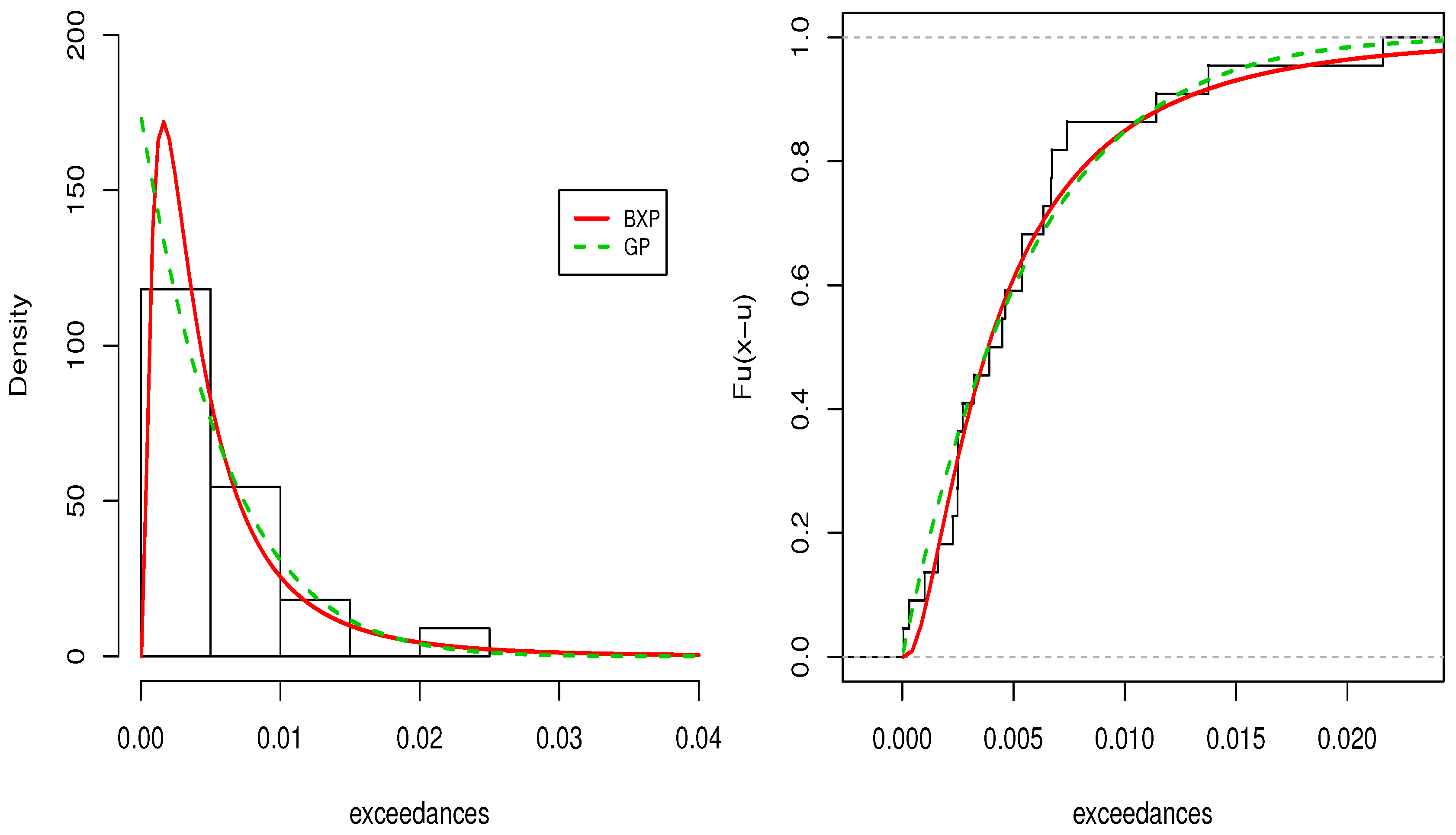
Figure 5 displays the fitted pdf and cdfs of the BXP and GP distributions.
Figure 5 reveals that the BXP distribution provides superior fits to the used dataset.
Here, VaR is estimated with the GP and BXP distribution using the POT method for values of
and
. The rolling window estimation method is used to evaluate the out-of-sample performance of the GP and BXP models. The first 1064 daily returns are used as the window length, and the next 400 data points are considered as out-of-sample period.
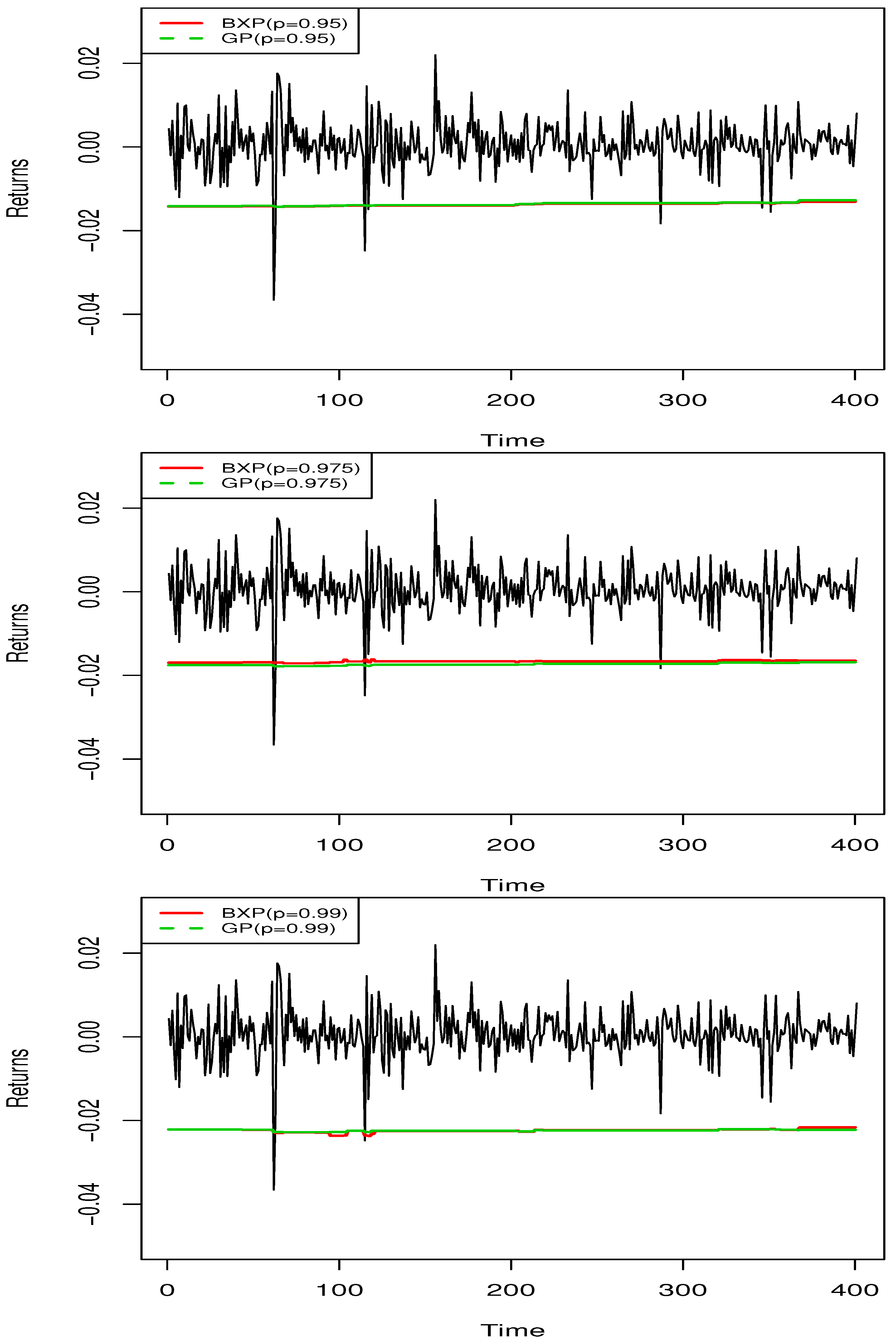
Figure 6 displays daily VaR estimates of the BXP and GP models. Based on
Figure 6, it is clear that the BXP and GP models produce similar VaR estimates. Therefore, the BXP model could be considered as an alternative VaR model against to GP model for financial institutions.
In VaR estimation, using the POT method is applied to raw return data assuming the distribution to be stationary or unconditional without considering the time-varying volatility. The POT method can also be considered as a dynamic model, where the conditional distribution of
F is taken into account and the volatility of returns is captured. The dynamic POT method based on the BXP distribution, combined with the generalized autoregressive conditional heteroscedasticity type process, introduced by
Bollerslev (
1986), could be considered as future work of this study.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}