1. Introduction
Econometric literature shows that modelling questions such as risk, resource use and the outcomes of alternative medical treatments is normally based on the use of covariates in regression models applied to microdata [
1–
6]. Several recent papers have proposed the use of covariates for the comparison of technologies through cost-effectiveness analysis (CEA). Hoch
et al. [
7] were pioneers in this research, showing that the use of regression analysis could produce more accurate estimates of treatment cost-effectiveness, by modelling the net monetary benefit in terms of covariates. Willan
et al. [
8] directly considered costs and effects jointly, assuming a bivariate normal distribution. Vázquez-Polo
et al. [
9] used an asymmetric framework in which costs are accounted for by effects, but effects, on the other hand, are not affected by cost. In a subsequent work, Vázquez-Polo
et al. [
10] proposed a general framework where effectiveness can be measured by means of a quantitative or a binary variable. In this study, costs were also analyzed taking into account the presence of a high degree of skewness in the distribution. Nixon and Thompson [
11] developed Bayesian methods whereby costs and effects are considered jointly, and allowed for the typically skewed distribution of cost data by using Gamma distributions. Manca
et al. [
12] also included covariates in a multilevel framework for multicentre studies.
One of the aims of regression models in CEA is to infer causal relationships between a dependent variable (cost or effectiveness) and the variable of interest (e.g., medical treatment). Other variables, known as control variables, are included to minimize the bias and uncertainty of the estimation when there are differences in the baseline characteristics of the treatment groups, as usually occurs in observational studies. Conditional on the model, estimates of these coefficients may be unbiased, but in the usual situation in which the single model selected is wrong, then estimates will be biased. However, most studies in this field omit from their analysis the selection of variables that are explanatory of treatment outcomes. The use of a single model may ignore the question of model uncertainty and thus lead to underestimation of the uncertainty concerning quantities of interest. In fact, the full model, including all control variables, would have a poorer predictive capacity than the true model when some of the covariate effects are zero. In this case, the uncertainty about the prediction may also be overestimated.
In this paper, we examine different methods for variable selection from a Bayesian perspective. The Bayesian approach to model selection and to accounting for model uncertainty overcomes the difficulties encountered with the classical approach, based on
p-values. Bayesian estimation expresses all uncertainty, including uncertainty about the correct model, in terms of probability. Therefore, we can directly estimate the subsequent probability of a model, or the probability that a covariate is included in the real model. Moreover, the estimation process for the Bayesian variable selection problem is, in principle, straightforward, with all results following directly from elementary probability theory, the definition of conditional probability, Bayes’ theorem and the law of total probability [
13–
15].
Raftery
et al. [
16] pioneered model selection and accounting for model uncertainty in linear regression models. The tutorial on Bayesian Model Averaging (BMA) given by Hoeting
et al. [
14] provides a historical perspective on the combination of models and gives further references. Although many papers have been published about Bayesian model selection in applied economic models [
17–
21, among others], there are few examples of this methodology in the health economics field. Recently, Negrín and Vázquez-Polo [
22] showed that the BMA methodology can potentially be used to guide the practitioner in choosing between models, and proposed the use of the Fractional Bayes Factor (FBF) for model comparison. In the present paper, we extend this study, to compare four alternative Bayesian procedures for model selection: the Bayes Information Criterion (BIC), the Intrinsic Bayes Factor (IBF), the Fractional Bayes Factor (FBF) and a novel procedure based on intrinsic priors [
23–
26]. The model selection is also applied to subgroup analysis and within the net benefit regression framework.
BMA has also been studied to account for uncertainty in non-linear regression models. For example, Conigliani and Tancredi [
27] proposed the use of Bayesian Model Averaging to model the distribution of costs as an average of a set of highly skewed distributions, while Jackson
et al. [
28] applied BMA in a long-term Markov model using Akaike’s Information Criterion (AIC) and BIC approximations. These authors concluded that the BIC method is more suitable when there is believed to be a relatively simple true model underlying the data. Jackson
et al. [
29] included uncertainty about the choice between plausible model structures for a Markov decision model, using Pseudo Marginal Likelihood (PML) and the Deviance Information Criterion (DIC) for model comparison.
Bayesian statistics are commonly employed in the field of cost-effectiveness analysis, with Spiegelhalter
et al. [
30] and Jones [
31] being among the first to discuss the Bayesian approach for statistical inference in the comparison of health technologies. Since then, many studies have used the Bayesian approach to compare treatment options by means of cost-effectiveness analysis [
32–
38].
The rest of this paper is organized as follows. Section 2 briefly reviews the Bayesian variable selection procedures, and presents the four methods that are compared in this paper. Section 3 describes a simulation study carried out to validate the different methods. A practical application with real data is shown in Section 4, together with some possible applications of variable selection in the economic evaluation context. Finally, in Section 5, the work is summarised and some conclusions drawn.
3. A Simulated Experiment
In this section we validate the variable selection methods proposed in the previous section for linear regression models, using simulated data. Our aim is not to study the differences between methods in a wide variety of circumstances, but rather to show how the models perform and how large the posterior probability of inclusion must be to suggest that a variable, such as treatment, influences the outcome.
We simulate six variables (
x1, ...,
x6) following the distributions described in
Table 1. The first three variables are simulated from normal distributions, the next two are discrete variables following a Bernoulli process, and the last one is distributed as a Poisson distribution. The parameters of the simulated distributions are shown in
Table 1. The dependent variable
y is obtained as a linear combination of three of them (
x2,
x4 and
x6). The expression used to obtain
y is also shown in
Table 1.
We evaluate the results of the different methods for three different sample sizes
n1 = 30,
n2 = 100,
n3 = 300. For every method, we estimate the probability of all possible models. To calculate the probability of inclusion for each covariate, we sum the probabilities of the different models that include this covariate. The results are shown in
Tables 2,
3 and
4, respectively.
Some conclusions can be drawn from these results. For our standard sampling model, the four models tested obtain very similar and accurate results. The BIC and the Bayes Factor for intrinsic priors seem to be slightly better than the others, providing higher probabilities of inclusion for the explanatory variables (x2, x4 and x6). For the smallest sample size (n1 = 30), the methods only estimate around 55% of inclusion for the binary variable x4. As expected, with large sample sizes the probabilities of inclusion for the relevant covariates are close to one and the results for the four methods are very similar.
The simulation results suggest that the probability of a true covariate being accepted depends on the distribution of the covariate and the sample size. With a small sample size, covariates with a probability of inclusion greater than 50% could be judged to truly affect the outcome. However, with sample sizes exceeding 300, the required probability of inclusion should be more than 80%.
As well as the probability of inclusion, using the Bayesian variable selection described in Section 2 it is possible to estimate the posterior probability of each model. The selection of the model with the highest probability can lead to erroneous conclusions being drawn, because this ignores the probability associated with the other models. Of course, this method would be appropriate when the posterior probability of the best model is very high. In our simulated experiment, the true model was always found to be the model with the highest posterior probability for the selection model based on BIC, although this probability varied for different sample sizes (22.32%, 33.08% and 77.61%, for the sample sizes 30, 100 and 300, respectively). The IBF obtains similar results to those of the BIC model. However, the FBF and the procedure based on intrinsic priors produce the model that includes the covariates x2, x3, x4 and x6 as the most probable model for a sample size of 100, although the posterior probability is very similar to that obtained by the real model (32.83% vs. 32.35% for the FBF, and 27.96% vs. 25.34% for the procedure based on intrinsic priors).
4. Practical Application
We analyzed the usefulness of these methods for variable selection with a real clinical trial, comparing two highly-active antiretroviral treatment protocols applied to asymptomatic HIV patients [
51]. Each treatment combines three drugs and we denote them as control treatment (d4T + 3TC + IND) and new treatment (d4T + ddl + IND).
We obtained data on effectiveness, QALYs using EuroQol-5D [
52], and on the direct costs for the 361 patients included in the study. The QALYs were calculated as the area above/below the utility value. This approach to QALYs takes into account the differences in baseline utility values [
53]. All patients kept a monthly diary for six months to record resource consumption and quality of life progress.
As control variables we considered the
age, the
gender (value 0 for a male patient and value 1 for a female) and the existence of any concomitant illness (
cc1 with a value of 1 if a concomitant illness is present, and 0 otherwise, and
cc2 with a value of 1 if two or more concomitant illnesses are present, and 0 otherwise). The concomitant illnesses considered were hypertension, cardiovascular disease, allergies, asthma, diabetes, gastrointestinal disorders, urinary dysfunction, previous kidney pathology, high levels of cholesterol and/or triglycerides, chronic skin complaints and depression/anxiety. The time (in months) elapsed from the start of the illness until the moment of the clinical trial was also included in the model. Finally, the treatment was included as a dichotomous variable (
T) that was assigned a value of 1 if the patient received the (d4T + ddl + IND) treatment protocol and a value of 0 if the (d4T + 3TC + IND) treatment was applied.
Table 5 summarizes the statistical data.
Our aim is to explain the effectiveness and cost as a function of the treatment received, and controlled by covariates. The full model includes all the control variables and is given by:
The joint likelihood for β,δ,Σ is defined by a multivariate normal distribution:
where
.
Effectiveness and cost are not independent and so we allow some correlation between the error terms of both equations. However, model selection is computationally complex when bivariate distributions are considered [
54,
55]. Posterior probabilities cannot be calculated analytically, and Markov Chain Monte Carlo (MCMC) techniques are required. For this reason, we performed Bayesian variable selection for each equation separately (assuming σ
uv = 0). Although the proposed model allows for the existence of correlation between effectiveness and costs, in this practical application, as in many others, this correlation is low (the sample correlation is −0.0006). The final model is estimated assuming this correlation after calculating the probabilities of inclusion for each covariate [
8,
10].
Cost transformations, as a logarithm, are often proposed to take account of the right skewing which is often present. However, this transformation poses a difficulty for the interpretation of the results, because due to the robustness of linear methods, costs are not transformed in the presence of low levels of right-skewing, as has been shown by Willan
et al. [
8] with simulated data. Log-normal, gamma or other skewed distributions would be more suitable for very skewed data [
11]. Selection and averaging between models with non-normal distributions are discussed in [
27] although covariates are not considered in the latter paper.
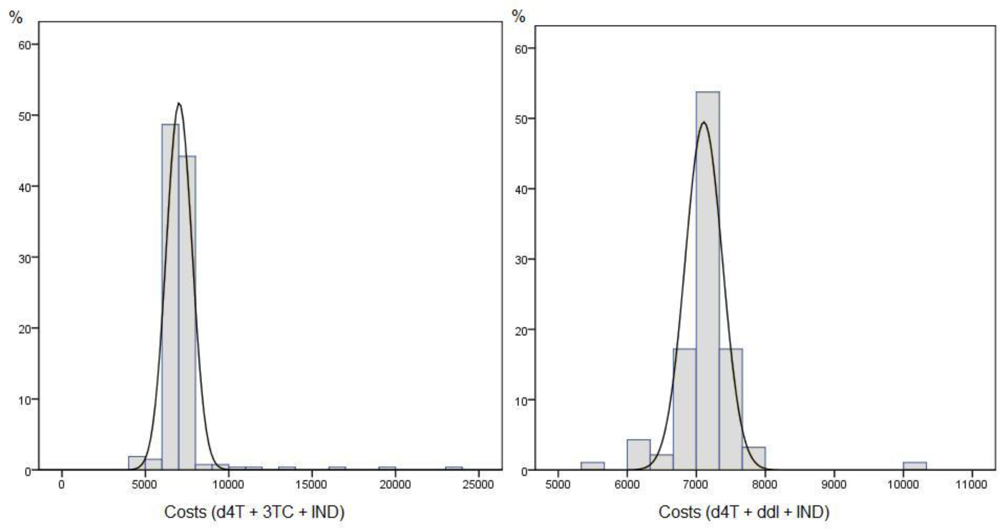
Figure 1 shows the costs histogram for each treatment in our practical application.
The results of variable selection under the four methods and for both equations, effectiveness and cost, are shown in
Table 6.
Only one control variable was found to have relevant explanatory power (cc2 in the effectiveness equation). The posterior probabilities for the other control variables were always below 30%. In this example, the analysis based on the full model would achieve very different conclusions from those obtained by the real model.
The most probable model for effectiveness includes only one control variable in the equation (cc2). The probability associated with this variable varies from 56.02%, for the BIC criterion, to 48.70% for the procedure based on intrinsic priors.
The most probable model for cost does not include any control variables. The posterior probabilities of this model are 67.47% for BIC, 15.36% for IBF, 50.69% for FBF and 61.94% for the procedure based on intrinsic priors. Results for the most probable model are shown in
Table 7.
The aim of a regression framework applied to cost-effectiveness analysis is to calculate the incremental effectiveness and incremental cost by estimating the coefficient of the treatment indicator in the effectiveness and cost equations, respectively. For this reason, we also include the treatment indicator in the final model. The incremental effectiveness is estimated as being 0.001714, with a posterior 95% Bayesian interval (−0.01341, 0.01699). The incremental cost is estimated as being 164.1 euros, with a posterior 95% Bayesian interval (−215.9, 543.6).
4.1. Probability of the Inclusion of the Treatment in the Regression Model
One probability that deserves special mention is the posterior probability of the treatment. The aim of cost-effectiveness analysis is to estimate the incremental effectiveness and incremental cost of a new treatment versus the control. The inclusion of the treatment indicator in the equations of cost and effectiveness allows the analyst to estimate the incremental effectiveness and cost from their respective coefficients (β
T and δ
T). In this practical application, we show that the probabilities of inclusion of the treatment indicator in the effectiveness and cost equations are very low (0.05304 and 0.07019, respectively for the BIC method). The conclusion of this result is that the treatment indicator is not a good predictor of the effectiveness or cost, as the incremental effectiveness and cost are close to zero. However, in the model shown in
Table 7, the treatment indicator is included in the final model, ignoring model uncertainty. From the width of the Bayesian intervals of the treatment indicator in both equations, we conclude that differences in incremental effectiveness and cost are not relevant between different treatments, and that a point estimation based on the posterior mean would be biased.
We can estimate only the most probable model, but in our example this model only has a probability close to 50% and the estimation based on this model ignores the uncertainty about the other models. BMA [
14,
56,
57] provides a natural Bayesian solution to estimation in the presence of model uncertainty. The estimation of the coefficients is obtained as a combination of the coefficients estimated for each model, weighted by the posterior probability of each model. Therefore, the mean of the incremental effectiveness (the expression is analogous for the incremental cost) is obtained by the expressions:
An expression for the posterior variance of β
T is given by Leamer [
58]:
Negrín and Vázquez-Polo [
22] described an application of BMA in a cost-effectiveness analysis using the same data set. The estimated incremental effectiveness was 0.00141, with a standard deviation of 0.0047, for the full model and 0.00018, with a standard deviation of 0.00162, when BMA methodology was applied. The incremental cost was 164.3125 euros, with a standard deviation of 196.5101, for the full model and 98.9067, with a standard deviation of 170.4027, for the BMA model. It is important to point out that these results are not fully comparable with those given in this paper because [
22] included prior information on the models.
4.2. Subgroup Analysis
Subgroup analysis is becoming a relevant aspect of economic evaluation [
8,
11]. For example, suppose that we are interested in determining whether a certain subgroup has the same incremental effectiveness or incremental cost as a reference subgroup. The regression model allows for subgroup analysis by including the interaction between the subgroup indicator and the treatment indicator. The existence of subgroups is studied by analyzing the statistical relevance of this interaction. Classical hypothesis tests have been proposed for this item, but Bayesian variable selection allows a natural quantity to be estimated, as this is the posterior probability of inclusion.
As an example, suppose that we are interested in studying whether there are differences in treatment results between males and females. To analyze the relevance of the subgroup, we include the interaction gender × T as an explanatory covariate of effectiveness and cost.
The posterior probability of inclusion of the interaction in the effectiveness equation varies from the 9.1844% of the BIC method to the 17.2234% of the intrinsic priors method. In view of these results, we cannot accept the existence of a subgroup in the effectiveness model. Analogously, the posterior probability of inclusion in the cost equation varies from the 19.0928% of the BIC method to the 49.4215% of the IBF method. In this case, the probability of there being a subgroup in the cost model is higher, although it is always below 50%.
It is important to recall that in conventional frequentist clinical trial protocols, it is mandatory to specify any intended subgroup analysis in advance, and drug regulatory agencies are very wary of allowing claims for subgroup effects, because of the risk of data dredging [
59–
61]. In Bayesian analysis, the corresponding guidance should be that the prior distributions for the coefficients of these interaction terms must be specified to reflect genuine belief about how large such subgroup effects might realistically be, based on the existence and plausibility of appropriate biological mechanisms [
62]. We have shown in this subsection that Bayesian variable selection methodology can be used for exploratory subgroup analysis.
4.3. Net Benefit Regression Framework
The Net Benefit regression framework was introduced to facilitate the use of regression tools in economic evaluation [
7]. Net benefit regression uses as the dependent variable the net benefit,
z =
R·
e–
c, where
e refers to the effectiveness,
c refers to the cost and
R is the ceiling ratio, which can be interpreted as the decision maker’s willingness to pay for an increment in effectiveness. The equation should include an indicator of the treatment provided. The coefficient of this indicator is equal to the difference in mean net benefit for the new and control treatments. It has been shown [
7,
8] that when this difference is greater than zero then the incremental net benefit is positive and the new treatment is preferred.
A difficulty with the net benefit regression framework is that the net benefit depends upon the decision maker’s willingness to pay (
R), a value that is not known from the cost and effect data. Thus, it is necessary to estimate a new equation for each value of
R considered. The variable selection procedures can be applied to this framework. As an example,
Table 8 shows the results of the variable selection with the intrinsic priors method for three different values of
R (
R1 = 0,
R2 = 50,000 and
R3 = 100,000). As expected, the probabilities of inclusion for
R = 0 coincide with the cost equation in
Table 6. For greater values of
R, the probabilities of inclusion will be more similar to those obtained for the effectiveness equation.
5. Conclusions
Linear regression is often used to account for the cost and effectiveness of medical treatment. The covariates may include sociodemographic variables, such as age, gender or race; clinical variables, such as initial health status, years of treatment or the existence of concomitant illnesses; and a binary variable indicating the treatment received. The coefficient of the treatment variable for the effectiveness and cost regression can be interpreted as the incremental effectiveness and incremental cost, respectively. Several recent studies have been made of the usefulness of including covariates in cost-effectiveness analysis, using approaches based on incremental cost-effectiveness or incremental net benefit [
7–
8,
11]. These studies were carried out in a frequentist framework, while Vázquez-Polo
et al. [
10] developed a similar analysis from a Bayesian perspective.
However, most studies assume only one model, usually the full one. In so doing, they ignore the uncertainty in model selection. In the present paper, we consider the four most important alternative Bayesian variable selection methods for estimating the posterior probability of inclusion of each covariate. A simulation exercise shows the performance of these methods with linear regression models, and we conclude that all of them have high and similar levels of accuracy. It has long been known that when sample sizes are large, the BIC criterion provides a reasonable preferred model, in view of its straightforward approximation procedure and the use of an implicit prior. As the four proposed methods in the paper do not give widely varying conclusions in the real example, the choice of which of these criteria to use depends on the purpose of the model assessment [
28]. In our practical application, we considered a moderately large sample, and thus the BIC measure yielded an easily computable quantity with no need for computer-intensive calculations. For small sample sizes, we recommend the use of IBF or BF under intrinsic priors, due to the good properties presented by these methods: the measures are completely automatic Bayes factors, IBFs are applicable to nested as well as nonnested models, and they are invariant to univariate transformations of the data, among other advantages [
40]. The Bayesian procedures for variable selection with intrinsic priors are consistent and, furthermore, Lindley’s paradox (
i.e., a point null hypothesis on the normal mean parameter is always accepted when the variance of the conjugate distribution tends to infinity) does not arise. We believe, in accordance with Casella
et al. [
25] that ‘intrinsic priors provide a type of objective Bayesian prior for the testing problem. They seem to be among the most diffuse priors that are possible to use in testing, without encountering problems with indeterminate Bayes factors, which was the original impetus for the development of Berger and Pericchi [
40]. Moreover, they do not suffer from “Lindley’s paradox” behavior. Thus, we believe they are a very reasonable choice for experimenters looking for an objective Bayesian analysis with a frequentist guarantee.’
All the Bayesian model selection procedures presented enable the estimation of the posterior probability of each possible model and the probability of inclusion of each covariate. When the posterior probability of the “best” model is reasonably high, the use of this model is accurate. However, when the number of models compared is large, then the associated probability of the “best” model might be low. In this case, the BMA strategy provides a more appropriate alternative.
Moreover, complementary analyses are possible with variable selection. Thus, the incremental effectiveness and incremental cost may be estimated using BMA. Here, we advocate BMA analysis as the most coherent way to estimate the quantities of interest under model uncertainty.
Another interesting application of variable selection is subgroup analysis. The regression model allows for subgroup analysis by the inclusion of the interaction between the subgroup indicator and the treatment indicator. The existence of subgroups is studied by analyzing the statistical relevance of this interaction; this is precisely the aim of variable selection.
One difficulty with the variable selection approach is the computational burden involved when the number of possible regressors
k is large or when interactions are considered. Then, the number of models becomes so large that it is impossible to compute all the posterior probabilities. In this case, we need to resort to a stochastic algorithm to compute only the high posterior probability model. An example of such an algorithm is given by Casella and Moreno [
23]. This difficulty is not inherent to any specific variable selection procedure but is shared by all existing procedures.


{kind=link}