_Garrett.png)
Distinguish the Severity of Illness Associated with Novel Coronavirus (COVID-19) Infection via Sustained Vowel Speech Features


Abstract
1. Introduction
2. Method
2.1. Ethical Considerations
2.2. Data Collection
2.3. Subject Classification and Extraction for Machine Learning
2.4. Voice Recording
2.5. Voice Analysis
3. Results
3.1. Selection of Voice Data for Analysis
3.2. Feature Selection
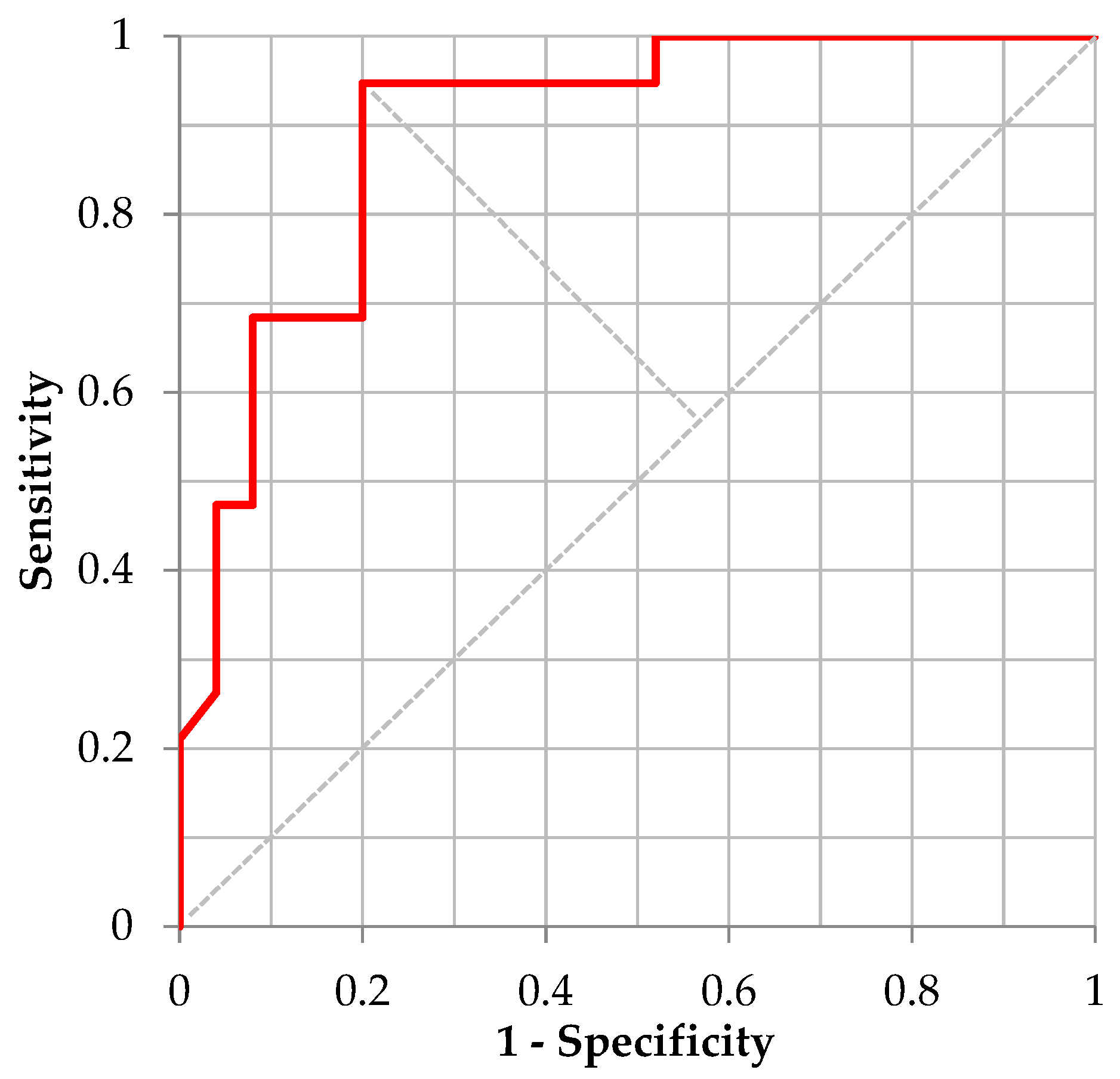
3.3. Validation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ministry of Health, Labour and Welfare, Japan. A Guide to Medical Care of COVID-19, Version 8.1 (Japanese). 5 October 2022. Available online: https://www.mhlw.go.jp/content/000936655.pdf (accessed on 22 November 2022).
- Higuchi, M.; Nakamura, M.; Shinohara, S.; Omiya, Y.; Takano, T.; Mitsuyoshi, S.; Tokuno, S. Effectiveness of a Voice-Based Mental Health Evaluation System for Mobile Devices: Prospective Study. JMIR Form. Res. 2020, 4, e16455. [Google Scholar] [CrossRef] [PubMed]
- Shinohara, S.; Nakamura, M.; Omiya, Y.; Higuchi, M.; Hagiwara, N.; Mitsuyoshi, S.; Toda, H.; Saito, T.; Tanichi, M.; Yoshino, A.; et al. Depressive Mood Assessment Method Based on Emotion Level Derived from Voice: Comparison of Voice Features of Individuals with Major Depressive Disorders and Healthy Controls. Int. J. Environ. Res. Public Health 2021, 18, 5435. [Google Scholar] [CrossRef] [PubMed]
- Shimon, C.; Shafat, G.; Dangoor, I.; Ben-Shitrit, A. Artificial Intelligence Enabled Preliminary Diagnosis for COVID-19 from Voice Cues and Questionnaires. J. Acoust. Soc. Am. 2021, 149, 1120–1124. [Google Scholar] [CrossRef]
- Dang, T.; Han, J.; Xia, T.; Spathis, D.; Bondareva, E.; Siegele-Brown, C.; Chauhan, J.; Grammenos, A.; Hasthanasombat, A.; Floto, R.A.; et al. Exploring Longitudinal Cough, Breath, and Voice Data for COVID-19 Progression Prediction via Sequential Deep Learning: Model Development and Validation. J. Med. Internet Res. 2022, 24, e37004. [Google Scholar] [CrossRef] [PubMed]
- Quatieri, T.F.; Talkar, T.; Palmer, J.S. A Framework for Biomarkers of COVID-19 Based on Coordination of Speech-Production Subsystems. IEEE Open J. Eng. Med. Biol. 2020, 1, 203–206. [Google Scholar] [CrossRef] [PubMed]
- Brown, C.; Chauhan, J.; Grammenos, A.; Han, J.; Hasthanasombat, A.; Spathis, D.; Xia, T.; Cicuta, P.; Mascolo, C. Exploring Automatic Diagnosis of COVID-19 from Crowdsourced Respiratory Sound Data. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; ACM: New York, NY, USA, 2020; pp. 3474–3484. [Google Scholar]
- Bartl-Pokorny, K.D.; Pokorny, F.B.; Batliner, A.; Amiriparian, S.; Semertzidou, A.; Eyben, F.; Kramer, E.; Schmidt, F.; Schönweiler, R.; Wehler, M.; et al. The Voice of COVID-19: Acoustic Correlates of Infection in Sustained Vowels. J. Acoust. Soc. Am. 2021, 149, 4377–4383. [Google Scholar] [CrossRef] [PubMed]
- Maor, E.; Tsur, N.; Barkai, G.; Meister, I.; Makmel, S.; Friedman, E.; Aronovich, D.; Mevorach, D.; Lerman, A.; Zimlichman, E.; et al. Noninvasive Vocal Biomarker Is Associated with Severe Acute Respiratory Syndrome Coronavirus 2 Infection. Mayo Clin. Proc. Innov. Qual. Outcomes 2021, 5, 654–662. [Google Scholar] [CrossRef]
- Stasak, B.; Huang, Z.; Razavi, S.; Joachim, D.; Epps, J. Automatic Detection of COVID-19 Based on Short-Duration Acoustic Smartphone Speech Analysis. J. Healthc. Inform. Res. 2021, 5, 201–217. [Google Scholar] [CrossRef] [PubMed]
- Ren, Z.; Nishimura, M.; Tjan, L.H.; Furukawa, K.; Kurahashi, Y.; Sutandhio, S.; Mori, Y. Large-scale serosurveillance of COVID-19 in Japan: Acquisition of neutralizing antibodies for Delta but not for Omicron and requirement of booster vaccination to overcome the Omicron’s outbreak. PLoS ONE 2022, 17, e0266270. [Google Scholar] [CrossRef]
- Trend in the Number of Newly Confirmed Cases (Daily) in Japan. Available online: https://covid19.mhlw.go.jp/public/opendata/confirmed_cases_cumulative_daily.csv (accessed on 10 February 2023).
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile. In Proceedings of the international conference on Multimedia—MM ’10, Firenze, Italy, 25–29 October 2010; ACM Press: New York, NY, USA, 2010; p. 1459. [Google Scholar]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation Importance: A Corrected Feature Importance Measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef]
- Ke, G. LightGBM: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems 30 (NIPS 2017); NeurlPS: Long Beach, CA, USA, 2017; pp. 3146–3154. [Google Scholar]
- Marquez, C.; Kerkhoff, A.D.; Schrom, J.; Rojas, S.; Black, D.; Mitchell, A.; Wang, C.-Y.; Pilarowski, G.; Ribeiro, S.; Jones, D.; et al. COVID-19 Symptoms and Duration of Rapid Antigen Test Positivity at a Community Testing and Surveillance Site During Pre-Delta, Delta, and Omicron BA.1 Periods. JAMA Netw. Open 2022, 5, e2235844. [Google Scholar] [CrossRef] [PubMed]
- Vihta1, K.D.; Pouwels, K.B.; Peto1, T.E.; Pritchard, E.; House, T.; Studley, R.; Rourke, E.; Cook, D.; Diamond, I.; Crook, D.; et al. Omicron-Associated Changes in SARS-CoV-2 Symptoms in the United Kingdom. Clin. Infect. Dis. 2022, 76, e133–e141. [Google Scholar] [CrossRef] [PubMed]
- Takuya, A.; Shotaro, S.; Toshihiko, Y.; Takeru, O.; Masanori, K. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- van Rossum, G.; Drake, F.L. Python Language Reference Manual. In Python Language Reference Manual; Network Theory Ltd.: Godalming, UK, 2003. [Google Scholar]
- Abitbol, J.; Abitbol, P.; Abitbol, B. Sex hormones and the female voice. J. Voice 1999, 13, 424–446. [Google Scholar] [CrossRef] [PubMed]
- Taguchi, T.; Tachikawa, H.; Nemoto, K.; Suzuki, M.; Nagano, T.; Tachibana, R.; Arai, T. Major depressive disorder discrimination using vocal acoustic features. J. Affect. Disord. 2018, 225, 214–220. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Severity | Oxygen Saturation | Clinical State |
|---|---|---|
| Mild illness | SpO2 ≥ 96% | No respiratory symptom (no findings consistent with pneumonia) or Cough only without any shortness of breath (no findings consistent with pneumonia) |
| Moderate illness I No respiratory failure | 93% < SpO2 < 96% | Shortness of breath and pneumonia findings |
| Moderate illness II Respiratory failure | SpO2 ≤ 93% | Oxygen administration required |
| Acute | ICU admission or Ventilator needed |
| Timing | Item | Description |
|---|---|---|
| Join | Participation | Explaining the research outline and obtaining consent |
| Basic Data | Sex, Age, Symptom onset date, Diagnosis confirmation date, Treatment start date | |
| At the time of participation in research | Vitals data | Body temperature, Blood oxygen saturation |
| Questionnaire | Change of symptoms, Symptomatic or not, Respiratory distress, Taste/olfactory disorder, Cough/sputum, Chest pain, Runny nose/nasal congestion, Sore throat, Nausea/vomiting, Diarrhea, Appetite, Fatigue, Headache, Joint pain, Rash, Red eyes | |
| Voice recording | Three sustained vowels | |
| During treatment (recuperation) | Questionnaire | Confirmation on reason for treatment end (discontinuation) |
| Follow up (1 month, 3 months, and 6 months after the end of the recuperation period) | Vitals data | Body temperature, Blood oxygen saturation (for possible subjects only) |
| Questionnaire | Change of symptoms, Symptomatic or not, Respiratory distress, Taste/olfactory disorder, Cough/sputum, Chest pain, Runny nose/nasal congestion, Sore throat, Nausea/vomiting, Diarrhea, Appetite, Fatigue, Headache, Joint pain, Rash, Red eyes | |
| Voice recording | Three sustained vowels |
| Target Period | Age | Male | Male Age (Mean ± SD) | Female | Female Age (Mean ± SD) |
|---|---|---|---|---|---|
| 5th wave and prior (~31 December 2021) | 20–29 | 13 (1) | 37.5 ± 12.1 | 19 (9) | 32.0 ± 11.0 |
| 30–39 | 13 (6) | 3 (0) | |||
| 40–49 | 9 (5) | 3 (2) | |||
| 50–59 | 7 (4) | 5 (3) | |||
| 60–69 | 0 (0) | 0 (0) | |||
| 70–79 | 1 (1) | 0 (0) | |||
| 80–89 | 0 (0) | 0 (0) | |||
| subtotal | 43 (17) | - | 30 (14) | - | |
| 6th wave and beyond (1 January 2022~) | 20–29 | 30 (1) | 46.3 ± 12.9 | 54 (9) | |
| 30–39 | 44 (6) | 67 (0) | |||
| 40–49 | 70 (5) | 70 (2) | |||
| 50–59 | 55 (4) | 59 (3) | 41.9 ± 12.6 | ||
| 60–69 | 35 (0) | 14 (0) | |||
| 70–79 | 7 (1) | 3 (0) | |||
| 80–89 | 0 (0) | 1 (0) | |||
| subtotal | 241 (17) | - | 267 (14) | - | |
| All periods | Total | 284 (34) | 45.0 ± 13.2 | 297 (28) | 40.9 ± 12.8 |
| Symptom | 5th Wave and Prior (~31 December 2021) | 6th Wave and Beyond (1 January 2022~) |
|---|---|---|
| SpO2 ≤ 95% | 9 (12.3%) | 34 (6.7%) |
| Body temperature ≥ 37.5 °C | 7 (9.6%) | 22 (4.3%) |
| Symptomatic | 44 (60.3%) | 386 (76.0%) |
| Respiratory distress | 13 (17.8%) | 96 (18.9%) |
| Taste/olfactory disorder | 14 (19.2%) | 77 (15.2%) |
| Cough/sputum | 37 (50.7%) | 366 (72.0%) |
| Chest pain | 9 (12.3%) | 78 (15.4%) |
| Runny nose/nasal congestion | 27 (37.0%) | 299 (58.9%) |
| Sore throat | 21 (28.8%) | 270 (53.1%) |
| Nausea | 9 (12.3%) | 25 (4.9%) |
| Diarrhea | 16 (21.9%) | 75 (14.8%) |
| Loss of appetite | 21 (28.8%) | 111 (21.9%) |
| Fatigue | 28 (38.4%) | 215 (42.3%) |
| Headache | 20 (27.4%) | 147 (28.9%) |
| Joint pain | 15 (20.5%) | 95 (18.7%) |
| Rash | 3 (4.1%) | 17 (3.3%) |
| Red eyes | 5 (6.8%) | 24 (4.7%) |
| Total | 73 | 508 |
| No. | Contents |
|---|---|
| Phrase01 | /Ah/ |
| Phrase02 | /Eh/ |
| Phrase03 | /Uh/ |
| Parameters | /Ah/ | /Eh/ | /Uh/ |
|---|---|---|---|
| objective | binary | binary | binary |
| metric | binary_logloss | binary_logloss | binary_logloss |
| learning rate | 0.01 | 0.01 | 0.01 |
| lambda_l1 | 2.53 × 10−6 | 0.00 | 0.00 |
| lambda_l2 | 6.50 × 10−3 | 0.00 | 0.00 |
| num_leaves | 31 | 31 | 31 |
| feature fraction | 0.42 | 0.40 | 0.80 |
| bagging_fraction | 0.84 | 1.00 | 1.00 |
| bagging_freq | 5 | 0 | 0 |
| min_child_samples | 10 | 10 | 5 |
| Severity | ||
|---|---|---|
| Target Period | Mild Illness | Moderate Illness I |
| 5th wave and prior | 19 | 12 |
| 6th wave and beyond | 19 | 12 |
| All periods | 38 | 24 |
| Phrase | Selected Features with Rank_Importance |
|---|---|
| /Ah/ | 1. mfcc_sma(10)_upleveltime50 |
| 2. audSpec_Rfilt_sma_de(16)_mtmAmpStddevRel | |
| 3. pcm_fftMag_spectralMinPos_sma_de_peakRangeRel | |
| 4. mfcc_sma(11)_max | |
| 5. audSpec_Rfilt_sma_de(11)_rightctime | |
| /Eh/ | 1. pcm_fftMag_fband90-180_sma_de_rightctime |
| 2. mfcc_sma(3)_downleveltime75 | |
| 3. mfcc_sma(8)_downleveltime90 | |
| 4. pcm_fftMag_spectralRollOff90.0_sma_de_peakRangeAbs | |
| 5. audSpec_Rfilt_sma_de(1)_stddevFallingSlope | |
| 6. audSpec_Rfilt_sma_de(1)_lpc3 | |
| 7. audSpec_Rfilt_sma_de(1)_lpc4 | |
| 8. mfcc_sma(14)_percentile98.0 | |
| /Uh/ | 1. audSpec_Rfilt_sma(13)_lpc4 |
| 2. pcm_fftMag_spectralHarmonicity_sma_de_minRangeRel | |
| 3. audSpec_Rfilt_sma(12)_lpc4 | |
| 4. audSpec_Rfilt_sma_de(19)_numPeaks | |
| 5. audSpec_Rfilt_sma(21)_ptpAmpStddevAbs | |
| 6. pcm_fftMag_spectralMinPos_sma_de_ptpAmpMeanAbs | |
| 7. audSpec_Rfilt_sma(16)_lpc4 | |
| 8. audSpec_Rfilt_sma_de(11)_ptpAmpMeanRel | |
| 9. audSpec_Rfilt_sma(19)_upleveltime25 | |
| 10. audSpec_Rfilt_sma_de(8)_numSegments | |
| 11. pcm_fftMag_spectralCentroid_sma_de_leftctime | |
| 12. mfcc_sma_de(11)_quartile1 | |
| 13. voicingFinalUnclipped_sma_de_lpc4 | |
| 14. pcm_fftMag_psySharpness_sma_de_leftctime | |
| 15. mfcc_sma(9)_linregc2 | |
| 16. mfcc_sma_de(14)_ptpAmpStddevAbs |
| Predicted Group | |||
|---|---|---|---|
| Mild Illness | Moderate Illness I | ||
| Actual group | Mild Illness | 37 | 1 |
| Moderate Illness I | 9 | 15 |
| Predicted Group | |||
|---|---|---|---|
| Mild Illness | Moderate Illness I | ||
| Actual group | Mild Illness | 20 | 5 |
| Moderate Illness I | 1 | 18 |
| Predicted Group | |||
|---|---|---|---|
| Mild Illness | Moderate Illness I | ||
| Actual group | Mild Illness | 19 | 5 |
| Moderate Illness I | 2 | 13 |
| Predicted Group | |||
|---|---|---|---|
| Mild Illness | Moderate Illness I | ||
| Actual group | Mild Illness | 36 | 2 |
| Moderate Illness I | 5 | 19 |
| Target Data | Judgement | Data Count | ||
|---|---|---|---|---|
| /Ah/ | /Eh/ | /Uh/ | ||
| Voice | Normal | 983 | 1122 | 1073 |
| Noisy (low) | 447 | 474 | 544 | |
| Noisy (high) | 379 | 367 | 507 | |
| Cough | 12 | 13 | 9 | |
| Volume | 526 | 352 | 207 | |
| Short, sustained duration | 25 | 16 | 16 | |
| Other issues | 224 | 248 | 235 | |
| No recording | 464 | 468 | 469 | |
| Questionnaire | Normal value | 2975 | ||
| Anomalous value | 85 | |||
| Total registrations | 3060 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Omiya, Y.; Mizuguchi, D.; Tokuno, S. Distinguish the Severity of Illness Associated with Novel Coronavirus (COVID-19) Infection via Sustained Vowel Speech Features. Int. J. Environ. Res. Public Health 2023, 20, 3415. https://doi.org/10.3390/ijerph20043415
Omiya Y, Mizuguchi D, Tokuno S. Distinguish the Severity of Illness Associated with Novel Coronavirus (COVID-19) Infection via Sustained Vowel Speech Features. International Journal of Environmental Research and Public Health. 2023; 20(4):3415. https://doi.org/10.3390/ijerph20043415
Chicago/Turabian StyleOmiya, Yasuhiro, Daisuke Mizuguchi, and Shinichi Tokuno. 2023. "Distinguish the Severity of Illness Associated with Novel Coronavirus (COVID-19) Infection via Sustained Vowel Speech Features" International Journal of Environmental Research and Public Health 20, no. 4: 3415. https://doi.org/10.3390/ijerph20043415
APA StyleOmiya, Y., Mizuguchi, D., & Tokuno, S. (2023). Distinguish the Severity of Illness Associated with Novel Coronavirus (COVID-19) Infection via Sustained Vowel Speech Features. International Journal of Environmental Research and Public Health, 20(4), 3415. https://doi.org/10.3390/ijerph20043415