


Diagnostic Accuracy of Differential-Diagnosis Lists Generated by Generative Pretrained Transformer 3 Chatbot for Clinical Vignettes with Common Chief Complaints: A Pilot Study

 ,
,  , ,
, ,
Abstract
1. Introduction
1.1. Clinical Decision Support and Artificial Intelligence
1.2. GPT-3 and ChatGPT-3
1.3. Other CDS Systems
1.4. Related GPT-3 Work for Healthcare
2. Materials and Methods
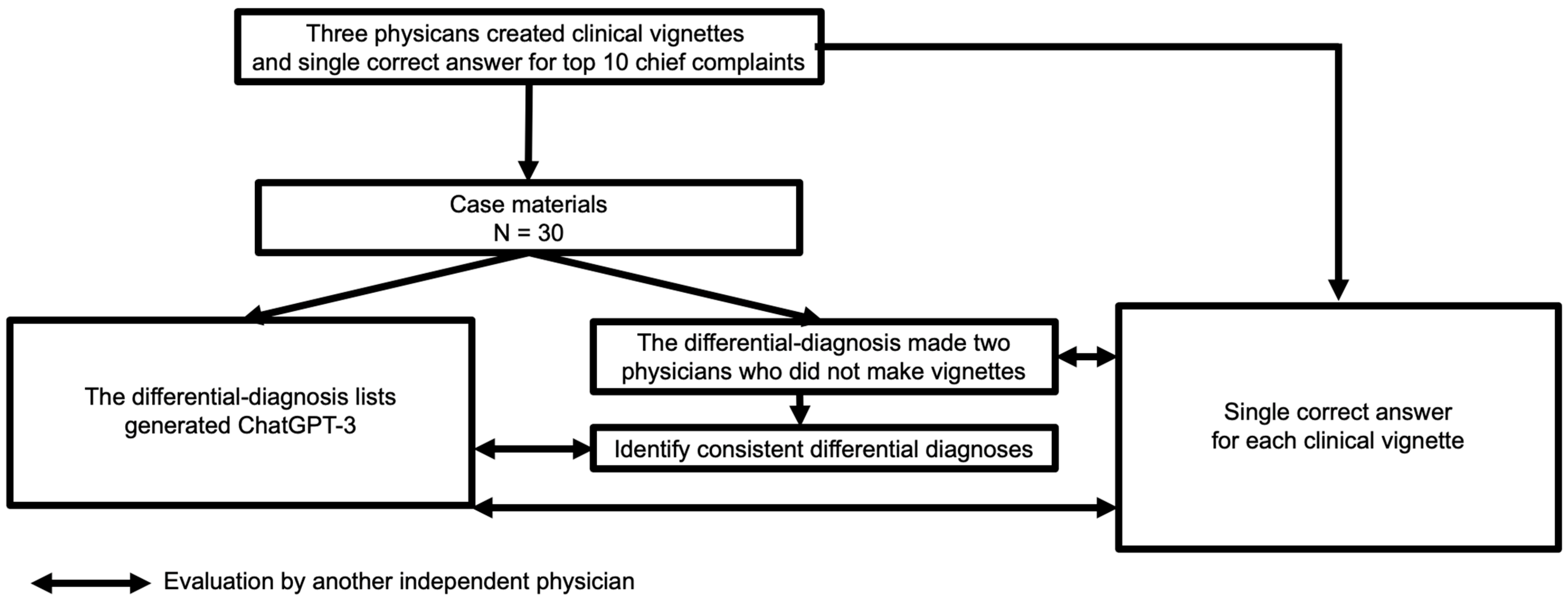
2.1. Study Design
2.2. Case Materials
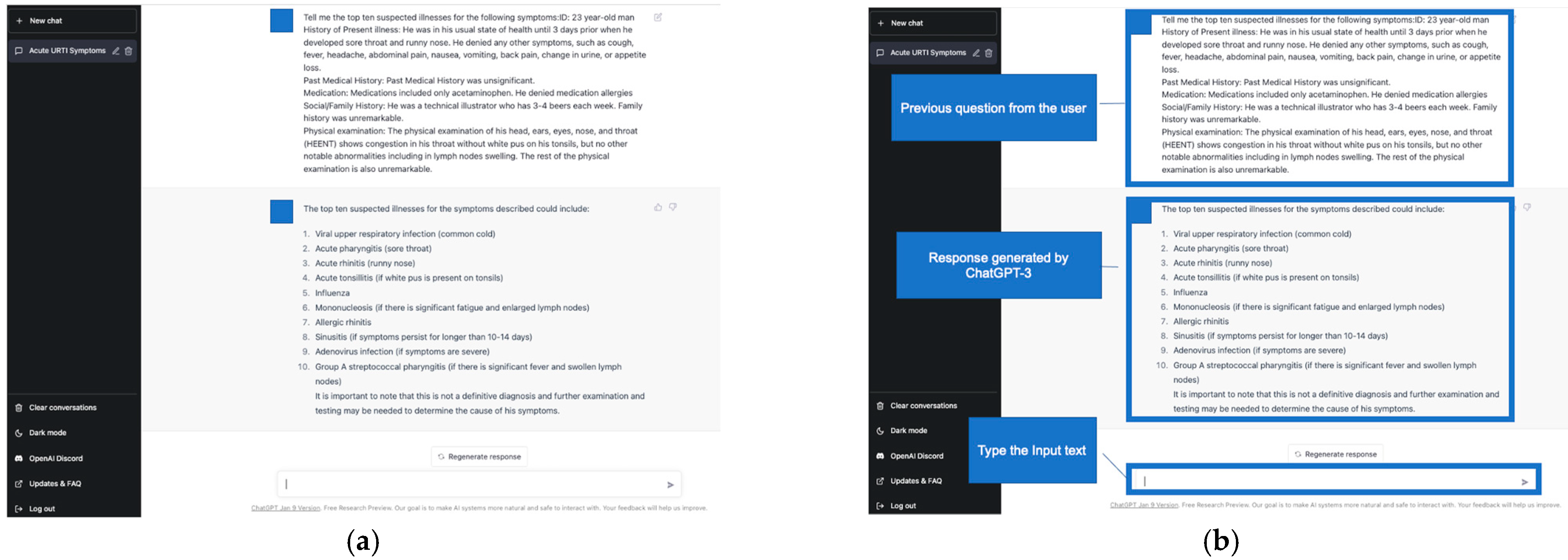
2.3. Differential-Diagnosis Lists Generated by ChatGPT-3
2.4. Measurements and Definitions
2.5. Sample Size
2.6. Analysis
3. Results
4. Discussion
4.1. Principal Findings
4.2. Strengths
4.3. Limitations
4.4. Risk for General User
4.5. Comparison with Prior Work
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, B.; Yang, G.; Shi, Z.; Ma, S. Natural language processing for smart healthcare. arXiv 2021, arXiv:2110.15803. [Google Scholar] [CrossRef]
- Chen, J.H.; Dhaliwal, G.; Yang, D. Decoding Artificial Intelligence to Achieve Diagnostic Excellence: Learning from Experts, Examples, and Experience: Learning from Experts, Examples, and Experience. JAMA 2022, 328, 709–710. [Google Scholar] [CrossRef] [PubMed]
- Bulla, C.; Parushetti, C.; Teli, A.; Aski, S.; Koppad, S. A Review of AI Based Medical Assistant Chatbot. Res. Appl. Web Dev. Des. 2020, 3, 1–14. [Google Scholar]
- Nath, S.; Marie, A.; Ellershaw, S.; Korot, E.; Keane, P.A. New Meaning for NLP: The Trials and Tribulations of Natural Language Processing with GPT-3 in Ophthalmology. Br. J. Ophthalmol. 2022, 106, 889–892. [Google Scholar] [CrossRef]
- Korngiebel, D.M.; Mooney, S.D. Considering the Possibilities and Pitfalls of Generative Pre-Trained Transformer 3 (GPT-3) in Healthcare Delivery. NPJ Digit. Med. 2021, 4, 93. [Google Scholar] [CrossRef] [PubMed]
- Safi, Z.; Abd-Alrazaq, A.; Khalifa, M.; Househ, M. Technical Aspects of Developing Chatbots for Medical Applications: Scoping Review. J. Med. Internet Res. 2020, 22, e19127. [Google Scholar] [CrossRef] [PubMed]
- Sezgin, E.; Sirrianni, J.; Linwood, S.L. Operationalizing and Implementing Pretrained, Large Artificial Intelligence Linguistic Models in the US Health Care System: Outlook of Generative Pretrained Transformer 3 (GPT-3) as a Service Model. JMIR Med. Inform. 2022, 10, e32875. [Google Scholar] [CrossRef] [PubMed]
- Goodwin, T.R.; Harabagiu, S.M. Medical Question Answering for Clinical Decision Support. Proc. ACM Int. Conf. Inf. Knowl. Manag. 2016, 2016, 297–306. [Google Scholar] [CrossRef]
- Zahid, M.A.H.; Mittal, A.; Joshi, R.C.; Atluri, G. CLINIQA: A Machine Intelligence Based CLINIcal Question Answering System. arXiv 2018, arXiv:1805.05927. [Google Scholar]
- Xu, G.; Rong, W.; Wang, Y.; Ouyang, Y.; Xiong, Z. External Features Enriched Model for Biomedical Question Answering. BMC Bioinform. 2021, 22, 272. [Google Scholar] [CrossRef]
- Wu, X.; Chen, J.; Yun, D.; Yuan, M.; Liu, Z.; Yan, P.; Sim, D.A.; Zhu, Y.; Chen, C.; Hu, W.; et al. Effectiveness of an Ophthalmic Hospital-Based Virtual Service during the COVID-19 Pandemic. Ophthalmology 2021, 128, 942–945. [Google Scholar] [CrossRef]
- Jackson, R.G.; Patel, R.; Jayatilleke, N.; Kolliakou, A.; Ball, M.; Gorrell, G.; Roberts, A.; Dobson, R.J.; Stewart, R. Natural Language Processing to Extract Symptoms of Severe Mental Illness from Clinical Text: The Clinical Record Interactive Search Comprehensive Data Extraction (CRIS-CODE) Project. BMJ Open 2017, 7, e012012. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.; Lan, L.; Yang, D.; Huang, S.; Li, M.; Yin, J.; Xiao, J.; Zhou, X. Early Prediction of Organ Failures in Patients with Acute Pancreatitis Using Text Mining. Sci. Program. 2021, 2021, 6683942. [Google Scholar] [CrossRef]
- Zeng, J.; Gensheimer, M.F.; Rubin, D.L.; Athey, S.; Shachter, R.D. Uncovering Interpretable Potential Confounders in Electronic Medical Records. Nat. Commun. 2022, 13, 1014. [Google Scholar] [CrossRef] [PubMed]
- Patrick, T.B.; Demiris, G.; Folk, L.C.; Moxley, D.E.; Mitchell, J.A.; Tao, D. Evidence-Based Retrieval in Evidence-Based Medicine. J. Med. Libr. Assoc. 2004, 92, 196–199. [Google Scholar] [PubMed]
- Zong, M.; Krishnamachari, B. A survey on GPT-3. arXiv 2022, arXiv:221200857. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Dodge, J.; Sap, M.; Marasović, A.; Agnew, W.; Ilharco, G.; Groeneveld, D.; Mitchell, M.; Gardner, M. Documenting large webtext corpora: A case study on the colossal clean crawled corpus. arXiv 2021, arXiv:210408758. [Google Scholar]
- Heilman, J.M.; West, A.G. Wikipedia and Medicine: Quantifying Readership, Editors, and the Significance of Natural Language. J. Med. Internet Res. 2015, 17, e62. [Google Scholar] [CrossRef]
- Christiano, P.F.; Leike, J.; Brown, T.; Martic, M.; Legg, S.; Amodei, D. Deep reinforcement learning from human preferences. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Haque, M.U.; Dharmadasa, I.; Sworna, Z.T.; Rajapakse, R.N.; Ahmad, H. “I Think This Is the Most Disruptive Technology”: Exploring Sentiments of ChatGPT Early Adopters Using Twitter Data. arXiv 2022, arXiv:2212.05856. [Google Scholar] [CrossRef]
- Stokel-Walker, C. AI bot ChatGPT writes smart essays-should professors worry? Nature 2022. [Google Scholar] [CrossRef]
- Schmieding, M.L.; Kopka, M.; Schmidt, K.; Schulz-Niethammer, S.; Balzer, F.; Feufel, M.A. Triage Accuracy of Symptom Checker Apps: 5-Year Follow-up Evaluation. J. Med. Internet Res. 2022, 24, e31810. [Google Scholar] [CrossRef]
- Bond, W.F.; Schwartz, L.M.; Weaver, K.R.; Levick, D.; Giuliano, M.; Graber, M.L. Differential Diagnosis Generators: An Evaluation of Currently Available Computer Programs. J. Gen. Intern. Med. 2012, 27, 213–219. [Google Scholar] [CrossRef]
- Riches, N.; Panagioti, M.; Alam, R.; Cheraghi-Sohi, S.; Campbell, S.; Esmail, A.; Bower, P. The Effectiveness of Electronic Differential Diagnoses (DDX) Generators: A Systematic Review and Meta-Analysis. PLoS ONE 2016, 11, e0148991. [Google Scholar] [CrossRef]
- Semigran, H.L.; Linder, J.A.; Gidengil, C.; Mehrotra, A. Evaluation of Symptom Checkers for Self Diagnosis and Triage: Audit Study. BMJ 2015, 351, h3480. [Google Scholar] [CrossRef]
- Ceney, A.; Tolond, S.; Glowinski, A.; Marks, B.; Swift, S.; Palser, T. Accuracy of Online Symptom Checkers and the Potential Impact on Service Utilisation. PLoS ONE 2021, 16, e0254088. [Google Scholar] [CrossRef]
- Chintagunta, B.; Katariya, N.; Amatriain, X.; Kannan, A. Medically aware GPT-3 as a data generator for Medical Dialogue Summarization. In Proceedings of the Second Workshop on Natural Language Processing for Medical Conversations, Online, 6 June 2021; pp. 66–76. [Google Scholar]
- Agbavor, F.; Liang, H. Predicting Dementia from Spontaneous Speech Using Large Language Models. PLoS Digit. Health 2022, 1, e0000168. [Google Scholar] [CrossRef]
- Levine, D.M.; Tuwani, R.; Kompa, B.; Varma, A.; Finlayson, S.G.; Mehrotra, A.; Beam, A. The Diagnostic and Triage Accuracy of the GPT-3 Artificial Intelligence Model. medRxiv 2023. [Google Scholar] [CrossRef]
- Thompson, D.A.; Eitel, D.; Fernandes, C.M.B.; Pines, J.M.; Amsterdam, J.; Davidson, S.J. Coded Chief Complaints—Automated Analysis of Free-Text Complaints. Acad. Emerg. Med. 2006, 13, 774–782. [Google Scholar] [CrossRef]
- Barnett, M.L.; Boddupalli, D.; Nundy, S.; Bates, D.W. Comparative Accuracy of Diagnosis by Collective Intelligence of Multiple Physicians vs Individual Physicians. JAMA Netw. Open 2019, 2, e190096. [Google Scholar] [CrossRef]
- King, M.R. The Future of AI in Medicine: A Perspective from a Chatbot. Ann. Biomed. Eng. 2022, 51, 291–295. [Google Scholar] [CrossRef]
- Improving Language Understanding by Generative Pre-Training. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 9 February 2023).
- Caliskan, A.; Bryson, J.J.; Narayanan, A. Semantics Derived Automatically from Language Corpora Contain Human-like Biases. Science 2017, 356, 183–186. [Google Scholar] [CrossRef]
- Urs, S. The Power and the Pitfalls of Large Language Models: A Fireside Chat with Ricardo Baeza-Yates. SSRN Electron. J. 2022, 2. [Google Scholar] [CrossRef]
- Cirillo, D.; Catuara-Solarz, S.; Morey, C.; Guney, E.; Subirats, L.; Mellino, S.; Gigante, A.; Valencia, A.; Rementeria, M.J.; Chadha, A.S.; et al. Sex and Gender Differences and Biases in Artificial Intelligence for Biomedicine and Healthcare. NPJ Digit. Med. 2020, 3, 81. [Google Scholar] [CrossRef]
- Lucy, L.; Bamman, D. Gender and Representation Bias in GPT-3 Generated Stories. In Proceedings of the Third Workshop on Narrative Understanding, Association for Computational Linguistics, Stroudsburg, PA, USA, 11 June 2021. [Google Scholar]



{kind=link}
{kind=link}
| Variable | ChatGPT-3 | Physicians’ Diagnoses | p Values | |||||
|---|---|---|---|---|---|---|---|---|
| Within Top 10 | Within Top 5 | As top Diagnoses | Within Top 5 | As Top Diagnoses | Within Top 5 1 | As Top Diagnoses 2 | ||
| total, n(%) | 28/30 (93.3) | 25/30 (83.3) | 16/30 (53.3) | 59/60 (98.3) | 56/60 (93.3) | 0.03 | <0.001 | |
| 1. | abdominal pain, n(%) | 3/3 (100) | 3/3 (100) | 2/3 (66.7) | 6/6 (100) | 5/6 (83.3) | >0.99 | >0.99 |
| 2. | fever, n(%) | 3/3 (100) | 3/3 (100) | 2/3 (66.7) | 6/6 (100) | 5/6 (83.3) | >0.99 | >0.99 |
| 3. | chest pain, n(%) | 3/3 (100) | 3/3 (100) | 2/3 (66.7) | 6/6 (100) | 6/6 (100) | > 0.99 | 0.71 |
| 4. | breathing difficulty, n(%) | 2/3 (66.7) | 1/3 (33.3) | 1/3 (33.3) | 6/6 (100) | 6/6 (100) | 0.16 | 0.16 |
| 5. | joint pain, n(%) | 3/3 (100) | 3/3 (100) | 2/3 (66.7) | 6/6 (100) | 6/6 (100) | >0.99 | 0.71 |
| 6. | vomiting, n(%) | 3/3 (100) | 1/3 (33.3) | 0/3 (0) | 6/6 (100) | 6/6 (100) | 0.16 | 0.02 |
| 7. | ataxia/difficulty walking, n(%) | 3/3 (100) | 3/3 (100) | 2/3 (66.7) | 6/6 (100) | 6/6 (100) | >0.99 | 0.71 |
| 8. | back pain, n(%) | 2/3 (66.7) | 2/3 (66.7) | 1/3 (33.3) | 5/6 (83.3) | 5/6 (83.3) | >0.99 | 0.45 |
| 9. | cough, n(%) | 3/3 (100) | 3/3 (100) | 1/3 (33.3) | 6/6 (100) | 5/6 (83.3) | >0.99 | 0.45 |
| 10. | dizziness, n(%) | 3/3 (100) | 3/3 (100) | 3/3 (100) | 6/6 (100) | 6/6 (100) | >0.99 | >0.99 |
| Variable | ChatGPT-3 1 | Consistent Differential Diagnoses by Two Physicians | |
|---|---|---|---|
| total, n(%) | 62/88 (70.5) | 88/150 (58.7) | |
| 1. | abdominal pain, n(%) | 7/9 (77.8) | 9/15 (60.0) |
| 2. | fever, n(%) | 4/8 (50.0) | 8/15 (53.3) |
| 3. | chest pain, n(%) | 9/11 (81.8) | 11/15 (73.3) |
| 4. | breathing difficulty, n(%) | 7/8 (87.5) | 8/15 (53.3) |
| 5. | joint pain, n(%) | 7/8 (87.5) | 8/15 (53.3) |
| 6. | vomiting, n(%) | 6/9 (66.7) | 9/15 (60.0) |
| 7. | ataxia/difficulty walking, n(%) | 6/10 (60.0) | 10/15 (66.7) |
| 8. | back pain, n(%) | 5/7 (71.4) | 7/15 (46.7) |
| 9. | cough, n(%) | 4/10 (40.0) | 10/15 (66.7) |
| 10. | dizziness, n(%) | 7/8 (87.5) | 8/15 (53.3) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hirosawa, T.; Harada, Y.; Yokose, M.; Sakamoto, T.; Kawamura, R.; Shimizu, T. Diagnostic Accuracy of Differential-Diagnosis Lists Generated by Generative Pretrained Transformer 3 Chatbot for Clinical Vignettes with Common Chief Complaints: A Pilot Study. Int. J. Environ. Res. Public Health 2023, 20, 3378. https://doi.org/10.3390/ijerph20043378
Hirosawa T, Harada Y, Yokose M, Sakamoto T, Kawamura R, Shimizu T. Diagnostic Accuracy of Differential-Diagnosis Lists Generated by Generative Pretrained Transformer 3 Chatbot for Clinical Vignettes with Common Chief Complaints: A Pilot Study. International Journal of Environmental Research and Public Health. 2023; 20(4):3378. https://doi.org/10.3390/ijerph20043378
Chicago/Turabian StyleHirosawa, Takanobu, Yukinori Harada, Masashi Yokose, Tetsu Sakamoto, Ren Kawamura, and Taro Shimizu. 2023. "Diagnostic Accuracy of Differential-Diagnosis Lists Generated by Generative Pretrained Transformer 3 Chatbot for Clinical Vignettes with Common Chief Complaints: A Pilot Study" International Journal of Environmental Research and Public Health 20, no. 4: 3378. https://doi.org/10.3390/ijerph20043378
APA StyleHirosawa, T., Harada, Y., Yokose, M., Sakamoto, T., Kawamura, R., & Shimizu, T. (2023). Diagnostic Accuracy of Differential-Diagnosis Lists Generated by Generative Pretrained Transformer 3 Chatbot for Clinical Vignettes with Common Chief Complaints: A Pilot Study. International Journal of Environmental Research and Public Health, 20(4), 3378. https://doi.org/10.3390/ijerph20043378