
All-People-Test-Based Methods for COVID-19 Infectious Disease Dynamics Simulation Model: Towards Citywide COVID Testing

 ,
, 
 and
and 
Abstract
:1. Introduction
- By establishing a micro-epidemic prevention and control mechanism, the SETPG (A + I) RD + APT model takes into account a more complex population network, adding several key features of asymptomatic and symptomatic carrier transmission, especially for individuals with mild infection, to help scientific researchers develop insights that may contribute to public health policymaking, including contributions to public health-forecasting teams.
- A more realistic reconstruction of the pandemic situation would be to take into account epidemic prevention policies in the model, when virus carriers are found or when the number of infected exceeds a threshold determined by the capacity of the regional health care system, including the specific implementation of containment and putting other social distancing measures, such as “intermittent lockdown”, in place.
- Moreover, attention must be paid to the potential risk posed by re-infection, which is especially of concern with new variants.
- This model can also inform resource requirements of citywide COVID testing diagnostic capacity and the changes of target people groups (TPG) associated with different strategies.
2. Literature Review
3. Epidemiological Model Proposal
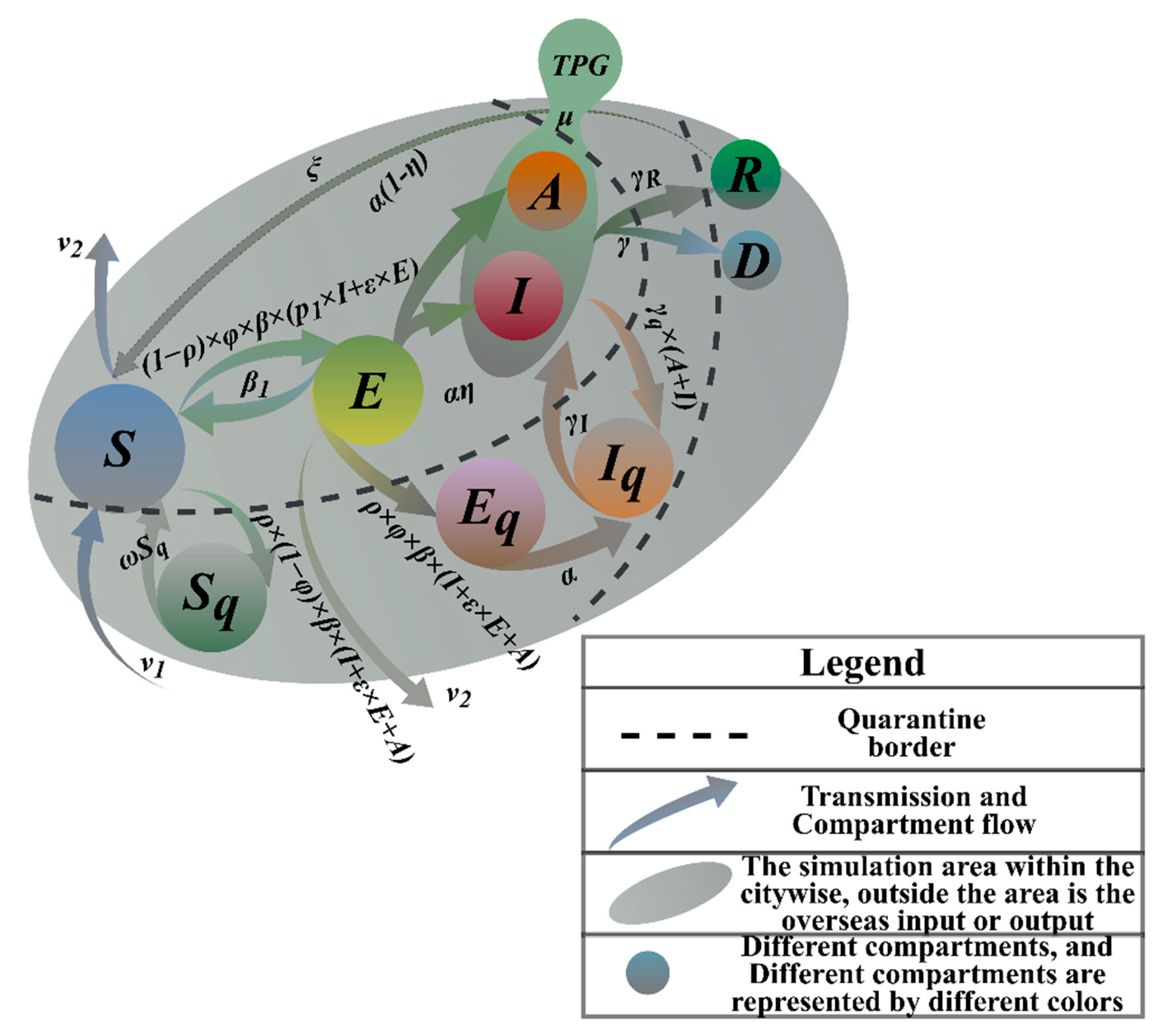
3.1. Multiple Groups Compartment Model
3.2. Parameter Setting
3.3. Epidemiological Parameters Estimation
- Suppose now that a very good performance of the novel coronavirus nucleic acid kit (sensitivity and specificity is 95%) is used to screen all HK people [15].
- The population is uniformly mixed, and the probability distribution of the positive population is uniformly distributed overall. We can treat it as an absolute uniform distribution.
- After a patient is cured, he becomes a healthy person who can still be infected again.
- Models incorporate birth and death.
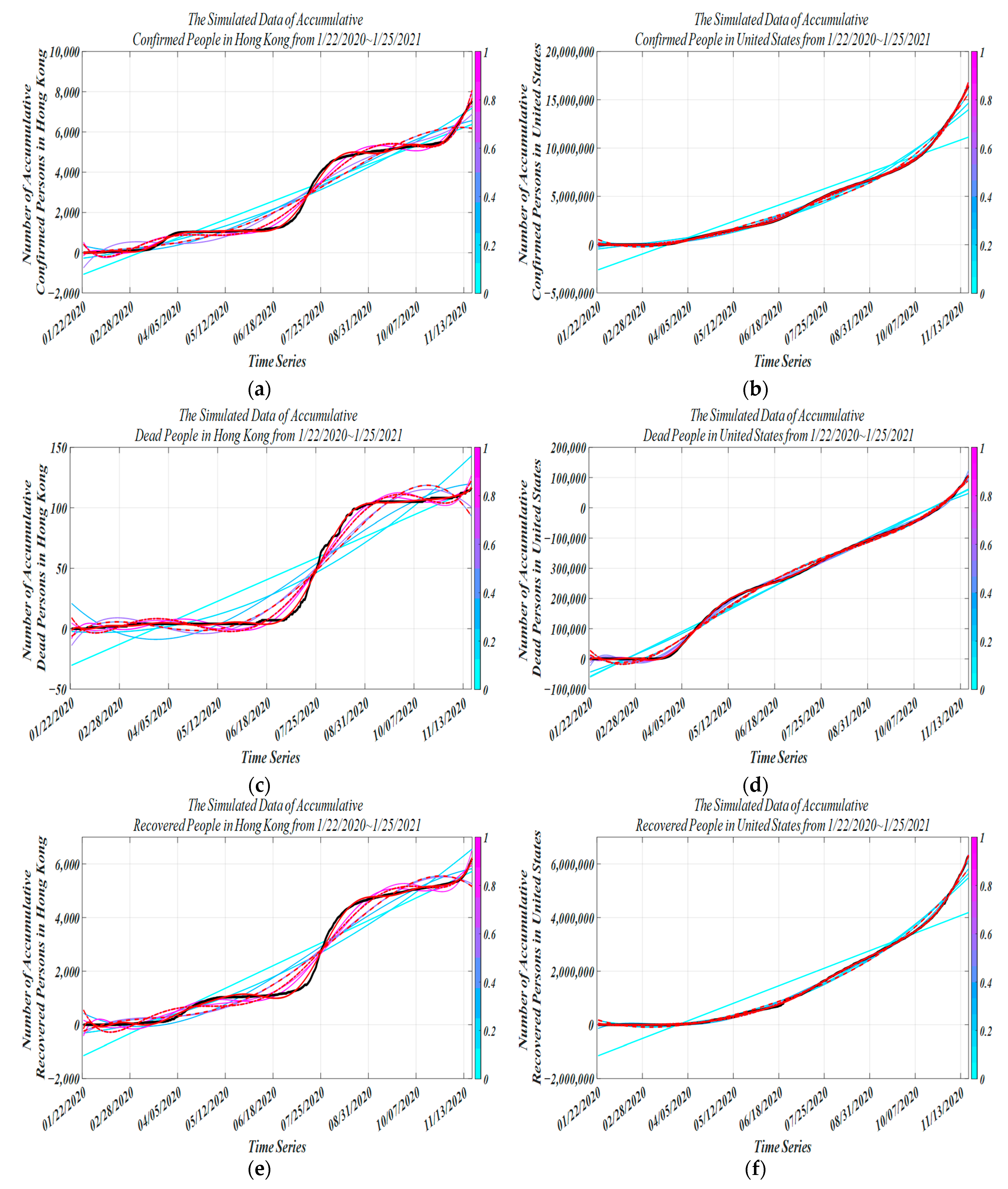
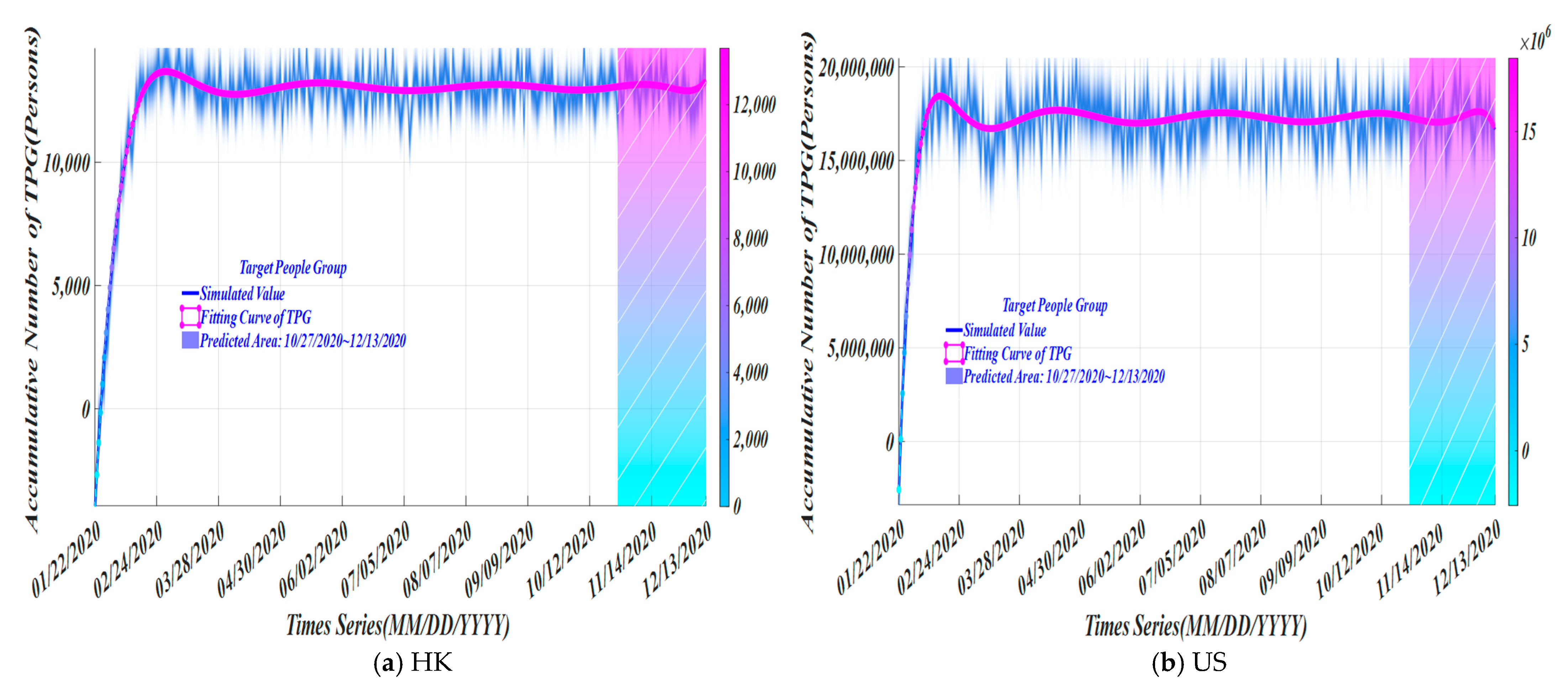
4. Experimental Simulation
4.1. Binary Encoding Nucleic Acid Screening Test
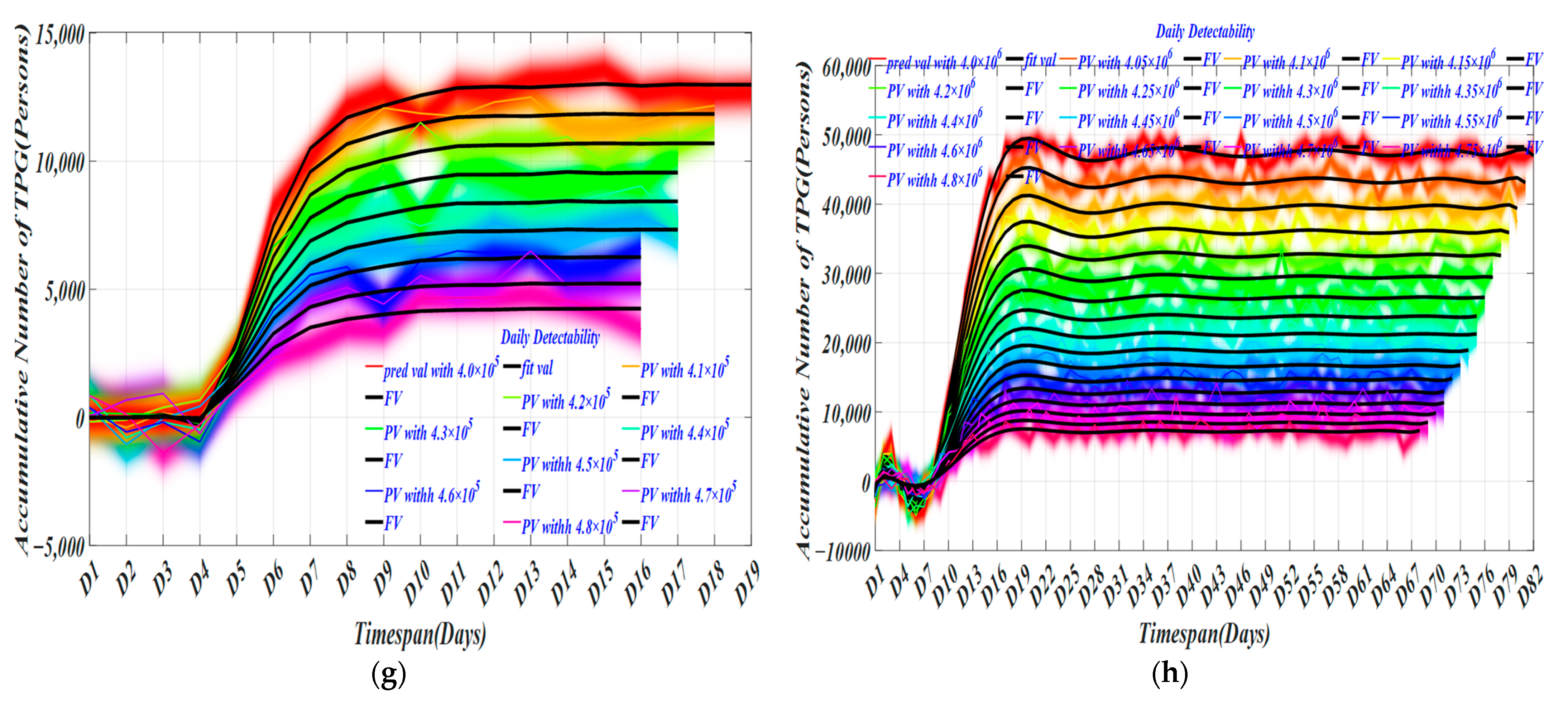
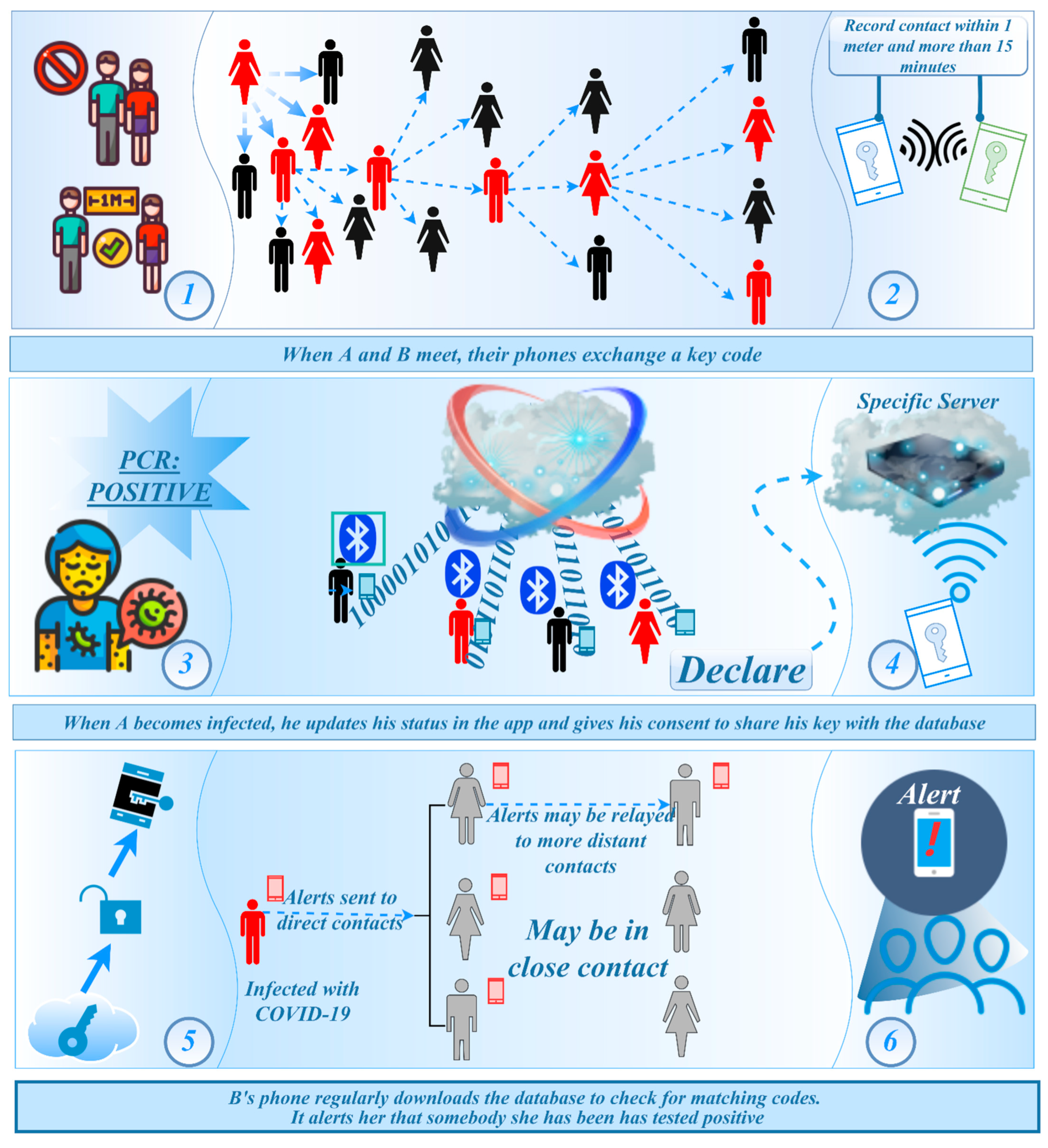
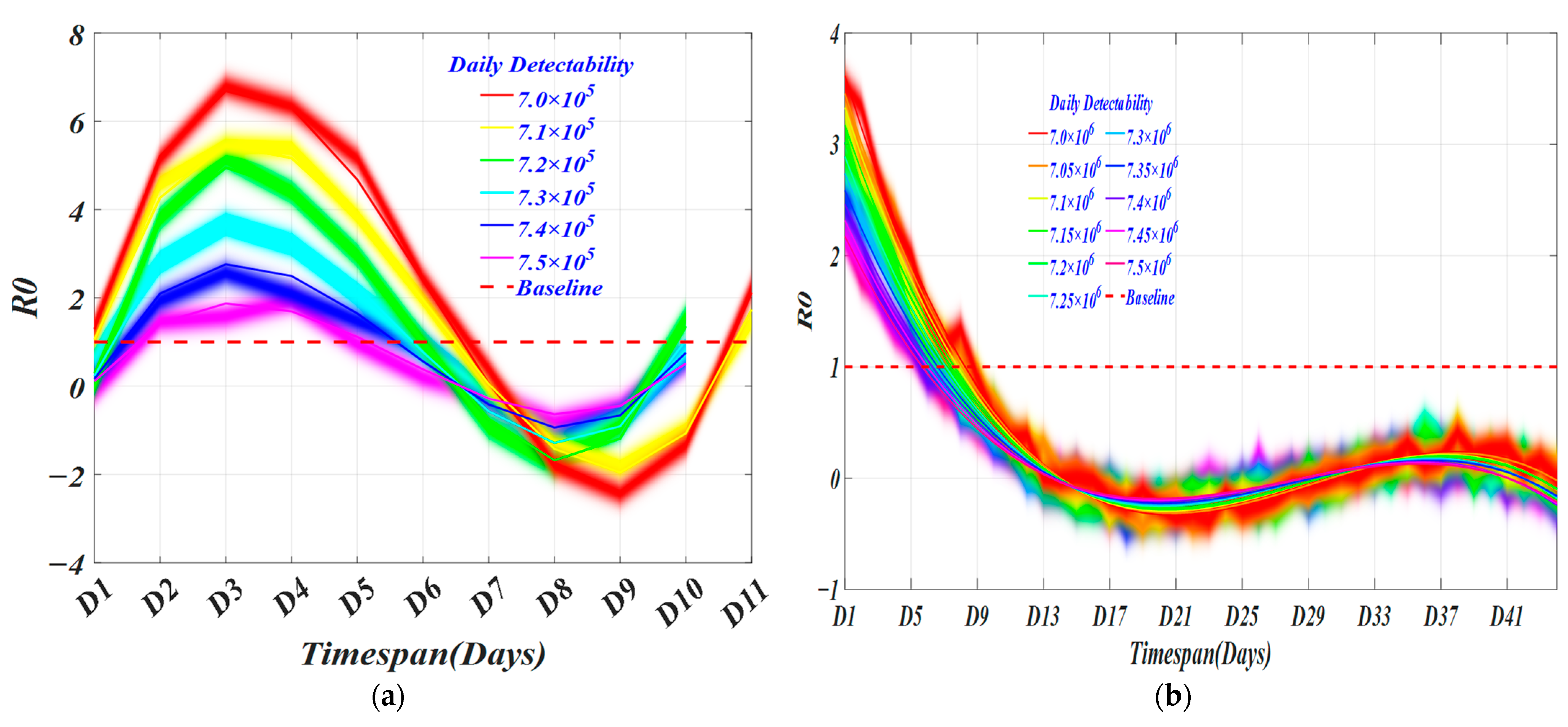
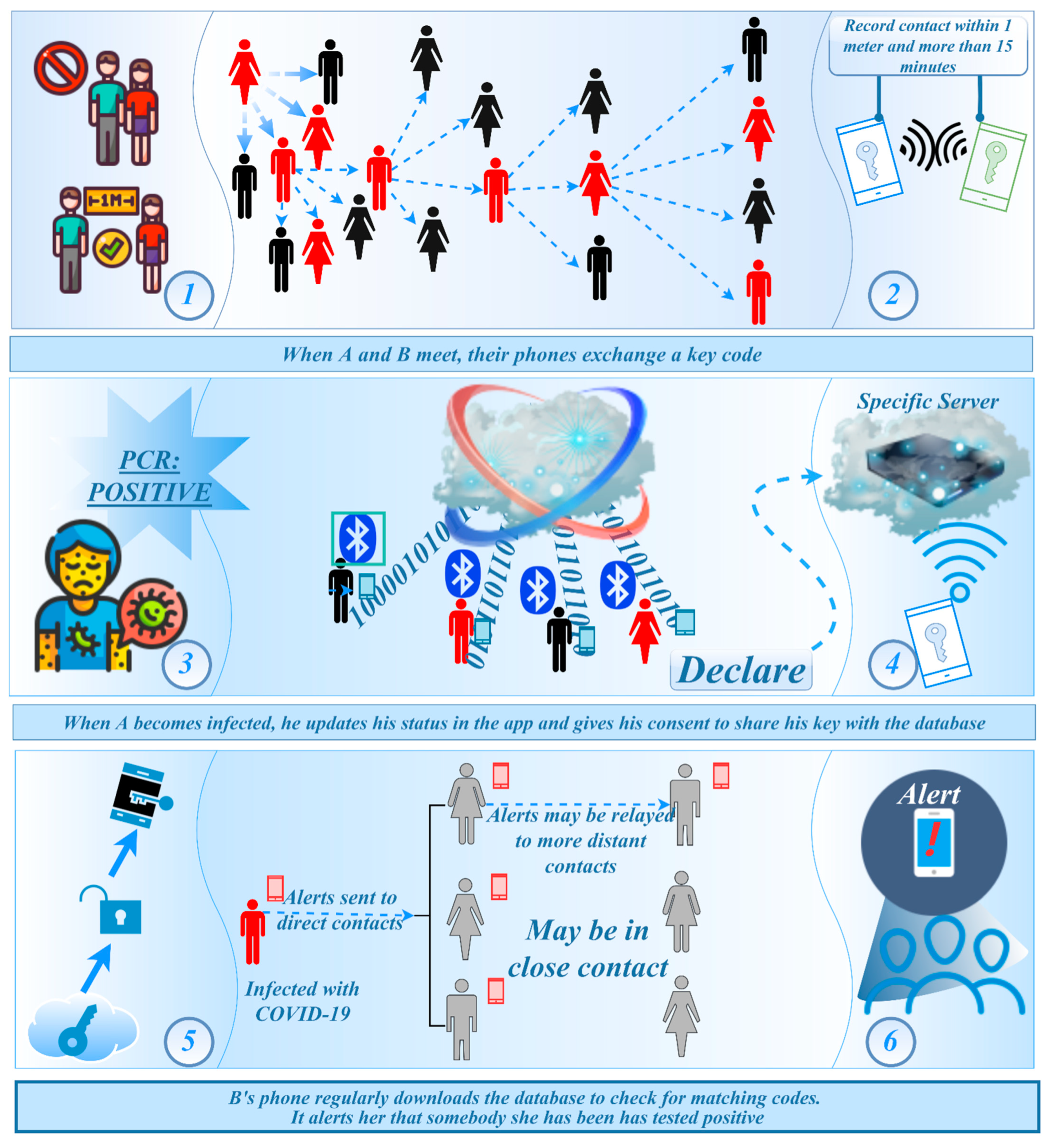
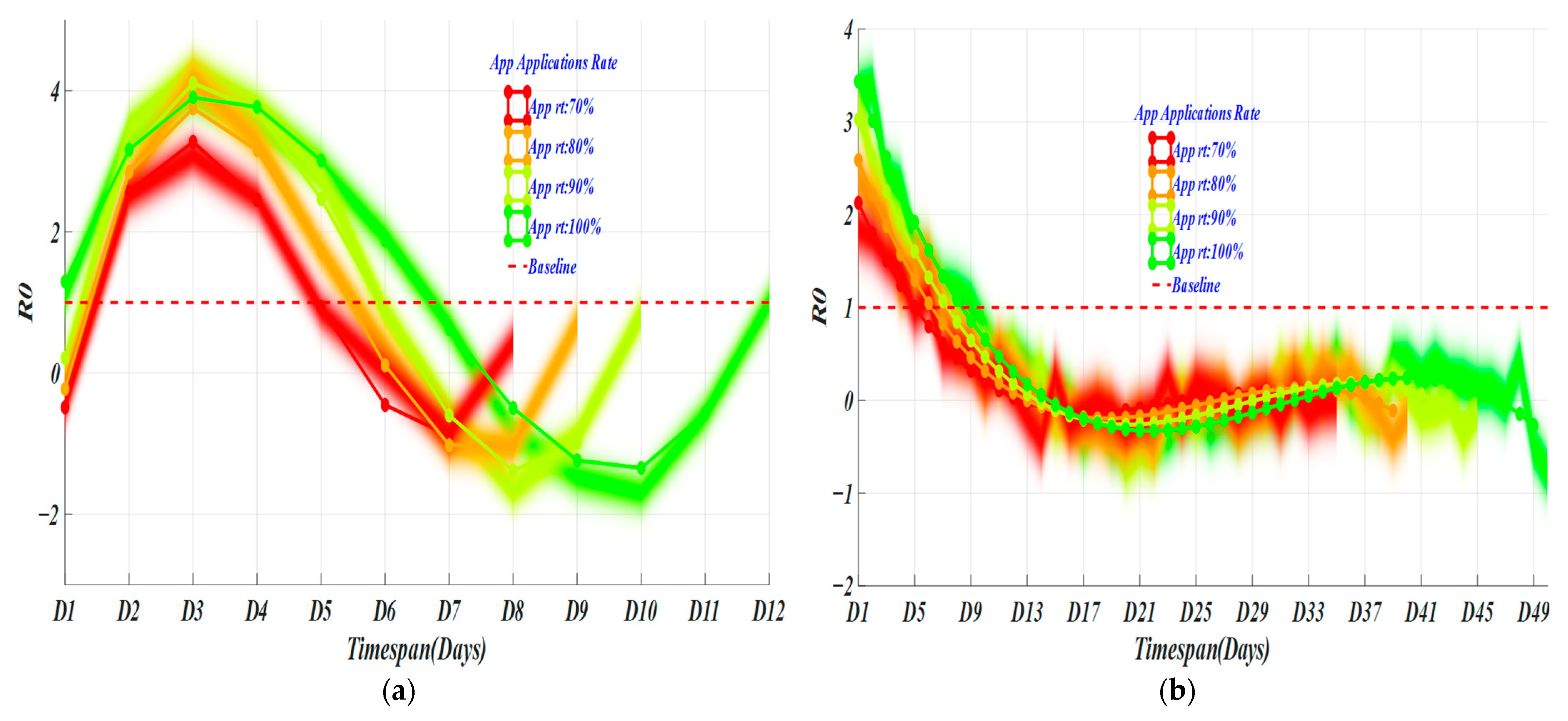
4.2. Invisible Virus Catcher—Artificial Intelligence Digital Technology to Achieve Precise Prevention and Control of the Epidemic
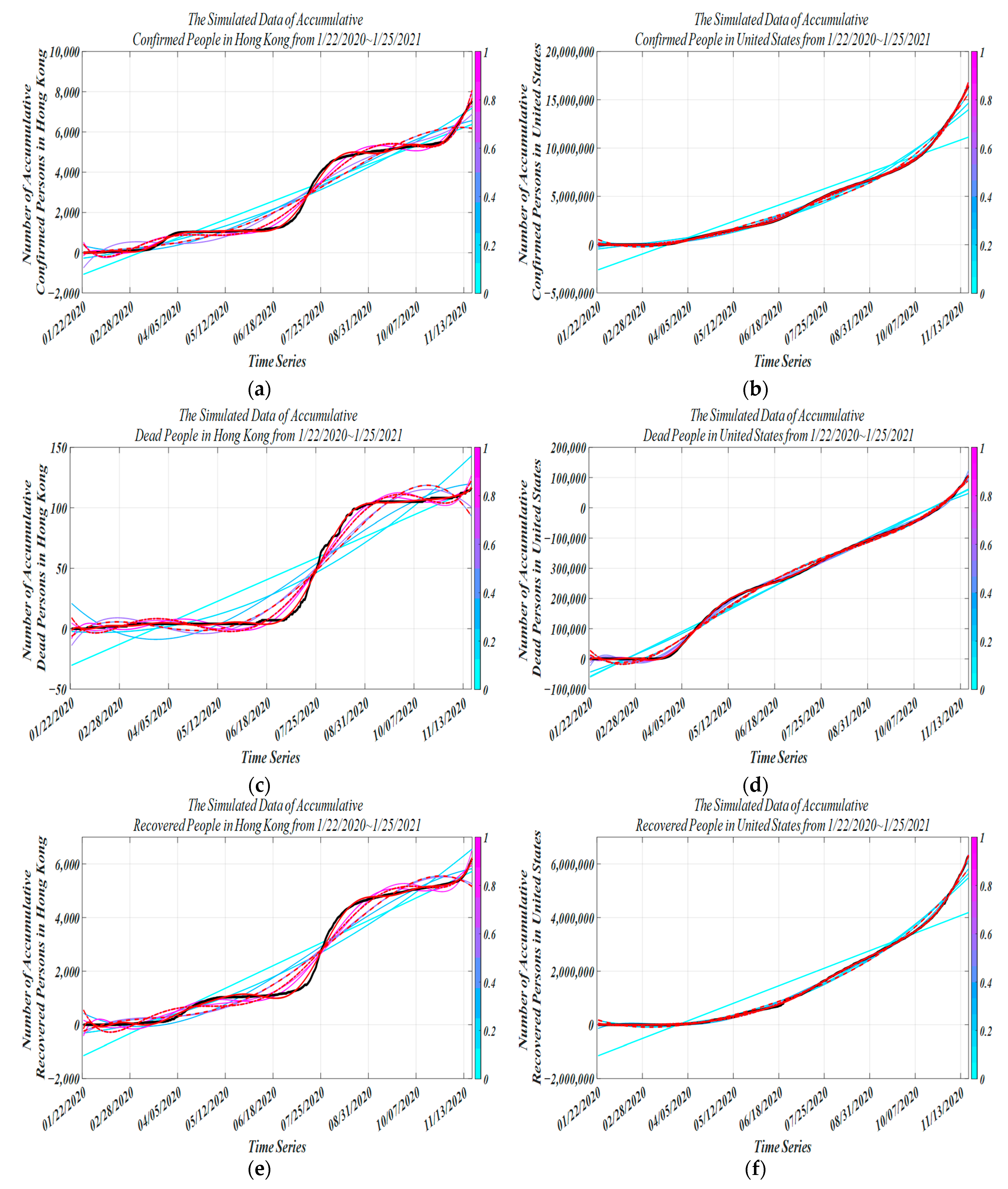
4.3. Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, N.; Zhang, D.; Wang, W.; Li, X.; Yang, B.; Song, J.; Zhao, X.; Huang, B.; Shi, W.; Lu, R.; et al. A Novel Coronavirus from Patients with Pneumonia in China, 2019. N. Engl. J. Med. 2020, 382, 727–733. [Google Scholar] [CrossRef] [PubMed]
- Jia, X.; Chen, J.; Li, L.; Jia, N.; Jiangtulu, B.; Xue, T.; Zhang, L.; Li, Z.; Ye, R.; Wang, B. Modeling the Prevalence of Asymptomatic Covid-19 Infections in the Chinese Mainland. Innovation 2020, 1, 100026. [Google Scholar] [CrossRef] [PubMed]
- He, X.; Lau, E.H.Y.; Wu, P.; Deng, X.; Wang, J.; Hao, X.; Lau, Y.C.; Wong, J.Y.; Guan, Y.; Tan, X.; et al. Temporal Dynamics in Viral Shedding and Transmissibility of Covid-19. Nat. Med. 2020, 26, 672–675. [Google Scholar] [CrossRef] [PubMed]
- Oran, D.P.; Topol, E.J. Prevalence of Asymptomatic Sars-Cov-2 Infection: A Narrative Review. Ann. Intern. Med. 2020, 173, 362–367. [Google Scholar] [CrossRef]
- Zhou, Y.-H.; Ma, K.; Xiao, P.; Ye, R.-Z.; Zhao, L.; Cui, X.-M.; Cao, W.-C. An Optimal Nucleic Acid Testing Strategy for COVID-19 during the Spring Festival Travel Rush in Mainland China: A Modelling Study. Int. J. Environ. Res. Public Health 2021, 18, 1788. [Google Scholar] [CrossRef]
- Heo, G.; Apio, C.; Han, K.; Goo, T.; Chung, H.W.; Kim, T.; Kim, H.; Ko, Y.; Lee, D.; Lim, J.; et al. Statistical Estimation of Effects of Implemented Government Policies on COVID-19 Situation in South Korea. Int. J. Environ. Res. Public Health 2021, 18, 2144. [Google Scholar] [CrossRef]
- Blake, H.; Corner, J.; Cirelli, C.; Hassard, J.; Briggs, L.; Daly, J.M.; Bennett, M.; Chappell, J.G.; Fairclough, L.; McClure, C.P.; et al. Perceptions and Experiences of the University of Nottingham Pilot SARS-CoV-2 Asymptomatic Testing Service: A Mixed-Methods Study. Int. J. Environ. Res. Public Health 2021, 18, 188. [Google Scholar] [CrossRef]
- Zhao, H.; He, Y.; Brister, F.; Yang, L.; Li, G.; Ling, Y.; Ying, Y. How Can Nursing Teams Respond to Large-Scale COVID-19 Screening? Front Public Health 2021, 9, 681255. [Google Scholar] [CrossRef]
- Wang, C.; Dong, X.; Zhang, Y.; Luo, Y. Community Resilience Governance on Public Health Crisis in China. Int. J. Environ. Res. Public Health 2021, 18, 2123. [Google Scholar] [CrossRef]
- Fonseca i Casas, P.; García i Carrasco, V.; Garcia i Subirana, J. SEIRD COVID-19 Formal Characterization and Model Comparison Validation. Appl. Sci. 2020, 10, 5162. [Google Scholar] [CrossRef]
- Faruk, O.; Kar, S. A Data Driven Analysis and Forecast of COVID-19 Dynamics during the Third Wave Using SIRD Model in Bangladesh. COVID 2021, 1, 503–517. [Google Scholar] [CrossRef]
- Antonelli, E.; Loli Piccolomini, E.; Zama, F. Switched forced SEIRDV compartmental models to monitor COVID-19 spread and immunization in Italy. medRxiv 2021, 7, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Biswas, G.C.; Choudhury, S.; Rabbani, M.M.; Das, J. A Review on Potential Electrochemical Point-of-Care Tests Targeting Pandemic Infectious Disease Detection: COVID-19 as a Reference. Chemosensors 2022, 10, 269. [Google Scholar] [CrossRef]
- Mińko, A.; Turoń-Skrzypińska, A.; Rył, A.; Tomska, N.; Bereda, Z.; Rotter, I. Searching for Factors Influencing the Severity of the Symptoms of Long COVID. Int. J. Environ. Res. Public Health 2022, 19, 8013. [Google Scholar] [CrossRef]
- de Paula Dias, B.; Gonçalves, R.L.; Ferreira, C.S.; Barbosa, C.C.; Arrieta, O.A.P.; dos Santos, S.M.S.A.; Malta, W.C.; Alves e Silva, M.; Gomes, M.L.M.D.; Guimarães, A.G.; et al. Update on Rapid Diagnostics for COVID-19: A Systematic Review. Int. J. Transl. Med. 2022, 2, 252–274. [Google Scholar] [CrossRef]
- Mularczyk-Tomczewska, P.; Żarnowski, A.; Gujski, M.; Sytnik-Czetwertyński, J.; Pańkowski, I.; Smoliński, R.; Jankowski, M. Preventive Health Screening during the COVID-19 Pandemic: A Cross-Sectional Survey among 102,928 Internet Users in Poland. J. Clin. Med. 2022, 11, 3423. [Google Scholar] [CrossRef]
- Branda, F.; Abenavoli, L.; Pierini, M.; Mazzoli, S. Predicting the Spread of SARS-CoV-2 in Italian Regions: The Ca-labria Case Study, February 2020–March 2022. Diseases 2022, 10, 38. [Google Scholar] [CrossRef]
- Wijesekara, P.A.D.S.N.; Wang, Y.-K. A Mathematical Epidemiological Model (SEQIJRDS) to Recommend Public Health Interventions Related to COVID-19 in Sri Lanka. COVID 2022, 2, 793–826. [Google Scholar] [CrossRef]
- Ussai, S.; Pistis, M.; Missoni, E.; Formenti, B.; Armocida, B.; Pedrazzi, T.; Castelli, F.; Monasta, L.; Lauria, B.; Mariani, I. “Immuni” and the National Health System: Lessons Learnt from the COVID-19 Digital Contact Tracing in Italy. Int. J. Environ. Res. Public Health 2022, 19, 7529. [Google Scholar] [CrossRef]
- Alsyouf, A.; Lutfi, A.; Al-Bsheish, M.; Jarrar, M.; Al-Mugheed, K.; Almaiah, M.A.; Alhazmi, F.N.; Masa’deh, R.; Anshasi, R.J.; Ashour, A. Exposure Detection Applications Acceptance: The Case of COVID-19. Int. J. Environ. Res. Public Health 2022, 19, 7307. [Google Scholar] [CrossRef]
- Alshami, M.; Abdulghafor, R.; Aborujilah, A. Extending the Unified Theory of Acceptance and Use of Technology for COVID-19 Contact Tracing Application by Malaysian Users. Sustainability 2022, 14, 6811. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method (s)/Type of Modeling | Pros | Cons | The Research Found in the Literature |
|---|---|---|---|
| SEIRD model | The model has good prediction ability and decent performance. Obtained long-term predictions reflect the general dynamic of the outbreak and are especially useful for the healthcare system workers and government officials. Obtained short-term predictions allow us not only to forecast the future number of infected, recovered, and deceased patients but also estimate forecast error under adverse or optimistic circumstances. The proposed method can be used as an effective tool for prediction and analysis of the dynamics of the COVID-19 pandemic. | The model does not consider that the exposed category may have a partial infection ability and does not distinguish symptomatic from asymptomatic people. | Maher et al., 2021 [10] |
| SIRD-RM growth models | The Richards models are valid epidemiological models not only because they can successfully describe the empirical data but also because they capture, in an effective way, the underlying dynamics of an infectious disease. In this sense, the free parameters of growth models acquire a biological meaning to the extent that they can be put in correspondence with parameters of compartmental model, which have a more direct epidemiological interpretation. | Due to lack of knowledge of the epidemiological cycle and absence of any type of vaccine or medications, the government issued various non-pharmacological measures to end the COVID-19 pandemic. | Macêdo et al., 2021 [11] |
| Switched forced SEIRDV compartmental models | The model introduces a model extension that takes into account the reduced vaccine efficacy and presents a preliminary experiment in the hypothesis of mass vaccination with a single vaccine dose. | The possibility of reinfection and the difference between one-dose and two-dose vaccinations were not considered. | Erminia et al., 2022 [12] |
| State Para | |||
|---|---|---|---|
| Symbol | Meaning | ||
| Non-quarantined state | S | Susceptible people | |
| E | In incubation period | ||
| A | Asymptomatic patients | ||
| I | Infected population | ||
| Quarantine state | TPG | The target population (including asymptomatic infections and confirmed populations with mild symptoms) | |
| Sq 1 | Isolated susceptible people | ||
| Eq 1 | Isolated people in incubation period, no risk of infection | ||
| Iq 2 | Isolated infections without risk of infection | ||
| Others | R | Cure (fully recovered, not fully recovered) | |
| D | Dead | ||
| Conversion Para | |||
| Symbol | Description | Meaning | |
| φ | Infection rate | Probability of exposure to infection | |
| ε | Relative infection ratio | Infection rate of people in incubation period | |
| α | Positive feedback | Probability that people in incubation period will turn positive | |
| ƞ | Input rate | Ratio of symptomatic infections to all infections | |
| β | Exposure rate | Rate of exposure of susceptible people to people in incubation period or the infection | |
| β1 | Immunization rate | Probability that people in incubation period will turn negative | |
| ξ | System input rate | The ratio of reverting to susceptibility after recovery | |
| p1 | Input rate | Ratio of mild infections to symptomatic infections | |
| μ | Daily detection rate | Daily nucleic acid testing capacity | |
| θ | Prevalence rate | The proportion of people suffering from a certain disease at a certain period of time | |
| Removal Rate | |||
| Symbol | Description | Meaning | |
| γ | Mortality rate | Removal rate of infected persons (mortality rate) | |
| γR | Cure rate | Removal rate of infected persons (cure rate) | |
| Quarantined Rate | |||
| Symbol | Description | Meaning | |
| ω | De-quarantine rate | Isolation rate of susceptible population | |
| γq | Overload rate of medical conditions | Probability of quarantined infected person | |
| γI | Treatment rate | Probability of hospital admission from isolation state | |
| Quarantined rate | The proportion of medical observation subjects in the real epidemic | ||
| Natural Conversion Rate | |||
| Symbol | Description | Meaning | |
| ν1 | Input rate | Birth rate | |
| ν2 | Output rate | Natural mortality rate | |
| Parameters Setting Class | State Parameter | ||||
|---|---|---|---|---|---|
| Term | Simulated Value | Fixed Experience Value | Relative Error (%) | ||
| No. | Parameters | ||||
| With initial accumulation value | 1 | S | 1 × 105 | 1 × 105 | 0 |
| 2 | E | 45 | 1 × 103 | 0.9550 | |
| 3 | A | 0 | 10 | 1 | |
| 4 | I | 6 | 20 | 0.7000 | |
| Without initial accumulation value | 5 | TPG 1 | - | - | 0 |
| 6 | Sq 1 | - | - | 0 | |
| 7 | Eq 1 | - | - | 0 | |
| 8 | Iq 1 | - | - | 0 | |
| 9 | R1 | - | - | 0 | |
| 10 | D1 | - | - | 0 | |
| Term | Estimate | SEM | t-Statistic | TSTAT 1 | p-Value (pr > |t|) |
|---|---|---|---|---|---|
| 0.02385 | 0.0037 | 6.447 |  | 0.05590 | |
| 5.2844 × 10−4 | 8.1374 × 10−5 | 6.494 | 0.27123 | ||
| 0.0095 | 7.0950 × 10−4 | 13.395 | 0.13234 | ||
| 3.4812 × 10−4 | 1.6785 × 10−4 | 2.074 | 0.05877 |
| Class | Value | Basis | |
|---|---|---|---|
| Parameter estimate | 0.1198 | Model simulation + Method of moments | |
| 0.000986415 | |||
| 0.107358 | |||
| 0.0063073 | |||
| Conversion rate | α | 0.000187 | Model simulation |
| ƞ | 0.001 | ||
| β | 0.0009 | ||
| β1 | 0.1 | ||
| Quarantine rate | ω | 0.0714 | 1/Quarantine days |
| γq | 0.1 | 1/Course of disease | |
| γI | 0.1 | ||
| Natural conversion rate | ν1 | 0.1 | Model simulation |
| Group (Accepted ✔ or Non-Accepted ×) | Group Testing k | Average Number of Screenings (Person) | Time Reduction Rate (%) | Single Tube Detection Capability (before Mixing Experiment) | Solution Concentration (mL) | Positive Detection Rate (%) | Application Area |
|---|---|---|---|---|---|---|---|
| A✔ | 5:1 | 0.2050 | 7.1428 | 50,000 tubes/day (the daily testing volume of private hospitals and private laboratories)~100,000 tubes/day (Huo-Yan air membrane laboratory) | 3000 | 100 | Beijing, Xinjiang |
| B✔ | 6:1 | 0.1727 | - | 2000 | 100 | - | |
| C✔ | 8:1 | 0.1330 | 6~7 | 1000 | 100 | Shanghai | |
| D✔ | 10:1 | 0.1100 | 6.5175 | 500 | 83 | Hubei, Wuhan | |
| E× | 12:1 | 0.0953 | - | 250 | 50 | - | |
| F× | 24:1 | 0.0654 | - | 100 | 17 | - |
 | TS | TD | DR | TS | TD | DR | TS | TD | DR | TS | TD | DR |  |
| 11/16 | 63,939/105,360 | 0.009/0.015 | 13/18 | 7404/114,721 | 0.012/0.019 | 15/18 | 8153/143,688 | 0.016/0.020 | 19/19 | 9182/176,043 | 0.023/0.044 | ||
| 11/15 | 5459/79,803 | 0.008/0.011 | 12/17 | 6060/90,696 | 0.01/0.015 | 15/16 | 7280/124,444 | 0.014/0.024 | 18/17 | 8188/159,719 | 0.02/0.039 | ||
| 10/15 | 4118/56,976 | 0.006/0.008 | 12/16 | 5211/70,540 | 0.008/0.011 | 14/15 | 6150/102,399 | 0.012/0.020 | 18/15 | 7407/144,852 | 0.018/0.034 | ||
| 10/14 | 3368/41,251 | 0.005/0.006 | 12/15 | 4398/53,893 | 0.007/0.009 | 14/14 | 5350/83,141 | 0.01/0.016 | 17/13 | 6454/131,711 | 0.015/0.031 | ||
| 10/13 | 2670/29,139 | 0.004/0.004 | 12/14 | 3626/40,376 | 0.006/0.006 | 14/13 | 4575/66,545 | 0.008/0.012 | 17/12 | 5706/112,371 | 0.013/0.026 | ||
| 10/13 | 2027/19,065 | 0.003/0.003 | 12/13 | 2901/29,601 | 0.004/0.005 | 14/12 | 3831/52,450 | 0.007/0.010 | 17/10 | 4971/102,735 | 0.011/0.023 | ||
| 11/13 | 2065/20,075 | 0.003/0.003 | 13/11 | 2971/40,662 | 0.005/0.007 | 16/8 | 4128/95,971 | 0.009/0.021 | |||||
| 11/12 | 1501/13,897 | 0.002/0.002 | 13/10 | 2342/30,968 | 0.004/0.005 | 16/7 | 3460/81,653 | 0.007/0.017 | |||||
| 13/9 | 1761/23,137 | 0.003/0.004 | 16/5 | 2821/81,792 | 0.006/0.017 | ||||||||
 | |||||||||||||
| TS (Days) | Region | Total Detection Number (Persons) | Asymptomatic Infection Detected (Persons) | Mild Infection Detected (Persons) 1 | Detection Rate (Per 100,000 and 1,000,000 People) | Residual Rate of Total Infected Persons |
|---|---|---|---|---|---|---|
| 8/9.5 | HK/U.S. | 8153/2,064,970 | 5708/1,445,479 | 2445/619,491 | 0.0815/2.0650 | −0.0547 |
| 8.5/9 | HK/U.S. | 9182/1,541,830 | 6427/1,079,281 | 2754/462,549 | 0.0918/1.5418 | −0.0413 |
| Average Screening Result | ||||||
| 8.25/9.25 | HK/U.S. | 8667/1,803,400 | 6067/1,262,380 | 2599/541,020 | 0.0867/1.8034 | −0.048 |
| Screening Experiment 1 | Actual Data/Gold Standard | Total | |||
|---|---|---|---|---|---|
| P(+) PatientHK/U.S. | N(−) Non-Patient HK/U.S. | ||||
| Encoding All-People Test | Simulated Data | P(+) | TP = 7541/16,408,710 | FP = 5502/884,250 | 13,043/17,292,960 |
| N(−) | FN 1 = 3159/66,581 | TN = 5508/1,736,819 | 8667/1,803,400 | ||
| Total | 10,700/16,475,291 | 11,010/2,621,069 | 21,710/19,096,360 2 | ||
| Screening Experiment 2 | Actual Data/Gold Standard | Total | |||
| P(+) HK/U.S. | N(−) HK/U.S. | ||||
| App Epidemic-Tracking Platform | Simulated Data | P(+) | TP = 7541/16,408,710 | FP = 5502/884,250 | 13,043/17,292,960 |
| N(−) | FN 1 = 2262/29,601 | TN = 5508/1,736,819 | 6060/1,766,420 | ||
| Total | 10,442/16,438,311 | 8661/2,621,069 | 19,103/19,059,380 2 | ||
| Evaluation Index | Formula (×100%) | Experiment 1% HK/U.S. | Experiment 2% HK/U.S. |
|---|---|---|---|
| Sensitivity, sen | ΣTP/Σ (TP + FN) | 70.48/99.60 | 72.22/99.82 |
| Specificity, sp | ΣTN/Σ (TN + FP) | 50.03/66.26 | 63.60/66.24 |
| False-positive rate, Fpr | ΣFP/Σ (FP + TN) | 49.97/33.74 | 63.53/33.74 |
| False-negative rate, Fnr | ΣFN/Σ (TP + FN) | 29.52/0.40 | 21.66/0.18 |
| Positive likelihood ratio, +LR | sen/(1 − sp) | 1.4104/2.9520 | 1.9841/2.9568 |
| Negative likelihood ratio, −LR | (1 − sen)/sp | 0.8900/0.0142 | 0.4368/0.0027 |
| Accuracy, AC | Σ(TP + TN)/Σ(TP + TN + FP + FN) | 60.11/95.02 | 62.70/95.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.-X.; Yang, J.; Fong, S.; Dey, N.; Millham, R.C.; Fiaidhi, J. All-People-Test-Based Methods for COVID-19 Infectious Disease Dynamics Simulation Model: Towards Citywide COVID Testing. Int. J. Environ. Res. Public Health 2022, 19, 10959. https://doi.org/10.3390/ijerph191710959
Liu X-X, Yang J, Fong S, Dey N, Millham RC, Fiaidhi J. All-People-Test-Based Methods for COVID-19 Infectious Disease Dynamics Simulation Model: Towards Citywide COVID Testing. International Journal of Environmental Research and Public Health. 2022; 19(17):10959. https://doi.org/10.3390/ijerph191710959
Chicago/Turabian StyleLiu, Xian-Xian, Jie Yang, Simon Fong, Nilanjan Dey, Richard C. Millham, and Jinan Fiaidhi. 2022. "All-People-Test-Based Methods for COVID-19 Infectious Disease Dynamics Simulation Model: Towards Citywide COVID Testing" International Journal of Environmental Research and Public Health 19, no. 17: 10959. https://doi.org/10.3390/ijerph191710959
APA StyleLiu, X.-X., Yang, J., Fong, S., Dey, N., Millham, R. C., & Fiaidhi, J. (2022). All-People-Test-Based Methods for COVID-19 Infectious Disease Dynamics Simulation Model: Towards Citywide COVID Testing. International Journal of Environmental Research and Public Health, 19(17), 10959. https://doi.org/10.3390/ijerph191710959