
A Social Media Infodemic-Based Prediction Model for the Number of Severe and Critical COVID-19 Patients in the Lockdown Area


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Description
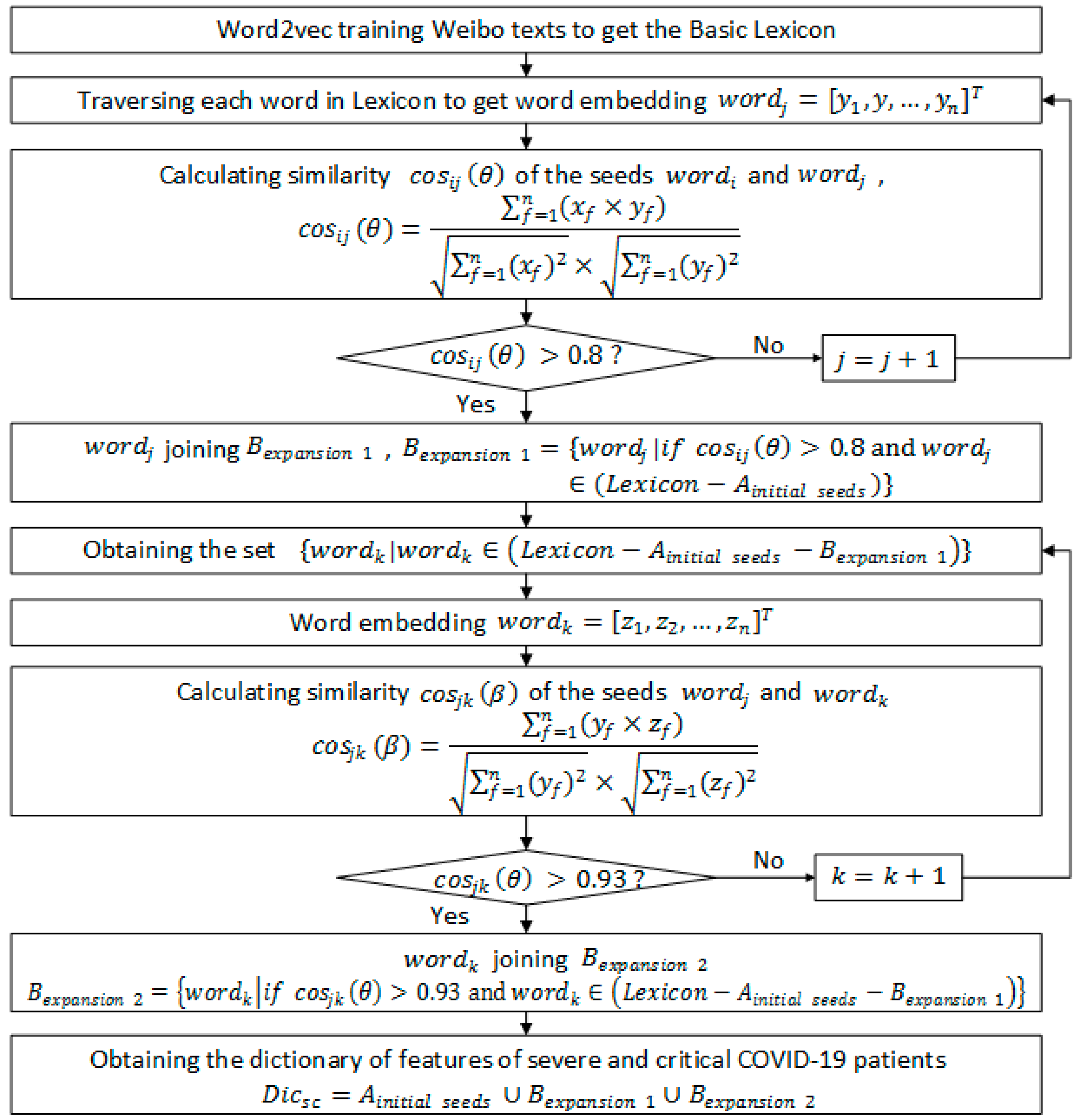
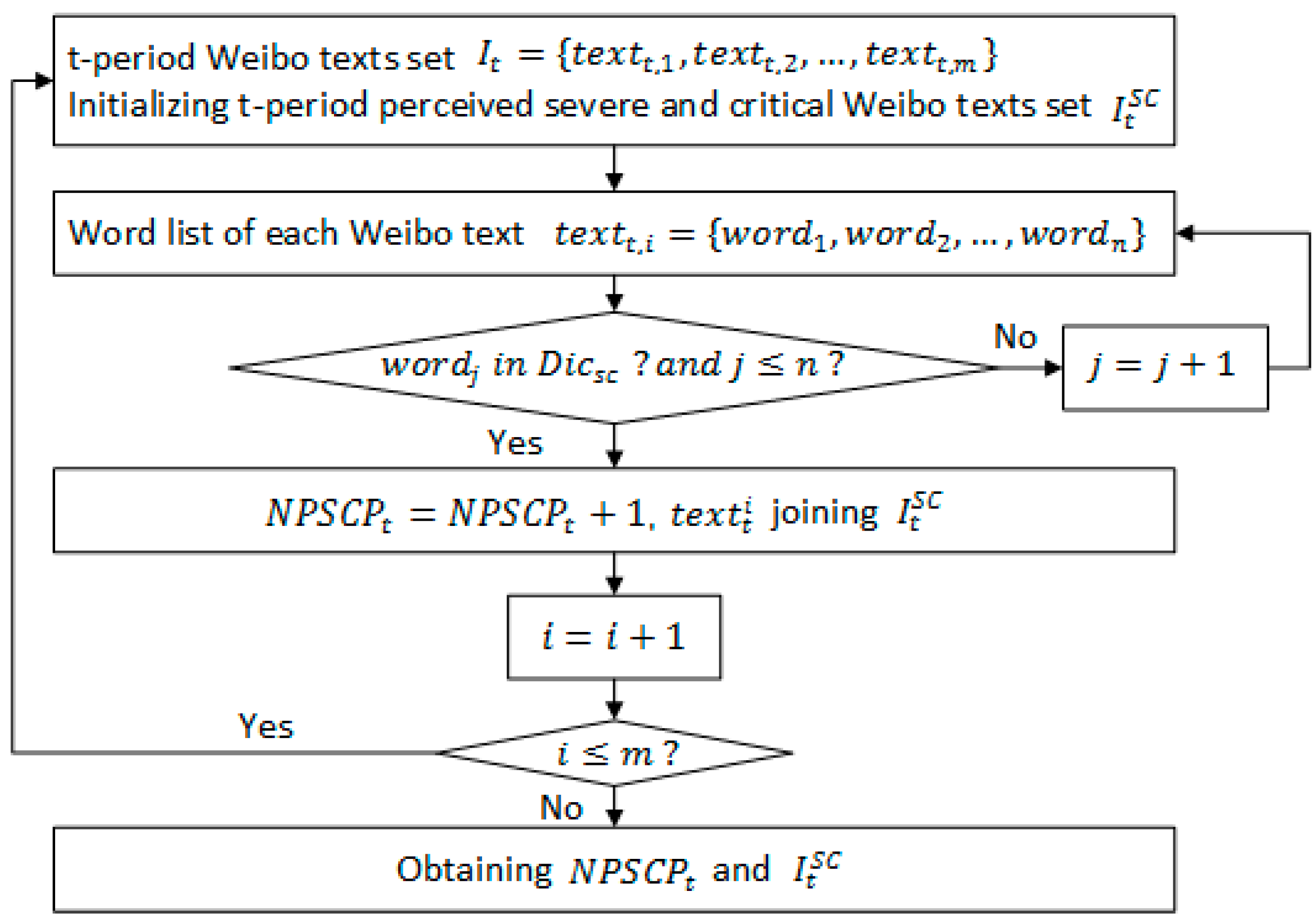
2.2. Research Model
2.3. Ethics Statement
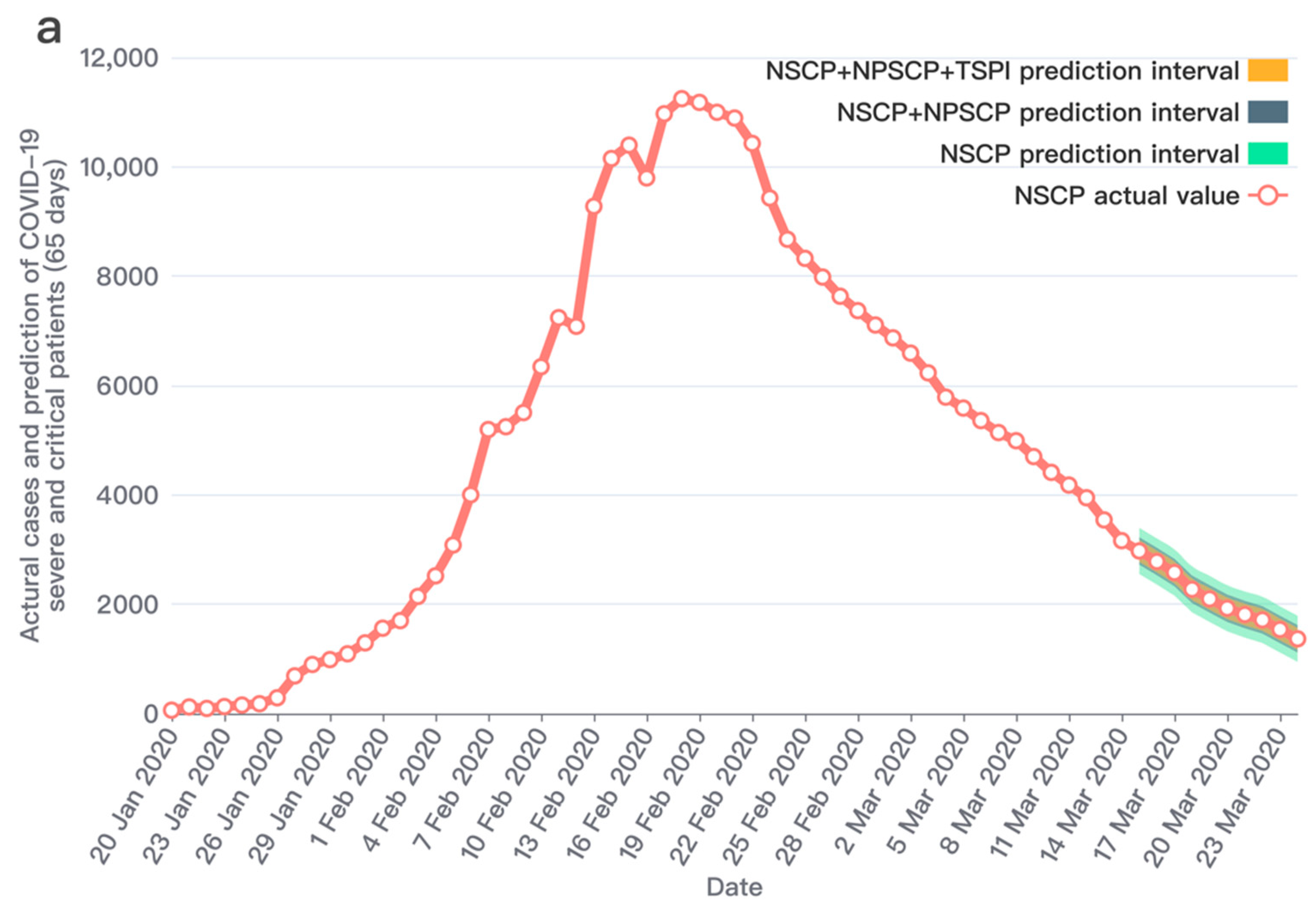
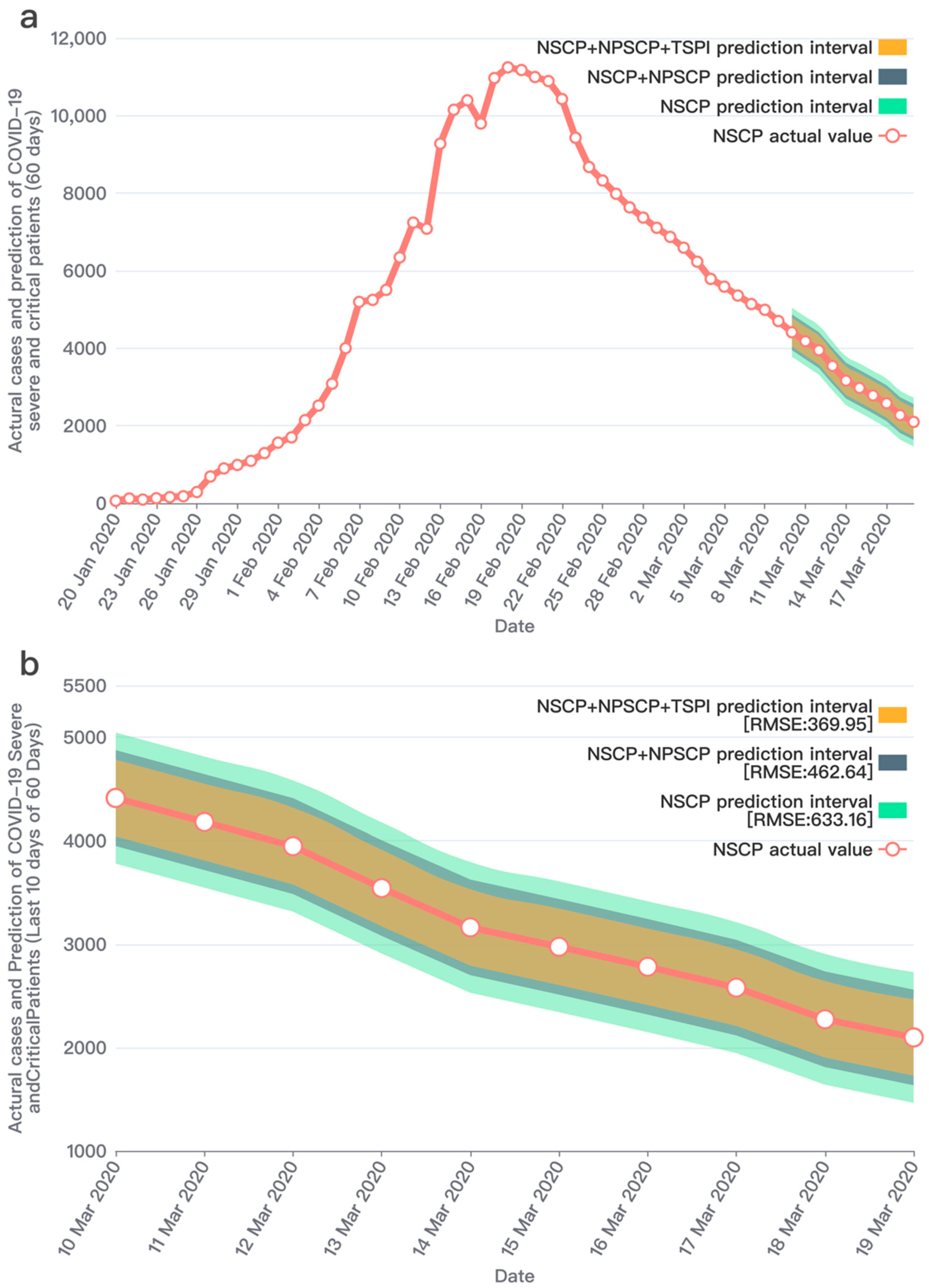
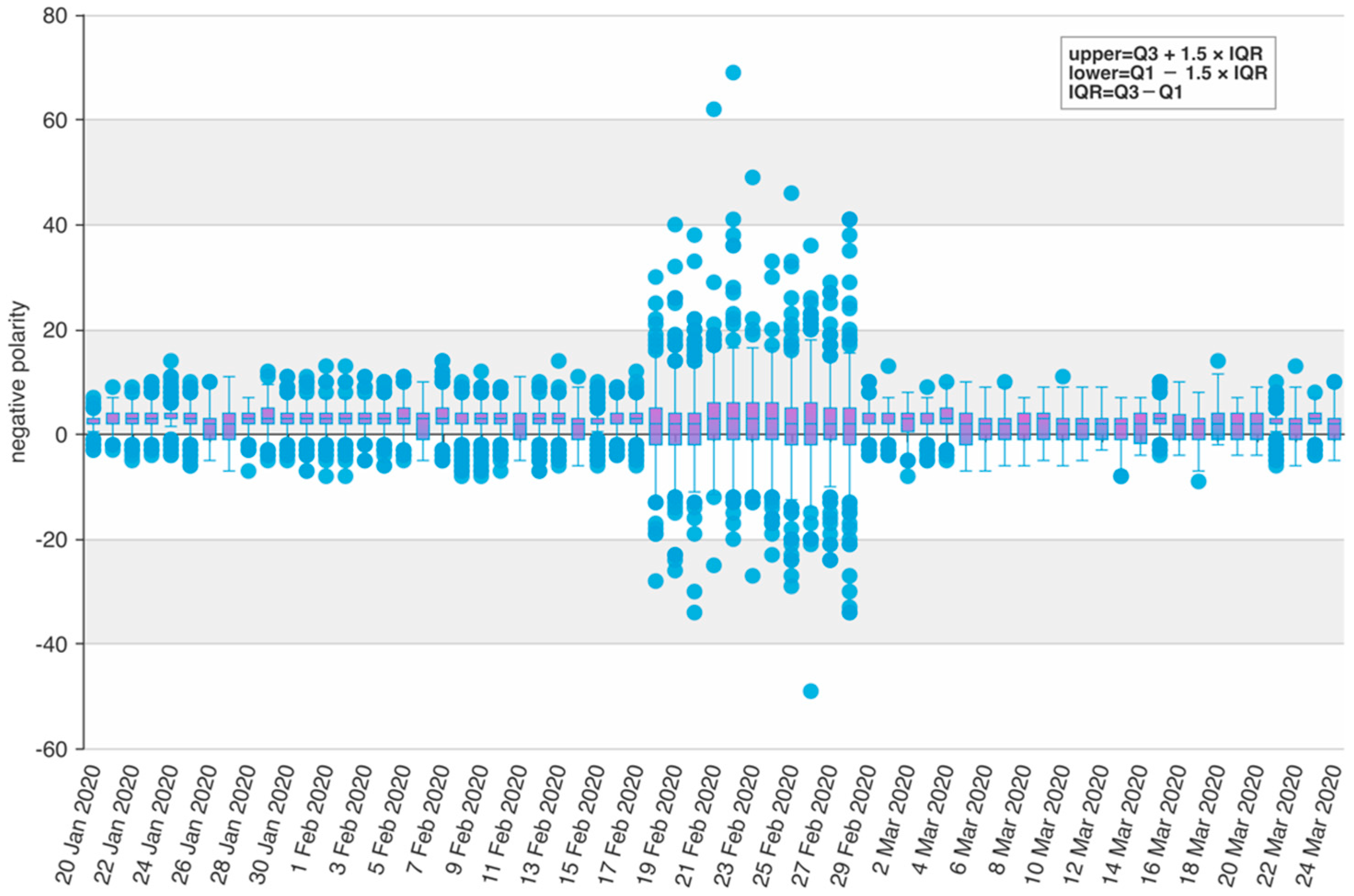
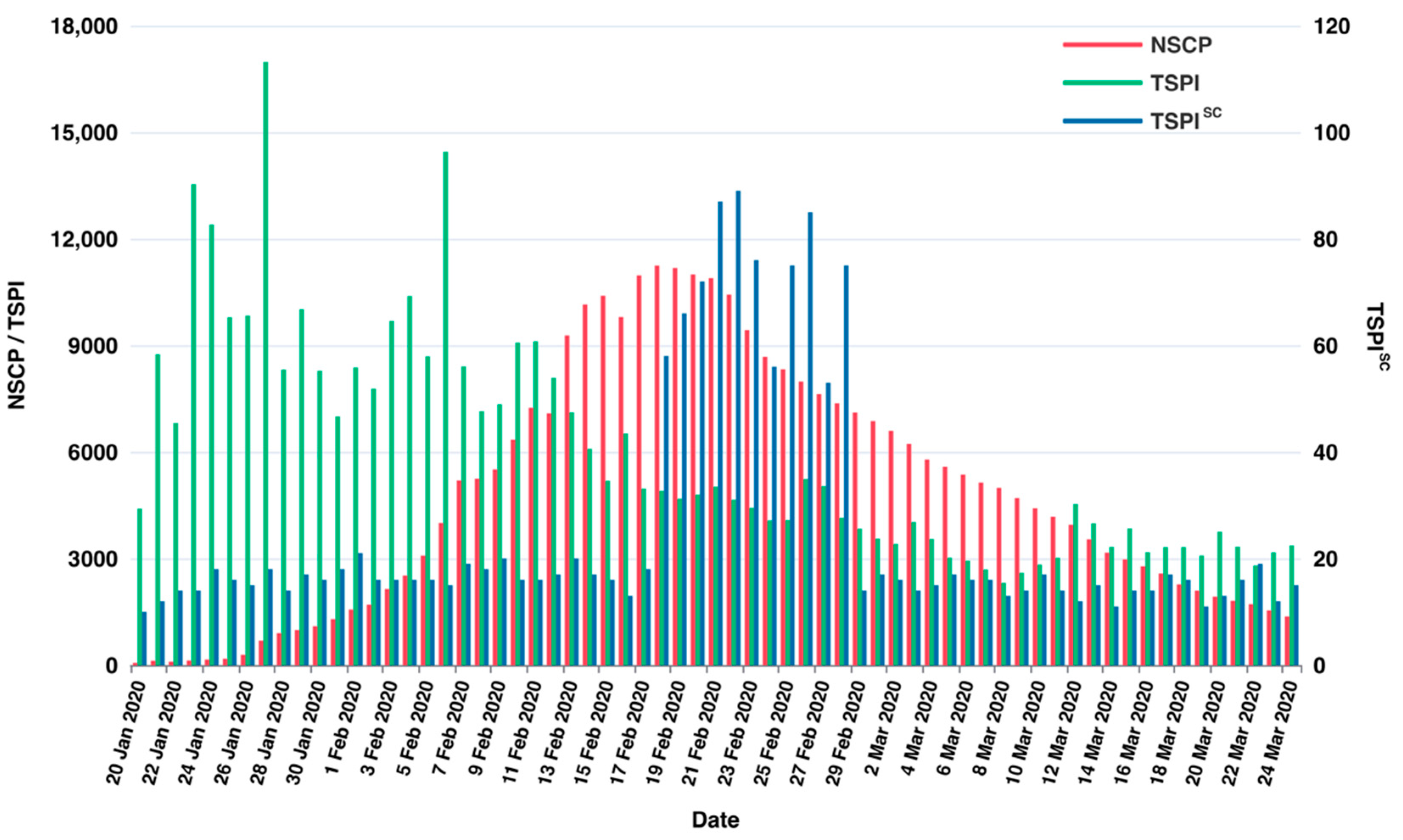
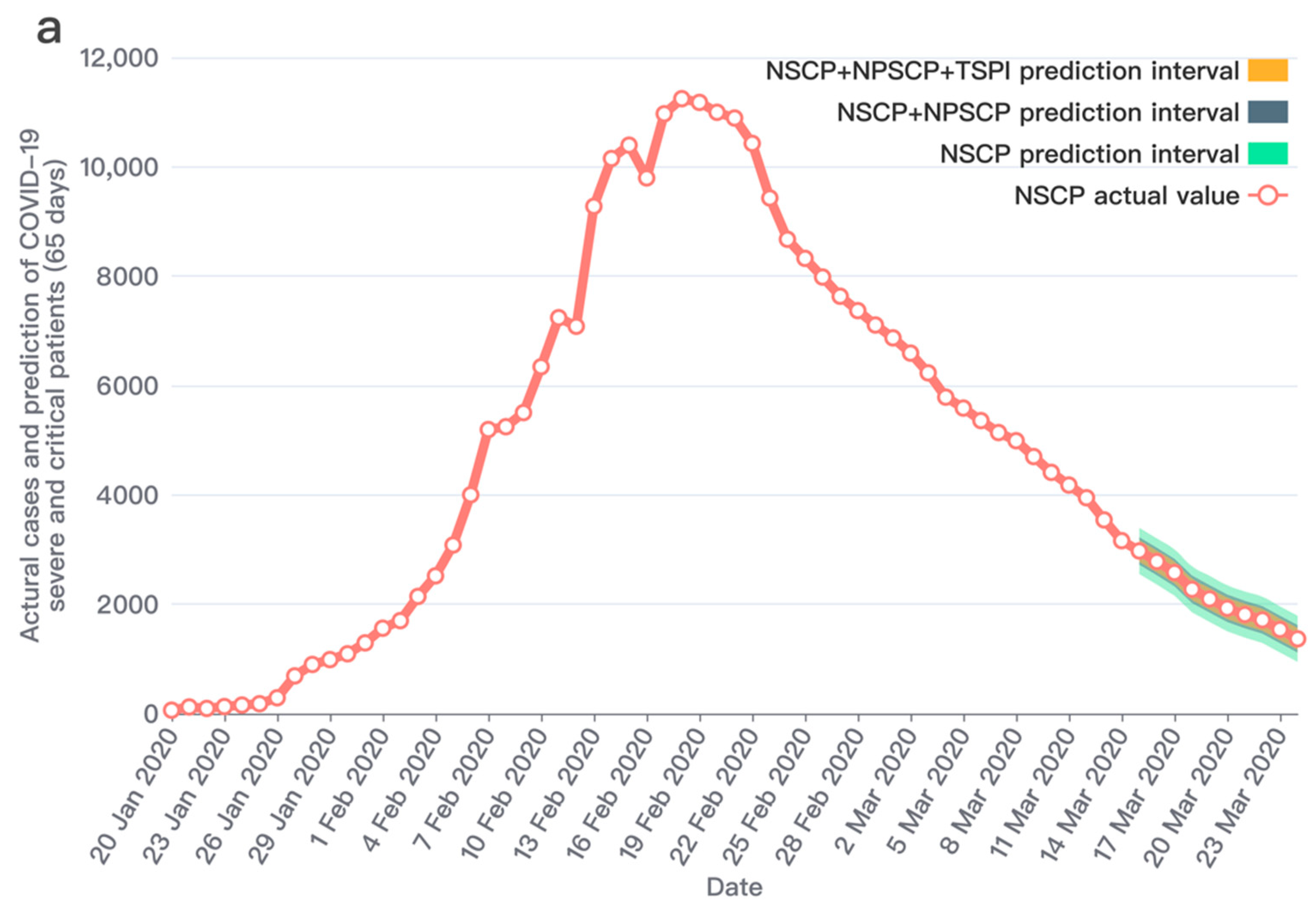
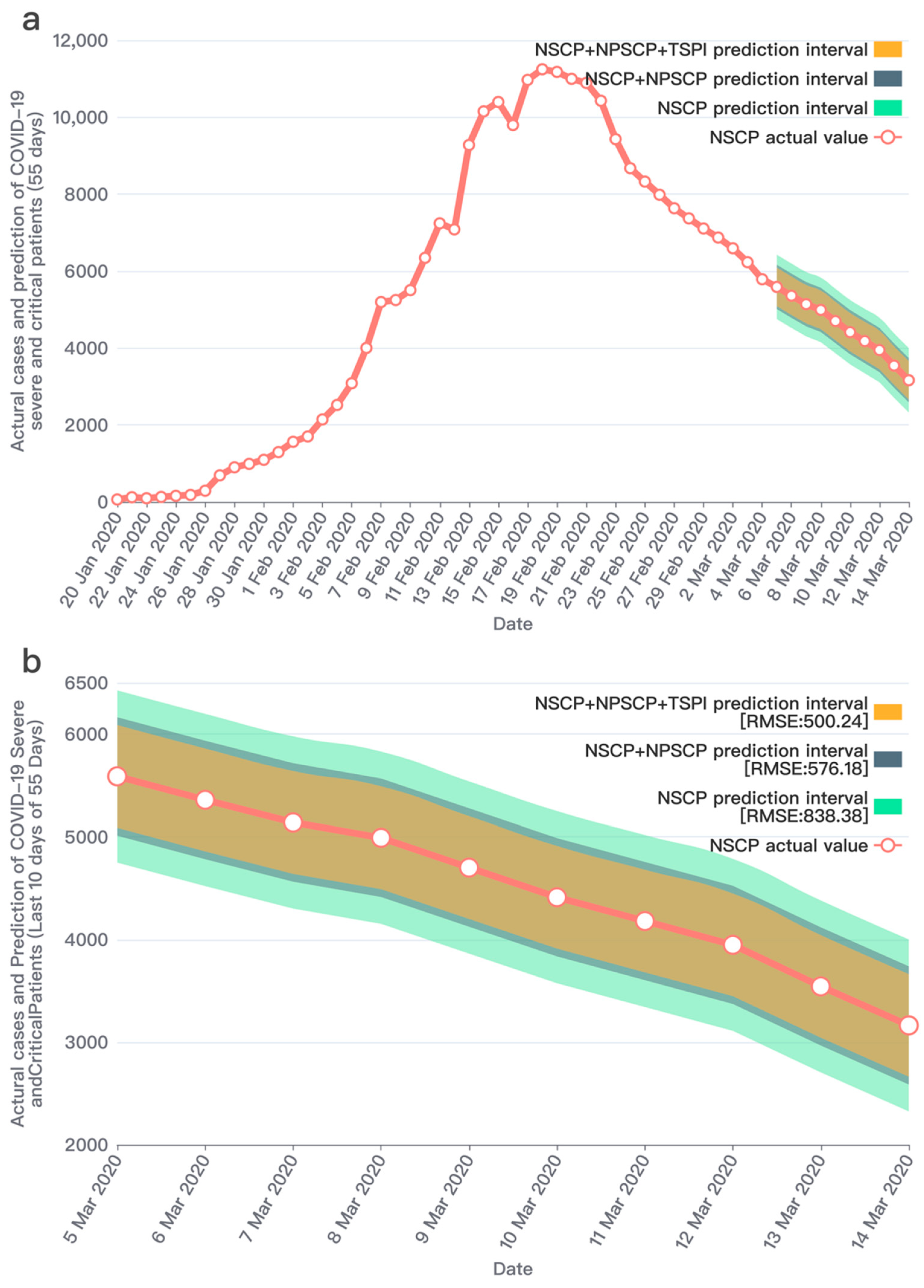
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nguyen, H.; Calantone, R.; Krishnan, R. Influence of Social Media Emotional Word of Mouth on Institutional Investors’ Decisions and Firm Value. Manag. Sci. 2020, 66, 887–910. [Google Scholar] [CrossRef]
- He, S.; Rui, H.; Whinston, A.B. Social Media Strategies in Product-Harm Crises. Inf. Syst. Res. 2018, 29, 362–380. [Google Scholar] [CrossRef] [Green Version]
- Menni, C.; Valdes, A.M.; Freidin, M.B.; Sudre, C.H.; Nguyen, L.H.; Drew, D.A.; Ganesh, S.; Varsavsky, T.; Cardoso, M.J.; El-Sayed Moustafa, J.S.; et al. Real-time tracking of self-reported symptoms to predict potential COVID-19. Nat. Med. 2020, 26, 1037–1040. [Google Scholar] [CrossRef]
- Yan, L.; Zhang, H.-T.; Goncalves, J.; Xiao, Y.; Wang, M.; Guo, Y.; Sun, C.; Tang, X.; Jing, L.; Zhang, M.; et al. An interpretable mortality prediction model for COVID-19 patients. Nat. Mach. Intell. 2020, 2, 283–288. [Google Scholar] [CrossRef]
- Tsang, T.K.; Wu, P.; Lin, Y.; Lau, E.; Leung, G.; Cowling, B.J. Effect of changing case definitions for COVID-19 on the epidemic curve and transmission parameters in mainland China: A modelling study. Lancet Public Health 2020, 5, e289–e296. [Google Scholar] [CrossRef]
- Kucharski, A.J.; Russell, T.W.; Diamond, C.; Liu, Y.; Edmunds, J.; Funk, S.; Eggo, R.M.; Sun, F.; Jit, M.; Munday, J.D.; et al. Early dynamics of transmission and control of COVID-19: A mathematical modelling study. Lancet Infect. Dis. 2020, 20, 553–558. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.F.; Zeng, Z.Q.; Wang, K.; Wong, S.S.; Liang, W.; Zanin, M.; Liu, P.; Cao, X.; Gao, Z.; Mai, Z.; et al. Modified SEIR and AI prediction of the epidemics trend of COVID-19 in China under public health interventions. J. Thorac. Dis. 2020, 12, 165. [Google Scholar] [CrossRef]
- Leung, K.; Wu, J.T.; Liu, D.; Leung, G.M. First-wave COVID-19 transmissibility and severity in China outside Hubei after control measures, and second-wave scenario planning: A modelling impact assessment. Lancet 2020, 395, 1382–1393. [Google Scholar] [CrossRef]
- Chinazzi, M.; Davis, J.T.; Ajelli, M.; Gioannini, C.; Litvinova, M.; Merler, S.; Piontti, Y.; Pastore, A.; Mu, K.; Rossi, L.; et al. The effect of travel restrictions on the spread of the 2019 novel coronavirus (COVID-19) outbreak. Science 2020, 368, 395–400. [Google Scholar] [CrossRef] [Green Version]
- Tian, H.; Liu, Y.; Li, Y.; Wu, C.-H.; Chen, B.; Kraemer, M.U.G.; Li, B.; Cai, J.; Xu, B.; Yang, Q.; et al. An investigation of transmission control measures during the first 50 days of the COVID-19 epidemic in China. Science 2020, 368, 638–642. [Google Scholar] [CrossRef] [Green Version]
- Jia, J.S.; Lu, X.; Yuan, Y.; Xu, G.; Jia, J.; Christakis, N.A. Population flow drives spatio-temporal distribution of COVID-19 in China. Nature 2020, 582, 389–394. [Google Scholar] [CrossRef] [PubMed]
- Cummings, M.J.; Baldwin, M.R.; Abrams, D.; Jacobson, S.D.; Meyer, B.J.; Balough, E.M.; Aaron, J.G.; Claassen, J.; Rabbani, L.E.; Hastie, J.; et al. Epidemiology, clinical course, and outcomes of severe and critical adults with COVID-19 in New York City: A prospective cohort study. Lancet 2020, 395, 1763–1770. [Google Scholar] [CrossRef]
- Álvarez-Mon, M.; Ortega, M.A.; Gasulla, Ó.; Fortuny-Profitós, J.; Mazaira-Font, F.A.; Saurina, P.; Monserrat, J.; Plana, M.N.; Troncoso, D.; Moreno, J.S.; et al. A Predictive Model and Risk Factors for Case Fatality of COVID-19. J. Pers. Med. 2021, 11, 36. [Google Scholar] [CrossRef] [PubMed]
- Moghadas, S.M.; Shoukat, A.; Fitzpatrick, M.C.; Wells, C.R.; Sah, P.; Pandey, A.; Sachs, J.D.; Wang, Z.; Meyers, L.A.; Singer, B.H.; et al. Projecting hospital utilization during the COVID-19 outbreaks in the United States. Proc. Natl. Acad. Sci. USA 2020, 117, 9122–9126. [Google Scholar] [CrossRef] [Green Version]
- Mohsin, F.; Nahrin, R.; Tonmon, T.T.; Nesa, M.; Tithy, S.A.; Saha, S.; Mannan, M.; Shahjalal, M.; Faruque, M.O.; Hawlader, M.D.H. Lifestyle and Comorbidity-Related Risk Factors of Severe and Critical COVID-19 Infection: A Comparative Study Among Survived COVID-19 Patients in Bangladesh. Infect. Drug Resist. 2021, 14, 4057–4066. [Google Scholar] [CrossRef]
- Perveen, S.; Shahbaz, M.; Keshavjee, K.; Guergachi, A. Prognostic Modeling and Prevention of Diabetes Using Machine Learning Technique. Sci. Rep. 2019, 9, 13805. [Google Scholar] [CrossRef] [Green Version]
- Barra, M.; Dahl, F.A.; Vetvik, K.G.; MacGregor, E.A. A Markov chain method for counting and modelling migraine attacks. Sci. Rep. 2020, 10, 3631. [Google Scholar] [CrossRef] [Green Version]
- Shan, S.; Zhao, F.; Wei, Y.; Liu, M. Disaster management 2.0: A real-time disaster damage assessment model based on mobile social media data-A case study of Weibo (Chinese Twitter). Saf. Sci. 2019, 115, 393–413. [Google Scholar] [CrossRef]
- Deng, S.; Huang, Z.J.; Sinha, A.P.; Zhao, H. The Interaction between Microblog Sentiment and Stock Return: An Empirical Examination. MIS Q. 2018, 42, 895–918. [Google Scholar] [CrossRef]
- Roy, A.; Nikolitch, K.; McGinn, R.; Jinah, S.; Klement, W.; Kaminsky, Z.A. A machine learning approach predicts future risk to suicidal ideation from social media data. Npj Digit. Med. 2020, 3, 78. [Google Scholar] [CrossRef]
- Gan, C.C.R.; Feng, S.; Feng, H.; Fu, K.-W.; E Davies, S.; A Grépin, K.; Morgan, R.; Smith, J.; Wenham, C. #WuhanDiary and #WuhanLockdown: Gendered posting patterns and behaviours on Weibo during the COVID-19 pandemic. BMJ Glob. Health 2022, 7, e008149. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Statistical modeling: The two cultures (with comments and a rejoinder by the author). Stat. Sci. 2001, 6, 199–231. [Google Scholar] [CrossRef]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Yu, P.; Yan, X. Stock price prediction based on deep neural networks. Neural Comput. Appl. 2020, 32, 1609–1628. [Google Scholar] [CrossRef]
- Singh, G.; Pal, M.; Yadav, Y.; Singla, T. Deep neural network-based predictive modeling of road accidents. Neural Comput. Appl. 2020, 32, 12417–12426. [Google Scholar] [CrossRef]
- Montoya, R.; Gonzalez, C. A Hidden Markov Model to Detect On-Shelf Out-of-Stocks Using Point-of-Sale Data. Manuf. Serv. Oper. Manag. 2019, 21, 932–948. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Days | HMM Observed Variables | RMSE |
|---|---|---|
| 65 | 422.41 | |
| 251.55 | ||
| 198.48 | ||
| 60 | 633.16 | |
| 462.65 | ||
| 369.96 | ||
| 55 | 838.38 | |
| 576.18 | ||
| 500.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, Q.; Shan, S.; Sun, M.; Zhao, F.; Yang, Y.; Li, Y. A Social Media Infodemic-Based Prediction Model for the Number of Severe and Critical COVID-19 Patients in the Lockdown Area. Int. J. Environ. Res. Public Health 2022, 19, 8109. https://doi.org/10.3390/ijerph19138109
Yan Q, Shan S, Sun M, Zhao F, Yang Y, Li Y. A Social Media Infodemic-Based Prediction Model for the Number of Severe and Critical COVID-19 Patients in the Lockdown Area. International Journal of Environmental Research and Public Health. 2022; 19(13):8109. https://doi.org/10.3390/ijerph19138109
Chicago/Turabian StyleYan, Qi, Siqing Shan, Menghan Sun, Feng Zhao, Yangzi Yang, and Yinong Li. 2022. "A Social Media Infodemic-Based Prediction Model for the Number of Severe and Critical COVID-19 Patients in the Lockdown Area" International Journal of Environmental Research and Public Health 19, no. 13: 8109. https://doi.org/10.3390/ijerph19138109
APA StyleYan, Q., Shan, S., Sun, M., Zhao, F., Yang, Y., & Li, Y. (2022). A Social Media Infodemic-Based Prediction Model for the Number of Severe and Critical COVID-19 Patients in the Lockdown Area. International Journal of Environmental Research and Public Health, 19(13), 8109. https://doi.org/10.3390/ijerph19138109