
Identification of Risk Factors for Suicidal Ideation and Attempt Based on Machine Learning Algorithms: A Longitudinal Survey in Korea (2007–2019)


Abstract
:1. Introduction
2. Materials and Methods
2.1. Overview
2.2. Data Source
2.3. Data Preprocessing
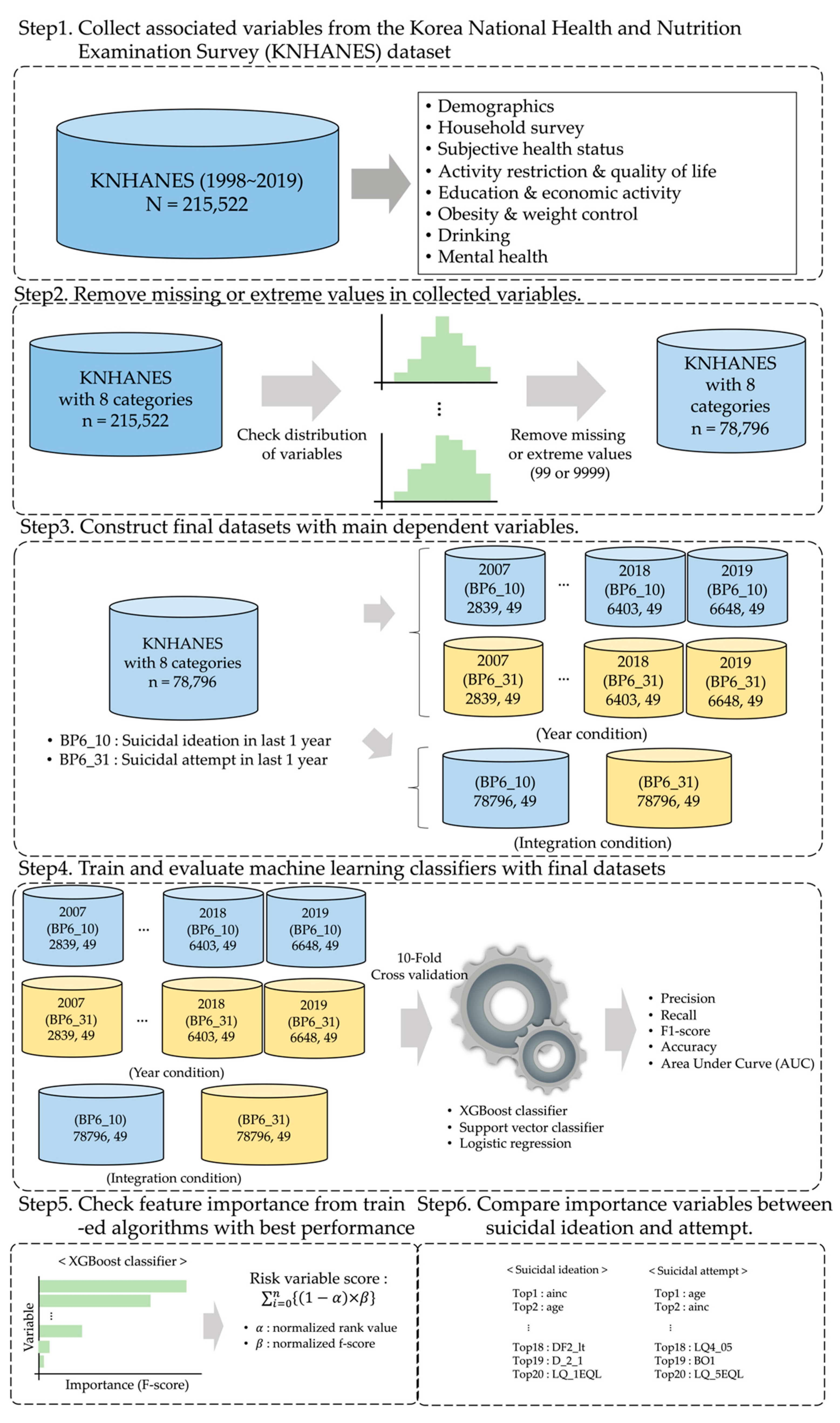
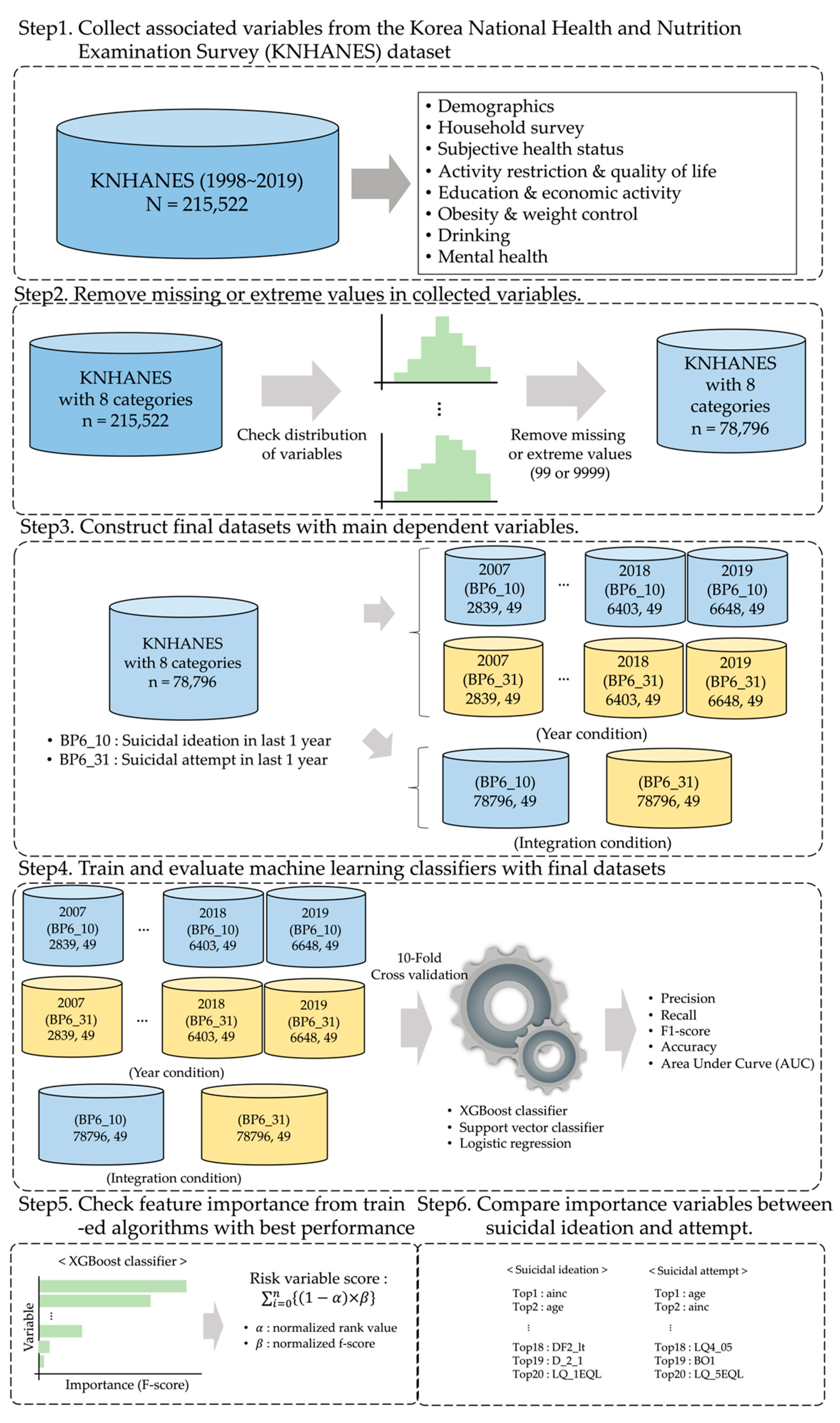
2.3.1. Collection and Selection of Associated Variables from Datasets
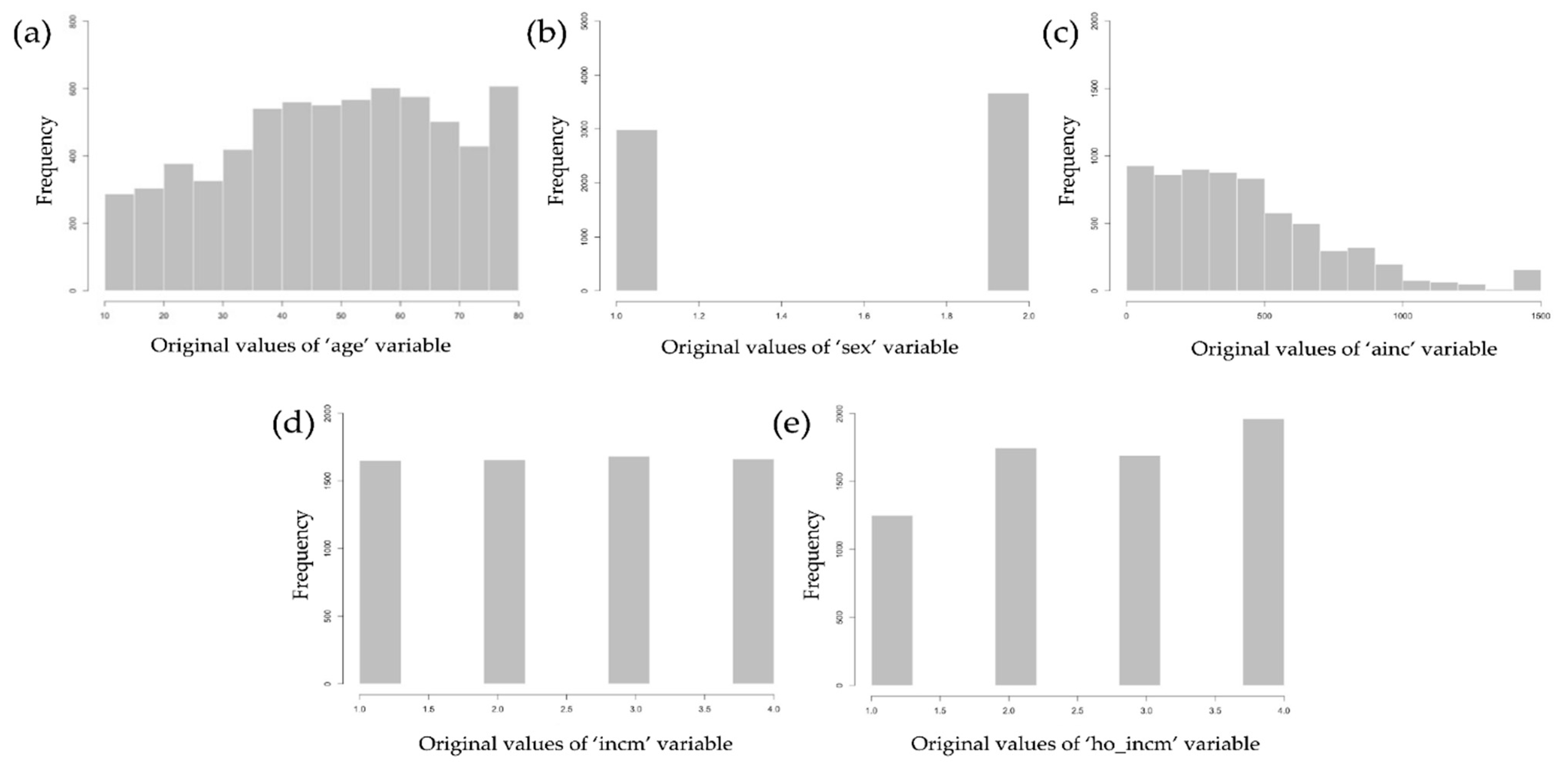
2.3.2. Removal of Missing or Extreme Data in the Dataset
2.3.3. Generation of the Final Datasets for the Evaluation of Machine Learning Classifiers
2.4. Training and Evaluation of Machine Learning Classification Algorithm
2.5. Calculation of the Risk-Factor Score from Feature Importance Results
2.6. Machine Learning (ML) Classification Algorithms
2.6.1. XGBoost Classifier
2.6.2. Support Vector Classifier
2.6.3. Logistic Regression
2.7. Evaluation Metrics
2.8. Tools
3. Results
3.1. Classification Performance Results from ML Classifiers
3.2. Feature Importance for the Identification of Risk Factors
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Suicide Worldwide in 2019. Available online: https://www.who.int/publications/i/item/9789240026643 (accessed on 30 September 2021).
- World Health Organization. Suicide in the World. Available online: https://www.who.int/publications/i/item/suicide-in-the-world (accessed on 30 September 2021).
- World Health Organization. Suicide in the World: Global Health Estimates. 2019. Available online: https://apps.who.int/iris/handle/10665/326948 (accessed on 30 September 2021).
- Birt, C.; Bille-Brahe, U.; Cabecadas, M.; Chishti, P.; Corcoran, P.; Elgie, R.; Williamson, E. Suicide mortality in the European Union. Eur. J. Public Health 2003, 13, 108–114. [Google Scholar] [CrossRef]
- Hedegaard, H.; Curtin, S.C.; Warner, M. Increase in Suicide Mortality in the United States, 1998–2018. Available online: https://stacks.cdc.gov/view/cdc/86670 (accessed on 29 September 2021).
- Mustard, C.A.; Bielecky, A.; Etches, J.; Wilkins, R.; Tjepkema, M.; Amick, B.C.; Aronson, K.J. Suicide mortality by occupation in Canada, 1991–2001. Can. J. Psychiatry 2010, 55, 369–376. [Google Scholar] [CrossRef] [Green Version]
- Jeon, S.Y.; Reither, E.N.; Masters, R.K. A population-based analysis of increasing rates of suicide mortality in Japan and South Korea, 1985–2010. BMC Public Health 2016, 16, 356. [Google Scholar] [CrossRef] [Green Version]
- Thibodeau, L.; Lachaud, J. Impact of economic fluctuations on suicide mortality in Canada (1926–2008): Testing the Durkheim, Ginsberg, and Henry and Short theories. Death Stud. 2016, 40, 305–315. [Google Scholar] [CrossRef]
- Sverre, J.M. Trends in suicide mortality among the elderly in Norway, 1966–1986. Epidemiology 1991, 2, 252–256. [Google Scholar] [CrossRef] [PubMed]
- Yip, P.S.; Liu, K.Y.; Law, C.K.; Law, Y.W. Social and economic burden of suicides in Hong Kong SAR: A year of life lost perspective. Crisis 2005, 26, 156–159. [Google Scholar] [CrossRef] [PubMed]
- Sharmin Salam, S.; Alonge, O.; Islam, M.I.; Hoque, D.M.E.; Wadhwaniya, S.; Ul Baset, M.K.; El Arifeen, S. The burden of suicide in rural Bangladesh: Magnitude and risk factors. Int. J. Environ. Res. Public Health 2017, 14, 1032. [Google Scholar] [CrossRef] [Green Version]
- Gunnell, D.; Appleby, L.; Arensman, E.; Hawton, K.; John, A.; Kapur, N.; Yip, P.S. Suicide risk and prevention during the COVID-19 pandemic. Lancet Psychiatry 2020, 7, 468–471. [Google Scholar] [CrossRef]
- McIntyre, R.S.; Lee, Y. Preventing suicide in the context of the COVID-19 pandemic. World Psychiatry 2020, 19, 250–251. [Google Scholar] [CrossRef]
- John, A.; Pirkis, J.; Gunnell, D.; Appleby, L.; Morrissey, J. Trends in suicide during the covid-19 pandemic. BMJ 2020, 371, m4352. [Google Scholar] [CrossRef] [PubMed]
- Haney, E.M.; O’Neil, M.E.; Carson, S.; Low, A.; Peterson, K.; Denneson, L.M.; Kansagara, D. Suicide Risk Factors and Risk Assessment Tools: A Systematic Review; Department of Veterans Affairs (US): Washington, DC, USA, 2012.
- Mościcki, E.K. Identification of suicide risk factors using epidemiologic studies. Psychiatr. Clin. N. Am. 1997, 20, 499–517. [Google Scholar] [CrossRef]
- Gould, M.S.; Fisher, P.; Parides, M.; Flory, M.; Shaffer, D. Psychosocial risk factors of child and adolescent completed suicide. Arch. Gen. Psychiatry 1996, 53, 1155–1162. [Google Scholar] [CrossRef] [PubMed]
- Brown, G.K.; Beck, A.T.; Steer, R.A.; Grisham, J.R. Risk factors for suicide in psychiatric outpatients: A 20-year prospective study. J. Consult. Clin. Psychol. 2000, 68, 371–377. [Google Scholar] [CrossRef]
- Agerbo, E.; Nordentoft, M.; Mortensen, P.B. Familial, psychiatric, and socioeconomic risk factors for suicide in young people: Nested case-control study. BMJ 2002, 325, 74. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nock, M.K.; Banaji, M.R. Prediction of suicide ideation and attempts among adolescents using a brief performance-based test. J. Consult. Clin. Psychol. 2007, 75, 707–715. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Michel, K. Suicide risk factors: A comparison of suicide attempters with suicide completers. Br. J. Psychiatry 1987, 150, 78–82. [Google Scholar] [CrossRef]
- Nock, M.K.; Borges, G.; Bromet, E.J.; Alonso, J.; Angermeyer, M.; Beautrais, A.; Williams, D. Cross-national prevalence and risk factors for suicidal ideation, plans and attempts. Br. J. Psychiatry 2008, 192, 98–105. [Google Scholar] [CrossRef]
- Simon, M.; Chang, E.S.; Zeng, P.; Dong, X. Prevalence of suicidal ideation, attempts, and completed suicide rate in Chinese aging populations: A systematic review. Arch. Gerontol. Geriatr. 2013, 57, 250–256. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, J.D.; Huang, X.; Fox, K.R.; Franklin, J.C. Depression and hopelessness as risk factors for suicide ideation, attempts and death: Meta-analysis of longitudinal studies. Br. J. Psychiatry 2018, 212, 279–286. [Google Scholar] [CrossRef]
- Baca-Garcia, E.; Perez-Rodriguez, M.M.; Oquendo, M.A.; Keyes, K.M.; Hasin, D.S.; Grant, B.F.; Blanco, C. Estimating risk for suicide attempt: Are we asking the right questions?: Passive suicidal ideation as a marker for suicidal behavior. J. Affect. Disord. 2011, 134, 327–332. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gutierrez, P.M.; Rodriguez, P.J.; Garcia, P. Suicide risk factors for young adults: Testing a model across ethnicities. Death Stud. 2001, 25, 319–340. [Google Scholar] [CrossRef]
- Berman, A.L. Risk factors proximate to suicide and suicide risk assessment in the context of denied suicide ideation. Suicide Life-Threat. Behav. 2018, 48, 340–352. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Jang, H. Correlations between suicide rates and the prevalence of suicide risk factors among Korean adolescents. Psychiatry Res. 2018, 261, 143–147. [Google Scholar] [CrossRef]
- Mani, S.; Chen, Y.; Elasy, T.; Clayton, W.; Denny, J. Type 2 diabetes risk forecasting from EMR data using machine learning. In AMIA Annual Symposium Proceedings; American Medical Informatics Association: Bethesda, MD, USA, 2012. [Google Scholar]
- Khare, S.; Kavyashree, S.; Gupta, D.; Jyotishi, A. Investigation of nutritional status of children based on machine learning techniques using Indian demographic and health survey data. Procedia Comput. Sci. 2017, 115, 338–349. [Google Scholar] [CrossRef]
- De la Garza, Á.G.; Blanco, C.; Olfson, M.; Wall, M.M. Identification of suicide attempt risk factors in a national US survey using machine learning. JAMA Psychiatry 2021, 78, 398–406. [Google Scholar] [CrossRef]
- Fodeh, S.; Li, T.; Menczynski, K.; Burgette, T.; Harris, A.; Ilita, G.; Raicu, D. Using machine learning algorithms to detect suicide risk factors on twitter. In Proceedings of the IEEE 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019. [Google Scholar]
- The Korea National Health and Nutrition Examination Survey (KNHANES). Korea Centers for Disease Control and Prevention. Available online: https://knhanes.cdc.go.kr/knhanes/eng/index.do (accessed on 25 September 2021).
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Tong, S.; Koller, D. Support vector machine active learning with applications to text classification. J. Mach. Learn. Res. 2001, 2, 45–66. [Google Scholar]
- Bhavsar, H.; Panchal, M.H. A review on support vector machine for data classification. Int. J. Adv. Res. Comput. Eng. Technol. IJARCET 2012, 1, 185–189. [Google Scholar]
- Feng, J.; Xu, H.; Mannor, S.; Yan, S. Robust logistic regression and classification. Adv. Neural Inf. Process. Syst. 2014, 27, 253–261. [Google Scholar]
- Hintikka, J.; Koivumaa-Honkanen, H.; Lehto, S.M.; Tolmunen, T.; Honkalampi, K.; Haatainen, K.; Viinamäki, H. Are factors associated with suicidal ideation true risk factors? Soc. Psychiatry Psychiatr. Epidemiol. 2009, 44, 29–33. [Google Scholar] [CrossRef] [PubMed]
- Weber, B.; Metha, A.; Nelsen, E. Relationships among multiple suicide ideation risk factors in college students. J. Coll. Stud. Psychother. 1997, 11, 49–64. [Google Scholar] [CrossRef]
- Kleiman, E.M.; Turner, B.J.; Fedor, S.; Beale, E.E.; Huffman, J.C.; Nock, M.K. Examination of real-time fluctuations in suicidal ideation and its risk factors: Results from two ecological momentary assessment studies. J. Abnorm. Psychol. 2017, 126, 726–738. [Google Scholar] [CrossRef]
- Beautrais, A.L.; Joyce, P.R.; Mulder, R.T. Risk factors for serious suicide attempts among youths aged 13 through 24 years. J. Am. Acad. Child Adolesc. Psychiatry 1996, 35, 1174–1182. [Google Scholar] [CrossRef] [PubMed]
- Teti, G.L.; Rebok, F.; Rojas, S.M.; Grendas, L.; Daray, F.M. Systematic review of risk factors for suicide and suicide attempt among psychiatric patients in Latin America and Caribbean. Rev. Panam. Salud Pública 2014, 36, 124–133. [Google Scholar]
- Parra-Uribe, I.; Blasco-Fontecilla, H.; Garcia-Parés, G.; Martínez-Naval, L.; Valero-Coppin, O.; Cebrià-Meca, A.; Palao-Vidal, D. Risk of re-attempts and suicide death after a suicide attempt: A survival analysis. BMC Psychiatry 2017, 17, 163. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taneja, I.; Damhorst, G.L.; Lopez-Espina, C.; Zhao, S.D.; Zhu, R.; Khan, S.; Bashir, R. Diagnostic and prognostic capabilities of a biomarker and EMR-based machine learning algorithm for sepsis. Clin. Transl. Sci. 2021, 14, 1578–1589. [Google Scholar] [CrossRef] [PubMed]
- Walsh, C.G.; Ribeiro, J.D.; Franklin, J.C. Predicting suicide attempts in adolescents with longitudinal clinical data and machine learning. J. Child Psychol. Psychiatry 2018, 59, 1261–1270. [Google Scholar] [CrossRef]
- Walsh, C.G.; Ribeiro, J.D.; Franklin, J.C. Predicting risk of suicide attempts over time through machine learning. Clin. Psychol. Sci. 2017, 5, 457–469. [Google Scholar] [CrossRef]
- Su, C.; Aseltine, R.; Doshi, R.; Chen, K.; Rogers, S.C.; Wang, F. Machine learning for suicide risk prediction in children and adolescents with electronic health records. Transl. Psychiatry 2020, 10, 413. [Google Scholar] [CrossRef] [PubMed]
- Ferretti, F.; Coluccia, A. Socio-economic factors and suicide rates in European Union countries. Leg. Med. 2009, 11, S92–S94. [Google Scholar] [CrossRef]
- Mortensen, P.B.; Agerbo, E.; Erikson, T.; Qin, P.; Westergaard-Nielsen, N. Psychiatric illness and risk factors for suicide in Denmark. Lancet 2000, 355, 9–12. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| No | Categories | Type of Variables |
|---|---|---|
| 1 | Health behavior | Categorical |
| 2 | Blood pressure measurement | Continuous |
| 3 | Blood test | Continuous |
| 4 | Grip strength test | Continuous |
| 5 | Dietary life survey | Categorical |
| 6 | Food safety investigation | Categorical |
| 7 | Food intake frequency survey | Categorical |
| 8 | Food intake survey | Continuous |
| 9 | Dietary life evaluation index | Continuous |
| Characteristic | KNHANES | |
|---|---|---|
| Age (years), mean (SD) | 48.5 (18.0) | |
| No. of participants (n) | 78,796 | |
| Gender, n (%) | Male | 34,230 (43.5%) |
| Female | 44,566 (56.5%) | |
| Height (cm), mean (SD) | 156.1 (19.7) | |
| Weight (kg), mean (SD) | 57.1 (18.0) | |
| BMI, mean (SD) | 22.6 (4.2) | |
| Year | Dimension (# of Columns, # of Rows) | No. of Participants |
|---|---|---|
| 2007 | (2839, 49) | 2839 |
| 2008 | (6585, 49) | 6585 |
| 2009 | (7399, 49) | 7399 |
| 2010 | (6175, 49) | 6175 |
| 2011 | (5977, 49) | 5977 |
| 2012 | (6125, 49) | 6125 |
| 2013 | (5941, 49) | 5941 |
| 2014 | (5655, 49) | 5655 |
| 2015 | (5899, 49) | 5899 |
| 2016 | (6542, 49) | 6542 |
| 2017 | (6608, 49) | 6608 |
| 2018 | (6403, 49) | 6403 |
| 2019 | (6648, 49) | 6648 |
| Algorithm | Hyperparameter | Value (Argument) |
|---|---|---|
| XGBoost classifier | Eta | 0.3 |
| Gamma | 0 | |
| max_depth | 6 | |
| min_child_weight | 1 | |
| Support vector classifier | Kernel | rbf |
| Gamma | auto | |
| Logistic regression | Penalty | L2 |
| Solver | newton-cg |
| Year | Dependent Variable | Classifier | Precision | Recall | F1-Score | Accuracy | AUC 1 |
|---|---|---|---|---|---|---|---|
| 2007 | BP6_10 2 | XGBoost | 0.850 | 0.866 | 0.859 | 0.886 | 0.920 |
| SVC 4 | 0.846 | 0.605 | 0.600 | 0.856 | 0.843 | ||
| LR 5 | 0.707 | 0.711 | 0.727 | 0.816 | 0.859 | ||
| BP6_31 3 | XGBoost | 0.883 | 0.935 | 0.911 | 0.935 | 0.958 | |
| SVC | 0.868 | 0.530 | 0.523 | 0.658 | 0.656 | ||
| LR | 0.527 | 0.600 | 0.595 | 0.758 | 0.798 | ||
| 2008 | BP6_10 | XGBoost | 0.869 | 0.841 | 0.851 | 0.887 | 0.893 |
| SVC | 0.721 | 0.586 | 0.523 | 0.815 | 0.805 | ||
| LR | 0.704 | 0.758 | 0.706 | 0.784 | 0.829 | ||
| BP6_31 | XGBoost | 0.893 | 0.941 | 0.911 | 0.938 | 0.955 | |
| SVC | 0.471 | 0.506 | 0.485 | 0.459 | 0.649 | ||
| LR | 0.530 | 0.600 | 0.496 | 0.710 | 0.692 | ||
| 2009 | BP6_10 | XGBoost | 0.894 | 0.857 | 0.879 | 0.883 | 0.898 |
| SVC | 0.743 | 0.648 | 0.644 | 0.824 | 0.807 | ||
| LR | 0.688 | 0.737 | 0.708 | 0.783 | 0.828 | ||
| BP6_31 | XGBoost | 0.908 | 0.933 | 0.913 | 0.932 | 0.958 | |
| SVC | 0.549 | 0.537 | 0.484 | 0.419 | 0.731 | ||
| LR | 0.551 | 0.682 | 0.567 | 0.751 | 0.761 | ||
| 2010 | BP6_10 | XGBoost | 0.916 | 0.924 | 0.911 | 0.937 | 0.920 |
| SVC | 0.726 | 0.554 | 0.497 | 0.840 | 0.809 | ||
| LR | 0.676 | 0.757 | 0.698 | 0.806 | 0.833 | ||
| BP6_31 | XGBoost | 0.906 | 0.937 | 0.913 | 0.937 | 0.963 | |
| SVC | 0.667 | 0.540 | 0.527 | 0.814 | 0.725 | ||
| LR | 0.550 | 0.673 | 0.565 | 0.763 | 0.752 | ||
| 2011 | BP6_10 | XGBoost | 0.948 | 0.965 | 0.948 | 0.959 | 0.925 |
| SVC | 0.789 | 0.533 | 0.523 | 0.817 | 0.830 | ||
| LR | 0.685 | 0.782 | 0.709 | 0.818 | 0.848 | ||
| BP6_31 | XGBoost | 0.913 | 0.945 | 0.925 | 0.942 | 0.956 | |
| SVC | 0.469 | 0.503 | 0.487 | 0.728 | 0.637 | ||
| LR | 0.509 | 0.589 | 0.577 | 0.692 | 0.601 | ||
| 2012 | BP6_10 | XGBoost | 0.943 | 0.954 | 0.937 | 0.943 | 0.924 |
| SVC | 0.793 | 0.860 | 0.799 | 0.861 | 0.786 | ||
| LR | 0.857 | 0.791 | 0.801 | 0.790 | 0.819 | ||
| BP6_31 | XGBoost | 0.919 | 0.951 | 0.932 | 0.951 | 0.965 | |
| SVC | 0.476 | 0.500 | 0.488 | 0.865 | 0.710 | ||
| LR | 0.535 | 0.644 | 0.515 | 0.765 | 0.731 | ||
| 2013 | BP6_10 | XGBoost | 0.930 | 0.948 | 0.936 | 0.948 | 0.978 |
| SVC | 0.538 | 0.507 | 0.499 | 0.525 | 0.833 | ||
| LR | 0.586 | 0.778 | 0.602 | 0.833 | 0.842 | ||
| BP6_31 | XGBoost | 0.985 | 0.992 | 0.988 | 0.992 | 0.988 | |
| SVC | 0.496 | 0.500 | 0.498 | 0.604 | 0.852 | ||
| LR | 0.519 | 0.800 | 0.502 | 0.864 | 0.826 |
| Year | Dependent Variable | Classifier | Precision | Recall | F1-Score | Accuracy | AUC 1 |
|---|---|---|---|---|---|---|---|
| 2014 | BP6_10 2 | XGBoost | 0.914 | 0.953 | 0.932 | 0.953 | 0.981 |
| SVC 4 | 0.475 | 0.500 | 0.487 | 0.516 | 0.865 | ||
| LR 5 | 0.587 | 0.749 | 0.599 | 0.839 | 0.828 | ||
| BP6_31 3 | XGBoost | 0.960 | 0.980 | 0.969 | 0.980 | 0.977 | |
| SVC | 0.490 | 0.500 | 0.495 | 0.785 | 0.687 | ||
| LR | 0.560 | 0.677 | 0.585 | 0.683 | 0.745 | ||
| 2015 | BP6_10 | XGBoost | 0.927 | 0.943 | 0.932 | 0.943 | 0.980 |
| SVC | 0.653 | 0.555 | 0.549 | 0.464 | 0.851 | ||
| LR | 0.616 | 0.817 | 0.646 | 0.858 | 0.870 | ||
| BP6_31 | XGBoost | 0.983 | 0.991 | 0.987 | 0.991 | 0.989 | |
| SVC | 0.496 | 0.500 | 0.498 | 0.535 | 0.742 | ||
| LR | 0.518 | 0.757 | 0.501 | 0.844 | 0.854 | ||
| 2016 | BP6_10 | XGBoost | 0.917 | 0.942 | 0.929 | 0.955 | 0.989 |
| SVC | 0.481 | 0.500 | 0.490 | 0.637 | 0.797 | ||
| LR | 0.593 | 0.743 | 0.600 | 0.746 | 0.888 | ||
| BP6_31 | XGBoost | 0.988 | 0.994 | 0.991 | 0.994 | 0.990 | |
| SVC | 0.497 | 0.500 | 0.498 | 0.884 | 0.789 | ||
| LR | 0.509 | 0.676 | 0.479 | 0.850 | 0.744 | ||
| 2017 | BP6_10 | XGBoost | 0.939 | 0.952 | 0.941 | 0.952 | 0.980 |
| SVC | 0.501 | 0.501 | 0.491 | 0.652 | 0.866 | ||
| LR | 0.605 | 0.811 | 0.634 | 0.861 | 0.881 | ||
| BP6_31 | XGBoost | 0.988 | 0.994 | 0.991 | 0.994 | 0.990 | |
| SVC | 0.497 | 0.500 | 0.498 | 0.395 | 0.862 | ||
| LR | 0.513 | 0.730 | 0.494 | 0.862 | 0.844 | ||
| 2018 | BP6_10 | XGBoost | 0.918 | 0.958 | 0.938 | 0.958 | 0.972 |
| SVC | 0.479 | 0.500 | 0.498 | 0.583 | 0.837 | ||
| LR | 0.560 | 0.725 | 0.564 | 0.838 | 0.829 | ||
| BP6_31 | XGBoost | 0.984 | 0.992 | 0.988 | 0.992 | 0.990 | |
| SVC | 0.497 | 0.500 | 0.498 | 0.836 | 0.876 | ||
| LR | 0.512 | 0.712 | 0.485 | 0.852 | 0.864 | ||
| 2019 | BP6_10 | XGBoost | 0.937 | 0.950 | 0.939 | 0.950 | 0.982 |
| SVC | 0.475 | 0.500 | 0.487 | 0.504 | 0.866 | ||
| LR | 0.599 | 0.805 | 0.624 | 0.851 | 0.879 | ||
| BP6_31 | XGBoost | 0.991 | 0.995 | 0.993 | 0.995 | 0.990 | |
| SVC | 0.498 | 0.500 | 0.499 | 0.549 | 0.806 | ||
| LR | 0.509 | 0.727 | 0.490 | 0.872 | 0.821 |
| Dependent Variable | Classifier | Precision | Recall | F1-score | Accuracy | AUC 1 |
|---|---|---|---|---|---|---|
| BP6_10 2 | XGBoost | 0.874 | 0.893 | 0.878 | 0.893 | 0.950 |
| SVC 4 | 0.442 | 0.500 | 0.470 | 0.885 | 0.811 | |
| LR 5 | 0.653 | 0.779 | 0.677 | 0.808 | 0.853 | |
| BP6_31 3 | XGBoost | 0.977 | 0.986 | 0.981 | 0.986 | 0.990 |
| SVC | 0.493 | 0.500 | 0.497 | 0.682 | 0.766 | |
| LR | 0.524 | 0.794 | 0.493 | 0.805 | 0.850 |
| Rank | DV | Variable | Variable Description | Risk Variable Score | DV | Variable | Variable Description | Risk-Factor Score |
|---|---|---|---|---|---|---|---|---|
| 1 | BP6_10 1 | ainc | Average monthly income | 0.2023 | BP6_31 2 | ainc | Average monthly income | 0.2030 |
| 2 | age | Age of participant | 0.1653 | age | Age of participant | 0.1472 | ||
| 3 | BD2 | Drinking age | 0.1088 | BD2 | Drinking age | 0.1107 | ||
| 4 | BP8 | Average sleep time per day | 0.0729 | BP8 | Average sleep time per day | 0.0969 | ||
| 5 | educ | Education level | 0.0518 | educ | Education level | 0.0392 | ||
| 6 | BO1 | Subjective body type recognition | 0.4209 | BO1 | Subjective body type recognition | 0.0389 | ||
| 7 | D_1_1 | Subjective health status | 0.0377 | D_1_1 | Subjective health status | 0.0330 | ||
| 8 | BP1 | Awareness of usual stress | 0.0301 | BO1_1 | Weight change in past 1 year | 0.0292 | ||
| 9 | BO1_1 | Weight change in past 1 year | 0.0277 | BP1 | Awareness of usual stress | 0.0274 | ||
| 10 | incm | Personal income | 0.0244 | house | Home ownership | 0.0231 | ||
| 11 | house | Home ownership | 0.0244 | DF2_lt | Prevalence of depression | 0.0216 | ||
| 12 | DF2_lt | Prevalence of depression | 0.0220 | LQ_5EQL | EuroQoL: anxiety/depression | 0.0208 | ||
| 13 | EC1_1 | Economic activity | 0.0202 | incm | Personal income | 0.0208 | ||
| 14 | LQ_4EQL | EuroQoL: pain/discomfort | 0.0188 | LQ_4EQL | EuroQoL: pain/discomfort | 0.0190 | ||
| 15 | ho_incm | Household income | 0.0178 | BP5 | Depression for 2 weeks or more | 0.0189 | ||
| 16 | D_2_1 | Uncomfortable experience in past 2 weeks | 0.0167 | EC1_1 | Economic activity | 0.0171 | ||
| 17 | sex | Sex of participant | 0.0166 | sex | Sex of participant | 0.0163 | ||
| 18 | LQ_5EQL | EuroQoL: anxiety/depression | 0.0149 | D_2_1 | Uncomfortable experience in past 2 weeks | 0.0140 | ||
| 19 | BP5 | Depression for 2 weeks or more | 0.0142 | ho_incm | Household income | 0.0140 | ||
| 20 | LQ_1EQL | EuroQoL: athletic ability | 0.0111 | LQ_3EQL | EuroQoL: daily activity | 0.0118 |
| Rank | DV | Variable | Variable Description | Risk Variable Score | DV | Variable | Variable Description | Risk-Factor Score |
|---|---|---|---|---|---|---|---|---|
| 1 | BP6_10 1 | ainc | Average monthly income | 0.1700 | BP6_31 2 | age | Age of participant | 0.2000 |
| 2 | age | Age of participant | 0.1651 | ainc | Average monthly income | 0.1545 | ||
| 3 | LQ_VAS | EuroQoL: total score | 0.1168 | LQ_VAS | EuroQoL: total score | 0.1241 | ||
| 4 | BD2 | Drinking age | 0.1045 | BD2 | Drinking age | 0.1049 | ||
| 5 | BP8 | Average sleep time per day | 0.0516 | BP8 | Average sleep time per day | 0.0337 | ||
| 6 | educ | Education level | 0.0447 | educ | Education level | 0.0299 | ||
| 7 | BO1 | Subjective body type recognition | 0.0375 | BO1_1 | Weight change in past 1 year | 0.0297 | ||
| 8 | D_1_1 | Subjective health status | 0.0350 | BO1 | Subjective body type recognition | 0.0297 | ||
| 9 | BO1_1 | Weight change in past 1 year | 0.0310 | DF2_lt | Prevalence of depression | 0.0278 | ||
| 10 | BP1 | Awareness of usual stress | 0.0288 | incm | Personal income | 0.0248 | ||
| 11 | incm | Personal income | 0.0266 | ho_incm | Household income | 0.0231 | ||
| 12 | house | Home ownership | 0.0228 | LQ_5EQL | EuroQoL: anxiety/depression | 0.0210 | ||
| 13 | EC1_1 | Economic activity | 0.0203 | house | Home ownership | 0.0202 | ||
| 14 | ho_incm | Household income | 0.0184 | BP5 | Depression for 2 weeks or more | 0.0168 | ||
| 15 | sex | Sex of participant | 0.0147 | EC1_1 | Economic activity | 0.0161 | ||
| 16 | LQ_4EQL | EuroQoL: pain/discomfort | 0.0136 | D_1_1 | Subjective health status | 0.0159 | ||
| 17 | BP5 | Depression for 2 weeks or more | 0.0135 | LQ4_22 | Activity restriction: old age | 0.0145 | ||
| 18 | D_2_1 | Uncomfortable experience in past 2 weeks | 0.0127 | D_2_1 | Uncomfortable experience in past 2 weeks | 0.0134 | ||
| 19 | DF2_lt | Prevalence of depression | 0.0114 | LQ_4EQL | EuroQoL: pain/discomfort | 0.0125 | ||
| 20 | LQ_1EQL | EuroQoL: athletic ability | 0.0085 | LQ_1EQL | EuroQoL: athletic ability | 0.0097 |
| Rank | DV | Variable | Variable Description | Risk Variable Score | DV | Variable | Variable Description | Risk-Factor Score |
|---|---|---|---|---|---|---|---|---|
| 1 | BP6_10 1 | ainc | Average monthly income | 0.2007 | BP6_31 2 | ainc | Average monthly income | 0.2158 |
| 2 | age | Age of participant | 0.1594 | age | Age of participant | 0.1703 | ||
| 3 | LQ_VAS | EuroQoL: total score | 0.1232 | LQ_VAS | EuroQoL: total score | 0.1505 | ||
| 4 | BD2 | Drinking age | 0.1014 | BD2 | Drinking age | 0.1420 | ||
| 5 | BP8 | Average sleep time per day | 0.0486 | BP8 | Average sleep time per day | 0.0342 | ||
| 6 | educ | Education level | 0.0442 | D_1_1 | Subjective health status | 0.0223 | ||
| 7 | BO1 | Subjective body type recognition | 0.0372 | BO1 | Subjective body type recognition | 0.0197 | ||
| 8 | D_1_1 | Subjective health status | 0.0305 | educ | Education level | 0.0196 | ||
| 9 | BP1 | Awareness of usual stress | 0.0258 | LQ4_08 | Activity restriction: high blood pressure | 0.0186 | ||
| 10 | BO1_1 | Weight change in past 1 year | 0.0248 | BO1_1 | Weight change in past 1 year | 0.0185 | ||
| 11 | house | Home ownership | 0.0222 | BP1 | Awareness of usual stress | 0.0184 | ||
| 12 | incm | Personal income | 0.0212 | incm | Personal income | 0.0163 | ||
| 13 | EC1_1 | Economic activity | 0.0206 | LQ_5EQL | EuroQoL: anxiety/depression | 0.0156 | ||
| 14 | LQ4_08 | Activity restriction: high blood pressure | 0.0175 | DF2_lt | Prevalence of depression | 0.0145 | ||
| 15 | D_2_1 | Uncomfortable experience in past 2 weeks | 0.0156 | LQ4_10 | Activity restriction: cancer | 0.0136 | ||
| 16 | LQ_4EQL | EuroQoL: pain/discomfort | 0.0156 | sex | Sex of participant | 0.0133 | ||
| 17 | ho_incm | Household income | 0.0143 | house | Home ownership | 0.0119 | ||
| 18 | sex | Sex of participant | 0.0140 | BP5 | Depression for 2 weeks or more | 0.0119 | ||
| 19 | BP5 | Depression for 2 weeks or more | 0.0140 | EC1_1 | Economic activity | 0.0102 | ||
| 20 | DF2_lt | Prevalence of depression | 0.0114 | LQ4_01 | Activity restriction: fracture/joint injury | 0.0098 |
| Rank | DV | Variable | Variable Description | Risk Variable Score | DV | Variable | Variable Description | Risk-Factor Score |
|---|---|---|---|---|---|---|---|---|
| 1 | BP6_10 1 | ainc | Average monthly income | 0.2107 | BP6_31 2 | ainc | Average monthly income | 0.2338 |
| 2 | age | Age of participant | 0.1574 | age | Age of participant | 0.2127 | ||
| 3 | LQ_VAS | EuroQoL: total score | 0.1208 | LQ_VAS | EuroQoL: total score | 0.1690 | ||
| 4 | BD2 | Drinking age | 0.1085 | BD2 | Drinking age | 0.0694 | ||
| 5 | BP8 | Average sleep time per day | 0.0482 | ho_incm | Household income | 0.0412 | ||
| 6 | educ | Education level | 0.0400 | educ | Education level | 0.0281 | ||
| 7 | BO1 | Subjective body type recognition | 0.0336 | BP8 | Average sleep time per day | 0.0261 | ||
| 8 | D_1_1 | Subjective health status | 0.0270 | BO1 | Subjective body type recognition | 0.0203 | ||
| 9 | BP1 | Awareness of usual stress | 0.0264 | BO1_1 | Weight change in past 1 year | 0.0185 | ||
| 10 | BO1_1 | Weight change in past 1 year | 0.0245 | DF2_lt | Prevalence of depression | 0.0169 | ||
| 11 | incm | Personal income | 0.0244 | EC1_1 | Economic activity | 0.0163 | ||
| 12 | EC1_1 | Economic activity | 0.0207 | D_1_1 | Subjective health status | 0.0152 | ||
| 13 | house | Home ownership | 0.0168 | BP1 | Awareness of usual stress | 0.0152 | ||
| 14 | sex | Sex of participant | 0.0168 | LQ_5EQL | EuroQoL: anxiety/depression | 0.0136 | ||
| 15 | BP5 | Depression for 2 weeks or more | 0.0159 | D_2_1 | Uncomfortable experience in past 2 weeks | 0.0117 | ||
| 16 | ho_incm | Household income | 0.0155 | BP5 | Depression for 2 weeks or more | 0.0116 | ||
| 17 | D_2_1 | Uncomfortable experience in past 2 weeks | 0.0143 | incm | Personal income | 0.0094 | ||
| 18 | LQ_4EQL | EuroQoL: pain/discomfort | 0.0143 | LQ1_sb | Lying in a sickbed in past 1 month | 0.0083 | ||
| 19 | DF2_lt | Prevalence of depression | 0.0111 | LQ_4EQL | EuroQoL: pain/discomfort | 0.0082 | ||
| 20 | LQ_5EQL | EuroQoL: anxiety/depression | 0.0094 | LQ4_05 | Activity restriction: breathing problem/lung disease | 0.0077 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.; Cho, S.; Ko, I.; Han, S. Identification of Risk Factors for Suicidal Ideation and Attempt Based on Machine Learning Algorithms: A Longitudinal Survey in Korea (2007–2019). Int. J. Environ. Res. Public Health 2021, 18, 12772. https://doi.org/10.3390/ijerph182312772
Choi J, Cho S, Ko I, Han S. Identification of Risk Factors for Suicidal Ideation and Attempt Based on Machine Learning Algorithms: A Longitudinal Survey in Korea (2007–2019). International Journal of Environmental Research and Public Health. 2021; 18(23):12772. https://doi.org/10.3390/ijerph182312772
Chicago/Turabian StyleChoi, Junggu, Seoyoung Cho, Inhwan Ko, and Sanghoon Han. 2021. "Identification of Risk Factors for Suicidal Ideation and Attempt Based on Machine Learning Algorithms: A Longitudinal Survey in Korea (2007–2019)" International Journal of Environmental Research and Public Health 18, no. 23: 12772. https://doi.org/10.3390/ijerph182312772
APA StyleChoi, J., Cho, S., Ko, I., & Han, S. (2021). Identification of Risk Factors for Suicidal Ideation and Attempt Based on Machine Learning Algorithms: A Longitudinal Survey in Korea (2007–2019). International Journal of Environmental Research and Public Health, 18(23), 12772. https://doi.org/10.3390/ijerph182312772