
Space Power in Inclusive Development: Industrial Clusters and Rural Anti-Poverty


Abstract
:1. Introduction
2. Literature Review
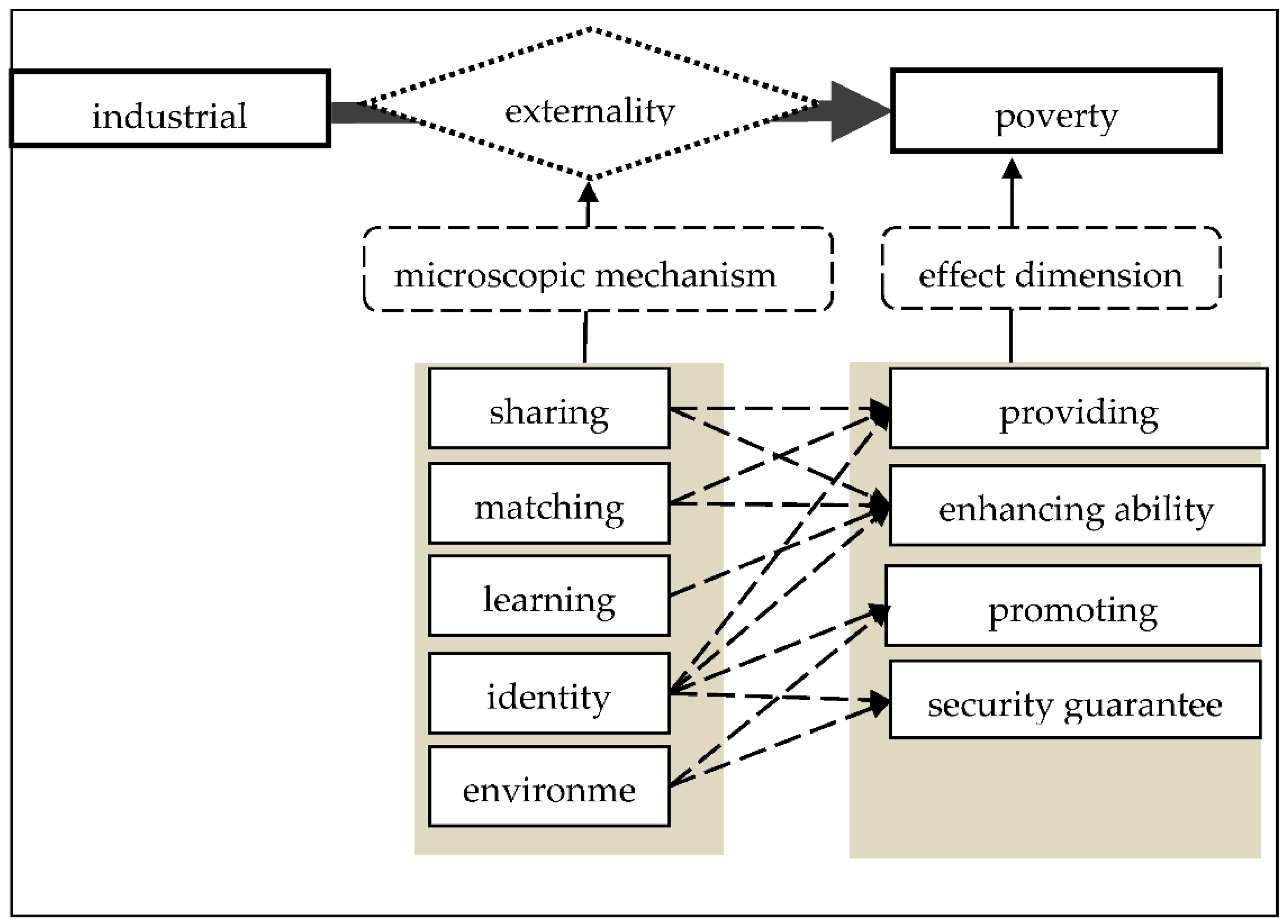
3. The Conceptual Model
4. Research Design
4.1. Data Source
4.2. Econometric Model
5. Results
5.1. Preliminary Estimation Results
5.2. Robustness Test and GMM Model Estimation Results
5.3. Estimated Results of Differentiating Farmers
5.4. Estimated Results of Classifying Industries
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, J.; Ruan, J.; Xu, G. Economies agglomeration, economies distance, and farmer’s income growth: A study on direct and spillover effects. China Econ. Q. 2017, 1, 297–320. [Google Scholar]
- Ruan, J. Cluster-Based Rural Industrial Empirical Analysis to the Germination and Development Mechanism; Zhejiang University: Hangzhou, China, 2009. [Google Scholar]
- Duranton, G.; Puga, D. Micro-foundations of urban agglomeration economies. In Handbook of Regional and Urban Economics; Henderson, V., Thisse, J.F., Eds.; Elsevier: Amsterdam, The Netherlands, 2004; pp. 2063–2117. [Google Scholar]
- March, J.G. Primer on Decision Making: How Decisions Happen; Free Press: New York, NY, USA, 1994. [Google Scholar]
- Fujita, M.; Thisse, J.F. Economics of Agglomeration: Cities, Industrial Location, and Globalization; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Nadvi, K.; Barrientos, S. Industrial Clusters and Poverty Reduction; UNIDO: Vienna, Austria, 2004. [Google Scholar]
- Mccormick, D. African enterprise clusters and industrialization: Theory and reality. World Dev. 1999, 27, 1531–1551. [Google Scholar] [CrossRef]
- Fleisher, B.; Hu, D.; McGuire, W.; Zhang, X. The evolution of an industrial cluster in China. China Econ. Rev. 2010, 21, 456–469. [Google Scholar] [CrossRef] [Green Version]
- Sonobe, T.; Hu, D.; Otsuka, K. Industrial development in the inland region of China: A case study of the motorcycle industry. J. Comp. Econ. 2006, 34, 818–838. [Google Scholar] [CrossRef] [Green Version]
- Visser, E. A comparison of clustered and dispersed firms in the small-scale clothing industry of Lima. World Dev. 1999, 27, 1553–1570. [Google Scholar] [CrossRef]
- Fowler, C.S.; Kleit, R.G. The effects of industrial clusters on the poverty rate. Econ. Geogr. 2014, 90, 129–154. [Google Scholar] [CrossRef]
- Sen, A. Development as Freedom; OUP Oxford: Oxford, UK, 1999. [Google Scholar]
- Batra, V.; Aneja, S. Cluster Development Programme: A Methodology for Sustainable Business Development for Poverty Alleviation and Micro Enterprise Promotion; National Conference on Emerging Challenges for Sustainable Business: Roorkee, India, 2012. [Google Scholar]
- Das, R.; Das, A.K. Industrial cluster: An approach for rural development in north east India. Int. J. Trade Econ. Financ. 2011, 2, 161–165. [Google Scholar] [CrossRef] [Green Version]
- Long, C.; Zhang, X. Cluster-based industrialization in China: Financing and performance. J. Int. Econ. 2011, 84, 112–123. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X. Has transport infrastructure promoted regional economic growth? With an analysis of the spatial spillover effects of transport infrastructure. Soc. Sci. China 2012, 3, 60–77. [Google Scholar]
- Krugman, P. Increasing returns and economic geography. J. Political Econ. 1991, 99, 483–499. [Google Scholar] [CrossRef]
- Ruan, J.; Zhang, X.; Wei, L. Crisis begets quality upgrade: Evidence from Zhejiang industrial clusters. Manag. World 2010, 2, 69–79. [Google Scholar]
- Marshall, A. Principles of Economics, 1890 ed.; Macmillan: London, UK, 1920. [Google Scholar]
- Jacobs, J. The Economy of Cities; Random House: New York, NY, USA, 1969. [Google Scholar]
- Combes, P.; Mayer, T.; Thisse, J. Economic Geography: The Integration of Regions and Nations; China Renmin University Press: Beijing, China, 2011. [Google Scholar]
- World Bank. World Development Report: Attacking Poverty; Chinese Financial & Economic Publishing House: Beijing, China, 2000. [Google Scholar]
- Hayami, Y.; Godo, Y. Development Economics: From the Poverty to the Wealth of Nations; Social Sciences Academic Press: Beijing, China, 2009. [Google Scholar]

{kind=link}
| Dependent Variable | The Probability of Poverty (2004) | The Probability of Poverty (2008) | ln(Farmers’ per Capita Net Income) |
|---|---|---|---|
| Logit | Logit | Fe | |
| Model 1 | Model 2 | Model 3 | |
| local industrial clusters | −0.01 ** | −0.01 *** | 0.01 ** |
| (−2.00) | (−2.61) | (2.32) | |
| industrial clusters in other regions | −0.25 *** | −0.24 *** | 0.16 *** |
| (−3.96) | (−4.61) | (4.97) | |
| age | 0.02 ** | 0.02 ** | −0.005 |
| (2.41) | (2.18) | (−0.96) | |
| education | −0.04 | −0.05 * | 0.05 *** |
| (−1.44) | (−1.66) | (3.19) | |
| gender | 0.06 | 0.11 | −0.12 |
| (0.18) | (0.35) | (−0.64) | |
| pop | 0.25 *** | 0.24 *** | −0.12 *** |
| (3.62) | (3.76) | (−3.33) | |
| land | 0.11 ** | 0.09 ** | −0.04 |
| (2.35) | (2.13) | (−1.39) | |
| capital | −3.7 *** | −3.5 *** | 2.9 *** |
| (−5.38) | (−6.01) | (8.97) | |
| intercept item | −0.72 | −0.23 | 9.17 *** |
| (−0.92) | (−0.31) | (21.22) | |
| observations | 975 | 975 | 974 |
| Dependent Variable | ln(Farmers’ per Capita Net Income) | the Probability of Poverty (2004) |
|---|---|---|
| Model 4 | Model 5 | |
| economic density | 1.95 *** | −1.18 *** |
| (5.95) | (−3.10) | |
| age | −0.003 | 0.02 * |
| (−0.62) | (1.87) | |
| education | 0.05 *** | −0.04 |
| (3.17) | (−1.41) | |
| gender | −0.12 | 0.02 |
| (−0.61) | (0.07) | |
| pop | −0.11 *** | 0.22 *** |
| (−3.00) | (3.39) | |
| land | −0.03 | 0.12 *** |
| (−1.28) | (2.69) | |
| capital | 3.01 *** | −3.43 *** |
| (9.31) | (−5.24) | |
| intercept item | 9.42 *** | −1.31 * |
| (21.98) | (−1.82) | |
| observations | 974 | 975 |
| Dependent Variable | ln(Farmers’ per Capita Net Income) | The Probability of Poverty (2004) |
|---|---|---|
| Model 6 | Model 7 | |
| local industrial clusters | 0.004 *** | −0.001 * |
| (2.88) | (−1.88) | |
| industrial clusters in other regions | 0.07 *** | −0.04 *** |
| (3.26) | (−3.46) | |
| age | −0.01 * | 0.004 ** |
| (−1.78) | (2.47) | |
| education | 0.03 *** | −0.01 * |
| (2.81) | (−1.90) | |
| gender | −0.23 * | 0.02 |
| (−1.66) | (0.34) | |
| pop | −0.12 *** | 0.04 *** |
| (−4.46) | (2.94) | |
| land | −0.05 *** | 0.02 ** |
| (−2.59) | (2.19) | |
| capital | 2.71 *** | −5.52 *** |
| (11.77) | (−4.91) | |
| intercept item | 9.98 *** | 0.27 * |
| (31.92) | (1.75) | |
| observations | 974 | 975 |
| Dependent Variable | ln(Farmers’ Per Capita Net Income) | |
|---|---|---|
| The Poverty | Non-Poverty | |
| Model 8 | Model 9 | |
| local industrial clusters | 0.004 * | 0.004 ** |
| (1.86) | (2.31) | |
| industrial clusters in other regions | 0.22 *** | −0.06 ** |
| (7.09) | (−2.39) | |
| age | −0.01 | −0.001 |
| (−1.21) | (−0.26) | |
| education | 0.03 ** | 0.04 ** |
| (2.03) | (2.50) | |
| gender | −0.004 | −0.33 * |
| (−0.02) | (−1.93) | |
| pop | −0.15 *** | −0.10 *** |
| (−4.15) | (−2.98) | |
| land | −0.03 | −0.02 |
| (−1.28) | (−1.03) | |
| capital | 2.91 *** | 1.95 *** |
| (8.88) | (6.98) | |
| intercept item | 8.75 *** | 10.74 *** |
| (19.25) | (29.28) | |
| observations | 475 | 499 |
| Dependent Variable | ln(Farmers’ Per Capita Net Income) | The Probability of Poverty (2004) | ||
|---|---|---|---|---|
| Code | Industry Names | Results | Industry Names | Results |
| Three Digits | Spinning, weaving and finishing of textiles | 0.66 *** | Dyeing and finishing of cotton and chemical fiber textiles | −3.96 *** |
| Manufacture of parts for general-purpose machinery and mechanical repair | 0.16 *** | Metal surface treatment and heat treatment | −3.30 *** | |
| Manufacture of parts for general-purpose machinery and mechanical repair | −2.76 *** | |||
| Spinning, weaving and finishing of textiles | −1.15 ** | |||
| Four Digits | Spinning and weaving of silk textiles | 0.66 *** | Manufacture of wool knitwear | −4.51 *** |
| Manufacture of paper and cardboard containers | 0.31 *** | Metal surface treatment and heat treatment | −1.51 *** | |
| Fasteners, springs manufacturing | 0.33 * | Manufacture of textile and garment | −1.15 ** | |
| Inorganic salt manufacturing | −0.97 * | |||
| Code | Dependent Variables | |||
|---|---|---|---|---|
| ln(Farmers’ Per Capita Net Income) | The Probability of Poverty (2004) | |||
| Three Digits | Paper industries | −1.16 * | Wholesale of textile, clothing and daily necessities | 0.19 *** |
| Four Digits | Manufacture of paper and paperboard making machinery | −1.16 * | Corporate production management Service | 0.26 * |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Liu, X.; Ruan, J.; Qi, X.; Wang, C.; Fan, D. Space Power in Inclusive Development: Industrial Clusters and Rural Anti-Poverty. Int. J. Environ. Res. Public Health 2021, 18, 10943. https://doi.org/10.3390/ijerph182010943
Wu J, Liu X, Ruan J, Qi X, Wang C, Fan D. Space Power in Inclusive Development: Industrial Clusters and Rural Anti-Poverty. International Journal of Environmental Research and Public Health. 2021; 18(20):10943. https://doi.org/10.3390/ijerph182010943
Chicago/Turabian StyleWu, Junqian, Xiaoqian Liu, Jianqing Ruan, Xiulin Qi, Chang’an Wang, and Dan Fan. 2021. "Space Power in Inclusive Development: Industrial Clusters and Rural Anti-Poverty" International Journal of Environmental Research and Public Health 18, no. 20: 10943. https://doi.org/10.3390/ijerph182010943
APA StyleWu, J., Liu, X., Ruan, J., Qi, X., Wang, C., & Fan, D. (2021). Space Power in Inclusive Development: Industrial Clusters and Rural Anti-Poverty. International Journal of Environmental Research and Public Health, 18(20), 10943. https://doi.org/10.3390/ijerph182010943