An Application of Item Response Theory to Scoring Patient Safety Culture Survey Data


Abstract
1. Introduction
2. Methods
2.1. Data Source
2.2. Calculating Traditional Mean Domain Scores
2.3. Confirmatory Factor Analysis with IRT
2.4. Calculating IRT-Based Domain Scores
2.5. Comparing Traditional Mean and IRT-Based Scores
3. Results
3.1. Characteristics of Respondents
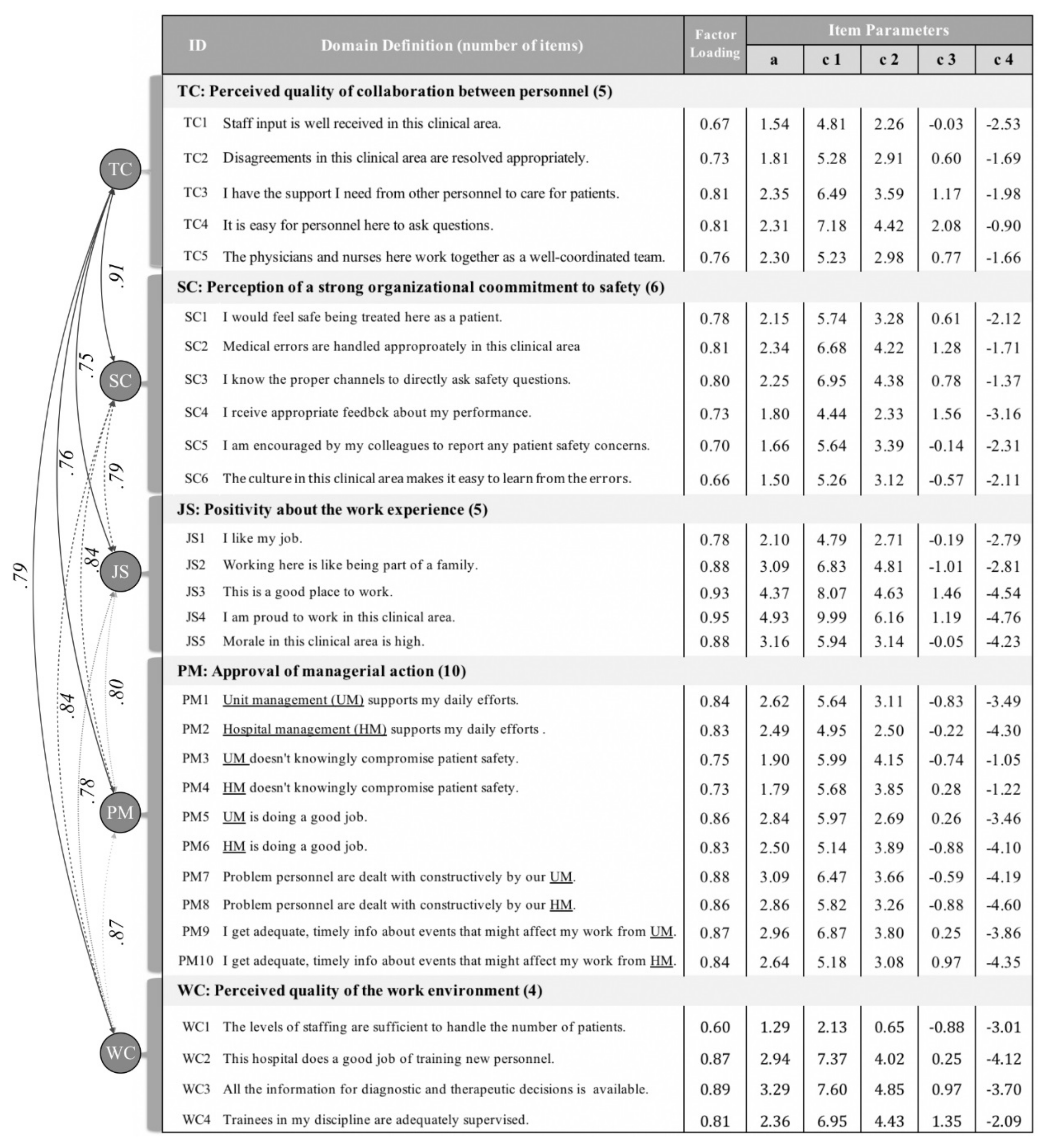
3.2. Results of Confirmatory Factor Analysis
3.3. Item Properties
3.4. Comparing the Results from Two Scoring Methods
4. Discussion
4.1. Which Method Is Correct or Better?
4.2. Barriers against Switching to the IRT Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wachter, R.M. The end of the beginning: Patient safety five years after ‘To Err is Human’. Health Aff. 2004, 23, W4-534–W4-545. [Google Scholar] [CrossRef] [PubMed]
- Leape, L.L.; Berwick, D.M. Five years after To Err Is Human: What have we learned? JAMA 2005, 293, 2384–2390. [Google Scholar] [CrossRef] [PubMed]
- Clancy, C.M. Ten years after To Err is Human. Am. J. Med. Qual. 2009, 24, 525–528. [Google Scholar] [CrossRef] [PubMed]
- Pronovost, P.; Needham, D.; Berenholtz, S.; Sinopoli, D.; Chu, H.; Cosgrove, S.; Sexton, B.; Hyzy, R.; Welsh, R.; Roth, G.; et al. An intervention to decrease catheter-related bloodstream infections in the ICU. N. Engl. J. Med. 2006, 355, 2725–2732. [Google Scholar] [CrossRef] [PubMed]
- Morello, R.T.; Lowthian, J.A.; Barker, A.L.; McGinnes, R.; Dunt, D.; Brand, C. Strategies for improving patient safety culture in hospitals: A systematic review. BMJ Qual. Saf. 2013, 22, 11–18. [Google Scholar] [CrossRef] [PubMed]
- Jeong, H.-J.; Pham, J.C.; Kim, M.; Engineer, C.; Pronovost, P.J. Major cultural-compatibility complex: Considerations on cross-cultural dissemination of patient safety programmes. BMJ Qual. Saf. 2012, 21, 612–615. [Google Scholar] [CrossRef]
- Jeong, H.-J.; Kim, M.; An, E.A.; Kim, S.Y.; Song, B.J. A strategy to develop tailored patient safety culture improvement programs with latent class analysis method. Biom. Biostat. Int. J. 2015, 2, 00027. [Google Scholar] [CrossRef]
- Pronovost, P.J.; Goeschel, C.A.; Marsteller, J.A.; Sexton, J.B.; Pham, J.C.; Berenholtz, S.M. Framework for patient safety research and improvement. Circulation 2009, 119, 330–337. [Google Scholar] [CrossRef]
- Wachter, R.M. Creating a culture of safety. In Understanding Patient Safety, 2nd ed.; McGraw-Hill Medical: New York, NY, USA, 2012; pp. 255–279. [Google Scholar]
- Watts, B.V.; Percarpio, K.; West, P.; Mills, P.D. Use of the Safety Attitudes Questionnaire as a measure in patient safety improvement. J. Patient Saf. 2010, 6, 206–209. [Google Scholar] [CrossRef]
- Berenholtz, S.M.; Lubomski, L.H.; Weeks, K.; Goeschel, C.A.; Marsteller, J.A.; Pham, J.C.; Sawyer, M.D.; Thompson, D.A.; Winters, B.D.; Cosgrove, S.E. Eliminating central line-associated bloodstream infections: A national patient safety imperative. Infect. Control Hosp. Epidemiol. 2014, 35, 56–62. [Google Scholar] [CrossRef]
- Timmel, J.; Kent, P.S.; Holzmueller, C.G.; Paine, L.; Schulick, R.D.; Pronovost, P.J. Impact of the Comprehensive Unit-based Safety Program (CUSP) on safety culture in a surgical inpatient unit. Jt. Comm. J. Qual. Patient Saf. 2010, 36, 252–260. [Google Scholar] [CrossRef]
- Lee, G.-S.; Park, M.-J.; Na, H.-R.; Jeong, H.-J. A Strategy for Administration and Application of a Patient Safety Culture Survey. Qual. Improv. Health Care 2015, 21, 80–95. [Google Scholar] [CrossRef][Green Version]
- Colla, J.B.; Bracken, A.C.; Kinney, L.M.; Weeks, W.B. Measuring patient safety climate: A review of surveys. Qual. Saf. Health Care 2005, 14, 364–366. [Google Scholar] [CrossRef] [PubMed]
- Sexton, J.B.; Helmreich, R.L.; Neilands, T.B.; Rowan, K.; Vella, K.; Boyden, J.; Roberts, P.R.; Thomas, E.J. The Safety Attitudes Questionnaire: Psychometric properties, benchmarking data, and emerging research. BMC Health Serv. Res. 2006, 6, 44. [Google Scholar] [CrossRef] [PubMed]
- Carifio, J.; Perla, R. Resolving the 50-year debate around using and misusing Likert scales. Med. Educ. 2008, 42, 1150–1152. [Google Scholar] [CrossRef]
- Jeong, H.-J.; Lee, W.-C. Ignorance or negligence: Uncomfortable truth regarding misuse of confirmatory factor analysis. J. Biom. Biostat. 2016, 7, 298. [Google Scholar] [CrossRef]
- Fayers, P. Item response theory for psychologists. Qual. Life Res. 2004, 13, 715–716. [Google Scholar] [CrossRef]
- Weiss, D.J.; Yoes, M.E. Item response theory. In Advances in Educational and Psychological Testing: Theory and Applications; Hambleton, R.K., Zaal, J.N., Eds.; Springer science+business media: New York, NY, USA, 2003; pp. 69–95. [Google Scholar]
- Lee, G.-S.; Park, M.J.; Na, H.-R.; Jeong, H.-J. Are healthcare workers trained to be impervious to stress? Biom. Biostat. In. J. 2015, 2, 00028. [Google Scholar]
- Jeong, H.-J.; Jung, S.M.; An, E.A.; Kim, S.Y.; Yoon, H.; Kim, M.; Song, B.J. Development of the Safety Attitudes Questionnaire—Korean version (SAQ-K) and its novel analysis methods for safety managers. Biom. Biostat. Int. J. 2015, 2, 00020. [Google Scholar] [CrossRef]
- Lee, W.-C.; Wung, H.-Y.; Liao, H.-H.; Lo, C.-M.; Chang, F.-L.; Wang, P.-C.; Fan, A.; Chen, H.-H.; Yang, H.-C.; Hou, S.-M. Hospital safety culture in Taiwan: A nationwide survey using Chinese version Safety Attitude Questionnaire. BMC Health Serv. Res. 2010, 10, 234. [Google Scholar] [CrossRef]
- Han, K.T.; Wells, C.S.; Sireci, S.G. The impact of multidirectional item parameter drift on IRT scaling coefficients and proficiency estimates. App. Meas. Edu. 2012, 25, 97–117. [Google Scholar] [CrossRef]
- Samejima, F. Graded response models. In Handbook of Item Response Theory, Volume One; van der Linden, W.J., Ed.; Chapman and Hall/CRC: New York, NY, USA, 2016; pp. 123–136. [Google Scholar]
- Jeong, H.-J.; Lee, W.-C.; Liao, H.-H.; Chu, F.-Y.; Chen, T.-J.; Wang, P.-C. The Hospital Patient Safety Culture Survey: Reform of Analysis and Visualization Methods. Int. J. Environ. Res. Public Health 2019, 16, 3624. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Choi, J. A comparison of maximum likelihood and expected a posteriori estimation for polychoric correlation using Monte Carlo simulation. J. Mod. Appl Stat. Meth. 2009, 8, 32. [Google Scholar] [CrossRef]
- Embretson, S.E.; Reise, S.P. Item Response Theory; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 2000; p. 23. [Google Scholar]
- Acock, A.C. Discovering Structural Equation Modeling Using Stata; Stata Press Books: College Station, TX, USA, 2013; pp. 21–29. [Google Scholar]
- Cai, L.; Hansen, M. Limited-information goodness-of-fit testing of hierarchical item factor models. Br. J. Math. Stat. Psychol. 2013, 66, 245–276. [Google Scholar] [CrossRef] [PubMed]
- Maydeu-Olivares, A.; Joe, H. Limited-and full-information estimation and goodness-of-fit testing in 2n contingency tables: A unified framework. J. Am. Stat. Assoc. 2005, 100, 1009–1020. [Google Scholar] [CrossRef]
- Tanaka, J.S. Multifaceted conceptions of fit in structural equation models (SAGE Focus Editions). In Testing Structural Equation Models, 1st ed.; Bollen, K.A., Long, S.J., Eds.; SAGE Publications: Thousand Oaks, CA, USA, 1993; Volume 154, p. 10. [Google Scholar]
- Alphen, A.; Halfens, R.; Hasman, A.; Imbos, T. Likert or Rasch? Nothing is more applicable than good theory. J. Adv. Nurs. 1994, 20, 196–201. [Google Scholar] [CrossRef]
- McHorney, C.A.; Haley, S.M.; Ware Jr, J.E. Evaluation of the MOS SF-36 physical functioning scale (PF-40): II. Comparison of relative precision using Likert and Rasch scoring methods. J. Clin. Epidemiol. 1997, 50, 451–461. [Google Scholar] [CrossRef]
- Khan, A.; Chien, C.-W.; Brauer, S.G. Rasch-based scoring offered more precision in differentiating patient groups in measuring upper limb function. J. Clin. Epidemiol. 2013, 66, 681–687. [Google Scholar] [CrossRef]
- Jeong, H.-J.; Lee, W.-C. Item response theory-based evaluation of psychometric properties of the safety attitudes questionnaire—Korean version (SAQ-K). Biom. Biostat. Int. J. 2016, 3, 00079. [Google Scholar] [CrossRef][Green Version]
- Cai, L. Metropolis-Hastings Robbins-Monro Algorithm for Confirmatory Item Factor Analysis. J. Educ. Behav. Stat. 2010, 35, 307–335. [Google Scholar] [CrossRef]
- Cai, L. High-dimensional exploratory item factor analysis by a Metropolis–Hastings Robbins–Monro algorithm. Psychometrika 2010, 75, 33–57. [Google Scholar] [CrossRef]
- Strang, G. Linear Algebra and Its Applications, 4th ed.; Thompson Brooks/Cole: Belmiont, CA, USA, 2006. [Google Scholar]



{kind=link}
{kind=link}
| Characteristics | N | % |
|---|---|---|
| Gender | ||
| Male | 4,375 | 11.8 |
| Female | 32,788 | 88.2 |
| Age group (years) | ||
| ≤20 | 110 | 0.3 |
| 21–30 | 19,668 | 55.5 |
| 31–40 | 11,656 | 31.7 |
| 41–50 | 4,422 | 12.0 |
| 51–60 | 829 | 2.3 |
| >60 | 58 | 0.2 |
| Job types | ||
| Physicians | 2,369 | 6.4 |
| Nurses | 26,229 | 70.6 |
| Technicians | 3,054 | 8.2 |
| Pharmacists | 1,835 | 4.9 |
| Administrative staff | 792 | 2.1 |
| Others | 806 | 2.2 |
| Missing | 2,078 | 5.6 |
| Hospital levels (N) | ||
| Medical centers (20) | 16,613 | 44.7 |
| Regional hospitals (57) | 13,510 | 36.4 |
| District hospitals (104) | 5,698 | 15.3 |
| Psychiatric hospitals (19) | 1,342 | 3.6 |
| Total | 37,163 | 100 |
| Domain | N | Range of Scores | Correlation Between Methods | |||||
|---|---|---|---|---|---|---|---|---|
| Mean | IRT | |||||||
| Mean | IRT | Lowest | Highest | Lowest (a) | Highest (b) | |a–b| | ||
| TC | 21 | 473 | 0 | 100 | −3.43 | 1.83 | 5.26 | 0.97 |
| SC | 25 | 498 | 0 | 100 | −3.41 | 2.06 | 5.47 | 0.97 |
| JS | 21 | 464 | 0 | 100 | −3.15 | 1.95 | 5.10 | 0.97 |
| PM | 41 | 511 | 0 | 100 | −3.37 | 2.37 | 5.74 | 0.99 |
| WC | 17 | 440 | 0 | 100 | −2.88 | 2.15 | 5.03 | 0.96 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, H.-J.; Liao, H.-H.; Han, S.H.; Lee, W.-C. An Application of Item Response Theory to Scoring Patient Safety Culture Survey Data. Int. J. Environ. Res. Public Health 2020, 17, 854. https://doi.org/10.3390/ijerph17030854
Jeong H-J, Liao H-H, Han SH, Lee W-C. An Application of Item Response Theory to Scoring Patient Safety Culture Survey Data. International Journal of Environmental Research and Public Health. 2020; 17(3):854. https://doi.org/10.3390/ijerph17030854
Chicago/Turabian StyleJeong, Heon-Jae, Hsun-Hsiang Liao, Su Ha Han, and Wui-Chiang Lee. 2020. "An Application of Item Response Theory to Scoring Patient Safety Culture Survey Data" International Journal of Environmental Research and Public Health 17, no. 3: 854. https://doi.org/10.3390/ijerph17030854
APA StyleJeong, H.-J., Liao, H.-H., Han, S. H., & Lee, W.-C. (2020). An Application of Item Response Theory to Scoring Patient Safety Culture Survey Data. International Journal of Environmental Research and Public Health, 17(3), 854. https://doi.org/10.3390/ijerph17030854