Teleconsultations between Patients and Healthcare Professionals in Primary Care in Catalonia: The Evaluation of Text Classification Algorithms Using Supervised Machine Learning

 , ,
, , 
Abstract
:1. Introduction
2. Methodology
2.1. Data Acquisition
2.2. Vector Representation of Text in eConsulta Messages
2.3. Training and Testing AI Algorithms
2.4. Ethical Considerations
3. Results
4. Discussion
Limitations
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| GP | General Practitioner |
| BOW | Bag of Words |
| TF-IDF | Term Frequency—Inverse Document Frequency |
| ROC | Receiver Operating Characteristics |
Appendix A
Appendix A.1. Administrative
- 1
- Management of test results
- ○
- The patient provides the results of tests carried out in an external centre in order that they are recorded in their medical history.
- ○
- The GP provides the results of tests with normal results.
- ○
- The GP deals with questions related to tests requested by the patient.
- ○
- The GP requests tests after conducting a follow-up teleconsultation.
- 2
- Temporary disability management
- ○
- The patient communicates changes to their health related to an upcoming temporary disability.
- ○
- The GP tracks the progress of a temporary disability in conjunction with face-to-face visits.
- 3
- Management of visits/referrals
- ○
- The patient has an enquiry which the GP thinks ought to be dealt with by a specialist and refers them. They can also report incidents resulting from any referrals made.
- ○
- The GP resolves incidents relating to the timing of visits.
- ○
- The GP cancels visits from other clinicians in cases in which the problem has been resolved following completion of the e-consultation.
- ○
- Validation of appointments with other specialists where the citizen needs more information about the motivation of the appointment.
- 4
- Request for a clinical report/sick-note
- ○
- The patient asks for a report/sick-note while consulting their medical history.
- ○
- The GP asks the patient for more information in order to prepare the report.
- 5
- Repeat prescriptions
- ○
- The patient asks for their prescription to be updated if it has been modified by an external specialist, either because they do not use it or because it has expired.
- ○
- The GP warns the patient that their prescription is about to expire and updates it.
- ○
- The GP cancels an unnecessary prescription following an e-consultation.
- 6
- Vaccinations
- ○
- Updates of immunization schedules and general enquiries regarding vaccinations.
- ○
- Questions concerning vaccinations for travel overseas.
- 7
- Other administrative issues: Any administrative procedure which can be resolved without being physically present.
Appendix A.2. Medical
- 8
- Medical enquiries: The patient has a question about their health that can be resolved without a physical examination. They can also attach photographs to accompany the description.
- 9
- Issues regarding medicines: the patient asks a question about a prescription.
- 10
- Questions regarding anticoagulants and dosage.
Appendix A.3. Others
- 11
- Messages sent in error: The patient made a mistake.
- 12
- Other.
- 13
- Test messages.
References
- López Seguí, F.; Vidal Alaball, J.; Sagarra Castro, M.; García Altés, A.; García Cuyàs, F. Does teleconsultation reduce face to face visits? Evidence from the Catalan public primary care system. JMIR Prepr. 2019. [Google Scholar] [CrossRef]
- Triantafyllidis, A.K.; Tsanas, A. Applications of Machine Learning in Real-Life Digital Health Interventions: Review of the Literature. JMIR 2019, 21, e12286. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luo, W.; Phung, D.; Tran, T.; Gupta, S.; Rana, S.; Karmakar, C.; Shilton, A.; Yearwood, J.; Dimitrova, N.; Ho, T.B.; et al. Guidelines for Developing and Reporting Machine Learning Predictive Models in Biomedical Research: A Multidisciplinary View. JMIR 2016, 18, e323. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Z.; Keel, S.; Liu, C.; He, Y.; Meng, W.; Scheetz, J.; Lee, P.Y.; Shaw, J.; Ting, D.; Wong, T.Y.; et al. An Automated Grading System for Detection of Vision-Threatening Referable Diabetic Retinopathy on the Basis of Color Fundus Photographs. Diabetes Care. 2018, 41, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gulshan, V.; Peng, L.; Coram, M. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Vidal-Alaball, J.; Dídac Royo, F.; Zapata, M.A.; Gomez, F.M.; Fernandez, O.S. Artificial Intelligence for the Detection of Diabetic Retinopathy in Primary Care: Protocol for Algorithm Development. JMIR Res. Protoc. 2019, 8, e12539. [Google Scholar] [CrossRef] [PubMed]
- Alessa, A.; Faezipour, M. Preliminary Flu Outbreak Prediction Using Twitter Posts Classification and Linear Regression with Historical Centers for Disease Control and Prevention Reports: Prediction Framework Study. JMIR Public Health Surveill. 2019, 5, e12383. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, S.; Markson, C.; Costello, K.L.; Xing, C.Y.; Demissie, K.; Llanos, A.A. Leveraging Social Media to Promote Public Health Knowledge: Example of Cancer Awareness via Twitter. JMIR Public Health Surveill. 2016, 2, e17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Doan, S.; Ritchart, A.; Perry, N.; Chaparro, J.D.; Conway, M. How Do You #relax When You’re #stressed? A Content Analysis and Infodemiology Study of Stress-Related Tweets. JMIR Public Health Surveill. 2017, 3, e35. [Google Scholar] [PubMed] [Green Version]
- McRoy, S.; Rastegar-Mojarad, M.; Wang, Y.; Ruddy, K.J.; Haddad, T.C.; Liu, H. Assessing Unmet Information Needs of Breast Cancer Survivors: Exploratory Study of Online Health Forums Using Text Classification and Retrieval. JMIR Cancer 2018, 4, e10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bobicev, V.; Sokolova, M.; El Emam, K.; Jafer, Y.; Dewar, B.; Jonker, E.; Matwin, S. Can Anonymous Posters on Medical Forums be Reidentified? JMIR 2013, 15, e215. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Lalor, J.; Liu, W.; Druhl, E.; Granillo, E.; Vimalananda, V.G.; Yu, H. Detecting Hypoglycemia Incidents Reported in Patients’ Secure Messages: Using Cost-Sensitive Learning and Oversampling to Reduce Data Imbalance. JMIR 2019, 21, e11990. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- IDESCAT. Noms de la Població. Available online: http://www.idescat.cat/noms/ (accessed on 24 September 2019).
- Bojanowski, P.; Grave, E.; Jouilin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Le, Q.; Tomas, M. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Ljubesic, N.; Toral, A. caWaC-A web corpus of Catalan and its application to language modeling and machine translation. LREC 2014, L14-1647, 1728–1732. [Google Scholar]
- Rennie, J.D.; Shih, L.; Teevan, J.; Karger, D.R. Tackling the poor assumptions of naive bayes text classifiers. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003. [Google Scholar]
- Van Der Walt, S.; Chris Colbert, S.; Varoquaux, G. The NumPy array: A structure for efficient numerical computation. Comput. Sci. Eng. 2011, 13, 22. [Google Scholar] [CrossRef] [Green Version]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 9–95. [Google Scholar] [CrossRef]
- mwaskom/seaborn: v0. 9.0. Available online: https://zenodo.org/record/1313201 (accessed on 30 January 2020).
- Altair. Available online: https://altair-viz.github.io/index.html (accessed on 8 February 2020).
- Pedregosa, F.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; Vanderplas, J.; Passos, A.; Cournapeau, D. Scikit-learn: Machine Learning in Python. JMLR 2011, 12, 2825–2830. [Google Scholar]
- McKinney, W. Data structures for statistical computing in python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 9–15 July 2010; Volume 445. [Google Scholar]
- Rehurek, R.; Sojka, P. Software framework for topic modelling with large corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valetta, Malta, 22 May 2010. [Google Scholar]
- Bird, S.; Loper, E.; Klein, E. Natural Language Processing with Python; O’Reilly Media Inc.: Newton, MA, USA, 2009. [Google Scholar]
- Paszke, A. Automatic differentiation in pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks-a publishing format for reproducible computational workflows. ELPUB 2016. [Google Scholar] [CrossRef]
- World Medical Association. World Medical Association Declaration of Helsinki. Ethical Principles for Medical Research Involving Human Subjects Helsinki. 2013. Available online: https://www.wma.net/what-we-do/medical-ethics/declaration-of-helsinki/ (accessed on 27 January 2020).

{kind=link}
| Conversation Title | Conversation ID | Message ID | From | To | Message | Files Attached? |
|---|---|---|---|---|---|---|
| Travelling to Australia | C1 | M1 | Mr. John Patient | Ms. Jane Doctor | Dear doctor, I’m travelling to Australia on 15 December. Do I need to have any vaccinations? Many thanks | No |
| M2 | Ms. Jane Doctor | Mr. John Patient | Hi, vaccination is required for travel to Australia | No |
| Conversation ID | Face-to-Face Visit Avoided? | Increased Demand? | Type of Visit |
|---|---|---|---|
| C1 | Yes | No | 6 (Vaccinations) |
| Text Representations | Algorithms |
|---|---|
| BoW | Random Forest |
| TF–IDF | Gradient Boosting (lightGBM) |
| Word2Vec | Fasttext |
| Doc2Vec | Multinomial Naive Bayes |
| Complement Naive Bayes |
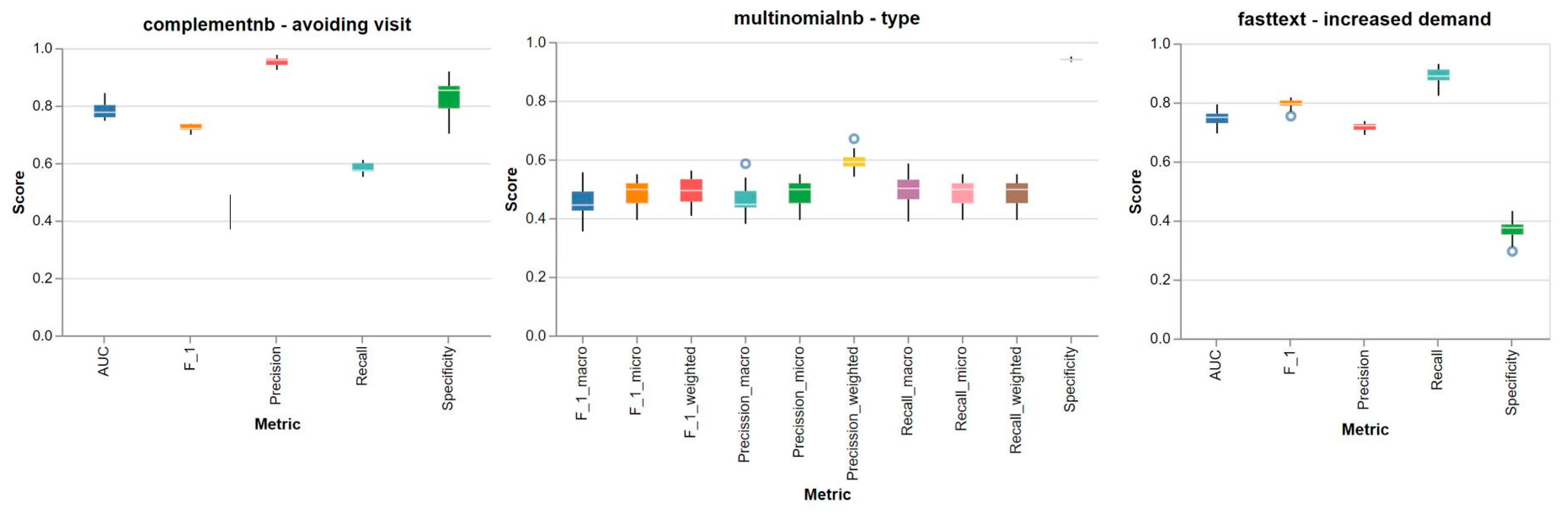
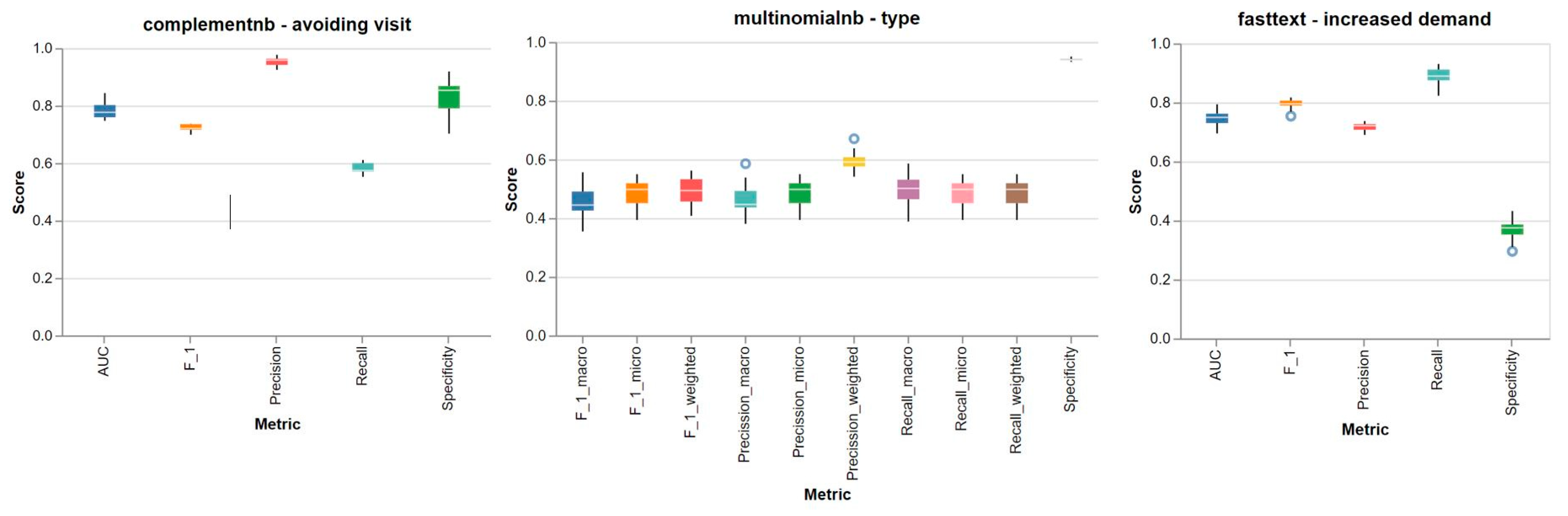
| Variable | Precision | Recall | F1 | Roc_AUC |
|---|---|---|---|---|
| Avoiding the need of a face-to-face visit | Random Forest TF-IDF 0.98 (0.026) | FastText Word2Vec 0.99 (0.005) | FastText Word2Vec 0.92 (0.004) | ComplementNB TF-IDF 0.79 (0.032) |
| Increased demand | Random Forest TF-IDF 0.97 (0.057) | FastText Word2Vec 0.89 (0.029) | FastText Word2Vec 0.79 (0.018) | FastText Word2Vec 0.75 (0.031) |
| Type of use of the teleconsultation (micro averaged score) | MultinomialNB BOW 0.48 (0.049) | MultinomialNB BOW 0.48 (0.049) | MultinomialNB BOW 0.48 (0.049) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
López Seguí, F.; Ander Egg Aguilar, R.; de Maeztu, G.; García-Altés, A.; García Cuyàs, F.; Walsh, S.; Sagarra Castro, M.; Vidal-Alaball, J. Teleconsultations between Patients and Healthcare Professionals in Primary Care in Catalonia: The Evaluation of Text Classification Algorithms Using Supervised Machine Learning. Int. J. Environ. Res. Public Health 2020, 17, 1093. https://doi.org/10.3390/ijerph17031093
López Seguí F, Ander Egg Aguilar R, de Maeztu G, García-Altés A, García Cuyàs F, Walsh S, Sagarra Castro M, Vidal-Alaball J. Teleconsultations between Patients and Healthcare Professionals in Primary Care in Catalonia: The Evaluation of Text Classification Algorithms Using Supervised Machine Learning. International Journal of Environmental Research and Public Health. 2020; 17(3):1093. https://doi.org/10.3390/ijerph17031093
Chicago/Turabian StyleLópez Seguí, Francesc, Ricardo Ander Egg Aguilar, Gabriel de Maeztu, Anna García-Altés, Francesc García Cuyàs, Sandra Walsh, Marta Sagarra Castro, and Josep Vidal-Alaball. 2020. "Teleconsultations between Patients and Healthcare Professionals in Primary Care in Catalonia: The Evaluation of Text Classification Algorithms Using Supervised Machine Learning" International Journal of Environmental Research and Public Health 17, no. 3: 1093. https://doi.org/10.3390/ijerph17031093
APA StyleLópez Seguí, F., Ander Egg Aguilar, R., de Maeztu, G., García-Altés, A., García Cuyàs, F., Walsh, S., Sagarra Castro, M., & Vidal-Alaball, J. (2020). Teleconsultations between Patients and Healthcare Professionals in Primary Care in Catalonia: The Evaluation of Text Classification Algorithms Using Supervised Machine Learning. International Journal of Environmental Research and Public Health, 17(3), 1093. https://doi.org/10.3390/ijerph17031093