Unveiling COVID-19 from CHEST X-Ray with Deep Learning: A Hurdles Race with Small Data

 ,
, 
Abstract
1. Introduction
2. Materials and Methods
- Transfer learning: in the literature it is widely recognized that transfer learning-based approaches prove to be effective, also for medical imaging [21]. However, it is very important to be careful on the particular task the feature extractor is trained on: if such task is very specific, or contains biases, then the transfer learning approach should be carefully carried on.
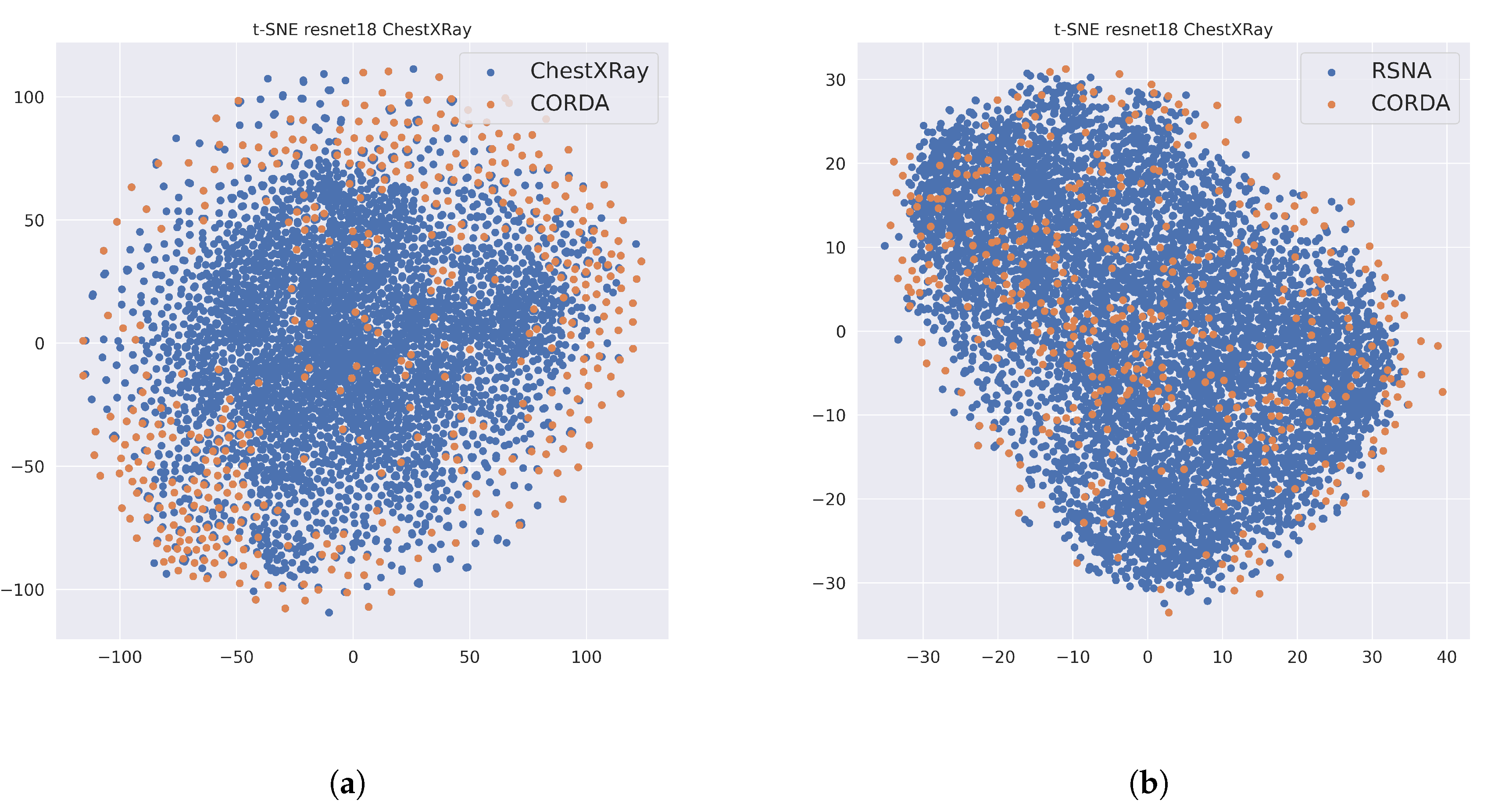
- Hidden biases in the dataset: most of the current works rely on very small datasets, due to the limited availability of public data on COVID positive cases. These few data, then, contain little or even no metadata on age, gender, different pathologies also present in these subjects, and other necessary information necessary to spot on this kind of biases. Besides these, there are other biases we can try to correct. For example, every CXR has its own image windowing parameters or other acquisition settings that a deep model could potentially learn to discriminate. For example, one model may cluster images according to the scan tool used for the exam; if some scan settings correspond to all COVID examples, these generate a spurious correlation that the model can exploit to yield apparently optimal classification accuracy. Another example is given by textual labeling in images: if all the negative examples are sampled from the same dataset, the deep model could learn to recognize such feature instead of focusing on the lung content etc.
- Very small test sets: as a further consequence of having very little data, test set sizes are extremely small and they do not provide any statistical certainty on learning.
3. Results
3.1. Datasets
- COVID-ChestXRay: this dataset was developed by gathering CXR and CT images from various website and publications. At the time of writing, it comprises 287 images with different type of pneumonia (COVID-19, SARS, MERS, Streptococcus spp., Pneumocystis spp., ARDS) [20]. Currently, a subset of 137 CXRs (PA) containing 108 COVID positive images and 29 COVID negatives is available at https://github.com/ieee8023/covid-chestxray-dataset.
- CORDA: this dataset was created for this study by retrospectively selecting chest x-rays performed at a dedicated Radiology Unit in a reference Hospital in Piedmont (CDSS) in all patients with fever or respiratory symptoms (cough, shortness of breath, dyspnea) that underwent nasopharingeal swab to rule out COVID-19 infection. Patients were collected over a 15-day period between the 16th and 30th March, 2020. It contains 447 CXRs from 386 patients, with 150 images coming from COVID-negative patients and 297 from positive ones. Patients’ average age is 61 years (range 17–97 years old). The data collection is still in progress, with other 5 hospitals in Italy willing to contribute at time of writing. We plan to make CORDA available for research purposes according to EU regulations as soon as possible.
- ChestXRay: this dataset contains 5857 X-ray images collected at the Guangzhou Women and Children’s Medical Center, Guangzhou, China. In this dataset, three different labels are provided: normal patients (1583), patients affected by bacterial pneumonia (2780) and affected by viral pneumonia (1493). This dataset was collected before COVID pandemic and is granted under CC by 4.0 and is part of a work on Optical Coherence Tomography [22]. The dataset is publicly available at https://data.mendeley.com/datasets/rscbjbr9sj/2/files/f12eaf6d-6023-432f-acc9-80c9d7393433.
- RSNA: developed by the joint effort of the Radiological Society of North America, US National Institute of Health, The Society of Thoracic Radiology and MD.ai for the RSNA Pneumonia Detection Challenge, this dataset contains pneumonia cases found in the NIH Chest X-ray dataset [23]. It comprises 20,672 normal CXR scans and 6012 pneumonia cases, for a total of 26,684 images. The dataset is publicly available at https://www.kaggle.com/c/rsna-pneumonia-detection-challenge. As the previous one, this dataset was created before COVID pandemic and therefore those not report COVID positive cases.
- Montgomery County X-ray Set: the X-ray images in this dataset have been acquired under a tuberculosis control program of the Department of Health and Human Services of the Montgomery County, MD, USA. Such a dataset contains 138 samples: 80 are normal patients and 58 are abnormal. In these images lungs have been manually segmented. The dataset is open-source and available at http://openi.nlm.nih.gov/imgs/collections/NLM-MontgomeryCXRSet.zip.
- Shenzhen Hospital X-ray Set: the X-ray images in this dataset have been collected by Shenzhen No.3 Hospital in Shenzhen, Guangdong providence, China. This dataset contains a total of 662 images: 326 images are from healthy patients while 336 show abnormalities. Such a dataset is also open-source and available at http://openi.nlm.nih.gov/imgs/collections/ChinaSet_AllFiles.zip. Ground truths for this dataset have been provided by Stirenko et al. [24].
3.2. Pre-Processing
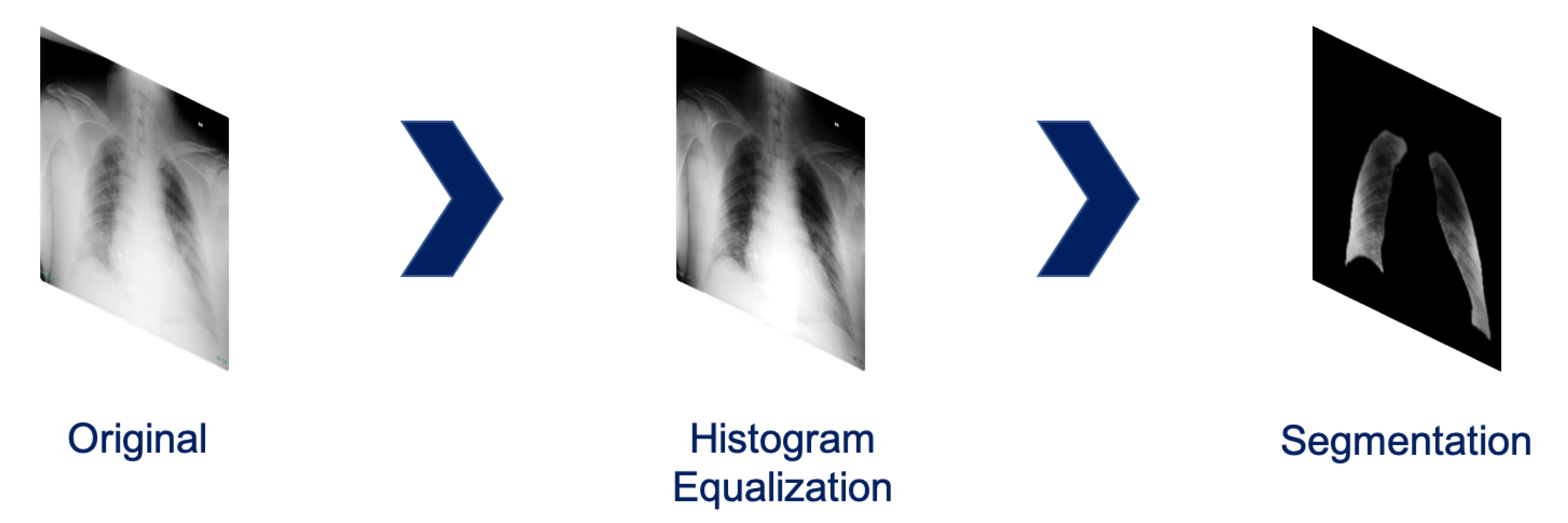
- Histogram equalization: when acquiring a CXR, the so-called radiographic contrast depends on a large variety of factors, typically depending on subject contrast, receptor contrast or other factors like scatter radiations [25]. Hence, the raw acquisition has to be filtered through Value Of Interest transformation. However, due to different calibrations, different range dynamics can be covered, and this potentially is a bias. Histogram equalization is a simple mean to guarantee quite uniform image dynamic in the data.
- Lung segmentation: the lung segmentation problem has been already faced and successfully tackled [26,27,28]. Being able to segment the lungs only, discarding all the rest of the CXRs, potentially prunes away possible bias sources, like for example the presence of medical devices (typically correlated to sick patients), various text which might be embed in the scan etc. In order to address this task, we train a U-Net [29] on Montgomery County X-ray Set and Shenzhen Hospital X-ray Set. The lung masks obtained are then blurred to avoid sharp edges using a 3 pixel radius. An example of the segmentation outcome is shown in Figure 2.
- Image intensity normalization in the range .
3.3. Training
- Pre-training the feature extractor (i.e., the convolutional layers of the CNN). In particular, the pre-training is performed on a related task, like pneumonia classification for CXRs. It has been shown that such an approach can be effective for medical imaging [11], in particular when the amount of available data is limited as in our classification task. Clearly, pre-training the feature extractor on a larger dataset containing related features may allow us to exploit deeper models, potentially exploiting richer image feature.
- The feature extractor is then fine-tuned on COVID data. Freezing it certainly prevents over-fitting the small COVID data; however, we have no warranty that COVID related features can be extracted at the output of a feature extractor trained on a similar task. Of course, its initialization on a similar task helps in the training process, but in any case a fine-tuning is still necessary [30].
- Proper sizing of the encoder to-be-used is an issue to be addressed. Despite many recent works use deeper architectures to extract features on the COVID classification task, larger models are prone to over-fit data. Considering the minimal amount of data available, the choice of the appropriate deep network complexity significantly affects the performance.
- Balancing the training data is yet another extremely important issue to be considered. Unbalanced data favor biases in the learning process [31] and the choice of the data to include in the learning process is critical.
- Data augmentation techniques should be carefully used in such context. No generic plastic deformations for the CXR images can be safely introduced since the basic lung structure is typically the same for any human subject, and should be consistently realistic through all the augmented samples. Towards this end, rigid transformations (translation, rotation) are the only data augmentation transformations safely applicable in such context.
- Testing with different data than those used at training time is also fundamental. Excluding from the test-set exams taken from patients already present in the training-set is important to correctly evaluate the performance and to exclude the deep model has not learned a “patient’s lung shape” feature.
- Pre-training of the feature extractor: the feature extractor can be pre-trained on large generic CXR datasets, or can not be pre-trained.
- Composition of the training-set: the CORDA dataset is unbalanced (in fact, there is a prevalence of positive COVID cases) and some data balancing is possible, borrowing samples from publicly available non-COVID datasets. A summary of the dataset composition is displayed in Table 1. For all the datasets we used 70% of data at training time and 30% as test-set. Training data are then further divided in training-set (80%) and validation-set (20%). Training-set data are finally balanced between COVID+ and COVID—: where possible, we increased the COVID—cases (CORDA&ChestXRay, CORDA&RSNA), where not possible we sub-sampled the more populated class. This percentages were not used for the COVID-ChestXRay dataset: in this case only 15 samples are used for testing in order to compare with other works [16,17,18] that use the same partitioning. Please notice that, through all the datasets, test data are mutually exclusive with training ones, and are never used at training time.
- Testing on different datasets: in order to observe the possible presence of hidden biases, testing on different, qualitatively-similar datasets is a necessary step.
- AUC (area under the ROC curve), provides an aggregate measure of performance across all possible classification thresholds. For every other metric, the classification threshold is set to 0.5;
- sensitivity;
- specificity;
- BA (balanced accuracy), since the test-set might be un-balanced;
- DOR (diagnostic odds ratio).
4. Discussion
- impact of pre-training for COVID detection (Section 4.1) and how should it be performed (Section 4.2);
- effect of augmenting the COVID datasets with negative cases (Section 4.3);
- selection of the proper architecture for the COVID detection (Section 4.4 and Section 4.5).
4.1. To Pre-Train or Not to Pre-Train?
4.2. Pre-Training on Different Datasets
4.3. Augmenting COVID—Data with Different Datasets
4.4. How Deep Should We Go?
4.5. Comparison between Deep Networks Trained on Covid-Chestxray
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CXR | Chest X-Ray |
| CT | Computed Tomography |
| COVID | COrona VIrus Disease |
| ILD | Interstitial Lung Disease |
| CNN | Convolutional Neural Network |
| SVM | Support Vector Machine |
| AUC | Area Under the ROC Curve |
| BA | Balanced Accuracy |
| DOR | Diagnostic Odds Ratio |
Appendix A. Results for All the Proposed Experiments

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Dataset | Test Dataset | Sensitivity | Specificity | F-Score | Accuracy | BA | AUC | DOR |
|---|---|---|---|---|---|---|---|---|
| AC | A | 0.56 | 0.42 | 0.60 | 0.51 | 0.49 | 0.52 | 0.91 |
| AB | 0.56 | 0.22 | 0.15 | 0.26 | 0.39 | 0.33 | 0.36 | |
| AC | 0.56 | 0.96 | 0.49 | 0.95 | 0.76 | 0.95 | 34.23 | |
| AD | 0.52 | 0.48 | 0.58 | 0.51 | 0.50 | 0.53 | 1.00 | |
| A | A | 0.56 | 0.58 | 0.63 | 0.56 | 0.57 | 0.59 | 1.71 |
| AB | 0.56 | 0.37 | 0.18 | 0.39 | 0.46 | 0.43 | 0.74 | |
| AC | 0.56 | 0.38 | 0.08 | 0.39 | 0.47 | 0.46 | 0.76 | |
| AD | 0.56 | 0.58 | 0.63 | 0.57 | 0.57 | 0.59 | 1.76 | |
| AD | A | 0.58 | 0.64 | 0.66 | 0.60 | 0.61 | 0.63 | 2.48 |
| AB | 0.58 | 0.63 | 0.27 | 0.63 | 0.61 | 0.63 | 2.37 | |
| AC | 0.58 | 0.54 | 0.11 | 0.54 | 0.56 | 0.58 | 1.62 | |
| AD | 0.57 | 0.66 | 0.66 | 0.60 | 0.61 | 0.64 | 2.57 | |
| D | A | 0.91 | 0.11 | 0.77 | 0.64 | 0.51 | 0.54 | 1.28 |
| AB | 0.91 | 0.66 | 0.41 | 0.69 | 0.78 | 0.87 | 19.56 | |
| AC | 0.91 | 0.11 | 0.09 | 0.14 | 0.51 | 0.45 | 1.22 | |
| AD | 0.91 | 0.18 | 0.78 | 0.67 | 0.55 | 0.58 | 2.22 | |
| AB | A | 0.88 | 0.18 | 0.77 | 0.64 | 0.53 | 0.58 | 1.55 |
| AB | 0.88 | 0.94 | 0.76 | 0.93 | 0.91 | 0.97 | 112.93 | |
| AC | 0.88 | 0.14 | 0.09 | 0.17 | 0.51 | 0.42 | 1.14 | |
| AD | 0.87 | 0.20 | 0.77 | 0.65 | 0.54 | 0.60 | 1.67 |
| Pre-Trained Encoder | Training Dataset | Test Dataset | Sensitivity | Specificity | F-Score | Accuracy | BA | AUC | DOR |
|---|---|---|---|---|---|---|---|---|---|
| C | AC | A | 0.68 | 0.44 | 0.69 | 0.60 | 0.56 | 0.61 | 1.68 |
| AB | 0.68 | 0.22 | 0.18 | 0.27 | 0.45 | 0.49 | 0.59 | ||
| AC | 0.68 | 0.90 | 0.37 | 0.89 | 0.79 | 0.90 | 19.82 | ||
| AD | 0.67 | 0.50 | 0.70 | 0.61 | 0.58 | 0.63 | 2.03 | ||
| A | A | 0.54 | 0.80 | 0.66 | 0.63 | 0.67 | 0.72 | 4.78 | |
| AB | 0.54 | 0.31 | 0.16 | 0.34 | 0.43 | 0.48 | 0.54 | ||
| AC | 0.54 | 0.55 | 0.10 | 0.55 | 0.55 | 0.61 | 1.48 | ||
| AD | 0.57 | 0.76 | 0.67 | 0.63 | 0.67 | 0.72 | 4.20 | ||
| AD | A | 0.70 | 0.49 | 0.72 | 0.63 | 0.59 | 0.67 | 2.23 | |
| AB | 0.70 | 0.30 | 0.20 | 0.34 | 0.50 | 0.59 | 0.98 | ||
| AC | 0.70 | 0.37 | 0.10 | 0.39 | 0.53 | 0.61 | 1.37 | ||
| AD | 0.71 | 0.52 | 0.73 | 0.65 | 0.61 | 0.70 | 2.65 | ||
| D | A | 0.94 | 0.09 | 0.79 | 0.66 | 0.52 | 0.57 | 1.66 | |
| AB | 0.94 | 0.61 | 0.39 | 0.65 | 0.78 | 0.92 | 26.24 | ||
| AC | 0.94 | 0.08 | 0.09 | 0.12 | 0.51 | 0.58 | 1.50 | ||
| AD | 0.95 | 0.14 | 0.80 | 0.68 | 0.54 | 0.62 | 3.09 | ||
| AB | A | 0.82 | 0.38 | 0.77 | 0.67 | 0.60 | 0.63 | 2.81 | |
| AB | 0.82 | 0.95 | 0.75 | 0.94 | 0.89 | 0.97 | 89.14 | ||
| AC | 0.82 | 0.30 | 0.10 | 0.32 | 0.56 | 0.59 | 1.98 | ||
| AD | 0.83 | 0.38 | 0.78 | 0.68 | 0.60 | 0.64 | 2.99 | ||
| B | AC | A | 0.86 | 0.31 | 0.78 | 0.67 | 0.58 | 0.60 | 2.67 |
| AB | 0.86 | 0.29 | 0.24 | 0.36 | 0.58 | 0.48 | 2.47 | ||
| AC | 0.86 | 0.95 | 0.61 | 0.95 | 0.90 | 0.97 | 122.64 | ||
| AD | 0.82 | 0.38 | 0.77 | 0.67 | 0.60 | 0.61 | 2.79 | ||
| A | A | 0.54 | 0.58 | 0.62 | 0.56 | 0.56 | 0.67 | 1.64 | |
| AB | 0.54 | 0.37 | 0.17 | 0.39 | 0.46 | 0.49 | 0.70 | ||
| AC | 0.54 | 0.73 | 0.15 | 0.72 | 0.64 | 0.72 | 3.21 | ||
| AD | 0.56 | 0.62 | 0.64 | 0.58 | 0.59 | 0.70 | 2.08 | ||
| AD | A | 0.71 | 0.49 | 0.72 | 0.64 | 0.60 | 0.67 | 2.35 | |
| AB | 0.71 | 0.25 | 0.20 | 0.31 | 0.48 | 0.51 | 0.83 | ||
| AC | 0.71 | 0.47 | 0.11 | 0.48 | 0.59 | 0.64 | 2.16 | ||
| AD | 0.73 | 0.52 | 0.74 | 0.66 | 0.62 | 0.70 | 2.93 | ||
| D | A | 0.91 | 0.20 | 0.79 | 0.67 | 0.56 | 0.61 | 2.56 | |
| AB | 0.91 | 0.70 | 0.44 | 0.73 | 0.81 | 0.89 | 24.38 | ||
| AC | 0.91 | 0.15 | 0.09 | 0.19 | 0.53 | 0.55 | 1.83 | ||
| AD | 0.92 | 0.28 | 0.81 | 0.71 | 0.60 | 0.66 | 4.47 | ||
| AB | A | 0.88 | 0.24 | 0.78 | 0.67 | 0.56 | 0.66 | 2.32 | |
| AB | 0.88 | 0.94 | 0.77 | 0.94 | 0.91 | 0.97 | 122.67 | ||
| AC | 0.88 | 0.24 | 0.10 | 0.27 | 0.56 | 0.67 | 2.26 | ||
| AD | 0.88 | 0.26 | 0.78 | 0.67 | 0.57 | 0.68 | 2.58 |
| Pre-Trained Encoder | Training Dataset | Test Dataset | Sensitivity | Specificity | F-Score | Accuracy | BA | AUC | DOR |
|---|---|---|---|---|---|---|---|---|---|
| C | AC | A | 0.74 | 0.49 | 0.74 | 0.66 | 0.62 | 0.65 | 2.79 |
| AB | 0.74 | 0.40 | 0.24 | 0.44 | 0.57 | 0.64 | 1.92 | ||
| AC | 0.74 | 0.92 | 0.43 | 0.91 | 0.83 | 0.93 | 31.76 | ||
| AD | 0.70 | 0.54 | 0.73 | 0.65 | 0.62 | 0.66 | 2.74 | ||
| A | A | 0.61 | 0.71 | 0.70 | 0.64 | 0.66 | 0.67 | 3.87 | |
| AB | 0.61 | 0.40 | 0.20 | 0.43 | 0.51 | 0.53 | 1.06 | ||
| AC | 0.61 | 0.58 | 0.12 | 0.58 | 0.60 | 0.63 | 2.20 | ||
| AD | 0.62 | 0.74 | 0.71 | 0.66 | 0.68 | 0.69 | 4.64 | ||
| AD | A | 0.53 | 0.64 | 0.62 | 0.57 | 0.59 | 0.64 | 2.07 | |
| AB | 0.53 | 0.56 | 0.22 | 0.56 | 0.55 | 0.58 | 1.47 | ||
| AC | 0.53 | 0.57 | 0.10 | 0.57 | 0.55 | 0.58 | 1.53 | ||
| AD | 0.55 | 0.68 | 0.64 | 0.59 | 0.61 | 0.66 | 2.60 | ||
| D | A | 0.97 | 0.04 | 0.79 | 0.66 | 0.51 | 0.57 | 1.35 | |
| AB | 0.97 | 0.45 | 0.32 | 0.51 | 0.71 | 0.89 | 23.29 | ||
| AC | 0.97 | 0.09 | 0.09 | 0.13 | 0.53 | 0.56 | 2.91 | ||
| AD | 0.97 | 0.10 | 0.80 | 0.68 | 0.54 | 0.62 | 3.59 | ||
| AB | A | 0.76 | 0.33 | 0.72 | 0.61 | 0.54 | 0.65 | 1.55 | |
| AB | 0.76 | 0.95 | 0.72 | 0.93 | 0.85 | 0.97 | 63.61 | ||
| AC | 0.76 | 0.36 | 0.10 | 0.38 | 0.56 | 0.63 | 1.75 | ||
| AD | 0.76 | 0.32 | 0.72 | 0.61 | 0.54 | 0.64 | 1.49 | ||
| B | AC | A | 0.73 | 0.40 | 0.72 | 0.62 | 0.57 | 0.58 | 1.83 |
| AB | 0.73 | 0.25 | 0.20 | 0.31 | 0.49 | 0.44 | 0.92 | ||
| AC | 0.73 | 0.96 | 0.58 | 0.95 | 0.85 | 0.97 | 68.71 | ||
| AD | 0.70 | 0.46 | 0.71 | 0.62 | 0.58 | 0.60 | 1.99 | ||
| A | A | 0.64 | 0.56 | 0.69 | 0.61 | 0.60 | 0.65 | 2.27 | |
| AB | 0.64 | 0.49 | 0.24 | 0.51 | 0.57 | 0.61 | 1.72 | ||
| AC | 0.64 | 0.63 | 0.14 | 0.63 | 0.64 | 0.69 | 3.06 | ||
| AD | 0.67 | 0.60 | 0.72 | 0.65 | 0.64 | 0.69 | 3.05 | ||
| AD | A | 0.63 | 0.38 | 0.65 | 0.55 | 0.51 | 0.63 | 1.05 | |
| AB | 0.63 | 0.46 | 0.22 | 0.48 | 0.55 | 0.61 | 1.46 | ||
| AC | 0.63 | 0.62 | 0.14 | 0.62 | 0.63 | 0.70 | 2.86 | ||
| AD | 0.65 | 0.44 | 0.67 | 0.58 | 0.55 | 0.66 | 1.46 | ||
| D | A | 0.98 | 0.13 | 0.81 | 0.70 | 0.56 | 0.61 | 6.77 | |
| AB | 0.98 | 0.72 | 0.48 | 0.75 | 0.85 | 0.90 | 112.57 | ||
| AC | 0.98 | 0.11 | 0.10 | 0.15 | 0.55 | 0.61 | 5.59 | ||
| AD | 0.98 | 0.20 | 0.82 | 0.72 | 0.59 | 0.65 | 12.25 | ||
| AB | A | 0.81 | 0.29 | 0.75 | 0.64 | 0.55 | 0.64 | 1.74 | |
| AB | 0.81 | 0.94 | 0.73 | 0.93 | 0.88 | 0.97 | 73.35 | ||
| AC | 0.81 | 0.25 | 0.09 | 0.28 | 0.53 | 0.57 | 1.43 | ||
| AD | 0.80 | 0.30 | 0.74 | 0.63 | 0.55 | 0.64 | 1.71 |
| Pre-Trained Encoder | Training Dataset | Test Dataset | Sensitivity | Specificity | F-Score | Accuracy | BA | AUC | DOR |
|---|---|---|---|---|---|---|---|---|---|
| C | AC | A | 0.68 | 0.51 | 0.71 | 0.62 | 0.59 | 0.64 | 2.20 |
| AB | 0.68 | 0.22 | 0.18 | 0.27 | 0.45 | 0.43 | 0.58 | ||
| AC | 0.68 | 0.93 | 0.44 | 0.92 | 0.80 | 0.93 | 27.98 | ||
| AD | 0.67 | 0.54 | 0.71 | 0.63 | 0.60 | 0.65 | 2.38 | ||
| A | A | 0.77 | 0.38 | 0.74 | 0.64 | 0.57 | 0.63 | 1.99 | |
| AB | 0.77 | 0.08 | 0.18 | 0.16 | 0.42 | 0.31 | 0.29 | ||
| AC | 0.77 | 0.37 | 0.11 | 0.39 | 0.57 | 0.62 | 1.97 | ||
| AD | 0.77 | 0.42 | 0.75 | 0.65 | 0.59 | 0.66 | 2.42 | ||
| AD | A | 0.60 | 0.64 | 0.68 | 0.61 | 0.62 | 0.68 | 2.72 | |
| AB | 0.60 | 0.36 | 0.19 | 0.39 | 0.48 | 0.51 | 0.84 | ||
| AC | 0.60 | 0.54 | 0.11 | 0.54 | 0.57 | 0.63 | 1.73 | ||
| AD | 0.61 | 0.68 | 0.69 | 0.63 | 0.65 | 0.71 | 3.32 | ||
| D | A | 0.87 | 0.11 | 0.75 | 0.61 | 0.49 | 0.62 | 0.81 | |
| AB | 0.87 | 0.37 | 0.26 | 0.43 | 0.62 | 0.70 | 3.80 | ||
| AC | 0.87 | 0.11 | 0.09 | 0.14 | 0.49 | 0.49 | 0.79 | ||
| AD | 0.88 | 0.18 | 0.77 | 0.65 | 0.53 | 0.66 | 1.61 | ||
| AB | A | 0.81 | 0.31 | 0.75 | 0.64 | 0.56 | 0.67 | 1.94 | |
| AB | 0.81 | 0.93 | 0.71 | 0.92 | 0.87 | 0.97 | 61.00 | ||
| AC | 0.81 | 0.13 | 0.08 | 0.16 | 0.47 | 0.47 | 0.62 | ||
| AD | 0.82 | 0.30 | 0.76 | 0.65 | 0.56 | 0.67 | 1.95 | ||
| B | AC | A | 0.67 | 0.56 | 0.71 | 0.63 | 0.61 | 0.66 | 2.50 |
| AB | 0.67 | 0.36 | 0.21 | 0.39 | 0.51 | 0.48 | 1.11 | ||
| AC | 0.67 | 0.98 | 0.63 | 0.96 | 0.82 | 0.98 | 90.25 | ||
| AD | 0.62 | 0.60 | 0.68 | 0.61 | 0.61 | 0.66 | 2.45 | ||
| A | A | 0.63 | 0.62 | 0.70 | 0.63 | 0.63 | 0.70 | 2.84 | |
| AB | 0.63 | 0.34 | 0.19 | 0.37 | 0.49 | 0.52 | 0.88 | ||
| AC | 0.63 | 0.45 | 0.10 | 0.46 | 0.54 | 0.59 | 1.42 | ||
| AD | 0.66 | 0.64 | 0.72 | 0.65 | 0.65 | 0.73 | 3.45 | ||
| AD | A | 0.63 | 0.62 | 0.70 | 0.63 | 0.63 | 0.68 | 2.84 | |
| AB | 0.63 | 0.47 | 0.23 | 0.49 | 0.55 | 0.63 | 1.56 | ||
| AC | 0.63 | 0.61 | 0.13 | 0.61 | 0.62 | 0.70 | 2.74 | ||
| AD | 0.65 | 0.66 | 0.71 | 0.65 | 0.66 | 0.71 | 3.61 | ||
| D | A | 0.99 | 0.07 | 0.81 | 0.68 | 0.53 | 0.61 | 6.36 | |
| AB | 0.99 | 0.62 | 0.41 | 0.66 | 0.80 | 0.91 | 142.68 | ||
| AC | 0.99 | 0.04 | 0.09 | 0.08 | 0.51 | 0.53 | 3.41 | ||
| AD | 0.99 | 0.14 | 0.82 | 0.71 | 0.56 | 0.65 | 16.12 | ||
| AB | A | 0.78 | 0.44 | 0.76 | 0.67 | 0.61 | 0.69 | 2.80 | |
| AB | 0.78 | 0.96 | 0.75 | 0.94 | 0.87 | 0.97 | 86.56 | ||
| AC | 0.78 | 0.37 | 0.11 | 0.39 | 0.57 | 0.66 | 2.02 | ||
| AD | 0.80 | 0.50 | 0.78 | 0.70 | 0.65 | 0.72 | 4.00 |
References
- Zu, Z.Y.; Jiang, M.D.; Xu, P.P.; Chen, W.; Ni, Q.Q.; Lu, G.M.; Zhang, L.J. Coronavirus disease 2019 (COVID-19): A perspective from China. Radiology 2020, 296, 200490. [Google Scholar] [CrossRef] [PubMed]
- Covid-19, Situation in the World. Available online: http://www.salute.gov.it (accessed on 9 August 2020).
- ACR Recommendations for the Use of Chest Radiography and Computed Tomography (CT) for Suspected COVID-19 Infection. Available online: https://www.acr.org/ (accessed on 9 August 2020).
- Yang, Y.; Yang, M.; Shen, C.; Wang, F.; Yuan, J.; Li, J.; Zhang, M.; Wang, Z.; Xing, L.; Wei, J. Laboratory diagnosis and monitoring the viral shedding of 2019-nCoV infections. medRxiv 2020. [Google Scholar] [CrossRef]
- Italian Radiology Society. Utilizzo Della Diagnostica Per Immagini Nei Pazienti Covid 19. Available online: https://www.sirm.org/ (accessed on 9 August 2020).
- Rubin, G.D.; Ryerson, C.J.; Haramati, L.B.; Sverzellati, N. The Role of Chest Imaging in Patient Management during the COVID-19 Pandemic: A Multinational Consensus Statement from the Fleischner Society. RSNA Radiol. 2020, 158, 106–116. [Google Scholar] [CrossRef] [PubMed]
- Shi, H.; Han, X.; Jiang, N.; Cao, Y.; Alwalid, O.; Gu, J.; Fan, Y.; Zheng, C. Radiological findings from 81 patients with COVID-19 pneumonia in Wuhan, China: A descriptive study. Lancet Infect. Dis. 2020, 20, 425–434. [Google Scholar] [CrossRef]
- Wong, H.Y.F.; Lam, H.Y.S.; Fong, A.H.T.; Leung, S.T.; Chin, T.W.Y.; Lo, C.S.Y.; Lui, M.M.S.; Lee, J.C.Y.; Chiu, K.W.H.; Chung, T.; et al. Frequency and Distribution of Chest Radiographic Findings in COVID-19 Positive Patients. Radiology 2020, 296, 201160. [Google Scholar] [CrossRef]
- Hope, M.D.; Raptis, C.A.; Shah, A.; Hammer, M.M.; Henry, T.S. A role for CT in COVID-19? What data really tell us so far. Lancet 2020, 395, 1189–1190. [Google Scholar] [CrossRef]
- Lang, Z.W.; Zhang, L.J.; Zhang, S.J.; Meng, X.; Li, J.Q.; Song, C.Z.; Sun, L.; Zhou, Y.S.; Dwyer, D.E. A clinicopathological study of three cases of severe acute respiratory syndrome (SARS). Pathology 2003, 35, 526–531. [Google Scholar] [CrossRef]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef]
- Bondfale, N.; Bhagwat, D.S. Convolutional Neural Network for Categorization of Lung Tissue Patterns in Interstitial Lung Diseases. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 1150–1154. [Google Scholar]
- Anthimopoulos, M.; Christodoulidis, S.; Ebner, L.; Christe, A.; Mougiakakou, S. Lung Pattern Classification for Interstitial Lung Diseases Using a Deep Convolutional Neural Network. IEEE Trans. Med. Imaging 2016, 35, 1207–1216. [Google Scholar] [CrossRef]
- Xie, X.; Gong, Y.; Wan, S.; Li, X. Computer Aided Detection of SARS Based on Radiographs Data Mining. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 1–4 September 2005; pp. 7459–7462. [Google Scholar]
- Tang, X.; Tao, D.; Antonio, G.E. Texture classification of SARS infected region in radiographic image. In Proceedings of the 2004 International Conference on Image Processing, Singapore, 24–27 October 2004; Volume 5, pp. 2941–2944. [Google Scholar]
- Sethy, P.K.; Behera, S.K. Detection of coronavirus Disease (COVID-19) based on Deep Features. Preprints 2020. [Google Scholar] [CrossRef]
- Apostolopoulos, I.D.; Bessiana, T. Covid-19: Automatic detection from X-Ray images utilizing Transfer Learning with Convolutional Neural Networks. arXiv 2020, arXiv:2003.11617. [Google Scholar] [CrossRef]
- Narin, A.; Kaya, C.; Pamuk, Z. Automatic Detection of Coronavirus Disease (COVID-19) Using X-ray Images and Deep Convolutional Neural Networks. arXiv 2020, arXiv:2003.10849. [Google Scholar]
- Wang, L.; Wong, A. COVID-Net: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases from Chest Radiography Images. arXiv 2020, arXiv:2003.09871. [Google Scholar]
- Cohen, J.P.; Morrison, P.; Dao, L. COVID-19 image data collection. arXiv 2020, arXiv:2003.11597. [Google Scholar]
- Lopes, U.; Valiati, J.F. Pre-trained convolutional neural networks as feature extractors for tuberculosis detection. Comput. Biol. Med. 2017, 89, 135–143. [Google Scholar] [CrossRef] [PubMed]
- Kermany, D.; Zhang, K.; Goldbaum, M. Labeled optical coherence tomography (oct) and chest X-ray images for classification. Mendeley Data 2018, 2. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R. ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3462–3471. [Google Scholar]
- Stirenko, S.; Kochura, Y.; Alienin, O.; Rokovyi, O.; Gordienko, Y.; Gang, P.; Zeng, W. Chest X-ray analysis of tuberculosis by deep learning with segmentation and augmentation. In Proceedings of the 2018 IEEE 38th International Conference on Electronics and Nanotechnology (ELNANO), Kyiv, Ukraine, 24–26 April 2018; pp. 422–428. [Google Scholar]
- Bushberg, J.T.; Boone, J.M. The Essential Physics of Medical Imaging; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2011. [Google Scholar]
- Candemir, S.; Jaeger, S.; Palaniappan, K.; Musco, J.P.; Singh, R.K.; Xue, Z.; Karargyris, A.; Antani, S.; Thoma, G.; McDonald, C.J. Lung segmentation in chest radiographs using anatomical atlases with nonrigid registration. IEEE Trans. Med. Imaging 2013, 33, 577–590. [Google Scholar] [CrossRef]
- Hu, S.; Hoffman, E.A.; Reinhardt, J.M. Automatic lung segmentation for accurate quantitation of volumetric X-ray CT images. IEEE Trans. Med. Imaging 2001, 20, 490–498. [Google Scholar] [CrossRef]
- Mansoor, A.; Bagci, U.; Xu, Z.; Foster, B.; Olivier, K.N.; Elinoff, J.M.; Suffredini, A.F.; Udupa, J.K.; Mollura, D.J. A generic approach to pathological lung segmentation. IEEE Trans. Med. Imaging 2014, 33, 2293–2310. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef]
- More, A. Survey of resampling techniques for improving classification performance in unbalanced datasets. arXiv 2016, arXiv:1608.06048. [Google Scholar]
- Prechelt, L. Early stopping-but when? In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 1998; pp. 55–69. [Google Scholar]
- Yao, Y.; Rosasco, L.; Caponnetto, A. On early stopping in gradient descent learning. Constr. Approx. 2007, 26, 289–315. [Google Scholar] [CrossRef]
- Tartaglione, E.; Perlo, D.; Grangetto, M. Post-synaptic potential regularization has potential. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2019; pp. 187–200. [Google Scholar]
- Šimundić, A.M. Measures of diagnostic accuracy: Basic definitions. Ejifcc 2009, 19, 203. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. Densenet: Implementing efficient convnet descriptor pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- Chu, B.; Madhavan, V.; Beijbom, O.; Hoffman, J.; Darrell, T. Best practices for fine-tuning visual classifiers to new domains. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 435–442. [Google Scholar]
- Maaten, L.v.d.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]




| COMPOSED DATASET | ORIGINAL DATASETS | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | C | B | D | TOTAL | |||||||
| + | — | + | — | + | — | + | — | + | — | ||
| A | train | 126 | 105 | - | - | - | - | - | - | 126 | 105 |
| test | 90 | 45 | - | - | - | - | - | - | 90 | 45 | |
| AB | train | 207 | 105 | - | - | - | 102 | - | - | 207 | 207 |
| test | 90 | 45 | - | - | - | 45 | - | - | 90 | 90 | |
| AC | train | 207 | 105 | - | 102 | - | - | - | - | 207 | 207 |
| test | 90 | 45 | - | 45 | - | - | - | - | 90 | 90 | |
| AD | train | 116 | 105 | - | - | - | - | 49 | 24 | 165 | 129 |
| test | 90 | 45 | - | - | - | - | 10 | 5 | 100 | 50 | |
| D | train | - | - | - | - | - | - | 98 | 24 | 98 | 24 |
| test | - | - | - | - | - | - | 10 | 5 | 10 | 5 | |
| Architecture | Pre-Trained Encoder | Training Dataset | Test Dataset | Sensitivity | Specificity | BA | AUC | DOR |
|---|---|---|---|---|---|---|---|---|
| ResNet-18 | none | AB | AB | 0.88 | 0.94 | 0.91 | 0.97 | 112.93 |
| none | AB | AD | 0.87 | 0.20 | 0.54 | 0.60 | 1.67 | |
| none | A | A | 0.56 | 0.58 | 0.57 | 0.59 | 1.71 | |
| B | AB | AB | 0.88 | 0.94 | 0.91 | 0.97 | 122.67 | |
| B | AB | A | 0.88 | 0.24 | 0.56 | 0.66 | 2.32 | |
| C | A | A | 0.54 | 0.80 | 0.67 | 0.72 | 4.78 | |
| C | AB | AB | 0.82 | 0.95 | 0.89 | 0.97 | 89.14 | |
| C | AB | A | 0.82 | 0.38 | 0.60 | 0.63 | 2.81 | |
| B | D | A | 0.91 | 0.20 | 0.56 | 0.61 | 2.56 | |
| B | D | D | 1.00 | 1.00 | 1.00 | 1.00 | ∞ | |
| ResNet-50 | B | D | AB | 0.98 | 0.72 | 0.85 | 0.90 | 112.57 |
| B | D | AC | 0.98 | 0.11 | 0.55 | 0.61 | 5.59 | |
| B | D | AD | 0.98 | 0.20 | 0.59 | 0.65 | 12.25 | |
| COVID-Net | B | D | A | 0.12 | 0.98 | 0.55 | 0.55 | 6.68 |
| B | D | D | 0.90 | 0.80 | 0.85 | 0.85 | 36.00 | |
| DenseNet-121 | B | D | A | 0.99 | 0.07 | 0.53 | 0.61 | 6.36 |
| B | D | D | 1.00 | 0.80 | 0.90 | 0.98 | ∞ |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tartaglione, E.; Barbano, C.A.; Berzovini, C.; Calandri, M.; Grangetto, M. Unveiling COVID-19 from CHEST X-Ray with Deep Learning: A Hurdles Race with Small Data. Int. J. Environ. Res. Public Health 2020, 17, 6933. https://doi.org/10.3390/ijerph17186933
Tartaglione E, Barbano CA, Berzovini C, Calandri M, Grangetto M. Unveiling COVID-19 from CHEST X-Ray with Deep Learning: A Hurdles Race with Small Data. International Journal of Environmental Research and Public Health. 2020; 17(18):6933. https://doi.org/10.3390/ijerph17186933
Chicago/Turabian StyleTartaglione, Enzo, Carlo Alberto Barbano, Claudio Berzovini, Marco Calandri, and Marco Grangetto. 2020. "Unveiling COVID-19 from CHEST X-Ray with Deep Learning: A Hurdles Race with Small Data" International Journal of Environmental Research and Public Health 17, no. 18: 6933. https://doi.org/10.3390/ijerph17186933
APA StyleTartaglione, E., Barbano, C. A., Berzovini, C., Calandri, M., & Grangetto, M. (2020). Unveiling COVID-19 from CHEST X-Ray with Deep Learning: A Hurdles Race with Small Data. International Journal of Environmental Research and Public Health, 17(18), 6933. https://doi.org/10.3390/ijerph17186933