1. Introduction
The quality of health care can be assessed by observing the structure, processes, and outcomes of healthcare [
1]. Processes in organisations, such as hospitals, may deviate from intended standard processes, due to unforeseeable events and the complexity of the organisation. For hospitals, the knowledge of actual patient streams for different patient populations (e.g., severe or non-severe cases) is important for quality control and improvement. Electronic health records (EHR) contain a wealth of information about patients, including timestamps of diagnoses and treatments. Thus, EHR can serve as input data to discover the as-is processes [
2] in healthcare. In order to investigate patient processes for patient populations of interest (e.g., severe or non-severe cases), their process models have to be constructed and compared. Manual comparison of process models requires expertise in understanding process models and is time-consuming, which makes it unfeasible for many populations of interest. In this paper, we present an approach to automatically compare process models that were obtained from EHR event logs in order to have an initial quantification of the degree of similarity between different patient subgroups. More specifically, we compare three different approaches for obtaining a similarity between process models: (i) visual inspection, i.e., human judgment, (ii) cross-log conformance checking, and (iii) similarity measures on directed graphs extracted from the process model. For cross-log conformance checking, we apply the replay technique using the event log of one population against the process model that was discovered for a second population (and vice versa). Then, we evaluate which of the methods for measuring process similarities best approximate human judgment. The two cases that we considered are the publicly available MIMIC data (
https://mimic.physionet.org/, last accessed on 25 February 2020) with the focus on different cancer patients in intensive care, and data on breast cancer patients from Ziekenhuis Group Twente (ZGT). In summary, the contributions of this paper are the following:
We present process models for different cancer types obtained on MIMIC, and process models for breast cancer patients for different patient sub-populations.
We show how process models obtained by inductive visual miner and Petri nets can be converted to general graphs.
We propose methods to quantitatively compare process models, based on conformance checking and graph similarity measure.
We performed a user study to obtain a ground-truth for visual similarity of process model pairs and evaluate our methods in the domain of cancer care in order to compare different patient populations.
This work extends own previous work [
3], as follows: Additional to process model analysis for breast cancer sub-populations, we added an analysis for general cancer types on the publicly available MIMIC data base. Further, we show how to create general graphs from Petri-nets to obtain graph-based similarity metrics. Lastly, we strengthened the measured human-based visual comparison by obtaining visual similarity measures from a user study with 20 users.
In the remainder of this paper, we first introduce the application domain cancer care (cf.
Section 2), review related work (cf.
Section 3). We then present the approach in detail (cf.
Section 4), and its evaluation for MIMIC cancer populations (cf.
Section 5) and for breast cancer populations from ZGT hospital (cf.
Section 6).
3. Related Work
Quality in health care and the corresponding reporting and evaluation is an issue of national and international importance. Donabedian [
1] proposed that the quality of health care can be assessed by observing the structure, processes, and the outcomes of healthcare. The Institute of Medicine (IOM) defines health care quality as “the degree to which health services for individuals and populations increase the likelihood of desired health outcomes and are consistent with current professional knowledge” [
7]. Process-based quality measures are more suited to explain how and what is required to improve health care processes, as compared to outcome-based measures [
8,
9]. Measuring the quality of various processes can also answer questions, like accuracy of diagnosis, disease monitoring and therapy, and percentage of patients, who received care as recommended [
8]. Better process quality can also lead to better patient satisfaction with the series of transactions occurring during their hospital visit [
10]. To summarize, the previous works state that quality of health care can be improved by measuring the health care processes, which can further lead to better health outcome.
The goal of
process mining is to extract process models from event logs [
11], also known as transactional logs or audit trails [
12]. An event corresponds to an activity (i.e., a well-defined step in the process) affiliated with a particular case (i.e., process instance) [
13] and particularly consist of a time stamp and optional information, such as resources or costs. Process mining as a discipline consists of three dimensions, process discovery, conformance checking and process enhancement [
14].
Process discovery refers to the construction of a comprehensive process model, e.g., Petri-Nets or State-charts, to reproduce the behaviour seen in the log file [
13]. We use the Inductive Visual Miner(IvM) [
15] plug-in of ProM (
promtools.org, last accessed on 1 May 2020), since it provides an user-friendly visualization, with an opportunity to investigate deviations. The deviations represent cases which do not follow the most common behaviours and thus correspond to event log traces that the process does not explain.
Conformance checking is applied to compare process models and event logs in order to find commonalities and discrepancies between the modeled behavior and the observed behavior [
16]. Our goal is to compare two processes; therefore, we use the (ProM) plug-in “Replay a Log on Petri Net for Conformance Analysis” to play the event log of one patient population to the discovered process model of another population and use the obtained fitness, precision and generalization measures for our similarity analysis. A case study explored the applicability of
process mining in health care and raised the concern that traditional process mining techniques have problems with unstructured processes, as they can be found in hospitals [
17]. In this paper, we will focus on a very small sub-domain, breast cancer care, in order to reduce the complexity of the EHR extraction and resulting process models.
Kurniati et al. [
18] worked on process mining on oncology using a public dataset, MIMIC-III. Their work involved—(i) finding the most followed path and some exceptional paths taken by patients, (ii) finding the differences in the paths followed by different cancer types, and (iii) finding the activities with long waiting times. They used the top level granularity of events to create process models, consisting of events—admission, emergency department, ICU, discharge etc. They compared three process models generated from cancer types with the three highest cases. They evaluated their process models using fitness and precision scores and found that the most frequent events are admission and discharge. They also found, through visual inspection, that admission, discharge, ICU in, and ICU out are the common activities in each cancer type. In our paper, we use the same cancer types from MIMIC dataset to create process models, but for different activities and apart from visual inspection, we use cross-log conformance checking and similarity measure to compare the processes.
Even for a small set of EHR to have a useful insight into the patients’ health path, we need to compare extracted business processes models. Process models are traditionally compared with linear search techniques where a query model is compared to each model in the collection and focuses on process models that are composed of atomic tasks and connectors [
19]. In a complex domain like health care, a lot of research attention has been paid to other process modeling constructs, such as sub-process invocation, exception handlers, control-flow view of process models, and resource allocation views [
20]. In the health care domain, we need to differentiate between slightly different models and completely different models. Process model equivalence notions are not sufficient, because they produce a binary answer. In practice, the process models are compared with respect to some typical properties [
21]. Becker et al., proposed 23 desirable properties for business process comparison. Experiments show that hardly any experiment fulfills all desirable properties [
22]. Thus, there is not a single “perfect” business process model comparison method. In this paper, we investigate the applicability of similarity metrics proposed for general graphs (e.g., [
23]).
When
comparing two graphs and
one is either interested in exact matches of full or sub-graphs (graph homomorphisms) [
24] or a measure of structural similarity (e.g., [
23,
25]), among which the graph edit distance (GED) [
24] is most widely adopted. The GED is defined as the minimum number of operations (add/remove/substitute nodes and edges) needed to transform
to
. The problem of calculating the GED is NP-hard in general, which makes it unfeasible to solve for larger graphs and giving rise to heuristic approximation approaches [
26]. More recently, supervised machine learning approaches have been suggested. For instance, Li et al. use a combination of two neural networks to learn a similarity score for
and
[
27]. As the authors demonstrate, supervised machine learning approaches can generate highly accurate similarity scores, but they require ground-truth graph-similarity data for training the models. In this work, a graph-similarity ground-truth is not available; therefore, we use approximations of GED and an unsupervised machine learning approach based on hand-crafted features for
and
and standard distance metrics on these features.
4. Approach
In this work, we are interested in the care processes followed by different patient populations and how these processes compare to each other. In this section, we describe our approach for obtaining and comparing process models from EHR.
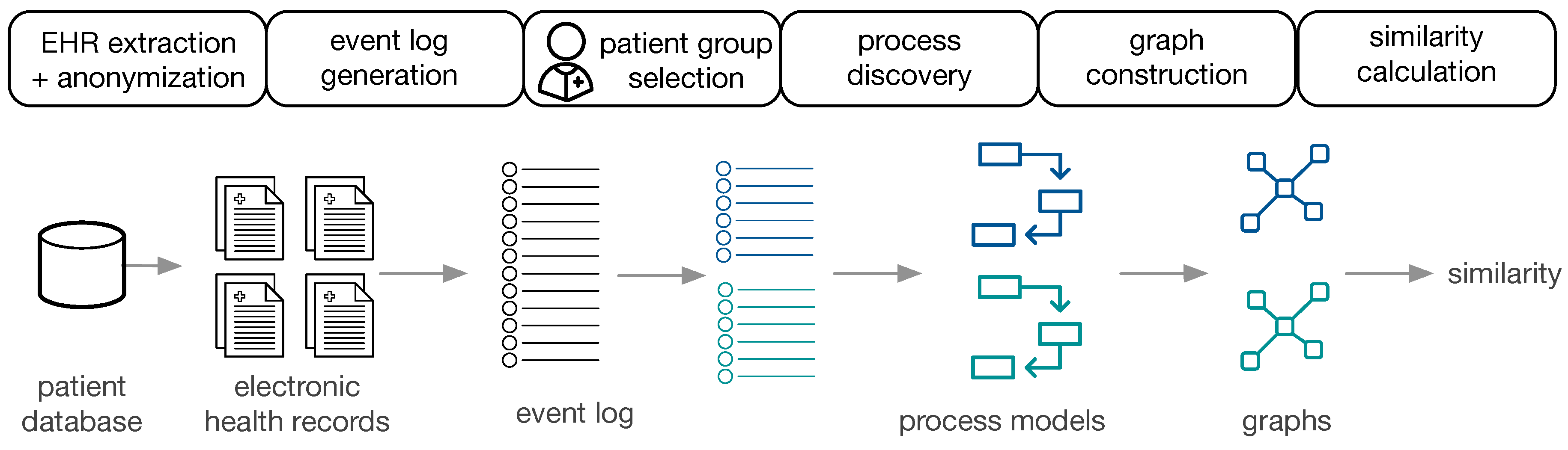
Figure 1 provides an overview of the approach.
The available data are EHR, extracted and anonymized from a patient database. Subsequently, event logs are constructed for populations of interest, the corresponding process models are constructed (cf.
Section 4.1) and transformed to directed graphs (cf.
Section 4.2). Two process models are then compared by (i) visual inspection using obtaining a similarity measure based on human judgment, (ii) cross-log conformance checking, and (iii) graph comparison methods (cf.
Section 4.3). The approach is performed on the general cancer types from MIMIC-II and on ZGT breast cancer populations.
4.1. Process Discovery from EHR
In a first step, the EHR of patient subgroups of interest are extracted from the hospital data base. After defining the events of interest, only information related to those events are extracted from the EHR. Depending on the hospital database, this process involves a combination of hand-crafted filtering and extraction rules. Additionally, personal data have to be anonymized. In order to apply process mining techniques, EHRs are transformed to event logs. Each event is associated with a case, i.e., a patient, and events are chronologically ordered. Each case can have multiple events. Based on the question of interest, patient data can be divided in different ways, creating various populations of interest. For each subpopulation, the event log and the process models is generated using the Inductive Visual Miner [
28], which is also capable of detecting deviations. In our setting, deviations are patients whose behaviour differs from the most frequently observed paths.
4.2. Graph Construction
We converted the process models to directed graphs in order to use graph comparison methods.
Graph Construction from Petri Nets: petri nets consist of transitions, places and events. The edges are directed and unweighted. We construct directed (unweighted) graphs from Petri nets as follows: Nodes in , and represent places, transitions and events, respectively. Edges between the respective nodes in the Petri net are added to the set of edges E.
Graph Construction from IvM Models: process models discovered with the IvM plugin consist of nodes, with an associated weight and directed, weighted edges. These process models were translated to directed, weighted graphs , as follows: nodes in represent activities and nodes in correspond to logical operators in the process model. A directed edge is inserted between two nodes if it in between activities or activities and operators in the underlying process model. We used Boolean function operators to capture the semantic meaning of the process model in the directed graph. Operators can either be AND or XOR, the addition of “-split” or “-join” indicates the start and end of the respective paths. Thus, an “AND-split” means that patients have to follow both paths that the operator outlines, without particular order. The “AND-join” indicates the end of the paths that must be executed in parallel. The XOR operators work similarly, but states that the patient takes either one path, but not both. “Loop” indicates a cycle in the process. Each edge has an associated weight that is set to the frequencies of the connection in the process model.
4.3. Process Model Comparison
The reason to strive for automatic comparison of process models is the following: we define a potential large number of interesting patient sub-populations. Depending on the number of events of interest, the process models become very large and understanding the processes and their differences is a complex task in itself. We aim for grouping of process models along the questions “What are very similar patient groups” and “Which patient groups take very different paths through the hospital?” in order to support efficient and effective initial assessment. To facilitate such grouping, a similarity measure between process models is required that reflects the human-judged similarity. Therefore, we use human judgment as ground truth proxy and evaluate different similarity measures against this ground-truth.
Figure 2 provides an overview of the approaches for process model comparison.
4.3.1. Visual Similarity Assessment
For visual similarity assessment, pairs of process models were judged by humans for their similarity. We used a five-point Likert scale (0: Identical, 1: Slightly Different, 2: Somewhat Different, 3: Very Different, 4: Extremely Different). We performed a user study with 20 users (11 male, 9 female; aged 20 to 50 years). All of the participants have at least a University bachelor degree, in particular 11 of them have a master degree, five a bachelor degree, and four a PhD. Participants judged pairs of process models independently, and they were given the instruction to focus on the structure of the process and not on the numbers of the edges when assessing the similarity. The user groups were the same for both experiments (MIMIC and ZGT data).
4.3.2. Cross-Log Conformance Checking
We used the (ProM) plug-in “Replay a Log on Petri Net for Conformance Analysis” to play the event log of one subpopulation with the process model generated by the second subgroup (and vice versa) and recorded standard conformance checking metrics: fitness, precision, and generalization.
4.3.3. Graph-Based Comparison
For graph-based comparison of process models, we used the networkx graph library for python for calculation graph metrics and similarities (
https://networkx.github.io/, last accessed on 25 February 2020). The graphs constructed from IvM models are weighted, whereas the graphs that are obtained from Petri nets are unweighted graphs (see
Section 4.2). For both graph types, we calculate the graph edit distance (GED) using an approximation algorithm [
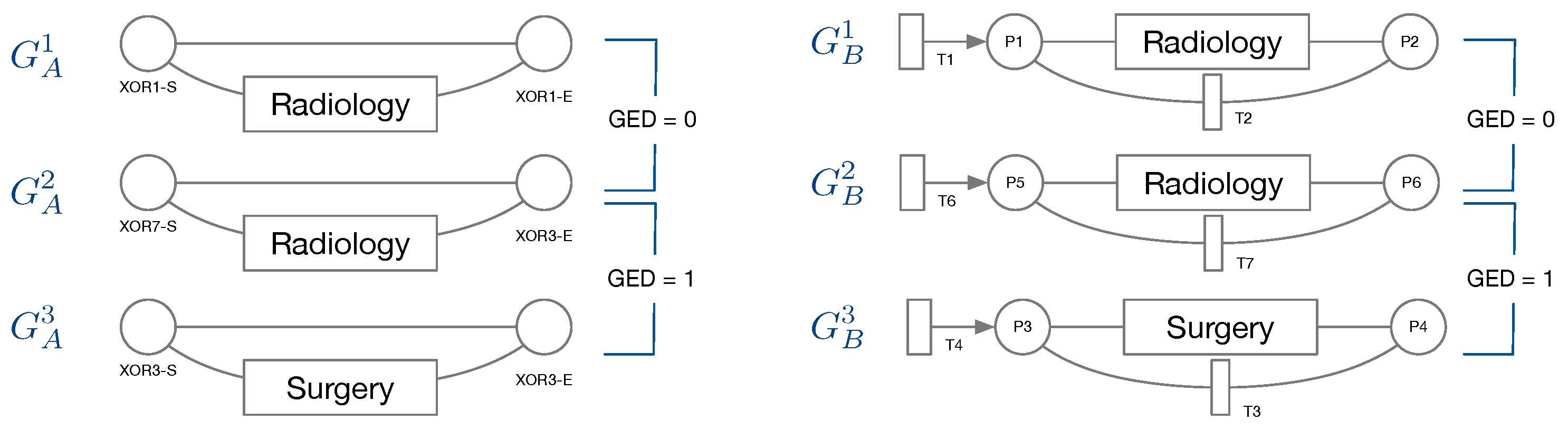
29]. The GED function requires a function deciding when two nodes are considered a match, i.e., when two nodes are considered equal for the purpose of graph comparison. We would like to compare the structure of two graphs, but also retain some semantics for graph comparison. For this reason, we only consider a pair of nodes as a match, if they belong to the same type. In the following, we detail the types of nodes for both, IvM based graphs and Petri-Nets.
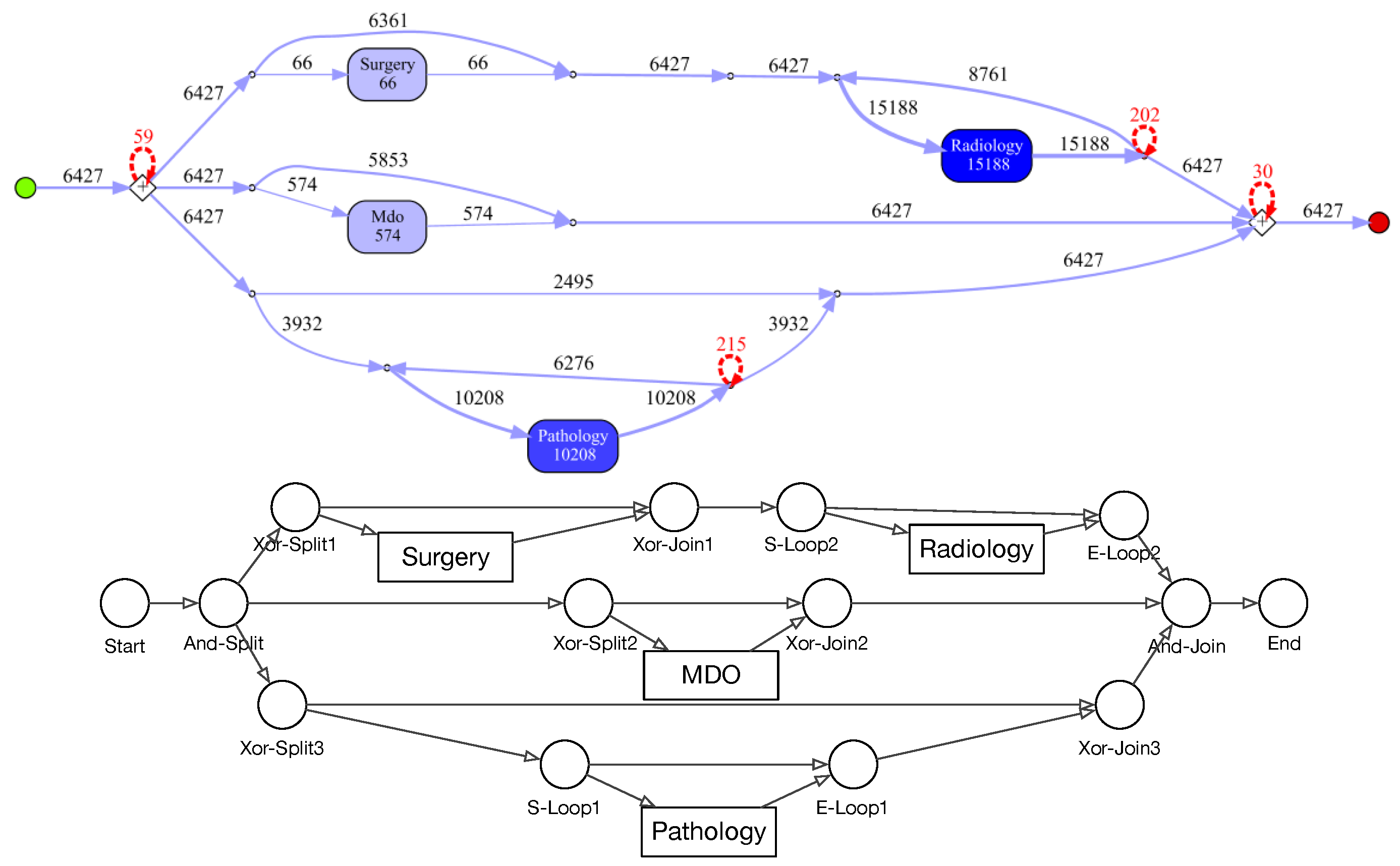
Node types of IvM based graphs are events and branching nodes that represent logical functions, like AND or XOR, or indicating loops. Event nodes match, if they are identical, whereas other nodes match if they have the same type. Consider the example in
Figure 3, left. Graphs
and
have the same structure and node types and their event “Radiology” matches. Their only difference are the ids of the non-event nodes. Thus, the GED of
and
is 0.
has the same structure and types of non-event nodes, but a different event “Surgery”. The GED of
and
is 1, since the 1 operation, i.e., a node substitution of “Surgery” with “Radiology”), is needed in order to match the graphs. The principle of node matching is similar for Petri nets, as shown in
Figure 3, right. Node types of Petri-net based graphs are transitions, places, and events. Transition and place nodes match if they have the same type. Event nodes only match if they represent the same event.
and
only differ in the node ids of transitions and places, thus their GED is 0. Similarly to
and
,
, and
require one operation to be transformed into the respective other graph, resulting in a GED of 1. We ran the GED approximation for one hour for all graph pairs and report the minimum value obtained within this time frame.
For feature-based comparison of two graphs, we generated a feature vector for each graph. For the weighted directed graphs that were obtained from IvM models, we used the following measures: number of nodes, number of edges, average degree, average weighted degree, average clustering coefficient, average shortest path, average closeness, and average betweenness centrality. For the unweighted directed graphs obtained from Petri nets, we omitted the average weighted degree and the cluster coefficient. The former is equal to the average degree and the latter is 0 for all graphs constructed from Petri nets. We then obtained the similarity score for two graphs by first normalizing the feature vectors to unit length and then calculating the Euclidean distance of the two normalized vectors. The similarity score is then one minus the obtained distance.
6. Experiments on Breast Cancer Subgroups at ZGT
In our experiments, we collected EHRs from the hospital database (cf.
Section 6.1), designed the event structure (cf.
Section 6.2), created event logs for populations of interest (cf.
Section 6.3), and obtained process models for these populations (cf.
Section 6.4). We then compared these process models pairwise, by (i) visual inspection, (ii) cross-log conformance checking, and (iii) graph-based similarity measures and investigate how the obtained similarity measures reflect the similarity obtained by human judgment (cf.
Section 6.5).
6.1. EHRs Extraction and Event Log Preparation
Free-text reports on breast cancer patients from 2012–2018 were collected from the hospital database. The following rules defined whether a patient was included in the analysis: with the purpose of identifying the complete health path of the patients inside the hospital, a patient has to be a “new patient”: in the range of time considered, the patient must have a first visit, which is not described in the referring report by keywords like “MRI”, “punctie” (biopsy), “mammatumor” (tumor in the breast). Also, it is not represented by a MDO or Surgery report, because it is impossible that the first visit of a patient is one of them. Accordingly, the start event is the first report for each patient that complies with these exclusions. We could not define clear criteria for determining an end event when a patient has finished the treatments in the hospital. Therefore, there is no end event in health path analysis. The gathered patients are 12,220, for a total of 44,219 reports.
6.2. Event Structure
We collected patient events on two levels of detail as shown in
Figure 7. In the first level of granularity, events correspond to reports: radiology, pathology, MDO, and surgery reports. In the second level of granularity, data extraction and transformation techniques are applied in order to select and group event types. Starting from each sub-category, seven levels are finally established. The most complex (radiology event) includes 55 different procedures, some really different, others the same but written differently: they are collapsed in three sub-levels, diagnostic, biopsy, and other. “Diagnostic” refers to non-invasive imaging scans to diagnose a patient. “Biopsy” is a minimally invasive procedure that consists of taking a small piece of tissue to be analysed. “Other" groups the exceptions that are not included in the other two (few cases). Pathology is further divided into cytological and histological. Surgery report are divided based on the malignancy of the tumor. Finally, MDO is not further divided, hence is kept in the second level of granularity with the same label.
6.3. Patient Populations
We considered 6 different patient populations. We used an age threshold of 50 because of a known empirically established increased risk for breast cancer development at this age.
- SVOB:
patients coming from a national breast cancer screening program;
- NoSVOB:
patients sent to the hospital by the general practitioner;
- Birad12:
patients with a BIRAD score 1 or 2 (0% likelihood of cancer);
- Birad3-6:
patients with a BIRAD score of 3 (probably benign), 4 (suspicious), 5 (highly suggestive of malignancy) or 6 (known biopsy-proven);
- Age ≥ 50:
Patients of age 50 or older; and,
- Age < 50:
Patients younger than 50.
Table 4 provides an overview for the selected populations showing the number of events with a breakdown on event type, i.e., the specific type of report, and the number of cases (patients). For each population, the event log contains at least 12,000 events, with radiology reports being the most frequent and surgery being the least frequent event type in all populations. Note that the radiology report is always present for each case. This result will be graphically confirmed by process figures where an AND condition is always existing for radiology events. Surgery events are generally occurring less frequently than the others event types. In particular, the percentage of surgeries for Birad12 and Birad 3-6 populations are significantly different. We also compare sub-populations on the second level of granularity only based on BI-RADS score.
Table 5 shows the number of the events similarly to
Table 4, but with a breakdown on event type on second level of granularity. The event distribution on this level is uneven. In all cases, one type is more frequent than the others.
We compared process models of populations that are of clinical interest, namely screening vs. non-screening patients (SVOB/NoSVOB), low vs. high probability of malignancy both in first and second level of granularity (Birad12 vs. Birad3-6, 2-Birad12 vs. 2-Birad3-6) and age groups before and after screening age (Age
vs. Age
). We also included a comparison of patients with an age that do not require screening and non-screening patients (NoSVOB vs. Age
) and screening patients that were transferred to the hospital, but had a low probability of malignancy (SVOB vs. Birad12).
Table 6 provides an overview of the compared groups and shows the Jaccard similarity for different population pairs. As can be seen, there is a 30% overlap between NoSVOB patients and patients younger than 50, as well as between SVOB patients and patients with low likelihood of cancer (Birad12).
6.4. Process Discovery and Graph Construction
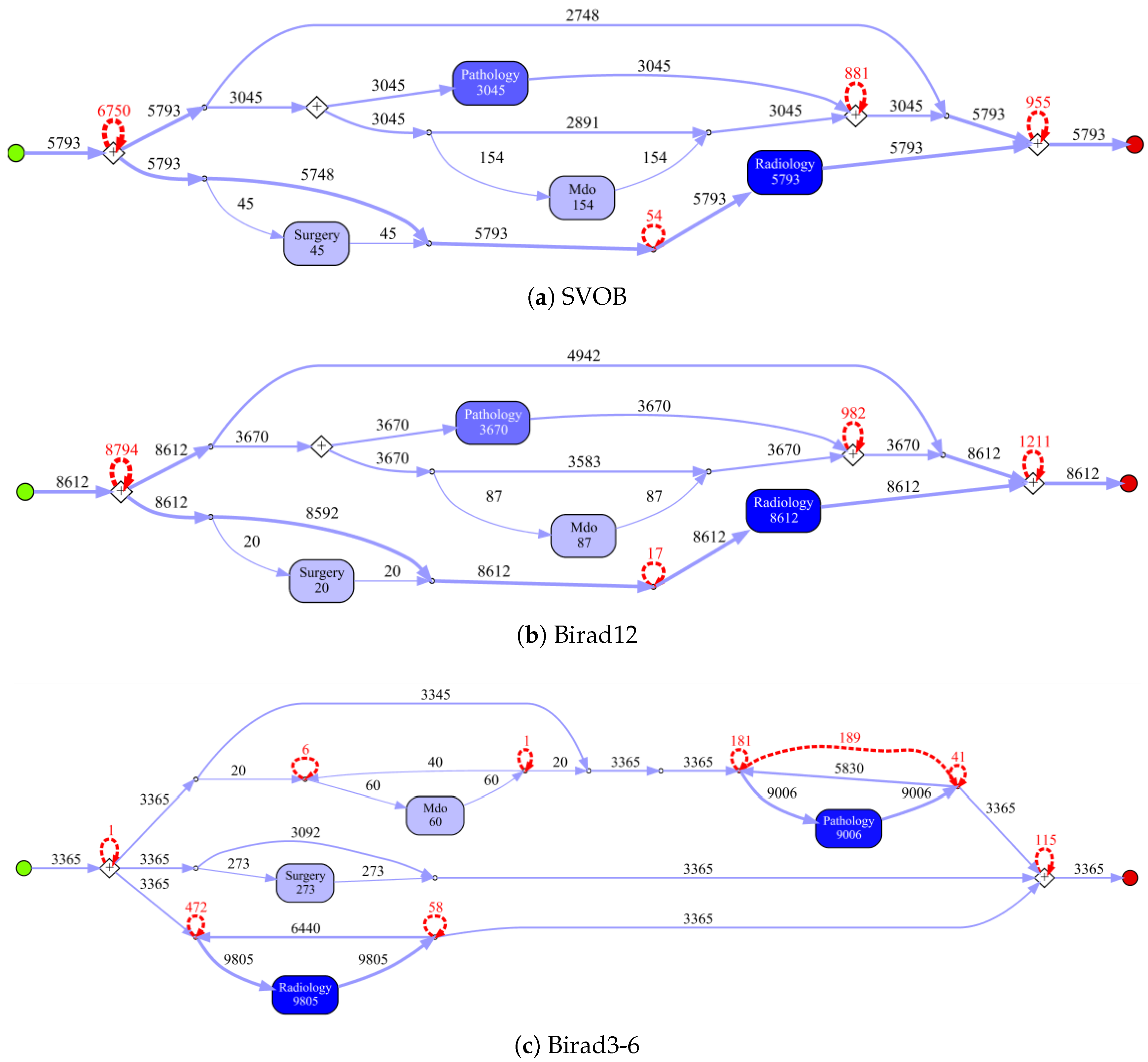
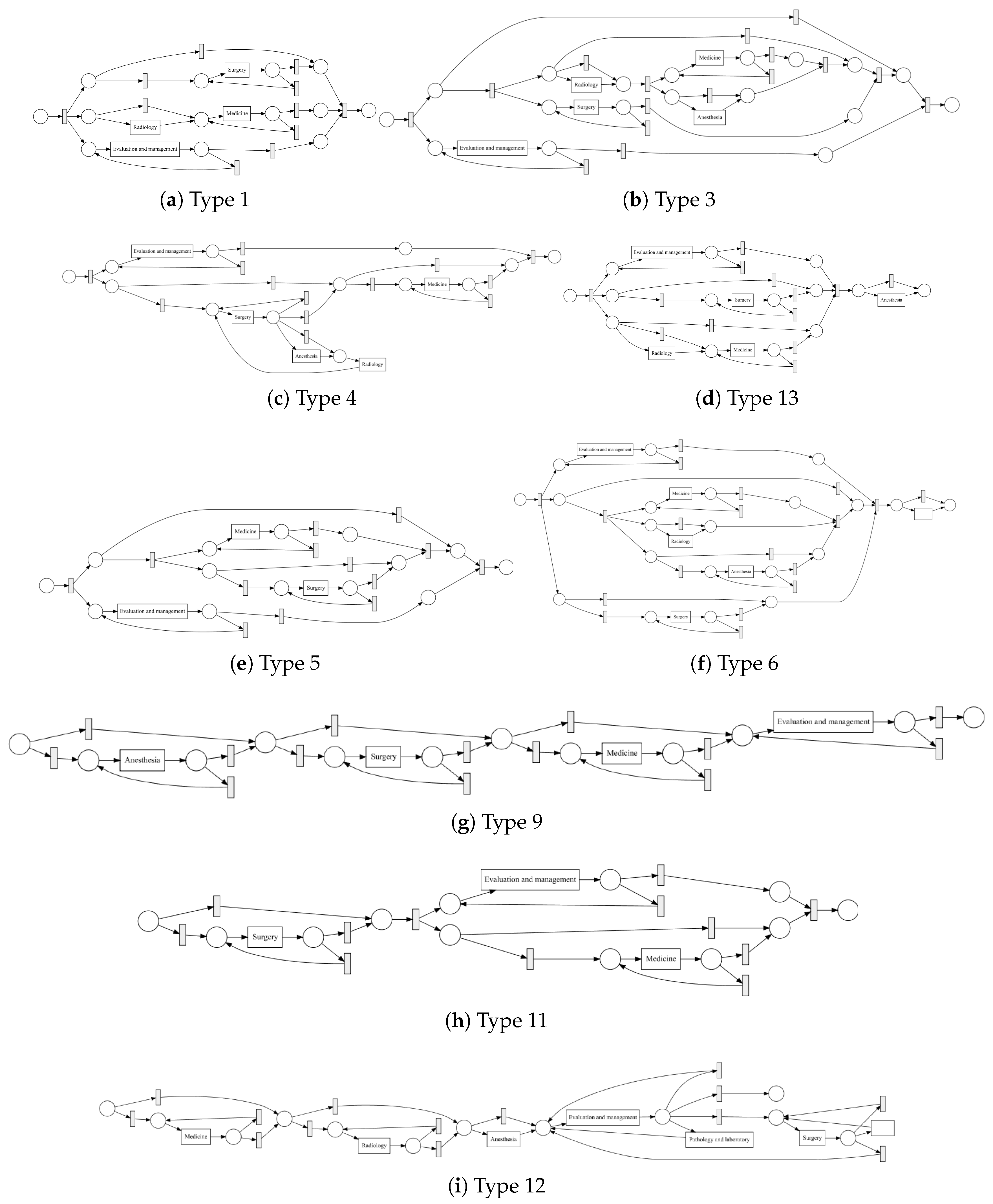
Process models obtained by the IvM plug-in of ProM (noise filtering set to 90%) with first level events for four example populations are shown in
Figure 8 and
Figure 9 (top). The models for the remaining population can be found in
Appendix B.1. Blue rectangles represent events, the color intensity represents the amount. The process models for SVOB and Birad12 have the same structure (but different frequencies), although their patient populations are not the same (Jaccard similarity of 0.42, cf.
Table 6). The process model for Birad3-6 patients has a complex structure, which indicates that patients with non-zero probability of malignancy follow quite complex paths in the hospital. Many deviations, represented by red dashed lines, exist in all processes.
Figure 9 shows the process model for NoSVOB patients and the correspondent translated graph. Circles denote the logic operators while rectangles represent events. The un-normalized feature vector
f obtained from the graph for NoSVOB patients is
, the features are in the order, as described in
Section 4.3.
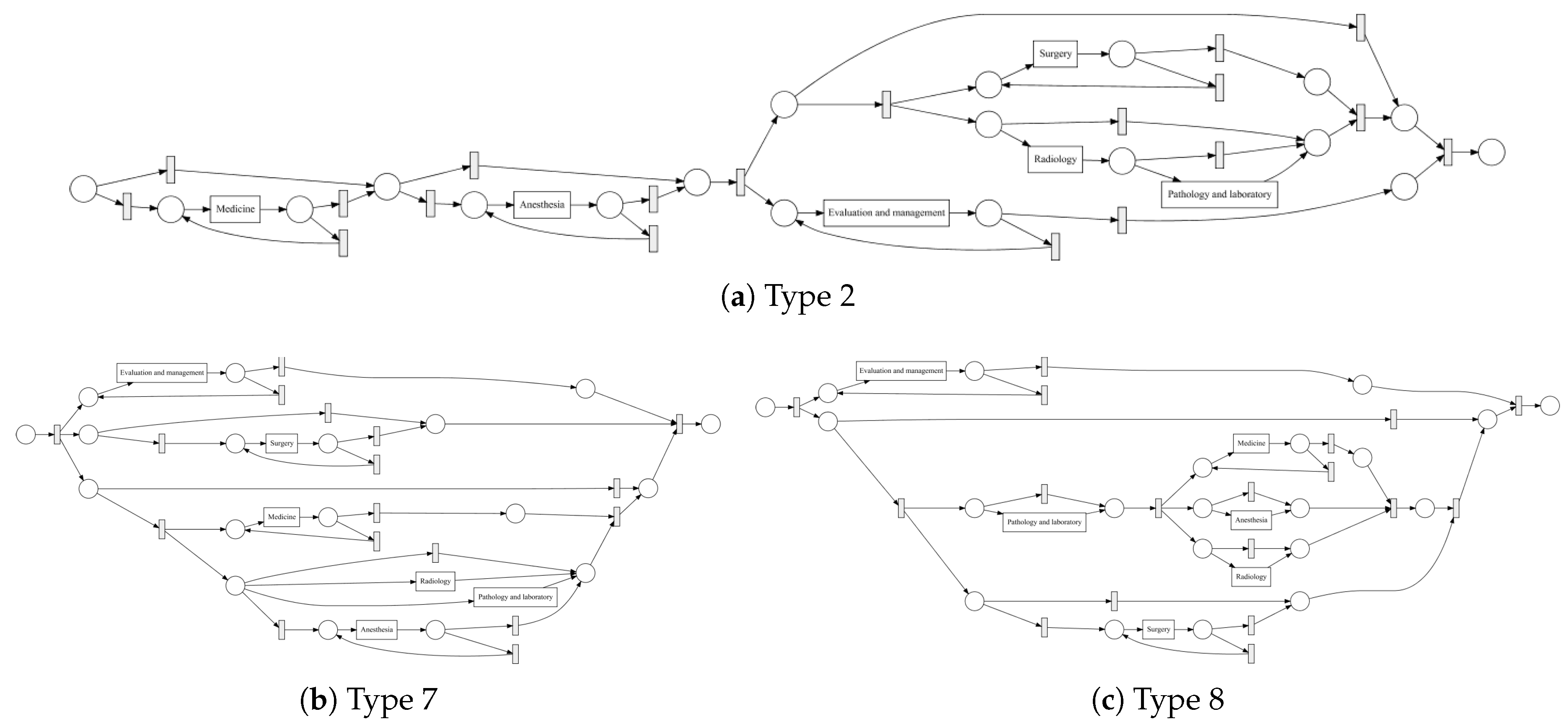
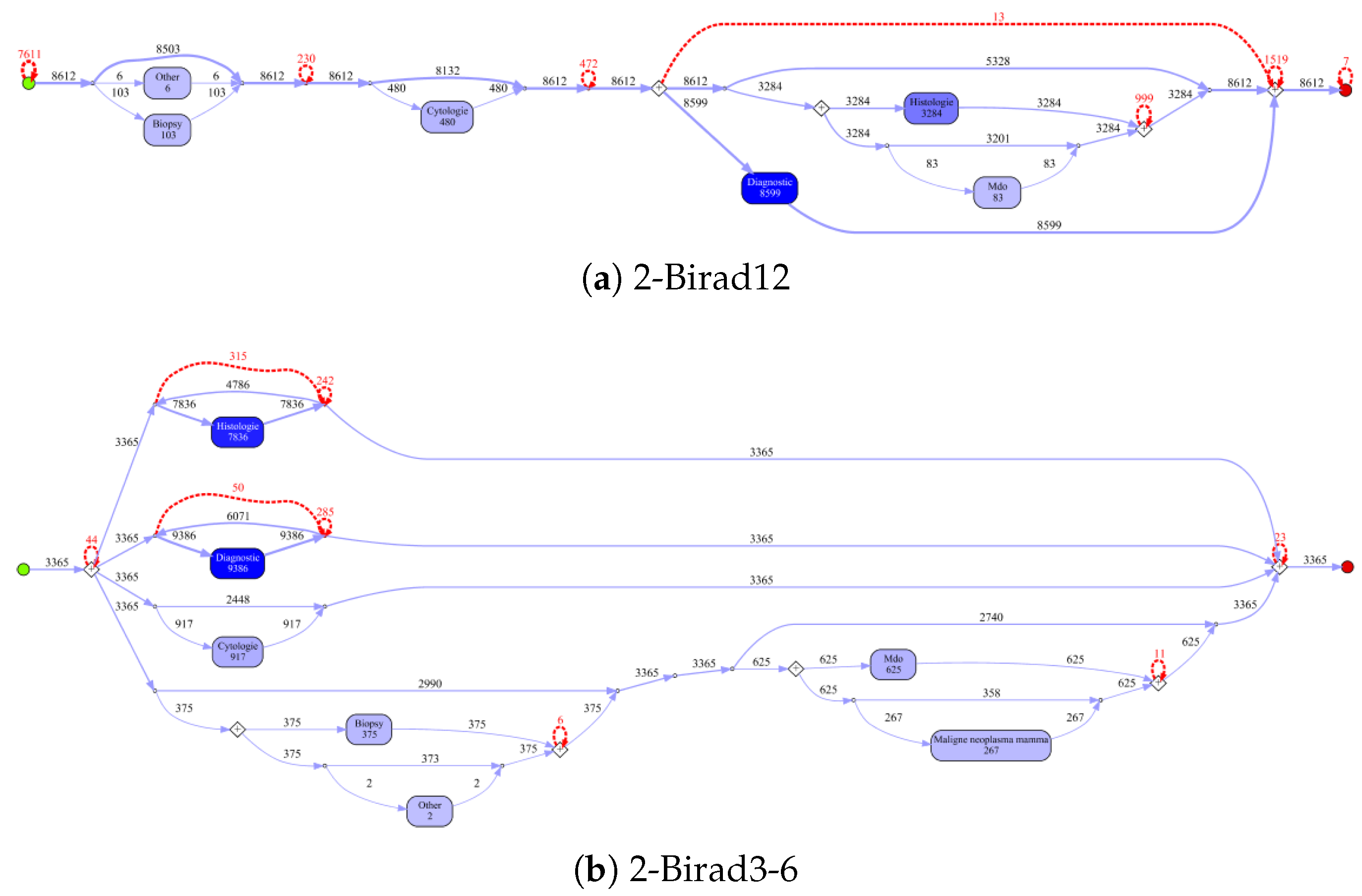
Figure 10 shows the process models for 2-Birad12 and 2-Birad3-6 patients with more fine grained events. We have twice as much event types on the second level, and the processes become clearly more complex. The model generated for patients with 2-Birad3-6 (3365 cases) is more complex than the other one, even though the patient population for 2-Birad12 (8612 cases) more than twice as large.
Figure 10a shows no loop conditions and deviations are significant, similarly to the process that was generated for the same sub-population with only first-level events (cf.
Figure 8b). This means that there are many patients that do not follow the most common behaviour. In
Figure 10b, one rare event is missing (benign neoplasma mamma).
6.5. Process Model Comparison
Table 7 summarizes the comparison of process models. For visual assessment, we reported the average similarity score and standard deviation obtained by human judgment on a five-point Likert scale (0: identical to 4: extremely different). Further, we reported the fitness and precision values obtained by cross-log conformance checking and their averages.
We also reported the GED and the similarity obtained by feature-based graph comparison (FS). As the FS values are generally all above 0.9 and similar, they do not seem useful for comparing the underlying process models. Fitness and precision varies more and interestingly differs depending on whether the log of group 1 is played on the process model of group 2 or vice versa.
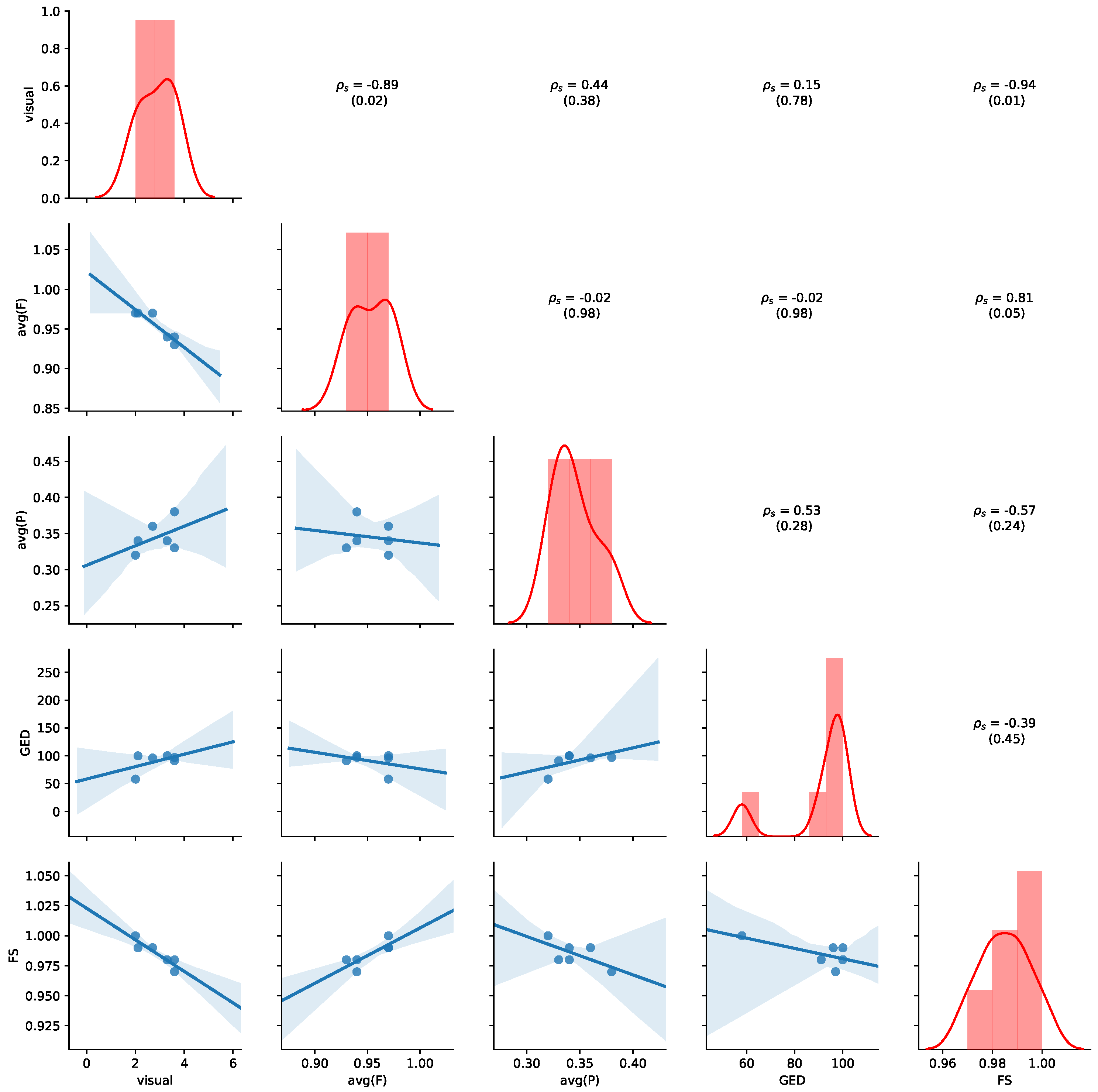
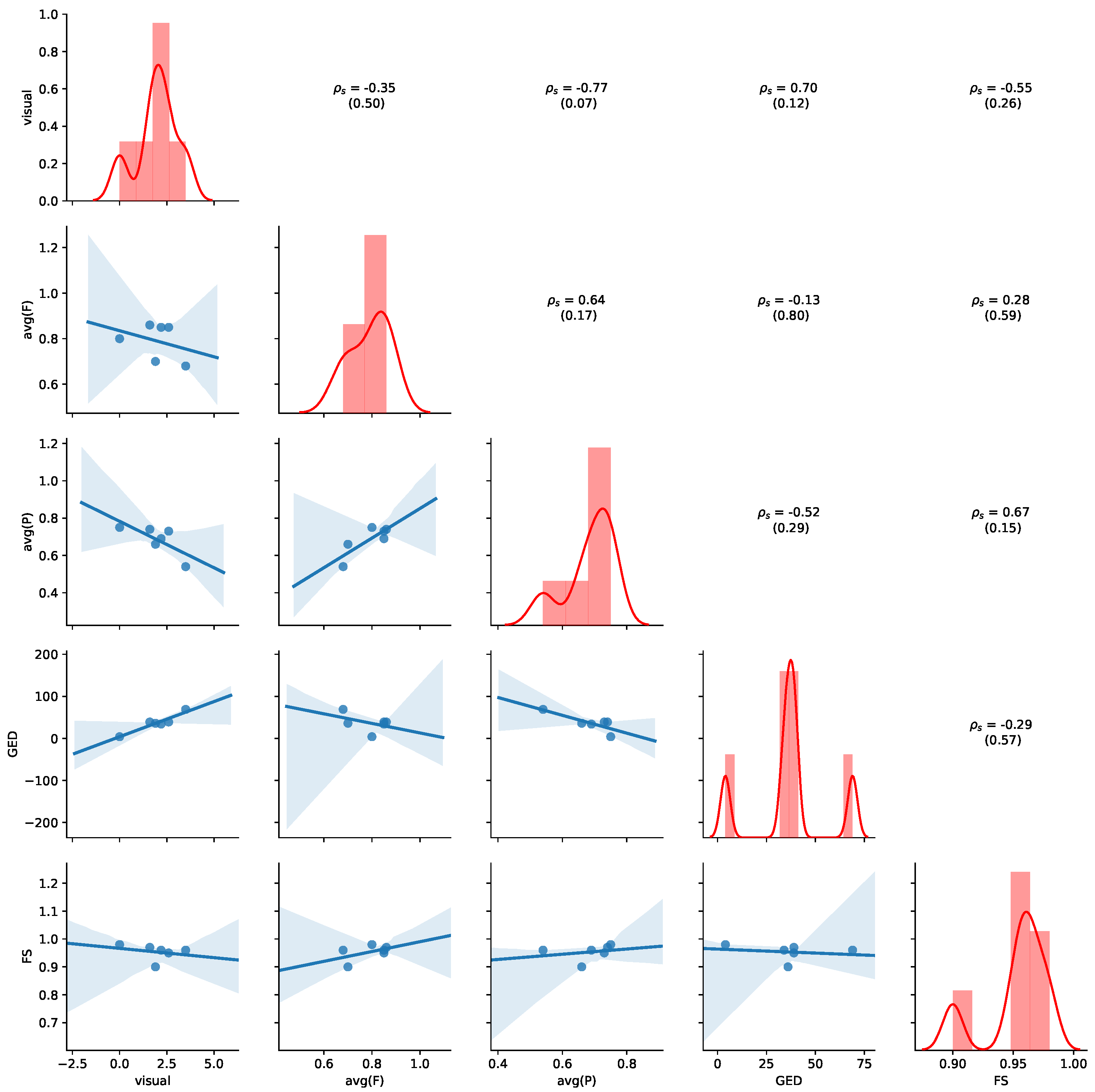
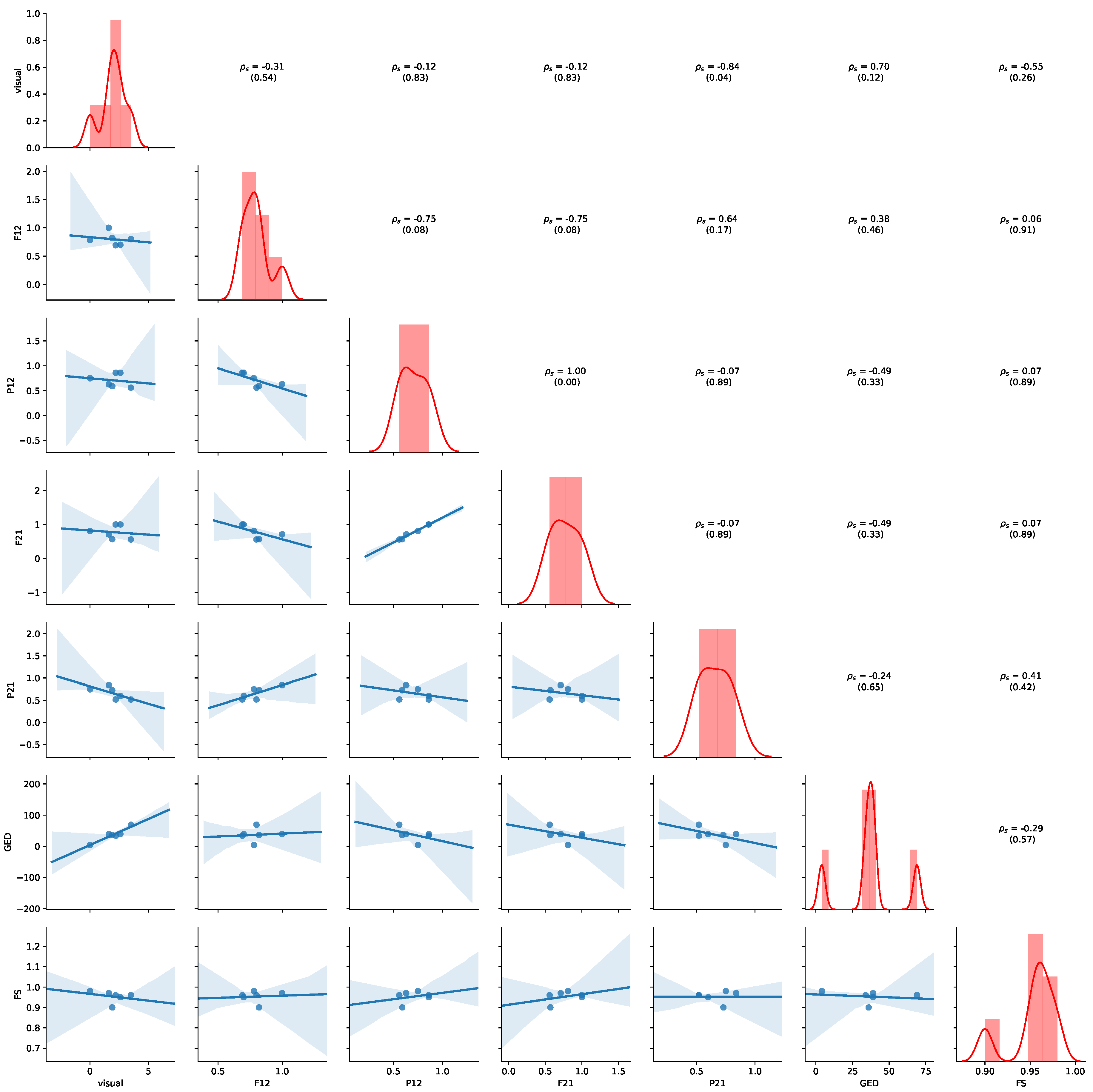
Figure 11 provides an overview of the results for the aggregated values of
Table 7. Detailed results for all non-aggregated values can be found in
Appendix B.2. Please refer to
Section 5.4 for details of how to read the figure. Average precision shows the highest negative correlation with visual judgment (
,
p-value = 0.07), while GED shows the highest positive correlation with the visual judgement (
,
p-value = 0.12), indicating human judgement to be aligned with GED. We also observe that a positive correlation between average precision and average fitness (
,
p-value = 0.17) and FS (
,
p-value = 0.15). Thus, the results show that GED and average precision are appropriate indications of visual similarity for this dataset.
7. Discussion
We addressed the problem of automatically comparing process models of different patient sub-populations in cancer care. Our experiments were performed in two related, but different applications areas (cancer types in ICU and breast cancer care) on two different data sets. We consider our work as a first step towards a solution for fully automatically comparing process models in order to alleviate manual effort. In this section, we discuss methodological choices and limitations of our work.
Human Judgments. Our user study comprised 20 participants each rating 6 (MIMIC) + 6 (ZGT) pairs of process models. The visual judgement scores showed a rather high standard deviation for most cases (cf.
Table 3 and
Table 7), except in the case for the two process that were exactly equal (SVOB and Birad12 on ZGT). In a preliminary study, in which four of the authors visually assessed the same process models independently, we observed smaller differences between assessors. This indicates that process model similarity scoring is a difficult task for untrained humans. Future experiments on artificially constructed process models in a more general domain, which does not require domain knowledge, could evaluate the validity of the human ground truth for process model comparison.
Similarity measures. We compared process models using (i) human visual assessment, (ii) graph-based measures and (iii) cross-log conformance checking. We assume that humans compare graphs by considering both, graph structure as well as global and local semantics. We leave a qualitative investigation for future work. For the graph based measures, GED mostly focuses on graph structure, but incorporates some semantics by only considering nodes of the same types as matches. Our feature similarities, on the other hand only consider the structure of graphs. Future work might explore semantic embeddings [
30] as features for graph comparison. Cross-log conformance checking replays event data from one population on the process model constructed from events of a different population. Similarity based on cross-conformance metrics can thus be considered a semantic comparison, since event types and their sequences are considered.
Approximation of GED. While the GED provides the highest positive correlation with the visual judgement on ZGT data, the results need to be judged with care. We used an iterative algorithm for calculating the GED, and stopped the approximation after 1 h of calculation if the values did not change anymore. This means, that reported values might not be the true GED, as exemplified in the case of SVOB–Birad12 comparison on ZGT data, where GED should be 0 (cf.
Figure 8 and
Table 7). Additional research is needed to improve the computational efficiency for applications in practice.
Validity of Results. Different notions of equivalence (e.g., trace equivalence), produce binary answers (i.e., two processes and models are either equivalent or not). Such binary results are not very beneficial, especially in the complicated domains (such as health care), where we need to distinguish between marginally different models and entirely different models. To address the problem, we evaluated three different approaches (i) visual inspection, (ii) cross-log conformance checking, and (iii) graph-based comparison. We evaluated on two different application domains (general cancer types on MIMIC and breast cancer on ZGT) and used two different types of process models: Petri nets on MIMIC data and IvM based process models in the ZGT experiment. In each experiment, we compared six pairs of models, amounting to six data points per similarly measure per process model type. Thus, the underlying data for the analysis are quite limited. We observe different results on both datasets. For MIMIC, average fitness is an appropriate measure for quantifying visual judgement. For ZGT, GED and average precision are appropriate indications of visual similarity. Therefore, we would like to emphasize that our results are a first indication, and they can serve as a starting point for further investigations. However, further experiments are needed to verify the applicability and generalizability of the results to more process models pairs of the same data sets, different types of process models, other application domains, or more complex process models.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}