Leveraging Machine Learning Techniques and Engineering of Multi-Nature Features for National Daily Regional Ambulance Demand Prediction


 ,
,  , ,
, , 
Abstract
1. Introduction
2. Materials and Methods
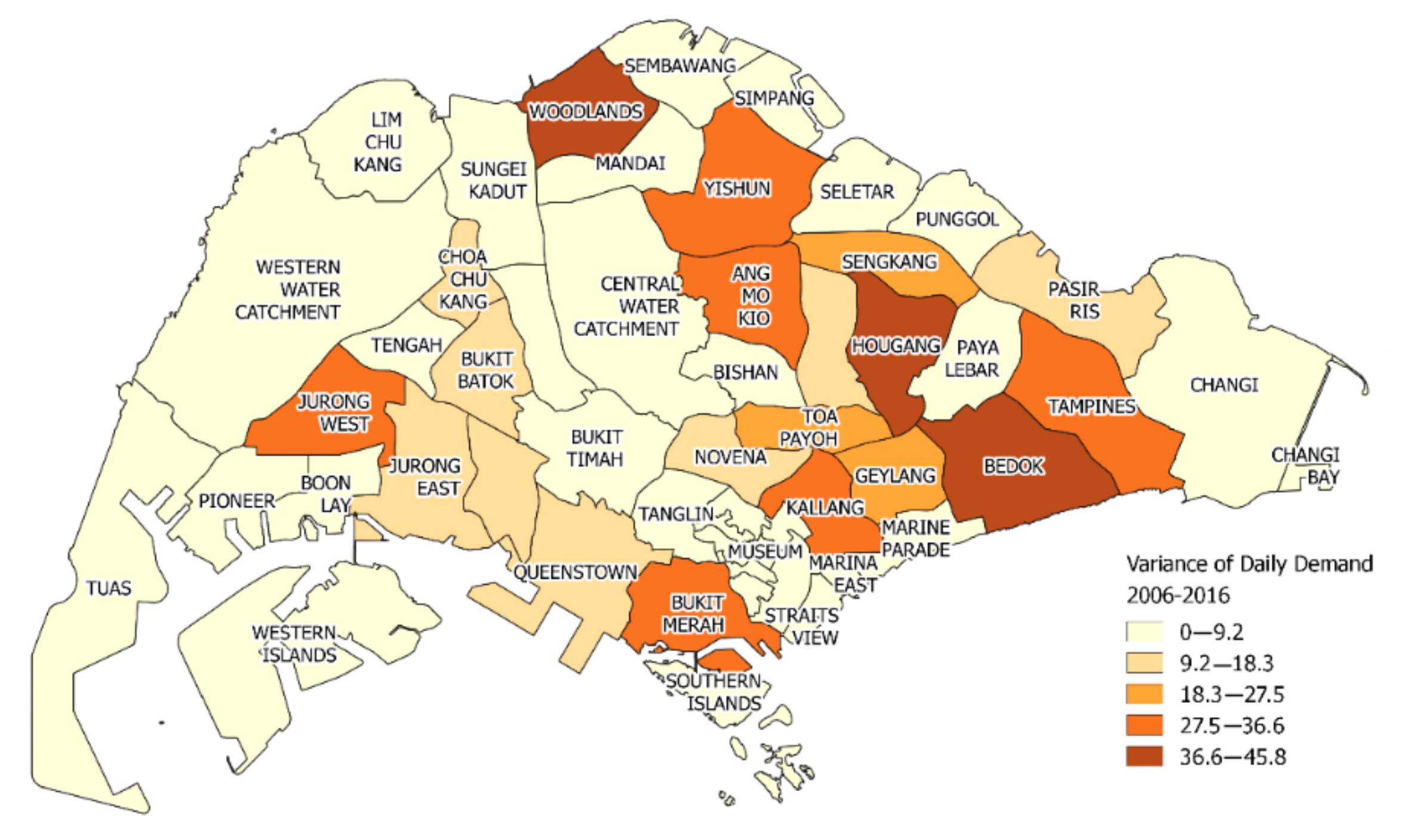
2.1. Data Sources
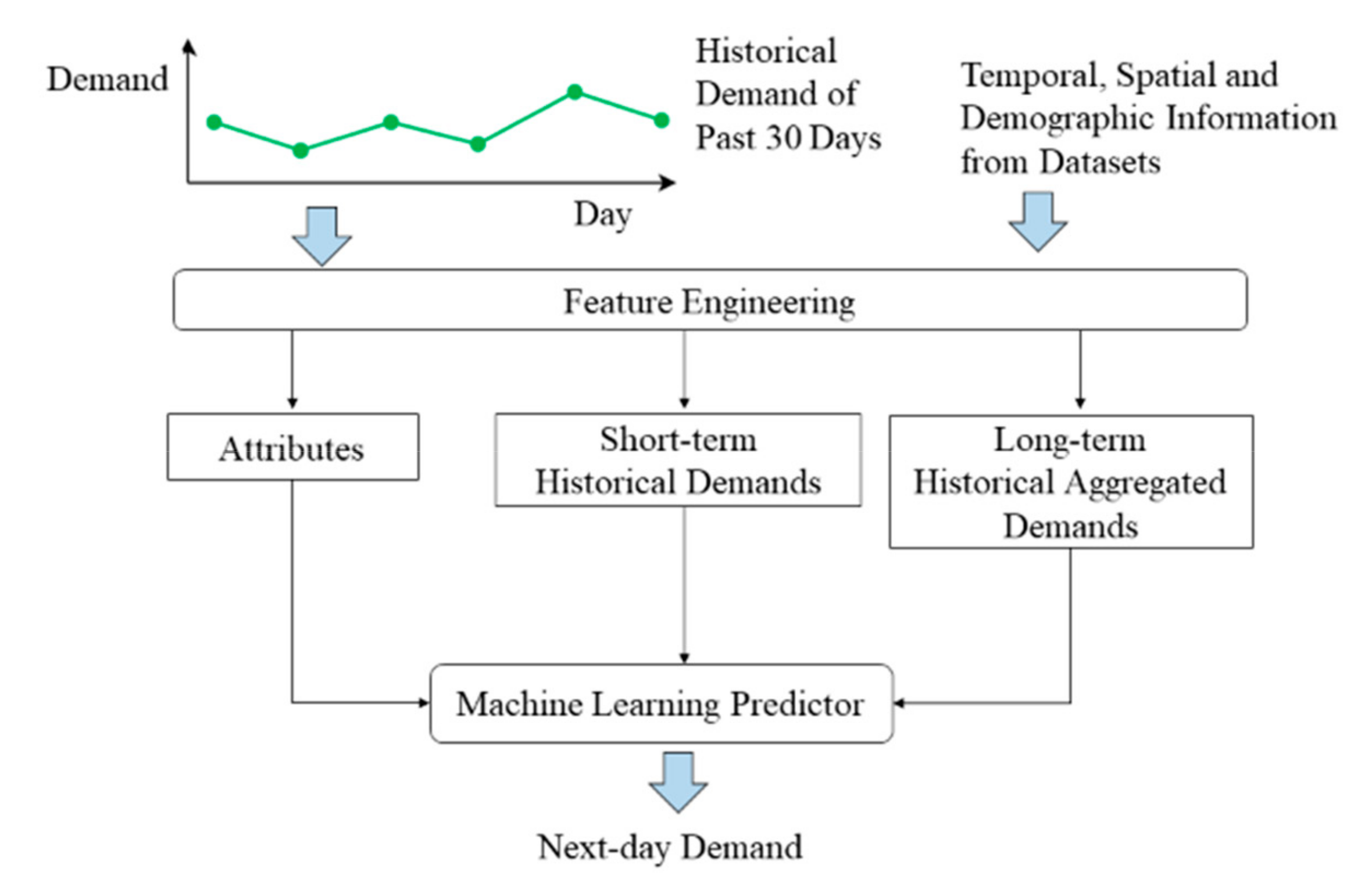
2.2. Model Overview
2.3. Feature Engineering
- Attributes. These are categorical features that provide high-level information about the record. These features are multi-nature and can be further classified into (1) spatial, (2) temporal, and (3) demographic attributes. Specifically, the spatial attributes consist of the region ID, which is a number that uniquely identifies each DGP region. The rationale behind its inclusion is to differentiate the regions within Singapore, since different regions may have different demand characteristics. For example, a region with more elderly people may experience a higher demand than another region with mostly young people. The temporal attributes consist of the following features: day of week, day of month, and month of year. These are included to account for the periodicity of ambulance demands. Finally, since the demand at a region may be higher if it has more people who are older in age, we also consider a demographic attribute: the total no. of people in that region who are aged 50 and above on that particular year
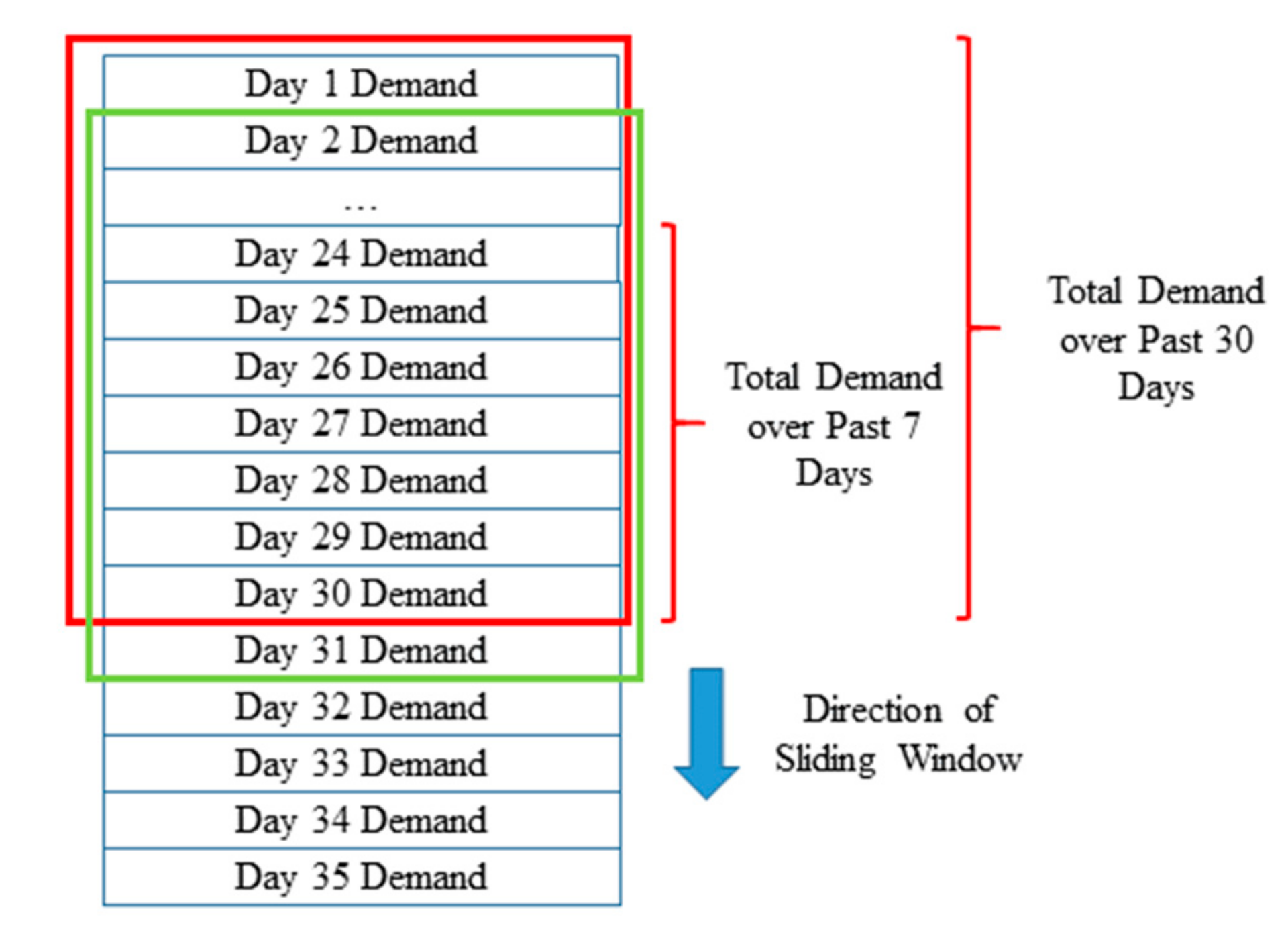
- Short-term Historical Demands. These features are demands at a region over each of the previous 7 days. These 7 continuous features are considered to account for the correlations between the demands of a particular day with that of the previous days. For example, a sudden spike in the dengue mosquitos’ population at a region may result in the rise of dengue-related cases over a few consecutive days.
- Long-term Historical Aggregated Demands. These features consist of the total demand at a region over the past 30 days, the total demand over the past 7 days, the total demand of the week up until the sample date, and the total demand of the month up until the sample date. These aggregated demands are included to account for the demand on the broader scale without the higher variances present in short-term demands. For example, a region may experience a high short-term historical demand solely due to a recent occurrence of a large-scale traffic accident but does not typically have high demands as it is not a populous area.
2.4. Key Implementation Details of Feature Engineering
2.5. Primary Outcome
2.6. Machine Learning Methods Considered
- Regional Moving Average. This method estimates the next-day demand at a region simply by taking the average of the daily demand values over the past 7 days at this region.
- Linear Regression. This method is a popular regression method that finds the best-fit hyperplane across the multi-feature data samples [23]. It assumes a linear relationship between the dependent variable, i.e., demand, and the independent variables, i.e., features. To model this relationship, the mean square error function is first considered as a loss function. Then, the gradient descent algorithm is used to iteratively find the minimum of this function and also the resulting hyperplane. The coefficients of this hyperplane represent the degree of impact each feature has on the predicted value. To accurately represent the categorical features, i.e., Attributes, one-hot encoding is used during preprocessing. Min-max scaling is also applied on the continuous features. This method is applied using the Python Scikit-Learn library [24].
- Support Vector Regression (SVR). SVR is a support-vector machine that performs regression by finding a hyperplane, i.e., support vector, that fits as many points as possible within a space that is bounded by two boundary hyperplanes parallel to this support vector. Unlike Linear Regression, SVR typically finds the best-fitting hyperplane in the higher dimensions. To this end, it utilizes a kernel, which is a function that maps lower-dimensional data points to higher-dimension data points. The advantage of doing so is that it allows the method to capture certain non-linear relationships, which may not be possible with Linear Regression. SVR has been demonstrated to be one of the more effective machine learning approaches for predicting ambulance demand in [18]. Similar to Linear Regression, we apply this method using the Python Scikit-Learn library [24] and process the categorical features with one-hot encoding.
- Multi-layer Perceptron (MLP). This method is an artificial neural architecture that has been explored and demonstrated in [19] to be an improvement over the traditional ambulance demand prediction method. The MLP is a standard neural architecture that is essentially made up of a sequence of linear layers. In this baseline, the size of the hidden layer is equal to that of the input layer, and 3 hidden layers are considered in total. Furthermore, the loss function used for the training of the model is the squared loss function. The learning rate used is 0.01, and the activation function used is the ReLU function. This method is also applied from the Python Scikit-Learn library [24].
- Radial Basis Function Network (RBFN). We also consider the Radial Basis Function (RBF) network, a variant of the artificial neural network (ANN), for comparison. Unlike a typical MLP network, a RBFN consists of three layers: an input layer, a linear output layer, and a hidden layer that uses the non-linear radial basis function as the activation function. It has been demonstrated to be more effective than traditional MLPs in certain problems [25].
- Light Gradient Boosting Machine (LightGBM). LightGBM [26] is one of the most efficient and high-performing gradient-boosting decision tree methods. The key idea behind such gradient-boosting methods is that they consider the ensemble of various individual regression trees to fine-tune the accuracy of prediction. This is achieved by sequentially combining the trees such that each tree fits to the residual of the previous tree it is extended from. The input for this method is similar to that of the previous methods, with the exception that attributes are specified as categorical features in the program. Furthermore, the specific key settings considered in this work are as follows. (1) Number of trees, 2000; (2) number of leaves, 31; (3) learning rate, 0.005; (4) feature fraction, 0.8. The boosting approach considered is gradient boosting decision tree. This method can be applied by using the LightGBM library [26] in Python.
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fitch, J. Response times: Myths, measurement & management. J. Emerg. Med. Serv. 2005, 30, 47–56. [Google Scholar]
- Henriksen, F.L.; Schorling, P.; Hansen, B.; Schakow, H.; Larsen, M.L. FirstAED emergency dispatch, global positioning of community first responders with distinct roles - a solution to reduce the response times and ensuring an AED to early defibrillation in the rural area Langeland. Int. J. Netw. Virtual Organ. 2016, 16, 86. [Google Scholar] [CrossRef]
- Peleg, K.; Pliskin, J.S. A geographic information system simulation model of EMS: Reducing ambulance response time. Am. J. Emerg. Med. 2004, 22, 164–170. [Google Scholar] [CrossRef] [PubMed]
- Peters, J.; Hall, G. Assessment of ambulance response performance using a geographic information system. Soc. Sci. Med. 1999, 49, 1551–1566. [Google Scholar] [CrossRef]
- Simonsen, S.A.; Andresen, M.; Michelsen, L.; Viereck, S.; Lippert, F.; Iversen, H.K. Evaluation of pre-hospital transport time of stroke patients to thrombolytic treatment. Scand. J. Trauma. Resusc. Emerg. Med. 2014, 22, 65. [Google Scholar] [CrossRef]
- Timm, A.; Maegele, M.; Lefering, R.; Wendt, K.; Wyen, H. Pre-hospital rescue times and actions in severe trauma. A comparison between two trauma systems: Germany and the Netherlands. Injury 2014, 45, S43–S52. [Google Scholar] [CrossRef]
- Setzler, H.; Saydam, C.; Park, S. EMS call volume predictions: A comparative study. Comput. Oper. Res. 2009, 36, 1843–1851. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, Z.; Ho, A.F.W.; Ong, M.E.H. Artificial intelligence in emergency medicine. J. Emerg. Crit. Care Med. 2018, 2, 82. [Google Scholar] [CrossRef]
- Rendell, K.; Koprinska, I.; Kyme, A.Z.; Ebker-White, A.; Dinh, M. The Sydney Triage to Admission Risk Tool (START2) using machine learning techniques to support disposition decision-making. Emerg. Med. Australas. 2018, 31, 429–435. [Google Scholar] [CrossRef]
- Chiew, C.J.; Liu, N.; Wong, T.H.; Sim, Y.E.; Abdullah, H.R. Utilizing Machine Learning Methods for Preoperative Prediction of Postsurgical Mortality and Intensive Care Unit Admission. Ann. Surg. 2019. [Google Scholar] [CrossRef]
- Eken, C.; Bilge, U.; Kartal, M.; Eray, O. Artificial neural network, genetic algorithm, and logistic regression applications for predicting renal colic in emergency settings. Int. J. Emerg. Med. 2009, 2, 99–105. [Google Scholar] [CrossRef] [PubMed]
- Harrison, R.; Kennedy, R.L. Artificial Neural Network Models for Prediction of Acute Coronary Syndromes Using Clinical Data From the Time of Presentation. Ann. Emerg. Med. 2005, 46, 431–439. [Google Scholar] [CrossRef]
- Silva, A.; Cortez, P.; Santos, M.F.; Gomes, L.; Neves, J. Mortality assessment in intensive care units via adverse events using artificial neural networks. Artif. Intell. Med. 2006, 36, 223–234. [Google Scholar] [CrossRef] [PubMed]
- Taylor, R.A.; Pare, J.R.; Venkatesh, A.K.; Mowafi, H.; Melnick, E.R.; Fleischman, W.; Hall, M.K. Prediction of In-hospital Mortality in Emergency Department Patients With Sepsis: A Local Big Data-Driven, Machine Learning Approach. Acad. Emerg. Med. 2016, 23, 269–278. [Google Scholar] [CrossRef] [PubMed]
- Boutilier, J.J.; Chan, T.C.Y. Ambulance Emergency Response Optimization in Developing Countries. arXiv 2018, arXiv:1801.05402. [Google Scholar]
- Westgate, B.S.; Woodard, D.B.; Matteson, D.S.; Henderson, S. Large-network travel time distribution estimation for ambulances. Eur. J. Oper. Res. 2016, 252, 322–333. [Google Scholar] [CrossRef]
- Li, Y.; Zheng, Y.; Ji, S.; Wang, W.; Leong, H.U.; Gong, Z. Location selection for ambulance stations. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems-GIS ’15, Association for Computing Machinery (ACM), Seattle, WA, USA, 3–6 November 2015; Volume 85, pp. 1–4. [Google Scholar]
- Chen, A.; Lu, T.-Y.; Ma, M.H.-M.; Sun, W.-Z. Demand Forecast Using Data Analytics for the Preallocation of Ambulances. IEEE J. Biomed. Health Inform. 2015, 20, 1178–1187. [Google Scholar] [CrossRef]
- Channouf, N.; L’Ecuyer, P.; Ingolfsson, A.; Avramidis, A.N. The application of forecasting techniques to modeling emergency medical system calls in Calgary, Alberta. Heal. Care Manag. Sci. 2007, 10, 25–45. [Google Scholar] [CrossRef]
- Zhou, Z.; Matteson, D.S. Predicting Ambulance Demand. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining-KDD ’15, Sydney, NSW, Australia, 10–15 August 2015; Association for Computing Machinery (ACM): New York, NY, USA; pp. 2297–2303. [Google Scholar]
- Singapore Civil Defence Force. EMERGENCY MEDICAL SERVICES STATISTICS 2016. Singapore Civil Defence Force. Available online: https://www.scdf.gov.sg/docs/default-source/scdf-library/publications/amb-fire-inspection-statistics/ems-stats-2016 (accessed on 4 June 2020).
- Ho, A.F.W.; Chew, D.; Wong, T.H.; Ng, Y.Y.; Pek, P.P.; Lim, S.H.; Anantharaman, V.; Ong, M.E.H. Prehospital Trauma Care in Singapore. Prehospital Emerg. Care 2014, 19, 409–415. [Google Scholar] [CrossRef]
- Ho, A.F.W.; To, B.Z.Y.S.; Koh, J.M.; Cheong, K.H. Forecasting Hospital Emergency Department Patient Volume Using Internet Search Data. IEEE Access 2019, 7, 93387–93395. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar] [CrossRef]
- Arnaiz-González, A.; Fernández-Valdivielso, A.; Bustillo, A.; De Lacalle, L.N.L. Using artificial neural networks for the prediction of dimensional error on inclined surfaces manufactured by ball-end milling. Int. J. Adv. Manuf. Technol. 2015, 83, 847–859. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Fildes, R. The evaluation of extrapolative forecasting methods. Int. J. Forecast. 1992, 8, 81–98. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Gilles, S. Shapely: Manipulation and analysis of geometric objects. Available online: https://github.com/Toblerity/Shapely (accessed on 4 June 2020).
- Lundberg, S.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]
- Geng, X.; Li, Y.; Wang, L.; Zhang, L.; Yang, Q.; Ye, J.; Liu, Y. Spatiotemporal Multi-Graph Convolution Network for Ride-Hailing Demand Forecasting. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19), Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3656–3663. [Google Scholar]
- Yao, H.; Wu, F.; Ke, J.; Tang, X.; Jia, Y.; Lu, S.; Gong, P.; Ye, J.; Li, Z. Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018; pp. 2588–2595. [Google Scholar]
- Cheong, K.H.; Ngiam, N.J.; Morgan, G.G.; Pek, P.P.; Tan, B.Y.-Q.; Lai, J.W.; Koh, J.M.; Ong, M.E.H.; Ho, A.W.F. Acute Health Impacts of the Southeast Asian Transboundary Haze Problem—A Review. Int. J. Environ. Res. Public Health 2019, 16, 3286. [Google Scholar] [CrossRef]
- Ho, A.F.W.; Zheng, H.; Cheong, K.H.; En, W.L.; Pek, P.P.; Zhao, X.; Morgan, G.G.; Earnest, A.; Tan, B.Y.Q.; Ng, Y.; et al. The Relationship Between Air Pollution and All-Cause Mortality in Singapore. Atmosphere 2019, 11, 9. [Google Scholar] [CrossRef]
- Ho, A.F.W.; Zheng, H.; Earnest, A.; Cheong, K.H.; Pek, P.P.; Seok, J.Y.; Liu, N.; Kwan, Y.H.; Tan, J.W.C.; Wong, T.H.; et al. Time-Stratified Case Crossover Study of the Association of Outdoor Ambient Air Pollution With the Risk of Acute Myocardial Infarction in the Context of Seasonal Exposure to the Southeast Asian Haze Problem. J. Am. Hear. Assoc. 2019, 8, e011272. [Google Scholar] [CrossRef]
- Cheong, K.H.; Koh, J.M. A hybrid genetic-Levenberg Marquardt algorithm for automated spectrometer design optimization. Ultramicroscopy 2019, 202, 100–106. [Google Scholar] [CrossRef]
- Cheong, K.H.; Poeschmann, S.; Lai, J.W.; Koh, J.M.; Acharya, U.; Yu, S.C.M.; Tang, K.J.W. Practical Automated Video Analytics for Crowd Monitoring and Counting. IEEE Access 2019, 7, 183252–183261. [Google Scholar] [CrossRef]
- Jahmunah, V.; Oh, S.L.; Rajinikanth, V.; Ciaccio, E.J.; Cheong, K.H.; Arunkumar, N.; Acharya, R.U. Automated detection of schizophrenia using nonlinear signal processing methods. Artif. Intell. Med. 2019, 100, 101698. [Google Scholar] [CrossRef]
- Koh, J.M.; Cheong, K.H. Automated electron-optical system optimization through switching Levenberg–Marquardt algorithms. J. Electron Spectrosc. Relat. Phenom. 2018, 227, 31–39. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Characteristics | Value |
|---|---|
| Incident Year | |
| 2006–2007 | 190,608 (13.6%) |
| 2008–2009 | 216,841 (15.5%) |
| 2010–2011 | 237,451 (17.0%) |
| 2012–2013 | 268,596 (19.2%) |
| 2014–2016 | 311,251 (22.3%) |
| 2016 | 172,009 (12.3%) |
| Patient Age (yrs) | 55 (34–73) |
| 2006–2007 | 51 (32–71) |
| 2008–2009 | 52 (32–71) |
| 2010–2011 | 53 (33–72) |
| 2012–2013 | 56 (35–73) |
| 2014–2016 | 57 (36–74) |
| 2016 | 58 (36–75) |
| Incident Classification | |
| Medical | 968,375 (69.3%) |
| Trauma | 391,986 (28.1%) |
| Assistance Not Required | 35,460 (2.54%) |
| Patient Incident Subclass | |
| Nervous System | 381,634 (27.3%) |
| No Medical Complaint/Un-Injured | 385,430 (27.6%) |
| Bone/Connective Tissue | 116,173 (8.32%) |
| Alcoholic Intoxication | 25,865 (1.85%) |
| Respiratory System | 132.163 (9.46%) |
| Reproductive System | 117,21 (0.839%) |
| Cardiovascular System | 115,587 (8.28%) |
| Digestive System | 98,129 (7.03%) |
| Poisoning/Drug Overdose | 6791 (0.486%) |
| Ear/Nose/Throat/Eye Condition | 5601 (0.401%) |
| Kidney/Urinary System | 16,433 (1.18%) |
| Blood Related | 5590 (0.400%) |
| Maternity/Childbirth | 5062 (0.362 %) |
| Liver/Biliary Tract | 1438 (0.103%) |
| Psychiatric Emergencies | 4413 (0.316%) |
| Endocrine System | 31,850 (2.28%) |
| Infectious Disease/Disorder of Skin | 4649 (0.333%) |
| Others | 35,240 (2.52%) |
| Unknown | 9474 (0.678%) |
| Unclassified | 2705 (0.194%) |
| Gender | |
| Male | 838,737 (60.0%) |
| Female | 554,237 (39.7%) |
| Unclassified | 2163 (0.213%) |
| Characteristics | Value |
|---|---|
| Daily Regional Demand | 6.33 (0–10) |
| Total Regional Demands over Past 7 Days | 44. (4–69) |
| Total Regional Demands over Past 30 Days | 190 (20–294) |
| Method | WAPE (%) | MAE | MSE |
|---|---|---|---|
| Regional Moving Average | 25.8 | 2.20 | 11.2 |
| Linear Regression | 24.5 | 2.09 | 10.1 |
| MLP | 24.6 | 2.10 | 10.1 |
| RBFN | 25.1 | 2.14 | 10.8 |
| SVR | 25.2 | 2.15 | 11.2 |
| LightGBM | 24.5 | 2.09 | 10.2 |
| Feature | Gain-Based Importance | Mean Absolute SHAP Value |
|---|---|---|
| Region ID | 14,121,071 | 0.230 |
| Day of Week | 844,283 | 0.069 |
| Day of Month | 2,400,462 | 0.043 |
| Month of Year | 723,054 | 0.031 |
| Demand 1 Day Ago | 308,590 | 0.022 |
| Demand 2 Days Ago | 138,543 | 0.011 |
| Demand 3 Days Ago | 159,649 | 0.012 |
| Demand 4 Days Ago | 209,771 | 0.014 |
| Demand 5 Days Ago | 144,138 | 0.015 |
| Demand 6 Days Ago | 146,966 | 0.009 |
| Demand 7 Days Ago | 432,136 | 0.022 |
| Total Demand of the Week up to the Data Sample Day | 1,368,848 | 0.101 |
| Total Demand of the Month up to the Data Sample Day | 82,847 | 0.005 |
| Total Demand over Past 30 Days | 820,758,893 | 4.626 |
| Total Demand over Past 7 Days | 77,034,386 | 0.466 |
| Total Number of People Aged 50 and Above in the Year | 2,528,021 | 0.223 |
| Dataset | WAPE (%) | MAE | MSE |
|---|---|---|---|
| SCDF-Engineered-Socio | 22.0 | 3.00 | 16.3 |
| SCDF-Engineered-Socio, excluding regional socioeconomic features | 22.0 | 3.00 | 16.3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, A.X.; Ho, A.F.W.; Cheong, K.H.; Li, Z.; Cai, W.; Chee, M.L.; Ng, Y.Y.; Xiao, X.; Ong, M.E.H. Leveraging Machine Learning Techniques and Engineering of Multi-Nature Features for National Daily Regional Ambulance Demand Prediction. Int. J. Environ. Res. Public Health 2020, 17, 4179. https://doi.org/10.3390/ijerph17114179
Lin AX, Ho AFW, Cheong KH, Li Z, Cai W, Chee ML, Ng YY, Xiao X, Ong MEH. Leveraging Machine Learning Techniques and Engineering of Multi-Nature Features for National Daily Regional Ambulance Demand Prediction. International Journal of Environmental Research and Public Health. 2020; 17(11):4179. https://doi.org/10.3390/ijerph17114179
Chicago/Turabian StyleLin, Adrian Xi, Andrew Fu Wah Ho, Kang Hao Cheong, Zengxiang Li, Wentong Cai, Marcel Lucas Chee, Yih Yng Ng, Xiaokui Xiao, and Marcus Eng Hock Ong. 2020. "Leveraging Machine Learning Techniques and Engineering of Multi-Nature Features for National Daily Regional Ambulance Demand Prediction" International Journal of Environmental Research and Public Health 17, no. 11: 4179. https://doi.org/10.3390/ijerph17114179
APA StyleLin, A. X., Ho, A. F. W., Cheong, K. H., Li, Z., Cai, W., Chee, M. L., Ng, Y. Y., Xiao, X., & Ong, M. E. H. (2020). Leveraging Machine Learning Techniques and Engineering of Multi-Nature Features for National Daily Regional Ambulance Demand Prediction. International Journal of Environmental Research and Public Health, 17(11), 4179. https://doi.org/10.3390/ijerph17114179