A Machine Learning-Based Approach for Predicting Patient Punctuality in Ambulatory Care Centers


Abstract
1. Introduction
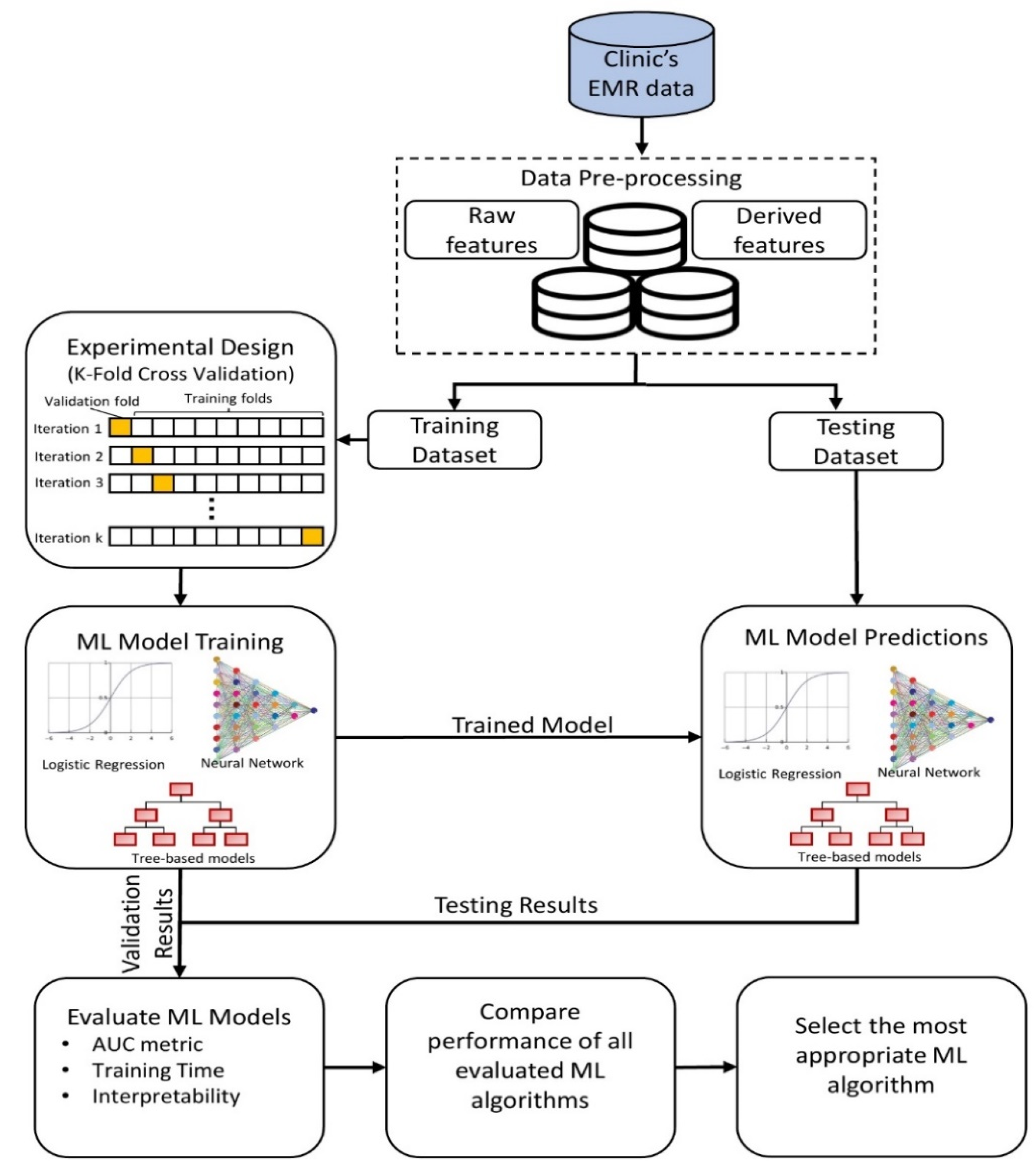
2. Materials and Methods
2.1. Data Collection and Pre-Processing
- Patient characteristics—age, gender, race, marital status, insurance type, patient type (new vs. return), medical record number (MRN), and zip code;
- Visit information—appointment duration, appointment time, appointment date, timestamps of patient arrival time, treatment begin time, and check-out time.
2.2. Predictive Modeling
2.2.1. Logistic Regression
2.2.2. Feed-Forward Artificial Neural Networks with Backpropagation Learning
2.2.3. Tree-based Ensemble Methods
2.3. Model Evaluation
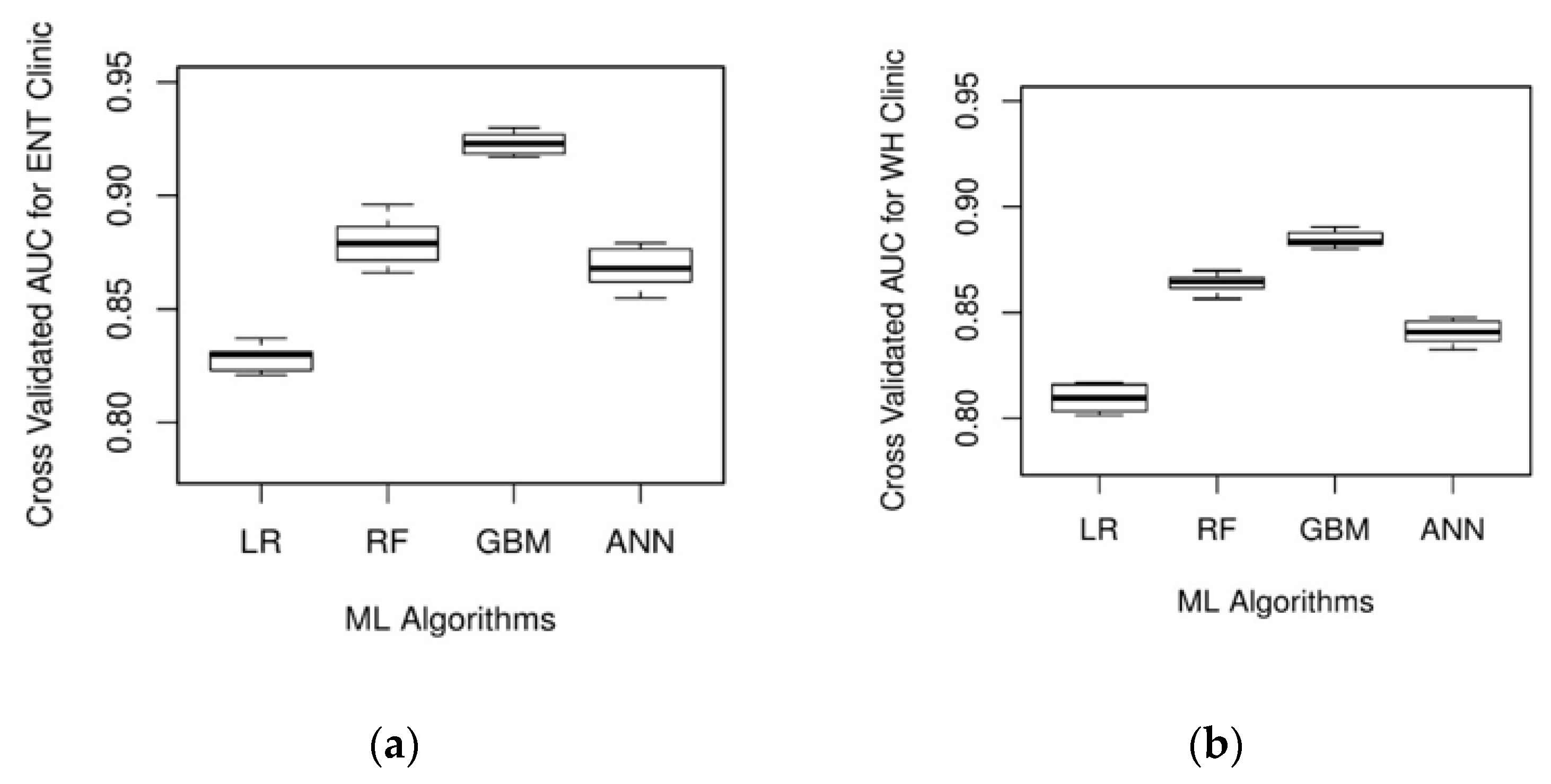
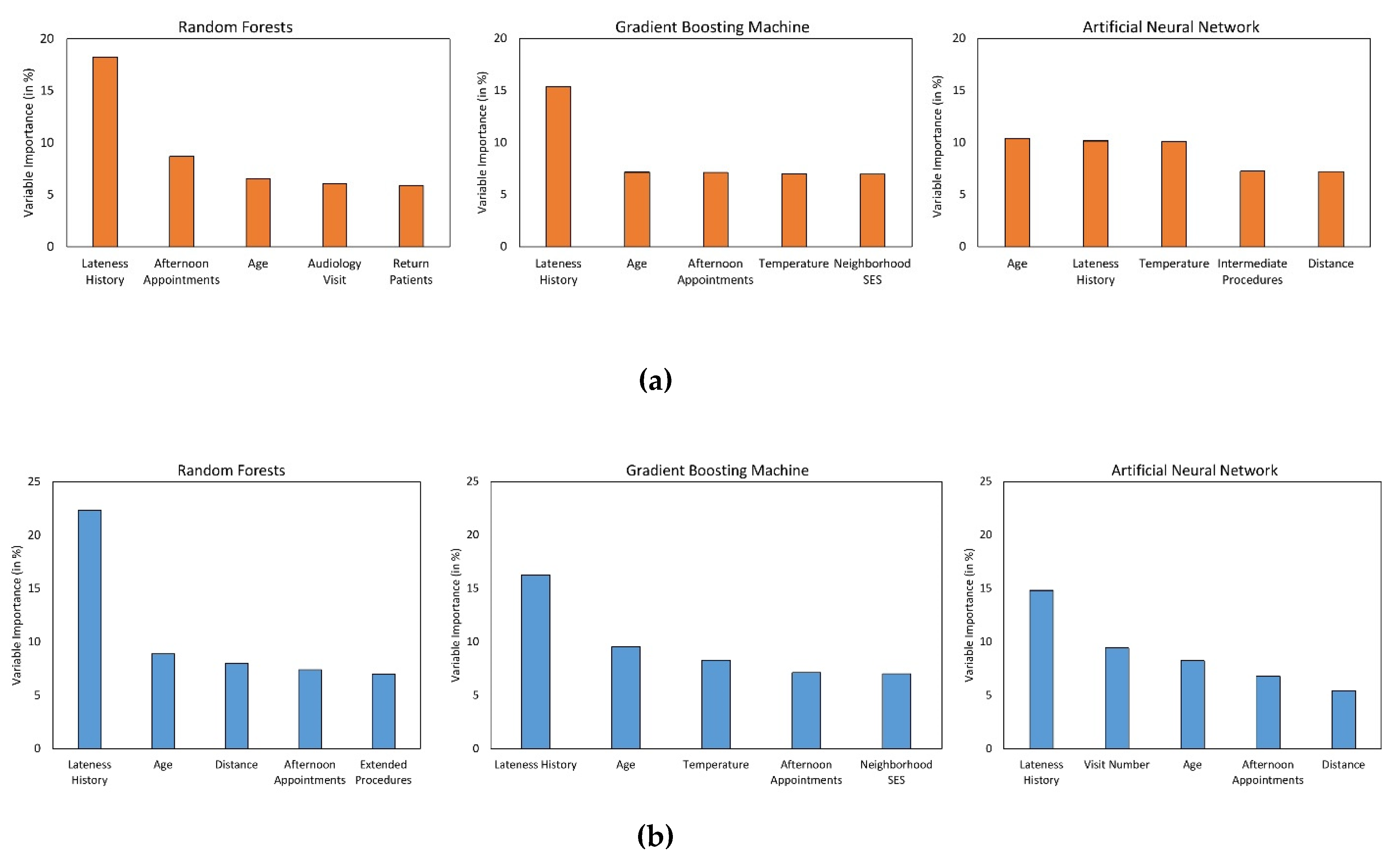
3. Results
4. Discussion
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- White, B.; Pike, M. Appointment systems in out-patients’ clinics and the effect of patients’ unpunctuality. Med. Care 1964, 2, 133–145. [Google Scholar] [CrossRef]
- Okotie, O.; Patel, N.; Gonzalez, C. The effect of patient arrival time on overall wait time and utilization of physician and examination room resources in the outpatient urology clinic. Adv. Urol. 2008, 2008, 1–3. [Google Scholar] [CrossRef][Green Version]
- Zhu, H.; Chen, F.Y.; Leung, E.; Liu, X. Outpatient appointment scheduling with unpunctual patients. Int. J. Prod. Res. Int. J. Prod. Res. 2018, 56, 1982–2002. [Google Scholar] [CrossRef]
- Hang, S.C.; Lich, K.H.; Kelly, K.J.; Howell, D.M.; Steiner, M.J. Patient- and Visit-Level Variables Associated With Late Arrival to Pediatric Clinic Appointments. Clin. Pediatr. 2016, 56, 634–639. [Google Scholar] [CrossRef] [PubMed]
- Gorodeski, E.Z.; Joyce, E.; Gandesbery, B.T.; Blackstone, E.H.; Taylor, D.O.; Tang, W.H.W.; Starling, R.C.; Hachamovitch, R. Discordance between actual’ and scheduled’ check-in times at a heart failure clinic. PLoS ONE 2017, 12, e0187849. [Google Scholar] [CrossRef] [PubMed]
- Klassen, K.J.; Yoogalingam, R. Strategies for Appointment Policy Design with Patient Unpunctuality. Decis. Sci. 2014, 45, 881–911. [Google Scholar] [CrossRef]
- Glowacka, K.J.; May, J.H.; Goffman, R.M.; May, E.K.; Milicevic, A.S.; Rodriguez, K.L.; Tjader, Y.C.; Vargas, D.L.; Vargas, L.G. On prioritizing on-time arrivals in an outpatient clinic. IISE Trans. Healthc. Syst. Eng 2017, 7, 93–106. [Google Scholar] [CrossRef]
- Williams, K.A.; Chambers, C.G.; Dada, M.; McLeod, J.C.; Ulatowski, J.A. Patient punctuality and clinic performance: Observations from an academic-based private practice pain centre: A prospective quality improvement study. BMJ Open 2014, 4, e004679. [Google Scholar] [CrossRef]
- Tan, J.; Christie, A.; Montalvo, S.K.; Wallace, C.; Yan, Y.; Folkerts, M.; Yingling, A.; Sher, D.; Choy, H.; Jiang, S.; et al. Automated Text Message Reminders Improve Radiation Therapy Compliance. Int. J. Radiat. Oncol. 2019, 103, 1045–1052. [Google Scholar] [CrossRef]
- Faiz, K.W.; Kristoffersen, E.S. Association between age and outpatient clinic arrival time: Myth or reality? BMC Health Serv. Res. 2018, 18, 235. [Google Scholar] [CrossRef]
- Abdallah, S.; Malik, M.; Ertek, G. A Data Mining Framework for the Analysis of Patient Arrivals into Healthcare Centers. In Proceedings of the 2017 International Conference on Information Technology, Amman, Jordan, 27–29 December 2017; pp. 52–61. [Google Scholar]
- Ivan, T.; Rico, E.; Hanna, K.; Jones, A.; O’Meara, M.; Ross, K.; da Fonseca, C.; DeFreitas, M.; Marquina, W.; Navarro, A.; et al. Make it on Time: Quality Improvement in Family Medicine Outpatient Setting. Poster Presented at 2016 West Kendall Baptist Hospital Scholarly Showcase, Miami, FL, USA, 19 January 2016. [Google Scholar]
- Menard, S. Applied Logistic Regression Analysis Summary Statistics for Evaluating the Logistic Regression Model; SAGE Publications Inc.: Thousand Oaks, CA, USA, 2002. [Google Scholar]
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press: New York, NY, USA, 2014. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Dreiseitl, S.; Ohno-Machado, L. Logistic regression and artificial neural network classification models: A methodology review. J. Biomed. Inform. 2003, 35, 352–359. [Google Scholar] [CrossRef]
- Srinivas, S.; Rajendran, S.; Anand, K.; Chockalingam, A. Self-reported depressive symptoms in adolescence increase the risk for obesity and high BP in adulthood. Int. J. Cardiol. 2018, 269, 339–342. [Google Scholar] [CrossRef]
- Srinivas, S.; Ravindran, A.R. Optimizing outpatient appointment system using machine learning algorithms and scheduling rules: A prescriptive analytics framework. Expert Syst. Appl. 2018, 102, 245–261. [Google Scholar] [CrossRef]
- Lisboa, P.J.G. A review of evidence of health benefit from artificial neural networks in medical intervention. Neural Netw. 2002, 15, 11–39. [Google Scholar] [CrossRef]
- Cunningham, P.; Carney, J.; Jacob, S. Stability problems with artificial neural networks and the ensemble solution. Artif. Intell. Med. 2000, 20, 217–225. [Google Scholar] [CrossRef]
- Polikar, R. Ensemble learning. In Ensemble Machine Learning; Springer: Boston, MA, USA, 2012; pp. 1–34. [Google Scholar]
- Whalen, S.; Pandey, G. A comparative analysis of ensemble classifiers: Case studies in genomics. In Proceedings of the IEEE International Conference on Data Mining, ICDM, Dallas, TX, USA, 7–10 December 2013; pp. 807–816. [Google Scholar]
- Wainer, J. Comparison of 14 Different Families of Classification Algorithms on 115 Binary Datasets. ArXiv 2016, arXiv:1606.00930. [Google Scholar]
- Swenson, E.R.; Bastian, N.D.; Nembhard, H.B. Data analytics in health promotion: Health market segmentation and classification of total joint replacement surgery patients. Expert Syst. Appl. 2016, 60, 118–129. [Google Scholar] [CrossRef]
- Delong, E.R.; Delong, D.M.; Clarke-Pearson, D.L. Comparing the Areas under Two or More Correlated Receiver Operating Characteristic Curves: A Nonparametric Approach. Biometrics 1988, 44, 837. [Google Scholar] [CrossRef]
- Kuhn, M. Building predictive models in R using the caret package. J. stat. softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.-C.; Müller, M. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef] [PubMed]
- Reddy, B.K.; Delen, D.; Agrawal, R.K. Predicting and explaining inflammation in Crohn’s disease patients using predictive analytics methods and electronic medical record data. Heal. Inform. J. 2018, 25, 1201–1218. [Google Scholar] [CrossRef] [PubMed]
- Alaka, S.A.; Brobbey, A.; Menon, B.K.; Williamson, T.; Goyal, M.; Demchuk, A.M.; Hill, M.D.; Sajobi, T. Machine Learning Models are More Accurate Than Regression-based Models for Predicting Functional Impairment Risk in Acute Ischemic Stroke. Stroke 2019, 50 (Suppl. 1). [Google Scholar] [CrossRef]
- Tseng, Y.-J.; Huang, C.-E.; Wen, C.-N.; Lai, P.-Y.; Wu, M.-H.; Sun, Y.-C.; Wang, H.-Y.; Lu, J.-J. Predicting breast cancer metastasis by using serum biomarkers and clinicopathological data with machine learning technologies. Int. J. Med. Inform. 2019, 128, 79–86. [Google Scholar] [CrossRef] [PubMed]
- Jamshidi, A.; Pelletier, J.-P.; Martel-Pelletier, J. Machine-learning-based patient-specific prediction models for knee osteoarthritis. Nat. Rev. Rheumatol. 2018, 15, 49–60. [Google Scholar] [CrossRef]
- López-Martínez, F.; Schwarcz, A.; Núñez-Valdez, E.R.; García-Díaz, V. Machine learning classification analysis for a hypertensive population as a function of several risk factors. Expert Syst. Appl. 2018, 110, 206–215. [Google Scholar] [CrossRef]
- Weng, S.F.; Reps, J.; Kai, J.; Garibaldi, J.M.; Qureshi, N. Can Machine-learning improve cardiovascular risk prediction using routine clinical data? PLoS ONE 2017, 12, e0174944. [Google Scholar] [CrossRef]
- Alghamdi, M.; Al-Mallah, M.; Keteyian, S.; Brawner, C.; Ehrman, J.; Sakr, S. Predicting diabetes mellitus using SMOTE and ensemble machine learning approach: The Henry Ford ExercIse Testing (FIT) project. PLoS ONE 2017, 12, e0179805. [Google Scholar] [CrossRef]
- Robaina, J.A.; Bastrom, T.P.; Richardson, A.C.; Edmonds, E.W. Predicting no-shows in paediatric orthopaedic clinics. BMJ Health Care Inform. 2020, 27, e100047. [Google Scholar] [CrossRef]
- Shih, H.; Rajendran, S. Comparison of Time Series Methods and Machine Learning Algorithms for Forecasting Taiwan Blood Services Foundation’s Blood Supply. J. Healthc. Eng. 2019, 2019, 6123745. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Li, X.; Mitri, H.S. Classification of Rockburst in Underground Projects: Comparison of Ten Supervised Learning Methods. J. Comput. Civ. Eng. 2016, 30, 04016003. [Google Scholar] [CrossRef]
- Wiens, J.; Shenoy, E.S. Machine Learning for Healthcare: On the Verge of a Major Shift in Healthcare Epidemiology. Clin. Infect. Dis. 2017, 66, 149–153. [Google Scholar] [CrossRef]
- Donzé, J.; Aujesky, D.; Williams, D.; Schnipper, J.L. Potentially Avoidable 30-Day Hospital Readmissions in Medical Patients. JAMA Intern. Med. 2013, 173, 632. [Google Scholar] [CrossRef]
- UT Dallas Student Health Center. Patient Portal Appointment Scheduler. Available online: https://www.utdallas.edu/healthcenter/appointments/ (accessed on 14 May 2019).
- University of Houston Student Health Center. Appointment No Show/Late Arrival/Late Cancellation Policy—University of Houston. Available online: https://www.uh.edu/healthcenter/about/appointment-policy/ (accessed on 14 May 2019).
- Advent Health Group. No Show/Late Arrival Policy. Available online: http://www.adventhealthgroup.com/late-policy/ (accessed on 14 May 2019).
- Xakellis, G.C.; Bennett, A. Improving clinic efficiency of a family medicine teaching clinic. Fam. Med. 2001, 33, 533–538. [Google Scholar] [PubMed]
- Srinivas, S.; Khasawneh, M.T. Design and analysis of a hybrid appointment system for patient scheduling: An optimisation approach. Int. J. Oper. Res. 2017, 29, 376–399. [Google Scholar] [CrossRef]
- Srinivas, S.; Ravindran, A.R. Designing schedule configuration of a hybrid appointment system for a two-stage outpatient clinic with multiple servers. Heal. Care Manag. Sci. 2020, 1–27. [Google Scholar] [CrossRef]
- Srinivas, S.; Ravindran, A. Systematic review of opportunities to improve Outpatient appointment systems. In Proceedings of the 67th Annual Conference and Expo of the Institute of Industrial Engineers 2017, Pittsburgh, PA, USA, 20–23 May 2017; pp. 1697–1702. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Features | Variable Type | Source |
|---|---|---|
| Patient-related | ||
| ● Age (in years) | Continuous | Raw |
| ● Gender | Categorical (Male, Female) | Raw |
| ● Marital Status | Categorical (Single, Married, Divorced, Separated, Widowed) | Raw |
| ● Race | Categorical (African American, Asian, Caucasian, Other) | Raw |
| ● Visit Count | Continuous | Derived |
| ● Insurance Group | Categorical (Medicare, Medicaid, Private, Uninsured) | Raw |
| ● Patient Types | Categorical (New, Return) | Raw |
| ● Commuting Distance (in miles) | Continuous | Derived |
| ● Neighborhood SES | Continuous | Derived |
| Appointment-related | ||
| ● Month of the Year | Categorical (Jan, Feb, …, Dec) | Raw |
| ● Day of the Week | Categorical (Mon, Tue, …, Fri) | Raw |
| ● Appointment Time | Categorical (Morning, Afternoon) | Raw |
| ● Procedure Duration | Categorical (Brief, Intermediate, Extended) | Raw |
| ● Before National Holiday | Categorical (Yes, No) | Derived |
| ● After National Holiday | Categorical (Yes, No) | Derived |
| ● Lateness History | Continuous | Derived |
| Clinic-related | ||
| ● Resource Type | Categorical (MD, Nurse,….) | Raw |
| ● Visit Type | Categorical (ENT, Audiology,…) | Raw |
| Environment-related | ||
| ● Temperature (in oF) | Continuous | Derived |
| ● Visibility (in miles) | Continuous | Derived |
| ● Weather Condition | Categorical (fog, light rain, normal, thunderstorms, snow) | Derived |
| Predictors | ENT Clinic | WH Clinic | ||
|---|---|---|---|---|
| On-time Arrival (n = 36,191) | Late Arrival (n = 10,230) | On-time Arrival (n = 59,965) | Late Arrival (n = 19,329) | |
| Gender | ||||
| ● Female | 45.93% | 46.87% | 100% | 100% |
| ● Male | 54.07% | 53.13% | - | - |
| Marital Status | ||||
| ● Divorced | 4.42% | 4.89% | 5.53% | 5.14% |
| ● Married | 21.63% | 30.71% | 60.39% | 55.35% |
| ● Separated | 0.72% | 0.81% | 1.68% | 2.06% |
| ● Single | 70.14% | 59.42% | 30.79% | 36.38% |
| ● Widowed | 3.09% | 4.17% | 1.61% | 1.07% |
| Race | ||||
| ● African American | 6.06% | 8.98% | 4.87% | 8.29% |
| ● Asian | 2.06% | 2.15% | 1.85% | 2.46% |
| ● Caucasian | 80.04% | 73.48% | 83.49% | 75.86% |
| ● Other | 11.84% | 15.39% | 9.79% | 13.39% |
| Insurance Group | ||||
| ● Medicaid | 31.13% | 38.91% | 25.31% | 18.91% |
| ● Medicare | 22.68% | 14.62% | 4.75% | 7.3% |
| ● Private | 44.54% | 44.05% | 68.08% | 72.51% |
| ● Uninsured | 1.65% | 2.42% | 1.86% | 1.28% |
| Holiday Event | ||||
| ● Before National Holiday | 1.66% | 1.86% | 1.81% | 1.66% |
| ● After National Holiday | 3.94% | 3.52% | 4.52% | 4.41% |
| Patient Type | ||||
| ● New | 27.74% | 28.54% | 19.07% | 19.16% |
| ● Return | 72.26% | 71.46% | 80.93% | 80.84% |
| Procedure Duration | ||||
| ● Brief | 35.29% | 32.58% | 35.29% | 32.58% |
| ● Extended | 9.69% | 11.26% | 9.69% | 11.26% |
| ● Intermediate | 55.02% | 56.16% | 55.02% | 56.16% |
| Appointment Day of Week | ||||
| ● Monday | 20.44% | 19.06% | 20.46% | 19.32% |
| ● Tuesday | 18.57% | 17.14% | 23.87% | 24.26% |
| ● Wednesday | 22.652% | 23.47% | 16.15% | 16.22% |
| ● Thursday | 21.67% | 22.23% | 21.14% | 21.12% |
| ● Friday | 16.67% | 18.1% | 18.38% | 19.08% |
| Appointment Time | ||||
| ● Afternoon | 46.38% | 40% | 42.57% | 38.47% |
| ● Morning | 53.62% | 60% | 57.43% | 61.53% |
| Weather Conditions | ||||
| ● Fog | 3.84% | 3.77% | 3.97% | 3.93% |
| ● Light Rain and Drizzle | 5.8% | 6.11% | 6.15% | 6.49% |
| ● Normal | 87.79% | 87.49% | 87.27% | 86.92% |
| ● Rain and Thunderstorms | 1.33% | 1.44% | 1.33% | 1.3% |
| ● Snow | 1.24% | 1.19% | 1.28% | 1.36% |
| Continuous Variables | ||||
| Age | 35.24 ± 28.89 | 28.04 ± 26.88 | 34.16 ± 11.62 | 36.73 ± 13.73 |
| Lateness History | 0.07 ± 0.16 | 0.73 ± 0.3 | 0.61 ± 0.3 | 0.11 ± 0.18 |
| Neighborhood SES | 0.115 ± 0.35 | 0.1018 ± 0.36 | 0.1 ± 0.37 | 0.11 ± 0.35 |
| Distance | 29.42 ± 38 | 28.81 ± 36.49 | 19.9 ± 50.84 | 20.63 ± 44.54 |
| Temperature | 57.04 ± 19.7 | 58.06 ± 19.74 | 58.09 ± 19.69 | 57.6 ± 19.56 |
| Visibility (MPH) | 8.82 ± 2.54 | 8.86 ± 2.5 | 8.82 ± 2.52 | 8.81 ± 2.53 |
| ML Algorithm | ENT Clinic | WH Clinic |
|---|---|---|
| Logistic Regression | 0.828 | 0.781 |
| Random Forests | 0.868 | 0.849 |
| Gradient Boosting Machines | 0.904 | 0.863 |
| Artificial Neural Network | 0.861 | 0.837 |
| ML Algorithm | Computational Time (in seconds) | |
|---|---|---|
| ENT Clinic | WH Clinic | |
| Logistic Regression | 8.55 | 13.70 |
| Random Forests | 1447.49 | 4392.15 |
| Gradient Boosting Machines | 1001.32 | 3082.68 |
| Artificial Neural Network | 1101.53 | 3260.67 |
| Variable (Reference) | Odds Ratio | Odds Ratio 95% CI | p-Value |
|---|---|---|---|
| Visit | 1.08 | (1.07, 1.09) | < 0.0001 |
| Lateness History | 19.24 | (15.48, 23.9) | < 0.0001 |
| Visibility | 0.97 | (0.95, 0.99) | 0.0139 |
| Marital Status (Married) | |||
| ● Divorced | 0.78 | (0.61, 0.98) | 0.0342 |
| ● Single | 0.86 | (0.72, 1.02) | 0.0460 |
| After National Holiday | 0.78 | (0.6, 1.01) | 0.0484 |
| Resource Type (MD) | |||
| ● Audiologist Assistant | 2.75 | (1.89, 4.01) | 0.0000 |
| ● Audiologist | 2.28 | (1.52, 3.43) | 0.0001 |
| ● Other | 2.41 | (1.76, 3.3) | 0.0000 |
| ● Physician Assistant | 1.17 | (0.99, 1.39) | 0.0480 |
| ● Speech Pathologist | 1.80 | (1.32, 2.46) | 0.0002 |
| Visit Type (Pediatric Surgery) | |||
| ● Audiology | 0.65 | (0.47, 0.9) | 0.0093 |
| ● ENT | 0.76 | (0.61, 0.95) | 0.0171 |
| Procedure Duration (Brief) | |||
| ● Extended | 0.57 | (0.44, 0.73) | 0.0000 |
| ● Intermediate | 0.80 | (0.69, 0.93) | 0.0037 |
| Appointment Time (Morning) | |||
| ● Afternoon | 0.62 | (0.56, 0.68) | < 0.0001 |
| Appointment Weekday (Monday) | |||
| ● Thursday | 0.84 | (0.72, 0.98) | 0.0225 |
| Weather Conditions (Normal) | |||
| ● Thunderstorm | 1.43 | (0.96, 2.12) | 0.0358 |
| ● Snow | 1.59 | (1, 2.53) | 0.0483 |
| Variable (Reference) | Odds Ratio | Odds Ratio 95% CI | p-Value |
|---|---|---|---|
| Visit | 1.04 | (1.03, 1.05) | < 0.0001 |
| Lateness History | 4.81 | (4.21, 5.49) | < 0.0001 |
| Age | 0.99 | (0.98, 1.00) | 0.0002 |
| Marital Status (Married) | |||
| ● Single | 0.93 | (0.86, 0.99) | 0.0283 |
| Resource Type (MD) | |||
| ● Nurse | 1.96 | (1.21, 3.18) | 0.0060 |
| Visit Type (Gynecology) | |||
| ● Obstetrics | 1.28 | (1.18, 1.4) | < 0.0001 |
| ● Gynecologic Surgery | 1.32 | (1.17, 1.48) | < 0.0001 |
| ● Urogynecology | 1.88 | (0.90, 3.92) | 0.0412 |
| ● Maternal-fetal Medicine | 1.37 | (1.19, 1.59) | < 0.0001 |
| ● Endocrinology | 1.25 | (1.08, 1.44) | 0.0023 |
| ● Radiology | 1.61 | (1.42, 1.81) | < 0.0001 |
| Patient Type (New) | |||
| ● Return | 1.41 | (1.25, 1.60) | < 0.0001 |
| Appointment Duration (Brief) | |||
| ● Intermediate | 1.18 | (1.08, 1.29) | 0.0002 |
| Appointment Time (Morning) | |||
| ● Afternoon | 0.8 | (0.75, 0.85) | < 0.0001 |
| Weather Conditions (Normal) | |||
| ● Thunderstorm | 1.16 | (1.02, 1.31) | 0.0235 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Srinivas, S. A Machine Learning-Based Approach for Predicting Patient Punctuality in Ambulatory Care Centers. Int. J. Environ. Res. Public Health 2020, 17, 3703. https://doi.org/10.3390/ijerph17103703
Srinivas S. A Machine Learning-Based Approach for Predicting Patient Punctuality in Ambulatory Care Centers. International Journal of Environmental Research and Public Health. 2020; 17(10):3703. https://doi.org/10.3390/ijerph17103703
Chicago/Turabian StyleSrinivas, Sharan. 2020. "A Machine Learning-Based Approach for Predicting Patient Punctuality in Ambulatory Care Centers" International Journal of Environmental Research and Public Health 17, no. 10: 3703. https://doi.org/10.3390/ijerph17103703
APA StyleSrinivas, S. (2020). A Machine Learning-Based Approach for Predicting Patient Punctuality in Ambulatory Care Centers. International Journal of Environmental Research and Public Health, 17(10), 3703. https://doi.org/10.3390/ijerph17103703