SEIR Modeling of the Italian Epidemic of SARS-CoV-2 Using Computational Swarm Intelligence




Abstract
1. Introduction
2. Materials and Methods
2.1. Database
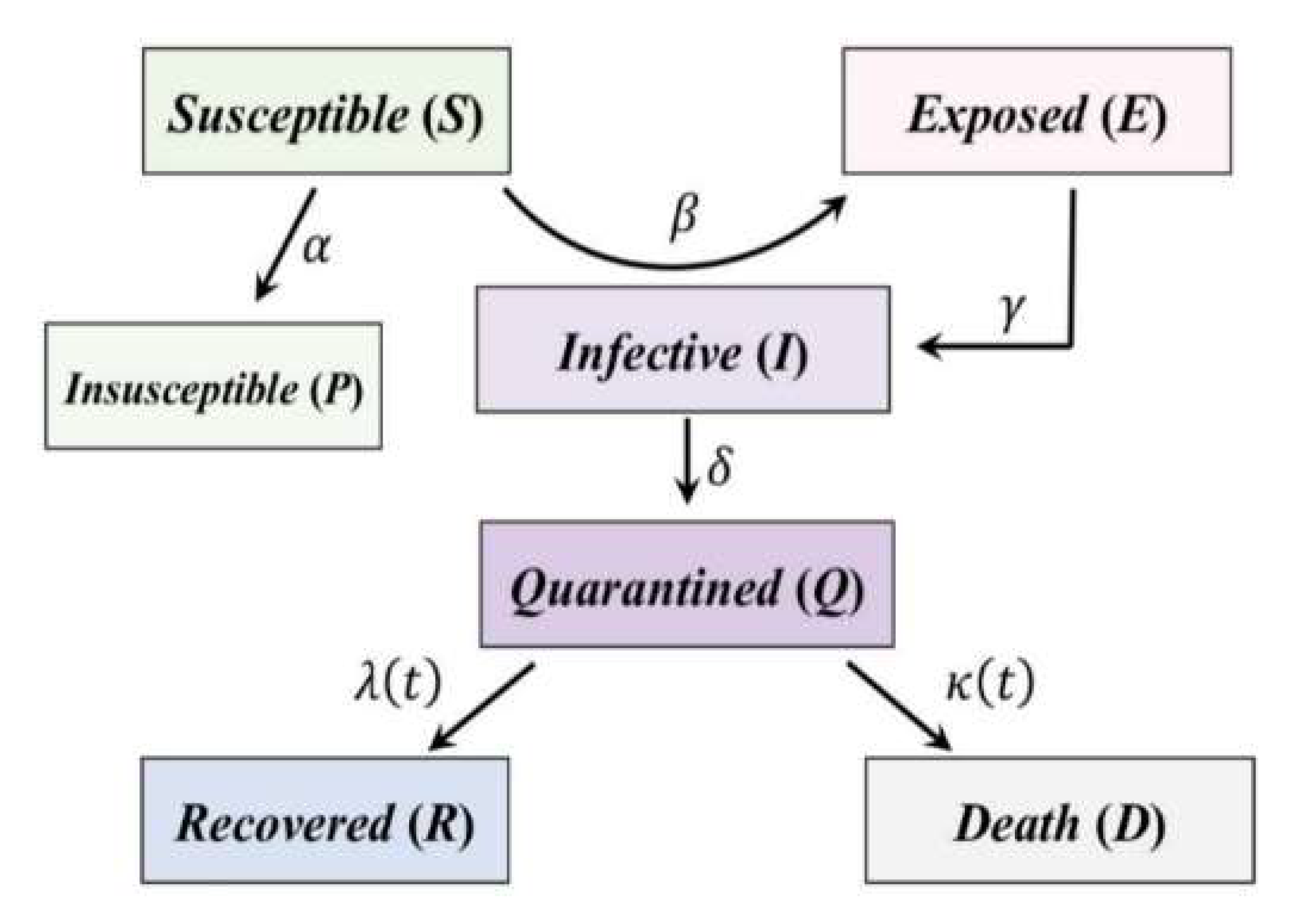
2.2. Overview of the Generalized SEIR Model
- β is called infection rate. It is the number of people that an infective person infects each day. It is equal to , where b, or the contact rate, is the number of people an average person enters into contact with each day, and p is the probability that a contact provokes the transmission of the disease. In the SEIR model, β is the vector which transports people from the S category to the E category. It is multiplied by the ratio S/N to avoid counting contacts between two people who cannot infect each other (e.g., because one of them has already recovered, or because both are infective).
- γ is the inverse of the average latent time and governs the lag between having undergone an infectious contact and showing symptoms: in the equations, it brings people from the E category to the I category.
- λ and κ are the recovery rate and the death rate, respectively, and they are united together in a single parameter in the classical SEIR model. They give information about how fast the people may recover from the disease (1/λ is the average recovery time), and how many of them, unfortunately, die.
- S, target time-histories of the susceptible cases,
- E, the target time-histories of the exposed cases,
- I the target time-histories of the infective cases,
- Q, the target time-histories of the quarantined cases,
- R, the target time-histories of the recovered cases,
- D, the target time-histories of the death cases,
- P, the target time-histories of the insusceptible cases.
2.3. Implementation of the SEIR Model with a Stochastic Approach
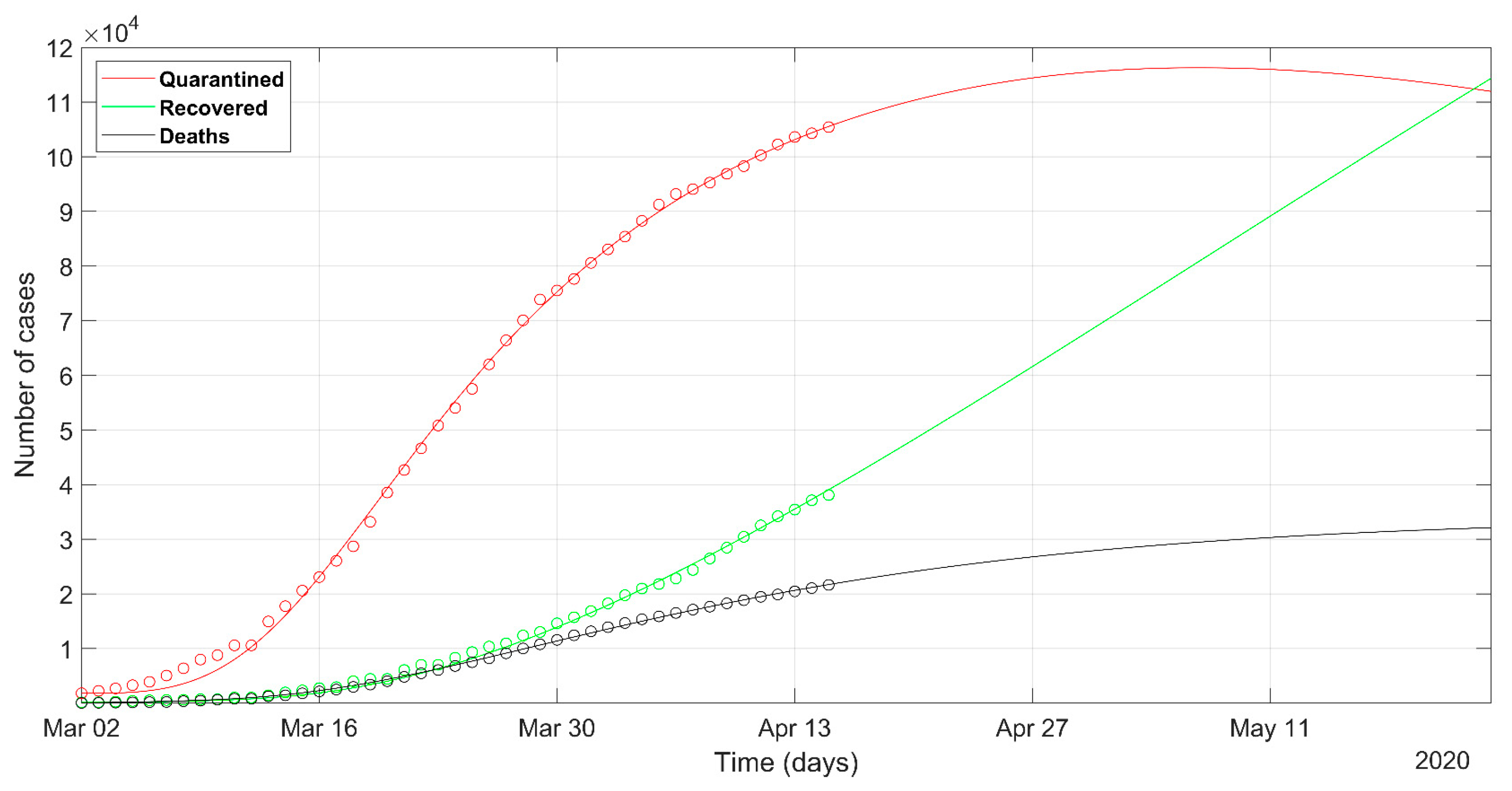
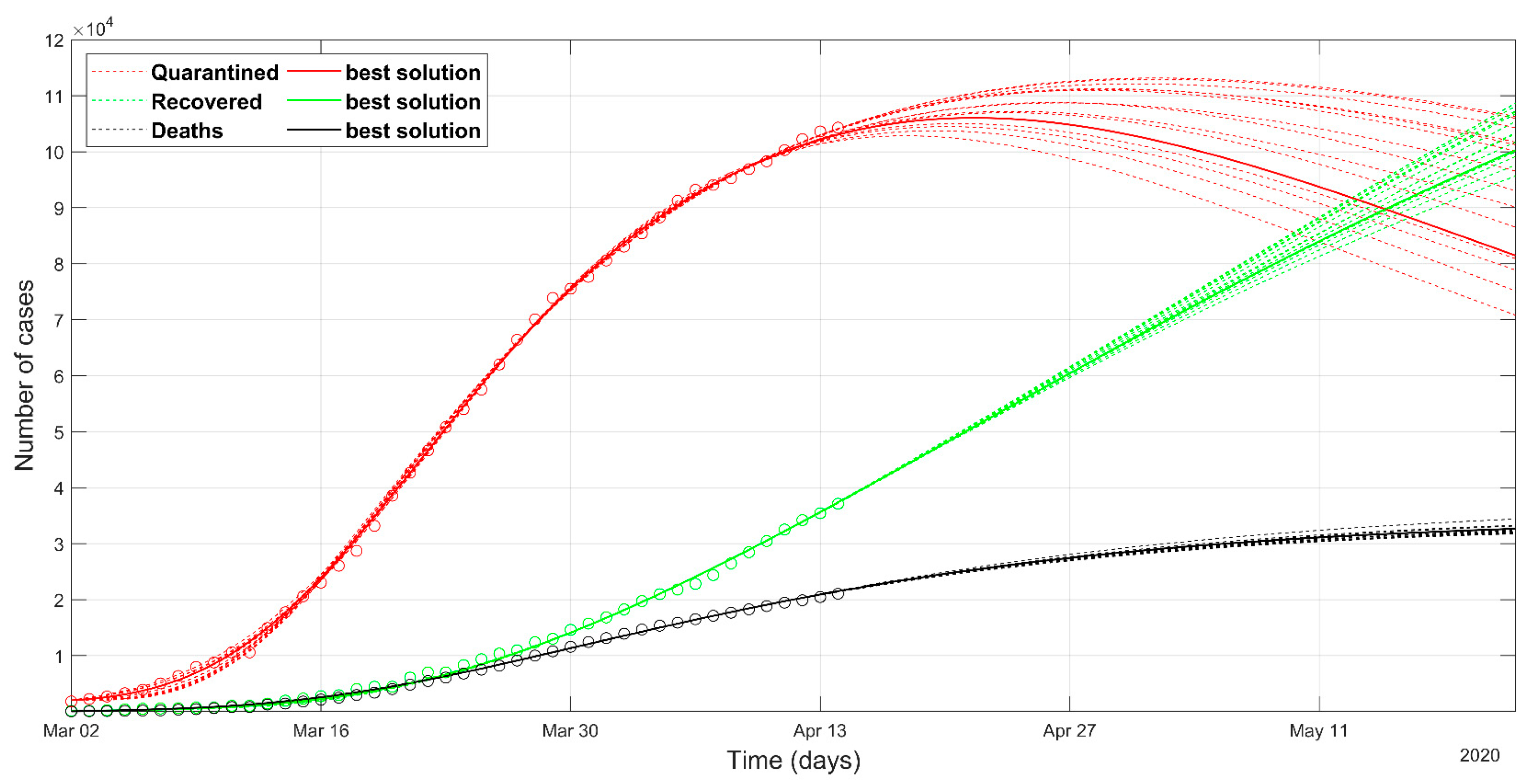
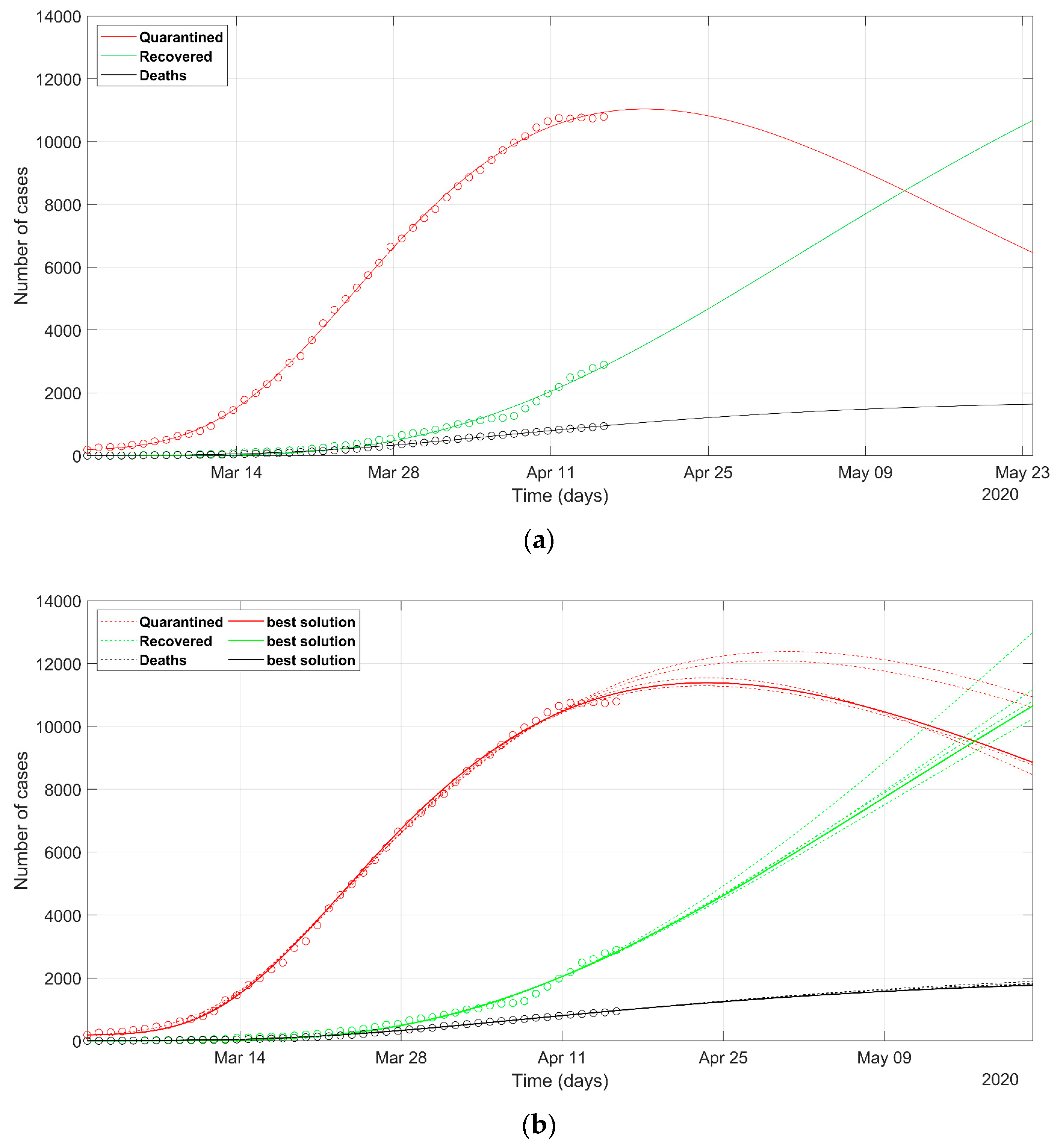
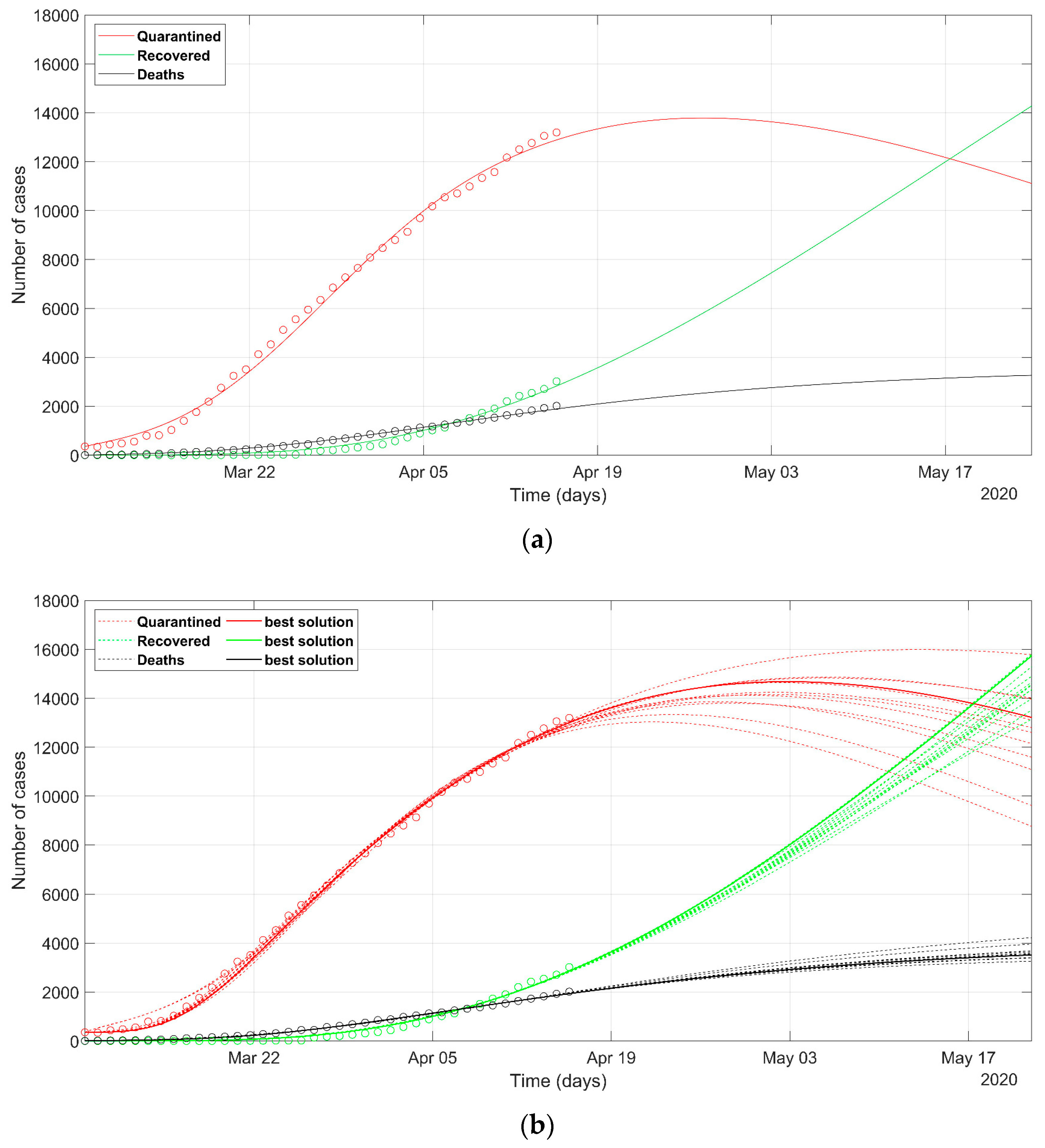
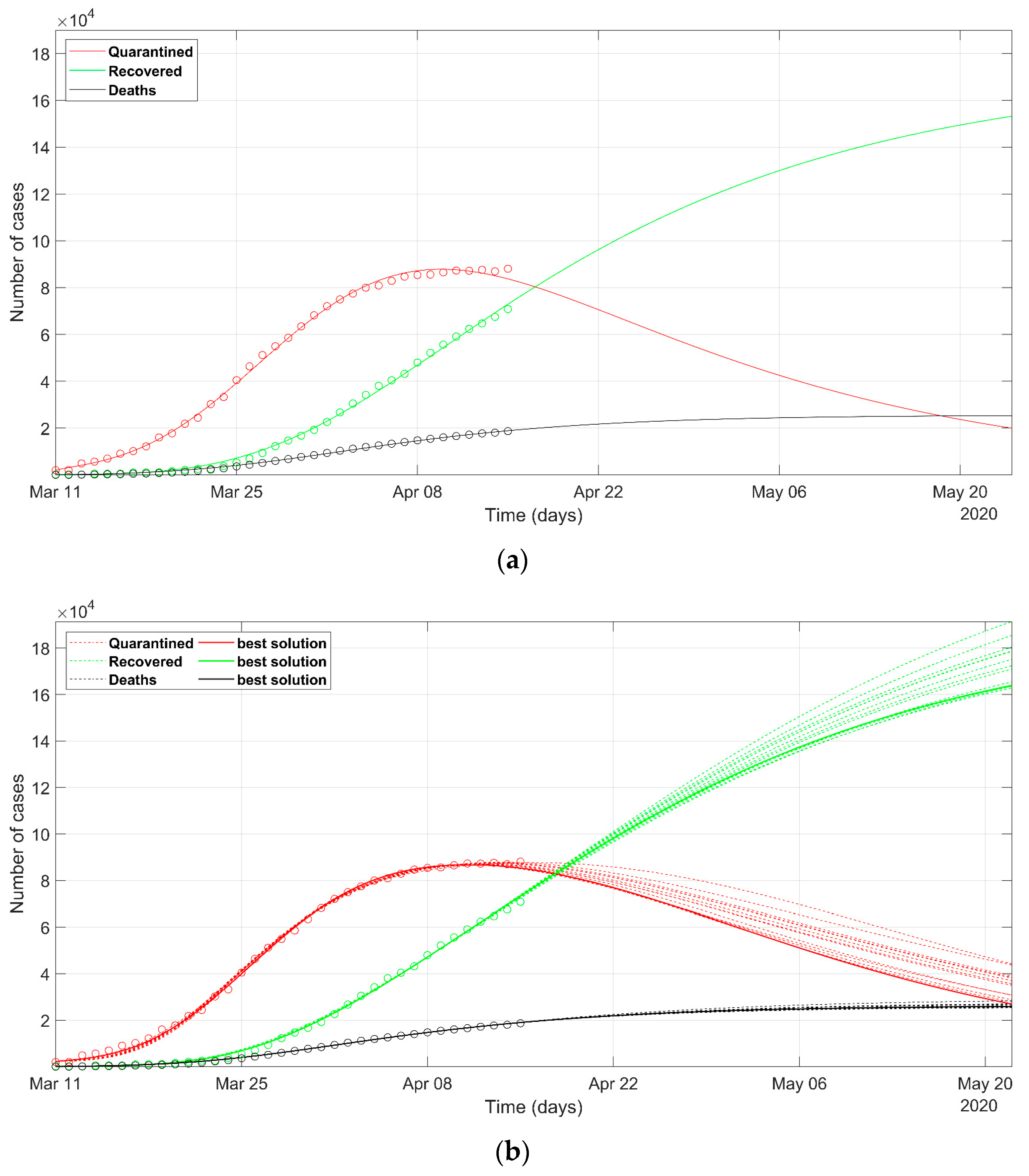
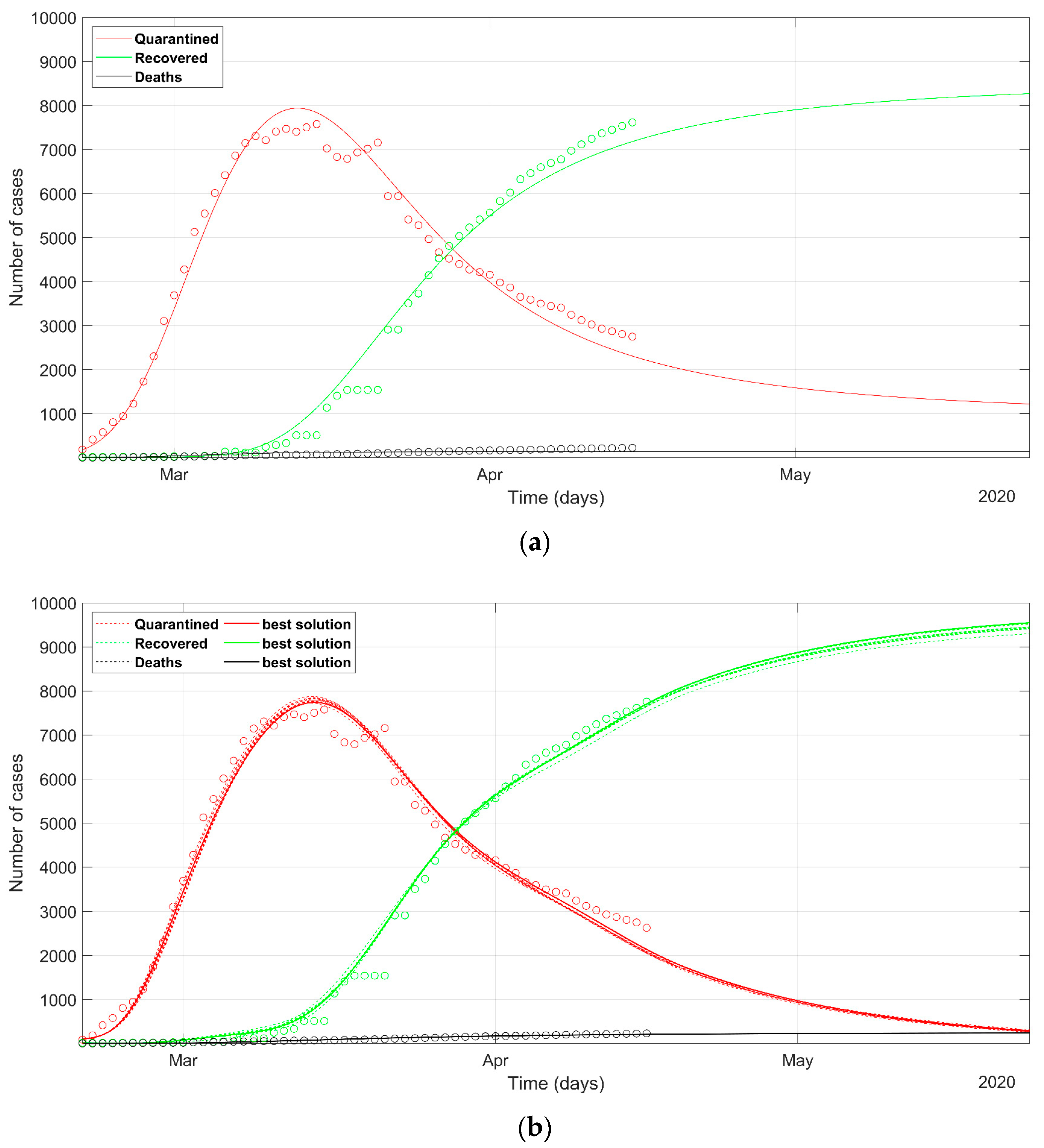
3. Results
4. Discussion
- as we already stated, the problem is underdetermined, so it is preferable to have an acceptable range of values than a unique point value, that could result in being uncertain, as could happen considering only a deterministic approach solution;
- the set of possible predicted scenarios, although related to different solutions with different sets of parameters, are quite similar, thus offering an acceptable level of variability of future predictions.
- We have currently not sufficient information to say that, after recovery, an individual becomes totally immune to the disease, but we made this assumption: the model did not allow the passage from the recovered category to the susceptible category.
- The model does not consider the testing differences between different health system structures and country policies.
- While Italian and Spanish data are well fitted, the South Korean data fitting presents some issues. This evidences that different policies between countries can induce different trends in the spread of the epidemic and that the models should be adapted to different situations, with the introduction or removal of parameters. This would be especially valid in analyzing the situation of the least developed countries, that are not able to afford strict lockdown policies like the developed countries.
- Except for the death rate parameter, the model does not have a strong link to the health resiliency of citizens. The death rate parameter could also be related to external factors like air pollution, which makes people more sensitive to respiratory diseases [19].
- The introduction of Google’s COVID-19 Community Mobility Report represents a constraint that was easily implemented in the model. Further studies on the quality of those data and a rigorous implementation could represent a novel and interesting research topic.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Parham, P.E.; Michael, E. Outbreak properties of epidemic models: The roles of temporal forcing and stochasticity on pathogen invasion dynamics. J. Theor. Biol. 2011, 271, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Guan, X.; Wu, P.; Wang, X.; Zhou, L.; Tong, Y.; Ren, R.; Leung, K.S.M.; Lau, E.H.Y.; Wong, J.Y.; et al. Early Transmission Dynamics in Wuhan, China, of Novel Coronavirus–Infected Pneumonia. N. Engl. J. Med. 2020, 382, 1199–1207. [Google Scholar] [CrossRef] [PubMed]
- Peng, L.; Yang, W.; Zhang, D.; Zhuge, C.; Hong, L. Epidemic analysis of COVID-19 in China by dynamical modeling. MedRxiv Epidemiol. 2020. [Google Scholar] [CrossRef]
- Bacaër, N. A Short History of Mathematical Population Dynamics; Springer: London, UK, 2011. [Google Scholar]
- Calafiore, G.C.; Novara, C.; Possieri, C. A Modified SIR Model for the COVID-19 Contagion in Italy. arXiv 2020, arXiv:physics/2003.14391. Available online: https://arxiv.org/abs/2003.14391 (accessed on 16 May 2020).
- COVID-19 Community Mobility Report. Available online: https://www.google.com/covid19/mobility (accessed on 29 April 2020).
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; IEEE: Piscataway, NJ, USA, 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Shi, P.; Cao, S.; Feng, P. SEIR Transmission dynamics model of 2019 nCoV coronavirus with considering the weak infectious ability and changes in latency duration. MedRxiv Infect. Dis. (Except HIV/AIDS) 2020. [Google Scholar] [CrossRef]
- Cheynet, E. Generalized SEIR Epidemic Model (Fitting and Computation). Available online: https://it.mathworks.com/matlabcentral/fileexchange/74545-generalized-seir-epidemic-model-fitting-and-computation (accessed on 29 April 2020).
- WHO 2019 Novel Coronavirus: Overview of the State of the Art and Outline of Key Knowledge Gaps/Slides. Available online: https://www.who.int/who-documents-detail/2019-novel-coronavirus-overview-of-the-state-of-the-art-and-outline-of-key-knowledge-gaps-slides (accessed on 29 April 2020).
- Dandekar, R.; Barbastathis, G. Neural Network aided quarantine control model estimation of global Covid-19 spread. arXiv 2020, arXiv:physics/2004.02752. Available online: https://arxiv.org/abs/2004.02752 (accessed on 16 May 2020).
- Shaikh, A.S.; Shaikh, I.N.; Nisar, K.S. A Mathematical Model of COVID-19 Using Fractional Derivative: Outbreak in India with Dynamics of Transmission and Control. Preprints 2020. [Google Scholar] [CrossRef]
- Lin, Q.; Zhao, S.; Gao, D.; Lou, Y.; Yang, S.; Musa, S.S.; Wang, M.H.; Cai, Y.; Wang, W.; Yang, L.; et al. A conceptual model for the coronavirus disease 2019 (COVID-19) outbreak in Wuhan, China with individual reaction and governmental action. Int. J. Infect. Dis. 2020, 93, 211–216. [Google Scholar] [CrossRef] [PubMed]
- Iwata, K.; Miyakoshi, C. A Simulation on Potential Secondary Spread of Novel Coronavirus in an Exported Country Using a Stochastic Epidemic SEIR Model. JCM 2020, 9, 944. [Google Scholar] [CrossRef] [PubMed]
- Engelbrecht, A.P. Computational Intelligence; John Wiley & Sons, Ltd.: Chichester, UK, 2007. [Google Scholar]
- Ratnaweera, A.; Halgamuge, S.K.; Watson, H.C. Self-Organizing Hierarchical Particle Swarm Optimizer with Time-Varying Acceleration Coefficients. IEEE Trans. Evol. Comput. 2004, 8, 240–255. [Google Scholar] [CrossRef]
- Pace, F.; Santilano, A.; Godio, A. Particle swarm optimization of 2D magnetotelluric data. Geophysics 2019, 84, E125–E141. [Google Scholar] [CrossRef]
- Pisano, G.P.; Sadun, R.; Zanini, M. Lessons from Italy’s Response to Coronavirus. Available online: https://hbr.org/2020/03/lessons-from-italys-response-to-coronavirus (accessed on 16 May 2020).
- Wu, X.; Nethery, R.C.; Sabath, B.M.; Braun, D.; Dominici, F. Exposure to air pollution and COVID-19 mortality in the United States: A nationwide cross-sectional study. MedRxiv Epidemiol. 2020. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Countries/Regions | Overall Population | Database (Year) |
|---|---|---|
| Italy | 60,359,546 | Istituto Nazionale di Statistica—ISTAT (2019) |
| Lombardy | 10,060,574 | Istituto Nazionale di Statistica—ISTAT (2019) |
| Veneto | 4,905,854 | Istituto Nazionale di Statistica—ISTAT (2019) |
| Piedmont | 4,356,406 | Istituto Nazionale di Statistica—ISTAT (2019) |
| Spain | 47,100,396 | Istituto Nacional de Estadìstìca—INE (2019) |
| South Korea | 51,629,512 | Korean Statistical Information Service—KOSIS (November 2018) |
| Authors | Country/Region | Date | α | β | γ | δ | λ | κ |
|---|---|---|---|---|---|---|---|---|
| Peng et al. (2020) [3] | China without Hubei province | 20 Jan–9 Feb | 0.172 | 1 | 0.5 | 0.15 | 0.005–0.04 | 0.005–0.015 |
| Peng et al. (2020) | Hubei province without Wuhan city | 20 Jan–9 Feb | 0.133 | 1 | 0.5 | 0.139 | 0.005–0.015 | 0.005–0.02 |
| Peng et al. (2020) | Wuhan | 20 Jan–9 Feb | 0.085 | 1 | 0.5 | 0.135 | 0.005–0.015 | 0.005–0.03 |
| Peng et al. (2020) | Beijing | 20 Jan–9 Feb | 0.175 | 0.99 | 0.5 | 0.175 | 0.005–0.04 | 0.002 |
| Peng et al. (2020) | Shanghai | 20 Jan–9 Feb | 0.183 | 1 | 0.5 | 0.179 | 0.005–0.04 | 0 |
| Calafiore et al. (2020) [5] | Italy | 23 Feb–30 Mar | 0.22 | 0.017 | 0.012 | |||
| WHO report [10] | China | 12 Feb | 0.1–0.2 | |||||
| Dandekar et al. (2020) [11] | Wuhan | 1 Mar–1 Apr | 1 | 0.023 | ||||
| Dandekar et al. (2020) | Italy | 1 Mar–1 Apr | 0.74 | 0.032 | ||||
| Dandekar et al. (2020) | South Korea | 1 Mar–1 Apr | 0.68 | 0.004 | ||||
| Dandekar et al. (2020) | US | 1 Mar–1 Apr | 0.69 | 0.008 | ||||
| Shaikh et al. (2020) [12] | India | 14–26 Mar | 0.59 | 0.1 | ||||
| Lin et al. (2020) [13] | Wuhan | 15 Jan–24 Feb | 0.59–1.68 | 0.33 | 0.2 | |||
| Iwata et al. (2020) [14] | General case | 0.1–1 | 0.07–0.5 | 0.1–1 |
| Country | α | β * | γ | δ | λ0 | λ1 | κ0 | κ1 | NRMSE |
|---|---|---|---|---|---|---|---|---|---|
| Italy | 0.021 (0.086, 0.004) 0.012 | 0.510 (1.058, 0.200) 1.170 | 0.265 (0.859, 0.226) 1.065 | 0.103 (0.095, 0.01) 0.020 | 0.017 (0.017, 6.3 × 10−9) 0.017 | 2 (1.696, 0.180) 1.983 | 0.029 (0.030, 2.7 × 10−6) 0.033 | 0.038 (0.040, 3.8 × 10−6) 0.043 | 0.035 0.043 |
| Spain | 0.037 (0.087, 0.002) 0.026 | 1.777 (1.376, 0.082) 2 | 0.946 (0.954, 0.198) 0.154 | 0.238 (0.095, 0.004) 0.614 | 0.044 (0.044, 6.8 × 10−7) 0.043 | 0.156 (0.159, 0.0004) 0.160 | 0.030 (0.030, 1.6 × 10−6) 0.028 | 0.046 (0.047, 3.7 × 10−6) 0.044 | 0.046 0.052 |
| South Korea | 0.292 (0.270 0.0004) 0.1 | 2 (1.915, 0.009) 0.974 | 2 (1.846, 0.046) 1.902 | 0.123 (0.136, 7.8 × 10−5) 0.313 | 0.05 ** | - | 8.3 × 10−4 (8.3 × 10−4, 3.5 × 10−11) 0.007 | 7 × 10−6 (2.1 × 10−6, 2.1 × 10−11) 0.134 | 0.074 0.078 |
| Lombardy | 0 (0.132, 0.012) 8.9 × 10−4 | 0.460 (1.658, 0.188) 0.81 | 0.295 (1.093, 0.531) 0.302 | 0.145 (0.198, 0.065) 0.253 | 0.027 (0.026, 3 × 10−8) 0.027 | 0.981 (1.576, 0.247) 1.925 | 0.036 (0.036, 6.9 × 10−6) 0.045 | 0.031 (0.031, 6.9 × 10−6) 0.0405 | 0.062 0.061 |
| Veneto | 0.133 (0.102, 0.002) 0.049 | 1.704 (1.175, 0.190) 0.97 | 0.920 (0.698, 0.144) 0.246 | 0.032 (0.034, 0.0004) 0.09 | 0.049 (0.182, 0.093) 0.099 | 0.009 (0.008, 0.000) 0.004 | 0.008 (0.008, 6.4 × 10−8) 0.009 | 0.0215 (0.021, 1.3 × 10−6) 0.024 | 0.035 0.040 |
| Piedmont | 0.240 (0.163, 0.009) 0 | 1.990 (1.518, 0.232) 0.994 | 0.265 (1.191, 0.374) 0.195 | 0.012 (0.117, 0.052) 0.344 | 0.386 (0.309, 0.104) 0.069 | 0.001 (0.005, 2.5 × 10−5) 0.007 | 0.019 (0.018, 3.7 × 10−6) 0.019 | 0.034 (0.031, 1.9 × 10−5) 0.035 | 0.056 0.050 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Godio, A.; Pace, F.; Vergnano, A. SEIR Modeling of the Italian Epidemic of SARS-CoV-2 Using Computational Swarm Intelligence. Int. J. Environ. Res. Public Health 2020, 17, 3535. https://doi.org/10.3390/ijerph17103535
Godio A, Pace F, Vergnano A. SEIR Modeling of the Italian Epidemic of SARS-CoV-2 Using Computational Swarm Intelligence. International Journal of Environmental Research and Public Health. 2020; 17(10):3535. https://doi.org/10.3390/ijerph17103535
Chicago/Turabian StyleGodio, Alberto, Francesca Pace, and Andrea Vergnano. 2020. "SEIR Modeling of the Italian Epidemic of SARS-CoV-2 Using Computational Swarm Intelligence" International Journal of Environmental Research and Public Health 17, no. 10: 3535. https://doi.org/10.3390/ijerph17103535
APA StyleGodio, A., Pace, F., & Vergnano, A. (2020). SEIR Modeling of the Italian Epidemic of SARS-CoV-2 Using Computational Swarm Intelligence. International Journal of Environmental Research and Public Health, 17(10), 3535. https://doi.org/10.3390/ijerph17103535