2.1. Quantile Modeling for Count Data
The application of quantile modeling has been widely used in epidemiological studies for continuous response. However, when dealing with count data, a primary challenge is that the quantiles of a discrete random variable are not continuous due to the discrete nature of their cumulative distribution functions. Therefore, they cannot be expressed directly as a continuous function of the covariates of interest. A way to overcome this challenge is to smooth the outcome artificially by adding a noise, usually assumed to be uniformly distributed. The general idea of the approach is to replace the count response with a jittered variable so that the conditional quantiles of the transformed variable after noise added are still preserved as in the quantiles of the original outcome [
14]. The jittering methods have been adopted in many econometric (see examples [
15,
16]) and spatial health applications [
10]. Although the approach can solve the problem of a non-continuous response distribution, the mean and variance for small values of the response in the transformed variable will be largely affected by the added noise which can result in inaccurate estimation of the conditional quantiles [
17]. Therefore, we propose an alternative to model space-time count data based on the log Laplace (LL) distribution.
According to the paper originally done by Koenker and Bassett [
1], the distribution of the error term does not need to be specified as it is allowed to take arbitrary form except the constraint that its
-quantile equals zero. Typically, the quantile prediction is estimated by optimizing the weighted absolute loss function. However, it is challenging to find an optimal solution for a complex model such as with space-time structured random effects and non-linear functions [
18]. Hence flexible Bayesian approaches have been widely implemented and a common model of Bayesian quantile regression is applying an AL distribution to the error term. The method aims to find posterior maximums that are equivalent to the estimates yielded from the quantile loss function using the asymmetrically quantile loss function in linear quantile modeling [
11]. However, the support of AL variable is on the real line which might not be appropriate for count data. Thus for analyzing space-time count data, we then apply a log Laplace distribution for modeling the areal data instead. The development of the proposed method is provided in the next section.
2.2. Quantile Modeling for Spatiotemporal Relative Risk
2.2.1. Log-Laplace Distribution
Log-Laplace models have seen to appear sporadically in the statistical, economical and scientific literature in past years (see examples in [
19,
20,
21]). A log-Laplace density can be represented as a combination of the Pareto and power function distributions [
22]. With an additional parameter, the resulting three-parameter log-Laplace distribution, LL(
) of relative risk,
, is given by the probability density function:
where
. Then, we can re-parameterize Equation (1) as and let
and
. Hence, the probability density function of LL(
) can be re-written (please see details in
Supplementary Material S1) as:
where
is the variance,
is the mean of relative risk at the
th quantile level. However, we can see that minimizing of the quantile loss function (
Supplementary Material S2) is identically equivalent to maximizing of the re-parameterized log-Laplace distribution in Equation (2) above. Hence we propose to use the log-Laplace distribution to directly model the
th quantile of relative risk for areal count data.
Then we redefine the notation as being the number of cases observed in area i and time t. To model the conditional quantiles, the relative risk whose cumulative distribution function is continuous can be modeled instead of the count itself using the log Laplace density. A generic structure of the spatiotemporal model for areal health data can be specified via a Poisson likelihood as by assuming where the quantile level is usually pre-defined to have a common value across spatial and temporal units as . is the expected rate, is the mean relative risk, and is the th—quantile relative risk for area i and time t. Note that the expected rates can be seen as the offset in Poisson models. To estimate the rates, a standard practice is to adopt the concept of indirect standardization (same as in epidemiology) which is the most common form of adjustment for population in each location in which the disease outcomes are compared.
2.2.2. Spatiotemporal Relative Risk Quantile Modeling
To model the th quantile relative risk, the predictor is decomposed as a linear combination of covariates and space-time random effects as where is a design matrix of area-level predictors; is a vector of regression coefficients for the specified quantile; and are the conditional quantile spatial and temporal random effects of area i and time period t, respectively; and denotes a corresponding conditional quantile space-time interaction. To estimate the quantile parameters, a fully Bayesian framework is adopted in which for all parameters in the model a prior distribution needs to be specified.
We structure the model by borrowing information across neighboring regions and time periods to incorporate spatiotemporal smoothing. The convolution model is modeled to the quantile-specific spatial random effect as
where
and
are employed to capture spatially correlated and unstructured extra variation in the model. It is often important to include both structured and unstructured random effects in a spatial analysis since without prior knowledge unobserved confounding can take various forms. The uncorrelated random effect is described by a zero mean Gaussian prior distribution with variance
. The spatially correlated effect is assumed to have the intrinsic conditional autoregressive model (ICAR) model proposed by Besag et al. [
23]. That is, conditionally,
where
is the vector containing the correlated effect of all regions except the
ith area.
,
and
are a set of spatial neighbors, cardinality and the mean of the neighborhood of the
ith tract respectively, and
is the spatial component variance. Notably there are a number of models can be specified for these spatial random effects, including simultaneous autoregressive (SAR) or geostatistical models. Among those models, CAR priors are perhaps the most common practice in areal data mapping. A number of globally smooth CAR priors have been proposed, and a review and comparison can be found in [
24].
To capture the temporal trend a random walk model is adopted. In general, a random walk is assumed to have a prior distribution as a Gaussian distribution with mean the previous time point which can be both positive and negative. Then the temporal trend can be expressed as which allows for a type of non-parametric temporal trend effect. The space-time interaction random effect, , is specified by a Gaussian distribution with zero mean and variance . All variances in Gaussian prior distributions are described by a relatively non-informative Uniform distribution as , where .
Hence incorporating this stochastic representation of quantile error term and random effects, our proposed model becomes:
Note that the detail of quantile error,
, approximation using log-Laplace distribution in Equation (3) is provided in
Supplementary Material S3.
An aim of this study is not only to theoretically develop a generic and robust methodology for spatiotemporally varying quantile-specific estimation for areal health data, it is also of practical importance to consider a computationally feasible and robust methodology to implement in user-friendly environment. The proposed framework provides accessibility to a wide range of practitioners especially in public health applications as the model specification can be conveniently implemented in standard software such as R or BUGS. Thus not only our method has theoretical foundation but also offers practical flexibility to non-technical users. Then a simulation study with ground-truth scenarios was carried out to demonstrate the performance of the approach.
2.3. Simulation Study
A traditional way to estimate the th quantiles of spatiotemporal count data is using the posterior distribution produced from mean regression. By the mean regression here we imply to the model that the th quantiles are estimates from the posterior quantiles in the converged samplers from fitting the conventional model without assuming a density for the error quantiles. A simulation study was conducted to assess how the mean and proposed quantile models could robustly estimate quantiles of spatiotemporal count data. For an unbiased evaluation, a non-standard form of the simulated error distribution was assumed to neither be Gaussian nor Laplace distributions because assuming the error to have a Laplace distribution could lead to overly optimistic estimation and assuming a Normal density would imply the conventional regression.
The map used in this simulation study was the state of South Carolina (SC), USA, which has 46 counties and the time periods were assumed to be yearly over a 5-year period. The expected counts were calculated from real data, the total number of emergency room discharges (ERD) for respiratory conditions, both infectious and non-infectious diseases, in SC in 2009 and assumed to be constant over the time periods. Note that we would like the simulation study to reflect some features from a real situation in which the expected rates are obtained, and calculation details of the expected rate will be provided later in the case study. Let the observed incidence for county
i and year
t be a Poisson random variable as
. The relative risk is set to link with the logarithm function as
. The errors were generated from a
t-distribution with zero center and variance
with the degree of freedom as
in Equation (4), i.e.,
. The pseudocode is provided in the
Supplementary Material S4 for details of the simulated data. The expected number (please see more calculation details in the case study) can be seen as the offset in Poisson models. To estimate the rates, a standard practice is to adopt the concept of indirect standardization (same as in epidemiology) which is the most common form of adjustment for population in each location in which the disease outcomes are compared. The number of expected rate in each location can generally be calculated as the average disease rate for the whole study region multiplied by the population at risk at each location. For further information about calculation of standardized rate, please refer more to, for example, [
25,
26].
Without covariates, the linear predictor linked to random effects was specified as . With the intercept assumed to be zero, the spatial components, and respectively, were specified to have an ICAR and zero-mean Gaussian models with variances of 1 and 0.2 respectively. The temporal random effect, , was modeled using the random walk prior with variance of 0.2 and generated from a Normal distribution with zero mean at t = 1. The interaction term, , was generated by a zero-mean Gaussian prior with variance of 0.2. It should be noted that the random effects and error terms were simulated on the log scale. Thus, although the variances used in simulation seem to be small (on log scale), the middle 80% of the generated relative risks is on the range of 0.12 and 9.07. Although the simulated risks seem to be extreme, there was evidence of high relative risk in some areas from the real data used later in case study section. For example, the relative risk in Greenwood county (please see in the case study Section) had reached the level of 8 during a peak period. Hence the parameter setting was chosen so that the extreme behavior was captured in the simulation study.
An aim of the simulation study is to evaluate whether the proposed model can well predict the true quantiles as the fitting under a log-Laplace distribution is not assumed. Since we assume a symmetric zero-mean distribution for the errors, the error median is zero and hence the simulated log relative risk is determined entirely by the linear predictor, , at median, i.e., . For other quantile levels, the simulated is driven by both the random effect and error terms. Therefore, the true model was generated from non-Laplace likelihood.
To compare the performance of the proposed quantile and mean models, fifty simulated data sets were generated and the regression models were fitted at the quantile levels of 0.9, 0.5, and 0.1. For each scenario, the estimated quantiles from log-Laplace and mean models were compared with the true simulated values. The estimated quantiles from the mean model were obtained at the
th level out of the converged posterior samplers with the same prior specification as the quantile model while the estimated quantiles from the proposed quantile model were calculated under the log-Laplace model as
since
. The simulation was conducted using WinBUGS software. Each model was run for 50,000 MCMC iterations with a burn-in period of 50,000 samplers and the results were from 100 simulations. To assess the mixing of posterior samplers, we adopted Gelman’s
statistics proposed in [
27,
28] for multiple chain convergence. Various MCMC methods are implemented in WinBUGS and defaults algorithms are used depending on the hierarchical structure in each part of the model such as direct sampling using standard algorithms and slice samplings [
29]. A WinBUGS code for quantile estimation is provided in
Supplementary Material S5.
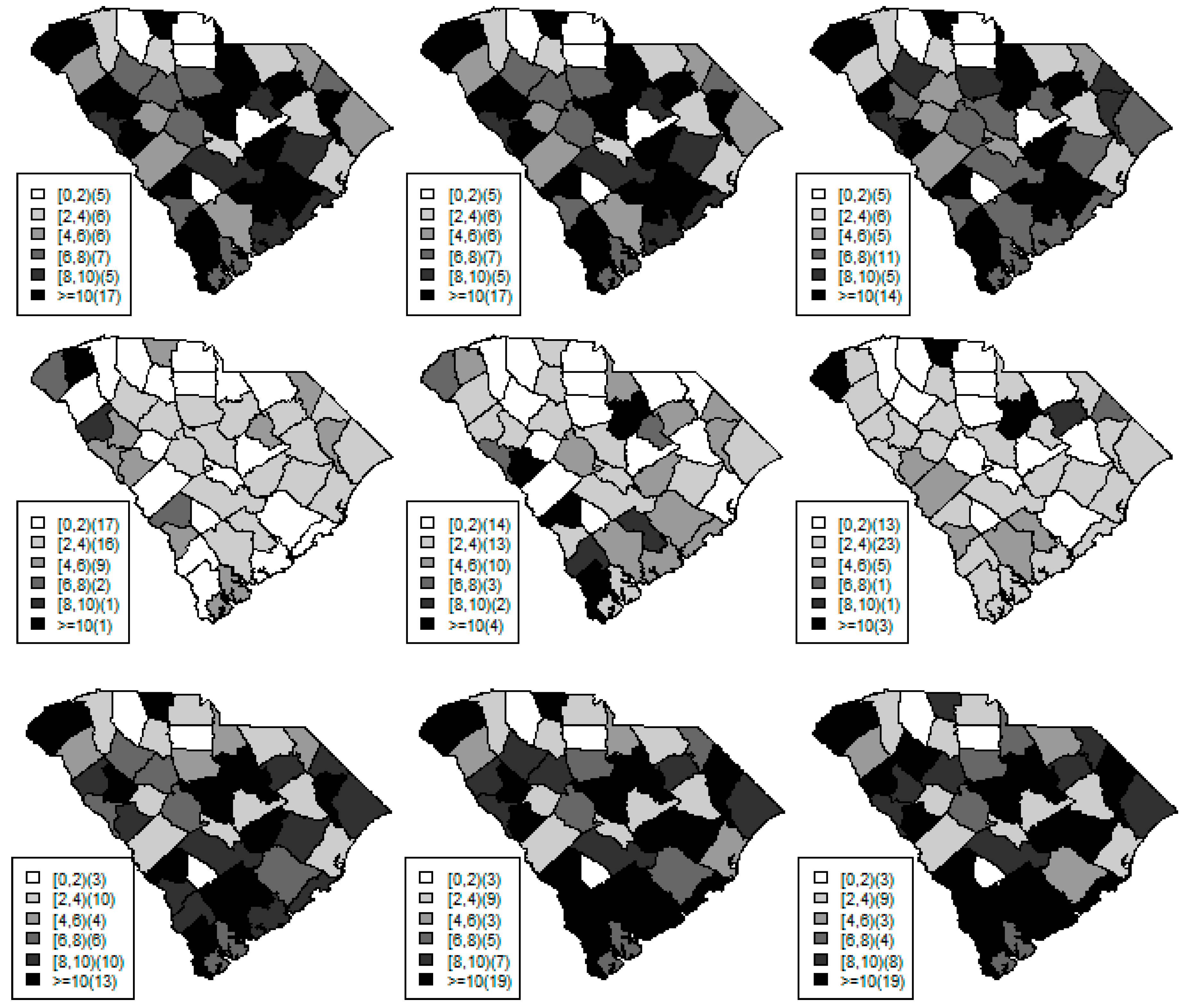
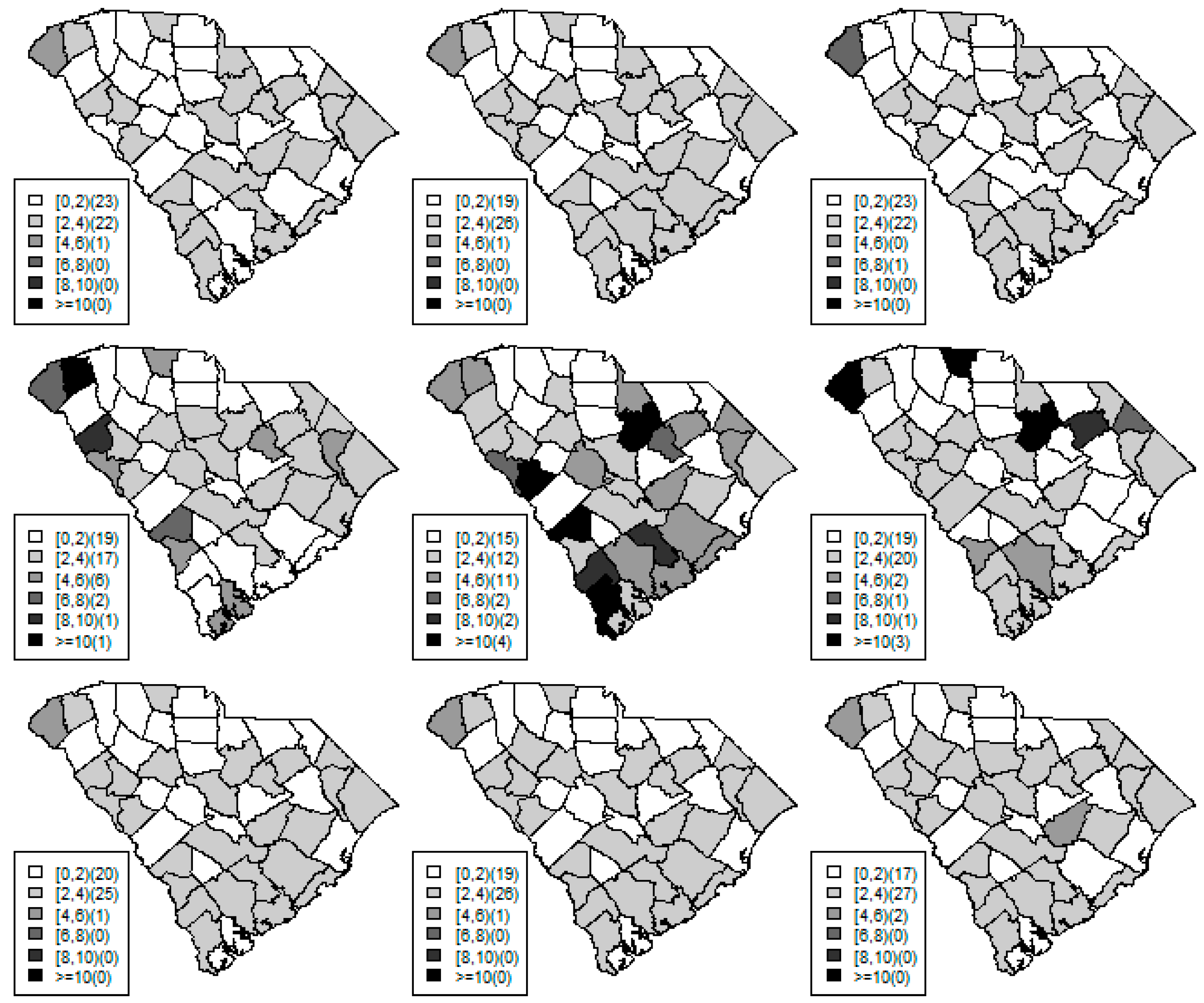
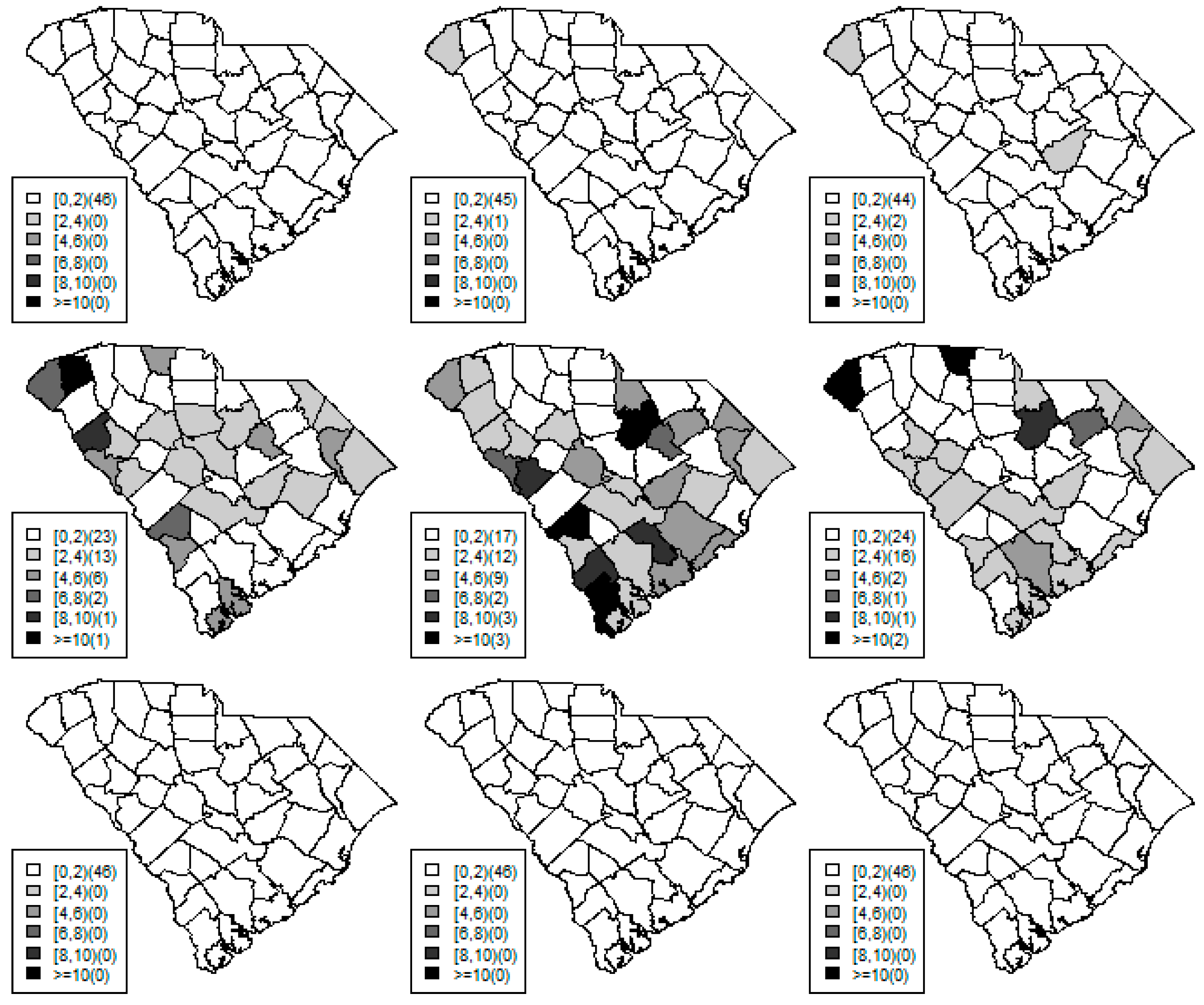
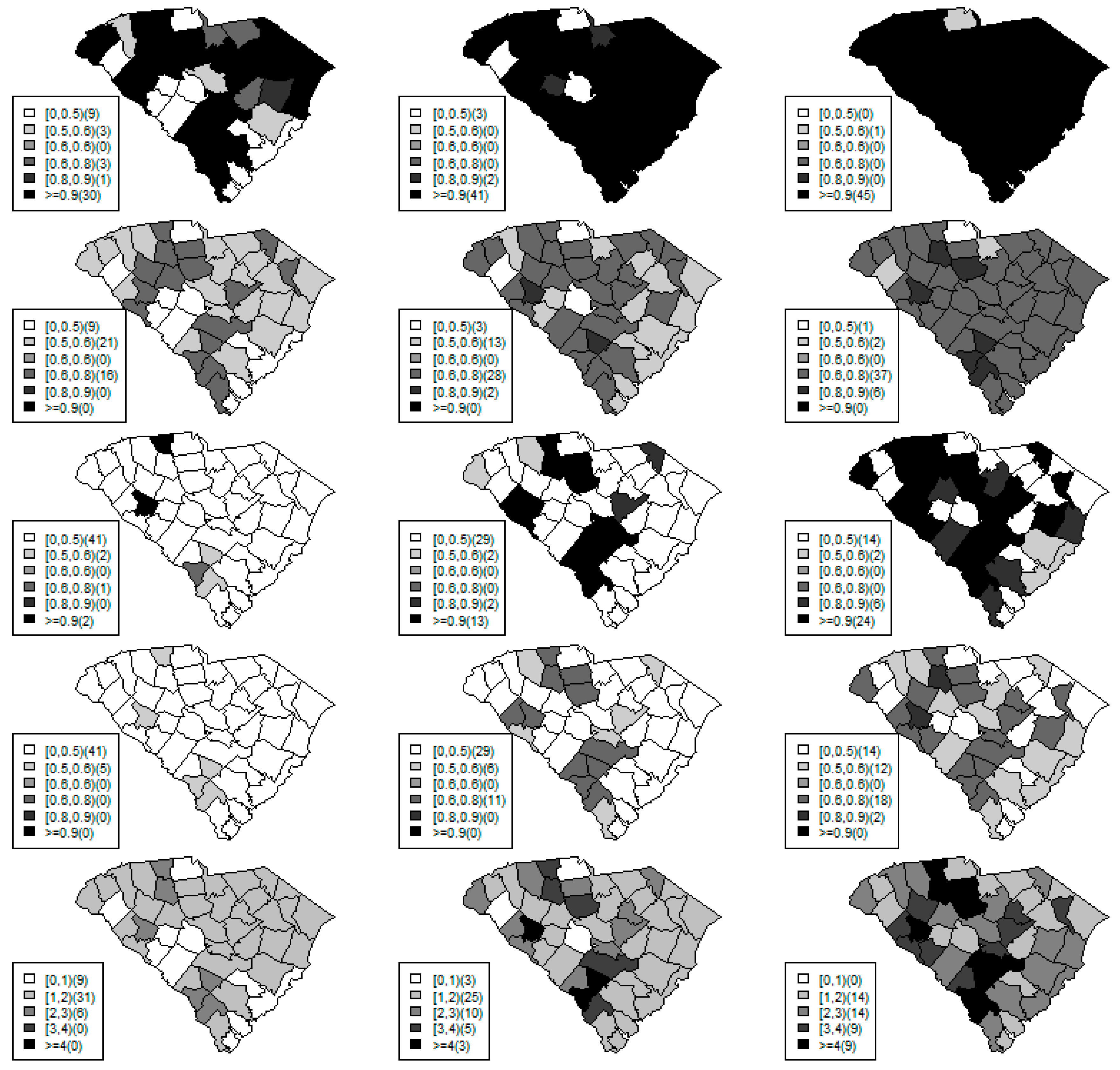
Figure 1,
Figure 2 and
Figure 3 display the true and estimated relative risk quantiles averaged over simulated data sets at 90th, 50th, and 10th respectively for each county during years 2–4. The upper and middle rows show the estimated quantiles from the proposed quantile and conventional mean regression models whereas the bottom row displays the true relative risks for each area and time period.
The estimated and true space-time relative risks are similar at the quantile levels under log Laplace regression while mean regression appears to underestimate the true 90th quantiles and overestimate the 10th quantiles. Importantly, from
Figure 2, our proposed model seems to produce space-time quantile estimates more similar to the simulated than the ones from the mean regression model even at the 50th quantile level. This suggests that our proposed model can reliably estimate extreme quantiles and perhaps even more robustly predict medians than the mean regression across the space-time units although the error density was not assumed by the fitted model.
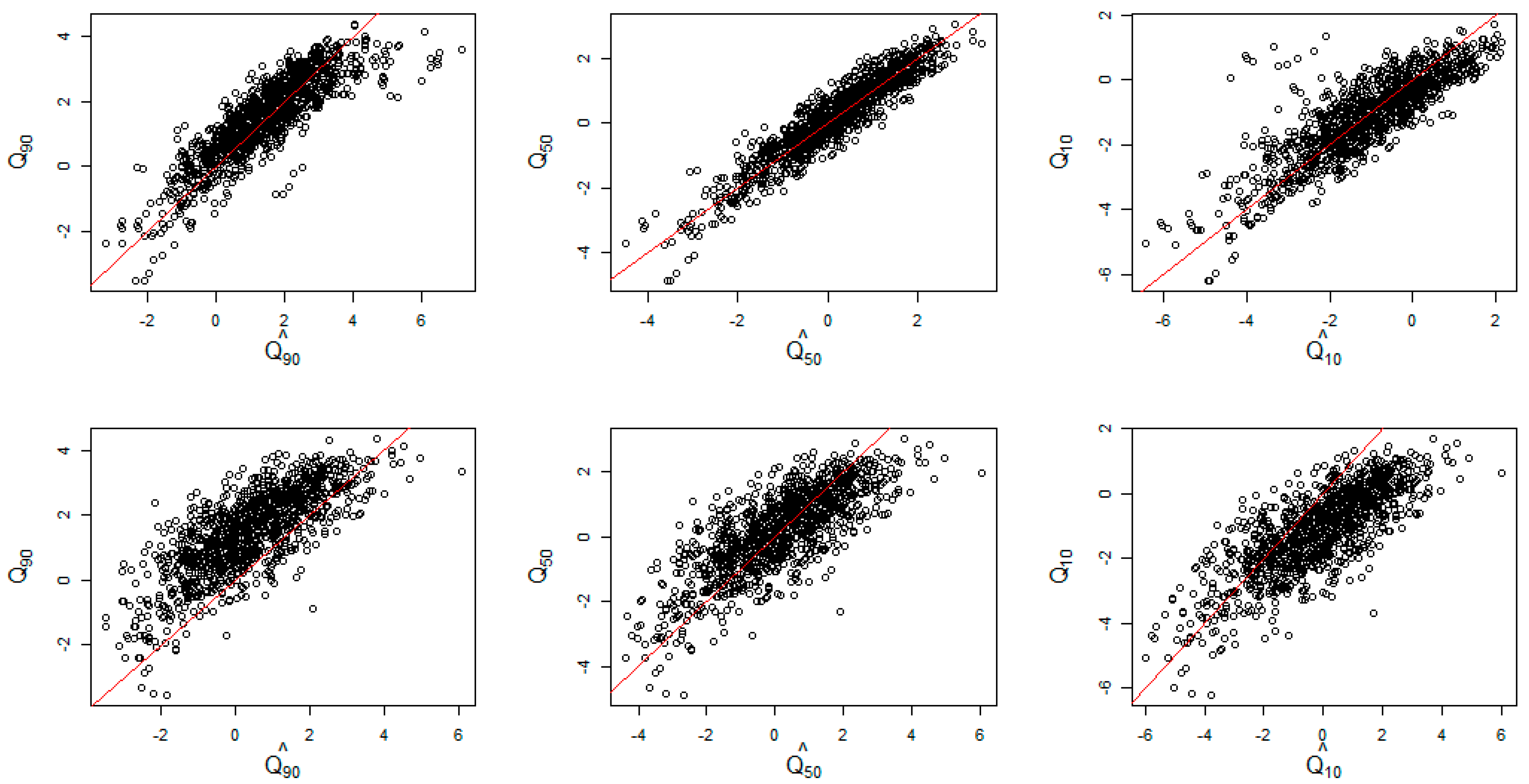
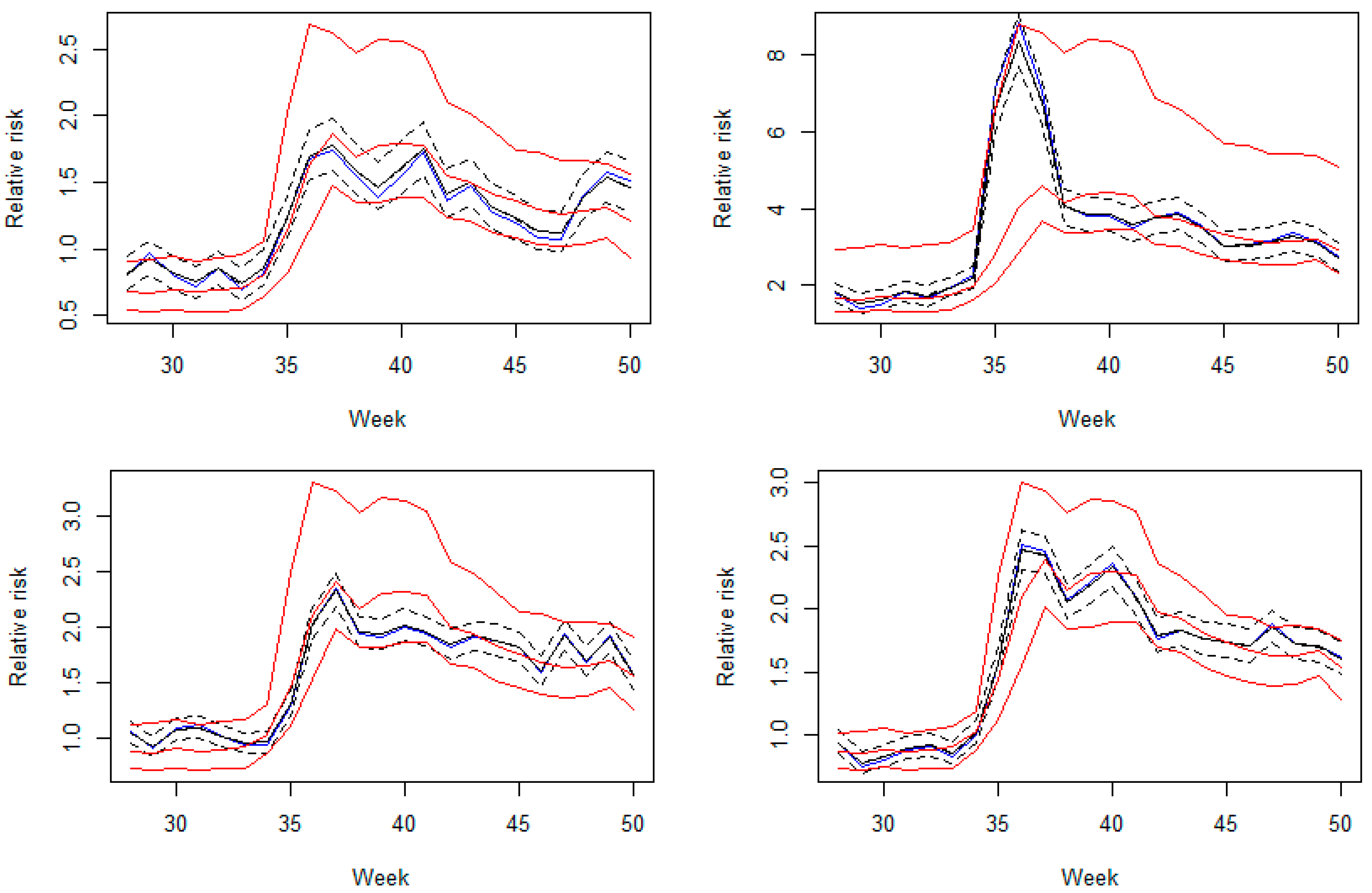
Figure 4 displays the scatterplots of simulated and estimated from quantile (upper) versus mean (lower) regression models at 10th (left), 50th (middle), and 90th (right) quantiles. The red line represents the equality of the predicted and true quantiles. Both the log Laplace and mean regression appear to provide the most accurate estimates of spatiotemporal quantiles at
. To evaluate the models quantitatively, the mean squared error (MSE) were compared as shown in
Table 1. The MSE at the 50th quantile level under the proposed regression was almost six times less than that under the mean model.
The difference of the log-Laplace and mean models were further apparent at more extreme quantile levels. At
0.9 and 0.1, the MSEs from our proposed model were much smaller than the ones from mean regression. Also as seen from
Figure 4, the predicted values from the log-Laplace regression (upper row) were closer to the red line with smaller variation than the mean regression (lower row) at both
0.9 and 0.1. This supports the earlier result that the mean model tends to overestimate at the low quantile levels and underestimate the true values at the high quantile levels. From these findings it appears show that the more accurate quantile estimates for spatiotemporal areal data can be achieved by our proposed modeling strategy opposed to the conventional mean model, even though the error distributional assumptions fail or even at the central quantile.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}