1. Introduction
Hazardous gas emissions and leaks pose important threats to air quality and public health. For instance, the methyl isocyanate leak accident in Bhopal (1984) caused thousands of deaths [
1]. Meanwhile, the airborne contaminants released from industrial areas also have an adverse impact on the lives of nearby residents. Consequently, gas emissions and accidental leaks have been attracting increasing attention in recent years. Considering the aforementioned issues about hazardous gases, predicting their atmospheric dispersion is of great value. Based on the predicted concentration distribution, managers are able to not only evaluate the harm of hazardous gas to human health, but also develop evacuation plans more responsibly.
The atmospheric dispersion (ADS) model is widely applied to predict the transportation and dispersion of gas in air. There have been many effective models for predicting gas dispersion. Conventional ADS models can be roughly categorized in three main types: the Gaussian model [
2,
3], the Lagrangian stochastic (LS) model [
4,
5], and the computational fluid dynamics (CFD) model [
6,
7]. The Gaussian model is the most widely used model in atmospheric dispersion prediction. Requiring only a few input parameters, this model uses a simple expression with fast computing. However, built on the ideal dispersion environment, the Gaussian model takes few terrain conditions into consideration. Therefore, this model is not accurate enough in some complex environment conditions (e.g., urban areas with complex topography). The LS model uses a stochastic method, and describes the gas transport as a Markov process with a number of particles. In contrast, the CFD model is based on sophisticated fluid dynamics equations [
7]. Compared with Gaussian models, these two models are usually more accurate but less efficient for atmospheric dispersion prediction. Their higher computational costs limit their applications in emergency response to gas leak accidents. Therefore, there is a need for an atmospheric dispersion model with both high accuracy and acceptable efficiency.
To address this problem, many researchers have introduced machine learning (ML) models into atmospheric dispersion prediction, such as the artificial neural network (ANN) [
8,
9,
10,
11,
12] and support vector regression (SVR) [
13,
14,
15,
16]. ML models usually have an excellent capacity for predicting the complex relationship between the input and output [
17,
18]. Trained by some pre-determined dispersion scenarios, these models tend to obtain relatively high prediction accuracy for these scenarios. Moreover, the computation of trained ANN or SVR prediction models is relatively fast. Among various types of ANN, the back propagation (BP) network is most widely used to predict atmospheric dispersion. Compared with other ANNs like the radial basis function (RBF) network, the BP network has fewer hyperparameters to determine [
19]. Therefore, the BP network is relatively easy to build and train. Boznar et al. [
8] developed a neural network-based method to predict the
pollution around a thermal power plant in Slovenia, and acquired promising results. Pelliccioni [
9] developed an integrated model for air pollution dispersion prediction. This model filtered the concentration produced by the Gaussian dispersion model with a neural network, and consequently improved the prediction accuracy of the virtual height dispersion model (VHDM) and the skewed puff model (SPM). As for the SVR, it is derived from the support vector machine (SVM) [
13] and inherits the beneficial properties of the SVM, such as good performance for small-scale data. Yeganeh et al. [
14] used the combination of SVR as a predictor and partial least squares (PLS) as a data selection tool to predict daily
concentrations. The results demonstrated that the hybrid PLS-SVR model is quicker and more accurate than the SVR model.
However, most of ML models in the aforementioned research are directly constructed on the inputs of some original monitoring parameters. With these inputs, the ML models usually yield acceptable prediction results. However, this selection of input parameters possibly increases the difficulty in model training and consequently reduces the prediction accuracy, because the relationship between the original monitoring parameters and the output (concentration) is usually quite complex. Therefore, although these ML models were tested successfully in the research mentioned above, they can be further improved by the more effective input selection. In addition, existing research usually focuses on one particular ML model, instead of comparing different ML models in gas dispersion prediction and giving some guidance on model selection. In fact, different ML models vary greatly in terms of performance, for example in fitting and generalization ability. Moreover, trained by pre-determined scenarios and tested by particular cases, the performances of the ML model heavily depend on the training set and test set. Therefore, the influence of the sizes of training set and test set on the prediction performance should be analyzed. This analysis also helps to further reveal the difference of ML models on the fitting and generalization abilities.
In this paper, two machine learning models (i.e., the BP network and SVR model) are respectively involved and applied in the hazardous gas dispersion prediction. To improve the prediction performance of the ML models with original input parameters, the Gaussian integrated parameters are formed and used as the inputs. To comprehensively compare the performances of proposed models with different input selections, they are firstly tested and evaluated on two field data sets (Project Prairie Grass [
20] and Indianapolis [
21,
22]) with different terrain conditions. Next, by varying the sizes of the training set and test set, these ML models are further evaluated and compared. Based on the results, the fitting and generalization abilities of these two ML models are discussed, which is followed by some guidance for model selection.
The rest of this paper is organized as follows.
Section 2 describes the two field data sets and structures of the BP network and SVR model for prediction, as well as the input selection. The performances of these ML prediction models are tested on two field cases in
Section 3. The discussion is given in
Section 4, followed by the conclusions in
Section 5.
2. Materials and Methods
2.1. Brief Desciption of the Field Data Sets
2.1.1. Project Prairie Grass Data Set
The Prairie Grass data set is a well-known field experimental data set referring to a typical hazardous gas emission case with flat terrain and low stack emission. This tracer experiment was carried out in an open country in O’Neil, NE (USA, 42.493° N and 98.572° W) from July to August, 1956. The sulfur dioxide () tracer was released from a continuous point source at the height of 0.46 m without buoyancy. Concentration data were collected by five semi-circular arcs (50, 100, 200, 400, 800 m downwind of the release) of receptors. All receptors over the 180-degree arcs had the same height of 1.5 m. They were centered on the emission source. The receptor spacing was two degrees on the inner four arcs, and one degree on the outer arc of 800 m. As for the meteorological data, the horizontal mean wind direction and wind speed were collected at two locations (i.e., (a) 25 m west of the release source, and (b) 450 downwind of the source and 30 m west of the centerline of the receptor array) for two periods (i.e., 10 min and 20 min). Other meteorological data (e.g., air temperature) were observed by the meteorological tower and rawinsonde. There are 68 releases containing tracer data (6888 valid samples used in this paper) and meteorological data in the data set.
2.1.2. Indianapolis Data Set
The Indianapolis tracer experiment was conducted in a typical urban area of Indianapolis, Indiana, USA, from 16 September to 11 October 1985. In this experiment, the source was an 83.8 m stack (with diameter 4.72 m) at the Perry K power plant in Indianapolis, which released the tracer. The geographic coordinates of this stack were UTM-N (Universal Transverse Mercator) 4401.59 km (39.8° E latitude) and UTM-E 571.40 km (86.2° E longitude). In contrast to the Prairie Grass field experiment, the Indianapolis experiment was carried out under complex terrain conditions. There were many buildings within one or two kilometers of the source stack. These buildings can influence the tracer dispersion in air significantly, which is a challenge to the accurate concentration prediction. As for the experimental data, more than 100 h of tracer concentration data in 17 days were used here, as well as the meteorological data covering all atmospheric stability classes and most common wind direction and speed ranges. The tracer concentrations were measured by a network including about 160 ground-level sensors on several semi-circular arcs, at distances ranging from 0.25 to 12.0 km from the source stack. Therefore, the range of the monitoring distance was about 12 km. The unit of the tracer data is ppt (volume fraction: one billionth). Data were taken in subsets of 8 or 9 h each day. In total there are 17 such subsets used in our work, representing the data of different days and containing tracer data (23,900 valid samples used in our work) and meteorological data.
2.2. Back Propagation Network
The artificial neural network (ANN) is a most widely applied ML model in dispersion prediction. Because of its excellent fitting ability, the ANN is able to approximate complex nonlinear function. As for the computational efficiency, a trained ANN can compute the predictions rapidly. In this paper, the back propagation (BP) fitting network is built to predict the concentration of interest points. This type of network has been quite popular in the research of dispersion prediction [
8,
9]. The structure of the fitting BP network is shown in
Figure 1. To achieve higher prediction accuracy, two hidden layers are applied here. The inputs of the network are usually parameters associated with atmospheric dispersion. These parameters usually include the meteorological parameters, the parameters related to the points of interest, and the source terms. The details of input selection will be discussed in
Section 2.4. These inputs should be selected carefully for better performance. The selection of input will be discussed in
Section 2.4. As for the activation units, the activation functions of all hidden layers are “tansig” for better convergence speed and solution accuracy [
23]. The “tansig” is a kind of sigmoid function with the expression:
. In contrast, the activation function of the output layer (only one neuron) is “purelin” to output the continuous value of concentration. Further, the neuron numbers of two hidden layers, which are critical parameters for the network, should be adjusted according to the performance of the BP network. With appropriate neuron numbers of hidden layers, the BP network can perform well on both accuracy and the convergence speed. In our work, the BP network is trained by the MATLAB neural network toolbox. The detailed process of the model training and the optimization of the neuron numbers will be introduced in the
Section 3.1.
2.3. Support VectorRegression
Support vector regression (SVR) is an extension of the support vector machine (SVM) developed by Vapnik [
13] to solve the regression problem. The idea of SVR is based on the linear regression function in a high-dimensional feature space, where the input data is mapped via a kernel function. In addition, instead of minimizing the training error, the SVR attempts to minimize the generalization error bound to achieve better generalization. Given a set of training points
where
is an input and
is a target output, the standard form of SVR can be expressed as:
where
is the regularization parameter and
is the error tolerance.
and
are the lower and upper slack variables, respectively. The
and
are the parameters of the linear regression model in the high dimensional feature space. The goal of SVR is to determine the optimized
and
, and get the regression model. The approximate solution function is:
where
is the kernel function and
is the support vector. Here, the radial basis function (RBF), which is widely used in the SVR, is selected as the kernel function. The output of SVR is the concentration of the interest point, and the selection of the input will be introduced in
Section 2.4. To build an optimization SVR model, the tolerance
, regularization parameter
and the spread parameter
in the RBF function should be carefully selected (
Section 3.1). The Library for Support Vector Machines (LIBSVM) [
24] is applied here to build the SVR model.
2.4. Selection of the Input Parameters
The monitoring data in the Prairie Grass and Indianapolis field experiments are used to build the BP network and SVR model for prediction. For example, some common original monitoring parameters of Prairie Grass data set are displayed in the
Table 1. Selecting all the parameters as the inputs of ML models is impractical, because some of these parameters do not contribute greatly to the gas concentration. Using these redundant parameters barely improves the accuracy of prediction, and increases the difficulty of training. Therefore, only
are selected here. These parameters are the main factors affecting gas dispersion and are easy to obtain from the data set. In addition, these selected parameters are the inputs of many typical atmospheric dispersion models, like the Gaussian model. The target height
is not included because it is fixed in the data set. These parameters are also available in Indianapolis data set. Therefore, the aforementioned parameters are used as inputs in the two field cases.
Based on these original input parameters, a ML prediction model can be constructed. It should be noted that there are four different observations of wind direction and wind speed observed (i.e., by two stations for the 10-min and 20-min periods) in the Prairie Grass case, as mentioned in
Section 2.1. These wind field parameters are all used to build the ML model, and to generate four values of downwind distance
and crosswind distance
. Therefore, the input vector of the ML model has 20 elements. With regard to the Indianapolis data set, there are also four observations of wind speed and direction available. Therefore, the ML models constructed on the original monitoring parameters of the Indianapolis field data set also have 20 input parameters.
However, it may be still difficult to train the ML model with these original parameters because the features of the atmospheric dispersion should be extracted from these original parameters before the training process. Therefore, the integrated Gaussian parameters are considered. The Gaussian model is the most widely used atmospheric dispersion model and the results are trustworthy for near-field dispersion cases. The integrated Gaussian parameters, which are from the Gaussian plume model, are expressed as:
where
and
represent the Gaussian parameters in the crosswind and vertical directions, respectively.
is the crosswind distance.
and
describe the heights of the interest point and emission source, respectively.
and
are the standard deviations that determine the Gaussian distributions in the crosswind and vertical directions. The two standard deviations can be calculated by:
where
is the downwind distance.
and
are dispersion coefficients derived from the atmospheric stability class
[
25] according to Vogt’s scheme [
26]. To generate the input vector, the integrated Gaussian parameters are firstly derived from the original parameters, and then combined with
and
. The wind speed
and wind direction
both have four observed values. Consequently, four different
and
are generated accordingly. Therefore, the input vector also includes 20 elements.
3. Application: Prairie Grass and Indianapolis Field Case Study
In this section, the proposed BP network and SVR models for prediction with different types of input selections are all tested on the Prairie Grass and Indianapolis data sets, shown as follows:
BP network with original input parameters;
BP network with integrated Gaussian input parameters;
SVR with original input parameters;
SVR with integrated Gaussian input parameters.
The characteristics of BP network and SVR as well as the influence of different input parameters can be analyzed by evaluating their prediction performances. In addition, the fitting and generalization abilities of the two ML models are further discussed by evaluating their prediction performances on the varying-sized training set and test set.
3.1. Configurations and Results of the Machine Learning Models
According to the structures introduced in
Section 2, the ML models are constructed on the two field data sets, respectively. Firstly, the tracer data and original monitoring parameters are extracted from the data set. Then, the 68 releases in the Prairie Grass data set are randomly divided into 60 releases for training and validation (6239 samples in total) and 8 releases (649 samples) for testing. As for the Indianapolis case, the tracer and meteorological data from 20 September to 11 October (15 days) were used for training and validation (21,276 samples in total) while the data from 17 and 19 September were used for testing (2624 samples). The statistical indicators of the input parameters used in the two field cases are shown in
Appendix A.
3.1.1. BP Network with Original Monitoring Input Parameters
The selected original monitoring parameters and are firstly normalized to (0, 1) and then used to form the input vector. Afterwards, the training process of the BP network is conducted by the MATLAB neural network toolbox. The training algorithm is that of Levenberg–Marquardt, for which the maximum number of epochs is 400 (if early stopping is not triggered). If accuracy on validation set showed no improvement after more than six epochs or the mean squared error (MSE) on the training set is lower than the “goal” we set, the early stopping will be triggered.
To obtain an optimized BP network, the neuron numbers of first and second hidden layers (
and
) are selected by the cross-validation method [
27]. This method is widely used to select the hyper parameters of ML models. According to this method, the training and validation set is randomly divided into five subsets with same size. For each subset, we use it as the validation set and other four subsets as the training set. Therefore, we can get five prediction results on different validation sets. The mean value of the mean squared error (MSE) of these five results is calculated to optimize the
and
[
28]. When constructed on the Prairie Grass data set, the BP network with original monitoring parameters obtains the best MSE with
and
. With regard to the Indianapolis data set, the best parameter combination is
and
.
When tested on the Prairie Grass test set, the prediction results of the optimized BP network are as shown in
Figure 2. The
R2 and the NMSE are applied to evaluate the model performance [
29]. They are 0.6183 and 0.4539 respectively, indicating an acceptable accuracy (
R2 is higher than 0.6 and the NMSE is less than 0.5). The relatively high accuracy can also be reflected by the fact that the most predicted concentrations are close to the experimental concentration in this figure. However, there are still some negative concentrations occurring in the prediction, whose values are far from the experimental concentrations. Therefore, the BP network with original parameters should be further improved.
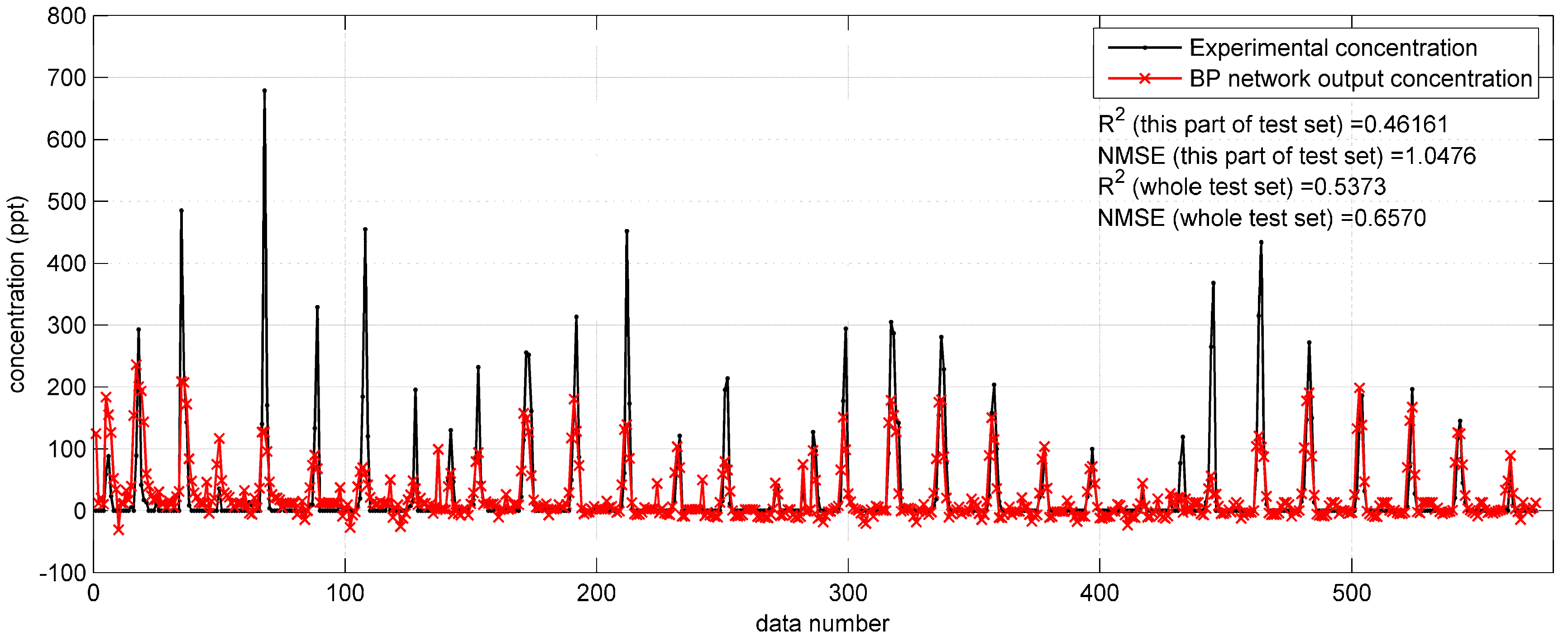
Figure 3 shows the prediction results on a part (only data from 11:00 a.m. to 2:00 p.m., 17 September) of the Indianapolis test set. In this figure, some relatively high concentrations (higher than 200 ppt) are underestimated by the BP network. The
and NMSE values of the results on the shown part of the test set are 0.5411 and 0.9542, respectively. For the whole test set, the two indicators are 0.5195 and 0.7070, respectively. Obviously, the prediction results are less satisfactory than those in the Prairie Grass case. The less satisfactory performance reflects that the BP network with original parameters is less feasible to predict the tracer dispersion in the Indianapolis case.
3.1.2. BP Network with Integrated Gaussian Input Parameters
To build the BP network with integrated Gaussian parameters, the integrated Gaussian parameters are firstly generated from the original monitoring parameters, and then normalized to form the input vector. The optimized combinations of
and
are (58, 8) and (38, 10) for the two field cases, respectively. The details of the training process are the same as the BP network with original parameters, which has been introduced in
Section 3.1.1.
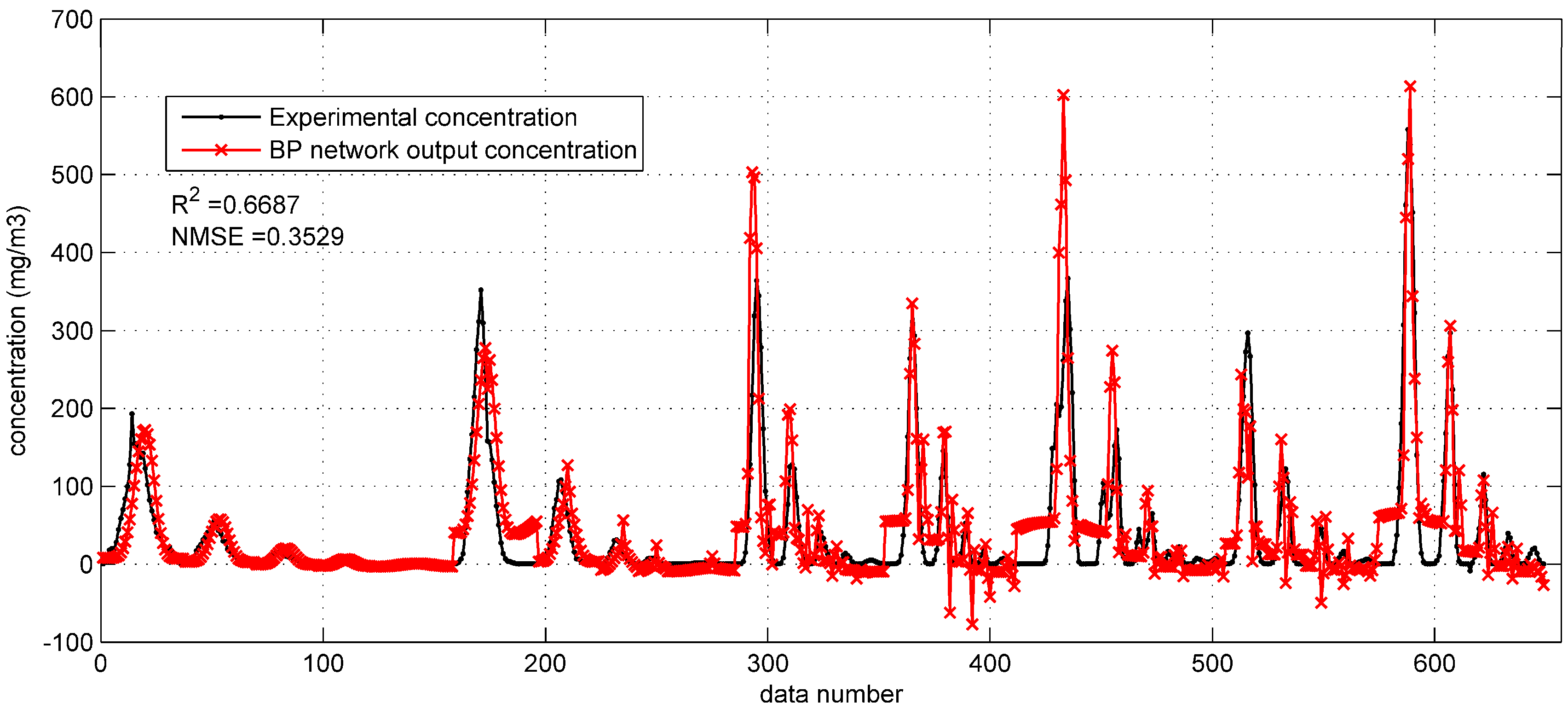
Figure 4 and
Figure 5 show the prediction results of the optimized BP networks on the test set in the two field cases. In
Figure 4, with the higher
(0.6687) and lower NMSE (0.3529), the BP network with Gaussian parameters yields more accurate predictions than that with original parameters. In addition, the fewer negative concentrations in
Figure 4 also indicate the better performance after utilizing the integrated Gaussian parameters. In
Figure 5, the
and NMSE values (the performance indicators) of the whole test set are 0.5373 and 0.6570, respectively, only showing a limited improvement as compared to the
(0.5195) and NMSE (0.7070) of the BP network in
Section 3.1.1.
The improvement brought about by the Gaussian parameters on the Prairie Grass data set implies that the Gaussian parameters decrease the difficulty of model training. This is because the Gaussian dispersion model is relatively accurate under the flat terrain condition, like the open country of the Prairie Grass field experiment. However, with regard to the reproduction the Indianapolis test set, no significant improvement occurred with Gaussian parameters applied. This difference illustrates that the Gaussian dispersion model is less feasible in the environment of the Indianapolis experiment. The complex topography of the Indianapolis case should be responsible for this difference, which will be analyzed in the
Section 3.2.
3.1.3. SVR with Original Monitoring Input Parameters
To build the optimized SVR model, the regression parameter and spread constant are selected by the cross-validation method as well. The SVR model has the smallest MSE when and in the Prairie Grass case, and and in the Indianapolis case, respectively. The construction of the SVR model is conducted by the LIBSVM. The error tolerance is set to 0.1.
Based on the optimized SVR model, the prediction results on the Prairie Grass test set can be obtained as shown in
Figure 6. This figure shows that the SVR with original monitoring parameters gets less satisfactory predictions than the BP network with the same inputs (
Section 3.1.1). More specifically, the SVR model tends to underestimate the concentration, especially when the experimental data is high. Another problem is that the SVR model also produces some negative concentrations. Therefore, with the relatively low
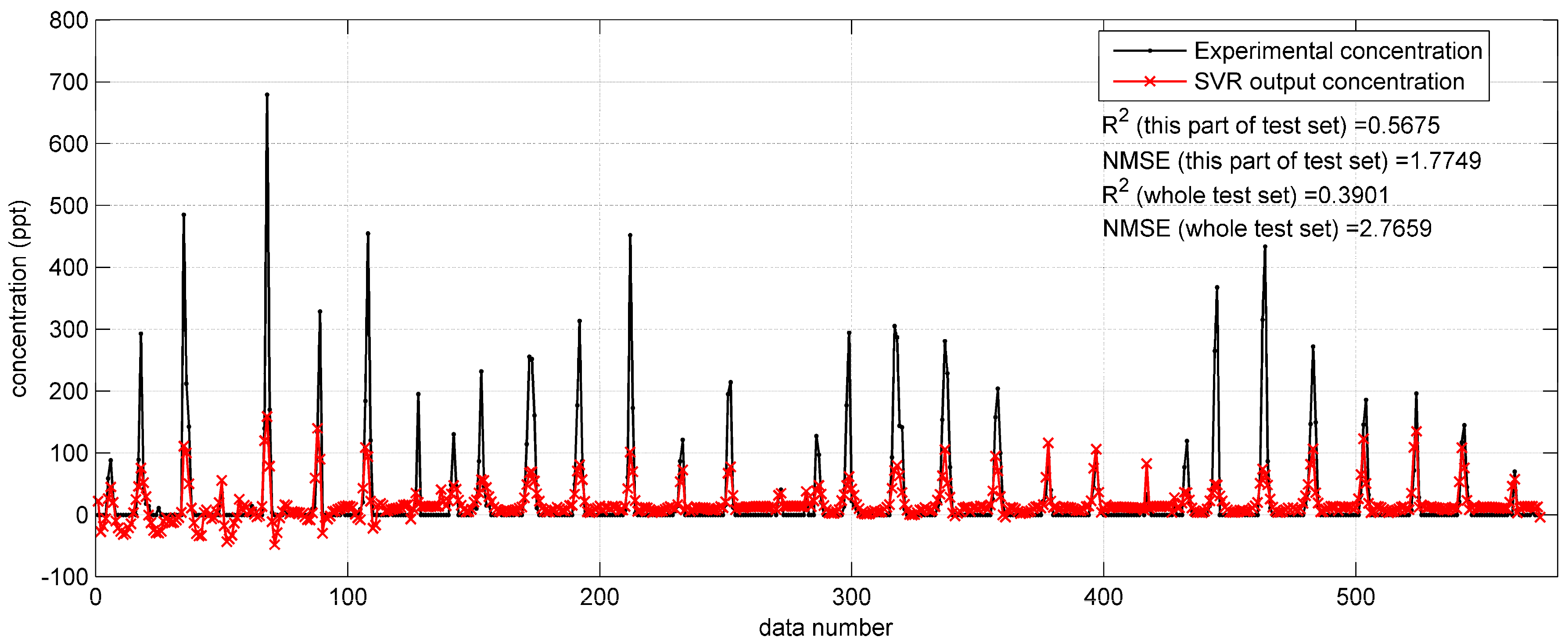
(0.4587) and large NMSE (1.0624), this SVR model needs improvement. As for the predictions on Indianapolis test set, they are also terrible (
= 0.3901, NMSE = 2.7659), as shown in
Figure 7. The performances of the SVR model with original monitoring inputs in the two field cases are both far from satisfactory, and poorer than the BP network with the same inputs. This comparison indicates that the SVR model is not as excellent as the BP network in terms of fitting ability.
3.1.4. SVR with Integrated Gaussian Parameters
To improve the SVR with original monitoring parameters, the SVR model with integrated Gaussian parameters is built. The optimized regression parameter
and spread constant
are determined at (
,
) and (
,
) for the two field cases, respectively. Other configurations of the training process are the same as the SVR with original parameters (
Section 3.1.3).
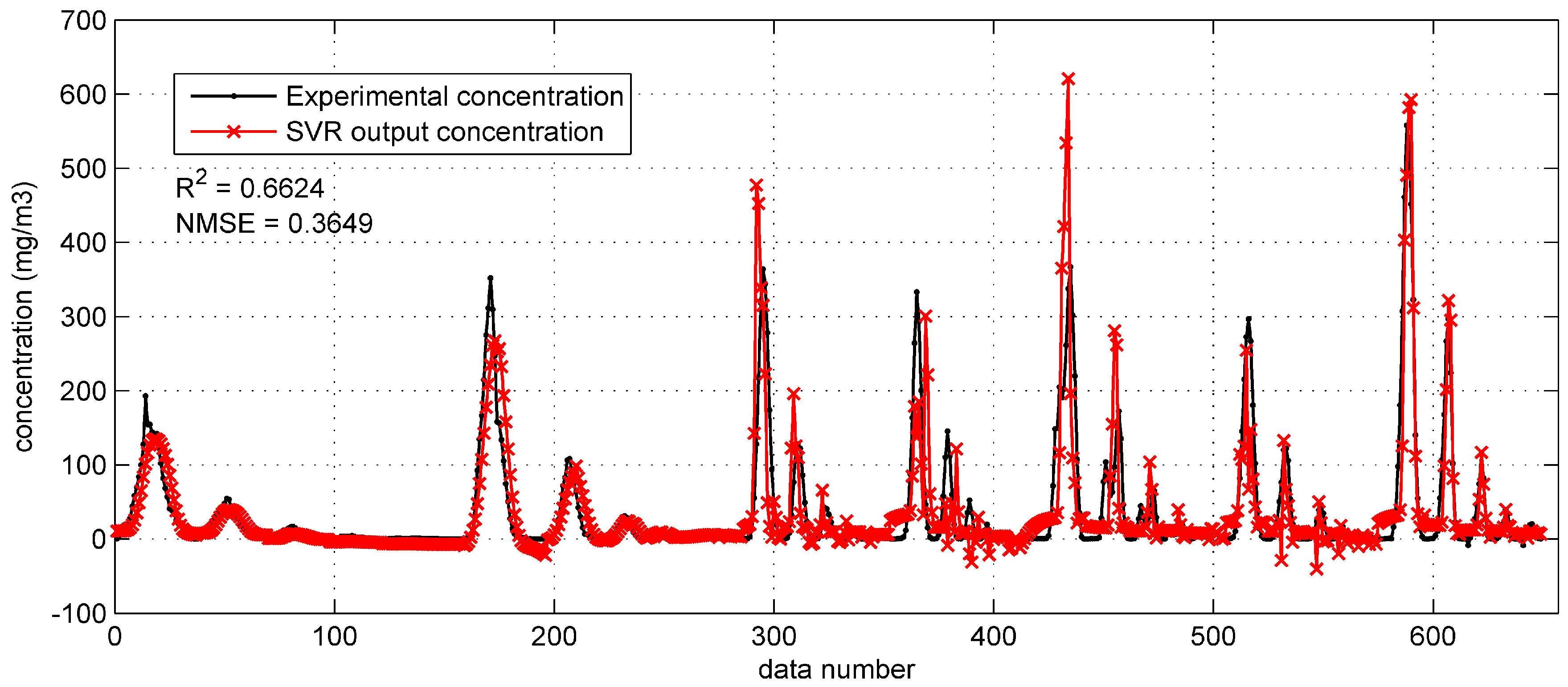
When applied on the Prairie Grass test set (
Figure 8), this SVR model apparently achieves a better performance on reproducing the test data. The two performance indicators are much better (
= 0.6624, NMSE = 0.3649) compared with the SVR model with original inputs. To be more specific, predictions in
Figure 8 approximate the experimental concentration well, even if the observed concentration is high. In addition, fewer negative concentrations appear in the
Figure 8.
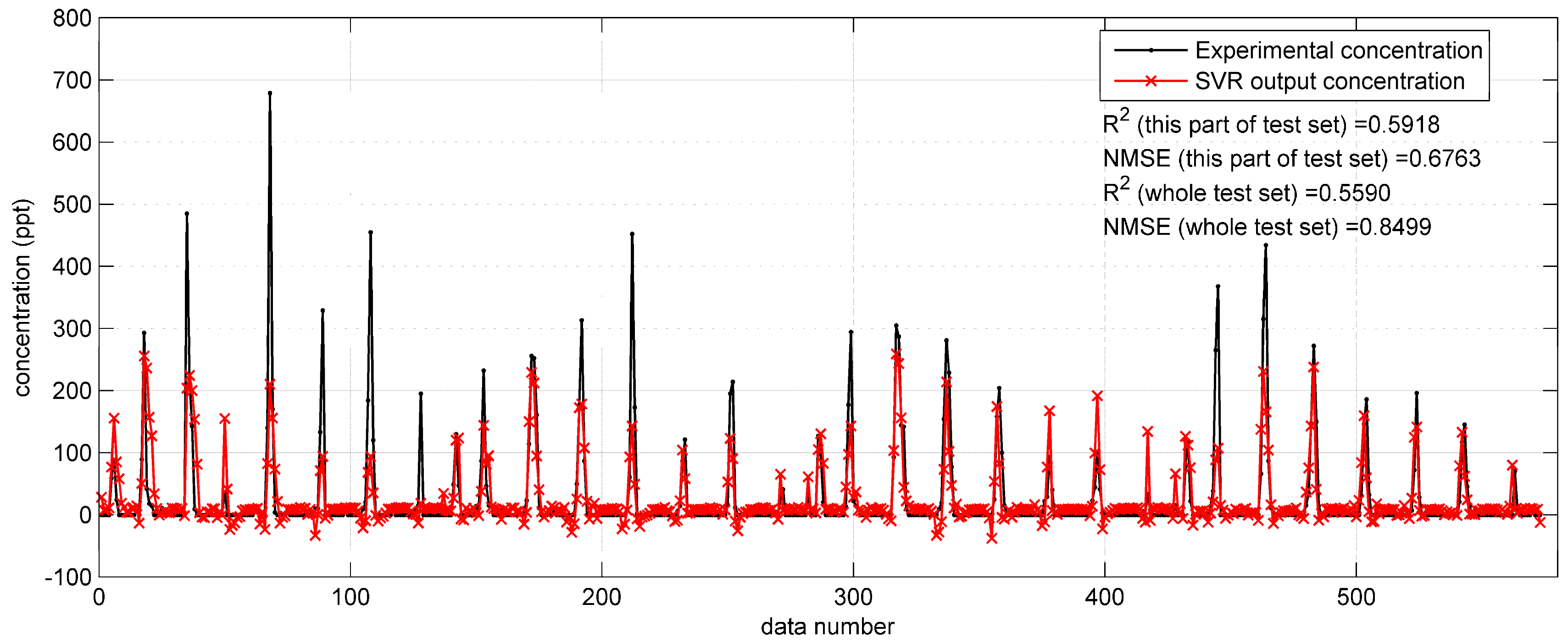
With regard to the prediction results on the Indianapolis test set, shown in
Figure 9, the
and NMSE values on the whole test set are 0.5590 and 0.8499, which are better than the indicators (
= 0.3901, NMSE = 2.7659,
Figure 7) of the SVR model with original monitoring inputs. However, the reproduction performance shown in
Figure 9 is still not as satisfactory as that in the Prairie Grass case (
Figure 8). Therefore, the improvement by the integrated Gaussian parameters is still limited. The reason of this limited improvement continues to be the Gaussian model’s inadaptability to the terrain condition (urban area) of the Indianapolis field experiment.
3.2. Results Analysis
The performances of proposed ML prediction models and the Gaussian plume model on test sets of the two field cases are listed in
Table 2 and
Table 3, respectively. In
Table 2, the comparison between the ML models with different input parameters indicates that in the Prairie Grass case, utilizing integrated Gaussian input parameters can improve the prediction performance, especially for the SVR model (
from 0.4587 to 0.6624, NMSE from 1.0624 to 0.3649). In comparison,
Table 3 shows that in the Indianapolis case, the use of integrated Gaussian parameters bring limited improvement to the BP network (
from 0.5190 to 0.5373, NMSE from 0.7070 to 0.6570). As for the SVR model, the improvement by the Gaussian parameters is more apparent (
from 0.3901 to 0.5590, NMSE from 2.7659 to 0.8499). However, the SVR model with Gaussian parameters still cannot yield accurate enough predictions as compared with that in Prairie Grass experiment (
: 0.5590 versus 0.6624, NMSE: 0.8499 versus 0.3649).
The differences between the improvements brought by Gaussian parameters in the two field cases is mainly resulted from the quite different terrain conditions. With almost no obstacle, the terrain of the Prairie Grass field tracer experiment is quite flat. The almost ideal terrain condition means the Gaussian model can describe the hazardous gas dispersion relatively well. This can be indicated by the acceptable performance of the Gaussian plume model in
Table 2 (
= 0.5385, NMSE = 0.7661). Therefore, using integrated Gaussian input parameters helps reduce the difficulty of approximating the input–output function, and improve the prediction performance of ML models. In contrast to the Prairie Grass case, the Indianapolis experiment was implemented on a typical urban area with a number of large buildings. Under this sophisticated terrain condition, the Gaussian model is less capable of modeling the atmospheric dispersion of the tracer. Therefore, the Gaussian parameters only bring limited improvement on the performance of the ML models. In summary, whether the Gaussian parameters can bring improvement depends on its adaptability to the field experiment.
The influence of the terrain conditions can also be reflected by the different performances of ML models in the two field cases. In general, proposed ML models constructed on the Prairie Grass data set (
Table 2) outperform those based on the Indianapolis data set (
Table 3). In the Indianapolis experiment, a number of large buildings make the tracer concentration distribution more sophisticated than that in the Prairie Grass experiment. Consequently, the difficulty of model training increases, and the performances of ML models in the Indianapolis case deteriorate.
The results also show that the BP network outperforms the SVR model in the fitting ability. It is reflected by the comparison of the BP network and SVR model with the original parameters. With the same inputs, the BP network clearly achieves a better performance than the SVR model in the two field cases. Therefore, this comparison illustrates that the BP network here has a stronger fitting ability to extract the features from the original input parameters and to approximate the input–output function well. In contrast, the poorer
and NMSE of the SVR model (even worse than the Gaussian plume model in
Table 2) indicate that this model encounters the possible under-fitting problem.
As for the computational efficiency, the model building times, prediction times and the total computing times in the two field cases are also listed in the two tables. The model building time represents the duration of the training phase. The total computing time includes the prediction time and the model building time. It is obvious that the Gaussian plume model has the highest efficiency. With regard to other models, their total computing time is acceptable. In addition, it can be seen from the two tables that the greatest computational cost comes from model-building. In contrast, a trained model has fast prediction computation. In terms of conditions, the total computing time of proposed ML models is acceptable, and the computing of prediction is fairly fast. It should be noted that the ML models constructed on the Indianapolis data set has longer building time than the Prairie Grass, because the scale of this data set is larger. In summary, the proposed models can meet the efficiency requirement of the emission management and emergency response.
3.3. The Influence of the Training Set and Test Set Scales
Table 2 and
Table 3 present the prediction performances of proposed models which are constructed on particular training sets and test sets. In the Prairie Grass case, 60 releases are used for training and 8 releases are for testing, while in the Indianapolis case, 16-day data and 2-day data are applied in the training and test, respectively. As ML models, the performances of proposed models depend on not only the model structure and input selection, but also the training data and test data. Therefore, to further reveal the characteristics (i.e., abilities of fitting and generalization) of proposed ML models, they are constructed on training sets of different scales and evaluated on the remaining test data. Here, the BP network and SVR model with integrated Gaussian parameters are considered. In the Prairie Grass case, the training set size varies from 5 to 67 releases. Therefore, the test set size changes from 63 releases to only one release. In the Indianapolis case, the training set size varies from one day to 16 days, with the test set size changing from 16 days to one day accordingly. For each configuration of training set and test set, the model performances on the two field cases are evaluated.
Table A3 and
Table A4 in
Appendix A display the 32 and 16 different configurations of training set and test set in the two field cases, respectively. Other configurations of the ML models are the same as those optimized models introduced in
Section 3.1.
The prediction results of BP network and SVR models trained by variable-sized training sets are obtained.
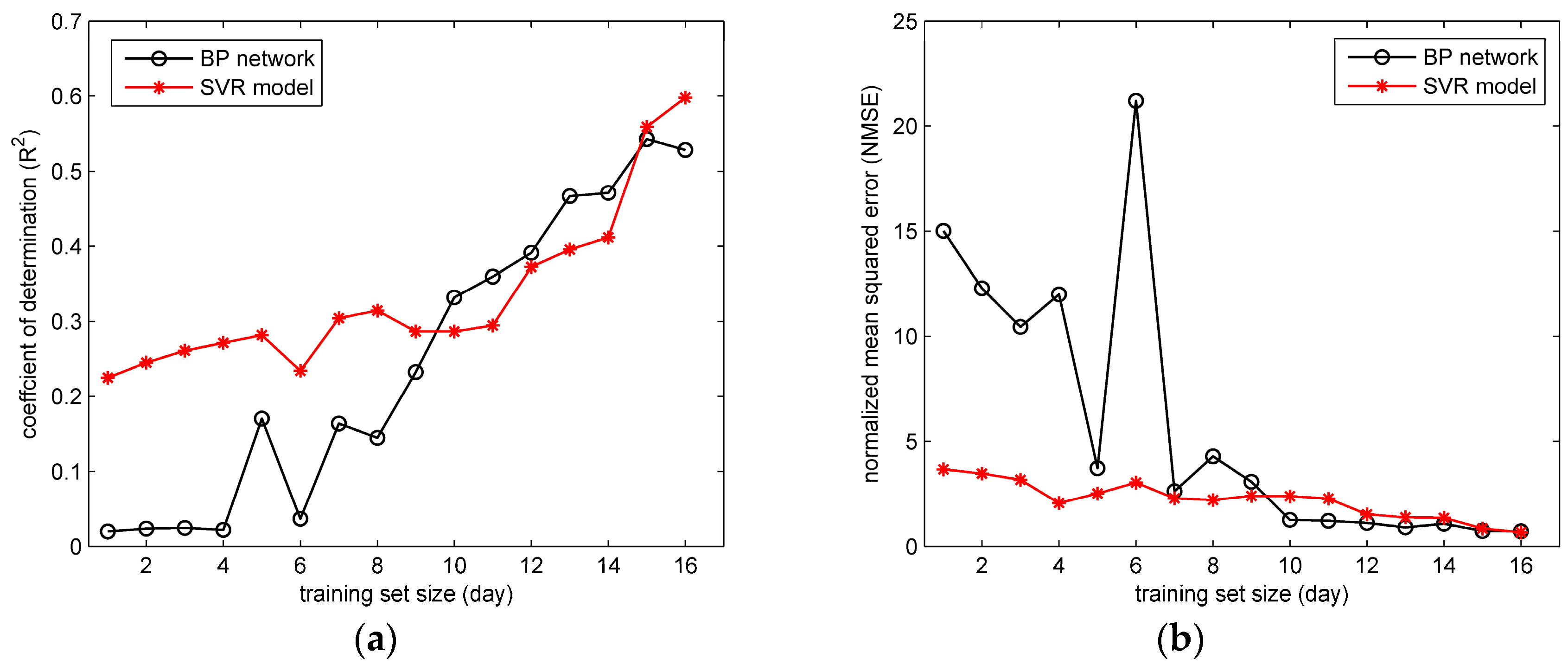
Figure 10 and
Figure 11 show the values of
and NMSE in the two field cases. It can be seen from the
Figure 10 that with the training set scale increasing, the performances of BP network and SVR model both improve (indicated by the rising
and falling NMSE). These two models both perform well with relatively large training set sizes, especially when the training set has more than 60 releases. Similar trends of
and NMSE can be found in the
Figure 11. The trends of
and NMSE indicate that the size of training set has a significant impact on the performance of the ML model here. With more training data, the ML model tends to cover more gas dispersion scenarios, and consequently obtain more accurate reproduction results on the test data.
In terms of the comparison between the BP network and SVR model, in
Figure 10 the differences between their performances mainly appear when the training set size is relatively small (less than 35 releases). Under this condition, the SVR model apparently achieves higher
and lower NMSE than BP network. In contrast, the performance of the BP network is unsatisfactory, especially when the training set size is smaller than 23 releases (most values of
are lower than 0.4, and NMSE are larger than 1.0). Similarly, in
Figure 11 the SVR model with Gaussian parameters shows a better performance on
and NMSE than the BP network when the training set size is smaller than 10 days. This comparison indicates that the performance of SVR model with Gaussian parameters is less dependent on the training data scale, which implies a better ability of generalization. The better generalization results from the optimization goal of the SVR model. Instead of minimizing the training error, the SVR attempts to minimize the generalization error bound (the loss function parameter
) so as to achieve a generalized performance [
30]. Therefore, the SVR model yields more accurate predictions on the test set under the condition of small-sized training sets. As for the BP network, the unsatisfactory results under the small-scale training sets reflect the possible over-fitting problem. When over-fitting the training data, the BP network tends to reproduce the training set “too accurately”, which means the model is only valid on the training set. Therefore, when applied in the test data (which is usually quite different from the training data), the BP network sometimes obtains unsatisfactory results, especially when the training set scale is limited. Therefore, considering all the experiment results, the SVR has a better ability for generalization, but tends to encounter the under-fitting problem when the input–output relationship is quite complex. In contrast, the BP network has an excellent fitting ability, but it is likely to over-fit the training data, and achieve unsatisfactory generalization especially when the scale of training set is relatively small. These characteristics are valuable for the prediction model selection in field cases.
4. Discussion
The results analysis shows that the Gaussian parameters method is case-sensitive, and whether the Gaussian parameters can bring improvement depends on its adaptability to the field experiment. Therefore, specifying the application condition or the application case of the Gaussian parameters method is useful to the user of our ML prediction models. The performance of the Gaussian parameters method depends on the adaptability of the Gaussian plume model to the field case. An ideal environment for the Gaussian plume model should meet some conditions. Firstly, the terrain should be open and flat, and the surface property should be uniform. Then, the Gaussian plume model is accurate in the near-field case where the dispersion range is usually less than 10 km. Moreover, the Gaussian plume model does not take the chemical reaction of the dispersion material into consideration. Finally, the Gaussian plume model requires the wind field to be stable and uniform, because this model uses the mean value of the wind field to calculate concentration. When a field case satisfies these conditions well, the Gaussian plume model and the ML model with Gaussian parameters tend to have high accuracy accordingly.
The ML model provides an effective method to predict the hazardous gas dispersion in a particular field case. Compared with the deterministic atmospheric dispersion model (e.g., the Gaussian model), the ML model can adjust itself according to the training data, and tend to produce more reliable predictions. Therefore, the ML model is suitable for the hazardous gas dispersion prediction in the field case, especially for complex field experiments (e.g., the urban area). However, this characteristic is also the limit of the ML model. That is the ML prediction model is valid only in the situations where it is developed. The ability to export the results of a particular situation to others is dependent on the similarity of the these situations. For example, the ML model developed from the Prairie Grass data set is clearly not feasible on the Indianapolis data set, because the two field tracer experiments were conducted in quite different terrain conditions. Therefore, a new ML model for the Indianapolis case should be built.
The results of the two field cases reflect the differences between BP network and SVR model on the abilities of fitting and generalization. The SVR model has a better ability of generalization but tends to under-fit the training data sometimes. In contrast, the BP network shows a better fitting ability but encounters the over-fitting problem more easily. Therefore, how to overcome the drawbacks of the two models is valuable for improving the model performance. The hybrid model combining the advantages of both models may be a feasible alternative. Further, the characteristics of the two ML models provide some guidance for the model selection in the hazardous gas dispersion prediction. When the scale of observed data is limited or the input–output relationship is not so complex, the SVR is a better choice due to its good generalization. If the observation size is large enough to cover most scenarios, or the function to be fitted is quite complex, the BP network is better because of its excellent fitting ability.
Moreover, there are still several measures to further improve the performances of proposed ML models, especially in the Indianapolis case. First, more observed data is likely to contribute to the model accuracy. Although the Indianapolis data set has more than 20,000 samples of the tracer, more than three quarters of these samples are zero measurements, which are almost meaningless. Therefore, more valid observations are necessary. In addition, some more sophisticated parameters can be considered in the model construction. For example, the LS or CFD model may be able to accurately describe the tracer dispersion in air in the Indianapolis case. Therefore, the LS-related or CFD-related parameters may possibly help to improve model accuracy.
In
Section 3.2 (Results Analysis), we attribute the different model performances in the two field cases to the different topography. In fact, besides the terrain condition, there are still other factors that influence the atmospheric dispersion potentially. These factors include the tracer type (SO
2 and SF
6), the measurement distance and time, etc. For example, SO
2 and SF
6 have different chemical properties in air. Therefore, their lifetimes in the atmospheric dispersion may be different, causing the difference in the concentration observations. In addition, the measurement distance in the Prairie Grass case is closer to the source. This may lead to the more satisfactory performance of the ML models with Gaussian parameters, because the Gaussian model is more accurate in the near field case. Therefore, in the future work, we will analyze the impact of other factors on the atmospheric dispersion, and give a more clear explanation of the model performances in the two field cases.
5. Conclusions
This paper compares two machine learning models (i.e., the BP network and SVR) for hazardous gas dispersion prediction in field cases. These ML models are built firstly by original input parameters. Then, in order to enhance the prediction accuracy, the integrated Gaussian parameters are formed by the original monitoring parameters, and used as the inputs of the ML models. The two ML models with different inputs are tested and compared using two typical field data sets. Further, the influence of the training set scale is analyzed as well.
Results illustrate that the performances of proposed ML models in the Prairie Grass data set are more satisfactory than those of the Indianapolis case generally, because the Indianapolis field experiment involves complex terrain conditions. As for the input selection, the use of the integrated Gaussian parameters indeed improves prediction accuracy. However, the extent of the improvement relies on the adaptability of the Gaussian model to the field experiment. In terms of the comparison of the two ML models, the BP network usually has a stronger fitting ability, while the SVR model achieves a better generalization. This comparison can help researchers and managers to select models for hazardous gas dispersion prediction.
In conclusion, the proposed ML models provide an effective way of predicting hazardous gas dispersion in field cases. With relatively high prediction accuracy, these ML models will provide strong support for the management and emergency response to hazardous gas emissions and accidental leaks. However, under complex terrain conditions (like the Indianapolis case) the prediction accuracy of the proposed ML models still needs improvement. Future work will focus on the further improvement of the ML models, especially in some complex field cases. For example, the LS or CFD-related parameters can be used to enhance the prediction accuracy of the ML models. In addition, besides the terrain condition, other factors such as the tracer type, and the measurement distance and time will be considered to explain the atmospheric dispersion in the two field cases more clearly.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










