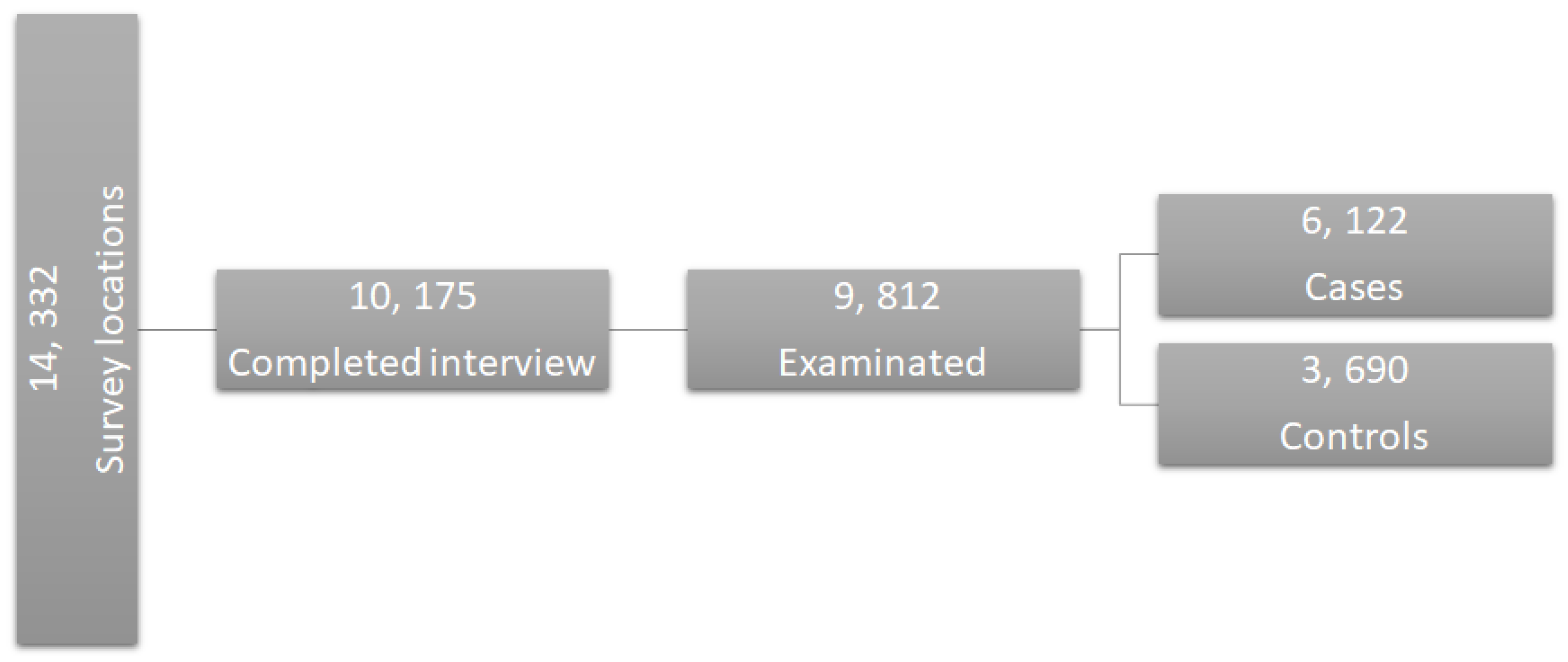
1. Introduction
Health is a condition that presents difficulties in its description due to its different definitions. According to the World Health Organization (WHO), health can be defined as a physical, mental, and social healthy status and not only as the absence of diseases. Quality of life is included, defined as an individual perception of life position, in the context of the cultural environment and the individual’s relationships with the objectives, expectations, standards, and concerns in life. Due to this concept, there are some factors that affect the health of subjects. These factors can be evaluated through three different dimensions: general (lifestyle), particular (life conditions), and singular (type of life) [
1,
2].
Oral health is considered to be an integral and essential part of health, and can compromise the quality of life of all groups of people, including infants, adolescents, young people, adults, and older adults without distinguishing between age; sex; social level; culture; economic, educational, and marital status; previous caries history; current caries index; levels of microbiological factors; drawing of family caries; and the environment in which they are found [
1,
2,
3].
These characteristics have supported and facilitated the recognition of different determinants that contribute to negatively modifying oral health status, since its appearance depends on the conjugation of biological factors such as dental anatomy, diet consumption, and the appearance of oral diseases, where the relationship between dietary and demographic features and the appearance of dental caries is widely demonstrated [
4,
5,
6,
7,
8,
9]. In oral public health, dental caries are a challenge because it is a condition that represents a chronic and preventable disease, affecting around 90% of the global population [
8], becoming an oral health problem. In the early stages of life, teeth usually do not present problems related to this disease, but throughout life, dental caries can be developed by different factors such as those mentioned above, being the main reason for the attention of such conditions [
9].
Due to the difficulty of controlling the incidence of caries, some studies have been developed that have implemented algorithms and performed analysis based on computer-aided diagnosis (CADx) in order to provide an automated tool for the detection of caries based on different types of features, with the aim of obtaining a better prognosis for patients and identifying the risk factors that can contribute to their prevention. One of the main CADx tools that has been used for the detection of diseases is the net reclassification index (NRI), which is a measure for evaluating the improvement in the prediction performance of the disease gained by adding a marker to baseline predictors. Other statistical parameters that are commonly used in clinical research include the receiver operating characteristic (ROC) curve, the area under the curve (AUC), the benefit function, and the Brier score, among others [
10].
Based on this general oral health problem description, the main contribution of this paper is to analyze the relationship between demographic and dietary features and the dental caries status, in order to develop a multivariate model (based on CADx) for three different age groups for the classification of subjects according to their dental caries status (presence/absence), in addition to looking for the different features that affect the age groups. These multivariate models were developed through a statistical approach using fast backward selection (FBS) for the feature selection, NRI for the validation, in order to know the reclassification proportion of subjects, and the ROC curve, which allows the sensitivity (true positives) and specificity (true negatives) of the model’s classification to be obtained.
According to the contributions mentioned above, the hypothesis of this work makes reference to the possibility of developing a multivariate model through statistical analysis—based on demographic and dietary features that were provided from National Health and Nutrition Examination Survey (NHANES) 2013–2014—that is able to automatically classify between patients with the presence and absence of caries, in order to find a tool that provides information about the risk factors that make subjects vulnerable to dental caries, according to their age range.
4. Discussion and Conclusions
This section presents the discussion and conclusions for the reported results obtained for this case–control study, where the main objective was to find a multivariate model that allows for classification of subjects with the presence of caries from subjects with their absence, according to their age, looking for the demographic and dietary features that bring the most descriptive information for cases and controls. This helps to indicate when a subject is at risk of suffering from dental caries, making it possible to take preventive measures and thus decreasing this public health problem.
The three multivariate models that were obtained for the age groups present different characteristics in the classification of subjects. Some of the features are present in all three models; nevertheless, there are remarkable differences in specific features that were selected for each group, besides the quantity of features that are contained in each. It is important to remark that due to the difference in the number of subjects belonging to each age group, it was necessary to use two different cutoff values in the selection process; nevertheless, the impact of this difference was not significant according to the results obtained, since it did not cause problems of overfitting and the validation remained consistent between the age groups. Therefore, it is possible to compare them.
In
Table 2 it is possible to observe that according to the OR values obtained, most features in the model were statistically significant and the proportion of demographic features was very similar to the proportion of dietary features (15 features and 18 features, respectively), which means that for age group 2, both types of features provided important information in very similar proportion for the classification of subjects. On the other hand, the values obtained from the NRI analysis showed that the reclassification of subjects through the developed multivariate model had a mean proportion of −0.080, which means that the classification was 0.080 better if the standard model (all features) was used to classify cases instead of the new model obtained trough the feature selection. The correct reclassification of subjects with presence of caries had a proportion of 0.040, while the incorrect had a proportion of 0.120. The correct reclassification of control subjects had a proportion of 0.048, which is the same as that obtained for the incorrect reclassification. These values are very significant considering that the reclassification was performed using 33 features instead of 56. In
Table 3 it is easier to observe that the reclassification presented a confusion problem to classify subjects in the upper cutoff (i.e., the cases) subjects, showing a higher error in that proportion in comparison with the reclassification proportion of the lower cutoff (i.e., the controls) subjects, being evident in the reclassification of cases subjects exclusively, which means that the features that were selected for this age group may be presenting similar values for some subjects in both type of outcomes, case and control, inducing a classification error in the new model.
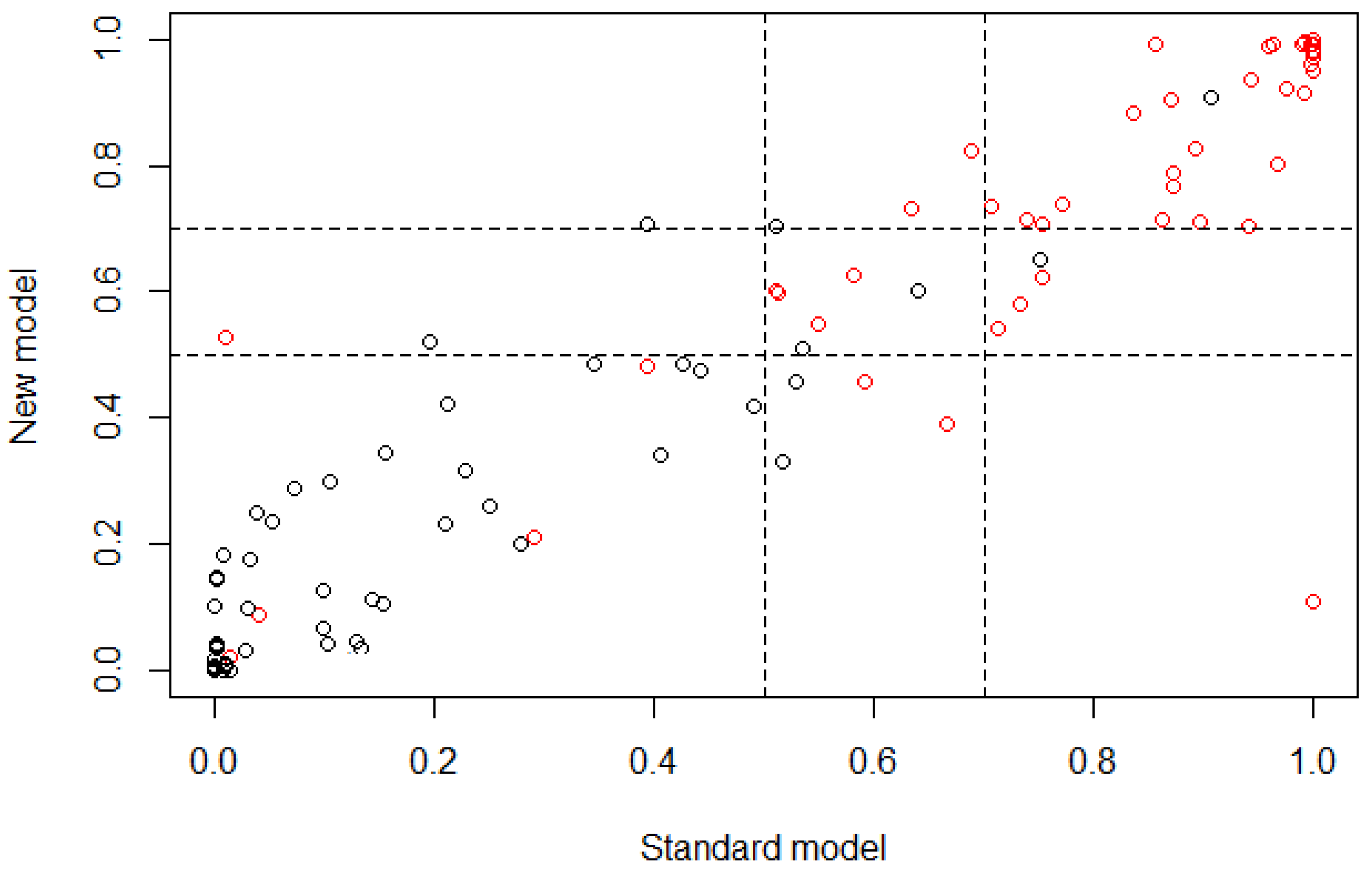
Figure 3 is a graphical represenation indicating that most subjects were classified in a similar way for both models (standard and new), according to the linear behavior that is shown. Nevertheless, the classification of case and control subjects in the cutoff region can be wrong because it is the range of values where the threshold between both outcomes is present, which means that the subjects that are part of this range of values may belong to controls with a similar probability of belonging to cases.
For age group 3, in
Table 4 it is possible to observe that according to the OR values obtained, all features presented a probability of subjects being case very similar to them being control, which means that any feature provided more information to classify cases than the others. The proportion of demographic features was reduced in comparison to the proportion of dietary features (6 demographic features and 12 dietary features), which means that for age group 3, there were more dietary features that provided information for the classification of subjects than demographic fetures. On the other hand, the values obtained from the NRI analysis show that the reclassification of subjects through the developed multivariate model had a mean proportion of −0.024, which means that the classification was 0.024 better if the standard model (all features) was used instead of the new model. From this mean value, 0.019 proportion belongs to the classification of cases and 0.005 proportion belongs to controls; this value is not relatively significant in comparison with the NRI values obtained for age group 2. The correct reclassification of subjects with presence of caries had a proportion of 0.055, while the incorrect had a proportion of 0.074. The correct reclassification of control subjects had a proportion of 0.055, while the incorrect had a proportion of 0.060. Based on these values, it is possible to say that for this new model is was easier to classify control subjects than case. However, the increase of the error in the classification of case subjects is not very significant, considering that the reclassification was performed using 18 features instead of 104. In
Table 5 it is easier to observe that the reclassification presented a small proportion of false positives and false negatives; however, the cutoff range presented a significant value of uncertainty due to the high number of subjects that were between the threshold values, which means that the features that were extracted for this age group may be presenting similar values for some subjects in both types of outcome, inducing an error in the classification through the new model.
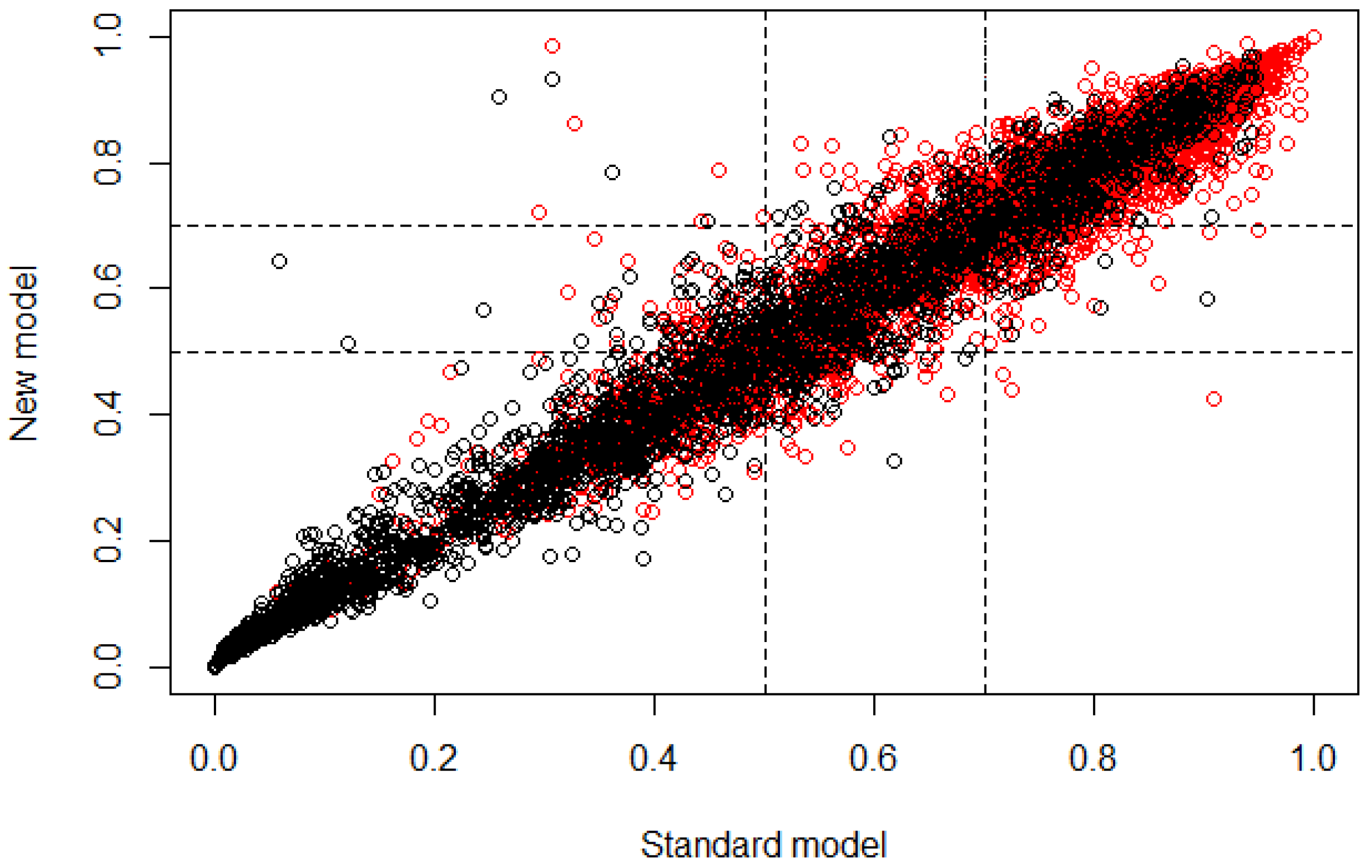
Figure 4 allows graphical observation that most subjects were classified similarly for both models (standard and new), according to the linear behavior that is shown. Nevertheless, the classification of case and control subjects in the cutoff region can be wrong because it is the range of values where subjects may belong to controls with a similar probability of belonging to cases.
Finally, for age group 4, in
Table 6 it is possible to observe that according to the OR values obtained, all features presented a probability of subjects being case very similar to the probability of them being control, as in age group 3. This multivariate model presented the smallest number of features in comparison with age groups 2 and 3, and the proportion of demographic features was very similar to the proportion of dietary features (four demographic features and six dietary features), which means that for this age group, both types of features provided important information and in very similar proportion for the classification of subjects. The statistical values obtained from the NRI analysis show that the reclassification of subjects through the developed multivariate model had a mean proportion of −0.129, which means that the classification was 0.129 better if the standard model (all features) was used instead of the new model, being the highest value in the three age groups, where the standard model classified with a better behavior than the new one. This may occur due to the small number of features that are part of this age group. The correct reclassification of subjects with the presence of caries had a proportion of 0.083, while the incorrect had a proportion of 0.096. The correct reclassification of control subjects had a proportion of 0.081, while the incorrect had a proportion of 0.197. Based on these values it is possible to say that for this new model it is easier to classify control subjects than case; however, the increase of the error in the classification of case subjects was not very significant considering that the reclassification was performed using 10 features instead of 104. In
Table 7 it is easier to observe that the reclassification presented a very similar proportion of false positives and false negatives. The lower cutoff (i.e., the controls) presented the highest error in the reclassification, and the subjects that were located in the cutoff range also presented a significant value, which means that the features that were extracted for this age group may be presenting similar values for some subjects in both type of outcomes, inducing an error in the classification through the new model.
Figure 5 demonstrates that most subjects were classified similarly for both models (standard and new), according to the linear behavior that is shown. Nevertheless, the classification of case and control subjects in the cutoff region can be wrong because it is the range of values where subjects may belong to controls with a similar probability of belonging to cases, besides being remarkable that a significant number of control subjects appeared in those values that would be assigned to case subjects, causing the uncertainty value due to the false positives.
According to the NRI values obtained using the new models, all of them presented statistically significant reclassification values, obtaining parallel proportions of true positives/true negatives, considering that the number of subjects was very different for each age group, as the number of features for each model.
It is important to remark that age group 2 contained the smallest number of subjects but the largest number of features, which means that the smaller the quantity of data, the more difficult it is to generate a general model that correctly classify them, making it necessary to use more features.
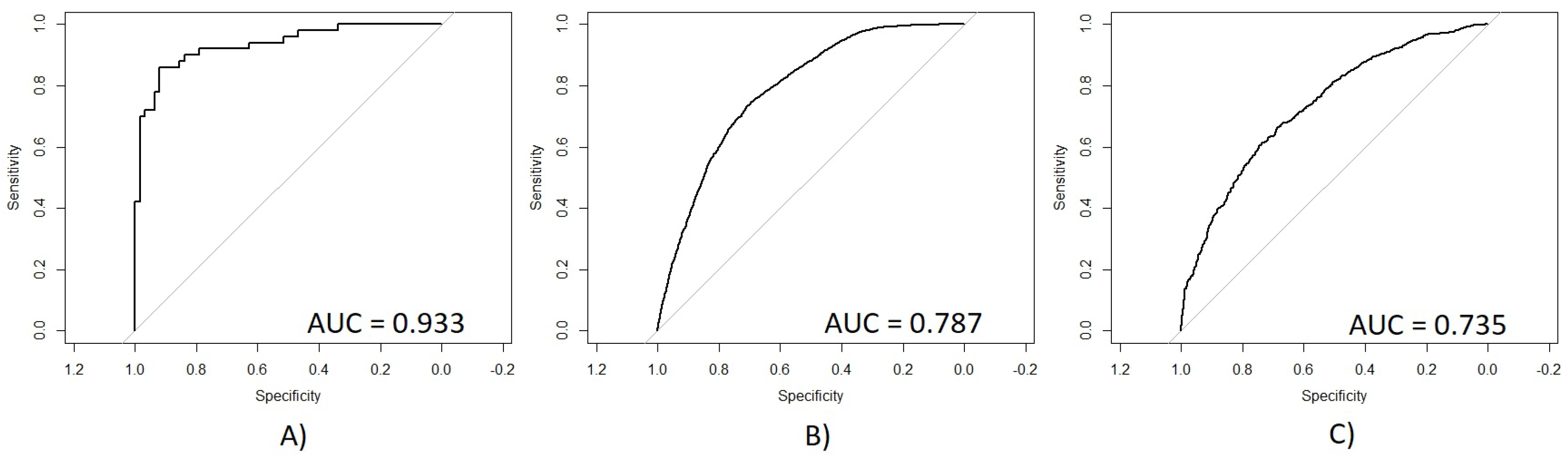
On the other hand,
Figure 6 presents the ROC obtained for each age group with their respective AUC values. (A) shows a very significant ROC with a sensitivity/specificity proportion of 0.933, which means that 93.3% of subjects from age group 2 were correctly classified using the new model. (B) shows the ROC curve for age group 3 with a sensitivity/specificity proportion of 0.787, which means that 78.7% of the total subjects were correctly classified using the new model. (C) shows the ROC curve for age group 4 with a sensitivity/specificity proportion of 0.735, which means that 73.5% of the subjects were correctly classified. According to these results, it is possible to observe that age group 2 had a remarkably better performance than the other two age groups, which presented very similar AUC values. The accuracy of age group 2 may be reached because this group had a smaller number of subjects and a higher number of features on its multivariate model. However, this relationship of subjects and features may cause an overfit problem, making difficult to generalize this multivariate model. On the other hand, the AUC values obtained for age groups 3 and 4 were also statistically significant, which means that these models presented a good performance in calculating the correct outcome for each subject using the smallest number of data possible, extracted from a very large quantity of data, which means that age groups 3 and 4 did not present the problem of overfitting like age group 2.
According to these results, it is possible to conclude that the use of FBS for feature selection presents a good performance, based on the statistical validation using NRI, ROC, AUC, and OR. The feature selection was used to develop three different multivariate models for the classification of control and case subjects, taking into account the age groups to which the patients belonged in order to know if the age of subjects changed the risk of suffering caries, based on their demographic and dietary information.
All multivariate models that were developed were significant, and each presented different characteristics from the others. The model of age group 2 presented the highest accuracy in the classification of subjects and the proportion of demographic and dietary features was very similar, which means that for subjects that were between 10 and 19 years old (age group 2), both types of features influenced the development of caries. This may occur because at this age range, aside from the importance of the good feeding (information that is present in dietary features), it is important to teach or educate children ranging from 10 years old to teenagers to have good oral health, taking into account the environment in which they are developed (information that is present in demographic features).
For age group 3 a model was developed that presented double the number of dietary features than demographic, which means that subjects between 20 and 59 years old (age group 3) need the information of dietary features more than demographic features to know their dental status and their risk of developing dental caries. Finally, for age group 4, it was more important for subjects that are 60 years old or more (age group 4) to pay more attention in their feeding than in their demographic status in order to avoid caries problems.
Through this statistical analysis it was possible to find which demographic and dietary features were the most significant to bring information about the development of caries in three different groups of people, being a case/control study. These groups of people correspond to three different age ranges. Nevertheless, it is important to consider that one of the main limitations of these results is the type of subjects that were used for the statistical analysis and the number of subjects in the datasets. These databases collected a series of data from a great diversity of subjects, which may represent a general view of the public health problem, but for a centralization of the problem, it would be important to use a more specific dataset with the demographic and dietary features of the population under study (i.e., Mexican subjects). On the other hand, the number of subjects corresponding to each age group is unbalanced, which may induce a bias in the feature selection and the validation process. Another limitation is presented for age groups 3 and 4, which obtained an uncertainty value of around 30%, representing a relative significant error for the prediction of dental caries. Finally, even when the most accurate model was obtained using the data from age group 2, it is important to note that in this age range (10–19 years), those subjects that are younger are dependent on their relatives for their demographic and dietary circumstances, making dental caries reduction not an exclusive problem of the subjects of study, but the environment that surrounds them.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





