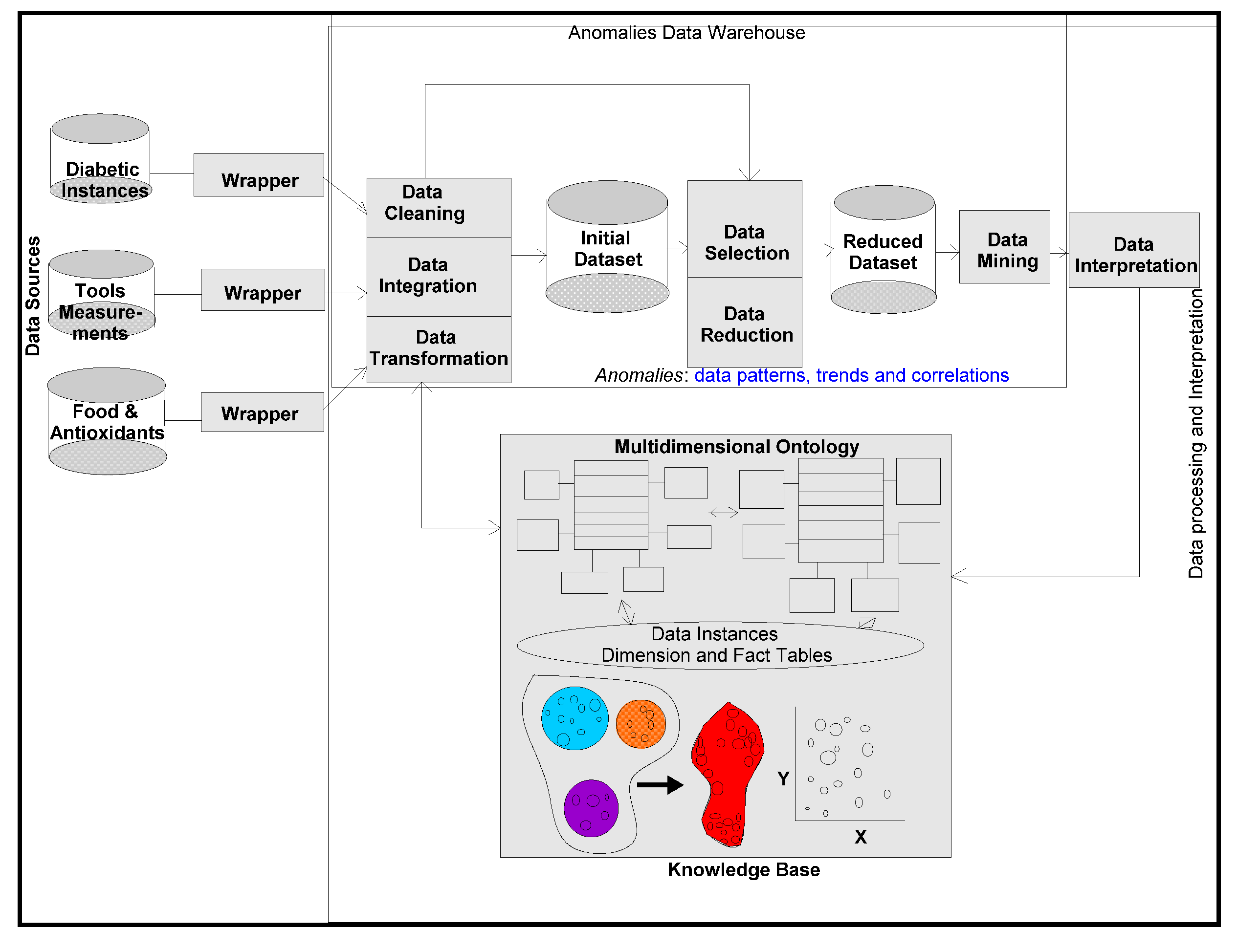
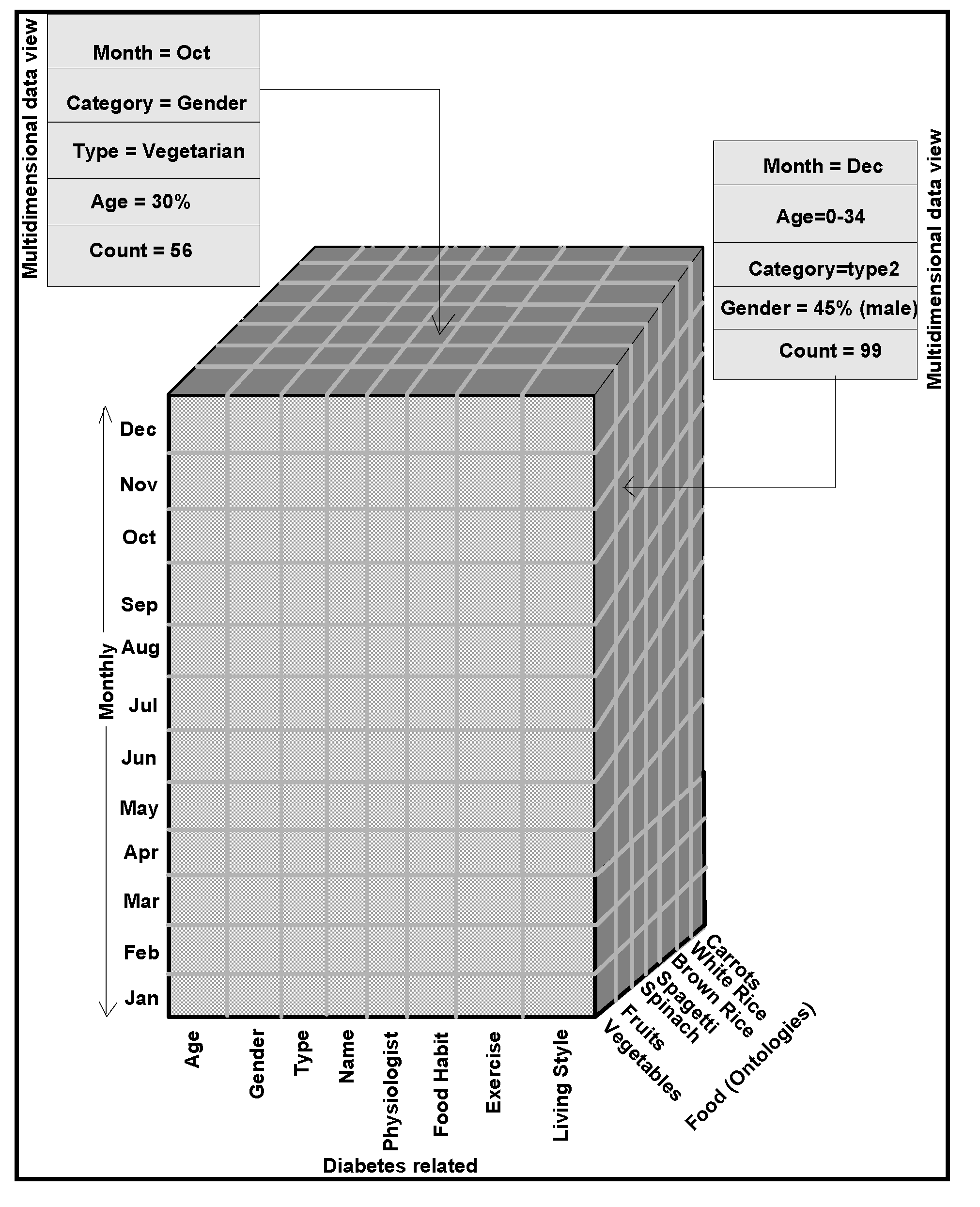
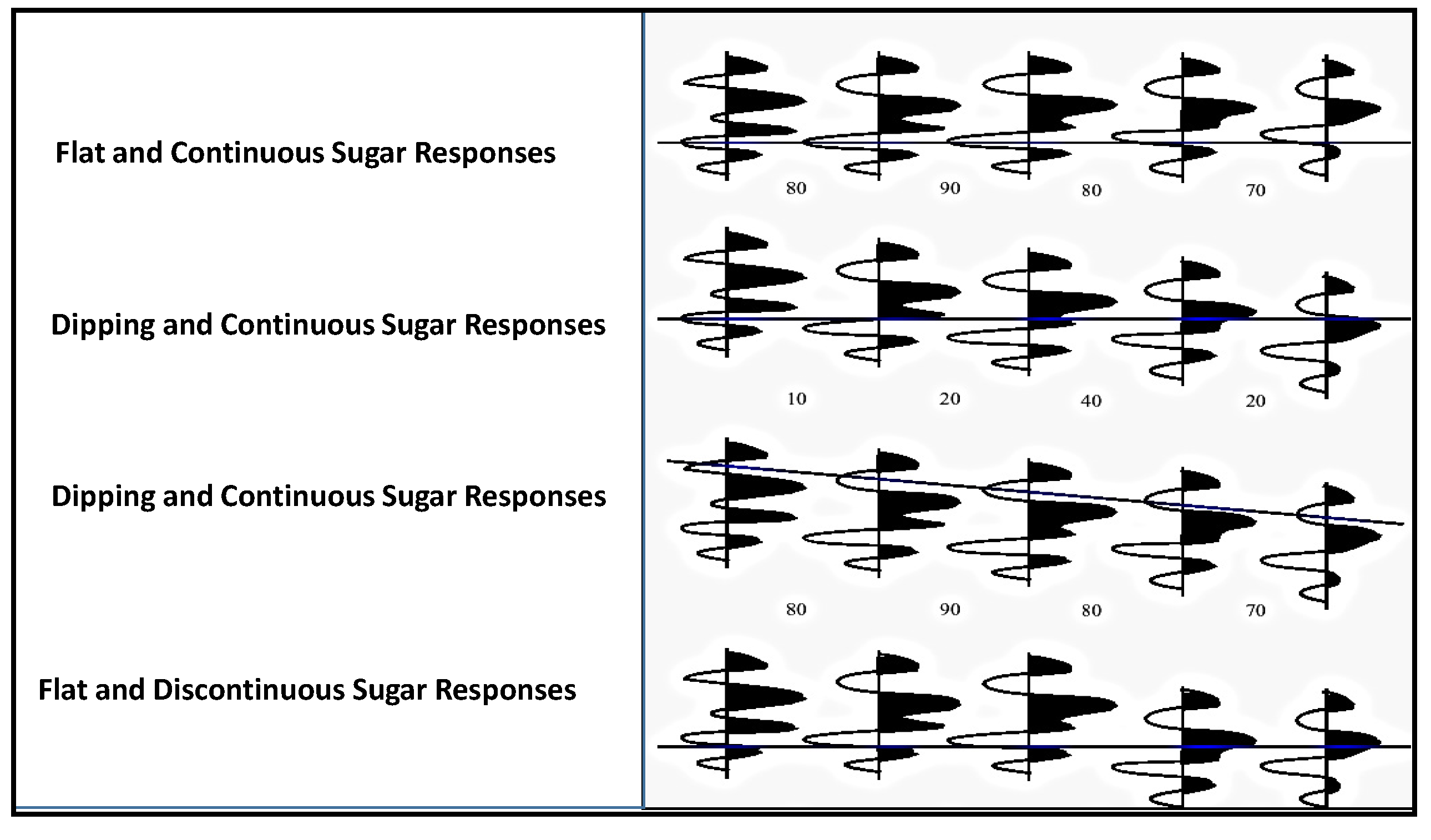
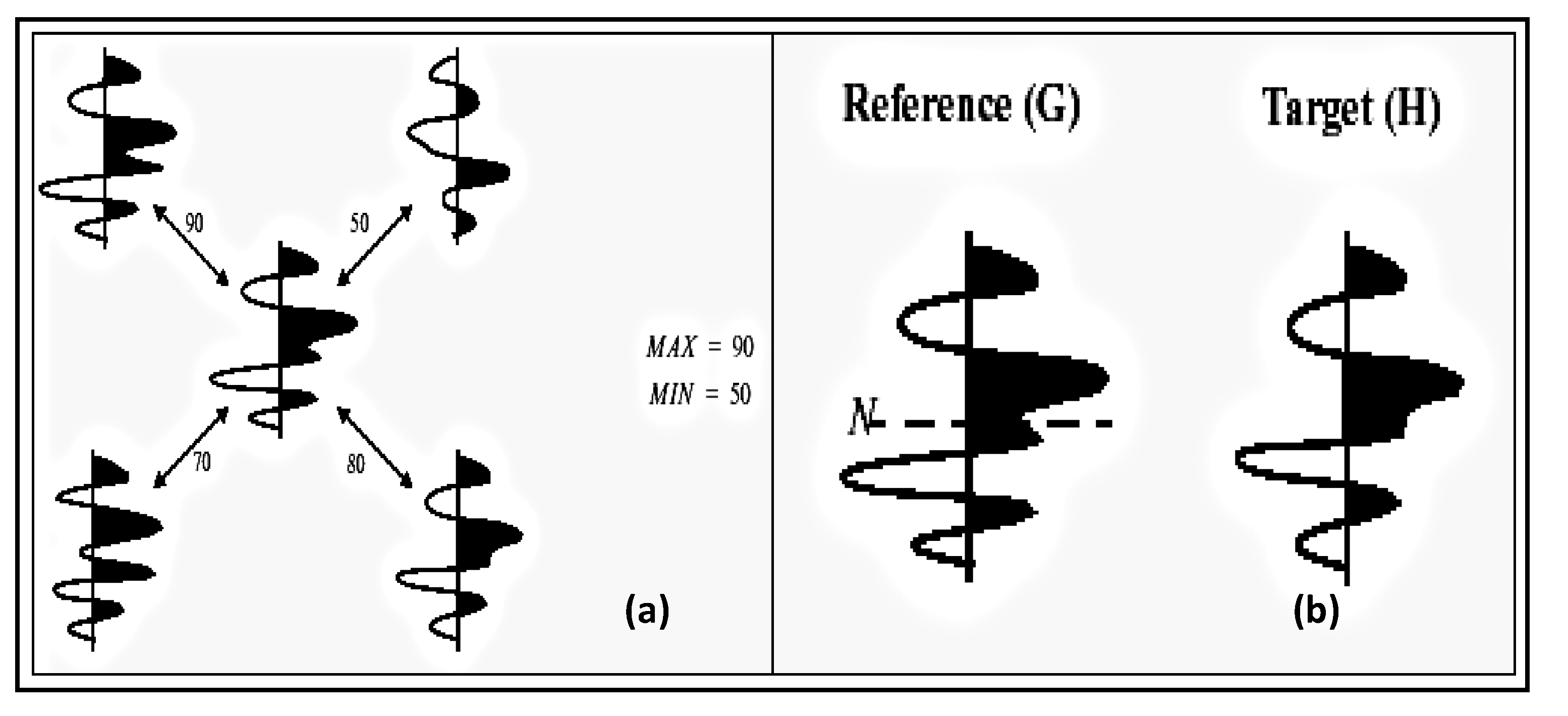
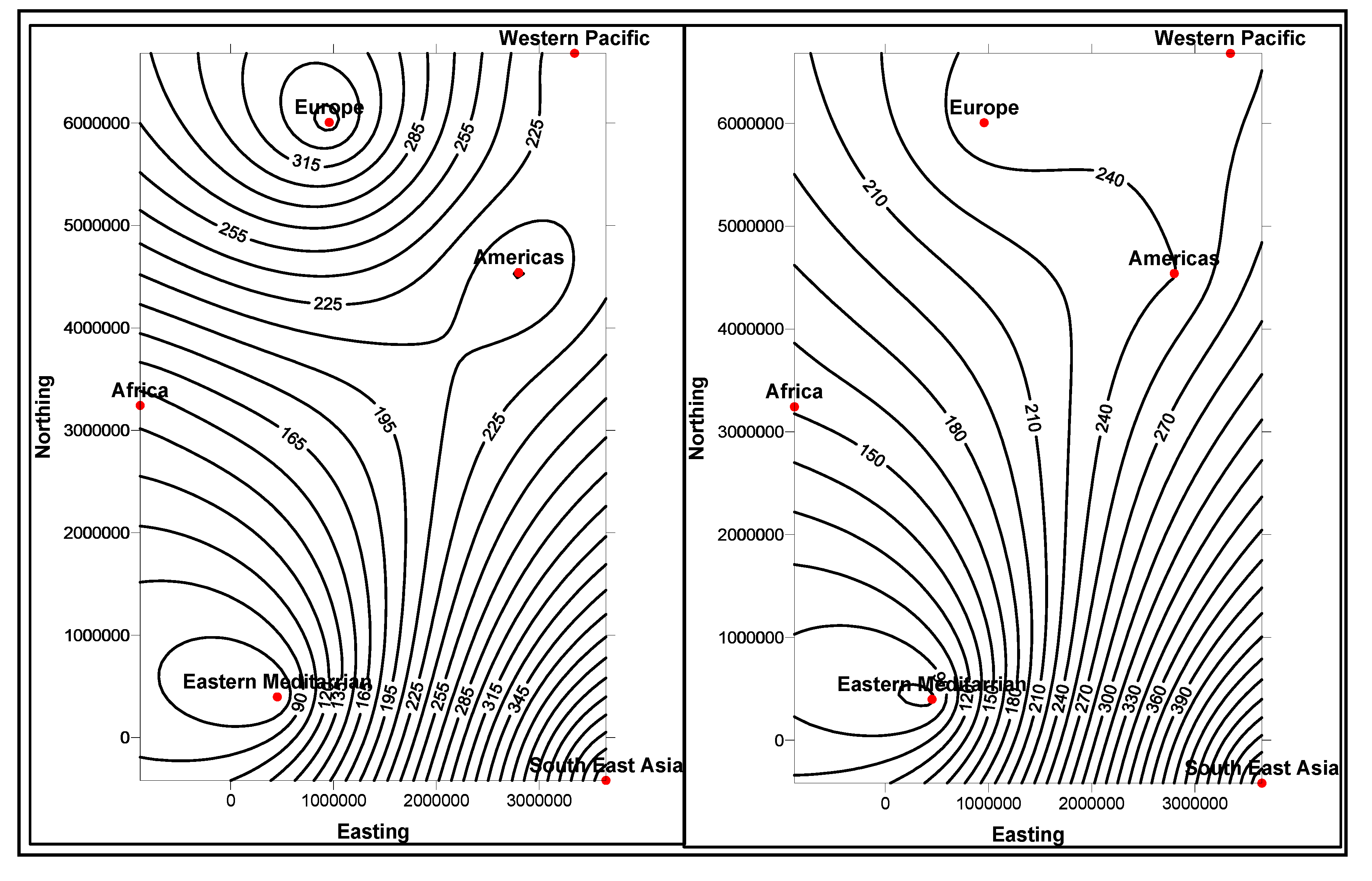
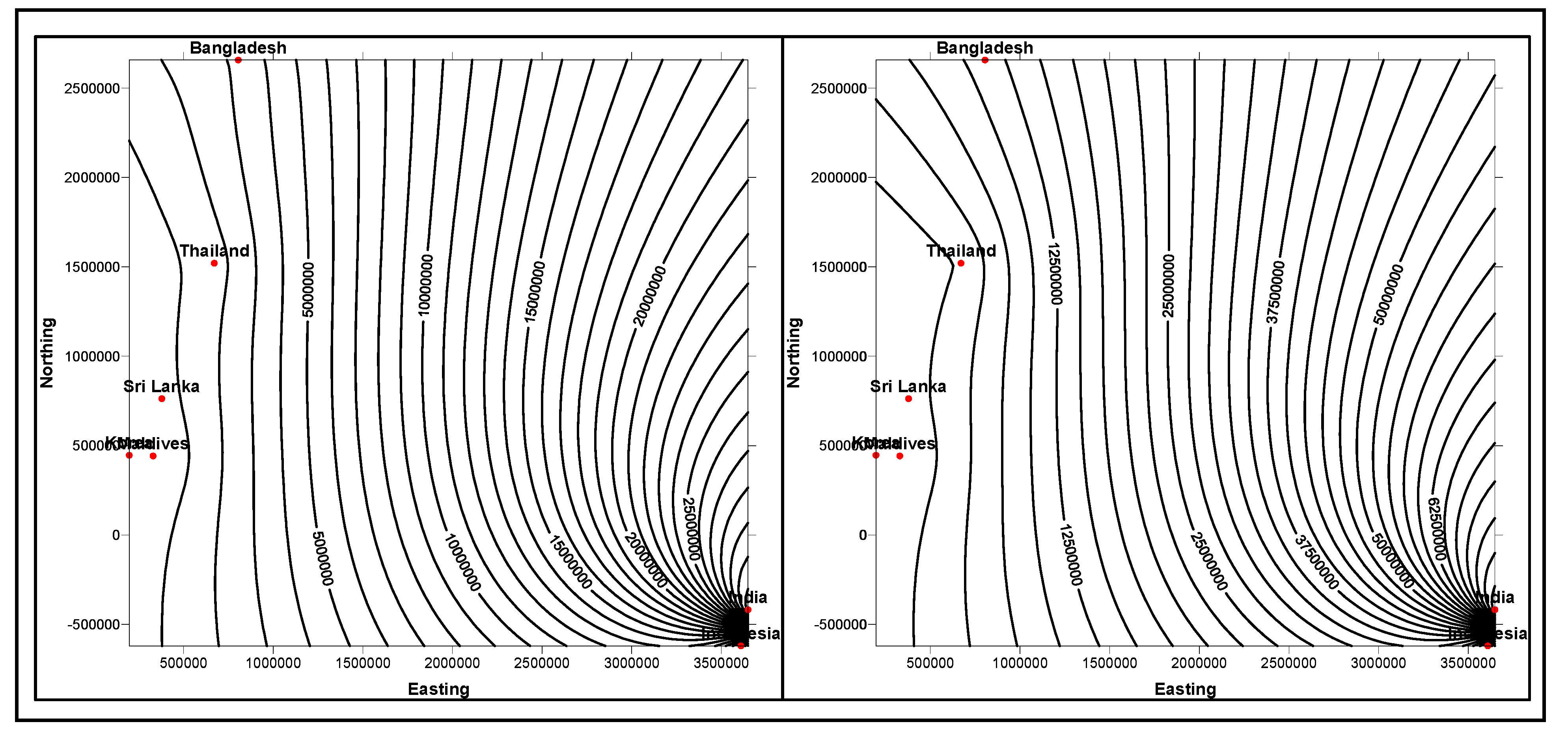
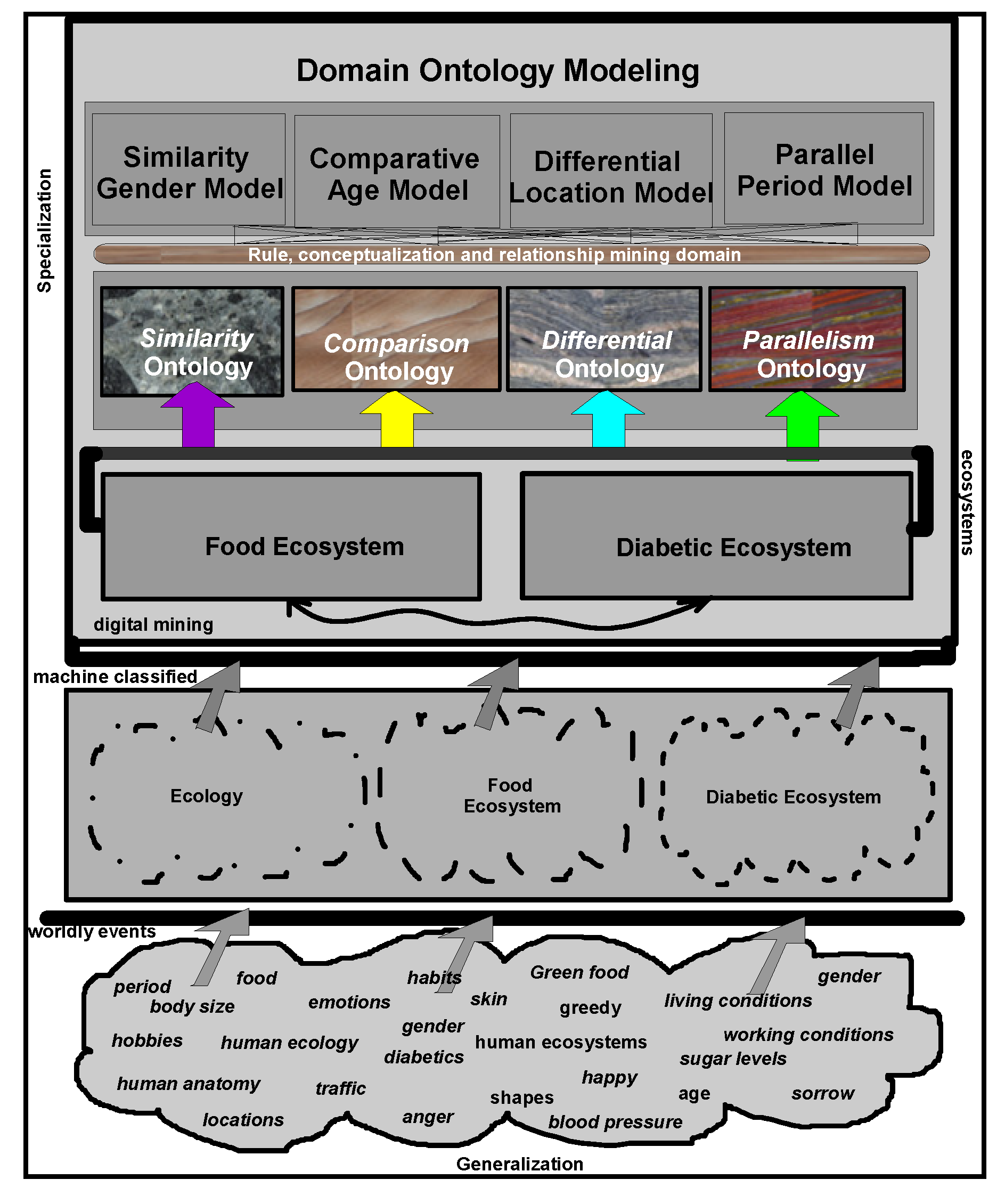
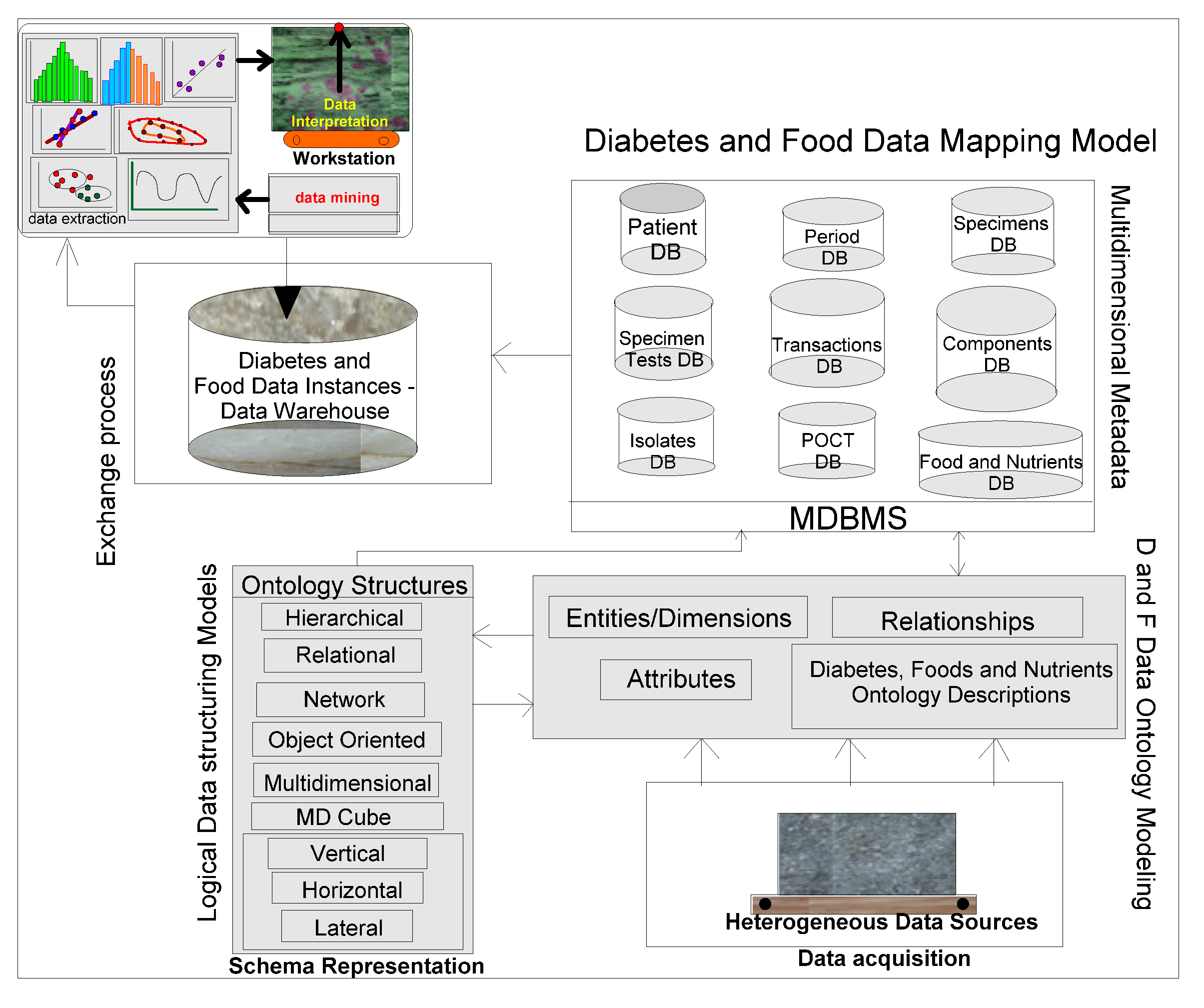
4.1. Ontology-based Warehouse Modelling of Multidimensional Diabetes Data Instances
The proposed methodologies are comprehensively used in various business environments [
8,
9,
10]. They are further extended in other domains robustly, such as the human ecosystems and human anatomy domains [
4,
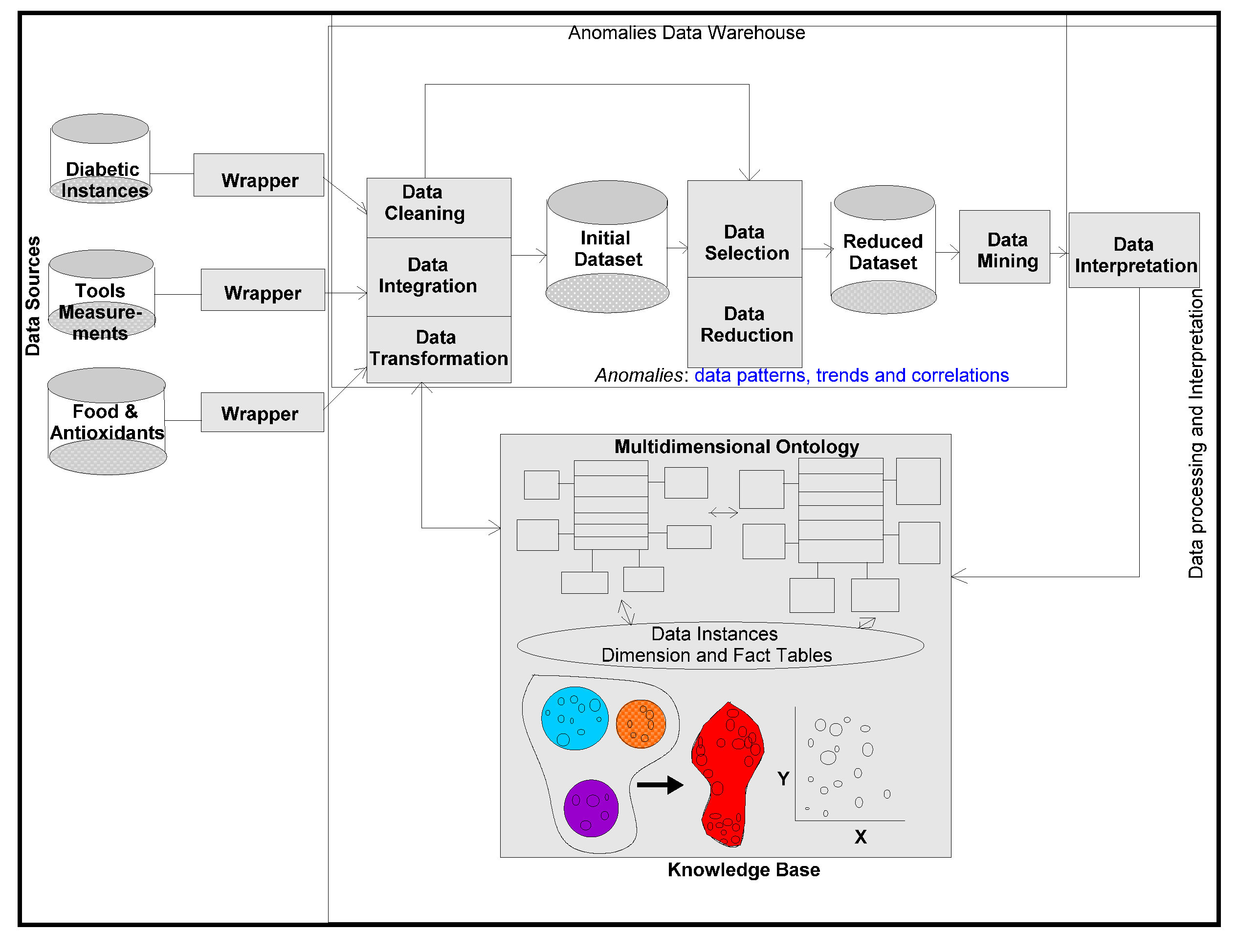
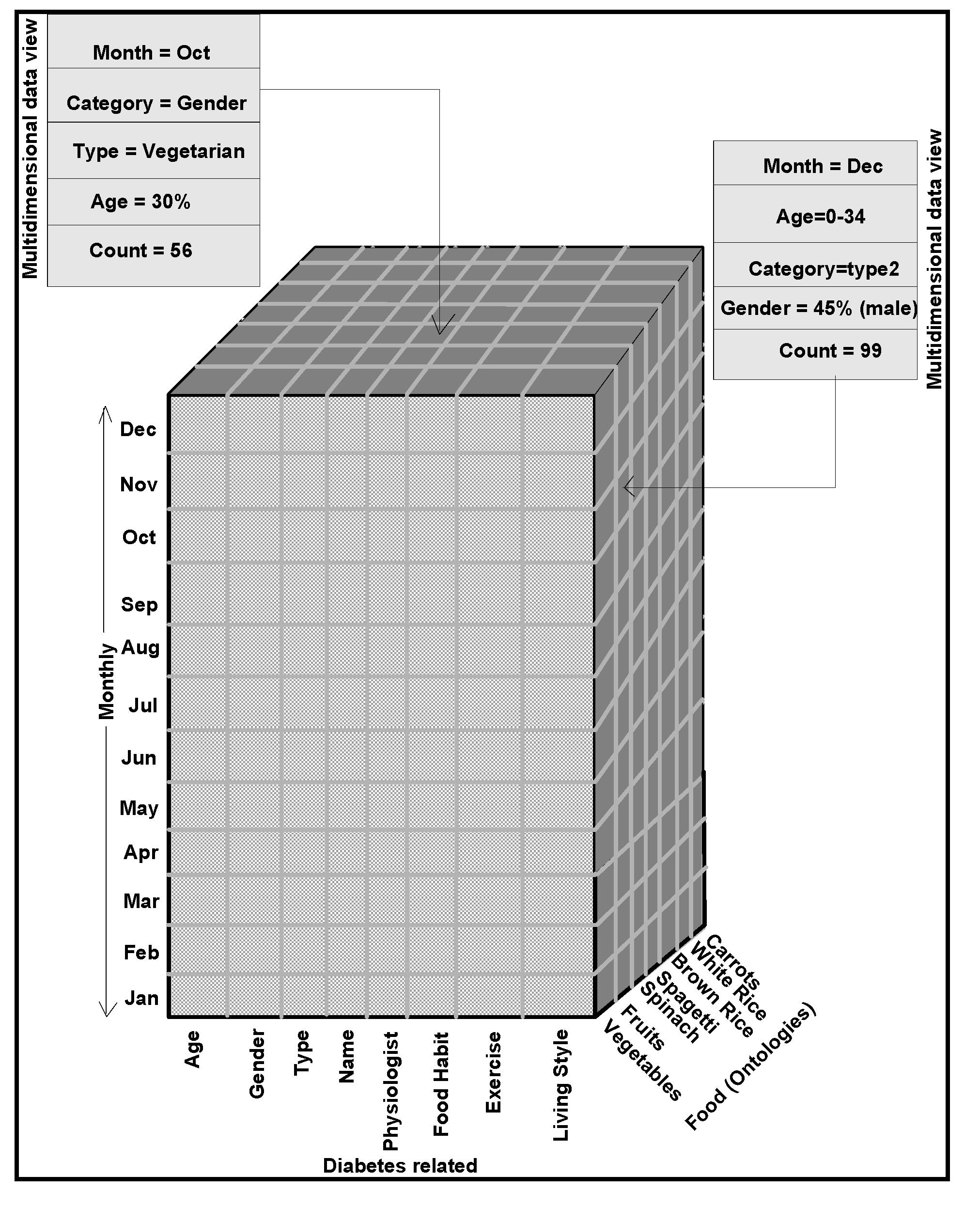
11] to test their validity and versatility. For this purpose, ontological descriptions written in the form of schemas in different domains, are integrated in a warehouse environment to make connectivity among domains. A metadata is constructed from which several data views are extracted for visualization and interpretation purposes.
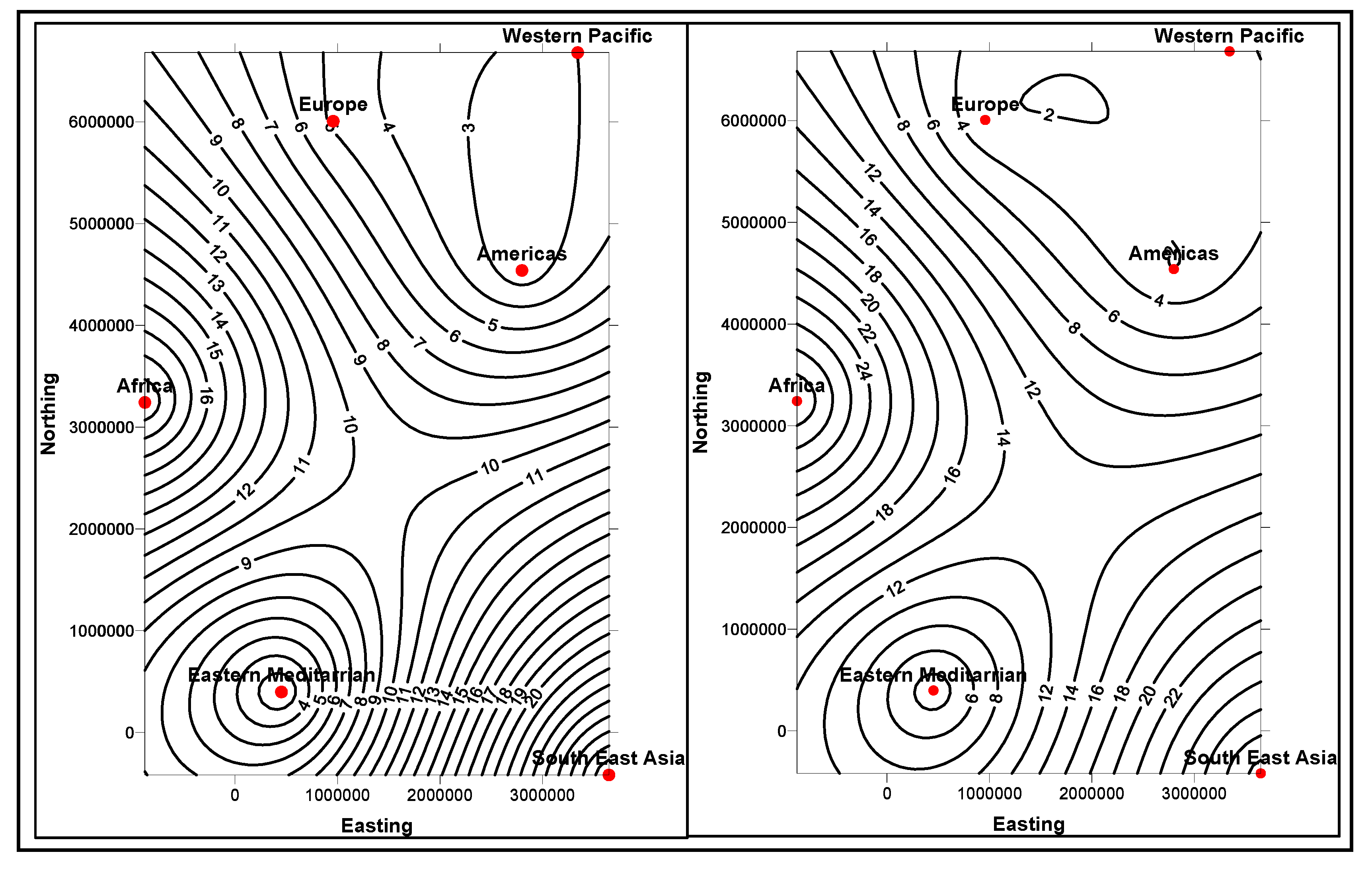
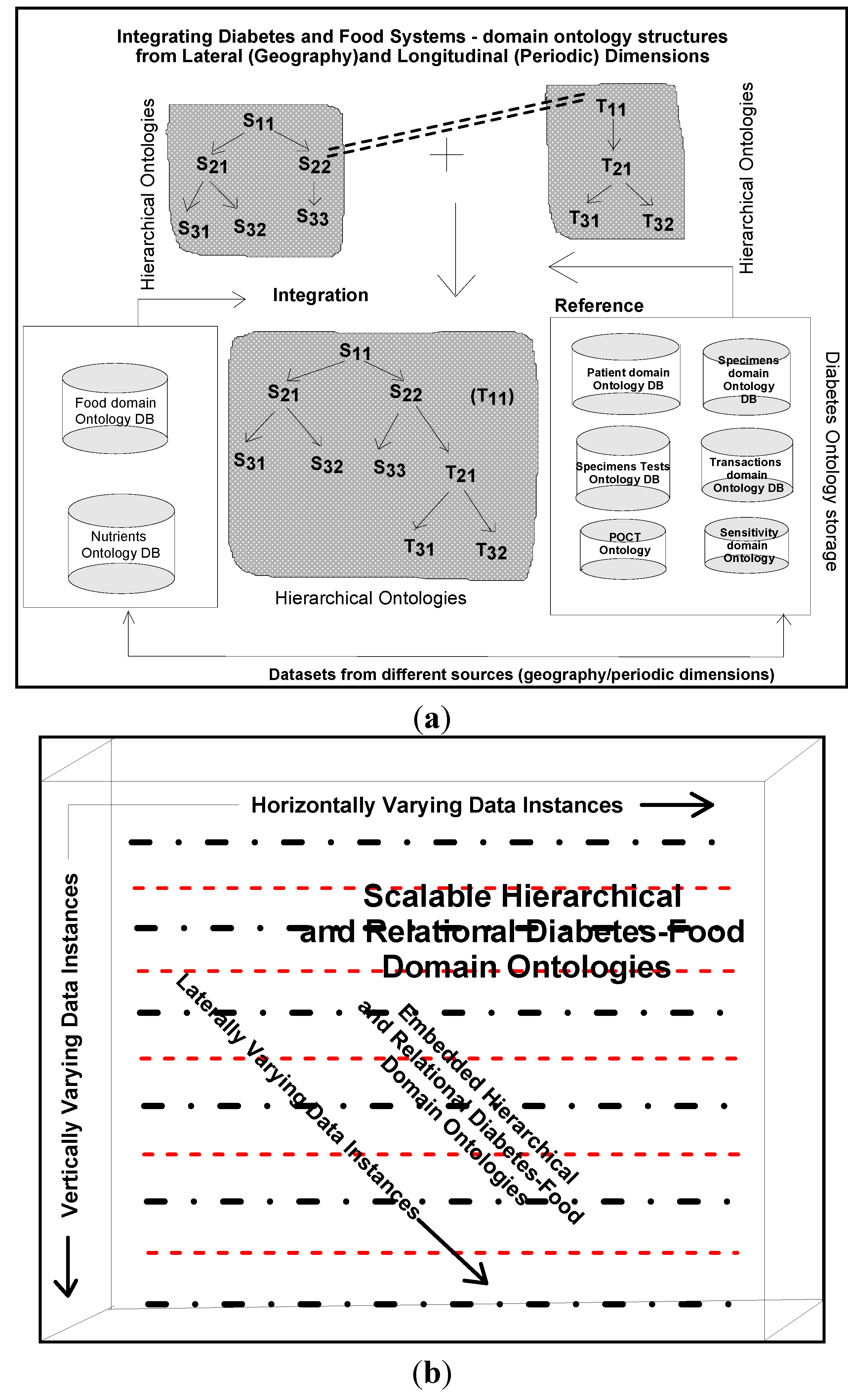
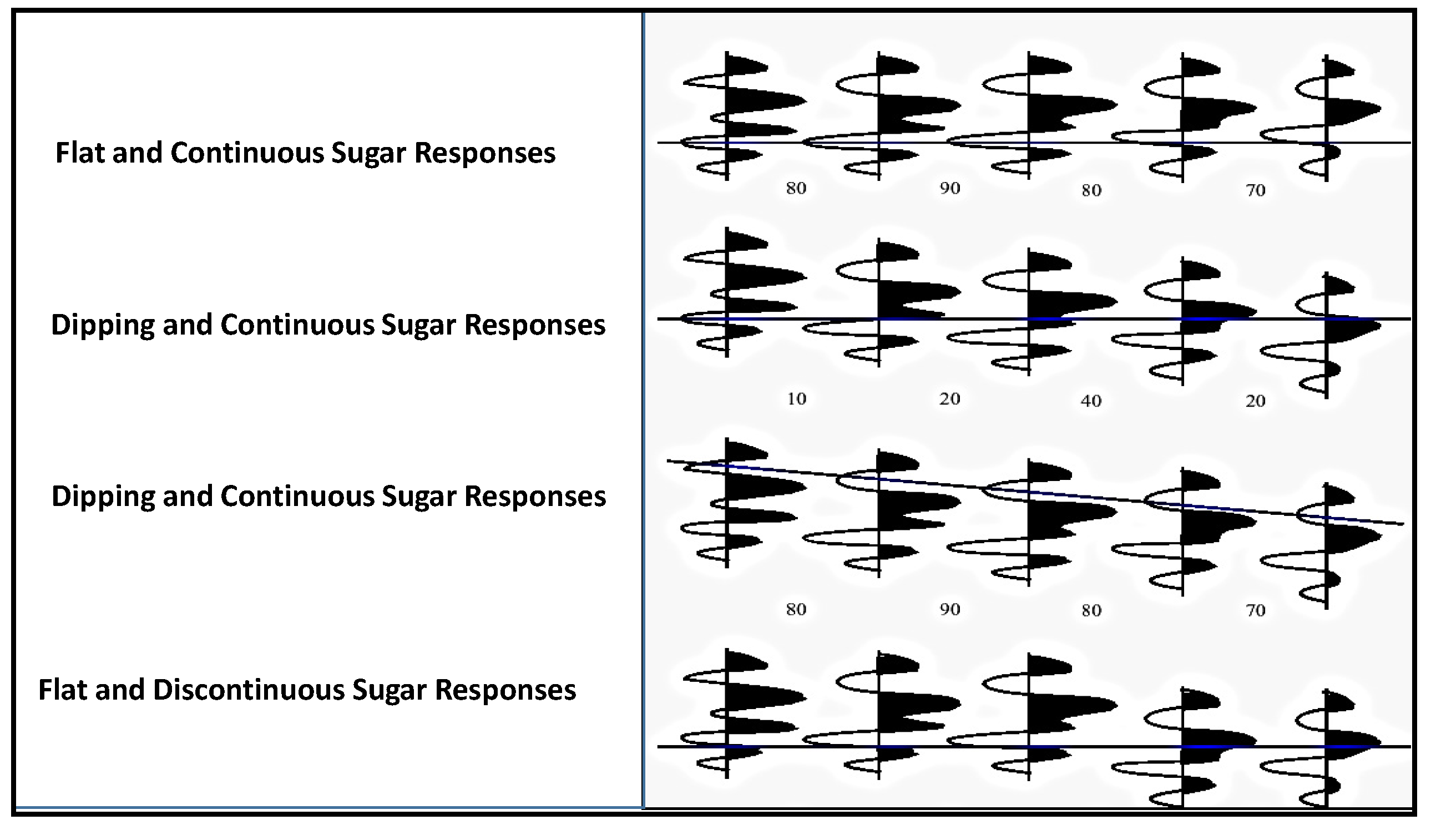
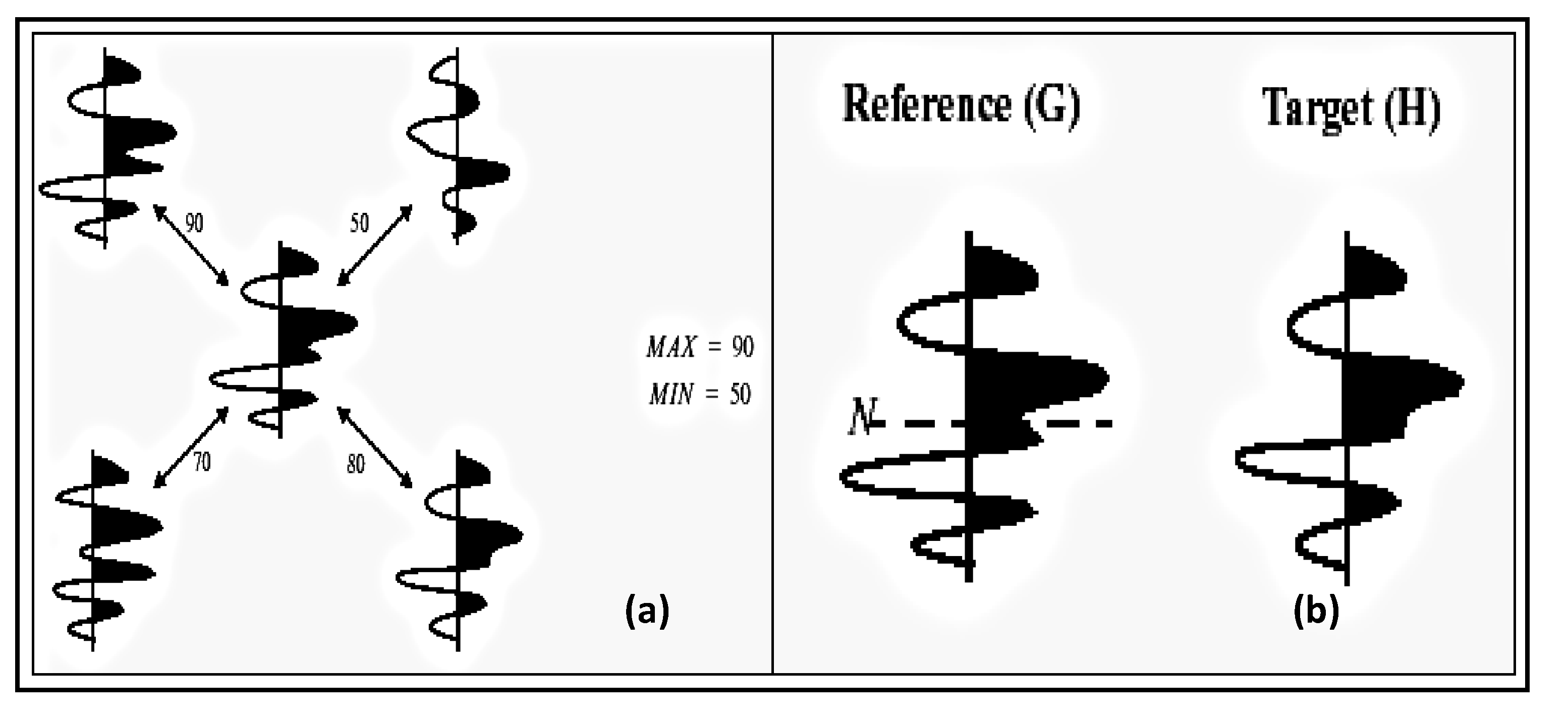
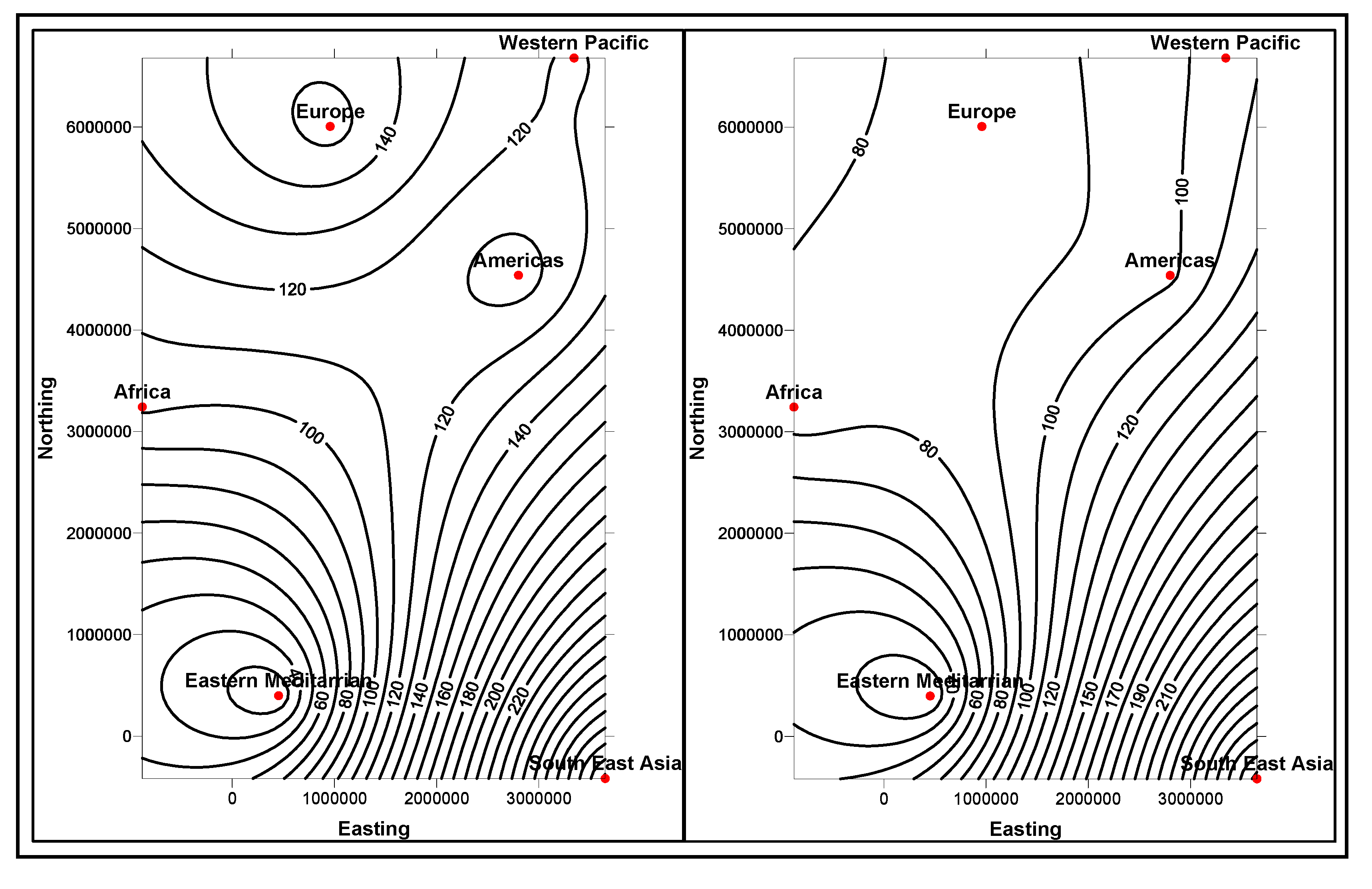
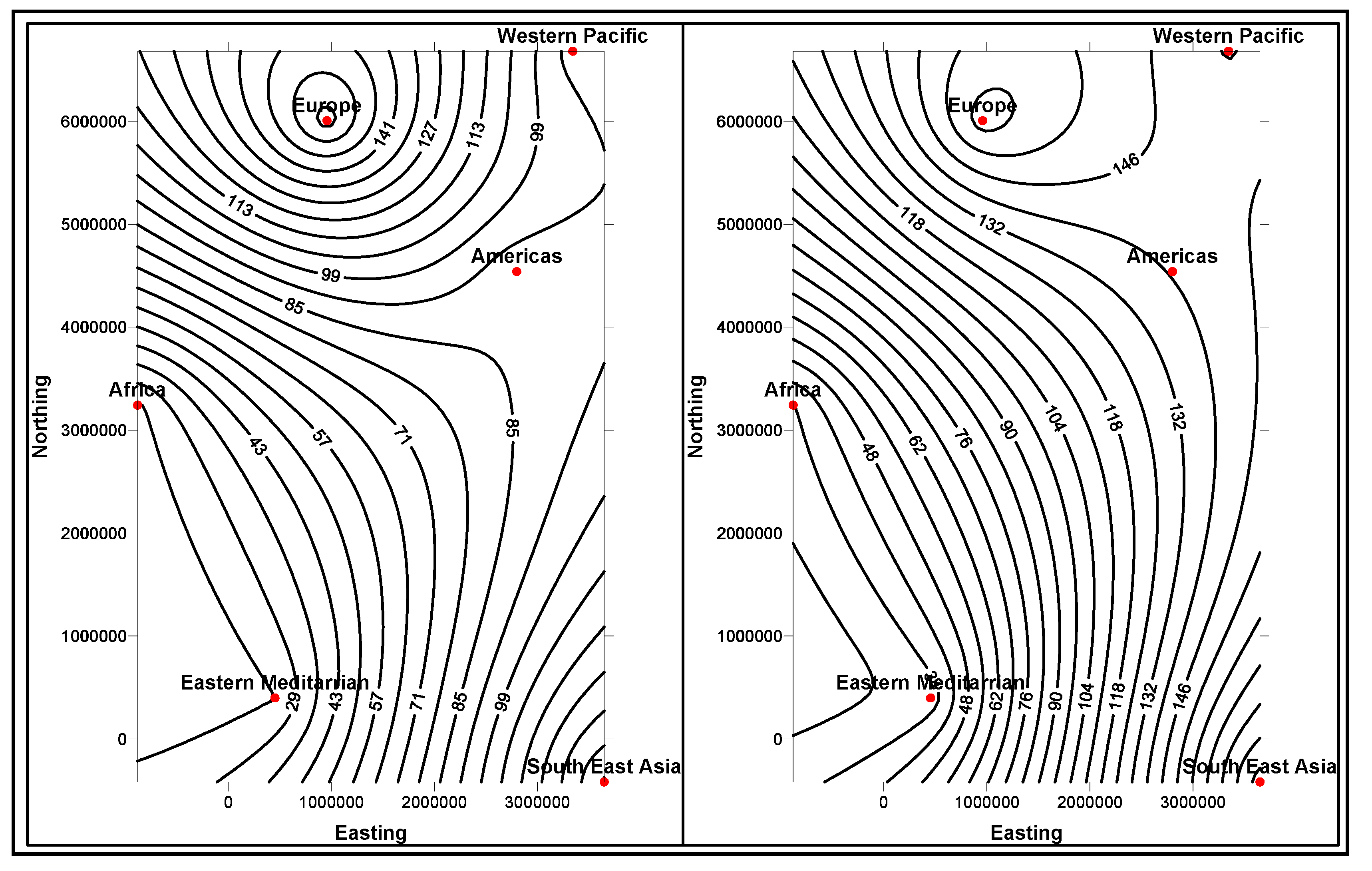
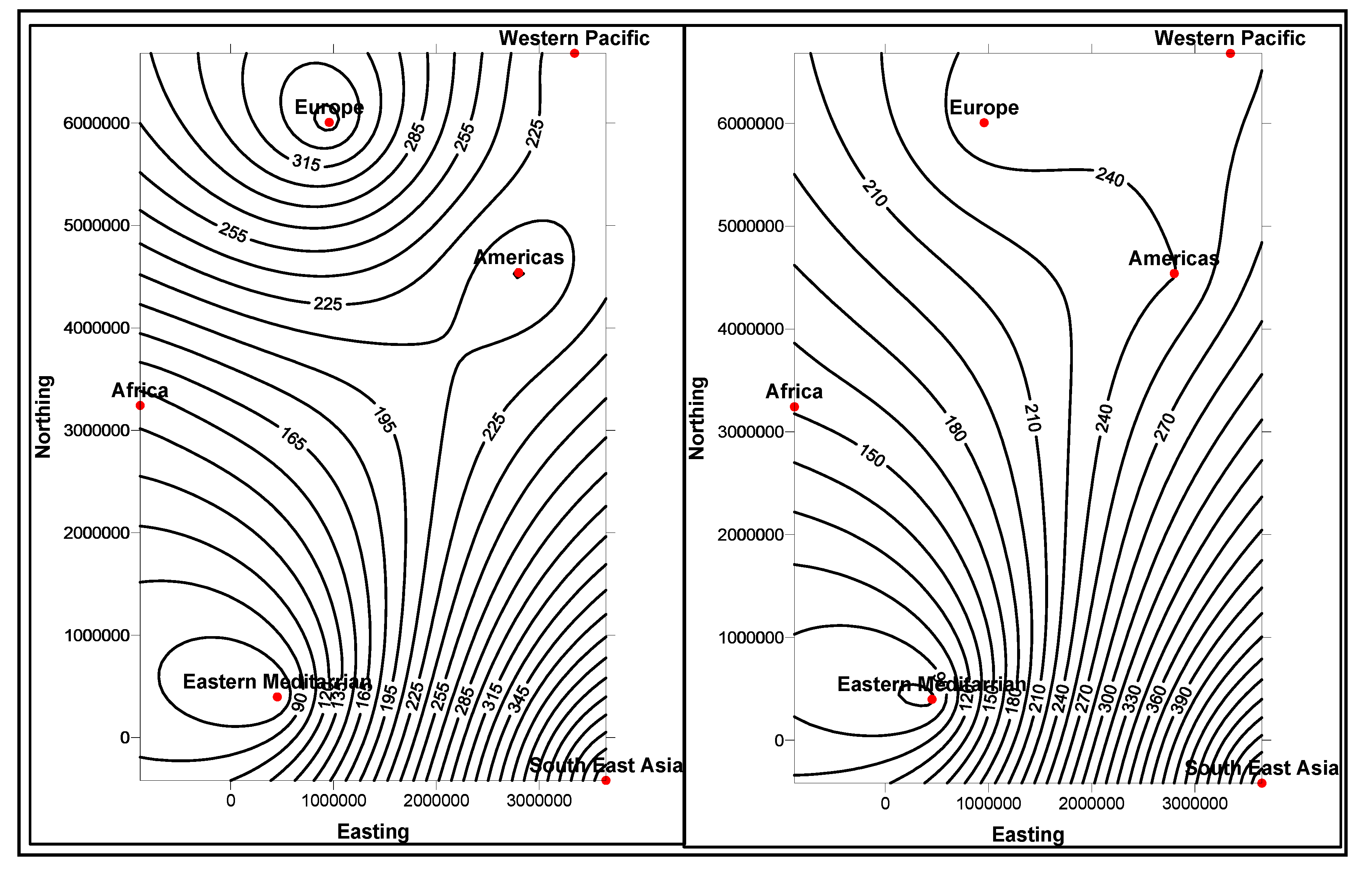
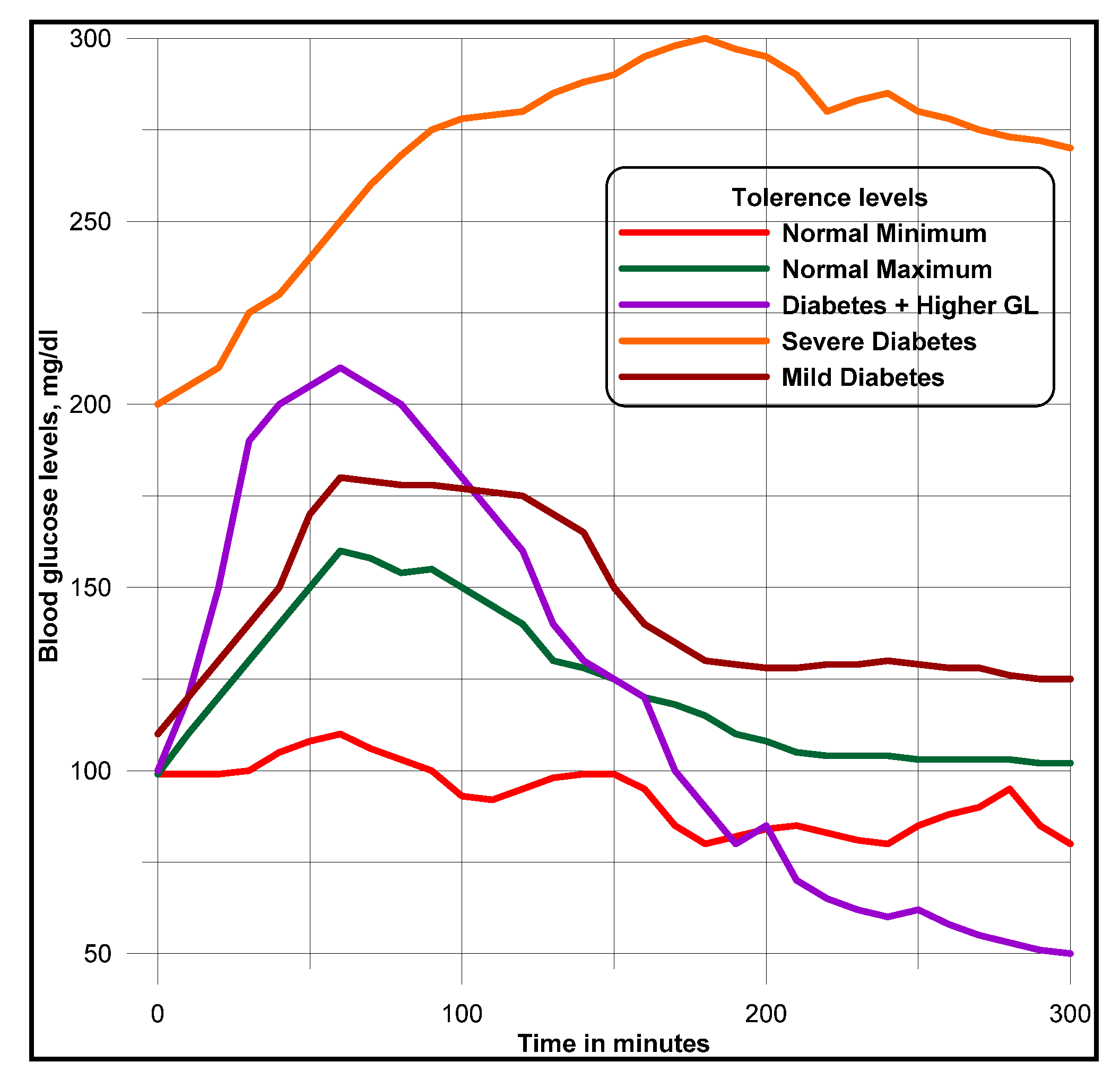
Similarity and
comparison ontologies (
Figure 1) are worth analyzing in understanding of
similarity of patients’ ailments, in adition to comparing different domain data of similar and dissimilar data instances of patients, symptoms, food habits, medications and preventive care regimes. For example, same gender persons may have similar food habits, with similar symptoms and or among
age attribute groups. They may need similar medications/prescriptions and preventive care. Another example is, preventive care of early symptoms for those patients, not yet diabetic nature (with symptoms persisting); medication and treatment phenomena may be in high risk and priority patients, in which, these ailments reported, are under medication for long periods of time. Another example is, in such areas (geographically distributed, such as Africa, Asia, and Latin America), where people have similar lifestyles, with similar ailments and similar or dissimilar food-habits. Similar age groups (such as 45–55 age groups) have similar diabetic type symptoms and or prescriptions. Adults may have diabetes type 1, with similar age and food-habit groups or categories. Event Similarity Prediction (ESP) is an algorithm that can compare, compute attributes and narrate histories of ailments among mass populations. Frequent occurrence of diabetic symptoms in a period of time under analysis is also significant. Other events are, blood sugar and pressure levels under definitive age and gender groups. Non-medical events could be daily intake of food and daily time spent on body exercises. All these data instances are populated in dimension and fact tables, with details of patients, doctors’ notes and facilities, where preventive care and medication are in progress.
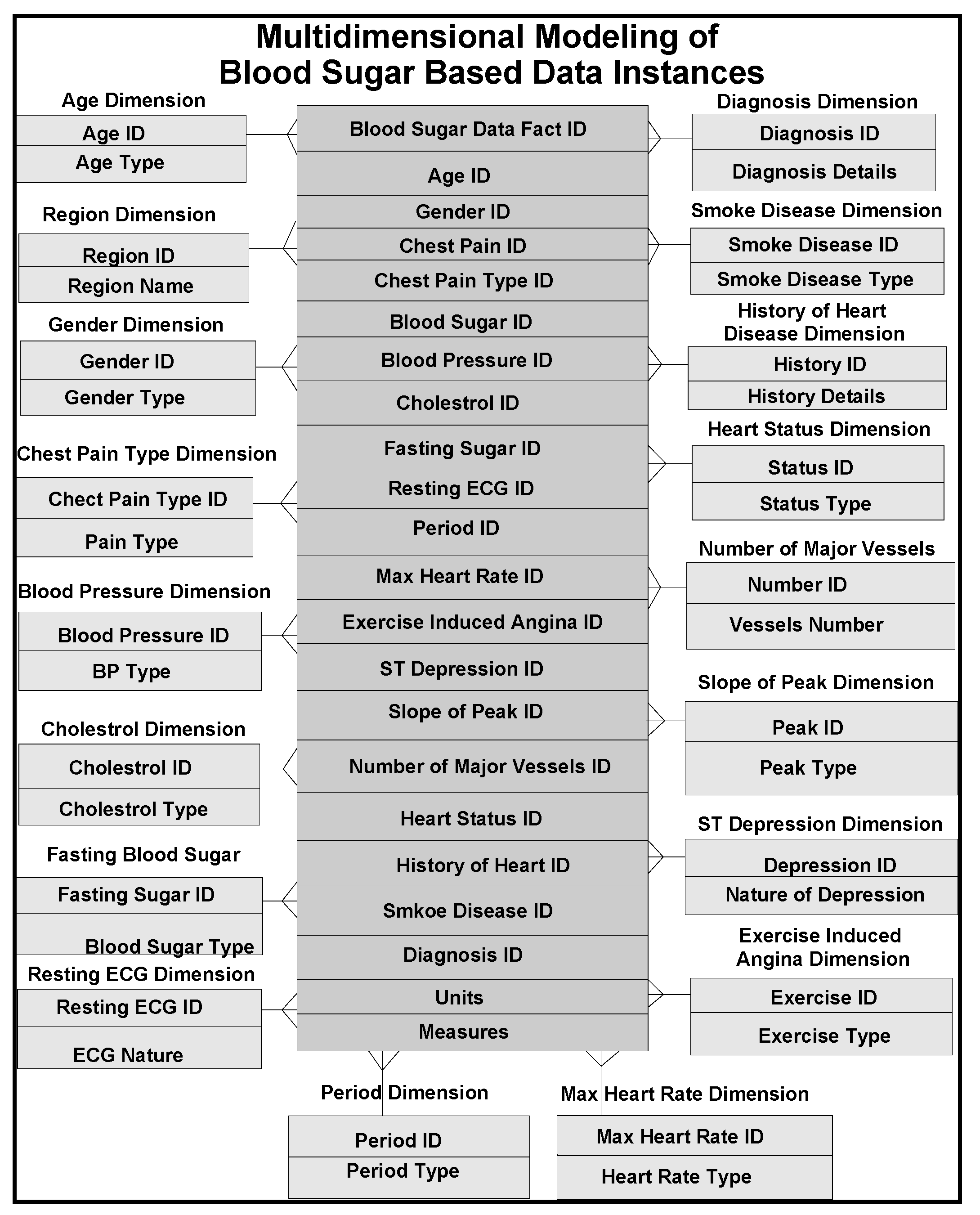
As described in [
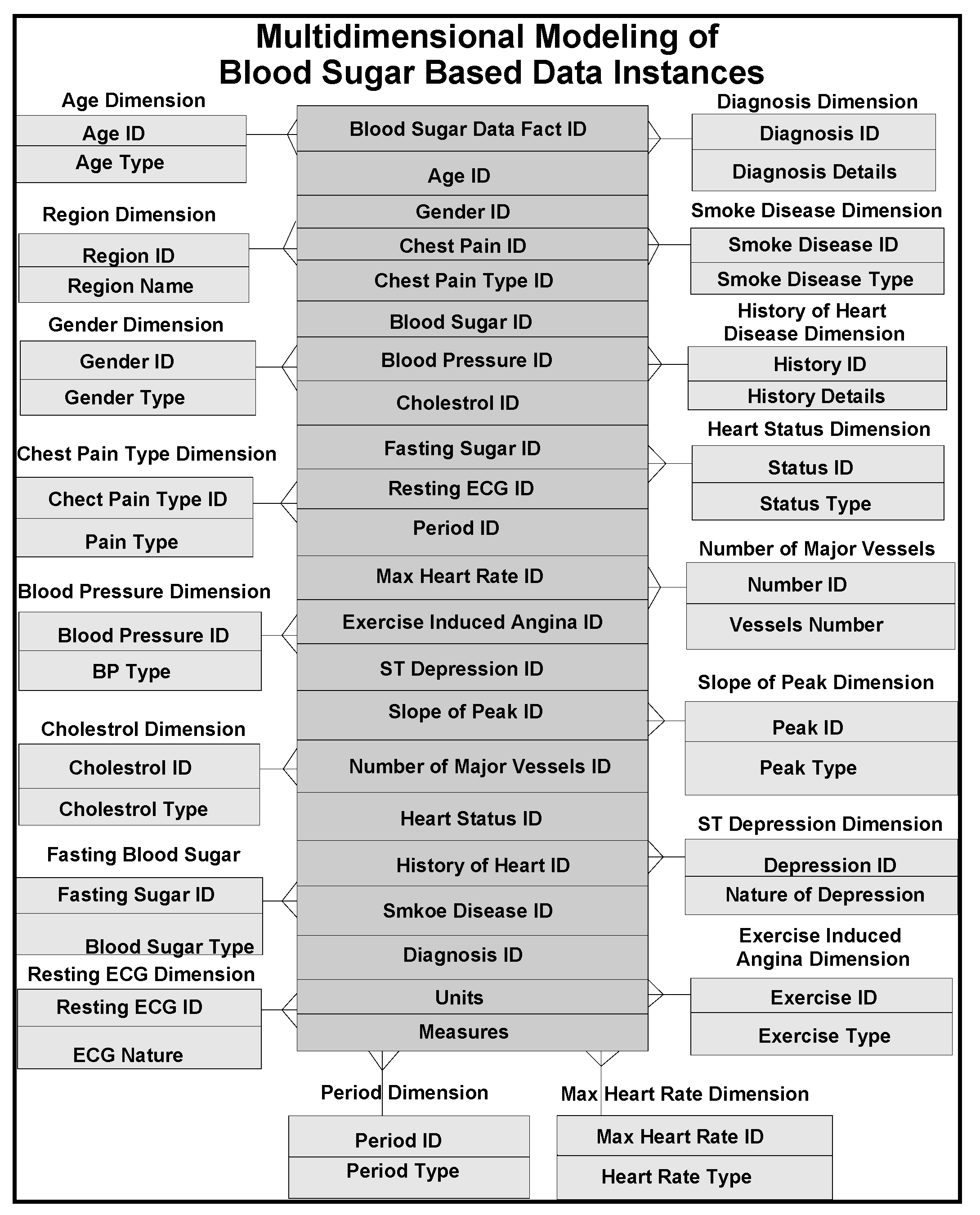
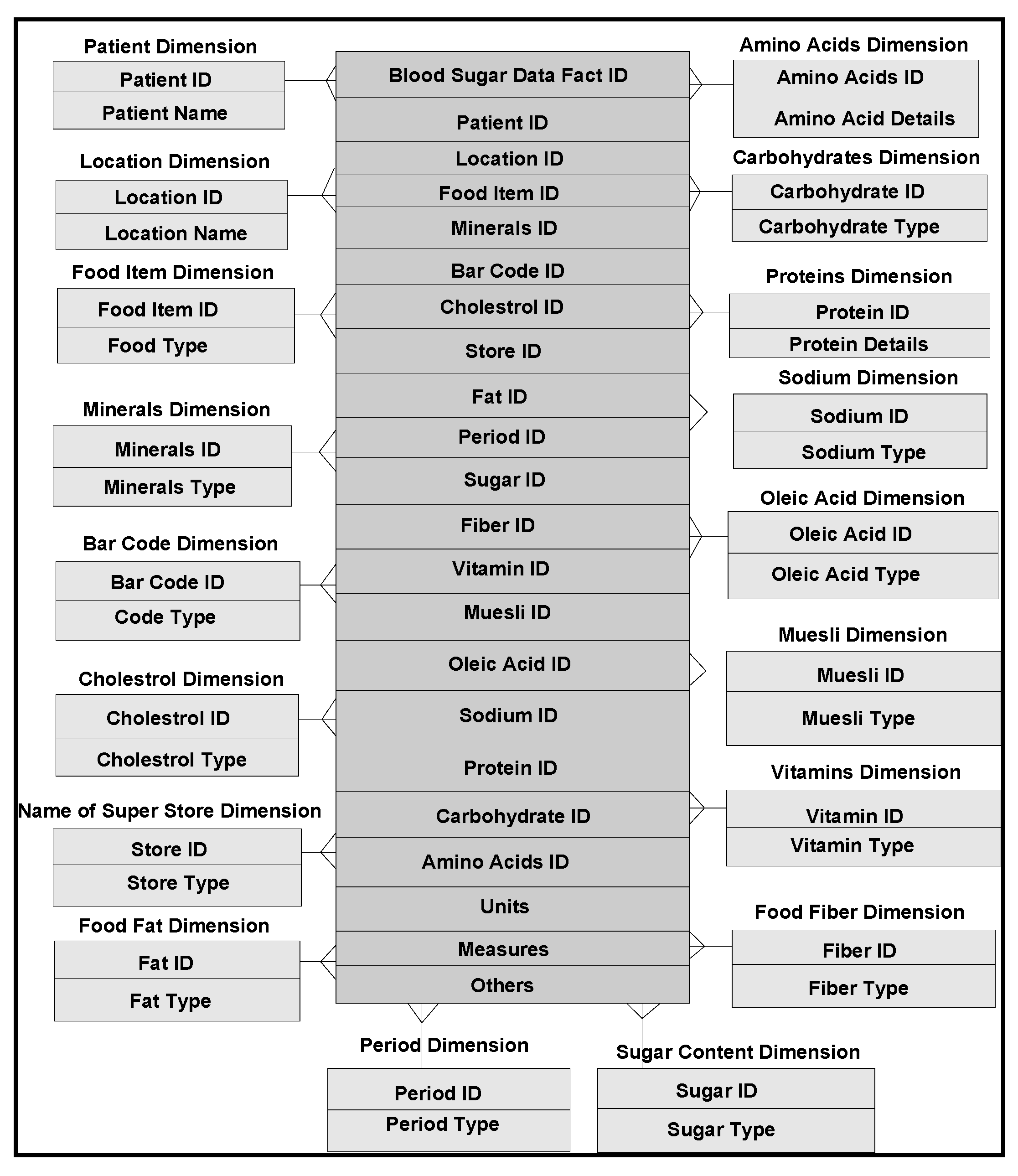
11], several models comprising of dimensions and their attributes in a warehouse environment, focus on rules and constraints, templates, mappings, domains, formats, measurement types, instruments, dimensions, attributes, fields, treatments, patients, medical practitioners, medical prescriptions, bench marks, test results, specimens, specimen types, specimen sizes, periods and units. In addition, glucose levels, glucose type, ophthalmology, eye tests, daily food intake, types of food, food hygiene, normal daily routines, and amount of time spent in daily exercises, cholesterol level are other relevant dimensions. These multidimensional schemas are integrated with other schemas, related to lab test data instances from several other dimensions and fact tables. Star schema models that can handle multidimensional data instances are represented in
Figure 3. A few of such tables are described below with their characteristics in the subsequent sections.
Patient Dimension (Pat Dim): Name, date of birth, history number dimensions are highlights of this table. This table stores demographic information of all patients with laboratory tests. The data warehouse generates internal identifiers for all patients and responsible for linking all the other pertinent dimensions and fact tables, such as specimen test dimension and fact tables. The data warehouse considers the concatenation of patient name, date of birth and history number as primary keys used in the identification patient dimension fact tables. In a more conventional approach, several primary keys of other dimension and fact tables, including outpatient care systems of given patient with different patient’s history numbers of their dimension tables, are connected, including the correct spelling of patient’s name, units of history numbers and dates of birth. A variety of heuristics are used at query time to determine when it is safe to assume that different primary key instances are associated with a single patient. In most cases, data warehouse designers chase the records of the patients and check physically which records are kept or discarded in consultation with physician.
Specimen Dimension (Spc Dim): This table organizes, storing all the specimen records which are collected from laboratory tests. This dimension table has typical attributes such as identification number, the specimen collection date and time, and hospital or outpatient collection location. Specimens are typically identified by the combination of specimen numbers and collection date and time. The data warehouse generates an internal identifier for all the patients’ specimens. This internal identifier is used in the Specimen Test Dimension Table to link specimens and lab tests fact data tables.
Specimen Test Dimension (Spc Tst Dim): Test code or identification, test name, and consulting physician’s name, are typical dimensions in this table that represent the specimen tests. Internal patient and specimen identifiers are included to link specimen tests of patients and specimens, respectively, linking dimension and fact tables. Fact tables consist of storage of all data instances along with units of the specimens. Tests are identified by the combination of specimen identifier, test code and ordering physician instances. The data warehouse generates an internal identifier for specimen test entries. This identifier is linked with the transaction dimension and fact tables.
Transaction Dimension (Tran Dim): The transaction dimension possesses attributes of date and time and tests with their corresponding data instances in fact tables. Transaction dimension provides a mechanism by which the progressions of lab tests are documented. In the fact table, for each transaction, there is an internal identifier created, by the warehouse. Provisional test results may be generated before the final results are made available, to the patient or consulting physician. The Transaction Dimension Identified is connected to the preliminary and final test result dimension tables. Since the entire lab tests are tagged with transaction identifiers, lab results can easily be sorted out by transaction identifiers, such as transaction fact table identification, which can reveal the progression of the lab results from preliminary to final data instances.
Component Dimension (Comp Dim): The composite dimension and lab test results are stored in these dimension and fact tables. Typically they consist of component code, component name, reference ranges, units of measure and results. As narrated before, a transaction identification id, from the transaction dimension and fact tables is linked with all components to track the progression of component data instances.
The component dimension and fact tables are the finest level of granularity for a majority of lab tests (dimension tables). The typical result column contains the results of lab tests. There could be some other lab tests for which the value of the result column is just a reference (through attributes) into other dimension and fact tables. For this purpose, the component dimension table that contain a result type column, records the method of interpretation including diagnostic notes in the result column. Thus at places, the result column appears as the root of a hierarchical structure for specified lab tests. The component result is stored as reference data instances for lab result reports as blocks of test and microbiology culture results. Some lab results are reported as multiple lines of text. This is supported by creating a text dimension (and corresponding fact tables) identifier for the block of text, storing the identifier in the component result field and finally storing the block of text in the free text dimension table (fact tables). Similarly, microbiology culture data are stored in a separate dimension and fact tables. When culture results need to be reported, the transaction dimension identifier that is stored in the component result column is triggered and isolates (conceptualized/contextualized) relationships that are built and accordingly stored in an isolated table with the transaction dimension ID.
The component table is flexible enough to be used for other data types as well. To store other forms of complex lab results, a table is created with a new data type value to store the component result type column. When new data are made available, a unique identifier for the data is generated, the identifier is stored in the component result column and filled the component result type column appropriately. The lab results are added to the new table along with the data identifier that was added to the component result column.
Isolate Dimension (ISL): Portions of culture results from tests performed on specimens, are stored in tables, associated with these dimensions. This table stores the organism or organism class that was identified, the identifier for the isolate, and the transaction identifier that is stored in the component result column. The isolate dimension and tables are used in conjunction with the sensitivity tables by linking them.
Sensitivity Dimension (SEN, SCN, SCR): The antibiotic sensitivity/MIC results for all isolates are stores in these dimension tables. Typically, the table contains antibiotic name, antibiotic code, sensitivity results, and isolate identifiers. The sensitivity table stores, unscreened results as well. Screened results are stored in the sensitivity table, developed for screened results. It has the same design as the original sensitivity table but with stricter access permissions.
Free-Text Dimension: Blocks of texts are stored for various data types, previously mentioned table dimensions. Every block of text, has an identifier, text fact ID. This identifier is referenced by other tables to link data in them to free text comments. The free text table is referenced by the specimen table to store specimen lab notes. The specimen test table references it for test notes. The component table references it to store component comments and test results that are reported as multiple lines of text. Finally, the isolate and sensitivity tables reference it for culture specific comments.
POCT Transaction (POC TRN): The POCT transaction table stores the history of POCT device uploads to the data warehouse. This table stores the machine identifier, date and time, hospital1, location within the hospital, and a transaction identifier for each POCT device uploaded. The information in this table is used to monitor the frequency of POCT device uploads. The upload frequency can be sorted by device identifier, hospital, or location within a hospital.
The transaction identifier is used in the GTS and HEM tables, connecting the glucose and hemoglobin data, respectively, to several other transactions. This data schema provides an efficient mechanism for identifying collections of POCT data that were downloaded within a period of time and/or from select locations.
POCT Data (GTS, HEM): The POCT data tables store the contents of the POCT devices. These tables contain patient identifiers, operator identifiers, QC results, and test results. The patient identifiers can be used to link patients to lab results by cross-referencing with the patient table.
4.3. Ontology Modeling
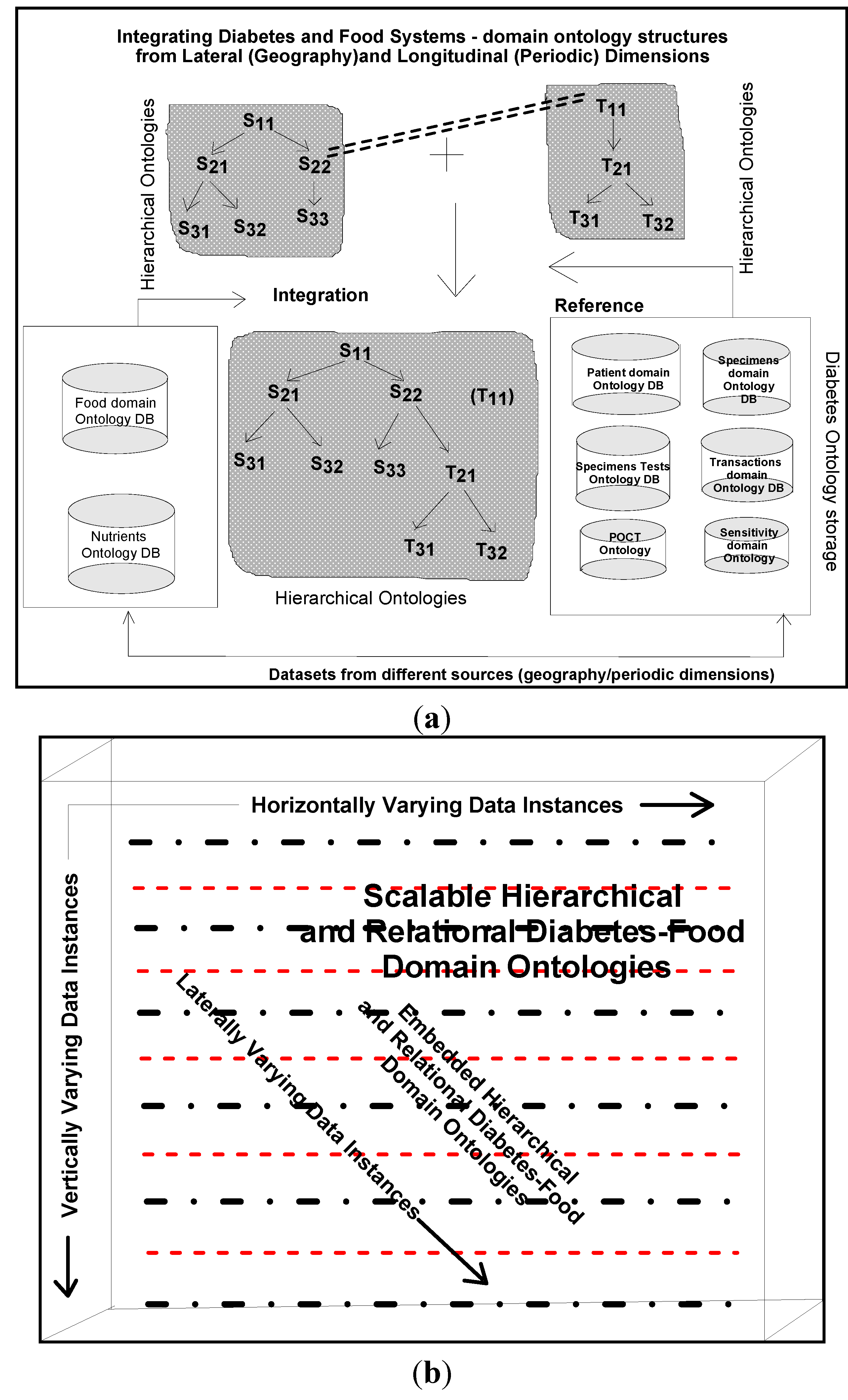
Ontologies are written to conceptualize and contextualize both existing (known data relationships) and emerging attributes (from unknown and or derived data relationships) of the dimensions and their classes that participate in the current modelling process. These are new descriptions, meant for interpretation and its refinement in each domain. Our work is initiated in the petroleum resources business domains and then extended in healthcare domains and applications. Ontologies written, are domain and application specific, and for connecting different food-diabetes domains, since these two compatible ontologies are integrable and mappable together, keeping in view that ontologies are shared in each other’s domain.
Ontology is a formal representation of knowledge, based on specification of conceptualization and contextualization. Different entities, objects and dimensions and their relationships (either known or unknown) chosen, appear to be existing in the domain of knowledge representation and interpretation. Conceptualization is a simplified view of abstraction, but needs to be represented in knowledge domains, so that they can easily be integrated and shared by other related domains. Web ontology languages or even the existing archetype patters of high levels ontology descriptions [
6], are used for describing semantics, schema, and syntaxes including system specifications and representations. They also address different naming conventions, vocabularies and contents including conflicts and ambiguities that arise during conceptualization of dimesions and structuring procedures and processes. Schemas and semantics of dimensions and their attributes can be swapped as long as they are cognitively associated domains, such as
food-diabetes are associated dimensions. Our idea is to integrate different cognitive ontology specifications and representations. For this purpose, the concept of warehousing is used for integration, in which all the multidimensional schemas are compatibly accommodated, structured and integrated into a metadata.
Golden software solutions are initially used for drawing schemas and sub-schemas. Rules and constraints, templates, mappings, domains, formats, measurement types, instruments, dimensions, attributes, fields, treatments, patients, medical practitioners, medical practices, benchmarks, test results, specimens, specimen types, specimen sizes, periods and units are used in the ontology descriptions. Besides glucose levels, glucose type, ophthalmology and eye tests, daily food intake, types of food, food hygiene, normal daily routines, amount of time spent in daily exercises and cholesterol level measurements are incorporated in the modelling process. These multidimensional structure descriptions (ontologically conceptualized at places) are made connected and shared in the form of schemas narrated in
Figure 3 and also in
Figure 4 and
Figure 5, as detailed in the following sections.
4.5. Description of Multidimensional Food-domain Ontologies
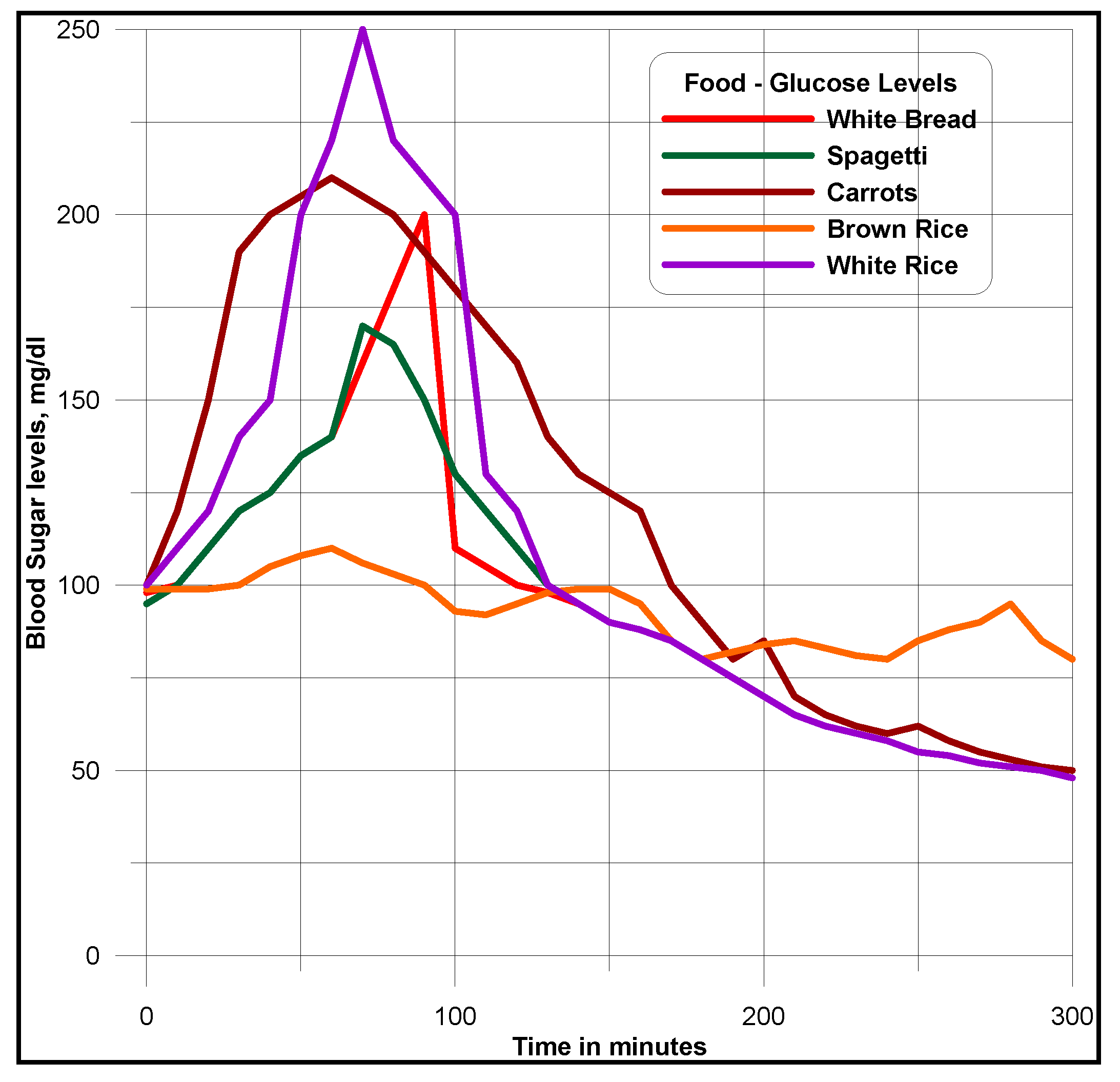
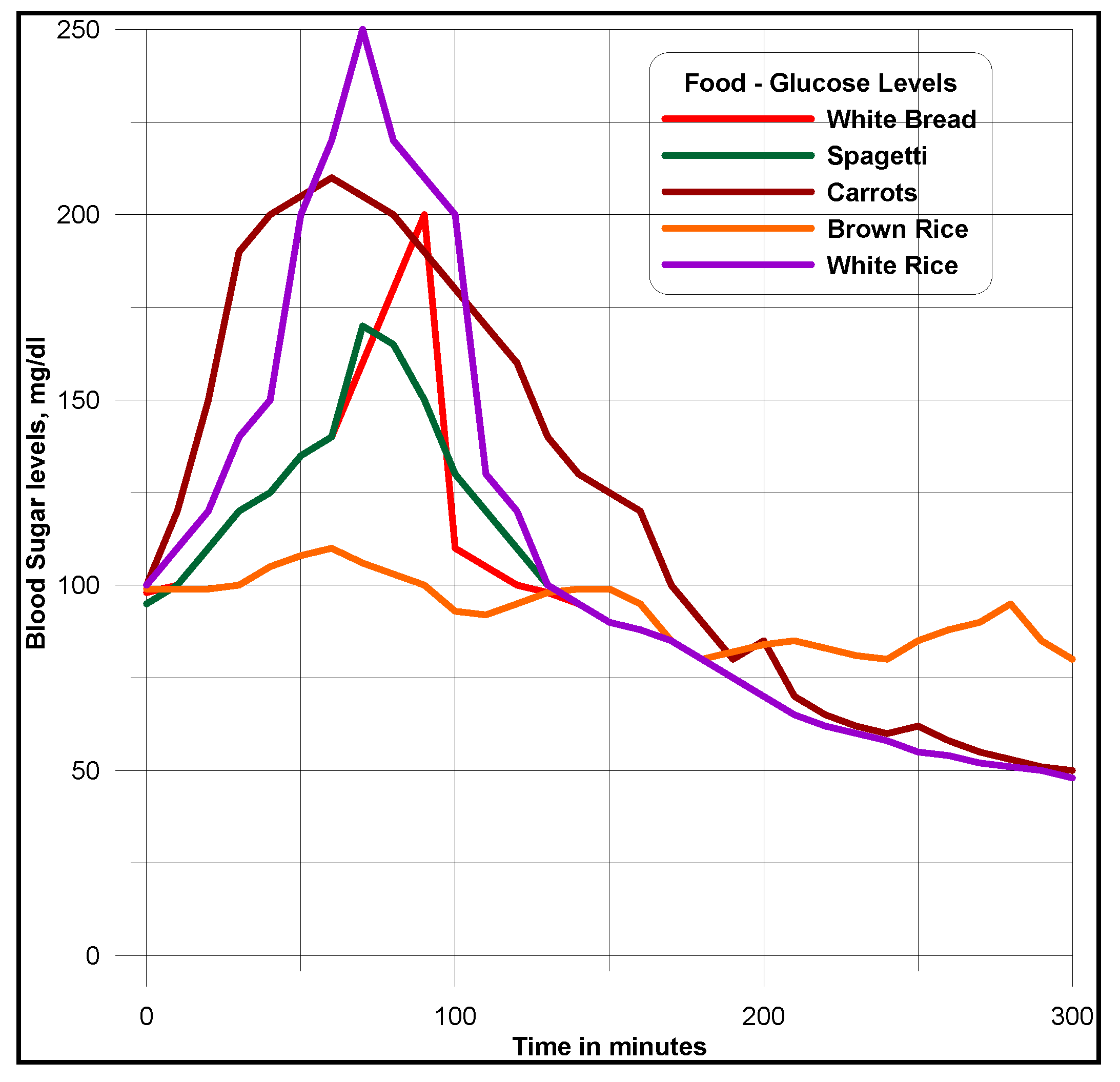
Food domain ontology (within the context of its associativity with diabetic domain) is aimed at understanding its connectivity with diabetes ontology and associated food domain ontologies, as suggested for diabetes meal plans, including the type, amount of nutrients and recommended daily food intakes. High insulin, carbohydrate food intakes and unhealthy life styles cause obesity, diabetes and their associated ailments. White bread, potatoes and white rice are high glycemic. Low glycemic foods such as whole grains, pasta, vegetables, fruits, beans, seeds, nuts and low fat cooking oils, such as olive and canola are chosen instead, for controlling weight, blood sugars and blood pressure. These foods possess much antioxidants, which can develop immune system and resistance to major illnesses. Americans, Europeans, Africans, Asians and people living in Pacific regions have different lifestyles and food intakes, based on their age. Based on these criteria, the real extent and magnitude of diabetic disease varies.
For example, though for sure the trend is changing, most American families do not prefer whole grains and vegetables on their shopping list. Europeans and Mediterranean people are vigilant on their diets, and especially prefer appetizing dishes made from vegetables, fruits and whole grains. Africans regularly consume medium to moderate fat meals with lot of vegetables, green bananas (steamed) and with lots of red meat including fish, fresh fruits and nuts. African populations, though cautious on sugar intake, are affected by high blood sugar levels. Asians, especially Indians include white sugar intake in their regular meals. Unlike Indians, intake of sugar by Chinese and Japanese is moderately low, especially among the aged population. Most of the sugar-related diseases are among Asian populations. As documented and interpreted in [
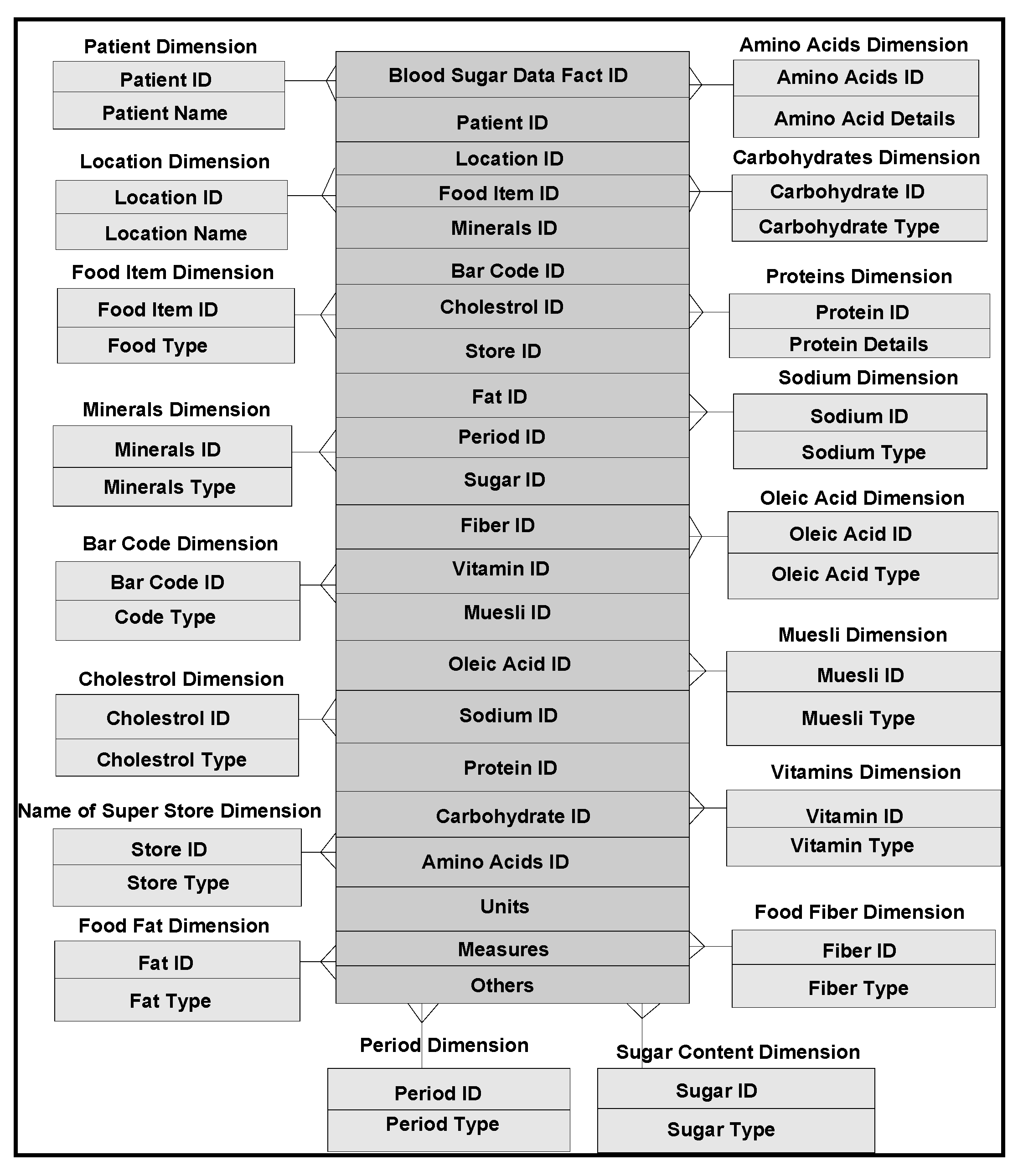
13], there are 177 classes (dimensions), 53 properties (attributes) and 632 data instances, in food domain ontologies compatible for domain integration criteria. Countrywise data instances acquired worldwide, are populated within dimension and fact-data tables. As per schema design and business constraints narrated in
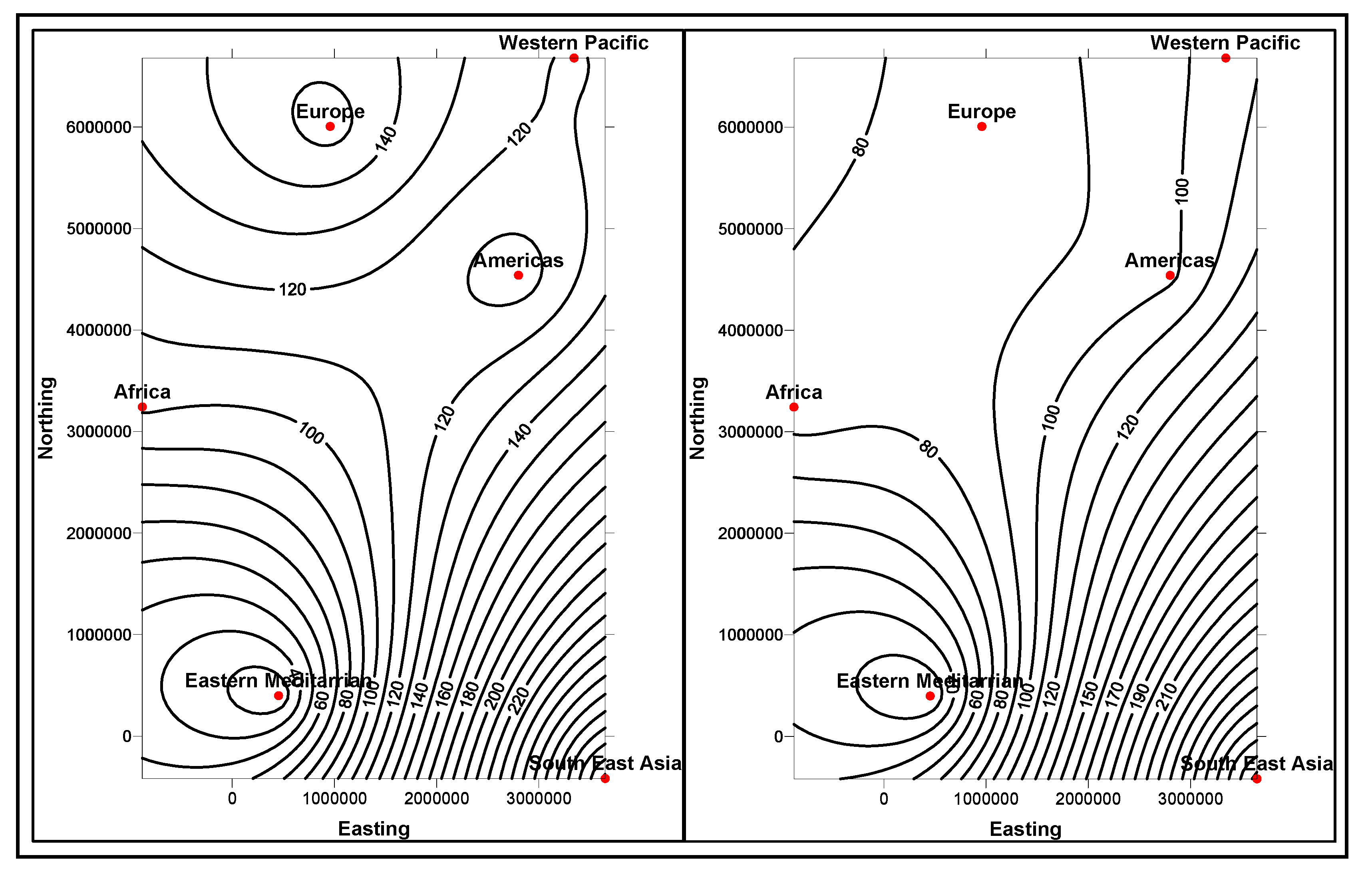
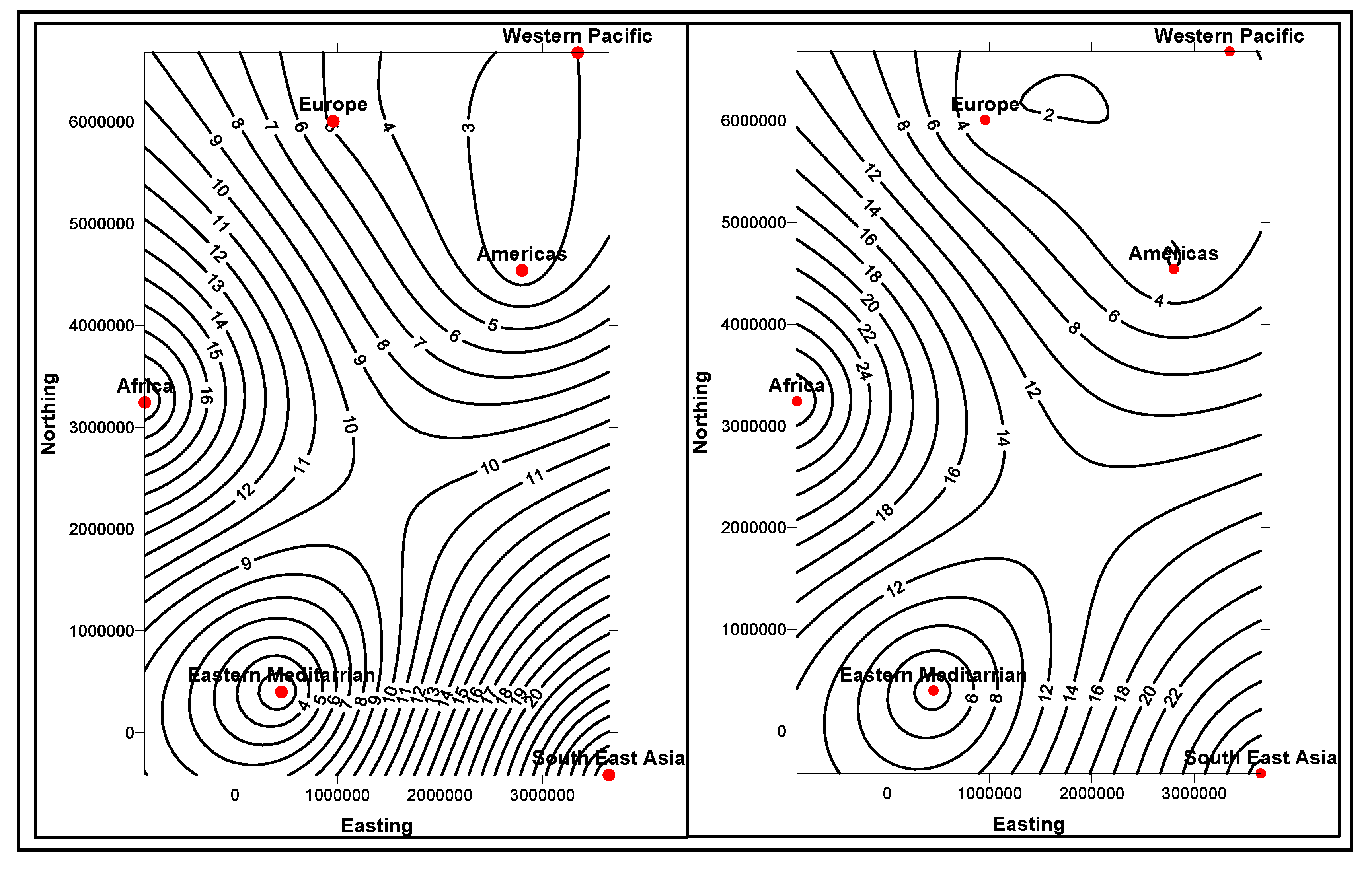
Figure 7, instances from multiple dimensions and fact tables are mapped.
Figure 7.
Multidimensional model of different qualities of foods that affect the blood sugar levels.
Figure 7.
Multidimensional model of different qualities of foods that affect the blood sugar levels.
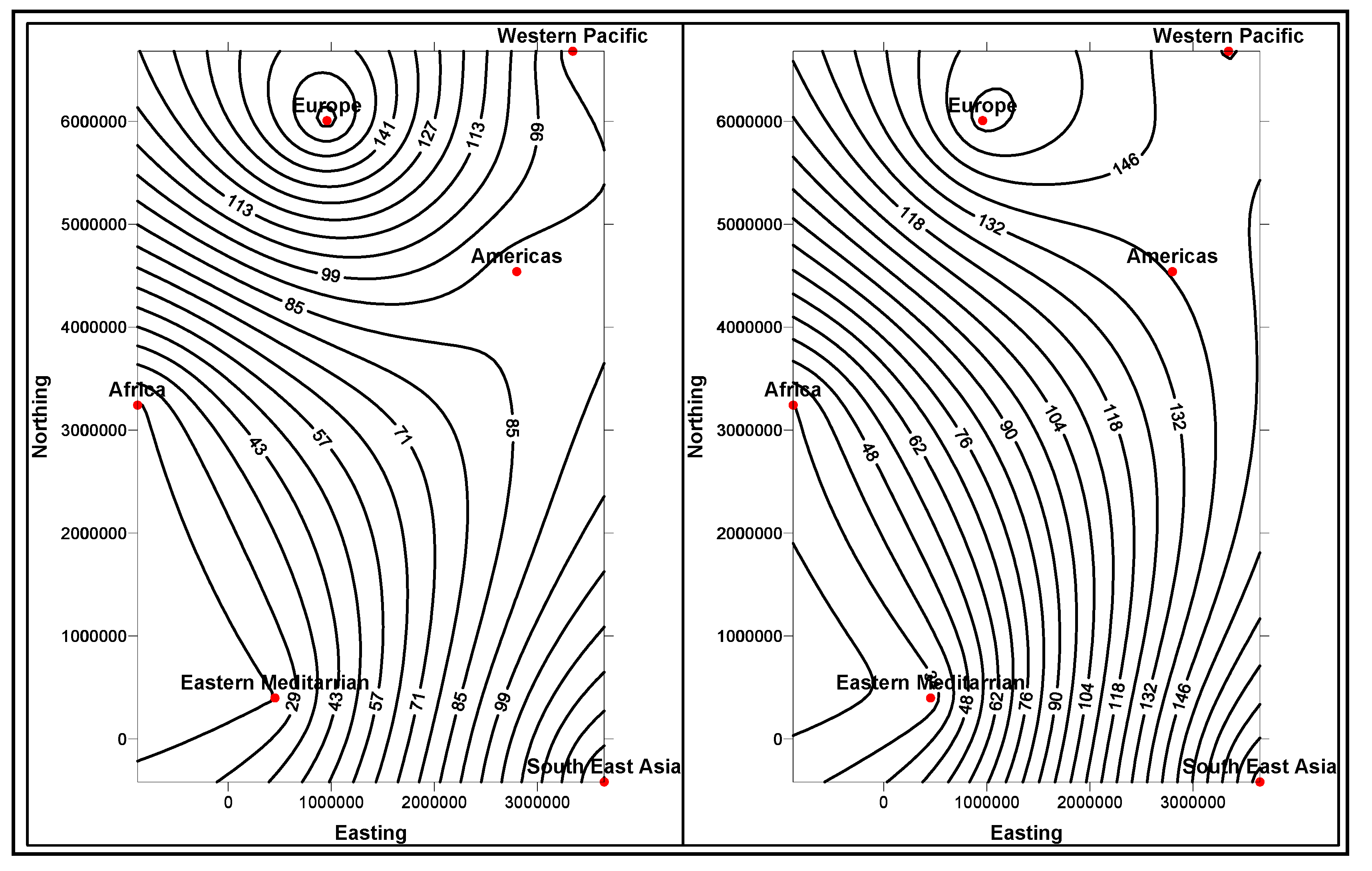
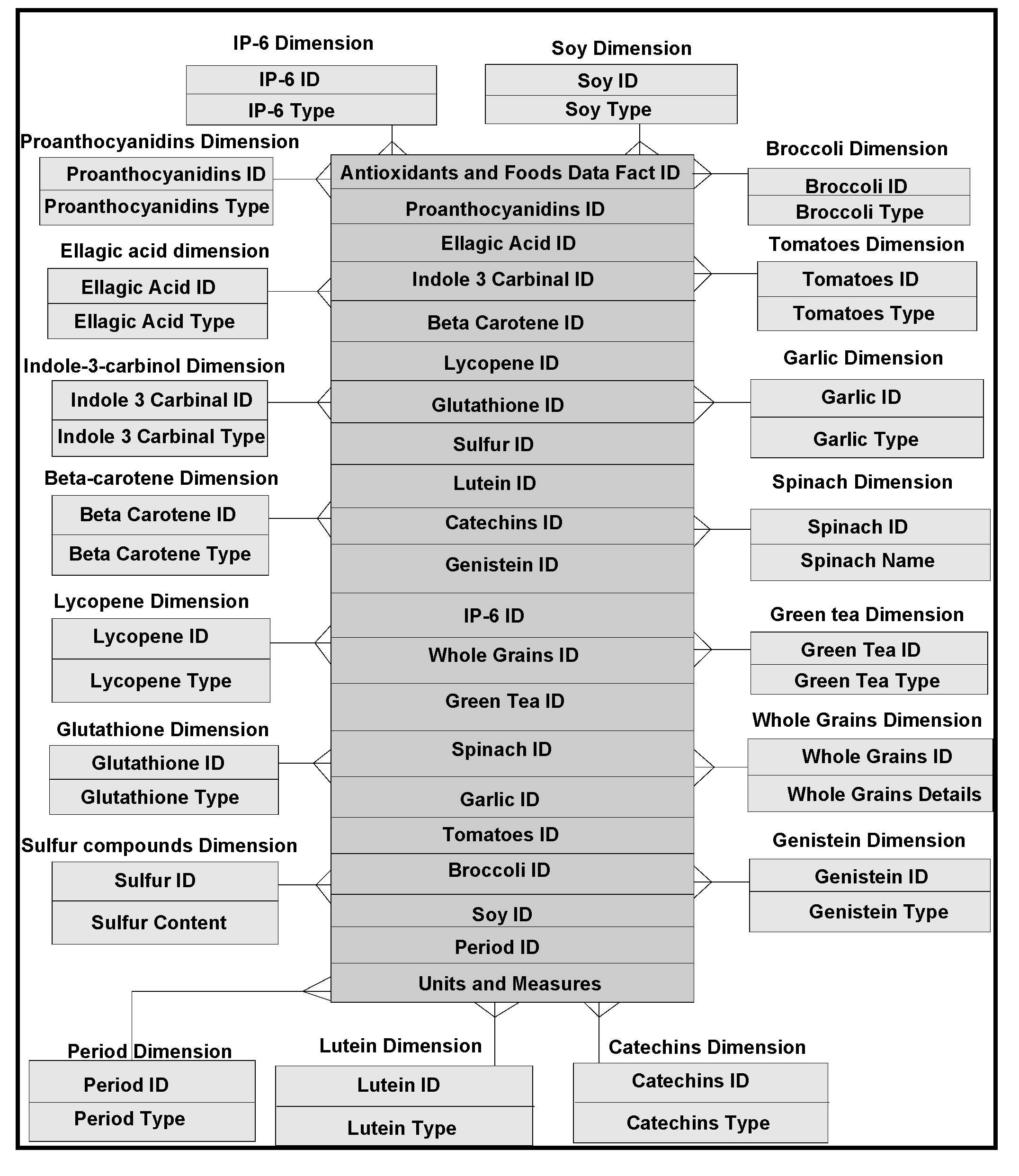
4.6. Domain Ontologies Representing Antioxidants
In addition to the awareness of healthy lifestyles
, in recent years,
antioxidants has become a new, exciting and rapidly expanding field of science. Information and knowledge on this growing science, need to be tied up with our daily routines. Certain foods such as
tomatoes,
chocolate and
green-tea are healthful. What is being emphasized here, are the effects of the antioxidants found within these foods. Many of the chemicals that provide natural coloring to fruits and vegetables are antioxidants. The data instances relevant to anti-oxidants are populated within dimension and fact data tables, setting business rules, for each schema (
Figure 5). There are literally several thousand of these compounds contained within foods. Their role in the prevention of cardiovascular disease, insulin resistance and perhaps even cancer, is poorly understood. Free radicals and antioxidants are commonly used in narrating disease mechanisms [
14]. Free radicals are either derived from normal essential metabolic processes in the human body or from external sources. Free radicals can also form in the cells as a consequence of reactions between enzymatic and nonenzymatic consequences. In the case of diabetic patients, free radicals are produced from noxious chemicals (formed on blood vessel walls), generated from daily intake of food. Foods may have high glycemic or high cholesterol values, and free radicals can overwhelm blood vessels’ natural defences. A balance between free radicals and antioxidants is necessary for proper physiological function. If free radicals overwhelm the body’s ability to regulate them, a condition known as oxidative stress ensues. Free radicals thus adversely alter lipids, proteins, DNA and trigger a number of human diseases. This is why additional antioxidants absorbed during a meal can be so helpful. If fruits, veggies and whole grains are neglected in the diet, an extra protection for arteries is denied. Proanthocyanidins and ellagic acid in berries, indole-3-carbinol and β-carotene in broccoli, lycopene (of the carotenoid family) and glutathione in tomatoes, sulfur compounds in garlic, lutein in spinach, the catechins in green tea, and β-carotene (a member of the healing family of carotenoids) are effective in controlling sugar levels. Genistein and other isoflavones in soy and vitamin E, rich in phytic acid, known as IP-6, a potent antioxidant in whole grains are very significant antioxidants, not only effective for diabetic patients, but for cancer, cholesterol, heart disease, eye-related diseases and osteoporosis.
Mediterranean meal plans rich in vegetables, whole grains, fruits, nuts seeds, olive and canola oils, limited red meat and fish are low fat, while others are more moderate in their fat content. A moderate wine intake has been a feature of some studies [
3].
4.7. Nutrition and Food-label Domain Ontologies
With today’s food labels in supermarkets, consumers get valuable guidance on food nutrients and required daily diets. Nutrition information about almost every food in the grocery store, with healthful food choices, is available by easy-to read formats. Information on amount per serving of fats, cholesterol, dietary fiber and other nutrients are major health concerns. Nutrient reference values with percentage daily intakes that can fit individual overall daily diets, uniformly describe food’s nutrients content, ensuring understandable relationships between nutrients, foods and diseases or health related conditions, such as diabetes and sugar, calcium, osteoporosis, fat and cancer. Standardized serving sizes making nutritional comparisons for similar products are helpful. Declaration of percentage of juice content in juice drinks, sugar content in juice, help consumers understand how much is required for daily intake and per serving. Food labels explaining uniformity of serving sizes of similar and dissimilar products for different healthy background people, similarities and comparisons among nutritional qualities of related foods are useful. Labels also provide grams of total carbohydrates, proteins, fat and sugar contents. Naturally present sugars in foods are healthful compared to manmade white sugars for managing diabetes. Labeling of grams of proteins intake is helpful for restricting protein intake either to reduce or avoid the risk of kidney disease. Label claims of low, saturated fat and high fiber are beneficial for diabetic patients. Other claims including diets low in saturated fat and cholesterol, rich in fruits, vegetables fiber-grains, and soluble fiber from whole oats, may help reduce the risk of coronary heart disease. These descriptions are incorporated in building schemas and sub-schemas, using all relevant multidimensional data instances.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}