
Necessity of Local Modification for Deep Learning Algorithms to Predict Diabetic Retinopathy

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
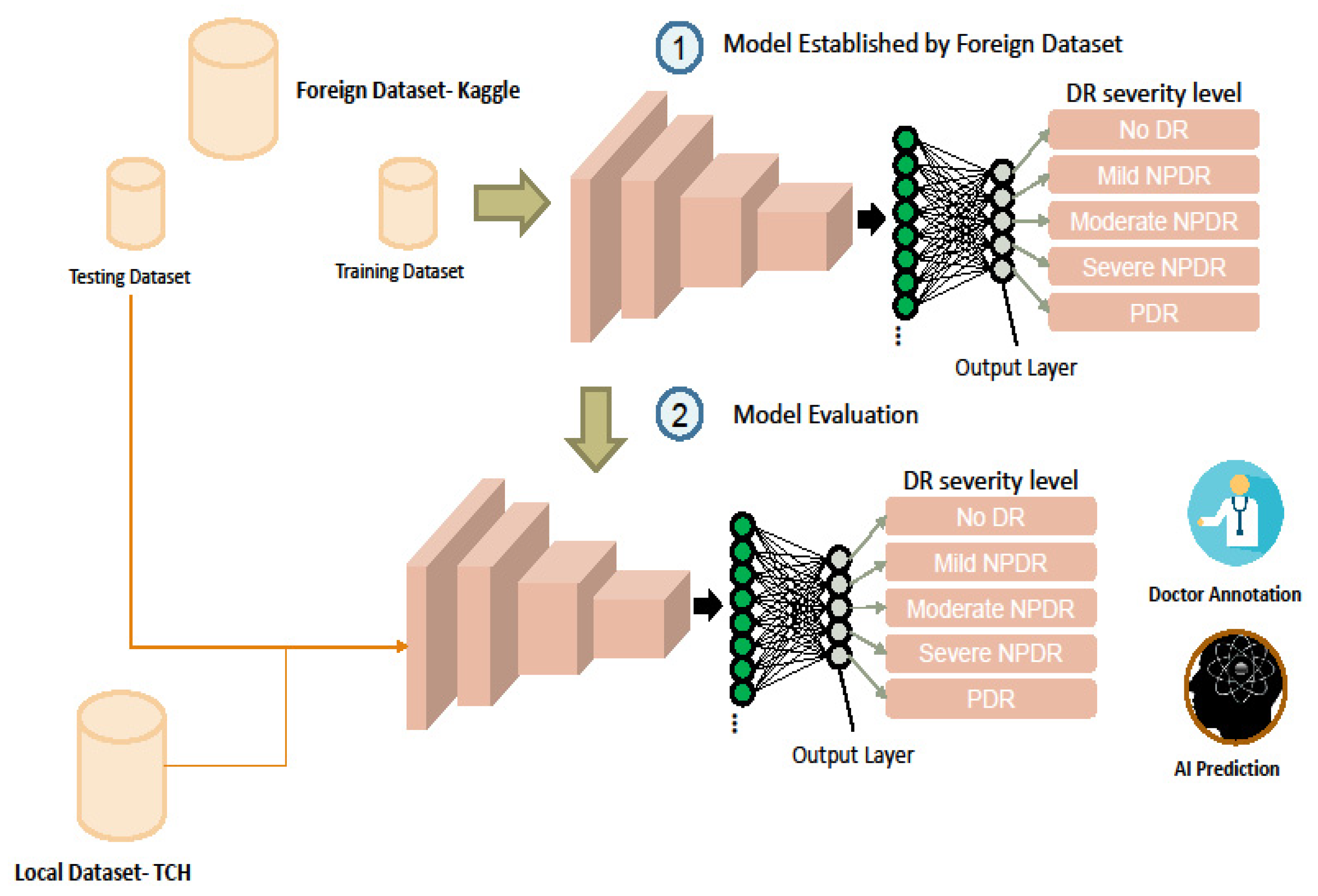
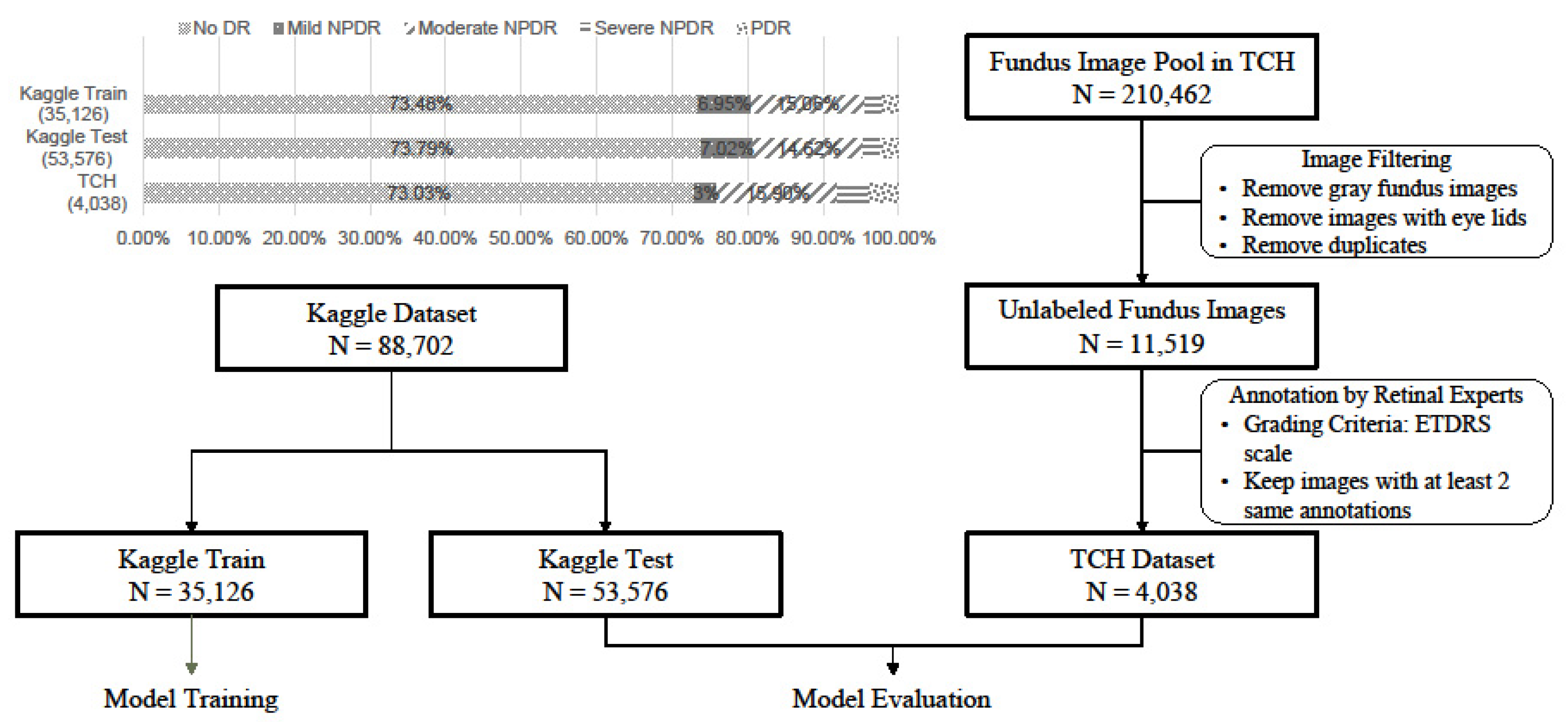
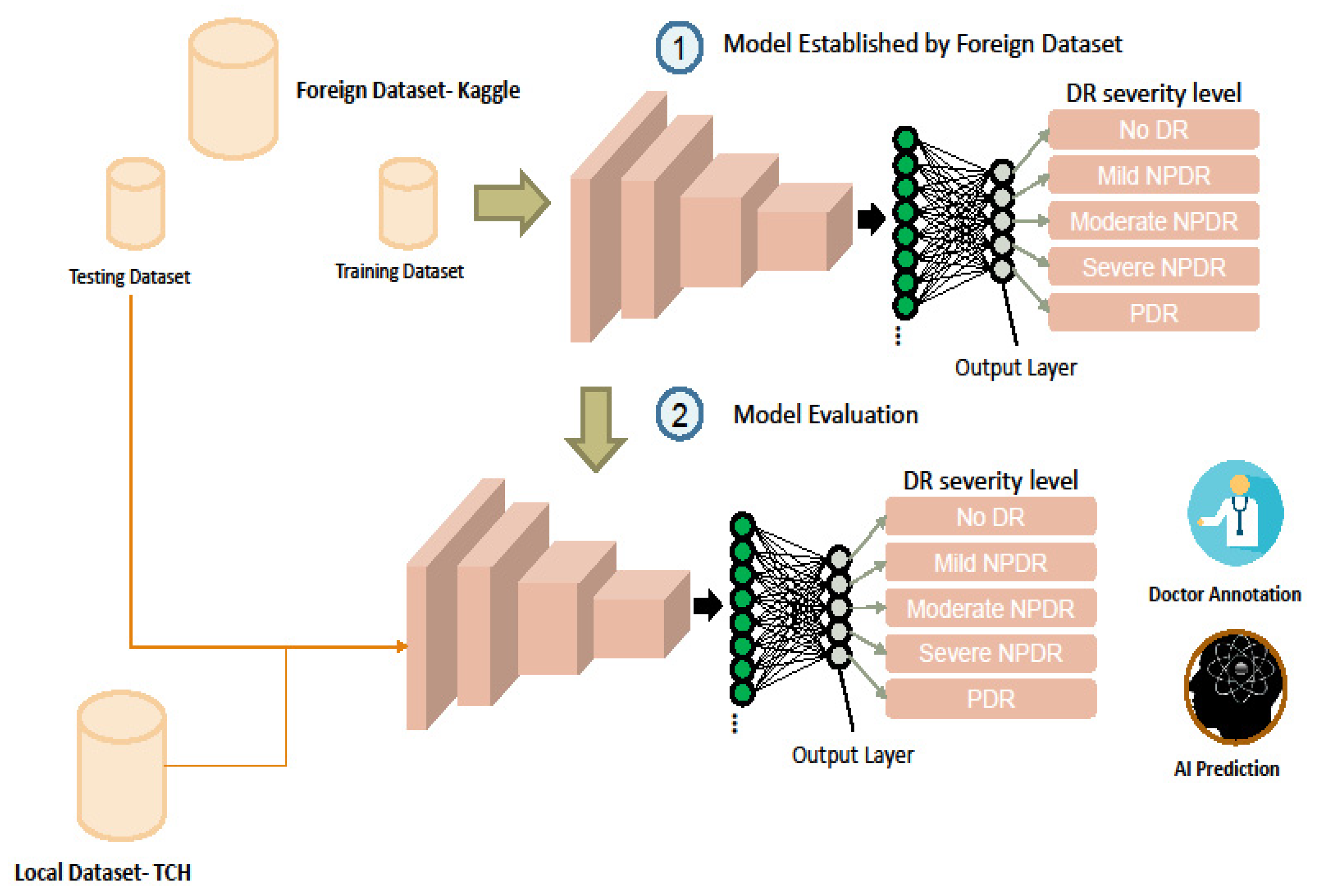
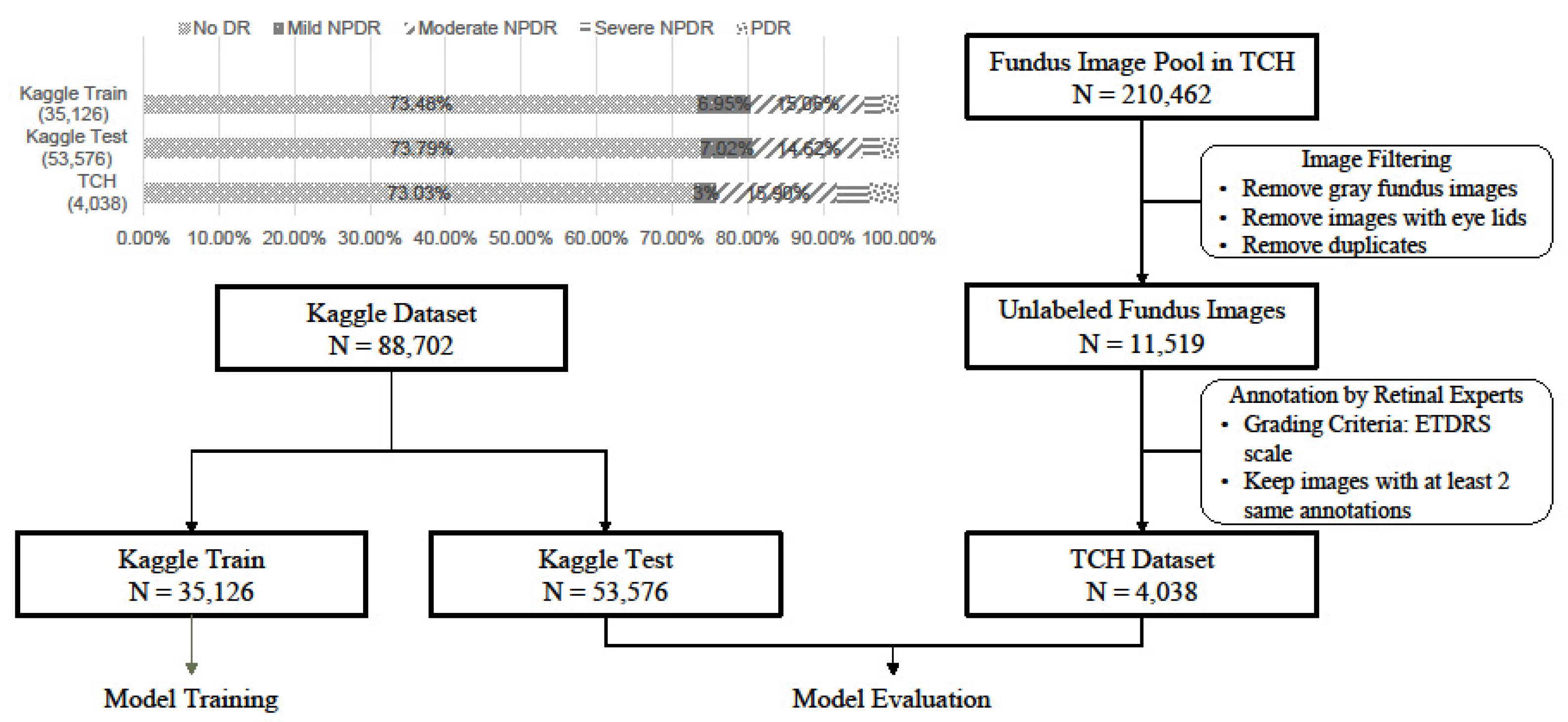
2.1. Dataset
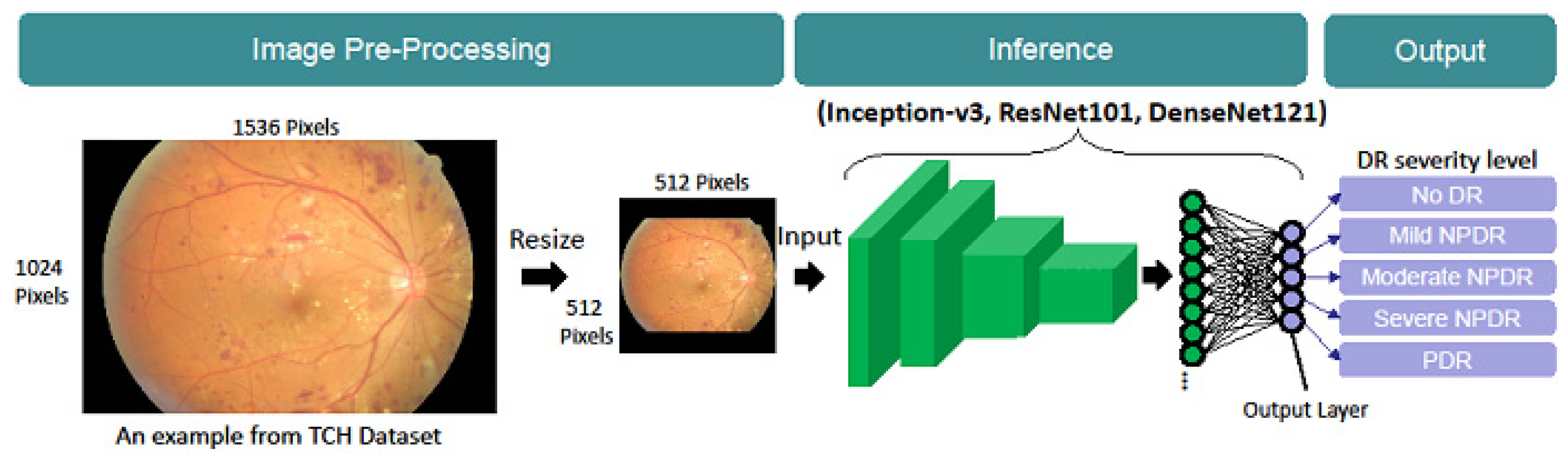
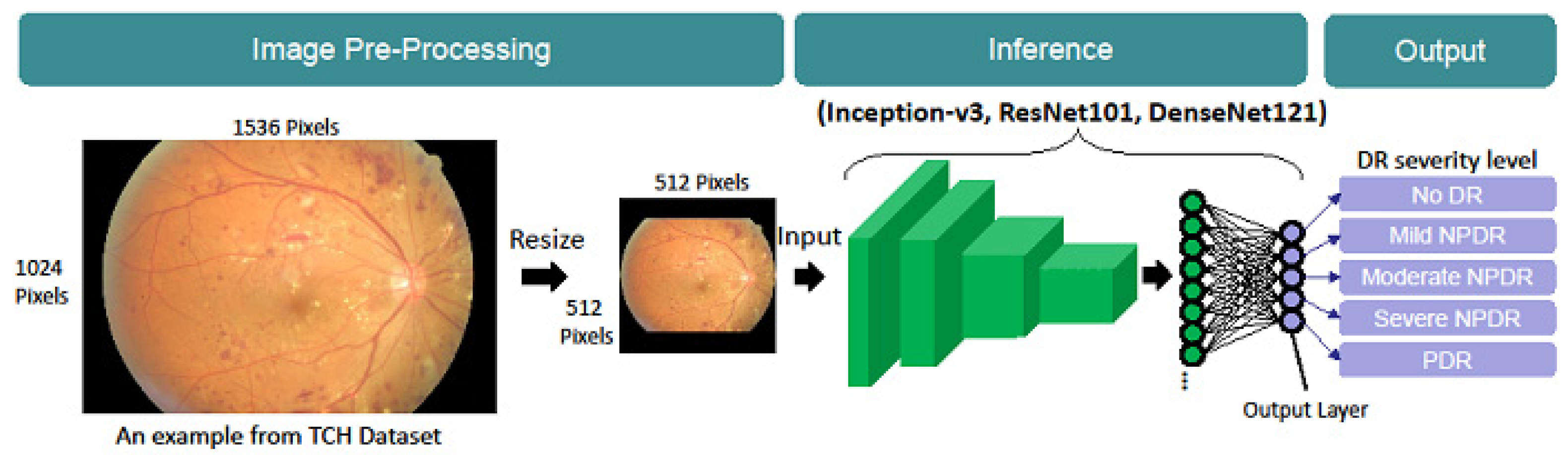
2.2. Model Architecture
2.3. Model Training and Testing
2.4. Evaluation Metrics
2.5. Implementation
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, T.; Liyan, M.; Zhijie, W.; Shaorong, X.; Yupeng, X. Learning discriminative representations for fine-grained diabetic retinopathy grading. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- Junjun, H.; Cheng, L.; Jin, Y.; Shanshan, W.; Yu, Q.; Lixu, G. Classification of ocular diseases employing attention-based unilateral and bilateral feature weighting and fusion. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1258–1261. [Google Scholar]
- Vitiello, G.; Sebillo, M.; Fornaro, L.; Di Gregorio, M.; Cirillo, S.; De Rosa, M.; Costagliola, G. Do you like my outfit? Cromnia, a mobile assistant for blind users. In Proceedings of the 4th EAI International Conference on Smart Objects and Technologies for Social Good, Bologna, Italy, 28 November 2018; ACM Digital Libraray: Beijing, China, 2018; pp. 249–254. [Google Scholar]
- Yi, Z.; Boyang, W.; Lei, H.; Shanshan, C.; Ling, S. A benchmark for studying diabetic retinopathy: Segmentation, grading, and transferability. IEEE Trans. Med. Imaging 2021, 40, 818–828. [Google Scholar]
- Raman, R.; Sangeetha, S.; Sunny, V.; Sobha, S.; Chetan, R.; Ramachandran, R. Fundus photograph-based deep learning algorithms in detecting diabetic retinopathy. Eye 2009, 33, 97–109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zilong, H.; Jinshan, T.; Ziming, W.; Kaia, Z.; Ling, Z.; Qingling, S. Deep learning for image-based cancer detection and diagnosis—A survey. Pattern Recognit. 2018, 83, 134–149. [Google Scholar]
- Zhuang, H.; Zhang, J.; Liao, F. A systematic review on application of deep learning in digestive system image processing. Vis Comput. 2021, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Ting, D.S.W.; Pasquale, L.R.; Peng, L.; Campbell, J.P.; Lee, A.Y.; Raman, R.; Tan, G.S.W.; Schmetterer, L.; Keane, P.A.; Wong, T.Y. Artificial intelligence and deep learning in ophthalmology. Br. J. Ophthalmol. 2019, 103, 167–175. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abràmoff, M.D.; Lou, Y.; Erginay, A.; Clarida, W.; Amelon, R.; Folk, J.C.; Niemeijer, M. Improved automated detection of diabetic retinopathy on a publicly available dataset through integration of deep learning. Investig. Ophthalmol. Vis. 2016, 57, 5200–5206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; He, Y.; Keel, S.; Meng, W.; Chang, R.T.; He, M. Efficacy of a deep learning system for detecting glaucomatous optic neuropathy based on color fundus photographs. Ophthalmology 2018, 125, 1199–1206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hwang, D.-K.; Hsu, C.-C.; Chang, K.-J.; Chao, D.; Sun, C.-H.; Jheng, Y.-C.; Yarmishyn, A.A.; Wu, J.-C.; Tsai, C.-Y.; Wang, M.-L.; et al. Artificial intelligence-based decision-making for age-related macular degeneration. Theranostics 2019, 9, 232–245. [Google Scholar] [CrossRef] [PubMed]
- Flaxman, S.R.; Bourne, R.A.; Resnikoff, S.; Ackland, P.; Braithwaite, T.; Cicinelli, M.V.; Das, A.; Jonas, J.B.; Keeffe, J.; Kempen, J.H.; et al. Global causes of blindness and distance vision impairment 1990–2020: A systematic review and meta-analysis. Lancet Glob. Health 2017, 5, e1221–e1234. [Google Scholar] [CrossRef] [Green Version]
- Prokofyeva, E.; Zrenner, E. Epidemiology of major eye diseases leading to blindness in Europe: A literature review. Ophthalmic Res. 2012, 47, 171–188. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wilkinson, C.; Ferris, F.; Klein, R.; Lee, P.; Agardh, C.D.; Davis, M.; Dills, D.; Kampik, A.; Pararajasegaram, R.; Verdaguer, J.T. Proposed international clinical diabetic retinopathy and diabetic macular edema disease severity scales. Ophthalmology 2003, 110, 1677–1682. [Google Scholar] [CrossRef]
- Holden, B.A.; Fricke, T.R.; Wilson, D.A.; Jong, M.; Naidoo, K.S.; Sankaridurg, P.; Wong, T.Y.; Naduvilath, T.; Resnikoff, S. Global prevalence of myopia and high myopia and temporal trends from 2000 through 2050. Ophthalmology 2016, 123, 1036–1042. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Inception v3 rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Ting, D.S.W.; Cheung, C.Y.-L.; Lim, G.; Tan, G.S.W.; Quang, N.D.; Gan, A.; Hamzah, H.; Garcia-Franco, R.; Yeo, I.Y.S.; Lee, S.Y.; et al. Development and validation of a deep learning system for diabetic retinopathy and related eye diseases using retinal images from multiethnic populations with diabetes. JAMA 2017, 318, 2211–2223. [Google Scholar] [CrossRef] [PubMed]
- Xiao, T.; Zhang, J.; Yang, K.; Peng, Y.; Zhang, Z. Error-driven incremental learning in deep convolutional neural network for large-scale image classification. In Proceedings of the ACM International Conference on Multimedia, Orlando, FL, USA, 3 November 2014; pp. 177–186. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localized. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Model | Dataset | Accuracy (%) | Quadratic Kappa (%) | Weighted Average Recall/Precision (%) |
|---|---|---|---|---|
| Inception-v3 | Kaggle Test | 84.64 | 79.33 | 84.64/82.41 |
| TCH Test | 83.80 | 85.32 | 83.80/85.23 | |
| ResNet101 | Kaggle Test | 83.89 | 78.12 | 83.89/81.47 |
| TCH Test | 82.99 | 83.60 | 82.99/84.91 | |
| DenseNet121 | Kaggle Test | 84.05 | 77.21 | 84.05/81.29 |
| TCH Test | 84.67 | 85.96 | 84.67/84.80 |
| Model | Metrics | Dataset | No DR (%) | NPDR (%) | PDR (%) | Weighted Average (%) | ||
|---|---|---|---|---|---|---|---|---|
| Mild | Moderate | Severe | ||||||
| Inception-v3 | SEN | Kaggle | 95.86 | 18.15 | 66.75 | 40.02 | 58.07 | 84.64 |
| TCH | 94.34 | 6.61 | 59.66 | 40.61 | 89.4 | 83.80 | ||
| PRE | Kaggle | 89.58 | 47.96 | 70.15 | 49.24 | 71.01 | 82.41 | |
| TCH | 97.10 | 27.59 | 62.99 | 50.00 | 35.82 | 85.23 | ||
| ResNet101 | SEN | Kaggle | 97.46 | 16.67 | 59.39 | 40.12 | 58.28 | 83.89 |
| TCH | 94.64 | 19.83 | 55.76 | 23.64 | 86.34 | 82.99 | ||
| PRE | Kaggle | 88.55 | 47.34 | 71.94 | 44.14 | 58.52 | 81.47 | |
| TCH | 96.31 | 28.24 | 68.32 | 38.61 | 32.33 | 84.91 | ||
| DenseNet121 | SEN | Kaggle | 98.62 | 9.30 | 60.41 | 29.79 | 54.45 | 84.05 |
| TCH | 97.12 | 1.65 | 59.50 | 20.00 | 85.71 | 84.67 | ||
| PRE | Kaggle | 87.30 | 53.50 | 72.76 | 44.09 | 66.84 | 81.29 | |
| TCH | 95.79 | 28.57 | 70.35 | 35.48 | 34.07 | 84.80 | ||
| Model | Dataset | No (%) | Mild (%) | Moderate (%) | Severe (%) |
|---|---|---|---|---|---|
| Inception-v3 | Kaggle Test | 3.14 | 16.37 | 5.90 | 5.11 |
| TCH | 5.66 | 59.50 | 34.89 | 49.69 | |
| ResNet101 | Kaggle Test | 2.54 | 14.00 | 8.56 | 14.23 |
| TCH | 5.35 | 45.45 | 36.92 | 55.76 | |
| DenseNet121 | Kaggle Test | 1.38 | 11.74 | 5.79 | 9.52 |
| TCH | 2.88 | 42.15 | 33.49 | 58.79 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, C.-Y.; Chen, C.-T.; Chen, G.-A.; Yeh, C.-F.; Kuo, C.-T.; Hsiao, Y.-C.; Hu, H.-Y.; Tsai, I.-L.; Wang, C.-H.; Chen, J.-R.; et al. Necessity of Local Modification for Deep Learning Algorithms to Predict Diabetic Retinopathy. Int. J. Environ. Res. Public Health 2022, 19, 1204. https://doi.org/10.3390/ijerph19031204
Tsai C-Y, Chen C-T, Chen G-A, Yeh C-F, Kuo C-T, Hsiao Y-C, Hu H-Y, Tsai I-L, Wang C-H, Chen J-R, et al. Necessity of Local Modification for Deep Learning Algorithms to Predict Diabetic Retinopathy. International Journal of Environmental Research and Public Health. 2022; 19(3):1204. https://doi.org/10.3390/ijerph19031204
Chicago/Turabian StyleTsai, Ching-Yao, Chueh-Tan Chen, Guan-An Chen, Chun-Fu Yeh, Chin-Tzu Kuo, Ya-Chuan Hsiao, Hsiao-Yun Hu, I-Lun Tsai, Ching-Hui Wang, Jian-Ren Chen, and et al. 2022. "Necessity of Local Modification for Deep Learning Algorithms to Predict Diabetic Retinopathy" International Journal of Environmental Research and Public Health 19, no. 3: 1204. https://doi.org/10.3390/ijerph19031204