
Exact Inference for Random Effects Meta-Analyses for Small, Sparse Data


Abstract
1. Introduction
2. Problem Setup
2.1. Notations and Assumptions
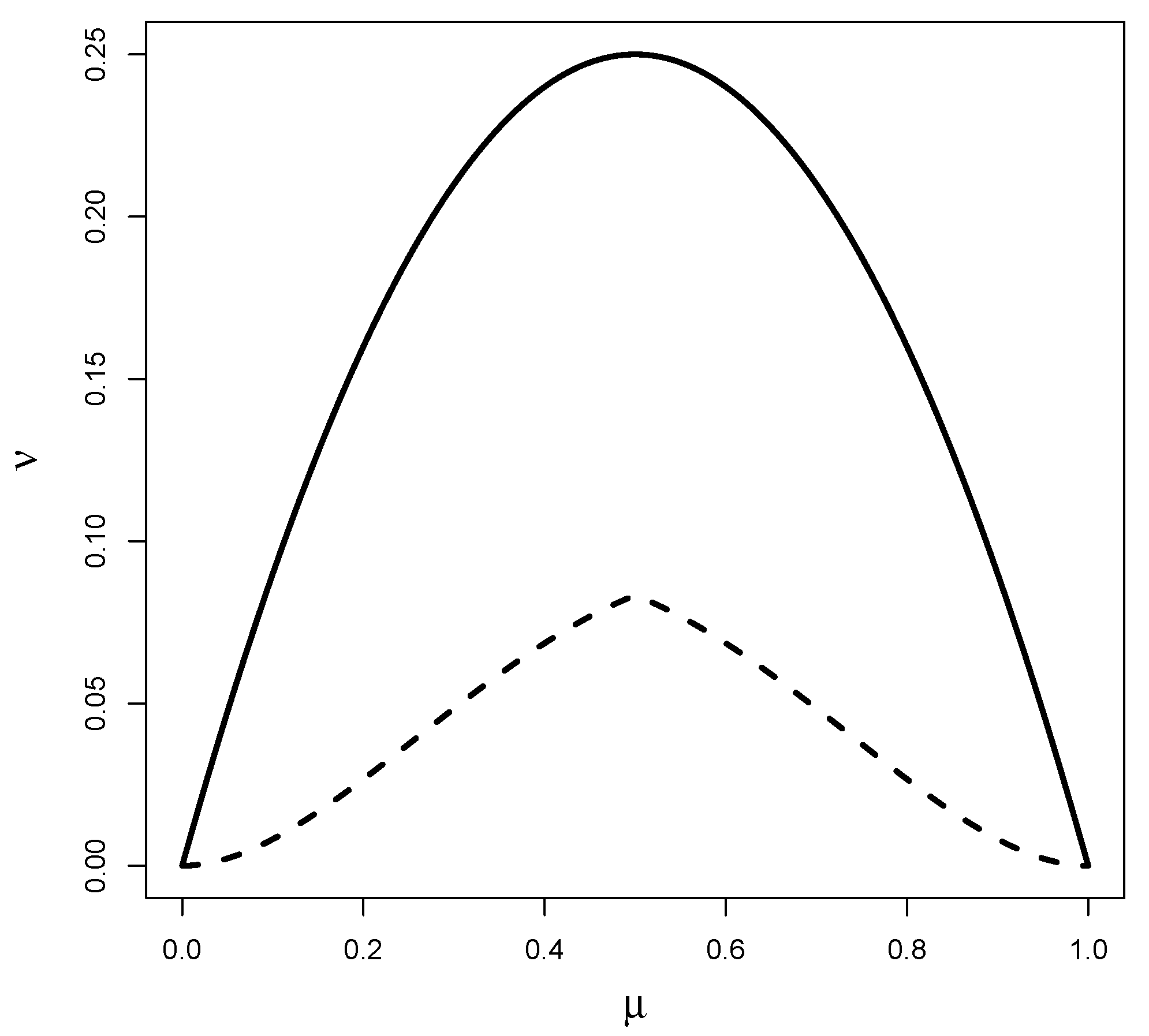
2.2. Parameter of Interest
3. Methods
3.1. Overview of the Exact Inference Procedure
- Step 1a. Generate a simulated dataset, where ,
- Step 1b. Compute the test statistic .
3.2. Proposed Test Statistic for the Exact Inference Procedure
3.2.1. Balanced Design
3.2.2. Unbalanced Design
3.3. Computational Details
4. Results
4.1. Simulation Studies
4.2. Real Data Examples
4.2.1. Rosiglitazone Study
4.2.2. Face Mask Study
5. Discussion
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Egger, M.; Smith, G.D. Meta-Analysis: Potentials and promise. BMJ Br. Med. J. 1997, 315, 1371. [Google Scholar] [CrossRef] [PubMed]
- Egger, M.; Smith, G.D.; Phillips, A.N. Meta-analysis: Principles and procedures. BMJ Br. Med. J. 1997, 315, 1533. [Google Scholar] [CrossRef] [PubMed]
- Normand, S.L. Tutorial in biostatistics meta-analysis: Formulating, evaluating, combining, and reporting. Stat. Med. 1999, 18, 321–359. [Google Scholar] [CrossRef]
- Brown, L.D.; Cai, T.T.; Dasgupta, A. Confidence intervals for a binomial proportion and asymptotic expansions. Ann. Stat. 2002, 30, 160–201. [Google Scholar] [CrossRef]
- Sweeting, M.; Sutton, A.; Lambert, P. What to add to nothing? Use and avoidance of continuity corrections in meta-analysis of sparse data. Stat. Med. 2004, 23, 1351–1375. [Google Scholar] [CrossRef]
- Bradburn, M.J.; Deeks, J.J.; Berlin, J.A.; Russell Localio, A. Much ado about nothing: A comparison of the performance of meta-analytical methods with rare events. Stat. Med. 2007, 26, 53–77. [Google Scholar] [CrossRef]
- Cai, T.; Parast, L.; Ryan, L. Meta-analysis for rare events. Stat. Med. 2010, 29, 2078–2089. [Google Scholar] [CrossRef] [PubMed]
- Vandermeer, B.; Bialy, L.; Hooton, N.; Hartling, L.; Klassen, T.P.; Johnston, B.C.; Wiebe, N. Meta-analyses of safety data: A comparison of exact versus asymptotic methods. Stat. Methods Med. Res. 2009, 18, 421–432. [Google Scholar] [CrossRef]
- Nissen, S.E.; Wolski, K. Effect of rosiglitazone on the risk of myocardial infarction and death from cardiovascular causes. N. Engl. J. Med. 2007, 356, 2457–2471. [Google Scholar] [CrossRef]
- Nissen, S.E.; Wolski, K. Rosiglitazone revisited: An updated meta-analysis of risk for myocardial infarction and cardiovascular mortality. Arch. Intern. Med. 2010, 170, 1191–1201. [Google Scholar] [CrossRef] [PubMed]
- Claggett, B.; Wei, L.J. Analytical issues regarding rosiglitazone meta-analysis. Arch. Intern. Med. 2011, 171, 179–180. [Google Scholar] [CrossRef] [PubMed]
- Efthimiou, O. Practical guide to the meta-analysis of rare events. BMJ Ment. Health 2018, 21, 72–76. [Google Scholar] [CrossRef] [PubMed]
- Tian, L.; Cai, T.; Pfeffer, M.A.; Piankov, N.; Cremieux, P.Y.; Wei, L. Exact and efficient inference procedure for meta-analysis and its application to the analysis of independent 2 × 2 tables with all available data but without artificial continuity correction. Biostatistics 2008, 10, 275–281. [Google Scholar] [CrossRef] [PubMed]
- Sankey, S.S.; Weissfeld, L.A.; Fine, M.J.; Kapoor, W. An assessment of the use of the continuity correction for sparse data in meta-analysis. Commun. Stat. Simul. Comput. 1996, 25, 1031–1056. [Google Scholar] [CrossRef]
- Liu, D.; Liu, R.; Xie, M.G. Exact inference methods for rare events. Wiley Statsref Stat. Ref. Online 2014, 1–6. [Google Scholar] [CrossRef]
- Shuster, J.J.; Jones, L.S.; Salmon, D.A. Fixed vs random effects meta-analysis in rare event studies: The rosiglitazone link with myocardial infarction and cardiac death. Stat. Med. 2007, 26, 4375–4385. [Google Scholar] [CrossRef]
- Jansen, K.; Holling, H. Random-effects meta-analysis models for the odds ratio in the case of rare events under different data-generating models: A simulation study. Biom. J. 2022, 65, 2200132. [Google Scholar] [CrossRef] [PubMed]
- DerSimonian, R.; Laird, N. Meta-analysis in clinical trials. Control. Clin. Trials 1986, 7, 177–188. [Google Scholar] [CrossRef] [PubMed]
- Friedrich, J.O.; Adhikari, N.K.; Beyene, J. Inclusion of zero total event trials in meta-analyses maintains analytic consistency and incorporates all available data. BMC Med. Res. Methodol. 2007, 7, 5. [Google Scholar] [CrossRef]
- Bhaumik, D.K.; Amatya, A.; Normand, S.L.T.; Greenhouse, J.; Kaizar, E.; Neelon, B.; Gibbons, R.D. Meta-analysis of rare binary adverse event data. J. Am. Stat. Assoc. 2012, 107, 555–567. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.; Pullenayegum, E.; Marshall, J.K.; Iorio, A.; Thabane, L. Impact of including or excluding both-armed zero-event studies on using standard meta-analysis methods for rare event outcome: A simulation study. BMJ Open 2016, 6, e010983. [Google Scholar] [CrossRef] [PubMed]
- Langan, D.; Higgins, J.P.; Jackson, D.; Bowden, J.; Veroniki, A.A.; Kontopantelis, E.; Viechtbauer, W.; Simmonds, M. A comparison of heterogeneity variance estimators in simulated random-effects meta-analyses. Res. Synth. Methods 2019, 10, 83–98. [Google Scholar] [CrossRef]
- Veroniki, A.A.; Jackson, D.; Viechtbauer, W.; Bender, R.; Bowden, J.; Knapp, G.; Kuss, O.; Higgins, J.P.; Langan, D.; Salanti, G. Methods to estimate the between-study variance and its uncertainty in meta-analysis. Res. Synth. Methods 2016, 7, 55–79. [Google Scholar] [CrossRef]
- Jiang, T.; Cao, B.; Shan, G. Accurate confidence intervals for risk difference in meta-analysis with rare events. BMC Med. Res. Methodol. 2020, 20, 98. [Google Scholar] [CrossRef]
- Zabriskie, B.N.; Corcoran, C.; Senchaudhuri, P. A permutation-based approach for heterogeneous meta-analyses of rare events. Stat. Med. 2021, 40, 5587–5604. [Google Scholar] [CrossRef] [PubMed]
- Beisemann, M.; Doebler, P.; Holling, H. Comparison of random-effects meta-analysis models for the relative risk in the case of rare events: A simulation study. Biom. J. 2020, 62, 1597–1630. [Google Scholar] [CrossRef] [PubMed]
- Böhning, D.; Sangnawakij, P. The identity of two meta-analytic likelihoods and the ignorability of double-zero studies. Biostatistics 2021, 22, 890–896. [Google Scholar] [CrossRef]
- Fleiss, J.L. Review papers: The statistical basis of meta-analysis. Stat. Methods Med. Res. 1993, 2, 121–145. [Google Scholar] [CrossRef]
- Gronsbell, J.; Nie, L.; Lu, Y.; Tian, L. Exact Inference for the Random-Effects Model for Meta-Analyses with Rare Events. Under Rev. 2018, 39, 252–264. [Google Scholar] [CrossRef] [PubMed]
- Christensen, W.F.; Rencher, A.C. A comparison of Type I error rates and power levels for seven solutions to the multivariate Behrens-Fisher problem. Commun. Stat. Simul. Comput. 1997, 26, 1251–1273. [Google Scholar] [CrossRef]
- Chu, D.K.; Akl, E.A.; Duda, S.; Solo, K.; Yaacoub, S.; Schünemann, H.J.; El-Harakeh, A.; Bognanni, A.; Lotfi, T.; Loeb, M.; et al. Physical distancing, face masks, and eye protection to prevent person-to-person transmission of SARS-CoV-2 and COVID-19: A systematic review and meta-analysis. Lancet 2020, 395, 1973–1987. [Google Scholar] [CrossRef] [PubMed]
- Higgins, J.P.; Green, S. Cochrane Handbook for Systematic Reviews of Interventions; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 4. [Google Scholar]
- Tsujimoto, Y.; Tsutsumi, Y.; Kataoka, Y.; Shiroshita, A.; Efthimiou, O.; Furukawa, T.A. The impact of continuity correction methods in Cochrane reviews with single-zero trials with rare events: A meta-epidemiological study. Res. Synth. Methods 2024, 15, 769–779. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
| Setting | Treatment Effect | |
|---|---|---|
| 1: High Heterogeneity | Null | (1.45, 1.45) |
| Protective | (1.10, 1.65) | |
| 2: Moderate Heterogeneity | Null | (5.50, 5.50) |
| Protective | (4.20, 6.30) | |
| 3: Low Heterogeneity | Null | (145, 145) |
| Protective | (110, 165) |
| Endpoint | Method | Point Estimates | CI | CI Length | p-Value |
|---|---|---|---|---|---|
| MI | MH | 1.42 | [1.03, 1.98] | 0.95 | 0.033 |
| MHcc | 1.23 | [0.92, 1.65] | 0.73 | 0.163 | |
| Peto-F | 1.43 | [1.03, 1.98] | 0.95 | 0.032 | |
| Peto-R | 1.43 | [1.03, 1.98] | 0.95 | 0.032 | |
| DL | 1.23 | [0.91, 1.67] | 0.76 | 0.178 | |
| XRRmeta | 0.67 | [0.51, 0.82] | 0.31 | 0.047 | |
| CVD | MH | 1.70 | [0.98, 2.93] | 1.95 | 0.057 |
| MHcc | 1.13 | [0.76, 1.69] | 0.93 | 0.541 | |
| Peto-F | 1.64 | [0.98, 2.74] | 1.76 | 0.060 | |
| Peto-R | 1.64 | [0.98, 2.74] | 1.76 | 0.060 | |
| DL | 1.10 | [0.73, 1.66] | 0.93 | 0.662 | |
| XRRmeta | 0.79 | [0.56, 0.90] | 0.34 | 0.010 |
| Method | Point Estimates | CI | CI Length | p-Value |
|---|---|---|---|---|
| MH | 0.22 | [0.18, 0.28] | 0.10 | < |
| MHcc | 0.23 | [0.18, 0.28] | 0.10 | < |
| Peto-F | 0.27 | [0.22, 0.32] | 0.10 | < |
| Peto-R | 0.24 | [0.18, 0.33] | 0.15 | < |
| DL | 0.22 | [0.16, 0.32] | 0.16 | < |
| XRRmeta | 0.19 | [0.11, 0.27] | 0.16 | < |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gronsbell, J.; McCaw, Z.R.; Regis, T.; Tian, L. Exact Inference for Random Effects Meta-Analyses for Small, Sparse Data. Stats 2025, 8, 5. https://doi.org/10.3390/stats8010005
Gronsbell J, McCaw ZR, Regis T, Tian L. Exact Inference for Random Effects Meta-Analyses for Small, Sparse Data. Stats. 2025; 8(1):5. https://doi.org/10.3390/stats8010005
Chicago/Turabian StyleGronsbell, Jessica, Zachary R. McCaw, Timothy Regis, and Lu Tian. 2025. "Exact Inference for Random Effects Meta-Analyses for Small, Sparse Data" Stats 8, no. 1: 5. https://doi.org/10.3390/stats8010005
APA StyleGronsbell, J., McCaw, Z. R., Regis, T., & Tian, L. (2025). Exact Inference for Random Effects Meta-Analyses for Small, Sparse Data. Stats, 8(1), 5. https://doi.org/10.3390/stats8010005