1. Introduction
A random variable Z follows a slash distribution if it can be generated as Z = X/U
1/q, where X and U are independent random variables and U is uniformly distributed over (0,1). This term leads back to [
1], where the authors considered the case in which the distribution of X, the so-called parent distribution, was normal. The slash distribution is particularly useful when models with heavy tails are necessary to fit a real data set. This simple concept has launched a remarkable creativity among researchers. In the last decade, slash distributions for many other parent distributions have been studied, for example, for the epsilon half-normal [
2], for the skew-normal distribution [
3], for the logistic distribution [
4,
5], and for the Birnbaum–Saunders distribution [
6]. In [
7,
8] are considered modifications of the slash distribution, dividing the variable X by a variable with exponential or specific gamma distribution. A strong generalization of the concept was presented in [
9], where a variable with elliptical distribution is divided by one with a beta distribution.
In the present article, we examine the distribution of X/Y, where X may be any continuous random variable and Y is a beta distributed variable, independent from X.
This distribution will be called a beta divided slash distribution (BDSL distribution). We will represent densities, distribution functions, and moments by hypergeometric or other special functions. Thereby, the general theory of hypergeometric functions becomes available for the study of a wide class of slash distributions. Several slash distributions known in the literature arise as special cases of BDSL distributions, and can thus be presented in a compact form.
In the next section, we define the generalized slash distribution and study in detail the case with the normal parent distribution. In
Section 3, the generalized slash distribution for some other parent distributions is studied. In
Section 4, we apply some of the newly introduced models to fit financial data of current importance. In
Section 5, some stochastic simulations are performed. Finally,
Section 6 indicates some possible generalizations and concluding remarks.
2. The Beta Divided Slash Distribution
Let X, Y be independent continuous random variables with densities f and g. Assume that Y has a beta distribution, that is, the density is given by for 0 ≤ y ≤ 1 where is the beta function and α,β > 0. We define the beta divided slash distribution (generated by the distribution of X) as the distribution of the quotient Z = X/Y. We will use the short notation BDSL distribution. The case β = 1 will be called the standard slash.
Theorem 1. The density of the r.v. Z is Proof. Defining the variables
Z = X/Y and
W = Y, yields
X = ZW,
Y = W, the joint probability distribution of (
Z,W) is
h(zw) =
f(zw) g(w) , where
denotes the Jacobian of the transformation. The marginal distribution of Z is thus
For
β = 1, we get the density
of the standard slash distribution, see, for example, [
4] (p. 112, Equation (2)). For the limiting case
β = 0, the density h(z) in Theorem 1 reduces to that of X. Note that for a random variable Y with beta distribution, we have
for any
α and c with
α > 0, 0 <
c < 1. Thus, Y converges in probability to the degenerate r.v. Y = 1 if
β tends to zero. Thus, the density of Z = X/Y converges to that of X.
In order to generate a BDSL distribution, we make use of the generalized hypergeometric functions defined for a complex number
z by
where
denotes the Pochhammer symbol, satisfying
n(k) =
n(
n+1)· ··(
n+k−1) when
k is a positive integer. The specific case of (1) with
p = 2 and
q = 1 is known as the ordinary or Gauss hypergeometric function. Many elementary functions can be expressed as hypergeometric functions, see, for example, [
10]; the most trivial case arises in the absence of parameters, then (1) yields
0F
0(-; -; z) = e
z. The function (1) converges for all complex
z with
p <
q + 1. In the case of
p =
q + 1, it converges for |
z| < 1, but analytic continuation to the complex plane is possible. For
p >
q + 1, the series (1) diverges, see, for example, [
11]. In the present article, only the cases with
p ≤
q + 1 will arise. By representing a probability density via a hypergeometric function, one accesses the powerful theory of these functions, which has applications in diverse scientific areas. Considering the steadily growing number of published probability models, it will no longer be sufficient to confine the modeling to the use of elementary functions. Hypergeometric functions can be easily calculated using adequate software like MAPLE, Matlab, or Mathematica. The increasing popularity of hypergeometric functions is also demonstrated by the development of diverse software packages to handle these functions. In the Internet, one can easily find packages for MAPLE developed by Tom H. Koornwinder and Bruno Gauthier. In the present paper, we occasionally use support of MAPLE, however, a proof is given for all essential results. An interesting feature of hypergeometric functions is that many of them can be represented by integrals. We will make use of the following general theorem due to Rainville, see [
12] (p. 116). Further integral representations can be found in [
13,
14].
Theorem 2. (Rainville): For any positive integer k and Re(α), Re(β) > 0, the following holds: In order to make the theorem applicable to integrals of the type in Theorem 1, we consider the following result.
Corollary 1. For any positive integer k and Re(
α), Re(
β) > 0, the following holds:
Proof. In Theorem 2, we set t = 1, substitute α by α + 1, and multiply the resulting equation by .∎
Theorem 3. The beta divided slash distribution generated by N(0,1) has the density Proof. The first equation follows from Theorem 1. Setting in the corollary
p =
q = 1,
k = 2,
c = −z
2/2 and a
1 = b
1 = 1, we get
because the hypergeometric function simplifies by shortening equal terms in the quotient of (1), that is, it holds that
p+1F
q+1(c,a
1,…a
p; c,a
1,…b
q;x) =
pF
q(a
1, … a
p; a
1, … b
q;x). The last equation yields the statement (after multiplying by 1/
).∎
In particular, the expression in Theorem 3 serves as a more compact form for the density (10) in [
9] (p. 221). The beta divided slash distribution generated by N(0,1) will be denoted by BDSL(α, β)(N(0,1)). Later, we will use analogous notations for other parent distributions. For the special cases β = 0 and β = 1, we obtain the standard normal distribution and the standard slash distribution. The latter is obtained from Theorem 3 as
This is the density of the standard slash distribution, which can be rewritten in various manners (usually the parameter is denoted by q in this context, see, for example, [
2] (p. 233), [
4] (p. 111) and [
15] (p. 1). In particular, Equation (1) implies
Using this, we can express the density (2) as
It can also be written by means of the Whittaker M function [
16] or by means of the lower incomplete gamma function
yielding
where the latter equals the first formula in [
17] (p. 4). Note that the Pareto scale mixture in this paper is identical with the standard slash distribution, because, in both cases, one divides by an r.v. with distribution Beta(α,1).
Specializing further by setting α = 1, and using the elementary transformation
Equation (2) yields the well-known canonical slash distribution, see [
4] (p. 112, Equation (1))
where
φ denotes the standardized normal density. An interesting property of a hypergeometric function is the relation
which allows one to determine derivatives and antiderivatives, see, for example, [
18]. By using Equation (7), we obtain the cumulative distribution function corresponding to the density in Theorem 3 as
The case
β = 0 yields an interesting representation of the standard normal distribution function Φ:
For
β = 1, Equation (8) yields the distribution function of the standard slash distribution as
Finally, setting
α = 1 gives the canonical slash distribution function as an explicit representation of Equation (5) in [
4] (p. 112):
Direct integration of (6) yields the alternative representation
where
φ denotes the density of the standard normal distribution. It might be interesting to observe that comparing the last two equations provides a representation for the hypergeometric function in (11).
The moments of the random variable Z in Theorem 1 can be calculated by means of the following statement.
Theorem 4. The non-central moments of a beta divided slash distribution are given by
where the
are the moments of the parent distribution.
Proof. From the stochastic representation Z = X/Y, it follows that Z = XW, where W = 1/Y. Thus, because of the independence of X and Y, we get E(Z
k) = E(X
k) E(W
k). The density of W can be easily obtained as
, where f is the beta density. Thus,
It follows that
for
α >
k. ∎
We will now determine the moments of the distribution BDSL(
α,β)(N(0,1)). Because of the symmetry of the density in Theorem 3, the odd non-central moments are zero; in particular, E(Z) = 0. Thus, the central moments are identical to the non-central ones:
. We obtain
Hence, the skewness
is zero and the kurtosis is
The formulas (14) and (15) yield the system
which can be used to determine moment estimators, when the moments are substituted by the corresponding sample moments. The resulting system can be easily solved for
α and
β.
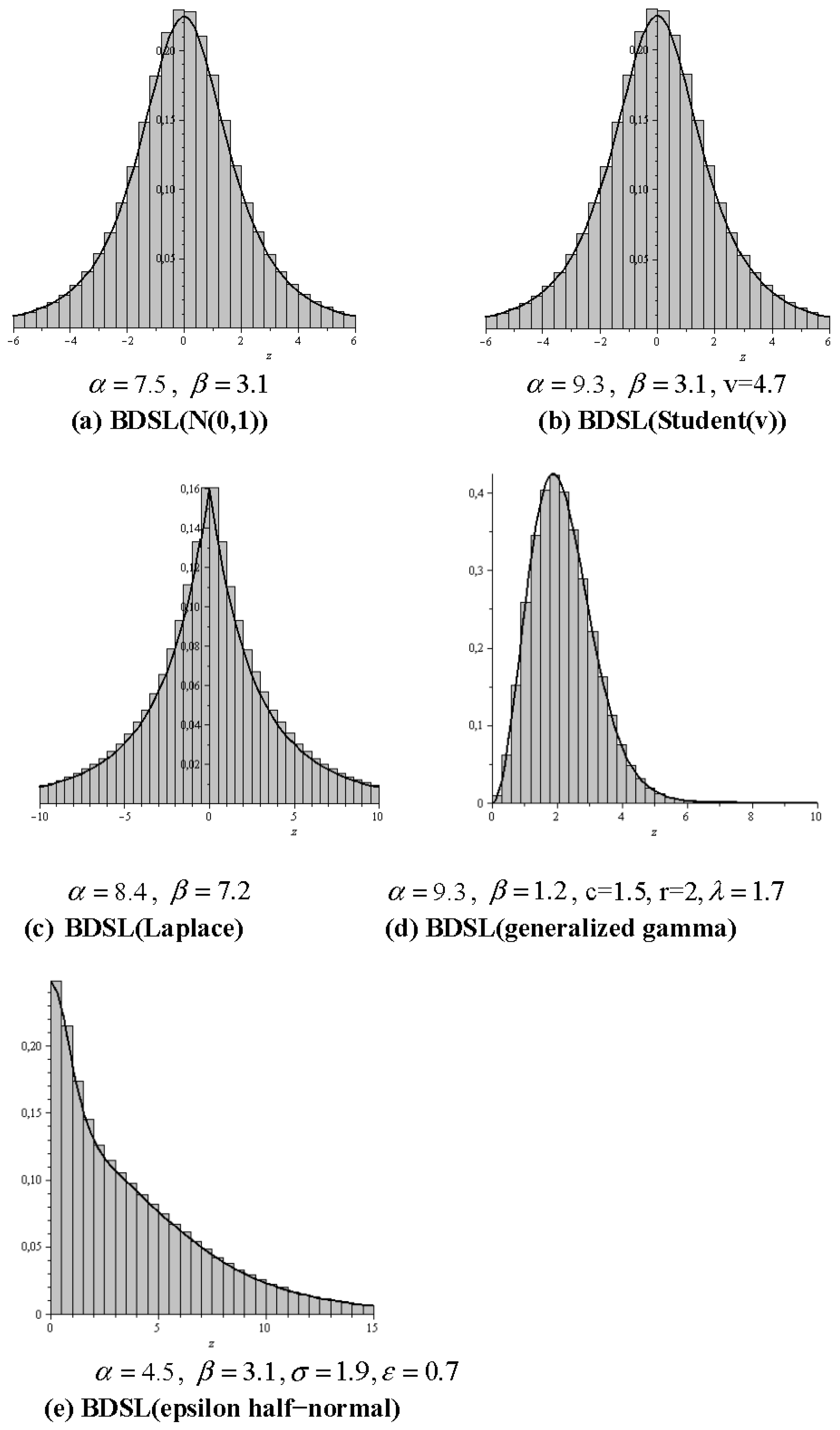
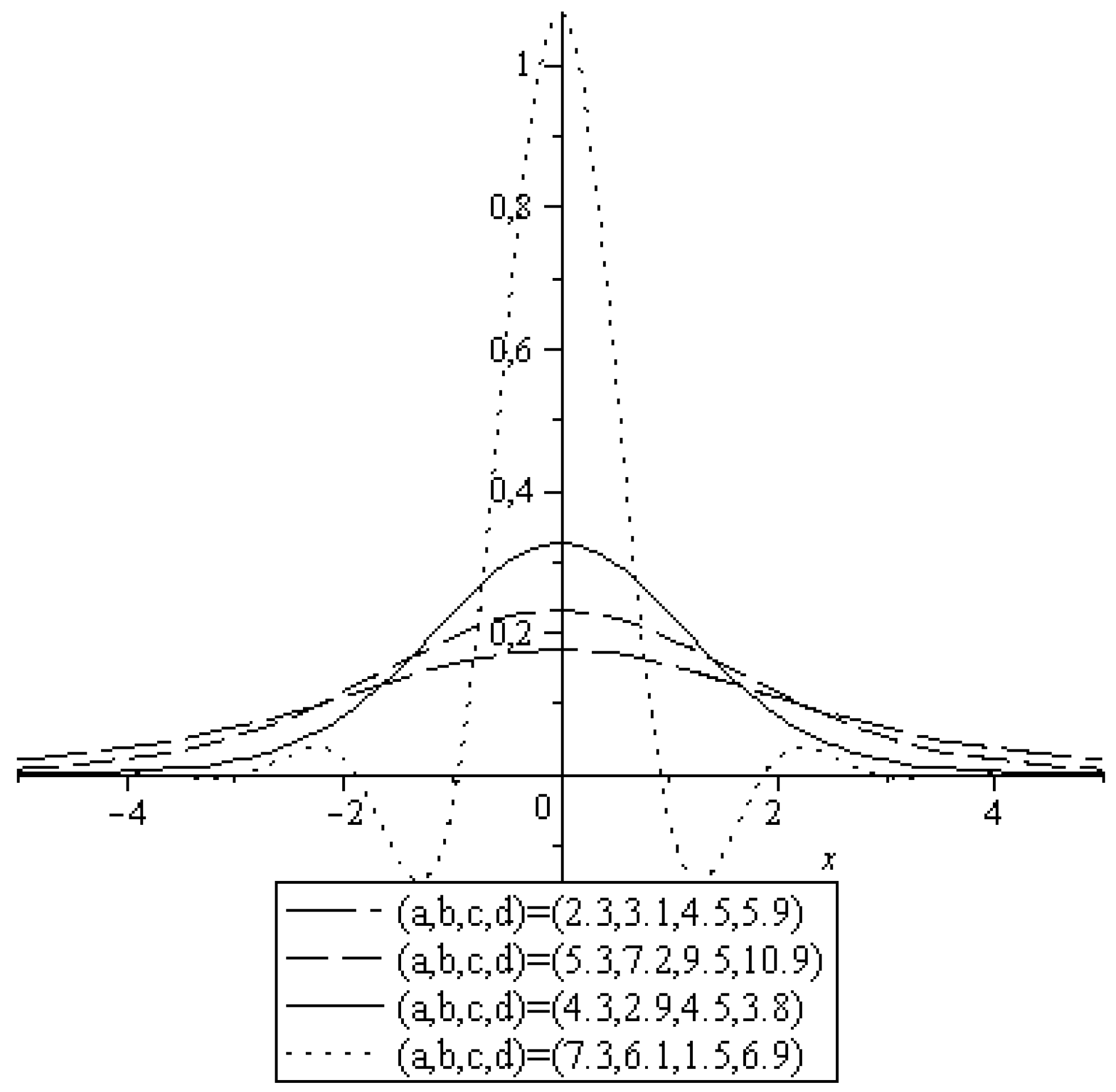
An important shape characteristic of a beta slash distribution is given by its maximum value. From Theorem 2, one obtains this value easily as
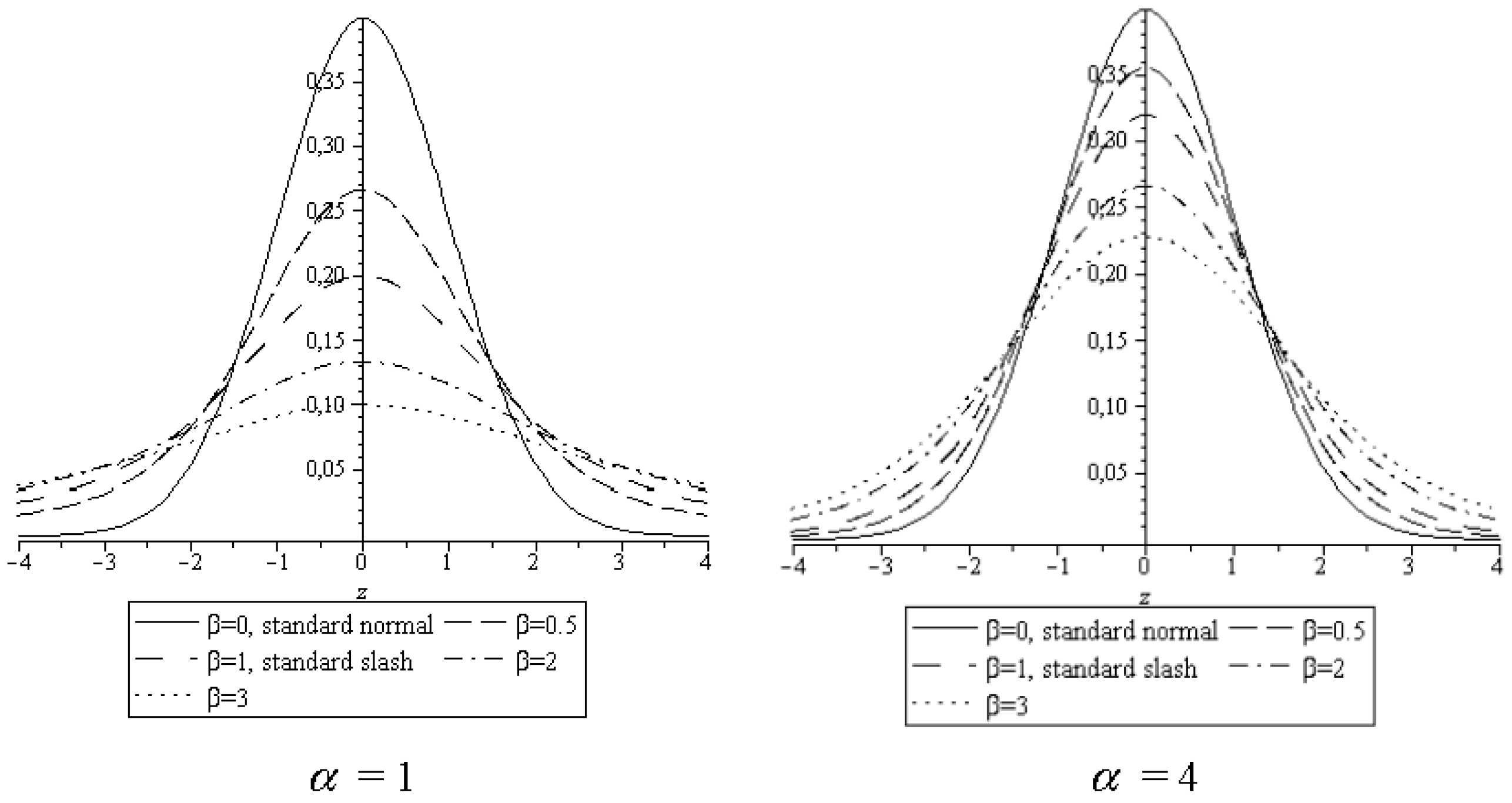
Figure 1 shows some specific densities of the distribution BDSL(
α,β)(N(0,1)). The graphics illustrate that this family of distributions offers a great flexibility when designing variations of the normal distribution is required. In particular, the normal distribution goes smoothly over into the standard slash distribution when
α increases from 0 to 1. In both parts of the figure, the
β values are 0, 0.5, 1, 2, and 3, where an increasing
β corresponds to a decreasing maximum value. As a result of (17), two densities with parameter pairs (
) and (
) have the same maximum value if
.
We now consider the limiting behavior of the BDSL distribution under parameter changes. It turns out that the densities converge to a normal distribution under different circumstances. It applies in detail:
where the limit is to be understood in the sense of a pointwise convergence of the densities.
We want to mention at this point that MAPLE can also determine the characteristic function of the BDSL(α,β)(N(0,1)), however, the formula is extremely complicated and will not be considered here.
Finally, in practical applications, it is useful to introduce location and scaling parameters into the density of Theorem 3, that is, one considers the density
having in mind that the reduced random variable
has the density in Theorem 3 if and only if Z has the density (18), see, for example, [
8] (eq. (4), p. 930), [
19] (eq. (1.1), p. 272 and [
20] (eq. (1), p. 32) and. We will apply this density in
Section 4.
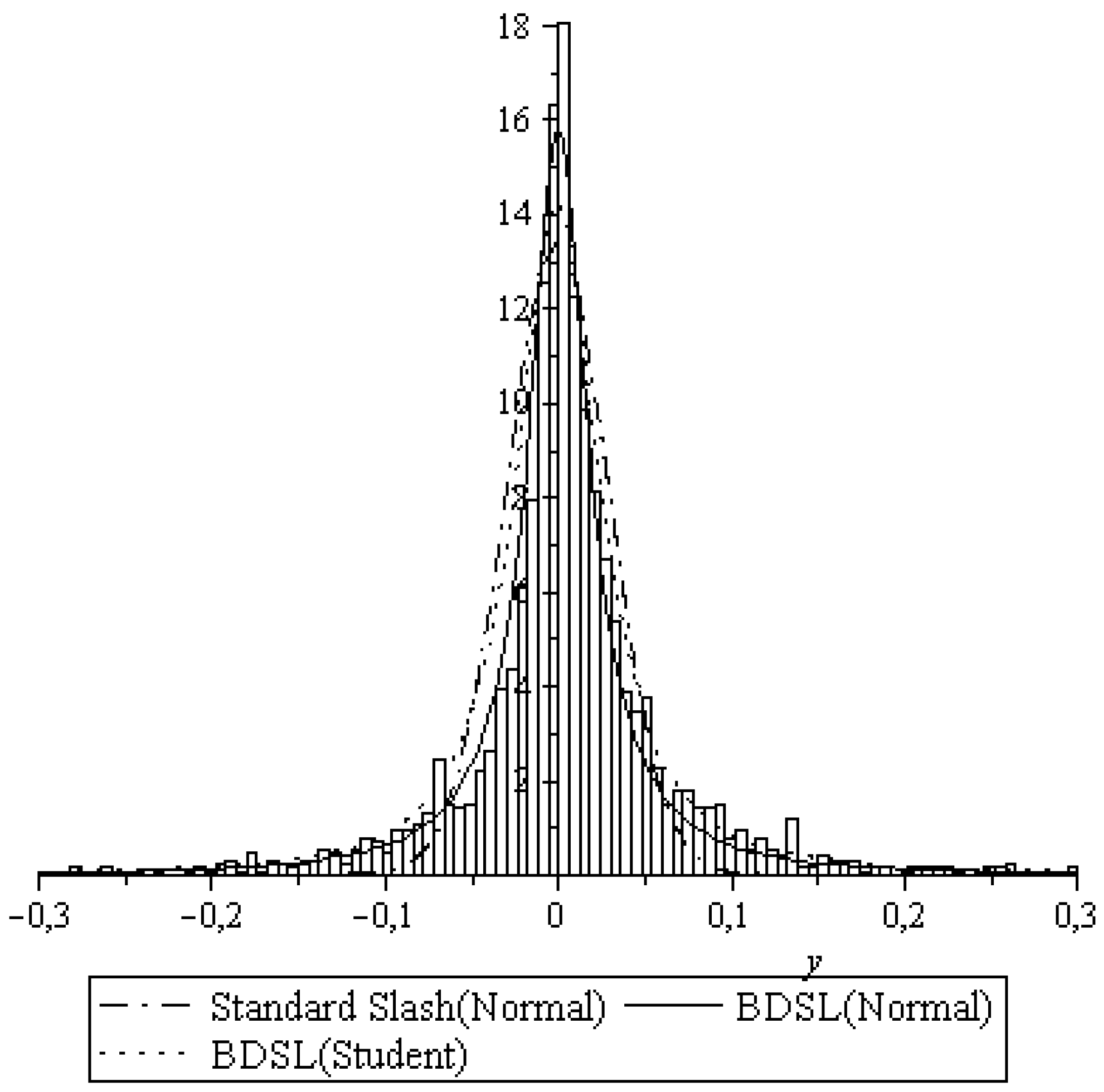
4. Fitting Financial Data
It has long been known that heavy-tailed distributions frequently occur in the financial area, specifically in the modelling of changes in exchange rates, see e.g., [
25]. As an example of a possible practical application, we fit some BDSL distributions to the Bitcoin values in Brazilian Real. We consider the sequence (x
1,...,x
n) of daily closing values over the period of the last eight years with 2125 values, obtained from the cite “Yahoo Finace”. The histogram in
Figure 6 contains the relative frequencies of the logarithmic changes ln(x
i+1/x
i). We fitted three BDSL distributions generated by the normal and Student distribution to the data (compare [
21] (Section 2.8) for a similar study). The dashdotted line represents the best possible fit of the standard normal slash distribution, that is, when fitting (18) with
and
to the data. The estimation was performed, maximizing the loglikelihood function
l by means of a search algorithm for optimization. The optimal parameter values are
and
with corresponding loglikelihood value
l = 1677.2. The solid line represents the best BDSL fit for a normal parent distribution, that is, when fitting (18) with
to the data, obtaining
,
and
with
l = 3308.8.
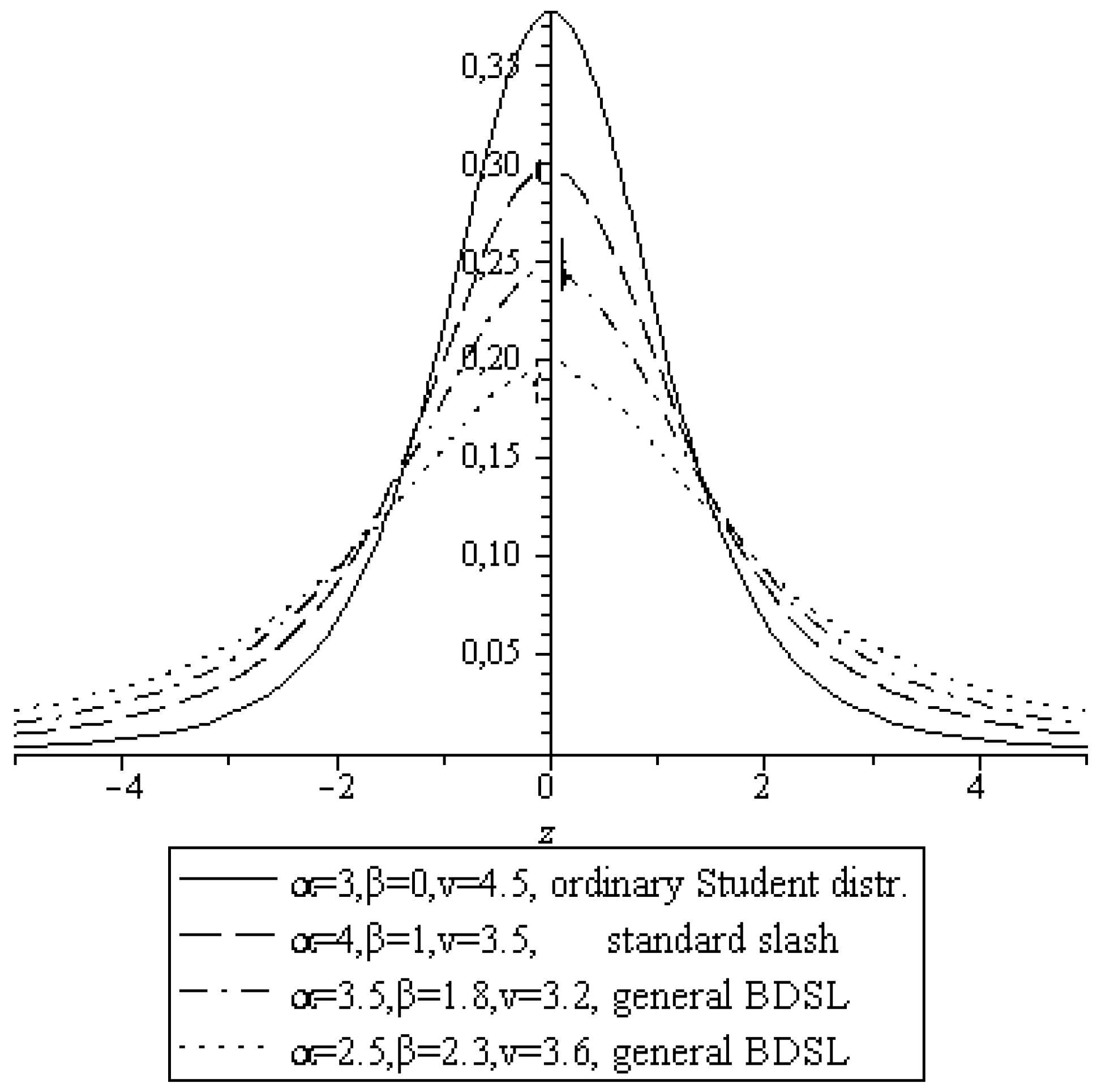
Finally, the dotted line represents the best fit of a BDSL based on a Student distribution, yielding the optimal parameter values
,
, v = 1.5, and
with
l = 2930.3. In order to quantify the goodness of fit, we calculate the usual Akaike information criterion (AIC) and Bayesian information criterion (BIC) (see [
26,
27]). The results are presented in
Table 1, where k denotes the number of parameters and n = 2124 is the sample size.
As both criteria AIC and BIC should be as small as possible, the general BDSL distribution based on the normal proves to be the best suitable model for the given financial data. For similar studies, compare with [
2,
15]. Further applications of the BDSL with a normal parent distribution, as well as estimation issues, can be found in [
9].



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}