Abstract
Classification has applications in a wide range of fields including medicine, engineering, computer science and social sciences among others. In statistical terms, classification is inference about the unknown parameters, i.e., the true classes of future objects. Hence, various standard statistical approaches can be used, such as point estimators, confidence sets and decision theoretic approaches. For example, a classifier that classifies a future object as belonging to only one of several known classes is a point estimator. The purpose of this paper is to propose a confidence-set-based classifier that classifies a future object into a single class only when there is enough evidence to warrant this, and into several classes otherwise. By allowing classification of an object into possibly more than one class, this classifier guarantees a pre-specified proportion of correct classification among all future objects. An example is provided to illustrate the method, and a simulation study is included to highlight the desirable feature of the method.
1. Introduction
Classification has applications in a wide range of fields including medicine, engineering, computer science and social sciences, among others. See, e.g., the recent books by [1,2,3,4]. Classical examples include medical diagnosis, automatic character recognition, data mining (such as credit scoring, consumer sales analysis and credit card transaction analysis) and artificial intelligence (such as the development of machines with brain-like performance). As many important developments in this area are not confined to the statistics literature, various other names, such as supervised learning, pattern recognition and machine learning, have been used. In recent years, there have been many exciting new developments in both methodology and applications, taking advantage of increased computational power readily available nowadays. Broadly speaking, classification methods can be divided into probabilistic methods (including Bayesian classifiers), regression methods (including logistic regression and regression trees), geometric methods (including support vector machines), and ensemble methods (combining classifiers for improved robustness).
A classifier is a decision rule built from a training data set that classifies all future objects as belonging to one or several of the k known classes, where k is a pre-specified number. The drawback of a classifier that classifies each future object into only one of k classes is that, when the object is close to the classification boundaries of several classes, say, the chance of misclassification is close to , which may be close to one when M is large. A sensible approach in this situation is to acknowledge that such an object has similar chances of belonging to M classes and hence to avoid classifying it into only one of the M classes. In medical diagnosis, for example, if there is not enough evidence to classify a patient as having a disease or not, then it is wise not to give a diagnosis that is quite likely to be wrong.
Various procedures have been proposed in the literature to deal with this difficulty. One type of procedure allows a rejection option, that is, if a future object falls into a ‘rejection’ region, then no classification is made for the object. Such a procedure aims to construct a suitable rejection region to minimize a pre-specified risk; see, e.g., [5,6,7,8,9] and the references therein. Non-deterministic classifiers are proposed in [10], which allow a future object to be classified possibly into several classes. Again, such a classifier is constructed to minimize a pre-specified risk.
For the binary classification problem (i.e., ), ref. [11] proposes to find two ‘tolerance’ regions (corresponding to the two classes) in the feature/predictor space, with a specific coverage level for each class that minimize the probability that an object falls into the intersection of the two tolerance regions since an object in this intersection will not be classified. This approach is akin to the decision-theoretic approaches mentioned in the last paragraph but uses this specific probability as the risk to minimize. As with other decision-theoretic approaches, it is not constructed to guarantee the proportion of correction classification and thus is different from the approach proposed in this paper. Further development of this approach is considered in [12].
The conformal prediction approach of [13,14] also classifies a future object into possibly several classes that contain the true class with a pre-specified probability. However, this approach is designed for the ‘online’ setting in which the true classes of all the observed objects are revealed and hence known before the classification of the next object is made. This online setting is different from the usual setting of classification considered in this paper, in which a classifier is built from the available training data set and then used to classify a large number of future objects without knowing their true classes.
For the binary classification problem, ref. [15] proposes a classifier that allows no classification of an object. By controlling the size of the non-classification region (for which classification error does not occur) via a tuning constant, a ‘generalized error’ of the classifier is controlled at a pre-specified level with a specified confidence about the randomness in the training data set . The construction of this classifier is related to the tolerance sets going back to [16]. Note, however, that the algorithm in [15] may result in a different classifier if a different observation in the training data set is used as the ‘base’ instance in the algorithm, which is quite odd from a statistical point of view. In addition, the ‘generalized error’ is different from the long run frequency of correct classification, which the procedure proposed in this paper aims to control.
The purpose of this paper is to propose a classifier that classifies a future object into a single class only when there is enough evidence to warrant this, and into several classes otherwise. By allowing classification of an object into potentially more than one class, this classifier guarantees a pre-specified proportion of correct classification among all future objects. Specifically, classification of a future object is treated as a standard problem of statistical inference about the unknown parameter c, the true class of the object, and the confidence set approach for c is adopted. In order to consider the probability of correct classification, it is necessary to assume certain probability distributions for the feature measurements from the k classes. In this paper the feature measurements of the k classes are assumed to follow multivariate normal distributions, which is widely used either directly or after some transformation (see [17,18]).
The layout of the paper is as follows: Section 2 contains some preliminaries, including the idea of [19,20] from which the new approach proposed in this paper is developed. The simple situation where the means and covariance matrices of the k multivariate normal distributions underlying the k classes are assumed to be known is considered in Section 3. The more realistic situation where both and are unknown parameters is studied in Section 4. Section 5 provides an illustrative example. A simulation study is given in Section 6 to highlight the major advantage of the new classifier proposed in this paper. Section 7 provides the conclusions. Finally, some mathematical details are provided in the Appendix A.
2. Preliminaries
Let the p-dimensional data vector denote the feature measurement on an object from the ith class, which has multivariate normal distribution , . The training data set is given by , where are i.i.d. observations from the ith class with distribution , . The classification problem is to make inference about c, the true class of a future object, based on the feature measurement observed on the object, which is only known to belong to one of the k classes and so follows one of the k multivariate normal distributions. In statistical terminology, c is the unknown parameter of interest that takes a possible value in the simple parameter space . We emphasize that c is treated as non-random in our frequentist approach.
A classifier that classifies an object with measurement into one single class in can be regarded as a point estimator of c. The classifier proposed in this paper provides a set as plausible values of c. Depending on and the training data set , may contain only a single value, in which case is classified into one single class given by . When contains more than one value in C, is classified as possibly belonging to the several classes given by . Hence, in statistical terms, the classifier proposed in this paper uses the confidence set approach. The inherent advantage of the confidence set approach over the point estimation approach is the guaranteed proportion of confidence sets that contain the true classes.
The confidence set for c is constructed below by inverting a family of acceptance sets for testing for each . This method of constructing a confidence set was given by [21] and has been used and generalized to construct numerous intriguing confidence sets; see, e.g., [22,23,24,25,26,27,28,29]
Now, the key idea of [19,20] is presented very briefly, which is crucial for understanding our proposed approach to classification. Assuming that response y and predictor x are related by a standard linear regression model and a training data set on is available for estimating and the error variance , refs. [19,20] consider how to construct confidence sets for the unknown (non-random) values of the predictor x corresponding to the large number of future observed values of the response y. As the same training data set is used in the construction of all these confidence sets, the randomness in the future y-values and the randomness in clearly play different roles and thus should be treated differently. The procedure proposed in [19,20] has a probability of at least , with respect to the randomness in that at least proportion of all the confidence sets, constructed from the same , include the true x-values, where and are pre-specfied probabilities. This idea/approach has been studied by many researchers; see, e.g., [30,31,32,33,34,35,36] and the references therein. One fundamental result is that the confidence sets constructed from simultaneous tolerance intervals do satisfy the ‘-probability-’-proportion property specified above. In particular, ref. [36] points out by constructing a counter example that the confidence sets constructed from pointwise tolerance intervals do not guarantee the ‘-probability--proportion’ property in general. A similar idea is also used in [37] to construct confidence sets for the numbers of coins in all future bags with known weights.
Since a classifier is built from the training data set and then used to classify a large number of future objects in terms of confidence sets for their true classes, the future observed y-values play similar roles as the future observed y-values whilst the unknown true classes of the future objects play similar roles as the unknown true x-values of the future observed y-values, in the approach of [19,20] given in the last paragraph. Hence, it is natural to adopt the approach of [19,20] to construct confidence sets for the unknown true classes of future objects with the ‘-probability--proportion’ property, that is, the probability, with respect to the randomness in , is at least that at least proportion of all the confidence sets constructed from the same do include the unknown true classes of all future objects.
3. Known and
In this section, the values of and are assumed to be known, which helps to motivate and understand the confidence sets constructed in Section 4 for the more realistic situation where the values of and are unknown. Since and are known, no training data set is required to estimate and . Hence, the confidence sets in this section are denoted as , without the subscript .
If is from the lth class, then and so has the chi-square distribution with p degrees of freedom. We construct a confidence set for the class c of the observed by using [21] method of inverting a family of acceptance sets for testing for each number l in C. Specifically, the acceptance set for is given by
where is the quantile of the distribution. It follows directly from Neyman’s method that the confidence set is given by
It is straightforward to show, by using the Neyman–Pearson lemma, that the acceptance set in Equation (1) is optimal in terms of having the smallest volume among all the acceptance sets for testing .
As for the usual confidence sets, it is desirable that, among the confidence sets for the corresponding unknown true classes of the infinitely many future with distribution (), at least proportion will contain the true ’s. That is, it is desirable that
where denotes the indicator function of set A and so is the proportion among the N confidence sets that contains the true classes . It is shown in the Appendix A that the property in Equation (3) holds with equality.
The interpretation of the property in Equation (3) is similar to that of a standard confidence set. The noteworthy difference is that the confidence sets are for possibly different parameters (). In addition, note that, for each j, is a standard level confidence set for , with being the only source of randomness.
Figure 1 gives an illustrative example with , :
and (and so ). Specifically, the acceptance set in Equation (1) is represented in Figure 1 by the ellipsoidal region centred at , marked by ’+’, . If then l is an element of the confidence set given in Equation (1). Hence, the following four situations can occur. (a) falls into only one and so has a single class. For example, if , then , i.e., is classified as belonging to class 1. (b) falls into two ’s but not the other one, and so contains two classes. For example, if , then , i.e., is classified as belonging to possibly classes 1 or 2. (c) falls into all the three ’s, i.e., , and so is classified as belonging to possibly all three classes. (d) falls outside all the ’s, i.e., , and so and is classified as not belonging to any one of the three classes. There is nothing wrong with this last classification since this is judged not to be from the class l by the acceptance set for each l, though such a must be rare in order to guarantee the property in Equation (3). On the other hand, since it is known that is from one of the k classes, it is sensible to classify according to any reasonable classifier, e.g., a Bayesian classifier illustrated in the next paragraph. As the resultant confidence set from this augmentation contains , the property in Equation (3) clearly still holds for .
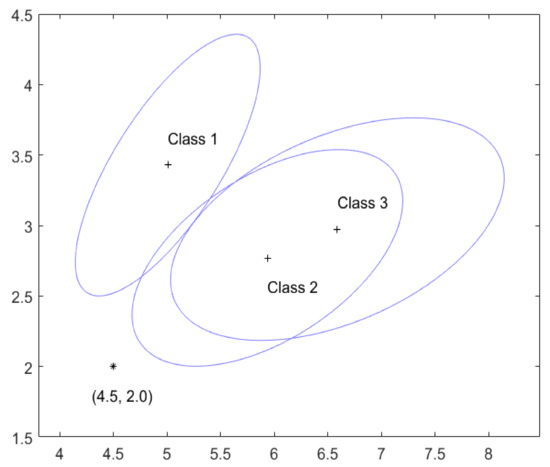
Figure 1.
The acceptance sets for the three classes with known and .
For example, if , which is marked by ‘*’ in Figure 1, then . The Bayesian classifier and the augmented confidence set can be worked out in the following way. Assume a non-informative prior about the class c of , then the posterior probability of belonging to class l is given by
where is the probability density function of and is the marginal density of and so does not depend on l. Hence, the Bayesian classifier classifies to the class that satisfies . For , we have , and . Hence, the Bayesian classifier and the augmented confidence set classify to class 2.
In this particular example, and do not intersect as seen from Figure 1 and so any future will not be classified to be in both classes 1 and 3. This reflects the fact that the distributions of the classes 1 and 3 are quite different/separated and so easy to distinguish. On the other hand, the distributions of the classes 2 and 3 are similar and so hard to distinguish. As a result, and have a large overlap and hence many future ’s will be classified as belonging to both classes 2 and 3.
4. Unknown and
4.1. Methodology
Now, we consider the more realistic situation where both the values of and are unknown and so need to be estimated from the training data set , independent of the future observations () whose classes are unknown and need to be inferred.
The training data set can be used to estimate and in the usual way: , . It is known [38] that , with being i.i.d. random vectors independent of .
Mimicking the confidence set in Equation (2), we construct the confidence set for the class c of as:
where is a suitably chosen critical constant whose determination is considered next.
As in Section 3, it is desirable that the proportion of the future confidence sets () that include the true classes () should be at least :
It is shown in the Appendix A that a sufficient condition for guaranteeing Inequality (5) is
where denotes the conditional expectation with respect to the random variable conditioning on the training data set (or, equivalently, ).
Since the value of the expression on the left-hand side of the inequality in Inequality (6) depends on and is random, Inequality (6) cannot be guaranteed for each observed ; more detailed explanation on this is given in the Appendix A. We therefore guarantee Inequality (6) with a large (close to 1) probability with respect to the randomness in , which is shown in the Appendix A to be equivalent to
where
and all the ’s, ’s and ’s are independent. This in turn guarantees that
The interpretation of this statement is that, based on one observed training data set , one constructs confidence sets for the ’s of all future () and claims that at least proportion of these confidence sets do contain the true ’s. Then, we are confident with respect to the randomness in the training data set that the claim is correct.
It is noteworthy that for the classification problem considered in this paper a classifier is built from one training data set and then used to classify a large number of future ’s. Hence, the randomness in both the training data set and the future ’s need to be accounted for but in different ways. This is reflected in our approach by the two numbers and , analogous to the idea of [19,20] as pointed out in Section 2.
If we treat the two sources of randomness in and simultaneously on equal footing (instead of the approach given above), then it is straightforward to show that ([38], Section 5.2)
where c is the true class of , and denotes an F random variable with degrees of freedom p and . It follows therefore from Neyman’s method that
is a confidence set for c, where is the quantile of . However, this confidence set has the following coverage frequency interpretation. Collect one training data set and the feature of one future object, both of which are then used to compute the confidence set for the class c of ; then, the frequency of the confidence sets that contain the true c’s is among a large number of confidence sets constructed in this way. Note that, in this construction, one training data set is used only once with one future to produce one confidence set , and so the randomness in one and the randomness in one future are treated on equal footing. This is clearly different from what is considered in this paper and how statistical classification is used in most applications: only one training data set is used to construct a classifier, which is then used repeatedly in classification of a large number of future objects with observed values. Hence, our proposed new method treats the two sources of randomness in and future ’s differently.
4.2. Algorithm for Computing
We now consider how to compute the critical constant so that the probability in Equation (7) is equal to . This is accomplished by simulation in the following way. From the distributions given in Equation (8), in the sth repeat of simulation, , generate independent
and find the so that
Repeat this S times to get and order these as . It is well known [39] that converges to the required critical constant with probability one as . Hence, is used as the required critical constant for a large S value, 10,000 say.
To find the in Equation (11) for each s, we also use simulation in the following way. Generate independent random vectors from , where Q is the number of simulations for finding . For each l, denote
and their ordered values as . Then, it is clear that is the sample quantile of in which only is random, and so converges to the population quantile with probability one as , where satisfies
Hence, converges to as and is used as an approximation to for a large Q value, 10,000 say.
It is noteworthy that depends only on (and the numbers of simulations S and Q which determine the numerical accuracy of due to simulation randomness). One can download from [40] our R computer program ConfidenceSetClassifier.R that implements this simulation method of computing the critical constant . While it is expected that larger values of S and Q will produce a more accurate value, it must be pointed out that there is no easy way to assess how the accuracy of depends on the values of S and Q. One practical way is to compute several values using different random seeds in the simulation for given S and Q, which form a random sample from the population of possible values. These values provide information on the variability among the possible values produced by the simulation method, and so accuracy of due to simulation randomness. See more details in Section 5.
As in Section 3, the confidence set in Equation (4) may be empty for a and so is classified as not belonging to any of the c classes. As discussed in Section 3, there is nothing wrong with this, but it is sensible to classify such a according to any reasonable classifier. The resultant confidence set from this augmentation contains , and so Inequality (9) still holds for .
5. An Illustrative Example
The famous iris data set introduced by [41] is used in this section to illustrate the method proposed in this paper. The data set is simple but serves the purpose of illustration nevertheless. It contains classes representing the three species/classes of Iris flowers ( setosa, versicolor, virginica), and has observations from each class in . Each observation gives the measurements (in centimetres) of the four variables: sepal length and width, and petal length and width. The data set iris can be found in ([42], Chapter 10) for example, and is also in the R base package.
First, we assume that only the first two measurements, sepal length and width, are used for classification in order to easily illustrate the method since the acceptance sets are two-dimensional and so can be easily plotted in this case. Based on the fifty observations on measurements from each of the three classes, one can calculate that
In the example in Section 3, these are used as the known values of and for the three classes. For and , the critical constant in Equation (7) is computed by our R program to be 9.175 using and . The confidence set in (4) is based on the acceptance sets , which are plotted in Figure 2 by the ellipsoidal region centred at , marked by ‘+’, . These ellipsoidal regions are larger than, but have the same centers and shapes as, the corresponding ellipsoidal regions given in Figure 1 of Section 3. This reflects the fact that the underlying multivariate normal distributions have been estimated from the training data in this case and so involve uncertainty, while the distributions in Section 3 are assumed to be known.
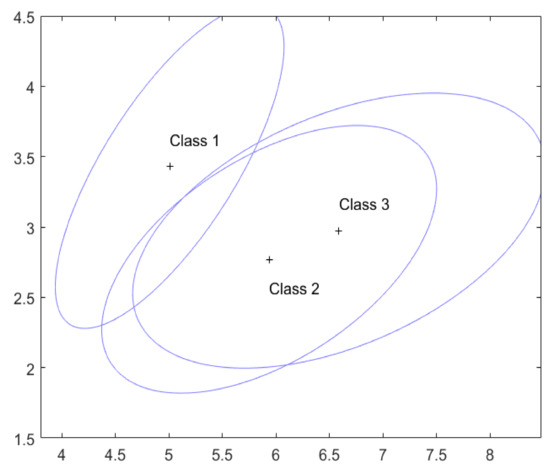
Figure 2.
The acceptance sets for the three classes with estimated and .
The index l is an element of the confidence set in Equation (3) if and only if . Hence, the following four situations can occur, similar to those in Section 3. (a) falls into only one and so has only one class. (b) falls into two ’s but not the other one, and so contains two classes. (c) falls into all the three ’s, i.e., , and so is classified as belonging to possibly all three classes. (d) falls outside all the ’s, i.e., , and so and is classified as not belonging to any one of the three classes.
From Figure 2, it is clear that and so for any future the confidence set that is, is judged to be possibly from any of the three classes.
As in Section 3, if does not belong to any , we compute the augmented confidence set by using, for example, the naive Bayesian classifier with a non-informative prior that classifies to the class that satisfies , where is the multivariate normal density function of the lth class with and replaced by the estimates and , respectively.
To get some idea of how sensitive the critical constant is to the simulation numbers S and Q, we have computed for various with and on an ordinary Windows PC (Core (TM2) Due CPU P8400@2.26 GHz ). As it is expected that larger values of S and Q will produce more accurate value, the results given in Table 1 indicate that the value based on , in comparison with the value based on , is accurate to at least the first decimal place and so probably sufficiently accurate for most real problems.

Table 1.
Constant and computation time for various .
Alternatively, one can compute several values for the given S and Q values using different random seeds to assess the accuracy of a value computed. For example, fourteen values based on based on fourteen different random seeds are computed to be: 9.231, 9.188, 9.172, 9.223, 9.192, 9.178, 9.203, 9.191, 9.198, 9.225, 9.182, 9.189, 9.224, 9.181, which form a sample of observations from the population distribution of all possible values of . This sample can then be used to infer the population and, in particular, the standard deviation of the population which gives the variability (or accuracy) of one value from the population. The mean and standard deviation of this sample of fourteen observations are given by and , respectively, and so the value based on is expected to be within the range using the “three-sigma” rule.
It is also worth emphasizing that only one needs to be computed based on the observed training dataset which is then used for classifications of all future objects. Hence, one can always increase S and Q to achieve better accuracy of as required and computation time should not be of a great concern.
If all the four measurements are used in classification, then and the acceptance sets are four dimensional ellipsoidal balls and so cannot be drawn. Nevertheless, the confidence set in Equation (4) is still valid and can be computed easily for a given . For and , the critical constant in Equation (8) is computed by our R program to be using and . Now, suppose a future Iris flower has measurements . Then, it is easy to check that since , while since for both and 3. Hence, the confidence set in (4) is , that is, this Iris flower is classified as from class 1, i.e., Setosa.
6. A Simulation Study
In this section, a simulation study is carried out to illustrate the desirable feature of the confidence-set based classifier (CS) proposed in this paper, and to highlight its differences from the following popular classifiers: classification tree (CT, implemented using R package tree), multinomial logistic regression (MLR, implemented using R package nnet), support vector machine (SVM, implemented using R package e1071) and naive Bayes (NB, implemented using R package e1071). The setting and is considered following the illustrative example in the last section.
Three configurations of the classes are considered in the simulation study. For the and given in the example in Section 3, the first configuration (CONF1) has the normal distributions given by , and . The second configuration (CONF2) has the distributions , and . The third configuration (CONF3) has the distributions , and . CONF1 represents the situation that all the classes are quite similar and thus hard to distinguish. CONF2 represents the situation that two of the classes (i.e., classes 2 and 3) are quite similar but quite different from the other class (i.e., class 1). In CONF3, all the classes are quite different and thus relatively easy to distinguish in comparison to CONF1 and CONF2.
For each configuration of the three population distributions, a random sample of size is generated from each class/distribution to form the training data set which is then used to train the classifiers CS, CT, MLR, SVM and NB. Each classifier is then used to classify future objects, with 1000 generated from each of the three classes/distributions; the proportion of correct classification, , of the objects is recorded. For CS, the average size M of the confidence sets for the objects is also recorded; note that all the other classifiers classify each future object to only one class. This process is repeated for 100 times to produce for each classifier, and for CS only. Denote and for each classifier, and for CS. The results on , and are given in Table 2, with the corresponding standard deviations given in brackets. One can download from [40] our R computer program SimulationStudyF.R that implements this simulation study.
Table 2.
Simulation results. Abbreviations are defined in the text.
Due to the property in Inequality (9) of CS, one expects that for CS. This is indeed the case for each of the three configurations from the results in Table 2. Note, however, that is either equal or close to zero for all the other classifiers. This is the advantage of CS, by construction, over the other classifiers. To guarantee the property in Inequality (9), the size of the confidence set may be larger than one as indicated by the values in Table 2, while all the other classifiers select only one class for each future object. The average size of the confidence set depends on the configuration of the classes. As expected, tends to be smaller when the classes are easier to distinguish, but larger when the classes are harder to distinguish. For example, CONF3 has a considerably smaller than CONF1.
As CS has the property in Inequality (9), it is not surprising that is likely to be larger than , which is born out by the results in Table 2. However, for the other classifiers, the value of depends on how different the classes are; tends to be larger when the classes are more different and thus easier to distinguish. For example, CONF3 has a larger than CONF1.
7. Conclusions
This paper considers how to deal with the classification problem using the novel confidence set approach by adapting the idea of [19,20] for inference about the predictor values of the observed response values in a standard linear regression model. Specifically, confidence sets for the true classes of infinitely many future objects (), based on one training data set , have been constructed so that, with confidence level about the randomness in , the proportion of the ’s that contain the true ’s is at least .
The intuitive motivation underlying this method is that, when an object is judged to be possibly from several classes, we should accept this objectively rather than forcing ourselves to pick just one class, which entails a large chance of misclassification. By allowing an object to be classified as possibly from more than one class, the proportion of correct classification can be guaranteed to be at least with a large probability about the randomness in the training data set . This ‘guaranteed probability about the randomness in ’ should be intuitive too since a that is very misleading about the k classes will likely produce a classifier that makes many wrong classifications, and so only proportion of well behaved will produce a classifier that give at least future correct classifications.
The two sources of randomness, those in the training data and in future objects , have been treated differently to reflect the fact that a classifier is built from one training data set and then used to classify many future objects . If the two sources of randomness are treated on equal footing, then the confidence set in Equation (10) should be used, which has a very different coverage frequency interpretation.
In this paper, the objects from each class are assumed to follow a multivariate normal distribution. How the proposed method can be generalized to, or may be affected by, non-normal distributions, such as the elliptically contoured distribution [38] (p. 47) is interesting and warrants further research.
A frequentist approach is proposed in this paper. One wonders whether a corresponding Bayesian approach is easier to construct. In a Bayesian approach, one uses the posterior distribution to make an inference about the true class of the future object . In particular, one can easily construct a Bayesian credible set for such that . However, it is not at all clear whether this construction guarantees that
since it can be shown that , i.e., the posterior distributions of and for the two future objects and are not independent. Nevertheless, Bayesian approach warrants further research.
Author Contributions
W.L., F.B., N.S., J.P., and A.J.H. all contributed to the writing of the paper, the data analysis, and the implementation of the simulations study.
Funding
The authors declare no funding.
Acknowledgments
We would like to thank the referees for critical and constructive comments.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Mathematical Details
In this appendix, we first show that the property in Equation (3) holds with equality. Note that we have
where the first equality above follows from the classical strong law of large numbers ([43], p. 333), the second from the definition of in Equation (2), and the third from . This completes the proof.
Next, we show that
where denotes the conditional expectation with respect to the random variable conditioning on the training data set (or, equivalently, all the and ). We have from the classical strong law of large numbers [43] that
in which the conditional expectation is used since all the confidence sets () use the same training data set . Hence,
The required result in Expression (12) now follows immediately from
for any since it is known that all the ’s are in C. This completes the proof.
Next, we provide a more tractable expression for in order to understand why Inequality (6) cannot be guaranteed for each observed . From the definition of in Equation (4), we have
where
with all the ’s, ’s and ’s being independent. Note that depends on the future observation but not the training data set , while and depend on the training data set but not the future observations.
Since the conditional probability in Equation (13) depends on the training data set (via the random vectors and ), Inequality (6), for any given value of , cannot be guaranteed for each observed training data set , i.e., and . For example, if the values of are such that
is substantially larger than (for a given constant ) for most possible values of , then the conditional probability in Equation (13) is smaller than and hence .
We therefore guarantee Inequality (6) with a large (close to 1) probability with respect to the randomness in , which is, from Equation (13), clearly equivalent to
where , and are given in Equations (14)–(16).
References
- Webb, A.R.; Copsey, K.D. Statistical Pattern Recognition, 3rd ed.; Wiley: New York, NY, USA, 2011. [Google Scholar]
- Flach, P. Machine Learning: The Art and Science of Algorithms that Make Sense of Data; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Theodoridis, S.; Koutroumbas, K. Pattern Recognition, 4th ed.; Academic Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Piegorsch, W.W. Statistical Data Analytics: Foundations for Data Mining, Informatics, and Knowledge Discovery; Wiley: New York, NY, USA, 2015. [Google Scholar]
- Chow, C.K. On optimum recognition error and reject tradeoff. IEEE Trans. Inf. Theor. 1970, 16, 41–46. [Google Scholar] [CrossRef]
- Bartlett, P.L.; Wegkamp, M.H. Classification with a reject option using a hinge loss. J. Mach. Learn. Res. 2008, 9, 1823–1840. [Google Scholar]
- Yuan, M.; Wegkamp, M. Classification methods with reject option based on convex risk minimization. J. Mach. Learn. Res. 2010, 11, 111–130. [Google Scholar]
- Yu, H.; Jeske, D.R.; Ruegger, P.; Borneman, J. A three-class neutral zone classifier using a decision—Theoretic approach with application to dan array analyses. J. Agric. Biolog. Environ. Stat. 2010, 15, 474–490. [Google Scholar] [CrossRef] [PubMed]
- Ramaswamy, H.G.; Tewari, A.; Agarwal, S. Consistent Algorithms for Multiclass Classification with a Reject Option. Available online: https://arxiv.org/abs/1505.04137 (accessed on 24 June 2019).
- Del Coz, J.J.; Diez, J.; Bahamonde, A. Learning nondeterministic classifiers. J. Mach. Learn. Res. 2009, 10, 2293–2293. [Google Scholar]
- Lei, J. Classification with confidence. Biometrika 2014, 101, 755–769. [Google Scholar] [CrossRef]
- Sadinle, M.; Lei, J.; Wasserman, L. Least Ambiguous Set-Valued Classifiers with Bounded Error Levels. Available online: https://arxiv.org/abs/1609.00451 (accessed on 24 June 2019).
- Shafer, G.; Vovk, V. A tutorial on conformal prediction. J. Mach. Learn. Res. 2008, 9, 371–421. [Google Scholar]
- Vovk, V.; Gammerman, A.; Shafer, G. Algorithm Learning in a Random World; Springer: Heidelberg, Germany, 2005. [Google Scholar]
- Campi, M.C. Classification with guarnateed probability of error. Mach. Learn. 2010, 80, 63–84. [Google Scholar] [CrossRef]
- Wilks, S.S. Determination of sample sizes for setting tolerance limits. Ann. Math. Stat. 1941, 14, 45–55. [Google Scholar] [CrossRef]
- Giles, P.J.; Kipling, D. Normality of oligonucleotide microarray data and implications for parametric statistical analyses. Bioinformatics 2003, 19, 2254–2262. [Google Scholar] [CrossRef] [PubMed]
- Hoyle, D.D.; Rattray, M.; Jupp, R.; Brass, A. Making sense of microarray data distributions. Bioinformatics 2002, 18, 576–584. [Google Scholar] [CrossRef] [PubMed]
- Lieberman, G.J.; Miller, R.G., Jr. Simultaneous tolerance intervals in regression. Biometrika 1963, 50, 155–168. [Google Scholar] [CrossRef]
- Lieberman, G.J.; Miller, R.G., Jr.; Hamilton, M.A. Simultaneous discrimination intervals in regression. Biometrika 1967, 54, 133–145. [Google Scholar] [CrossRef] [PubMed]
- Neyman, J. Outline of a theory of statistical estimation based on the classical theory of probability. Philos. Trans. R. Soc. Lond. Ser. A Math. Phys. Sci. 1937, 236, 333–380. [Google Scholar] [CrossRef]
- Hayter, A.J.; Hsu, J.C. On the relationship between stepwise decision procedures and confidence sets. J. Am. Stat. Assoc. 1994, 89, 128–136. [Google Scholar] [CrossRef]
- Lehmann, E.L. Testing Statistical Hypotheses, 2nd ed.; Wiley: New York, NY, USA, 1986. [Google Scholar]
- Finner, H.; Strassburge, K. The partitioning principle: A powerful tool in multiple decision theory. Ann. Stat. 2002, 30, 1194–1213. [Google Scholar] [CrossRef]
- Huang, Y.; Hsu, J.C. Hochberg’s step-up method: Cutting corners off Holm’s step-down method. Biometrika 2007, 94, 965–975. [Google Scholar] [CrossRef]
- Uusipaikka, E. Confidence Intervals in Generalized Regression Models; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Ferrari, D.; Yang, Y. Confidence sets for model selection by f-testing. Stat. Sin. 2015, 25, 1637–1658. [Google Scholar] [CrossRef]
- Wan, F.; Liu, W.; Bretz, F.; Han, Y. An exact confidence set for a maximum point of a univariate polynomial function in a given interval. Technometrics 2015, 57, 559–565. [Google Scholar] [CrossRef]
- Wan, F.; Liu, W.; Bretz, F.; Han, Y. Confidence sets for optimal factor levels of a response surface. Biometrics 2016, 72, 1285–1293. [Google Scholar] [CrossRef]
- Scheffé, H. A statistical theory of calibration. Ann. Stat. 1973, 1, 1–37. [Google Scholar] [CrossRef]
- Mee, R.W.; Eberhardt, K.R.; Reeve, C.P. Calibration and simultaneous tolerance intervals for regression. Technometrics 1991, 33, 211–219. [Google Scholar] [CrossRef]
- Mathew, T.; Zha, W. Multiple use confidence regions in mul- tivariate calibration. J. Am. Stat. Assoc. 1997, 92, 1141–1150. [Google Scholar] [CrossRef]
- Mathew, T.; Sharma, M.K.; Nordstrom, K. Tolerance regions and multiple-use confidence regions in multivariate calibration. Ann. Stat. 1998, 26, 1989–2013. [Google Scholar] [CrossRef]
- Aitchison, T.C. Discussion of the paper ‘Multivariate Calibration’ by Brown. J. R. Stat. Soc. Ser. B (Methodol.) 1982, 44, 309–360. [Google Scholar]
- Krishnamoorthy, K.; Mathew, T. Statistical Tolerance Regions: Theory, Applications and Computation; Wiley: New York, NY, USA, 2009. [Google Scholar]
- Han, Y.; Liu, W.; Bretz, F.; Wan, F.; Yang, P. Statistical calibration and exact one-sided simultaneous tolerance intervals for polynomial regression. J. Stat. Plan. Inference 2016, 168, 90–96. [Google Scholar] [CrossRef]
- Liu, W.; Han, Y.; Bretz, F.; Wan, F.; Yang, P. Counting by weighing: Know your numbers with confidence. J. R. Stat. Soc. Ser. C (Appl. Stat.) 2016, 65, 641–648. [Google Scholar] [CrossRef]
- Anderson, T.W. An Introduction to Multivariate Statistical Analysis, 3rd ed.; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Serfling, R. Approximation Theorems of Mathematical Statistics; Wiley: New York, NY, USA, 1980. [Google Scholar]
- Liu, W. R Computer Programs. Available online: http://www.personal.soton.ac.uk/wl/Classification/ (accessed on 24 June 2019).
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Martinez, W.L.; Martinez, A.R. Computational Statistics Handbook with Matlab, 2nd ed.; Chapman & Hall: Boca Raton, FL, USA, 2008. [Google Scholar]
- Chow, Y.S.; Teicher, H. Probability Theory: Independence, Interchangeability, Martingales; Springer: Heidelberg, Germany, 1978. [Google Scholar]


© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).