

Computers 2026, 15(6), 332; https://doi.org/10.3390/computers15060332 (registering DOI) - 22 May 2026
Abstract
Thyroid diseases are very common endocrine diseases that afflict millions of people around the world and need proper and timely diagnosis to ensure proper treatment. Although machine learning and hybrid metaheuristic methods have advanced, current models have high computation costs, low interpretability, and
[...] Read more.
Thyroid diseases are very common endocrine diseases that afflict millions of people around the world and need proper and timely diagnosis to ensure proper treatment. Although machine learning and hybrid metaheuristic methods have advanced, current models have high computation costs, low interpretability, and low probability calibration, which limit their use in clinical settings. In this research, a new DFSel-FT (Differentiable Feature Selection and an FT-Transformer) system is suggested, which combines DFSel-FT to allow one to diagnose thyroid disease effectively and interpretably. It employs Concrete (Gumbel-Softmax) gates to select the features end-to-end to make sure that only the most relevant clinical attributes are carried through the training. A Transformer-based architecture is then used to process the chosen features to learn intricate interdependencies. The model is trained with class-balanced focal loss and temperature scaling to better enhance calibration. Experimental evaluation on the UCI Thyroid Disease Dataset (22,632 samples) showed that the proposed model achieved 97.85% accuracy, 97.65% Macro-F1, and 98.10% AUC-OVR, showing competitive performance compared with traditional machine learning models, modern tabular deep learning baselines, and hybrid metaheuristic methods. Other indicators of robustness and reliability include MCC (0.955), Cohen Kappa (0.951), and small calibration error (ECE = 0.021). SHAP and LIME explainability analysis reveals clinically relevant features that include TSH, TT4, and T3. The proposed framework provides a balanced integration of predictive performance, interpretability, and probability calibration, making it a promising benchmark-level framework for interpretable and calibrated thyroid disease classification, requiring external clinical validation before real-world deployment.
Full article
(This article belongs to the Special Issue Application of Artificial Intelligence and Modeling Frameworks in Health Informatics and Related Fields)
►
Show Figures
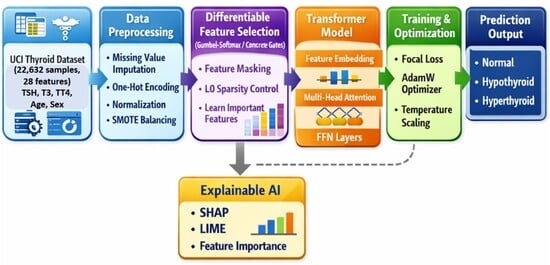
Graphical abstract



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}