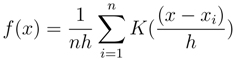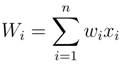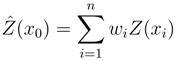1. Introduction
Flood disasters are a global problem capable of causing widespread destruction, loss of human lives, and extensive damage to property and the environment [
1]. Flooding is not limited to a particular region or continent and varies in scale from creek and river flooding to tsunami or hurricane driven coastal flooding. Flood events in 2011, which include disasters resulting from the Japanese tsunami and flooding in Thailand, affected an estimated 130 million people and caused approximately $70 billion spent on flood recovery [
2].
The ability to produce accurate and timely flood assessments before, during, and after an event is a critical safety tool for flood disaster management. Furthermore, knowledge of road conditions and accessibility is crucial for emergency managers, first responders, and residents. Over the past two decades, remote sensing has become the standard technique for flood identification and management because of its ability to offer synoptic coverage [
3]. For example, [
4] illustrate how MODIS (Moderate Resolution Imaging Spectroradiometer) data can be applied for near real-time flood monitoring. The large swath width of the MODIS sensor allows for a short revisit period (1–2 days), and can be ideal for large continental scale flood assessments, but data are relatively coarse with a 250 m resolution. While [
5] developed an algorithm for the almost automatic fuzzy classification of flooding from SAR (synthetic aperture radar) collected from the COSMO-SkyMed platform.
Unfortunately, satellite remote sensing for large scale flood disasters may be insufficient as a function of revisit time or obstructed due to clouds or vegetation. Aerial platforms, both manned and unmanned, are particularly suited for monitoring after major catastrophic events because they can fly below the clouds, and thus acquire data in a targeted and timely fashion, but may be cost prohibitive. Thus, it can be difficult to generate a complete portrayal of an event. The integration of additional data, such as multiple imagery, digital elevation models (DEM), and ground data (river/rain gauges) is often used to augment flood assessments or to combat inadequate or incomplete data. For example, [
6] combine SAR with Landsat TM imagery and a DEM to derive potential areas of inundation. Reference [
7] illustrate how fusing near real-time low spatial resolution SAR image and a Shuttle Radar Topography Mission (SRTM) DEM can produce results similar to hydraulic modeling. Reference [
8] propose the integration of Landsat TM data with a DEM and river gauge data to predict inundation areas under forest and cloud canopy. While [
9] used TerraSAR-X data with LiDAR to identify urban flooding.
The utilization of data from multiple sources can help provide a more complete description of a phenomena. For example, data fusion is often employed with remote sensing data to combine information of varying spatial, temporal, and spectral resolutions as well as to reduce uncertainties associated from using a single source [
10]. The fused data then provides new or better information than what would be available from a single source [
11]. The incorporation of multiple data sources or methods for improved performance or increased accuracy is not limited to the field of remote sensing. Boosting, a common machine learning technique, has been shown to be an effective method for generating accurate prediction rules by combining rough, or less than accurate, algorithms together [
12]. While the individual algorithms may be singularly weak, their combination can result in a strong learner.
This research extends this concept of employing multiple data sources for improved identification or performance by utilizing data from non-authoritative sources, in addition to traditional sources and methods, for flood assessment. Non-authoritative data describes any data which are not collected and distributed by traditional, authoritative sources such as government emergency management agencies or trained professionals. There is a spectrum of non-authoritative sources and the credibility, or level of confidence, in the data will vary by source characteristics (
Figure 1). These sources can range from those considered to be somewhat “authoritative” such as power outage information garnered from local power companies or flooded roads collected from traffic cameras to what is clearly non-authoritative, such as texts posted anonymously on social media. Even data which lean toward the authoritative can be categorized as non-authoritative because of the lack of a traditional scientific approach to their collection, processing, or sampling. For example, Volunteered Geographic Information (VGI), a specific type of user generated content, is voluntarily contributed data which contains temporal and spatial information [
13]. Because of the massive amount of real-time, on-the-ground data generated and distributed daily, the utilization of VGI during disasters is a new and growing research agenda. For example, VGI has been shown to document the progression of a disaster as well as promote situational awareness during an event [
14,
15,
16]. Non-authoritative data are not limited solely to VGI and may include data which were originally intended for other purposes, but can also be harnessed to provide information during disasters. For example, traffic cameras provide reliable, geolocated information regarding traffic and road conditions in many cities worldwide, but have yet to be used for flood extent estimation during disasters.
Figure 1.
Spectrum of confidence associated with authoritative and non-authoritative data sources.
Figure 1.
Spectrum of confidence associated with authoritative and non-authoritative data sources.
The integration of non-authoritative data with traditional, well established data and methods is a novel approach to flood extent mapping and road assessment. The application of non-authoritative data provides an opportunity to include real-time, on-the-ground information when traditional data sources may be incomplete or lacking. The level of confidence in the data sources, ranging from authoritative to varying degrees of non-authoritative, impart levels of confidence in the resulting flood extent estimations. Recently, methods for flood estimation are including confidence or uncertainty in their results. For example, [
17] used coarse resolution ENVISAT Advanced Synthetic Aperture Radar (ASAR) and high resolution ERS-2 SAR data to create various “uncertain flood extent” maps or “possibility of inundation” maps for calibrating hydraulic models. Reference [
18] fused remote sensing flood extent maps to create an uncertain flood map representing varying degrees of flood possibility based on the aggregation of multiple deterministic assessments. Reference [
19] highlight uncertainty in satellite remote sensing data for flood prediction, especially in areas near the confluence of rivers, to create a probability of flooding versus a binary interpretation.
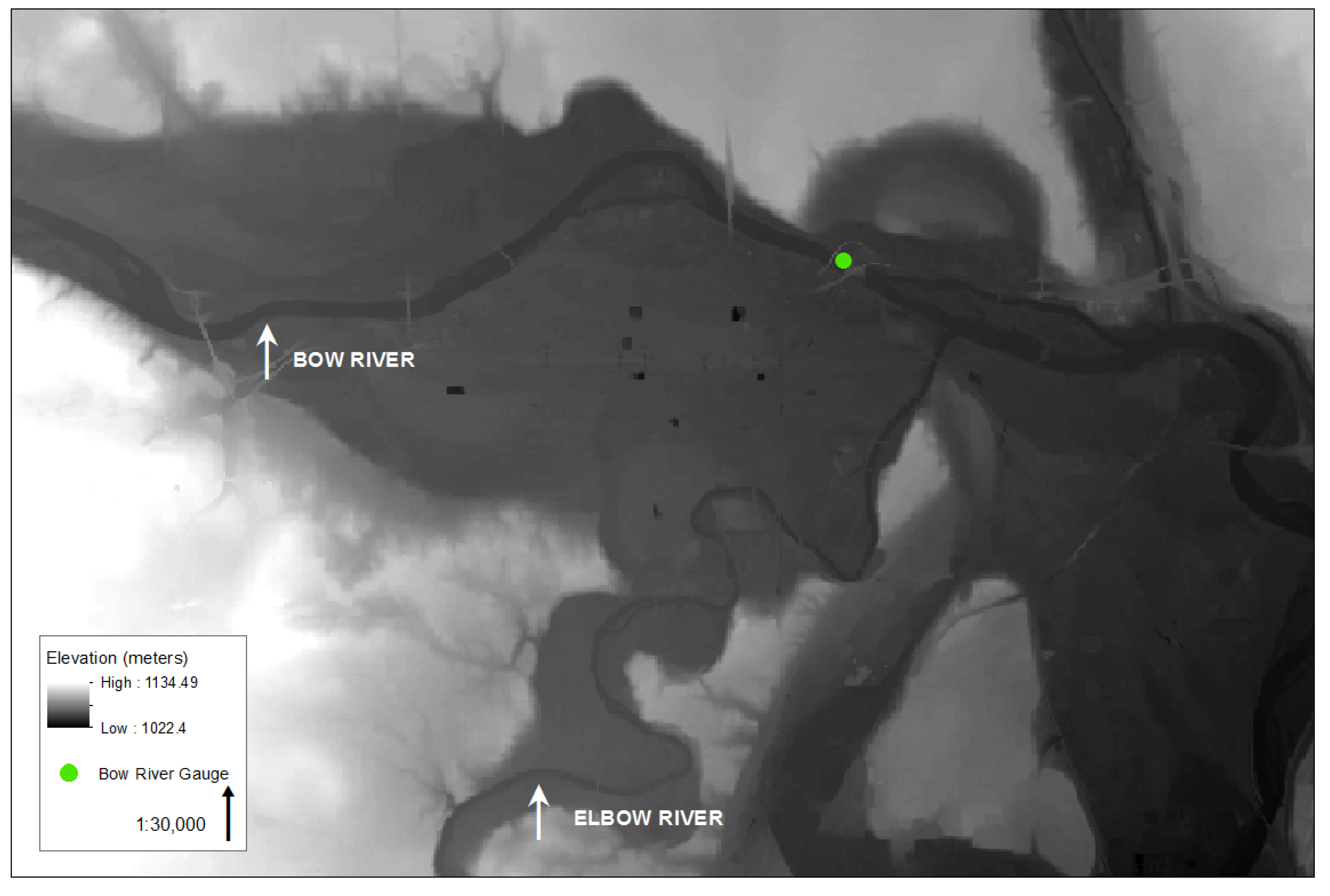
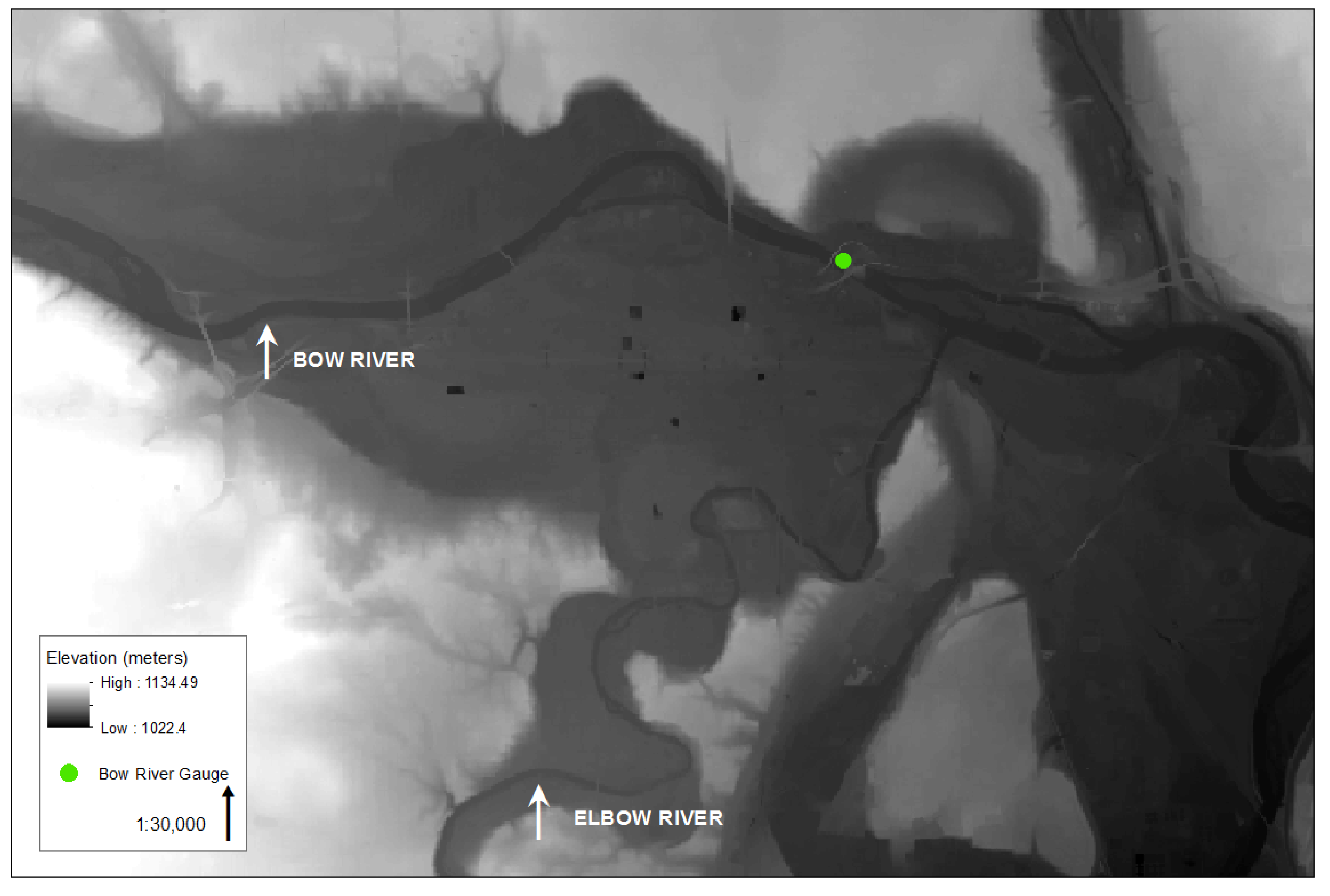
In June of 2013, the combination of excessive precipitation and saturated ground caused unprecedented flooding in the Canadian province of Alberta. The Bow River, the most regulated river in Alberta with 40% of its total annual flow altered by eight major upstream reservoirs, flows through the heart of downtown Calgary [
20]. Intersecting the Bow River in downtown Calgary is the Elbow River which flows south to the Glenmore Dam, a reservoir for drinking water. The June flooding of the Bow River in 2013 is the largest flood event since 1932 with a peak discharge of 1470 m
3/s, almost fifteen times the mean daily discharge of 106 m
3/s [
21]. The City of Calgary, in particular, experienced sudden and extensive flooding causing the evacuation of approximately 100,000 people [
22]. The damage and recovery costs for public buildings and infrastructure in the City of Calgary are estimated to cost over $400 million [
23]. Because of extensive cloud cover and revisit limitations, remote sensing data of the Calgary flooding in June 2013 are extremely limited. A case study of this flood event provides an opportunity to illustrate a proof of concept where the incorporation of freely available, non-authoritative data of various resolutions and accuracies are integrated with traditional data to provide an estimate of flood extent when remote sensing data are sparse or lacking. Furthermore, this research presents an estimation of the advancement and recession of the flood event over time using these sources.
3. Results
Using the methodology described in
Section 2.3 the data layers are merged together for each date, 21–26 June 2013, yielding 6 daily layers for geostatistical interpolation. The layer weights are assigned linearly based on confidence in the data source following the scale in
Figure 1. Specifically, the Tweets were assigned a weight of 1, photos a 2, road closures (local news) and traffic cameras a 3, and remote sensing and DEM data a 4. Because this research extended over a 6 day period, there were more data available on some days compared to others (
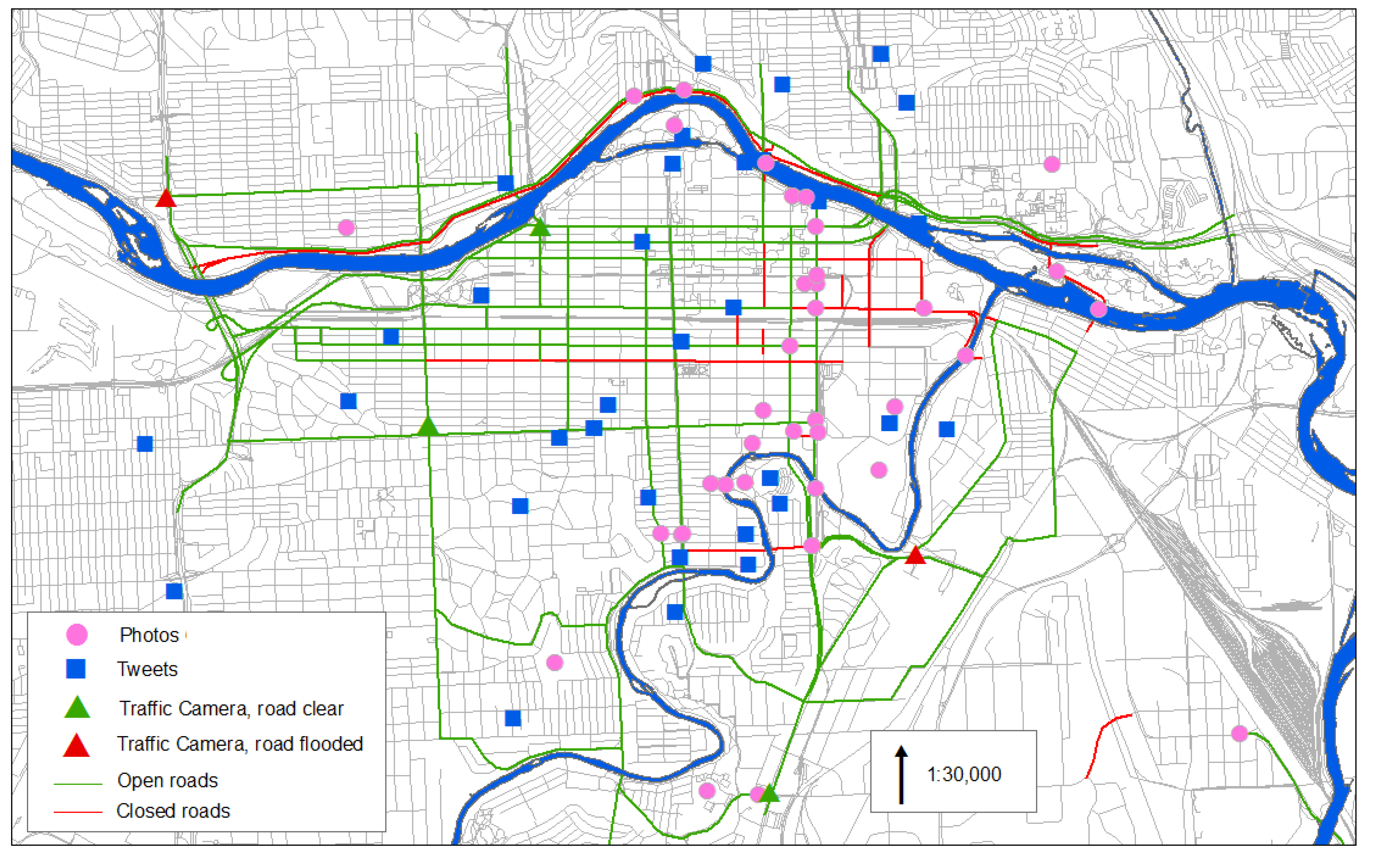
Table 1). This did not affect the actual methodology for layering, as the layers are weighted and summed together in one step regardless of the number of layers used. The locations of the non-authoritative data were generally well distributed across the domain (
Figure 6). Although the volume of non-authoritative data varied from day to day with some days only having a sparse amount, it has been shown that even a small amount of properly located VGI data can help improve flood assessment [
31].
Figure 6.
Distribution of non-authoritative data.
Figure 6.
Distribution of non-authoritative data.
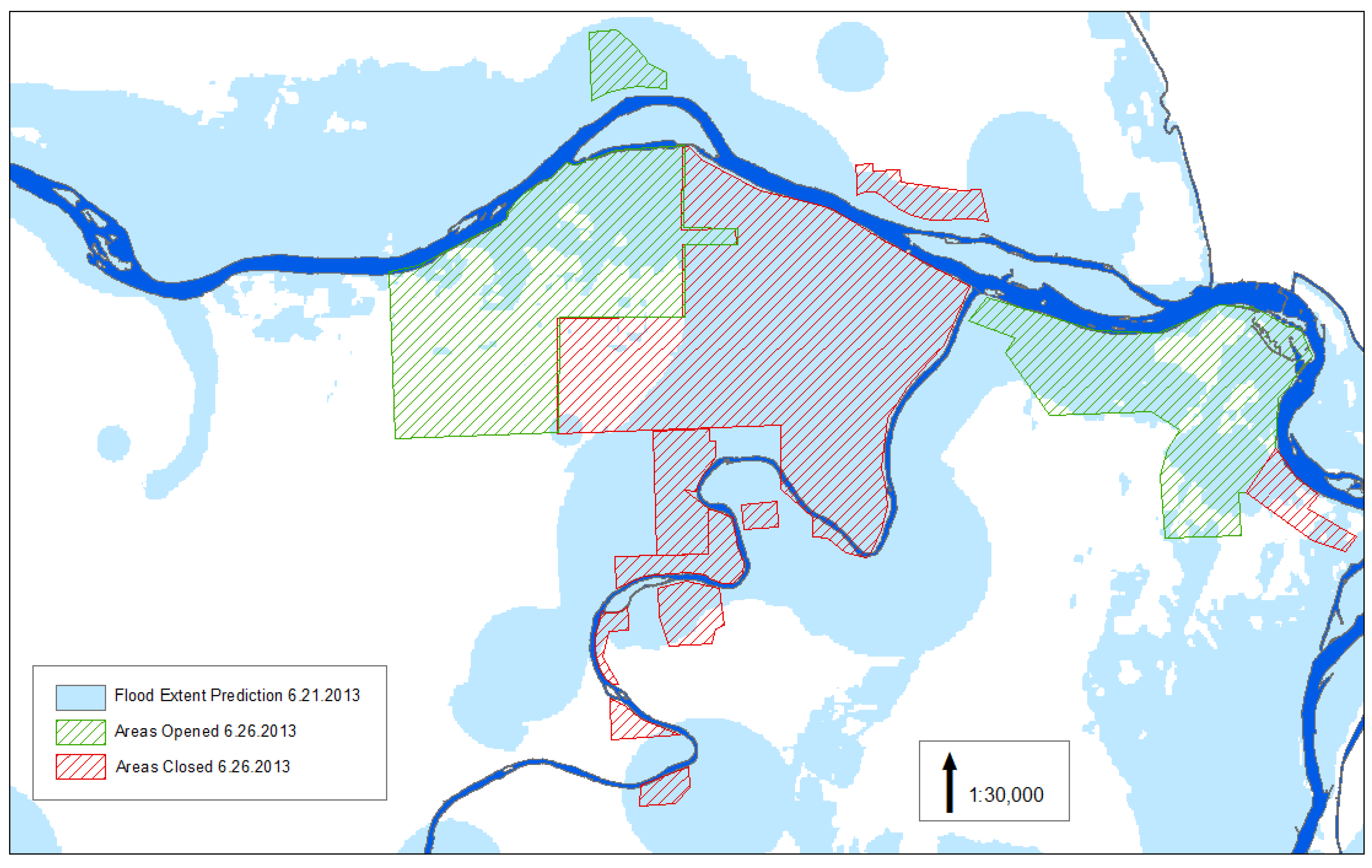
Figure 7.
Flood extent estimated for 21 June as compared to areas which had been previously closed (and opened as of 26 June) and areas still closed on 26 June.
Figure 7.
Flood extent estimated for 21 June as compared to areas which had been previously closed (and opened as of 26 June) and areas still closed on 26 June.
Following the merging of layers, flood estimation maps are generated as discussed in
Section 2.4.
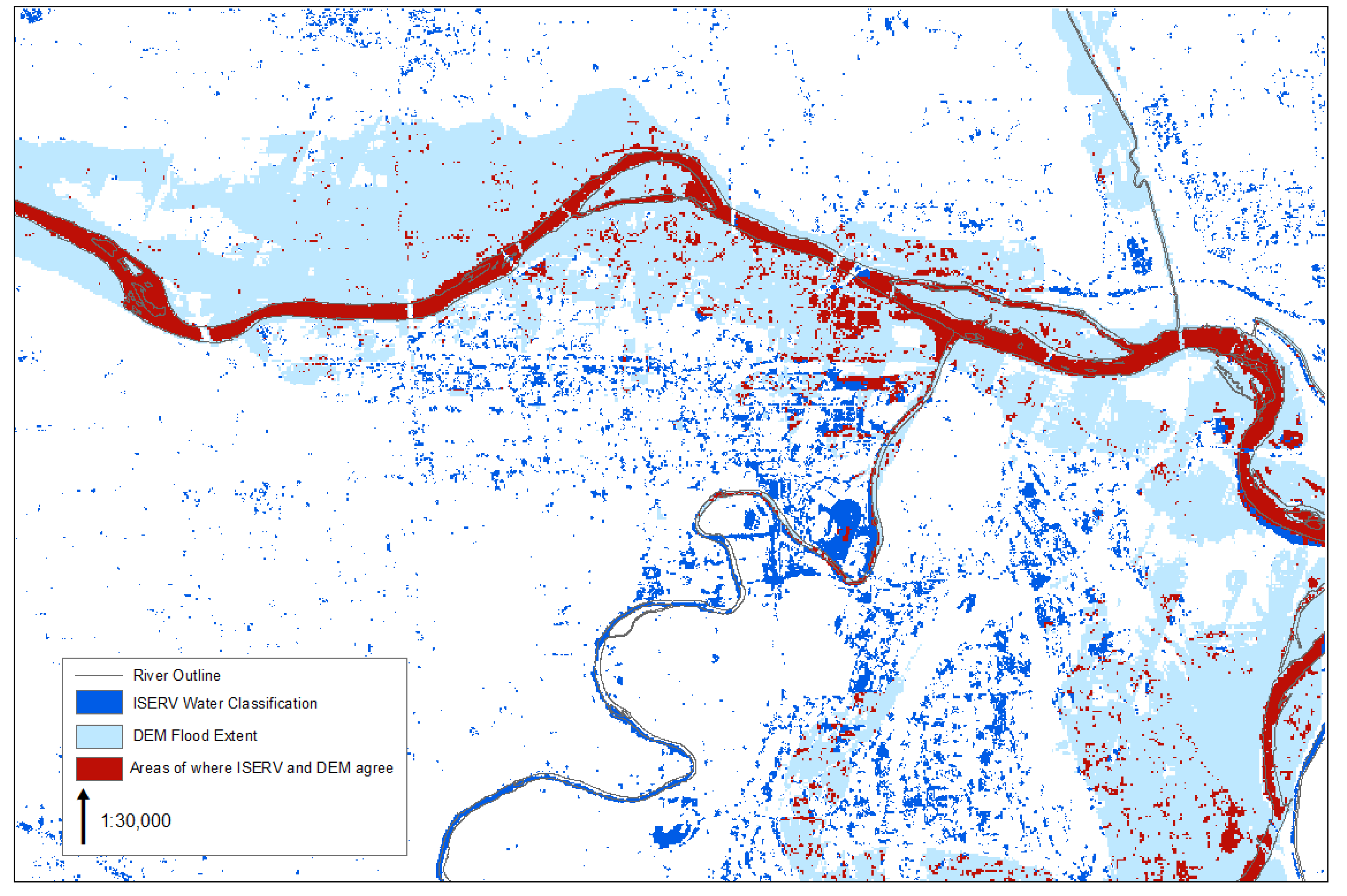
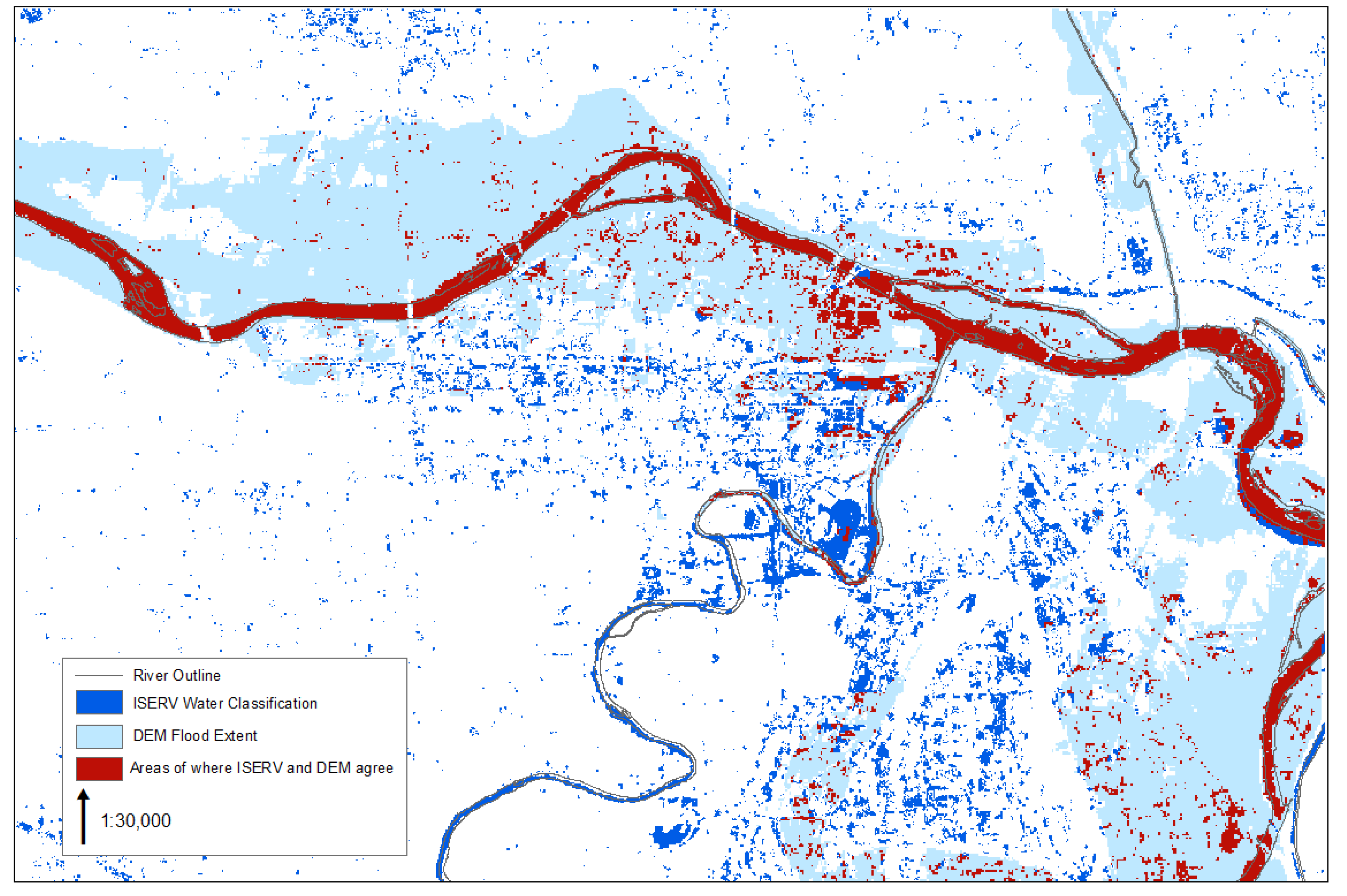
Figure 7 is a comparison of the maximum flood extent which was estimated on 21 June (
Figure 8a) and areas indicated as closed from a Google Crisis map available for this flood event. The maps agree well in some areas and not in others. Some of the areas of over estimation are likely due to the DEM utilized which had been manually normalized to account for changes in elevation in the scene. In addition, non-authoritatuve data may be providing flood information not captured in the Google Crisis map, specifically flooding which have receeded or localized neighborhood flooding at a “micro-level”.
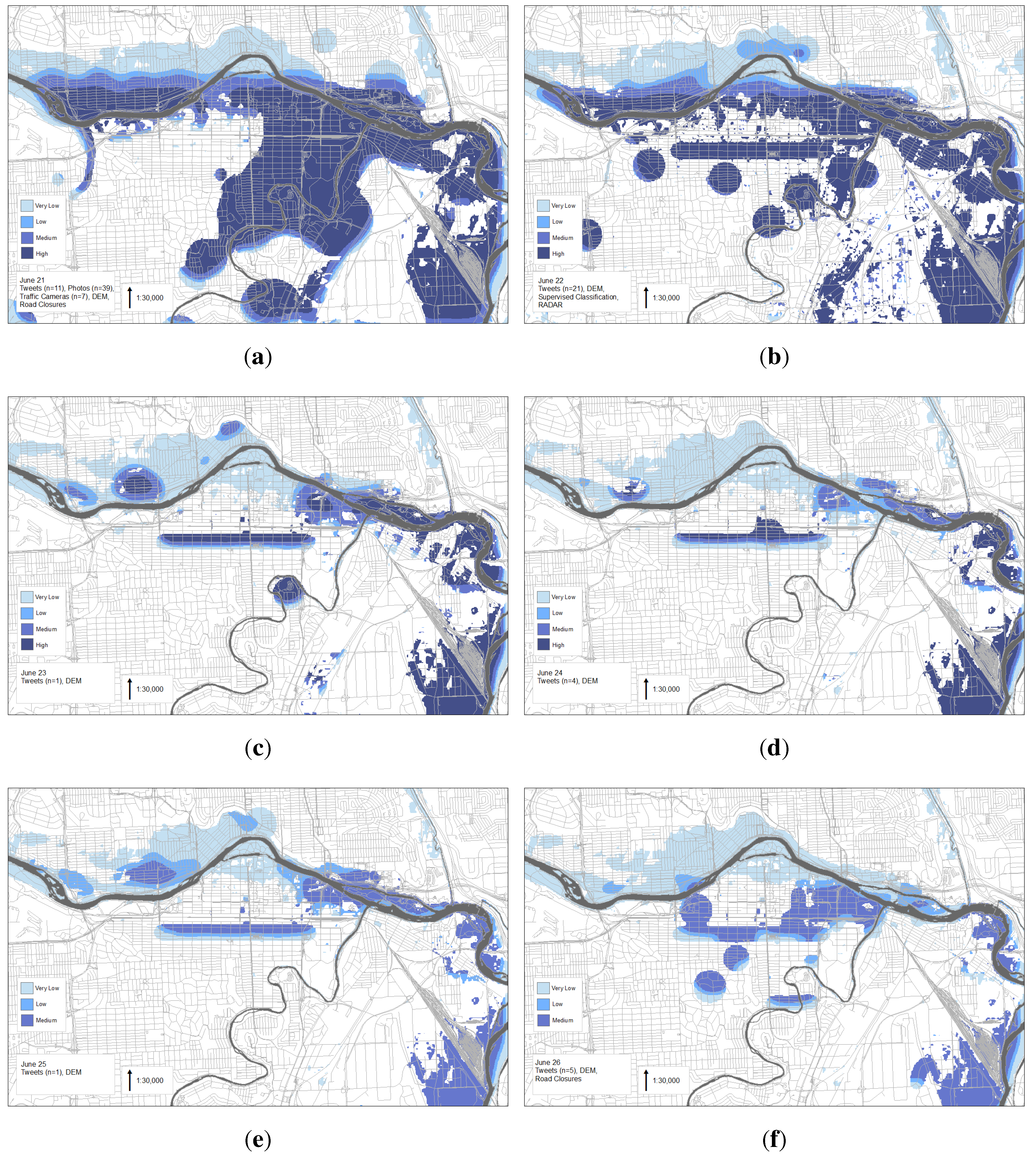
Figure 8 illustrates daily estimated flood extent for 21–26 June 2013. The flood time series maps are presented as an estimate of flood extent over the 6 day period as well as the level of confidence in the estimations. The daily series demonstrates a progression from severely flooded, 21 June, through a flood recession. The quantity of data available each day does appear to affect the map results. For example, only two days had road closure data, 21 June and 26 June. Because of the quantity and variety of the data for 21 June, the road closure layer is well assimilated with the rest of the data (
Figure 8a). This is not the case for 26 June, where a much smaller amount of data were available. This results in the road closure layer being evident as indicated by the horizontal flood estimated in the center of the image (
Figure 8f). An assumption was made that the road categorized as flooded on 26 June was likely flooded on previous days as well, but because of a lack of road data for 22–25 June, it was not included in the original analysis. Therefore, a decision was made to include the closed road on 26 June into the data sets for previous days. This results in the horizontal flooded area in (Figure 8b–e). The sparseness of data is also evident by the circular areas of flooding. These are the result of individual tweets which are located too far from the the majority of data in the scene to be properly integrated (
Figure 8b,c,f). By comparing these flood maps to the one created for 21 June (
Figure 8a) it is clear that a smoother and richer estimation can be accomplished as data volume and diversity increases.
Figure 8.
Flood extent estimation and road assessment. The categories (very low, low, medium, high) represent the confidence in a pixel being affected by flooding. (a) 21 June; (b) 22 June; (c) 23 June; (d) 24 June; (e) 25 June; (f) 26 June.
Figure 8.
Flood extent estimation and road assessment. The categories (very low, low, medium, high) represent the confidence in a pixel being affected by flooding. (a) 21 June; (b) 22 June; (c) 23 June; (d) 24 June; (e) 25 June; (f) 26 June.
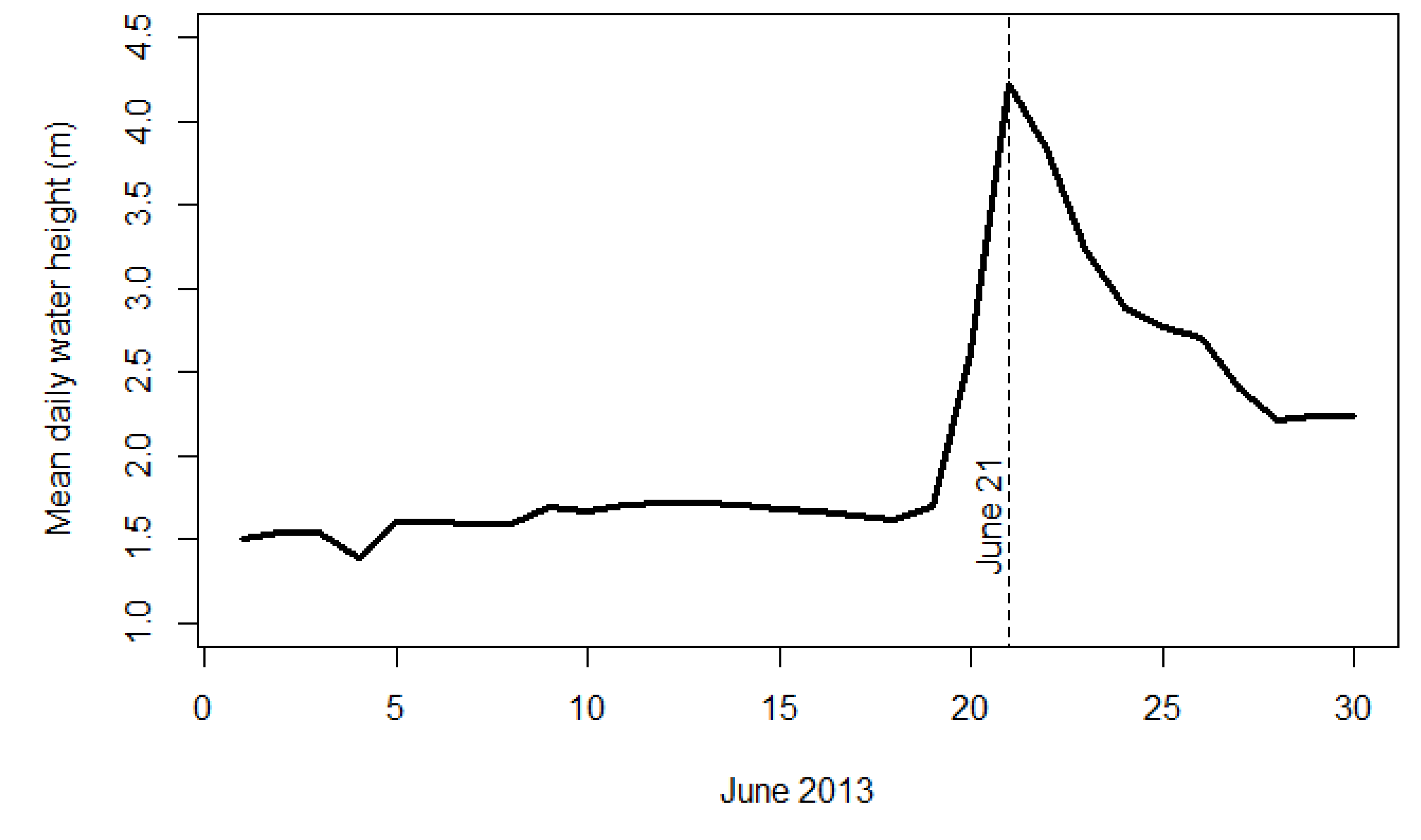
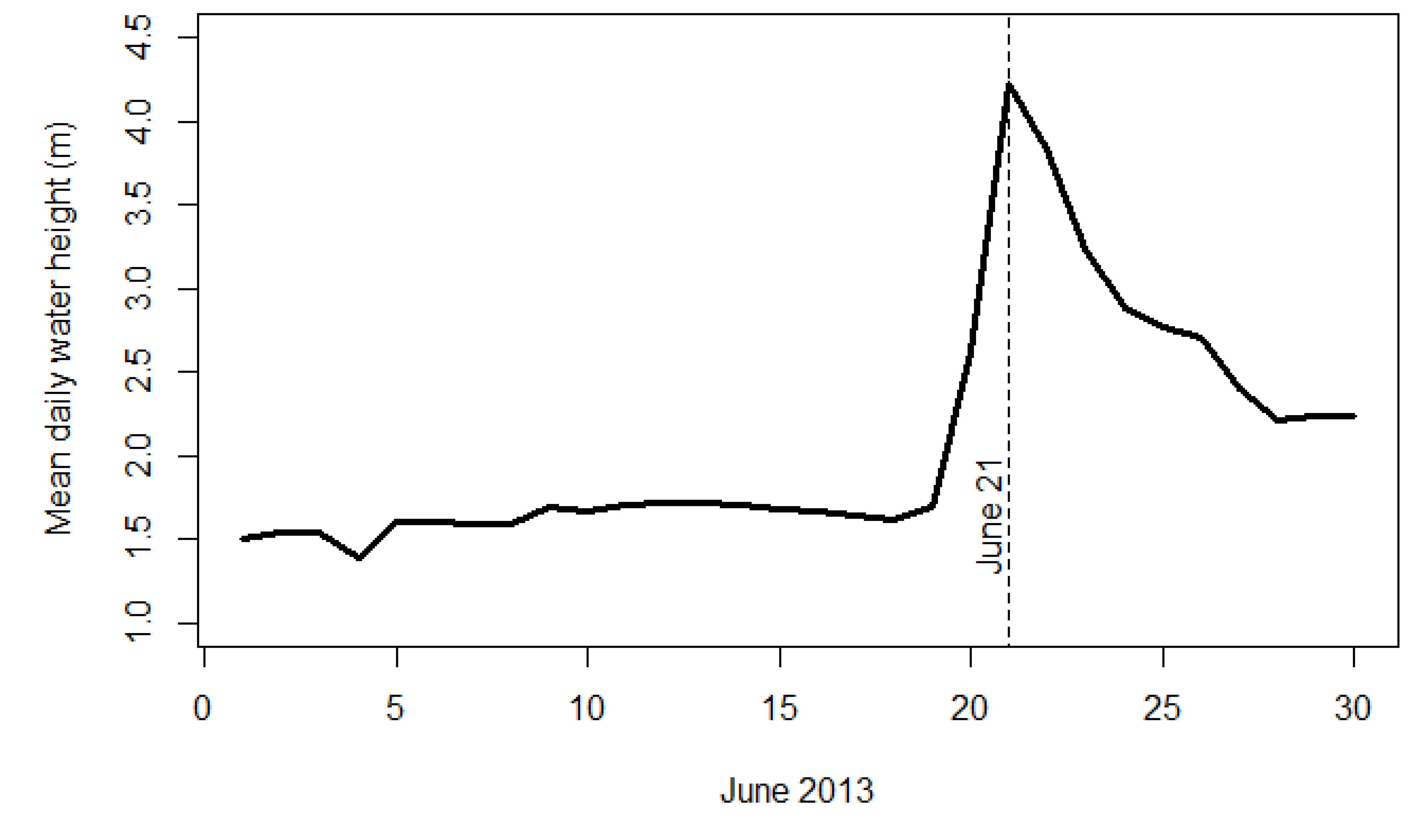
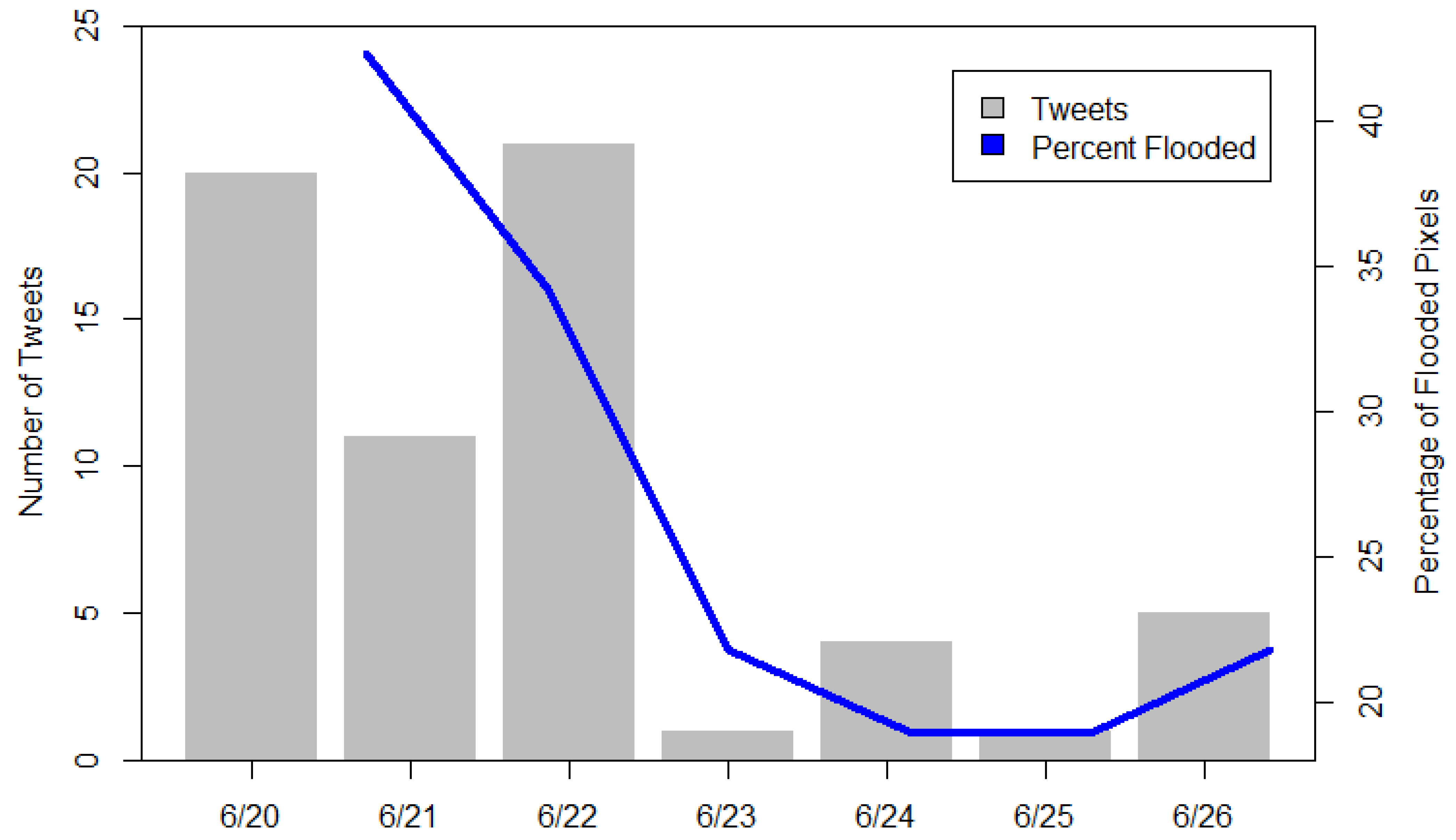
The overall tweet volume corresponds well to the progression of the flood event (
Figure 9). The maximum number of tweets are posted during the peak of the flood and then reduce as the flood recedes. It is unclear why there are small increases in the number of tweets during the later days of the flood event. These tweets may be related to flood recovery with information regarding power outages, drinking water, or closures/openings of public facilities.
Figure 9 also illustrates the area of the flood as a function of time. By using the flood extent estimations created with this methodology, flood area is represented as the percentage of pixels classified as flooded each day in (
Figure 8a–f). Flood area does increase slightly the last day of the study. This is likely the result of a corresponding increase in tweets for the same day and not an actual increase in flood area.
Figure 9.
Progression of tweet volume and flooded area over time.
Figure 9.
Progression of tweet volume and flooded area over time.
The estimation of flood extent can be further processed by applying an additional kernel smooting operation. This may be necessary for layers with lower data quantities. For this research, a smoother flood extent was desired. The flood maps were exported from ArcGIS as GeoTiff files and then smoothed using
R statistical software. The same kernel density estimator as in Equation (1) was applied. The specific methodology used for kernel smoothing and its
R implementation is described by [
32].
4. Discussion and Conclusions
The June 2013 flooding in Calgary is a good example of how remote sensing data, although a reliable and well tested data source, are not always available or perhaps cannot provide a complete description of a flood event. As a case study, this work illustrates how the utilization and integration of multiple data sources offers an opportunity to include real-time, on-the-ground information. Further, the identification of affected roads can be accomplished by pairing a road network layer with the flood extent estimation. Roads which are located within the areas classified as flooded are identified as regions which are in need of additional evaluation and are possibly compromised or impassable (
Figure 8a–f). Roads can be further prioritized as a function of distance from the flood source (
i.e., river or coastline) or distance from the flood boundary. This would aid in prioritizing site inspections and determining optimal routes for first responders and residents. In addition, pairing non-authoritative data with road closures collected from news and web sources provides enhanced temporal resolution of compromised roads during the progression of the event.
The addition of weights allows for variations in source characteristics and uncertainties to be considered. In this analysis weight was assigned based on confidence in the source, for example, observations published by local news are assumed to have more credibility than points volunteered anonymously. However, other metrics can be used to assign weight. For example, the volume of the data can be used to assign higher weight to data with dense spatial coverage and numerous observations. The timing of the data could also be used as a metric for quality. As shown, tweet volume decreases during the progression of the event, with perhaps non-local producers dropping out as interest fades. This may possibly yield a more valuable data set of tweets, those just generated by local producers, which could be inferred to be of higher quality and thus garner a higher weight. However, it is not possible to set the weights as an absolute because each flood event is unique and there will be differences in data sources, availability, and quantity.
Currently, authoritative flood maps from this event have not been made available to the general public, making the validation of the flood extent estimations in
Figure 8 difficult. However, even when available, the issue of correctness or accuracy in official estimates should be addressed. Non-authoritative data often provide timelier information than that provided through authoritative sources. In addition, these data can be used for the identification of flooding at a micro-level, which is often difficult to capture using authoritative sources or traditional methods. Although not considered ground truth, non-authoritative data does provide information in areas where there might otherwise be none. However, the flood estimations are controlled by the distribution and quantity of the data. For example, landmark areas are more likely to receive public attention and have flooding documented than other less notable areas. Therefore researchers should be aware of, and recognize, the potential for skewness in the spatial distribution of the available data, and thus the information garnered from it. Moreover, a lack of ground data can be simply an indication of no flooding or can be the result of differences in the characteristics of places within the domain. The importance of data quantity is evident in (
Figure 8) where a decrease in quantity and variability of data during the progression of the event creates a less consistent flooded surface, with single tweets standing out in isolation on days when the quantity of data is low. However, the fusion of data from multiple sources yields a more robust flood assessment providing an increased level of confidence in estimations where multiple sources coincide.
While the analysis presented in this work was performed after the flood event, this methodology can be extended for use during emergencies to provide near real-time assessments. The use of automated methods for the ingestion, filtering, and geolocating of all sources of non-authoritative data would decrease processing time as well as provide a larger volume of data which could also enhance results. In addition, the time required to collect and receive remote sensing data is moving toward real-time availability. For example, unmanned aerial vehicles (UAVs) were deployed during the Colorado floods in September 2013 with images processed and available to the Boulder Emergency Operations Center within an hour [
33]. Recent research is also utilizing social media to identify areas affected by natural disasters for the tasking of satellite imagery [
34]. Although in this work specific data sources were used, this methodology can be applied with any data available for a particular event.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}