VLSI Architecture for 8-Point AI-based Arai DCT having Low Area-Time Complexity and Power at Improved Accuracy

Abstract
:1. Introduction
2. Review of 1-D DCT Computation Algorithms
3. AI Encoding of DCT Computation Algorithms
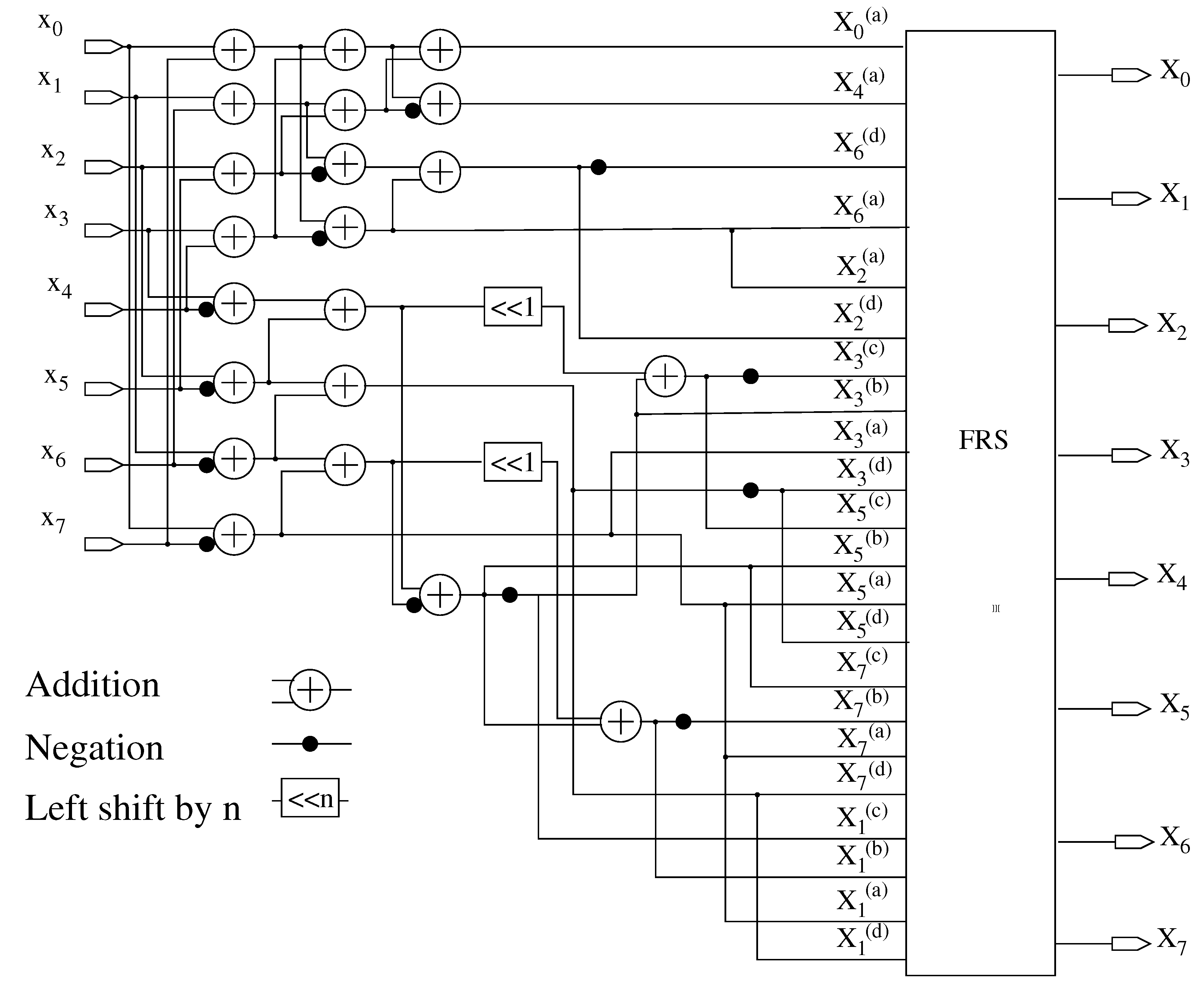
4. Final Reconstruction Step (FRS)
5. Proposed 1-D DCT Architecture
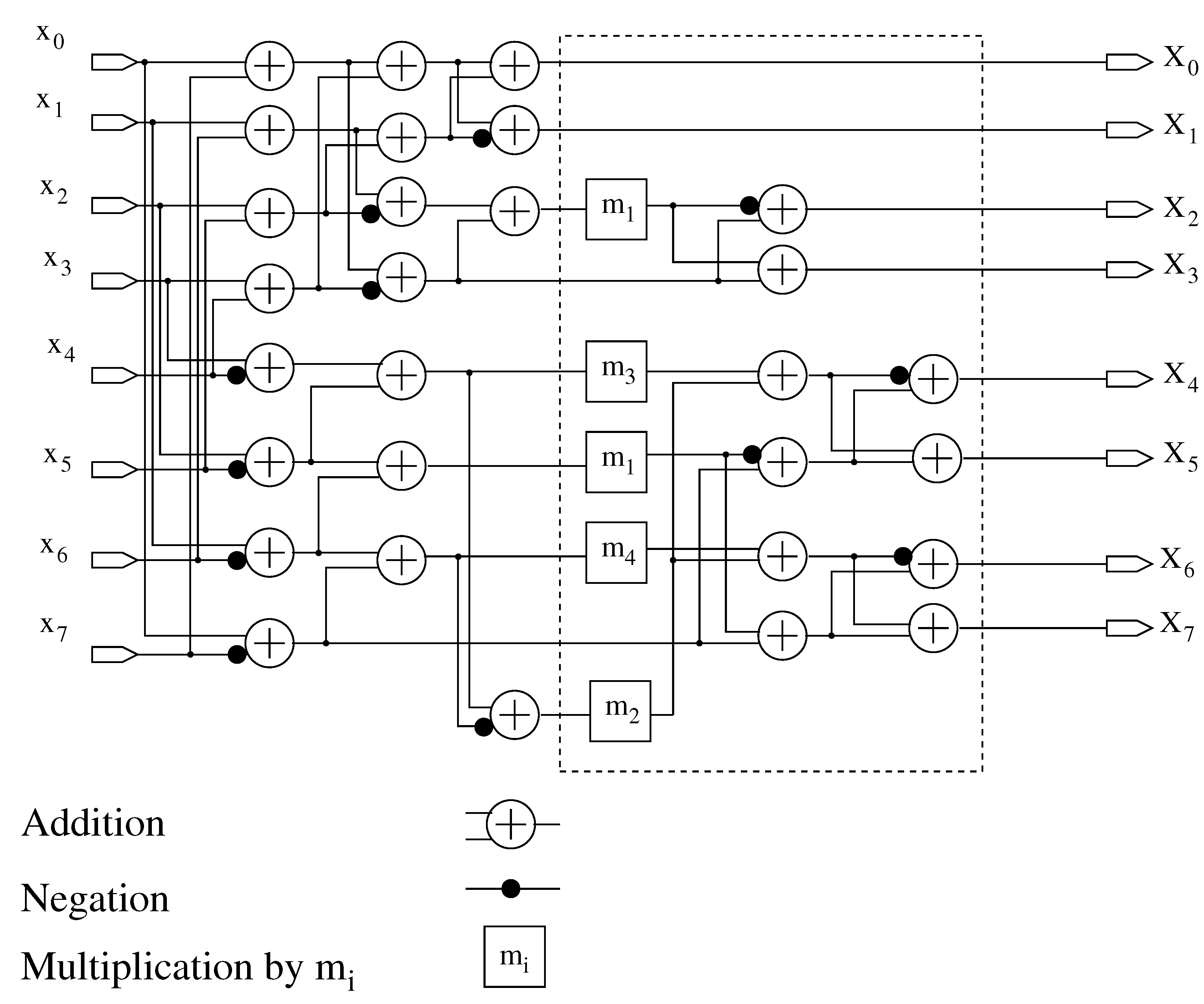
5.1. Decimation Block and 8-Point Arai-DCT Circuit
5.2. Low-Complexity Expansion-Factor FRS
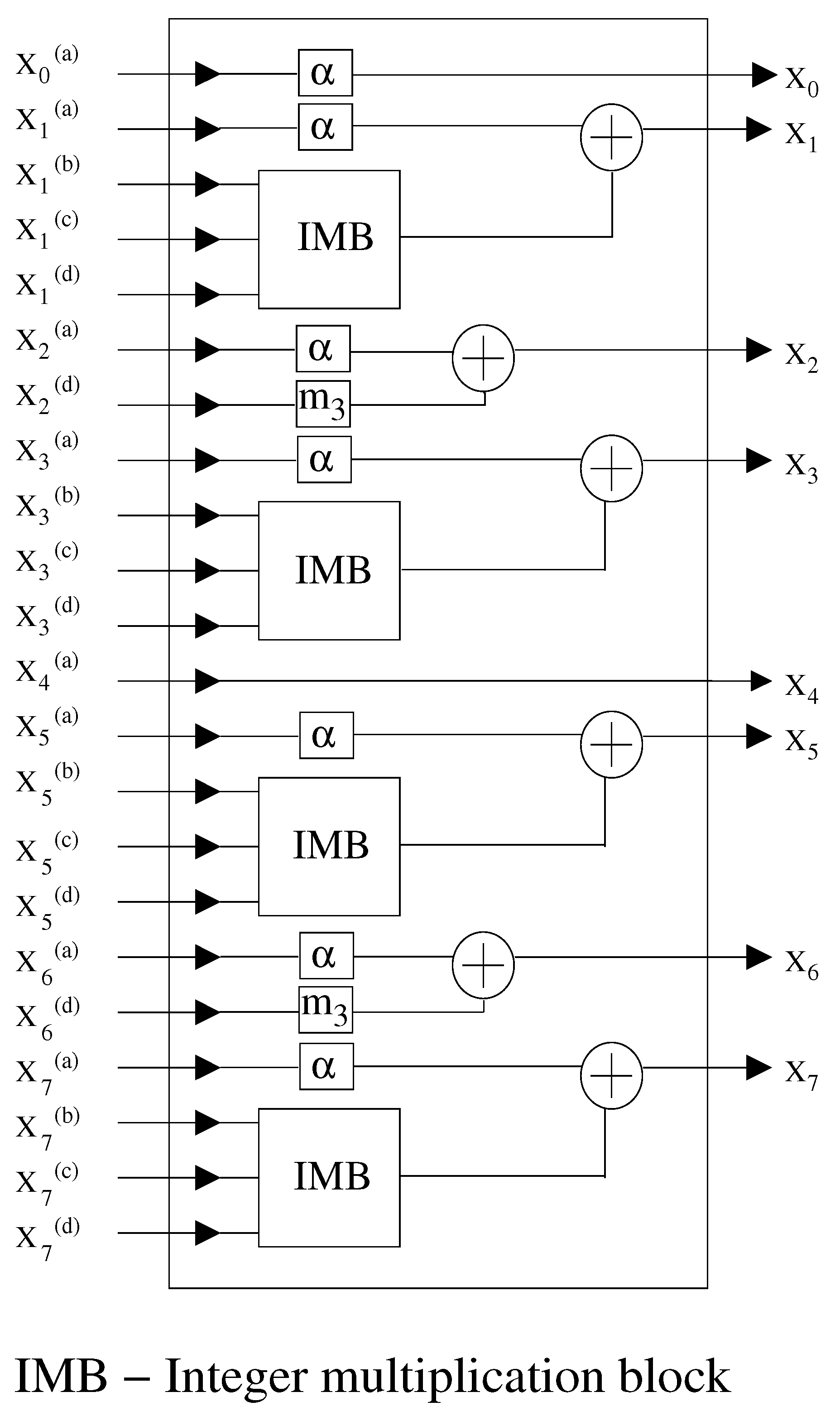
5.2.1. Integer Multiplication Block (IMB)
5.2.2. Multiplication by
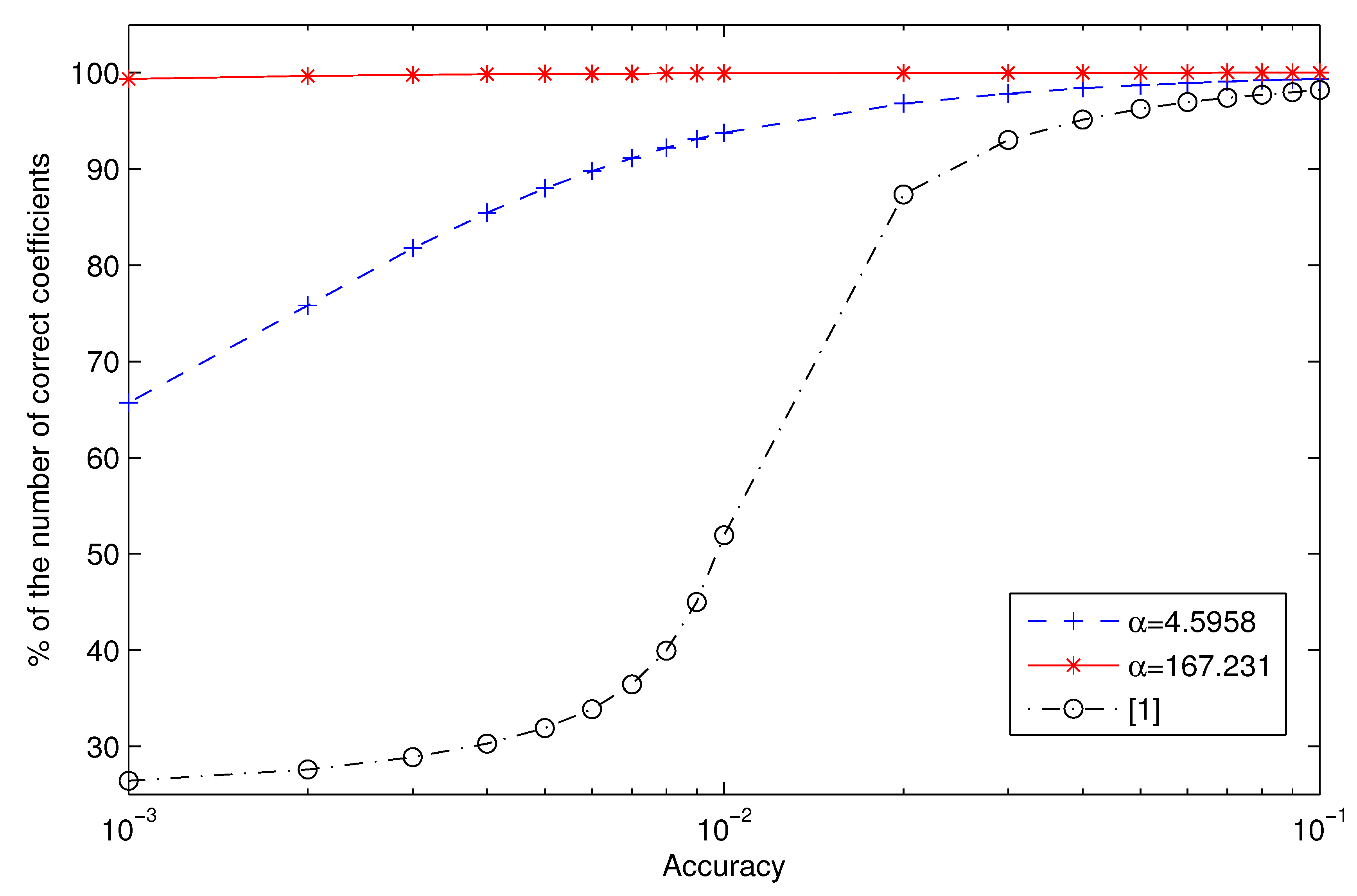
6. On-Chip Verification Using Success Rates
7. Results
7.1. 40 nm CMOS Virtex-6 FPGAs
7.2. Area Utilization
7.3. Operating Frequency
7.4. Power Consumption
7.5. 65 nm CMOS for ASICs
7.6. Area Utilization
7.7. Operating Frequency
7.8. Power Consumption
7.9. Overall Comparison With Existing Architectures
8. Conclusions
Acknowledgements
References
- Dimitrov, V.; Wahid, K.; Jullien, G. Multiplication-free 8 × 8 2D DCT architecture using algebraic integer encoding. Electron. Lett. 2004, 40, 1310–1311. [Google Scholar] [CrossRef]
- Blinn, J. What’s that deal with the DCT? IEEE Comput. Graph. Appl. 1993, 13, 78–83. [Google Scholar] [CrossRef]
- Britanak, V.; Yip, P.; Rao, K.R. Discrete Cosine and Sine Transforms; Academic Press: Waltham, MA, USA, 2007; p. 274. [Google Scholar]
- Cintra, R.J. An integer approximation method for discrete sinusoidal transforms. J. Circuits Syst. Signal Process. 2011, 30, 1481–1501. [Google Scholar] [CrossRef]
- Tun, I.D.; Lee, S.U. On the fixed-point-error analysis of several fast DCT algorithms. IEEE Trans. Circuits Syst. Video Technol. 1993, 3, 27–41. [Google Scholar]
- Lee, B. A new algorithm to compute the discrete cosine transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 1243–1245. [Google Scholar]
- Hou, H. A fast recursive algorithm for computing the discrete cosine transform. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 1455–1461. [Google Scholar]
- Vitterli, M. Simple FFT and DCT algorithms with reduced number of operations. Signal Process. 1984, 6, 267–278. [Google Scholar] [CrossRef]
- Duhamel, P.; H’Mida, H. New 2nDCT Algorithms Suitable for VLSI Implementation. In >Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP ’87), Boston, MA, USA, 14–16 April 1987; Volume 12, pp. 1805–1808. [Google Scholar]
- Loeffler, C.; Ligtenberg, A.; Moschytz, G. Practical Fast 1-D DCT Algorithms with 11 Multiplications. In Proceedings of the 1989 International Conference on Acoustics, Speech, and Signal Processing (ICASSP ’89), Glasgow, Scotland, 23–26 May 1989; Volume 2, pp. 988–991. [Google Scholar]
- Arai, Y.; Agui, T.; Nakajima, M. A fast DCT-SQ scheme for images. Trans. IEICE 1988, e 71, 1095–1097. [Google Scholar]
- Tseng, B.; Miller, W. On computing the discrete cosine transform. IEEE Trans. Comput. 1978, C-27, 966–968. [Google Scholar] [CrossRef]
- Dimitrov, V.; Jullien, G.; Miller, W. A New DCT Algorithm Based on Encoding Algebraic Integers. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Seattle, WA, USA, 12–15 May 1998; Volume 3, pp. 1377–1380. [Google Scholar]
- Baghaie, R.; Dimitrov, V. Systolic implementation of real-valued discrete transforms via algebraic integer quantization. Comput. Math. Appl. 2001, 41, 1403–1416. [Google Scholar] [CrossRef]
- Dimitrov, V.; Jullien, G. Multidimensional algebraic-integer encoding for high performance implementation of DCT and IDCT. Electron. Lett. 2003, 39, 602–603. [Google Scholar] [CrossRef]
- Fu, M.; Jullien, G.; Dimitrov, V.; Ahmadi, M.; Miller, W. The Application of 2D Algebraic Integer Encoding to a DCT IP Core. In Proceedings of the 3rd IEEE International Workshop on System-on-Chip for Real-Time Applications, Calgary, Canada, 30 June–2 July 2003; pp. 66–69. [Google Scholar]
- Fu, M.; Jullien, G.; Dimitrov, V.; Ahmadi, M. A Low-Power DCT IP Core Based on 2D Algebraic Integer Encoding. In Proceedings of the 2004 International Symposium onCircuits and Systems (ISCAS ’04), Vancouver, Canada, 23–26 May 2004; Volume 2, pp. 765–768. [Google Scholar]
- Madanayake, H.L.P.A.; Cintra, R.J.; Onen, D.; Dimitrov, V.S.; Bruton, L.T. Algebraic Integer Based 8 × 8 2-D DCT Architecture for Digital Video Processing. In Proceedings of the 2011 IEEE International Symposium on Circuits and Systems (ISCAS ’11), Rio de Janeiro, Brazil, 15–18 May 2011; pp. 1247–1250. [Google Scholar]
- Plonka, G. A global method for invertible integer DCT and integer wavelet algorithms. Appl. Comput. Harmon. Anal. 2004, 16, 79–110. [Google Scholar] [CrossRef]
- Cintra, R.J.; Bayer, F.M. A DCT approximation for image compression. IEEE Signal Process. Lett. 2011, 18, 579–583. [Google Scholar] [CrossRef]
- Bouguezel, S.; Ahmad, M.O.; Swamy, M.N.S. Low-complexity 8 × 8 transform for image compression. Electron. Lett. 2008, 44, 1249–1250. [Google Scholar] [CrossRef]
- Bouguezel, S.; Ahmad, M.O.; Swamy, M.N.S. A Low-Complexity Parametric Transform for Image Compression. In Proceedings of the 2011 IEEE International Symposium on Circuits and Systems, Rio de Janeiro, Brazil, 15–18 May 2011. [Google Scholar]
- Gong, D.; He, Y.; Cao, Z. New cost-effective VLSI implementation of a 2-D discrete cosine transform and its inverse. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 405–415. [Google Scholar] [CrossRef]
- Shams, A.; Bayoumi, M. A 108 Gbps, 1.5 GHz 1D-DCT Architecture. In Proceedings of the IEEE International Conference on Application-Specific Systems, Architectures, and Processors, Boston, MA, USA, 10–12 July 2000; pp. 163–172. [Google Scholar]
- Ghosh, S.; Venigalla, S.; Bayoumi, M. Design and Implementaion of a 2D-DCT Architecture Using Coefficient Distributed Arithmetic [Implementaion Read Implementation]. In Proceedings of the IEEE Computer Society Annual Symposium on VLSI, Tampa, FL, USA, 11–12 May 2005; pp. 162–166. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Representation | |
|---|---|
| 4.5961 | |
| 167.2309 |
| Percentage tolerance | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Design | Lena | Cameraman | Livingroom | ||||||
| 10% | 1% | 0.01% | 10% | 1% | 0.01% | 10% | 1% | 0.01% | |
| α = 4.5958 | 99.43 | 93.86 | 50.65 | 99.44 | 94.07 | 52.48 | 99.37 | 93.86 | 50.81 |
| α = 167.231 | 99.99 | 99.94 | 93.44 | 99.99 | 99.96 | 93.53 | 99.99 | 99.93 | 93.41 |
| [1] | 98.44 | 52.33 | 26.10 | 98.72 | 54.52 | 26.49 | 98.39 | 52.81 | 26.44 |
| Design | Area | Speed | AT | Power (mW) | |||||
|---|---|---|---|---|---|---|---|---|---|
| LUTs | Registers | Slices | (MHz) | Slices s | Clocks | Logic | Signals | Total | |
| α = 4.5958 | 1,412 | 602 | 409 | 268.7 | 1.522 | 13 | 12 | 11 | 36 |
| α = 167.231 | 2,217 | 696 | 621 | 288.1 | 2.155 | 10 | 17 | 14 | 41 |
| [1] | 2,656 | 702 | 721 | 244.4 | 2.949 | 10 | 22 | 19 | 51 |
| Design | Area | Speed | AT | Power (mW) | ||
|---|---|---|---|---|---|---|
| () | (MHz) | (s) | Dynamic | Leakage | Total | |
| α = 4.5958 | 48,386.88 | 2,083.33 | 23.23 | 4.36 | 0.365 | 4.725 |
| α = 167.231 | 52,904.88 | 2,083.33 | 25.4 | 4.67 | 0.424 | 5.094 |
| [1] | 54,299.52 | 2,083.33 | 26.06 | 4.74 | 0.427 | 5.167 |
| Parameter | Gong et al. [23] | Shams et al. [24] | Ghosh et al. [25] | Dimitrov et al. [1] | Proposed architectures | |
|---|---|---|---|---|---|---|
| Measured results | No | No | No | Yes | Yes | Yes |
| Structure | Vector matrix DCT core | Coefficient arithmetic DCT core based DCT | Coefficient arithmetic DCT core based DCT | AI based DCT+ Booth encoded FRS | AI based DCT+ expansion factor FRS | |
| Multipliers | 8 | 0 | 0 | 0 | 0 | 0 |
| Operating frequency | 125 MHz | 1.5 GHz | 50 MHz | 2.08 GHz | 2.08 GHz | 2.08 GHz |
| Pixel rate | 125 Mpix/s | 108 Gb/s | 10.922 Mpix/s | 16.67 Gb/s | 16.67 Gb/s | 16.67 Gb/s |
| Power consumption | N/A | 210 mW | 12.45 mW | 5.167 mW | 4.725 mW | 5.094 mW |
| Technology | 0.25 CMOS | 0.35 CMOS | 0.12 CMOS | 65 nm CMOS | 65 nm CMOS | 65 nm CMOS |
| Independently adjustable precision | No | No | No | Yes | Yes | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2012 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/3.0/).
Share and Cite
Edirisuriya, A.; Madanayake, A.; Dimitrov, V.S.; Cintra, R.J.; Adikari, J. VLSI Architecture for 8-Point AI-based Arai DCT having Low Area-Time Complexity and Power at Improved Accuracy. J. Low Power Electron. Appl. 2012, 2, 127-142. https://doi.org/10.3390/jlpea2020127
Edirisuriya A, Madanayake A, Dimitrov VS, Cintra RJ, Adikari J. VLSI Architecture for 8-Point AI-based Arai DCT having Low Area-Time Complexity and Power at Improved Accuracy. Journal of Low Power Electronics and Applications. 2012; 2(2):127-142. https://doi.org/10.3390/jlpea2020127
Chicago/Turabian StyleEdirisuriya, Amila, Arjuna Madanayake, Vassil S. Dimitrov, Renato J. Cintra, and Jithra Adikari. 2012. "VLSI Architecture for 8-Point AI-based Arai DCT having Low Area-Time Complexity and Power at Improved Accuracy" Journal of Low Power Electronics and Applications 2, no. 2: 127-142. https://doi.org/10.3390/jlpea2020127
APA StyleEdirisuriya, A., Madanayake, A., Dimitrov, V. S., Cintra, R. J., & Adikari, J. (2012). VLSI Architecture for 8-Point AI-based Arai DCT having Low Area-Time Complexity and Power at Improved Accuracy. Journal of Low Power Electronics and Applications, 2(2), 127-142. https://doi.org/10.3390/jlpea2020127