

Computers, Volume 11, Issue 8 (August 2022) – 9 articles
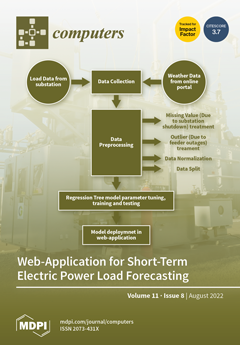
Cover Story (view full-size image):
Short-term electric power load forecasting is a critical and essential task for utilities in the electric power industry for proper energy trading, which enables the independent system operator to operate the network without any technical and economical issues. From an electric power distribution system point of view, it is essential for proper planning and operation. A machine learning model, namely a regression tree, is used to forecast the active power load an hour and one day ahead. Real-time active power load data to train and test the machine learning models are collected from a 33/11 kV substation located in Telangana State, India. View this paper
- Issues are regarded as officially published after their release is announced to the table of contents alert mailing list.
- You may sign up for e-mail alerts to receive table of contents of newly released issues.
- PDF is the official format for papers published in both, html and pdf forms. To view the papers in pdf format, click on the "PDF Full-text" link, and use the free Adobe Reader to open them.
Previous Issue
Next Issue