1. Introduction and Motivation
The observation of human behavior in public environments such as shopping malls, sport venues or stations is a common application. To increase our understanding of these data and utilize them more efficiently, we must associate attributes to individual pedestrians. The attributes of interest depend considerably on applications. For instance, resolving the social relation between customers such as mother-son, friends or couple is relevant in customer profiling [
1]. Similarly, in intelligent environments, service quality can be improved by providing different services to clients by inferring their relation to their partners. Besides, in public environments, such as prisons or stadiums, recognizing the leader or the subordinates of groups is helpful for investigating aggressive or criminal activities [
2,
3].
However, the association of such attributes is considerably difficult due to the inherent contextual asperities and complex social relations. We propose treating this problem primarily by decomposing the entire crowd into smaller structures. In other words, we propose handling the crowd as a combination of social groups and single individuals. Once we obtain such a categorization, assigning social attributes is easier. We base our definition of
social groups on the work of McPhail and Wohlstein [
4], who regard a group as people engaged in a social relation to one or more pedestrians and move together toward a common goal.
The detection of pedestrian groups is challenging from several perspectives.
Figure 1 illustrates a scene, where the detection of group relations is not straightforward. This figure illustrates a scene from a public space, where friends and families are walking. Here, gender, clothing and age of the pedestrians are important cues indicating a social relation such as a couple or friends. Human cognition has evolved in such a way that these personal properties are identified easily in an unconscious manner. However, estimation of such cues from surveillance footage is not possible in most cases since traditional image based methods do not perform well for such recordings.
Therefore, we propose taking a closer look at the trajectories, namely the distribution of the displacements and scalar product of the velocity vectors. Based on these, we develop two explicit schemes for modeling the interaction among group members, in addition to two other schemes for modeling the interaction between groups and single pedestrians. The models are calibrated for different sorts of environments, group structures, and densities. With our proposed hypothesis testing scheme, we show that our method can resolve group relation to a considerable degree for various conditions.
The outline of the paper is as follows. Section 2 presents prominent works in this field, and Section 3 elaborates on the properties of the datasets employed in modeling and evaluation. Sections 4 and 5 discuss the motion models and the integration of individual indicators with the help of uncertainty measures. Finally, Section 6 presents our experimental results indicating stability, performance, sensitivity, and generalization issues in addition to a comparison with an earlier work in literature and an alternative decision scheme.
2. Background and Related Work
As smart environments spread, a vast amount of data is gathered, particularly from public spaces. The analysis of the crowd behavior in this sort of data is of great interest to numerous research fields such as crowd modeling and simulation, public space design, visual surveillance, and event interpretation [
5]. In this section, we focus on previous works that interpret ambient information from a social relation perspective.
Human activity analysis bears numerous challenging traits [
6]. For the solution of this problem, a social signaling standpoint is adopted by Cristani
et al. [
7], utilizing primarily the nonverbal cues of human behavior. Gatica-Perez gives a detailed overview of the nonverbal cues of small group relation, such as internal states, personality, and social relations [
8]. Additionally, Costa demonstrates that group behavior presents distinctions in interpersonal distances depending on dominance, attraction, age similarity, and gender of the group members [
9]. In the rest of this section, we refer to such complex features as the high-level cues of group relation. Such cues are specific to individuals. On the contrary, low-level cues involve features like spatial position, velocity or motion direction, which are not specific to individuals. We categorize low-level cues into two classes, linear and circular variables. Linear variables involve spatial position, trajectory shape, and the configuration of group members, while circular variables are composed of motion direction and the correlation of velocities.
Recently, the utilization of high-level cues has become a popular approach in the association of attributes to individuals, particularly in social network research. Several works address investigation of social relations based on such universally valid implicit cues as the age difference between parents and children or the opposite genders of heterosexual couples [
10,
11]. Some studies investigate kin relationships using photo albums that span a long time window of several years or even decades [
12,
13]. On the other hand, the proximity relation of faces on an image [
14], clothing, or facial expressions [
15] are used to estimate social relations.
For several contextual and practical reasons, these studies apply only to image domain and not to surveillance footage. First of all, in images from family albums or social network it is evident that the individuals appearing in the same image are related to each other. Then the question becomes resolving the type of relationship. However, the relation among pedestrians in a crowd is not obvious. Moreover, in video surveillance high-level cues are not available at all times.
To account for these challenging conditions, several studies propose integrating low-level and high-level cues. For instance, Ding
et al. employ low-level cues in concept detection and define a Gaussian process based affinity learning for spotting social networks in theatrical movies and Youtube videos [
16]. However, the appearance matrix relating the actors in a movie is derived from the script by searching for the names of the characters, which is not applicable in surveillance footage. By identifying the group structure, such behaviors as aggression or agitation are analyzed in [
2]. Yu
et al. assume that the 3D tracks of individuals and corresponding high-resolution face images are provided to investigate social groups and their organizations [
3], which cannot be generalized to most other problems.
Compared with high-level cues, low-level ones are easier to derive. However, the analysis of group level activity based on low-level cues is profoundly integrated with stable multi-object tracking [
1,
17]. In other words, the occlusion arising from the group motion, which stands as a significant challenge at the first glance, can potentially be exploited for the enhancement of data association [
18,
19]. Namely, the search area is restricted based on the estimated future location of the objects from their past trajectories and motion models. Therefore, the dynamic models accounting for the collective locomotion behavior of pedestrians are proposed to improve tracking performance particularly against occlusions in [
20–
22].
By exploiting the low-level linear cues, several studies propose employing the contextual information provided by the configuration of groups to detect collective unusual behavior in public spaces. However, note that the problem of the resolution of group relations cannot be reduced to determining the similarity of trajectories [
23]. The methods, which investigate similarity between individual trajectories, are mainly used in semantic scene modeling. They do not establish a relationship between simultaneously observed trajectories, which is the core of our problem [
24,
25]. Instead of finding the similarities between trajectories, Habe
et al. propose finding interactions between trajectories to solve for mutual relationship between pedestrians. The influence that pedestrians exert on each other in the transition of motion states is investigated [
26]. Floor control constitutes another commonly used low-level linear cue of collective human activities [
27,
28]. However, French
et al. propose employing only the circular low-level cue of velocity correlation in a Bayesian framework and ignore the interpersonal distances [
29]. In their framework, close proximity is not regarded as an indicator of group motion since it is claimed to be misleading in complex settings. Similarly, Calderara
et al. omit the spatial relationships of trajectory points and focus on trajectory shapes [
30]. Namely, they handle the problem from a circular statistics standpoint and cluster trajectories into similarity classes.
Yücel
et al. suggest combining the linear and circular attributes [
31–
33]. In their framework, group relation is characterized by the distance between the moving parties and the alignment of their velocity vectors. Similarly, Ge
et al. propose an algorithm to detect pedestrian groups through a bottom-up hierarchical clustering scheme based on locomotion similarities derived from an aggregated measure of velocity difference vectors and spatial proximity [
34]. Similar to [
34], Sandιkcι
et al. propose to integrate the positional and directional cues in the resolution of group relations by defining similarity metrics for position, velocity, and direction, all of which in turn are expressed in a joint similarity matrix, followed by an agglomerative clustering approach [
35]. Nonetheless, their motion models assume a very simple structure, which might not suffice to capture the distinctive attributes of group behavior. Bahlmann integrates linear and circular variables in a fairly different problem: online handwriting recognition [
36]. Integration is achieved through an approximated wrapped Gaussian distribution, which only holds for data with low deviation,
i.e.,
σ < 1. Besides, this approach assumes that the probability density function of the linear variable is Gaussian. These two assumptions enable integration into multivariate semicircular wrapped distribution. However, neither holds for pedestrian trajectory data.
In addition to multi-object tracking and activity recognition, group models play an important role in such other fields as traffic analysis, evacuation dynamics, and the social sciences. Numerous works in pedestrians simulations are inspired by the social force model [
37,
38]. Lerner
et al. describe a pedestrian simulation method, where a real world recording is employed to reflect behavioral complexity on individual level and group levels [
39].
In light of these observations, we introduce a fundamental insight to collective pedestrian motion models by focusing on a short time interval and deriving low-level cues to infer the social relation. We aim to introduce a fundamental insight to collective pedestrian motion models. We relax the conditions defining group motion and provide a flexible means of identification for group relations. Since the final decision regarding group relations is based on the combination of positional and directional indicators, this problem is regarded as compound hypothesis testing. Various experiments prove that our proposed method effectively grasps the characterizing features of group relations and can recognize group activity with significantly high performance rates under varying environmental conditions and group configurations. Our paper makes the following contributions:
Positional modeling accounting for dyadic as well as multi-partner groups;
Directional modeling in both uniform and non-uniform environments;
Integration of positional and directional indicators through compound hypothesis testing;
Definition of local and global indicators and an uncertainty measure.
3. Datasets
Three publicly available datasets are employed in development and testing of the motion models, namely Caviar, BIWI Walking Pedestrians dataset, and APT Pedestrian Behavior Analysis dataset [
20,
40,
41]. These are picked so as to effectively demonstrate the generalization capabilities of our proposed approach against varying environmental conditions and distinctions in group structure.
In Caviar dataset, five videos which are recorded from an oblique view over the entrance hall of a building involve group motion. The pedestrians present meeting and splitting behavior as well as uninterrupted group motion [
40]. Although its size is quite moderate, Caviar dataset is considered in this study mainly due to the publicly available ground truth concerning groups, which provides a fair comparison with other methods. BrWI Walking Pedestrians dataset contains two sequences, BIWI-ETH and BIWI-Hotel, recorded from birds-eye view with a total of 650 tracks over 20 minutes [
20]. The experiment scenes are the entrance of a building and a sidewalk. Due to the characteristics of these scenes, there is a dominant direction in the pedestrian flux (see
Figure 2(b)). APT Pedestrian Behavior Analysis dataset is recorded in the entrance hall of a shopping center [
41] (see
Figure 2(c)). Unlike BIWI, such a prominent flow does not exist in any direction but a tendency to walk along a certain direction is noticed. Due to the homogeneous distribution of the flow, APT dataset is regarded as coming from a uniform environment.
Table 1 shows the total number of observed pedestrians and group sizes. The Caviar dataset involves a fairly small number of pedestrians. BIWI-ETH contains various multi-partner groups, whereas BIWI-Hotel and APT are composed of mainly dichotomous groups, who are often walking abreast. As the group size gets larger the possibility of abreast configuration decreases particularly in high pedestrian densities,
i.e., the groups may be bent forward or backward as well as arranged in a single file [
42]. Among these sets, BIWI-ETH has the highest density followed by BIWI-Hotel, APT and Caviar, consecutively.
From
Figure 2 and
Table 1 the main differences between these sets are concluded to be the presence of preferred direction in BIWI-ETH and BIWI-Hotel against more homogeneous distribution in Caviar and APT and the frequent observation of multi-partner groups in BIWI-ETH against the dominance of dichotomous groups in BIWI-Hotel and APT. These variations are taken into consideration in the development of motion models.
Since this study proposes an identification method for groups of pedestrians rather than a tracking algorithm, we consider well-tracked trajectories and carry out our analysis to identify the pedestrian groups from these trajectories. For BIWI-ETH, BIWI-Hotel and ATR datasets, the trajectories which are obtained by state-of-the-art tracking algorithms, are publicly available [
20,
41,
43,
44]. For Caviar dataset, we performed manual annotation and estimated the homography matrix to map the annotated pixel coordinates to ground plane. The sampling period of trajectory points is 160 ms concerning BIWI-ETH and BIWI-Hotel sets and 100 ms concerning APT set. For Caviar dataset, the sampling rate is 200 ms. The group relations for all datasets are provided as ground truth [
41,
44,
45]. Using these trajectories and ground truth values, a convenient formulation is offered in accordance with the characteristics of the environment and the group structure.
4. Modeling Indicators of Group Motion
The question addressed in this study is which parameters characterize group motion, how we can model them and determine whether two pedestrians belong to the same group or not. In what follows, we introduce the terminology used in the rest of this study and then describe our proposed models of the indicators of group motion.
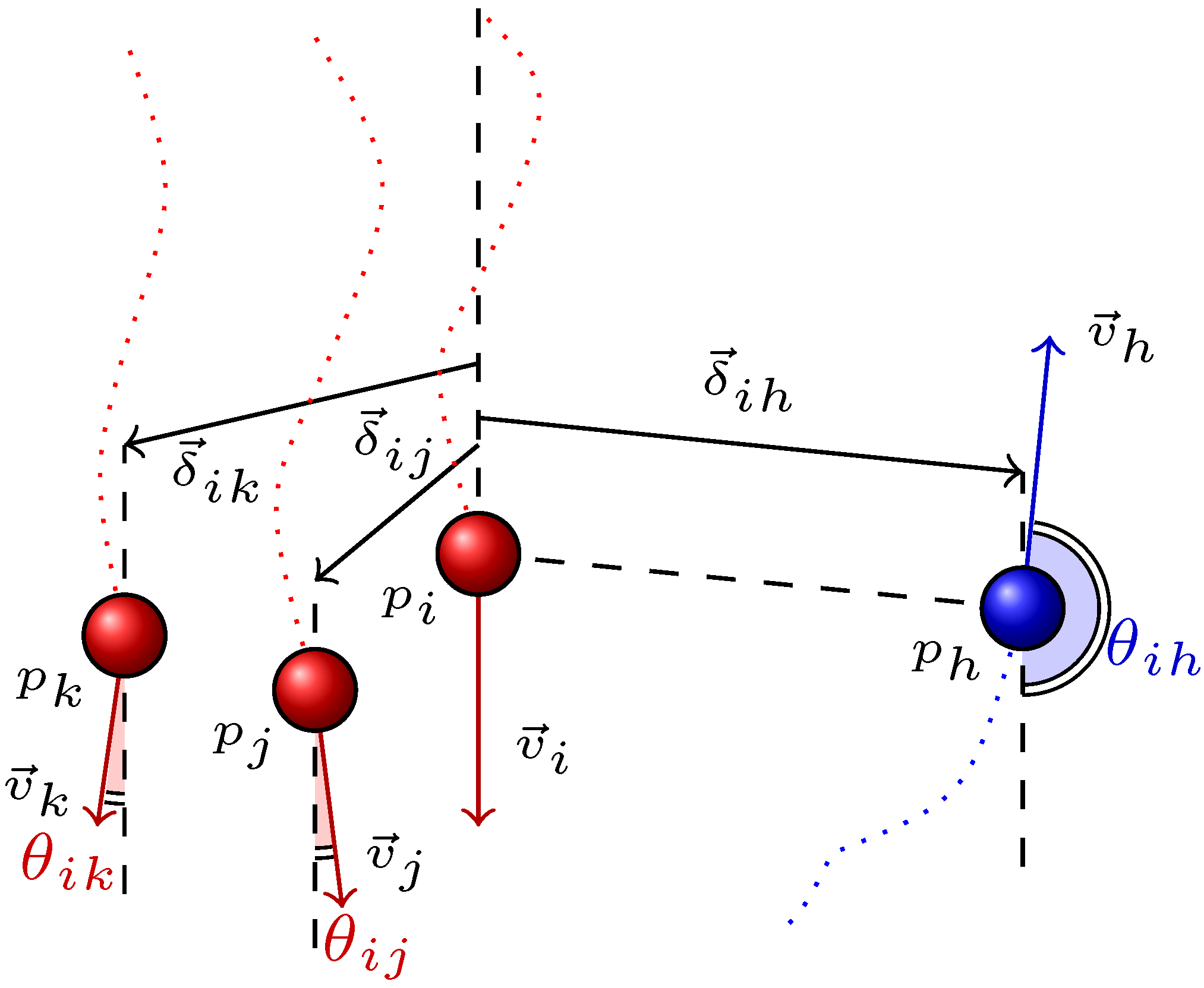
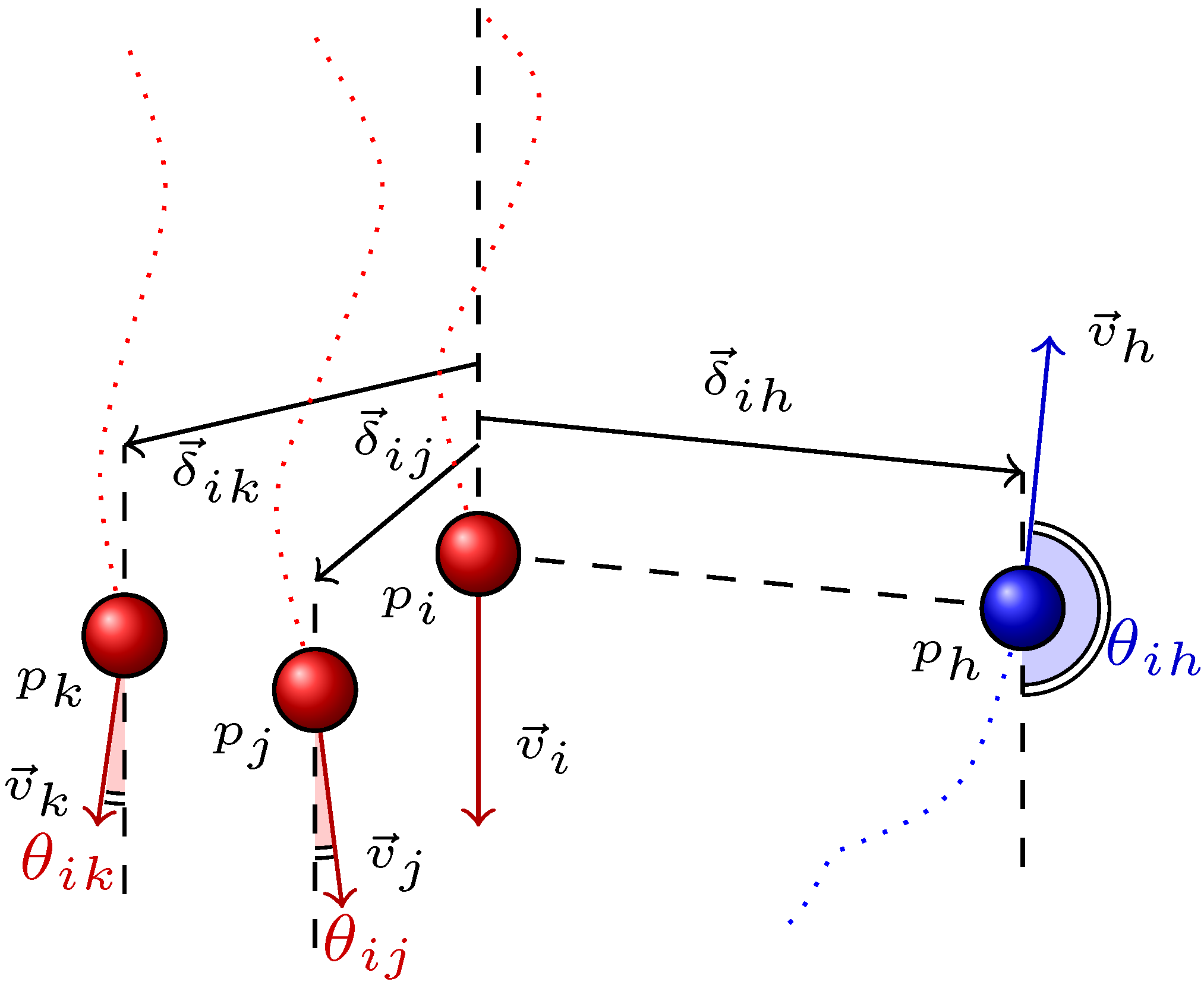
We term any two pedestrians who are observed simultaneously as
a pair. Suppose that the pairs who are engaged in a group relation such as {
pi,
pj} of
Figure 3 constitute the set G, whereas the pairs who are not engaged in a group relation such as {
pi,
Ph} comprise the complementary set Ḡ [
4].
Based on the findings of [
46], group motion is mainly characterized by positional indicators and directional indicators. We quantify positional indicators in terms of interpersonal distance, whereas directional indicators are defined based on motion directions. In explicit terms, the positional indicator of group motion is represented by Δ and is composed of a set of linear variables {
δ}, where
δ stands for the instantaneous distance between pedestrians (see
Figure 3). On the other hand, the directional indicator, which is represented by Θ, is a set of circular variables,
i.e., angles between simultaneously observed velocity vectors {
θ} (see
Figure 3).
Obviously, in order to define a meaningful value for
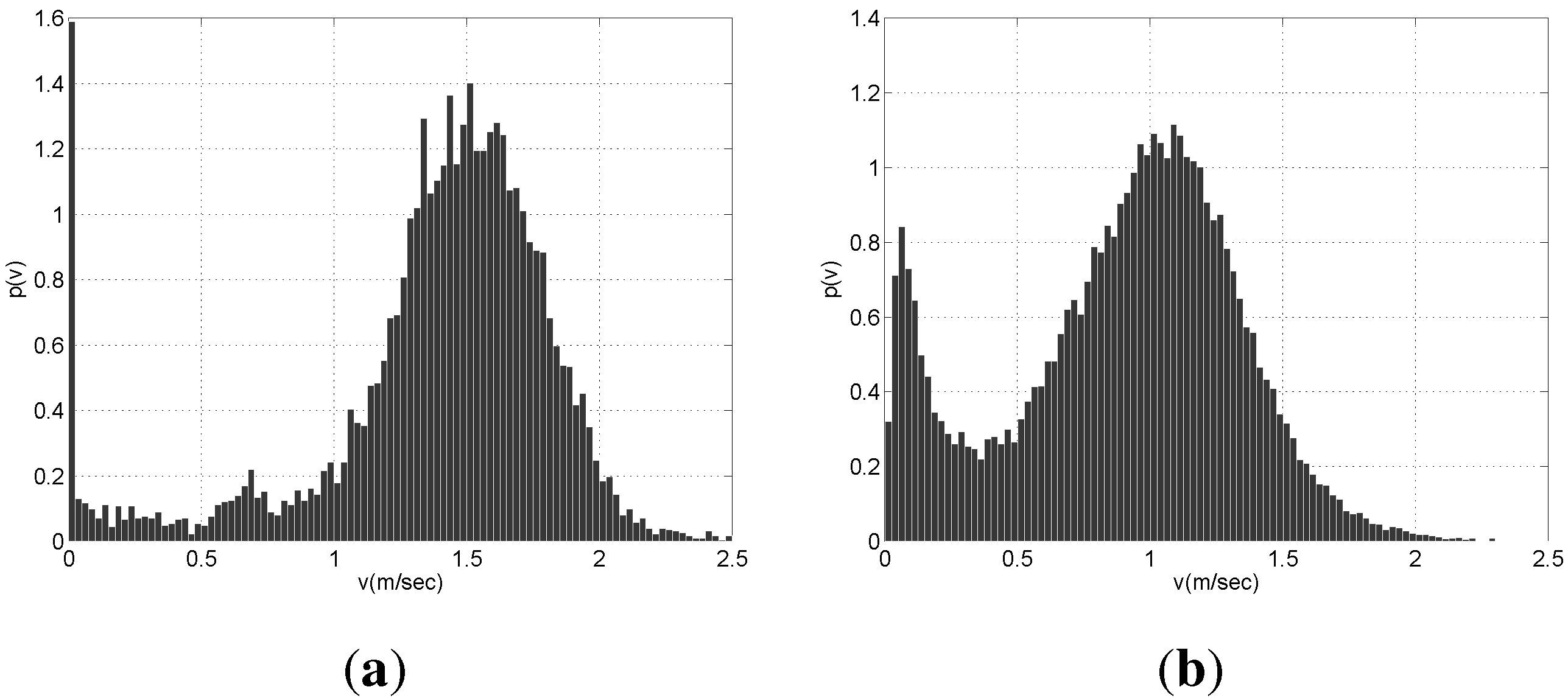
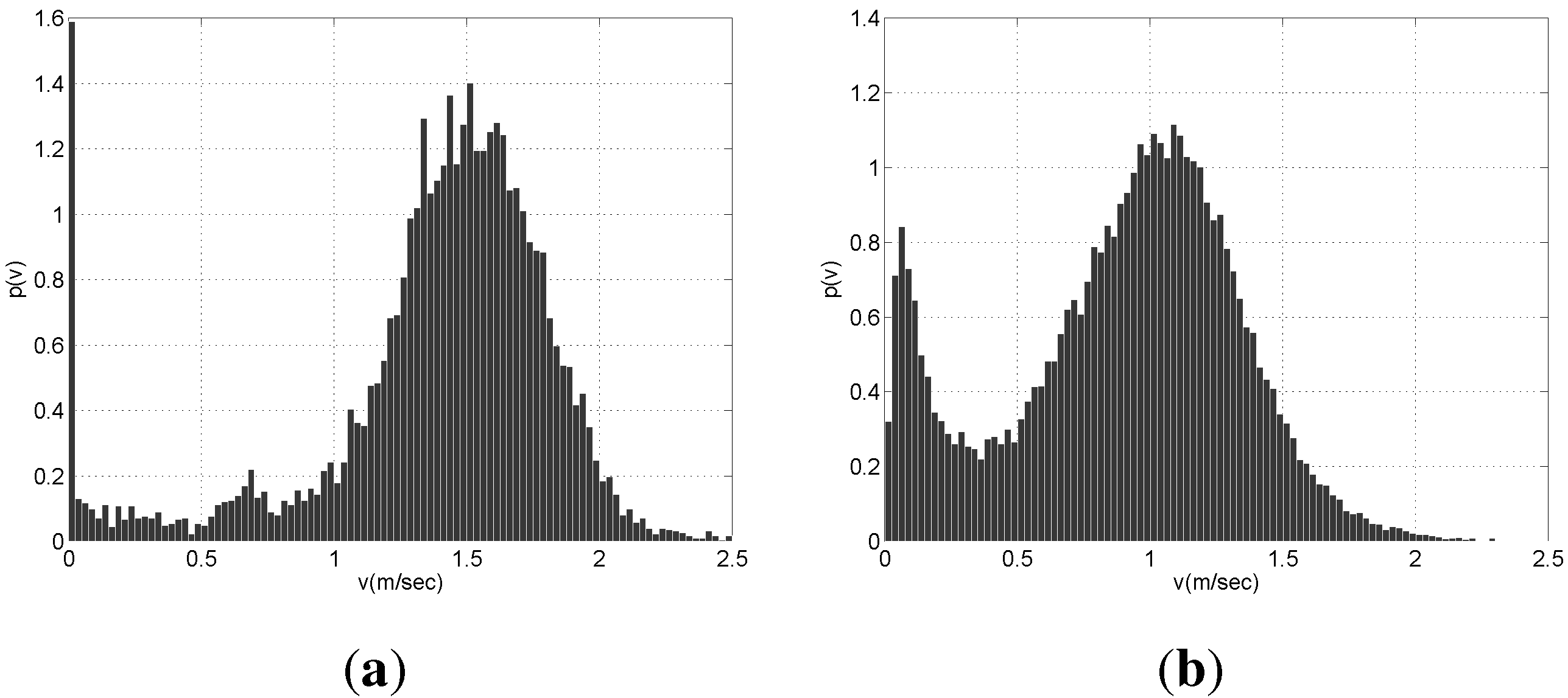
θ, the pedestrians should be moving with a velocity larger than a reasonable threshold. We picked this value examining the distribution of velocity for all people in the environment (see
Figure 4). In BrWI-ETH dataset the people who wait at the tram station have low velocities distributed more or less uniformly over 0 to 0.5 m/s. On the other hand, there are basically two peaks in velocity distribution for APT dataset. The first peak is entered around 0.1 m/s and it relates the people who are watching the shelves, whereas the second peak is centered around 1.2 m/s and it relates the people who walk steadily. Nevertheless, the number of these people is quite low compared with the steadily walking pedestrians. Thus, we picked 0.375 m/s as velocity threshold.
Since the velocity threshold is picked around the local minima of the velocity distribution separating the moving and stationary pedestrians, shifting the velocity threshold slightly would not affect a large number of pedestrians and thus not change the performance of the proposed method drastically. Moreover, the local minima observed in BIWI-ETH and APT datasets do not arise due the specific characteristics of these environments. According to Helbing
et al., at normal density the velocity of pedestrians is given by a normal distribution with an average of 1.34 m/s and a standard deviation of 0.26 m/s [
47]. These values may change slightly according to the environment but putting the velocity threshold around 0.3 ∼ 0.5 m/s we will be sure to locate it at least 2
σ from the peak [
48].
Based on these definitions, each pair of pedestrians is represented by a set, which is composed of these two indicators {Δ,Θ}. Moreover, each of G and Ḡ is described by two models characterizing the positional and directional relations, i.e., ΔG and ΘG or ΔḠ and ΘḠ. The identification problem is deliberated with two different applications of the same approach in parallel, i.e., investigating whether Δ ∼ ΔG or Δ ∼ ΔḠ and Θ ∼ ΘG or Θ ∼ ΘḠ. The final decision is rendered based on the outcomes of these two, where the outcome implicating a lower uncertainty is preferred in case of ambiguities.
In our previous study we followed a similar strategy and proposed a simplistic method to identify group motion [
31]. Ideally, the pedestrians involved in group motion are proposed to be in close proximity and have perfectly aligned velocity vectors. Since these ideal conditions are met seldom, certain thresholds are applied to account for the non-ideal nature of the behavior. In this manner, satisfactory performance rates are achieved. Nevertheless, explicit models are necessary to improve the performance and to make the method flexible in order to effectively adapt to different settings. To that end, the proximity and motion direction of pedestrians involved in a group relationship are investigated closely and a mathematical model is proposed for each of the relating probability density functions (pdf) in what follows.
4.1. Modeling Positional Indicators
The positional indicators are modeled based on the following assumptions. First an arbitrary reference frame is assigned to the observation environment. In addition, the probability of visiting each point in the environment is assumed to be equal,
where
P(
p m) denotes the probability of visiting point
p m and
A stands for the observation environment.
4.1.1. Modeling Positional Indicators Regarding G
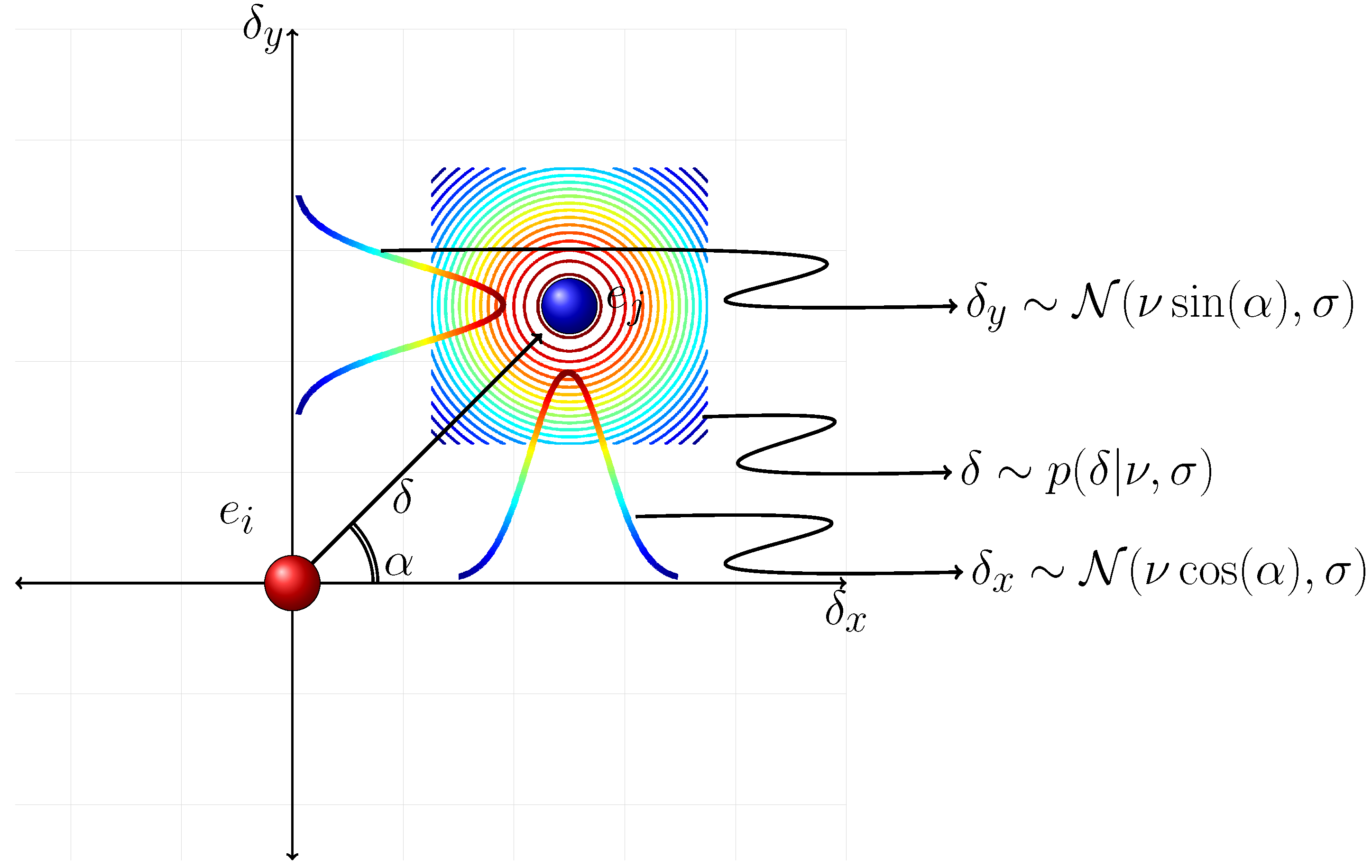
Any displacement vector
δ⃗ can be decomposed into two components,
δx and
δy, where
. Namely,
δx =
δ cos(
α) and
δy =
δ sin(
α), where
α stands for the argument of
δ⃗ based on the chosen reference frame (see
Figure 5). Since group members prefer to keep a comfortable distance of
ν between each other,
δx and
δy are statistically independent normally distributed random variables,
Equation (2) implies that
δ is distributed as a Rice distribution,
where
I0 stands for the modified Bessel function of the first kind with order 0 [
49].
This distribution is independent of the choice of reference frame. Of course, in the presence of a strong pedestrian flow along a certain direction, the distributions of
δx and
δy have different representations according to different choices of reference frame. This is due to the fact that
α is determined by the major flow direction in such environments. In the presence of a major flow direction
α is distributed in a non-uniform manner, which affects
δx and
δy. However, the distribution of
δ given by
Equation (3) is invariant to the orientation
α. Thus, the distribution of
δ is still given by
Equation (3). This result obviously holds in the absence of any prominent direction such that
α is a uniformly distributed circular random variable.
The unimodal formulation defined by
Equation (3) provides a reasonable interpretation for the distance among members of a dichotomous group. However, multi-partner groups which are composed of three or more pedestrians, present more complex proxemics bearing a multimodal approach.
In order to have a better insight into the structure of multi-partner groups, we define
the degree of neighborhood based on the configuration of the group members. Namely, the group structure is expressed in terms of a minimum spanning tree (MST). The degree of neighborhood concerning any two pedestrians is defined by the number of edges along the shortest path of the MST connecting them. According to this definition, {
pi,
pj} of
Figure 3 has a degree of neighborhood that equals 1. In other words, they are are
first neighbors, whereas {
pi,
pk} of
Figure 3 are
second neighbors.
In this framework, within multi-partner groups, the distance between first neighbors is modeled using the unimodal formulation of
Equation (3). Assuming that the relative position of all first neighbors is given by the same function,
i.e., the distribution function for the position of first neighbors is the same within the group, the distance between
nth order neighbors,
n > 1, is modeled by the convolution of the unimodal model to the
nth power. A multimodal framework, which is the linear combination of these
N models is suggested to embrace the relation among members of a multi-partner group composed of
N + 1 people. Namely,
where
Kn is the observation frequency of
nth neighborhood. The function Δ
Gn denotes the distribution between the
nth neighbors and is equivalent to the convolution of
Equation (3) to the
nth power. It is suggested to restrict
N ∈ {1, 2, 3}. Because large groups (of 5 or more people; tend to be arranged in complex configurations instead of abreast formation [
42]. This limits the degree of neighborhood and eliminates the need to extend
N over 3.
4.1.2. Modeling Positional Indicators Regarding Ḡ
If any two simultaneously observed pedestrians are not engaged in a group relation, their relative locations at a particular instant are independent. This assumption, together with
Equation (1), makes the problem equivalent to randomly selecting two points from a uniform distribution in the observation environment and measuring the distance between them. Suppose that the dimensions of the observation environment along the
x− and
y−axes are
D. Then,
while the pdf concerning
δy is computed in the same manner. Assuming that
δx and
δy are independent, the relating joint pdf is resolved [
50] as,
This distribution describes
δ regarding Ḡ in a large environment,
D ≫
c, where
c ≈ 400 mm stands for the width of the human body. However, it does not account for the constraint imposed by the physical dimensions of the pedestrians, that represent a minimum distance (cutoff) below which
5 cannot assume values. To account for this cutoff,
δ is substituted with
δ′ =
δ −
c and
p(
δ) is renormalized by replacing
D with
. Note that this distribution does not need to be calibrated since it only depends on the geometry of the observation area.
4.2. Modeling Directional Indicators
The directional indicator of group motion regarding any two pedestrians
pi and
pj is derived from their velocities. The scalar product of velocity vectors
υ⃗i and
υ⃗j is defined as,
where
θ denotes the angle between these vectors (see
Figure 3). The directional indicators of group motion are represented in terms of this angle
θ.
The pairs in G, excluding those exhibiting behaviors like meeting, splitting or standing, are expected to have the direction of the velocity vectors aligned to a considerable degree, whereas the pairs in Ḡ do not present any correlation of direction. This suggests that the expected value of θ is 0 for both G and Ḡ. If θ were a linear random variable over (−∞, ∞), such a behavior could be approximated with a normal distribution of mean 0 and standard deviation σθ. However, θ is a circular random variable defined over [−π, π] and, thus, it cannot be modeled in terms of a standard normal distribution.
Hence, the principles of directional statistics are invoked and the behavior of
θ is modeled as a von Mises distribution [
51], which is the circular analogue of the Gaussian distribution. The following is the explicit form of the von Mises distribution,
where
μ denotes the mean value and
κ is analogous of 1/
σ2 of the normal distribution.
Note that the
θ distribution relating G and Ḡ is described using the same function given by
Equation (8), where the parameter
κ enables modeling of different behaviors. In other words, for the pedestrian pairs in G, the distribution of
θ is very localized around
μ = 0 and
κ ≫ 1. On the other hand, for the pedestrian pairs in Ḡ, the distribution is uniform if there is no prominent flow and
κ → 0. Furthermore, in the presence of major flow
θ has two peaks for each major flow,
i.e., one for pedestrians moving in the same direction and another for pedestrians moving in opposite directions. In that case, the distribution of
θ regarding Ḡ is modeled as a linear combination of two von Mises distributions, one with
μ = 0 and the other with
μ =
π. Even in this case, the distribution around a particular peak is expected to be larger than that of pairs in G.
5. Hypothesis Testing
The decision whether a pair belongs to G or Ḡ is carried out using a compound hypothesis testing scheme, as shown in Algorithm 1. Since G or Ḡ are mutually exclusive and complementary events, a decision can confidently be made as long as the individual indicators point to the same sort of group relation. In case of conflicts, a measure of uncertainty needs to be defined to resolve the final decision. In what follows we describe how the individual decisions are carried out and we define the uncertainty measures for resolving the final decision in case of contradictions.
|
| Algorithm 1: Compound hypothesis testing. |
|
| Input: Trajectories of pedestrian pi and simultaneously observed pedestrians {pj}, 1 ≤ j ≤ J. |
| Output: The nature of group relation of pi with {pj} |
| for j ← 1 to J do |
| - Δ={|δ⃗ij|}; |
| - Θ = {/(υi,υj)}; |
| - Lδ, Lθ; | /* Equation 9 */ |
| if (Lδ > 0) ∧ (Lθ > 0); | /* Equation 10 */ |
| then {pi,pj} ∈ G; |
| else if (Lδ < 0) ∧ (Lθ < 0); | /* Equation 10 */ |
| then {pi,pj} ∈ Ḡ; |
| else | |
| - Compute ρδ and ρθ; | /* Equation 13 */ |
| if [(Δ ∼ ΔG) ∧ (Θ ∼ ΘḠ) ∧ (ρδ < 1/ρθ)] ∨ [(Δ ∼ ΔḠ) ∧ (Θ ∼ ΘG) ∧ (ρθ < 1/ρδ)] |
| then {pi,pj} ∈ G; |
| else {pi,pj} ∈ Ḡ |
|
In binary decisions, a likelihood ratio test is one way of determining the underlying model. Concerning Δ, the log-likelihood ratio of being in a group relation over not being in a group relation,
Lδ, is defined as,
The following is the decision based on
δ,
The decision based on
θ is carried out in a similar manner through the log-likelihood ratio concerning Θ,
Lθ, computed in an analogous way to
Equation (9).
As long as Lδ and Lθ have the same sign, a confident decision is made regarding the group relation (Algorithm 1 Lines 1 and 1). However, contradictions might arise. For example, when pedestrians cross next to each other, move along a flow, or go through passages, their relative position might become close or their velocity vectors might be aligned, independent of their social relation. One may argue that an intuitive way of resolving such cases is to pick the decision that implies a larger absolute value. However, we demonstrate in Section 6 that this straightforward approach is not capable of compensating for the effect of these misleading cues. Therefore, we devise an uncertainty measure.
Inspired by the Kullback-Leibler divergence, a reliability estimate is employed to quantify the uncertainty of individual decisions rendered through
Equation (10) [
52]. The Kullback-Leibler divergence of two distributions such as
P and
Q is defined as,
Note that this measure is not symmetric,
i.e.,
DKL(
Q‖
P) ≠
DKL(
P‖
Q). Thereby, mathematically speaking, it is not a distance measure but it quantifies the difference between two probability distributions. To have a common reference point, the divergence terms are computed with respect to the observed distributions. Hence, the divergences relating
8 with respect to G and Ḡ are defined as
and
. Since these terms embrace all {
δ} through the summation term in
Equation (11), we call them
global indicators of group motion.
However,
θ relating G does not present a behavior as regular as
δ of G. Thus, it is proposed to focus on its local characteristics so as to avoid the misleading temporal imperfections that might lead to a false similarity to Ḡ. Namely, the divergence term relating
θ with respect to G is defined as,
where the divergence of
θ with respect to Ḡ is computed in a similar manner. This equation implies that only the divergence value that indicates the maximum dissimilarity is accounted for. Thereby, it defines a local indicator of group motion.
A direct comparison of the divergence terms defined above is not possible since they are not defined in terms of comparable measures. To enable a comparison, two uncertainty measures are defined regarding each individual decision as the ratio of the concerning divergence values,
The final resolution is determined by picking the decision with lower uncertainty (Algorithm 1 Line 1).
6. Experimental Results
This section discusses the performance of the estimated distributions in terms of a qualitative comparison, the stability of the model parameters with respect to varying training sets, the identification performance of groups, sensitivity, generalization, and improvement introduced by compound hypothesis testing over individual models and the method of [
31] and maximum absolute log-likelihood ratio method.
6.1. Model Calibration
The models defined in Section 4 bear a number of parameters, which need to be tuned for different environments and group behaviors. For instance, the positional relation model regarding G, Δ
G, given in
Equation (4) requires the determination of
ν and
σ. Similarly, the directional relation models, Θ
G and Θ
Ḡ, given in
Equation (8) require calibration of
κ.
For solving these model parameters, we propose shuffling the dataset and randomly selecting 10% of the pairs in G and 10% of the pairs in Ḡ. The squared error between the distributions of the positional and directional indicators concerning these randomly selected sets and the proposed models is minimized using a golden section search. Subsequently, the remaining 90% of the data is employed to evaluate of the proposed models. Section 6.2 presents the performance of this estimation scheme.
In our investigation of the stability of the model parameters, and the sensitivity of the model against varying training sets, this procedure is repeated by shuffling the dataset 50 times. Sections 6.3 and 6.4 report the performance metrics following such a validation scheme.
6.2. Estimated Distributions
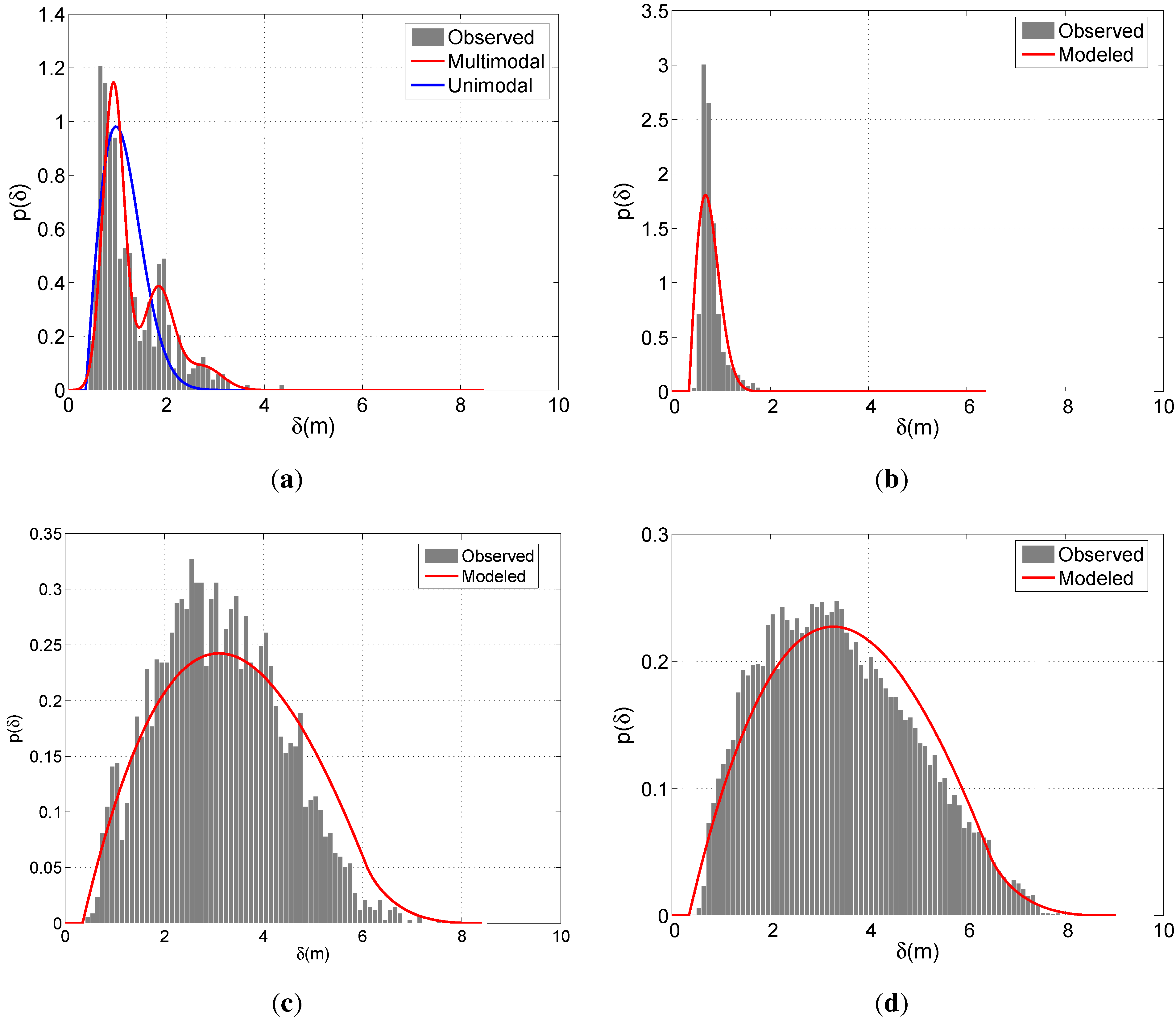
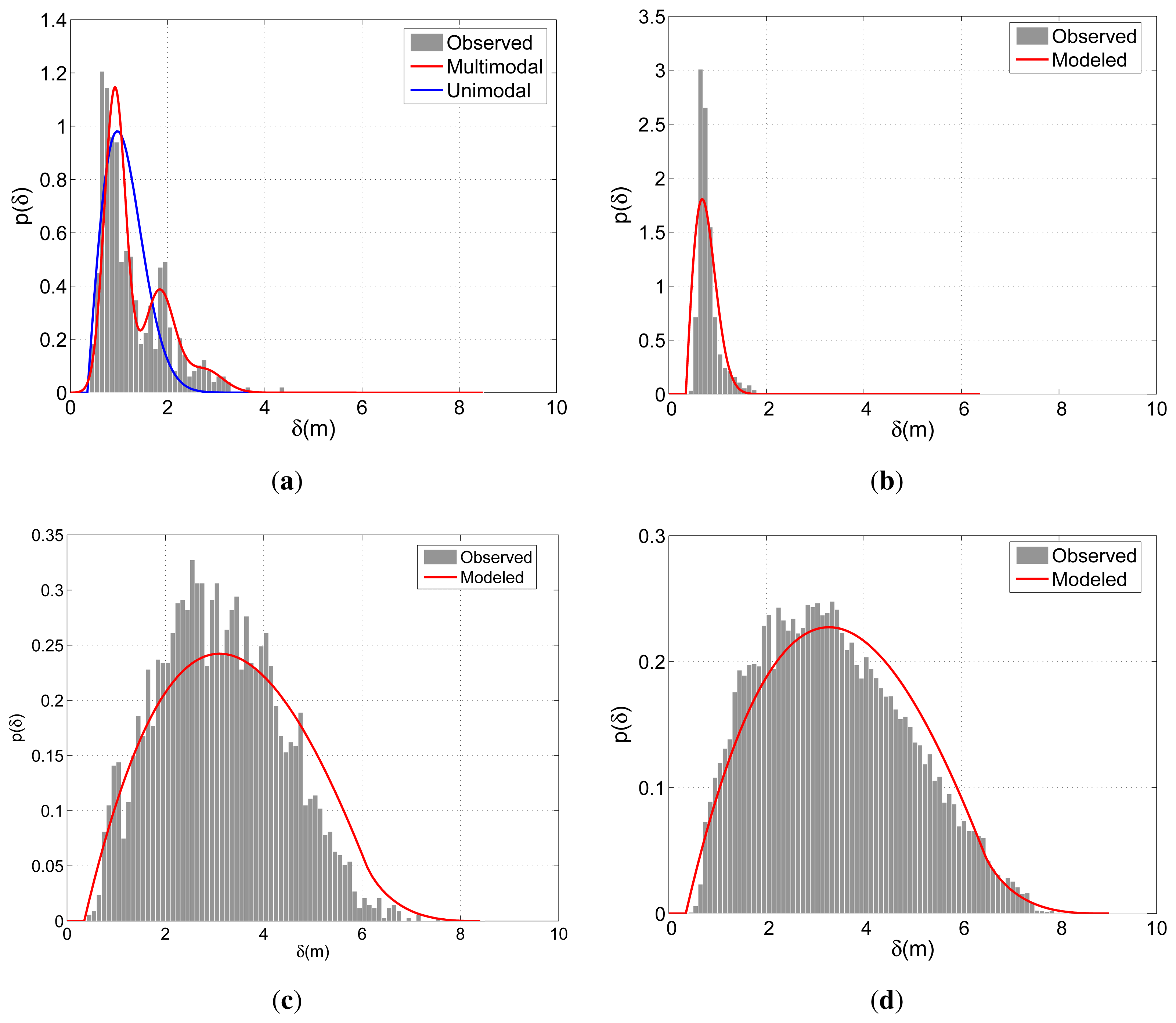
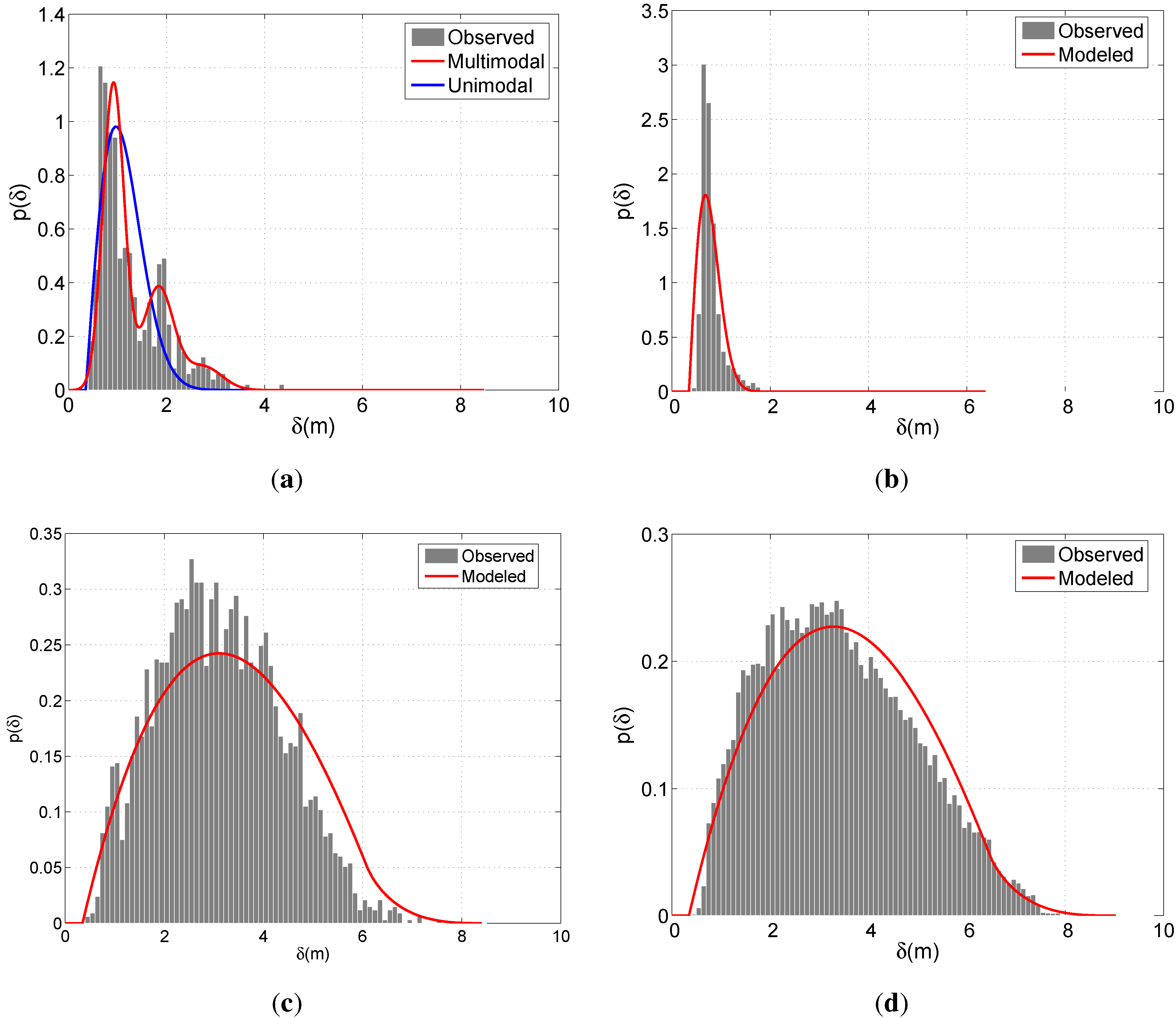
Figure 6 demonstrates the modeled and observed distributions of the positional indicators for a particular run of the calibration scheme described in Section 6.1. The observed distribution is expressed in terms of the histograms that relate the samples constituting the 90% of all observations. The model concerning Δ
G of BIWI-ETH is modeled with both unimodal and multimodal approaches. For this case, the multimodal approach in
Equation (4) considers
N to be 3. Since BIWI-ETH contains various multi-partner groups (see
Table 1), the improvement of the multimodal approach over the unimodal approach can easily be observed in
Figure 6(a). On the other hand, due to the dominance of the dichotomous groups in APT, the unimodal scheme provides satisfactory performance in modeling Δ
G concerning APT. For Δ
Ḡ, fairly good results are obtained for both sets. The smoother shape of the observed distribution of APT is due to the larger number of observations compared with BIWI-ETH.
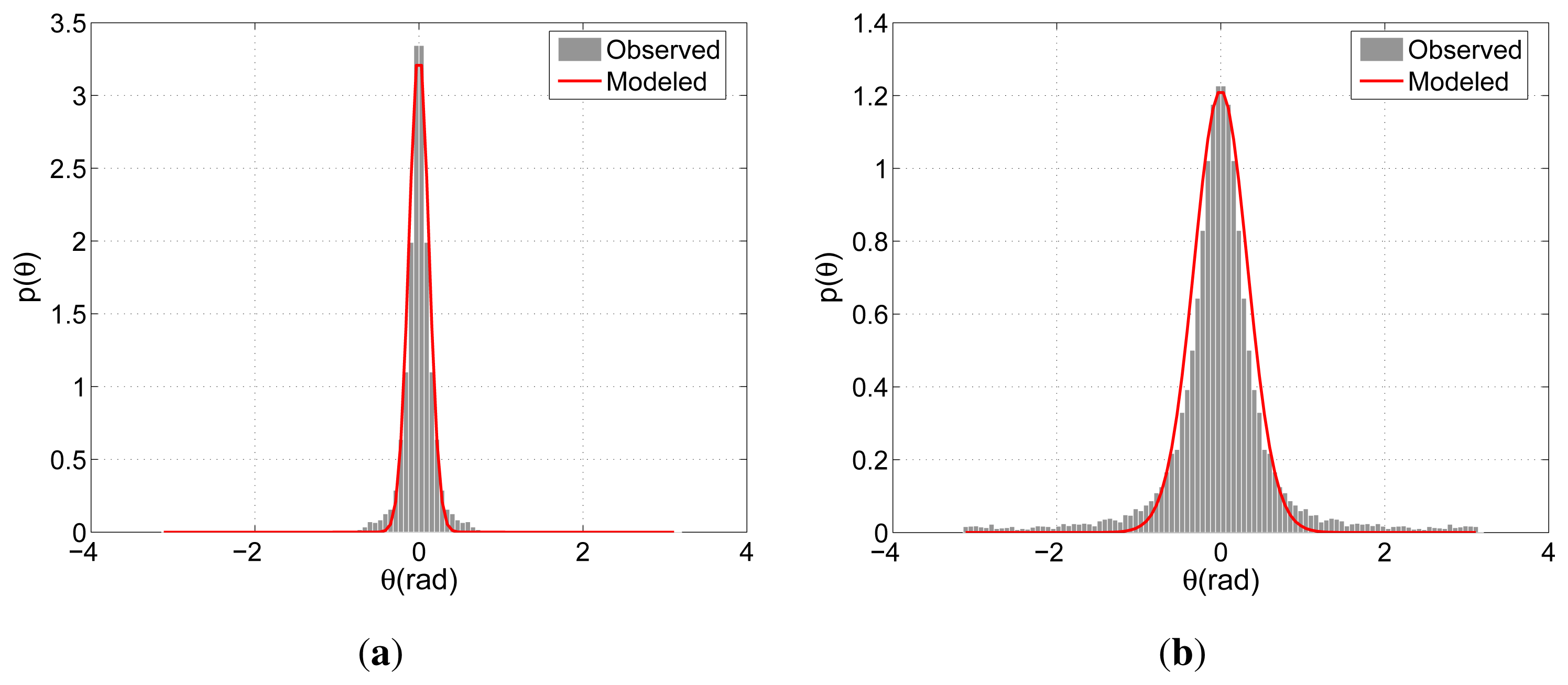
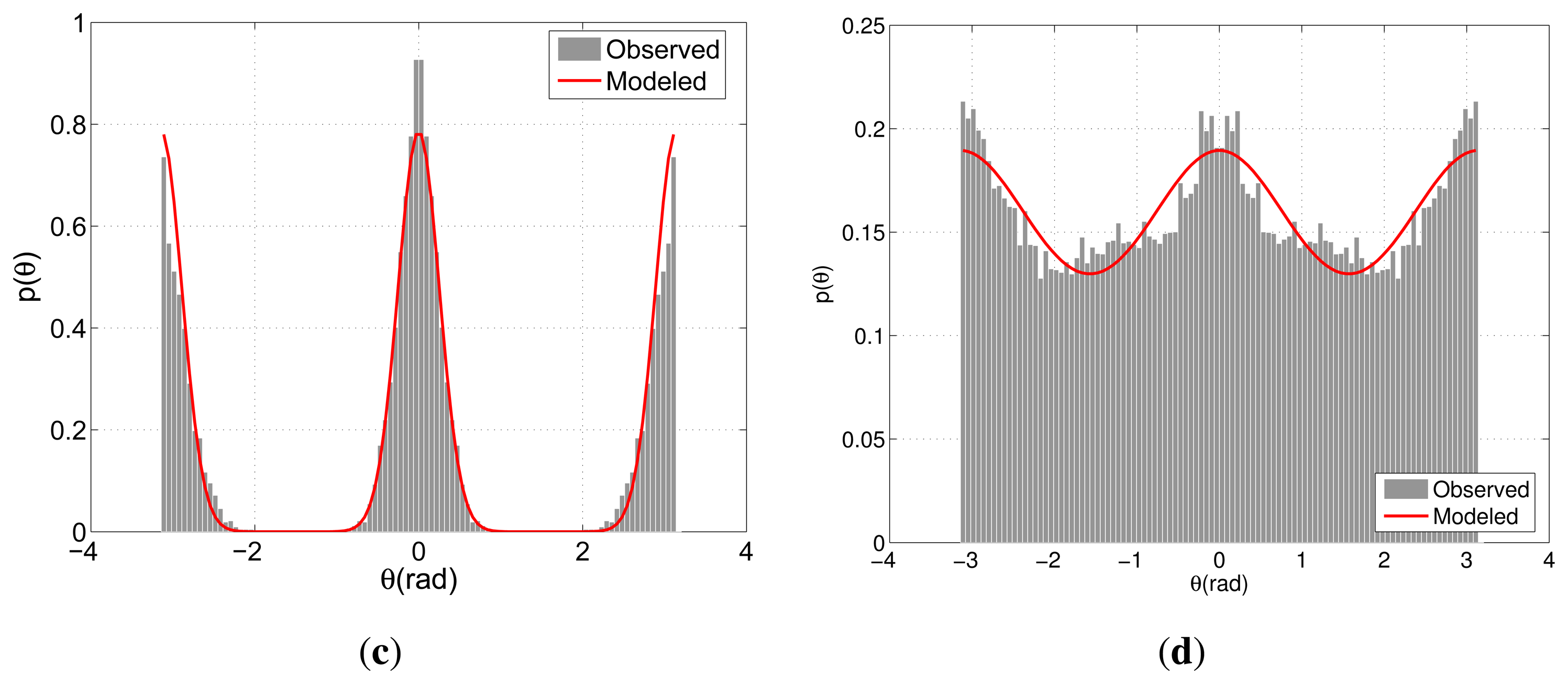
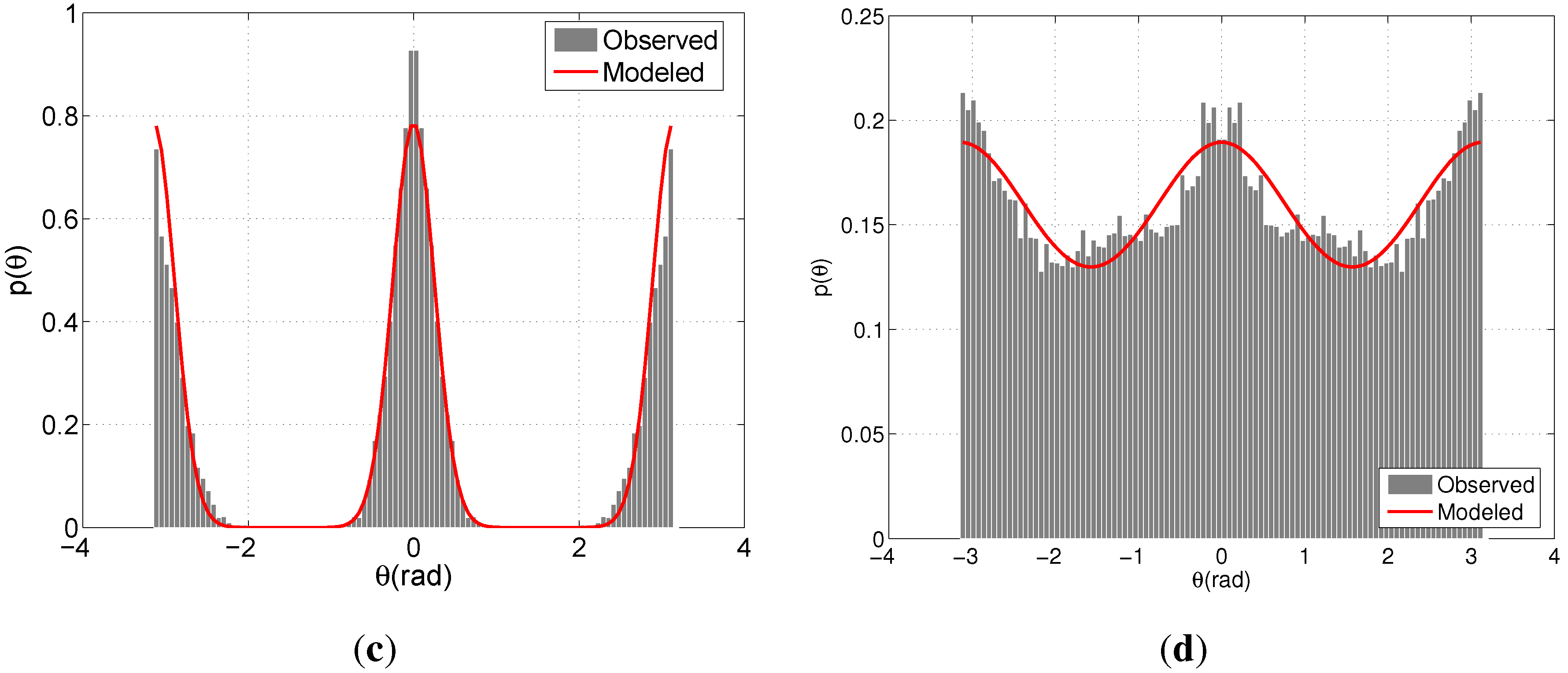
Figures 7(a,b) illustrate the modeled and observed distributions of the directional indicators relating G. As expected, both models peak around 0, where the spread concerning APT is slightly larger than that of BIWI-ETH. This difference reflects the more regular motion pattern of the pedestrians due to fewer distractions in comparison with APT's shopping center environment. On the other hand, the models concerning Ḡ present a clear distinction arising from the different flow characteristics. Due to the lack of prominent flow direction,
θ is distributed more evenly for APT and is concentrated around 0 and
π for BIWI-ETH.
6.3. Stability of Parameters
Repeating the calibration method described in Section 6.1 50 times using a set of randomly selected samples that constitutes 10% of all the data, we obtain the statistics shown in
Table 2.
The Δ
G models relating different datasets lead to similar values for
ν, changing between 0.81 cm and 0.67 m with a fairly small variation within 0.06 m. Hall defines close phase personal distance to be between 46 cm and 75 cm and far phase personal distance to be between 76 cm and 120 cm [
53]. Our findings are consistent with these values.
Regarding the θ models, the κ values relating G are always larger than those of Ḡ. As explained in Section 4.2, this indicates that the θ pattern concerning G is more structured than that of Ḡ. Nonetheless, the distinction becomes most clear in APT due to the lack of prominent flow direction. Moreover, the deviations of κ have quite insignificant values, provided that the sample set is large, as in BIWI-ETH and APT, whereas in BIWI-Hotel the deviation of κ regarding both G and Ḡ is higher relative to κ due to the reduced number of samples.
6.5. Comparison and Generalization
This section presents the performance rates based on the decisions of each individual indicator and ascertains that compound hypothesis testing improves the identification of group relations. Moreover, the alternative of hypothesis testing described in Section 5, where a decision is made in favor of the maximum absolute log-likelihood ratio, is applied and the superiority of our proposed method is verified. In addition, the detection performance of method of [
31] is reported and it is ascertained that our proposed method outperforms it.
The improvement introduced by the integration of two observations through compound hypothesis testing as described in Section 5 is presented in
Table 4. The improvement achieved by using both indicators (Δ + Θ), in comparison with using a single indicator (Δ or Θ), is presented in terms of the difference in performance rates of the individual decisions and performance rates after integration. It is observed that the numbers are often positive, which indicates that compound hypothesis testing provides an improvement over the individual models in almost every case.
The detection of G in Caviar is the only exception. Using the positional indicator Δ, a detection rate of 93.18% is achieved. Integrating positional and directional indicators, the detection rate decreases to 86.68%. This is due to the fact that the pedestrians in Caviar follow scenarios such as meeting and splitting, which cannot be determined using the directional indicators as explained in Section 4.2. The ground truth is given based on the video sequence, where visual cues are available. However, group relation is resolved using the indicators derived only from trajectory data. This implies that certain cues are not reflected such as gaze direction or body posture, whereas cues like position are still present. Therefore, it is not surprising that for describing behaviors like meeting and splitting, using only the positional indicator Δ results in a better performance than Δ + Θ.
Table 5 illustrates the performance rates of the model of [
31] for pairs in G, pairs in Ḡ and all pairs. In BIWI-ETH, which involves a non-uniform environment with high pedestrian density, Reference [
31] has a positive bias for Ḡ, which misleadingly increases the overall detection rate to 95.05%. However, G, which is observed less often than Ḡ is only detected by a 65.52% success rate. In BIWI-Hotel, which involves a dominant flow direction environment with low pedestrian density, the identification rates of [
31] and the proposed method are comparable. In APT, Reference [
31] detects both G and Ḡ with roughly 9% lower rates than our method.
In Section 5, it is mentioned that a straightforward way of dealing with conflicting decisions is to pick the decision that implies a larger absolute value. The identification rates achieved by selecting the decision with a higher absolute log-likelihood ratio instead of applying compound hypothesis testing is presented in
Table 5. Although the overall performance rates seem close to the proposed method, the detection rates of G are considerably lower than those of Ḡ. In other words, this approach has a positive bias for Ḡ. Therefore, our proposed method proves to have no bias in favor of a particular class, which implies a fair distinction of group relation.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}