Abstract
Foreground detection has been used extensively in many applications such as people counting, traffic monitoring and face recognition. However, most of the existing detectors can only work under limited conditions. This happens because of the inability of the detector to distinguish foreground and background pixels, especially in complex situations. Our aim is to improve the robustness of foreground detection under sudden and gradual illumination change, colour similarity issue, moving background and shadow noise. Since it is hard to achieve robustness using a single model, we have combined several methods into an integrated system. The masked grey world algorithm is introduced to handle sudden illumination change. Colour co-occurrence modelling is then fused with the probabilistic edge-based background modelling. Colour co-occurrence modelling is good in filtering moving background and robust to gradual illumination change, while an edge-based modelling is used for solving a colour similarity problem. Finally, an extended conditional random field approach is used to filter out shadow and afterimage noise. Simulation results show that our algorithm performs better compared to the existing methods, which makes it suitable for higher-level applications.1. Introduction
Foreground detection algorithms have been implemented in many applications such as people counting, face recognition, license plate detection, crowd monitoring and robotic vision. The accuracy of those applications is heavily dependent on the effectiveness of the foreground detection algorithm used. For example, some people counting systems will not work well when the surrounding illumination is low, such as during rainy days or inside dark rooms. Such a system will not be able to give a correct count because of the inability of the algorithm to distinguish between foreground and background objects. It is very important for the background modelling algorithm to be robust to a variety of complex situations. However, it is almost impossible to make such a system robust to all situations and conditions such as low variation in illumination change, reasonable movement speed and high contrast between background and foreground object. In fact, a majority of previous papers such as [–] only function well within limited conditions and constraints. Any slight deviation from the required conditions significantly degrades performance. Algorithms such as face recognition fail to perform properly once the constraints are violated. The aims of our work are to improve accuracy and robustness of background modelling to (1) sudden as well as gradual illumination change; (2) small movements of background objects; (3) colour similarity between foreground and background; and (4) shadow and afterimage noise. This paper is part of Zulkifley's [] PhD thesis.
Illumination change is one of the key issues when robust video analytics are developed. The issue can be divided into the subcategories of local and global on one hand, while sudden and gradual on the other. Learning capability can be incorporated into background modelling to enable the algorithm to adapt to the surrounding change either instantaneously or gradually. However, to find a single good model that fits both slow and fast learning rate is a difficult task and too dependent on the situation. An example of algorithm developed for gradual illumination change is by Jimenez-Hernandez []. His works used independent component analysis by utilizing spatio-temporal data to classify the foreground and background pixels. Our approach to cope with sudden/gradual illumination change as well as the problem of small movements of background objects is to fuse good background modelling with a colour constancy algorithm. By using colour co-occurrence based background modelling [], we are able to achieve good foreground detection even under moving background noise and gradual illumination change. The background learning constant is set to a slow rate for handling gradual illumination change. Prior to this, the colour constancy approach is used to transform each input frame into a frame as seen by a canonical illuminant. This step allows the algorithm to be robust to sudden illumination change. We improve the grey world algorithm [] by introducing adaptive mask and statistical grey constants. We also modify the method by Renno et al. [] to filter out noise due to variation in grey constant values modelled by a Gaussian distribution.
Other flaws in the method of [] are the degradation in its performance both under low ambient illumination and where there is colour similarity between background and foreground. We exploit higher level information such as gradient and edge to solve these problems. However, we argue that gradient information alone is not enough to provide robustness to the system. We propose a method which fuses both gradient and intensity information for better detection. The colour co-occurrence method will provide the intensity aspect while improved edge-based background modelling by using a fattening algorithm and temporal difference frame edge will provide the gradient aspect. A Gaussian distribution is used to realize the probabilistic edge-based background modelling. Both intensity and gradient methods are combined before final filter is applied to remove noise, especially shadows. A Conditional random field (CRF) approach is used to remove shadow and afterimage probabilistically. The algorithm of Wang [] is improved by using a new shadow model and by incorporating previous neighbourhood values for decision making. As a result, algorithms that depend on foreground detection will produce sharper foreground which contributes to overall accuracy improvement.
This paper is organized into 9 sections. A literature review will be explained in Section 2. Section 3 will discuss a brief overview of the system. The details of the algorithms will be explained in Sections 4–7. Then, simulation results and discussion are presented in Section 8. Finally, conclusions are drawn in Section 9.
2. Literature Review
The most cited work for background modelling is the mixture of Gaussian (MoG) approach introduced in 1999 by Stauffer and Grimson []. The method has proven to be effective in handling gradual illumination change for indoor and outdoor situations, but it still lacks in terms of robustness, especially for the problems of sudden illumination changes, moving background objects, low ambient illumination and shadows. Lee and Chung [] then combined MoG with weighted subtraction method for health care surveillance system. Another method by Varcheie et al. [] also implemented MoG through a region-based updating by using colour histogram, texture information and successive division of candidate patch. Instead of using a mixture of Gaussian distributions, Ridder et al. [] predict and smooth out the mode of the pixel value by using Kalman filter. This algorithm suffers the same problem as both methods only use temporal information for their decision making. In [], Wang et al. used alpha-stable distribution instead of Gaussian distribution to detect background clutter. Synthetic aperture radar is used to detect the presence of a ship, and they obtained less spiky image or reduced fluctuation in the image due to improved modelling. They found that the ship detection is less spiky based on synthetic aperture radar image. In order to reduce intensity fluctuations due to noise, Bozzoli et al. [] and Yu et al. [] applied intensity gradient in their background modelling. Their approaches were found to be good in suppressing intensity value fluctuations but tend to produce wrong detection when the background object is moving, as in the case of an escalator or shaking tree.
The most popular method of gathering statistical information for each pixel is to use a colour histogram approach as in [,]. Li et al. [] introduced the colour co-occurrence method, invoking the relationship between two pixels in consecutive frames for background modelling. Their approach uses Bayes rule for classifying each pixel as either moving foreground or moving background. This approach performs well in handling gradual illumination changes and moving background noise. However, the image obtained is not crisp and the method failed under sudden illumination changes. Crispness of the image is the quality of the object boundary, whether the edge is clear or blurred. In 2005, Zhao and Tao [] used a colour correlogram which relates two pixel values within a certain distance inside the same frame. The algorithm performs well as the input for tracking non-deformed objects. The weakness of this approach is that it cannot handle non-rigid objects, especially in human detection algorithms where human foreground shapes change continuously as they walk. Another two popular methods of gathering statistical information are the fuzzy histogram approach [] and colour ratio histogram approach [].
Robust foreground detection is hard to achieve if each pixel is treated separately from its neighbours and from corresponding pixels in preceding frames. In order to improve the accuracy of background modelling, more information should be incorporated for decision making. Instead of making decisions based on a single pixel value; spatio-temporal information is used for better detection. Each of these approaches is further classified into deterministic or probabilistic. Temporal information is obtained by including previous data in the determination of the current pixel value or label. Haritaoglu et al. [] is one of the first papers to apply deterministic temporal information. The paper constructs the background model by using minimum and maximum intensity values, and the maximum intensity difference between consecutive frames during the training period. Some examples of probabilistic approaches can be found in the papers by Li et al. [], Bozzoli et al. [] and Barandiaran et al. []. Deterministic approaches normally employ fixed thresholds for decision making. Spatial information is important as it correlates each pixel with its neighbours. Spatial techniques assume that any pixel will have higher probability to be a foreground if the majority of its neighbours are foreground. The algorithm by Hsu et al. [] is an example of a deterministic spatial information approach, while Kumar and Hebert [] and Paragios and Ramesh [] implement a probabilistic approach of background modelling using Markov random fields. Spatio-temporal methods combine both spatial and temporal information, and most such algorithms are more robust to complex situations. Deterministic spatio-temporal approaches such as the algorithm of Zhao et al. [] achieve good foreground detection even during the night, and that of Pless [] is suitable for robust outdoor surveillance applications. Examples of probabilistic spatio-temporal approaches that provide effective foreground detection are the work of Kamijo et al. [] and Wang et al. []. Both algorithms use Markov random fields to model spatio-temporal information. In 2007, Wang [] introduced CRF in background modelling to classify each pixel into foreground, background or cast shadow. This approach provides sharper foreground detection, especially for a scene that contains a lot of cast shadow noise.
Few works [,] have implemented colour constancy approaches to adapt their algorithms to illumination changes. Most of the existing colour constancy algorithms are built for image processing applications and will not perform well for video analytics applications. This is due to the complexity of video scenes, which poses a tough challenge to estimate the reflectance dynamics in consecutive frames. As the scenes evolve, the estimated reflectance will also vary. Thus fixed reflectance values in image processing are no longer accurate. The most popular colour constancy method is the grey world algorithm, which was introduced by Buchsbaum [] in 1980. Since then, the algorithm has evolved rapidly into several forms. However, the main idea remains the same, namely to estimate the illuminant by using average intensity values. The major weakness of the original grey world algorithm is that it cannot distinguish moving objects for grey constant calculation. In [], Finlayson et al. applied the grey world algorithm to comprehensive image normalization, whereby two images with different illuminants are transformed into their canonical form. Their algorithm iterates until it reaches a stable state. In 2003, Ebner [] combined the white patch retinex and grey world approaches for producing the canonical image. Reflectances are obtained by applying both approaches in parallel. Local space average colour and maximum deviation are used to find the required adjustment. Renno et al. [] have implemented the grey world assumption for video processing to both indoor and outdoor situations. Their algorithm performs well if the moving object in the scene is considerably small compared to the frame size. If the moving object is relatively large, it occupies most of the frame, which leads to bad grey constant values because moving pixels are used to determine the values.
3. Overview of the System
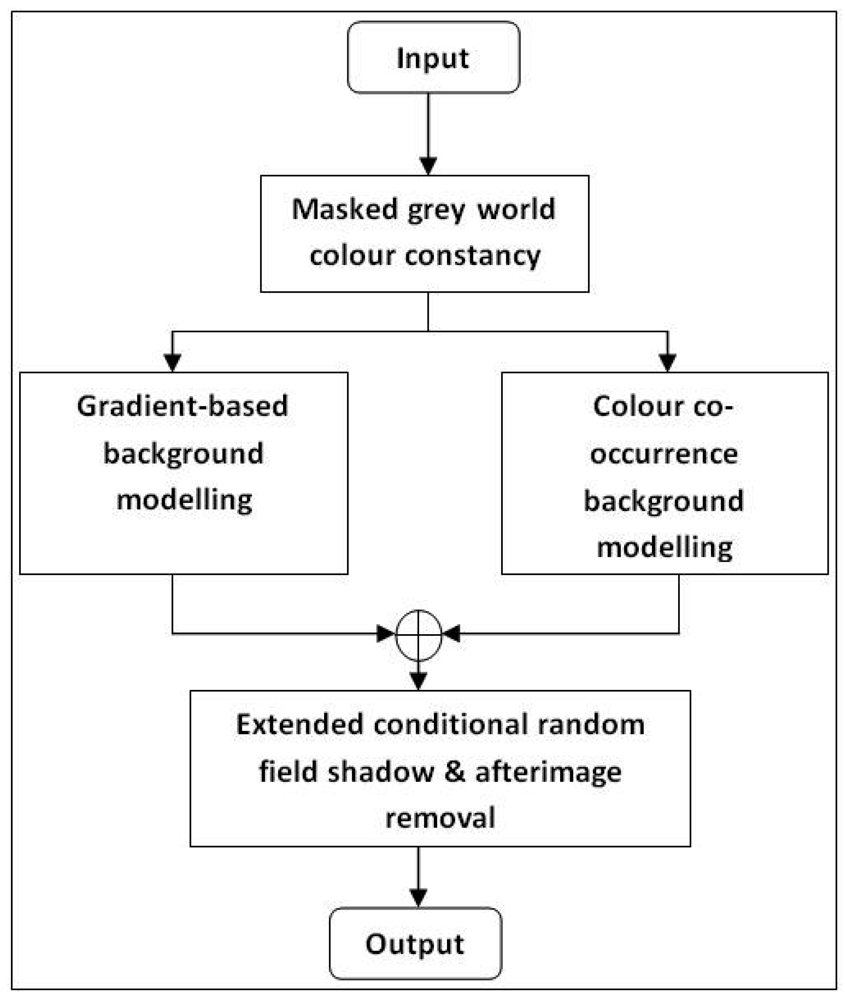
The goals of our algorithm are to improve background accuracy and modelling robustness to (1) sudden and slow illumination changes; (2) colour similarity between foreground and background objects; (3) shadows and afterimages; and (4) moving background objects. First, all input frames are transformed into canonical frames to solve the sudden illumination change problem. We then apply the grey world assumption and modify the algorithm by Renno et al. [] to handle for more complex situations. The algorithm is improved by introducing a 2-stage mask and a probabilistic approach to determine grey parameter values used to exclude moving objects from inclusion in grey parameter calculations. Then, probabilistic gradient-based background modelling is fused with the colour co-occurrence algorithm by Li et al. []. Gradient information is used to address the problem of colour similarity between foreground and background objects. A combination of temporal difference frame edge and current input frame edge is found to be effective in distinguishing colour similarity. A colour co-occurrence approach also handles the problem of gradual illumination change and movement of background objects. Finally, shadow and afterimage removal is performed to obtain sharper foreground objects. The method by Wang [] is improved by introducing a new shadow model, which is applied to a extended CRF model for decision making. This removal algorithm is applied only to pixels with label equal to 1 prior to the test. An overview of the whole system is shown in Figure 1.
4. Masked Grey World Colour Constancy
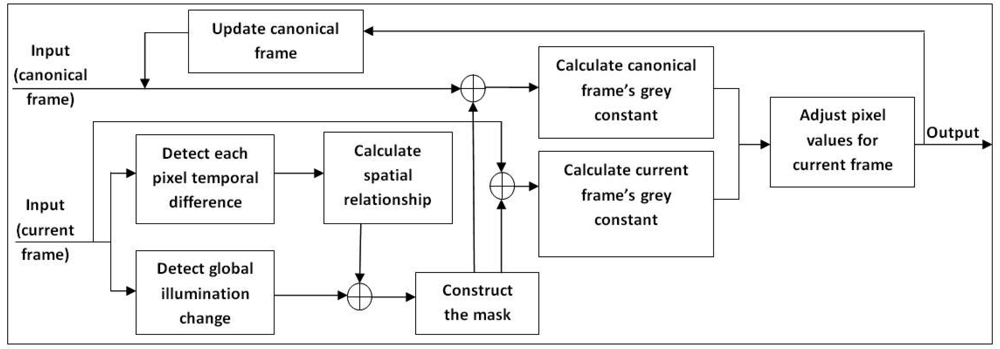
This method was first introduced in [,] by Zulkifley and Moran. The aim of this section is to transform each frame into a canonical frame using the masked grey world algorithm. The motivation for applying colour constancy approach is to overcome sudden illumination change issue. Learning rate for background modelling can be set to lower value, which is good for handling slow change in the scene as any sudden change will be handle by colour constancy approach. The grey world algorithm assumes that the spatial average of surface reflectance in a scene is achromatic. Therefore, it is constant if there is no illumination change. This is true for outdoor environments where strong global illumination from sunlight will make other sources of light insignificant. However, the single average assumption is inaccurate for indoor environments, which usually have multiple sources of illumination. Previous grey world algorithms such as [,,] are built for image processing applications, which assume no object movement between images. Some adjustments and alterations are required for video processing implementations because of the increased complexity of video content. In consequence, a 2-stage masking was introduced to improve the transformation accuracy of the algorithm by Renno et al. []. Figure 2 shows the simplified block diagram of the masked grey world algorithm.
The mask Mp is introduced to filter out moving objects from the grey world parameter calculation since the foreground object has no significant role in parameter calculation. This is done so that only stagnant pixels from both the reference frame Fc and the current input frame will be used in calculating the grey world parameters. Since grey world algorithm take the average values of the pixels in the frame, moving object is an inaccurate representation of the grey constant value. By removing the moving foreground, better estimation of grey constant can be obtained, which leads to better colour adjustment. In addition, the mask also plays a role in detecting overcrowded scenes. For this, we use the whole frame to achieve better average values when the normal grey world algorithm fails to adjust appropriately to a scene overcrowded with foreground objects. We propose using a mask to filter out moving object pixels as well as to detect global illumination changes. The reason foreground pixels are not included in the grey constant calculation is that the canonical frame does not contain their information. The first frame is designated as the canonical frame Fc and becomes the reference frame for the grey world parameter calculation. The first stage of calculating the mask involves classification of each pixel as belonging to a moving object or not. A Gaussian distribution is used to model the probability distribution of the temporal difference between the input frame, Ft,x,y(R,G,B) and the preceding frame, Ft−1,x,y (R, G, B). Variances are assumed to be identical for all colour channels of RGB space. This assumption is applied throughout this chapter. Let x and y be the spatial coordinates of a pixel at a time instant t.
Then, the label of each pixel is obtained by comparing the temporal differences with a threshold value, Τ1, to classify it into a moving object or background pixel. The assigned label, of each pixel is set high if it belongs to a foreground object and low otherwise.
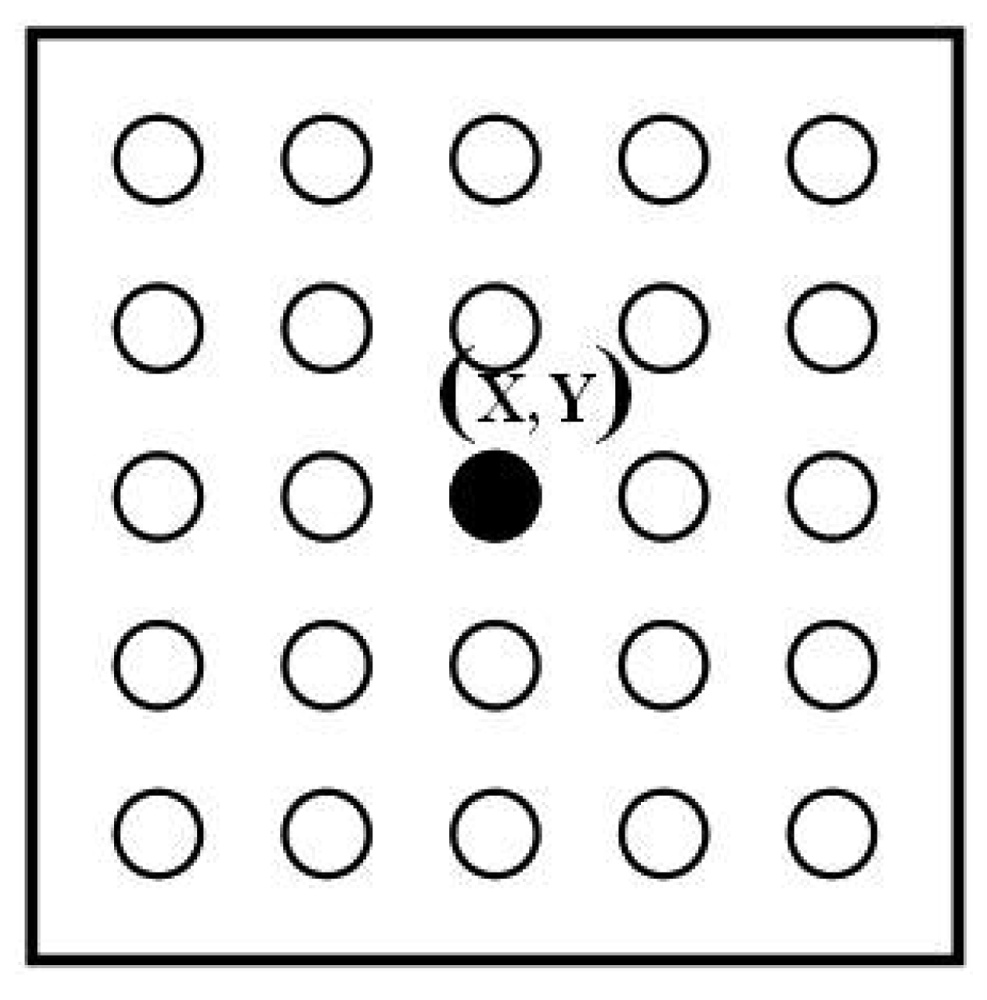
In order to filter out noise, the spatial correlation (St,x,y) of each pixel and its neighbouring labels are used to determine the mask. A k × l kernel size is applied as the pixel neighbourhoods (Kr1) as shown in Figure 3.
This is then compared with a threshold value Τ2 for assignment of the final label of the first-stage mask. Each pixel label remains high if a majority of the neighbouring labels are high and low otherwise. This is based on the assumption that a moving pixel should belong to a connected foreground region.
Once the initial mask is obtained, hypothesis testing based on the Neyman–Pearson method is performed to detect global illumination changes. If a change is detected, the mask (Mp2) will be the whole frame, which means every pixel will be considered in the grey world parameters calculation. This step is important in solving the problem of very crowded scenes with many moving objects. Usually, the first-stage mask will consist of only a small number of pixels, and this may lead to a wrong grey parameter value. For each pixel, the null hypothesis (H0) is modelled by the same Gaussian distribution as in Equation (1), while an alternative hypothesis (H1) is modelled as in Equation (6).
Detected changes in global illumination will be represented by the alternative hypothesis while the null hypothesis will represent no global illumination change. Both probabilities and are multiplied throughout the whole frame for finding the frame's and .
Then, hypothesis testing based on Neyman–Pearson is performed to get the final mask. The null hypothesis will be rejected if Equation (9) is true.
Using the resulting mask, the grey world parameters Gc(R,G,B) are calculated for both the current input frame and the canonical frame. For every colour channel, the grey parameter is the intensity averaged over the masked pixels. Each channel is treated separately, so each channel has its own grey parameter values and let Tn denote the total number of masked pixels.
The colour adjustment ratio, Ar(R,G,B) between the grey world parameters of the canonical frame and the input frame is the ratio by which each colour channel will be scaled. In order to guarantee that the difference between the grey parameters of the current input frame and the canonical frame is not due to noise, the difference between those frames is modelled as a Gaussian distribution as in Equation (11). If the likelihood of the difference P3 is less than the threshold value (Τ3), the colour adjustment ratio is reset to 1; if it is not, the original ratio will be retained.
Final output of the masked grey world algorithm is obtained by taking the dot product of the original input frame and colour adjustment ratio. Then the adjusted image is passed to both colour co-occurrence and probabilistic edge-based background modelling.
Maintenance of Canonical Frame
It is important for the canonical frame to be updated continuously because of the “noise” between frames. An example of the “noise” is when the canonical frame was first captured with some parts blurred. The frame will be updated with a better value when later frames contain less blurred image. A fixed canonical frame gives wrong grey constant values when a background object leaves the scene, for example when an object is removed from the scene. The canonical frame is maintained using an infinite impulse response filter where Τ4 is a small positive value. Only masked pixels will be updated. Τ4 should be given a larger value to increase the pace of learning if the scene contains many moving background objects.
5. Review of Colour Co-Occurrence Background Modelling
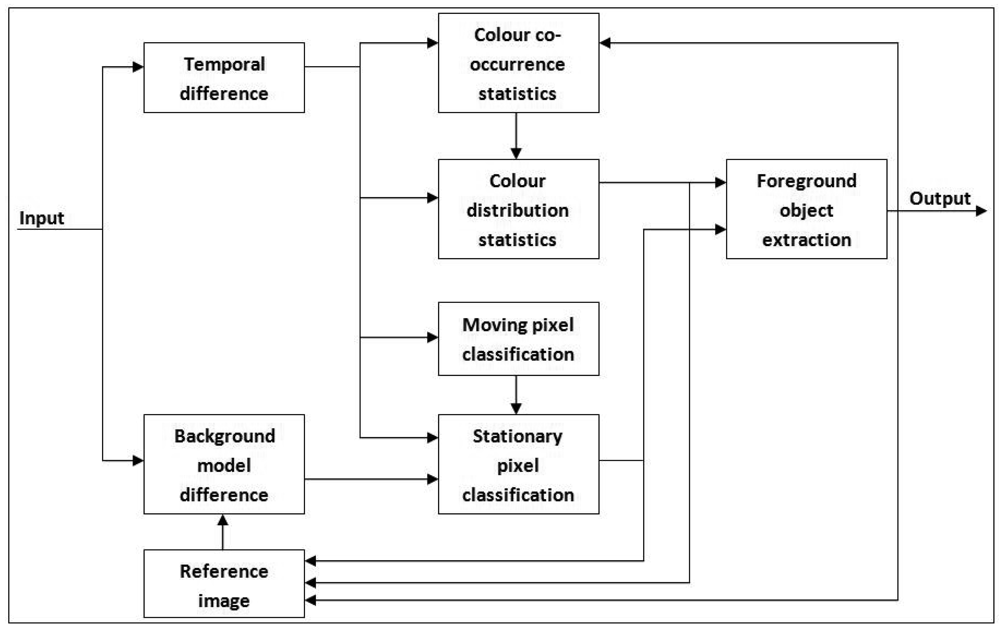
As shown in Figure 1, the transformed frame is fed to both colour co-occurrence modelling [] and our edge-based foreground detection []. Both methods run concurrently so that they can compensate for each other's weaknesses. The reason for choosing the colour co-occurrence algorithm as the basis for foreground detection is its ability to distinguish between moving background and moving foreground pixels. A detailed explanation of the original algorithm can be found in [] and []. The algorithm utilizes inter-frame colour co-occurrence as the input to a Bayesian decision rule so that each moving pixel can be classified either as moving background bc or moving foreground fc. Block diagram of the subsystem is shown in Figure 4.
Simple background subtraction is used to find both moving foreground and moving background pixels. Colour co-occurrence statistics are applied to filter out the moving background. Let be the output of colour co-occurrence algorithm. Initial background frame is obtained by using frame subtraction with respect to . A global threshold is applied to classify the pixel either as a moving object or static object. Using a similar method, a temporal difference frame is obtained by frame subtraction between and . For each pixel where is bigger than zero, a colour co-occurrence (ct, ct−1) pair is extracted, which is then compared with the values stored in the table of colour co-occurrence statistics, .
A Bayesian decision approach is used to classify which probabilities of background change (Pbc) and foreground change (Pfc) are modelled as follows
Moving background is recognized if the probability of background change is bigger than the probability of foreground change:
The universal set of colour co-occurrence changes between the frames can only be caused either by moving foreground or moving background.
The decision rule will be further simplified by substituting Equations (16)–(18) into Equation (19):
Both P(ct, ct−1|x,y) and P(ct, ct−1|bc, x,y) are obtained from the table of colour co-occurrence statistics while P(bc|x,y) is extracted from . If is bigger than zero, the colour co-occurrence (ct, ct−1) of that pixel is extracted, which will be compared with the stored statistical values. If a match is found, the corresponding probabilities are retrieved and inserted into Equation (20) for detecting moving background. If no match is found, both probabilities are assumed to be zero. The labelling for temporal inter frame change is classified as in Equation (21).
The final label for both backgrounds and temporal differencing are as follows
The output frame for colour co-occurrence algorithm is obtained by using a pixel-wise OR operator between and . Finally, OPEN and CLOSE operators are performed to clean up the output.
6. Probabilistic Edge-Based Background Modelling
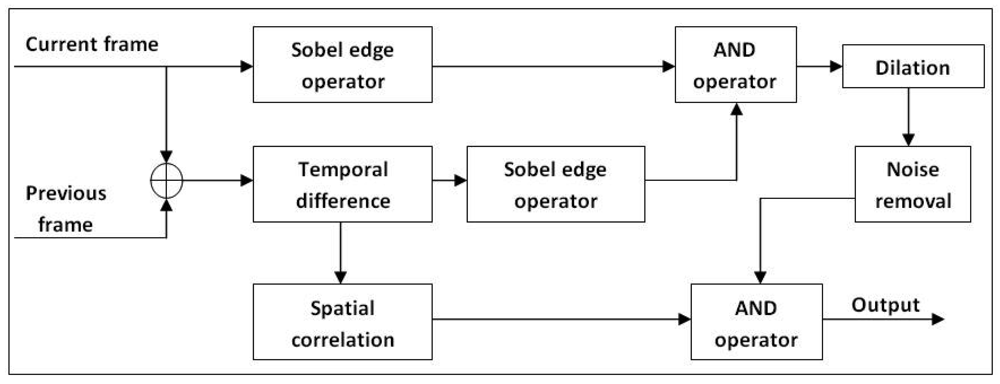
Our probabilistic edge-based background modelling is constructed primarily to deal with the colour similarity issue between background and foreground objects. The method proposed by Li et al. [] alone is not sufficient to produce good detection in the case of colour similarity because many foreground pixels are miscategorized as background pixels. We approach this problem by exploring higher-level information, especially edges. Edge information is known to be more robust to illumination change [], leading us to explore the effect of manipulating moving edges. The basis of our edge-based background modelling is the fusion between the temporal frame's edge and the current frame's edge . Figure 5 shows the framework of the proposed subsystem.
All edge detections are performed based on the Sobel edge operator []. The temporal difference frame (Ftd) that relates the current frame to previous frame is modelled by Gaussian distribution. The acquired probability P4(Ft,x,y, Ft−1,x,y) is then checked against a threshold value Τ5. The pixel is set to high if the corresponding probability is bigger than Τ5 and vice versa.
After that, the temporal frame edge and current input frame edge are extracted. Both edge frames are then fed into an AND operator to remove noise and afterimage. Let be the binary map which will be set high if both and are high.
Since the output obtained from will only add fine lines to the foreground detection, dilation is applied to increase the detection accuracy. The additional noise from the dilation process will be filtered out by Equation (31). Thus, the additional noise is kept at the minimum. This step proved to be critical in increasing detection accuracy for situations where foreground and background colour are similar. Dilation is performed using the decision rule given by Equation (28) where the size of the neighbourhood kernel Kr2 is k × l pixel.
From the temporal difference frame in Equation (27), spatial correlation is added to smooth out the noise. Later, it will be convolved with u × u kernel (Kr3) before being compared with a threshold value, Τ6. Let (ai, aj) be the kernel anchor. The sum of all kernel elements should be equal to one.
Dilation and erosion operations are performed to remove excess noise. The final output (Fo3) of the probabilistic edge algorithm is obtained by combining cleaned and with an AND operator.
Combining Both Outputs of Background Modelling
Since both methods of Sections 2.5 and 2.6 run concurrently, their outputs are independent of each other. In order to make full use of both detections, an OR operator is used so that the detection algorithms can compensate for each other's errors. For each pixel, the output, is set to high if any of the method's label is high as shown in Equation (33).
7. Extended Conditional Random Field Shadow & Afterimage Removal
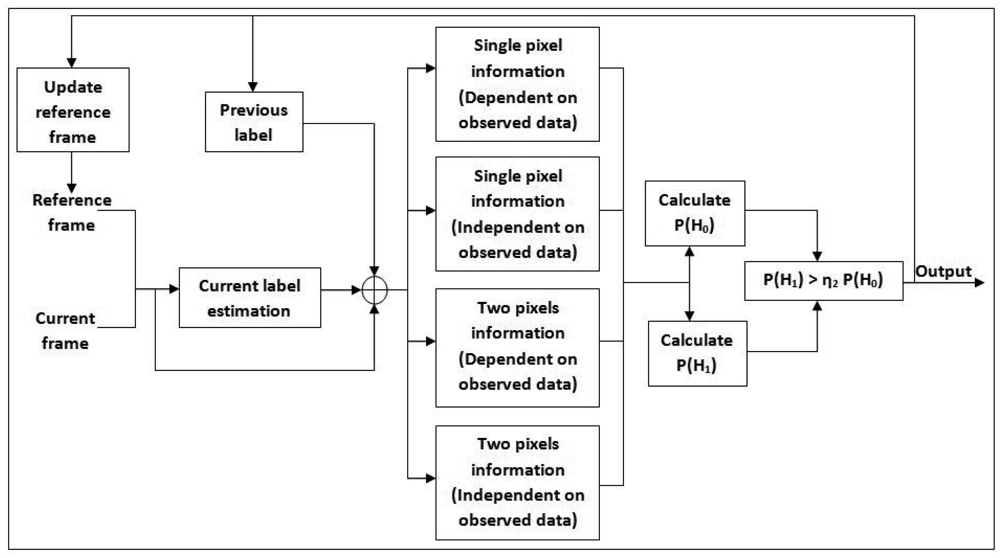
This section describes the suppression of “noise” added during earlier processes by removing the shadow and afterimage. Only pixels recognized as foreground pixel based on undergo the removal test. Usually for fast moving objects, the detected foreground is not crisp because of the afterimage noise. In addition, dynamic shadows are also detected as foreground, which creates a double counting problem in people counting systems. The fundamental idea in our approach is the use of conditional random fields as described by Wang [], which has been improved in []. The improved method introduces a fusion of Neyman–Pearson hypothesis testing with extended CRF and a new shadow model. Figure 6 shows a block diagram of the extended CRF shadow and afterimage removal algorithm.
The observation and label for the random field are denoted by gt,x,y and lt,x,y, respectively. Each label is modelled by ek, a k-dimensional unit vector with its kth component equal to one. Those vectors are used to segment the label into a real foreground pixel or cast shadow/afterimage pixel. A field can be classified as CRF if it fulfills these two requirements:
If the random field, L is conditioned on the observed data, G.
If the random field obeys Markov property:
where is neighboring sites of pixel at (i, j).
Based on the Hammersley–Clifford theorem, a Markov based random field can be shown to be equivalent to a Gibbs random field []. In our case, Fo4 is taken as the observation field (Gt), while the random field for the label is denoted as Lt. Only single potentials Vx1,y1 and pairwise potentials Vx1,y1,x2,y2 will be considered for our algorithm.
Both the 1-pixel potential and pairwise pixel potential can be broken into two components, either dependent or independent of the observations.
The independent component of a single pixel potential is modelled as Vlx1,y1 (lt,x1,y1) = −Τ7lt,x1,y1.lt−1,x1,y1, while the dependent component of single pixel potential can be further reduced to – ln P(gt,x1,y1 |lt,x1,y1). Since we are using Neyman-Pearson hypothesis testing, it will be represented by the likelihood of H0 and H1. The probability of detecting a region that is not a shadow, P5(H0), is modelled as a Gaussian distribution, which compares the difference between the observation frame Ft,x,y(R, G, B) and the reference frame .
On the other hand, the probability of the alternative hypothesis (P(H1)) is obtained by modelling the difference between the observation frame and modified reference frame with Gaussian distribution. Each channel will have its own difference value—in this case, (d1, d2, d3) ∈ D for RGB. By using these three difference values, three modified reference frames are established.
All three cases are investigated separately, and the minimum output probability is chosen as the null hypothesis probability.
The 1-pixel potential only contains temporal information, neglecting the spatial variation. This weakness is overcome by using pairwise pixel potentials where both past and current neighbouring data are taken into consideration for decision making. Let Kr5 be the kernel of the neighbourhood with size of k × l Thus independent component can be modelled as shown in Equations (40) and (41). The first equation represents the spatial relationship between each pixel with its current neighbours while the second equation represents the relationship between each pixel with its past neighbourhood label. All these equations are derived from the assumption that each pixel label will have a higher likelihood to retain its previous label.
The dependent component of the clique potential is the distinguishing factor between a Markov random field (MRF) and a conditional random field. Neighbourhood observation and label relationship will be assumed as zero for MRF approach. Here, we adopt the reduced version of the potential by Wang [].
All probability components are put together to get the final label, . A high label is retained from previous subsection if a non-shadow is detected. The pixel will be assigned a low label value if the shadow potential is higher than the non-shadow.
Maintenance of Reference Image
The reference frame needs to be updated so that it can adapt to changes in surroundings and illumination. Maintenance of the frame is divided into two cases: an illumination change is detected or it is not. When a global illumination change occurs, the current reference frame will no longer be accurate. A new reference frame is initialized by taking the next frame after the illumination change has stabilized.
8. Simulation Results and Discussions
Our algorithm has been tested on various video scenes to prove that accuracy and robustness have been improved over prior algorithms. Its performance has been compared with several existing approaches, including methods by Stauffer and Grimson [], Li et al. [], Renno et al. [], Wang [] and Varcheie et al. []. The parameters used has been tuned to perform as good as possible for that particular video where OpenCV library [] is used as the basis for coding the methods by Li et al. and MoG. Our algorithm was written in C++ using OpenCV library and run on a 2.66 GHz Intel core 2 Duo machine. The processor manages to execute the entire algorithm with the minimum speed of two frames per second for a 960 × 540 frame size. With the help of multicore machines, the algorithm is expected to achieve a speed-up to real-time. The parameters for both MoG and method by Li et al. are given in Tables 1 and 2 respectively.
The value of η for the Neyman-Pearson hypothesis test is initialized with 0.001 while all variances for Gaussian distribution are initialized as 5. Kernel neighbourhood size can be any odd number, and we obtained acceptable results by implementing 3 × 3 and 5 × 5 kernel sizes. Three evaluation metrics is used to assess the performance of foreground detections, which are total error rate (TER), true positive rate (TPR) and false positive rate (FPR). TER is calculated by taking the ratio between the total number of error pixels and the total number of pixels (TNP). The ground truth image has been processed manually, which is the reference for identifying the error pixels. The total number of errors is a combination of the false positive (fp) and false negative (fn) pixels. False positive is an error where the pixel is detected as foreground, but it is actually not. False negative occurs due to misdetection where the foreground pixel is recognized as a background. Total error rate is calculated as follows:
The analysis is separated into six categories, where we refer our algorithm as Zulkifley et al. The first and second videos are used to test the overall performance of the algorithms while the third, fourth and fifth videos are used to verify specific performance improvement of the subsystems. The role of the third video is to point out the advantage of using the masks in grey world algorithm compared to Renno et al. [] algorithm. The purpose of the fourth video is to demonstrate the advantage of fusing probabilistic edge algorithm compared to using the Li et al. [] algorithm alone. The fifth video will test the performance difference between our shadow model and the Wang [] shadow model. The last test compares our algorithm performance with respect to the state-of-the-art method, which is based on the algorithm by Varcheie et al. []. Videos 1, 4 and 5 will demonstrate performance improvement of using our method compared to the method by Varcheie et al.
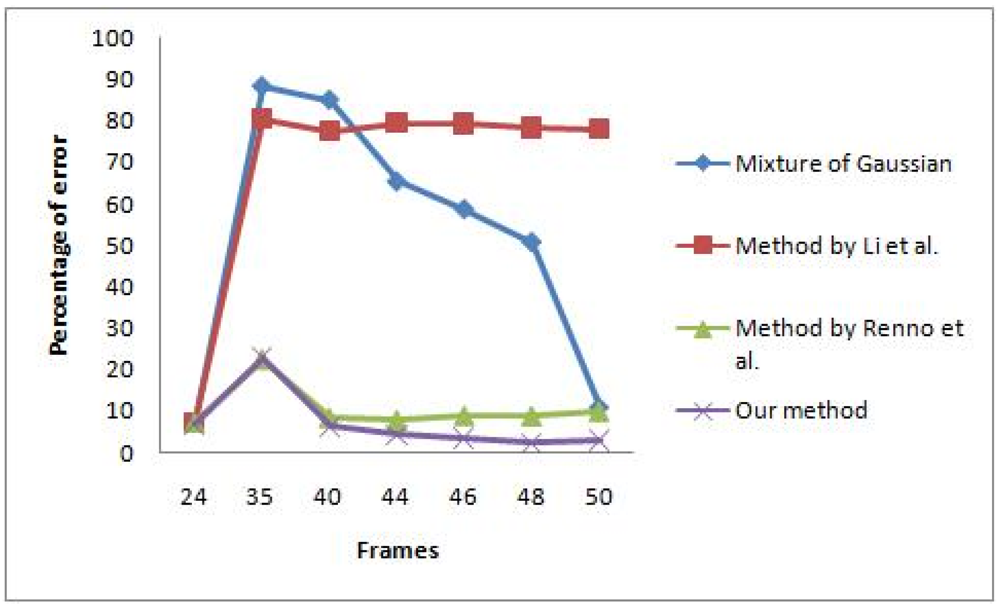
The first video contains a scene where global illumination has changed from a bluish to a more reddish illumination because of a lighting change. Some frames of the scene are shown in Figure 7, which is taken directly after sudden illumination change occurred. The learning rate for both MoG and colour co-occurrence methods is set to normal, which has been tuned for good performance in sudden and gradual illumination change. The video also contains some afterimage noise because of fast movement of the hand. The performance comparison between the algorithms is shown in Figure 8. Only the methods by Zulkifley et al. and Renno et al. [] managed to maintain an acceptable error rate after a sudden illumination change, which occurs at frame number 35. After 15 frames have lapsed, the MoG method manages to retrieve an acceptable error rate while the Wang [] and Li et al. [] algorithms still fail to obtain an acceptable error rate. We selected an acceptable error rate below 10% as most of the papers [,,] reported their error rate as less than 10%. Table 3 shows the total error rate which clearly indicates that our algorithm performed better than all the others. Note that every algorithm includes small component removal.
The result supports our earlier argument that it is hard to choose a single background learning rate to accommodate both sudden and gradual illumination changes. Our method lets colour constancy react to sudden illumination changes while the background learning rate is set to handle gradual change. Our 2-stage masked grey world managed to stabilize the input image, especially during the abrupt change in the illumination. This allows our background modelling to be more accurate as not much difference is detected due to good normalized input image. We also found that the methods by Li et al. and Wang had a higher TPR compared to us, which indicate better true positive detection. However, their FPR values are also high while ours is only 0.035. A high FPR value signifies that many background pixels are detected as foreground. This explains the reason why our TER is the lowest, which is supported by good TPR and FPR values. Therefore, our algorithm performs the best compared to the others, especially during the illumination change scene.
Samples of the second video scene are shown in Figure 9. It contains a complex situation in which the moving object appears similar to the background colour. The moving person took off her jacket and left it on the rostrum. She then walked in front of a white board in a white t-shirt. This poses a challenge for any algorithm that is dependent on colour information alone where the information will be quite similar. There is also an afterimage and shadow effect, which contributes to additional noise. Table 4 shows that the method by Zulkifley et al. has the lowest TER, which is just 1.49%, while MoG performs the worst at 6.79% error rate. The result also shows that we have the highest TPR value at 0.844. This proves that we managed to increase foreground detection in challenging situations, especially for the colour similarity issue. Our FPR is 0.011, not the lowest but still a good value. This small increment in false detection rate is a worthy trade-off for higher true detection. Note that MoG has the highest error rate since it only utilized colour information for detection where the shirt data has been recognized as the background data.
For the third video, the foreground object is a marble with variable speeds, as shown in Figures 10 and 11. Initially, the marble moves slowly and then after a sudden illumination change occurred, the marble rolls faster, creating some afterimage noise. Accuracy comparison is calculated between the methods by Zulkifley et al. and Renno et al. The result shows that our algorithm manages to react better to sudden illumination change as shown in Table 5 by introducing a mask in the grey world algorithm. Our method manages to reduce the error rate of foreground detection from 5.055% to 0.047%. In this video, misdetection is a critical issue since the object is very small. Our TPR is worse than the method by Renno et al. but our FPR value is better. This signifies that we managed to reduce false detection even for such a small object due to our good shadow and afterimage removal. Another reason why our algorithm produced better detection is due to foreground information subtraction while calculating grey constants. Therefore, more accurate normalization constants are obtained to lessen the effect of illumination change.
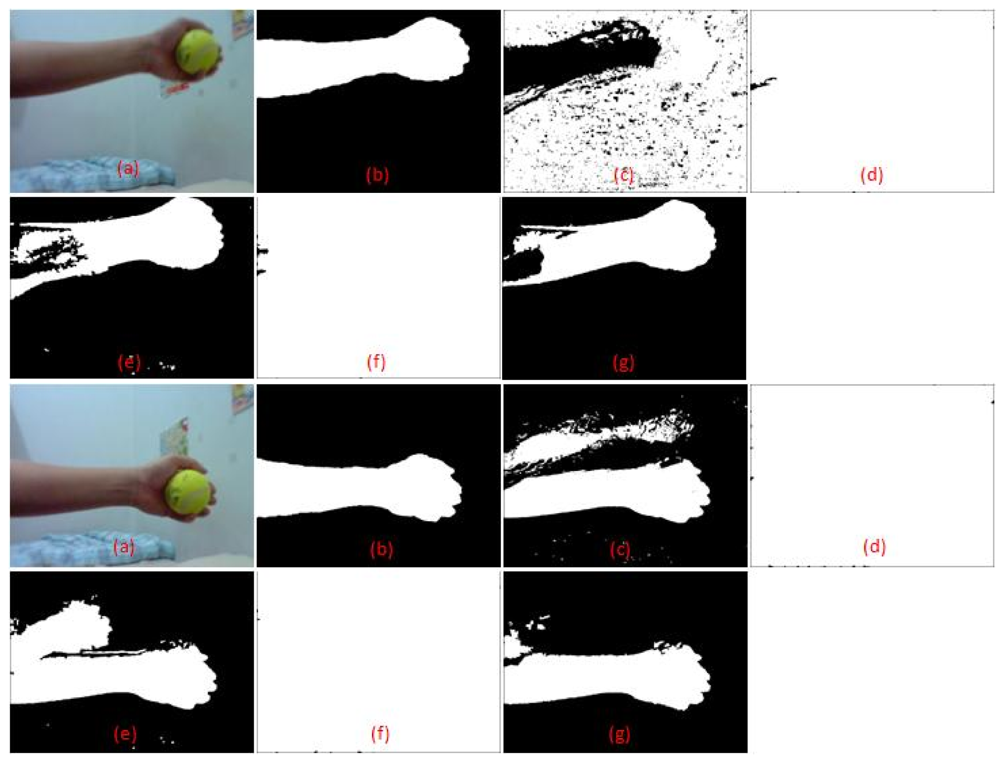
The fourth video is chosen to show the advantage of fusing edge and intensity information for background modelling. The foreground object in the test video is a moving human with dark grey trousers. He walked in front of a black colour background as shown in Figures 12 and 13. The performance of our algorithm is compared with the method by Li et al., which depends on colour values alone for background modelling. As shown in Table 6, the average error rate is reduced from 1.039% to 0.880%. Although the error reduction appears small quantitatively, in terms of qualitative analysis our algorithm managed to get more accurate outer appearance of the moving object. This is very important, especially for people counting systems in a complex scene where the bounding box size is used to determine the number of people. Our algorithm manages to increase the true detection as shown by a higher TPR value compared to the method by Li et al. Although our FPR has a higher value of 0.004 compared to 0.003 from the method by Li et al., this small increment can be neglected as better detection of true positive is obtained.
The fifth video scenes shown in Figures 14 and 15 are used to compare the performance of the shadow model between Wang's [] method and our algorithm. The scenes contain a moving hand where shadows are formed at the bottom of the frame. Figure 15 is quite a challenging scene since the shadow can still be seen at the bottom of the frame even though the hand is already out of the scene. Table 7 shows the error analysis of the scenes. There is no significant performance difference as algorithm 2(d) performs slightly better with 0.5486% error rate compared to 0.5538% for Wang's algorithm. Our TPR value is lower by 0.001 while our FPR value is higher by 0.0001. We can conclude that additional information from the past neighbourhoods did not improve shadow removal capability for this particular video.
The last results are meant to compare our algorithm performance with the state-of-the-art method. Method by Varcheie et al. was selected as the benchmark. This method is a derivative of mixture of Gaussian approach where selective updating is used. The frame is divided into variable size of boxes. The histogram and variance of each box are generated where the background model is based on the first frame data. It will be updated with the current information if any boxes are deemed to be the background. If the certain threshold of histogram and variance difference are met, the boxes are considered as the foreground region. This particular region is then updated by using the mixture of Gaussian method. This approach will not increase the detection of foreground pixels since the foundation is still MoG, yet it will reduce false detection since it filtered out any small region noise that has size of less than 4 × 3 pixels. For all three tested video, our TER values are less than the method by Varcheie et al. as shown in Table 8. Same conclusion can be made to our TPR values, which are higher for the tested videos. It shows that in the presence of sudden illumination change, shadow noise and colour similarity between foreground object and background, our algorithm performed better than the method by Varcheie et al. For the FPR values, Varcheie et al.'s method produced a better result for video 4 only compared to our algorithm. This is because our algorithm detected more foreground pixels, especially in challenging situations. Thus, more false positive is generated but the number is kept at the minimum through our shadow removal process. Basically, the method by Varcheie et al. will suffer the same problem as MoG but with reduced false detection. Some output samples of the algorithm by Varcheie et al. can be found in Figure 16.
9. Conclusions
We have presented a novel approach to enhance the robustness and accuracy of foreground detection. The integrated algorithm has been tested and proven to be robust to (1) colour similarity between background and foreground objects; (2) shadows and afterimages noise; and (3) sudden and gradual illumination changes. The main novelties of the algorithm are the introduction of 2-stage mask for grey world algorithm, probabilistic approach to edge-based background modelling and extended CRF shadows removal. Our algorithm is suitable to be applied in systems that require robust foreground detection such as face recognition, people counting, traffic monitoring and robotic vision. This work can be further improved in the future by using faster processor such as Field Programmable Gate Array (FPGA) []. Moreover, a more integrated modelling can be used to reduce the redundancy in some of the detections.
Acknowledgments
The authors would like to acknowledge the funding from Universiti Kebangsaan Malaysia (OUP/2012/181).
References
- Li, L.; Huang, W.; Gu, I.Y.H.; Tian, Q. Foreground Object Detection from Videos Containing Complex Background. Proceedings of the 11th ACM International Conference on Multimedia, Berkeley, CA, USA, 2–8 November 2003; pp. 2–10.
- Stauffer, C.; Grimson, W.E.L. Adaptive Background Mixture Models for Real-Time Tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 1999, Fort Collins, CO, USA, 23–25 June 1999; 2, p. 252.
- Wang, Y. Foreground and Shadow Detection Based on Conditional Random Field. Proceedings of the International Conference Computer Analysis of Images and Patterns, Vienna, Austria, 27–29 August 2007.
- Zulkifley, M.A. Topics in Robust Video Analytics (submitted). Ph.D. Thesis, University of Melbourne, Melbourne, Austrilia, 2012. [Google Scholar]
- Jimenez-Hernandez, H. Background subtraction approach based on independent component analysis. Sensors 2010, 10, 6092–6114. [Google Scholar]
- Buchsbaum, G. A spatial processor model for object colour perception. J. Franklin Inst. 1980, 310, 1–26. [Google Scholar]
- Renno, J.P.; Makris, D.; Ellis, T.; Jones, G.A. Application and Evaluation of Colour Constancy in Visual Surveillance. Proceedings of the 2nd Joint IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, 15–16 October 2005; Beijing, China; pp. 301–308.
- Lee, Y.S.; Chung, W.Y. Visual sensor based abnormal event detection with moving shadow removal in home healthcare applications. Sensors 2012, 12, 573–584. [Google Scholar]
- Varcheie, P.D.Z.; Sills-Lavoie, M.; Bilodeau, G.A. A multiscale region-based motion detection and background subtraction algorithm. Sensors 2010, 10, 1041–1061. [Google Scholar]
- Ridder, C.; Munkelt, O.; Kirchner, H. Adaptive Background Estimation and Foreground Detection Using Kalman-Filtering. Proceedings of the International Conference on Recent Advance in Mechatronics, Istanbul, Turkey, 14–16 August 1995; 1, pp. 193–199.
- Wang, C.; Liao, M.; Li, X. Ship detection in SAR image based on the alpha-stable distribution. Sensors 2008, 8, 4948–4960. [Google Scholar]
- Bozzoli, M.; Cinque, L.; Sangineto, E. A Statistical Method for People Counting in Crowded Environments. Proceedings of the 14th International Conference on Image Analysis and Processing 2007, Modena, Italy, 10–14 September 2007; pp. 506–511.
- Yu, S.; Chen, X.; Sun, W.; Xie, D. A Robust Method for Detecting and Counting People. Proceedings of the International Conference on Audio, Language and Image Processing, Shanghai, China, 7–9 July 2008; pp. 1545–1549.
- Tao, J.; Tan, Y.P. Color Appearance-Based Approach to Robust Tracking and Recognition of Multiple People. Proceedings of the 2003 Joint Conference of the 4th International Conference on Information, Communications and Signal Processing and the 4th Pacific Rim Conference on Multimedia, Singapore, 15–18 December 2003; 1, pp. 95–99.
- Verges-Llahi, J.; Tarrida, A.; Sanfeliu, A. New Approaches for Colour Histogram Adaptation in Face Tracking Tasks. Proceedings of the 16th International Conference on Pattern Recognition 2002, Quebec City, QC, Canada, 11–15 August 2002; 1, pp. 381–384.
- Li, L.; Huang, W.; Gu, I.Y.H.; Tian, Q. Foreground Object Detection in Changing Background Based on Color Co-Occurrence Statistics. Proceedings of the 6th IEEE Workshop on Applications of Computer Vision 2002, Orlando, FL, USA, 3–4 December 2002; pp. 269–274.
- Zhao, Q.; Tao, H. Object Tracking Using Color Correlogram. Proceedings of the 2nd Joint IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005; pp. 263–270.
- Viertl, R.; Trutschnig, W. Fuzzy Histograms and Fuzzy Probability Distributions; Forschungs-bericht SM-2006-1; Vienna University of Technology: Vienna, Austria, 2006. [Google Scholar]
- Huaifeng, Z.; Wenjing, J.; Xiangjian, H.; Qiang, W. Modified Color Ratio Gradient. Proceedings of the IEEE 7th Workshop on Multimedia Signal Processing, Shanghai, China, 30 October–2 November 2005; pp. 1–4.
- Haritaoglu, I.; Harwood, D.; Davis, L.S. W4: Who? When? Where? What? A Real Time System for Detecting And Tracking People. Proceedings of the 3rd IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 222–227.
- Barandiaran, J.; Murguia, B.; Boto, F. Real-Time People Counting Using Multiple Lines. Proceedings of the 9th International Workshop on Image Analysis for Multimedia Interactive Services, Klagenfurt, Austria, 7–9 May 2008; pp. 159–162.
- Hsu, W.; Chua, S.T.; Pung, K.H. An Integrated Color-Spatial Approach to Content-Based Image Retrieval. Proceedings of the 3rd ACM International Conference on Multimedia, San Francisco, CA, USA, 5–9 November 1995; pp. 305–313.
- Kumar, S.; Hebert, M. Discriminative Fields for Modelling Spatial Dependencies in Natural Images. Proceedings of the 17th Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–13 December 2003.
- Paragios, N.; Ramesh, V. A MRF-Based Approach for Real-Time Subway Monitoring. Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; 1, pp. 1034–1040.
- Zhao, Y.; Gong, H.; Lin, L.; Jia, Y. Spatio-Temporal Patches for Night Background Modeling by Subspace Learning. Proceedings of the 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4.
- Pless, R. Spatio temporal background models for outdoor surveillance. J. Appl. Signal Process. 2005, 14, 2281–2291. [Google Scholar]
- Kamijo, S.; Ikeuchi, K.; Sakauchi, M. Segmentations of Spatio-Temporal Images by Spatio-Temporal Markov Random Field Model. In Energy Minimization Methods in Computer Vision and Pattern Recognition; Springer: Berlin, Heidelberg, Germany, 2001; pp. 298–313. [Google Scholar]
- Wang, Y.; Loe, K.F.; Wu, J.K. A dynamic conditional random field model for foreground and shadow segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 279–289. [Google Scholar]
- Cubber, G.D.; Sahli, H.; Ping, H.; Colon, E. A Colour Constancy Approach for Illumination Invariant Colour Target Tracking. Proceedings of the IARP Workshop on Robots for Humanitarian Demining, Vienna, Austria, 3–5 November 2002; pp. 63–68.
- Nayak, A.; Chaudhuri, S. Self-Induced Color Correction for Skin Tracking under Varying Illumination. Proceedings of the International Conference on Image Processing 2003, Barcelona, Spain, 14–18 September 2003; pp. 1009–1012.
- Finlayson, G.D.; Schiele, B.; Crowley, J.L. Comprehensive Colour Image Normalization. Proceedings of the 5th European Conference on Computer Vision (ECCV '98), Freiburg, Germany, 2–6 June 1998; pp. 475–490.
- Ebner, M. Combining White-Patch Retinex and the Gray World Assumption to Achieve Color Constancy for Multiple Illuminants. Proceedings of the DAGM-Symposium, Magdeburg, Germany, 10–12 September 2003; pp. 60–67.
- Zulkifley, M.A.; Moran, B. Enhancement of Robust Foreground Detection through Masked Grey World and Color Co-Occurrence Approach. Proceedings of the 3rd IEEE International Conference on Computer Science and Information Technology, Chengdu, China, 9–11 July 2010; 4, pp. 131–136.
- Zulkifley, M.A.; Moran, B. Colour Co-Occurrence and Edge Based Background Modelling with Conditional Random Field Shadow Removal. Proceedings of the 3rd IEEE International Conference on Computer Science and Information Technology, Chengdu, China, 9–11 July 2010; 4, pp. 137–141.
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking: A survey. ACM Comput. Surv. 2006, 38. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E. A 3 × 3 Isotropic Gradient Operator for Image Processing. In Pattern Classification and Scene Analysis; Sobel, I., Feldman, G., Eds.; Wiley: New York, NY, USA, 1973; pp. 271–272. [Google Scholar]
- Bradski, G.; Kaehler, A. Learning OpenCV; O'Reilly Media: Sebastopol, CA, USA, 2008. [Google Scholar]
- Rodriguez-Gomez, R.; Fernandez-Sanchez, J.E.; Diaz, J.; Ros, E. FPGA implementation for realtime background subtraction based on horprasert model. Sensors 2012, 12, 585–611. [Google Scholar]









© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).