The “Dark Side” of Food Stuff Proteomics: The CPLL-Marshals Investigate


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Nutraceutical and Functional Foods
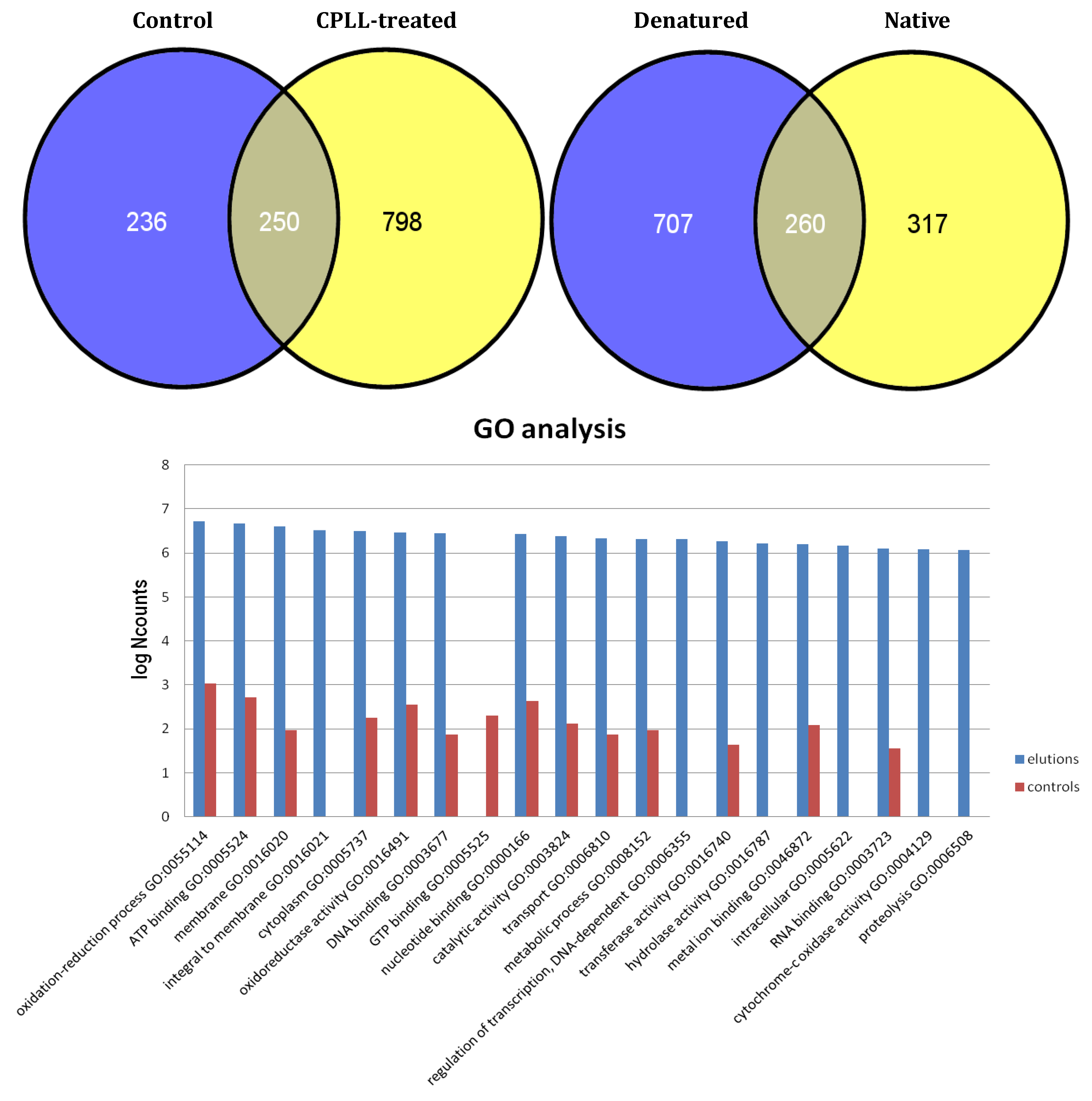
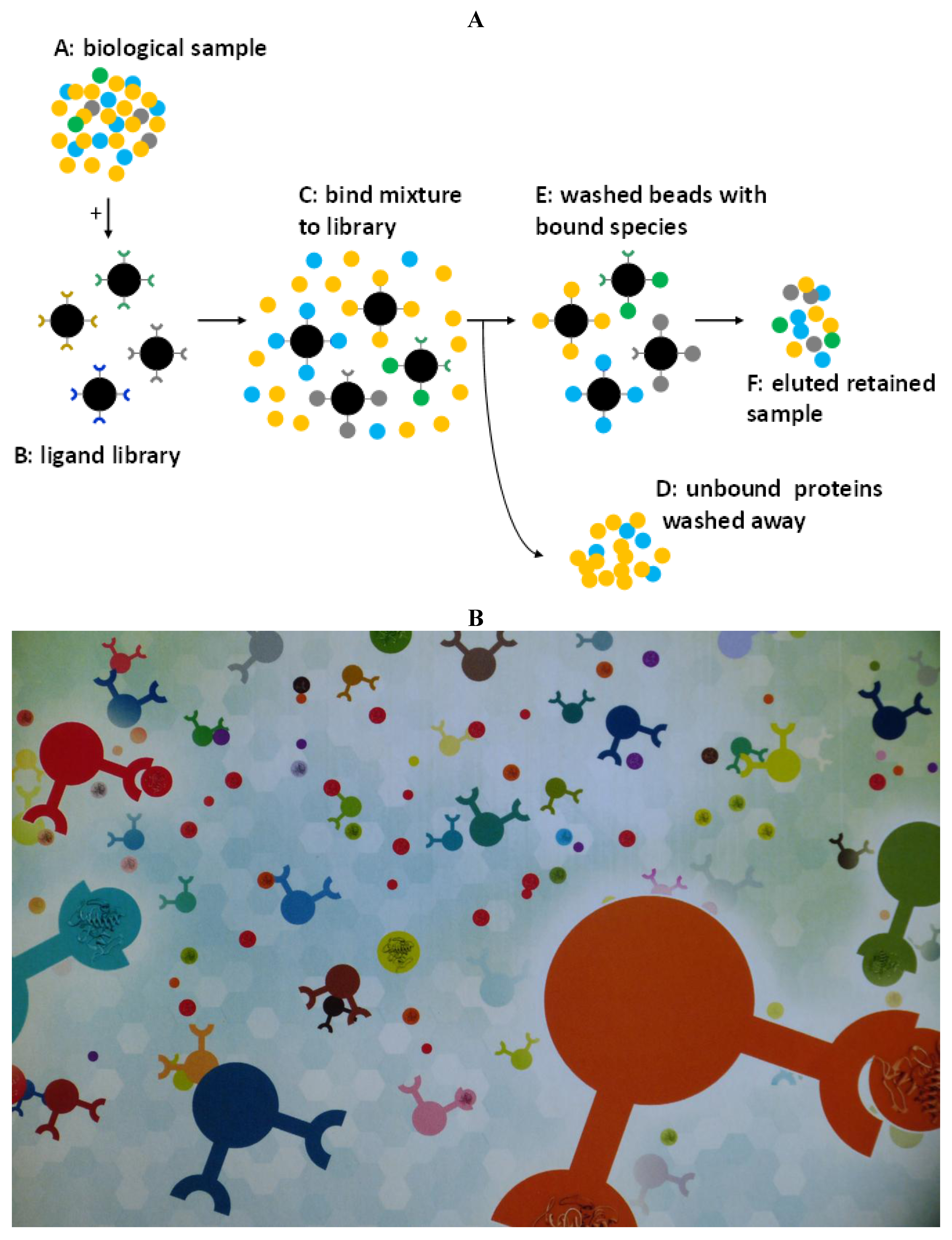
3. Separation Science at Work: Combinatorial Peptide Ligand Libraries (CPLL)
- to detect trace proteins/peptides exhibiting negative effects on health (e.g., allergens);
- to detect trace proteins/peptides displaying positive effects on health (e.g., anti-microbial, anti-hypertensive and anti-oxidant activities);
- to expose frauds in commercial food products and provide a proof of genuineness for “correct” commercial foods, as found in supermarkets.
4. Analysis of Animal Food Stuff
5. Analysis of Vegetable and Fruit Food Stuff
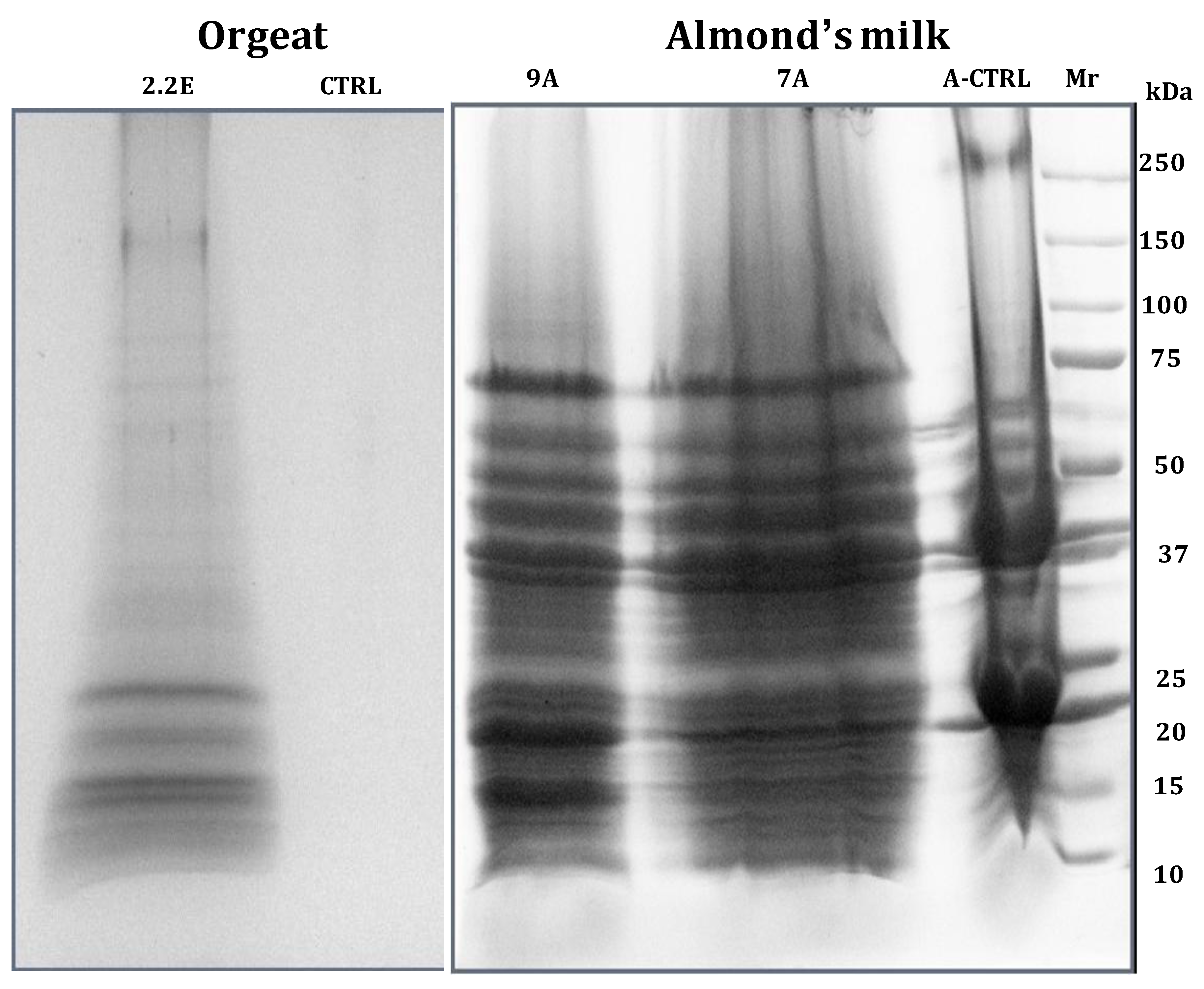
6. Proteome Analysis of Non-Alcoholic Beverages
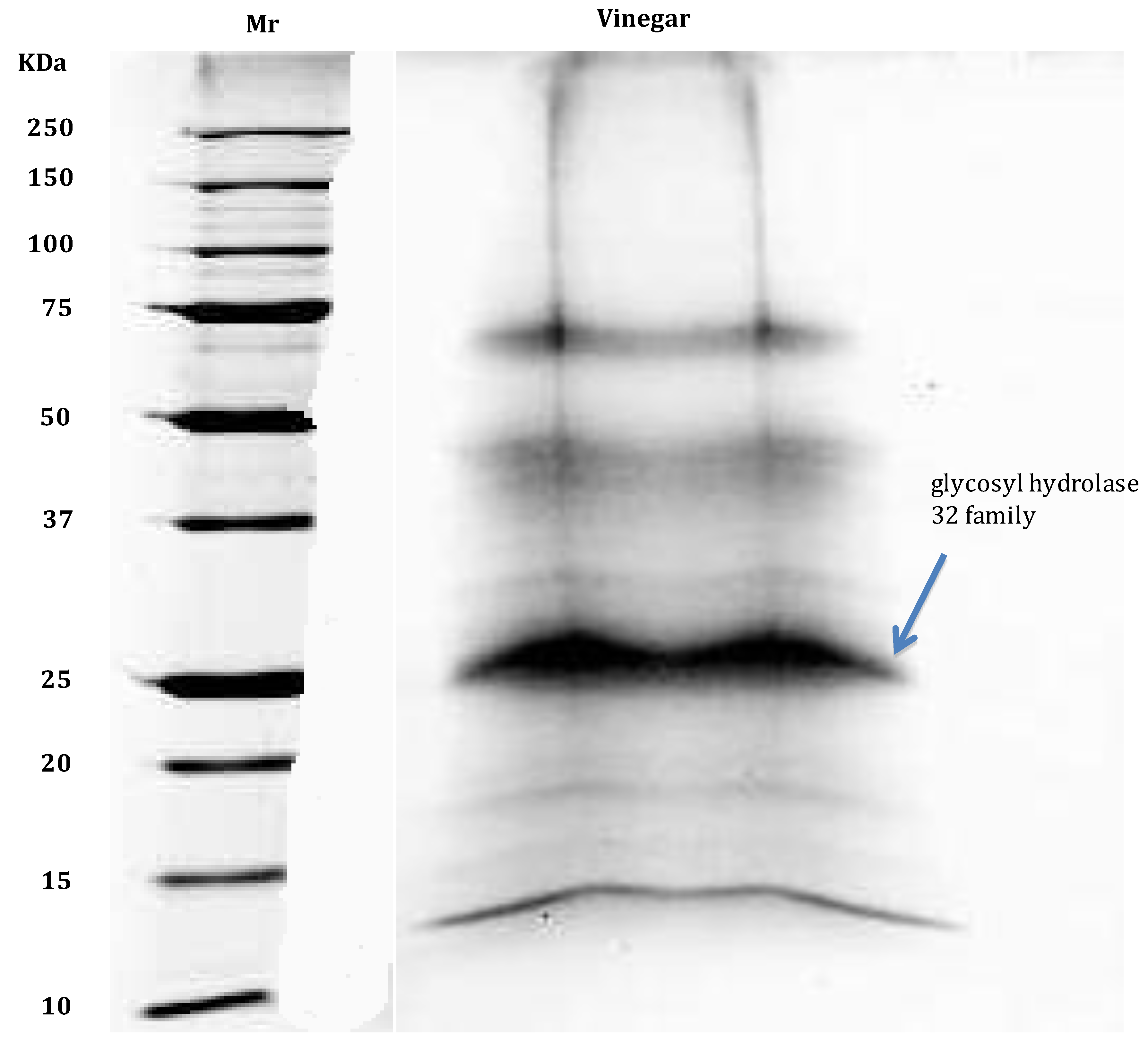
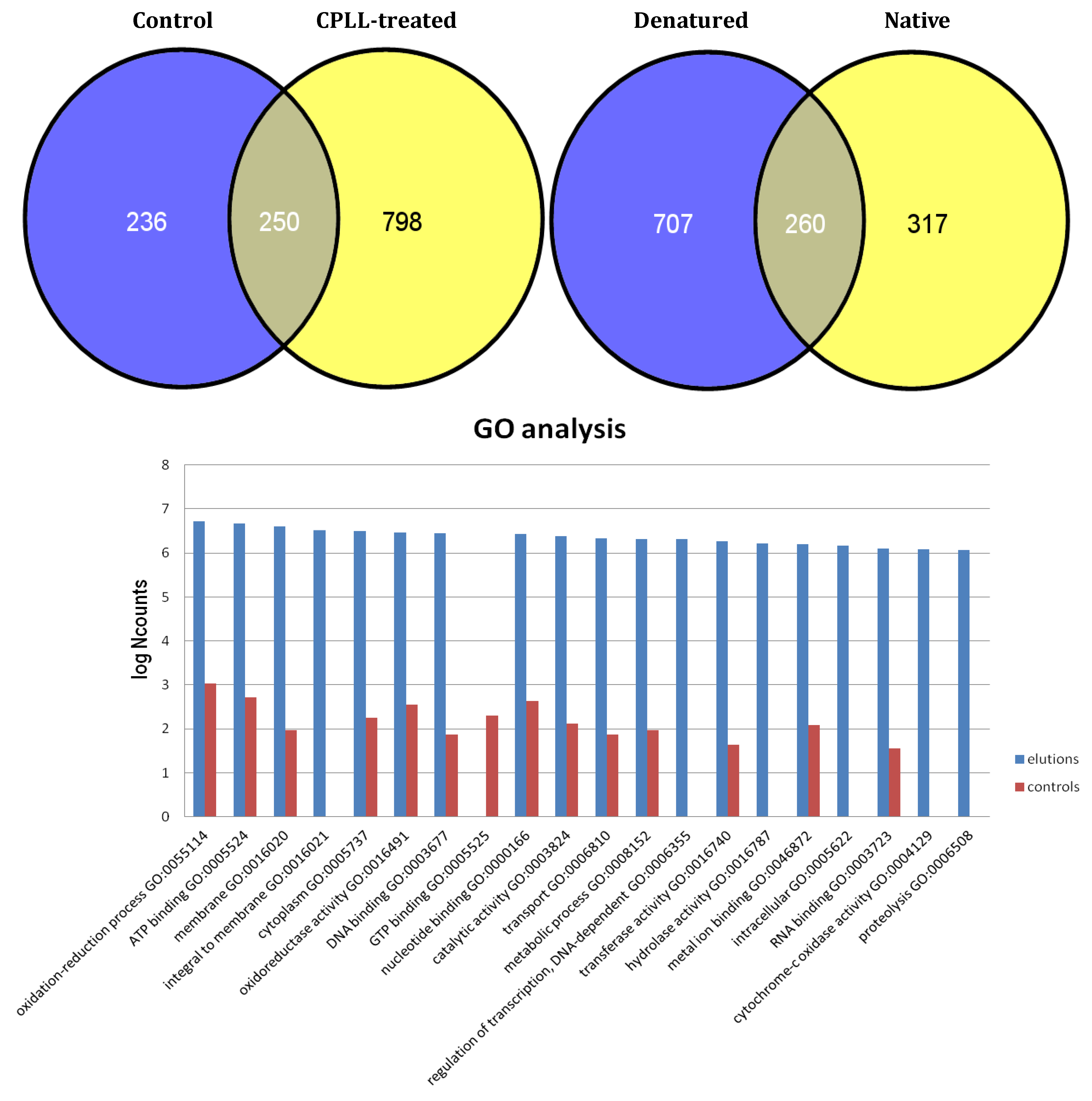
7. Proteome Analysis of Alcoholic Beverages
8. Conclusions: Mammalian versus Plant Proteomics
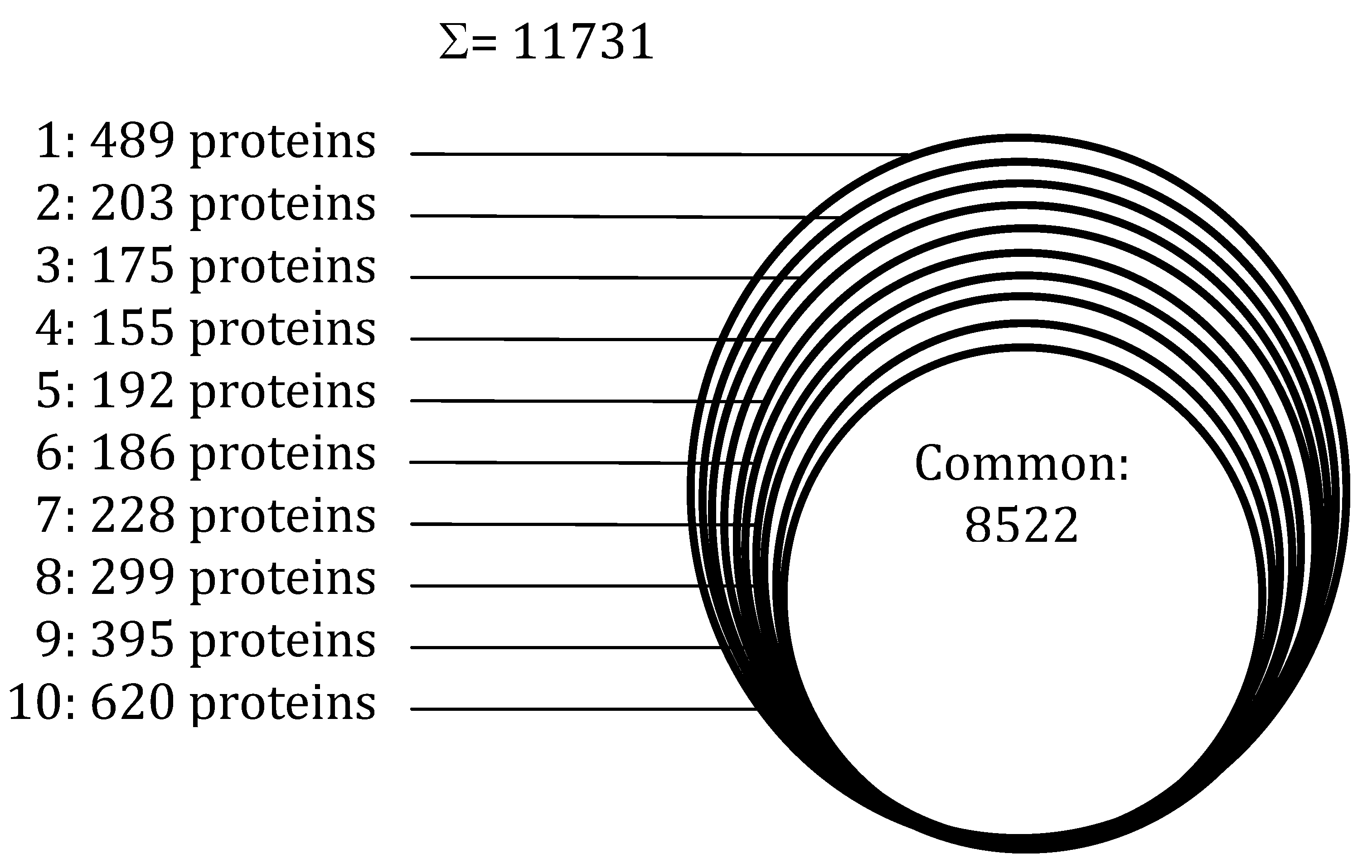
Conflicts of Interest
References
- Anderson, N.L.; Anderson, N.G. The human plasma proteome: History, character, and diagnostic prospects. Mol. Cell. Proteomics 2002, 1, 845–867. [Google Scholar] [CrossRef]
- Boschetti, E.; Righetti, P.G. Low-Abundance Protein Discovery: State of the Art and Protocols; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Brown, L.R. Full Planet, Empty Plates. The New Geopolitics of Food Scarcity; Earth Policy Institute: Washington, DC, USA, 2012. [Google Scholar]
- Wu, X.; Schuss, A.G. Mitigation of inflammation with foods. J. Agric. Food Chem. 2012, 60, 6703–6917. [Google Scholar] [CrossRef]
- Seiber, J.N.; Kleinschmidt, L. From detrimental to beneficial constituents of foods. J. Agric. Food Chem. 2012, 60, 6644–6647. [Google Scholar] [CrossRef]
- Tomàs-Barberàn, F.A.; Somoza, V.; Finley, J. Food bioactives research and the Journal of Agricultural and Food Chemistry. J. Agric. Food Chem. 2012, 60, 6641–6643. [Google Scholar] [CrossRef]
- Bagchi, D.; Lau, F.C.; Bagchi, M. Genomics, Proteomics and Metabolomics in Nutraceutical and Functional Foods; Wiley-Blackwell: Ames, IA, USA, 2010. [Google Scholar]
- Ganesh, V.; Hettiarachchy, N.S. Nutriproteomics: A promising tool to link diet and diseases in nutritional research. Biochim. Biophys. Acta 2012, 1824, 1107–1117. [Google Scholar]
- Kussmann, M.; Panchaud, A.; Affolter, M. Proteomics in nutrition: Status quo and outlook for biomarkers and bioactives. J. Proteome Res. 2010, 9, 4876–4887. [Google Scholar] [CrossRef]
- Gorduza, E.V.; Indrei, L.L.; Gorduza, V.M. Nutrigenomics in the post-genomic era. Rev. Med. Chir. Soc. Med. Nat. Isai 2008, 112, 152–164. [Google Scholar]
- Del Chierico, F.; Vernocchi, P.; Bonizzi, L.; Carsetti, R.; Castellazzi, A.M.; Dallapiccola, B.; de Vos, W.; Guerzoni, M.E.; Manco, M.; Marseglia, G.L.; et al. Early-life gut microbiota under physiological and pathological conditions: The central role of combined meta-omics-based approaches. J. Proteomics 2012, 75, 4580–4587. [Google Scholar] [CrossRef]
- Testori Coggi, P. EU rules on food information to consumers. Nutrafoods 2012, 11, 75–80. [Google Scholar] [CrossRef]
- Pieper, R.; Gatlin, C.L.; Makusky, A.J.; Russo, P.S.; Schatz, C.R.; Miller, S.S.; Su, Q.; McGrath, A.M.; Estock, M.A.; Parmar, P.P.; et al. The human serum proteome: Display of nearly 3700 chromatographically separated protein spots on two-dimensional electrophoresis gels and identification of 325 distinct proteins. Proteomics 2003, 3, 1345–1364. [Google Scholar] [CrossRef]
- Fang, X.; Zhang, W.W. Affinity separation and enrichment methods in proteomic analysis. J. Proteomics 2008, 71, 208–303. [Google Scholar]
- Tu, C.; Rudnick, P.A.; Martinez, M.Y.; Cheek, K.L.; Stein, S.E.; Slebos, R.J.; Liebler, D.C. Depletion of abundant plasma proteins and limitations of plasma proteomics. J. Proteome Res. 2010, 9, 4982–4991. [Google Scholar] [CrossRef]
- Shen, Y.; Kim, J.; Strittmatter, E.F.; Jacobs, J.M.; Camp, D.G., 2nd; Fang, R.; Tolié, N.; Moore, R.J.; Smith, R.D. Characterization of the human blood plasma proteome. Proteomics 2005, 5, 4034–4045. [Google Scholar] [CrossRef]
- Widjaja, I.; Naumann, K.; Roth, U.; Wolf, N.; Mackey, D.; Dangl, J.L.; Scheel, D.; Lee, J. Combining subproteome enrichment and RuBisCO depletion enables identification of low abundance proteins differentially regulated during plant defense. Proteomics 2009, 9, 138–147. [Google Scholar] [CrossRef]
- Boschetti, E.; Lomas, L.; Citterio, A.; Righetti, P.G. Romancing the “hidden proteome”, Anno Domini two zero zero six. J. Chromatogr. A 2007, 1153, 277–290. [Google Scholar]
- Righetti, P.G.; Boschetti, E.; Lomas, L.; Citterio, A. Protein Equalizer technology: The quest for a “democratic proteome”. Proteomics 2006, 6, 3980–3992. [Google Scholar] [CrossRef]
- Righetti, P.G.; Boschetti, E.; Kravchuk, A.V.; Fasoli, E. The proteome buccaneers: How to unearth your treasure chest via combinatorial peptide ligand libraries. Expert Rev. Proteomics 2010, 7, 373–385. [Google Scholar] [CrossRef]
- Agrawal, G.K.; Sarkar, A.; Righetti, P.G.; Pedreschi, R.; Carpentier, S.; Wang, T.; Barkla, B.J.; Kohli, A.; Ndimba, B.K.; Bykova, N.V.; et al. A decade of plant proteomics and mass spectrometry: Translation of technical advancements to food security and safety issues. Mass Spectrom. Rev. 2013, 32, 335–365. [Google Scholar] [CrossRef]
- Boggess, M.V.; Lippolis, J.D.; Hurkman, W.J.; Fagerquist, C.K.; Briggs, S.P.; Gomes, A.V.; Righetti, P.G.; Bala, K. The need for agriculture phenotyping: “Moving from genotype to phenotype”. J. Proteomics 2013, 93, 20–39. [Google Scholar] [CrossRef]
- Jorrín-Novo, J.; Valledor Gonzalez, L. Special Issue: Translational Plant Proteomics. J. Proteomics. 2013, 93, pp. 1–368. Available online: http://www.sciencedirect.com/science/journal/18743919/93 (accessed on 4 February 2014).
- Nakamura, R.; Teshima, R. Proteomics-based allergen analysis in plants. J. Proteomics 2013, 93, 40–49. [Google Scholar] [CrossRef]
- Lubica Uvackova, L.; Skultety, L.; Bekesova, S.; McClain, S.; Hajduch, M. The MSE-proteomic analysis of gliadins and glutenins in wheat grain identifies and quantifies proteins associated with celiac disease and baker’s asthma. J. Proteomics 2013, 93, 65–73. [Google Scholar] [CrossRef]
- Agrawal, G.K.; Timperio, A.M.; Zolla, L.; Bansal, V.; Shukla, R.; Rakwal, R. Biomarker discovery and applications for foods and beverages: Proteomics to nanoproteomics. J. Proteomics 2013, 93, 74–92. [Google Scholar] [CrossRef]
- Ribeiro Demartini, D.; Pasquali, G.; Regina Carlini, C. An overview of proteomics approaches applied to biopharmaceuticals and cyclotides research. J. Proteomics 2013, 93, 224–233. [Google Scholar] [CrossRef]
- D’Ambrosio, C.; Arena, S.; Scaloni, A.; Guerrier, L.; Boschetti, E.; Mendieta, M.E.; Citterio, A.; Righetti, P.G. Exploring the chicken egg white proteome with combinatorial peptide ligand libraries. J. Proteome Res. 2008, 7, 3461–3474. [Google Scholar] [CrossRef]
- Farinazzo, A.; Restuccia, U.; Bachi, A.; Guerrier, L.; Fortis, F.; Boschetti, E.; Fasoli, E.; Citterio, A.; Righetti, P.G. Chicken egg yolk cytoplasmic proteome, mined via combinatorial peptide ligand libraries. J. Chromatogr. A 2009, 1216, 1241–1252. [Google Scholar]
- Mann, K. The chicken egg white proteome. Proteomics 2007, 7, 3558–3568. [Google Scholar] [CrossRef]
- Mann, K.; Mann, M. The chicken egg yolk plasma and granule proteomes. Proteomics 2008, 8, 178–191. [Google Scholar] [CrossRef]
- D’Alessandro, A.; Righetti, P.G.; Fasoli, E.; Zolla, L. The egg white and yolk interactomes as gleaned from extensive proteomic data. J. Proteomics 2010, 73, 1028–1042. [Google Scholar] [CrossRef]
- D’Amato, A.; Bachi, A.; Fasoli, E.; Boschetti, E.; Peltre, G.; Sénéchal, H.; Righetti, P.G. In-depth exploration of cows whey proteome via combinatorial peptide ligand libraries. J. Proteome Res. 2009, 8, 3925–3936. [Google Scholar] [CrossRef]
- Cunsolo, V.; Muccilli, V.; Fasoli, E.; Saletti, R.; Righetti, P.G.; Foti, S. Poppea’s bath liquor: The secret proteome of she-donkey’s milk. J. Proteomics 2011, 74, 2083–2099. [Google Scholar] [CrossRef]
- Le, A.; Barton, L.D.; Sanders, J.T.; Zhang, Q. Exploration of bovine milk proteome in colostral and mature whey using an ion-exchange approach. J. Proteome Res. 2011, 10, 692–704. [Google Scholar] [CrossRef]
- Nissen, A.; Bendixen, E.; Ingvartsen, K.L.; Røntved, C.M. In-depth analysis of low abundant proteins in bovine colostrum using different fractionation techniques. Proteomics 2012, 12, 2866–2878. [Google Scholar] [CrossRef]
- Bislev, S.L.; Deutsch, E.W.; Sun, Z.; Farrah, T.; Aebersold, R.; Moritz, R.L.; Bendixen, E.; Codrea, M.C. A Bovine Peptide Atlas of milk and mammary gland proteomes. Proteomics 2012, 12, 2895–2899. [Google Scholar] [CrossRef]
- Di Girolamo, F.; D’Amato, A.; Righetti, P.G. Assessment of the floral origin of honey via proteomic tools. J. Proteomics 2012, 75, 3688–3693. [Google Scholar] [CrossRef]
- Won, S.R.; Lee, D.C.; Ko, S.H.; Kim, J.W.; Rhee, H.I. Honey major protein characterization and its application to adulteration detection. Food Res. Int. 2008, 41, 952–956. [Google Scholar]
- Fasoli, E.; D’Amato, A.; Kravchuk, A.V.; Boschetti, E.; Bachi, A.; Righetti, P.G. Popeye strikes again: The deep proteome of spinach leaves. J. Proteomics 2011, 74, 127–136. [Google Scholar] [CrossRef]
- Esteve, C.; D’Amato, A.; Marina, M.L.; García, M.C.; Citterio, A.; Righetti, P.G. Identification of olive (Olea europaea) seed and pulp proteins by nLC-MS/MS via combinatorial peptide ligand libraries. J. Proteomics 2012, 75, 2396–2403. [Google Scholar] [CrossRef]
- Esteve, C.; Cañas, B.; Moreno-Gordaliza, E.; Del Rio, C.; García, M.C.; Marina, M.L. Identification of olive (Olea europaea) pulp proteins by matrix-assisted laser desorption/ionization time-of-flight mass spectrometry and nano-liquid chromatography tandem mass spectrometry. J. Agric. Food Chem. 2011, 59, 12093–12101. [Google Scholar]
- Esteve, C.; D’Amato, A.; Marina, M.L.; Concepción García, M.; Righetti, P.G. Identification of avocado (Persea americana) pulp proteins by nanoLC-MS/MS via combinational peptide ligand libraries. Electrophoresis 2012, 33, 2799–2805. [Google Scholar] [CrossRef]
- Sun, J.; Chu, Y.F.; Wu, X.; Liu, R.H. Antioxidant and antiproliferative activities of common fruits. J. Agric. Food Chem. 2002, 50, 7449–7454. [Google Scholar] [CrossRef]
- Saravanan, R.S.; Rose, J.K.C. A critical evaluation of sample extraction techniques for enhanced proteomic analysis of recalcitrant plant tissues. Proteomics 2004, 4, 2522–2532. [Google Scholar] [CrossRef]
- Esteve, C.; D’Amato, A.; Marina, M.L.; Concepción García, M.; Righetti, P.G. In-depth proteomic analysis of banana (Musa spp.) fruit with combinatorial peptide ligand libraries. Electrophoresis 2013, 34, 207–214. [Google Scholar] [CrossRef]
- Fasoli, E.; Righetti, P.G. The peel and pulp of mango fruit: A proteomic samba. Biochim. Biophys. Acta 2013, 1834, 2539–2545. [Google Scholar]
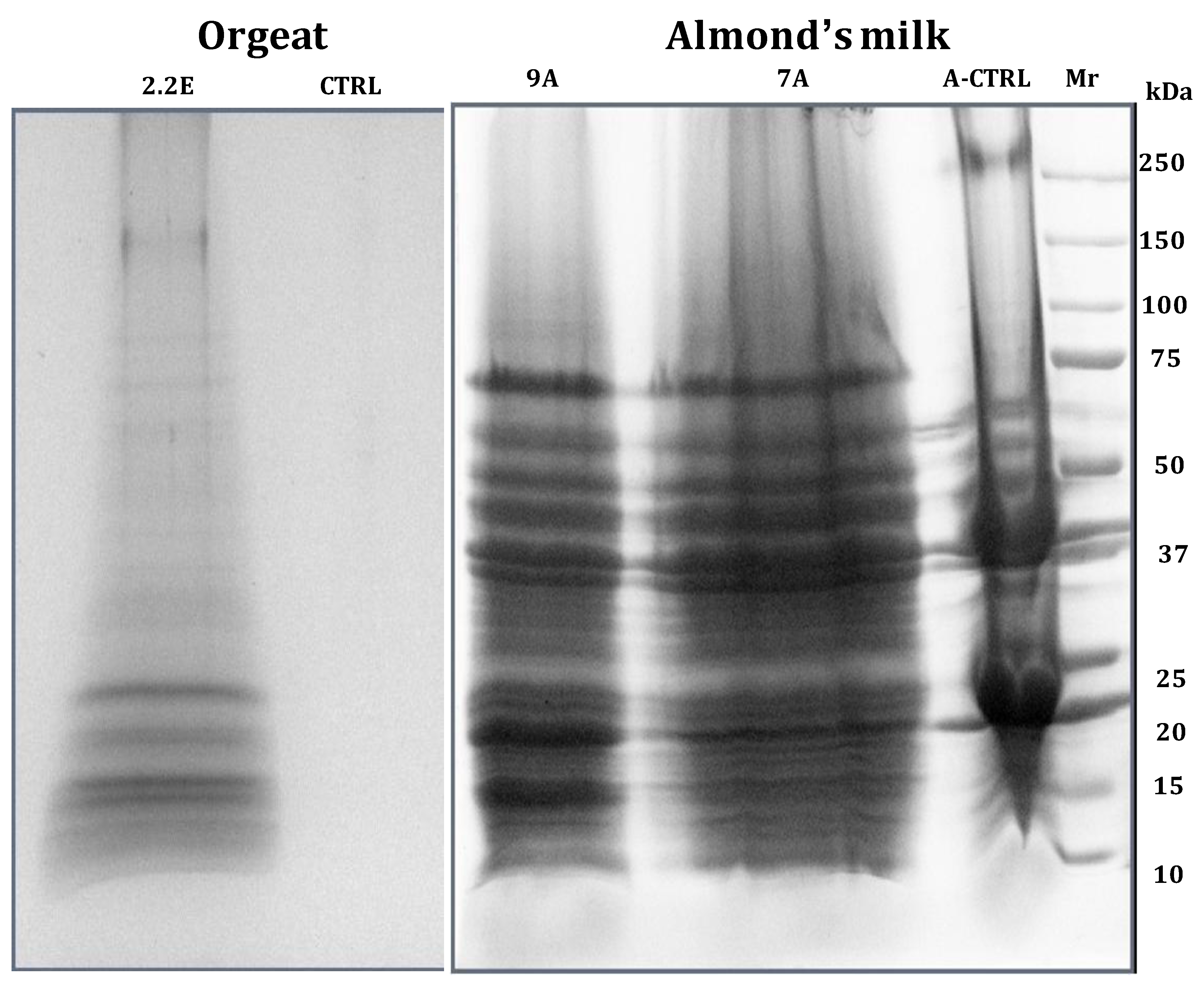
- Fasoli, E.; D’Amato, A.; Kravchuk, A.V.; Citterio, A.; Righetti, P.G. In-depth proteomic analysis of non-alcoholic beverages with peptide ligand libraries. I: Almond milk and orgeat syrup. J. Proteomics 2011, 74, 1080–1090. [Google Scholar] [CrossRef]
- D’Amato, A.; Fasoli, E.; Righetti, P.G. Harry Belafonte and the secret proteome of coconut milk. J. Proteomics 2012, 75, 914–920. [Google Scholar] [CrossRef]
- D’Amato, A.; Fasoli, E.; Kravchuk, A.V.; Righetti, P.G. going nuts for nuts? The trace proteome of a cola drink, as detected via combinatorial peptide ligand libraries. J. Proteome Res. 2011, 10, 2684–2686. [Google Scholar] [CrossRef]
- Fasoli, E.; D’Amato, A.; Citterio, A.; Righetti, P.G. Ginger rogers? No, Ginger Ale and its invisible proteome. J. Proteomics 2012, 75, 1960–1965. [Google Scholar] [CrossRef]
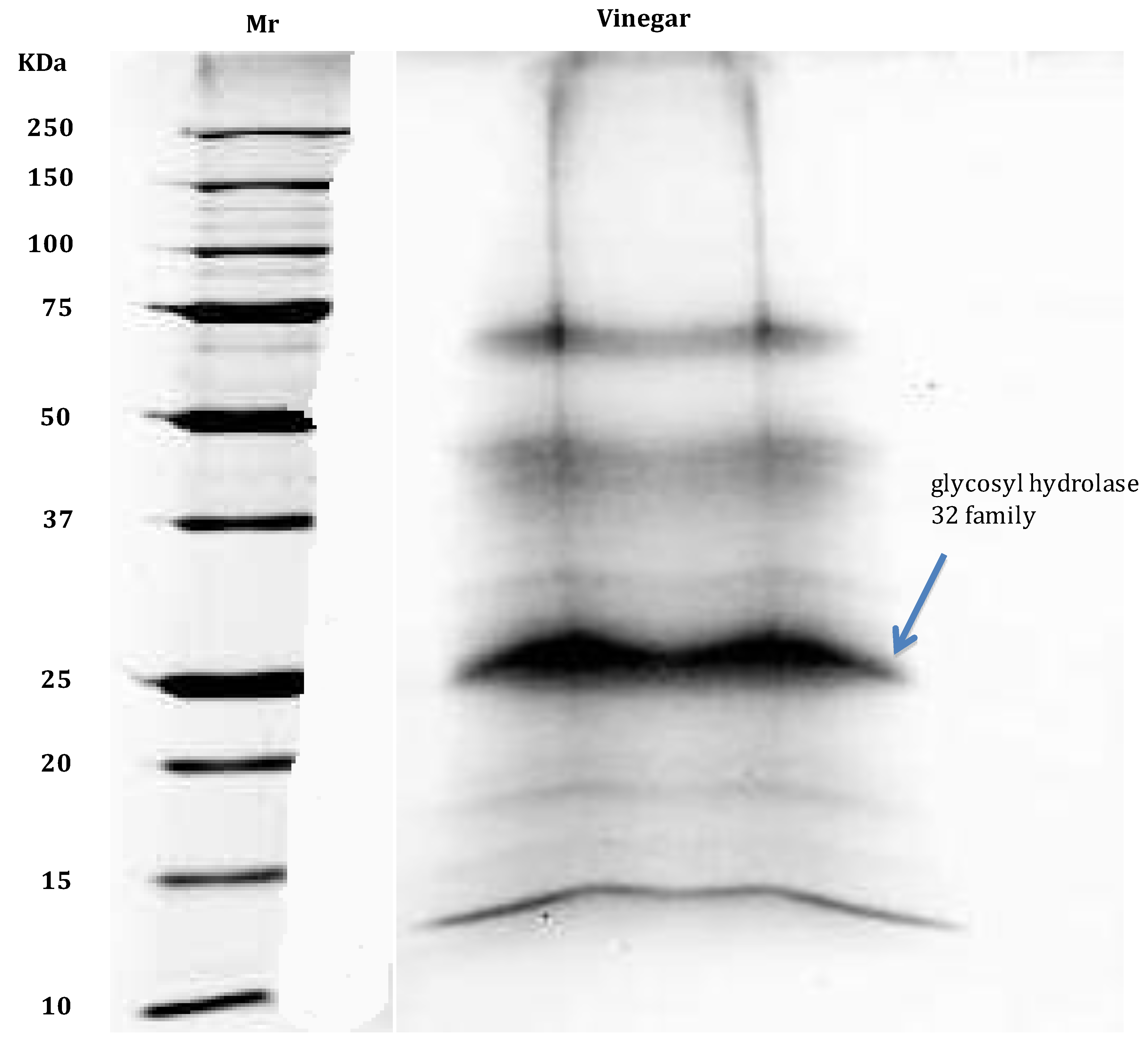
- Di Girolamo, F.; D’Amato, A.; Righetti, P.G. Horam nonam exclamavit: Sitio. The trace proteome of your daily vinegar. J. Proteomics 2011, 75, 718–724. [Google Scholar] [CrossRef]
- Cereda, A.; Kravchuk, A.V.; D’Amato, A.; Bachi, A.; Righetti, P.G. Proteomics of wine additives: Mining for the invisible via combinatorial peptide ligand libraries. J. Proteomics 2010, 73, 1732–1739. [Google Scholar] [CrossRef]
- Monaci, L.; Losito, I.; Palmisano, F.; Visconti, A. Identification of allergenic milk proteins markers in fined white wines by capillary liquid chromatography-electrospray ionization-tandem mass spectrometry. J. Chromatogr. A 2010, 1217, 4300–4305. [Google Scholar]
- Monaci, L.; Losito, I.; Palmisano, F.; Godula, M.; Visconti, A. Towards the quantification of residual milk allergens in caseinate-fined white wines using HPLC coupled with single-stage Orbitrap mass spectrometry. Food Addit. Contam. Part A Chem. Anal. Control Expo. Risk Assess. 2011, 28, 1304–1314. [Google Scholar] [CrossRef]
- Palmisano, G.; Antonacci, D.; Larsen, M.R. Glycoproteomic profile in wine: A “sweet” molecular renaissance. J. Proteome Res. 2010, 9, 6148–6159. [Google Scholar]
- D’Amato, A.; Fasoli, E.; Kravchuk, A.V.; Righetti, P.G. Mehercules, adhuc bacchus! The debate on wine proteomics continues. J. Proteome Res. 2011, 10, 3789–3801. [Google Scholar] [CrossRef]
- Cilindre, C.; Fasoli, E.; D’Amato, A.; Liger-Belair, G.; Righetti, P.G. It’s time to pop a cork on Champagne’s proteome! J. Proteomics 2014. submitted for publication. [Google Scholar]
- D’Amato, A.; Kravchuk, A.V.; Bachi, A.; Righetti, P.G. Noah’s nectar: The proteome content of a glass of red wine. J. Proteomics 2010, 73, 2370–2377. [Google Scholar] [CrossRef]
- Tolin, S.; Pasini, G.; Curioni, A.; Arrigoni, G.; Masi, A.; Mainente, F.; Simonato, B. Mass spectrometry detection of egg proteins in red wines treated with egg white. Food Control 2012, 23, 87–94. [Google Scholar] [CrossRef]
- Fasoli, E.; Aldini, G.; Regazzoni, L.; Kravchuk, A.V.; Citterio, A.; Righetti, P.G. Les Maîtres de l’Orge: The proteome content of your beer mug. J. Proteome Res. 2010, 9, 5262–5269. [Google Scholar] [CrossRef]
- Fasoli, E.; D’Amato, A.; Citterio, A.; Righetti, P.G. Anyone for an aperitif? Yes, but only a Braulio DOC with its certified proteome. J. Proteomics 2012, 75, 3374–3379. [Google Scholar] [CrossRef]
- Saez, V.; Fasoli, E.; D’Amato, A.; Simó-Alfonso, E.; Righetti, P.G. Artichoke and Cynar liqueur: Two (not quite) entangled proteomes. Biochim. Biophys. Acta 2013, 1834, 119–126. [Google Scholar] [CrossRef]
- Fasoli, E.; Colzani, M.; Aldini, G.; Citterio, A.; Righetti, P.G. Lemon peel and Limoncello liqueur: A proteomic duet. Biochim. Biophys. Acta 2013, 1834, 1484–1491. [Google Scholar]
- Geiger, T.; Wehner, A.; Schaab, C.; Cox, J.; Mann, M. Comparative proteomic analysis of eleven common cell lines reveals ubiquitous but varying expression of most proteins. Mol. Cell. Proteomics 2012, 11, M111–014050. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Righetti, P.G.; Fasoli, E.; D'Amato, A.; Boschetti, E. The “Dark Side” of Food Stuff Proteomics: The CPLL-Marshals Investigate. Foods 2014, 3, 217-237. https://doi.org/10.3390/foods3020217
Righetti PG, Fasoli E, D'Amato A, Boschetti E. The “Dark Side” of Food Stuff Proteomics: The CPLL-Marshals Investigate. Foods. 2014; 3(2):217-237. https://doi.org/10.3390/foods3020217
Chicago/Turabian StyleRighetti, Pier Giorgio, Elisa Fasoli, Alfonsina D'Amato, and Egisto Boschetti. 2014. "The “Dark Side” of Food Stuff Proteomics: The CPLL-Marshals Investigate" Foods 3, no. 2: 217-237. https://doi.org/10.3390/foods3020217
APA StyleRighetti, P. G., Fasoli, E., D'Amato, A., & Boschetti, E. (2014). The “Dark Side” of Food Stuff Proteomics: The CPLL-Marshals Investigate. Foods, 3(2), 217-237. https://doi.org/10.3390/foods3020217