
Radiation Hardened NULL Convention Logic Asynchronous Circuit Design

Abstract
:1. Introduction
2. Previous Work
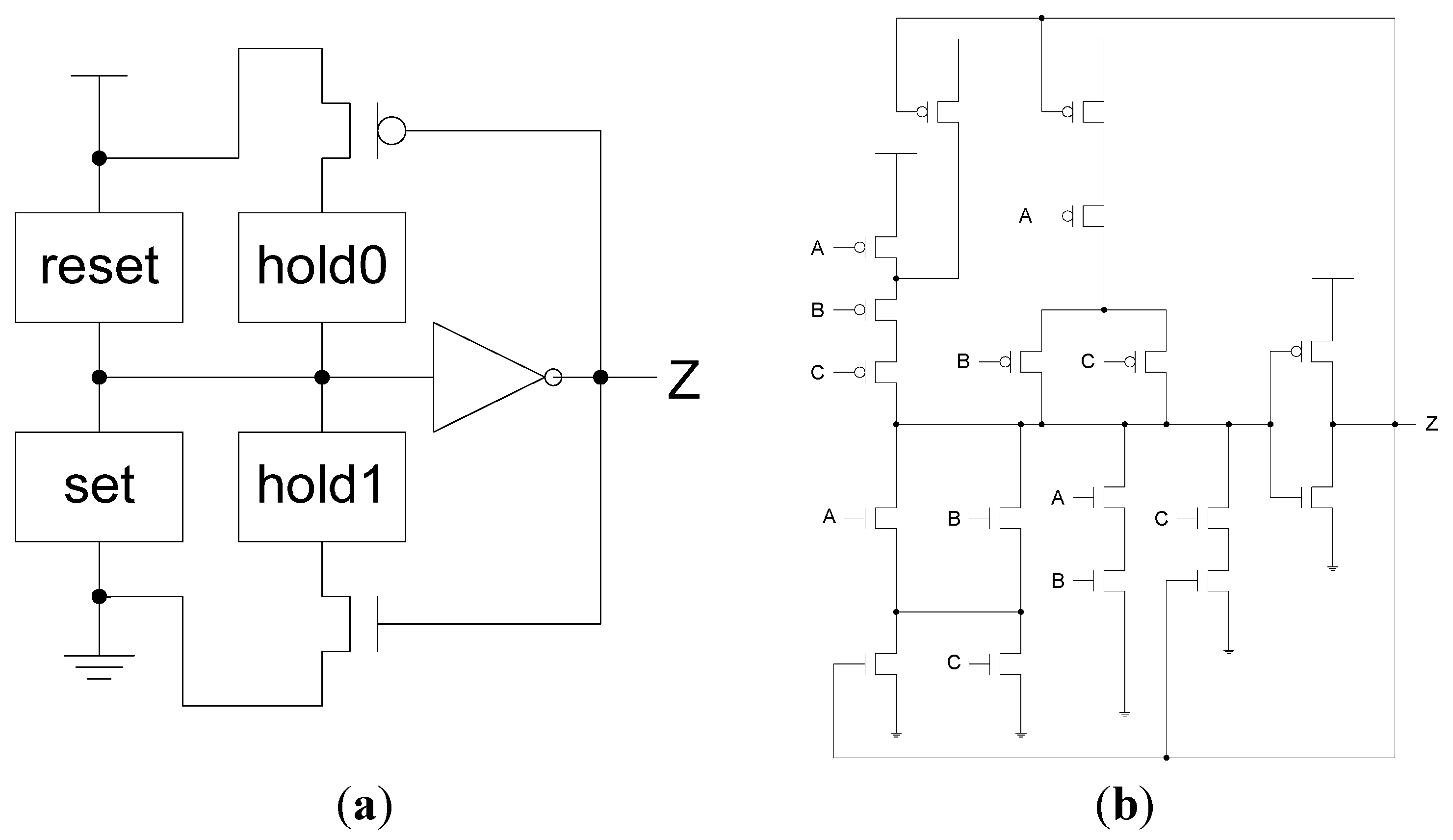
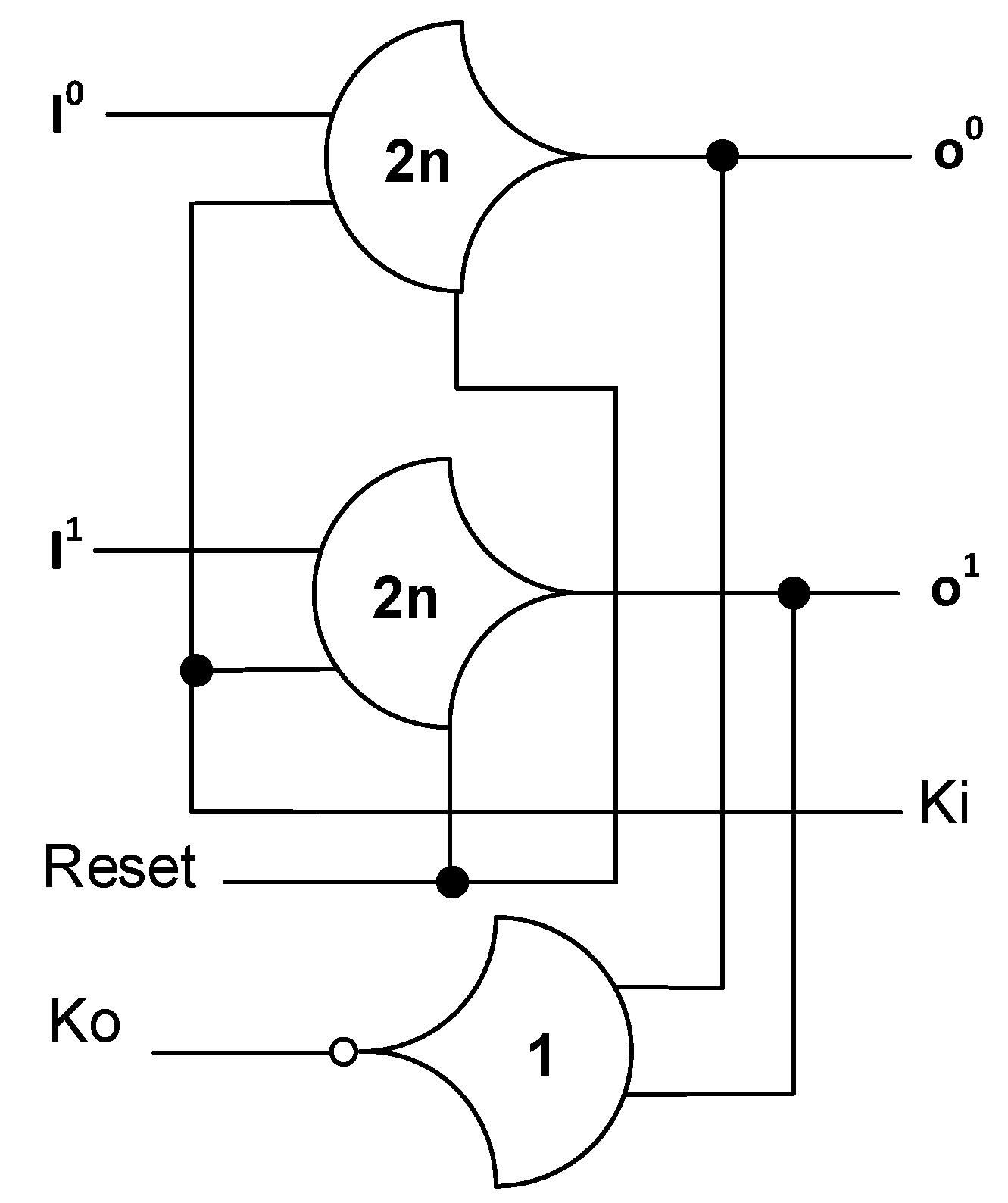
2.1. Introduction to NCL
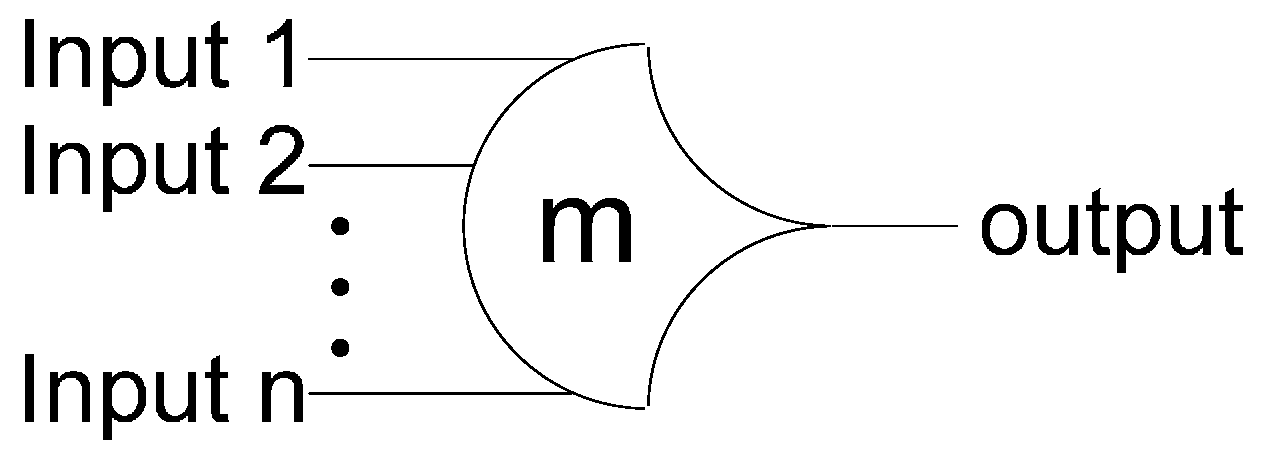
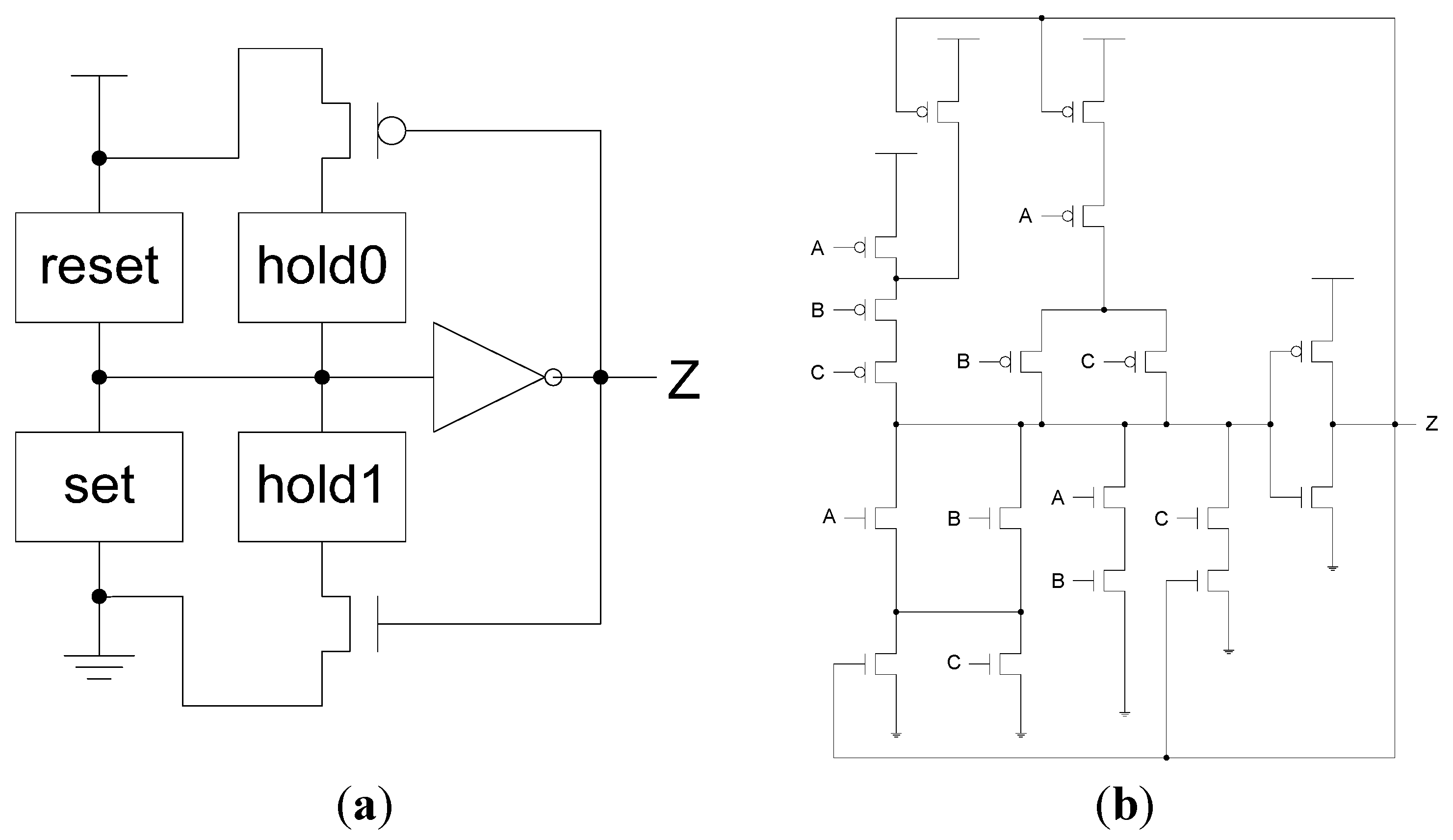


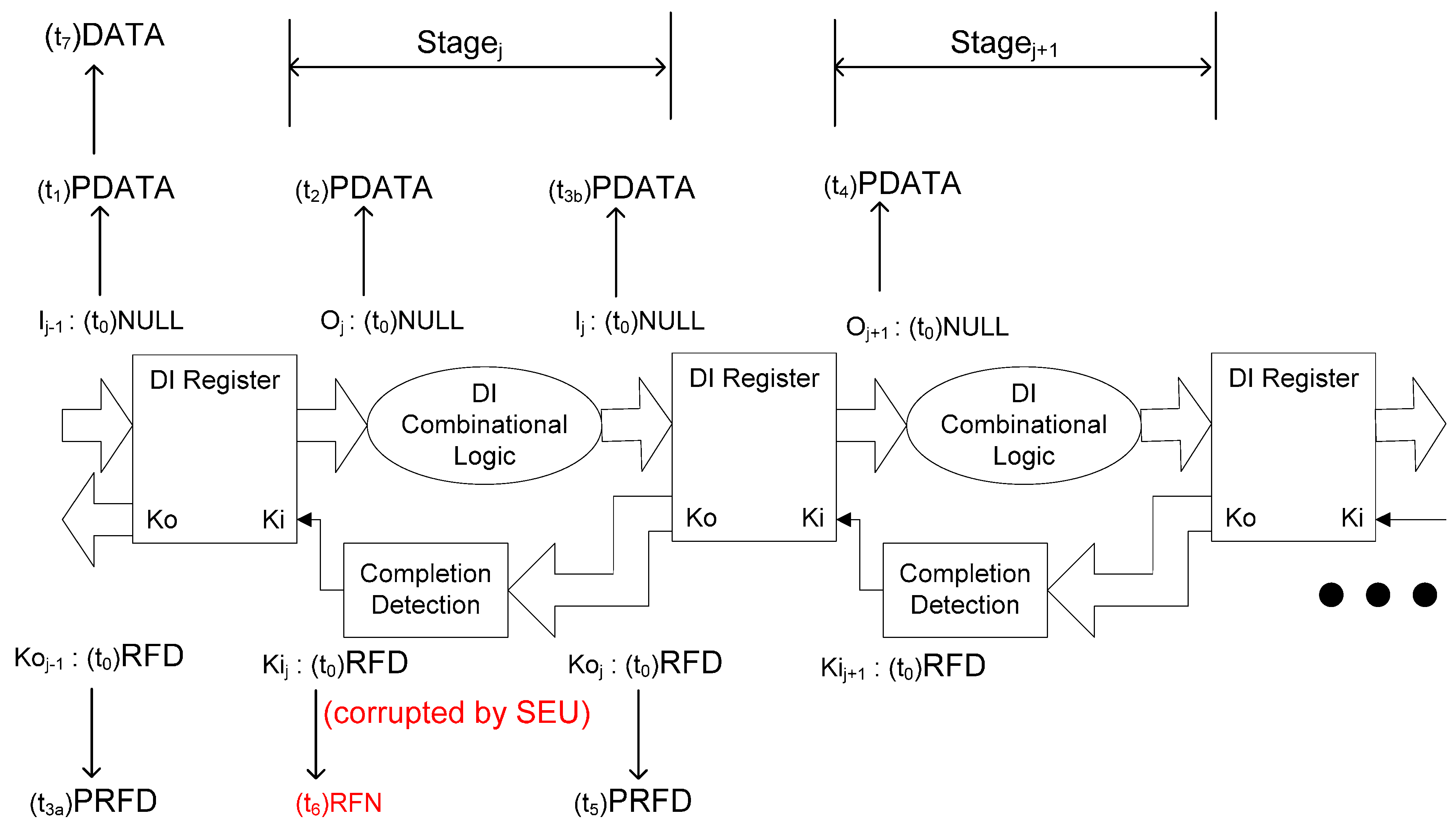
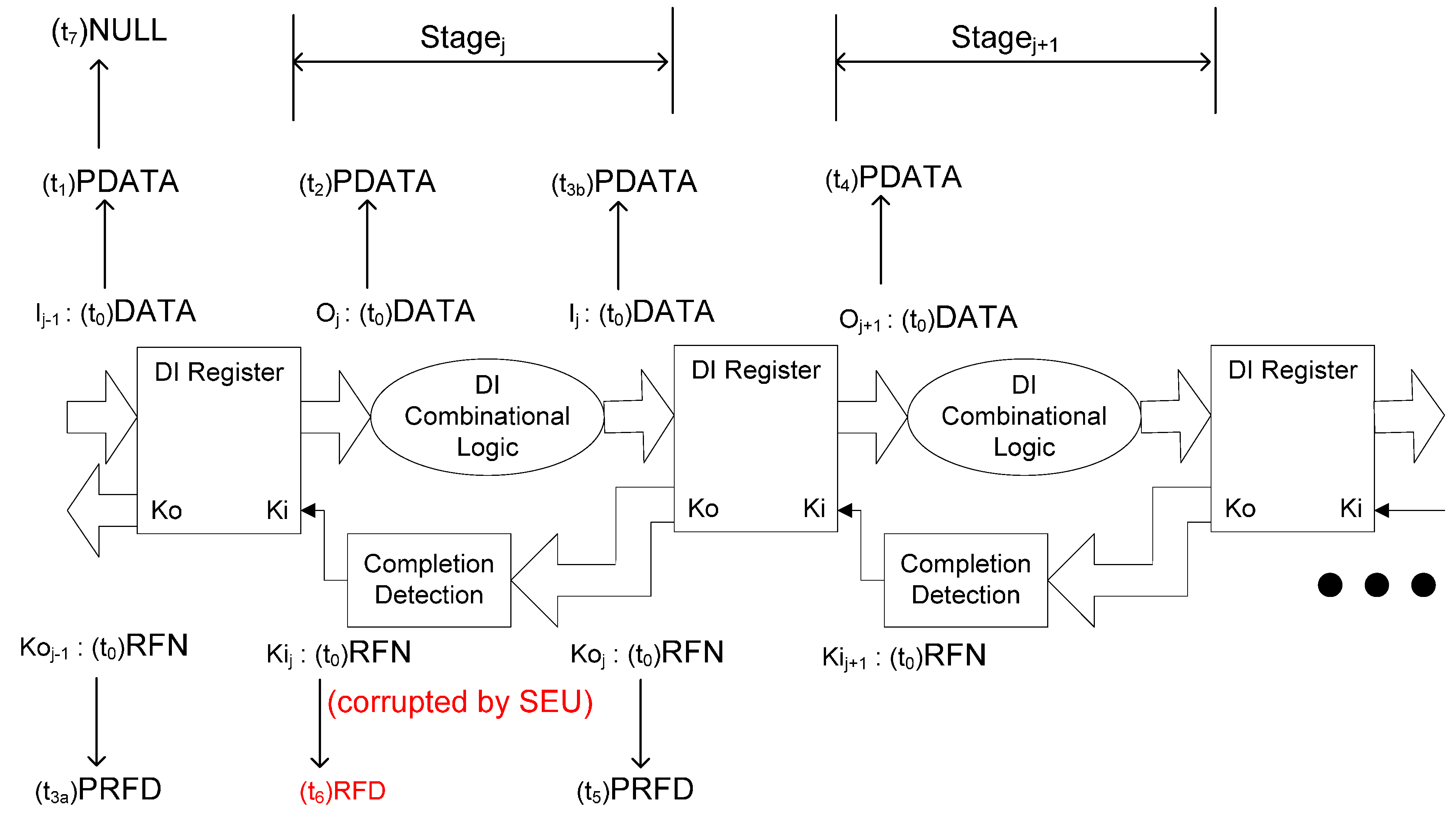
2.2. SEU/SEL Can Cause Deadlock in NCL Systems


2.3. Radiation Hardened Digital Circuit Design
3. Design Methodology
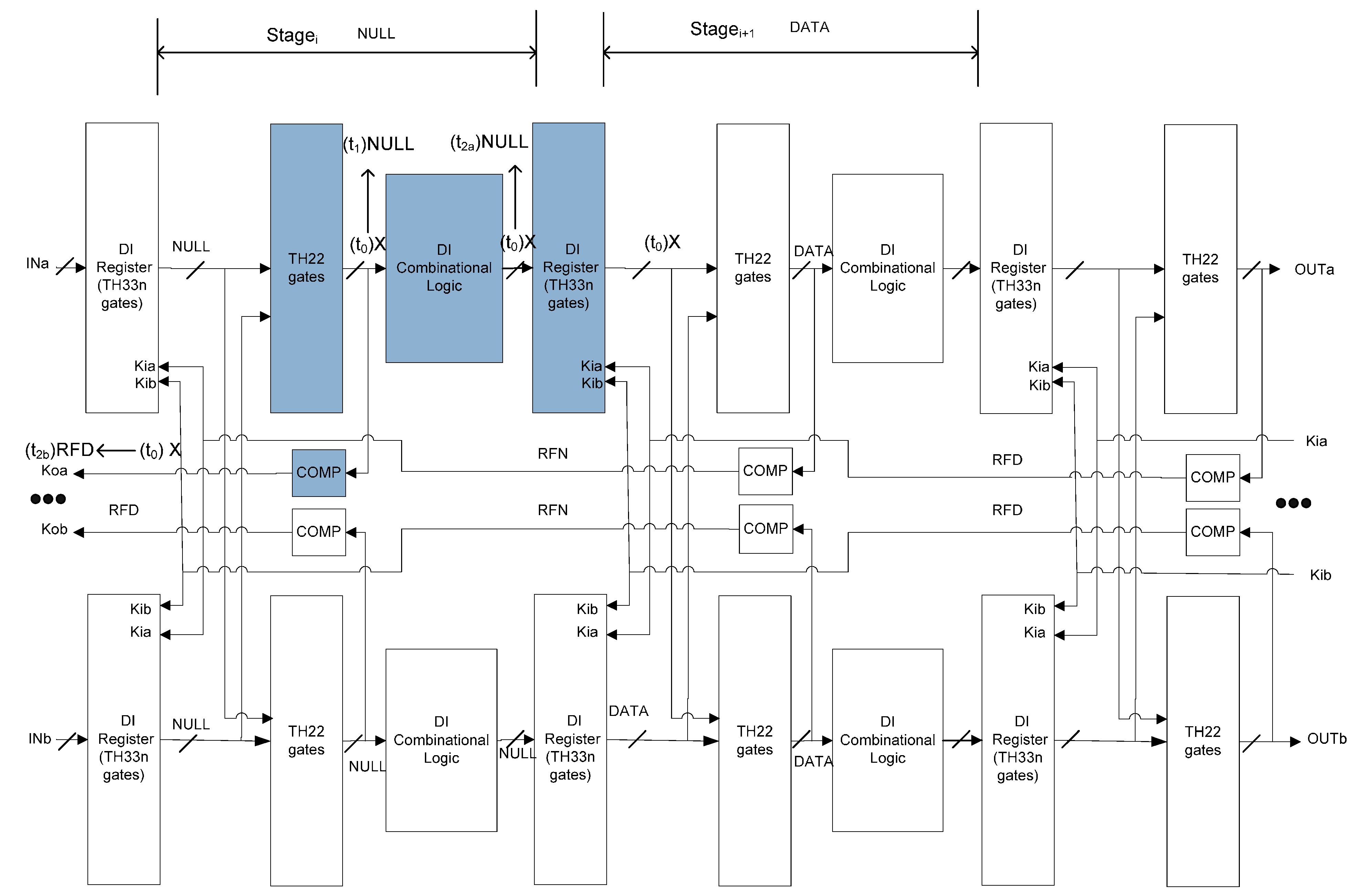
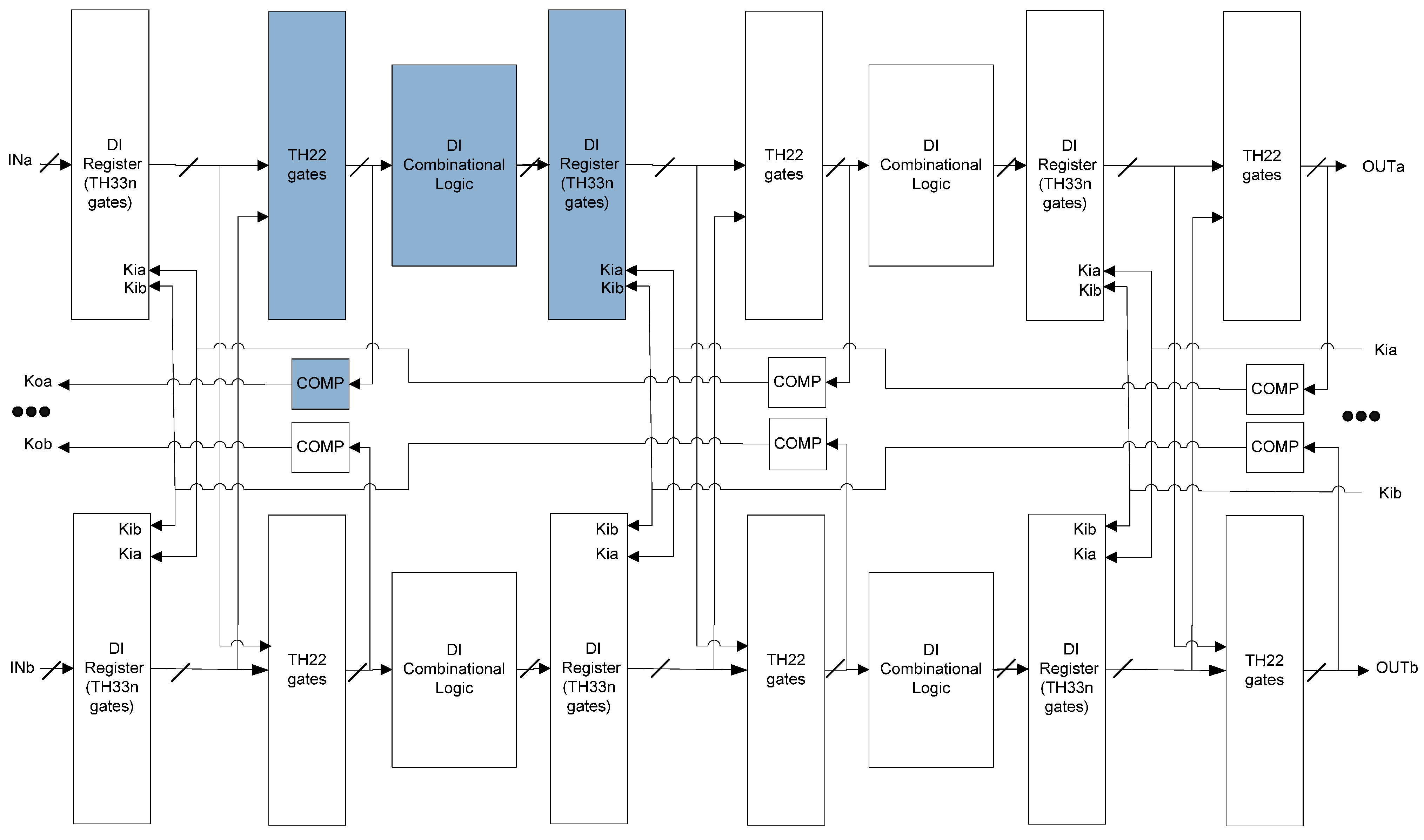
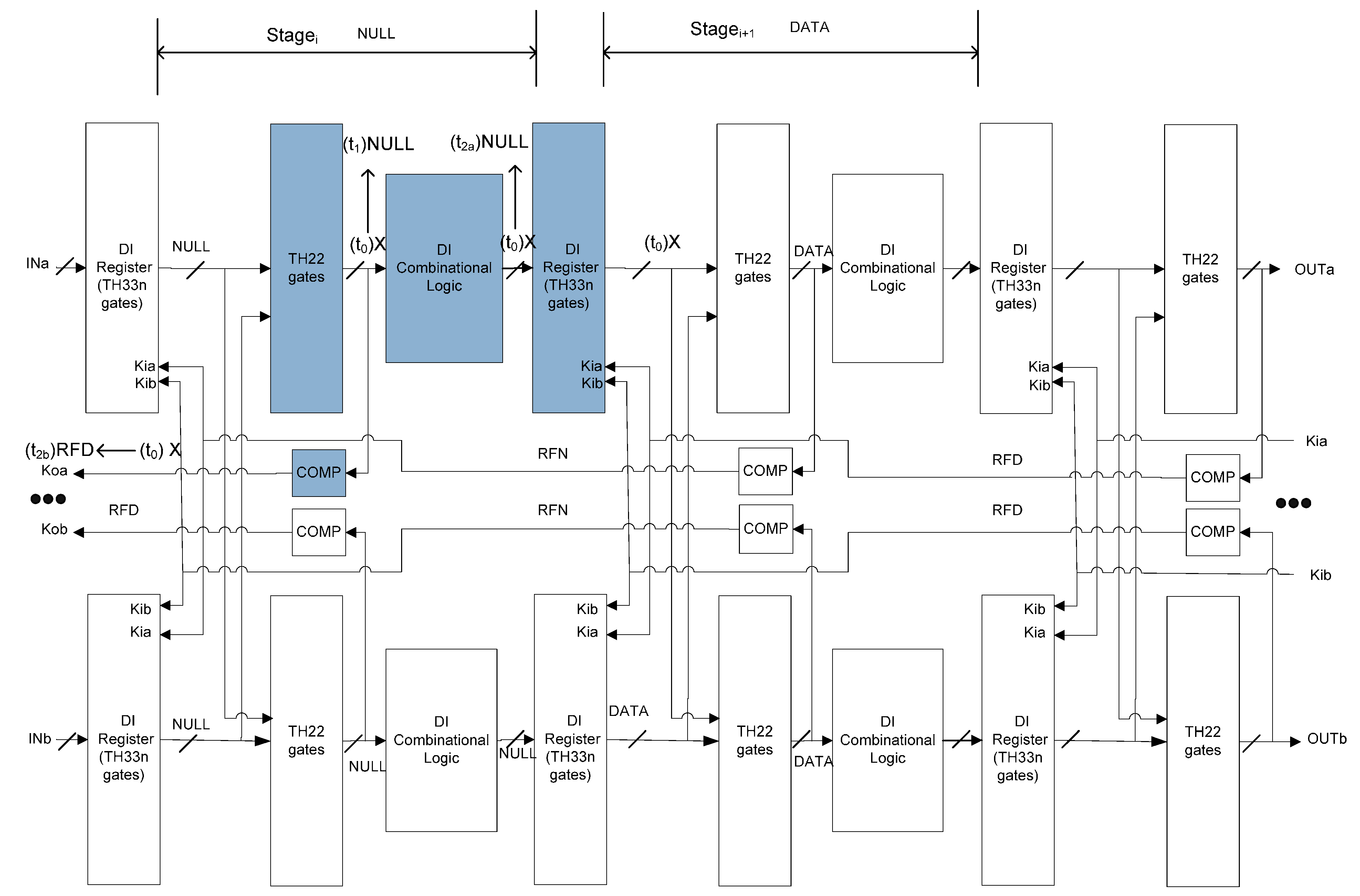
3.1. SEL/SEU Resistant NCL Architecture
- Double the original circuit.
- Replace TH22n gates in the original NCL register with TH33n gates that accept acknowledge signals from both copies.
- Insert TH22 gates at the output of NCL registers that accept register outputs from both copies.
- Move the inverting TH12 gate in the original NCL register and Completion Detection from the outputs of NCL registers to the outputs of the added TH22 gates. The resulting Completion Logic, COMP, in Figure 7 consists of the original Completion Detection in Figure 4 and the inverting TH12 gates moved from the original NCL register.

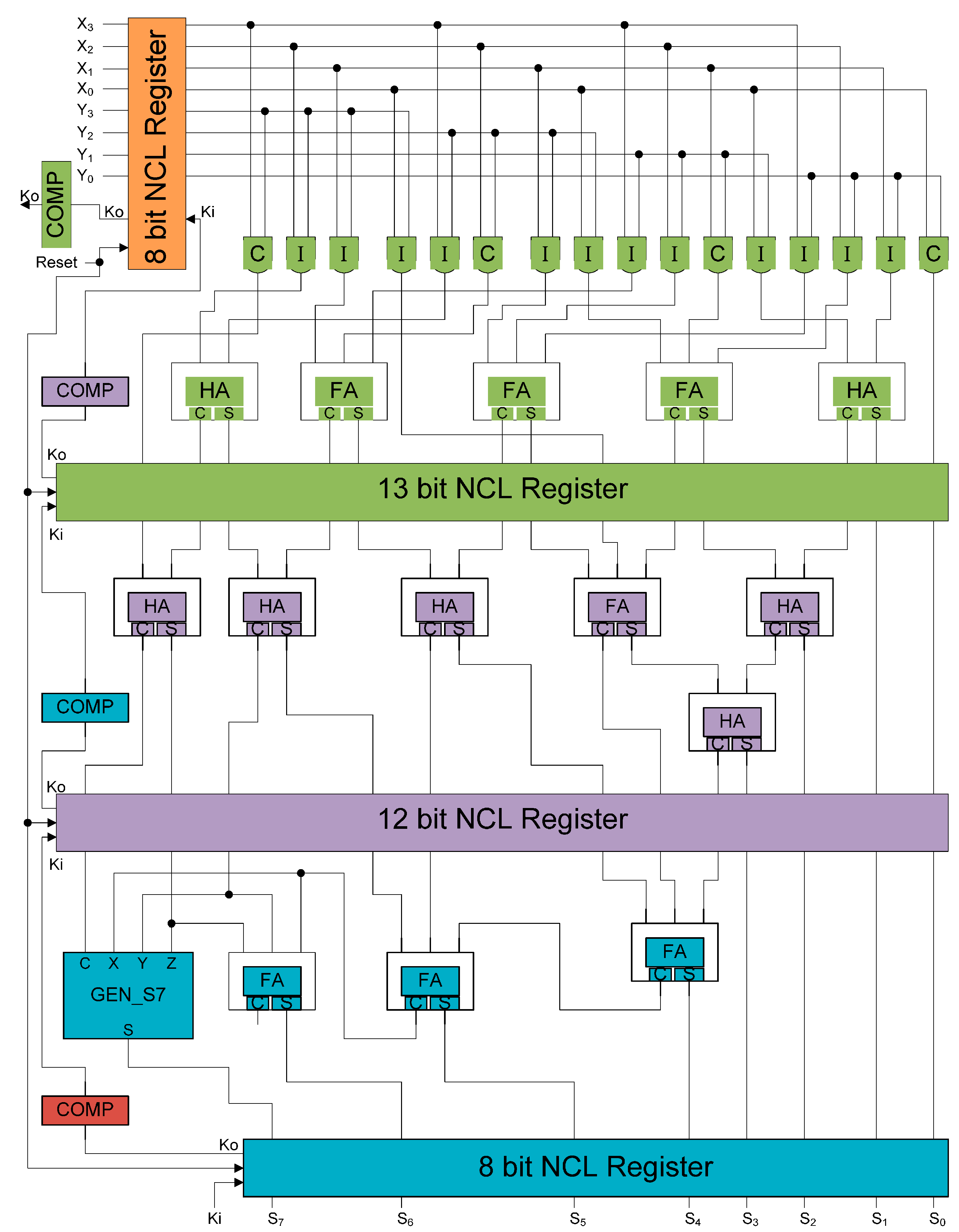
3.2. Area and Speed Overhead
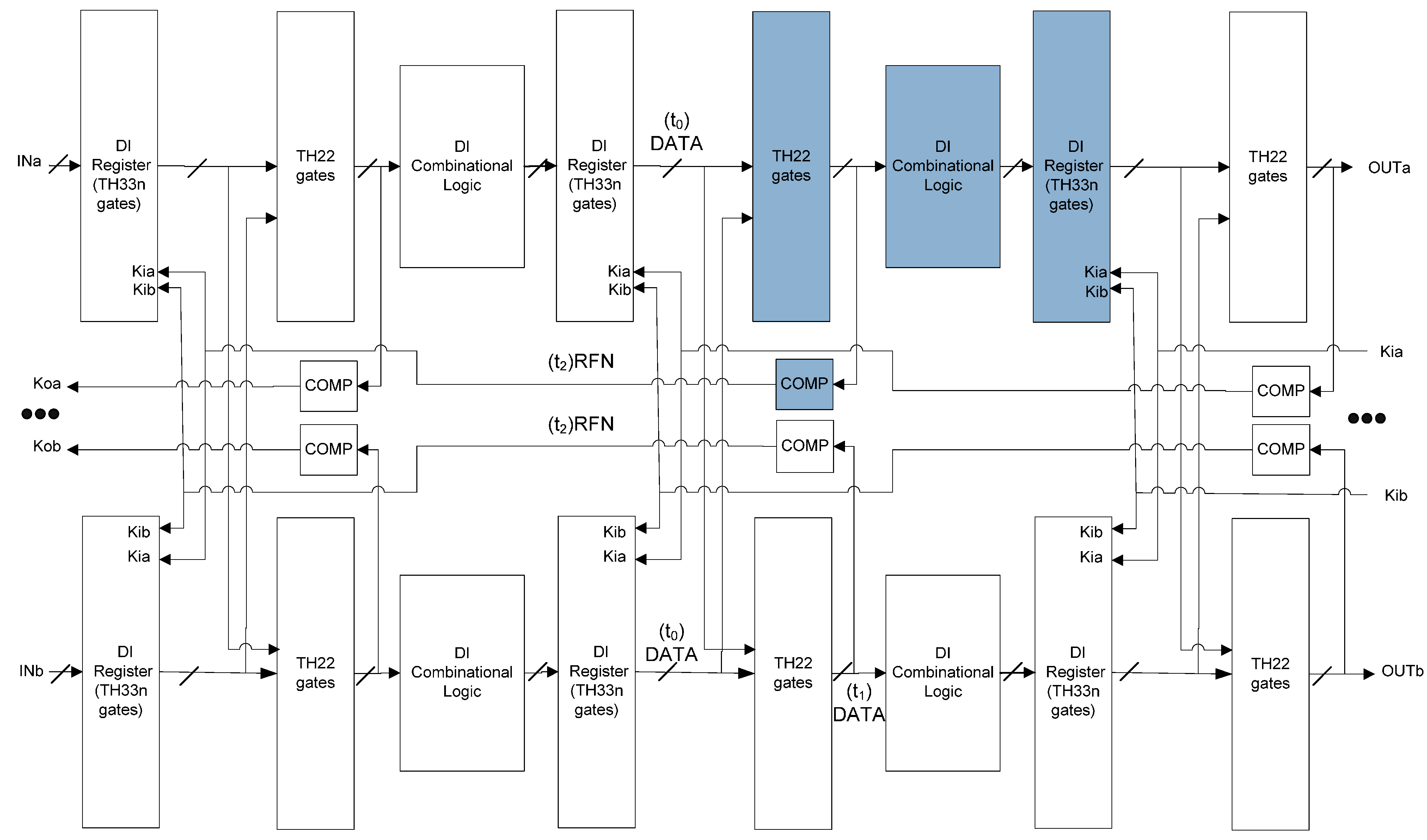
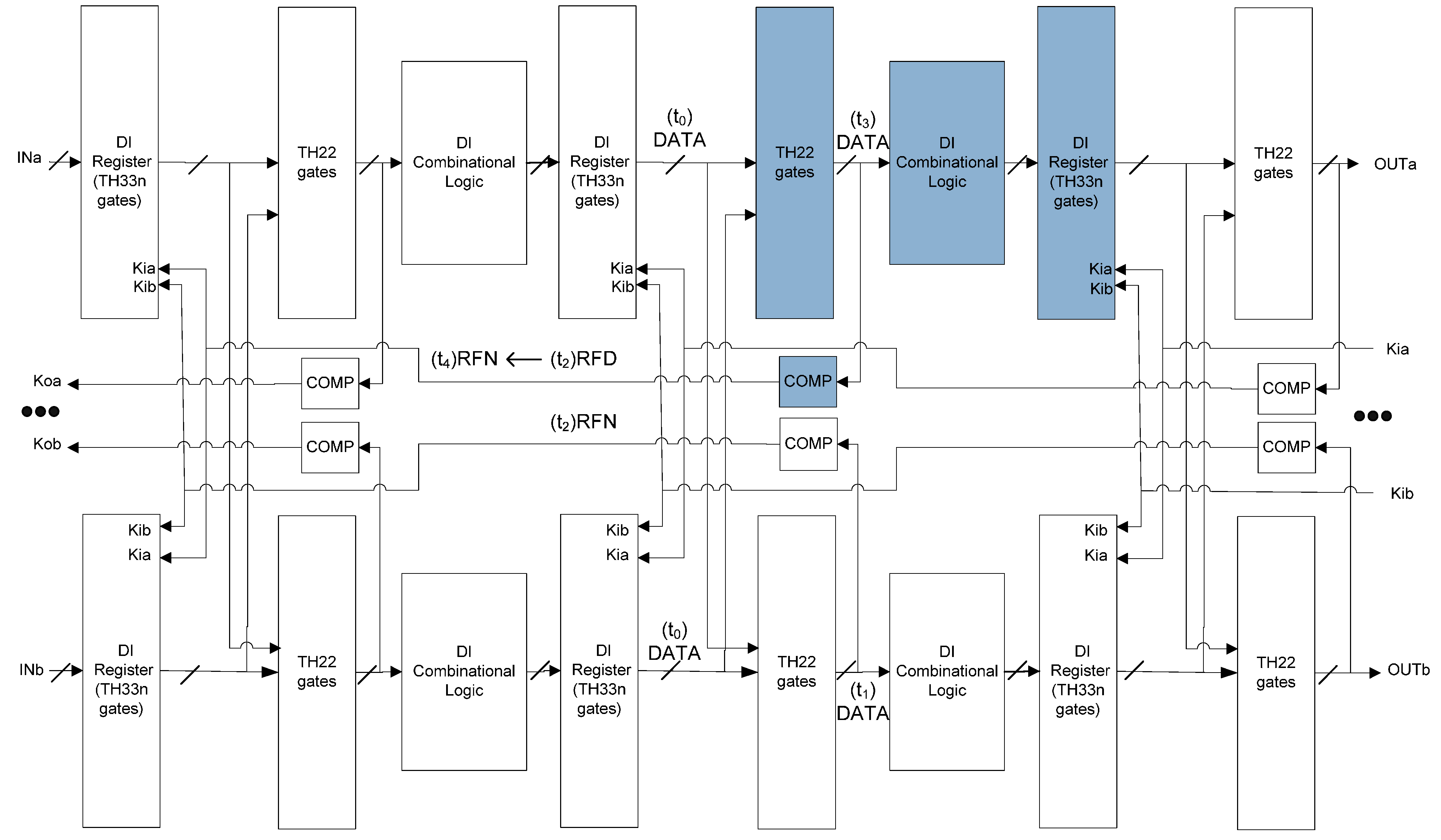
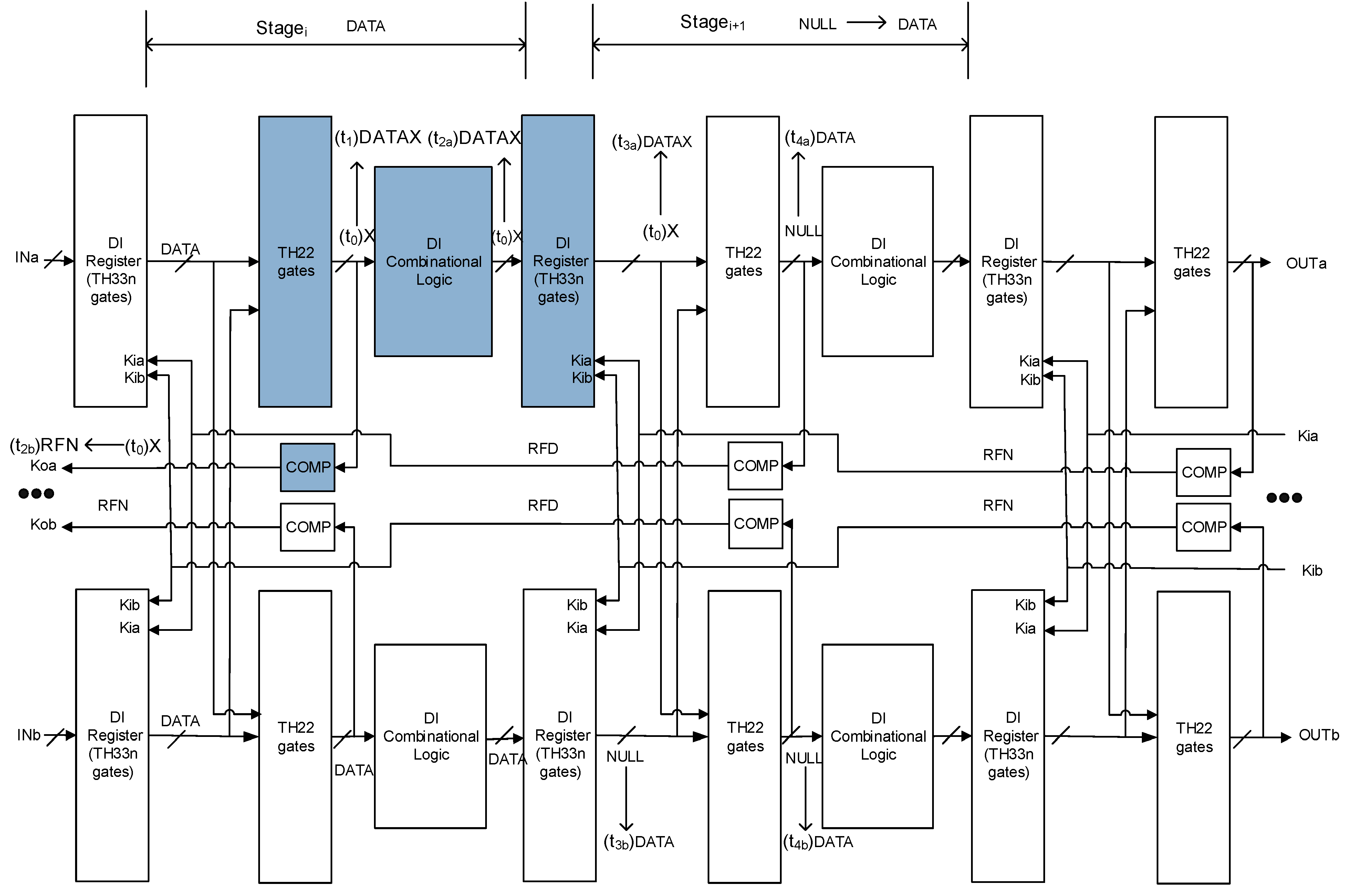
4. SEL/SEU Resistance Proof
4.1. SEL Will Not Cause Deadlock
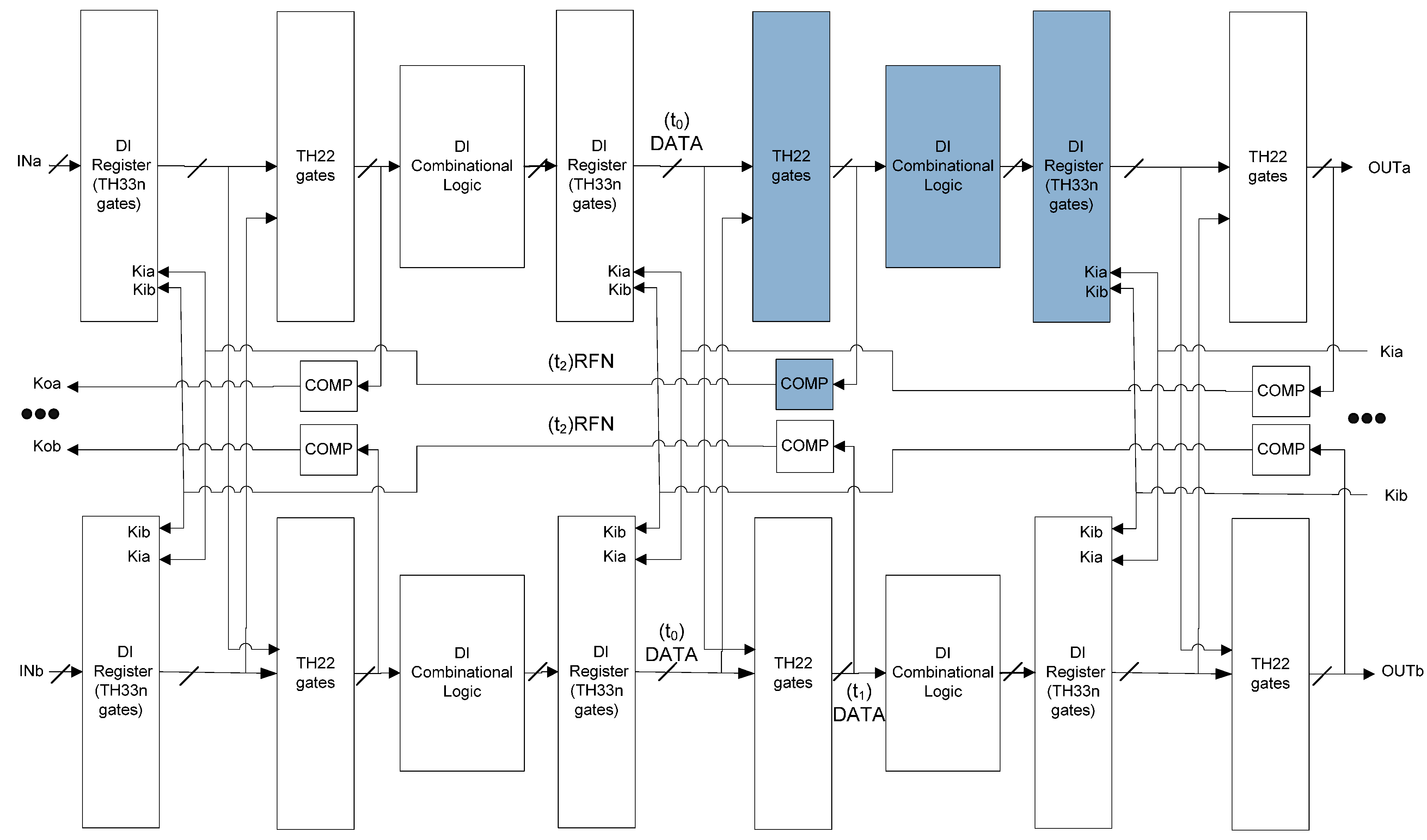
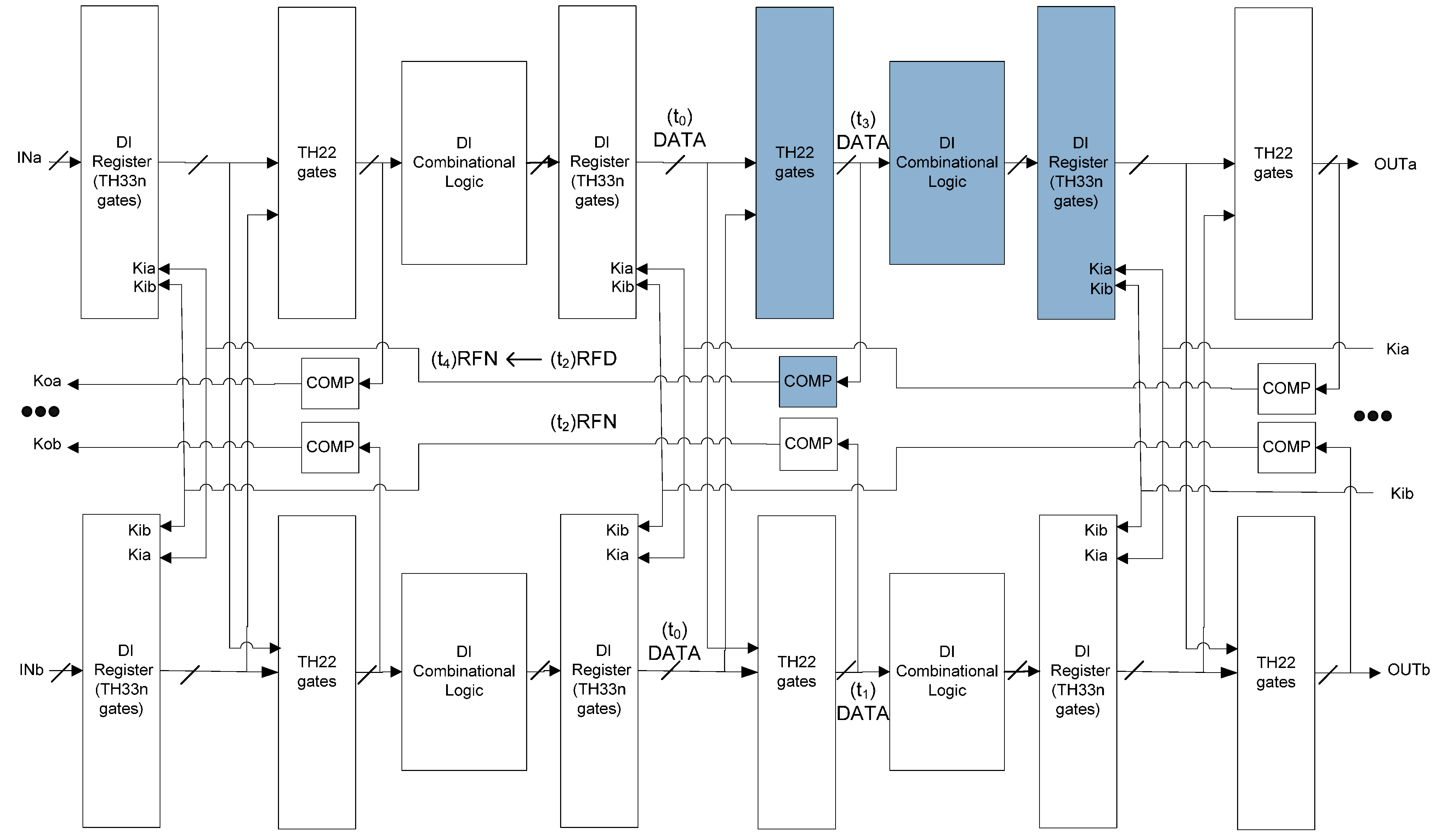
4.2. SEL Will Not Cause Incorrect Output

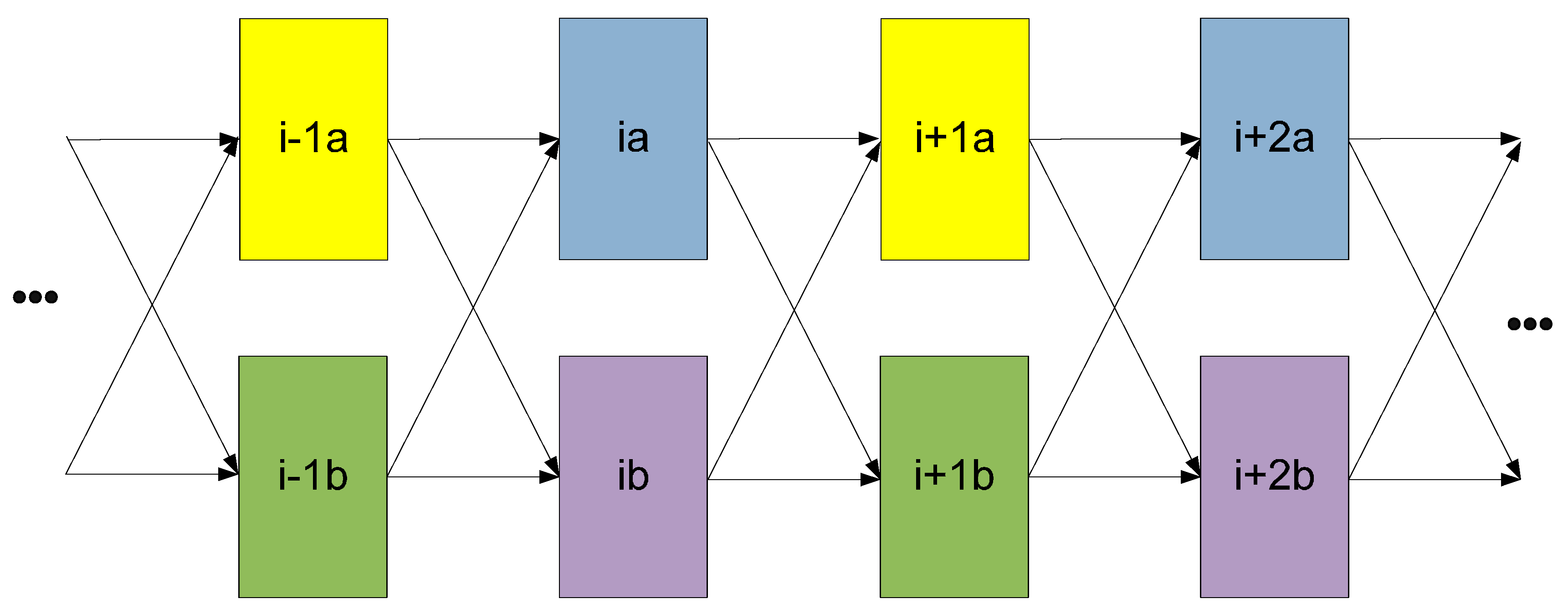
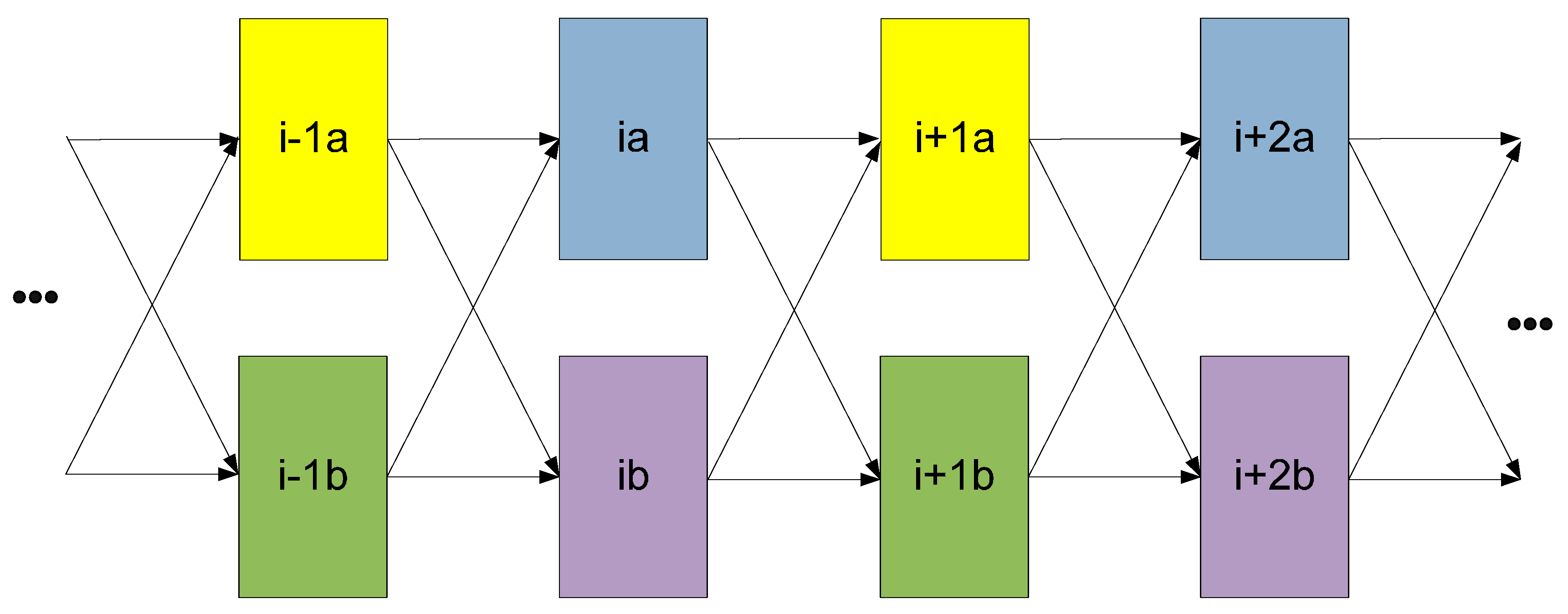
5. Optimal Four-Group Division
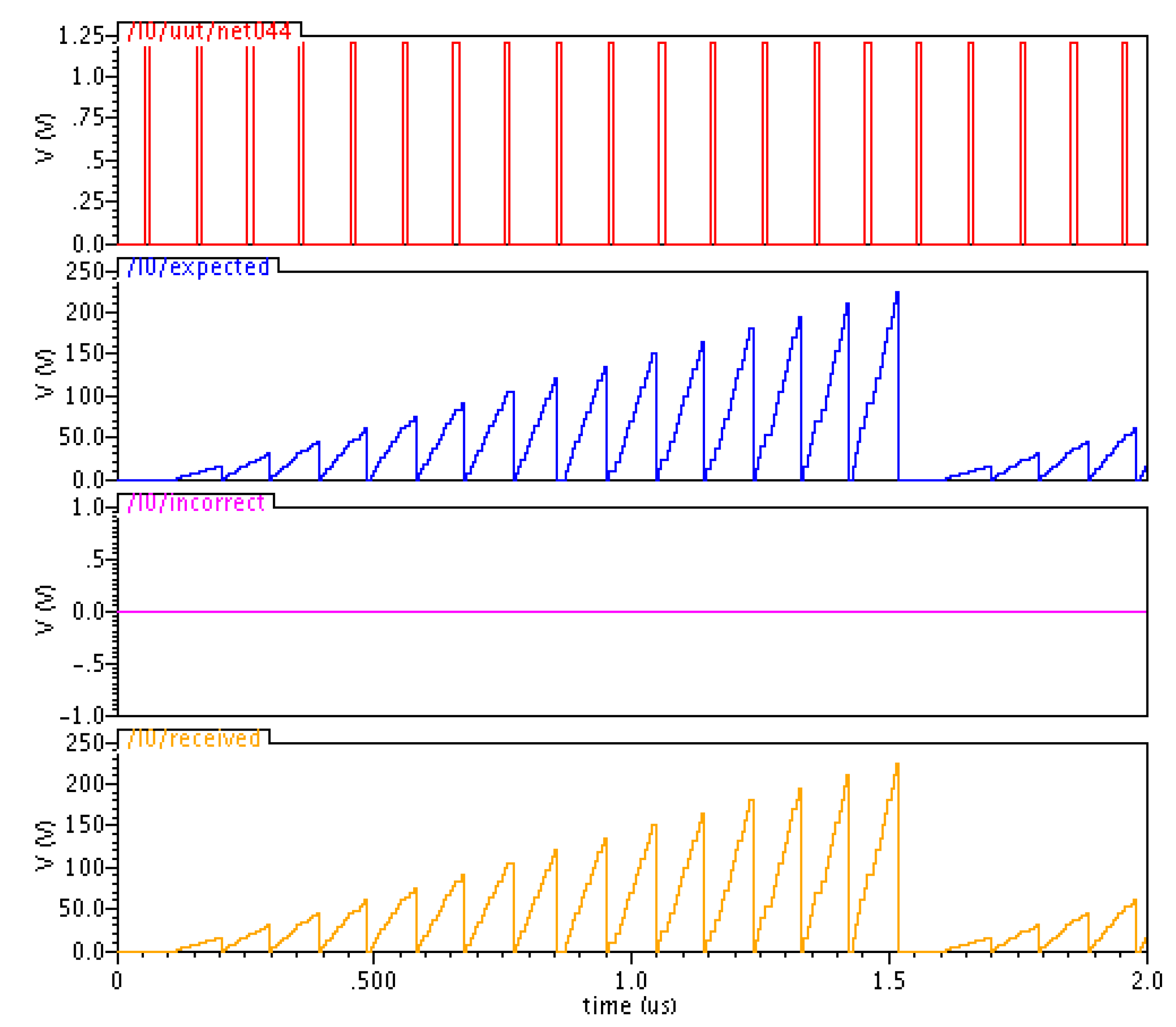
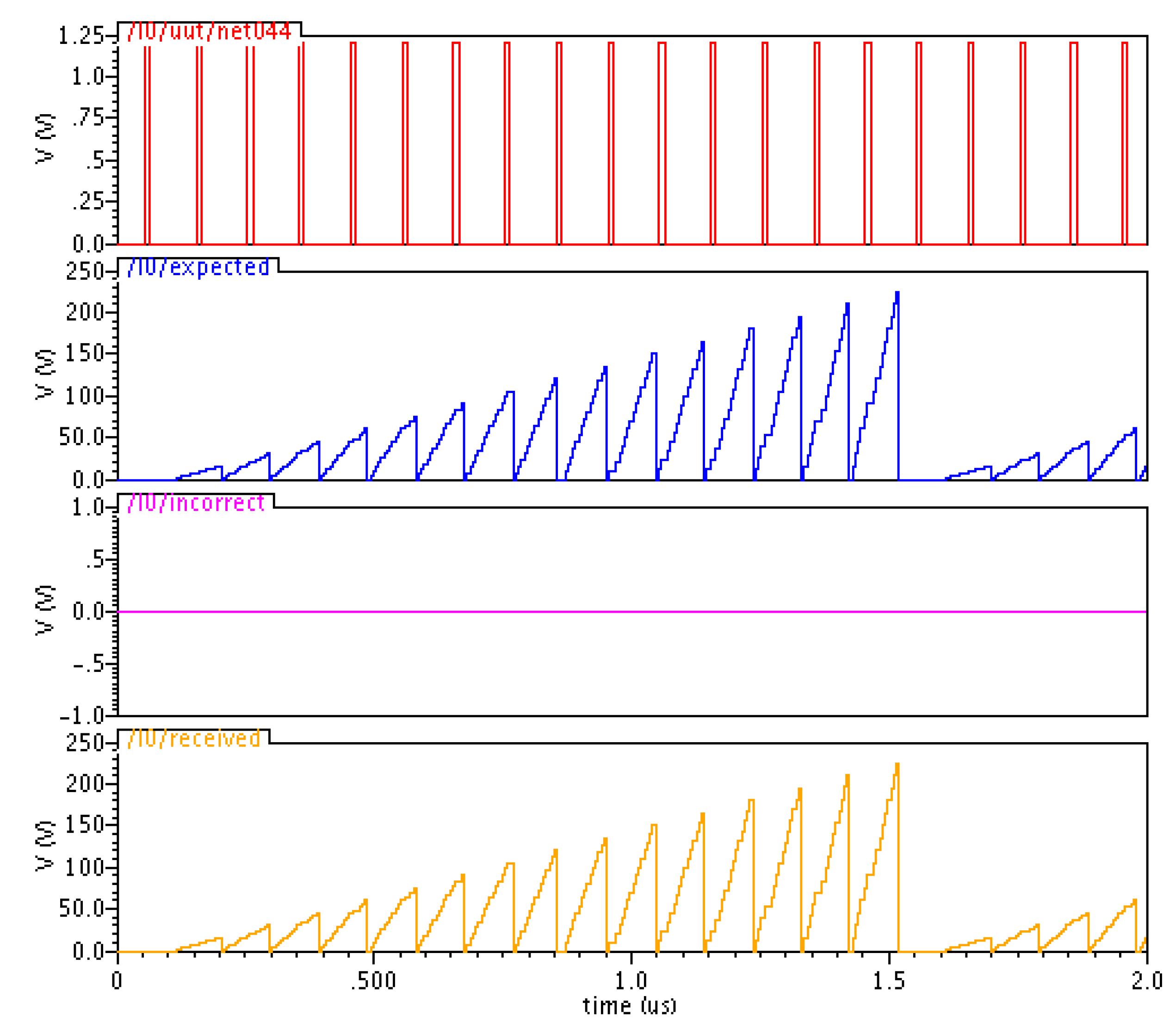
6. Simulation Results


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Circuit Type | Transistor# | TDD (ns) | Energy/Operation (pJ) |
|---|---|---|---|
| Original NCL | 1695 | 7.2 | 1.05 |
| SEL/SEU resistant NCL | 4646 | 9.4 | 2.93 |
7. Conclusions
Author Contributions
Conflicts of Interest
References
- Dodd, P.E.; Massengill, L.W. Basic Mechanisms and Modeling of Single-Event Upset in Digital Microelectronics. IEEE Trans. Nucl. Sci. 2003, 50, 583–602. [Google Scholar]
- Shoga, M.; Binder, D. Theory of single event latchup in complementary metal-oxide semiconductor integrated circuits. IEEE Trans. Nucl. Sci. 1986, 33, 1714–1717. [Google Scholar]
- Martin, A.J. The Limitations to Delay-Insensitivity in Asynchronous Circuits; Springer: New York, NY, USA, 1990; pp. 302–311. [Google Scholar]
- Fant, K.M.; Brandt, S.A. NULL Convention Logic: A Complete and Consistent Logic for Asynchronous Digital Circuit Synthesis. In Proceedings of the International Conference on Application Specific Systems, Architectures and Processors, Chicago, IL, USA, 19–21 August 1996; pp. 261–273.
- Sobelman, G.E.; Fant, K.M. CMOS Circuit Design of Threshold Gates with Hysteresis. In Proceedings of the 1998 IEEE International Symposium on Circuits and Systems (II), Monterey, CA, USA, 31 May–3 June 1998; pp. 61–65.
- Muller, D.E. Asynchronous Logics and Application to Information Processing. In Switching Theory in Space Technology; Stanford University Press: Redwood City, CA, USA, 1963; pp. 289–297. [Google Scholar]
- Parsan, F.A.; Smith, S.C. CMOS Implementation of Static Threshold Gates with Hysteresis: A New Approach. In Proceedings of the IFIP/IEEE International Conference on VLSI-SoC, Santa Cruz, CA, USA, 7–10 October 2012; pp. 41–45.
- Parsan, F.A.; Smith, S.C. CMOS Implementation Comparison of NCL Gates. In Proceedings of the IEEE International Midwest Symposium on Circuits and Systems, Boise, ID, USA, 5–8 August 2012; pp. 394–397.
- Smith, S.C.; DeMara, R.F.; Yuan, J.S.; Hagedorn, M.; Ferguson, D. Delay-Insensitive Gate-Level Pipelining. Elsevier’s Integr. VLSI J. 2001, 30, 103–131. [Google Scholar] [CrossRef]
- Smith, S.C.; DeMara, R.F.; Yuan, J.S.; Ferguson, D.; Lamb, D. Optimization of NULL convention self-timed circuits. Integr. VLSI J. 2004, 37, 135–165. [Google Scholar] [CrossRef]
- Seitz, C.L. System Timing. In Introduction to VLSI Systems; Addison-Wesley: Boston, MA, USA, 1980; pp. 218–262. [Google Scholar]
- Kondratyev, A.; Neukom, L.; Roig, O.; Taubin, A.; Fant, K. Checking Delay-Insensitivity: 104 Gates and Beyond. In Proceedings of the Eighth International Symposium on Asynchronous Circuits and Systems, Manchester, UK, 8–11 April 2002; pp. 149–157.
- Martin, A.J. Programming in VLSI: From Communicating Processes to Delay-Insensitive Circuits. In Developments in Concurrency and Communication; UT Year of Programming Institute on Concurrent Programming, Addison-Wesley: Boston, MA, USA, 1990; pp. 1–64. [Google Scholar]
- Van Berkel, K. Beware the isochronic fork. Integr. VLSI J. 1992, 13, 103–128. [Google Scholar] [CrossRef]
- Zhou, L.; Parameswaran, R.; Parsan, F.A.; Smith, S.C.; Di, J. Multi-Threshold NULL Convention Logic (MTNCL): An ultra-low power asynchronous circuit design methodology. J. Low Power Electron. Appl. 2015, 5, 81–100. [Google Scholar] [CrossRef]
- Jiang, W.; Martin, A.J. A Soft-Error Tolerant Asynchronous Microcontroller. In Proceedings of the 13th NASA Symposium on VLSI Design, Post Falls, ID, USA, 4–5 June 2007.
- Jiang, W.; Martin, A.J. Soft-Error Robustness in QDI Circuits. In Proceedings of the 1st Workshop on System Effects of Logical Soft Errors, Urbana-Champaign, IL, USA, 5–6 April 2005.
- Jiang, W.; Martin, A.J. SEU-Tolerant QDI Circuits. In Proceedings of the 11th IEEE International Symposium on Asynchronous Systems & Circuits, New York, NY, USA, 14–16 March 2005; pp. 156–165.
- Jiang, W.; Martin, A.J. Soft-Error Tolerant Asynchronous FPGA. In Proceedings of the Dependable System and Network 2005, Rio de Janeiro, Brazil, 22–25 June 2005.
- Kuang, W.; Zhao, P.; Yuan, J.S.; DeMara, R.F. Design of asynchronous circuits for high soft error tolerance in deep submicron CMOS Circuits. IEEE Trans. VLSI Syst. 2010, 18, 410–422. [Google Scholar] [CrossRef]
- Kuang, W.; Ibarra, C.M.; Zhao, P. Soft Error Hardening for Asynchronous Circuits. In Proceedings of the 22nd IEEE International Symposium on Defect and Fault-Tolerance in VLSI Systems, Rome, Italy, 26–28 September 2007; pp. 273–281.
- Kuang, W.; Xiao, E.; Ibarra, C.M.; Zhao, P. Design Asynchronous Circuits for Soft Error Tolerance. In Proceedings of the IEEE International Conference on Integrated Circuit Design and Technology, Austin, TX, USA, 30 May–1 June 2007; pp. 1–5.
- Nicolaidis, M. A Low-Cost Single-Event Latchup Mitigation Scheme. In Proceedings of the 12th IEEE International Symposium on On-Line Testing, Lake Como, Italy, 10–12 July 2006; pp. 111–118.
- Nicolaidis, M.; Torki, K.; Natali, F.; Belhaddad, F.; Alexandrescu, D. Implementation and Validation of a Low-Cost Single-Event Latchup Mitigation Scheme. In Proceedings of the IEEE Workshop on Silicon Errors in Logic-System Effects, Stanford, CA, USA, 24 March 2009.
- Zhou, L.; Smith, S.C. Accurate Throughput Derivation of Pipelined NULL Convention Logic Asynchronous Circuits. In Proceedings of the International Conference on Computer Design, Las Vegas, NV, USA, 16–19 July 2012; pp. 51–54.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, L.; Smith, S.C.; Di, J. Radiation Hardened NULL Convention Logic Asynchronous Circuit Design. J. Low Power Electron. Appl. 2015, 5, 216-233. https://doi.org/10.3390/jlpea5040216
Zhou L, Smith SC, Di J. Radiation Hardened NULL Convention Logic Asynchronous Circuit Design. Journal of Low Power Electronics and Applications. 2015; 5(4):216-233. https://doi.org/10.3390/jlpea5040216
Chicago/Turabian StyleZhou, Liang, Scott C. Smith, and Jia Di. 2015. "Radiation Hardened NULL Convention Logic Asynchronous Circuit Design" Journal of Low Power Electronics and Applications 5, no. 4: 216-233. https://doi.org/10.3390/jlpea5040216
APA StyleZhou, L., Smith, S. C., & Di, J. (2015). Radiation Hardened NULL Convention Logic Asynchronous Circuit Design. Journal of Low Power Electronics and Applications, 5(4), 216-233. https://doi.org/10.3390/jlpea5040216