4.1. River Basin Model Calibration
The river basin model calibration problem for the Tang-Wang River Basin is used to validate effectiveness of the new HDDS-S algorithm. The Yixin hydrologic station, located at the outlet of Tang-Wang River Basin, is chosen as the calibration station, and the streamflow data from the 1979–2001 periods are used to calibrate model parameters. Based on the two scenarios S0 and S1,
i.e., model auto-calibration with the HDDS-S and DDS algorithms respectively, performances of the two algorithms in the river basin model parameter auto-calibration are evaluated on Intel Core™ 2 Duo, with a 2.66-GHz CPU. In different scenarios, average required computation time under the same number of function evaluations,
i.e.,
, or the same simulation accuracy,
i.e.,
, through 30 optimization trials are shown in
Figure 6.
Figure 6.
Average required computation time under the same number of function evaluations () and the same simulation accuracy () in different scenarios through 30 optimization trials.
Figure 6.
Average required computation time under the same number of function evaluations () and the same simulation accuracy () in different scenarios through 30 optimization trials.
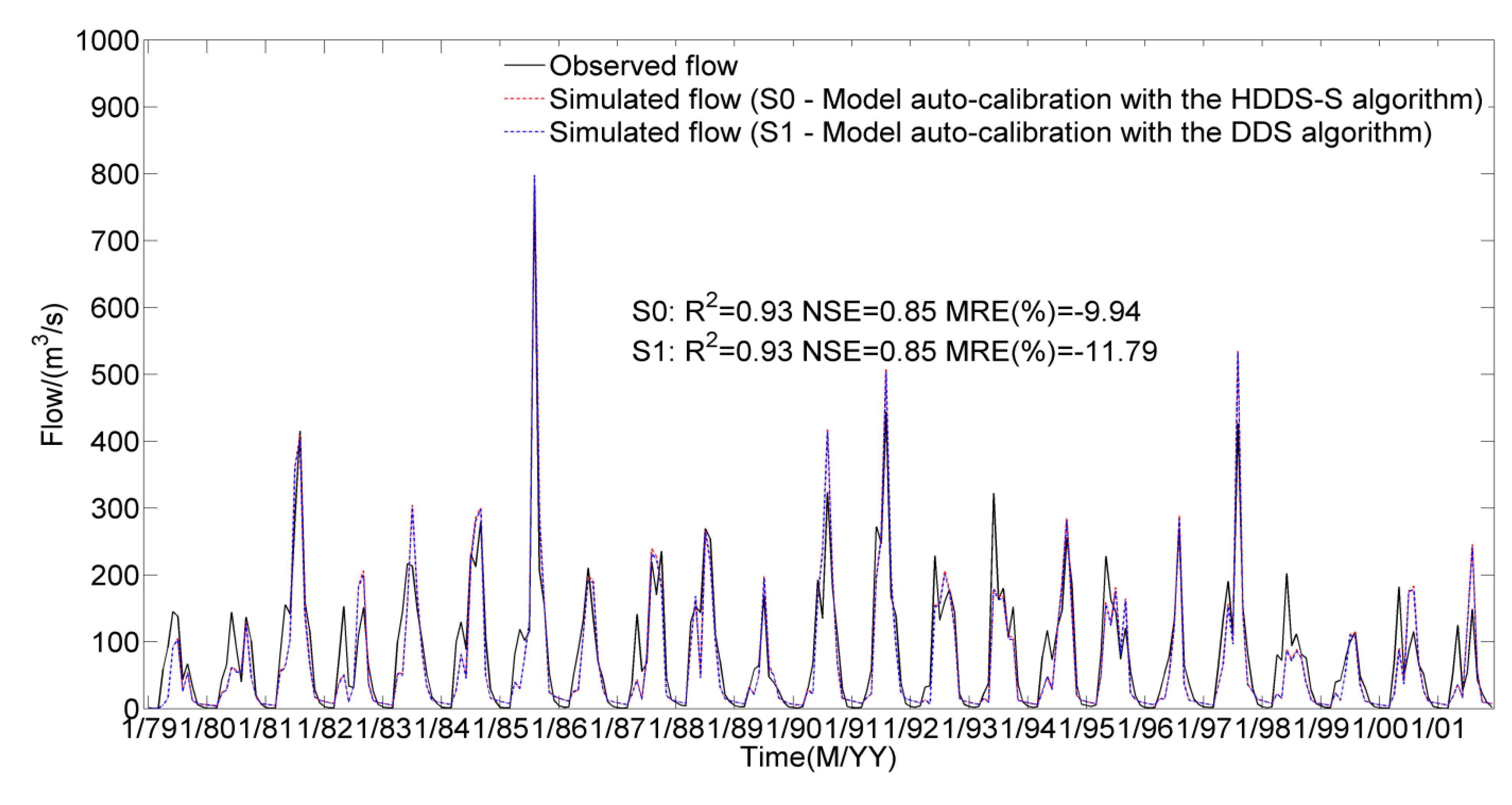
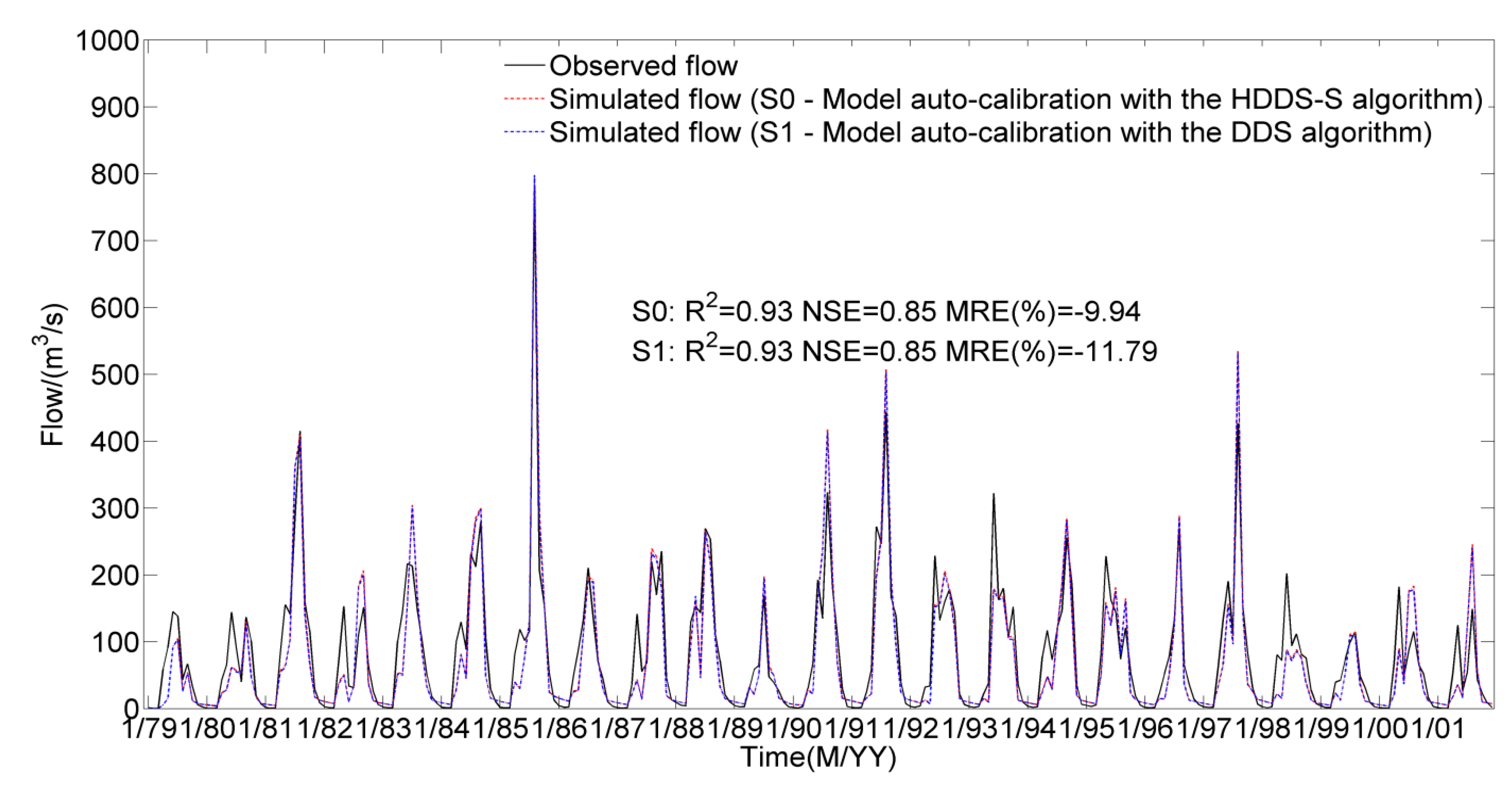
In different scenarios, average simulation results at the Yixin hydrologic station under the same number of function evaluations,
i.e.,
, through 30 optimization trials is shown in
Figure 7.
Figure 7.
Observed and average simulated monthly streamflows during the period from 1979 to 2001 at the Yixin hydrologic station through 30 optimization trials.
Figure 7.
Observed and average simulated monthly streamflows during the period from 1979 to 2001 at the Yixin hydrologic station through 30 optimization trials.
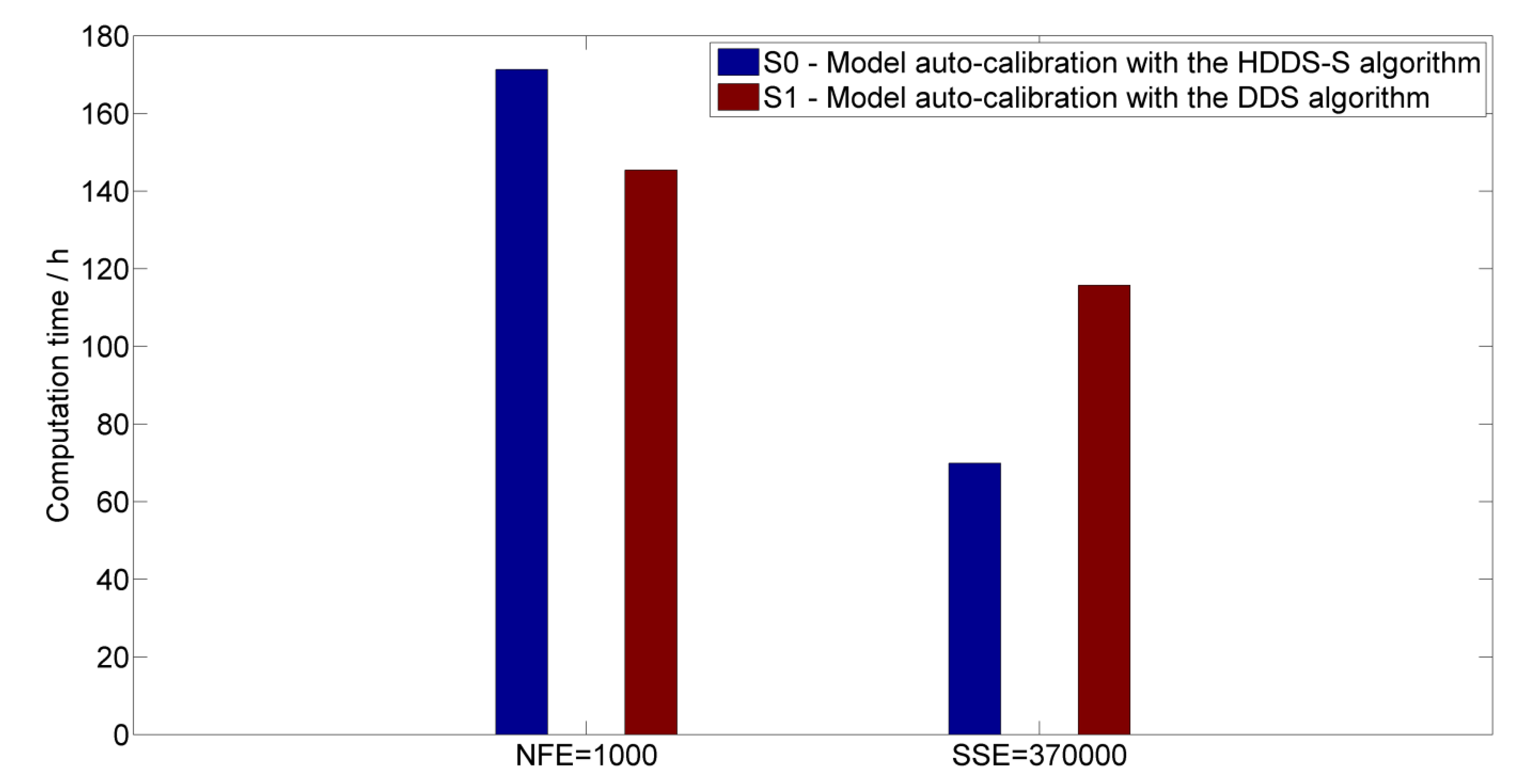
Seen from
Figure 6 and
Figure 7, under the same number of function evaluations (
), the average required computation time increases from 145.40 h in the case of the DDS algorithm to 171.32 h in the HDDS-S algorithm. Although the model performance improves from 11.79% (
) in the case of the DDS algorithm to 9.94% in the HDDS-S algorithm at the Yixin hydrologic station, there is little difference of model performances between the DDS algorithm and the HDDS-S algorithm in terms of the other two evaluation criterions because the simulation results will approximate their optimal values after 1000 function evaluations to a large extent. Under the same simulation accuracy (
), the average required computation time reduces from 115.74 h (
) in the case of the DDS algorithm to 69.90 h (
) in the HDDS-S algorithm through 30 optimization trials. Although the average computation time in the case of the HDDS-S algorithm increases due to the additive sensitivity computation of each dimension decision variable compared to the DDS algorithm under the same iteration number, the average computation time in the case of the HDDS-S algorithm reduces greatly compared to the DDS algorithm under the same simulation accuracy.
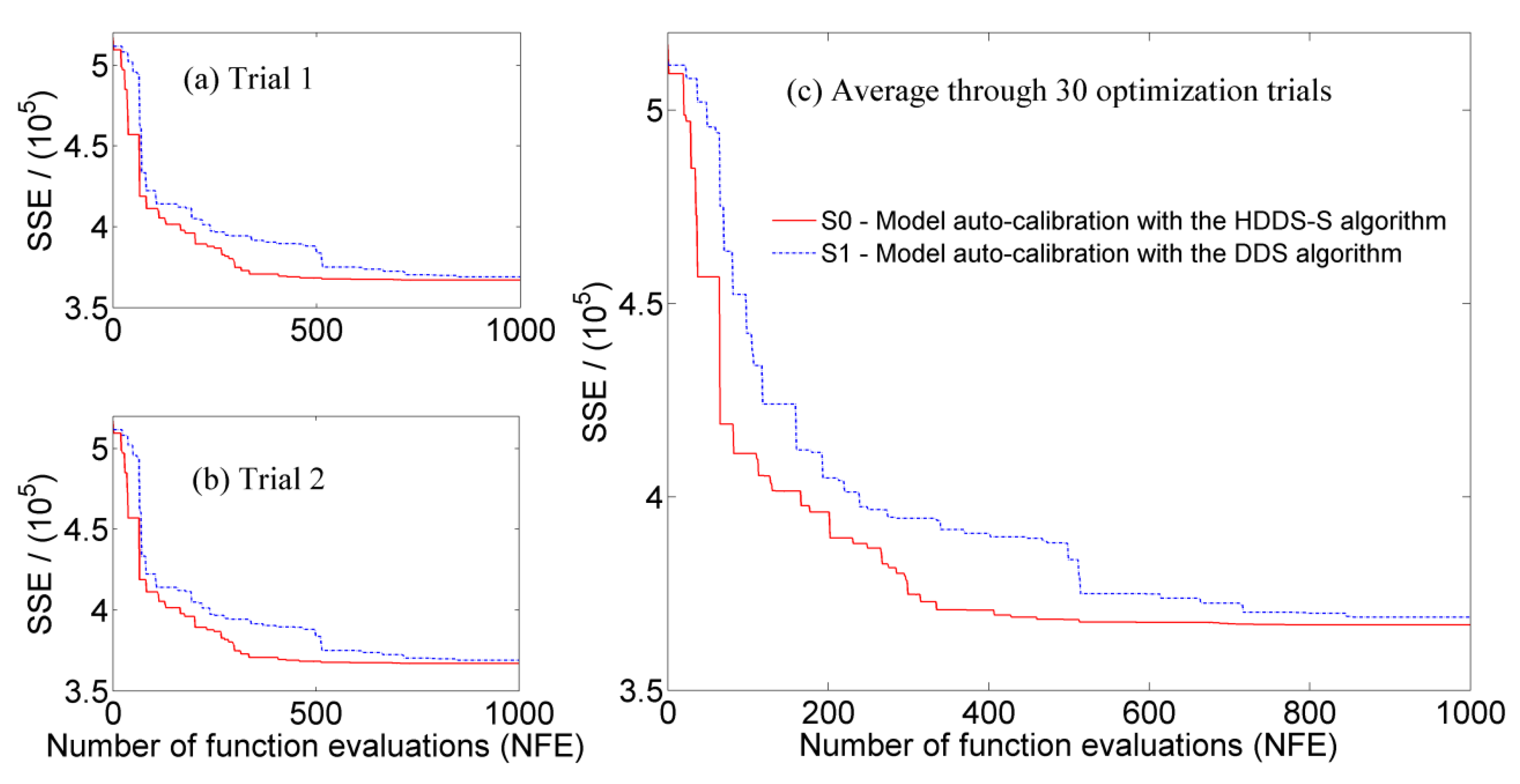
The performances of the two algorithms in river basin model calibration are evaluated not only from average required computation time under the same number of function evaluations, average required computation time under the same simulation accuracy, and average simulation results at Yixin hydrologic station under the same number of function evaluations, but also from average convergence process of the objective function and average calibration process of model parameters under the same number of function evaluations. Convergence processes of the objective function under the same number of function evaluations (
) through 30 optimization trials in different scenarios are shown in
Figure 8. It is further indicated that due to the consideration of the changing sensitivity information of each dimension decision variable, under the same number of function evaluations, convergence rate of the objective function is improved in the HDDS-S algorithm compared to the DDS algorithm. Additionally, there are few differences of the HDDS-S algorithm convergence processes among different optimization trials, which indicate the reliability and stability of the HDDS-S algorithm in solving model auto-calibration problem.
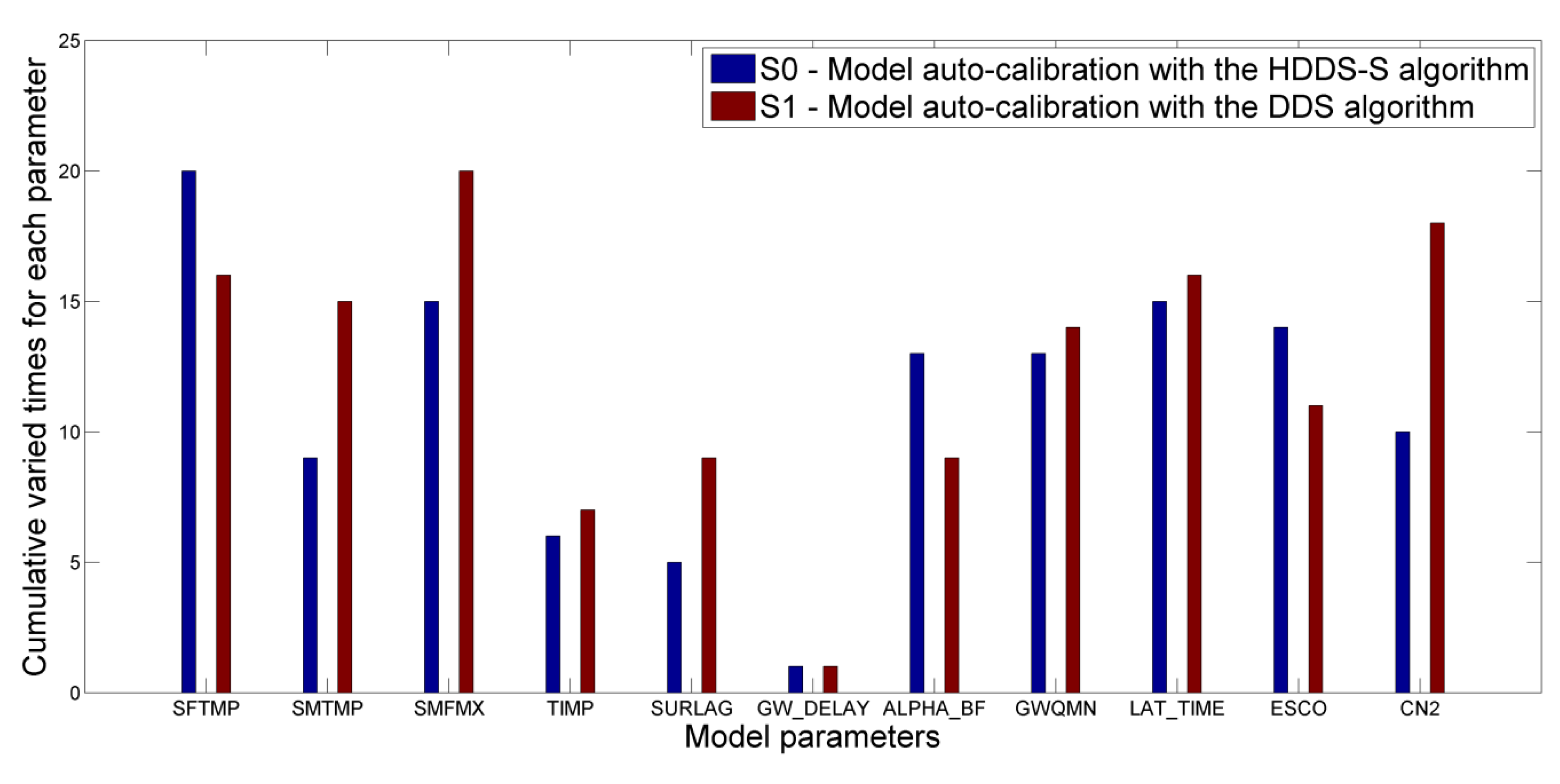
Under the same number of function evaluations (
), the average cumulative varied times for each parameter during model auto-calibration process in different scenarios through 30 optimization trials are shown in
Figure 9, where the average cumulative varied times in S0 indicate the cumulative sensitivity of each parameter.
Figure 8.
Convergence processes of the objective function under the same number of function evaluations () in different scenarios through 30 optimization trials, (a) and (b) convergence processes in two random optimization trials; (c) average convergence process through 30 optimization trials.
Figure 8.
Convergence processes of the objective function under the same number of function evaluations () in different scenarios through 30 optimization trials, (a) and (b) convergence processes in two random optimization trials; (c) average convergence process through 30 optimization trials.
Figure 9.
Average cumulative varied times for each parameter during model auto-calibration process under the same number of function evaluations (
) in different scenarios through 30 optimization trials, where the description of each parameter in the
x axis could be found in
Table 1.
Figure 9.
Average cumulative varied times for each parameter during model auto-calibration process under the same number of function evaluations (
) in different scenarios through 30 optimization trials, where the description of each parameter in the
x axis could be found in
Table 1.
The average cumulative varied times for each parameter during model auto-calibration process under the same number of function evaluations () through 30 optimization trials are different between the two scenarios, i.e., the DDS algorithm, which selects dimension for perturbation completely at random with a uniform probability, could not reflect the sensitivity information of each parameter. The details are indicated from two aspects.
(1) As indicated in the cumulative varied times in the case of the HDDS-S algorithm, some parameters need to be varied many times due to strong sensitivities, e.g., SFTMP, ALPHA_BF and ESCO. However, the cumulative varied times of these parameters in the DDS algorithm are less.
(2) Similarly, some parameters need to be varied fewer times due to weak sensitivities, e.g., SMTMP, SMFMX, SURLAG and CN2. However, their cumulative varied times in the DDS algorithm are greater than.
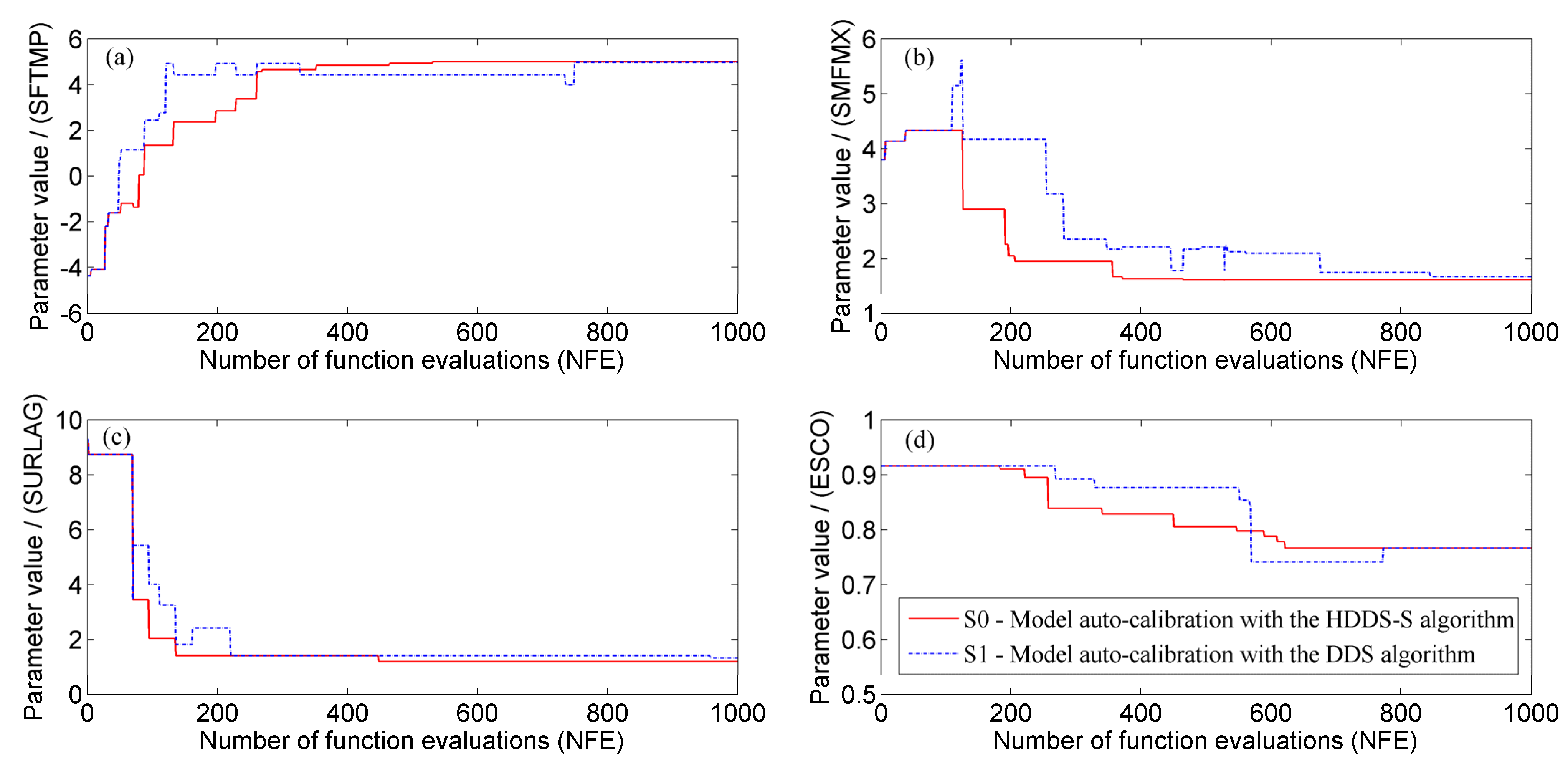
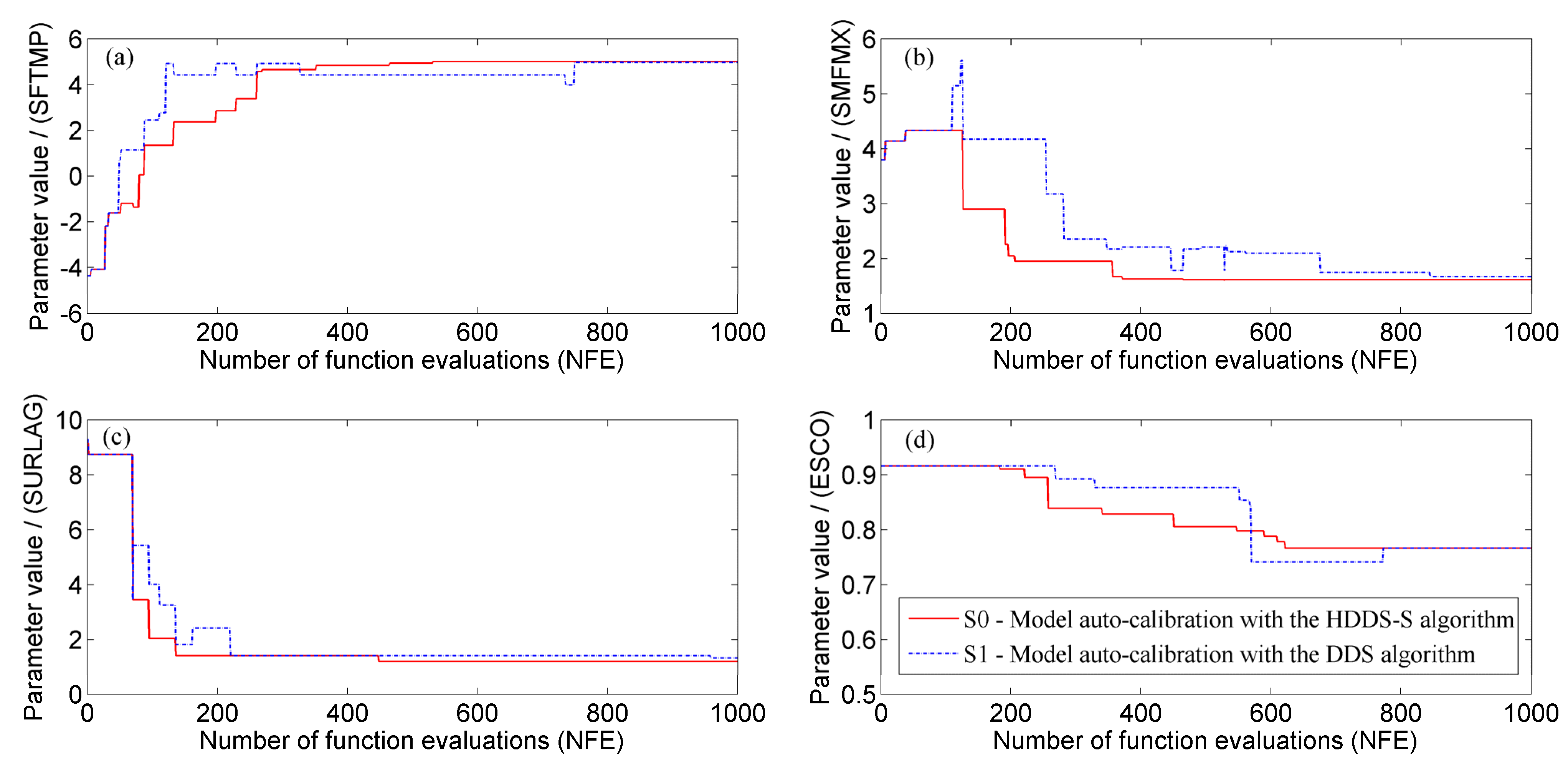
Under the same number of function evaluations (
) through 30 optimization trials, average calibration processes of model parameters SFTMP, SMFMX, SURLAG and ESCO, in different scenarios are shown in
Figure 10.
Figure 10.
Average calibration process of model parameters under the same iteration number () through 30 optimization trials in different scenarios, (a) SFTMP; (b) SMFMX; (c) SURLAG and (d) ESCO.
Figure 10.
Average calibration process of model parameters under the same iteration number () through 30 optimization trials in different scenarios, (a) SFTMP; (b) SMFMX; (c) SURLAG and (d) ESCO.
It is indicated from
Figure 9 and
Figure 10 that the value of the most sensitive parameter SFTMP needs to be varied through the whole calibration process, while its calibration is stopped when reaching some iteration number in the DDS algorithm. Similarly, the value of some more sensitive parameters, such as ESCO also needs to be varied many times, while it is calibrated with fewer variation times, scatter variation moments and obvious stagnation phenomenon in the DDS algorithm. However, less sensitive parameters SURLAG and SMFMX needs to be varied fewer times, while it is calibrated with more variation times, scatter variation moments and obvious stagnation phenomenon in the DDS algorithm. Therefore, no matter how sensitive these parameters are, they could be calibrated to their optimal values much faster with the HDDS-S algorithm than the DDS algorithm.
River basin model calibration results show that the computation time and efficiency could be improved in the HDDS-S algorithm, including the enhanced convergence rate of objective function, concentrated varied moments, reduced blind variation and stagnation phenomenon, compared to the DDS algorithm. Therefore, the HDDS-S algorithm is more efficient than the DDS algorithm in the river basin model calibration for the specific catchment.
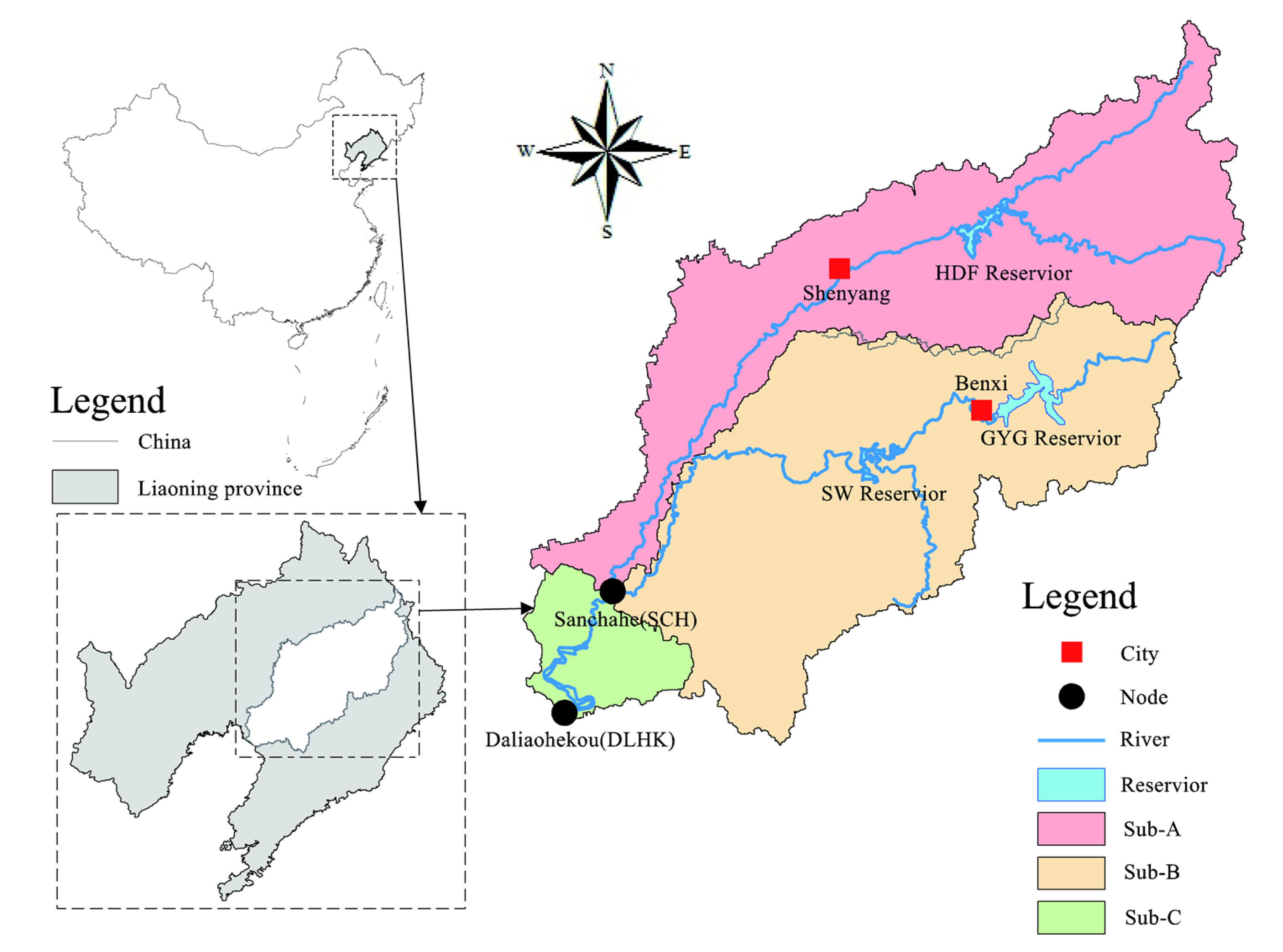
4.2. Multi-Reservoir Optimal Operation
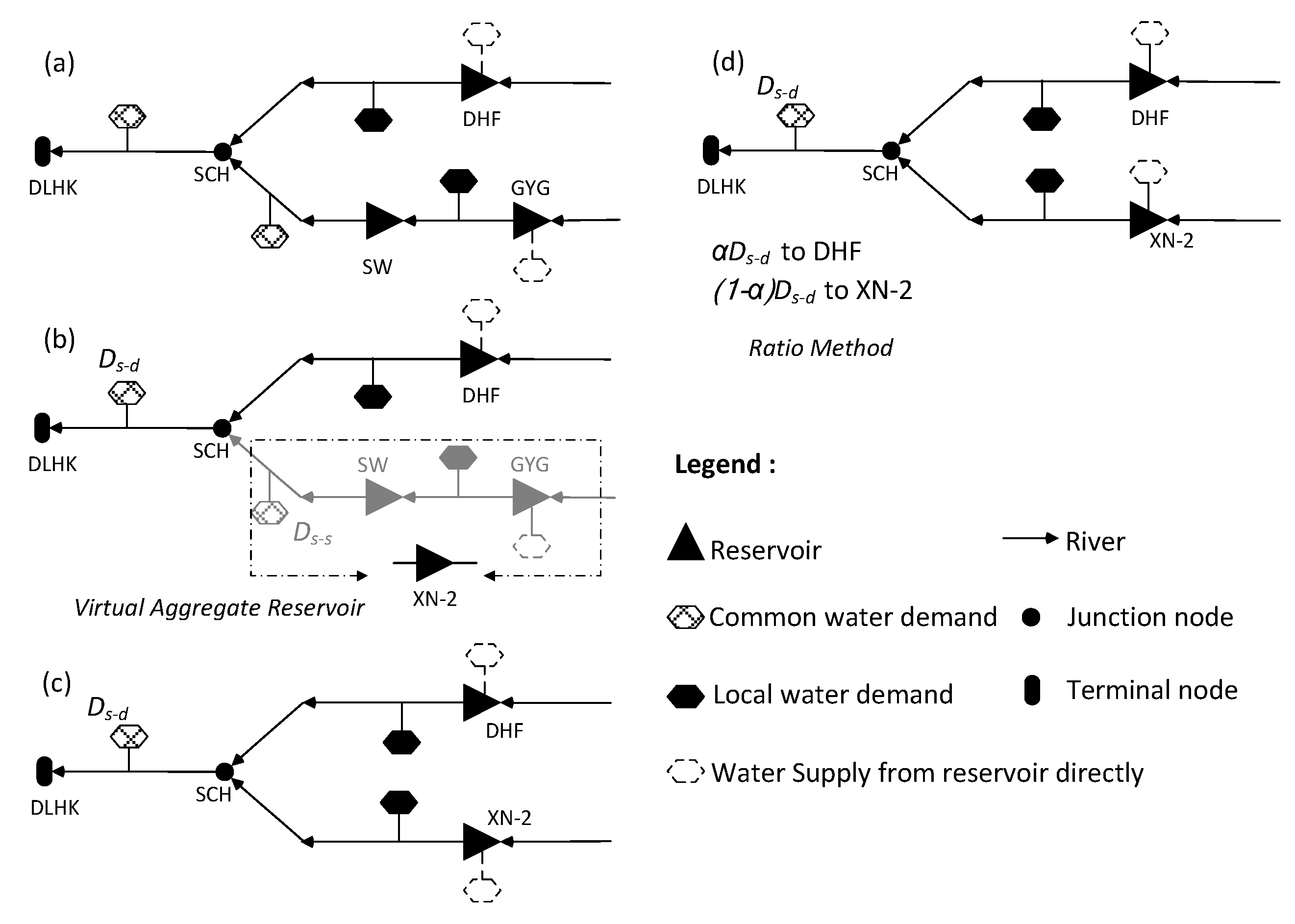
The optimal operation problem for DHF-GYG-SW multi-reservoir is used to evaluate the universality of the HDDS-S algorithm in river basin management. The input data are inflow and water demand data, including the industrial and agricultural water demands in the future planning year, i.e., 2030, and the history inflow from 1956 to 2006. Each calculation year is divided into 24 time periods (with ten days as scheduling horizon from April to September, and a month as scheduling horizon in the remaining months). Since the industrial water supply occurs through the whole year, there are twenty-four decision variables for industrial water supply. The agricultural water supply occurs only during the periods from the second ten-day of April to the first ten-day of September, thus there are fifteen decision variables for agricultural water supply. Therefore, the entire operation system has four rule curves and (24 + 15) × 2 = 78 decision variables in total.
Similarly, based on the two scenarios S0 and S1, i.e., multi-reservoir optimal operation in the case of the HDDS-S algorithm and multi-reservoir optimal operation in the DDS algorithm respectively, average performances of the two algorithms in multi-reservoir optimal operation are evaluated under the same iteration number () through 30 optimization trials from three aspects, including average required computation time, average objective function value, and average guaranteed water-supply rate on Intel Core™ 2 Duo, with a 2.66-GHz CPU.
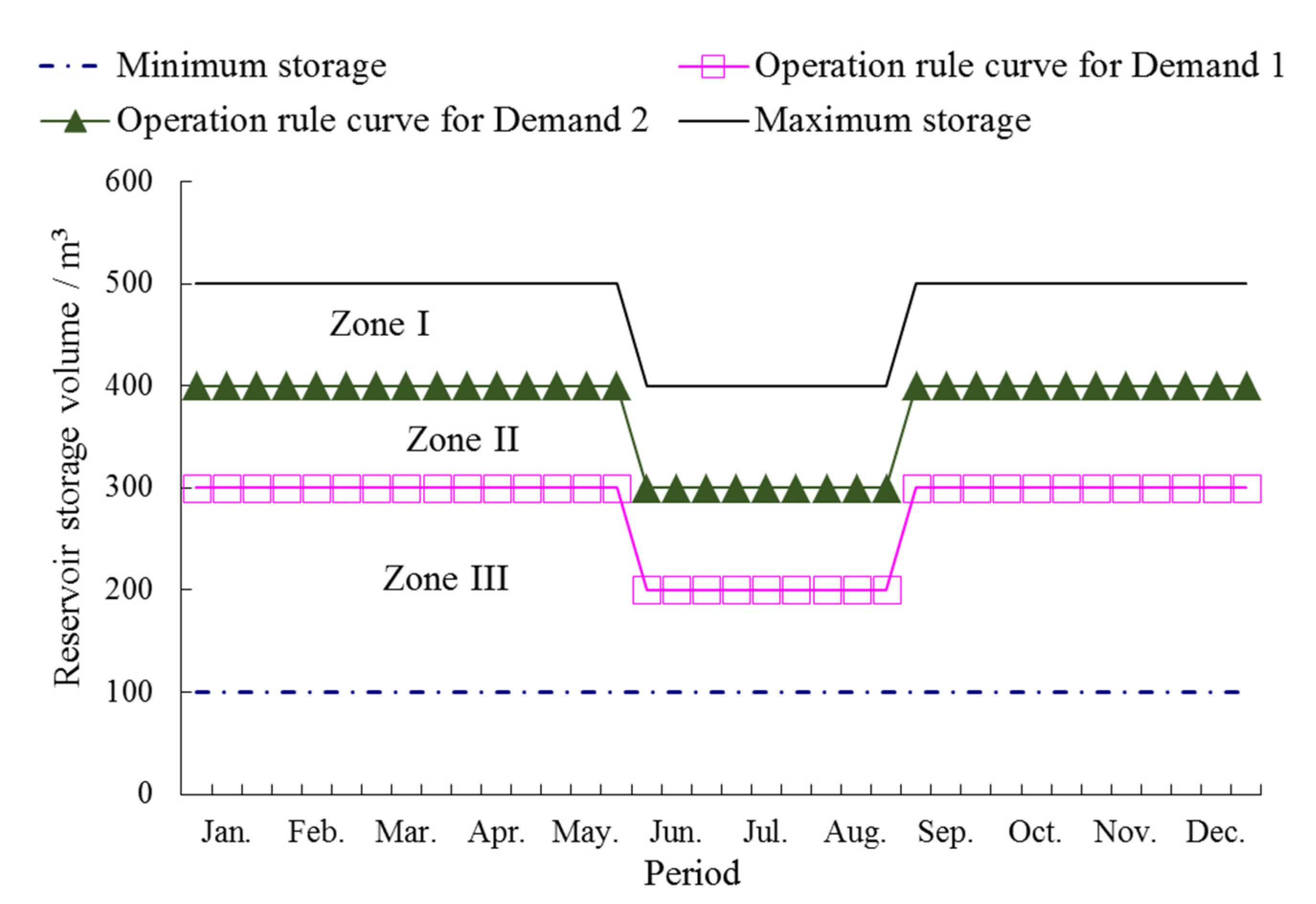
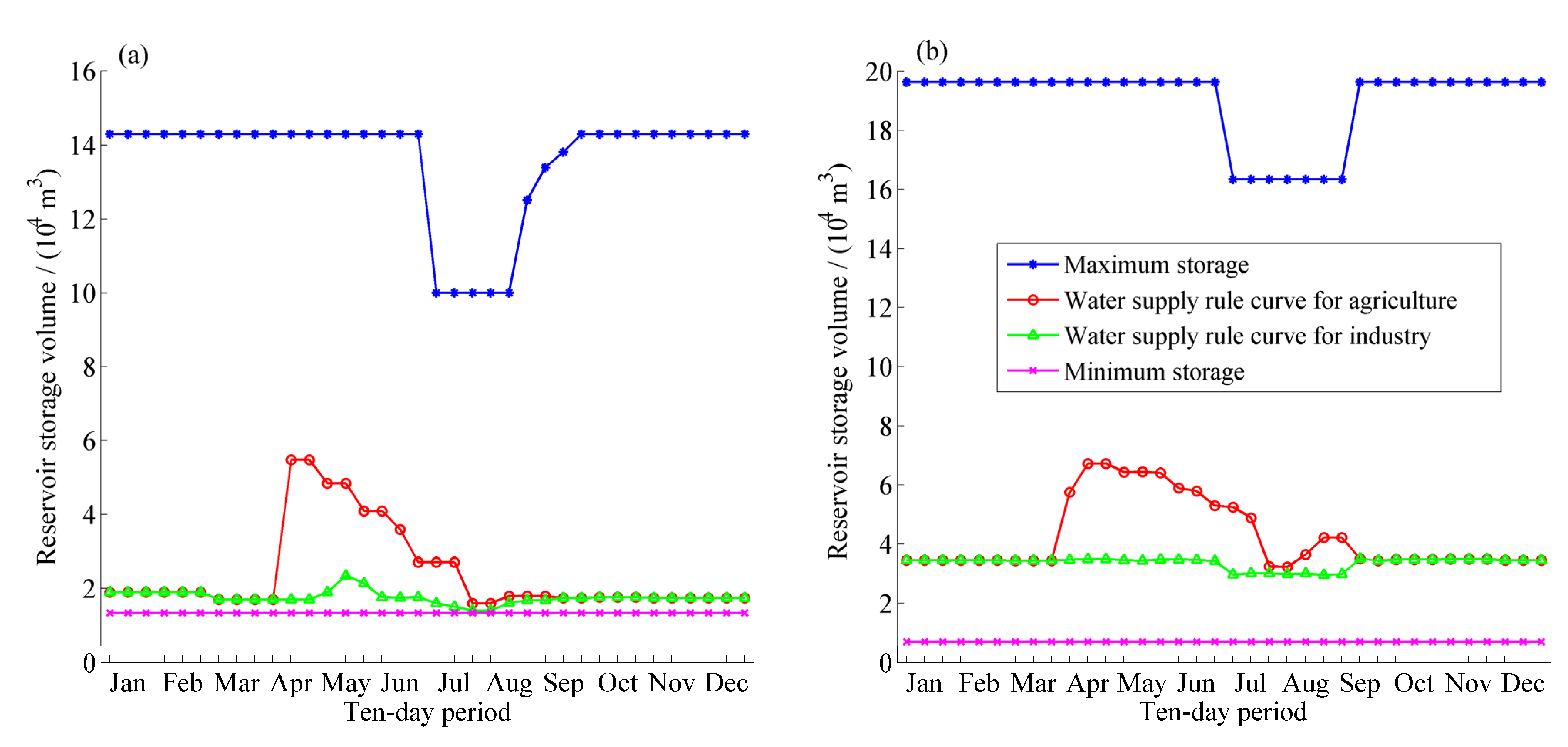
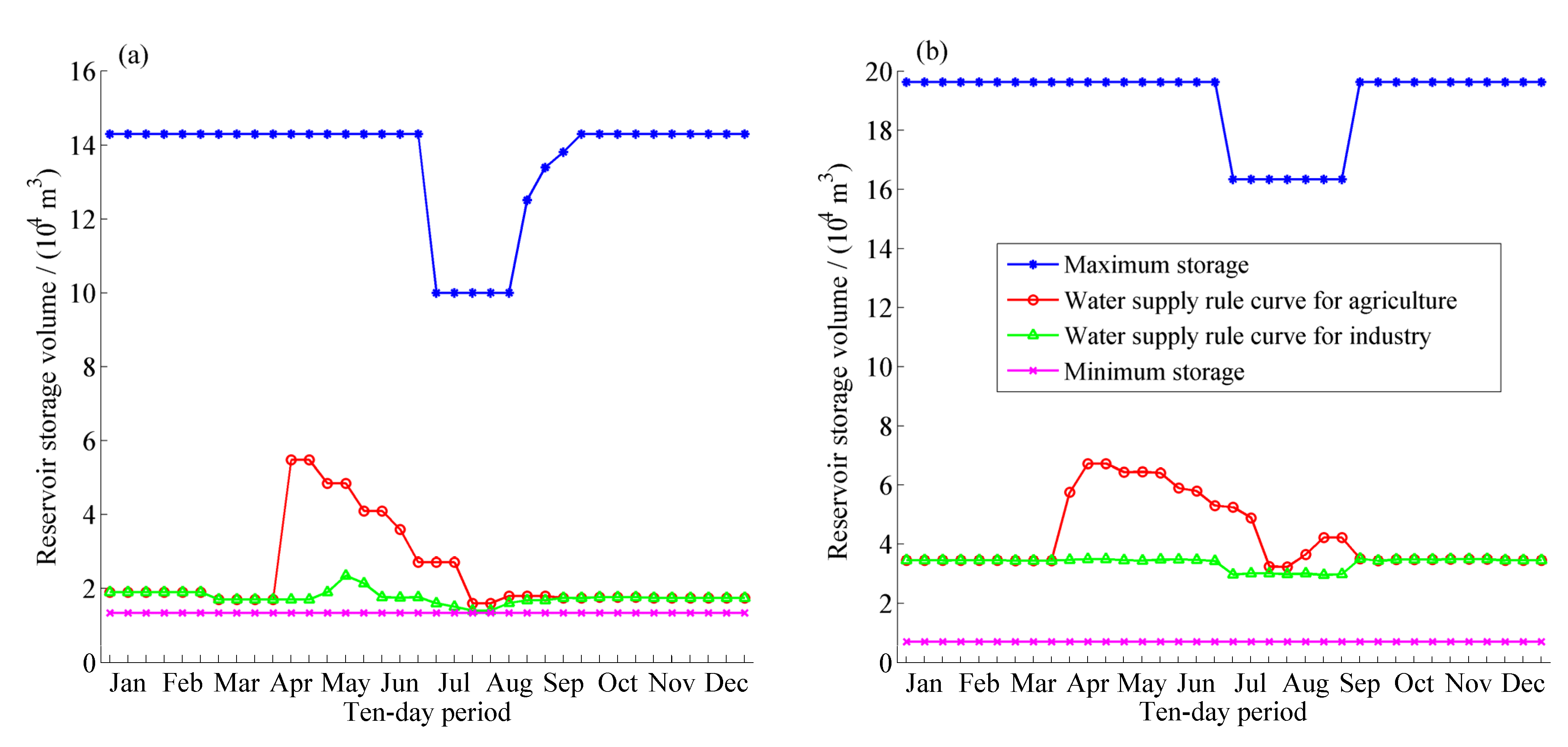
First of all, the rationality of operation rules derived after 10,000 function evaluations in one random optimization trial in the case of the HDDS-S algorithm is evaluated, and the joint scheduling charts are presented in
Figure 11.
As industrial water demand is more urgent than agricultural water demand, and the agricultural water would be limited primarily when reservoir storage is insufficient, the water supply rule curve for agriculture is above the operation rule curve for industry, as shown in
Figure 10. In the scheduling cycle duration, each rule curve decreases before the flood season and then has a different degree of uplift after the flood season. In order to prepare for the large inflow of the summer flood season and to reduce surplus water, the reservoir active storage before the flood season should be lowered and then the number of limited water supply is reduced,
i.e., the operation rule curves are decreased before the flood season. After the flood season, when the inflow decreases gradually, in order to ensure that no depth damage happens in dry years, the curves are raised to fill reservoirs as early as possible and the number of limited water supply is increased. In addition, the largest agricultural water use happens from April to May, thus the operation rule curve of agriculture is higher in the duration to conserve water and mitigate potential future shortages for industrial demand in some dry years. Specifically, referred to DHF reservoir, its water supply rule curve for industry falls in the duration from March to April due to spring floods produced by melting snow, meanwhile, its water supply rule curve for industry raises in May because the largest agricultural water use happens from April to May and much water has been supplied to agriculture.
Figure 11.
The derived operational rule curves with the HDDS-S algorithm after 10,000 function evaluations in one random optimization trial, (a) DHF reservoir operation rule curve; (b) XN-2 reservoir operation rule curve.
Figure 11.
The derived operational rule curves with the HDDS-S algorithm after 10,000 function evaluations in one random optimization trial, (a) DHF reservoir operation rule curve; (b) XN-2 reservoir operation rule curve.
Additionally, the average scheduling results determined by operation rule curves derived with the HDDS-S algorithm after 10,000 function evaluations in 30 random optimization trials are: (1) In Sub A, the guaranteed rate for industrial and agricultural water demands are 95.10% and 75.35% respectively; (2) In Sub B, the guaranteed rate for industrial and agricultural water demands are 95.81% and 75.46% respectively; (3) In Sub C, the guaranteed rate for industrial and agricultural water demands are 96.08% and 62.56% respectively. The average guaranteed rates in all three subsystems meet the requirement, i.e., guaranteed rate for industrial and agricultural water demands exceed 95% and 50% respectively.
Therefore, as mentioned above, the derived operational rule curves of DHF reservoir and XN-2 reservoir in the HDDS-S algorithm and the scheduling results are reasonable.
In different scenarios, under the same number of function evaluations (
), average required computation time and objective function value through 30 random optimization trials are shown in
Table 5.
Table 5.
Average computation time and objective function value under the same iteration number () through 30 random optimization trials in different scenarios.
Table 5.
Average computation time and objective function value under the same iteration number () through 30 random optimization trials in different scenarios.
| Scenario | Objective Function Value | Computation Time/Second |
|---|
| S0 | 9.13 | 723.73 |
| S1 | 25.68 | 294.37.2 |
Under the same number of function evaluations (), though larger differences of average required computation time exist in different scenarios, average objective function value decreases from 25.68 in the DDS algorithm to 9.13 in the HDDS-S algorithm, which improve obviously.
Average guaranteed water-supply rates for all water supply area under the same number of function evaluations (
) through 30 random optimization trials in different scenarios are shown in
Table 6. Under the same number of function evaluations (
), though few differences of average guaranteed rate for industrial water demand exist in different scenarios,
i.e., the guaranteed rate for industrial water demand in all three subsystems exceed 95%, the average guaranteed rates for agricultural water demand in all three subsystems increase from 67.52%, 64.78% and 50.94% in the DDS algorithm to 75.35%, 75.46% and 62.54% in the HDDS-S algorithm in Sub A, Sub B and Sub C respectively, which improved obviously.
Table 6.
Average guaranteed water-supply rate under the same iteration number () through 30 random optimization trials in different scenarios.
Table 6.
Average guaranteed water-supply rate under the same iteration number () through 30 random optimization trials in different scenarios.
| Water Supply Area | Guaranteed Water-Supply Rate (%) |
|---|
| Industry | Agriculture |
|---|
| S0 | S1 | S0 | S1 |
|---|
| Sub-system | Sub A (DHF subsystem) | 95.10 | 95.06 | 75.35 | 67.52 |
| Sub B (GYG-SW subsystem) | 95.81 | 96.00 | 75.46 | 64.78 |
| Sub C (SCH-DLHK subsystem) | 96.08 | 96.25 | 62.54 | 50.94 |
Optimal operation of DHF-GYG-SW multi-reservoir results show that the derived operational rule curves of DHF reservoir and XN-2 reservoir and the scheduling results from one random optimization trial are reasonable in the case of the HDDS-S algorithm, while average guaranteed water-supply rates in all subsystems could be improved in the HDDS-S algorithm under the same number of function evaluations () through 30 random optimization trials compared to the DDS algorithm. Therefore, the HDDS-S algorithm is able to derive good solutions and thus is effective in the specific large multi-reservoir optimal operation.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}