1. Introduction
In recent years, the development of nanoplasmonic has been a topic of increasing interest with significant applications, such as, e.g., surface enhanced Raman spectroscopy, photovoltaic devices optimisation, optical filters, photonic band gap structures, biological and chemical sensing [
1,
2,
3,
4,
5]. This recent progress has been obtained thanks to the advances in nanofabrication technology. Plasmonic nanoparticles are of great interest for light trapping in thin-film silicon solar cells, hence for the manipulation of light confined to small length scales. Therefore, the areas of propagating electromagnetic modes on metallic dielectric interfaces, resonances between the electron gas and surrounding dielectrics, and the interaction of light with metals, are widely studied [
6]. In such a field, optical systems made of a metal-dielectric interface are liable to electromagnetic modes called Surface Plasmon Polaritons (SPPs) and make it possible to control light having wavelengths below 100 nm [
7,
8,
9]. SPPs are collective oscillations of electrons occurring at the interface between a metal and a dielectric when a photon couples to the free electron gas of the metal. Some papers have appeared in the literature to describe the simulations and analyses of the excitation and propagation of SPPs on sinusoidal metallic gratings in conical mounting and the bending in metallic nanowires [
7,
10]. Several papers in the literature have proposed correlation models for SPPs propagation length and excitation wavelength, e.g., [
11] describes a correlation model in terms of center-to-center pitch among waveguide relative maxima. However, such proposed models are typically used in triple interfaces (dielectric-metal-dielectric or metal-dielectric-metal. Hence, more studies and investigations are needed due to the actual poor understanding of the propagation phenomena in the plasmonic nanostructures, especially concerning asymmetrical systems such as dielectric-metal structures [
12,
13].
In this paper, we examine the propagation of SPPs due to the combination of the molybdenum nanostructure in the presence of a dielectric exposed to an electric field and photon fluxes with energies spanning a wavelength range 400 to 700 nm. Therefore, we propose a novel neural network (NN) topology, dubbed Nested Neural Network Architecture (NNNA), assisting us to study the inner relation between SPPs exciting wavelength, metal thickness and SPP wavelength and propagation length at a metal flat interface separating dielectric medium. As a result, by employing such a suitable NNNA topology we can determine the interdependence between SPP propagation and metal thickness. Due to the high sensitivity level of the neural model to data oscillations a novel NN training procedure has been devised in order to avoid polarisations and miscorrections of some NN weights. Moreover, since such a training procedure could be computationally expensive and take a long time, a parallel version using an OpenMP environment, with shared memory, has been developed and optimised to obtain maximum advantage from the available parallel hardware. A big amount of data has been put into proper use for the investigated NN topology. Such data have been made available by solving 3D Maxwell equations with the relative boundary conditions. For the resolution of the electromagnetic field and for the investigations of SPPs characteristics in a simple plasmonic structure, we have been developed numerical calculations and simulations to solve Maxwell’s equation with the Finite Element Method (FEM). This has been performed by using the commercial software packages COMSOL Multiphysics (v 4.3b, COMSOL Inc., Burlington, MA, USA).
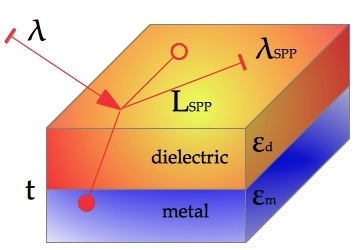
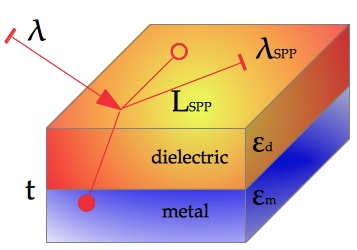
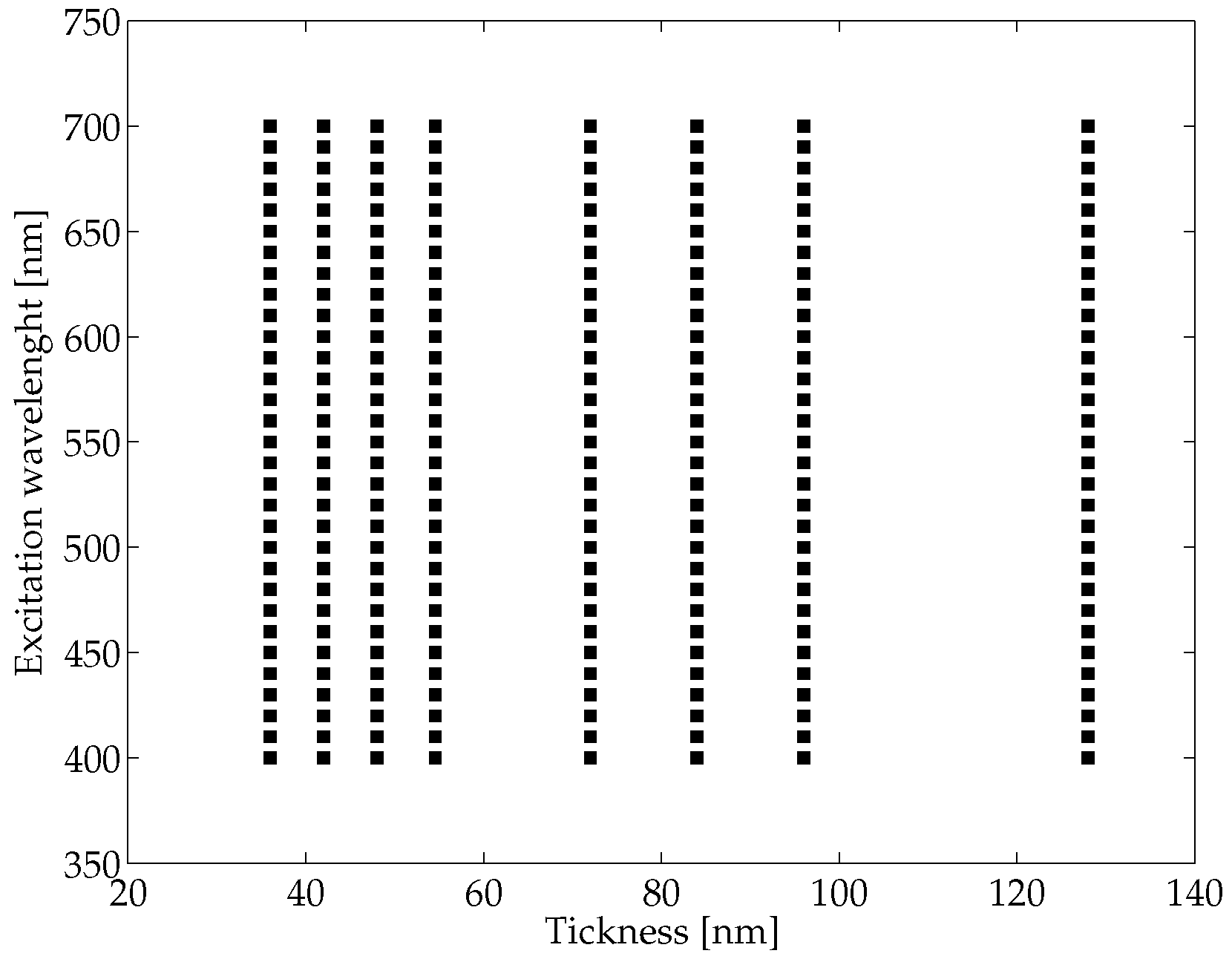
In our simulation, we used a 3D geometry (see
Figure 1) to represent the two media (metal and dielectric) and solved the full wave 3D Maxwell equations (using the above said software packages). Then, we have computed the propagation length
and plasmon wavelength
for different thickness conditions. The external surface of the plasmonic structure has been modeled by means of perfectly matched layer boundary conditions and taking into account the monochromaticity conditions for the exciting photon flux. The energy of such photons has been selected within an excitation wavelength, named
, in the range of 400 to 700 nm, therefore compatible with the visible light spectrum. As reported in
Figure 2, in our simulation we considered several excitation wavelengths (
) and thicknesses (
t). For each pair of values
and
t, we have computed the corresponding surface polaritons’ wave propagating from the dielectric-metal interface and decaying into the metal.
In the following we will first give, in
Section 2, an introduction to SPPs.
Section 3 describes how the initial data have been computed.
Section 4 explains the proposed novel neural network architecture that models the correlation between each scenario (in terms of excitation wavelength and thickness) to the related SPPs wavelength
and propagation length
.
Section 5 describes our parallel procedure for training. Finally,
Section 6 draws our conclusions.
2. Brief Introduction to Surface Plasmon Polaritons (SPPs)
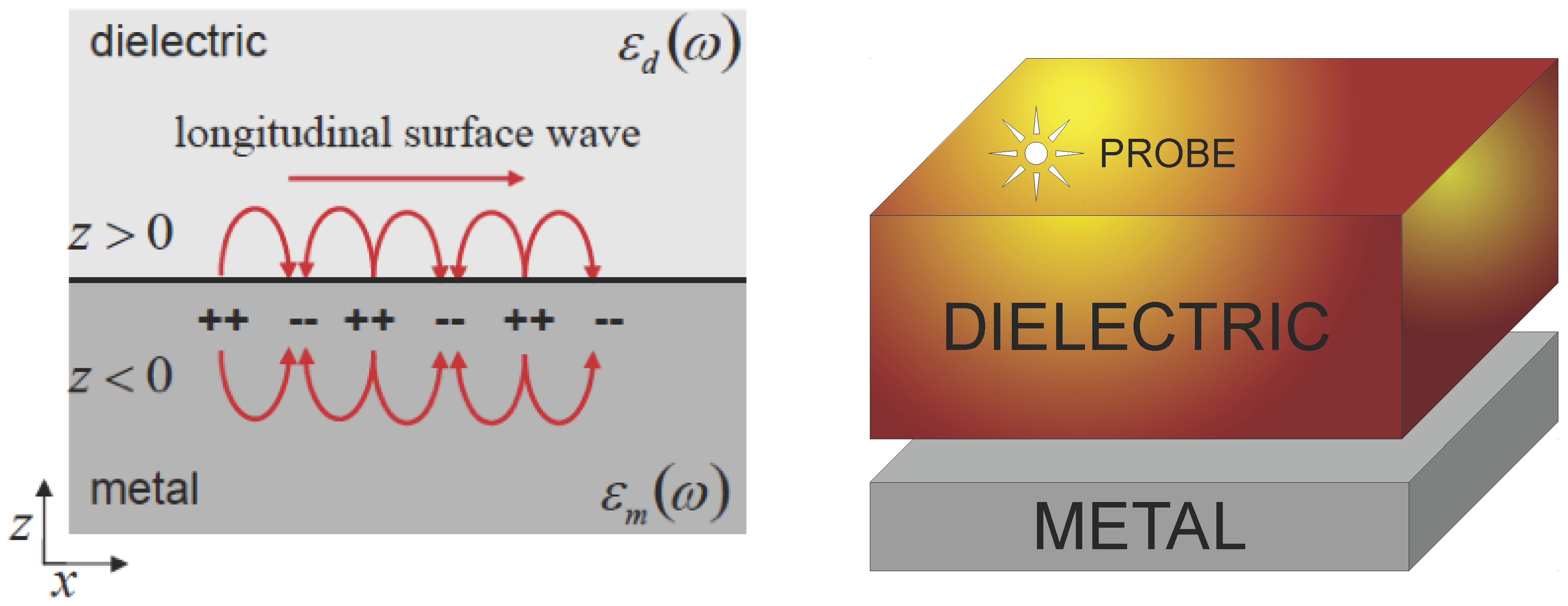
SPPs can only be generated along metal-dielectric interfaces over a wide range of frequencies and evanescently decay in the perpendicular direction of the metal-dielectric interface. Recently, the light absorption by solar cells patterned with metallic nanoparticles has been investigated; however, we consider light-excited SPPs at the metal surface proposing an investigation that can be used to efficiently capture light in solar energy conversion cells [
2].
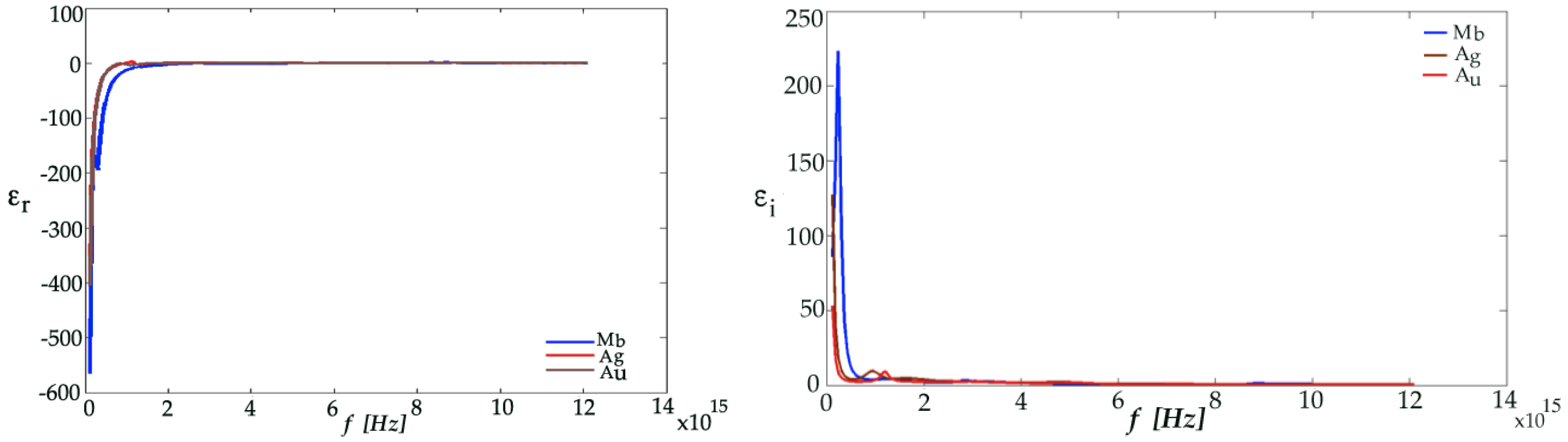
At ultraviolet and visible frequencies, the noble metals (Au, Ag, etc.) acquire a behaviour similar to that of a dielectric, and allow the propagation of electromagnetic (EM) waves with a significant penetration within the metal, where the losses of energy are strongly related to the electronic structure. The scattering properties can be represented by a complex dielectric constant. The losses in the conductor are due to collisions between the free electrons and interband transitions. The optical properties can be explained by the plasma model, where a number of free electrons move against the fixed ions (Drude model). The electrons oscillate in response to the applied electromagnetic field with a characteristic collision frequency and a certain relaxation time, determining the frequency dependence of the dielectric constant [
14].
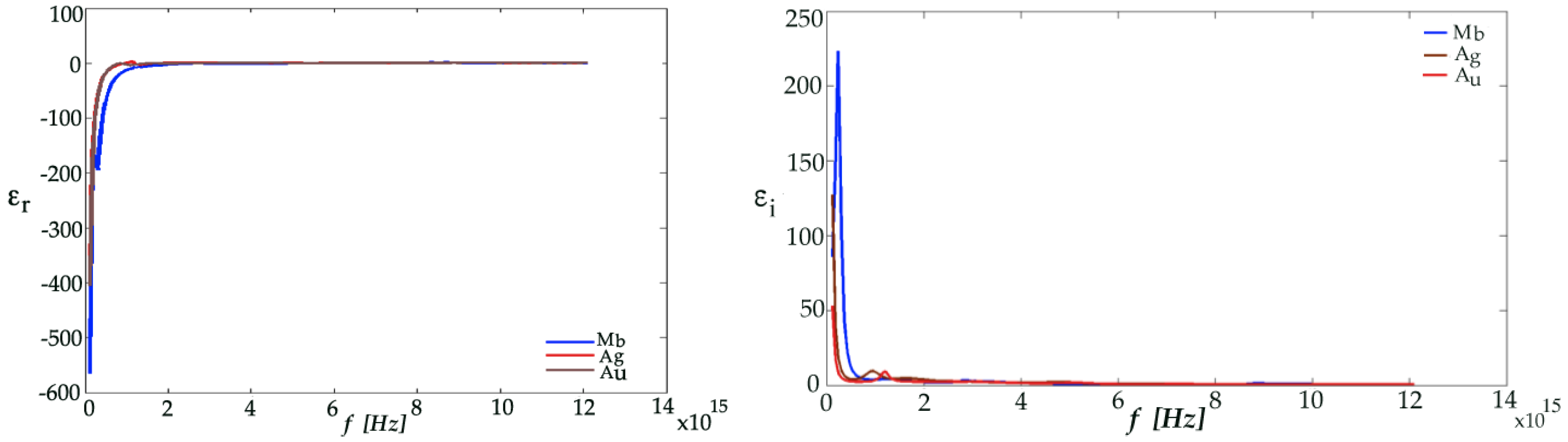
It was observed that the dielectric constant evaluated as a relative complex for the noble metals with the high negative real part value of the dielectric constant, would assure the existence of the plasmons. The negative real part of the dielectric constant of various metals such as Au, Ag and Mb decreases with the increase of wavelength, while the imaginary part is increased as shown in
Figure 3.
The simplest geometry that can generate SPPs is that of a single and flat interface (see
Figure 1 (left)) between a dielectric with a real dielectric constant
and an adjacent metal described by means of a dielectric function
, where
.
The following reports the mathematical equations that describe the propagation of SPPs in both the dielectric (
d) and the metal (
m). Of course, such equations have same mathematical form, however they differ in the constants describing the medium:
with boundary condition at
, we obtain the following equivalencies:
and finally, as implied, we have the Snell equation:
In this discussion, we have assumed that the interface is normal to the
z-axis and SPPs propagate along the
x direction (i.e.,
), the SPP wave vector
(or
β) is related to the optical frequency
ω through the dispersion relation:
We take
ω to be real and allow
to be complex, since our main interest is in stationary monochromatic SPP fields in a finite area, where:
is the wave vector in free space, and
is the wavelength in vacuum. For metals, the permittivity is complex, which leads to
being complex. The imaginary part of
defines the SPP’s damping as it propagates along the surface. The real part of
is related to the plasmon’s wavelength,
, as:
The SPPs propagation length,
, is defined as:
In conclusion of this brief review of SPPs, we report the expression of the electric field of plasmon wave:
where
,
.
3. Input Data for Our Nested Neural Network Architecture (NNNA)
In this paper we investigate a metal-dielectric interface composed of Molybdenum. This structure reduces the computational effort for the investigations on the relation between dispersion and thickness of metal. Even though, this relation is unaffected by the complexity of the structure.
Initially, in order to generate SPPs, we used an electromagnetic plane wave TM-polarised with angle of incidence equal to 45 degrees. The metal-dielectric interface was excited by a probe-antenna, with a size of 1320 nm by 6.6 nm, inserted through a glass film with a refractive index of 1.5 to induce the electric field in the metal/air interface. By solving the full wave 3D Maxwell equations in the simple geometry shown in
Figure 1 (left), which separates metal and dielectric, using the finite element method-based software package COMSOL Multiphysics, we have obtained the
and
data values for several thickness values. The perfectly matched layer boundary condition was chosen for the external surface of the plasmon structure.
The values of
and
were computed for different values of excitation wavelength
in the visible range (spanning from 400 to 700 nm) and for the following thickness values
t of the metal: 36, 42, 48, 54, 60, 72, 84, 96 and 128 nm (see
Figure 2). The produced data were used to train and then test a neural network architecture modelling two functions
and
, where
and
t represent the excitation wavelength and the metal tickness, respectively. As previously stated,
and
represent the propagation wavelength and length of the generated SPPs, respectively. Note that
depends on
, therefore the latter should be computed before the related
. However, the implemented NNNA is able to handle the intrinsic
dependence on
, therefore we have trained our NN to receive pairs
as input, and return pairs
as output.
After the training procedure, our NNNA has been tested by asking to produce the resulting and when given inputs differing from the training set. The results of the NN have then been compared with the result given by the COMSOL simulations. The initial dataset computed by COMSOL consisted of 279 pairs . Such a dataset has been shuffled randomly to avoid possible polarisation issues, then the resulting data points have been organised as a 1D input sequence.
In order to test our NNNA on the overall input space, we have organised the experiment in three phases, each dealing with its own set of input data. In each phase, firstly our NN starts from an untrained state and is given two thirds of the data derived by COMSOL as training set. The training phase lets our NN learn the respective input-output relations. Secondly, the trained NNNA is given the other one third of data, which was not used for training. Therefore, the NN gives results on data never seen before. Finally, for the last third of data an error is computed by comparing the NN results and the actual values given by COMSOL. The test goes on, for each phase repeating the said three steps, by having for each phase a different two third partition of data for training, and the remaining one third of data for test. Therefore, we have performed a blind cross validation on the overall input-output space, each time using data that were not fed to our NN during the training sequence on the same phase.
4. The Proposed Neural Network Architecture
The nature of the problem at hand presents several challenges that could tamper with both the performances and the precision of the results when trying to model such phenomena. The SPPs propagation length
and wavelength
depend on each other, i.e., the propagation length intrinsically depends on the relative polariton’s wavelength
λ. Therefore, the models for predictions of such values starting from
t and
are non trivial, therefore we decided to cope with the intrinsic complexity of the model by using a Neural Network based approach to obtain a data-driven parametrical model [
15,
16,
17,
18,
19,
20].
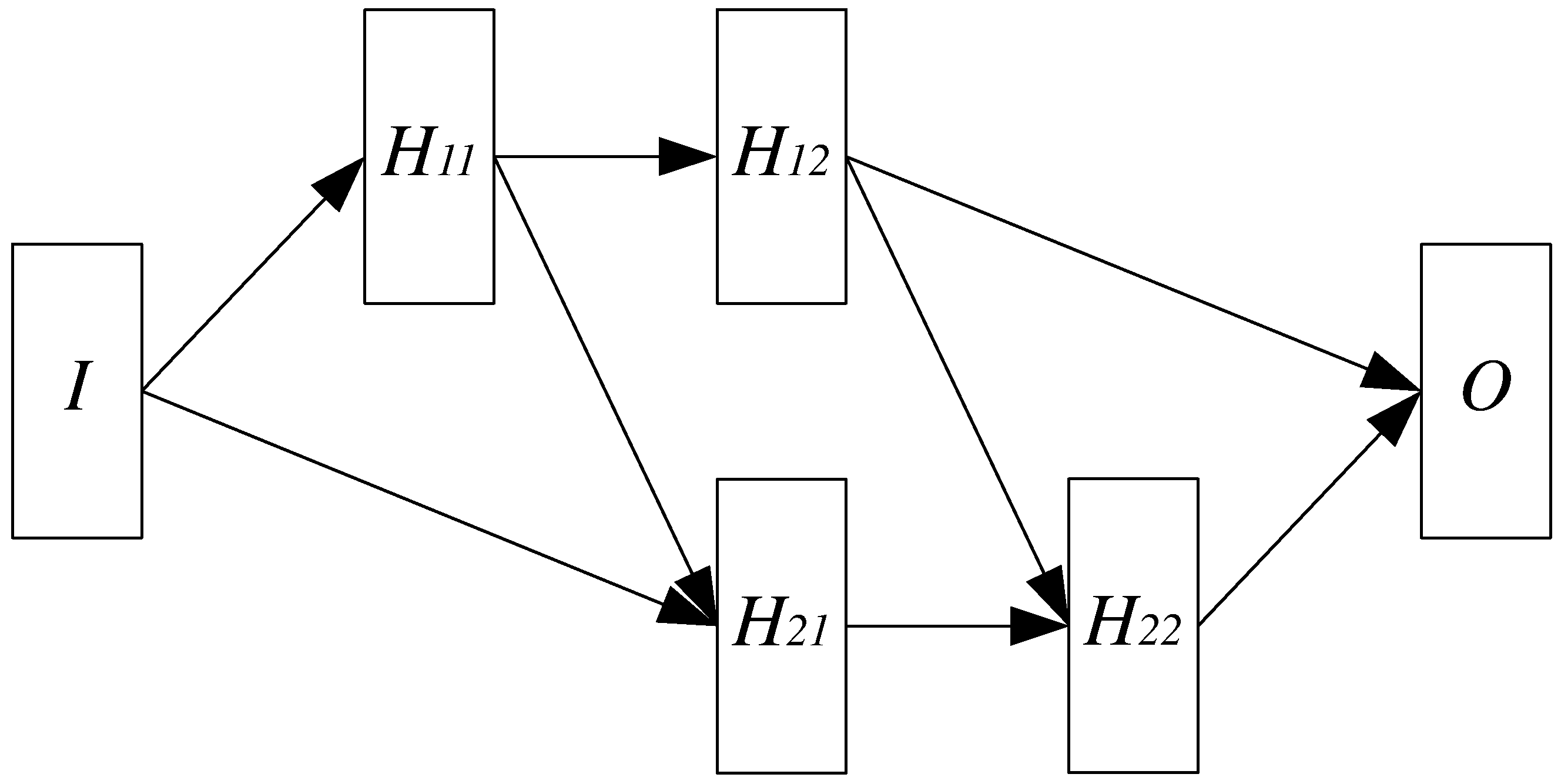
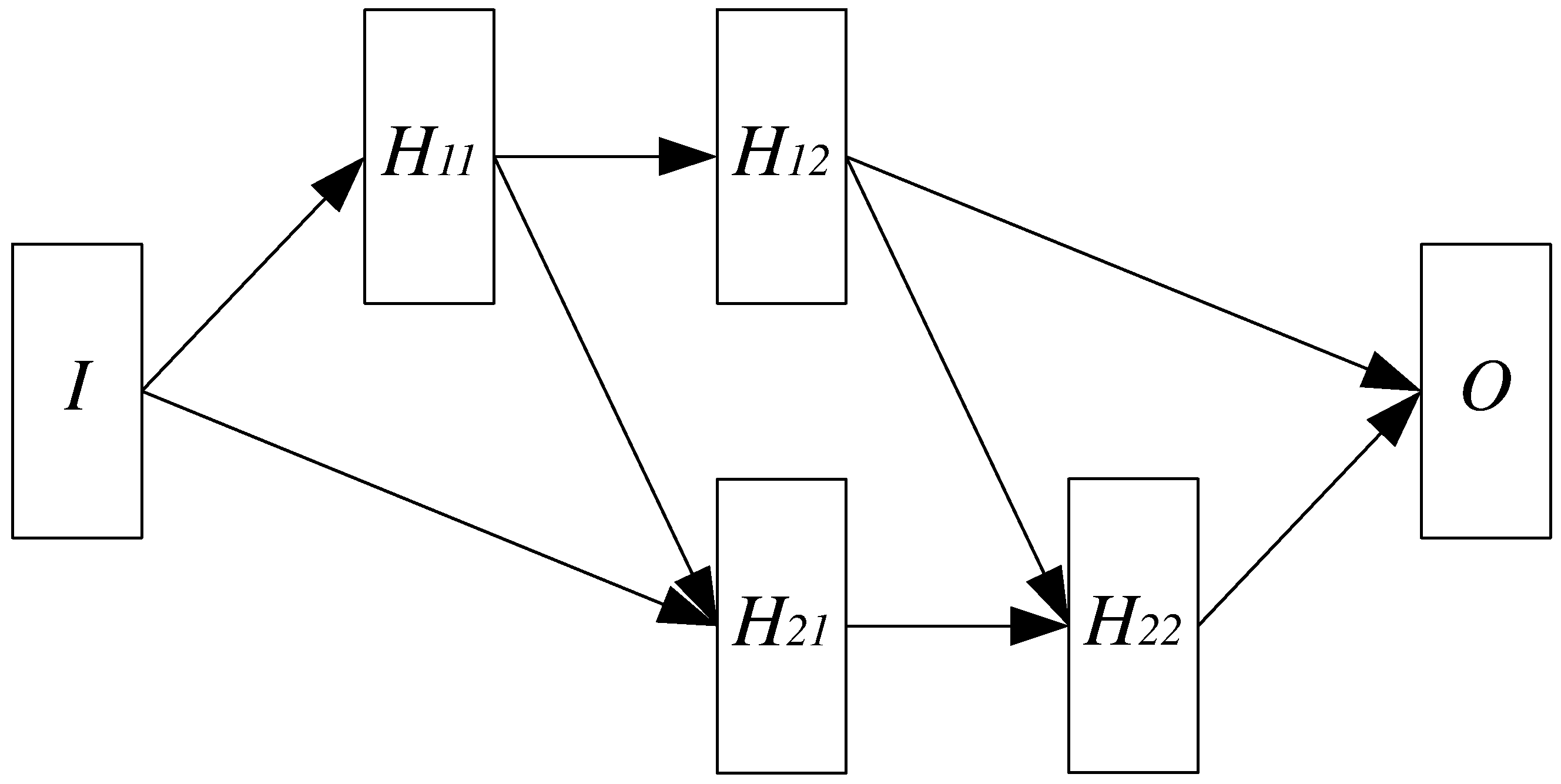
In this work we propose a Nested Neural Network Architecture (NNNA) as a basis of our approach, due to its ability to cope with data interdependency problems such as the one at hand. The proposed NNNA is depicted in
Figure 4 and consists of several stages, shown as rectangles. Overall, this architecture performs parallel asynchronous predictions of both
and
by letting the stages inherent the prediction of
, i.e.,
and
, to precede the respective stages inherent the prediction of
, i.e.,
and
, as can be seen by the interconnecting arrows.
This configuration achieves better performances when compared to a solution using two separate neural networks: the first to model and predict , and the second to obtain by taking as input the result obtained from the first neural network. For such a configuration, the two separate neural networks should be trained individually, then performance degradation would arise due to error composition among the two networks.
Previously, we had implemented an ad-hoc nested cascade network architecture and for it we had an accurate validation system that checks the performance status by considering the mean squared error, and the error introduced on the Fourier spectrum of the predicted signal [
10,
21]. The latter check was necessary in order to remove the possible artefacts introduced on the neural model used to predict
by taking the results of the predictive neural model for
. However, such a procedure is very expensive in terms of computational performance and overall elapsed time. Due to the interdependency of
and
, then, we have devised the proposed NNNA due to the possibility to train the neural system as an overall predictor for both
and
.
For the adopted NNNA, we can see that and are being produced by two different pipelines, and while the first pipeline, producing , is autonomous, the second pipeline receives data from the first one. By using the data jointly for the two pipelines, giving them the same input, the second pipeline can output the correct value of .
Figure 4 shows that the input layer
I and the output layer
O are distinct from other layers. Moreover, the hidden layers are organised as a shifted matrix, where the layers on the first row (namely
and
) are involved on the prediction of
, and the layers on the second row (namely
and
) are involved on the prediction of
.
As stated before, in order to predict
, the correspondent layers need to have input from the layers predicting
, therefore
and
are delayed by one time step with respect to
and
. This is the reason behind the polygonal shape of the adopted neural network topology, which basically derives from a pair of Feed Forward Neural Networks (FFNNs) [
22], with modified inputs and delayed time steps, each one dedicated to one prediction pipeline.
On the other hand, while the first pipeline is a standard FFNN, the second pipeline consists in a modified version of a FFNN where the input sources for and are twofold: the layer receives inputs both from the input layer I and the hidden layer , the layer receives inputs from and .
The internal composition detail of each layer for the proposed nested neural network architecture, as well as the activation functions and number of inputs is given in
Table 1.
5. Training Procedure on OpenMP
The neural network architecture proposed above has introduced a sequential validation phase for the results of the first neural module. Validation has to be performed before the first module results can be sent as input for the second module. Unfortunately, such sequential operations make the training process expensive in terms of CPU time. In order to shorten training time we have developed a parallel implementation of the same neural network architecture, using OpenMP, that manages to obtain asynchronous training and validation.
Generally, when parallelising an application using OpenMP, processes are forked, joined and synchronised (e.g., by means of a barrier). Such mechanisms, however, introduce a runtime overhead, e.g., when the processes having produced and communicated their results have to wait until the synchronisation barrier is over. This is often the case when the computation times of processes are not perfectly balanced [
23,
24,
25,
26,
27]. Therefore, our parallel version aims at reducing such an overhead by avoiding, as much as possible, the fork-join-barrier constructs, and by introducing instead processes that produce and consume data. The main reason for using OpenMP is that, by means of a shared memory, communication overhead among processes can be avoided, however, on the other hand, shared memory requires a complex handling of semaphores and locks before accessing some parts of the memory itself. We have handled the synchronisation concern in such a way that overhead is minimised [
28].
Mainly, the proposed parallel solution is based on the continuous execution of different processes to care for the different phases of training for the above NNNA. In our experiments a multi-core processor has been used, however any kind of shared memory system supporting OpenMP directives can be employed. The first process is responsible to train the pipeline and this process will be started at the beginning. The second process is responsible for training the pipeline , taking some input from the previous pipeline, and will be started after the first process has performed a given number of training epochs (see the following). The code of the second process has been developed so that it cannot change the weights of the connection between . The third process is responsible to train the stages and , hence to make the output converge according to the given input I and the subsequent transformations by the other layers. Such a process is started after the second process has performed a given number of training epochs (see the following). Once the third process ends, the training continues with another iteration that starts with the first process, then the second, etc.
The proposed NNNA has been trained to predict the values of
and
starting from an input vector.
To evaluate the performance of the NNNA two different kinds of errors were considered. We define two
local errors and
, as well as a
global error as follows:
where
indicates the expected value (as given by COMSOL simulation) and
indicates the NNNA result. As can be clearly seen in Equation (
10), the layer errors
and
have been computed as the module of the difference vector between the expected output vector and the output layer vector. Moreover, the global maximum error
has been computed as the maximum error between the previous two errors. For each training epoch, the outputs from layers
,
and
O (see
Figure 4) were used to compute the errors
,
and
as in Equation (
10), respectively.
The training has been organised in four different phases executed on an OpenMP environment. The first phase provides as input to the whole NNNA a training pattern, which has been previously generated (i.e., the results of the COMSOL simulation). A fair amount of 50 epochs has been selected for this phase. The second phase starts once the first phase has terminated and uses a gradient descent algorithm to adjust the neural weights of the hidden layers and as if they would be an independent neural network. On the other hand, the latter training procedure takes into account only the predicted values of excluding the evaluation of . For this second phase 10 training epochs will be performed. Then, a third phase begins to adjust the weights of and basing on the error prediction of . This third phase consists of 20 training epochs. Finally, in the fourth phase, the output layer weights will be adjusted.
The four phases above correspond each to a specific OpenMP process. At the end of the training epoch the global neural network performances are stored for further analysis. All the measures of performance involved in the training process are given by the Mean Squared Error (MSE), though for the global network performances, the formula is adjusted by using the global error
in Equation (
10).
Our effort during development has been to optimise the use of computational resources, hence autonomous processes needing as less synchronisation as possible have been implemented as described above. Our proposed solution manages to greatly reduce the wall-clock timeframe needed for the training.
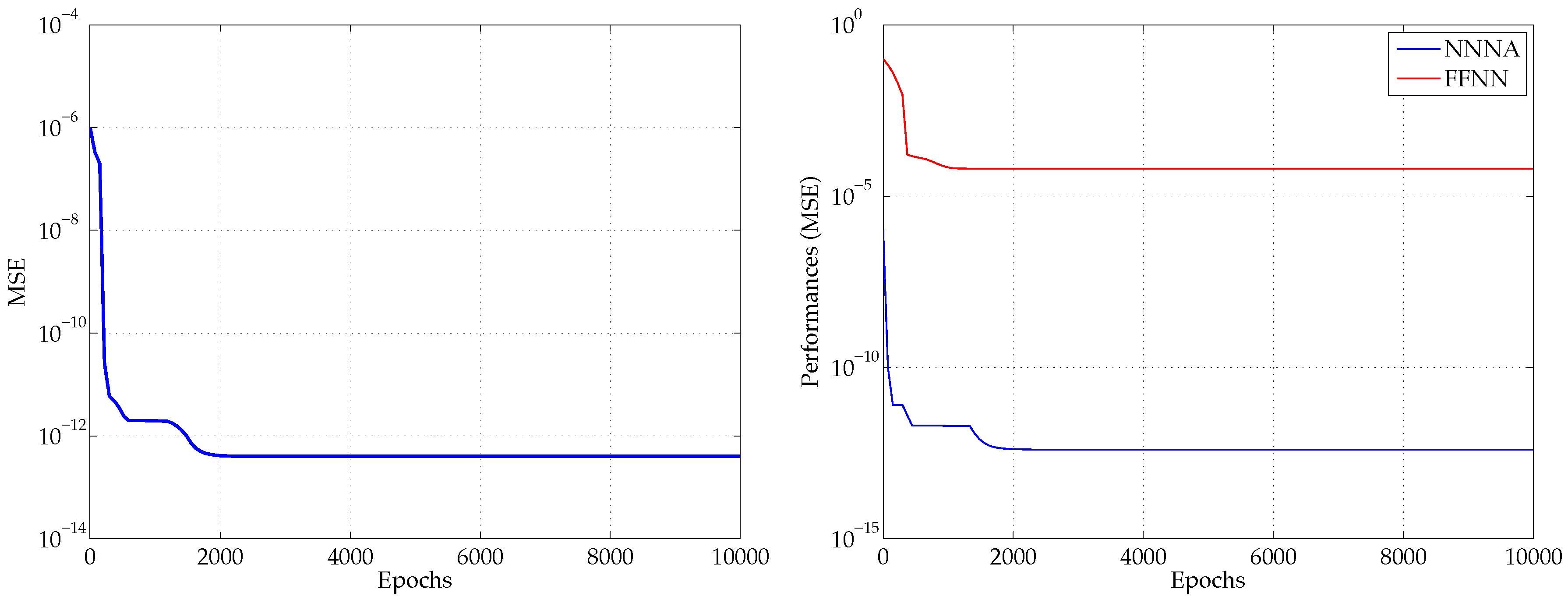
6. Results and Conclusions
Figure 5 shows both a performance plot for the proposed NNNA, when trained with the adopted multithread technique on an OpenMP environment, and a comparison with a different approach using two standard FFNNs, each one having two hidden layers, respectively counting 10 and 7 neurons and activated by means of a
tansig and a
logsig function. The comparison shows that our proposed approach outperforms the FFNN approach, and the latter presents an error having a magnitude exceeding the predicted data values.
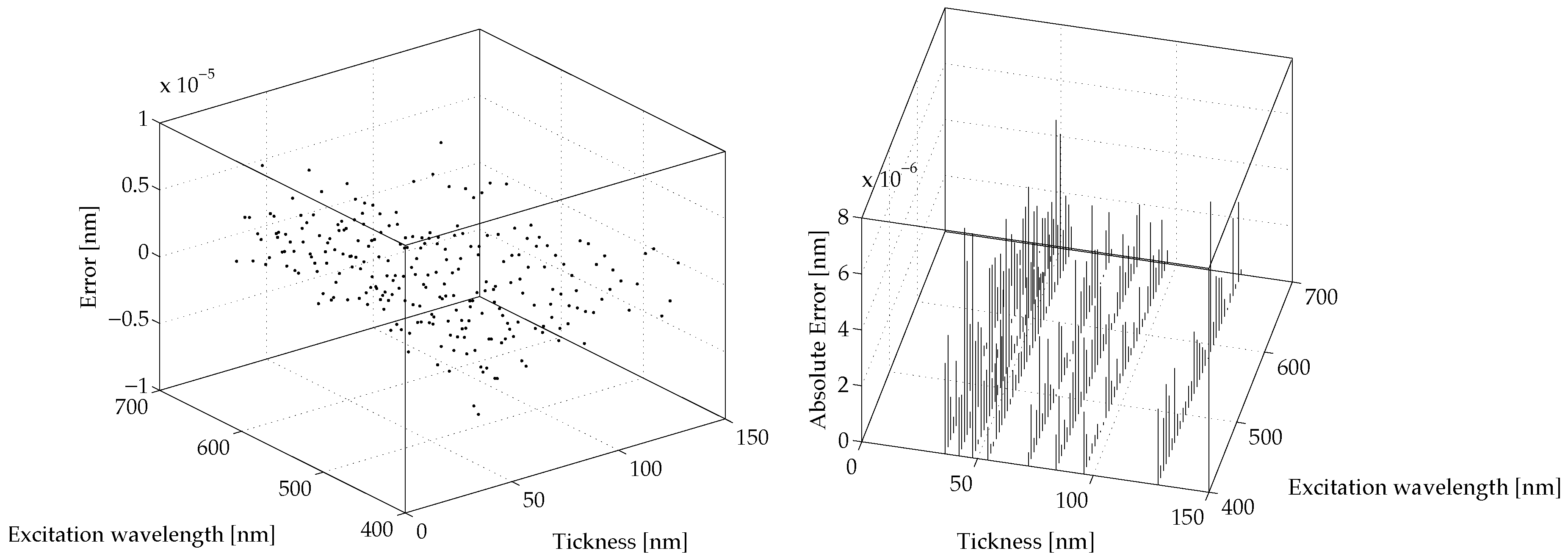
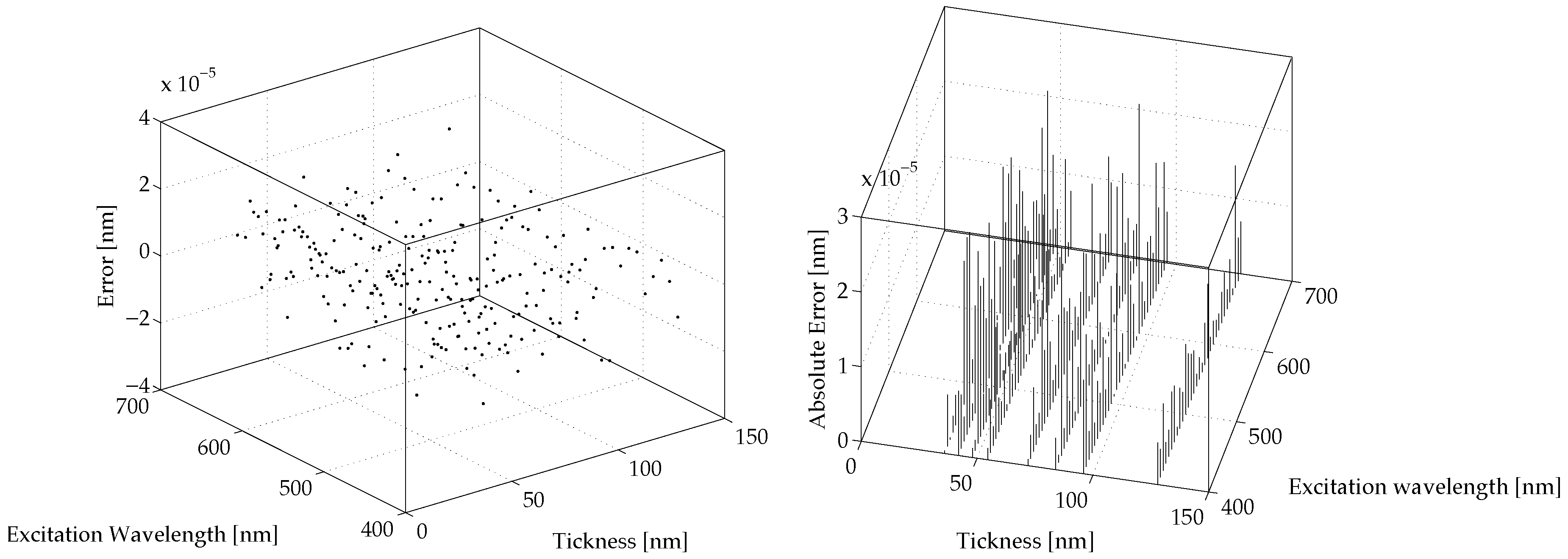
Figure 6 and
Figure 7 show the prediction errors for the proposed NNNA for the modeled values of
and
, respectively. The said prediction errors are computed as
by difference between the results produced by COMSOL simulation and the results produced by our NNNA during testing (see
Section 3).
For both and the error is greatly lower than a realistic measurement a priori error. The average RMS for the predicted is less than nm, while the average RMS for the predicted is less than nm.
The proposed NNNA constitutes a novel approach to model the propagation of collective electrical oscillation at the interface between a metal and a dielectric. Our architecture has been able to model and correctly predict both the polaritons propagation wavelength
and the related propagation length
, as well as to reproduce the effective dependence of
on
. The latter outcome derives from both the adopted topology and the innovative training method. The NNNA consists of a comprehensive structure similar to a pair of cascade FFNNs, however it greatly improves the individual performances of singularly trained FNNN (see
Figure 5).
This makes it possible to separately specialise each one of the two pipelines of the NNNA. While the first pipeline has been trained to predict , the second was dedicated to the prediction of also using the intermediate results produced by the first pipeline. Moreover, the adopted and dedicated training procedure is both advantageous in terms of computational performances, due to the multithread execution, and optimal for the training of the NNNA in order to model phenomena affected by a high degree of inner dependency.
Finally, the obtained errors, shown in
Figure 6 and
Figure 7, have positively validated the proposed techniques to model polaritons’ behaviour at a metal dielectric interface.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}