A Decoding-Complexity and Rate-Controlled Video-Coding Algorithm for HEVC

 , and
, and
Abstract
:1. Introduction
2. Background and Related Work
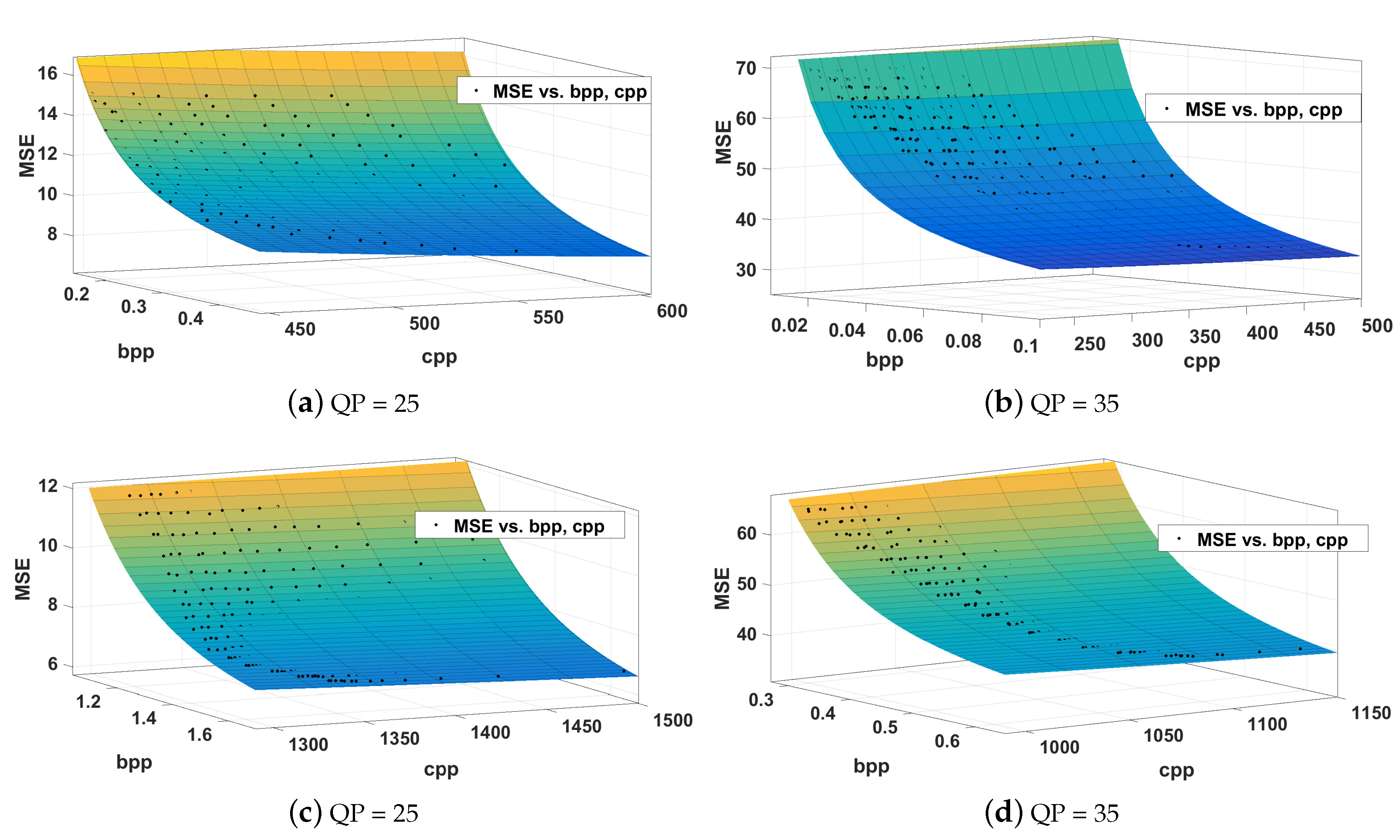
3. The Decoding-Complexity, Rate, and Distortion Relationship
3.1. The Decoding-Complexity, Rate, and Distortion Space
3.2. The Decoding-Complexity, Rate and Distortion Behaviour
4. Joint Decoding-Complexity and Rate Control
4.1. CTU-Level Rate and Decoding-Complexity Allocation
4.2. Determining the Model Parameters and Trade-Off Factors
4.2.1. Determining QP
4.2.2. Determining and
4.3. Dynamic Model Parameter Adaptation
5. Experimental Results and Discussion
5.1. Simulation Environment
5.2. Evaluation Metrics
5.2.1. Decoding-Complexity and Rate Control Performance
5.2.2. Decoding-Complexity, Energy Reduction Performance, and Video Quality Impact
5.3. Performance Evaluation and Analysis
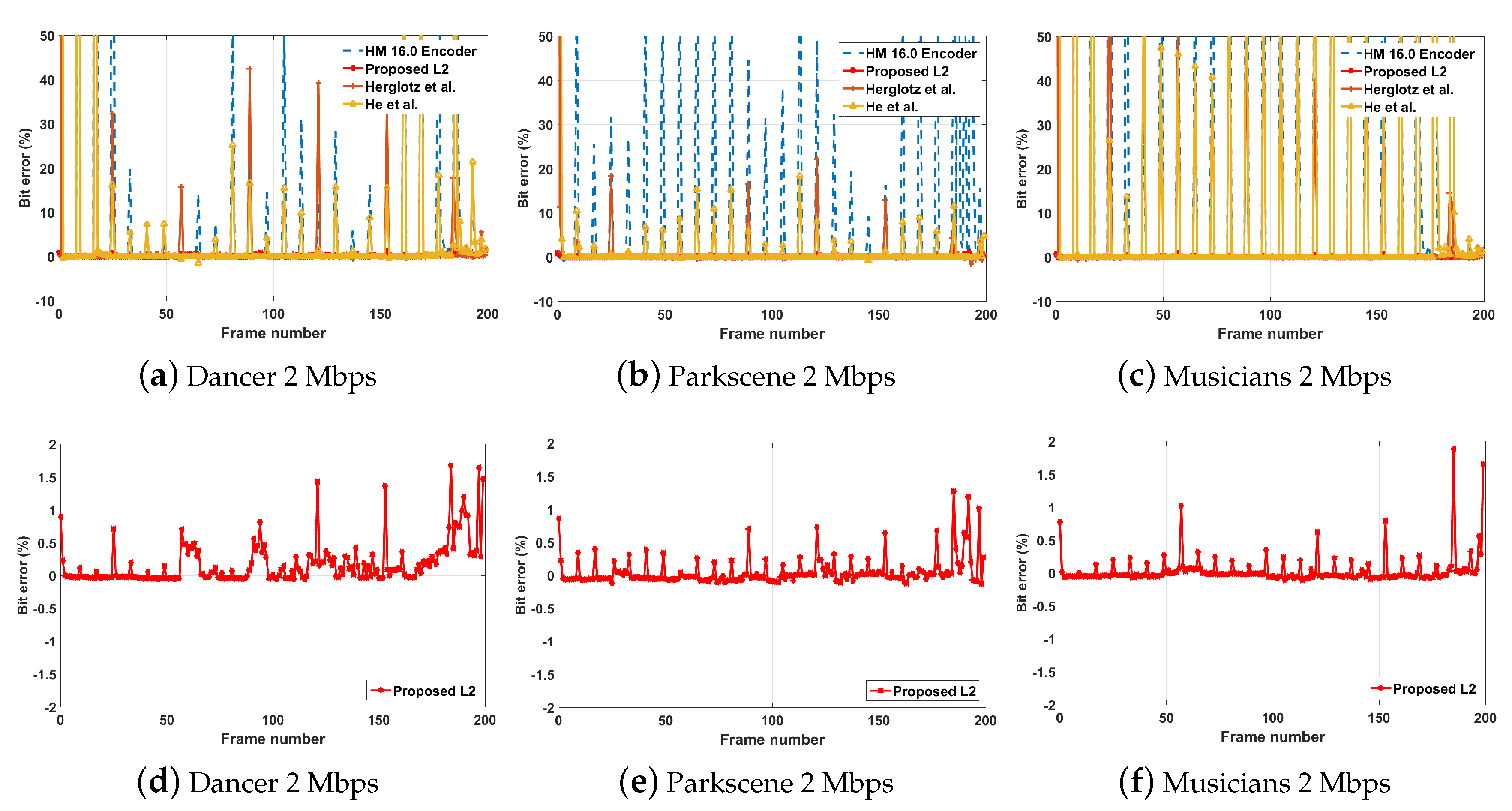
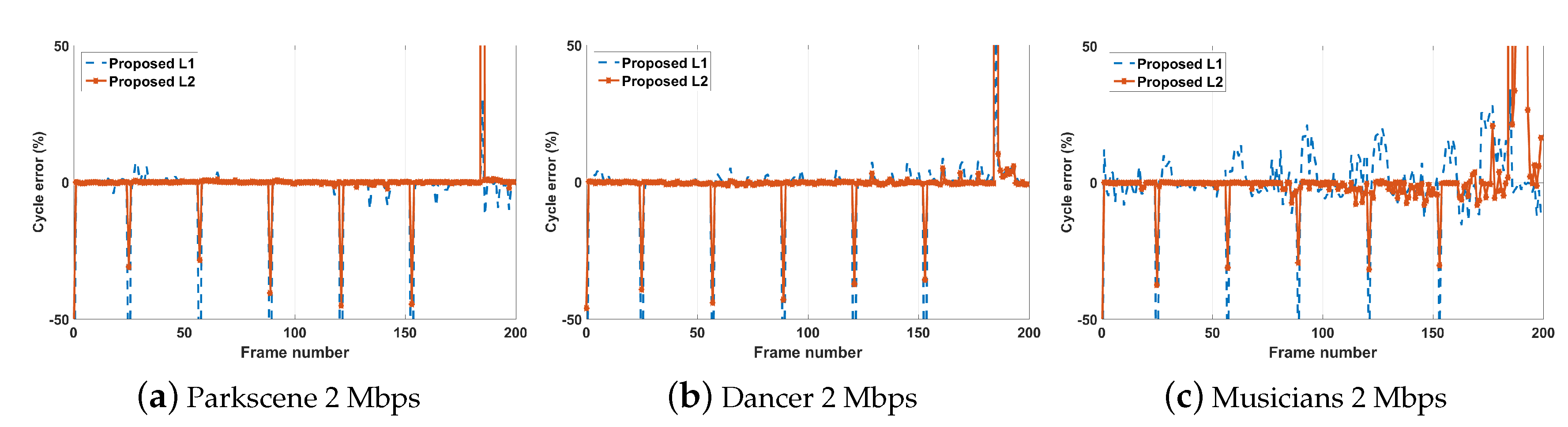
5.3.1. Rate Controlling Performance
5.3.2. Decoding-Complexity Controlling Performance
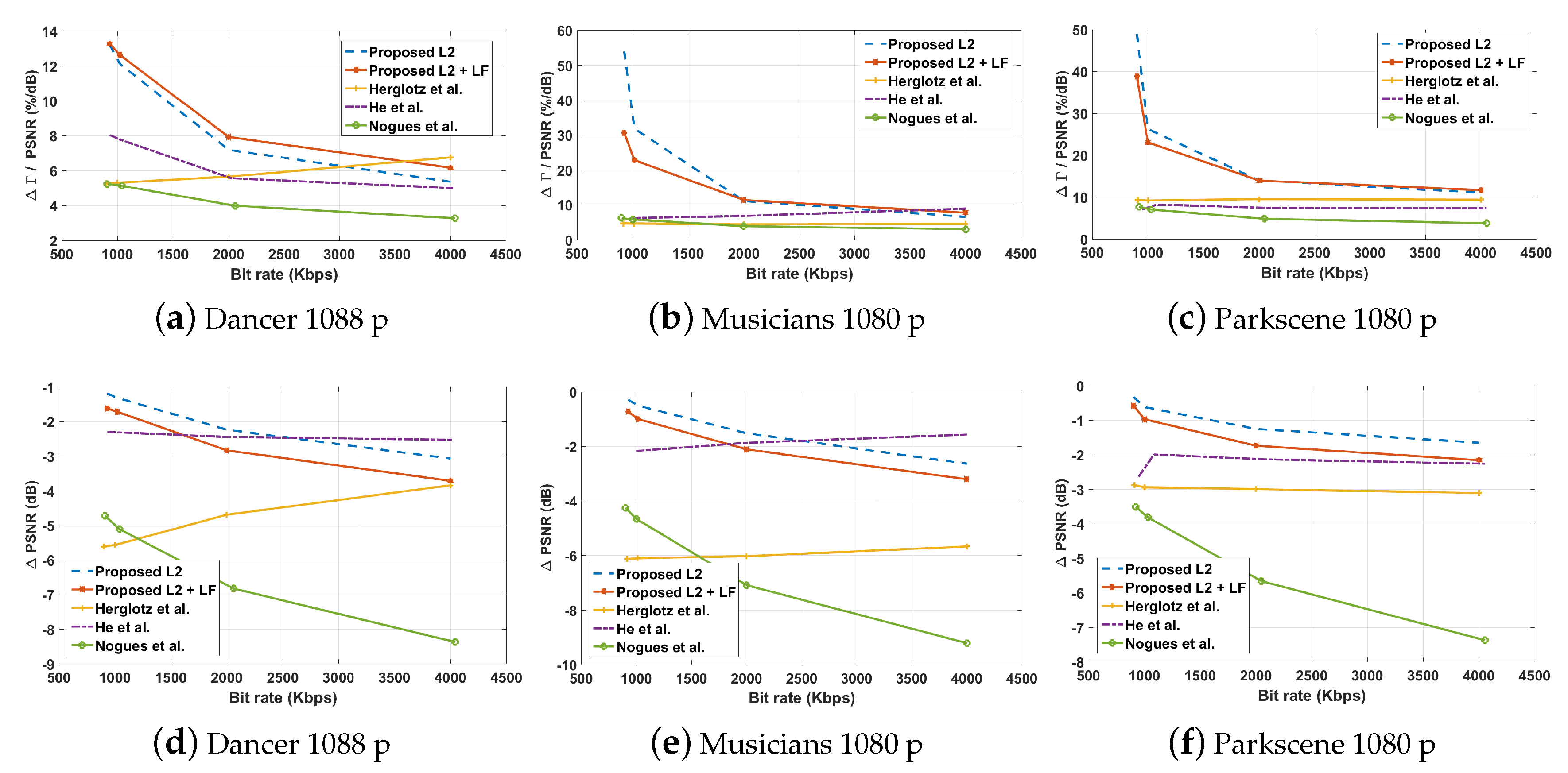
5.3.3. Decoding-Complexity Reduction and the Impact on Video Quality
5.3.4. Decoding Energy Reduction Performance
5.3.5. Impact of the Proposed Encoding Framework on Different Decoders and CPU Architectures
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cisco. Cisco Annual Internet Report (2018–2023) White Paper; Cisco: San Jose, CA, USA, 2020. [Google Scholar]
- Stockhammer, T.; Sodagar, I. MPEG DASH: The Enabler Standard for Video Delivery over the Internet. SMPTE Motion Imaging J. 2012, 121, 40–46. [Google Scholar] [CrossRef]
- Mallikarachchi, T. HEVC Encoder Optimization and Decoding-Complexity-Aware Video Encoding; University of Surrey: Guildford, UK, 2017. [Google Scholar]
- Erabadda, B.; Mallikarachchi, T.; Hewage, C.; Fernando, A. Quality of Experience (QoE)-Aware Fast Coding Unit Size Selection for HEVC Intra-Prediction. Future Internet 2019, 11, 175. [Google Scholar] [CrossRef] [Green Version]
- Ren, R.; Juarez, E.; Sanz, C.; Raulet, M.; Pescador, F. On-line energy estimation model of an RVC-CAL HEVC decoder. In Proceedings of the 2014 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–13 January 2014. [Google Scholar]
- Meng, S.; Duan, Y.; Sun, J.; Guo, Z. Highly optimized implementation of HEVC decoder for general processors. In Proceedings of the 2014 IEEE 16th International Workshop on Multimedia Signal Processing (MMSP), Jakarta, Indonesia, 22–24 September 2014. [Google Scholar]
- Magoulianitis, V.; Katsavounidis, I. HEVC decoder optimization in low power configurable architecture for wireless devices. In Proceedings of the 2015 IEEE 16th International Symposium on A World of Wireless, Mobile and Multimedia Networks (WoWMoM), Boston, MA, USA, 14–17 June 2015. [Google Scholar]
- Ren, R.; Juárez, E.; Sanz, C.; Raulet, M.; Pescador, F. Energy-aware decoders: A case study based on an RVC-CAL specification. In Proceedings of the IEEE International Conference Design and Architectures for Signal and Image Processing (DASIP), Madrid, Spain, 8–10 October 2014. [Google Scholar]
- Erwan Nogues, D.M.; Pelcat, M. Algorithmic-level Approximate Computing Applied to Energy Efficient HEVC Decoding. IEEE Trans. Emerg. Top. Comput. 2016, 7, 5–17. [Google Scholar] [CrossRef]
- Raffin, E.; Nogues, E.; Hamidouche, W.; Tomperi, S.; Pelcat, M.; Menard, D. Low power HEVC software decoder for mobile devices. J. Real Time Image Process. 2016, 12, 495–507. [Google Scholar] [CrossRef] [Green Version]
- Nogues, E.; Berrada, R.; Pelcat, M.; Menard, D.; Raffin, E. A DVFS based HEVC decoder for energy-efficient software implementation on embedded processors. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Kim, W.; Shin, D.; Yun, H.S.; Kim, J.; Min, S.L. Performance comparison of dynamic voltage scaling algorithms for hard real-time systems. In Proceedings of the IEEE Real-Time and Embedded Technology and Applications Symposium, San Jose, CA, USA, 27 September 2002. [Google Scholar]
- Benmoussa, Y.; Senn, E.; Derouineau, N.; Tizon, N.; Boukhobza, J. Green metadata based adaptive DVFS for energy efficient video decoding. In Proceedings of the IEEE Workshop on Power and Timing Modeling, Optimization and Simulation (PATMOS), Bremen, Germany, 21–23 September 2016. [Google Scholar]
- Van der Schaar, M.; Andreopoulos, Y. Rate-distortion-complexity modeling for network and receiver aware adaptation. IEEE Trans. Multimed. 2005, 7, 1520–9210. [Google Scholar] [CrossRef] [Green Version]
- Van der Schaar, M.; Andreopoulos, Y.; Li, Q. Real-time ubiquitous multimedia streaming using rate-distortion-complexity models. In Proceedings of the IEEE International Conference on Global Telecommunications, Dallas, TX, USA, 29 November–3 December 2004; pp. 639–643. [Google Scholar]
- Andreopoulos, Y.; der Schaar, M.V. Complexity-Constrained Video Bitstream Shaping. IEEE Trans. Signal Process. 2007, 55, 1967–1974. [Google Scholar] [CrossRef]
- Shenoy, P.; Radkov, P. Proxy-assisted power-friendly streaming to mobile devices. In Proceedings of the Multimedia Computing and Networking Conference, Santa Clara, CA, USA, 20–24 January 2003; pp. 177–191. [Google Scholar]
- Sodagar, I. The MPEG-DASH Standard for Multimedia Streaming Over the Internet. IEEE Multimed. 2011, 18, 62–67. [Google Scholar] [CrossRef]
- Kennedy, M.; Venkataraman, H.; Muntean, G. Battery and Stream-Aware Adaptive Multimedia Delivery for wireless devices. In Proceedings of the IEEE Conference on Local Computer Networks (LCN), Denver, CO, USA, 10–14 October 2010; pp. 843–846. [Google Scholar]
- He, Y.; Kunstner, M.; Gudumasu, S.; Ryu, E.S.; Ye, Y.; Xiu, X. Power aware HEVC streaming for mobile. In Proceedings of the IEEE International Conference on Visual Communications and Image Processing, Kuching, Malaysia, 17–20 November 2013; pp. 2–6. [Google Scholar]
- Moldovan, A.N.; Muntean, C.H. Subjective Assessment of BitDetect—A Mechanism for Energy-Aware Multimedia Content Adaptation. IEEE Trans. Broadcast. 2012, 58, 480–492. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.; Lee, Y.; Lee, J.; Lee, D.; Shin, H. Design of a mobile video streaming system using adaptive spatial resolution control. IEEE Trans. Consum. Electron. 2009, 55, 1682–1689. [Google Scholar] [CrossRef]
- Longhao, Z.; Trestian, R.; Muntean, G.M. eDOAS: Energy-aware device-oriented adaptive multimedia scheme for Wi-Fi offload. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Istanbul, Turkey, 6–9 April 2014; pp. 2916–2921. [Google Scholar]
- Mallikarachchi, T.; Talagala, D.S.; Arachchi, H.K.; Fernando, A. Decoding-Complexity-Aware HEVC Encoding Using a Complexity–Rate–Distortion Model. IEEE Trans. Consum. Electron. 2018, 64, 35–43. [Google Scholar] [CrossRef]
- Hoque, M.A.; Siekkinen, M.; Nurminen, J.K. Energy efficient multimedia streaming to mobile devices—A Survey. IEEE Commun. Surv. Tutor. 2014, 16, 579–597. [Google Scholar] [CrossRef]
- Almowuena, S.; Rahman, M.M.; Hsu, C.H.; Hassan, A.A.; Hefeeda, M. Energy-Aware and Bandwidth-Efficient Hybrid Video Streaming Over Mobile Networks. IEEE Trans. Multimed. 2016, 18, 102–115. [Google Scholar] [CrossRef]
- Sharangi, S.; Krishnamurti, R.; Hefeeda, M. Energy-Efficient Multicasting of Scalable Video Streams over WiMAX Networks. IEEE Trans. Multimed. 2011, 13, 102–115. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Dong, M.; Ma, Z.; Fernandes, F.C. GreenTube: Power Optimization for Mobile Videostreaming via Dynamic Cache Management. In Proceedings of the ACM International Conference on Multimedia, MM’12, Nara, Japan, 29 October–2 November 2012; ACM: New York, NY, USA, 2012; pp. 279–288. [Google Scholar]
- Wang, L.; Ukhanova, A.; Belyaev, E. Power consumption analysis of constant bit rate data transmission over 3G mobile wireless networks. In Proceedings of the in International Conference on ITS Telecommunications (ITST), St. Petersburg, Russia, 23–25 August 2011; pp. 23–25. [Google Scholar]
- Duan, Y.; Sun, J.; Yan, L.; Chen, K.; Guo, Z. Novel Efficient HEVC Decoding Solution on General-Purpose Processors. IEEE Trans. Multimed. 2014, 16, 1915–1928. [Google Scholar] [CrossRef]
- Pescador, F.; Chavarrias, M.; Garrido, M.J.; Juarez, E.; Sanz, C. Complexity analysis of an HEVC decoder based on a digital signal processor. IEEE Trans. Consum. Electron. 2013, 59, 391–399. [Google Scholar] [CrossRef]
- Moving Picture Experts Group (MPEG). Call for Proposals on Green MPEG; Joint Collaborative Team on Video Coding (JCT-VC): Incheon, Korea, 2013. [Google Scholar]
- Fernandes, F.C.; Ducloux, X.; Ma, Z.; Faramarzi, E.; Gendron, P.; Wen, J. The Green Metadata Standard for Energy-Efficient Video Consumption. Math. Comp. 2015, 22, 80–87. [Google Scholar] [CrossRef]
- Nogues, E.; Holmbacka, S.; Pelcat, M.; Menard, D.; Lilius, J. Power-aware HEVC decoding with tunable image quality. In Proceedings of the IEEE Workshop on Signal Processing Systems, Belfast, UK, 20–22 October 2014; pp. 1–6. [Google Scholar]
- Kim, E.; Jeong, H.; Yang, J.; Song, M. Balancing energy use against video quality in mobile devices. IEEE Trans. Consum. Electron. 2014, 60, 517–524. [Google Scholar] [CrossRef]
- Liang, W.Y.; Chang, M.F.; Chen, Y.L.; Lai, C.F. Energy efficient video decoding for the Android operating system. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 11–14 January 2013; pp. 344–345. [Google Scholar]
- Chen, Y.L.; Chang, M.F.; Liang, W.Y. Energy-efficient video decoding schemes for embedded handheld devices. Multimed. Tools Appl. 2015, 1–20. [Google Scholar] [CrossRef]
- Ahmad, H.; Saxena, N.; Roy, A.; De, P. Battery-aware rate adaptation for extending video streaming playback time. Multimed. Tools Appl. 2018, 77, 23877–23908. [Google Scholar] [CrossRef]
- Zhang, Q.; Dai, Y.; Ma, S.; Kuo, C.C.J. Decoder-Friendly Subpel MV Selection for H.264/AVC Video Encoding. In Proceedings of the IEEE International Conference on Intelligent Information Hiding and Multimedia, Pasadena, CA, USA, 18–20 December 2006. [Google Scholar]
- Hu, Y.; Li, Q.; Ma, S.; Kuo, C.C.J. Decoder-Friendly Adaptive Deblocking Filter (DF-ADF) Mode Decision in H.264/AVC. In Proceedings of the IEEE Symposium on Circuits and Systems, New Orleans, LA, USA, 27–30 May 2007. [Google Scholar]
- Lee, S.W.; Kuo, C.C.J. H.264/AVC entropy decoder complexity analysis and its applications. J. Vis. Commun. Image Represent. 2011, 22, 61–72. [Google Scholar] [CrossRef]
- Corrêa, D.; Correa, G.; Palomino, D.; Zatt, B. OTED: Encoding Optimization Technique Targeting Energy-Efficient HEVC Decoding. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018. [Google Scholar]
- Mallikarachchi, T.; Arachchi, H.K.; Talagala, D.; Fernando, A. CTU Level Decoder Energy Consumption Modelling for Decoder Energy-Aware HEVC Encoding. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 7–11 January 2016. [Google Scholar]
- Mallikarachchi, T.; Talagala, D.; Arachchi, H.K.; Fernando, A. A feature based complexity model for decoder complexity optimized HEVC video encoding. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 8–10 January 2017. [Google Scholar]
- Mallikarachchi, T.; Arachchi, H.K.; Talagala, D.; Fernando, A. Decoder energy-aware intra-coded HEVC bit stream generation. In Proceedings of the IEEE International Conference on Multimedia and Expo, Seattle, WA, USA, 11–15 July 2016. [Google Scholar]
- Herglotz, C.; Kaup, A. Joint optimization of rate, distortion, and decoding energy for HEVC intraframe coding. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Li, B.; Li, H.; Li, L.; Zhang, J. Lambda-Domain Rate Control Algorithm for High Efficiency Video Coding. IEEE Trans. Image Process. 2014, 23, 3841–3854. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Li, H.; Li, L.; Zhang, J. Rate Control by R-Lambda Model for HEVC. In Joint Collaborative Team on Video Coding (JCT-VC); ITU-T: Shanghai, China, 2012. [Google Scholar]
- JCT-VC. HEVC Reference Software—HM-16.0. Available online: https://hevc.hhi.fraunhofer.de/svn/svn_HEVCSoftware/tags/HM-16.0/ (accessed on 15 July 2020).
- McCann, K.; Rosewarne, C.; Bross, B.; Naccari, M.; Sharman, K.; Sullivan, G. High Efficiency Video Coding (HEVC) Test Model 16 (HM16) Encoder Description; Joint Collaborative Team on Video Coding (JCT-VC): Torino, Italy, 2014. [Google Scholar]
- Sun, H.; Zhang, C.; Gao, S. LCU-Level bit allocation for rate control in High Efficiency Video Coding. In Proceedings of the IEEE China Summit and Inter. Conference Signal and Information Processing (ChinaSIP), Xi’an, China, 9–13 July 2014. [Google Scholar]
- Choi, H.; Yoo, J.; Nam, J.; Sim, D.; Bajic, I.V. Pixel-Wise Unified Rate-Quantization Model for Multi-Level Rate Control. IEEE J. Sel. Top. Signal Process. 2013, 7, 1112–1123. [Google Scholar] [CrossRef]
- Haykin, S.; Widrow, B. Least-Mean-Square Adaptive Filters; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2005; pp. 175–240. [Google Scholar] [CrossRef]
- OpenHEVC. Open-Source HEVC Decoder. Available online: https://github.com/OpenHEVC/openHEVC (accessed on 15 July 2020).
- Bossen, F. Common Test Conditions and Software Reference Configurations; Joint Collaborative Team on Video Coding (JCT-VC): Torino, Italy, 2013. [Google Scholar]
- Valgrind. The Valgrind Quick Start Guide. Available online: http://valgrind.org/docs/manual/quick-start.html (accessed on 15 July 2020).
- UPower. Middleware for Power Management on Linux Systems. Available online: https://upower.freedesktop.org/ (accessed on 15 July 2020).
- Herglotz, C.; Springer, D.; Eichenseer, A.; Kaup, A. Modeling the energy consumption of HEVC intra decoding. In Proceedings of the IEEE International Conference on Systems, Signals, and Image Processing, Bucharest, Romania, 7–9 July 2013; pp. 91–94. [Google Scholar]
- Herglotz, C.; Springer, D.; Kaup, A. Modeling the energy consumption of HEVC P- and B-frame decoding. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 3661–3665. [Google Scholar]
- Herglotz, C.; Walencik, E.; Kaup, A. Estimating the HEVC decoding energy using the decoder processing time. In Proceedings of the IEEE Symposium on Circuits and Systems (ISCAS), Lisbon, Portugal, 24–27 May 2015; pp. 513–516. [Google Scholar]
- Brodowski, D.; Golde, N. CPU Frequency and Voltage Scaling Code in the Linux(TM) Kernel. Available online: https://www.kernel.org/doc/Documentation/cpu-freq/governors.txt (accessed on 15 July 2020).
- MXplayer. Video Player with Hardware Acceleration. Available online: https://play.google.com/store/apps/details?id=com.mxtech.videoplayer.ad&hl=en_GB (accessed on 15 July 2020).
- Exynos 8 Octa (8890). Available online: https://en.wikichip.org/wiki/samsung/exynos/8890 (accessed on 15 July 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
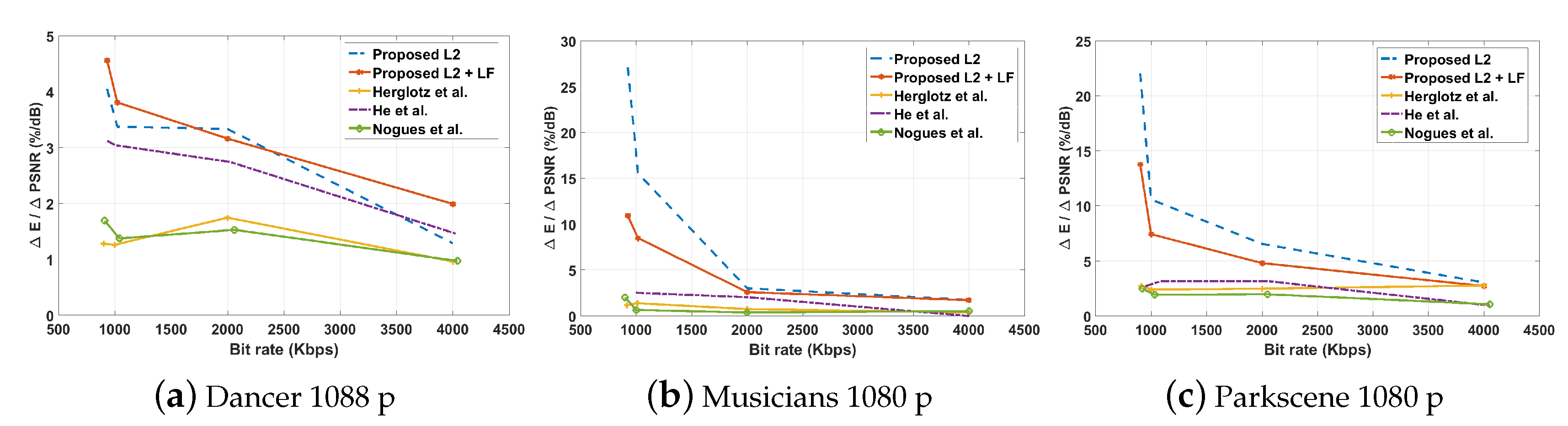{kind=link}
| Proposed L2 % | HM 16.0 [49] % | He et al. [20] % | Herglotz et al. [46] % | ||
|---|---|---|---|---|---|
| Band | (AM, LT) | 0.350 | 0.093 | −0.03 | 0.002 |
| Beergarden | (LM, HT) | 0.189 | 3.050 | 8.22 | 3.319 |
| Cafe | (AM, LT) | 0.010 | 1.229 | 0.12 | 0.443 |
| Dancer | (AM, LT) | 1.448 | 2.344 | 1.56 | 0.010 |
| GTFly | (HM, LT) | 0.018 | 0.067 | 0.14 | 0.129 |
| Kimono | (AM, HT) | 0.014 | 4.097 | 6.34 | 1.607 |
| Musicians | (LM, HT) | 1.125 | 0.054 | 3.78 | 0.725 |
| Parkscene | (HM, HT) | 0.105 | 2.352 | 4.56 | 0.386 |
| Poznan St. | (LM, HT) | 0.359 | 2.548 | 3.07 | 2.579 |
| Average | 0.40 | 1.75 | 3.08 | 1.02 |
| Proposed L1 | Proposed L2 | |||
|---|---|---|---|---|
| % | % | % | % | |
| Band | 0.638 | −1.348 | 0.350 | 3.395 |
| Beergarden | 0.383 | 0.733 | 0.189 | 6.716 |
| Cafe | 0.012 | −0.750 | 0.010 | 4.248 |
| Dancer | 1.534 | 8.485 | 1.448 | 1.448 |
| GTFly | 0.001 | −5.864 | 0.018 | −1.326 |
| Kimono | 0.015 | −9.019 | 0.014 | −4.276 |
| Musicians | 0.992 | −6.867 | 1.125 | −2.950 |
| Parkscene | 0.208 | −7.407 | 0.105 | −3.340 |
| Poznan St. | 1.140 | 1.973 | 0.359 | 8.265 |
| Average | 0.54 | −2.22 | 0.40 | 1.35 |
| Sequence |
Proposed L2 (Model Only) |
Proposed L2 * (Model + LF [34]) |
He et al. [20] (PUM + DBLK) | Herglotz et al. [46] |
Nogues et al. [34] (MC + LF) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
(dB) | % | (dB) | (dB) | % | (dB) | (dB) | % | (dB) | (dB) | % | (dB) | (dB) | % | (dB) | |
| Band | −0.89 | −9.77 | −2.09 | −1.36 | −16.74 | −2.78 | −0.46 | −7.11 | −9.37 | −3.00 | −15.24 | −1.36 | −2.38 | −15.33 | −2.58 |
| Beergarden | −1.26 | −7.12 | −3.88 | −2.01 | −14.14 | −4.86 | −4.05 | −9.63 | −9.15 | −2.56 | −15.88 | −2.85 | −3.41 | −13.40 | −3.93 |
| Cafe | −2.01 | −8.36 | −3.13 | −3.20 | −15.35 | −4.31 | −0.56 | −7.56 | −8.29 | −2.12 | −17.48 | −1.77 | −4.11 | −14.94 | −4.23 |
| Dancer | −1.95 | −16.05 | −3.50 | −2.47 | −22.05 | −4.07 | −2.09 | −11.71 | −2.36 | −4.93 | −27.90 | −4.66 | −6.58 | −24.37 | −6.62 |
| GTFly | −1.85 | −16.22 | −3.07 | −2.24 | −23.28 | −3.50 | −1.11 | −10.27 | −9.12 | −4.88 | −27.51 | −4.87 | −5.86 | −26.16 | −6.10 |
| Kimono | −1.06 | −17.48 | −1.30 | −1.28 | −24.62 | −2.88 | −1.02 | −11.19 | −8.54 | −4.05 | −27.71 | −3.92 | −3.78 | −25.86 | −3.96 |
| Musicians | −1.03 | −16.52 | −2.87 | −1.16 | −23.47 | −3.43 | −1.63 | −11.05 | −9.00 | −5.98 | −27.78 | −6.00 | −6.31 | −26.23 | −6.86 |
| Parkscene | −0.96 | −17.01 | −2.34 | −1.36 | −23.55 | −2.79 | −2.03 | −13.04 | −6.75 | −2.98 | −27.88 | −2.98 | −5.19 | −25.33 | −5.48 |
| Poznan St. | −2.00 | −5.92 | −3.47 | −3.25 | −13.03 | −4.86 | −2.08 | −9.18 | −8.06 | −1.81 | −15.61 | −1.55 | −3.00 | −12.04 | −3.11 |
| Average | −1.44 | −12.71 | −2.85 | −2.03 | −19.58 | −3.72 | −1.67 | −10.08 | −7.84 | −3.56 | −22.55 | −3.32 | −4.56 | −20.40 | −4.76 |
| Sequence |
Proposed L2 (Model Only) |
Proposed L2 (Model + LF [34]) |
He et al. [20] (PUM + DBLK) |
Nogues et al. [34] (MC + LF) | Herglotz et al. [46] | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| % | % | % | % | % | % | % | % | % | % | |
| Band | −1.56 | −5.61 | −3.49 | −7.71 | −1.16 | −3.49 | −2.34 | −5.47 | −1.56 | −5.03 |
| Beergarden | −2.22 | −3.73 | −2.78 | −5.34 | 0.19 | −2.53 | −2.75 | −5.52 | −0.19 | −4.91 |
| Cafe | −6.28 | −12.61 | −9.87 | −14.26 | −5.60 | −7.41 | −8.02 | −13.83 | −8.79 | −12.38 |
| Dancer | −2.17 | −5.19 | −5.11 | −7.59 | −1.83 | −4.13 | −4.98 | −8.42 | −4.02 | −6.51 |
| GTFly | −6.76 | −11.26 | −8.79 | −13.17 | −3.20 | −5.48 | −8.39 | −11.39 | −7.11 | −10.58 |
| Kimono | −4.55 | −11.16 | −5.92 | −12.61 | −.72 | −6.81 | −8.56 | −10.96 | −4.90 | −10.00 |
| Musicians | −2.11 | −6.24 | −4.06 | −6.86 | −1.12 | −3.64 | −1.53 | −4.85 | −2.68 | −5.56 |
| Parkscene | −3.82 | −6.74 | −4.14 | −7.33 | −1.69 | −3.52 | −5.32 | −8.82 | −3.61 | −7.79 |
| Poznan St. | −6.57 | −7.41 | −6.71 | −7.04 | −2.22 | −8.36 | −4.54 | −7.12 | −4.23 | −7.51 |
| Average | −4.00 | −7.77 | −5.65 | −9.10 | −2.22 | −5.04 | −5.15 | −8.48 | −4.12 | −7.80 |
| Sequence | Proposed L2 (Model Only) | Proposed L2 (Model + LF [34]) | He et al. [20] (PUM + DBLK) | Nogues et al. [34] (MC + LF) | Herglotz et al. [46] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Band | 10.97 | 1.75 | 6.30 | 12.30 | 2.56 | 5.66 | 15.45 | 2.52 | 7.58 | 5.08 | 0.78 | 1.82 | 6.44 | 0.65 | 2.11 |
| Beergarden | 5.65 | 1.76 | 2.96 | 7.03 | 1.38 | 2.65 | 2.37 | -0.04 | 0.62 | 6.20 | 1.07 | 2.15 | 3.92 | 0.05 | 1.43 |
| Cafe | 4.15 | 3.12 | 6.27 | 4.79 | 3.08 | 4.45 | 13.5 | 10 | 13.23 | 8.24 | 3.78 | 6.52 | 3.63 | 2.13 | 3.01 |
| Dancer | 8.23 | 1.11 | 2.66 | 8.92 | 2.06 | 3.07 | 5.60 | 0.87 | 1.97 | 5.65 | 1.01 | 1.70 | 3.70 | 0.61 | 0.98 |
| GTFly | 8.76 | 3.65 | 6.08 | 10.39 | 3.92 | 5.87 | 9.25 | 2.88 | 4.93 | 5.63 | 1.71 | 2.33 | 4.46 | 1.21 | 1.80 |
| Kimono | 16.49 | 4.29 | 10.52 | 19.23 | 4.62 | 9.85 | 10.97 | 4.62 | 6.67 | 6.84 | 2.11 | 2.70 | 6.84 | 1.29 | 2.64 |
| Musicians | 16.03 | 2.04 | 6.05 | 20.23 | 3.50 | 5.91 | 6.77 | 0.68 | 2.23 | 4.64 | 0.25 | 0.81 | 4.15 | 0.42 | 0.88 |
| Parkscene | 17.71 | 3.97 | 7.02 | 17.31 | 3.04 | 5.38 | 6.42 | 0.83 | 1.73 | 9.35 | 1.78 | 2.95 | 4.88 | 0.69 | 1.50 |
| Poznan St. | 2.96 | 3.28 | 3.70 | 4.00 | 2.06 | 2.16 | 4.41 | 1.06 | 4.01 | 8.62 | 2.50 | 3.93 | 4.013 | 1.41 | 2.50 |
| Average | 10.11 | 2.77 | 5.73 | 11.58 | 2.91 | 5.00 | 8.30 | 2.60 | 4.77 | 6.69 | 1.66 | 2.77 | 4.67 | 0.94 | 1.87 |
| Sequence | Proposed L2 (Model Only) |
He et al. [20] (PUM + DBLK) | Herglotz et al. [46] | |||
|---|---|---|---|---|---|---|
| % | (%/dB) | % | (%/dB) | % | (%/dB) | |
| Band | −20.89 | −23.47 | −6.37 | −13.86 | −29.03 | −9.67 |
| Beergarden | −18.49 | −14.67 | −10.81 | −2.66 | −29.30 | −11.44 |
| Cafe | −29.26 | −14.56 | −13.41 | −23.95 | −36.58 | −17.25 |
| Dancer | −30.20 | −15.49 | −36.13 | −17.28 | −47.68 | −9.67 |
| GTFly | −30.55 | −16.51 | −34.90 | −31.44 | −46.57 | −9.54 |
| Kimono | −26.56 | −25.06 | −32.63 | −31.99 | −46.23 | −11.41 |
| Musicians | −31.35 | −30.44 | −35.27 | −21.64 | −50.13 | −8.38 |
| Parkscene | −31.36 | −32.67 | −38.07 | −18.75 | −47.68 | −16.00 |
| Poznan St. | −20.63 | −10.31 | −10.96 | −5.27 | −31.16 | −17.22 |
| Average | −26.59 | −20.36 | −24.28 | −18.54 | −40.49 | −12.29 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mallikarachchi, T.; Talagala, D.; Kodikara Arachchi, H.; Hewage, C.; Fernando, A. A Decoding-Complexity and Rate-Controlled Video-Coding Algorithm for HEVC. Future Internet 2020, 12, 120. https://doi.org/10.3390/fi12070120
Mallikarachchi T, Talagala D, Kodikara Arachchi H, Hewage C, Fernando A. A Decoding-Complexity and Rate-Controlled Video-Coding Algorithm for HEVC. Future Internet. 2020; 12(7):120. https://doi.org/10.3390/fi12070120
Chicago/Turabian StyleMallikarachchi, Thanuja, Dumidu Talagala, Hemantha Kodikara Arachchi, Chaminda Hewage, and Anil Fernando. 2020. "A Decoding-Complexity and Rate-Controlled Video-Coding Algorithm for HEVC" Future Internet 12, no. 7: 120. https://doi.org/10.3390/fi12070120
APA StyleMallikarachchi, T., Talagala, D., Kodikara Arachchi, H., Hewage, C., & Fernando, A. (2020). A Decoding-Complexity and Rate-Controlled Video-Coding Algorithm for HEVC. Future Internet, 12(7), 120. https://doi.org/10.3390/fi12070120