No-Reference Depth Map Quality Evaluation Model Based on Depth Map Edge Confidence Measurement in Immersive Video Applications




Abstract
:1. Introduction
2. Background and Related Work
2.1. Background
2.2. Related Work on Conventional Approaches in No-Reference Quality Evaluation
3. Methods
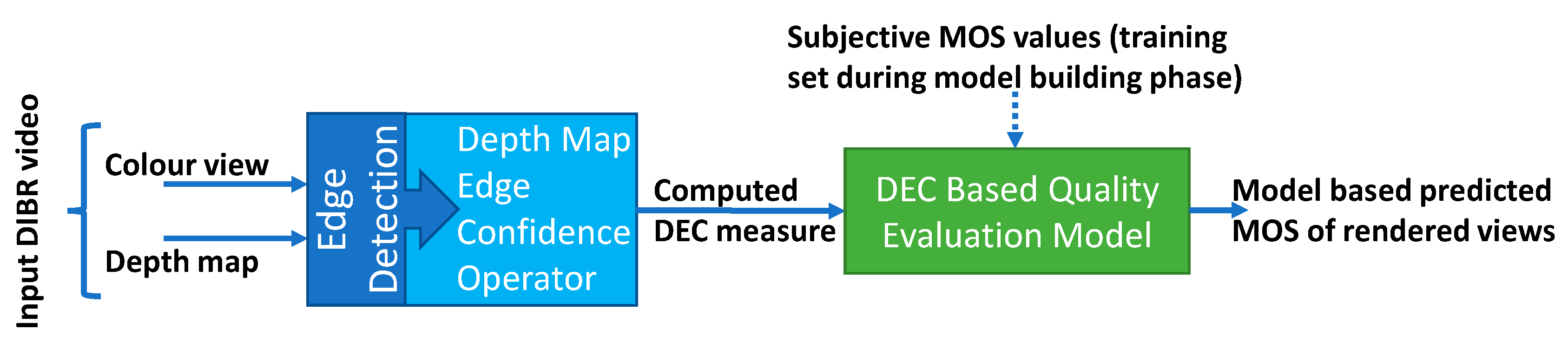
3.1. Proposed No-Reference Depth Map Quality Evaluation Model
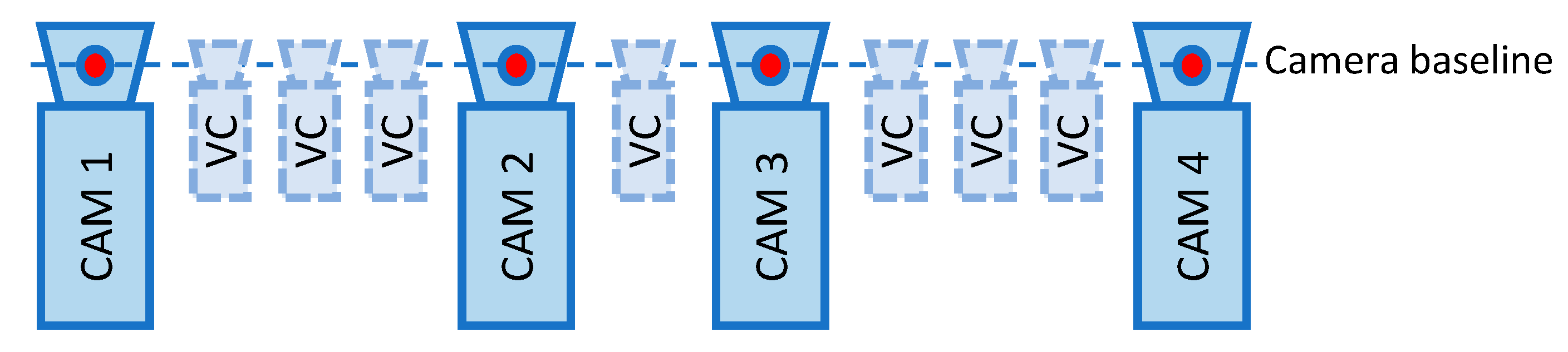
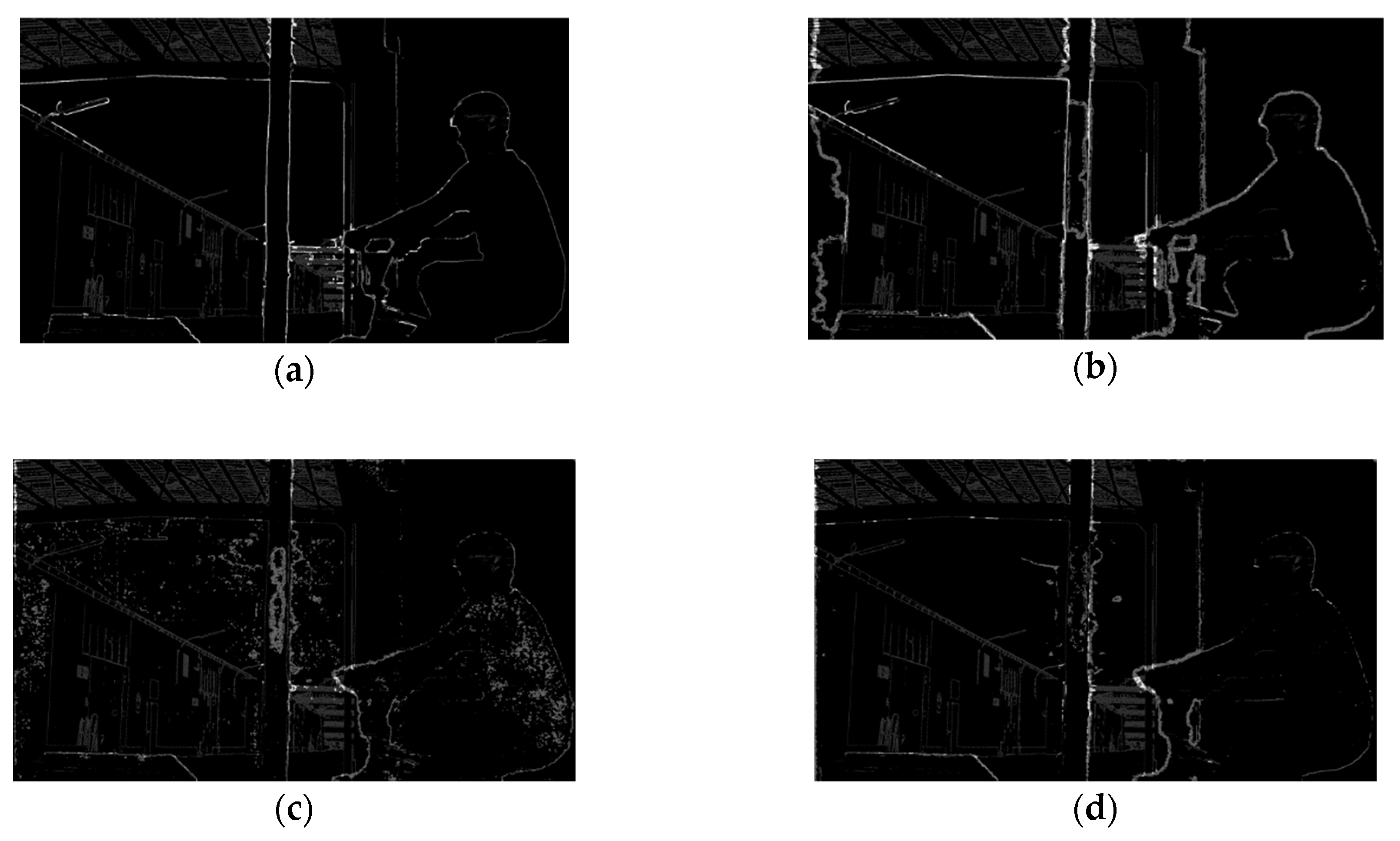
3.1.1. Depth Map Edge Confidence Measure
3.1.2. DEC Measurement-Based No-Reference Quality Evaluation Model
3.2. Dataset
3.3. Test Setup
4. Results
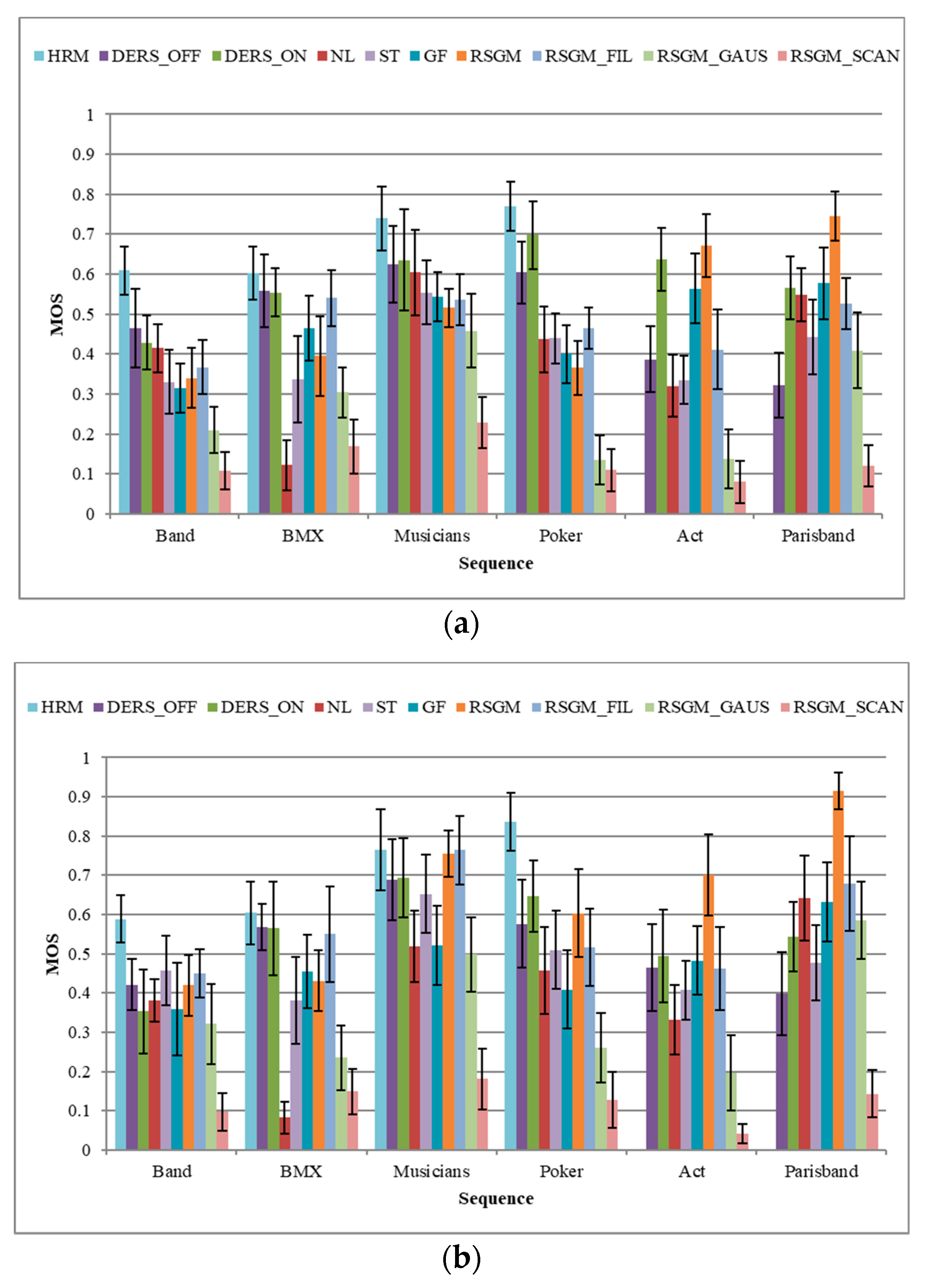
4.1. Initial Test Results
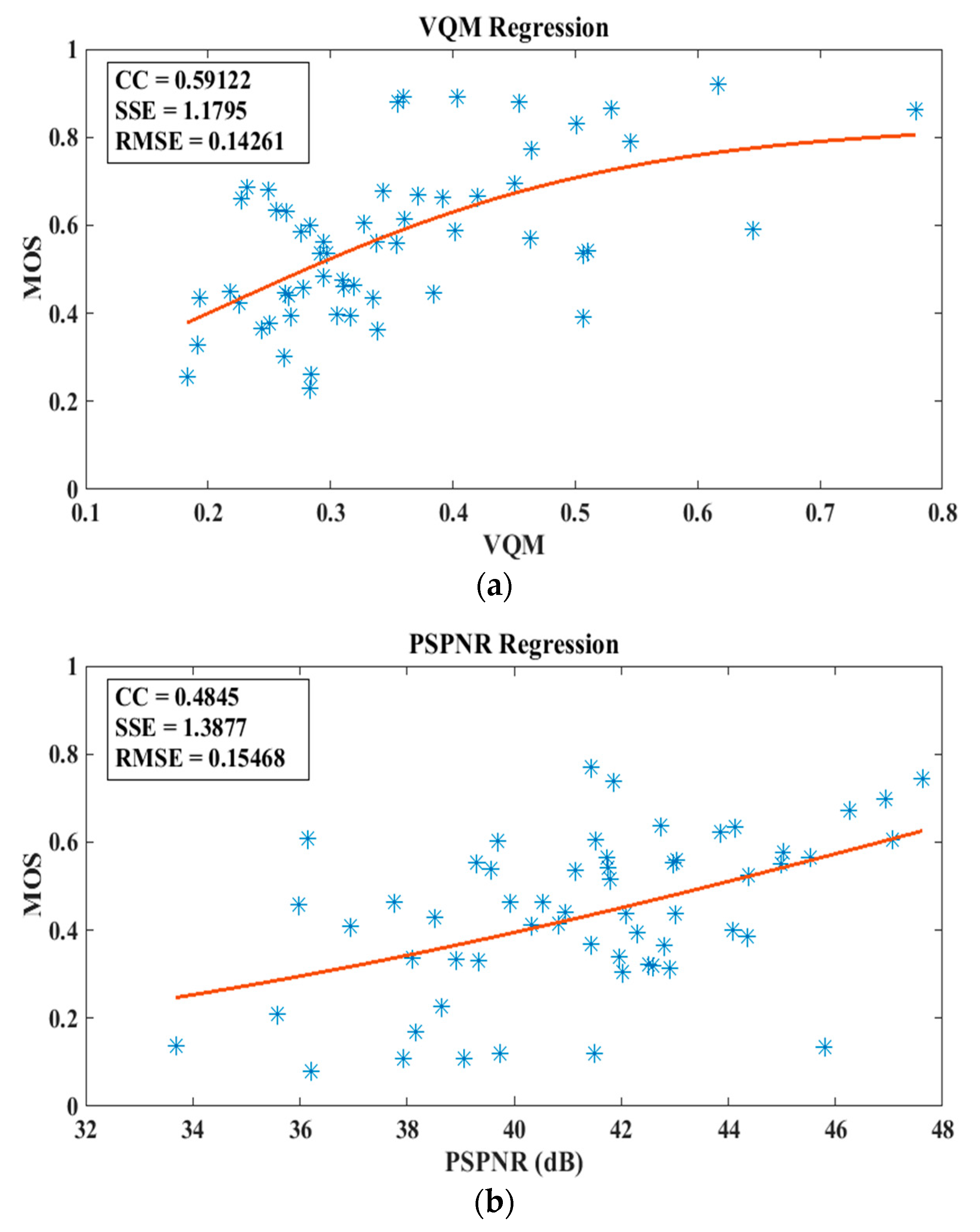
4.2. Performance of the Conventional Objective Quality Evaluation Methods
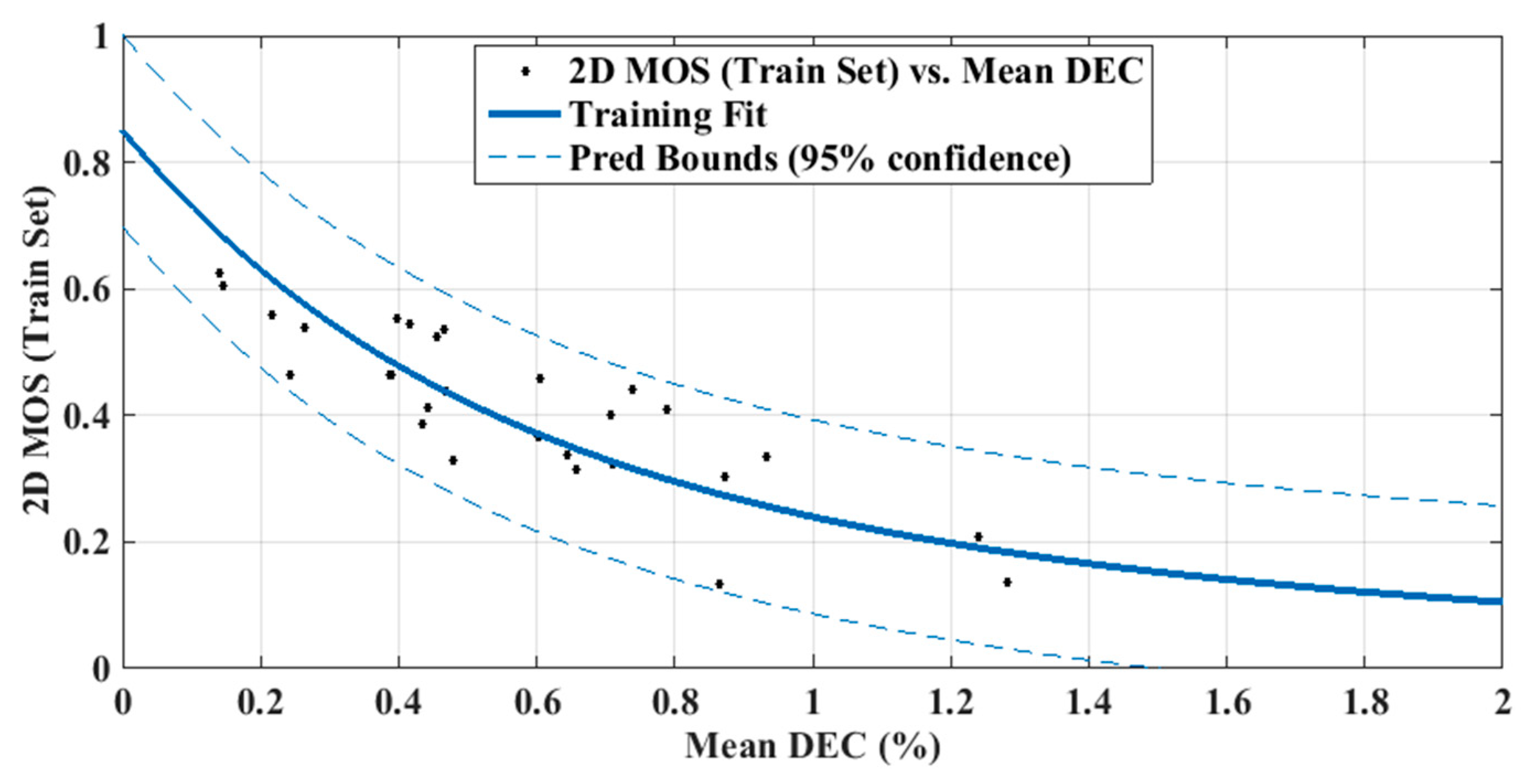
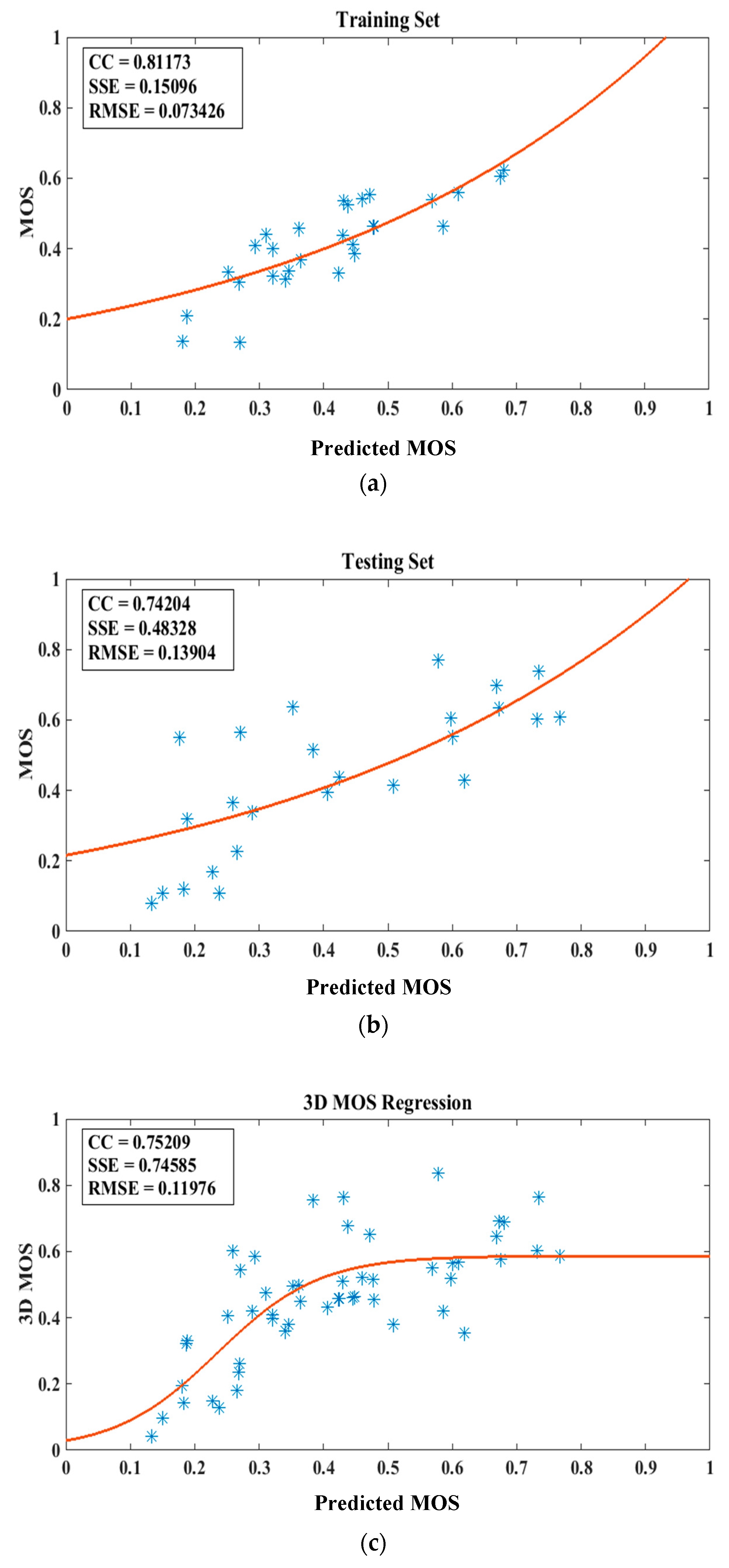
4.3. Validating the Accuracy of the Proposed DEC Measurement-Based Model
4.4. Performance of the Proposed Model
5. Discussion
5.1. Findings and Their Implications
5.2. Future Research Directions
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Vetro, A.; Tourapis, A.M.; Muller, K.; Tao, C. 3D-TV content storage and transmission. IEEE Trans. Broadcast. 2011, 57, 384–394. [Google Scholar] [CrossRef]
- Tanimoto, M. Overview of FTV (Free-Viewpoint Television). In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME 2009), New York, NY, USA, 28 June–3 July 2009; pp. 1552–1553. [Google Scholar]
- Merkle, P.; Smolic, A.; Muller, K.; Wiegand, T. Multi-view video plus depth representation and coding. In Proceedings of the IEEE International Conference on Image Processing (ICIP 2007), San Antonio, TX, USA, 16–19 September 2007; pp. 201–204. [Google Scholar]
- Fehn, C. Depth-image-based rendering (DIBR), compression, and transmission for a new approach on 3D-TV. Proc. SPIE 2004, 5291, 93–104. [Google Scholar]
- Middlebury Stereo Evaluation. Available online: http://vision.middlebury.edu/stereo/eval/ (accessed on 25 June 2019).
- The KITTI Vision Benchmark Suite. Available online: http://www.cvlibs.net/datasets/kitti/ (accessed on 25 June 2019).
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comp. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Yang, Q. A Non-local cost aggregation method for stereo matching. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2012), Providence, RI, USA, 16–21 June 2012; pp. 1402–1409. [Google Scholar]
- Hirschmuller, H. Accurate and efficient stereo processing by semi-global matching and mutual information. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–25 June 2005; pp. 807–814. [Google Scholar]
- Hirschmuller, H.; Innocent, P.R.; Garibaldi, J. Real-time correlation-based stereo vision with reduced border errors. Int. J. Comp. Vis. 2002, 47, 229–246. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Sun, J.; Zheng, N.-N.; Shum, H.-Y. Stereo matching using belief propagation. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 787–800. [Google Scholar]
- Ghanbari, M. Standard Codecs: Image Compression to Advanced Video Coding, 3rd ed.; IET: London, UK, 2011. [Google Scholar]
- Fernando, A.; Worrall, S.T.; Ekmekcioglu, E. 3DTV: Processing and Transmission of 3D Video Signals, 3rd ed.; John Wiley & Sons Ltd.: Chichester, UK, 2013. [Google Scholar]
- Tran, H.T.T.; Pham, C.T.; Ngoc, N.P.; Pham, A.T.; Thang, T.C. A study on quality metrics for 360 video communications. IEICE Trans. Inf. Syst. 2018, E101–D, 28–36. [Google Scholar] [CrossRef]
- Battisti, F.; Le Callet, P. Quality assessment in the context of FTV: Challenges, first answers and open issues. IEEE COMSOC MMTC Commun. Front. 2016, 11, 22–26. [Google Scholar]
- Galkandage, C.; Calic, J.; Dogan, S.; Guillemaut, J.-Y. Stereoscopic video quality assessment using binocular energy. IEEE J. Sel. Top. Sig. Process. 2017, 11, 102–112. [Google Scholar] [CrossRef]
- Kourtis, M.; Koumaras, H.; Liberal, F. Reduced-reference video quality assessment using a static video pattern. Spie J. Electron. Imaging 2016, 25, 1–10. [Google Scholar] [CrossRef]
- Paudyal, P.; Battisti, F.; Carli, M. Reduced reference quality assessment of light field images. IEEE Trans. Broadcast. 2019, 65, 152–165. [Google Scholar] [CrossRef]
- Tian, S.; Zhang, L.; Morin, L.; Deforges, O. NIQSV+: A no-reference synthesized view quality assessment metric. IEEE Trans. Image Process. 2018, 27, 1652–1664. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Zhou, W.; Li, W. Blind stereoscopic video quality assessment: From depth perception to overall experience. IEEE Trans. Image Process. 2018, 27, 721–734. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Wang, H.; Lu, W.; Li, B.; Atta, B.; Qinggang, M. A no-reference optical flow-based quality evaluator for stereoscopic videos in curvelet domain. Inf. Sci. 2017, 414, 133–146. [Google Scholar] [CrossRef] [Green Version]
- Xu, M.; Li, C.; Chen, Z.; Wang, Z.; Guan, Z. Assessing visual quality of omnidirectional videos. IEEE Trans. Circuits Syst. Video Technol. 2018, 12, 1–14. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Bovik, A.C.; Cormack, L. No-reference quality assessment using natural scene statistics: JPEG2000. IEEE Trans. Image Process. 2005, 14, 1918–1927. [Google Scholar] [CrossRef] [PubMed]
- Moorthy, A.K.; Bovik, A.C. A Two-stage Framework for Blind Image Quality Assessment. In Proceedings of the IEEE International Conference on Image Processing (ICIP 2010), Hong Kong, China, 26–29 September 2010; pp. 2481–2484. [Google Scholar]
- Moorthy, A.K.; Bovik, A.C. A two-step framework for constructing blind image quality indices. IEEE Sig. Process. Lett. 2010, 17, 513–516. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a completely blind image quality analyzer. IEEE Sig. Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Hassen, R.; Zhou, W.; Salama, M.M.A. Image sharpness assessment based on local phase coherence. IEEE Trans. Image Process. 2013, 22, 2798–2810. [Google Scholar] [CrossRef]
- Liu, L.; Liu, B.; Huang, H.; Bovik, A.C. No-reference image quality assessment based on spatial and spectral entropies. Sig. Process. Image Commun. 2014, 29, 856–863. [Google Scholar] [CrossRef]
- Atzpadin, N.; Kauff, P.; Schreer, O. Stereo analysis by hybrid recursive matching for real-time immersive video conferencing. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 321–334. [Google Scholar] [CrossRef]
- Mei, X.; Sun, X.; Dong, W.; Wang, H.; Zhang, X. Segment-tree based cost aggregation for stereo matching. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2013), Portland, OR, USA, 23–28 June 2013; pp. 313–320. [Google Scholar]
- Spangenberg, R.; Langner, T.; Adfeldt, S.; Rojas, R. Large scale semi-global matching on the CPU. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV 2014), Dearborn, MI, USA, 8–11 June 2014; pp. 195–201. [Google Scholar]
- Shen, Y.; Li, J.; Lu, C. Depth map enhancement method based on joint bilateral filter. In Proceedings of the International Congress on Image and Signal Processing (CISP 2014), Dalian, China, 14–16 October 2014; pp. 153–158. [Google Scholar]
- De Silva, D.V.S.X.; Fernando, W.A.C.; Kodikaraarachchi, H.; Worrall, S.T.; Kondoz, A.M. Improved depth map filtering for 3D-TV systems. In Proceedings of the IEEE International Conference on Consumer Electronics (ICCE 2011), Las Vegas, NV, USA, 9–12 January 2011; pp. 645–646. [Google Scholar]
- Zhu, C.; Zhao, Y.; Yu, L.; Tanimoto, M. 3D-TV System with Depth-Image-Based Rendering: Architectures, Techniques and Challenges, 1st ed.; Springer: New York, NY, USA, 2013. [Google Scholar]
- Abdulkadir, A.; Sadka, A.H. Metric aspect of depth image-based rendering. In Proceedings of the International Conference on Communications, Signal Processing, and their Applications (ICCSPA 2013), Sharjah, UAE, 12–14 February 2013; pp. 324–329. [Google Scholar]
- Haddad, N.; Dogan, S.; Arachchi, H.K.; De Silva, V.; Kondoz, A.M. A disocclusion replacement approach to subjective assessment for depth map quality evaluation. In Proceedings of the 3DTV-Conference: The True Vision-Capture, Transmission and Display of 3D Video (3DTV-CON 2014), Budapest, Hungary, 2–4 July 2014; pp. 1–4. [Google Scholar]
- International Telecommunication Union. ITU-R BT. 500-13: Methodology for the Subjective Assessment of the Quality of Television Pictures; International Telecommunication Union: Geneva, Switzerland, 2012. [Google Scholar]
- International Telecommunication Union. ITU-R BT. 1788: Methodology for the Subjective Assessment of Video Quality in Multimedia Applications; International Telecommunication Union: Geneva, Switzerland, 2007. [Google Scholar]
- Tanimoto, M.; Fujii, M.; Panahpour, M.; Wilderboer, M. Depth Estimation Reference Software DERS 5.0; Technical Report, ISO/IEC JTC1/SC29/WG11; International Organization for Standardization: Geneva, Switzerland, 2009. [Google Scholar]
- Lee, S.; Ho, Y. Enhancement of Temporal Consistency for Multi-view Depth Map Estimation; ISO/IEC MPEG Doc. M15594; International Organization for Standardization: Geneva, Switzerland, 2008. [Google Scholar]
- Hosni, A.; Rhemann, C.; Bleyer, M.; Rother, C.; Gelautz, M. Fast Cost-Volume Filtering for Visual Correspondence and Beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 504–511. [Google Scholar] [CrossRef] [PubMed]
- International Telecommunication Union. ITU-R J.340: Reference Algorithm for Computing Peak Signal to Noise Ratio of a Processed Video Sequence with Compensation for Constant Spatial Shifts, Constant Temporal Shift, and Constant Luminance Gain and Offset; International Telecommunication Union: Geneva, Switzerland, 2010. [Google Scholar]
- Zhao, Y.; Yu, L. Perceptual Measurement for Evaluating Quality of View Synthesis; ISO/IEC MPEG Doc. M16407; International Organization for Standardization: Geneva, Switzerland, 2009. [Google Scholar]
- Wang, Z.; Lu, L.; Bovik, A.C. Video quality assessment using structural distortion measurement. In Proceedings of the IEEE International Conference on Image Processing (ICIP 2002), Rochester, NY, USA, 22–25 September 2002; pp. 65–68. [Google Scholar]
- Pinson, M.H.; Wolf, S. A new standardized method for objectively measuring video quality. IEEE Trans. Broadcast. 2004, 50, 312–322. [Google Scholar] [CrossRef]
- Laboratory for Image and Video Engineering—The University of Texas at Austin. Available online: http://live.ece.utexas.edu/research/quality/index.htm (accessed on 25 June 2019).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RSGM_SCAN | RSGM_GAUS | |
|---|---|---|
| 2D MOS | 0.228 | 0.458 |
| VQM | 0.464 | 0.511 |
| PSPNR (dB) | 38.653 | 35.974 |
| PSNR (dB) | 28.168 | 25.082 |
| SSIM | 0.871 | 0.822 |
| 2D MOS | DEC | [27] | [28] | [24] | [25,26] | [29] | [30] | |
|---|---|---|---|---|---|---|---|---|
| HRM | 1 | 1 | 8 | 9 | 1 | 8 | 4 | 8 |
| DERS_OFF | 2 | 2 | 10 | 10 | 1 | 9 | 2 | 9 |
| DERS_ON | 3 | 3 | 9 | 6 | 1 | 10 | 1 | 10 |
| RSGM_FIL | 4 | 5 | 4 | 4 | 7 | 4 | 3 | 5 |
| ST | 5 | 4 | 5 | 3 | 1 | 2 | 6 | 6 |
| NL | 6 | 6 | 7 | 5 | 1 | 6 | 8 | 7 |
| GF | 7 | 7 | 3 | 8 | 6 | 5 | 10 | 3 |
| RSGM | 8 | 9 | 1 | 7 | 7 | 7 | 7 | 1 |
| RSGM_GAUS | 9 | 8 | 6 | 1 | 10 | 1 | 9 | 4 |
| RSGM_SCAN | 10 | 10 | 2 | 2 | 7 | 3 | 5 | 2 |
| CC | SSE | RMSE | |
|---|---|---|---|
| Band | 0.94015 | 0.019771 | 0.044640 |
| BMX | 0.97630 | 0.004586 | 0.022573 |
| Musicians | 0.95858 | 0.013428 | 0.036644 |
| Poker | 0.89905 | 0.079153 | 0.088968 |
| Act | 0.84098 | 0.056247 | 0.089639 |
| Parisband | 0.32950 | 0.133540 | 0.138120 |
| CC | SSE | RMSE | |
|---|---|---|---|
| Band | 0.78979 | 0.166160 | 0.128900 |
| BMX | 0.93044 | 0.022614 | 0.050127 |
| Musicians | 0.80634 | 0.078822 | 0.106110 |
| Poker | 0.73161 | 0.076600 | 0.087522 |
| Act | 0.36877 | 0.112690 | 0.137040 |
| Parisband | 0.16154 | 0.169690 | 0.130260 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dogan, S.; Haddad, N.; Ekmekcioglu, E.; Kondoz, A.M. No-Reference Depth Map Quality Evaluation Model Based on Depth Map Edge Confidence Measurement in Immersive Video Applications. Future Internet 2019, 11, 204. https://doi.org/10.3390/fi11100204
Dogan S, Haddad N, Ekmekcioglu E, Kondoz AM. No-Reference Depth Map Quality Evaluation Model Based on Depth Map Edge Confidence Measurement in Immersive Video Applications. Future Internet. 2019; 11(10):204. https://doi.org/10.3390/fi11100204
Chicago/Turabian StyleDogan, Safak, Nasser Haddad, Erhan Ekmekcioglu, and Ahmet M. Kondoz. 2019. "No-Reference Depth Map Quality Evaluation Model Based on Depth Map Edge Confidence Measurement in Immersive Video Applications" Future Internet 11, no. 10: 204. https://doi.org/10.3390/fi11100204