1. Introduction
As is well known, driving under the influence of alcohol is life-threatening. Data from both developed and developing countries show that the risks are similar. In Australia, a blood alcohol concentration (BAC) of 0.05% has been found in approximately 30% of all drivers fatally injured in crashes [
1,
2]. In Canada, 38.3% of the fatal driver injuries in 2003 were alcohol-related [
2]. Drinking and driving is thought to be responsible for approximately 20% of all road fatalities in Europe every year [
2,
3]. In the U.S., alcohol-impaired driving was the cause of nearly 11,000 deaths—approximately one–third of all U.S. traffic-related fatalities in 2009 [
4,
5]. Approximately 34% of the road crashes in China were related to alcohol consumption [
6], and Taiwan had 1973 fatal traffic accidents in 2010; of these, 373 were caused by drunk driving, resulting in 395 deaths [
7].
Countries worldwide have enacted laws to prohibit driving after alcohol consumption that impose severe penalties on violators. The blood alcohol test is a popular way to detect drunk driving; it measures alcohol concentration in a driver’s blood. Blood alcohol levels can be measured with instruments from blood, urine, or exhaled breath. At present, the breath alcohol content detector is the most common testing mechanism used by Chinese authorities to judge whether a driver is drunk, and it is the only means by which law enforcement officials can determine levels of drunkenness on the spot. The principle behind the breath alcohol concentration detectors is similar to the principle used by vehicle-mounted alcohol concentration test devices in Sweden, Finland, and other countries [
8,
9], which are commonly referred to as alcohol lock or alcohol ignition interlock devices. This device was first developed by Volvo. After installation, a driver must first complete a breath test before driving; if the test results exceed a threshold, the car interlock device is activated and the driver will not be able to start the car. However, alcohol locks can be defeated; for example, a driver can get people who have not been drinking to take the test and, thus, unlock the ignition. To solve this problem, detection methods based on other physiological measurements and on driving performance have been proposed.
Many studies have shown that physiological measurements, such as electroencephalography [
10], can be used to distinguish drowsy drivers. Similarly, the differences between drunk drivers and normal drivers can be used to detect drunk driving by analyzing other physiological characteristics, such as heart rate variability [
11]. Research into driving performance to explore the differences between drunk drivers and normal driver have also been carried out. Leung and Starmer [
12] investigated the effects of a moderate dose of alcohol on a driver’s perception of speed, hazards, and risk acceptance; they concluded that young and mature drivers demonstrated pivotal differences in behaviour. Helland et al. [
13] used ethanol as a positive control to examine how alcohol affects driving performances in a simulator and whether those effects were consistent with performances during real driving on a test track under the influence of alcohol. They found a positive dose-response relationship between higher ethanol concentrations and increases in the standard deviations of lateral position (SDLP) in both the simulator and on the test track.
However, few studies exist that explore the integration of physiological measurements and driving performance to distinguish drunk driving from normal driving. Artificial neural networks (ANN), K-nearest neighbour (KNN), Bayesian networks (BN), and support vector machine (SVM) classifiers are quite popular. The SVM model is particularly effective for classification problems with small sample sizes. SVM models have been increasingly implemented in various transportation studies. In 2008, Li et al. [
14] evaluated the efficiency of SVM models in predicting vehicle crashes. The results showed that SVMs were better than negative binomial models and back-propagation neural networks for crash prediction. Ren and Zhou [
15] proposed a hybrid method that incorporated particle swarm optimization and SVM to make traffic safety forecasts. Robinel and Puzenat [
16] used a multi-layer perceptron (MLP) and an SVM to determine whether a driver’s blood alcohol concentration (BAC) was above 0.4 g/L. Yu and Abdel-Aty [
17] applied an SVM model to predict potential crashes in real time by considering actual traffic data ranging from 5 to 10 min before the crash occurrence. Chen et al. [
18] employed SVM models to investigate the severity of driver injury patterns in rollover crashes based on two years of crash data gathered in New Mexico. Wang and Xi [
19] used a rapid pattern-recognition method, called kMC-SVM, which developed by combining the k-means clustering and SVM, to recognize driver’s curve negotiating patterns. Li et al. [
20] used an SVM classifier to classify drivers into two classes (normal or drunk) based on the extracted driving performance features. However, in this study, the driving performance and physiological measures were integrated together to classify the drunk drivers from normal drivers based on the SVM model. A disadvantage of the SVM model is that it lacks the capability to automatically select the significant factors that contribute to the target variable. Thus, principal component analysis (PCA) is often conducted to rank the variables by their relative importance and identify the most significant variables. This technique is increasingly used in the traffic field. Malagon-Borja and Fuentes [
21] adopted PCA-based reconstruction to detect pedestrians. Nguyen and Kim [
22] showed that using bidirectional PCA with vertical edge images was highly suitable for pedestrian detection. The PCA was also selected in the study of El Chliaoutakis et al. [
23] to find some latent variables.
The objective of this study was to predict whether drivers were drunk using both driving performance and physiological measurement data. The most previous algorithms have been based on only few eigenvalues, either the driving performance or the physiological signal, to make the determination of drunk driving. Therefore, they are prone to misjudge. The driving performance and physiological measurement data obtained in this study can be integrated by applying the support vector regression method to establish a better prediction model that can be used to prevent drunk driving.
2. Experiment Design
2.1. Participants
A total of 16 novice male drivers aged between 18 and 24 years and who had held a licence for no longer than 12 months were selected as the study participants. Most of the participants were recruited via paper flyers and the rest through recommendations.
2.2. Apparatus
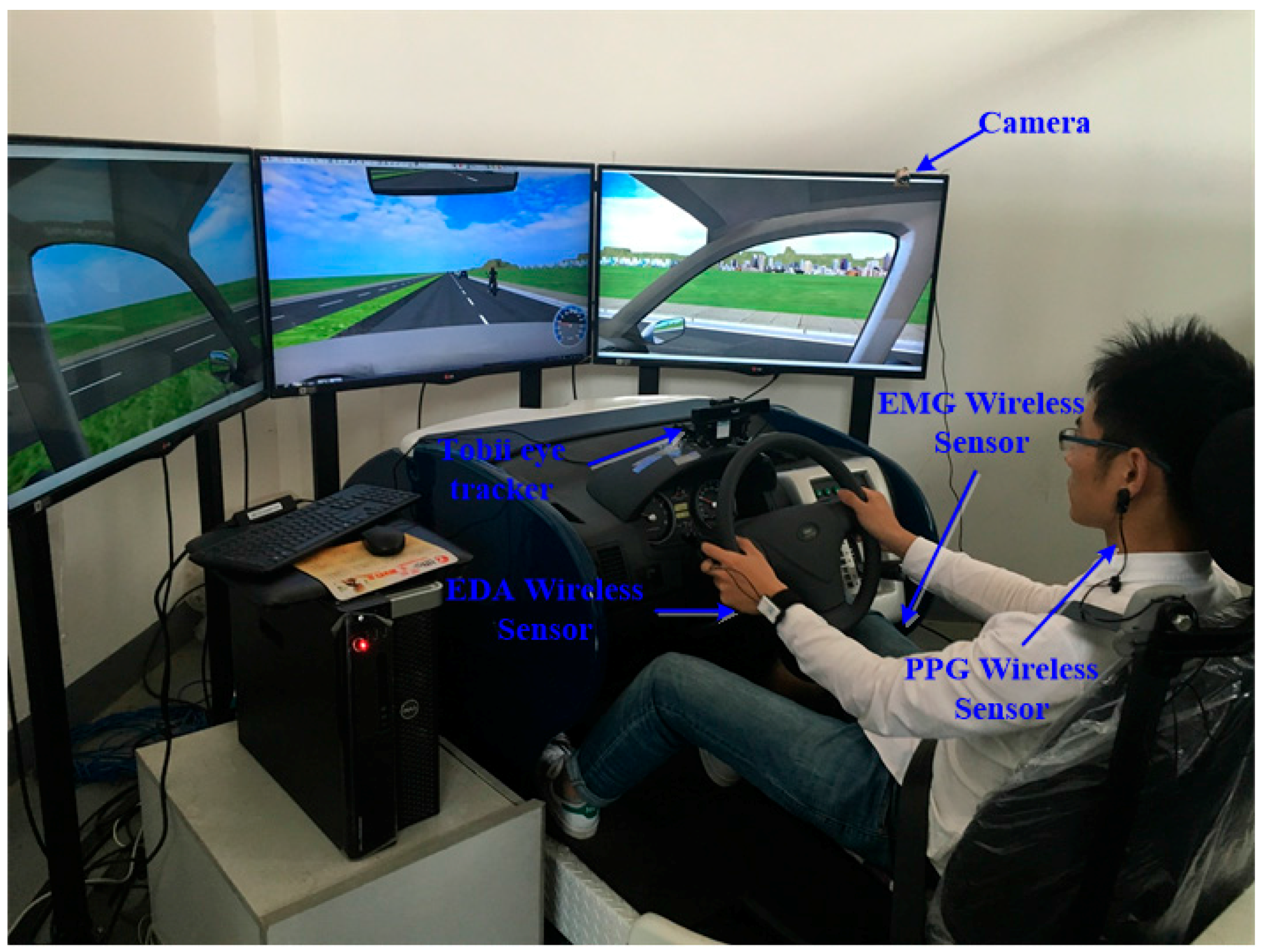
Driving Simulator: The experiment was conducted in a portable driving simulator. The simulator runs on a PC platform under the Microsoft Windows operating system. Standard 3D graphic boards generate images. Drivers interact with the images through real Hyundai car controls. The steering wheel is linked to an active force feedback system controlled by the software based on the simulated speed of the car, the road surface, and the type of power steering. Moreover, a passive force feedback mechanisms incorporated into the pedals reproduce the feel of the clutch and brake from a real car.
The simulator is built around a dedicated PC that integrates the visual system, the sound system, and a custom I/O board. The image of the driving simulation is displayed on three LED screens. The driver is positioned approximately 0.8 m from the centre screen. The visual angle to the screens is 90 degrees, but the simulator software adjusts the image to provide a 120-degree field of view. The simulator sampling rate was 30 Hz.
Breath Alcohol Analyser: A breath alcohol analyser (Alcostop A, Justec Co., Ltd., Shenzhen, China) of the same type used by police authorities in China for routine roadside breath alcohol screening was employed in this study to measure the subjects’ breath alcohol levels. The resulting measurements were converted to BAC levels [
24].
ErgoLab Human Machine Environment Synchronization System: Radio-frequency physiological recording technology, the behaviour code-analysis technology, and the human-machine environment synchronization technology was used in the ErgoLab human machine environment synchronization system, which achieves simultaneous recording, tracking and analysis of individual physiological, psychological, and behavioural factors. Electromyogram (EMG), electrodermal activity (EDA), and photo-plethysmography (PPG) wireless sensors were applied in this study. A Tobii eye tracker (Tobii, Danderyd, Sweden) with a sampling frequency of 60 Hz was employed to collect the participant’s eye movements, time of blink, and other visual measurements. Cameras were also used to collect driver behaviours.
2.3. Procedures
The participants were asked to obtain sufficient sleep the night before the experiment and refrain from consuming any food or drink that contained alcohol the day before the experiment. Two hours before the experiment, the participants were prohibited from consuming high-fat, high-sugar, or caffeinated substances that could affect alcohol absorption. The participants’ breath was analysed in the laboratory to ensure that their pre-test status was alcohol-free.
When the participants arrived in the simulation room, the laboratory staff introduced the basic processes: the driving task and the basic operation and safety information about the simulator. The participants signed consent forms officially consenting to participate in this experiment. The participants were then asked to provide demographic information such as gender, age and driving experience. The participants completed a current health questionnaire and were weighed. Then, the researcher explained the simulator study in detail. To familiarize participants with the simulator controls and dynamics, each participant practised driving in the simulator for 5 min. Eye tracker calibration was carried out before the practice session began. Then, the wireless sensors were put on. The ErgoLab physiological sensors (KingFar Technology Co., Ltd., Beijing, China) were applied to the participants as follows: the index and middle fingers were connected to the EDA sensors using finger buckles; the EMG sensors were fixed on the lower legs using bandages (to capture the electrical potential of leg muscles). The PPG sensor was attached to the earlobes to collect heartbeat signals. Finally, the Tobii eye tracker collected visual behaviour.
Figure 1 shows an image of a participant in the simulator.
The participants were then given one of the following two alcohol treatments: a 0.0 g/kg (placebo group) or 1 g/kg (high dose group). The 1 g/kg treatment was intended to produce a target BAC of 80 mg/100 mL [
24,
25]. Eighty milligrams per 100 millilitres is the official level that indicates drunk driving in China.
The alcohol dose was calculated based on body weight and administered as pure alcohol mixed with orange juice. Based on the participants’ weight, the staff calculated the amount of alcohol and mixed it with twice that amount of orange juice. The participants drank the beverages within 15 min. The first BAC measurement occurred 10 min later, and the resulting BAC values were recorded. Participants in the placebo group received a 200-mL beverage that consisted of orange juice containing 3 mL of white wine added to the top of each drink. Their BAC values were also recorded. Of the 16 participants who completed the full experimental sessions, eight were assigned to the placebo group and eight to the high dose group.
The ascending BAC test was conducted 30 min after beverage consumption. The simulated road had two lanes in each direction, and the posted speed limit was 60 km/h. The participants finished the ascending BAC test in 15 min. The BAC descending test was conducted 90 min after beverage consumption. The simulator scene was counterbalanced to minimize the practice effects. Each subject’s BAC was measured at 10 min, 30 min (before and after the test), 60 min, 90 min (before and after the test), and 120 min after treatment administration. Physiological measurements were collected during the whole experiment time; in addition, the participants’ driving performances were recorded by the simulator.
After the testing was completed, the subjects remained at leisure in the lounge until their BACs fell to 20 mg/100 mL or below. Transportation home was provided after the sessions. Each participant was paid RMB 80 yuan for their participation.
2.4. Data Collection
To initialize the support vector machine model for prediction, the physiological measurements were collected and specific features were identified as follows:
Heart Activity: Heart rate can be monitored to assess the individual physiological level of workload. It has been shown that heart rate decreases significantly during a monotonous driving task [
26]. Many studies have also validated the effectiveness of heart rate variability measures for diverse physiological conditions and the heart activity is a worthwhile research topic for further investigation [
27]. A photoplethysmograph (PPG) signal was used in this study to obtain heart activity measurement. The following features are physiologically meaningful: the average heart rate (AVHR); the standard deviation of R–R intervals (SDNN), the root mean square of the difference between adjacent R–R interval series (RMSSD), and the percentages of the differences between adjacent R–R intervals greater than 50 ms (PNN50). The frequency domain measurements of the HRV power spectrum analysis were performed by fast Fourier transforms on specific time periods of the continuously recorded ECG RR intervals to obtain the frequency domain, including low frequency (LF: 0.04–0.15 Hz), high frequency (HF: 0.15–0.40 Hz), and the ratio of low frequency and high frequency (LF/HF).
Electrodermal Activity: Electrodermal activity (EDA) is frequently used as an indirect measure of attention, cognitive effort, or emotional arousal [
27,
28]. EDA can be distinguished into tonic and phasic parts. The skin conductance level (SCL) is the tonic value and shows the continuity of activity over time. The skin conductance response (SCR) is the phasic part and reveals changes in skin conductance within a short time period [
27,
29]. When individuals experience stress, the sympathetic nerves increase sweat secretion, resulting in increased EDA values.
An electromyography (EMG) signal is associated with muscle contraction. EMG is the result of muscle excitation, which reflects the functional state of the muscle. EMG signals can be used to determine muscle fatigue and its degree. The following features are physiologically meaningful: root mean square amplitude (RMS), the average EMG (AEMG), the median frequency (Median Freq.), and the mean frequency (Mean Freq.).
Several eye activity parameters have been shown to be sensitive to time on task, and research has shown that the disappearance of blinks, mini-blinks in eye movement, are the earliest reliable signs of drowsiness [
27]. The eye activity monitoring could be used as an operator’s alertness level. The participants’ eye blink duration times were also analyzed in this study.
Finally, not only were physiological data collected, but the participants’ driving performances were also collected in this study. Speed is always used as an index to evaluate driver performance. Studies have shown that driving under influence offenders commit more moving violations, such as speeding, and are involved in more accidents compared with the general population [
30,
31]. Lane weaving is a common measure for assessing driving performance, and standard deviation of lateral position is a sensitive vehicular control indicator, often employed in drugged driving research [
32,
33]. Some studies have found that alcohol negatively affects behaviours such as steering wheel control and braking, as well, Fillmore et al. expressed that alcohol significantly impaired driving performance, which included deviation of lane position, line crossings, steering rate, and driving speed [
2,
34,
35,
36]. The statistical features of speed are maximum speed, minimum speed, mean speed. The standard deviation of steering wheel rotation angle and the standard deviation of lane position, where the lane position is the distance from the center of vehicle to the lane center, were also taken as features in this study.
The description of the features are listed as the following
Table 1.
2.5. Ethical Satetment
All subjects gave their informed consent for inclusion before they participated in the study. The study was conducted in accordance with the Declaration of Helsinki, and the protocol was approved by the Ethics Committee of Third Xiangya Hospital, Central South University (No: 2016-S251).
4. Results
The driving performance data were collected from the driving simulator, and the physiological behaviour data were collected from the wireless sensors. In addition, eye blink data were collected from the Tobii eye tracker. For the driving performance and physiological measurements, 20 original features were selected that represent the time domain or the frequency domain characteristics of the various signals. The raw physiological index data were filtered by 50 Hz power frequency. Fast Fourier transforms were used to transform the data from the time domain to the frequency domain. PCA was used to analyze the 20 selected features and obtain the primary components. There were six principal components whose eigenvalue is greater than one, and their cumulative contribution to the total variance is 81.098%, as listed in
Table 2. Other components whose eigenvalue is smaller than one were ignored in this study.
A component matrix can be obtained based on principal components method. The top six principal components, without the specific meaning, extracted in
Table 2 can be expressed as a linear combination of all features by the coefficient matrix as shown in
Table 3.
The normalized weight of each original feature can be calculated by the accumulation of the coefficient of each original feature of the principal component in
Table 3 multiplied by the percent of variance in
Table 2 and divided by the cumulative percent. The main original features—those with relatively higher weights—are listed in
Table 4.
The experiments involved 16 participants and each participant underwent two trials, finally yielding 32 samples. Among these 32 samples, 22 samples, called the training set, were used to train the SVM model. The accuracy of the model in estimating the drunk condition was then assessed by the remaining 10 samples called testing set. SVM is considered as a black box, and the analytical equation usually found was not obtained here. The features selected were Z = (E
1,E
2,...,E
22,E
20)
T. The expected outputs, y
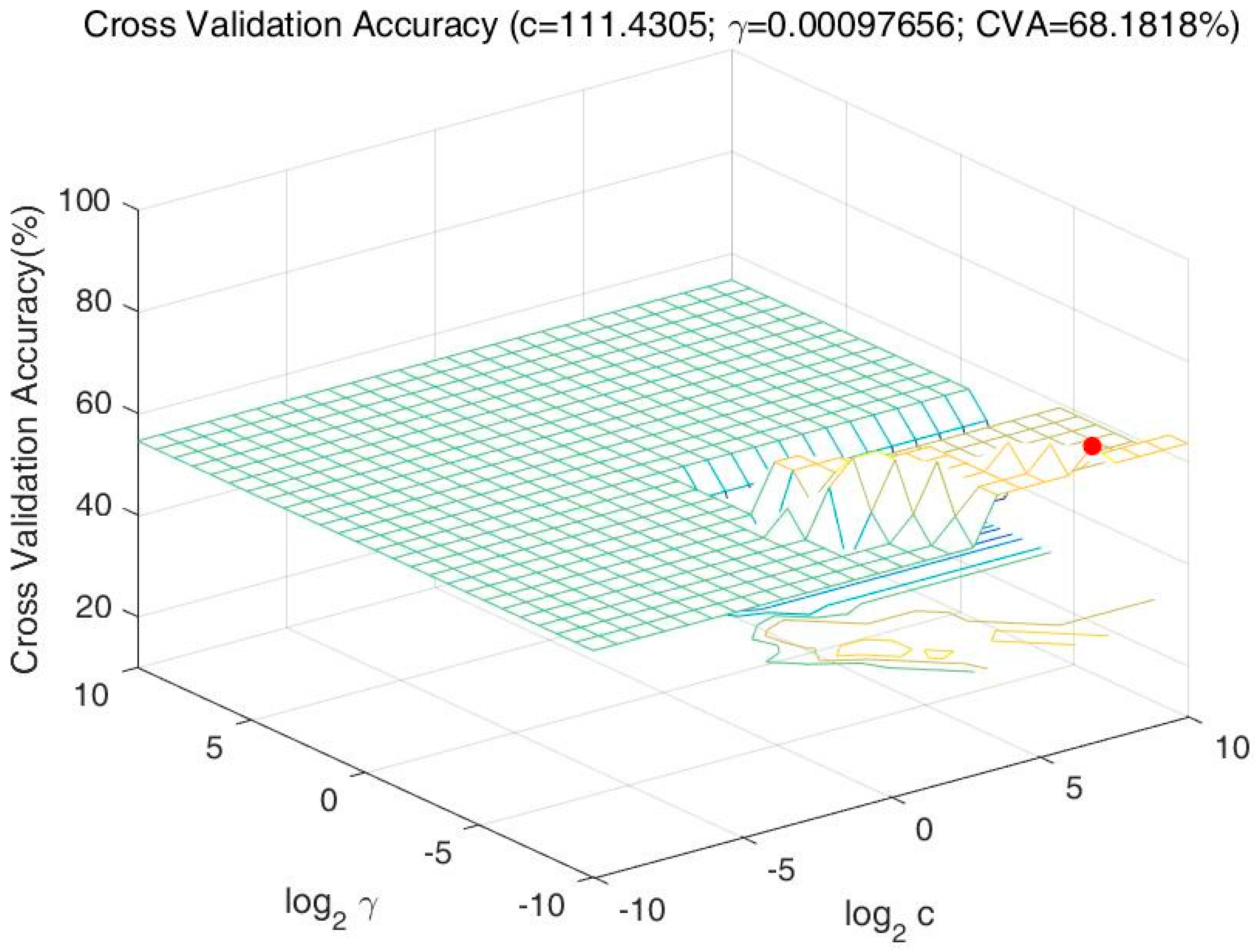
i {−1,+1}, represent the classification of the driver’s drinking status (−1 = Drunk, +1 = Normal). After data normalization, the key parameters obtained after cross-validation: (c, γ) = (111.4305, 0.00097656), where log
2c = 6.8 and log
2γ = −10. The relationship between the cross-validation accuracy and c, γ is shown in
Figure 2. For each pair of parameters to calculate the accuracy of cross validation, and the highest accuracy (68.1818%) presented as a red dot in the figure was obtained to determine the key parameters. Then the testing set was used to test the model’s classification accuracy, and the model’s accuracy rate is 70%.
5. Discussion
Analyses of physiological measures have been included in previous studies in the field of traffic safety and are integrated with the driving performance analysis performed by this study. Although some studies exist concerning physiological measurements of drinking drivers and others have studied individuals’ driving performances, studies that integrate the two are rare. The EMG, EDA, PPG, and blink frequency reflect the fatigue, emotional arousal, and stress levels of drivers while driving. Moreover, the speed, the standard deviation of lane position and the standard deviation of steering wheel rotation angle can reflect the driver’s level of control over the vehicle. Here, 20 features were extracted from drivers’ physiological and driving performance measurements. PCA was used to obtain the feature weights and SVM was used to learn a classification model for drunk driving.
The physiological signals includes features from RMS, AEMG, Median Freq, Mean Freq, Tonic Signal, Phasic Signal, SC, AVHR, SDNN, RMSSD, PNN50, LF, HF, LF/HF, and average blink duration, while the driving performance measurements included maximum speed, minimum speed, mean speed, standard deviation of lane position and standard deviation of steering wheel rotation angle. The simulated driving scenario was a straight road with two lanes in each direction for which the posted speed limit was 60 km/h.
The PCA results show that the weights of the original features have different impacts on the overall measurements. A relatively larger weight means the sensitivity of the feature is relatively larger when judging whether a driver is exhibiting drunk driving behaviour, and those features are more effective in accurately identifying drunk driving. SDNN, RMSSD, LF, HF, LF/HF, and average blink duration were the highest-weighted features in the study. SDNN index, which reflects the slow change of heart rate, is a sensitive index for evaluating the function of the sympathetic nerve. The RMSSD index reflects rapid changes in heart rate, which is a sensitive index to evaluate the function of the parasympathetic nerve. Its value decreases when the parasympathetic tone decreases. R–R time intervals were also extracted as the characteristic features for arrhythmia detection in Yu and Chou’s study [
38]. Existing literature has shown that the high-frequency power of heart rate variability is an index associated with parasympathetic activity, and quite sensitive to the frequency and depth of respiration. The low-frequency band power of heart rate variability is an index associated with sympathetic activity. Thus, the LF/HF ratio can be considered as an index to assess the sympatho-vagal balance [
39]. When a person is under stress, the LF band power and the LF/HF ratio increase. In addition, the LF power increases while the driving time increases, and the LF power decreases as the time of rest increases [
40]. These data were all extracted from the PPG signal, indicating the importance of collecting heart activity data in the detection of drunk driving. Average blink duration can be used to determine a person’s arousal level. Many previous studies on eye activity have shown that sustained attention to a monotonous task may lead to performance fluctuations and eye activity changes. The relatively poor eye performances, such as longer blink duration, are generated with the fatigue and drowsiness [
41,
42].
In this study, the SVM model was trained to distinguish drunk driving and normal driving by integrating both driving performance and physiological measure data. Although the PCA was conducted to rank the highest-weighted features, the 20 features were still all in the SVM model. Speed is always chosen as an index to evaluate driver performance. Drivers are likely to speed when they have imbibed large amounts of alcohol. Motor-impairing effects of alcohol can reduce driver precision, resulting in greater within-lane swerving and line crossings. The disinhibiting effects of alcohol can compromise driving performance by increasing reckless behaviours, such as speeding, excessive lane changing, and a disregard of traffic signals [
30]. Alcohol-impaired drivers can be slower to adjust the position of their vehicles in the road, a task that requires drivers to execute quick, abrupt steering wheel movements. Moreover, a driver’s steering wheel manipulations may change when drunk. These changes are reflected by an increase in steering wheel rotation angle. Driving performance, such as steering and braking control, is adversely affected by alcohol and previous studies indicated that the driver’s ability to control the steering wheel is seriously affected with a medium BAC level [
2]. Steering wheel movement can be used to analyze the lateral control of the vehicle [
43]. Another interesting indicator is the ability of the driver to position their car on the road in terms of lateral position (through its standard deviation) [
44]. When drivers are drunk, their attention is scattered, and their reactions are slow. Consequently, they may fail to keep their vehicles within the proper lane. In the data, this manifests as a greater offset or greater standard deviation of lane position, indicating a poorer driving performance. Alcohol consumption reliably produces impairments in some behavioural measures, such as lane keeping, the number of centerline crossings and, particularly, the standard deviation of lane position [
25,
45]. These data were important inputs for the training model.
There were 32 samples in the study, 22 were used to train the SVM model. The accuracy of the model in estimating the drunk condition was then assessed by the remaining 10 samples. The SVM results showed that the classification can successfully distinguish drunk driving from normal driving with an accuracy of 70%. Furthermore, this accuracy level could be improved by integrating detection of alcohol in the air. The main limitation of this study is its relatively small sample size, which undermines its statistical power and results in relatively lower prediction accuracy. However, the sample size is statistically sufficient to set up an SVM model, and the prediction accuracy may improve in future studies with larger sample sizes. University students are over-represented in the samples used in this study, and mature drivers would be studied in future studies. Since this SVM was developed as an early warning drunk driving detector, the trained SVM could be used as an automatic drunk driving detection method.
6. Conclusions
Alcohol’s effect on cognitive and neurological functions is well-known and may create a high probability of traffic accidents. Studies on driver behaviour after drinking would provide theoretical support for the development of alcohol-related active safety system. This study conducted the detection experiment to distinguish drunk driving from normal driving under simulated driving conditions. The classification was performed by the support vector machine (SVM) classifier trained to distinguish between these two classes by integrating both driving performance and physiological measurements. In addition, principal component analysis was conducted to rank the weights of the features. The standard deviation of R–R intervals (SDNN), the root mean square value of the difference of the adjacent R–R interval series (RMSSD), low frequency (LF), high frequency (HF), the ratio of the low and high frequencies (LF/HF), and average duration time of blink were the highest weighted features in the study. SDNN, RMSSD, LF, HF, and LF/HF were all extracted from the PPG signal, indicating the importance of collecting HRV data in the detection of drunk driving. Average blink duration explains the importance of eye tracking in the study of drunk driving prevention. The physiological signals extracted features from EMG, EDA and PPG signals which including RMS, AEMG, Median Freq., Mean Freq., tonic signal, phasic signal, SC, AVHR, SDNN, RMSSD, PNN50, LF, HF, LF/HF, and average blink duration, as well, while the driving performance measurements included maximum speed, minimum speed, mean speed, standard deviation of lane position, and standard deviation of steering wheel rotation angle. All the physiological features and driving performance were integrated to train a SVM model. The results show that SVM classification can successfully distinguish drunk driving from normal driving with an accuracy of 70%. The prediction accuracy may improve in future studies with larger sample sizes. The driving performance data and the physiological measurements reported by this paper combined with air-alcohol concentration could be integrated using the support vector regression classification method to establish a better early warning model, thereby improving vehicle safety.





{kind=link}
{kind=link}