Data Centric Sensor Stream Reduction for Real-Time Applications in Wireless Sensor Networks

Abstract
:1. Introduction
- Data-stream: In this work, we use sensor-stream algorithms as an in-network solution, and we improve the network performance by reducing the packet delay in real-time applications.
- Data reduction: Regarding data reduction, we show that we can meet real-time application deadlines when we use sensor-stream techniques during the routing task. This in-network approach represents a new contribution.
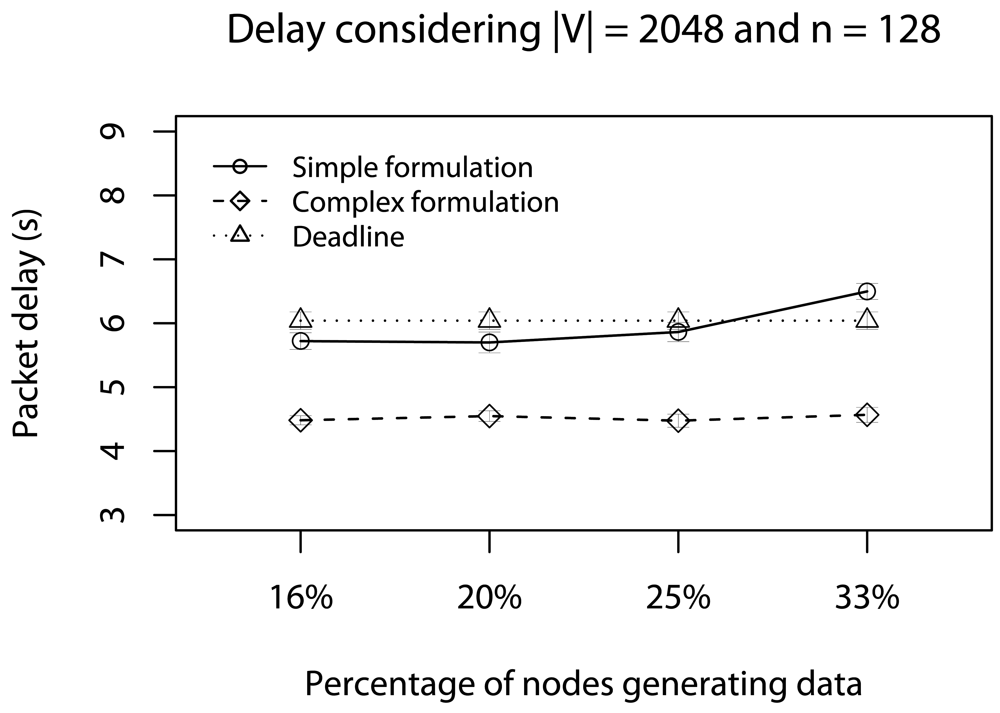
- Real-time: We present a analytical model to estimate the ideal amount of data-reduction, and we apply the stream-based solution in realistic real-time scenarios. To the best of our knowledge this is the first work that tries to quantify the reduction intensity based on real-time deadlines.
2. Problem Statement
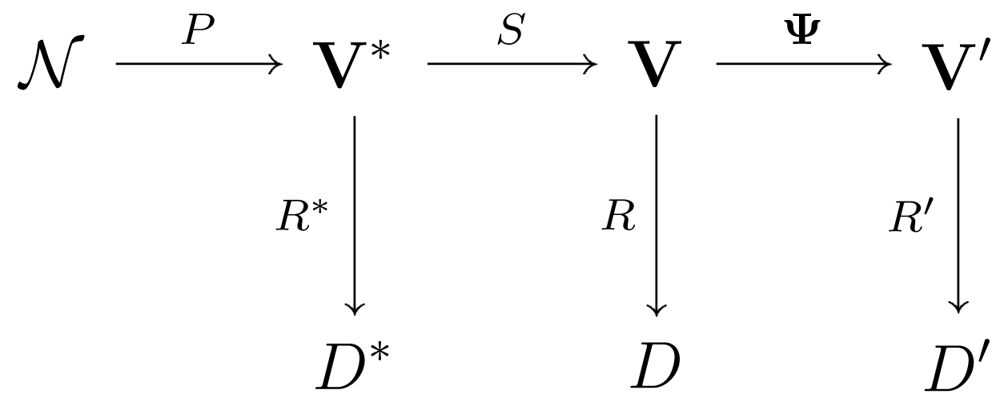
- The ideal behavior denoted by N → V* → D, where N denotes the environment and the process to be measured, P is the phenomenon of interest, with V* their space-temporal domain. If complete and uncorrupted observation was possible, we could devise a set of ideal rules R* leading to ideal decisions D*.
- The sensed behavior is denoted by N → V* → V → D. In this case, we have a set of s sensors S=(Sl,…,Ss), each one providing measurements of the phenomenon and producing a report in the domain Vi, with 1 ≤ i ≤ s; all possible domain sets are denoted V=(VU…, Vs). Using such information, we can conceive the set of rules R leading to the set of decisions D. We consider V to be a sensor-stream, due to its “time series” characteristics.
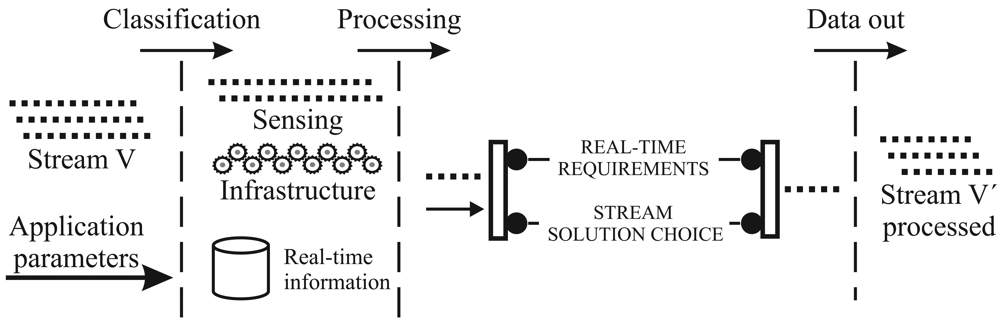
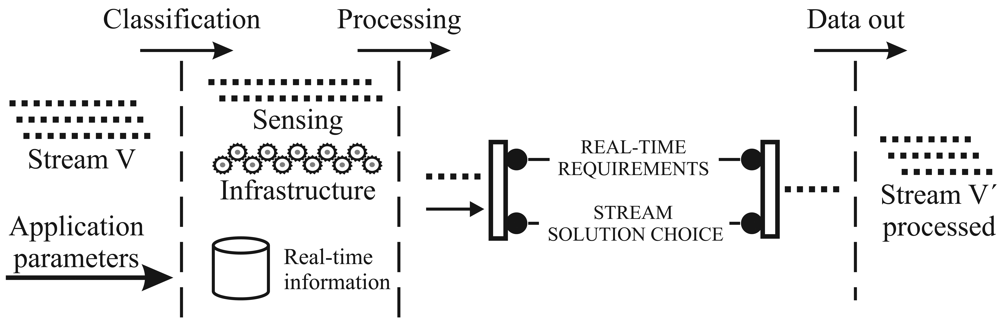
- The reduced behavior is denoted by N → V* → V → V → D′. Dealing with V may be too expensive in terms of, for instance, power, bandwidth, computer resources usage, and, specially, time delivery to meet the deadline requirements. Since the level of redundancy is not negligible in most situations, we can reduce this information volume. Sensor-stream reduction techniques are denoted by Ψ, and they transform the complete domain V into the smaller one V. New rules that use V are denoted by R′, and they lead to the set of decisions D′.
Problem definition
- WSN topology: The set of sensors S = (S1,…, Sn) is distributed in a squared area A = L × L. There is only one sink node located at (0, 0) on the left bottom corner. The density is kept constant and all nodes have the same hardware configuration.
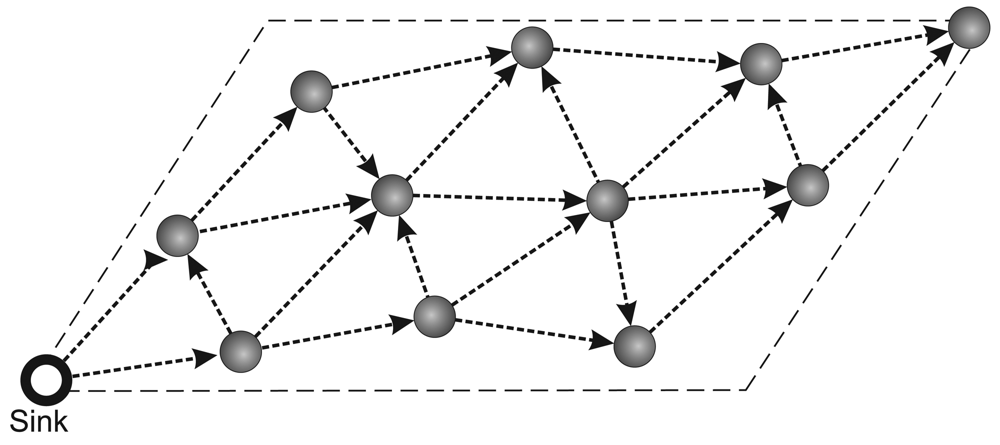
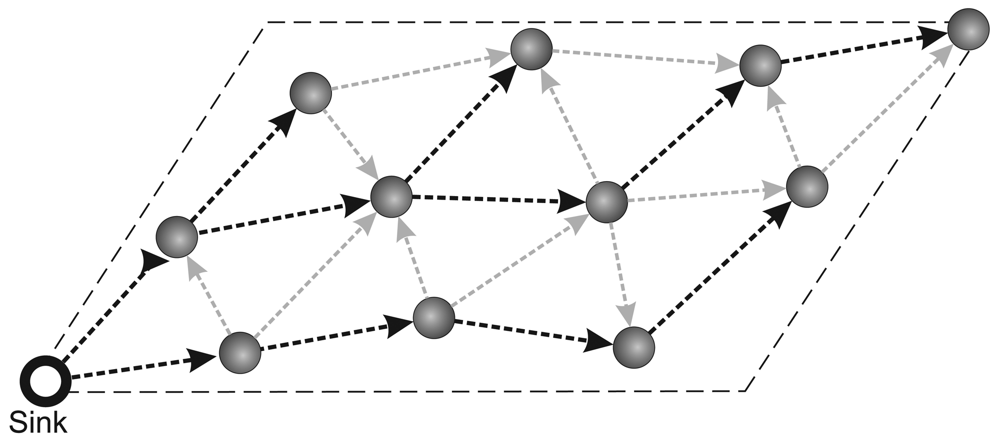
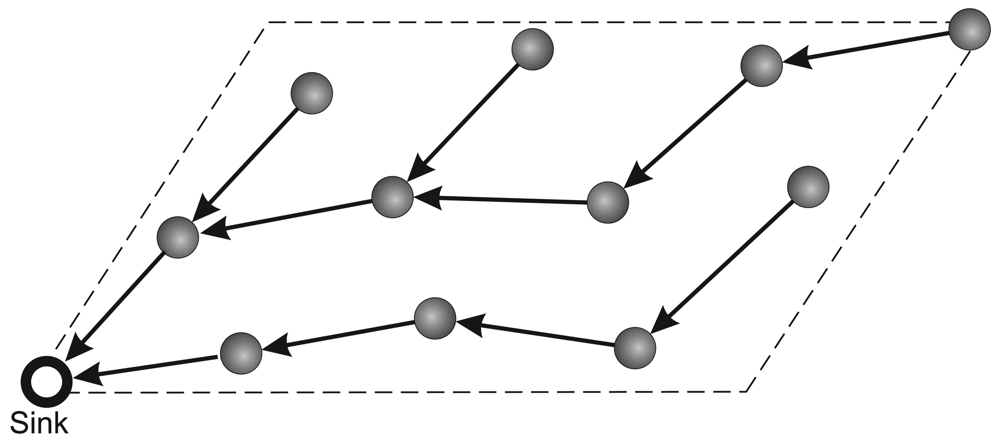
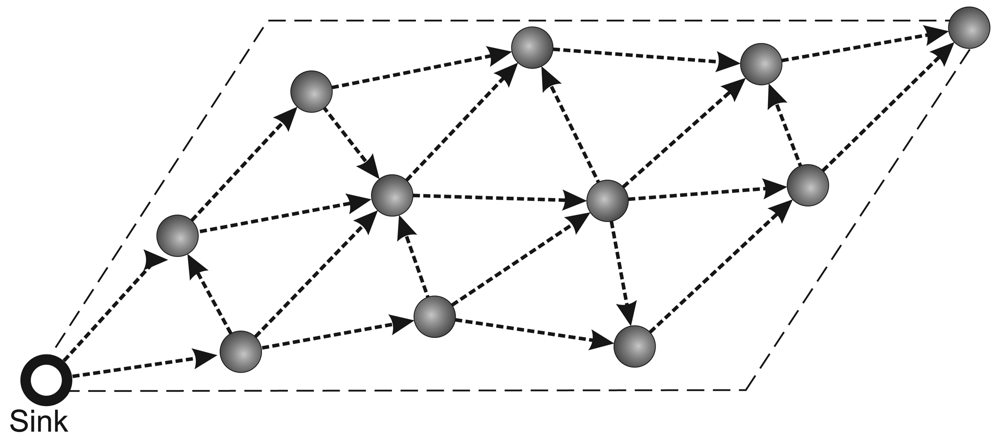
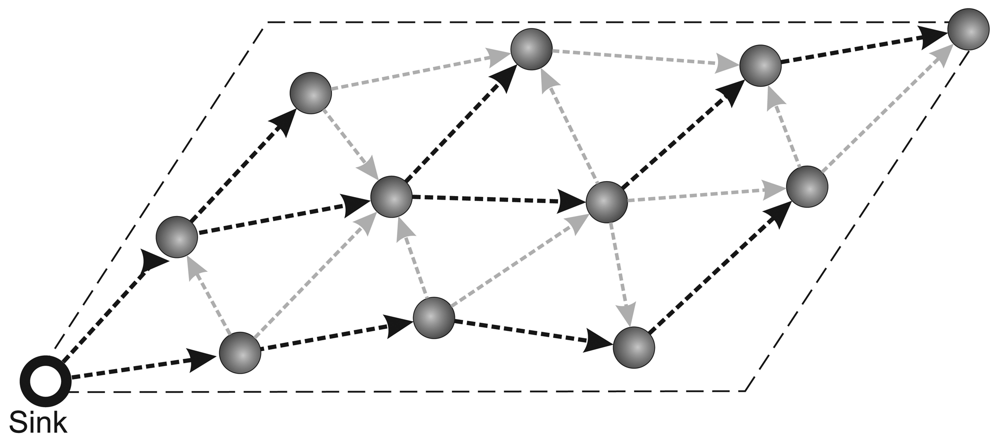
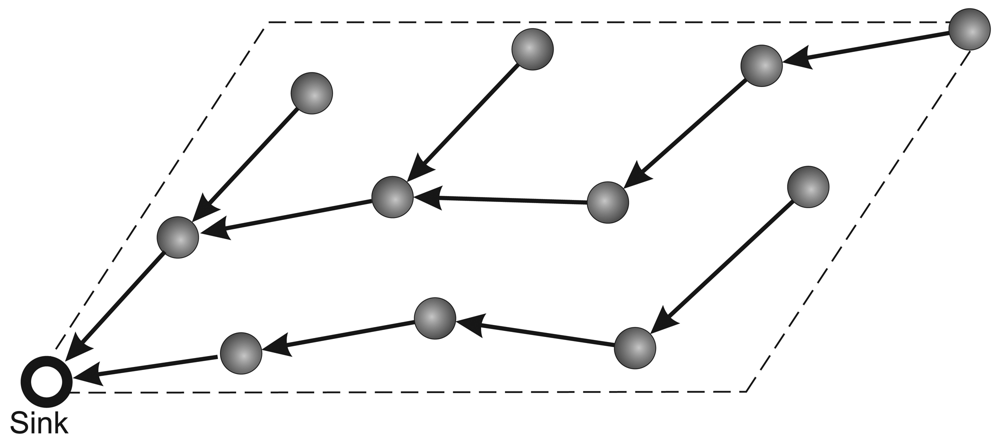
- Routing protocol: The network communication is based on a multihop shortest-path tree [38] as the routing protocol. To evaluate only the data-centric stream reduction performance, the tree is built just once before the traffic starts and the network is kept static. The build tree process is depict in Figure 1. First in (a), the sink node sends a flooding message requesting to build tree. After this, in (b), the nodes sets your father node considering the first message received in flooding process (it is considered that the first packet received represents the shortest path to sink). Finally, in (c), we have the complete tree mounted.
- Sensor-stream item: Vi values are generated by one specific sensor located at (L,L) on the right top corner (the opposite side of sink node), for convention we use V to represent the stream generated. For each stream, we process one stream item V = {V1,…, Vn{ where the amount of data stored before the data sent is | V| = N. The generation is continuous at regular intervals (periods) of time. We consider gaussian data (μ = 0.5 and σ = 0.1) sent in bursts.
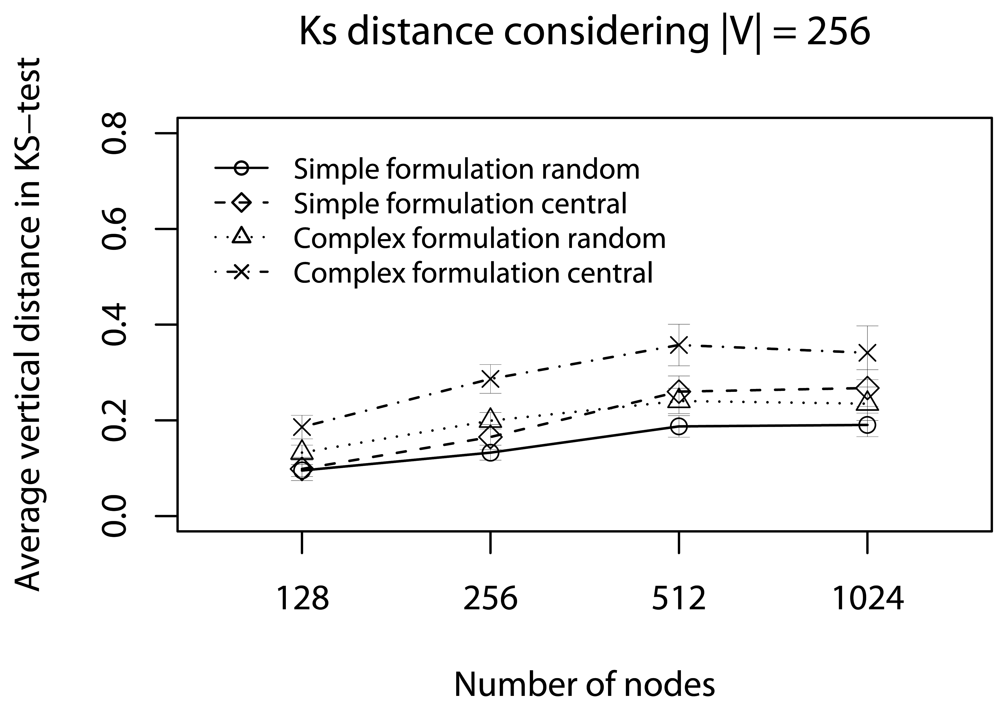
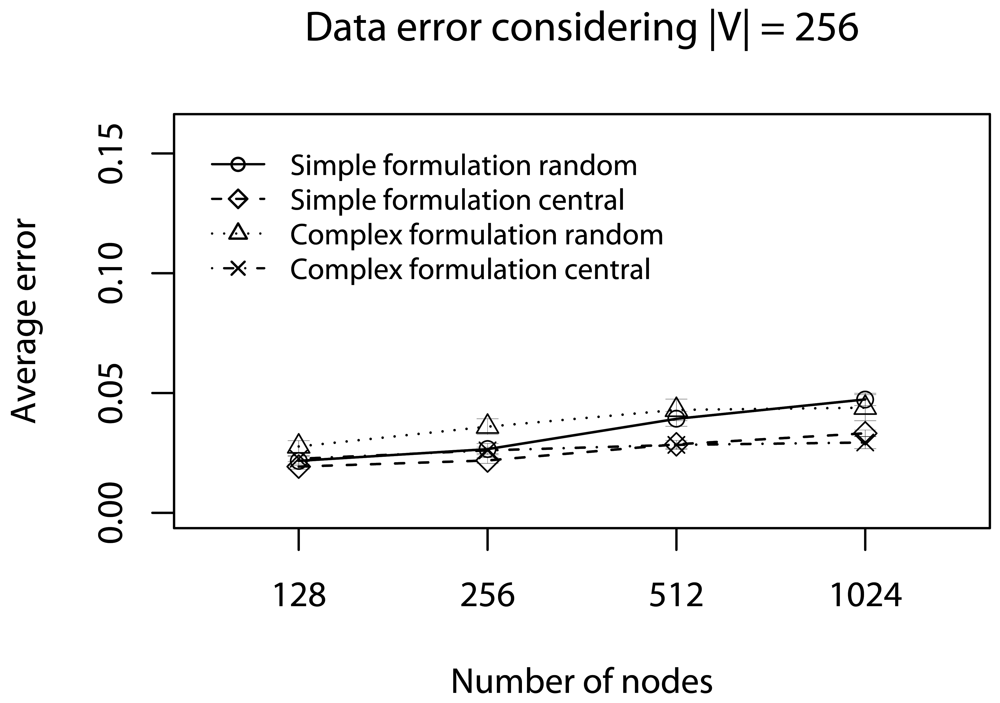
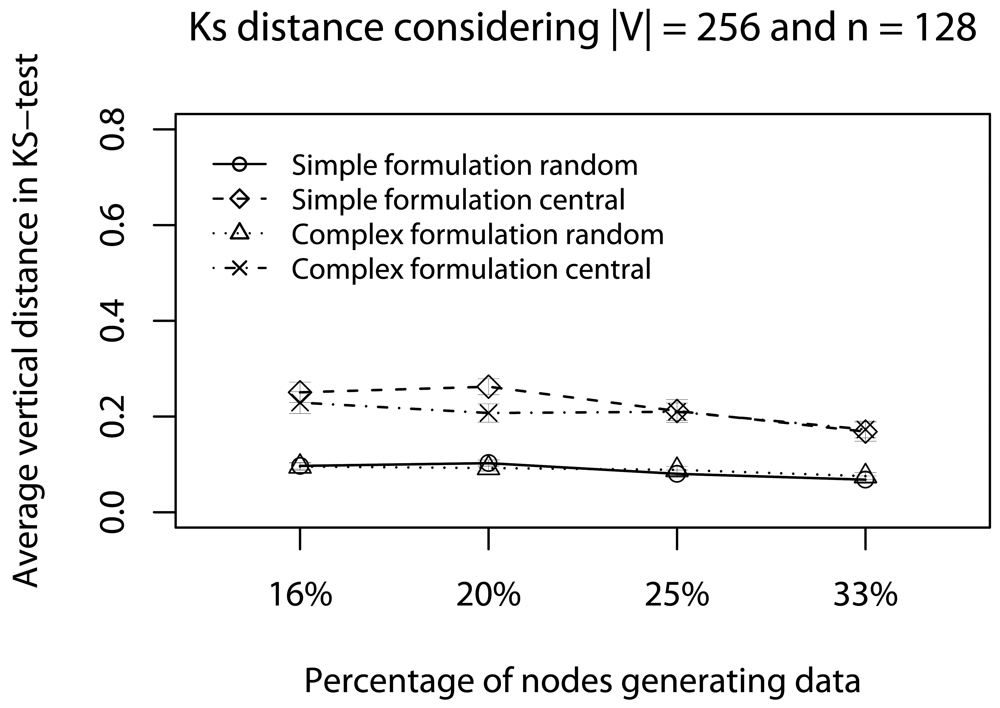
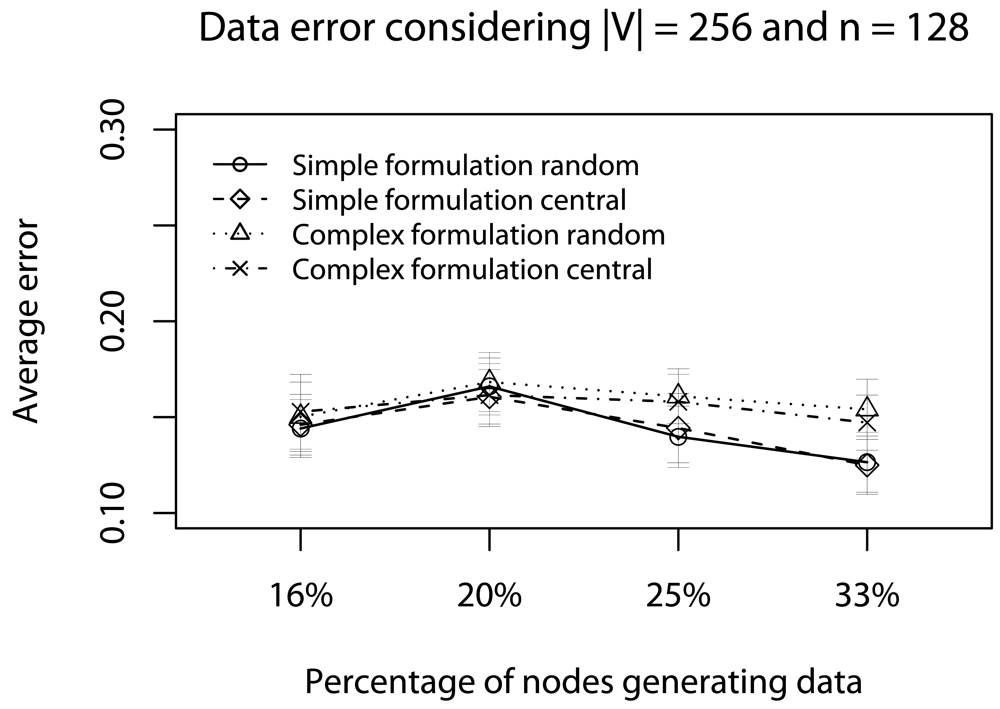
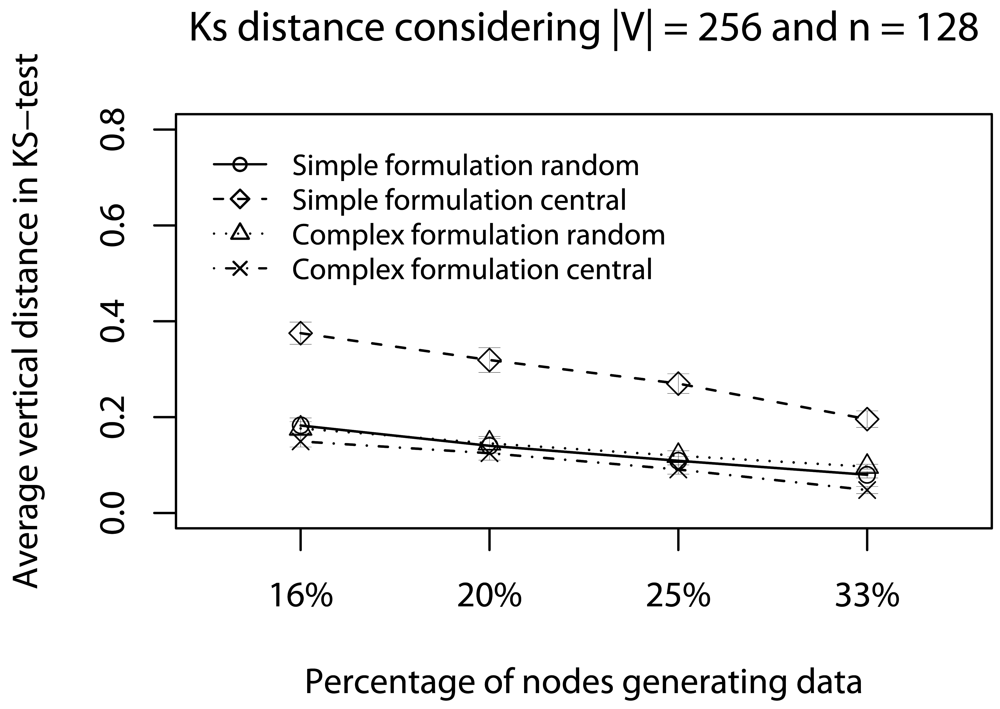
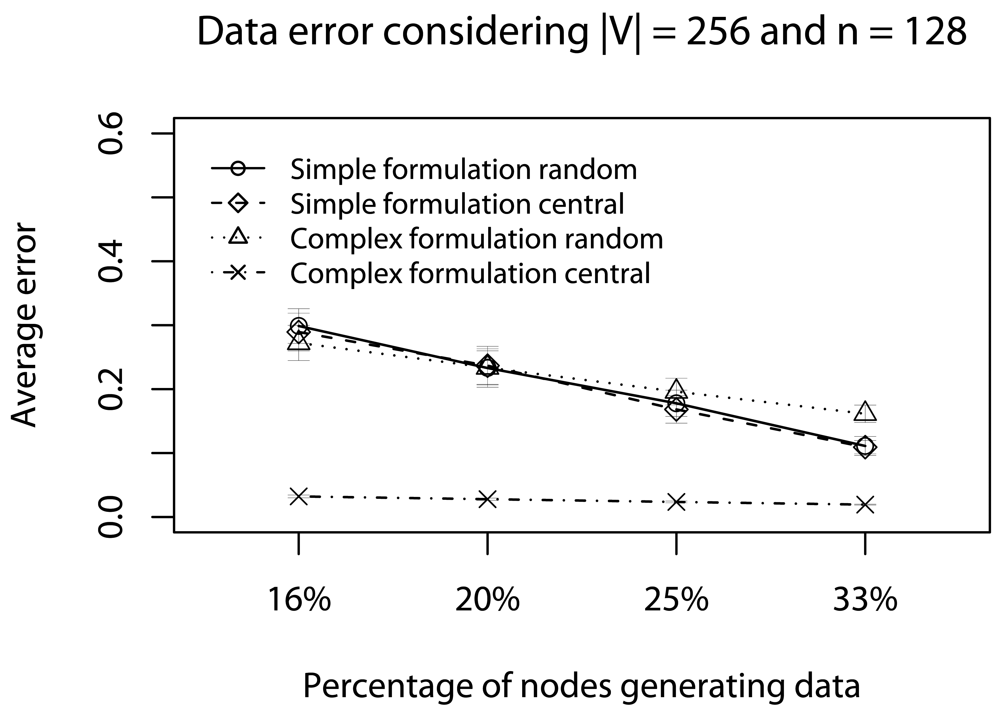
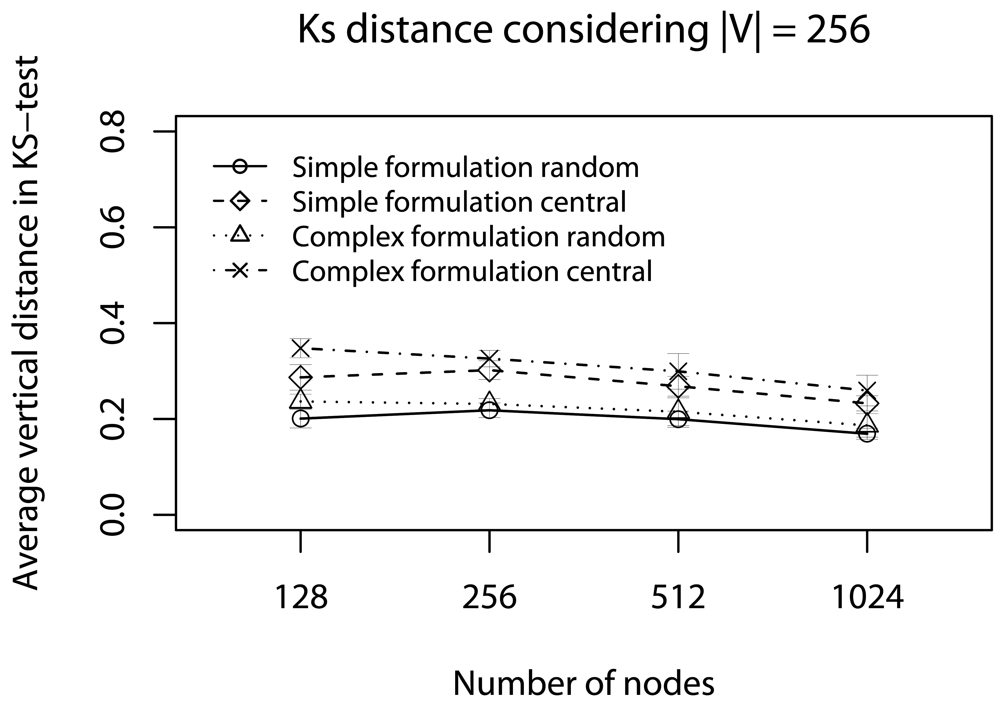
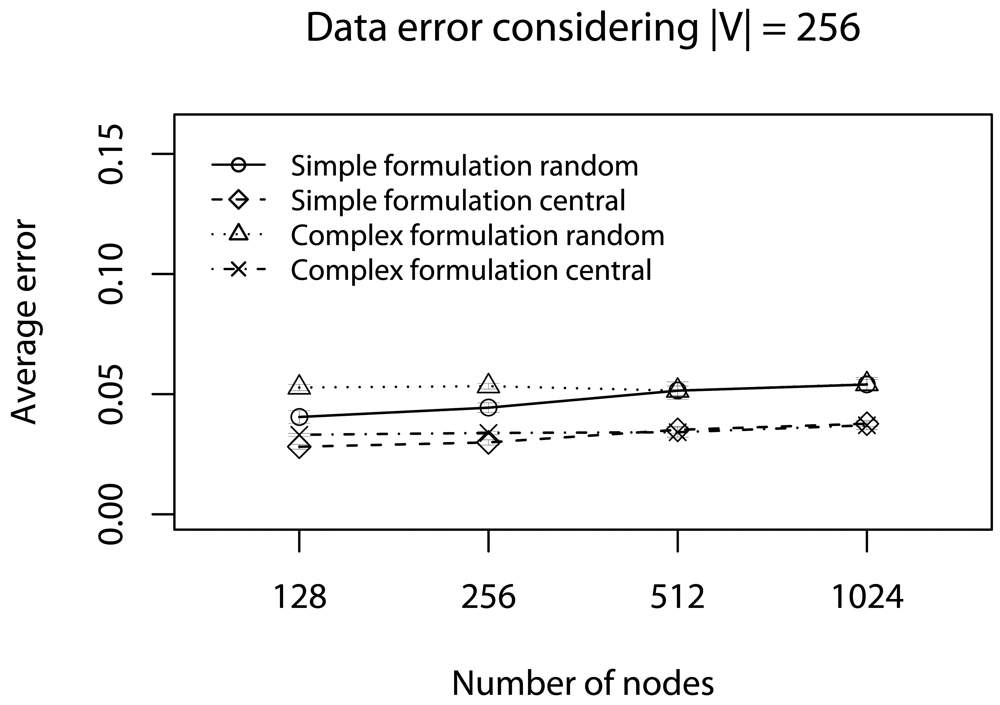
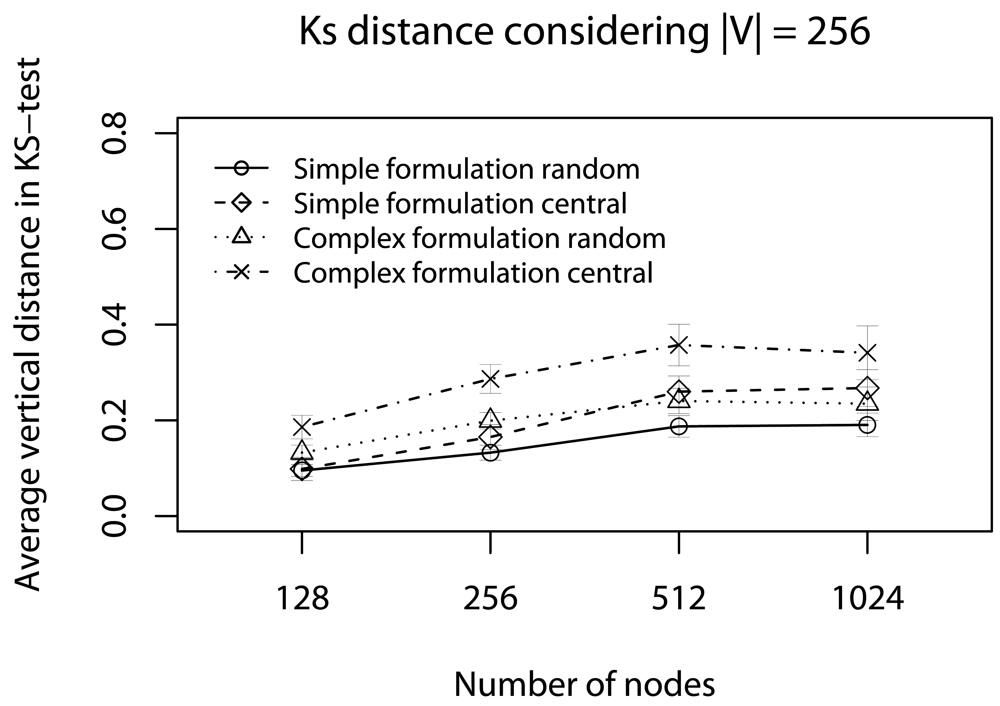
- Quality of a sample: To assess the impact of data reduction on data quality, based on decision D, we consider two rules: Rdst and Rval. The rule Rdst aims at identifying whether V and V′ data distributions are similar. To compute this distribution similarity (T), we use the Kolmogorov-Smirnov test [39]. The rule Rval evaluates the discrepancy among the values in sampled streams, i.e., if they still represent the original stream. To quantify this discrepancy (Φ), we compute the absolute value of the largest distance between the average value of the original data, and the lower or higher confidence interval values (95%) of the sampled data:in which the pair (vlow; vhig) is the confidence interval for the sampled data and avgg is the average (mean value) of original data [36]. These rules help us to identify the scenarios where our sampling algorithm is better than simple random sampling strategy.
3. Data-Centric Reduction Design in Real-Time WSNs Applications
4. What Is the Ideal Sample Size?
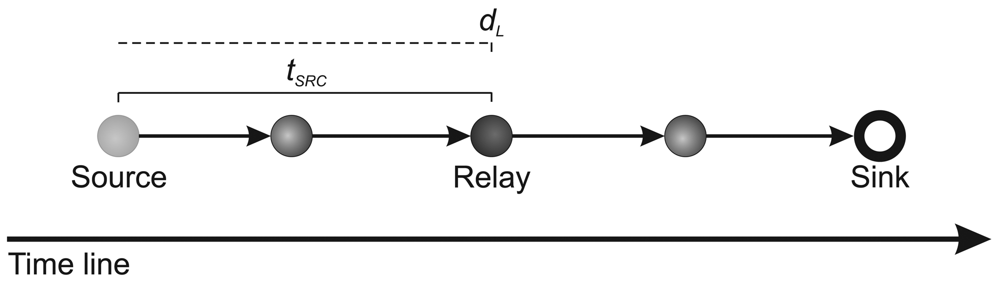
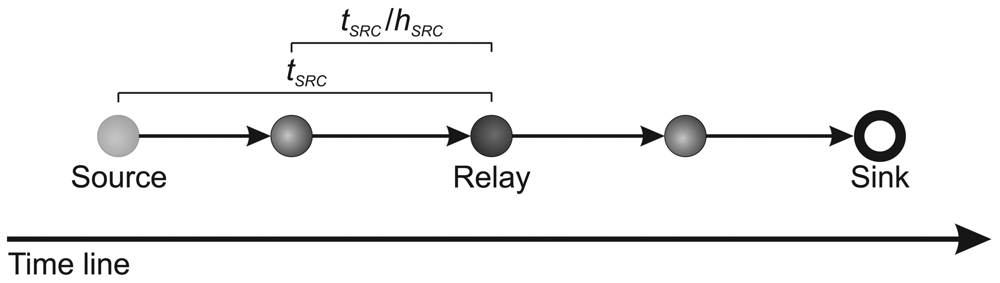
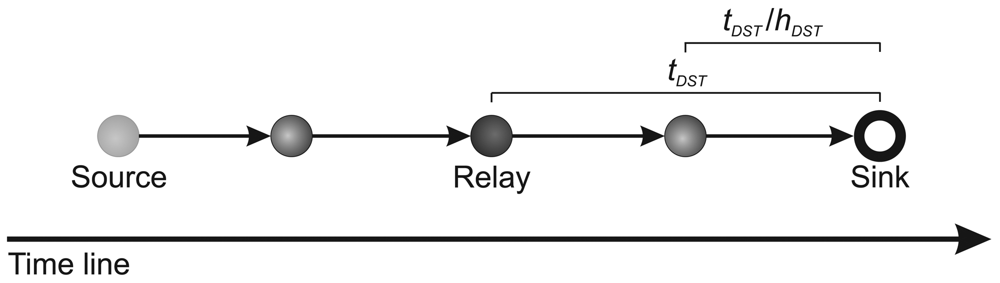
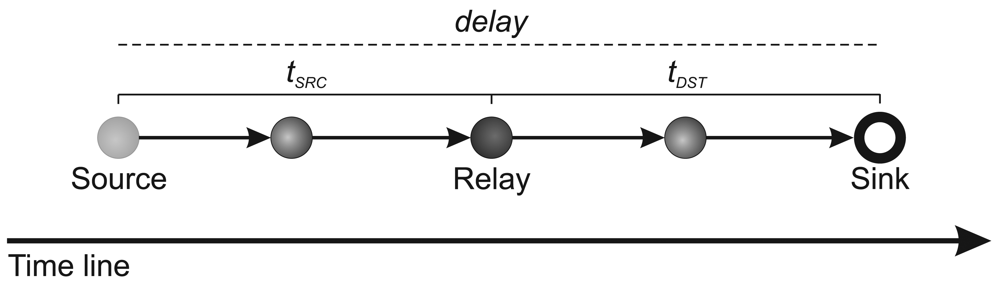
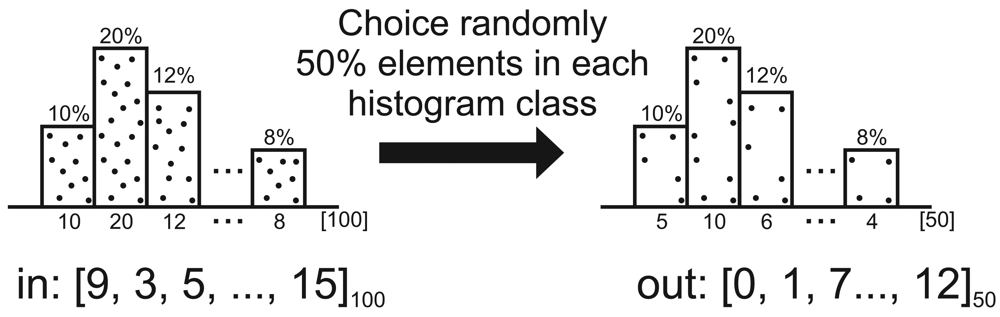
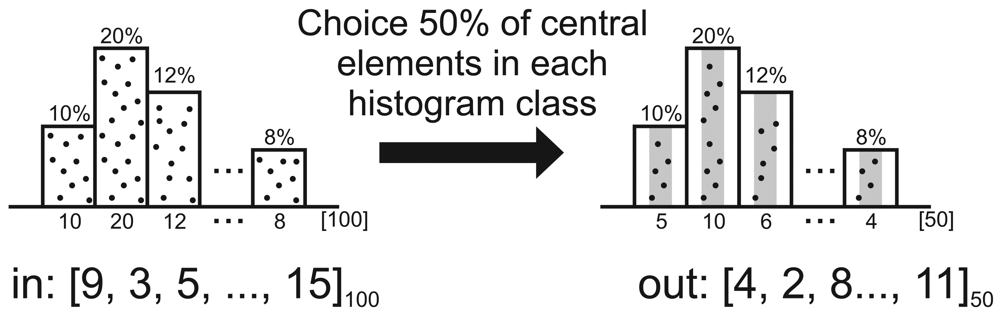
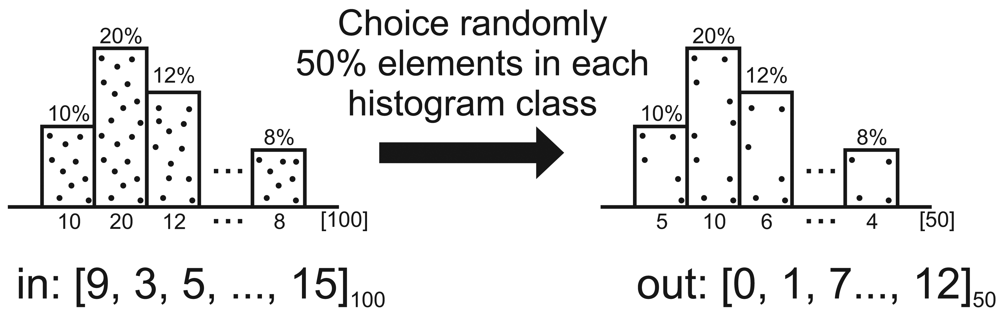
5. Sensor-Stream Reduction
| Algorithm 1: Pseudo-code of reduction decision. | ||
| Data: Vj – fragment stream received | ||
| 1 | begin | |
| 2 | “Get from Vj the fragments information” | |
| 3 | if j = 1 then | |
| 4 | “gap is computed through equations (2–4)” | |
| 5 | if gap > 0 then | |
| 6 | “Enable V storage” | |
| 7 | ||
| 8 | end | |
| 9 | end | |
| 10 | if Storage is enabled then | |
| 11 | “Store Vj” | |
| 12 | if j = nf then | |
| 13 | V ← “Compute Ψ on V with | V′| size” | |
| 14 | “SendV” | |
| 15 | end | |
| 16 | end | |
| 17 | else | |
| 18 | “Forward Vj” | |
| 19 | end | |
| 20 | end | |
Line 2
Lines 11-15
Lines 7-20
Line 21
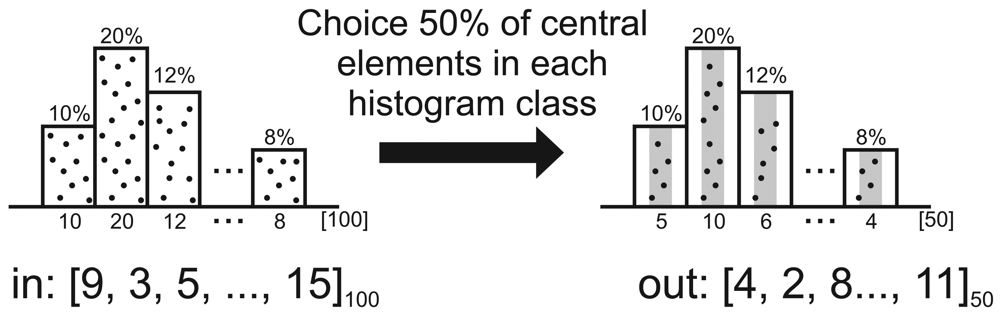
| Algorithm 2: Pseudo-code of Ψcentral sampling reduction. | |
| Data: V – original sensor-stream | |
| Data: |V′| - resulting sample size | |
| Result: V - resulting sample set | |
| 1 | begin |
| 2 | Sort(V) |
| 3 | wid ← “Histogram's class width” |
| 4 | fst←0 {first index of histogram class} |
| 5 | ncol ← 0 {number of elements per columns in V} |
| 6 | w←0 |
| 7 | for k←0 to|V|-1do |
| 8 | if V[k] > V [fst]+wid or k = |V|- 1 then |
| 9 | n'col ← ⌈n'col | V′|/|V| ⌉{number of elements per columns in V′} |
| 10 | index ←f st+⌈(ncol-n'col)/2⌉ |
| 11 | for l←0 to n'col do |
| 12 | V′[w] ← V[index] |
| 13 | w ← w + 1 |
| 14 | index ← nextIndex |
| 15 | end |
| 16 | ncol ← 0 |
| 17 | fst ← k |
| 18 | end |
| 19 | ncol ← ncol + 1 |
| 20 | end |
| 21 | Sort(V′) {according to the original order} |
| 22 | end |
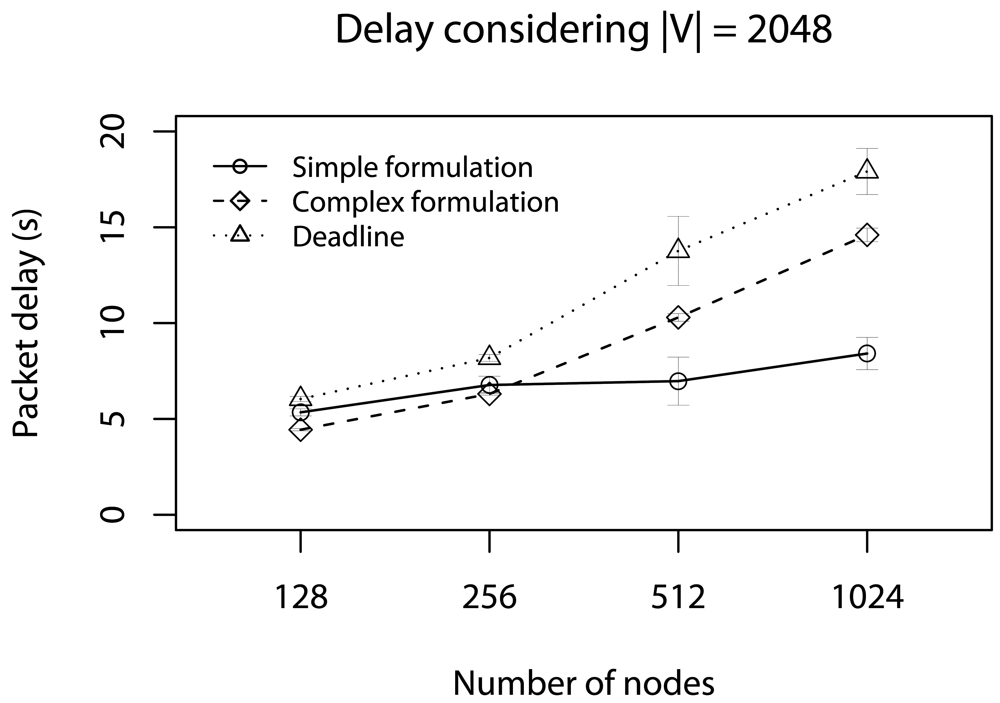
6. Simulation
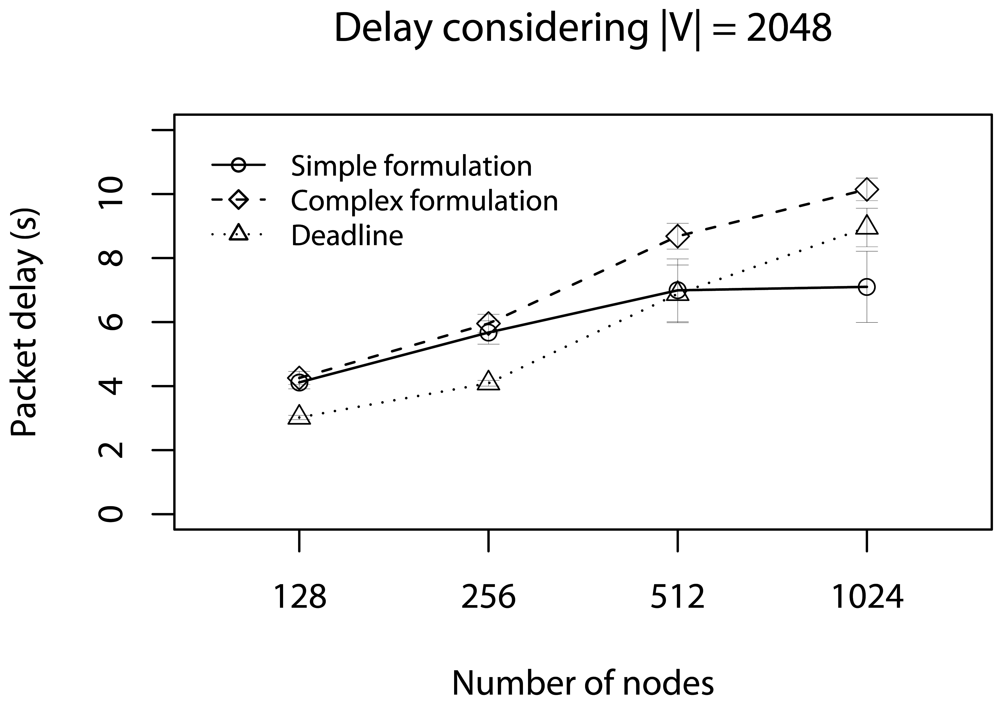
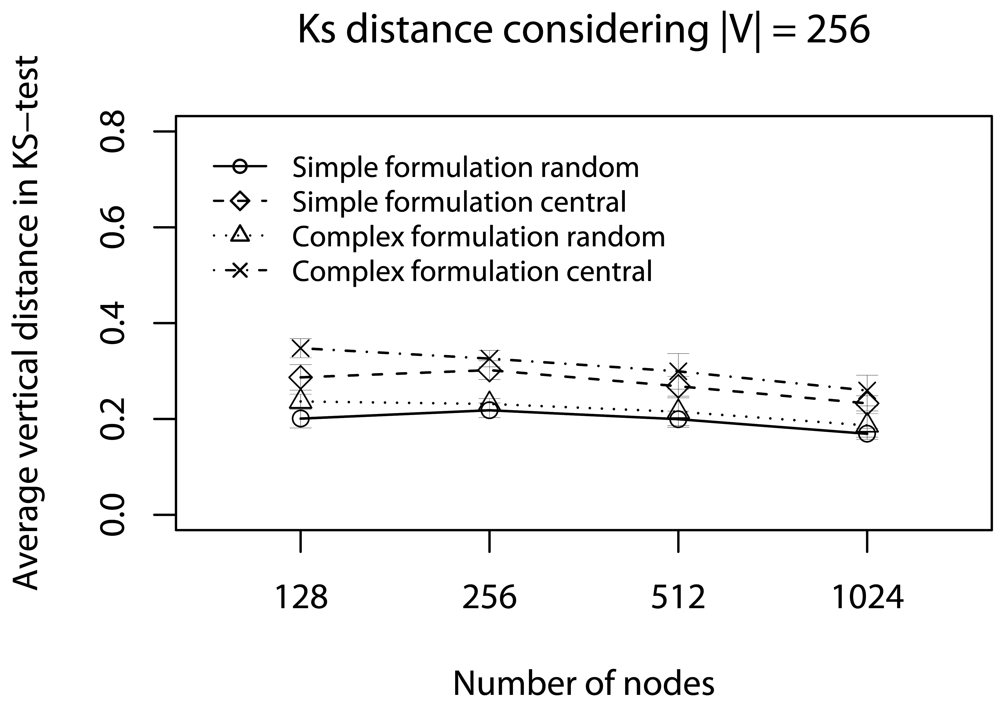
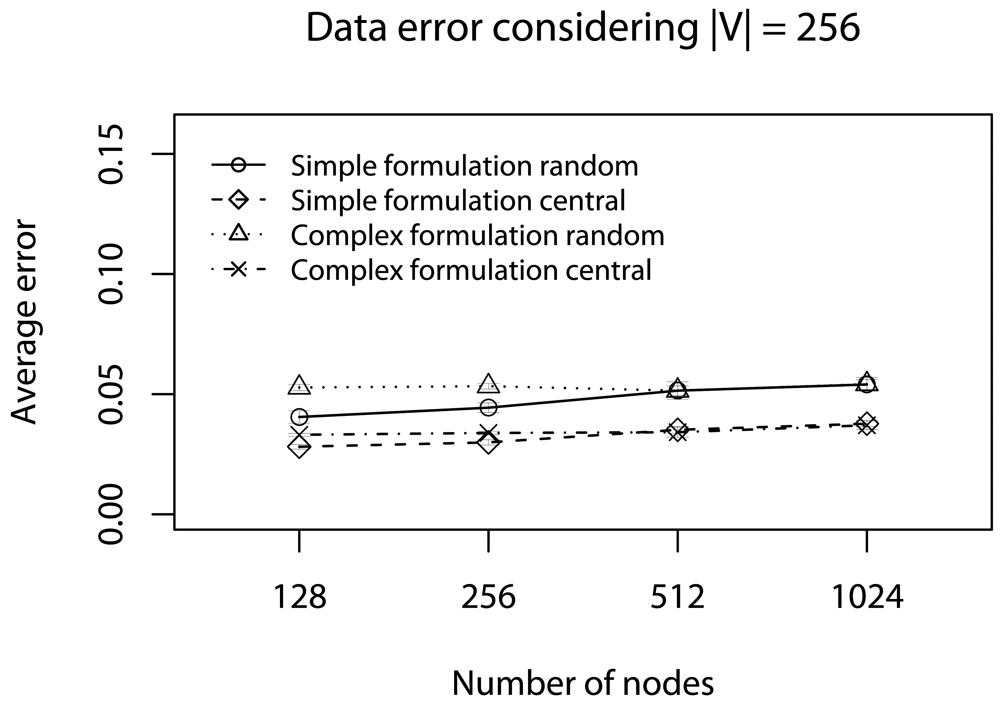
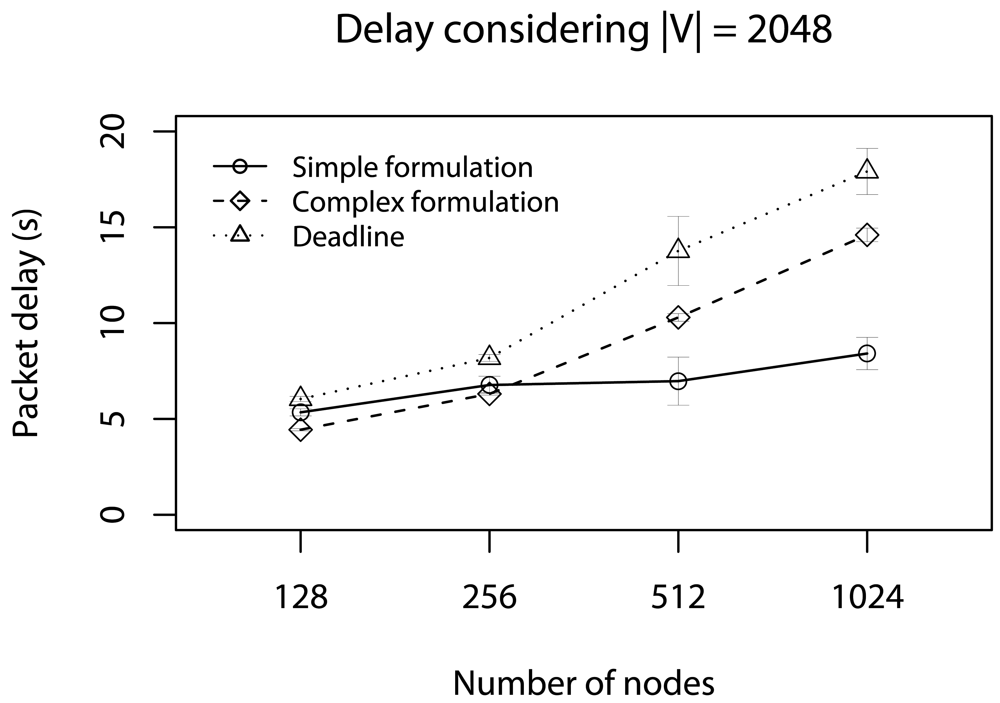
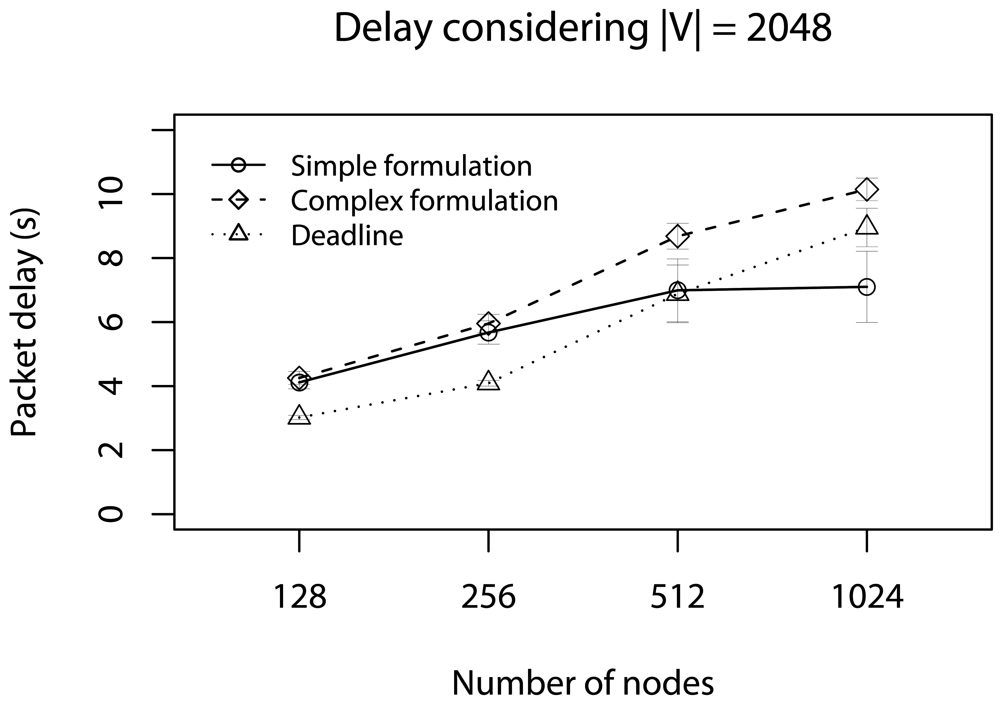
6.1. Half of Deadlines without Concurrent Traffic
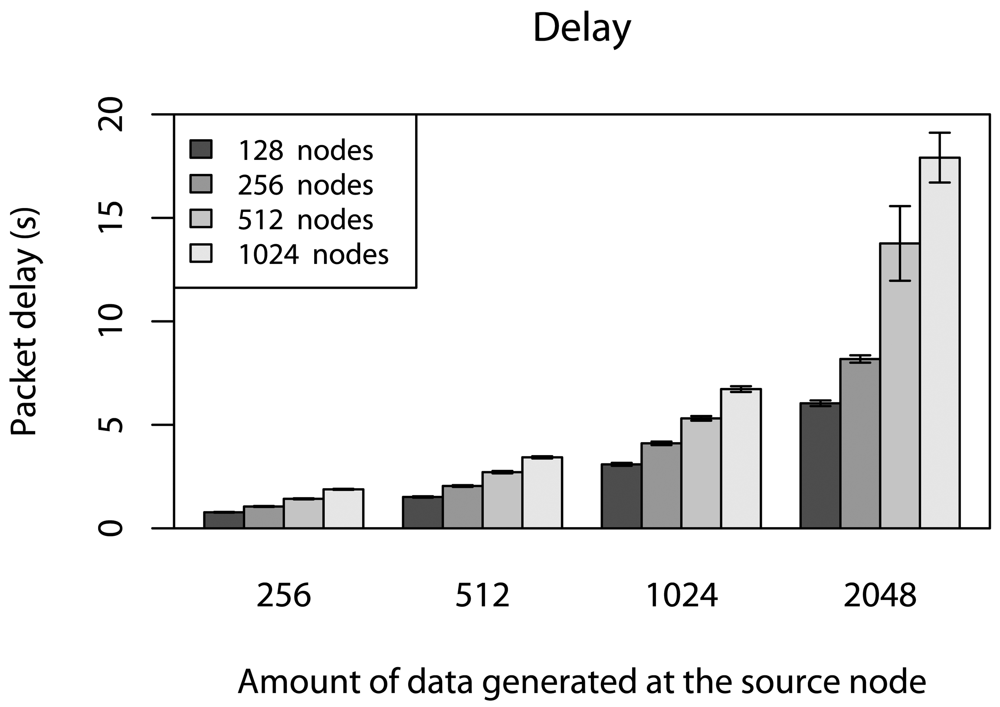
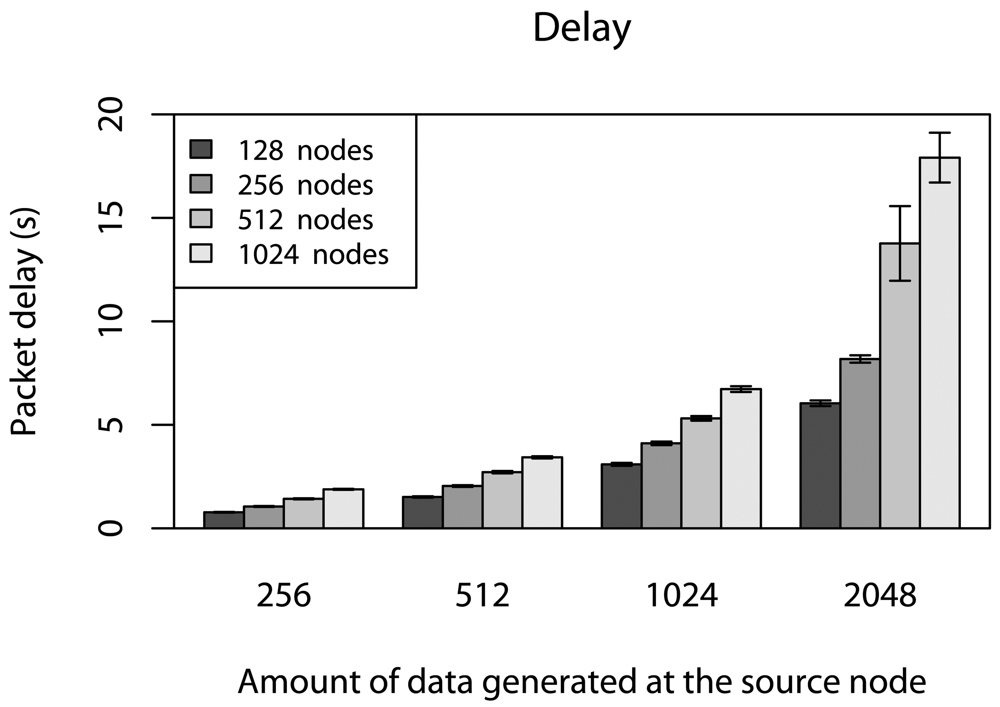
6.2. Delay Caused by Relay Nodes without Concurrent Traffic
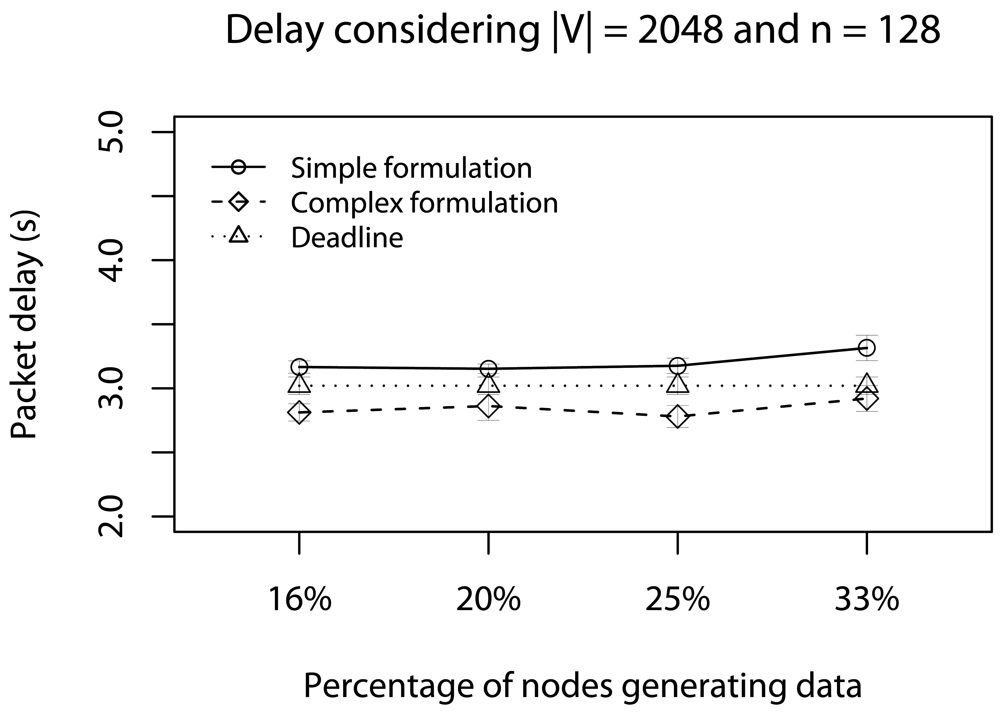
6.3. Half of Deadlines with Concurrent Traffic
6.4. Delay Caused by Relay Nodes with Concurrent Traffic
7. Conclusions
Acknowledgments
References
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. A Survey on Sensor Networks. IEEE Commun. Mag. 2002, 40, 102–114. [Google Scholar]
- Lins, A.; Nakamura, E.F.; Loureiro, A.A.F.; Coelho, C.J.N., Jr. BeanWatcher: A Tool to Generate Multimedia Monitoring Applications for Wireless Sensor Networks; Marshall, A., Agoulmine, N., Eds.; Springer: Belfast, UK, 2003; pp. 128–141. [Google Scholar]
- Nakamura, E.F.; Loureiro, A.A.F.; Frery, A.C. Information Fusion for Wireless Sensor Networks: Methods, Models, and Classifications. ACM Comput. Surv. 2007, 39, 9/1–9/55. [Google Scholar]
- He, T.; Stankovic, J.A.; Lu, C.; Abdelzaher, T. SPEED: A Stateless Protocol for Real-Time Communication in Sensor Networks; IEEE Computer Society: Providence, RI, USA, 2003; pp. 46–55. [Google Scholar]
- Li, H.; Shenoy, P.J.; Ramamritham, K. Scheduling Communication in Real-Time Sensor Applications; IEEE Computer Society: Toronto, Canada, 2004; pp. 10–18. [Google Scholar]
- Lu, C.; Blum, B.M.; Abdelzaher, T.F.; Stankovic, J.A.; He, T. RAP: A Real-Time Communication Architecture for Large-Scale Wireless Sensor Networks; IEEE Computer Society: San Jose, CA, USA, 2002; pp. 55–66. [Google Scholar]
- Aquino, A.L.L.; Figueiredo, C.M.S.; Nakamura, E.F.; Loureiro, A.A.F.; Fernandes, A.O.; Junior, C.N.C. On The Use Data Reduction Algorithms for Real-Time Wireless Sensor Networks; IEEE Computer Society: Aveiro, Potugal, 2007; pp. 583–588. [Google Scholar]
- Li, P.; Gu, Y.; Zhao, B. A Global-Energy-Balancing Real-time Routing in Wireless Sensor Networks; IEEE Computer Society: Tsukuba, Japan, 2007; pp. 89–93. [Google Scholar]
- Pan, L.; Liu, R.; Peng, S.; Yang, S.X.; Gregori, S. Real-time Monitoring System for Odours around Livestock Farms; IEEE Computer Society: London, UK, 2007; pp. 883–888. [Google Scholar]
- Peng, H.; Xi, Z.; Ying, L.; Xun, C.; Chuanshan, G. An Adaptive Real-Time Routing Scheme for Wireless Sensor Networks; IEEE Computer Society: Niagara Falls, Ontario, Canada, 2007; pp. 918–922. [Google Scholar]
- Muthukrishnan, S. Data Streams: Algorithms and Applications; Now Publishers: Hanover, MA, USA, 2005. [Google Scholar]
- Altiparmak, F.; Tuncel, E.; Ferhatosmanoglu, H. Incremental Maintenance of Online Summaries over Multiple Streams. IEEE Trans. Knowl. Data Eng. 2008, 20, 216–229. [Google Scholar]
- Datar, M.; Gionis, A.; Indyk, P.; Motwani, R. Maintaining Stream Statistics over Sliding Windows. SIAM J. Comput. 2002, 31, 1794–1813. [Google Scholar]
- Guha, S.; Meyerson, A.; Mishra, N.; Motwani, R.; O'Callaghan, L. Clustering Data Streams: Theory and Practice. IEEE Trans. Knowl. Data Eng. 2003, 15, 515–528. [Google Scholar]
- Lian, X.; Chen, L. Efficient Similarity Search over Future Stream Time Series. IEEE Trans. Knowl. Data Eng. 2008, 20, 40–54. [Google Scholar]
- Akcan, H.; Bronnimann, H. A New Deterministic Data Aggregation Method for Wireless Sensor networks. Signal Process. 2007, 87, 2965–2977. [Google Scholar]
- Bar-Yosseff, Z.; Kumar, R.; Sivakumar, D. Reductions in Streaming Algorithms, with an Application to Counting Triangles in Graphs; ACM: San Francisco, CA, USA, 2002; pp. 623–632. [Google Scholar]
- Buriol, L.S.; Leonardi, S.; Frahling, G.; Sholer, C.; Marchetti-Spaccamela, A. Counting Triangles in Data Streams; ACM: Chicago, IL, USA, 2006; pp. 253–262. [Google Scholar]
- Cammert, M.; Kramer, J.; Seeger, B.; Vaupel, S. A Cost-Based Approach to Adaptive Resource Management in Data Stream Systems. IEEE Trans. Knowl. Data Eng. 2008, 20, 202–215. [Google Scholar]
- Indyk, P. A Small Approximately min–wise Independent Family of Hash Functions; ACM: Baltimore, MD, USA, 1999; pp. 454–456. [Google Scholar]
- Abadi, D.J.; Lindner, W.; Madden, S.; Schuler, J. An Integration Framework for Sensor Networks and Data Stream Management Systems; Morgan Kaufmann: Toronto, Canada, 2004; pp. 1361–1364. [Google Scholar]
- Babcock, B.; Babu, S.; Datar, M.; Motwani, R.; Widom, J. Models and Issues in Data Stream Systems; ACM: Madison, WI, USA, 2002; pp. 1–16. [Google Scholar]
- Gehrke, J.; Madden, S. Query processing in Sensor Networks. IEEE Pervasive Comput. 2004, 3, 46–55. [Google Scholar]
- Madden, S.R.; Franklin, M.J.; Hellerstein, J.M.; Hong, W. TinyDB: An Acquisitional Query Processing System for Sensor Networks. ACM Trans. Database Syst. 2005, 30, 122–173. [Google Scholar]
- Xu, J.; Tang, X.; Lee, W.C. A New Storage Scheme for Approximate Location Queries in Object-Tracking Sensor Networks. IEEE Trans. Parallel Distrib. Syst. 2008, 19, 262–275. [Google Scholar]
- Elson, J.E. Time Synchronization in Wireless Sensor Networks. PhD. Thesis. University of California, Los Angeles, CA, USA, 2003. [Google Scholar]
- Yu, Y.; Krishnamachari, B.; Prasanna, V.K. Data Gathering with Tunable Compression in Sensor Networks. IEEE Trans. Parallel Distrib. Syst. 2008, 19, 276–287. [Google Scholar]
- Yuen, K.; Liang, B.; Li, B. A Distributed Framework for Correlated Data Gathering in Sensor Networks. IEEE Trans. Veh. Technol. 2008, 57, 578–593. [Google Scholar]
- Zheng, R.; Barton, R. Toward Optimal Data Aggregation in Random Wireless Sensor Networks; IEEE Computer Society: Anchorage, AK, USA, 2007; pp. 249–257. [Google Scholar]
- Chen, M.; Know, T.; Choi, Y. Energy-efficient Differentiated Directed Diffusion (EDDD) in Wireless Sensor Networks. Comput. Commun. 2006, 29, 231–245. [Google Scholar]
- Ganesan, D.; Ratnasamy, S.; Wang, H.; Estrin, D. Coping with Irregular Spatio-Temporal Sampling in Sensor Networks. ACM Sigcomm Comp. Commun. Rev. 2004, 34, 125–130. [Google Scholar]
- Gedik, B.; Liu, L.; Yu, P.S. ASAP: An Adaptive Sampling Approach to Data Collection in Sensor Networks. IEEE Trans. Parallel Distrib. Syst. 2007, 18, 1766–1783. [Google Scholar]
- Matousek, J. Derandomization in Computational Geometry. Algorithms 1996, 20, 545–580. [Google Scholar]
- Bagchi, A.; Chaudhary, A.; Eppstein, D.; Goodrich, M.T. Deterministic Sampling and Range Counting in Geometric Data Streams. ACM Trans. Algorithms 2007, 3. Article number 16. [Google Scholar]
- Nath, S.; Gibbons, P.B.; Seshan, S.; Anderson, Z.R. Synopsis Diffusion for Robust Aggregation in Sensor Networks. Proceedings of 2nd International Conference on Embedded Networked Sensor Systems, Baltimore, MD, USA; 2004; pp. 250–262. [Google Scholar]
- Aquino, A.L.L.; Figueiredo, C.M.S.; Nakamura, E.F.; Buriol, L.S.; Loureiro, A.A.F.; Fernandes, A.O.; Junior, C.N.C. A Sampling Data Stream Algorithm For Wireless Sensor Networks; IEEE Computer Society: Glasgow, Scotland, 2007; pp. 3207–3212. [Google Scholar]
- Aquino, A.L.L.; Figueiredo, C.M.S.; Nakamura, E.F.; Frery, A.C.; Loureiro, A.A.F.; Fernandes, A.O. Sensor Stream Reduction for Clustered Wireless Sensor Networks; ACM: Fortaleza, Brazil, 2008; pp. 2052–2056. [Google Scholar]
- Nakamura, E.F.; Figueiredo, C.M.S.; Nakamura, F.G.; Loureiro, A.A.F. Diffuse: A Topology Building Engine for Wireless Sensor Networks. Sign. Proces. 2007, 87, 2991–3009. [Google Scholar]
- Reschenhofer, E. Generalization of the Kolmogorov-Smirnov test. Comput. Stat. Data Anal. 1997, 24, 422–441. [Google Scholar]
- Aquino, A.L.L.; Loureiro, A.A.F.; Fernandes, A.O.; Mini, R.A.F. An In-Network Reduction Algorithm for Real-Time Wireless Sensor Networks Applications; ACM: Vancouver, British Columbia, Canada, 2008; pp. 18–25. [Google Scholar]
- Bustos, O.H.; Frery, A.C. Reporting Monte Carlo results in statistics: suggestions and an example. Rev. Soc. Chi. Estad. 1992, 9, 46–95. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Values |
|---|---|
| Network size | Varied with density |
| Queue size | Varied with stream |
| Simulation time (seconds) | 1100 |
| Stream periodicity (seconds) | 10 |
| Radio range (meters) | 50 |
| Bandwidth (kbps) | 250 |
| Initial energy (Joules) | 1000 |
© 2009 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Aquino, A.L.L.; Nakamura, E.F. Data Centric Sensor Stream Reduction for Real-Time Applications in Wireless Sensor Networks. Sensors 2009, 9, 9666-9688. https://doi.org/10.3390/s91209666
Aquino ALL, Nakamura EF. Data Centric Sensor Stream Reduction for Real-Time Applications in Wireless Sensor Networks. Sensors. 2009; 9(12):9666-9688. https://doi.org/10.3390/s91209666
Chicago/Turabian StyleAquino, Andre Luiz Lins, and Eduardo Freire Nakamura. 2009. "Data Centric Sensor Stream Reduction for Real-Time Applications in Wireless Sensor Networks" Sensors 9, no. 12: 9666-9688. https://doi.org/10.3390/s91209666