For this simulation assessment, we have implemented the CT-SIM simulation model [
47] for cluster-tree networks using the Castalia Simulator [
48]. Castalia (The Castalia Simulator for Wireless Sensor Network:
https://castalia.forge.nicta.com.au.) is an open-source discrete event simulator for WSNs, Body Area Networks (BAN) and general low-power embedded networks, that was developed at National ICT Australia (NICTA) and is based on the OMNeT++ platform. Castalia is a very popular simulator, widely used by researchers and developers to test their protocols using a realistic wireless channel and radio models [
49]. Castalia implements an advanced wireless channel model, based on empirically measured data. Also, the simulator provides radio models based on real low-power communication radios. Moreover, important features to simulate WSNs are available, such as: realistic node behaviour, node
clock drift, and energy consumption models.
8.1. Simulation Environment
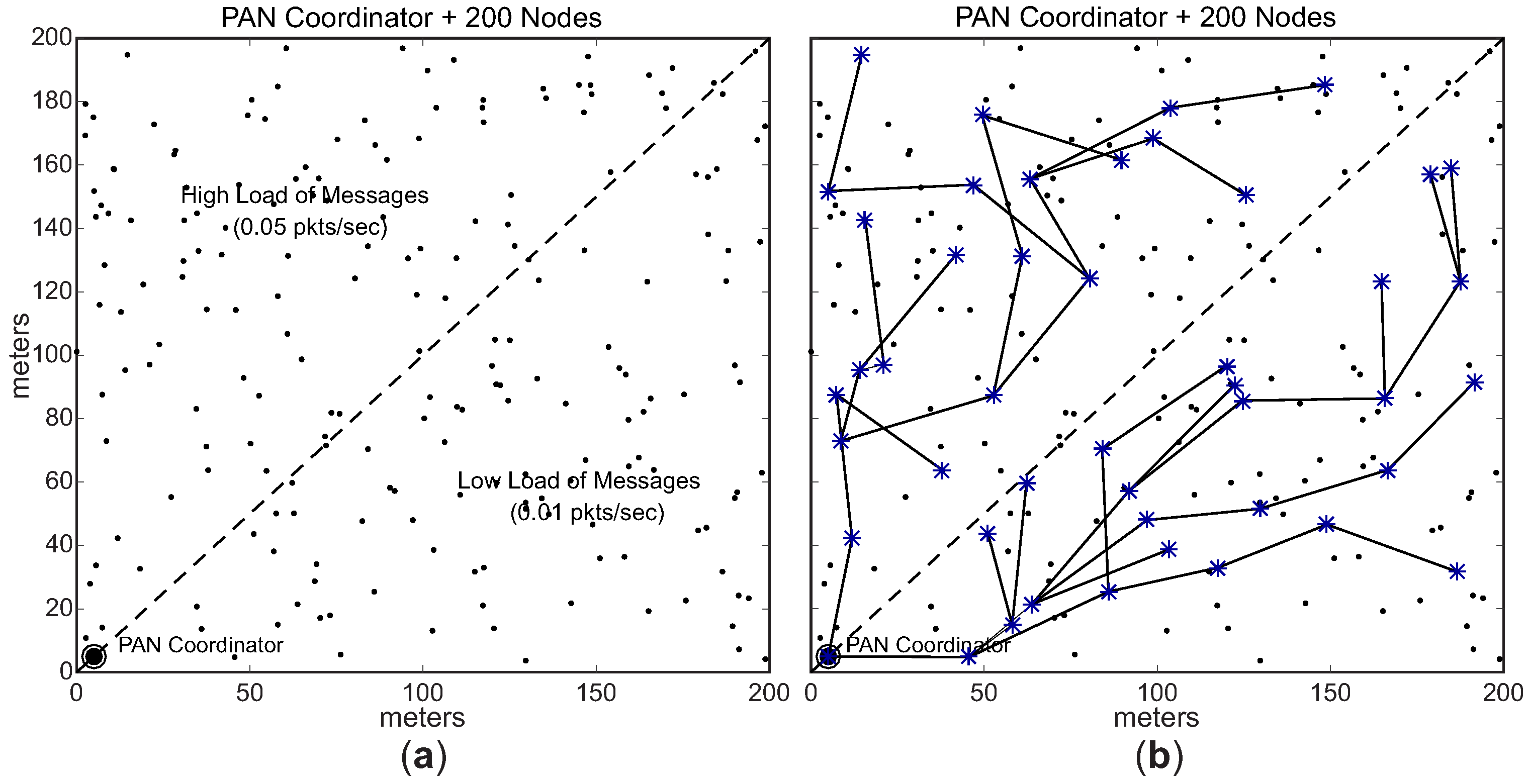
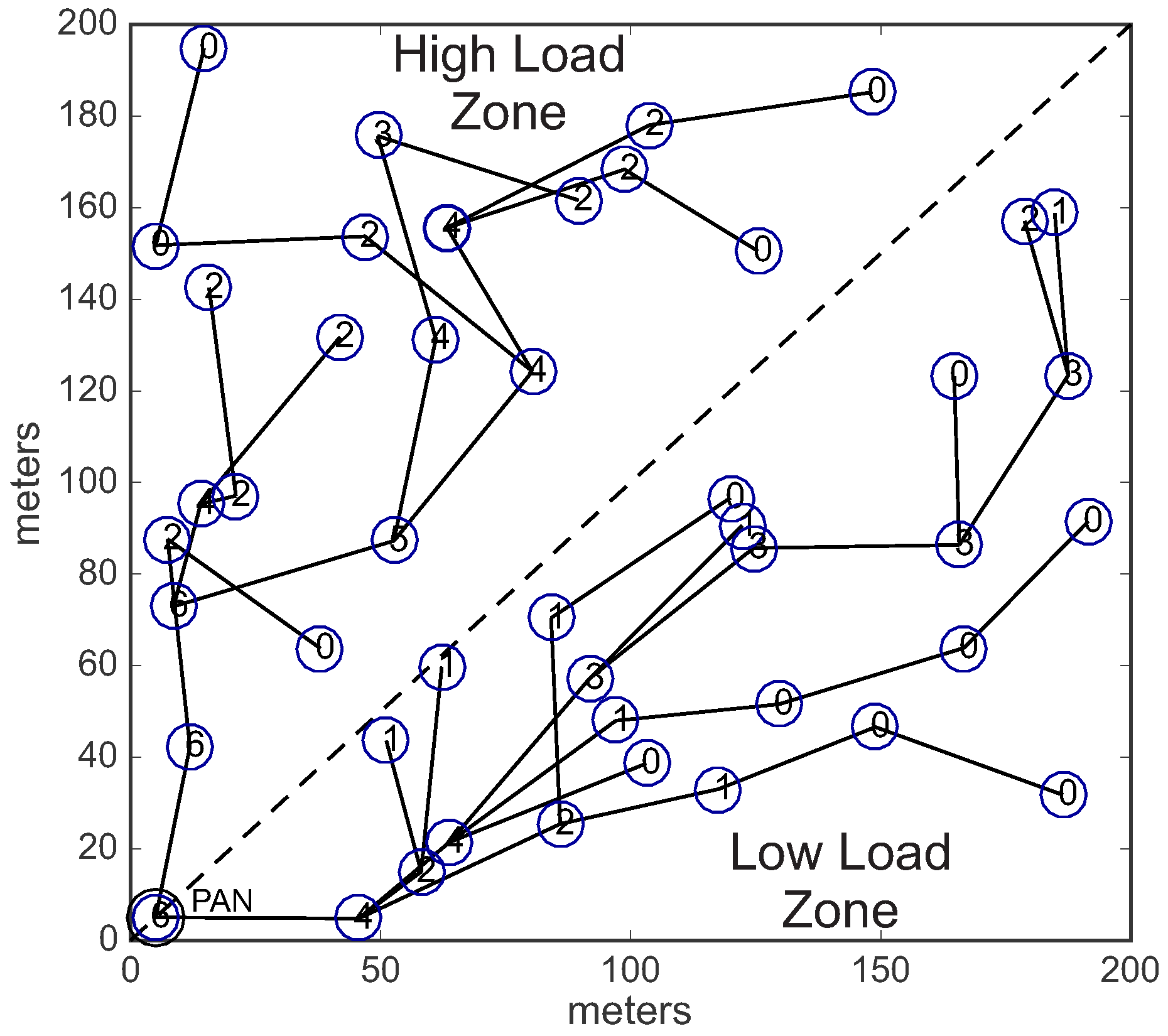
For this simulation assessment, it was considered a communication environment with a size of 200 m × 200 m, composed of 201 sensor nodes (one PAN coordinator, plus 200 sensing nodes). The PAN coordinator was located in position 5 m × 5 m of the environment, while 200 sensing nodes were randomly deployed. The PAN coordinator node was deployed in the corner of the environment, in order to build deep cluster-tree networks.
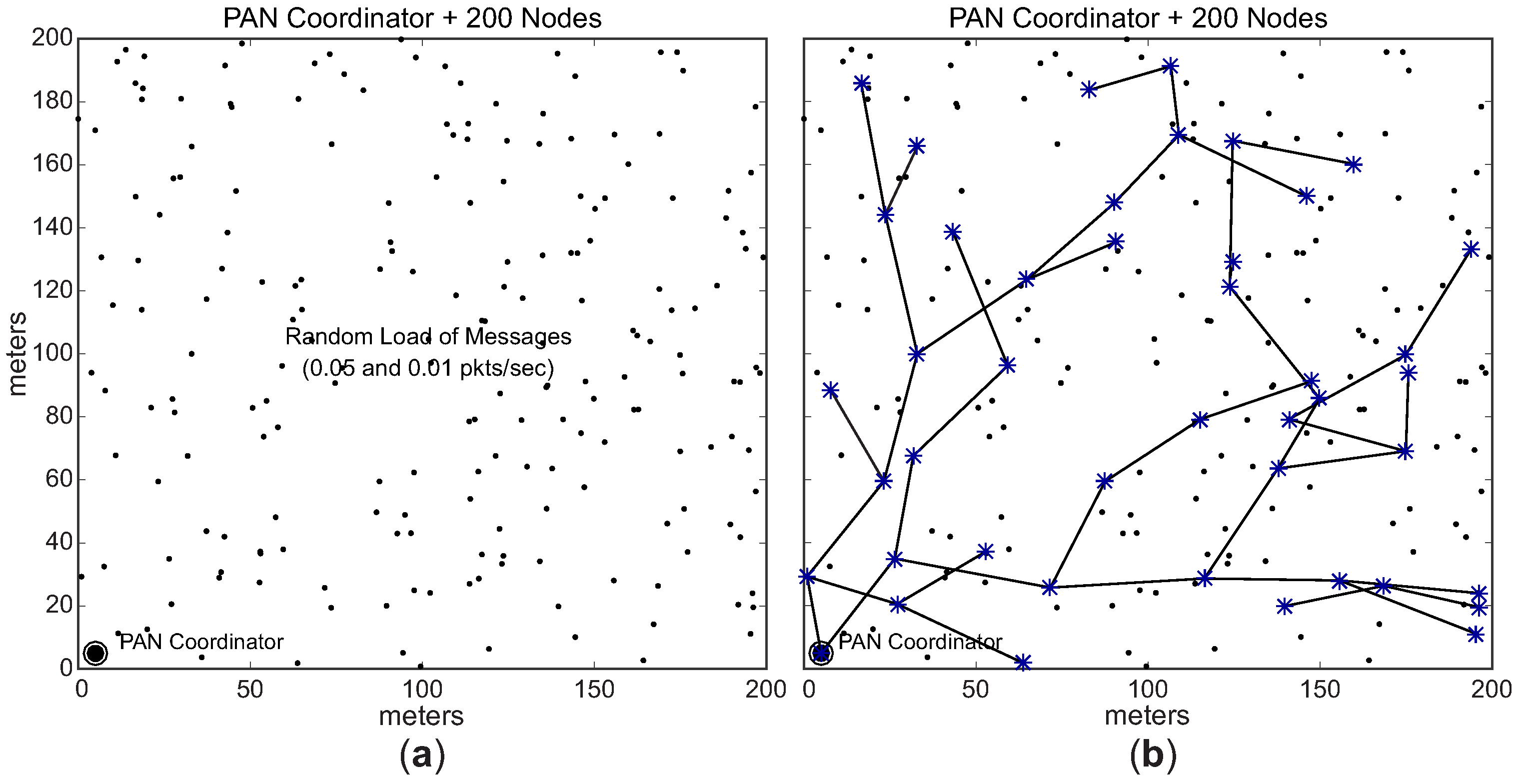
Figure 12a illustrates an example of the simulation environment used in this assessment.
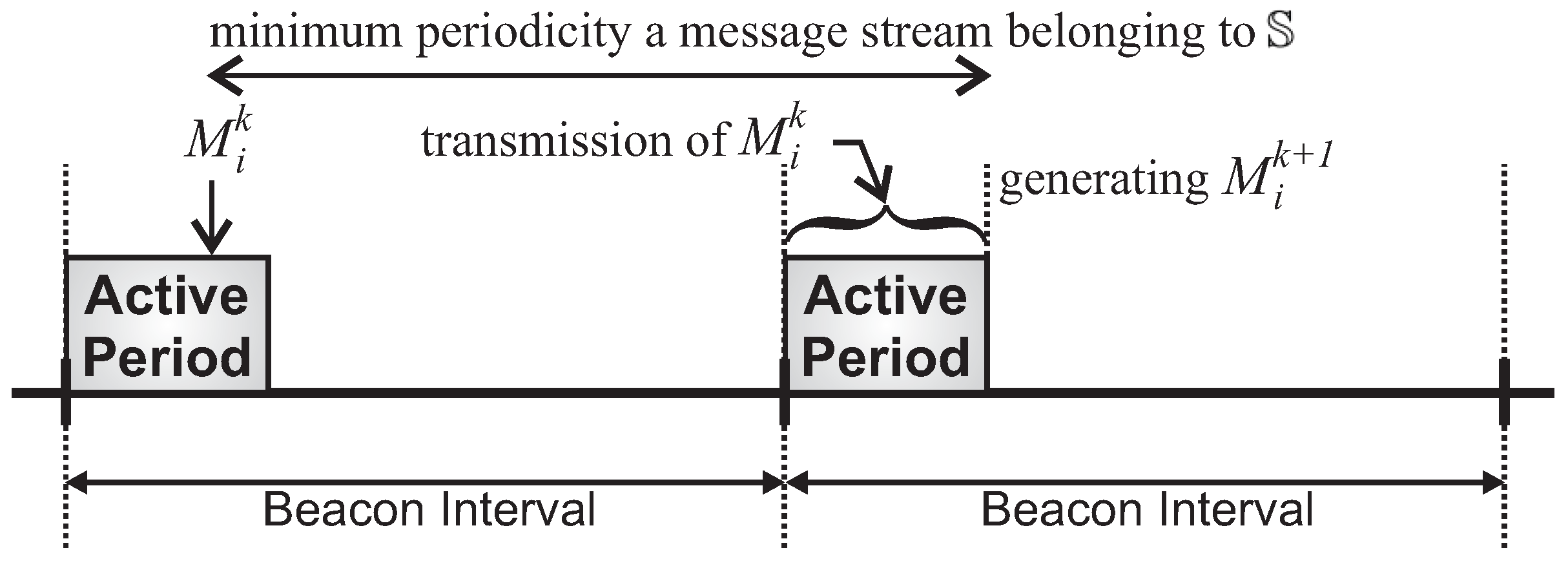
Regarding the monitoring traffic, sensing nodes generate periodic messages and send them to sink node (PAN coordinator). For the sake of simplification, we defined that each sensing node supports one message stream and that PAN coordinator does not generate any traffic itself. Each sensing node generates 1000 data messages, sending them to the PAN coordinator according to the rules defined by IEEE 802.15.4/ZigBee data communication. Thus, data messages are forwarded along the cluster-tree network according to the tree routing protocol. Importantly, cluster-heads do not perform any data aggregation or fusion mechanism, which implies that all monitoring traffic is forwarded towards the sink node. In order to generate different message loads for the cluster-heads, we defined two different data rates for the set of message streams: a higher data rate (0.05 pkts/s—periodicity of 20 s), and a lower data rate (0.01 pkts/s—periodicity of 100 s).
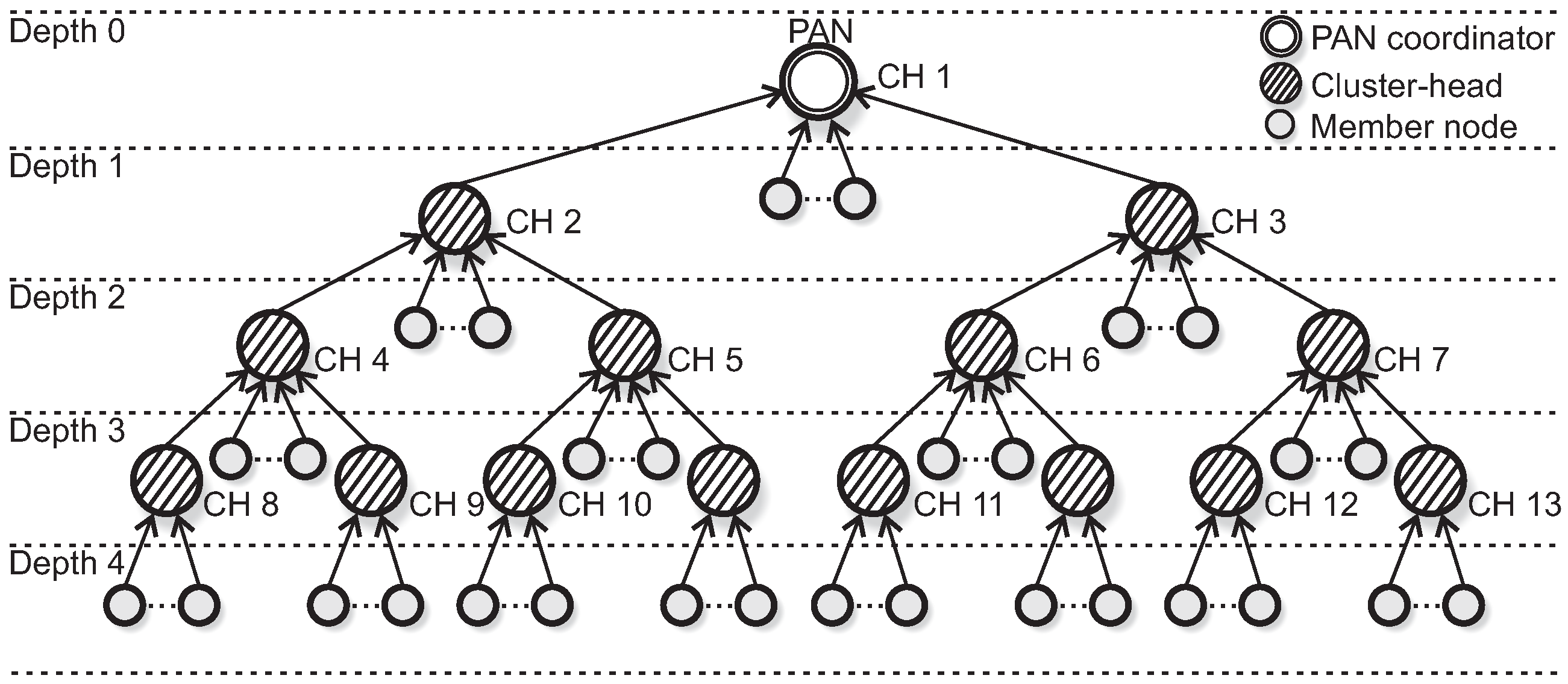
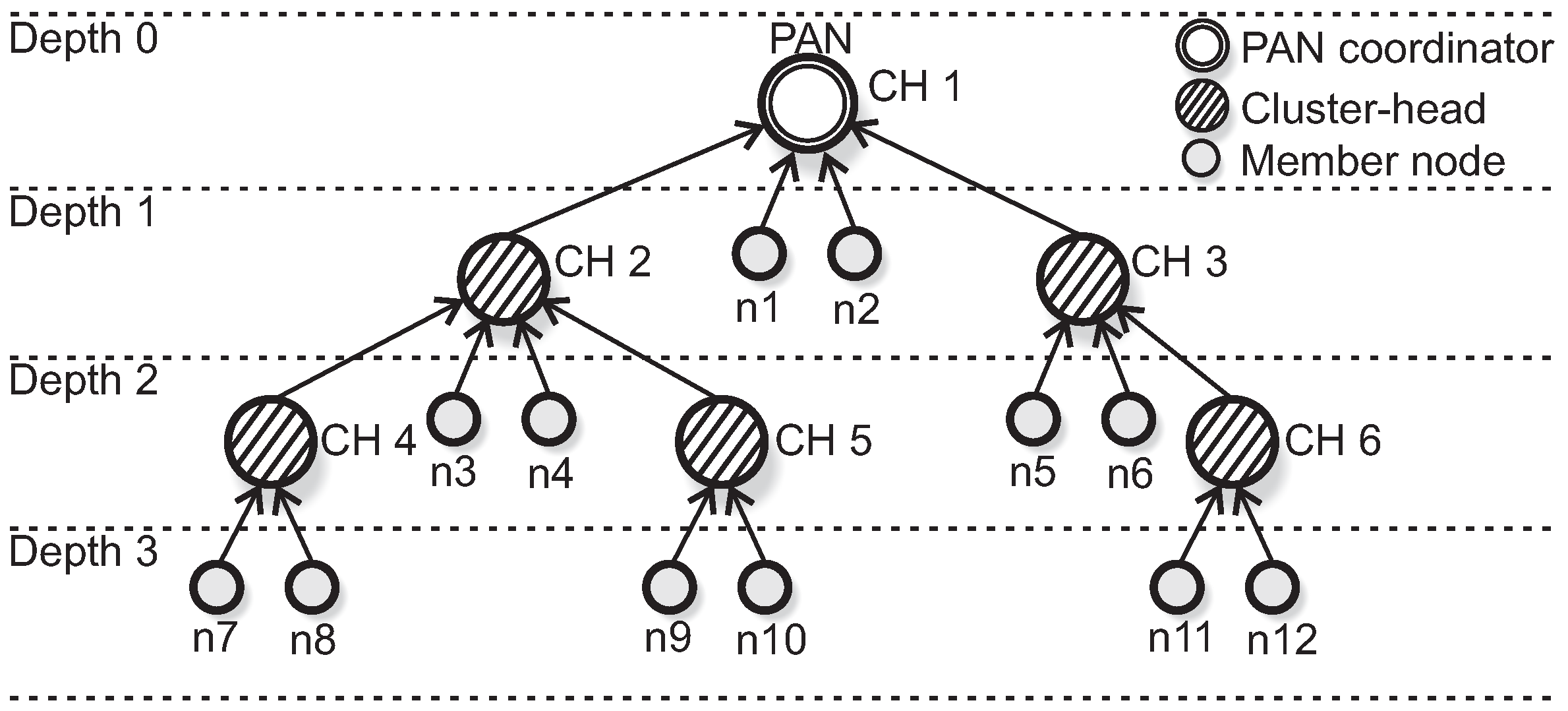
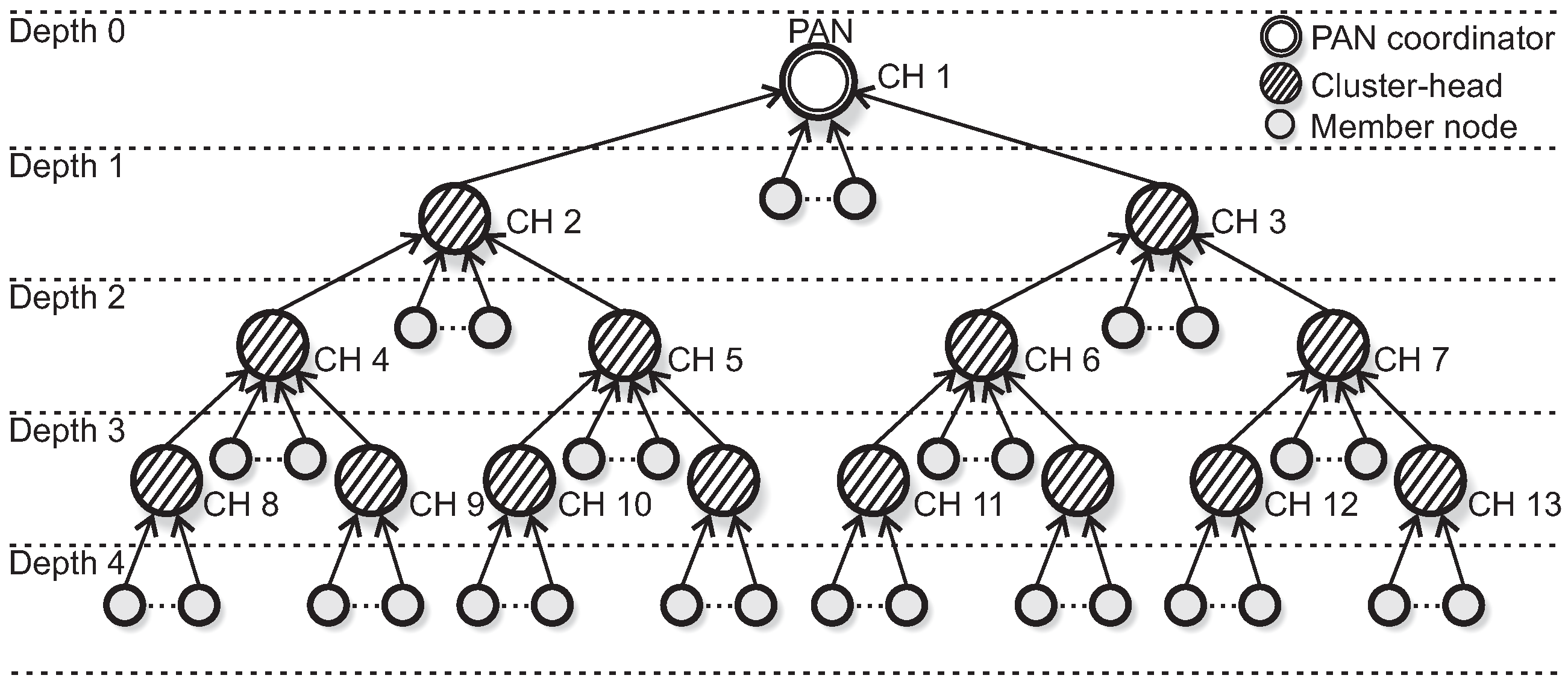
The cluster-tree formation process is based on the IEEE 802.15.4 standard/ZigBee specifications. The PAN coordinator (defined as depth 0 of the cluster-tree network) is responsible to trigger the formation procedure, by building its own cluster and acting as cluster-head. We defined the maximum number of child nodes per cluster to be 6 (six). For this simulation assessment, we have defined two cluster-tree formation procedures, in order to create two different simulation scenarios: an unconditioned cluster-tree (hereafter called unconditioned Scenario) and a conditioned cluster-tree (hereafter called conditioned Scenario).
In the first scenario (unconditioned formation), each CH (including the PAN coordinator) can select a maximum number of 2 (two) candidate child nodes to be cluster-heads. The selection of CH candidates is randomly performed and the cluster-tree network can grow in any direction. Each CH candidate can build its own cluster, following the same rules. The data rates are randomly distributed along the sensing nodes in the network environment.
Figure 12 shows an example of the
unconditioned Scenario.
Figure 12a illustrates the data rates randomly distributed along the environment, while
Figure 12b illustrates an example of the physical topology for the
unconditioned Scenario.
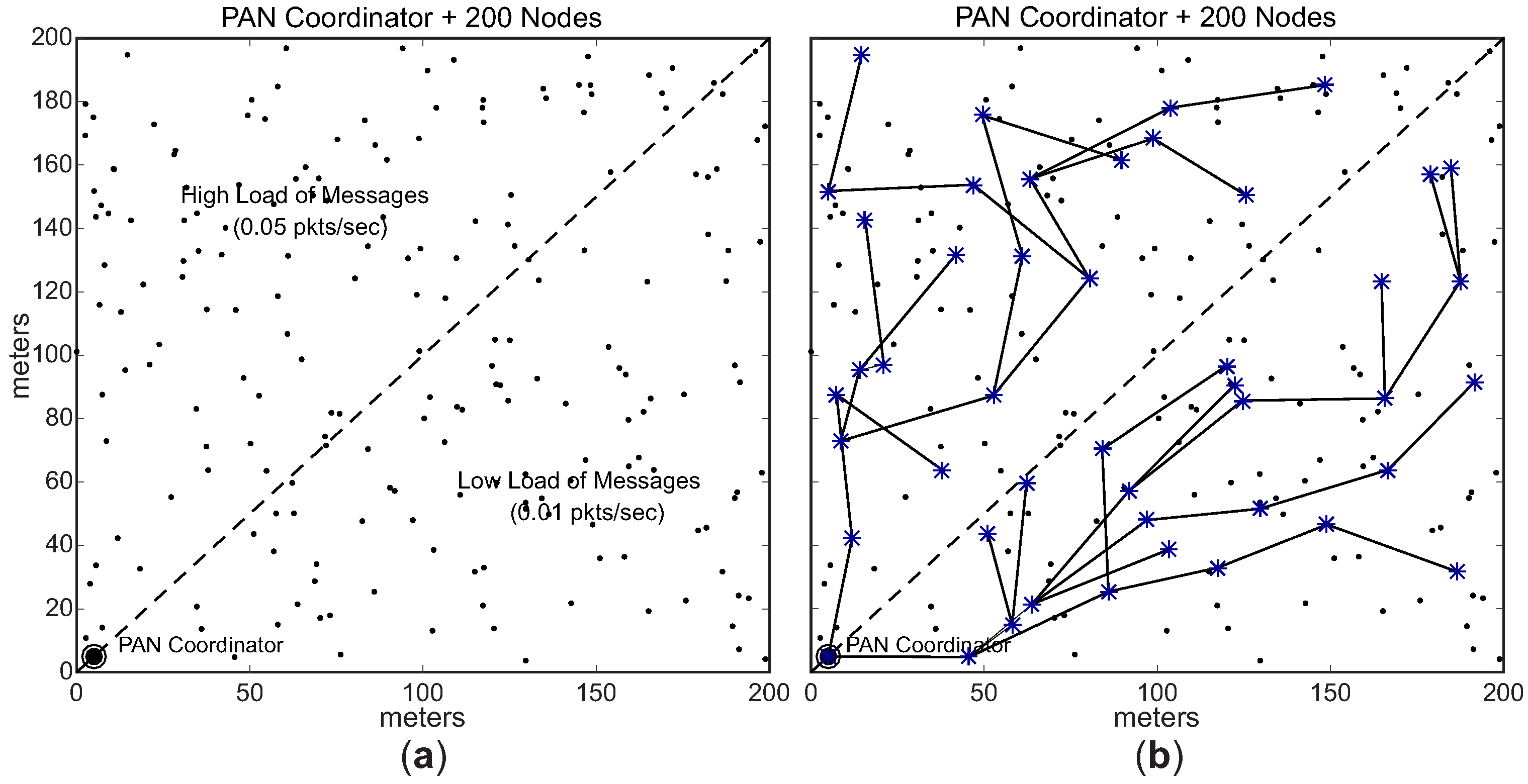
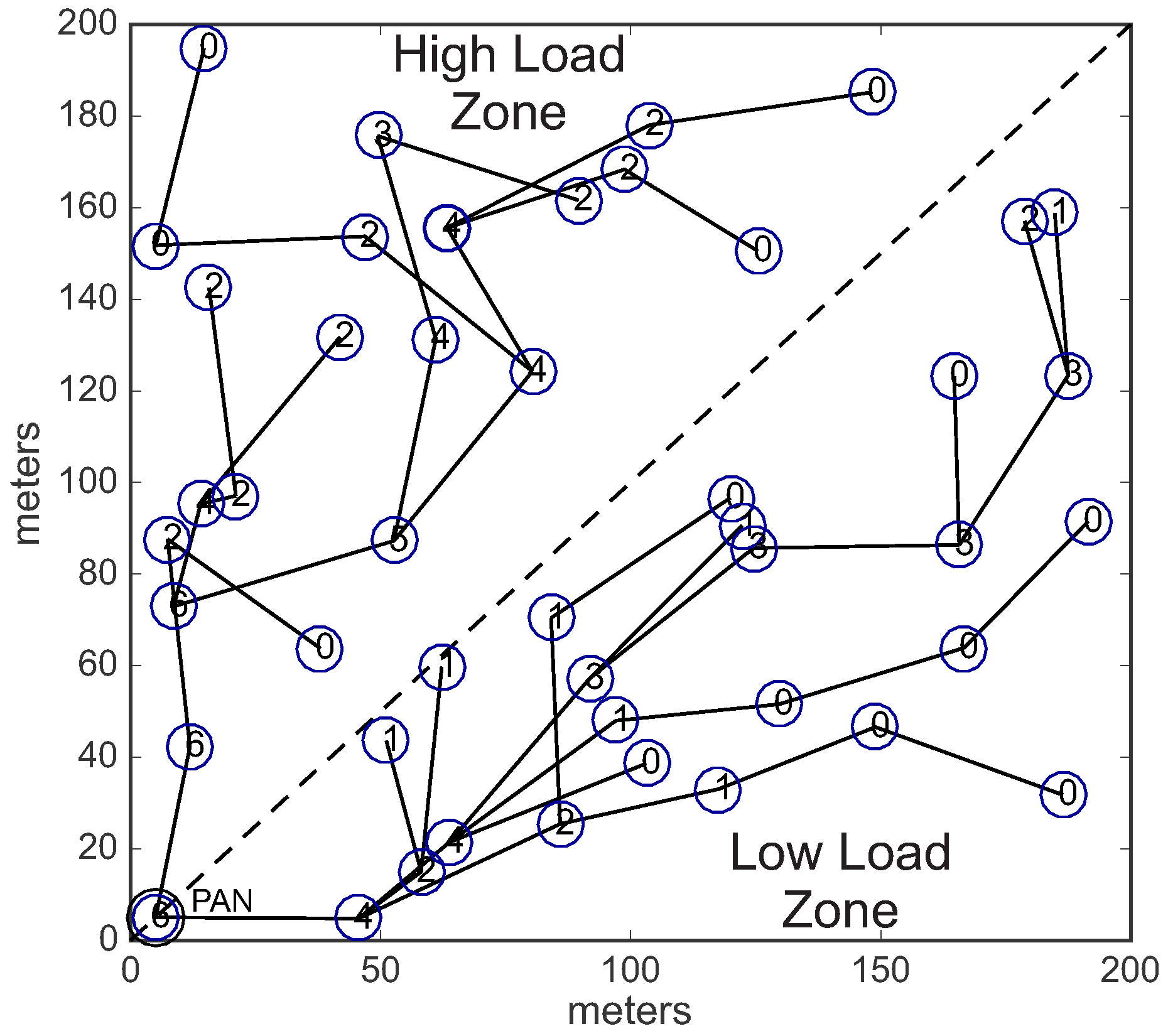
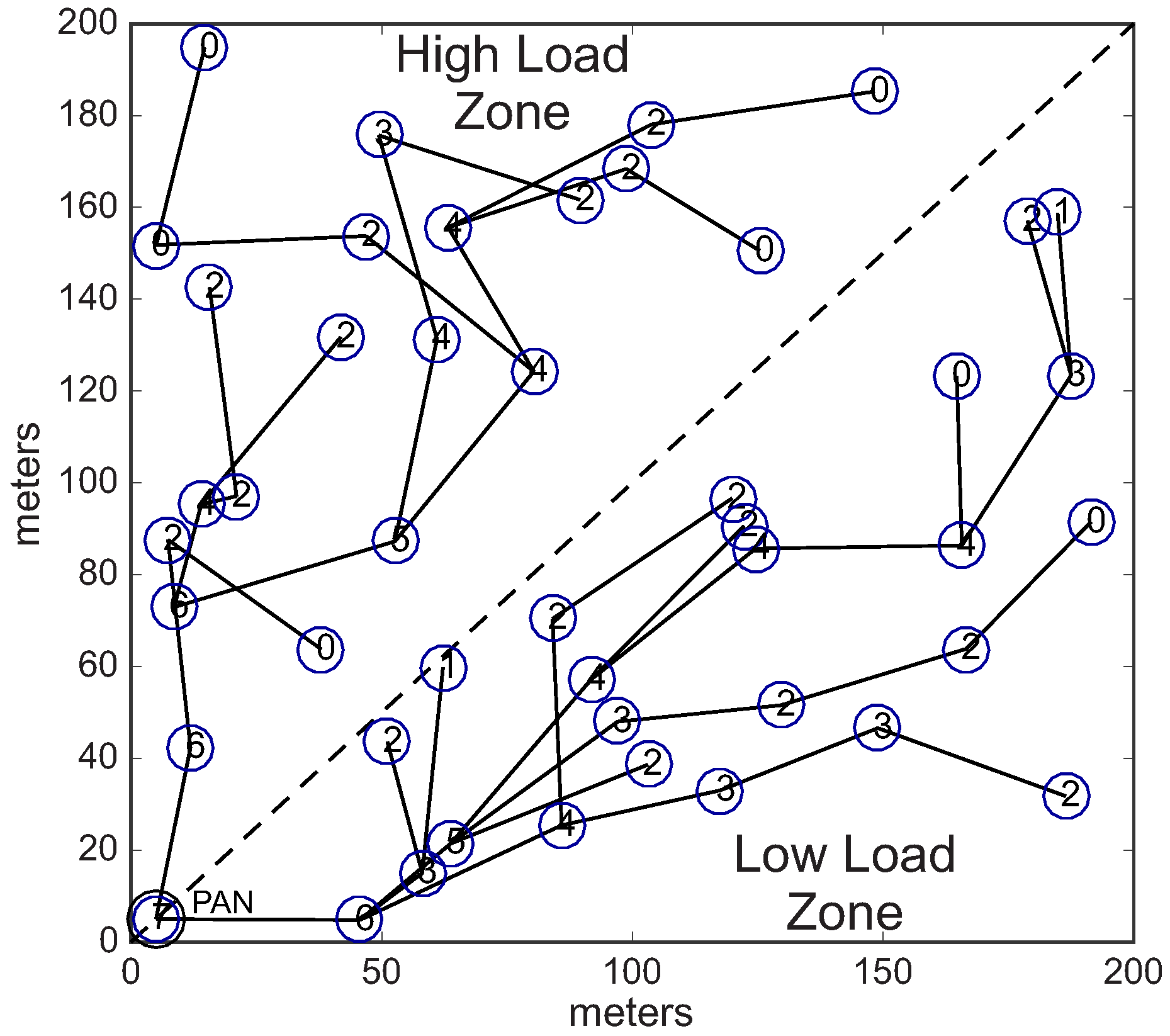
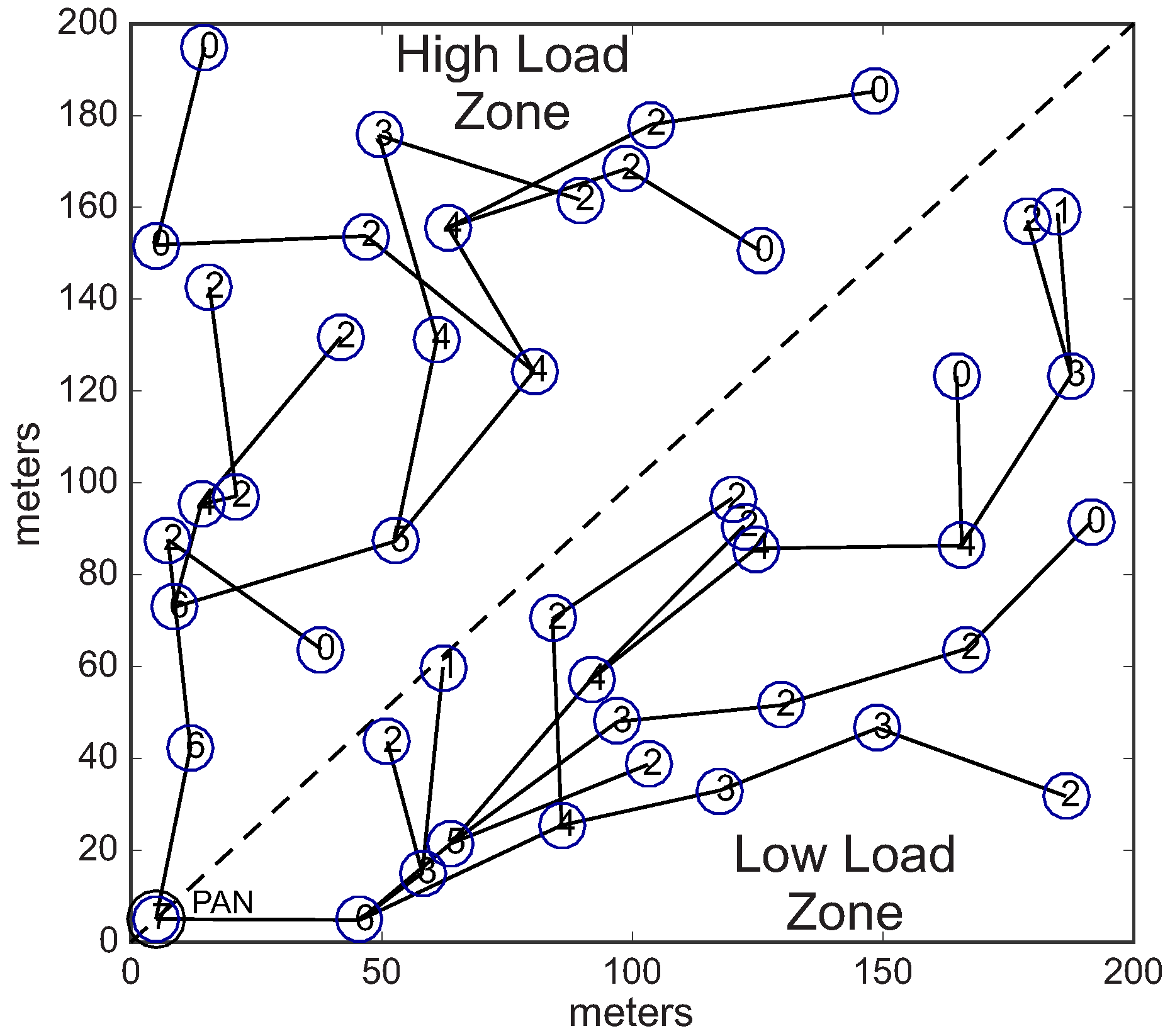
In the second scenario (conditioned formation), we have equally divided the environment in two different load zones: high load zone, and low load zone. Nodes located in the high load zone are configured with data rate of 0.05 pkts/s (higher data rate), whereas nodes located in the low load zone are configured with data rate of 0.01 pkts/s (lower data rate).
Considering these two different load zones, the cluster-tree formation process is started by the PAN coordinator, which selects one CH candidate in the high load zone and another candidate located in the low load zone. Following, each cluster-head can select a maximum number of 3 (three) CH candidates, that must also be located in the same load zone of their parent CHs. Therefore, we have a conditioned cluster-tree network, where one branch is built along the high load zone and the another branch is built along the low load zone.
Figure 13 shows this
conditioned Scenario.
Figure 13a illustrates the two defined load zones (high and low load zones), while
Figure 13b illustrates an example of a physical topology for the
conditioned Scenario.
Table 3 summarises the main features of the
unconditioned and
conditioned Scenarios.
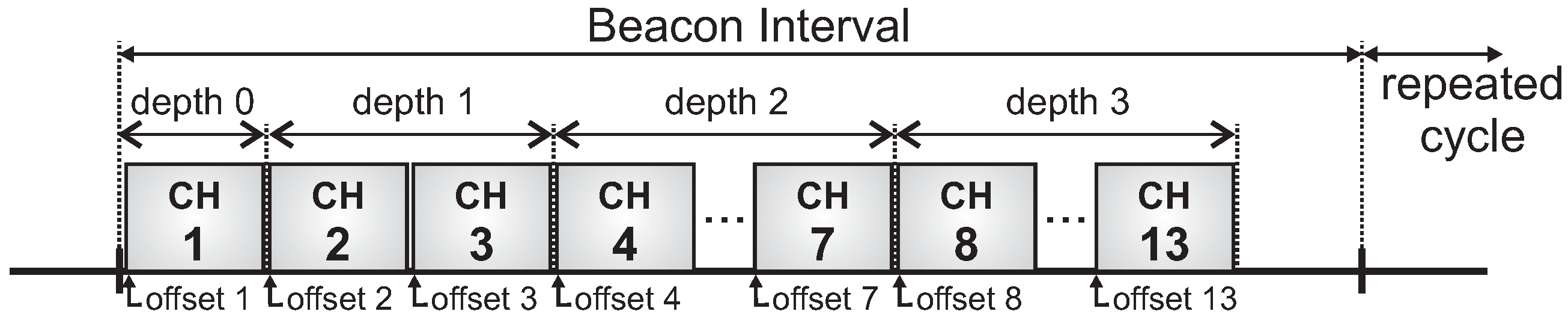
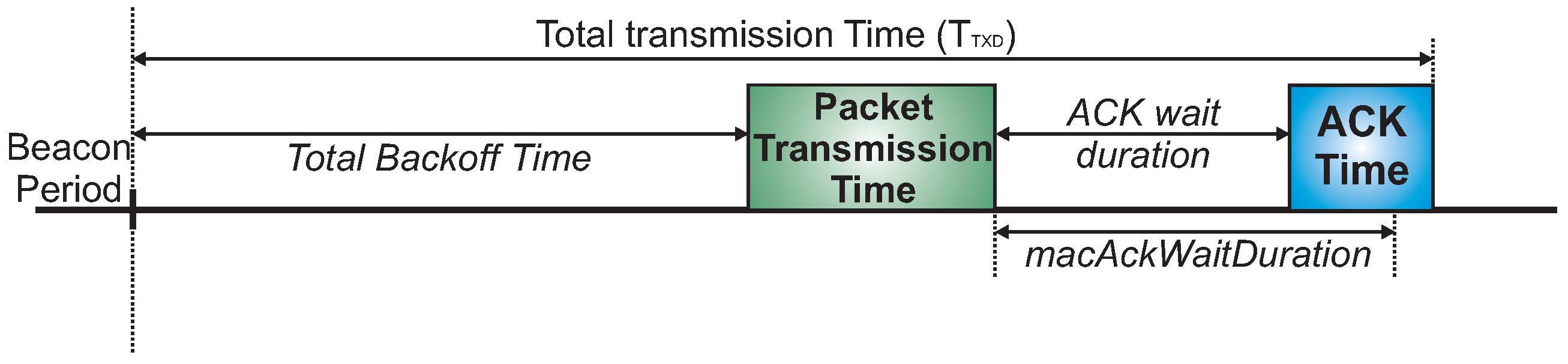
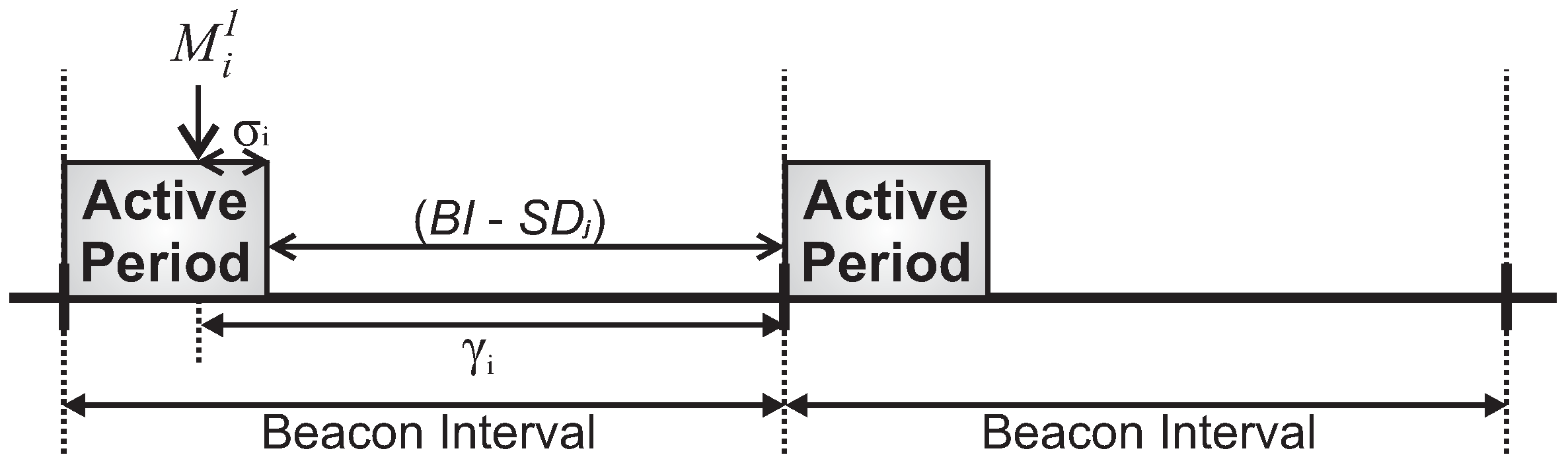
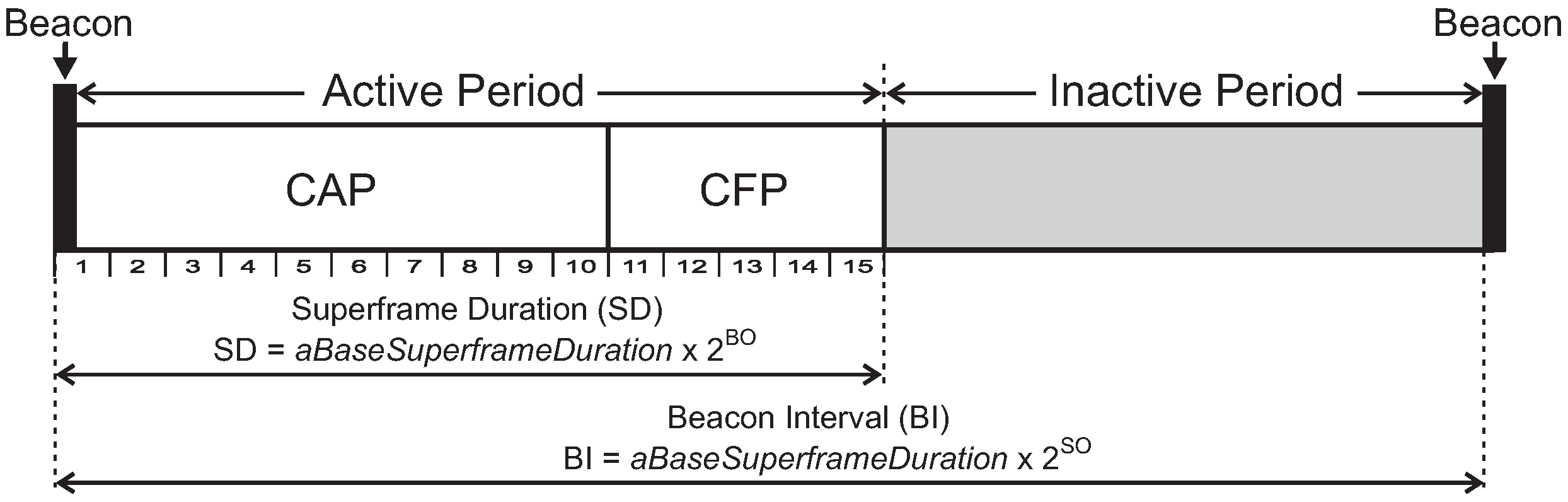
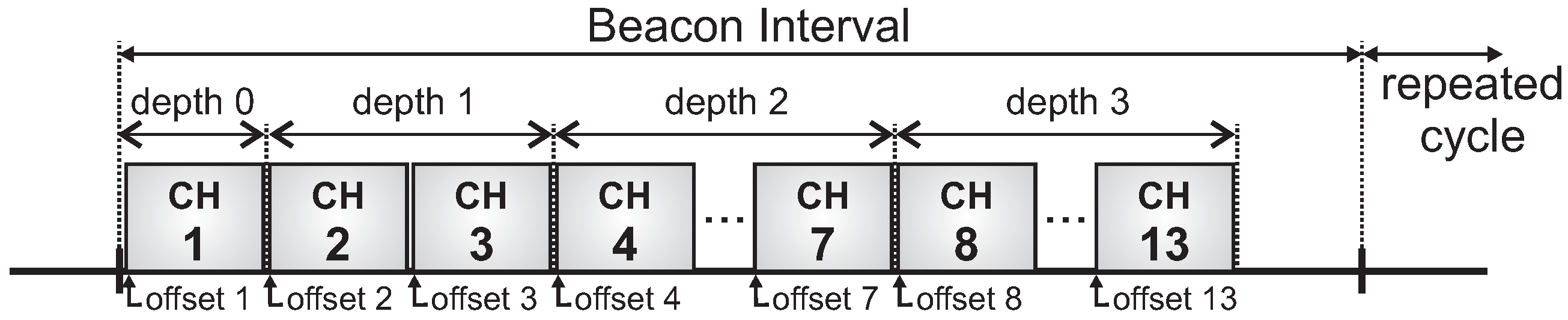
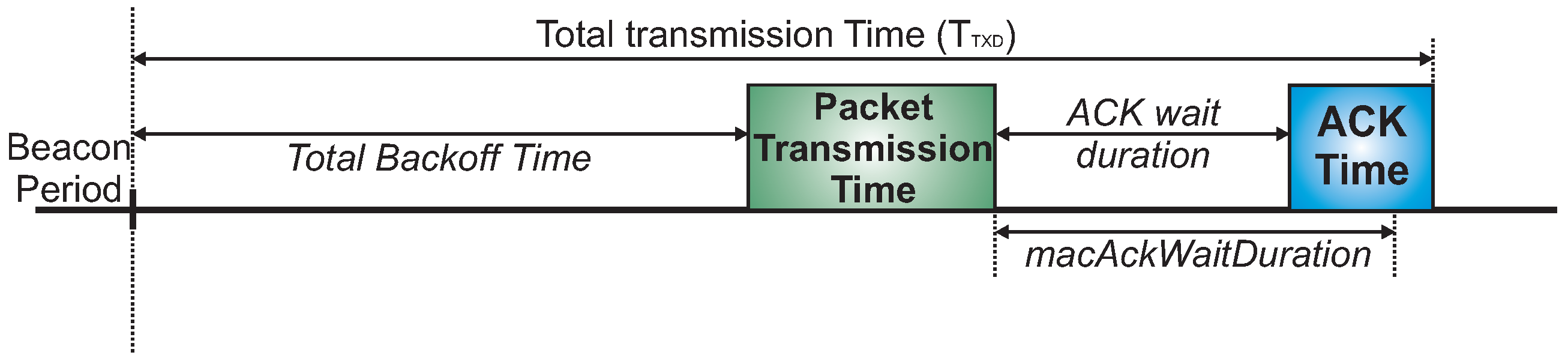
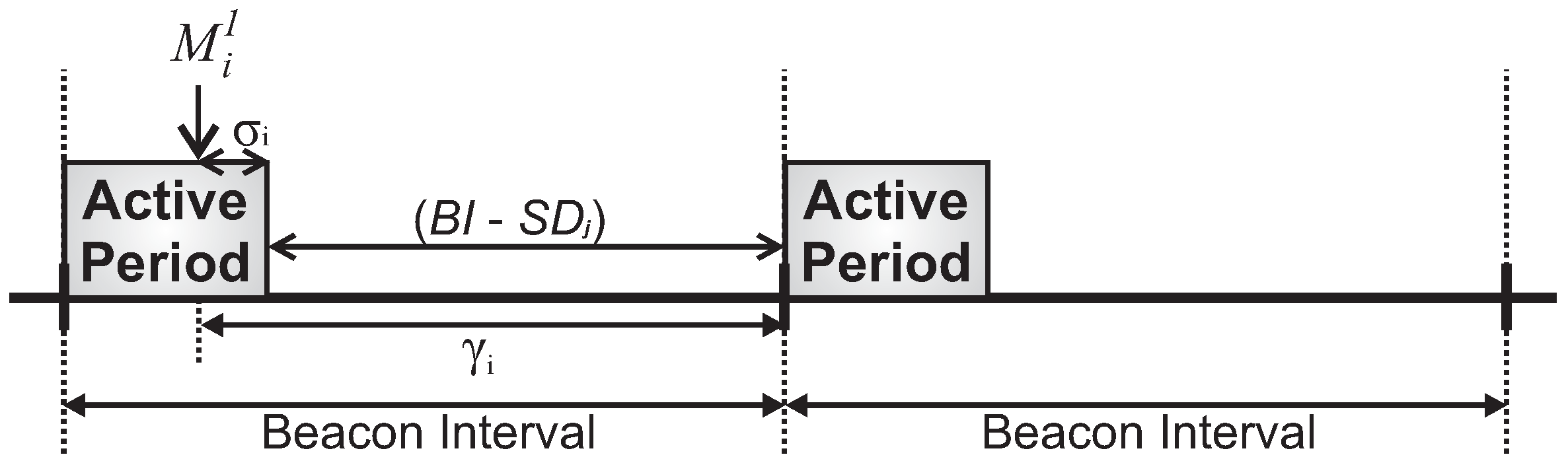
For this simulation assessment, we used the ZigBee-based hierarchical addressing scheme, in which each CH has its own sequential address block. Regarding the active period scheduling, we used a typical time division scheme. For the sake of simplification, we have used a bottom-up scheduling scheme, which prioritises the monitoring traffic (from leaf cluster-heads toward the PAN coordinator). Basically, the main difference between bottom-up and top-down scheduling schemes is related to the the protocol constraint, as the top-down scheme imposes more demanding beacon interval restrictions.
Regarding the node’s features, we have adopted the CC2420 (Texas Instruments/Chipcon CC2420 Datasheet:
http://www.ti.com/product/CC2420/technicaldocuments). radio model, which is compliant with the IEEE 802.15.4 standard. Furthermore, we adopted a linear energy model provided by Castalia and the initial energy for all nodes was set to 18.720 Joules (typical energy for two AA batteries). We also adopted the
unit disc model as the radio propagation model, where the range of the disk was defined to be 55 m. For the interference model, we use a simple interference model provided by Castalia, where concurrent transmissions generate collisions at the receiver.
Table 4 summarises the most important configuration parameters used in the simulations.
8.2. Results and Discussion
Firstly, we present some information about the cluster-tree network formation for each of the defined scenarios.
Table 5 shows the average number of generated clusters during the cluster-tree formation, the average maximum depth of the cluster-tree network, and the average number of children per cluster.
The main target of the proposed proportional SDA schemes is to allocate adequate communication resources (superframe durations and buffer sizes) for the cluster-heads, in order to avoid network congestion and message discards due to buffer overflows. Therefore, the buffer occupancy is an important performance metric to evaluate the proposed allocation schemes.
Table 6 shows the considered buffer sizes for the cluster-heads at each depth of the cluster-tree (average values for the different cluster-heads located at each level of the different tree branches).
Load-SDA and Nodes-SDA schemes define buffer sizes for cluster-heads that are proportional to the number of descendant nodes, according to the defined buffer constraint (Equation (
12)). As STD-SDA and SOA-SDA allocation schemes do not provide any mechanism to define buffer sizes, we have set the length of internal buffers to a value equal to the total number of sensing nodes (200).
Table 7 illustrates the average SO parameter values for cluster-heads, considering their depths in the cluster-tree network. Note that, as both SOA-SDA, Load-SDA and Nodes-SDA schemes allocate superframe durations based on the imposed traffic, allocations are proportional to depth: clusters closer to the PAN coordinator have higher superframe durations. The difference between these three schemes is that in Load-SDA scheme, superframe durations are based on the traffic load of the cluster itself and of its descendant nodes, while Nodes-SDA scheme only considers the number of descendant nodes. Instead, SOA-SDA allocation scheme imposes that a parent cluster-head must have duty-cycle greater or equal to the sum of duty-cycles of its child cluster-heads, leading to slightly different values for the allocations. Finally, STD-SDA scheme allocates the same superframe duration for all cluster-heads.
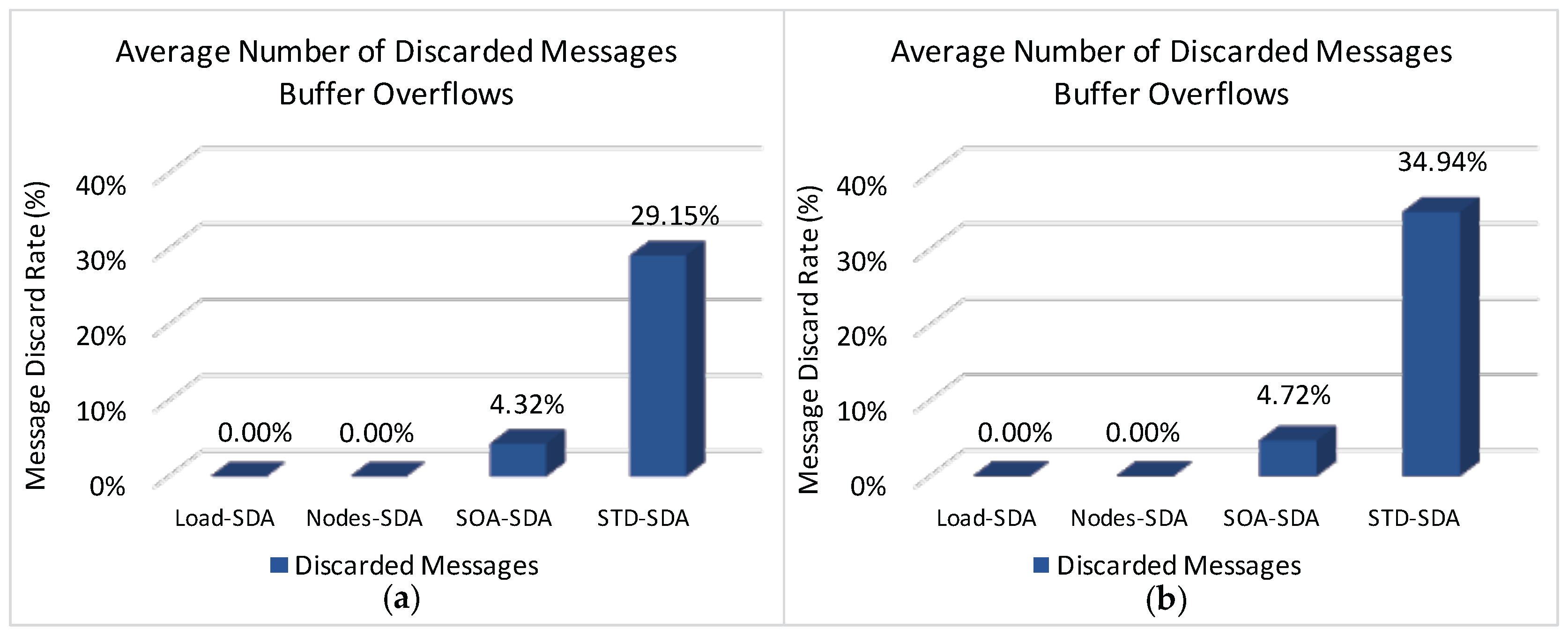
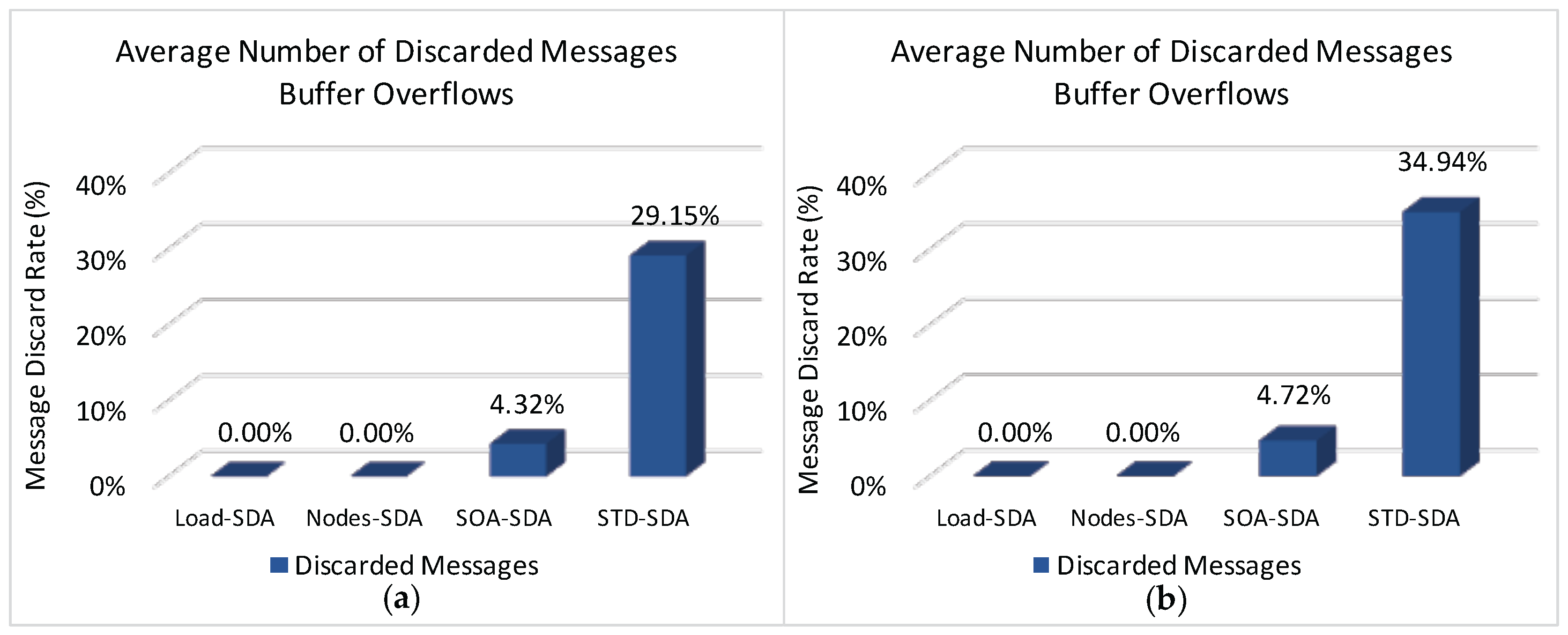
Figure 14 illustrates the average rate of discarded messages due to buffer overflows for the overall network, when applying the four allocation schemes to the defined scenarios.
It can be observed (
Figure 14) that both Load-SDA and Nodes-SDA schemes behave adequately for both communication scenarios, considering the defined set of message streams. All CHs were able to forward their messages and no messages were discarded due to buffer overflows. This behaviour highlights one of the major advantages of the Load-SDA and Nodes-SDA allocation schemes, where both superframe durations and buffer sizes are dimensioned according to the network load and number of nodes of each of the branches of the cluster-tree network, respectively. On the other hand, the STD-SDA scheme discarded 30%–35% of the messages due to the allocation of inappropriate superframe durations and also due to the inability of the cluster-heads to temporarily store the accumulated messages in their internal buffers, despite the larger number of allocated buffer resources. The SOA-SDA scheme presents a much smaller number of discarded messages due to buffer overflows (4%–5% of messages), as it considers the adjustment of the superframe durations according to the depth of each cluster-head in the cluster-tree network. These results clearly highlight that an equal allocation of the superframe durations is not adequate for cluster-tree networks, as it does not consider the tree topology effects of the network.
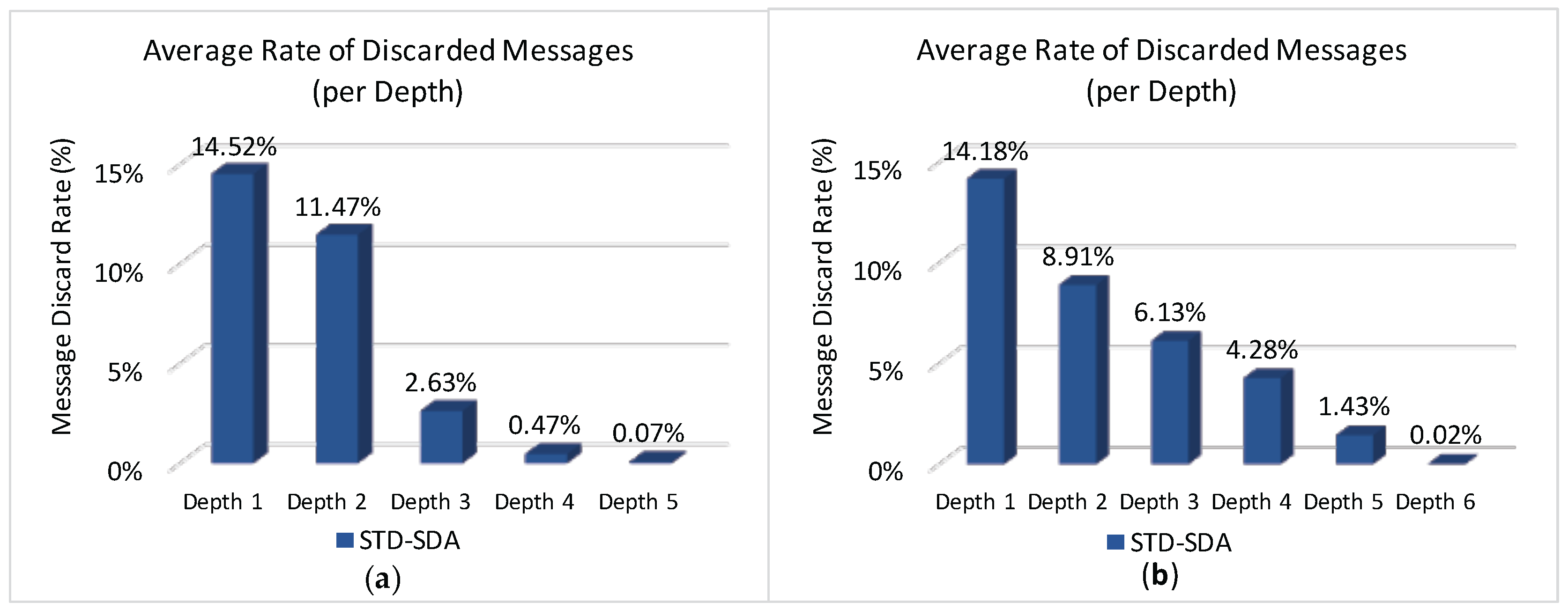
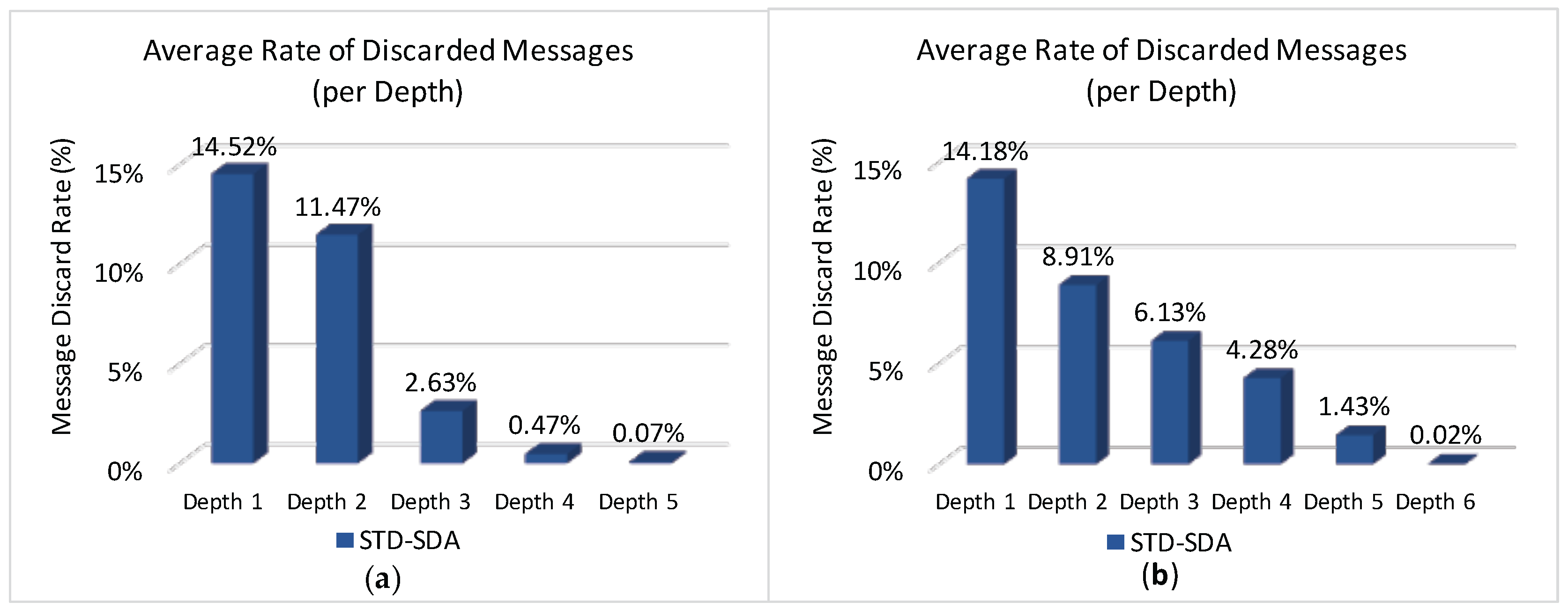
Considering that both STD-SDA allocation schemes have discarded messages, it is important to check where those messages were discarded.
Figure 15 illustrates the average number of discarded messages for the STD-SDA allocation scheme, as function of the CHs’ depth. As expected, the number of discarded messages is higher for cluster-heads located at depth 1, followed by cluster-heads of depth 2, and so on. In fact, as convergecast traffic is forwarded through the cluster-tree towards the PAN coordinator, the trend is that cluster-heads near the PAN coordinator will be more congested, where the network performance will be substantially affected. This behaviour is observed for both unconditioned and conditioned scenarios.
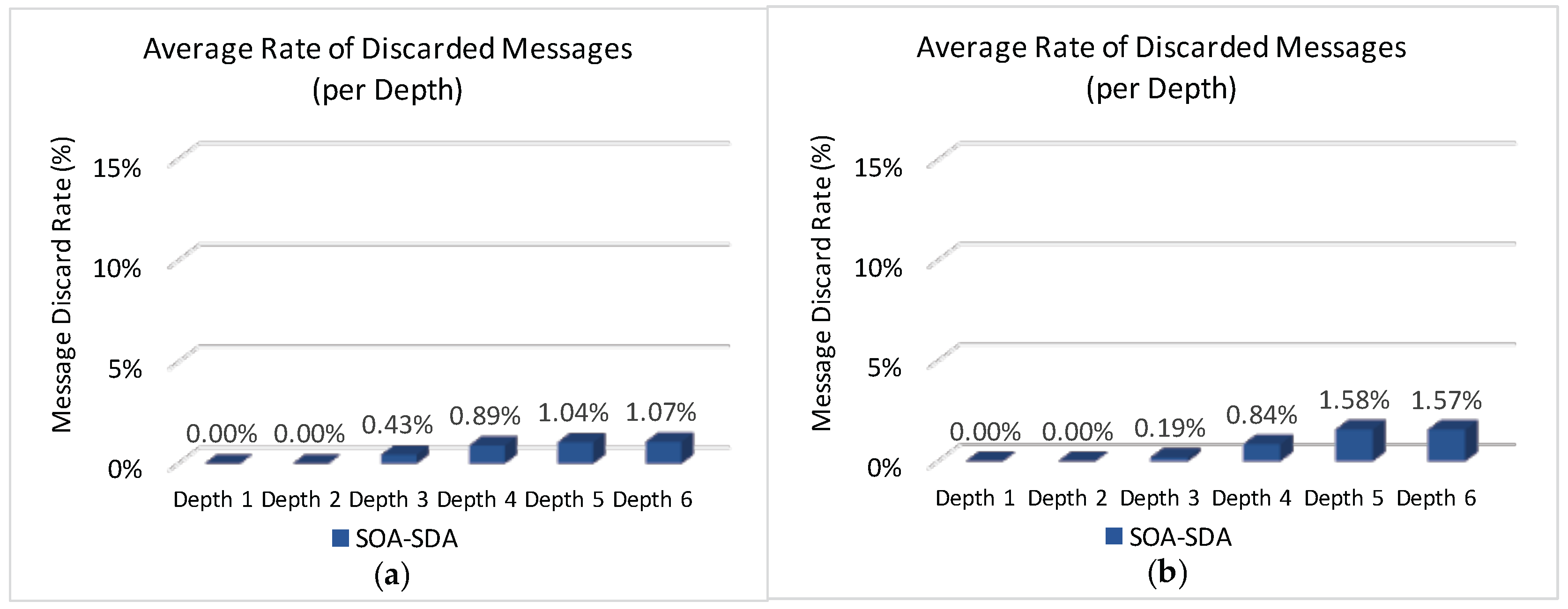
Figure 16 illustrates the average number of discarded messages as function of the CHs’ depth for the SOA-SDA allocation scheme. It can be observed that, this scheme adequately allocated superframe duration values for the clusters located closer to PAN coordinator, but not for the deepest clusters. This problem could be solved by increasing superframe duration values for leaf cluster-heads. However, as the SOA-SDA allocation scheme defines that the duty-cycle of a parent cluster-head must be greater or equal to the sum of duty-cycles of child cluster-heads, increasing the allocation values for the leaf cluster-heads could lead to the non-fulfilment of the overall protocol constraint (Equation (
10)).
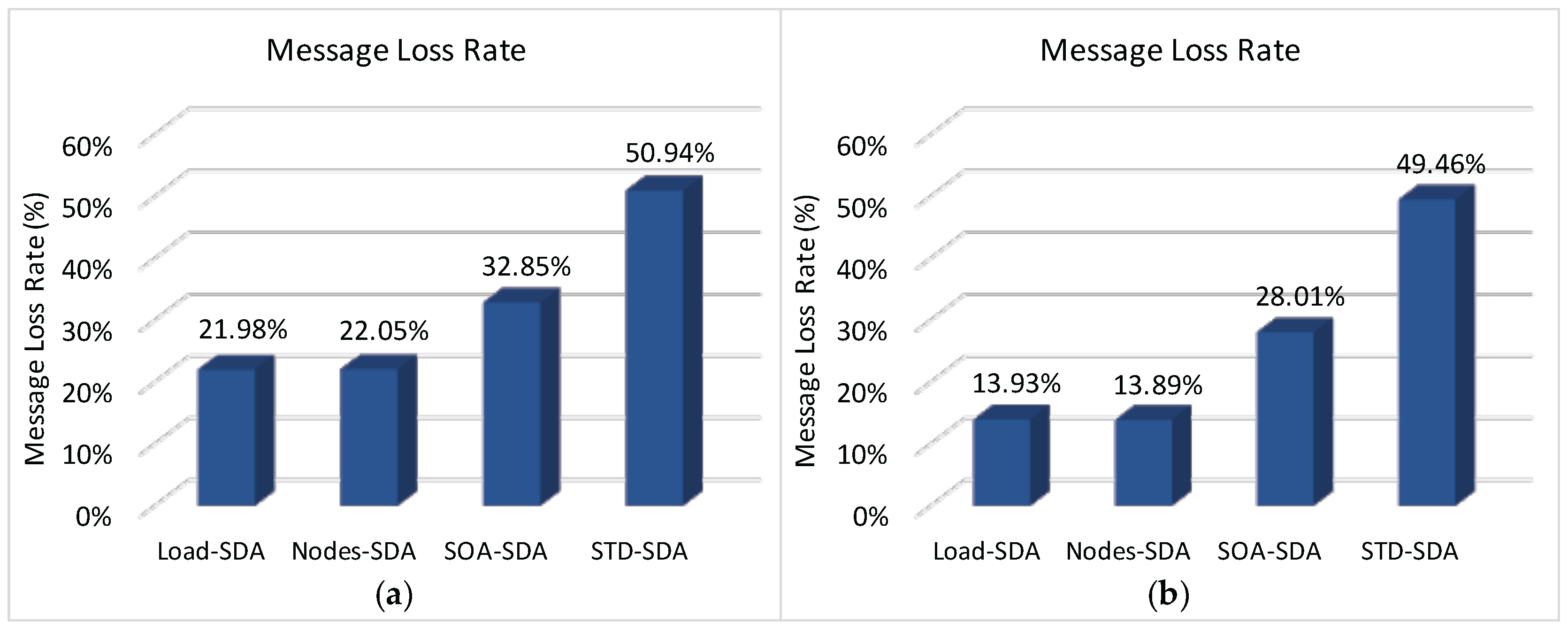
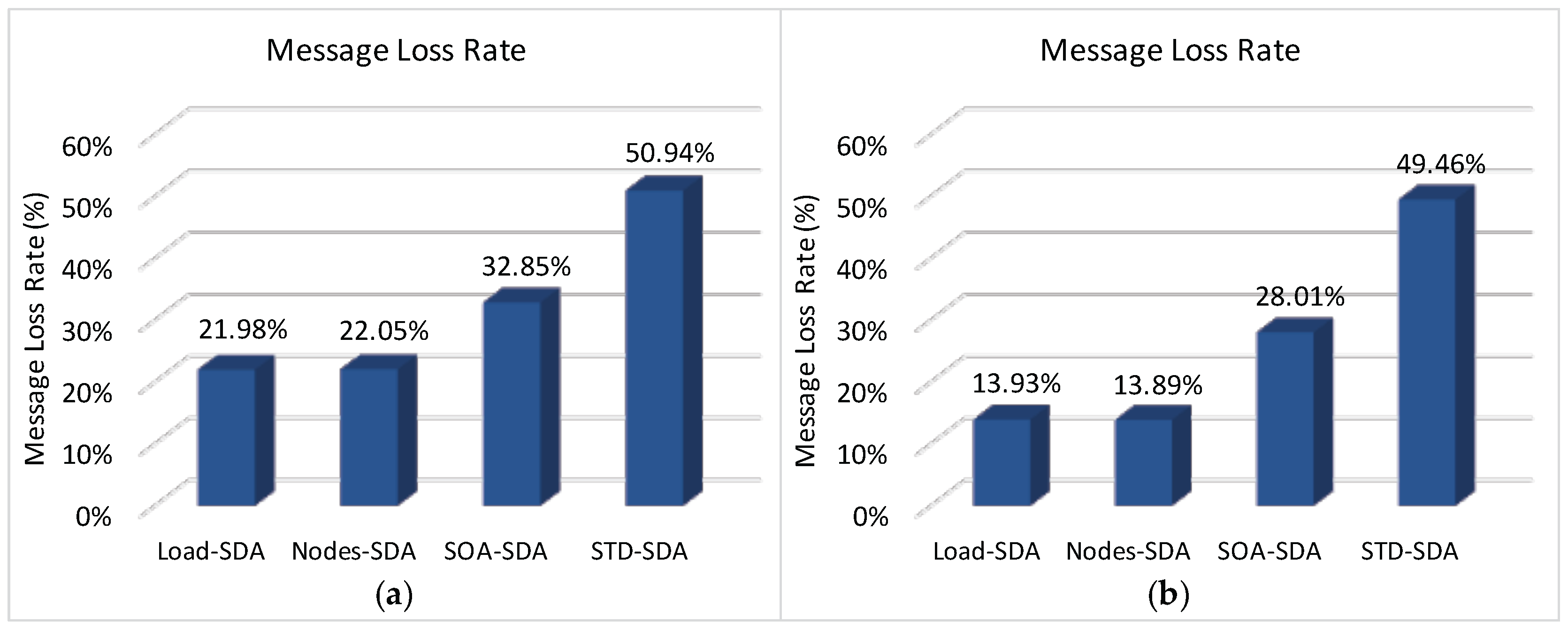
Finally,
Figure 17 illustrates the total message loss rate (considering both message collisions and message discards due to buffer overflows) for each of the defined allocation schemes. As it can be observed, the number of discarded messages due to buffer overflows strongly influences the number of lost messages, decreasing the number of successfully delivered messages. Comparing results of
Figure 14 and
Figure 17, it is clear that the message loss rate due to message collisions is around 22%–28% for the all allocation schemes. The main reason for this high number of message losses is due to the (default) CSMA/CA parameters used for the simulation assessment. As previously shown in [
9,
36], the default parameter values used for
macMinBE,
macMaxBE and
CW (Contention Window) can easily lead to a high number of message collisions, for a number of sensor devices as low as 6 devices per cluster-head.
According to this simulation assessment, it becomes clear the importance of defining adequate active communication periods and buffer sizes for the cluster-heads. An adequate allocation of superframe durations for the different clusters can significantly improve the network behaviour.
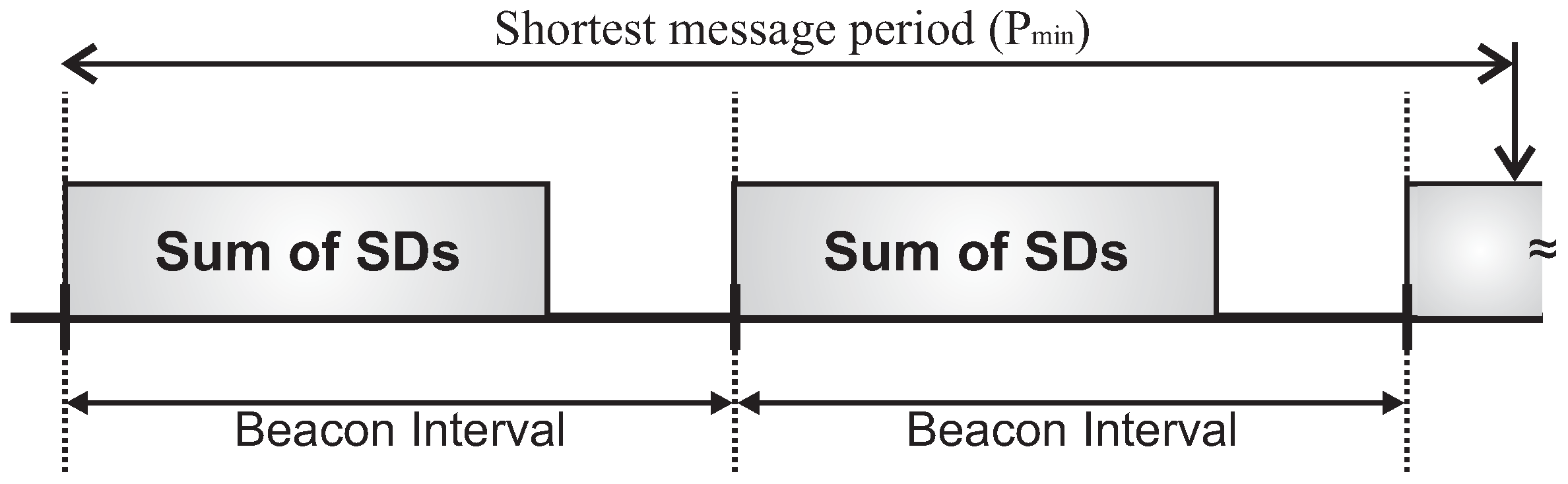
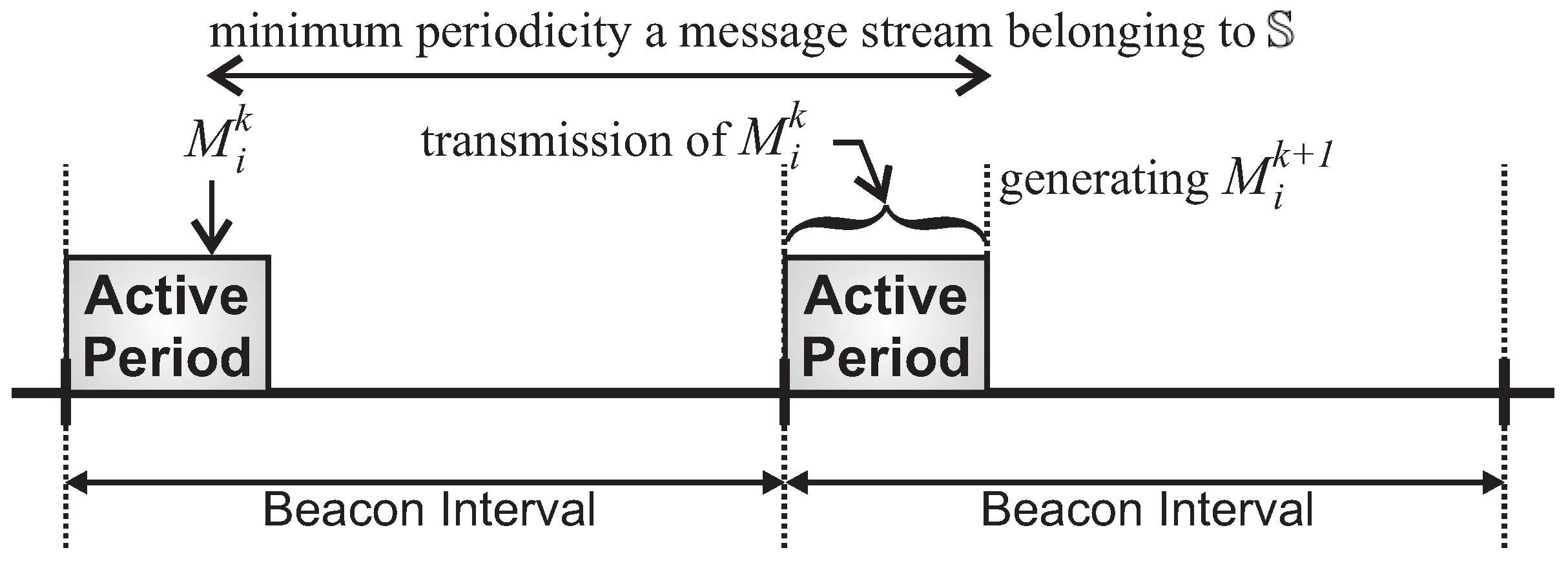
We have also assessed the average end-to-end delay for convergecast traffic, in order to evaluate the influence of the buffer sizes and superframe allocation schemes. Considering that the beacon interval parameter can directly influence the behaviour of the network (refer to
Section 4.1), we have assessed the different possibilities for the BI adjustment and its impact upon the network behaviour (end-to-end message delays and energy consumption of the nodes). As previously mentioned, the SOA-SDA allocation scheme was constrained to the use of a single beacon interval for all the clusters. Nevertheless, this would be the expected parameter settings for the case where all the supported traffic has the same periodicity.
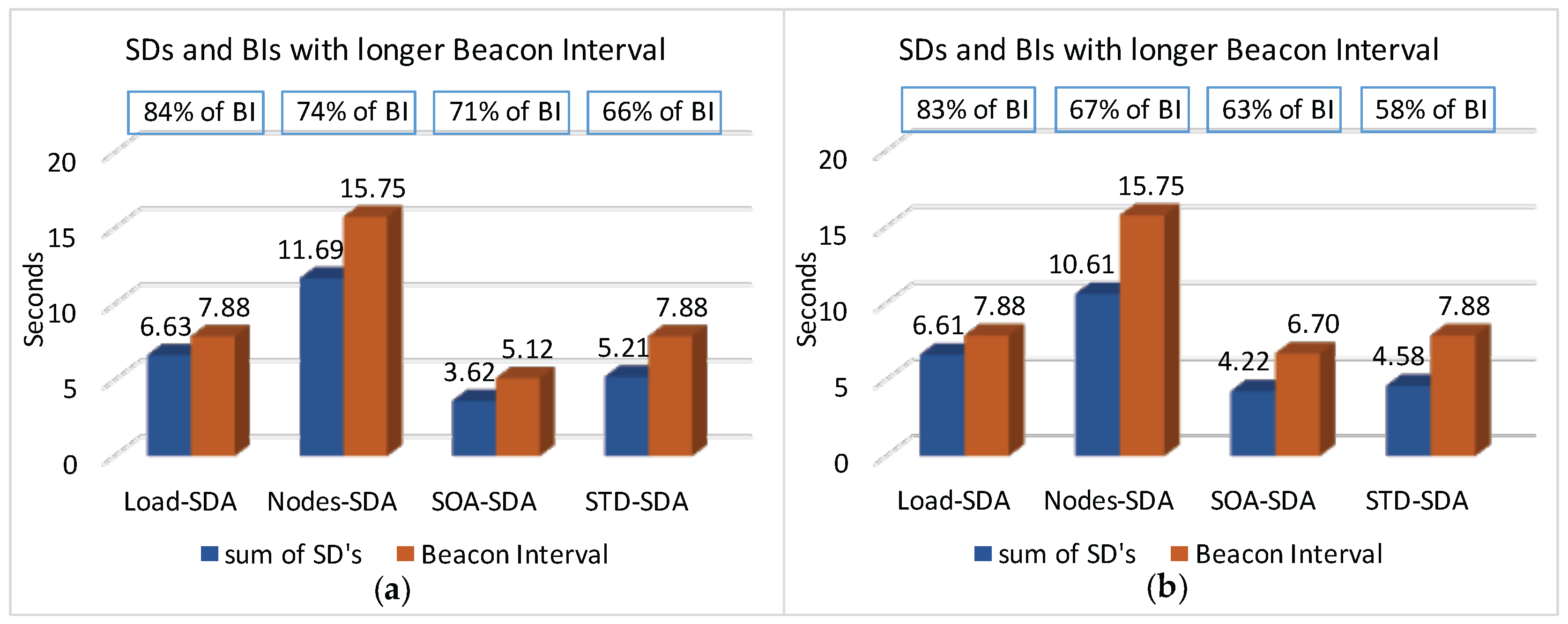
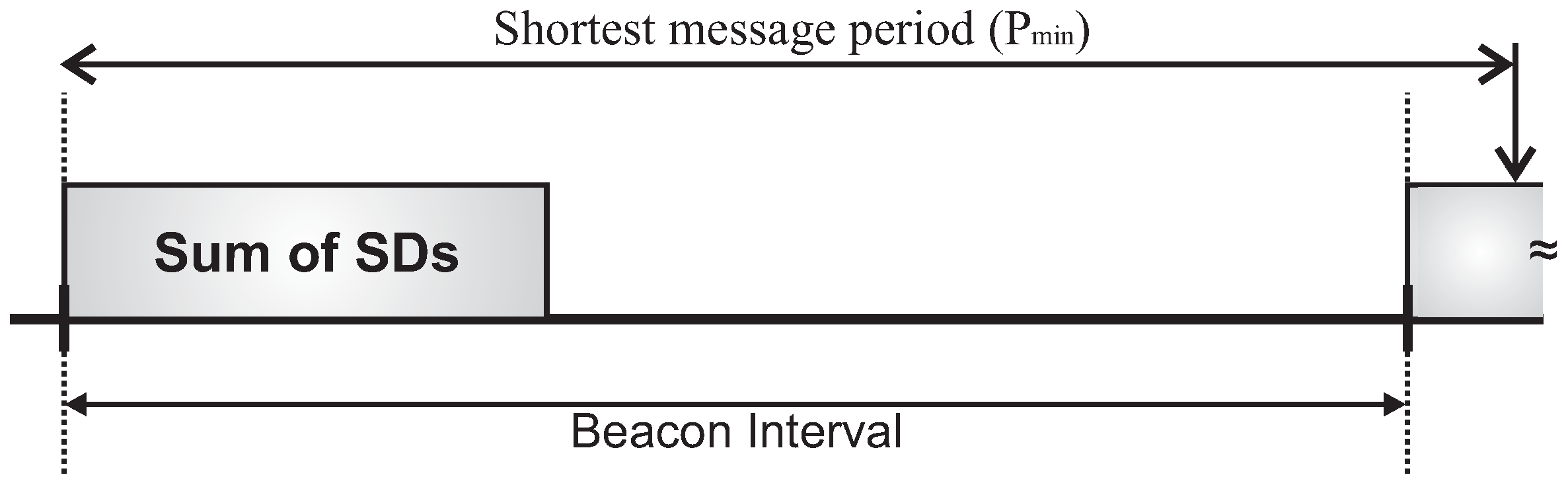
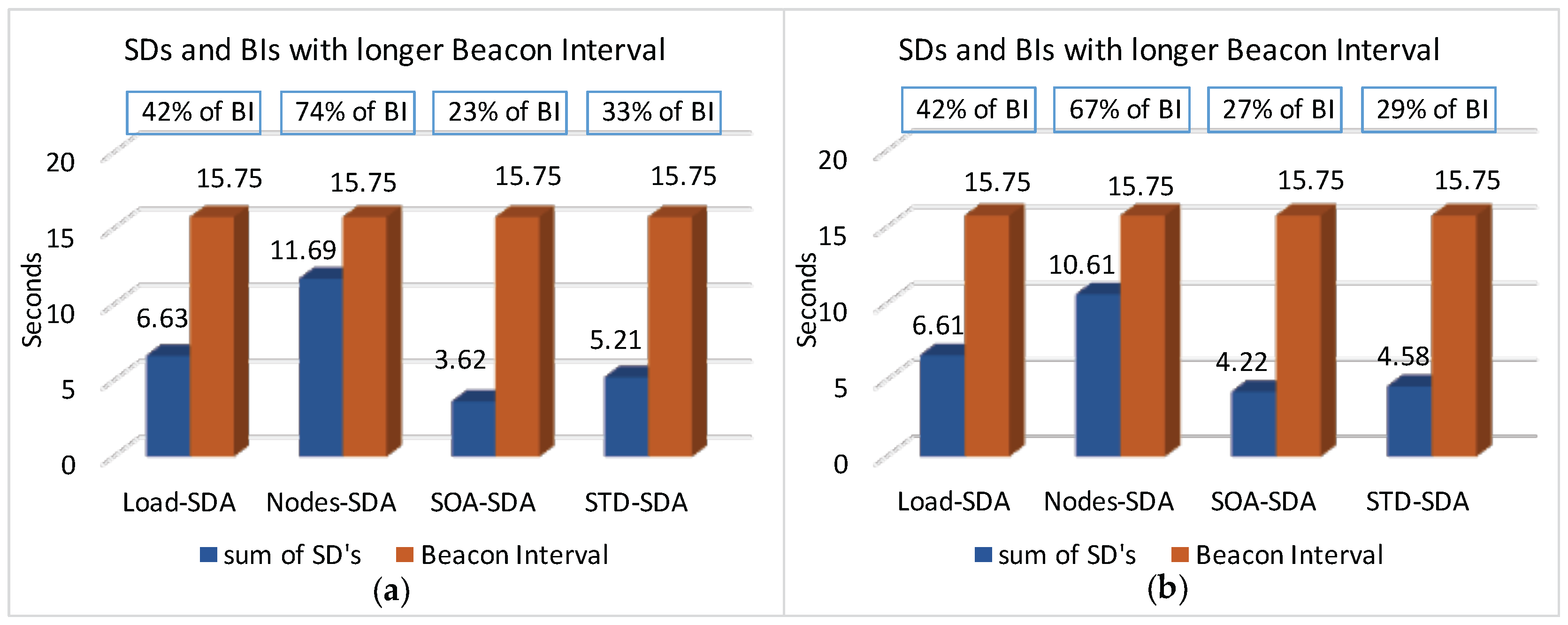
Firstly, we have considered the case where the beacon interval is set to a value close to the shorter message period (longer beacon interval).
Figure 18 illustrates both the beacon interval and the average sum of superframe durations defined for each of the allocation schemes (absolute average values and the percentage of the sum of superframe durations regarding to BI).
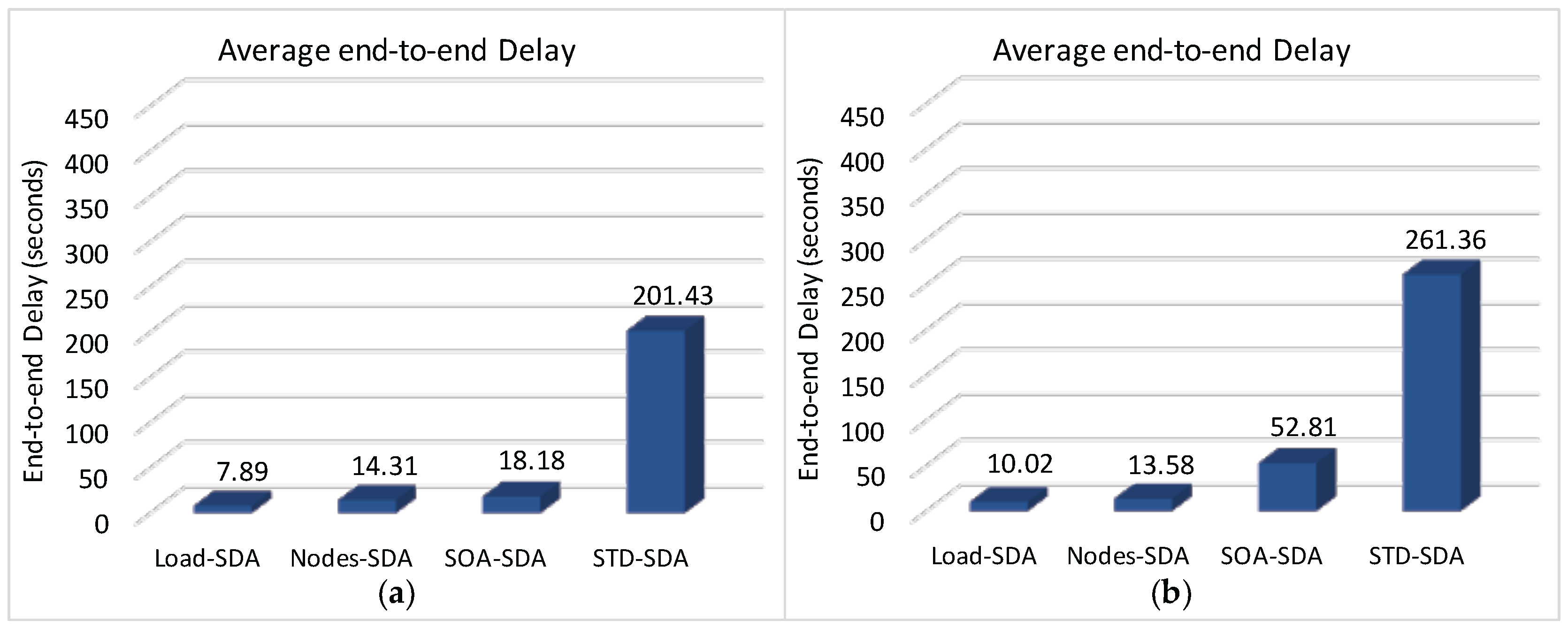
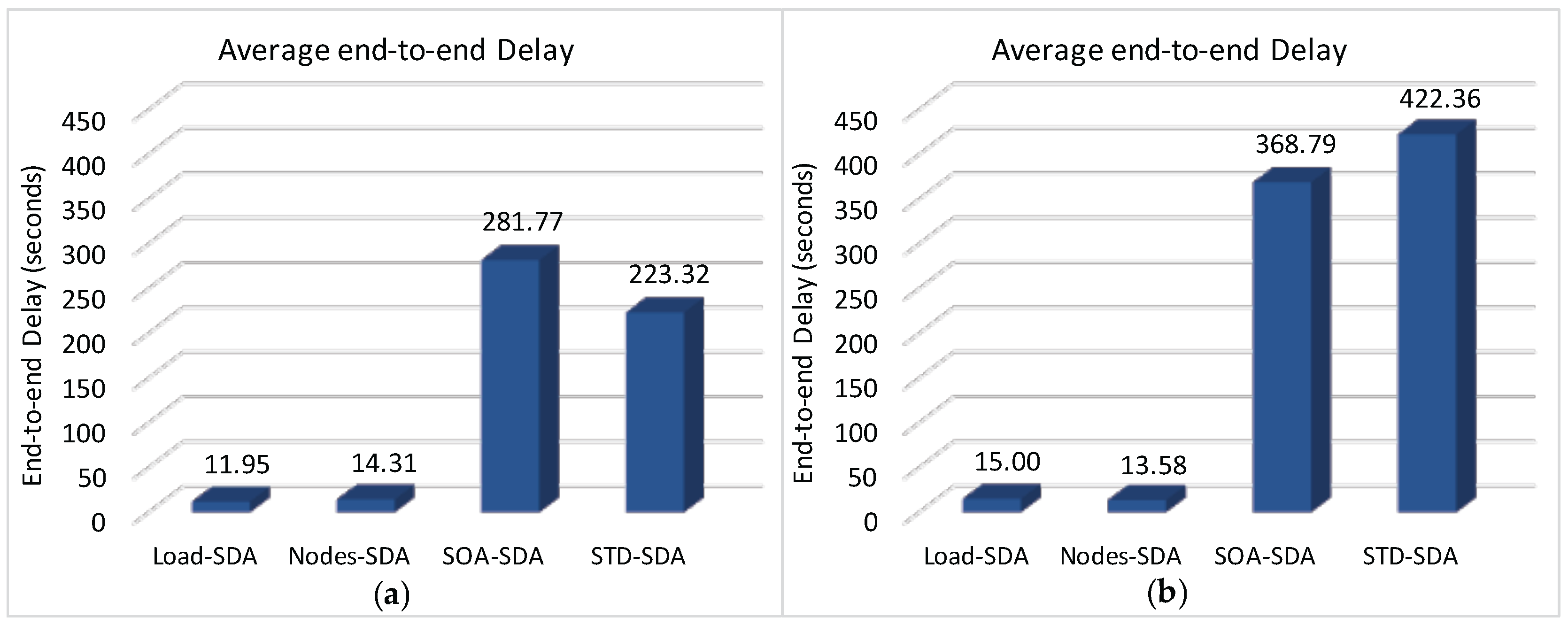
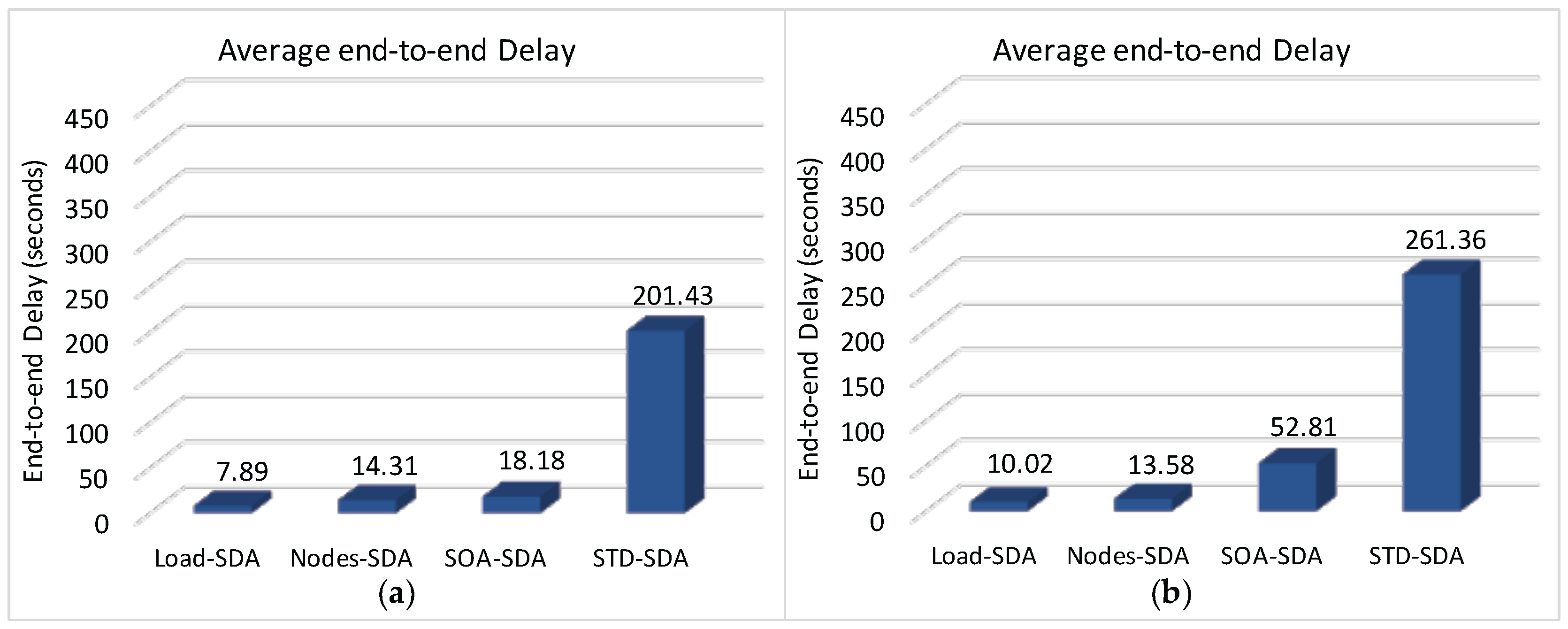
Figure 19 illustrates the average end-to-end communication delay for a network with longer Beacon Interval. It can be observed that end-to-end delays for the SOA-SDA and STD-SDA schemes are remarkably higher than for the case of the Load-SDA and Nodes-SDA schemes. The main reason is that, as the network is congested, messages are remaining more time in the internal buffers of cluster-heads. Therefore, message transfers require more beacon intervals to be forwarded, increasing their end-to-end communication delays. As the network, with the proposed Load-SDA and Nodes-SDA allocation schemes, does not face any congestion, messages can flow along the tree until the sink node, being their end-to-end communication delays slightly smaller than the beacon interval.
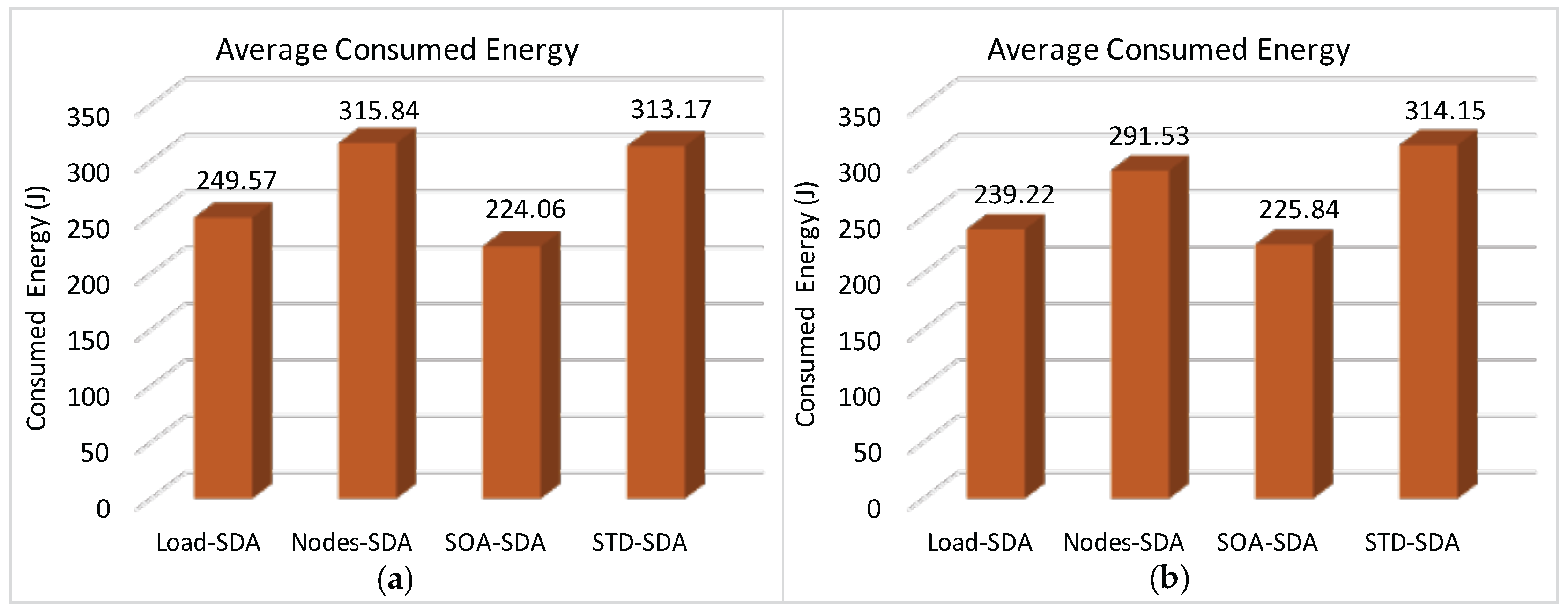
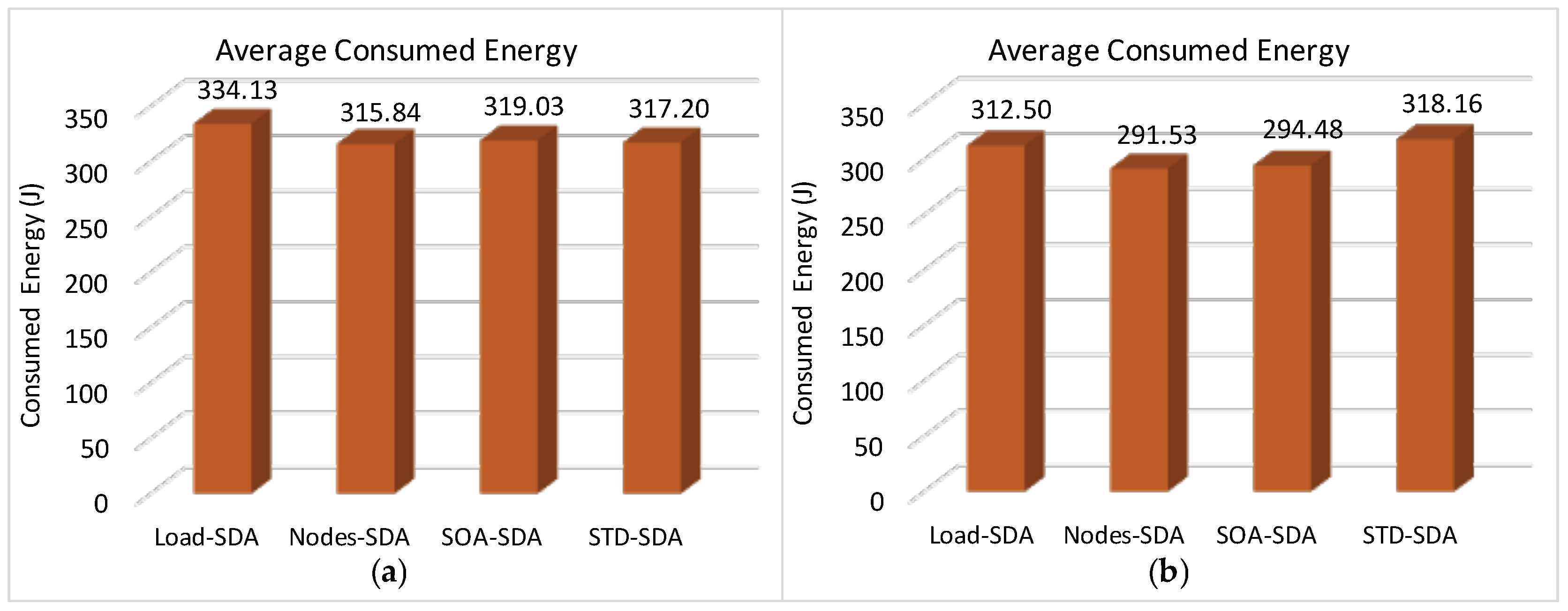
Figure 20 illustrates the average total energy consumption for a network with longer Beacon Interval. The energy consumption is mainly related to two factors: the time interval during which the nodes remain active, and the activities performed by them. As the active period (sum of superframe durations) of SOA-SDA is smaller than for Load-SDA scheme, it has a slightly better performance. Note also that, the average energy consumption for the Nodes-SDA scheme is larger than for both the Load-SDA and SOA-SDA schemes, considering both scenarios.
In what concerns the STD-SDA allocation scheme, it is important to highlight that the energy consumption is proportional to the number of non-discarded messages. Therefore, as there is a large number of messages being discarded due to buffer overflows, there is a consequent reduction of the energy consumption of the overall network.
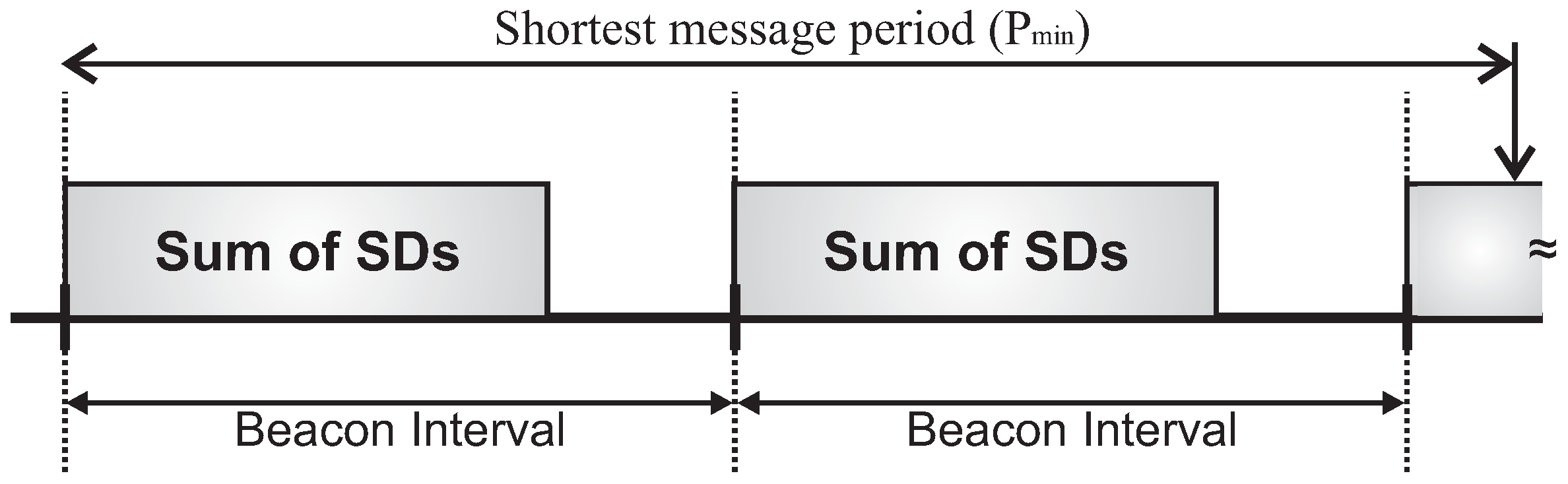
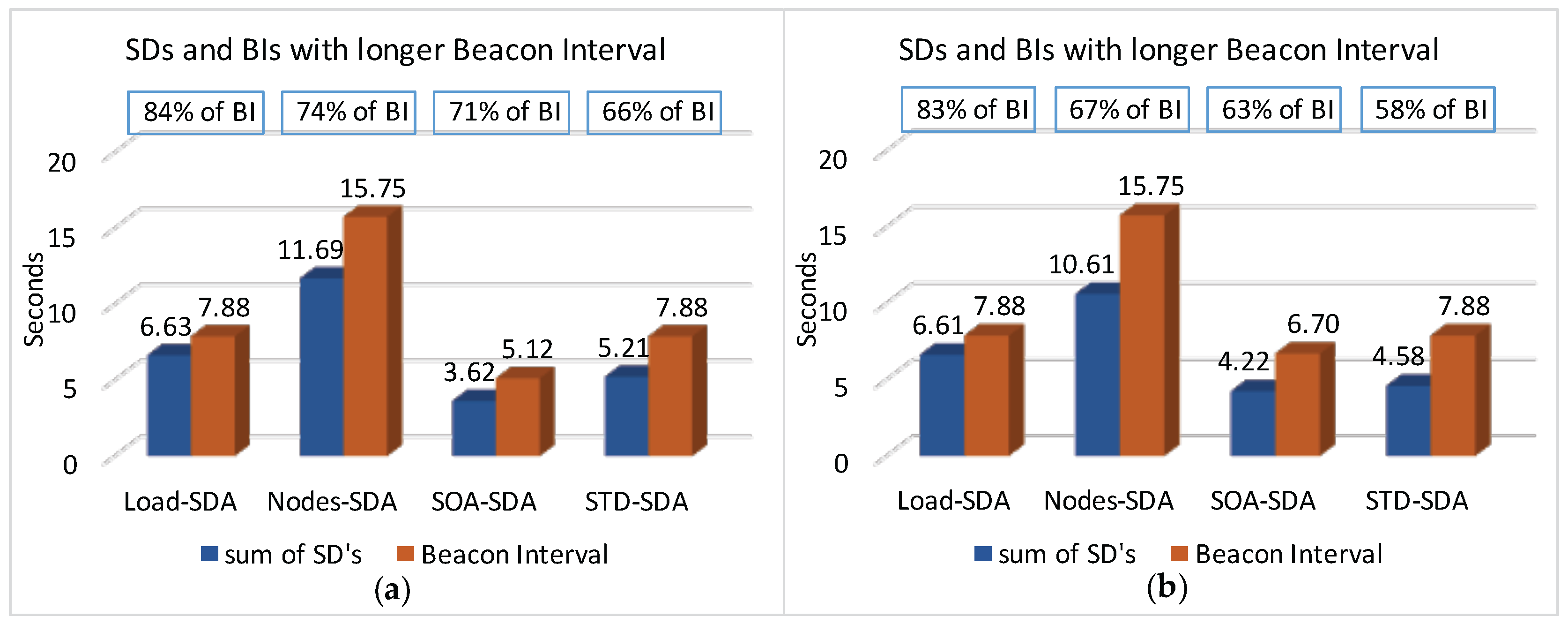
Figure 21 illustrates the beacon intervals and the average sum of superframe durations defined for each of the allocation schemes, considering the shorter beacon interval (absolute average values and percentage of the sum of superframe durations regarding to BI). In this case, the adjustment of the beacon interval was performed for all allocation schemes (except for the Nodes-SDA scheme), being that the SOA-SDA scheme had the smaller average beacon interval. For the Nodes-SDA scheme, if the beacon interval (in terms of beacon order) is decreased, the protocol constraint would no longer be respected.
Figure 22 shows the average end-to-end communication delay for a network with a shorter BI.
As it can be observed, the average end-to-end communication delay is significantly smaller when considering the reduction of the beacon interval, according to the reasoning previously presented in
Section 4.1. In fact, a shorter beacon interval always corresponds to shorter end-to-end communication delays. It is clear that there is a significant improvement of the end-to-end communication delay for the SOA-SDA allocation scheme, compared to the case with longer beacon interval. This behaviour is due to the fact that considering a shorter beacon interval, messages can be dispatched in a shorter time interval, decreasing network congestion and message discards. However, the energy consumption will increase, due to the higher activation rate of the sensor nodes.
Figure 23 illustrates the average total energy consumption for the allocation schemes, considering both unconditioned and conditioned allocation schemes with a shorter beacon interval. It can be concluded that, for the case of shorter beacon intervals, the Load-SDA, Nodes-SDA and SOA-SDA schemes have a better performance when compared to the STD-SDA schemes (similar energy consumption, but significantly smaller end-to-end communication delays).
Finally, in order to highlight the differences between Load-SDA and Nodes-SDA allocation schemes,
Figure 24 illustrates the superframe duration configuration (in terms of superframe order, respecting Equation (
5)) provided by the Load-SDA allocation scheme, while
Figure 25 illustrates the superframe duration configuration provided by the Nodes-SDA scheme for the same cluster-tree network, considering a conditioned scenario.
Figure 24 highlights that the Load-SDA scheme allocates higher values of Superframe Order for cluster-heads located in the high load zone, and lower values for cluster-heads located in the low load zone. On the other hand, the Nodes-SDA scheme allocates proportional values of Superframe Order for cluster-heads of the same depth (
Figure 25), regardless of being located in low load or high load zone. Note that, as the Nodes-SDA scheme does not consider the load imposed by descendant nodes (it considers only the number of nodes), this allocation scheme may over-allocate superframe durations for cluster-heads. Importantly, this behaviour was observed for all the simulation scenarios.
Table 8 presents the average superframe order values (per depth) defined by the Load-SDA and Nodes-SDA allocation schemes, for both high load and low load zones of the conditioned cluster-tree.
In general, the Nodes-SDA scheme allocates similar superframe durations (in terms of the superframe order parameter) for cluster-heads of same depth for both zones, showing that the difference of message loads does not interfere in its allocation mechanism. In turn, the Load-SDA scheme allocates highest superframe duration values for cluster-heads located in the high load zone, while that cluster-heads located in the low load zone receive lower superframe duration values.
From this simulation assessment, it can be concluded that proportional SDA schemes can adequately allocate the required communication resources for cluster-heads (active communication periods and buffer sizes), avoiding traditional problems that occur in cluster-tree networks, such as: network congestion, high end-to-end communication delays and discarded messages due to buffer overflows. The Load-SDA scheme presents better performance for cluster-tree networks than other schemes, but it requires the knowledge of both network topology and data traffic loads. Moreover, both Load-SDA and Nodes-SDA schemes only consider cluster-tree networks where the beacon interval parameter is similar to all clusters.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}