1. Introduction
Tactile sensors are an important sensory in robotics, since they contribute largely as the synthetic counterpart of biological skins on human and other animals. They are crucial in providing control feedback for safely and securely grasping and manipulating objects [
1,
2,
3].
However, a majority portion of biological skins are not sensitive enough for precise force sensing and localization for assisting controls [
4]. In the nature, bodily contact is an important aspect of emotional communication among humans [
5], as well as between human and animals [
6]. Tactile interaction has been shown to carry emotional information in a similar way as e.g., face expressions [
7]. Studies have also shown that body movements are specific for certain emotions [
8]. As pointed out in [
3], most tactile sensors are based on piezoresistive materials, which have the problem of poor hysteresis and linearity. However, for sensing emotional touches, precision tactile sensing is not necessary [
5,
7].
In recent years, the focus on robotics research has evolved from precise and delicate movements to perform various tasks, to a deeper communication between human and robotic interactions [
9,
10,
11]. In [
12], a humanoid robot WE-4RII (Waseda University, Tokyo, Japan) can effectively express seven emotion patterns with body languages. Touch is fundamental in human-human interaction and as robots enter human domains, touch becomes increasingly important also in human-robot interaction (HRI). In recent years, we’ve seen several approaches to whole-body tactile sensing for robots, e.g., for the iCub (Italian Institute of Technology, Genoa, Italy) [
13,
14] or the HPR-2 (Kawada Industries, Tokyo, Japan) [
15] robots. These systems are cell based, where each cell comprise a small circuit board holding necessary sensors and electronics and, while presenting excellent sensing capacity, they constitute a relatively hard surface with limited flexibility. In [
16] conductive serpentine structures and various silicon compounds are used to construct a skin-like bio-compatible sensor to detect touch on different zones and caress across zones.
In a recent study comprising 64 participants communicating emotions to an Aldebaran Nao robot (SoftBank Robotics, Tokyo, Japan) using touch, people interacted for longer time when the robot was dressed in a textile suite [
17], compared to a standard Nao with a hard plastic surface. These results indicate that the surface material of the robot may be significant for extending and directing tactile HRI. Inspired by these results, we here report on-going work investigating the use of touch sensitive smart textiles as a potential alternative to cell based robot skins.
One informative aspect of tactile HRI is the type of touch [
9]. In [
18], individually designed 56 capacitive sensors are installed in a toy bear to detect affection-related touch. The data processing algorithm relies on signal features such as amplitude and base frequency from all the sensors. In [
19], a touch sensing furry toy is developed with a conductive fur touch sensor and piezoresistive touch-localization sensor are combined. Using statistical features of the signal and random forests classifier, the prototype recognizes 8 gestures with a 86% accuracy. In [
20], using electrical impedance tomography (EIT), with 19 specially placed electrodes, an EIT sensor is used to detect 8 affective touch gestures, with accuracy of 90% for single person, and 71% for multiple participants.
In [
21], a commercially available 8-by-8 textile pressure sensor is used. With custom picked features, classification accuracy of 14 gestures is 60% for leave-one-participant-out cross validation. In the present work, we evaluate the capacity of distinguishing between seven different types of touch, listed in
Table 1, based on sensor data gathered from the smart fabric.
1.1. Contribution
In this paper, we propose to use textile pressure mapping sensors as tactile sensors for emotional related touch gesture detection. We use the smart fabric sensors from our previous research efforts. They have been used for wearable and ambient planar pressure sensing for activity recognition applications, such as monitoring muscle activity through tight fitted textile sensor [
22] or recognizing postures from the body pressure profile on the back of office chairs [
23].
We define 7 gestures to detect, and evaluate the method through two groups of mutually blinded experiments. The experiment datasets are evaluated by extracting basic statistic features and wavelet analysis. With various classifier, the recognition rate on an exclusive person independent basis is up to 93.3%.
We also analyzed the contribution of each aspect of the feature extraction process, which offers a detailed breakdown of the algorithm and the guideline for reducing the computational complexity with less recognition performance reduction.
1.2. Paper Structure
In
Section 2, we introduce the fabric tactile sensor and the driving electronics.
Section 3 describes the experiment set up and dataset composition; In
Section 4, we first explain how to extract features from the spatial-temporal data, then evaluate different features’ contribution to the recognition rate.
In
Section 5, we show the detailed classification results as confusion matrix and discuss the results such as the underlying meanings of the miss classifications.
Section 6 concludes the paper with the summary of our findings.
4. Data Processing Algorithm
4.1. Data Format and Digital Processing
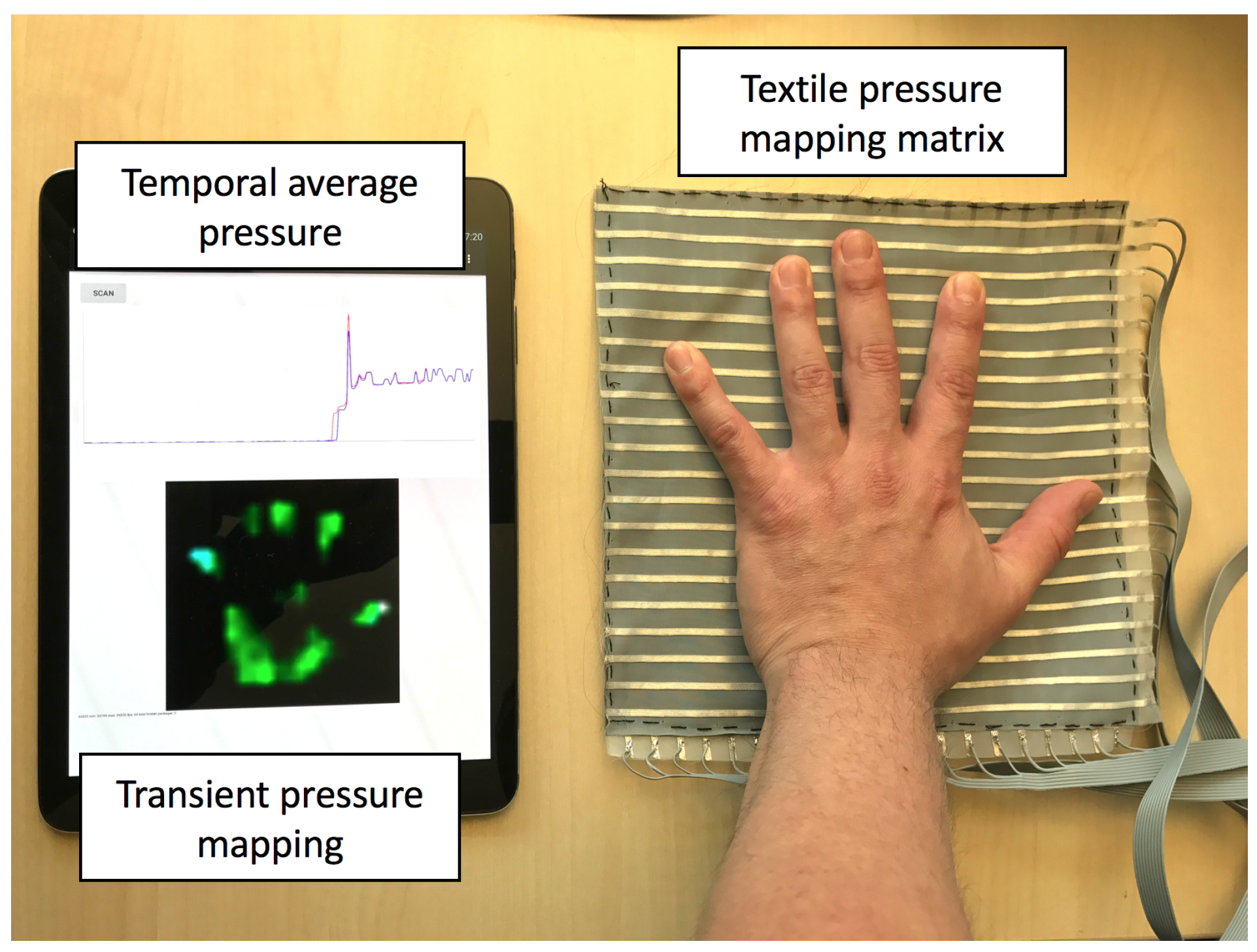
The pressure mapping sensor generates a temporal sequence of 2-dimensional pressure mapping
frames, at a speed of 50 frames per second.
Figure 5 shows the accumulated frame of a random example of every gestures from a random participant. Every
frame is up-sampled from 20-by-20 to 40-by-40 to increase the spatial resolution with bicubic interpolation. To extract information, we first reduce the 2D spatial data into limited information as
frame descriptors. The following descriptors are calculated from every frame:
: mean value of all pixels’ value
: maximum value of all pixels’ value
: standard deviation of all pixels’ value
: distance from center of gravity to the frame center
: distance from maximum point to the frame center
: the number of pixels that has higher value than a threshold ()
The frame descriptors therefore reduces the 2-dimensional information to a limited vector. For example, if a gesture lasts 3 s, a stream of 150 frames (each 20-by-20) are generated by the tactile sensor, and six arrays, each 150 in length, are abstracted as the temporal sequences of frame descriptors. and describes the intensity and location of the center of the pressure; and offers information of the highest pressure point; describes how scattered the pressure is on the surface; describes the surface area of the contact.
The experiment data is manually segmented by the experiment conductor roughly before and after the contact. To make sure the data samples cover exactly the contact time, we define a cut-off threshold:
The samples before the first when , and after the last when are removed.
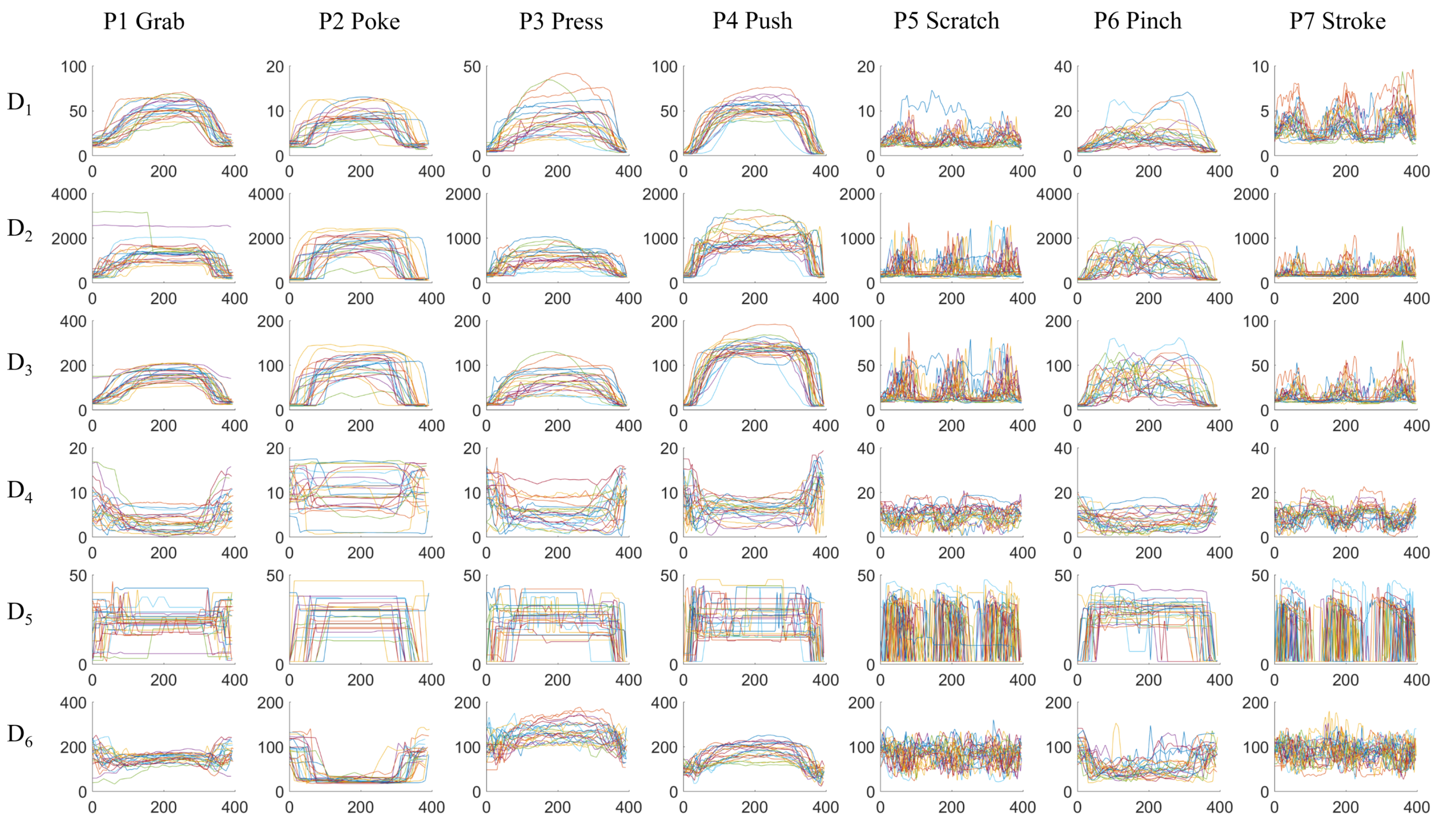
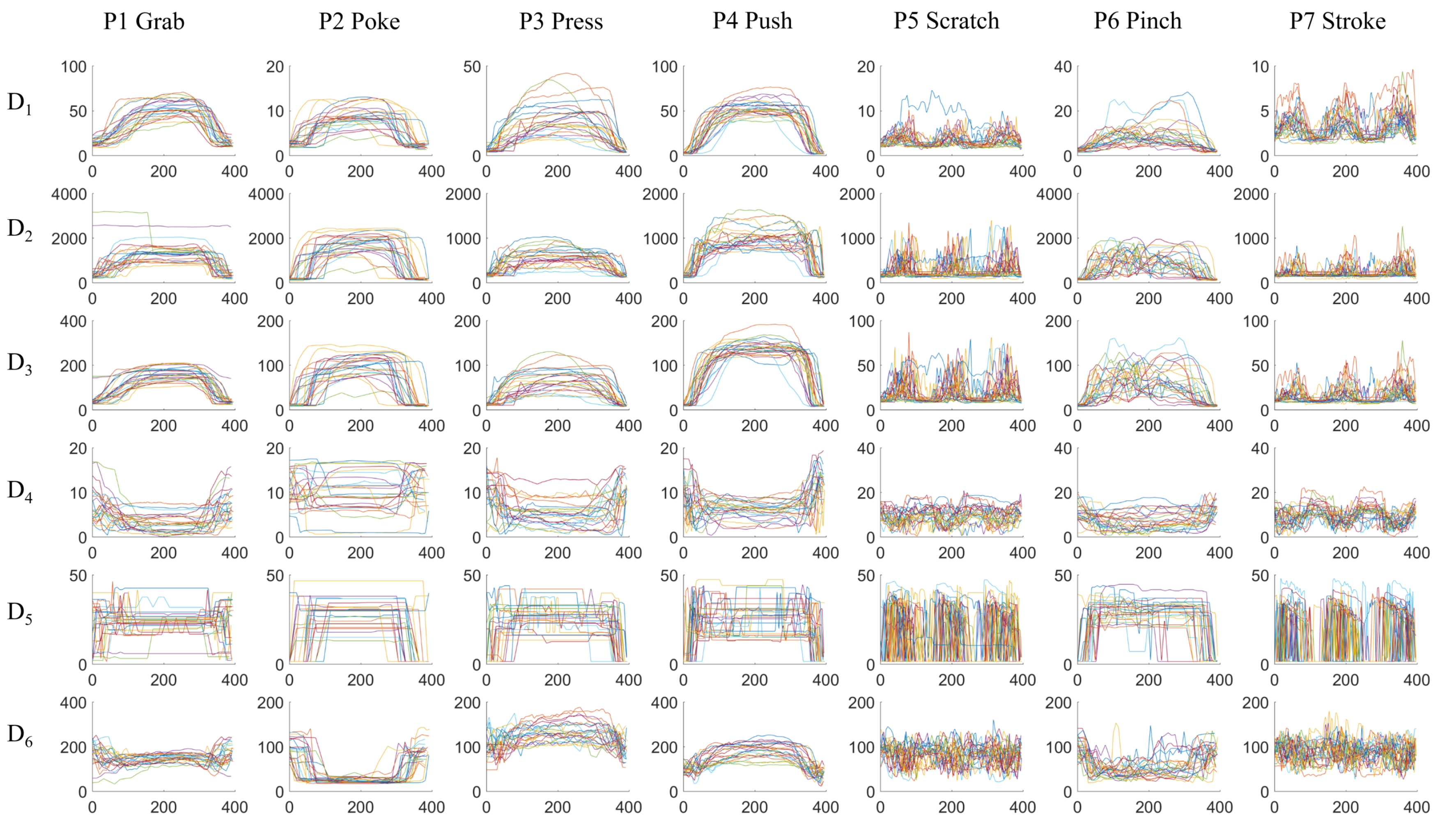
Figure 6 visualizes the temporal sequences of
frame descriptors from different classes. One action of each gesture from every person is randomly selected. For comparison purposes, the sequences are scaled to the same 400-sample window using linear interpolation; the original data sequences have different length. The next step is to extract features to distinguish between different classes. For example, in subplot
-
,
P2 Poke has significantly smaller
than the other gestures;
P5 Scratch and
P7 Stroke have distinct higher frequency movements than the other gestures in all the frame descriptors;
P1 Grab and
P4 Push has higher average value in
and
than the other gestures.
We investigate two types of features from the temporal sequences of size T: basic statistic representations, and wavelet analysis.
4.1.1. Basic Features
The 5 basic statistic representations are:
These features would describe the distribution of the temporal sequence, and are commonly used in statistic analysis.
The temporal features are not to be confused with the frame descriptors. For example, is the standard deviation of all the pixels from a frame at sample t at a particular point in time; is the sequence of the standard deviation of each frame within the window; is the standard deviation of all the 2D standard deviation frame descriptors within the window. Frame descriptors reduce the spatial domain data into limited measures, and the temporal features further reduce the temporal domain information. For one window of gesture, 6 sequences of frame descriptors are calculated, which results in overall 30 basic features.
4.1.2. Wavelet Features
To convert frequency-related information from the data into features, we use wavelet transform. Wavelet transform offers frequency and temporal localization of the target signal.
We first pad the
signal of length
T with its boundary values with a padding size of
: before
,
are inserted
times repeatedly, and at the end of
,
are inserted
times. Then the padded signal
is multiplied with a symmetric Hamming window
:
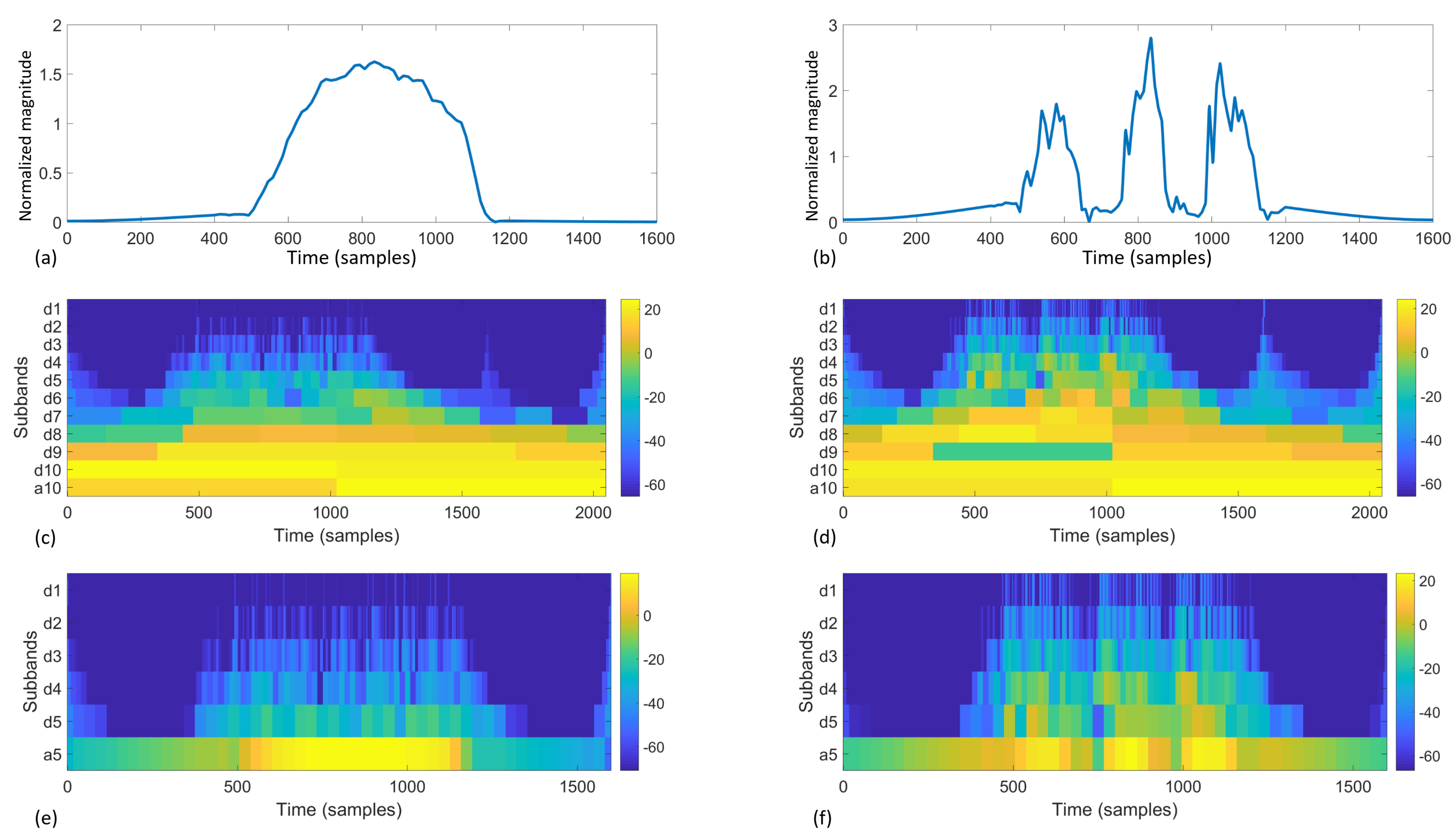
Figure 7 visualizes the boundary padding and hamming window process. Padding and window functions are typical techniques in signal processing to remove the influence of the sampling window.
We use fast wavelet transform implemented by the Large Time-Frequency Analysis Toolbox (LTFAT) [
30], which follows Mallat’s basic filterbank algorithm for discrete wavelet transform [
31].
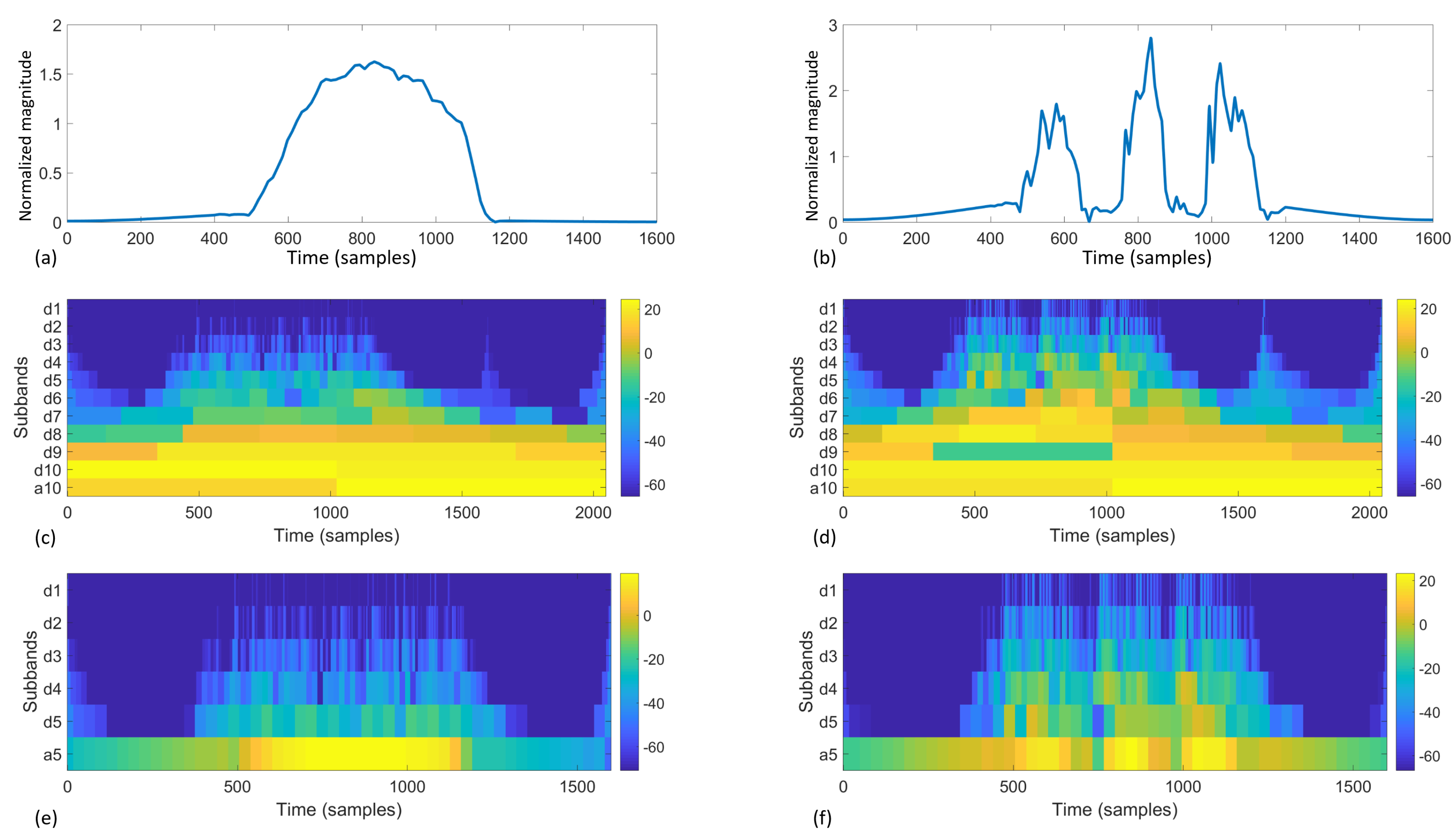
Figure 8 offers an illustration and comparison of two different source signals going through 5-level and 10-level filterbanks. Essentially, each filterbank iteration calculates a vector of coefficients as results. The calculation uses a mother wavelet, which is scaled and shifted to provide frequency variance and temporal localization. In this study, we used the Daubechies 8 (db8) wavelet as the motherwavelet [
32]. Other standard mother wavelets can also be used in this process; however, once chosen, the mother wavelet should not be changed because the wavelet transform will have different references. Higher iteration targets the higher frequency and finer temporal localization, which results in a longer vector of coefficients. For example, assume the sample frequency is
f, with
samples, a five-level filterbank discrete wavelet transform as in
Figure 8e,f results in wavelet coefficients as shown in
Table 2. We define the highest level as
J, therefore the coefficients are
These coefficients are unique to the specific signal, as they can be used to reconstruct the signal by the inverse wavelet transform. Each subband contains temporal localization of the corresponding frequency. Therefore their distribution information can be used as unique features.
For the last three subbands (in the example in
Table 2, level 3–5, subband d3, d4, d5, a5), we calculate the
as the first four wavelet features. For the lower levels
which have significantly finer temporal granularity and bigger number of coefficients, we calculate the following features to describe the distribution information:
Therefore, for every sequence of frame descriptors for , 14 features are calculated from the wavelet transform; for , 39 features are calculated.
4.2. Evaluation Methods
We use the classifiers from the Matlab Classification Learner app (2017a, MathWorks, Natick, MA, USA), which enables performance comparison of various classifiers in one stop. The classifiers we evaluated are:
Medium Tree (maximum 20 splits decision tree)
Linear Discriminant Analysis (LDA)
Support Vector Machine (SVM) with linear kernel
SVM with quadratic kernel
K-nearest neighbors (KNN) with
distance weighted KNN with
Bagged Trees (random forest bag, with decision tree learners)
For cross-validation, we consider three settings:
Random cross-validation: the training data and testing data are from the same data set with k-fold cross-validation.
Leave one recording out: as the data from the same experiment session may exhibit greater similarity, we use separate different sessions from the same person into training and testing data of the classifier.
Person independent exclusive: the training data and testing data are from two groups of persons; the two groups are mutually exclusive. So that the classifier has no previous knowledge of the person being tested.
In all three settings, the testing data samples do not appear in the training data pool. The results we present are calculated from the confusion matrix after comparing the prediction with the ground truth. We use accuracy (ACC) as the comparison measure, which is the proportion of correctly classified samples in all testing data.
4.3. Feature Contribution Decomposition
First we investigate the contribution from different feature sets by using only the specific set of features in the machine learning process. In this step, we use the random cross-validation setting, with all the data from Group A, with 5-fold cross-validation.
4.3.1. Basic Features
The basic features are defined in
Section 4.1.1. We consider all the frame descriptors (
). The results are listed in
Table 3. The average accuracy of all classifiers is
, which is well above the chance level of seven classes
. The best performed classifier is SVM with quadratic kernel with the accuracy of
.
4.3.2. Wavelet Features
Different from the basic features, the amount of wavelet features depends on the filterbank iteration (
J) of the discrete wavelet transform. Therefore, we evaluate the wavelet features by trying different filterbank iterations, as shown in
Table 4. The obvious trend is that as
J increases, the accuracy of all classifiers are increasing. On average, while
and
, the results are inferior to the basic features, while
and
yields slightly better results than the basic features most of the classifiers (except for LDA and KNN). Even though there are instances that a higher
J yields slightly lower accuracy (for example, Quadratic SVM with
and
, it is within the random error range, because every result is from a unique randomly separated 5-fold cross validation.
4.3.3. Combined Features
We combine both the basic features and wavelet features. From
Table 5, all of the results are better than either basic features as in
Table 3 and wavelet features from
Table 4. For example, with the LDA classifier, basic features and wavelet features (
) yield the accuracy of 79.10% and 77.20%; while both feature sets are combined, the accuracy is improved by 4.50% to 83.60%.
We assume the application is not limited by the computational power. Therefore, after comparing the contribution of the basic features and wavelet features, we choose basic features and wavelet features () combined for the following evaluation.
4.3.4. Contribution of Different Frame Descriptors
In
Section 4.1, we introduce 6
frame descriptors. During the previous feature contribution analysis, all six frame descriptors are used. The six frame descriptors offer information from different angles:
and
describes the average center pressure point by the value and location;
and
are the maximum pressure point;
is the variation of the pressure profile;
measures the pressed area. Here we discuss how each frame descriptor contributes to the classification result.
Table 6 shows the results of cross-validations with separate frame descriptors. The results are based on all basic features and wavelet features with
. Different descriptors contribute differently in combination with different classifiers. For example,
give less accuracy than
with the KNN classifiers, but more with Quadratic SVM. Overall, the combination of all frame descriptors
offer superior result than any of the individual descriptors. This means that all of the descriptors make positive contribution to the classification result.
5. Result and Discussion
From the previous analysis, we take all the frame descriptors, with both basic features and wavelet features (), because all analysis indicate that all of the factors contribute positively to the classification result. We choose the support vector machine classifier with quadratic kernel as it offers the best accuracy.
The first result in
Figure 9a is from the randomly separated 5-fold cross-validation from all participants in Group A, it is essentially the confusion matrix of the corresponding result from
Table 5. The values in the matrix are ratios of the current prediction in the overall ground truth of its class; on the diagonal, the values are the true positive ratio of each class. The F1 score is is calculated as the harmonic mean of the average precision and recall of all the classes; the ACC score is the accuracy, which is the average true positive rate.
As mentioned in
Section 4.2, data recorded in the same session may posses greater similarity than another session from the same person. In Group A, every participant attended two recording sessions on different days. We separate these sessions as two sets, each set contains one session from each participant. One set is used as training, and the other as testing; the process is then reversed as the training and testing sets are exchanged. The confusion matrix in
Figure 9b is the average of both results.
Next we evaluate how well the classifier can predict with a stranger’s data. We randomly separate the 24 participants in to 4 parties, each 6 people. Then every party is used as the testing data while the other three parties are the training data. This process is repeated 4 times so that every party is used as testing data once. The result in
Figure 9c is the average confusion matrix of the four repetitions.
All three results show very well separation among all of the classes. Major miss-classification happens between P3 Press and P4 Push, P5 Scratch and P7 Stroke. Press and Push are similar actions, except Push has greater contact area and generally greater force; Scratch and Stroke are both repeating actions, while Scratch may have smaller area of contact. Overall, the average 88.8% and 89.1% accuracy in leave-1-recording-out and person independent exclusive cases are also well above the random chance level of 14.3%.
As mentioned in
Section 3.2, we recorded two experiment groups in different environments settings with different directing persons. The directing persons from Group A and B do not know how each other has conducted the experiment; they are only given the instructions of how to set up the sensors, and the details of the gestures as shown in
Table 1. The confusion matrix of person independent exclusive validation of Group B is shown in
Figure 10. Except for the miss classifications observed in Group A, more data from
P6 Pinch are classified as
P3 Press.
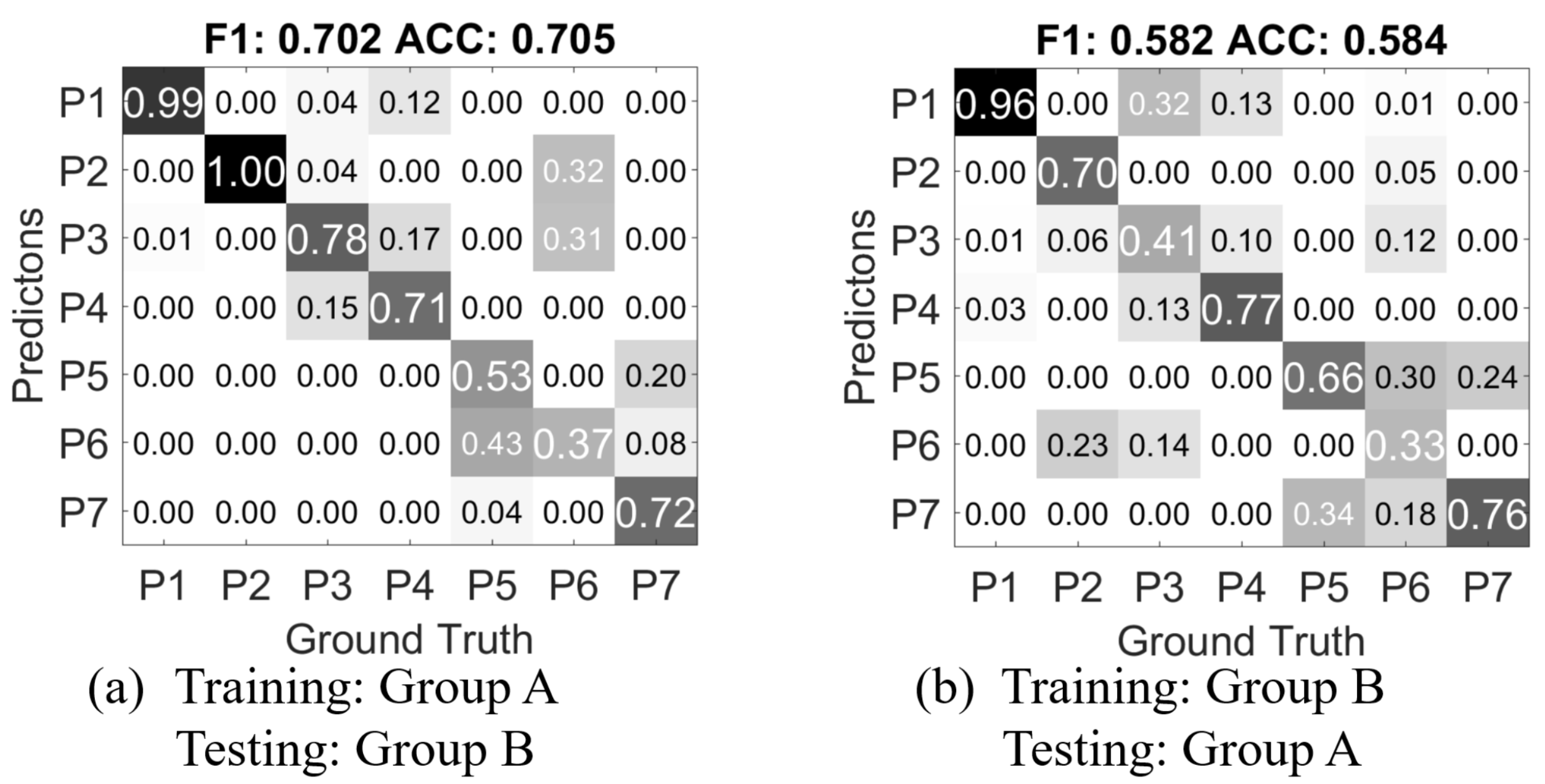
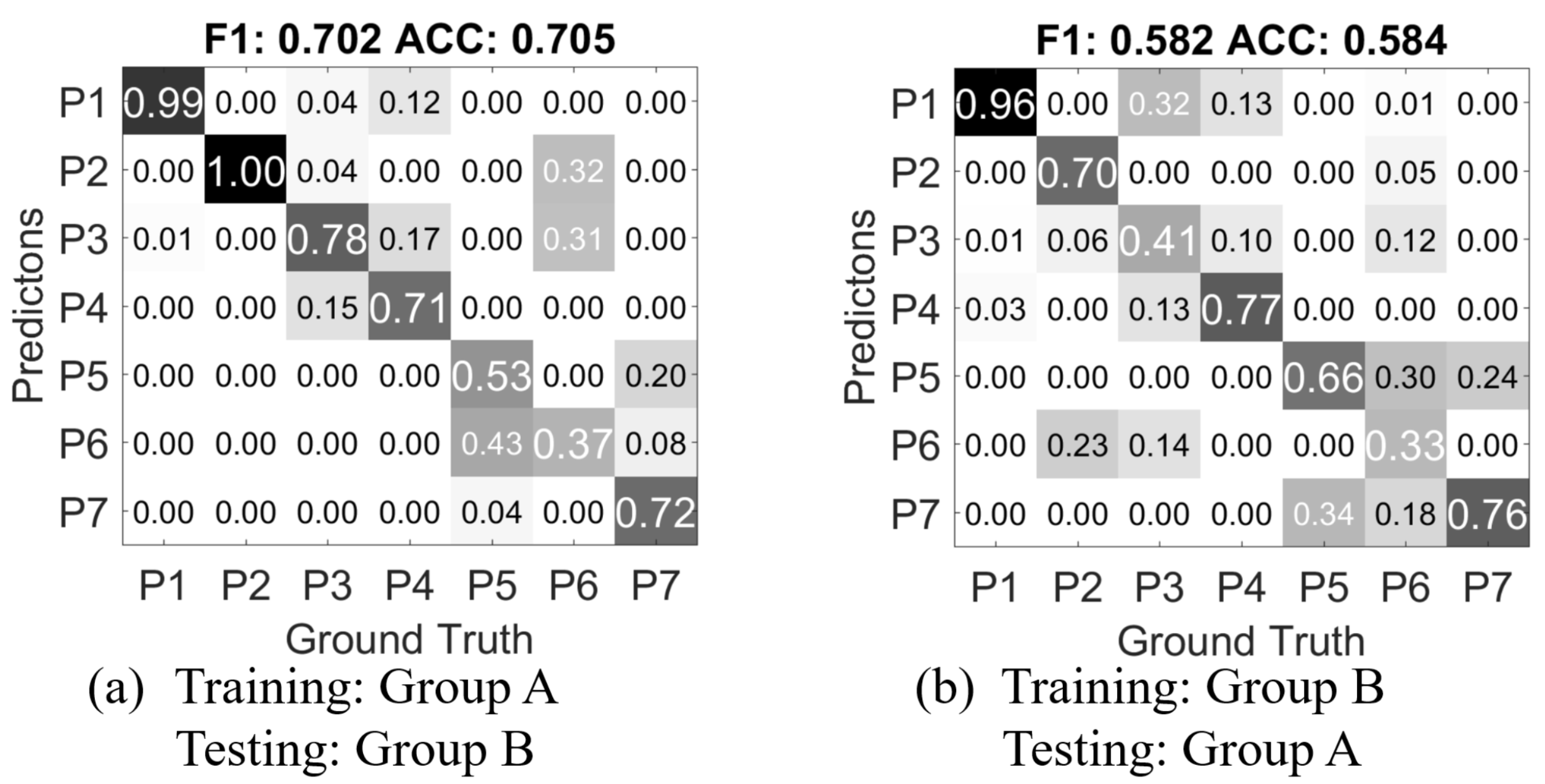
We then train a classifier with the feature data from Group A, and test with the data from Group B.
Figure 11a shows the confusion matrix result). Compared to the confusion matrix from
Figure 9c in the person independent exclusive case,
CM A-B has near 19% drop of accuracy and F1-score. This means the mutually blinded experiment setting does decrease the recognition rate of the gesture recognition approach. Notably, 12% of
P4 Push gestures are classified as
P1 Grab, but most of the
P1 Grab gestures are correctly classified. The mutual miss classifications between the pairs of
P3 Press and
P4 Push,
P5 scratch and
P7 stroke, which are observed in the cross-validation of Group A, are further increased. Most interestingly, in the Group A only cross-validation,
P6 Pinch is clearly distinguishable from the other classes, while in
CM A-B, it is largely miss classified into
P2 Poke and
P3 Press. Also gestures from
P5 Scratch is miss-classified as
P6 Pinch. This could be mainly caused by the mutually blind experiment setting as described in
Section 3.
Figure 11b shows the result of using Group B as training, and Group A as testing (
CM B-A). As the accuracy decreases, the classifier for
CM B-A has only 560 samples as training data, while in
CM B-A, the classifier is trained with 5376 samples. And also Group B contains only the data from one hand of each person, while in Group A, both hands are used for recording the data. The major miss classification caused by
P6 Pinch also exists in
CM B-A, which further suggests that the mutually blind setting is the underlying cause.
Overall, the comparison of CM A-B, CM B-A and the cross validations within Group A and Group B concludes that (1) a completely blinded setting regarding experiment and instruction can make a difference in recognition results; (2) more training data can improve the accuracy for person independent cases.
6. Conclusions and Future Work
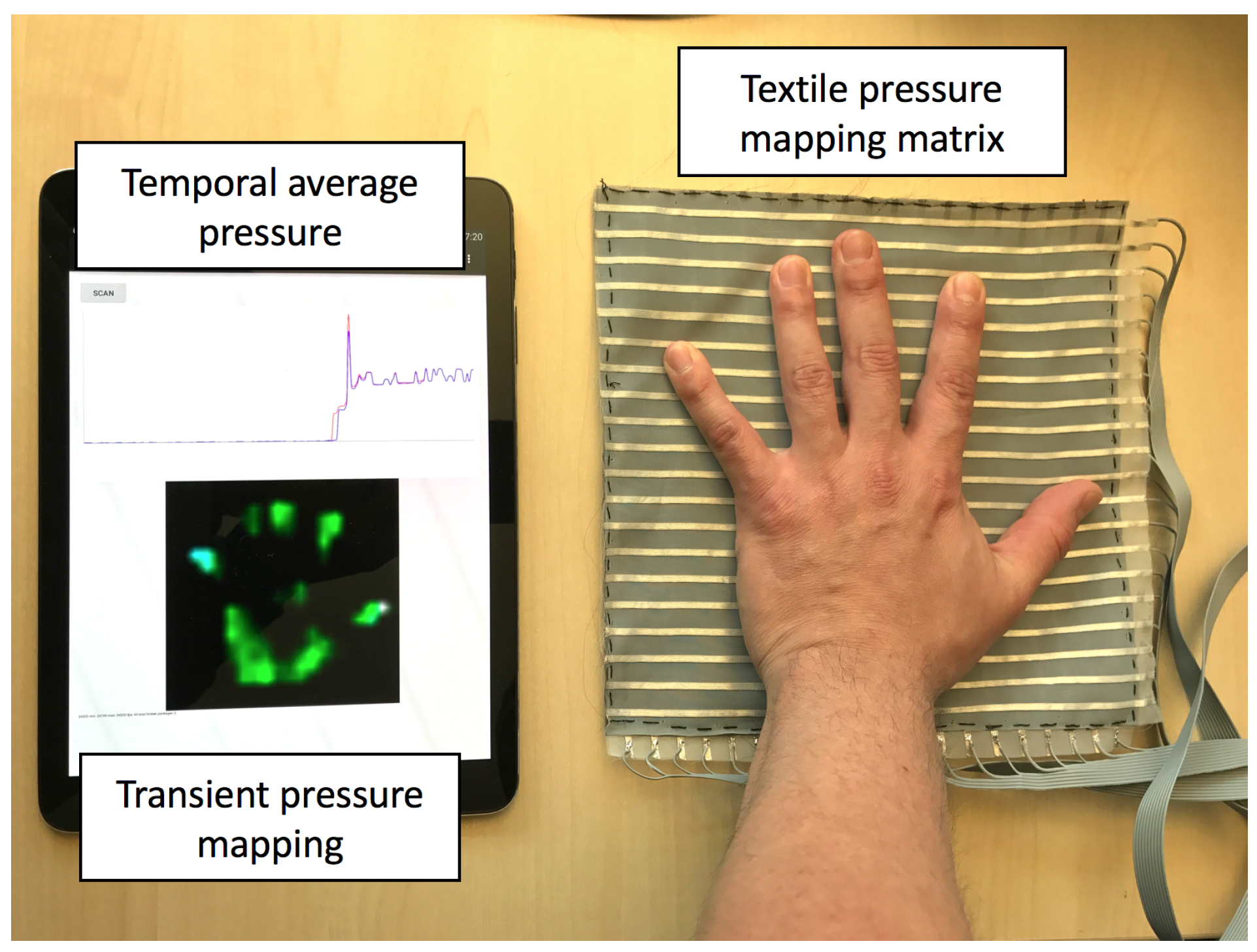
In this work, we developed a textile robot skin prototype from tactile pressure mapping sensors and algorithms to investigate Human-Robot interface through various kinds of touch, which is still an uncharted territory. The textile touch sensing skin is soft and the feel is close to clothing materials. In a small region, it can detect different modes of touch gestures with the same skin patch through our evaluation.
Our data processing algorithm first converts the spatial pressure profiles at each sample time into frame descriptors, and calculates features from the temporal sequences of the frame descriptors. We analyzed the contribution of each frame descriptor and each feature set, with different classifiers. The overall result is that all of the frame descriptors with all of the feature sets provides the optimal classification result of 93% with a support vector machine classifier with quadratic kernel. The contribution breakdown also helps further optimizing the computational complexity. For example, with only the basic features on all the frame descriptors, the accuracy drops less than 2% from the optimal accuracy; with only and frame descriptors, the accuracy only drops 5%. This information is helpful in the future work of implementing the algorithms on the micro-controller in the sensor driving electronics.
The increased miss-classification in the exclusive person independent settings (
Figure 9c and
Figure 10) and the mutual blind experiment settings (
Figure 11) evaluation reveals interesting aspects when it comes to strangers, which is similar to what may happen between human-human interactions: for example, someone’s normal pet on the shoulder may feel too heavy for some certain people. This opens the possibility to progressively improve tactile communication through learning or even differentiate between users of the robot through social-purposed touch sensing.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}