
Multi-Target Joint Detection and Estimation Error Bound for the Sensor with Clutter and Missed Detection

{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
- Set integral: For any real-valued function of a finite-set variable X, its set integral is [4]:where denotes a n-points set (that is, the cardinality of the set is n) and denotes the space of . In this paper, we note .
- Multi-Bernoulli RFS: A multi-Bernoulli RFS X is a union of M independent Bernoulli RFSs , . Its density is completely described by parameter as [6]:where denotes the cardinality of a set, denotes the probability of and denotes the density of .
- Poisson RFS: An RFS X is Poisson if its density is:where denotes the intensity function of the Poisson RFS X, η is the average number of elements in X and is the density of single element .
- Second-order OSPA distance: The OSPA distance of order between set X and its estimate is [19]:where denotes the set of permutations on , denotes the cut-off parameter, or denotes the maximization or minimization operation and denotes the two-norm. The OSPA metric is comprised of two components, each separately accounting for “localization” and “cardinality” errors between two sets. The localization error arises from the estimates paired with the nearest truths, while the cardinality error arises from the unpaired estimates. Schuhmacher et al. [19] have proven that the OSPA distance with and is indeed a metric, so it can be used as a principled performance measure.
- Information inequality and CRLB: Given a joint probability density on , under regularity conditions and the existence of , the information inequality states that [20,21]:where denotes an estimate of L dimensional vector based on , and are, respectively, the l-th components of and , , the notation means the expectation with respect to density f and J is known as the Fisher information matrix:where denotes the element on the i-th row and j-th column of matrix J.For the particular case in which the estimator is unbiased (that is, ), the information inequality of Equation (5) reduces to:which is a result known as the CRLB. The Fisher information matrix J in Equation (7) is also computed by Equation (6).Note that the ordinary information inequality of Equation (5) holds without the unbiasedness requirement on the estimator . However, unbiasedness is critical in the CRLB of Equation (7).Explanation: In the current set up of this paper, our attention is restricted to the unbiased estimator of multi-target states. Our future work will study the extension of the proposed bound to the biased estimator by using the ordinary information inequality of Equation (5).Moreover, Equation (5) or Equation (7) is satisfied with equality depending on a very restricted condition. In [21], Poor concludes that, within regularity, the information lower bound is achieved (that is, the “=” in Equation (5) or Equation (7) holds) by if and only if is in a one-parameter exponential family (e.g., the linear Gaussian models for target dynamics and sensor observation described in [11] for achieving the CRLB). More details about this can be found in [21].
- RFS-based multi-target dynamics and sensor observation models: Let denote the state vector of a target and the set of multi-target states at time k, where is the state space of a target. The multi-target dynamics is modeled by:where is the set evolved from the previous state , with surviving probability and transition density , otherwise with probability ; is the set of spontaneous births.Let denote a measurement vector and the set of measurements received by a sensor at time k, where is the sensor measurement space. The single-sensor multi-target observation is modeled by:where is the measurement set originated from state , with sensor detection probability and likelihood , otherwise with probability ; is the clutter set, which is modeled as a Poisson RFS with density:where is the clutter intensity, is the average clutter number and is the density of a clutter.The transition model in Equation (8) jointly incorporates motion, birth and death for multiple targets, while the sensor observation model in Equation (9) jointly accounts for detection uncertainty and clutter. Assume that the RFSs constituting the unions in Equations (8) and (9) are mutually independent. The multi-target JDE at time k is to derive the estimated state set using the collection of all sensor observations up to time k. The paper aims to derive a performance limit to multi-target joint detectors-estimators for the observation of a single sensor with clutter and missed detection. The performance limit is measured by the bound of the average error between and .
3. Single-Sensor Multi-Target JDE Error Bounds Using Multi-Bernoulli or Poisson Approximation
- MAP detection criterion: This is applied to determine the number of targets: given a measurement set at time k, the cardinality of the estimated state set is obtained as the maximum of the posterior probabilities :The reason for the use of the MAP detection rule will be clearly explained later in Remark 1 after Theorems 1 and 2.
- Unbiased estimation criterion: This is a necessary condition for applying the CRLB of Equation (7) in the proof of Theorems 1 and 2.
- Assumption A.1: At time k, the set of spontaneous births is a multi-Bernoulli RFS with the parameter (in general, is known a priori). Then, the predicted and posterior multi-target densities and are approximated as the multi-Bernoulli densities with parameters and , respectively. Specifically, the parameter of a multi-Bernoulli RFS that approximates the multi-target RFS is propagated under this assumption. The recursions for and have been presented in [6].
- Assumption A.2: At time k, the set of spontaneous births is a Poisson RFS with the intensity (in general, is known a priori). Then, the predicted and posterior multi-target densities and are approximated as the Poisson densities with intensities and , respectively. Specifically, the intensity of a Poisson RFS that approximates the multi-target RFS is propagated under this assumption. The recursions for and have been presented in [4].
- c is the cut-off of the second-order OSPA distance in Equation (4), L is the dimension of state and N is the maximum number of the targets observed by the sensor over the surveillance region;
- is a normalization factor of the density ; it actually denotes the probability of and given ,
- is the integration of the density over the region ,Note that the integration region in is the subspace in , where the MAP detector assigns the estimated target number to be (). are mutually disjoint and cover . Therefore, actually denotes the probability of and given and .
- is the Fisher information matrix of the t-th target given , , and . , and in Equation (17) are given by (assuming for , ):where is given by Equation (14), is the density of conditioned on and . in Equation (20), as well as the integration region in Equations (20) and (21) are given by:where denotes a function of and n given .
- Remark 1: It is well-known that the lower bound is independent of the specific estimation methods. However, it is necessary for the use of the MAP detection rule in deriving the bounds in Theorems 1 and 2. The reasons are as follows.First, we have known that the error metric in Equation (11) is the second-order OSPA distance in Equation (4). Obviously, the estimated target number has to be considered in the OSPA distance. At time k, the estimated target number depends on the measurement set received by the sensor. We assume that if , which is a subspace of the measurement space , then the estimated target number by the detector is (). Therefore, to compute the MSE in Equation (11), we have to partition the measurement space into the regions of , which correspond to all possible estimated target numbers , respectively. In addition, are mutually disjoint and cover .In the proof of Theorems 1 and 2, to obtain the bound on in Equation (A13) (Equation (A13) is the extended form of the MSE in Equation (11)), we need to find the best integration regions in Equation (A14) that minimizes Equation (A14). Nevertheless, it is very difficult to define for the detector without using the MAP criterion because the minimization of Equation (A14) depends on the estimator . This reflects the extreme complexity in defining for the detector that minimizes the in Equation (11) and its intricate interconnection with the estimator that may jointly achieve a lower using the MAP detector. A detailed analysis is presented in [16] to illustrate the complicated dependency of the detector and estimator for minimizing the MSE . As a result, without the MAP detector restriction, it is nearly impossible to characterize the joint detector-estimator that minimizes the MSE in Equation (11) due to their extremely complex interrelationship in determining the number of targets and estimating the states of existing targets.In summary, with the MAP detection constraint, the estimated target number at time k can be determined just by the detector (that is, independent of the estimator). However, this may make the minimum MSE defined by Equation (11) unachievable. Therefore, imposing the MAP constraint can be regarded as an approximated method to obtain the proposed JDE bounds. In our future work, we will study the JDE error bound without the MAP detection constraint.
- Remark 2: In general, the integration region for calculating and at time k is different from the previous integration region for calculating and at time , where the superscripts and denote the target indices, estimated target numbers, true target numbers and sensor measurement numbers at time k and time , respectively. As a result, cannot be derived directly from by using a closed-form recursion like the posterior CRLB (PCRLB) in [11]. The recursion of depends on the propagation of parameter or intensity of multi-Bernoulli or Poisson RFS that approximates the predicted multi-target RFS.
- Remark 3: In the special case of no clutter or missed detection, we have and for the sensor observation model in Equation (9). The numbers of estimated targets, true targets and measurements are obviously equal in this case, . As a result, multi-target JDE reduces to multi-target state estimation only (that is, target detection no longer exists here, and so, the restriction of MAP detection can be omitted) using the sensor measurement. Moreover, given multi-target state set , the total likelihood reduces to:and the second-order OSPA distance reduces to:because there is no need to consider the cut-off c for cardinality mismatches here. Only for the special case, a theoretically rigorous (that is, without multi-Bernoulli or Poisson approximation to multi-target Bayes recursion) single-sensor multi-target error bound can be derived in [18] using a PCRLB-like recursion.
4. Numerical Examples
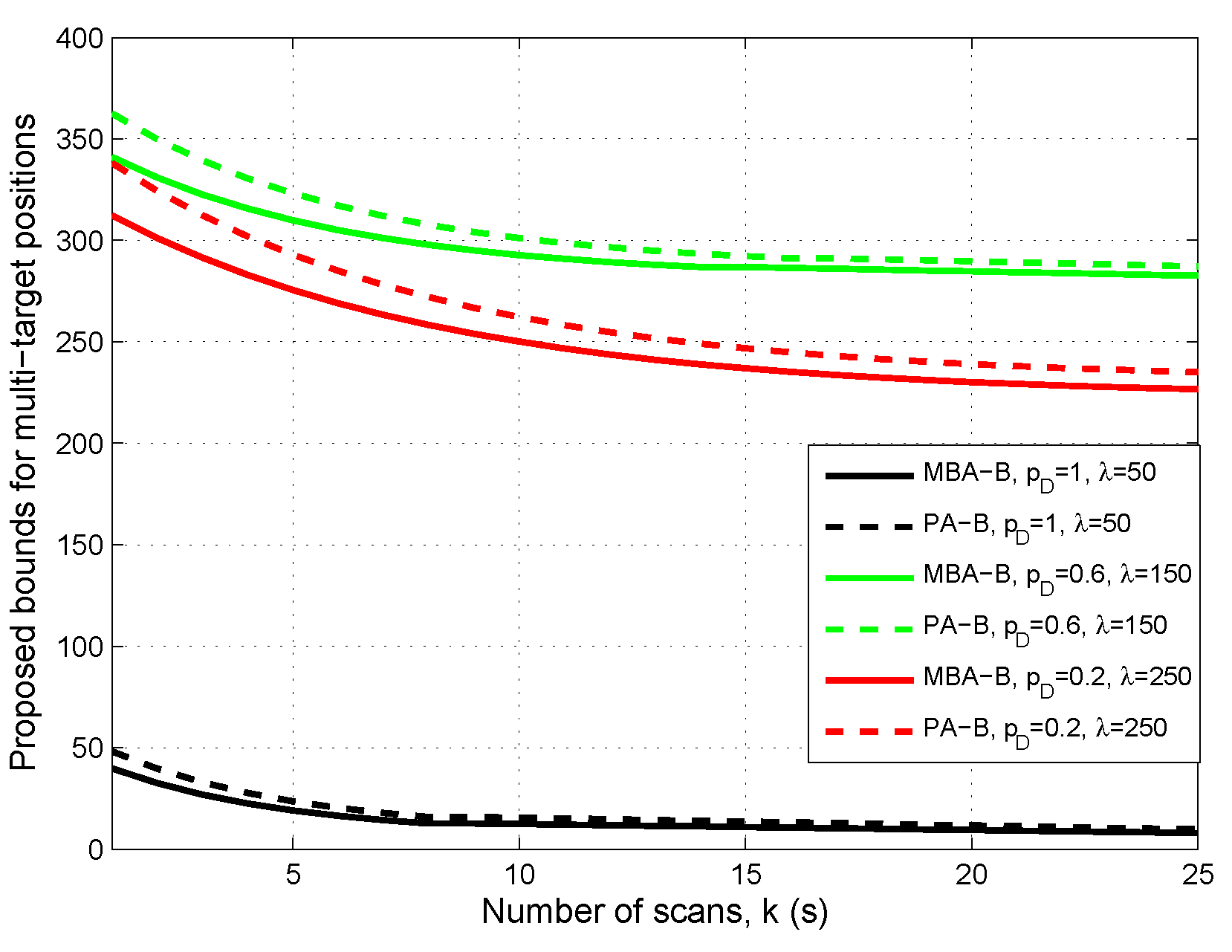
- The proposed bound does not always increase with λ for given or decrease with for given λ. This is because of the two contrary effects generated by the increase of λ or when or : reducing the possibility for missed targets and increasing the possibility for false targets. If the bound is dominated by the former, then it decreases with λ or ; otherwise, it increases with λ or . Moreover, PA-B is a little higher than MBA-B when λ is relatively large or is relatively small. However, they are very close in general. A possible reason for this is that the multi-Bernoulli assumption (Assumption A.1) outperforms the Poisson assumption (Assumption A.2) slightly for approximating the multi-target Bayes recursion under lower signal-noise-ratio (SNR) conditions.
- Although the JDE errors of the single-sensor PHD and CPHD filters are a little higher than the proposed bound, all of them are always close versus λ and . The extra errors of the two filters are generated by the first-order moment approximations for the posterior multi-target density and the clustering processes involved in their particle implementations for state extraction. Figure 2 also shows that the CPHD filter outperforms the PHD filter. The reason for this is that the former can propagate the cardinality distribution and, thus, has more stable target number estimation than the latter.
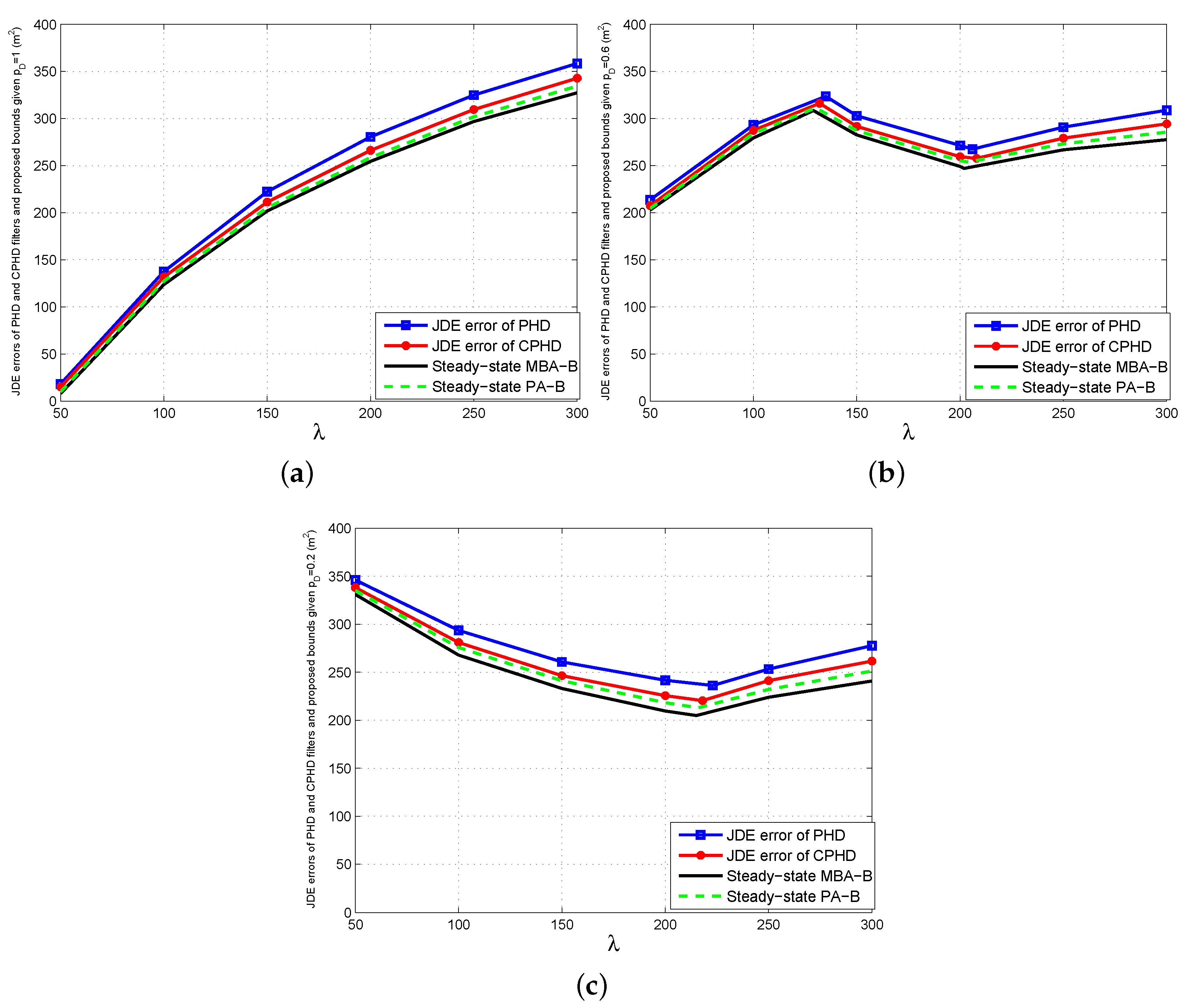
- 3.
- The bigger λ becomes for given , or the lower becomes for given λ, the bigger the gaps between the errors of the two filters and the proposed bound will be. This is because the aforementioned approximation errors of the two filters increase as λ becomes bigger or becomes smaller. However, the maximum relative errors of the PHD and CPHD filters, which seem to appear in the case of and , do not exceed 15% and 8% of MBA-B, as well as 12% and 5% of PA-B in any case, respectively. In fact, the total average relative errors of the two filters are about 7% and 4% of MBA-B, as well as about 6% and 3% of PA-B for various λ and , respectively.Finally, the comparison results in Figure 2 show that for various clutter densities and detection probabilities of the sensor, the proposed bounds are able to provide an effective indication of performance limitations for the two single-sensor multi-target JDE algorithms.
5. Conclusions
- Extending the results to the case of multiple sensors;
- Extending the results to the case of the biased estimator by using the ordinary information inequality of Equation (5);
- Studying the JDE error bounds without the MAP detection constraint;
- Studying the sensor management strategies based on the results.
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
Appendix B
References
- Bar-Shalom, Y.; Fortmann, T. Tracking and Data Association; Academic Press: San Diego, CA, USA, 1988. [Google Scholar]
- Mahler, R. Statistical Multisource Multitarget Information Fusion; Artech House: Norwood, MA, USA, 2007; pp. 332–335. [Google Scholar]
- Blackman, S. Multiple hypothesis tracking for multiple target tracking. IEEE Aerosp. Electron. Syst. Mag. 2004, 19, 5–18. [Google Scholar] [CrossRef]
- Mahler, R. Multi-target Bayes filtering via first-order multi-target moments. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1152–1178. [Google Scholar] [CrossRef]
- Mahler, R. PHD filters of higher order in target number. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 1523–1543. [Google Scholar] [CrossRef]
- Vo, B.T.; Vo, B.N.; Cantoni, A. The cardinality balanced multi-target multi-Bernoulli filter and its implementations. IEEE Trans. Signal Process. 2009, 57, 409–423. [Google Scholar]
- Xu, Y.; Xu, H.; An, W.; Xu, D. FISST based method for multi-target tracking in the image plane of optical sensors. Sensors 2012, 12, 2920–2934. [Google Scholar] [CrossRef] [PubMed]
- Vo, B.T.; Vo, B.N.; Hoseinnezhad, R.; Mahler, R. Robust multi-bernoulli filtering. IEEE J. Sel. Top. Signal Process. 2013, 7, 399–409. [Google Scholar] [CrossRef]
- Vo, B.N.; Vo, B.T.; Phung, D. Labeled random finite sets and the bayes multi-target tracking filter. IEEE Trans. Signal Process. 2014, 62, 6554–6567. [Google Scholar] [CrossRef]
- Zhang, F.H.; Buckl, C.; Knoll, A. Multiple vehicle cooperative localization with spatial registration based on a probability hypothesis density filter. Sensors 2014, 14, 995–1009. [Google Scholar] [CrossRef] [PubMed]
- Tichavsky, P.; Muravchik, C.; Nehorai, A. Posterior Cramér-Rao bounds for discrete time nonlinear filtering. IEEE Trans. Signal Process. 1998, 46, 1701–1722. [Google Scholar] [CrossRef]
- Hernandez, M.; Farina, A.; Ristic, B. PCRLB for tracking in cluttered environments: Measurement sequence conditioning approach. IEEE Trans. Aerosp. Electr. Syst. 2006, 42, 680–704. [Google Scholar] [CrossRef]
- Hernandez, M.; Ristic, B.; Farina, A.; Timmoneri, L. A comparison of two Cramér-Rao bounds for nonlinear filtering with Pd < 1. IEEE Trans. Signal Process. 2004, 52, 2361–2370. [Google Scholar]
- Zhong, Z.W.; Meng, H.D.; Zhang, H.; Wang, X.Q. Performance bound for extended target tracking using high resolution sensors. Sensors 2010, 10, 11618–11632. [Google Scholar] [CrossRef] [PubMed]
- Tang, X.W.; Tang, J.; He, Q.; Wan, S.; Tang, B.; Sun, P.L.; Zhang, N. Cramér-Rao bounds and coherence performance analysis for next generation radar with pulse trains. Sensors 2013, 13, 5347–5367. [Google Scholar] [CrossRef] [PubMed]
- Rezaeian, M.; Vo, B.N. Error bounds for joint detection and estimation of a single object with random finite set observation. IEEE Trans. Signal Process. 2010, 58, 1943–1506. [Google Scholar] [CrossRef]
- Tong, H.S.; Zhang, H.; Meng, H.D.; Wang, X.Q. A comparison of error bounds for a nonlinear tracking system with detection probability Pd < 1. Sensors 2012, 12, 17390–17413. [Google Scholar] [PubMed]
- Tong, H.S.; Zhang, H.; Meng, H.D.; Wang, X.Q. The recursive form of error bounds for RFS state and observation with Pd < 1. IEEE Trans. Signal Process. 2013, 61, 2632–2646. [Google Scholar]
- Schuhmacher, D.; Vo, B.T.; Vo, B.N. A consistent metric for performance evaluation of multi-object filters. IEEE Trans. Signal Process. 2008, 86, 3447–3457. [Google Scholar] [CrossRef]
- Herath, S.C.K.; Pathirana, P.N. Optimal sensor arrangements in angle of arrival (AoA) and range based localization with linear sensor arrays. Sensors 2013, 13, 12277–12294. [Google Scholar] [CrossRef] [PubMed]
- Poor, V. An Introduction to Signal Detection and Estimation; Springer-Verlag: New York, NY, USA, 1994. [Google Scholar]
- Cho, T.; Lee, C.; Choi, S. Multi-sensor fusion with interacting multiple model filter for improved aircraft position accuracy. Sensors 2013, 13, 4122–4137. [Google Scholar] [CrossRef] [PubMed]
- Press, W.; Teukolsky, S.; Vetterling, W.; Flannery, B. Numerical Recipes in C; Cambridge: New York, NY, USA, 1992. [Google Scholar]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lian, F.; Zhang, G.-H.; Duan, Z.-S.; Han, C.-Z. Multi-Target Joint Detection and Estimation Error Bound for the Sensor with Clutter and Missed Detection. Sensors 2016, 16, 169. https://doi.org/10.3390/s16020169
Lian F, Zhang G-H, Duan Z-S, Han C-Z. Multi-Target Joint Detection and Estimation Error Bound for the Sensor with Clutter and Missed Detection. Sensors. 2016; 16(2):169. https://doi.org/10.3390/s16020169
Chicago/Turabian StyleLian, Feng, Guang-Hua Zhang, Zhan-Sheng Duan, and Chong-Zhao Han. 2016. "Multi-Target Joint Detection and Estimation Error Bound for the Sensor with Clutter and Missed Detection" Sensors 16, no. 2: 169. https://doi.org/10.3390/s16020169